Chapter 2 Basic data cleaning with Excel
Before we can analyze data, we usually need to clean it. Cleaning data means putting it into a form that is ready to analyze, and can include importing data tables from various files, reorganizing complex tables into simple ones, combining data from multiple tables into a single table, modifying existing variables, and creating new variables. In this course, we will do most of our data cleaning using Excel.
This chapter will develop some principles of data cleaning as well as the basic Excel tools needed to implement them. The best way to learn data skills is by working on a real data project, so will also apply this knowledge by using Excel to clean a real data set.
Chapter goals
In this chapter, we will learn how to:
- Identify and implement the principles of reproducible research, including:
- Portability
- Provenance
- Version control
- Tidy data
- Identify and use ID variables.
- Use basic Excel terminology and concepts including:
- Workbooks, worksheets, and cells
- Cell contents and display format
- Cell addresses and ranges
- Fill and series
- Use Excel formulas to construct new variables.
- Use relative and absolute cell addresses in Excel formulas.
- Use logical and text data in Excel.
- Use dates in Excel.
- Use Excel to import and export CSV files.
To prepare for this chapter, please ensure you have a computer with Excel installed so you can follow along. Refer to the installation instructions as needed.
2.1 Introduction to Excel
Microsoft Excel is the most commonly-used example of a spreadsheet, which is a software program designed for the tabulation, analysis, and display of data. Its main competitors include Google Sheets and Apple Numbers. It is widely used in business and government, so good Excel skills are valuable in the labour market.
Many of you have probably used Excel before, but there are many features you are probably not yet familiar with. So we will start from the beginning.
2.1.1 Terminology and interface
Start Excel. Your screen should look something like this:
When giving instructions, it is necessary to refer to various elements of
Excel’s user interface by name:
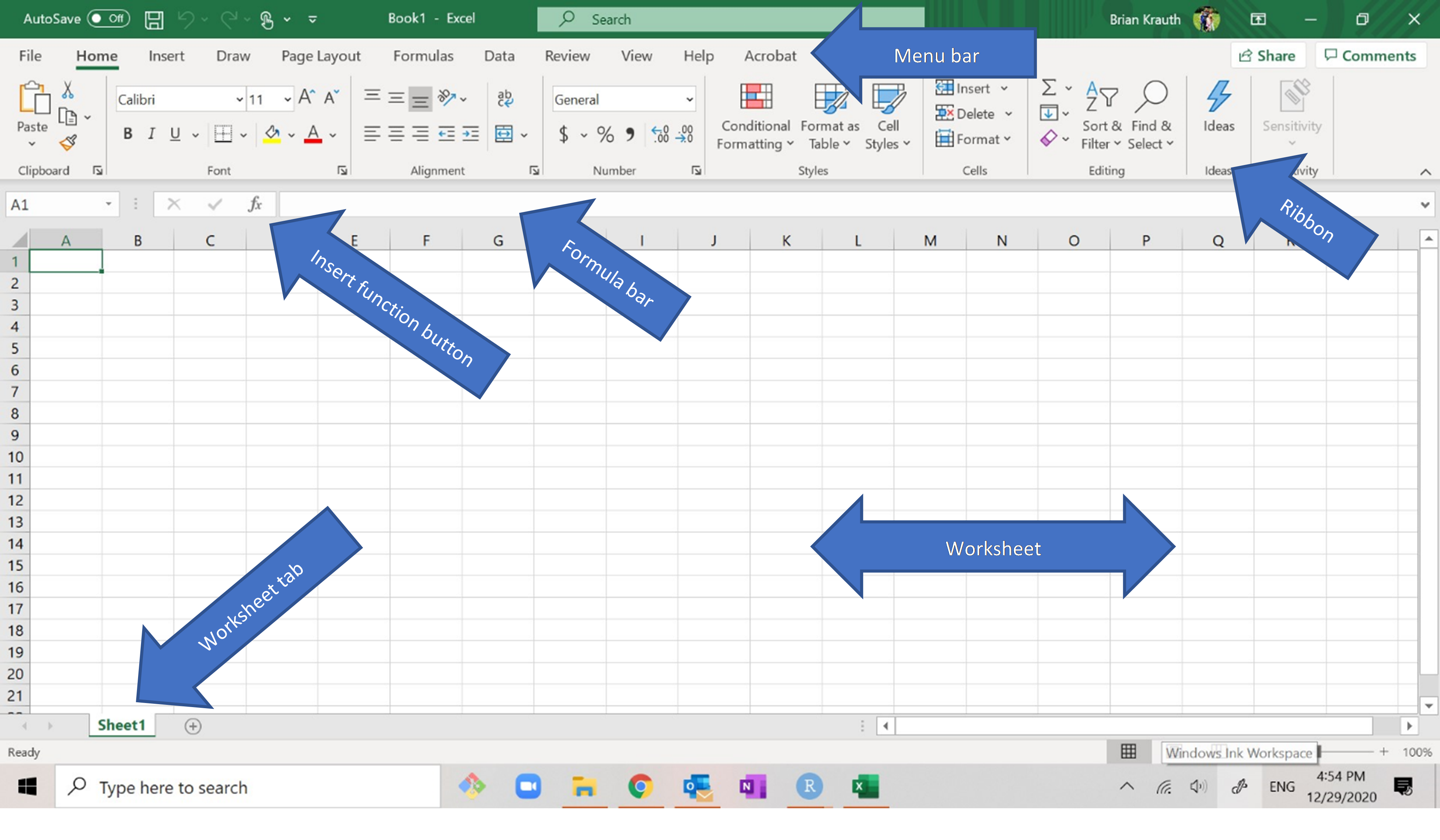
- The menu bar is at the top of the screen:

- The ribbon is below the menu bar:

- The ribbon has buttons for performing simple actions.
- The buttons are grouped by function, for example the ribbon above depicts
groups called
Clipboard,Font, etc.- Within each function group, there is usually a little
 icon in the lower-right corner that you can click for additional
options.
icon in the lower-right corner that you can click for additional
options.
- Within each function group, there is usually a little
- If the ribbon is not visible:
- You can make it visible by selecting any option (like
Home) on the menu bar. - Once you have made the ribbon visible, you can keep it visible by
clicking on the little thumbtack
 icon in its lower right corner.
icon in its lower right corner.
- You can make it visible by selecting any option (like
- The contents of the ribbon depend on the currently-active menu bar option
(usually but not always
Home).- I will assume that
Homeis the currently-active option; if it isn’t you can just selectHometo make it the currently-active option.
- I will assume that
- The formula bar is the long white box just below the ribbon:
 and the insert function button is to the left of the formula bar:
and the insert function button is to the left of the formula bar:
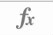
- Most of the screen displays a spreadsheet or worksheet,
which is a rectangular grid of cells:
- Columns are identified by letter.
- Rows are identified by number.
- Cells are identified by column and row. For example, the cell in column A, row 2 is called cell A2.
- Below the worksheet is a row of worksheet tabs:

- Each tab corresponds to a worksheet. In this example, there is a single worksheet named Book1.
- Click on a tab to switch to that worksheet.
- Double-click on a tab to change its name.
- Right-click on a tab to access additional options.
- Click on the “+” button to add a new worksheet.
Excel is used to modify and display workbooks, which are collections
of one or more worksheets. Each Excel workbook is stored on your computer in a
single file. In Windows, these files normally have the .xlsx extension but
older files sometimes have the .xls extension instead.
2.1.2 Application: Canadian employment data
We will demonstrate the key principles and tools in this chapter by cleaning the November 2020 employment data for Canadian provinces.
Economics review: Canadian employment statistics
Employment statistics are important macroeconomic indicators that are typically covered in your Principles of Macroeconomics course.
- In Canada, these statistics are reported monthly by Statistics Canada and
are based on the Labour Force Survey (LFS), a monthly survey of the
civilian, non-institutionalized, working-age population of Canada.
- “civilian” excludes those on active military duty.
- “non-institutionalized” excludes people in prison, hospitals, nursing homes, etc.
- “working-age” excludes those under age 15.
- People living in First Nations reserves and some other Indigenous settlements are also not covered by the LFS.
- The LFS population is grouped into three categories:
- Employed: worked for pay or profit in the previous week, or had a job and was absent (e.g. due to illness or vacation).
- Unemployed: not employed in the previous week, but either looking for work, on temporary layoff, or had a job to start within the next four weeks.
- Not in the labour force: everyone else. This includes retirees, full-time students who aren’t working for pay, and anyone else who is neither working nor looking for work.
- These basic counts are then used to calculate several other statistics
- The labour force is the total count of those who are employed or unemployed.
- The labour force participation rate is the proportion or percentage of the population that is in the labour force. The Canadian LFP rate is typically around 65%.
- The unemployment rate is the proportion of the labour force that is unemployed. The Canadian unemployment rate is typically 5-10%.
Almost all countries collect and report employment statistics using similar methodologies. For example, U.S. employment statistics are constructed and reported by the U.S. Bureau of Labor Statistics based on a survey called the Current Population Survey.
The unemployment rate and LFP rate are key indicators of labour market conditions. A higher-than-usual unemployment rate means that workers are having difficulty finding work, and a lower-than-usual LPF rate means that some workers have stopped looking for work.
The data can be found in the file https://bookdown.org/bkrauth/IS4E/sampledata/CanEmpNov20.xlsx.
Example 2.1 Opening the employment data
Open the file https://bookdown.org/bkrauth/IS4E/sampledata/CanEmpNov20.xlsx in Excel. The file should look something like this:
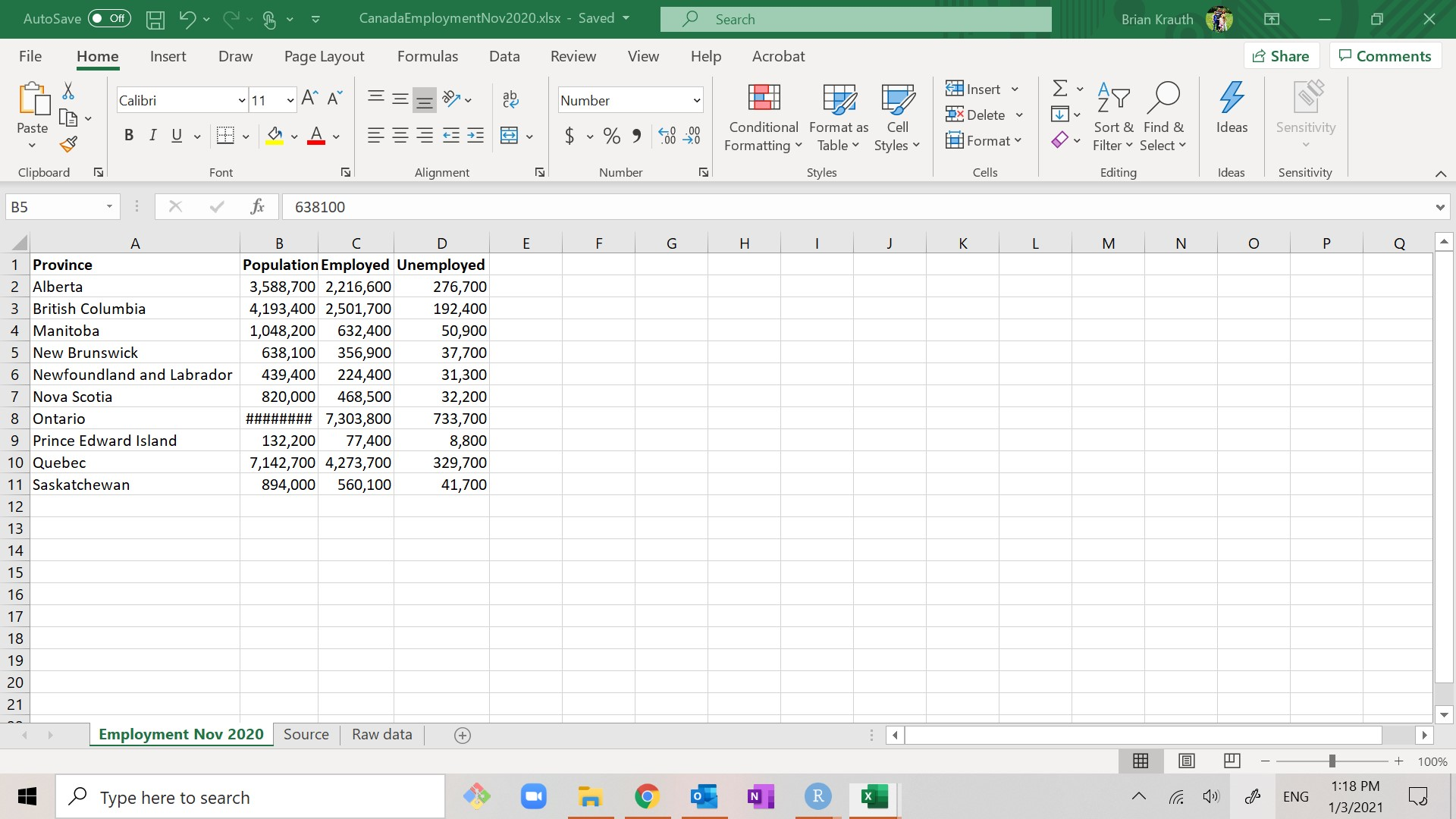
Note that three of the key employment variables (Population, Employed, and Unemployed) are in the data set, but the other ones are not. We will need to calculate them as part of our data cleaning project.
2.2 Data cleaning principles
Next, we describe some of the core principles we will follow in cleaning and managing our data. We will refer back to these principles as we go through the application.
2.2.1 Reproducibility
When analyzing data, it is important for the results of your analysis to be reproducible. Reproducibility means that an interested reader should be able to figure out exactly how you got your results, and should be able to generate those results themselves.
The “interested reader” might be you, as it is common to return to an analysis you did earlier. Without reproducibility, you may not remember where you found the data, what you have done with it, or what it means. The interested reader might also be your coworkers, your boss, or your clients.
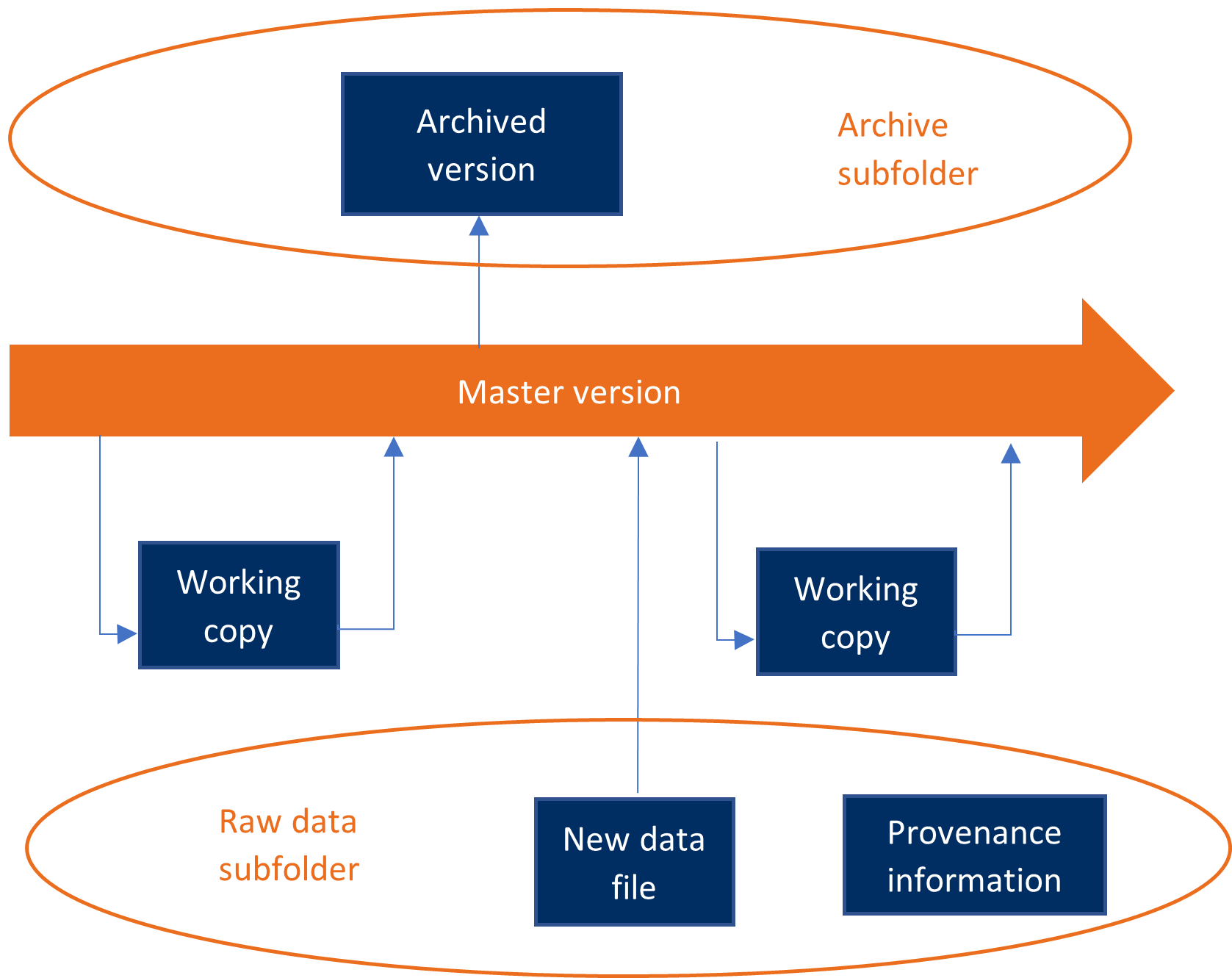 A simple workflow for version control.
A simple workflow for version control.
Reproducibility requires that we treat our data with care. In particular, we treat the various things we do with our data as part of a repeated sequence of steps called a workflow.
Your data analysis workflow should have three key features:
- Keep your data and analysis portable.
- Data is portable if it can be easily moved between operating systems, file formats, and applications.
- Organize your work into clear projects, and keep all of the files for a given project in a single project folder. This allows you to share your work with someone by giving them a copy of the project folder.
- Give files and variables brief, informative, and portable names.
- For example, stick to letters and numbers, and avoid using spaces, special characters, accents, etc.
- Following a naming convention may help make your names more informative without making them too long.
- Document the provenance of all data used.
- Provenance is the full history of the data including its origin and all subsequent changes.
- Keep an unmodified copy of all original data files, and avoid renaming
them.
- When downloading data files, document the original URL and date of access.
- Create and maintain a document (usually a small text file called
README.txt) that explains the provenance and provides other relevant information. - Avoid directly editing data. Data storage is cheap, and adding data is almost always preferable to changing or deleting it.
- Use version control to manage and track changes to your files as you
work. Version control systems can be very elaborate and use specialized
software, but I will teach you a simple workflow that requires no additional
tools:
- Create a working copy of each file you plan to edit.
- You can edit the working copy.
- There should be exactly one working copy of each file.
- Each time you add a feature to your project, make your current
working copy the master version of that file.
- A feature is a discrete and identifiable enhancement to the project: a new variable, a new table or chart, etc.
- The master version represents the project at its most-advanced stage; i.e., the file you would send to your boss to show how your work is going. It should not include any half-finished work.
- The master version should not be directly edited, but should regularly be replaced with the current working copy.
- There should be exactly one master version of each file.
- You can also have archived versions.
- An archived version is a previous master version or working copy that you want to keep for reference.
- Use some file naming convention to distinguish between archived versions.
- You could number them sequentially (e.g., “archive-01”).
- Or you could use dates (e.g., “archive-20dec2022”).
- Archived versions should not be directly edited.
- There can be as many archived versions as you like.
- Create a working copy of each file you plan to edit.
The first step in implementing these principles is usually to set up a project folder.
Example 2.2 Setting up a project folder
To set up a project folder for the cleaning and analysis of the November 2020 Canadian employment data, follow these steps:
- Create a project folder on your computer.
- It will contain all of your data and analysis for this project.
- Give it a brief, clear, and portable name (call it
employment-nov-2020).
- Create sub-folders inside your project folder.
- One will contain the original data (call it
raw-data). - One will contain archived versions of the data. (call it
archive).
- One will contain the original data (call it
- Obtain the source data.
- Download the file https://bookdown.org/bkrauth/IS4E/sampledata/CanEmpNov20.xlsx
- Put it in the
raw-datafolder. - Do not change the file name.
- Document the provenance of all data sources.
- Create a text file called
readme.txt. - Put it in the
raw-datafolder. - Enter information in this file about the provenance of the
CanEmpNov20.xlsxfile.
- Create a text file called
- Create a master version and working copy.
- Make two copies of the
CanEmpNov20.xlsxfile. - Put them in the main project folder (
employment-nov-2020). - One will be your original master version (call it
CanEmpNov20Clean.xlsx). - One will be your working copy (call it
CanEmpNov20-working.xlsx).
- Make two copies of the
We will return to these principles later as we complete our data cleaning project.
Version control systems
Software developers and professional data analysts use version control systems like Git and GitHub. These systems track every change ever made to a group of files, and can allow multiple users to work together on a project. It is based on a model in which each user has their own working copy, and can commit (or propose) changes to the master version, along with an explanation of the changes.
To see what Git and GitHub look like, you can see the GitHub page for this textbook at https://github.com/bvkrauth/is4e. Git and GitHub take a little time to set up and learn, but are extremely useful tools if you do a lot of coding or data analysis.
2.2.2 Tidy data
To keep analysis easy and minimize errors, data should be organized as what data scientists have come to call tidy data. Tidy data has the following seven properties:
- Data is arranged in one or more simple rectangular grids or tables.
- Excel tables should always start in cell A1.
- Each column in a table represents a distinct variable or attribute.
- Each row in a table (after the top row) represents a distinct observation, data point or case.
- Each variable has an informative and unique variable name.
- Variable names are often displayed in the top row of the table.
- Each observation has a unique value for some unique identifier or
ID variable.
- The ID variable is often displayed in the first column of the table.
- All observations in a given table come from the same
unit of observation.
- For example, we might have a table of Canadian cities, or a table of Canadian provinces.
- The order in which observations or variables are listed is irrelevant to
the analysis.
- That is, the interpretation of the table would not change if its rows or columns were in a different order.
Data that is not tidy is sometimes called messy data. One of the first steps in cleaning data is rearranging it from a messy format to a tidy format.
Example 2.3 Overview of the employment data
Open your working copy of the employment data file in Excel. As you can see, this Excel workbook contains three worksheets:
The worksheet Employment Nov 2020 is our main data table:
It is in tidy format:
- There is a single rectangular table starting in cell A1.
- Each row represents a Canadian province.
- Canadian provinces are the unit of observation.
- Each column represents a variable describing that province.
- The top row shows brief but clear names for each variable.
- The provinces are listed in alphabetical order, but the interpretation of the table would not change if they were listed in some other order.
The worksheet Raw data is the original data table as I downloaded it from Statistics Canada:
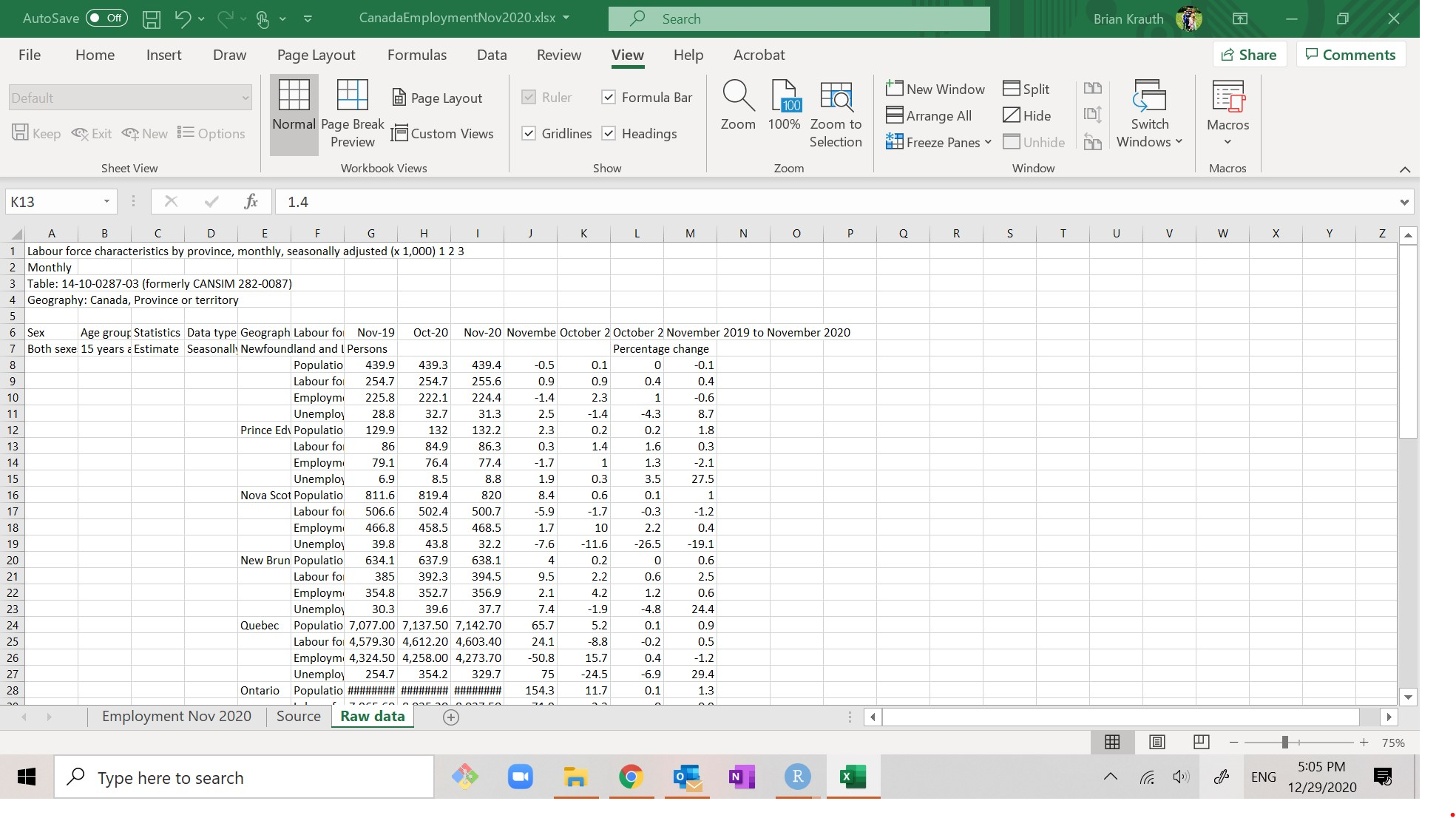 It is messy in various ways:
It is messy in various ways:
- The table starts in cell A6 rather than cell A1.
- Variables (Population, Labour Force, etc.) are in rows rather than columns.
- Observations (the unit of observation is the province-month) are in both rows and columns.
- Cells are filled in “implicitly”. For example, there is nothing in row 17 that says what province it describes, but we know that it describes Nova Scotia because it comes after row 16 (which does say it describes Nova Scotia). As a result, the order of rows is very important.
The worksheet Source describes the provenance of the data:
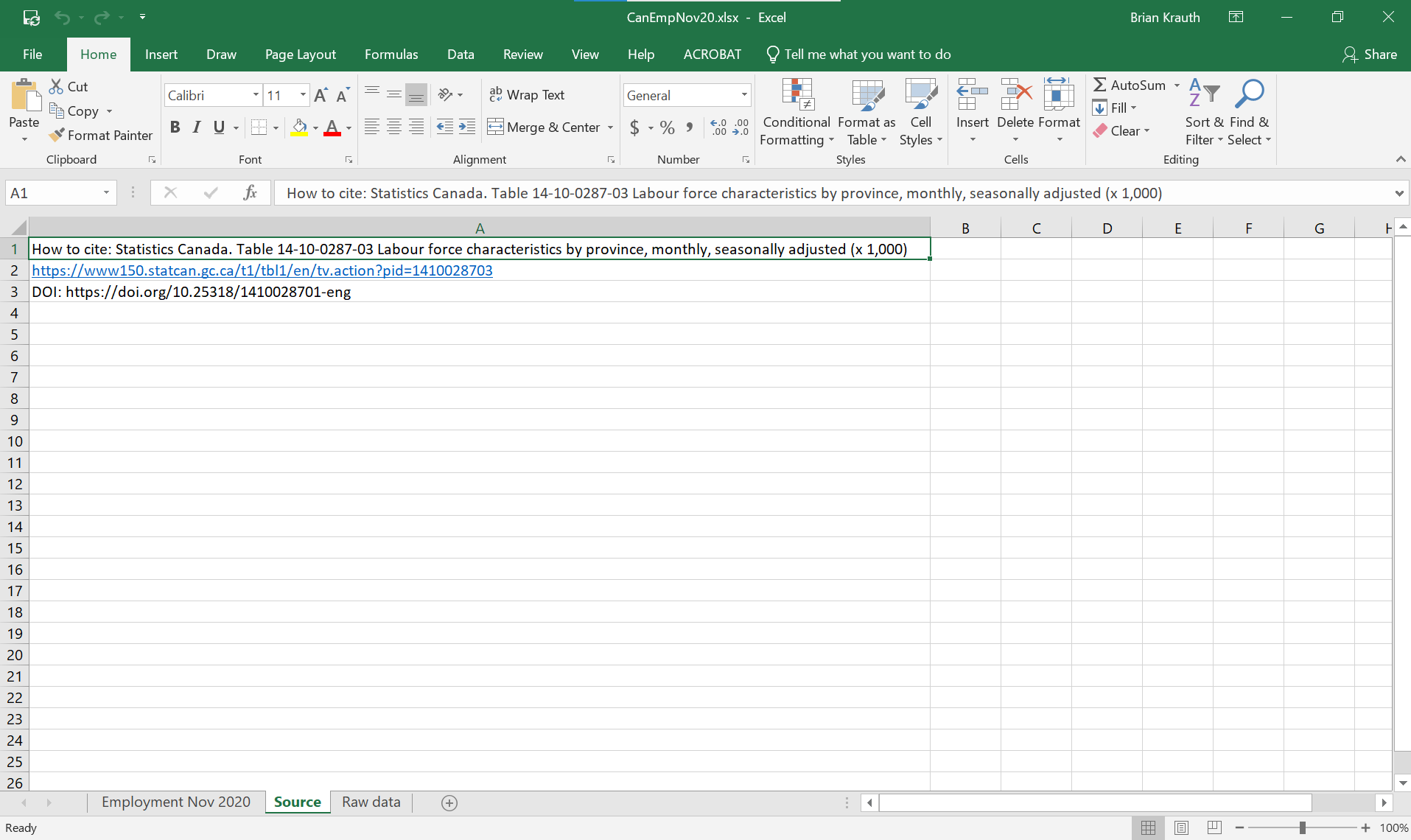 It is not a data table, just a few lines of text.
It is not a data table, just a few lines of text.
- There is a text description of the data, provided by Statistics Canada.
- There are also two URLs linking to the original data source. Copy and paste either of them into your browser to see what the original data source looks like.
- There should also be some information on the date of access, but there currently isn’t.
We will do all of our edits to the Employment Nov 2020 worksheet, and will leave both Raw data and Source alone.
Link rot and the DOI
One common barrier to reproducibility is “link rot” - the tendency of a given URL to stop working over time as organizations make changes to their websites. Most links only work for a few months or a few years, depending on the data provider and how careful they are. To minimize the potential consequences of link rot, you should always save an unmodified local copy of the original data.
Another strategy for addressing link rot is to use a digital object identifier or DOI if one is available. DOI is an international system that allows participating organizations to provide persistent links to documents, files and web pages. The Sources worksheet above provides both regular and DOI addresses.
- The regular URL (https://www150.statcan.gc.ca/t1/tbl1/en/tv.action?pid=1410028703
) tells your browser where the file is located:
- Go to the server www150.statcan.gc.ca.
- Look in the folder t1/tbl1/en/tv.action.
- Pass the server the parameter “pid=1410028703”.
- The DOI URL (https://doi.org/10.25318/1410028701-eng) also tells the browser where a file is located, but the file at that location is not the actual data file. Instead, the file at that location is a link that (currently) redirects the user to the address https://www150.statcan.gc.ca/t1/tbl1/en/tv.action?pid=1410028703.
At some point in the future, Statistics Canada will reorganize its website and move the original document. When this happens, the original URL will stop working, but the DOI will continue working as long as Statistics Canada updates the DOI entry for the document.
2.2.3 Observations and identifiers
Each tidy data set normally includes at least one unique identifier or ID variable. By definition, an ID variable must take on a different value for each observation. With this property, we can use ID variables to link and combine data from multiple sources.
Proper names of people, places or organizations are typically not used as ID variables since they are not necessarily unique. For example, there are many people in Canada named “Doug Smith.” In addition, proper names are not always written consistently. For example, the same person might be called “Doug Smith” in one data set and “Douglas Smith” in another.
Example 2.4 Is the province name a good ID variable?
The province name in our employment data is an example of a proper name, and we typically avoid using proper names as ID variables because they are not necessarily unique or consistently written. Although province names are unique within Canada, they are not always consistently written:
- Newfoundland and Labrador (as it is called in our employment data) is called “Newfoundland” in older data sets as that was the province’s official name before December 6, 2001.
- Quebec (as it is called in our employment data) is called “Québec” in some data sets.
This inconsistency may cause problems when we try to link data sources, so we should avoid using the province name as an ID variable.
ID variables have several common characteristics:
- They can be numbers or text strings.
- They can be:
- Assigned arbitrarily, i.e. following no consistent rule.
- Assigned sequentially according to some natural ordering.
- Assigned by a standardized code that is listed in some published table.
- Constructed by formula from other information.
- They can be defined by an explicit combination (a new ID variable is constructed) of other identifiers, or an implicit combination (no new variable is constructed) of those identifiers .
It’s OK for an ID variable to be nearly-but-not-exactly identical to some other variable. For example a Canadian data set might have both a Province variable that takes on values like “Québec” and “Nova Scotia” and a ProvinceID variable that takes on values like “QUEBEC” and “NOVASCOTIA.”
ID variables at SFU
SFU is one of British Columbia’s largest organizations. Like most large organizations, it maintains large administrative records that are organized and linked using various ID variables:
- Each person at SFU (faculty, staff or student) has a unique 16-digit ID number that is arbitrarily/sequentially assigned.
- Each computing account at SFU has a unique (text) user name that is also used as an email address. Some rules are used to construct user names, but those rules have not been applied consistently over the years so we can think of user names as arbitrarily assigned.
- Each academic program at SFU has a standardized 2-letter to 4-letter program code. For example, the program code for economics is ECON. The full list of program codes can be found at https://www.sfu.ca/students/calendar/2026/spring/courses.html.
- Each program assigns (mostly) arbitrary numeric course codes. For example the economics department has assigned the numeric course code 233 to its introductory statistics course.
- Each semester at SFU has a 4-digit semester code constructed by a formula based on the year and term. For example, Fall 2021 is assigned the semester code 1217. The first three digits represent the year (2021 -1900 = 121) and the last digit represents the term (Spring = 1, Summer = 4, Fall = 7).
- Each course at SFU is uniquely identified by the combination of its program code (e.g. ECON) its numeric course code (e.g. 233), its section number (e.g., D100), and its semester number (e.g., 1217). These can be explicitly combined into a unique course ID variable (e.g., “ECON233-D100-1217”).
Your library record, grades, financial records, and almost any other information SFU has about you includes one or more of these IDs.
Like file and variable names, ID variables are ideally portable across applications and platforms. That is, our ID variable should still work if we move data from a Windows PC to a Linux or Apple system, and should still work if we move from Excel to R or Python. Try to keep them short and simple.
Keeping ID variables portable
To maximize portability of ID variables, keep in mind the following potential issues and solutions for avoiding them:
| Issue | Description | Solution |
|---|---|---|
| Rounding | Some applications will round non-integer values (changing 1.23 to 1) or drop leading zeros (changing 00045 to 45). | Numeric ID variables should always be integers without leading zeros, or converted to text variables. |
| Special characters | Some applications will reject or transform spaces or unusual characters. | Text ID variables should only use (Latin) letters and (Arabic) digits. |
| Case | Some applications are case-sensitive (so that “hello” and “Hello” are different values) and others are not. | Text ID variables should typically use either all upper-case or all lower-case. |
| Length | Some applications will have a maximum length for a text variable, and will cut off everything above that maximum length. | Text ID variables should not be extremely long. |
Example 2.5 Choosing an ID variable
Having decided that the province name is not a good ID variable for our employment data, we need to choose another one. Although only one ID variable is needed, I will choose two for demonstration purposes:
- ID: an arbitrary/sequential number assigned to each observation.
- ProvAbb: a standardized (text) code based on the two-letter postal abbreviation.
We will add these two variables while cleaning our data.
Names, IDs, and probabilistic matching
Occasionally a data set will not have a standardized ID variable, and our only option is to match observations based on a proper name. For example, the government of British Columbia assigns each student in grades K to 12 an ID number called a Personal Education Number (PEN) while each person in the healthcare system is assigned a different ID number called a Personal Health Number (PHN). There is no direct way to match PEN and PHN, so we have to match education and health records on a combination of proper names and other information such as date of birth. Matches made this way are called “probabilistic” matches, meaning (roughly) that the records probably describe the same person but might not.
2.2.4 Planning
Before diving into cleaning our data, it is often wise to look closely at the data and construct a cleaning plan. Here is a simple template for such a plan:
- Convert all data sources into tidy-format tables in the application(s) we intend to use.
- Select or construct a unique ID variable for each table.
- Find and address problems in existing variables.
- Create new variables that may be useful.
The cleaning plan should be based around what we intend to do with the data, but should preserve flexibility in case we want to use the data for other purposes.
Example 2.6 A plan for cleaning the employment data
Following the template above, we can construct a simple data cleaning plan for the employment data:
Convert all data into tidy-format tables.
Our employment data table is already in tidy format, so no action is required.
Select or construct a unique ID variable for each table.
As discussed earlier, the province name is not an ideal ID variable so we will construct two alternative ID variables: an arbitrary/sequential number and the two-letter postal abbreviation.
Find and address problems in existing variables.
The only problem I see in the current data is in cell B8, which is supposed to display the population of Ontario but instead shows “########”. We will need to investigate and fix this.
Remember the general principle to avoid editing data. So if we do find problems, we would ideally fix them by creating new-and-improved versions of these variables rather than directly editing the existing variables.
Create new variables that may be useful.
We will want to construct new variables for:
- the specific month these observations are describing (November 2020)
- the two unique ID variables described in step 2
- the labour force
- the labour force participation rate
- the unemployment rate
We will also add a few more variables, mostly to demonstrate various features of Excel. It’s OK to move beyond the initial cleaning plan as we learn more about our data.
2.3 Cleaning data in Excel
We are now ready to start using Excel to actively clean our data. We will also introduce a set of important Excel tools and concepts that are useful in cleaning data.
Example 2.7 Getting started
Open your working copy of the employment data and go to the Employment Nov 2020 worksheet.
Each example in the rest of this chapter describes a task needed to clean this data set. Remember to save this file after completing each example task to ensure you don’t lose your work due to a mistake.
2.3.1 Cell formatting
Excel distinguishes between the contents of a cell and how those contents are displayed. You can usually see the contents of a cell by selecting it and looking at the formula bar.
We can change the appearance of our data without changing its content by adjusting the cell formatting for one or more cells. Cell formatting characteristics include:
- Text font, size, style (bold/italics/underline) and color
- Text alignment (left/right/center as well as top/bottom/middle)
- Column width
- Row height
- Background color
- Cell borders
- Number format (will be discussed in a later section)
The procedure for modifying a cell’s format is straightforward: select the cell(s) you are interested in modifying, then go through the menus to choose the modifications.
Example 2.8 Changing cell width
As mentioned earlier, cell B8 (Ontario population) appears to contain “######” rather than a number. If you select this cell and look in the formula bar you will see it actually does contain the number 12378900. The reason that the cell displays “######” is that the cell is not wide enough to show the correct number.
We can solve this problem by making column B wider. There are several ways of doing this:
- From the menu: Select cell B8, or select the whole column by clicking on the
“B” at the top of the column. Then you can either:
- Select
Home > Format > AutoFit Column Widthfrom the menu to make the column exactly fit the data OR - Select
Home > Format > Column Width...to set the exact width.
- Select
- With the mouse: Move your cursor to the line between column headers B
and C until the cursor looks like this:
 .
Then you can either:
.
Then you can either:
- Click on the mouse and drag the cursor to resize the column until you get a column width that you like.
- Double-click on the mouse to auto-fit.
You can follow similar procedures to adjust the row height.
2.3.2 Inserting and deleting cells
Most of the time, we will add data to the end of the existing table, adding new variables after the last column or new observations after the last row. But occasionally we will want to insert a column or row into our table.
Example 2.9 Inserting a column
We will want our first column to include a not-yet-constructed ID variable, so we need to insert a column to the left.
- Select any cell in column A.
- Select
Home > Insert > Insert Sheet Columnsfrom the menu.
This will shift all columns to the right, and insert a new blank column A. We will enter data in this column later.
We can also insert rows, delete rows or columns, and even insert or delete individual cells.
2.3.3 Data entry
The simplest way to add a variable to an Excel table is by typing data directly into the cells.
Example 2.10 Entering data
As we discussed earlier, we would like to add the two-letter postal abbreviation for each province:
| Province or Territory | ProvAbb |
|---|---|
| Alberta | AB |
| British Columbia | BC |
| Manitoba | MB |
| New Brunswick | NB |
| Newfoundland and Labrador | NL |
| Northwest Territories | NT |
| Nova Scotia | NS |
| Nunavut | NU |
| Ontario | ON |
| Prince Edward Island | PE |
| Quebec | QC |
| Saskatchewan | SK |
| Yukon | YT |
The postal abbreviation is useful for at least three reasons
- It is standardized, while the full province name may not be.
- The postal abbreviations were originally created by Canada Post.
- They are also internationally recognized through the ISO 3166-2 standard on “Codes for the representation of names of countries and their subdivisions.”
- It is short, which can be useful in charts.
- It is informative. Postal abbreviations are widely used, and are familiar to many Canadians.
To add this variable:
- Enter ProvAbb in cell F1 to name the variable.
- Fill in cells F2:F11 with the correct postal abbreviation.
- Save your working copy.
Choosing variable names
It takes a little bit of thought to choose brief and informative variable names that work well, but you will be glad you did it.
- Variable names need to be unique.
- Province would have been a nice short and clear variable name, but it was already taken.
- Variable names should be informative.
- X or MyVariable would have been bad variable names.
- So would Province2.
- Variable names should be short.
- In some older programs, variable names can be no longer than 8 characters long. Most modern programs allow much longer variable names, but long variable names are harder to remember, harder to type without errors, and less likely to display cleanly.
- 8 characters is a good target, but it’s OK to go a little over that.
- Abbreviation is a good way to shorten names, so we use ProvAbb instead of ProvinceAbbreviation.
- Variable names should avoid spaces and special characters:
- Special characters are anything other than the Latin letters (a through z),
Arabic digits (0 through 9), and the underscore
_. - When constructing variable names from multiple words, there are several
standard methods of distinguishing between the words:
- Pascal case: ProvAbb
- Camel case: provAbb
- Snake case: prov_abb
- Special characters are anything other than the Latin letters (a through z),
Arabic digits (0 through 9), and the underscore
- Variable names should be treated as potentially case independent.
- Some programs like R treat variable names as case dependent, and will consider ProvAbb, provabb, provAbb and PROVABB four different variables.
- Other programs like SAS treat variable names as case independent, so these four names all refer to the same variable.
- So once we create a variable called ProvAbb we should never create another variable called provabb, provAbb, or PROVABB, just in case we want to use this data set in SAS.
- Variable naming conventions should be consistent within each data set.
- We could have used camelCase or snake_case for our new variable, but the existing variables use PascalCase so we should use PascalCase for all new variables too.
Excel allows nearly anything in a variable name since it does not normally use the variable names in its calculations. But good naming practices are still important for portability.
2.3.4 Fill and series
Excel also has several tools available to speed the process of entering data. First, you can copy-and-paste or cut-and-paste the contents of any cell into any other cell. I’ll assume you know how to do this, though there are a few special tricks we will cover later on.
Excel’s fill tool allows you to quickly copy the contents of a cell into a set of cells immediately, above, below or to the left or right.
Example 2.11 Using fill
Our data cleaning plan includes adding a variable indicating which month and year these particular observations describe (November 2020).
- Enter MonthYr in cell G1 to name the variable.
- Enter “11/2020” in cell G2.
- You may notice that Excel displays the date differently from how you
entered it - on my computer it displays as
Nov-20but yours may look different. We will talk more later about how Excel handles dates.
- You may notice that Excel displays the date differently from how you
entered it - on my computer it displays as
Now we could enter the exact same date in cells G3:G11, but we can save ourselves some time by using Excel’s fill tool:
- Select cells G2:G11.
- Select
Home > Fill > Down. - Save your working copy.
As you can see, Excel fills in all selected cells with the value in the top cell.
Excel’s series tool allows you to fill in a group of cells with an ascending or descending sequence of numbers or dates.
Example 2.12 Using series
Let’s create a unique sequential ID variable in column A. We can enter these ID numbers by hand, but there is an easier way using Excel’s series tool:
- Enter ID in cell A1 to name the variable.
- Enter 1 in cell A2.
- Select cells A2:A11.
- Select
Fill > Series.... The Series dialog box will appear. - There are several options for constructing a series. Fortunately, the
default is exactly what we want, so select
OK. - Save your working copy.
As you can see, column A now contains a unique identifier that numbers provinces from 1 to 10.
Some useful Excel shortcuts
Switching between your keyboard and mouse/touchpad/touchscreen can be annoying and time-consuming. You can speed up your work by learning a few handy keyboard shortcuts.
The first set of shortcuts is that you can navigate around your spreadsheet by
using the arrow, Home, End, PgUp and PgDn keys. Try using them in
combination with the Ctrl key (which typically takes you to the end of the
spreadsheet) or the Shift key (which typically selects a group of cells).
In addition, most commonly used menu items have associated keyboard shortcuts. These are the ones I find most useful:
| Action | Shortcut |
|---|---|
| Cut | Ctrl-x |
| Copy | Ctrl-c |
| Paste | Ctrl-v |
| Fill Down | Ctrl-d |
| Fill Right | Ctrl-r |
| Undo | Ctrl-z |
| Cancel edit | Esc |
| Clear cell | Del |
| Save file | Ctrl-s |
| Bold | Ctrl-b |
| Italics | Ctrl-i |
| Underline | Ctrl-u |
Additional shortcuts and macOS information are available at https://support.microsoft.com/en-us/office/keyboard-shortcuts-in-excel-1798d9d5-842a-42b8-9c99-9b7213f0040f.
2.3.5 Formulas
Most of our new variables will be calculated from existing variables using formulas. A formula is just a rule for calculating a value from some other values.
Formulas always start with the equal sign = followed by a mathematical
expression that can include any combination of:
- Specific values, for example
=2or=TRUE - References to other cells, for example
=D2 - Standard arithmetic operators, for example
=2+2or=D2/4 - Functions, for example
=SQRT(D2)or=SUM(D2:D10)
Formulas can be simple, or they can be quite complex.
Example 2.13 A simple formula
Returning to our application, everyone who is either employed or unemployed is in what economists call the “labour force.” So let’s add that variable.
- Enter LabourForce in cell H1 to name the variable.
- Enter
= D2 + E2in cell H2. - Save your working copy.
Cell H2 now displays 2,493,300 which is in fact the value in cell D2
plus the value in cell E2.
As discussed earlier, it is important to distinguish between the contents of a
cell and how those contents are displayed. For example, the true contents of
cell H2 in our example above are the formula = D2 + E2 but the cell displays
the number 2,493,300. If you change the number in cell D2 or cell E2, the
number displayed in cell H2 will adjust accordingly.
Formulas can use the results from other formulas, as shown in the example below.
Example 2.14 Formulas can use other formulas
Let’s add a column for the labour force participation rate. To remind you, this is the proportion or percentage of the population (column C) that is in the labour force (column H).
- Enter LFPRate in cell I1 to name the variable.
- Enter
=H2/C2in cell I2 to calculate the variable. - Save your working copy.
Notice that this formula uses cell H2, which itself contains a formula. It is often easier to check your work and spot problems if you break up complex formulas into steps like this.
When building a formula, you can use the mouse to select the cells to use. You will find this feature useful when constructing formulas that rely on cells that are far away, or even in a different worksheet.
Example 2.15 Using the mouse to build formulas
Let’s also add a column for the unemployment rate. To remind you, this is the proportion or percentage of the labour force (column H) that is unemployed (column E).
- Enter UnempRate in cell J1 to name the variable.
- Select cell J2.
- Type
=in cell J2, but do not hit the enter key yet. - Select cell E2 with the cursor. You will see that the formula in cell J2 now
shows
=E2 - Type
/. Do not hit the enter key. - Select cell H2. You will see that the formula in cell J2 now
shows
=E2/H2 - Hit the enter key.
- Save your working copy.
Notice that Excel uses color-coding to help you out: cell E2 is the same color
as the text E2 in your formula, and cell H2 is the same color as the text
H2 in your formula
2.3.6 Functions
Excel has about 500 built-in functions that we can use in formulas. Each function has a function name and a set of arguments whose values you can set. To use a function, you simply include its name and its arguments as part of the formula.
Example 2.16 The LN() function
The LN() function takes a single numerical argument Number, and returns
the natural (base \(e\)) logarithm of that number.
- If you enter
=LN(10)in cell K2, it will display the natural logarithm of 10. - If you enter
=LN(C2)in cell K2, it will display the natural logarithm of whatever number is in cell C2.
You can find its official documentation at https://support.microsoft.com/en-us/office/ln-function-81fe1ed7-dac9-4acd-ba1d-07a142c6118f.
If you already know the name and arguments of the function you want to use, you can just type it in as part of your formula. But Excel has several tools to make its functions easier to use.
Example 2.17 Using the Insert Function button
Suppose that we want to add a new variable for the (natural) log of population,
and we don’t already know about the LN() function. Fortunately, we can use the
Insert Function button to find our function and use it in a formula.
- Enter LogPop in cell K1 to give the variable a name.
- Select cell K2.
- Click on the Insert Function button
to the left of the formula bar.
- The
Insert Functiondialog box will show a long list of functions:
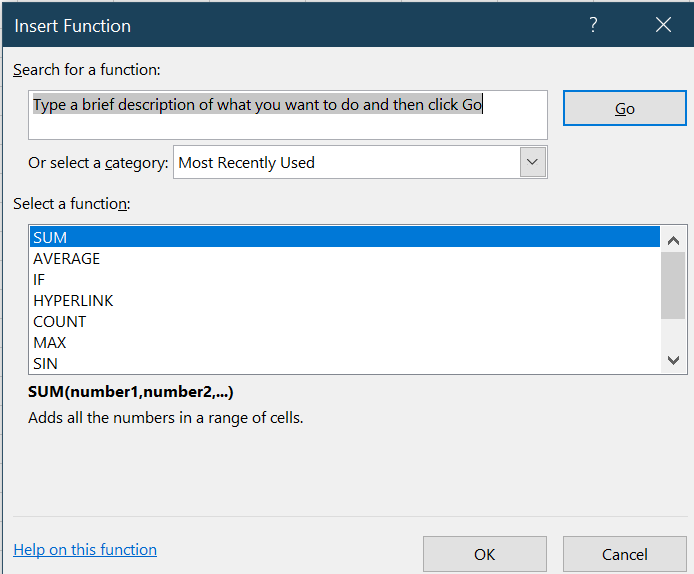 You have two options for narrowing this list down:
You have two options for narrowing this list down:
- Search: Enter
logarithmin theSearch for a functiontext box. - Browse: Select
Math & Trigfrom theOr select a categorydrop-down box.
- Search: Enter
- Select
LNfrom theSelect a functionlist box, and then selectOK. You will now see theFunction Argumentsdialog box for theLNfunction:
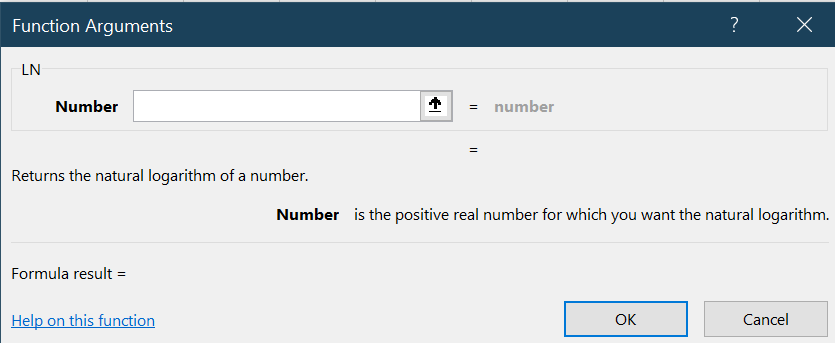
- Click in the entry box labeled
Number. - Either enter the text
C2here or select cell C2 with the mouse.- Notice that the dialog box displays the value in cell C2 (
3588700) as well as the calculated value for its logarithm (15.0933058).
- Notice that the dialog box displays the value in cell C2 (
- Select
OK. - Save your working copy.
You will see that cell K2 now contains the formula =LN(C2) which displays as
15.0933.
In addition to the features built in to Excel, you can always use search engines or AI to find the function you need. For example, you can Google “Excel function for logarithm” or “how to calculate the natural log in Excel.”
Advanced function capabilities
Excel has many built-in functions, and can be extended to include additional functions as needed for more advanced users.
- You can create your own custom functions using the JavaScript or Visual Basic for Applications (VBA) programming languages. You can also use these languages to modify the user interface, automate repetitive tasks, and perform various other advanced tasks.
- You can install and use various add-in packages from Microsoft or other sources. For example, Excel usually comes with an add-in called the Analysis ToolPak that provides additional functions and tools for use in statistical analysis.
These are relatively advanced Excel features, but are commonly used in a business environment. They also have some security risks, and Microsoft has substantially modified their functionality over the past few years to address these risks. So we will not create custom functions or use add-in packages in this course.
2.3.7 Cell ranges
Some functions like SUM() and AVERAGE() operate on a range of cells
rather than a single cell. A range is just a rectangular grid of cells,
and is described by its upper-left and lower-right cells, separated
by a colon (“:”). For example:
- Range A2:A5 consists of cells A2, A3, A4 and A5.
- Range A2:C2 consists of cells A2, B2, and C2.
- Range A2:B3 consists of cells A2, B2, A3, and C3.
A single cell can also be thought of as a range of cells with one row and one column.
Example 2.18 A formula using a cell range
Suppose we want to create a new variable that reports the total population
across all observations in the data. The function to do that is SUM().
- Enter TotPop in cell L1 to give the variable a name,
- Enter
=SUM(C2:C11)in cell L2.
- Save your working copy.
Cell L2 should display 31,275,600 which is indeed the sum of cells C2 to C11.
2.3.8 Copying formulas
In Excel, you can copy-and-paste the contents of a cell to any other cell. This is particularly handy when a cell contains a formula, as it would be inconvenient to type the same formula into each cell.
Example 2.19 Copying a formula
To use copy-and-paste to copy the formula in cell H2 to the other cells in column H:
- Select cell H2 and copy it.
- Select cells H3:H11 and paste.
- Save your working copy.
You can also use fill for this purpose, and it is usually quicker.
Example 2.20 Filling a formula
To use fill to copy the formulas in cells I2:L2 to the other cells in columns I through L:
- Select cells I2:L11.
- Select
Home > Fill > Down. - Save your working copy.
2.3.9 Relative and absolute references
Excel is smart and normally treats cell addresses in formulas as relative references when copying and pasting cells. That is, when a formula is copied to another cell \(r\) columns to the right and \(d\) rows down, the column letters in the formula are increased by \(r\) units, and the row numbers are increased by \(d\) units.
For example, suppose cell B5 contains the formula =A1. If we copy the
contents of this cell to other cells, we get:
| B | C | D | |
|---|---|---|---|
| 5 | =A1 | =B1 | =C1 |
| 6 | =A2 | =B2 | =C2 |
| 7 | =A3 | =B3 | =C3 |
This is usually exactly what we want Excel to do.
Example 2.21 Relative references are usually what we want
Select cell H3 and take a look at the formula bar to see its contents. Notice that:
- the original cell H2 contains
=D2+E2. - cell H3 contains
=D3+E3.
This is exactly what we would want; each cell in column H calculates the
province’s labour force by adding the unemployed count (column D) and employed
count (column E) from the same province (same row). So cell H2 should contain
=D2+E2 and cell H3 should contain =D3+E3.
Similarly, the formulas in columns I (LFPRate), J (UnempRate), and K (LogPop) have all copied exactly as we would would want them to be.
Sometimes we will want Excel to treat cell references as absolute references instead. That is, we want to copy the cell reference exactly as written.
Example 2.22 Relative references are not always what we want
Take a look at the TotPop variable in column L. This variable is supposed to represent the total Canadian population, but each cell in this column shows a different number.
Because Excel treats cell references as relative, copying the cell L2 to the rest of column L produces:
- Cell L2 contains
=SUM(C2:C11). - Cell L3 contains
=SUM(C3:C12). - Cell L4 contains
=SUM(C4:C13). - etc.
In this case, that is not what we want. We want all of the cells to contain
the total population of all provinces, which means all of them should contain
the formula =SUM(C2:C11).
We can tell Excel to treat a given cell reference as absolute by adding the
$ character in front of the reference. For example, suppose that we copy the
formula in cell C2 to cell D3. Then:
| If cell C2 contains | Then cell D3 contains |
|---|---|
=A1 |
=B2 |
=$A1 |
=$A2 |
=A$1 |
=B$1 |
=$A$1 |
=$A$1 |
Note that the presence or absence of the $ does not affect the calculation in
the cell, it only affects how the formula is copied over to other cells.
Example 2.23 Using absolute references in a formula
To fix the TotPop variable, we can change the relative references to absolute references:
- Go back to cell L2.
- Change
=SUM(C2:C11)to=SUM(C$2:C$11).- Notice that the value in this cell does not change.
- The
$operator affects how a formula is copied, not how it is calculated.
- Copy/paste or fill cell L2 into cells L3:L11.
- Notice that all cells in this column now contain the same formula
(
=SUM(C$2:C$11)) and display the same value (31,275,600). - This is what we want.
- Notice that all cells in this column now contain the same formula
(
- Save your working copy.
This is what we want.
Sometimes we will want to combine absolute and relative references in the same formula. This typically will happen when we want to compare the current observation to the other observations.
Example 2.24 Combining relative and absolute references
Suppose we want to create a new variable that is the province’s population
rank. That is, the province with the highest population has a rank of 1,
second highest has a rank of 2, etc. The function to do that is RANK.EQ(),
which takes two arguments: the value to rank, and the range of values to use for
the ranking. We want the first argument (the province’s population) to vary
across observations, but we want the range of values (the populations of all of
the provinces) to stay the same.
- Enter PopRank in cell M1 to give the variable a name.
- Enter the formula
=RANK.EQ(C2,C$2:C$11)in cell M2. Note that the first argument uses a relative reference, and the second uses absolute references. - Copy/paste or fill cell M2 into cells M3:M11.
- Save your working copy.
As you can see, Excel displays the correct ranks. If you aren’t sure how this works, look at the contents of each cell of column M to see how the formula copied from cell M2.
Advanced options for ranking in Excel
The RANK.EQ() function has several relatives with similar syntax:
- The
RANK()andRANK.AVG()functions also return the rank, but use slightly different rules for handling ties. - The
PERCENTRANK(),PERCENTRANK.EXC()andPERCENTRANK.INC()functions return ranks in percentiles.
2.4 Excel data types
Most of the data we work with is numeric. However, we also regularly encounter text, logical (true/false) values, dates, and times. Each of these data types need to be handled slightly differently in terms of how they are entered, stored, displayed, and used in calculations.
2.4.1 Numeric data
Most modern computer applications, including Excel, do numeric calculations in double-precision (64-bit) binary floating point format. Calculations in this format are typically accurate up to the 15th decimal place.
However, Excel displays the results of these calculations according to the cell’s numeric display format, which typically rounds to much fewer decimal places. Remember that we can always change the display format of a cell or group of cells without changing the cell contents.
Example 2.25 Displaying a cell in percentage format
UnempRate and LFPRate are both calculated in proportional units (a number between 0 and 1). But we might prefer to display them in percentage units (a number between 0 and 100).
We could do this by changing the formulas (for example, change the LPFRate
formula to =100*H2/C2). An easier approach is to change the cells’ numeric
display format:
- Select cells I2:J11.
- Select
Home > Number Format(it is a little drop down box that currently displaysGeneral), and then selectPercentage.- You will see that the cell now displays the rates in percentage, to two decimal places.
- I think it would be more readable if we round to just one decimal
place. To do that, select
Home > Decrease Decimal. - Save your working copy.
An important thing to understand here: all we have done is change how the numbers are displayed. If we do any calculations with these cells, the calculation will use the original proportional value without rounding.
2.4.2 Text data
Text data is also called character data or string data, and consist of a sequence (string) of letters, numbers, spaces, and symbols (collectively called “characters”). In Excel, text values can be entered directly in a cell, can be used in a formula, and can be the result of a formula.
Excel has many functions for working with text data. A particularly useful one
is the CONCAT() function, which allows you to join or concatenate
two or more strings. This is useful in building reports, in constructing ID
variables, and in many other applications.
Example 2.26 Concatenating strings
To use the CONCAT() function to create a sentence that describes our data as
if it we were writing a written report:
- Enter Description in cell N1 to name the variable.
- Enter
=CONCAT(C2," people live in ",B2)in cell N2.- The cell should display
3588700 people live in Alberta.
- The cell should display
- Copy/paste/fill in cells N3:N11.
- Save your working copy.
As you can see, CONCAT() is useful for converting data into human-readable
statements. It is also useful for constructing ID variables.
As you can see from the example above, numeric and logical values in formulas are automatically converted into text values as needed.
Advanced options for working with text data
There are many useful functions to manipulate text strings in Excel:
LEN()calculates the length (number of characters) of a string. For example:=LEN("Hello world!")returns the value of 12.
MID()allows you to extract part of a string. For example=MID("Hello world!",2,3)returns a value of “ell”.
UPPER(),LOWER()andPROPER()allow you to change the case of a string. For example:=UPPER("Hello world!")returns “HELLO WORLD!”.=LOWER("Hello world!")returns “hello world!”.=PROPER("Hello world!")returns “Hello World!”.
FIND()allows you to find a particular substring within a larger string. For example:=FIND("world!","Hello world!")returns 7.
REPLACE()allows you to replace part of a string. For example:=REPLACE("Hello world!",7,5,"mom")returns “Hello mom!”.
2.4.3 Logical data
In addition to text and numbers, cells can also contain logical values
(TRUE or FALSE). Logical values can be entered directly in a cell, can be
used in a formula, and can be the result of a formula.
Mathematical expressions using the comparison operators
= (equal), <> (not equal),
> (greater than), < (less than),
>= (greater than or equal), and <= (less then or equal)
can be used to create logical values.
Example 2.27 Creating a logical variable
To create a logical variable that indicates whether a province has a labour force participation rate below 64%.
- Enter LowLFP in cell O1 to name the variable.
- Enter
=(I2 < 0.64)in cell O2.- Notice that
(I2 < 0.64)is a statement that is either true or false, not a numeric expression. - Logical statements can use other comparison operators, including
=,<,>, and<=.
- Notice that
- Copy/paste or fill cell O2 into cells O3:O11.
- Save your working copy.
As you can see, the cells display TRUE in the three provinces with LFP rates
below 64%, and FALSE in the other seven.
Logical values are particularly powerful in combination with the IF()
function. This function takes three arguments:
- a statement
- a value to return if the statement is true
- a value to return if the statement is false
Example 2.28 Using IF() to create an indicator variable
An indicator variable is the numerical version of a logical variable: it takes on the value 1 if a particular statement is true, and 0 if the statement is false. We will use indicator variables regularly; they are discussed in more detail in the math review appendix.
To create an indicator variable for low labour force participation:
- Enter LowLFPInd in cell P1 to name the variable.
- Enter
=IF(I2 < 0.64,1,0)in cell P2. - Copy/paste or fill cell P2 into cells P3:P11.
- Save your working copy.
As you can see, the cells display 1 in the three provinces with LFP rates
below 64%, and 0 in the other seven. When cleaning data we will typically use
indicator variables rather than logical variables.
Logical values in formulas automatically convert to numeric values as needed,
with True converting to one and False converting to zero. For example,
the formula =3+True is equal to 4 and the formula =3+False is equal
to 3.
Advanced options for logical variables
Some additional functions that work with logical variables:
NOT()returnsTRUEif its argument isFALSEandFALSEif its argument isTRUE.AND()returnsTRUEif all of its arguments areTRUE.OR()returnsTRUEif any of its arguments areTRUE.SWITCH()andIFS()are extensions ofIF()that take multiple conditions.
2.4.4 Dates and times
Excel can also handle dates and times. Dates and times are a surprisingly complex subject that can create all sorts of problems on a computer, for several reasons:
- There are many conventional ways of writing the same date:
- November 1, 2020
- 2020 November 1
- 14 Heshvan 5781 (Hebrew calendar)
- 11/1/2020
- 11/1/20
- 11-1-2020
- 2020/11/1
- etc.
- Conventions vary across cultures and organizations:
- In some places, 11/1 means November 1 and in others it means January 11.
- We want to be able to sort and rank in time order rather than alphabetical
order:
- January 10, 2020 is before December 10, 2020 and after December 10, 2019.
- We want to be able to add and subtract dates and times:
- January 4, 2021 is 5 days after December 30, 2020.
- 11:30 pm on December 31, 2020 is 45 minutes before 12:15 am on January 1, 2021
- We want to handle time zones, daylight savings time, leap years, and even leap seconds.
Finally, we want to deal with these complexities in a way that is perfectly accurate when needed, but is simple in normal usage. As you might imagine, this is not easy. Each application has its own rules for handling dates and times, but there are some standards that have developed.
Excel handles dates and times as follows:
- Dates are stored as the number of days elapsed since some base date or
“epoch.” In Excel, the base date is January 0, 1900, which means that:
- January 1, 1900 is day 1.
- January 2, 1900 is day 2.
- November 1, 2020 is day 44136.
- Dates are displayed according to the cell’s display formatting:
- The default display formatting varies across regions.
- So the same date in the same Excel file might display differently on two different computers.
- When you enter text into a cell that looks like a date, Excel does
several things behind the scenes:
- Excel guesses the date format you are using.
- Following that guess, Excel converts your text into its storage format (days since base date).
- Excel changes the display format to what Excel thinks it should be. This format is based on your location settings, and may differ from what you have typed in.
This system works seamlessly most of the time.
Example 2.29 How dates are stored and displayed
The MonthYr variable in column G is a date. Remember that we created it by typing in “11/2020”. Let’s see what Excel did with that:
- Select cell G2, and compare the formula bar to what is displayed in the cell.
On my computer:
- The cell displays
Nov-20 - The formula bar displays
11/1/2020.
- The cell displays
- To see how Excel sees this date, change the cell’s number format to
GeneralorNumber:- Now the cell displays the number
44136, which is the date-time value that Excel uses to represent November 1, 2020.
- Now the cell displays the number
Now while a date of 44136 is quite clear to Excel, we want to display dates in
a more human-readable way. I don’t like the Nov-20 display format, since it
isn’t obvious whether that means November 2020 or November 20. So let’s change
the formatting:
- Select cells G2:G11.
- Select
Number Format > Short Date. - Save your working copy.
You can see even more options if you select More number formats.
We can also do calculations with dates, and there are various functions using dates.
Example 2.30 Some date calculations
To calculate how long ago November 2020 was:
- Enter Today in cell Q1 to name the variable.
- Enter
=TODAY()in cell Q2 to put in today’s date.- This will display today’s date.
- Tomorrow, the cell will display tomorrow’s date.
- Enter HowLongAgo in cell R1.
- Enter
=Q2-G2in cell R2.- This will display the number of days that have passed between November 1, 2020 and today.
- Save your working copy.
Unfortunately, Excel sometimes guesses wrong, and this can create all sorts of problems. Understanding how Excel handles dates and times can help you avoid or address these problems.
Excel dates and genetics
Excel is a widely used tool in the scientific field of human genetics, and its handling of dates caused a significant unanticipated problem in genetics research.
Each gene has a standard abbreviation like “TCEA1” or “CTCF” assigned by a scientific body called the HUGO Gene Nomenclature Committee (HGNC). Unfortunately, 27 of these genes have abbreviations that Excel misinterprets as dates, for example “Membrane Associated Ring-CH-Type Finger 2,” also known as “MARCH2”. If you enter the text “MARCH2” in an Excel cell, Excel will automatically convert it to the date of March 2 in the current year. A 2016 research paper found that roughly 20% of published research articles in the field used data that was affected by this problem.
Unfortunately, it is too late to “fix” Excel to keep this from happening. Any change to its behavior would “break” Excel in thousands of other applications that rely on its current behavior. Excel has added an option to turn off this kind of automatic conversion, but the default behavior remains the same.
When you can’t fix a problem in a computer application, you need to find a workaround: a modification to how you use the application that avoids or minimizes the effects of the problem. So the HGNC changed the names of these 27 genes in 2020. For example, the gene MARCH2 is now called MARCHF2.
In addition to dates, Excel can also handle time values such as 12 pm and
date-time values such as 11/1/2020 12:00:00 PM.
How Excel handles times
Excel treats times as partial days. For example:
- The time
12:00 pmis stored as time0.5. - The time
1:00 pmis stored as time0.5416666667. - The date-time
11/1/2020 12:00:00 PMis stored as day44136.5. - The date-time
11/1/2020 1:00:00 PMis stored as day44136.5416666667.
There are also functions that work with date-time values. For example, we have
already seen the function TODAY(.) which returns the current date but there is
also a function NOW(.) that returns the current date-time.
2.5 Data file management
At this point our data cleaning project is complete, and our data is ready for analysis. This is a good time to return to the version control concepts and workflow discussed in the section on reproducibility.
2.5.1 Version control, again
We have added a complete new feature - a set of new variables - to our working copy, we should update the master version.
Example 2.31 Updating the master version
To update your master version, follow these steps:
Check your working copy for mistakes and incomplete work.
You can compare your working copy to my master version at https://bookdown.org/bkrauth/IS4E/sampledata/CanEmpNov20Clean.xlsx.
(optional) Archive your current master version by renaming it and moving it to the
archivessub-folder.- This step is not necessary in this case since your current master version is identical to the source data.
Make your current working copy the master version.
- In Excel: You can select
File > Save Asto save the open file under another name. - Outside of Excel: You can copy, paste, and rename the working copy.
- In Excel: You can select
You should now have two identical cleaned data sets (one master file and one
working copy), one raw data set (in the raw-data subfolder), and possibly
one archived data set (in the archives subfolder).
How often should you update your master version?
Your master version should be updated regularly, but it should only be updated after a new feature has been completed and checked for errors. But what if you are halfway through adding a feature, and need to stop work for the day?
Making your updates both frequent and complete may require a modification to how your work habits: plan your work before you do it, divide big features into smaller features, work on one feature at a time, and avoid starting tasks you don’t have time to finish.
2.5.2 Saving and exporting data
Portability is also a key element of reproducibility. We may want to save our Excel data in a form that is easily read by other programs like R.
Deep down, every file on a computer is just a long sequence of binary numbers: zeros and ones. In order to obtain any useful information from a file, we need to know its file format. A file format is a set of rules for interpreting the sequence of zeros and ones, much like a language is a set of rules for interpreting the sounds that come out of people’s mouths. You can often infer a file’s format from its extension (the part of the file name after the “.”).
Applications usually save data in the application’s native format: a file
format specifically designed for use with that application. Excel workbooks
are normally saved in Excel’s native format, which is typically indicated by
the .xlsx extension.
Many applications can also import (open) or export (save) information in other file formats, These other formats can be the native format of some other application or they can be a standardized format that is designed to be used by many applications.
File formats are like languages, and importing and exporting data in something other than the application’s native format is like translating to or from a foreign language. People work most comfortably in their native language, and translations are never perfect. Similarly, applications work most comfortably with their native format, and importing and exporting data can result in the loss or unintentional modification of information in the original data source.
The most commonly-used export format for Excel is called the comma-separated values or CSV file. CSV is a standardized text format that is very useful for representing tables of data. It is simple, platform-independent, human-readable, compact, and (mostly) secure. CSV files are easily read by Excel, R, and many other applications.
You can save any worksheet in an Excel workbook as a CSV file.
Example 2.32 Exporting a CSV file in Excel
To export the Employment Nov 2020 worksheet to a CSV file:
Select the Employment Nov 2020 tab.
Select
File > Save Asfrom the menu, then select the button markedBrowse.This will produce the
Save Asdialog box which looks something like this: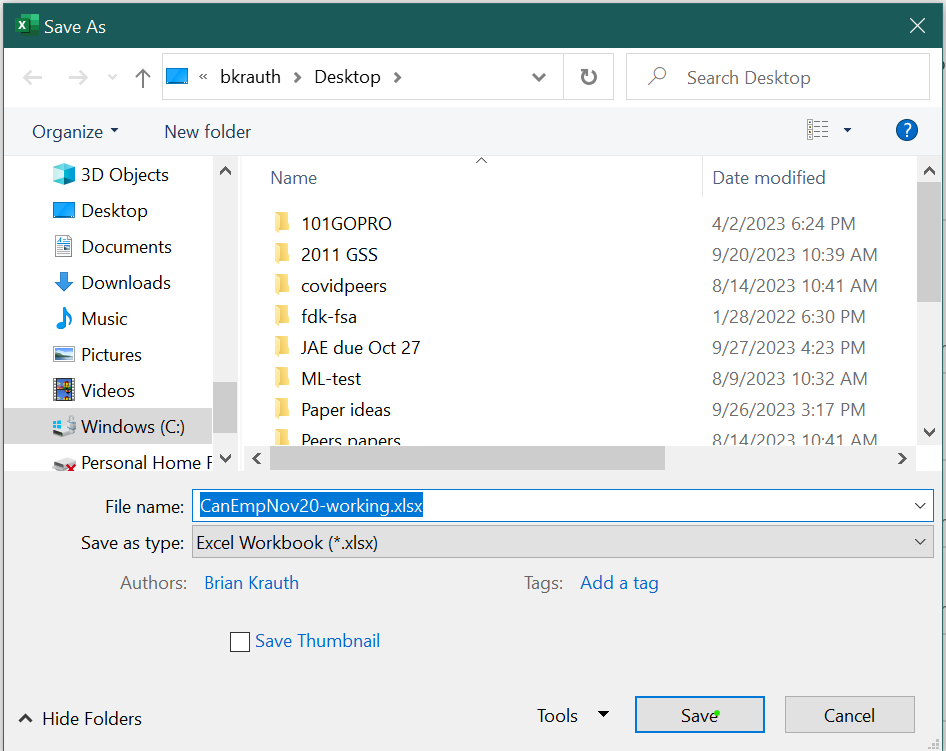 Click on the
Click on the Save as typedrop-down box, and selectCSV (Comma delimited)(*.csv). Note that this will change the file extension from.xlsxto.csv.Change the file name to
CanEmpNov20.csv, adjust the destination folder if you want, then selectSave.You may get a warning that looks like this:
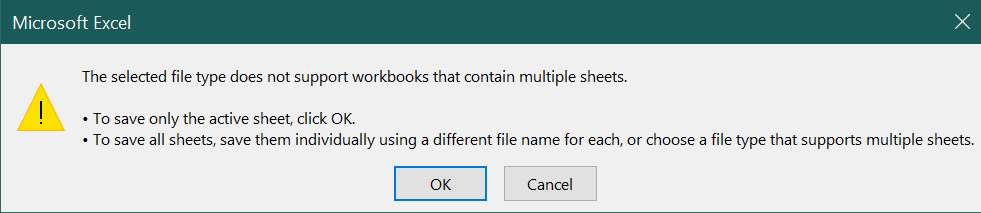 Select
Select OK.Close Excel.
You now have a CSV file.
You can also import CSV files that have been created with Excel, or by some other program.
Example 2.33 Importing a CSV file into Excel
Use Excel to open the CSV file you have just created. You can do this either by double-clicking on the file, or you can start Excel and use its menus to find and open the files.
Your CSV file will look something like this:
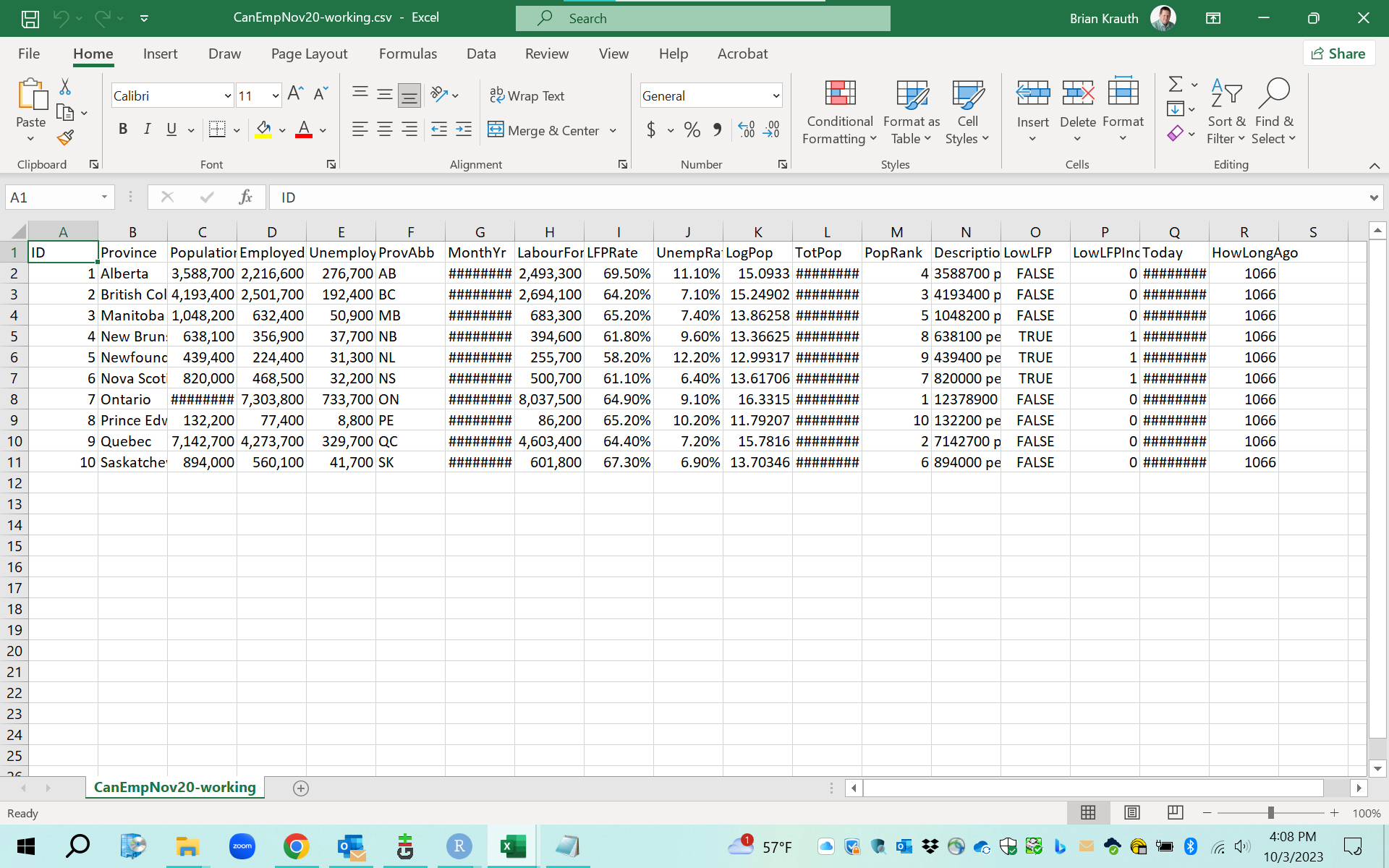 We can compare this worksheet to the original Excel workbook from which it was
exported. They are similar, but there are several important differences:
We can compare this worksheet to the original Excel workbook from which it was
exported. They are similar, but there are several important differences:
- It only contains the EmploymentData worksheet.
- CSV files can only contain a single table.
- All cell formatting is gone: the columns are all the same width, and the top
row is not in boldface.
- CSV files do not include formatting information.
- All formulas have been replaced with the corresponding values. For example,
the cell H2 contains the formula
=D2 + E2in the Excel file, and the value 2493300 in the CSV file.- Excel does not include formulas when exporting to CSV files.
- All values have been rounded. This may not be obvious, but to see an example:
- Change the number format in cell I2 so that the value is displayed to 5 decimal places.
- Cell I2 will display as
69.47641%in the original Excel file. - Cell I2 will display as
69.50000%in the CSV file.
When importing and exporting CSV files, always check to make sure that important information is not lost in the translation between formats.
There are many commonly-used data file formats other than Excel and CSV. Section 9.1 in Chapter 9 discusses some of these formats and how to work with them in Excel. It also discusses CSV files in greater detail.
Chapter review
Data cleaning is among the most important practical skills one can develop in applied statistical analysis. Simple statistical methods like averages and frequencies are all most people will ever use, but everyone who works with data regularly encounters complex and messy data in need of cleaning.
In this chapter, we have learned some important data cleaning concepts, including reproducible research, tidy data, ID variables, and version control. We have also learned how to implement these concepts in Excel using tools such as fill/series, formatting, formulas, and functions.
Once we have clean data, we can use it to do some basic statistical analysis and graphing in Excel. Later on, we will learn more advanced data cleaning concepts such as linking, aggregating, error validation/handling, importing and exporting, as well has how to to implement them in both Excel and R.
Practice problems
Each chapter includes a few simple practice problems to help you check your knowledge. They are organized by the specific skill or knowledge base you are practicing.
Answers can be found in the appendix.
GOAL #1: Identify and implement the principles of reproducible research
- Which of the following tables shows a tidy data set?
PersonID 101 102 Name Bob Joe Age 30 35 Occupation Chef Waiter Name Age Occupation Bob 30 Chef Joe 35 Waiter Variable Value Name Bob Age 30 Occupation Chef Name Joe Age 35 Occupation Waiter
- A typical version control system includes three different version types. For
each of these version types, indicate its purpose, whether you should
edit it directly, and the maximum number of files of the type you should
have.
- Master version/versions
- Working copy/copies
- Archive copy/copies
GOAL #2: Identify and use ID variables
- Which of the following characteristics is necessary for a variable to
function as an ID variable?
- It takes on a different value for each observation.
- Each value it can take on has an associated observation.
- It can take only one value.
GOAL #3: Use basic Excel terminology and concepts
- Which tool (fill, series, insert, or copy/paste) would you use for each of
the following tasks?
- Copy the contents of a cell to one or more adjacent cells.
- Copy the contents of a cell to a far-away range of cells.
- Fill a cell range with a sequence of ascending even numbers (e.g., 2, 4, 6).
- Add a row or column to the middle of your data set.
GOAL #4: Use Excel formulas to construct new variables
- Construct an Excel formula to do each of the following:
- Find the square root of the number in cell A2.
- Find the lowest value in cells A2:A100.
- Find the absolute value of the difference between cells A2 and B2.
GOAL #5: Use absolute and relative cell references in Excel formulas
- For each of the following Excel formulas, suppose we copy that from cell
C12 to cell E15. What formula appears in cell E15?
=B2=$B$2=$B2=B$2=SUM(B2:B10)=SUM($B$2:$B$10)=SUM($B2,$B10)=SUM(B$2,B$10)
If you aren’t sure, try it out in Excel and see what happens.
GOAL #6: Use logical and text data in Excel
- Construct an Excel formula to do each of the following.
- Display “Reject” if cell A2 contains a number less than 0.05, and display “Fail to reject” otherwise.
- Display the text “A2 =” followed by the value in cell A2.
- Display the first two letters of the text in cell A2.
GOAL #7: Use dates in Excel
- Construct an Excel formula to do each of the following:
- Display the current month.
- Display the date 100 days from today.
- Display the number of days since your birth.
GOAL #8: Use Excel to import and export CSV files
- Download the file
https://bookdown.org/bkrauth/IS4E/sampledata/CanEmpHist.xlsx
and open it in Excel.
- Export the file to a CSV file named
CanEmpHist.csv. - Close Excel.
- Open both
CanEmpHist.xlsxandCanEmpHist.csvin Excel. - Compare the original worksheet in
CanEmpHist.xlsxwith the worksheet inCanEmpHist.csv. How are they different?
- Export the file to a CSV file named