5 Logistic Regression (R)
5.1 Lab Overview
This web page provides a brief overview of logistic regression and a detailed explanation of how to run this type of regression in R. Download the script file to execute sample code for logistic regression. The last section of the script will ask you to apply the code you’ve learned with a simple example.
Research Question: What rookie year statistics are associated with having an NBA career longer than 5 years?
Lab Files
Data:
Download nba_rookie.csv
Script File:
Download lab2_LR.R
Script with answers to application question:
Download lab2_LR_w.answers.R
Packages for this lab:
You may need to install packages that you have never used before with install.packages("packagename")
# Basic data cleaning and visualization packages
library(tidyverse)
library(ggplot2)
library(janitor)
# To plot predicted values
library(ggeffects)
# To get average marginal effect
library(margins)
# Show exponentiated coefficients
library(gtsummary)
# Calculate vif
library(car)Loading the data for this lab
When you load the csv file for this lab, the variable names apper in all caps. I prefer lowercase so I’m going to use a handy command from the janitor package. clean_names() will make sure that your variable names are all lowercase, remove any special characters, and replace any spaces with _.
df_nba <- read.csv("data_raw/nba_rookie.csv") %>% clean_names()5.2 Logistic Regression Review
In logistic regression you are predicting the log-odds of your outcome as a function of your independent variables. To understand why our dependent variable becomes the log-odds of our outcome, let’s take a look at the binomial distribution.
Binary outcomes follow what is called the binomial distribution, whereas our outcomes in normal linear regression follow the normal distribution. In this scenario we are assuming that the probabilities following this binomial distribution fall on a logistic curve. It looks somewhat like an “S,” in contrast to the straight line we are used to seeing in linear regression.
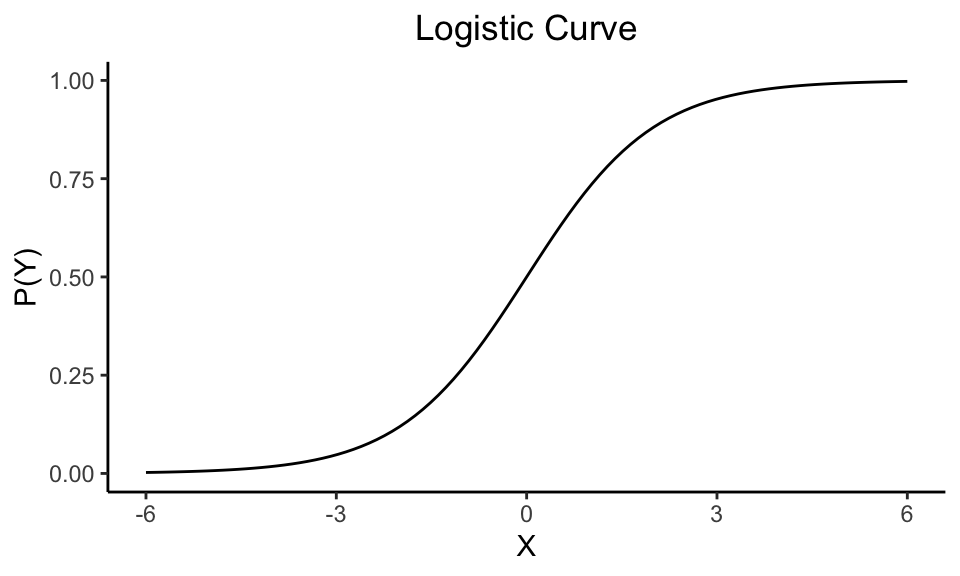
This distribution says that the probability of an event occurring \(P(Y=1)\) follows the logistic equation, where \(X\) is your independent variable. I promise there is math behind this that makes it all make sense, but for this class you can take my word for.
\[P(Y=1) = \displaystyle \frac{e^{\beta_0 + \beta_1X_1 + ... \beta_kX_k}}{1 + e^{\beta_0 + \beta_1X_1 + ... \beta_kX_k}}\]
But how in the world are we supposed use this equation in a regression?
Well, you might spot our handy linear equation in there (\(\beta_0 + \beta_1X_1 + ... \beta_kX_k\)). We want to be able to predict our outcome by adding together the effects of all our covariates using that linear equation. If we solve for that familiar equation we get:
\[\ln(\displaystyle \frac{P}{1-P}) = \beta_0 + \beta_1X_1 + ... \beta_kX_k\] Now that’s more like it! On the right side of the equals sign we have our familiar linear equation. The connection to the linear equation is why both logistic regression and normal linear regression are part of the same family: generalized linear models. On the left side of the equals sign we have log odds, which literally means “the log of the odds.” And as a reminder odds equals the probability of success (\(P\)) divided by the probability of failure (\(1-P\)).
5.2.1 Interpreting Log Odds – the Odds Ratio!
A one unit change in X is associated with a one unit change
in the log-odds of Y.
Running a logistic regression in R is going to be very similar to running a linear regression. The big difference is we are interpreting everything in log odds. Your coefficients are all in log odds units. Except…you are pretty much never going to describe something in terms of log odds. You will want to transform it into a (drum roll)…odds ratio.
An odds ratio (OR) is the odds of A over the odds of B. Let’s see how that works with a concrete example.
Example: The odds ratio for women vs men graduating from high school is 1.2.
Interpretation: Women are 1.2x more likely to graduate from high school than men.
Odds ratio makes interpreting coefficients in logistic regression very intuitive. Here’s a continuous variable example.
Example: The odds ratio for the effect of mother’s education on whether their child graduates high school is 1.05.
Interpretation: For every additional year of a mother’s education, a child is 1.05 times more likely to graduate from high school.
How do you go from a log odds to an odds ratio?
All you have to do to go from log odds to an odds ratio is “undo” the log part of log-odds. We do this by exponentiating exp() our coefficients, aka…
\[ e^\beta\]
So if the coefficient sex in a linear regression of high school graduation is 0.183…
\[ e^{0.183} = 1.2\]
And that is your odds ratio. In R you can use a command that automatically displays the odds ratios for each coefficient, no math necessary!
5.2.2 Assumptions of the model
(1) The outcome is binary
A binary variable has only two possible response categories. It is often referred to as present/not present or fail/success. Examples include: male/female, yes/no, pass/fail, drafted/not drafted, and many more!
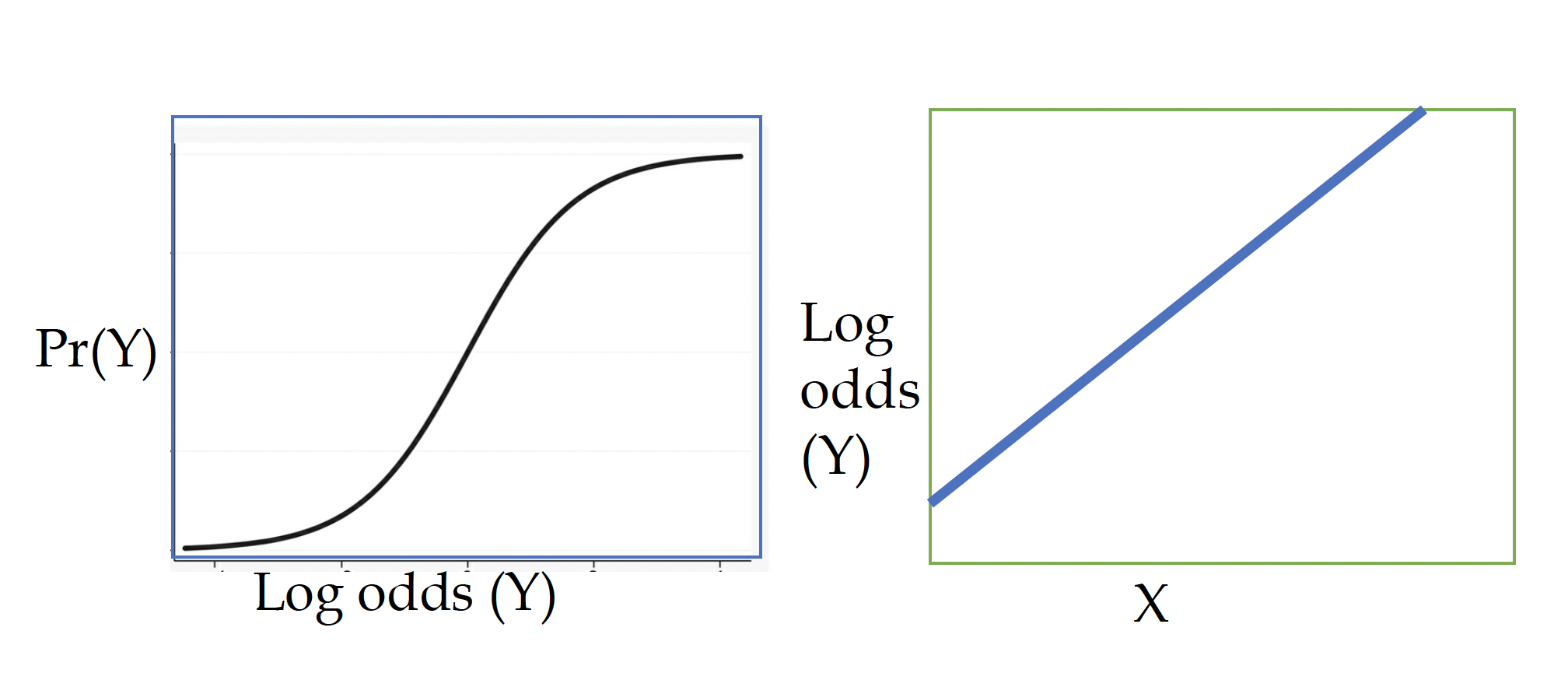
(2) The log-odds of the outcome and independent variable have a linear relationship
Although a smoothing line of your raw data will often reveal an s-shaped relationship between the outcome and explanatory variable, the log-odds of the outcome vs the explanatory variable should have a linear relationship. In the plots below, the blue box on the right shows the raw s-shape and the green plot on the left shows the transformed, linear log-odds relationship.
How to address it?
Like a linear regression, you can play around with squared and cubed terms to see if they address the curved relationship in your data.
(3) Errors are independent
Like linear regression we don’t want to have obvious clusters in our data. Examples of clusters would be multiple observations from the same person at different times, multiple observations withing schools, people within cities, and so on.
How to address it?
If you have a variable identifying the cluster (e.g., year, school, city, person), you can run a logistic regression adjusted for clustering using cluster-robust standard errors (rule of thumb is to have 50 clusters for this method). However, you may also want to consider learning about and applying a hierarchical linear model.
(4) No severe multicolinearity
This is another carryover from linear regression. Multicollineary can throw a wrench in your model when one or more independent variables are correlated to one another.
How to address it?
Run a VIF (variance inflation factor) to detect correlation between your independent variables. Consider dropping variables or combining them into one factor variable.
Differences to linear regression assumptions
Logistic regression and linear regression belong to the same family of models, but logistic regression DOES NOT require an assumption of homoskedasticity or that the errors be normally distributed.
5.2.3 Pros and Cons of the model
Pros:
- You can interpret an odds ratio as how many more times someone is likely to experience the outcome (e.g., nba players with high scoring averages are 1.5 times more likely to have a career over five years).
- Logistic regression are the most common model used for binary outcomes.
Cons:
- Odds ratios and log-odds are not as straightforward to interpret as the outcomes of a linear probability model.
- It assumes linearity between log-odds outcome and explanatory variables.
5.3 Running a logistic regression in R
Now we will walk through running and interpreting a logistic regression in R from start to finish. The trickiest piece of this code is interpretation via predicted probabilities and marginal effects.
These steps assume that you have already:
- Cleaned your data.
- Run descriptive statistics to get to know your data in and out.
- Transformed variables that need to be transformed (logged, squared, etc.)
We will be running a logistic regression to see what rookie characteristics are associated with an NBA career greater than 5 years. Here are the key variables:
target_5yrs: a binary indicator of whether an NBA career lasted longer than 5 years.
pts: Average points per gamegp: Games playedfg: Percentage of field goals madex3p: Percentage of three pointers madeast: Average assists per gameblk: Average blocks per game
STEP 1: Plot your outcome and key independent variable
This step isn’t strictly necessary, but it is always good to get a sense of your data and the potential relationships at play before you run your models.
To get a sense of the relationship in a logistic regression you can plot your outcome over your key independent variable. You can also do this with any other independent variable in your model.
ggplot(df_nba, aes(x = pts, y = target_5yrs)) +
geom_point() +
geom_smooth(method = "loess", se = FALSE) +
theme_classic()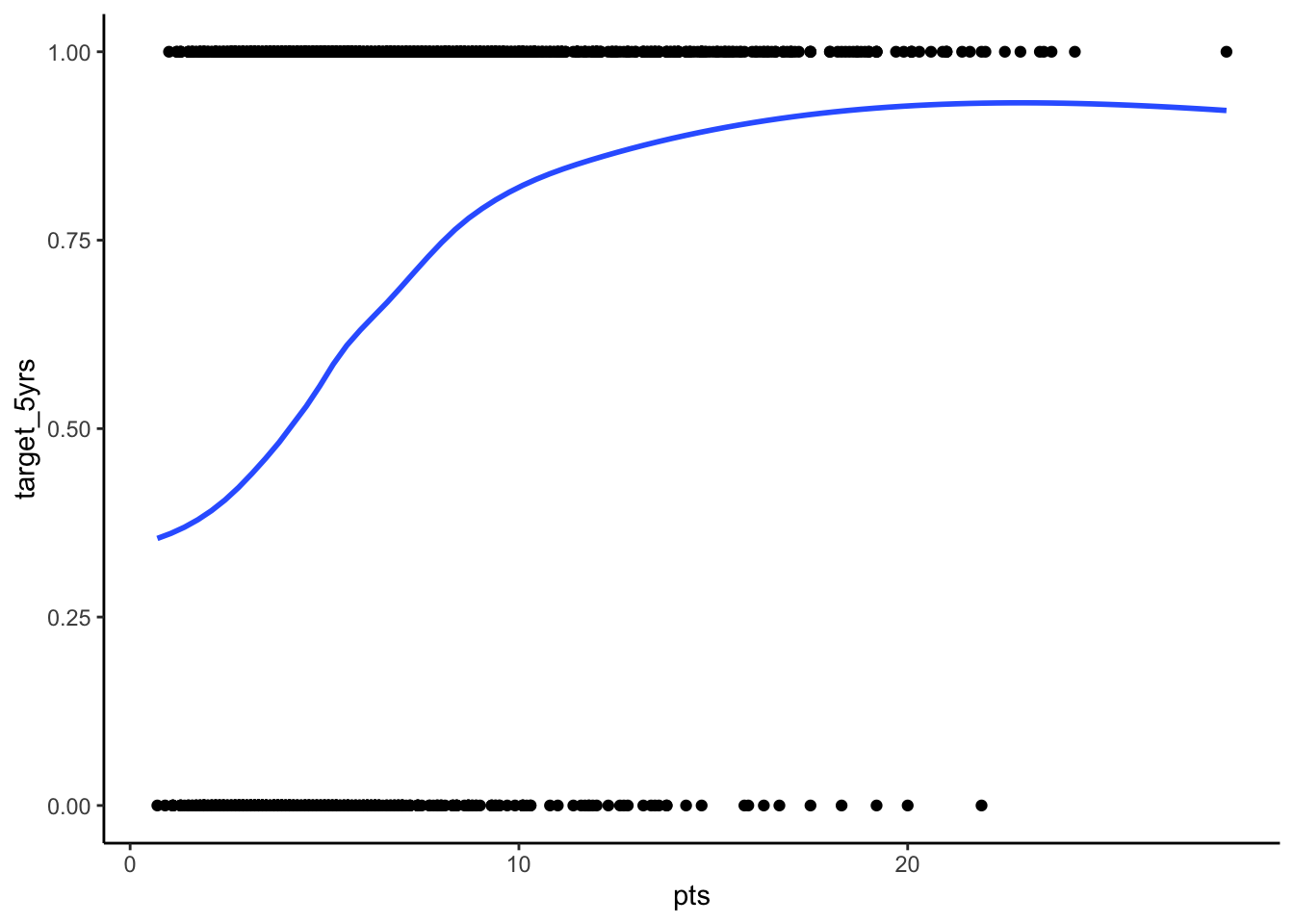
STEP 2: Run your models
You can run this with the logit command or the logistic command. Because it is more common to present odds ratios, I will go ahead and use the logistic command.
Like with linear regression and linear probability models, it is good practice to run the most basic model first without any other covariates. Then you can get a sense of how the effect has changed once you add in your control variables. Our key variable is average points per game. I want to see the exponentiated coefficients, so I’ll use tbl_regression() from the gtsummary package.
fit_basic <- glm(target_5yrs ~ pts, data = df_nba, family = binomial(link = logit))
tbl_regression(fit_basic, exp = TRUE)| Characteristic | OR1 | 95% CI1 | p-value |
|---|---|---|---|
| pts | 1.23 | 1.18, 1.27 | <0.001 |
|
1
OR = Odds Ratio, CI = Confidence Interval
|
|||
And then run the full model with all your covariates. You can also add them one at a time or in groups, depending on how you anticipate each independent variable affecting your outcome and how it ties back to your research question.
fit_full <- glm(target_5yrs ~ pts + gp + fg + x3p + ast + blk,
data = df_nba, family = binomial(link = logit))
tbl_regression(fit_full, exp = TRUE)| Characteristic | OR1 | 95% CI1 | p-value |
|---|---|---|---|
| pts | 1.07 | 1.02, 1.12 | 0.010 |
| gp | 1.04 | 1.03, 1.05 | <0.001 |
| fg | 1.04 | 1.02, 1.07 | 0.001 |
| x3p | 1.00 | 0.99, 1.01 | 0.7 |
| ast | 1.05 | 0.93, 1.20 | 0.4 |
| blk | 1.71 | 1.11, 2.72 | 0.018 |
|
1
OR = Odds Ratio, CI = Confidence Interval
|
|||
STEP 3: Interpret your model
As you’ve seen, running the logistic regression model itself isn’t that much different than a linear regression. What gets more complicated is interpretation. There are four ways you can interpret a logistic regression:
- Log odds (the raw output given by a logistic regression)
- Odds ratios
- Predicted probabilities
- Marginal effects
This lab will cover the last three. A change in log odds is a pretty meaningless unit of measurement. So you will want to report your results in at least one of these three forms. This lab cannot cover every variation of running predicted probability and marginal effects in R. We will practice margins in a future lab, but for now try to wrap your mind around these basic variations.
Odds Ratios
Remember, we go from log odds to odds ratios by exponentiating the raw log odds coefficients. But logistic has already done that for us. Let’s interpret two of the coefficients:
Points per game: Each additional point scored per game makes a player 1.07 times more likely to have an NBA career longer than 5 years OR the odds a player has an NBA career longer than 5 years increases the odds by 7%.
Blocks per game: Each additional block per game makes a player 1.71 times more likely to have an NBA career longer than 5 years OR the odds a player has an NBA career longer than 5 years increases the odds by 71%.
Predicted Probability Plots
Here we return to our good friend the margins command. In linear regression, the margins command produces predicted values. So if the outcome of the linear regression was income, the predicted value would be some income value based on the model. In logistic regression, the outcome of the margins command is a predicted probability. Our outcome ranges from 0 to 1, and the predicted probability tells us the likelihood the outcome will occur based on the model. You can then plot those predicted probabilities to visualize the findings from the model. There are three approaches to calculating these probabilities. Why are there multiple approaches, because we get predicted probabilities/values from plugging in values to our regression equation. R needs to know what value to plug into each variable in our equation. Let’s look at the three approaches to doing those calculations…
(1) Predicted probabilities with all other variables held AT MEANS
In this method, you choose an explanatory variable you want to plot your probabilities over and plug in the average value for each of the other variables. For example, here we ask R to calculate the predicted probabilities for our outcome over the range of our pts variable. We have to specify which values of pts we want R to calculate. We can use the ggpredict() function from the ggeffects package to calculate predicted probabilities. The default for this command is to plug in the average value for the other variables, aka holding them at means.
What values of pts do we want to get probabilities for? I’m using the [start:end by = interval] format to predict values from 0 (start) to 25 (end) at intervals of 5.
pp_atmeans <- ggpredict(fit_full, terms = "pts[0:25 by = 5]")
pp_atmeans# Predicted probabilities of target_5yrs
pts | Predicted | 95% CI
------------------------------
0 | 0.56 | [0.47, 0.65]
5 | 0.64 | [0.61, 0.68]
10 | 0.71 | [0.67, 0.76]
15 | 0.78 | [0.69, 0.84]
20 | 0.83 | [0.71, 0.91]
25 | 0.87 | [0.73, 0.95]
Adjusted for:
* gp = 63.00
* fg = 44.12
* x3p = 19.31
* ast = 1.56
* blk = 0.37Note: For some reason this is plugging in something other than the average for the gp variable. I’m looking into it.
plot(pp_atmeans)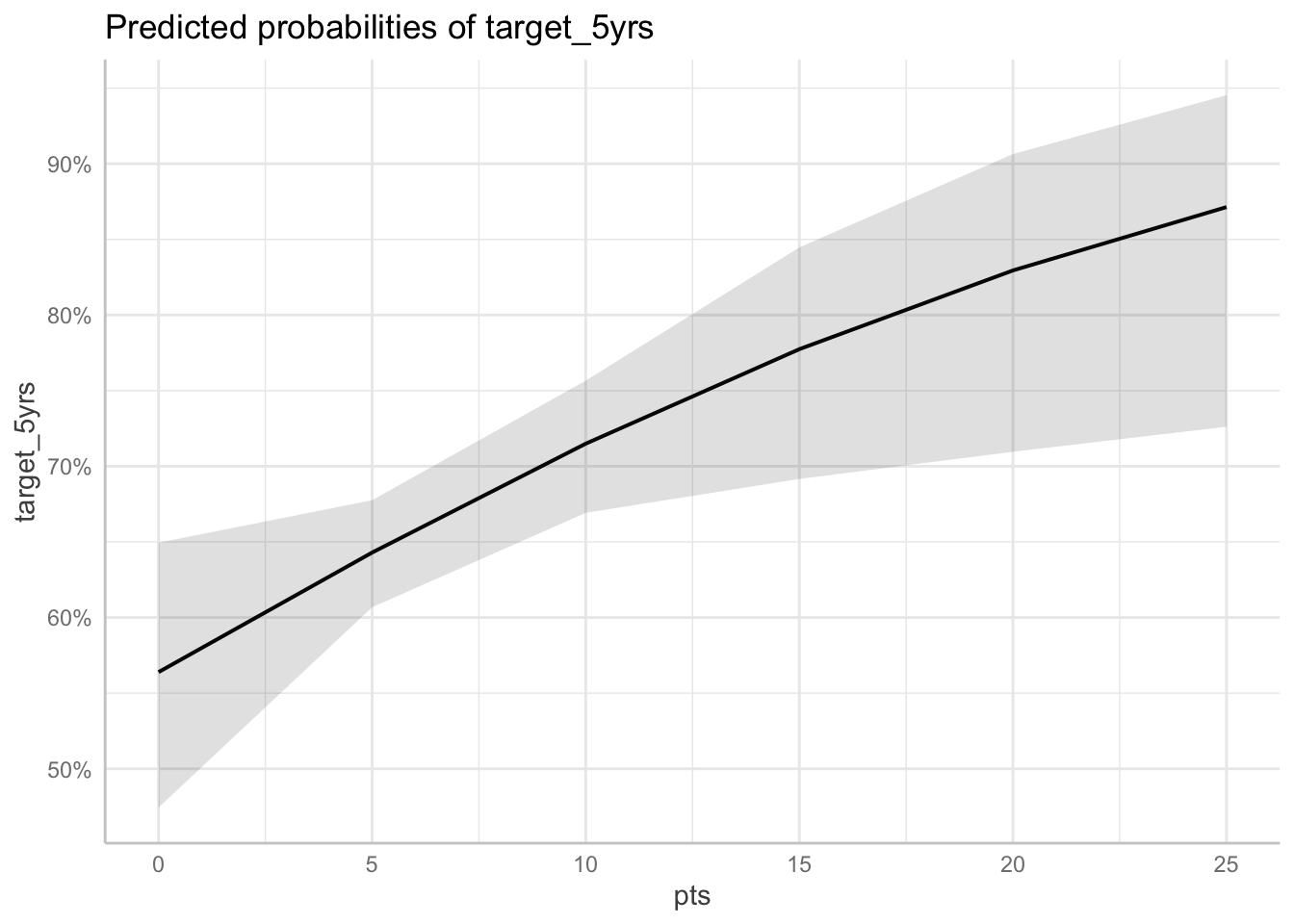
(2) Predicted probabilities with all other variables at REPRESENTATIVE VALUES
In this method, you choose an explanatory variable you want to plot your probabilities over and plug in representative values for the other variables. Remember, there is no “average” person. So maybe you are predicting the probability of high school graduation and want to show the probability for a low-income student with a lot of adverse childhood experiences. You specify the values of the main explanatory variable you want to predict over and fill in the other variables with the values corresponding to that profile.
Let’s say we think Michael Finley is a mid-level rookie player (this is totally made up, I know very little about basketball). So we’ll plug in his values to get our predicted probability.
NOTE: I ran into a wall trying to figure out how to cleaning produce probabilities with other variables at representative values in R. I will update this page and the scripts once I find the right code.
(3) AVERAGE predicted probabilities
This is the most common method of predicting probabilities. In this method, you choose an explanatory variable you want to plot your probabilities over. You will use a function that plugs in the actual observed values for every observation, calculates the probability over your specified range of values, and then calculates the average probability across all observations.
NOTE: I ran into a wall trying to figure out how to cleaning produce probabilities with other variables at representative values in R. I will update this page and the scripts once I find the right code.
Marginal Effects
Now we are going to move from calculating the probability to calculating how the probability changes when we increase one unit of an explanatory variable. Because probabilities aren’t linear, the effect of a one-unit change will be different as we move across the range of X values. We can use these three approaches to get a single value answer for how a one unit change in X affects the probability of Y.
For this we are going to move to the margins package, which attempts to replicate some of Stata’s margins command capabilities. We’re plugging values in the equation again, but using calculus to find this marginal effect.
(1) Marginal effect of a one unit change in X AT MEANS (MEM)
This is an annoying way to replicate what Stata does, because the builders of the margins package decided that they didn’t need to include an “atmeans” option and we could just do it ourselves. So here we go…
Create new dataframe, dropping any observations with missing values on our covariates (aka those that were not included in our model), and setting all the observations to their mean. Here we are dropping 11 observations with missing values on x3p.
df_new <- df_nba %>%
drop_na(pts, gp, fg, x3p, ast, blk) %>%
mutate(
pts = mean(pts),
gp = mean(gp),
fg = mean(fg),
x3p = mean(x3p),
ast = mean(ast),
blk = mean (blk)
)Now we use the margins() command from the margins package. Here you specify the saved model results, the new data frame you created, and which variable you want to find the marginal effect for. The new dataframe allows this command to plug in means for all the variables.
margins(fit_full, data = df_new, variables = "pts")Average marginal effectsglm(formula = target_5yrs ~ pts + gp + fg + x3p + ast + blk, family = binomial(link = logit), data = df_nba) pts
0.01508Interpretation: Holding all variables at their means, a one unit increase in avg points per game is associated with a 0.015 increase in the probability of an NBA career beyond 5 years.
You can also see all the marginal effects at means for all X variables:
margins(fit_full, data = df_new)Average marginal effectsglm(formula = target_5yrs ~ pts + gp + fg + x3p + ast + blk, family = binomial(link = logit), data = df_nba) pts gp fg x3p ast blk
0.01508 0.008098 0.008841 0.00036 0.01192 0.1228(2) Marginal effect of one unit change in X at REPRESENTATIVE VALUES (MER)
Now for this approach we specify the model results, the variable we want to find the marginal effect for, and then the specific values for the other variables that correspond with our “representative case.” We’ll use Michael Finley’s profile again.
Get the marginal effect of average points per game with representative values:
margins(fit_full, variables = "pts",
at = list(gp=82, fg=47.6, x3p = 32.8, ast=3.5, blk=.4))Average marginal effects at specified valuesglm(formula = target_5yrs ~ pts + gp + fg + x3p + ast + blk, family = binomial(link = logit), data = df_nba) at(gp) at(fg) at(x3p) at(ast) at(blk) pts
82 47.6 32.8 3.5 0.4 0.008969Interpretation: For a player with these stats in their rookie year, a one unit increase in avg points per game is associated with a 0.008 increase in the probability of an NBA career past 5 years.
(3) AVERAGE marginal effects (AME)
Again, this is the most common/default method in margins() to produce marginal effects in R. You only have to specify the variable you want to calculate the marginal effects for.
Get the average marginal effect for points per game with representative values:
margins(fit_full, variables = "pts")Average marginal effectsglm(formula = target_5yrs ~ pts + gp + fg + x3p + ast + blk, family = binomial(link = logit), data = df_nba) pts
0.01262Interpretation: Holding all other variables at their observed values, on average a one unit increase in average points per game is associated with a 0.012 increase in the probability of an NBA career past 5 years.
STEP 4: Check your assumptions
The outcome is binary
This is another logic check. Are we using a binary outcome in this analysis? Yes a player either does or does not have a career longer than 5 years.
The log-odds of the outcome and independent variable have a linear relationship
We can check this assumption by predicting the logits (aka the log odds), saving them to our dataset, and then plotting them against each independent variable.
First, create a new dataset with only the observations from the model (aka drop missing again) and the numeric covariates.
# Select only outcome and numeric predictors
# drop missing and save in new dataset
df_model <- df_nba %>%
select(pts, gp, fg, x3p, ast, blk) %>% # enter numeric variables
drop_na(pts, gp, fg, x3p, ast, blk) # drop cases with missing values on these variables.
# save names of predictors to plug into command below.
predictors <- colnames(df_model)
# Save predicted probabilities
df_model$probabilities <- fit_full$fitted.values
# Manually calculate the logit values and tidy data for the plot
df_model <- df_model %>%
mutate(logit = log(probabilities/(1-probabilities))) %>%
select(-probabilities) %>%
gather(key = "predictors", value = "predictor.value", -logit) Then you can plot logit values over each of the numeric variables.
ggplot(df_model, aes(y = logit, x = predictor.value))+
geom_point(size = 0.5, alpha = 0.5) +
geom_smooth(method = "loess") +
theme_bw() +
facet_wrap(~predictors, scales = "free_x")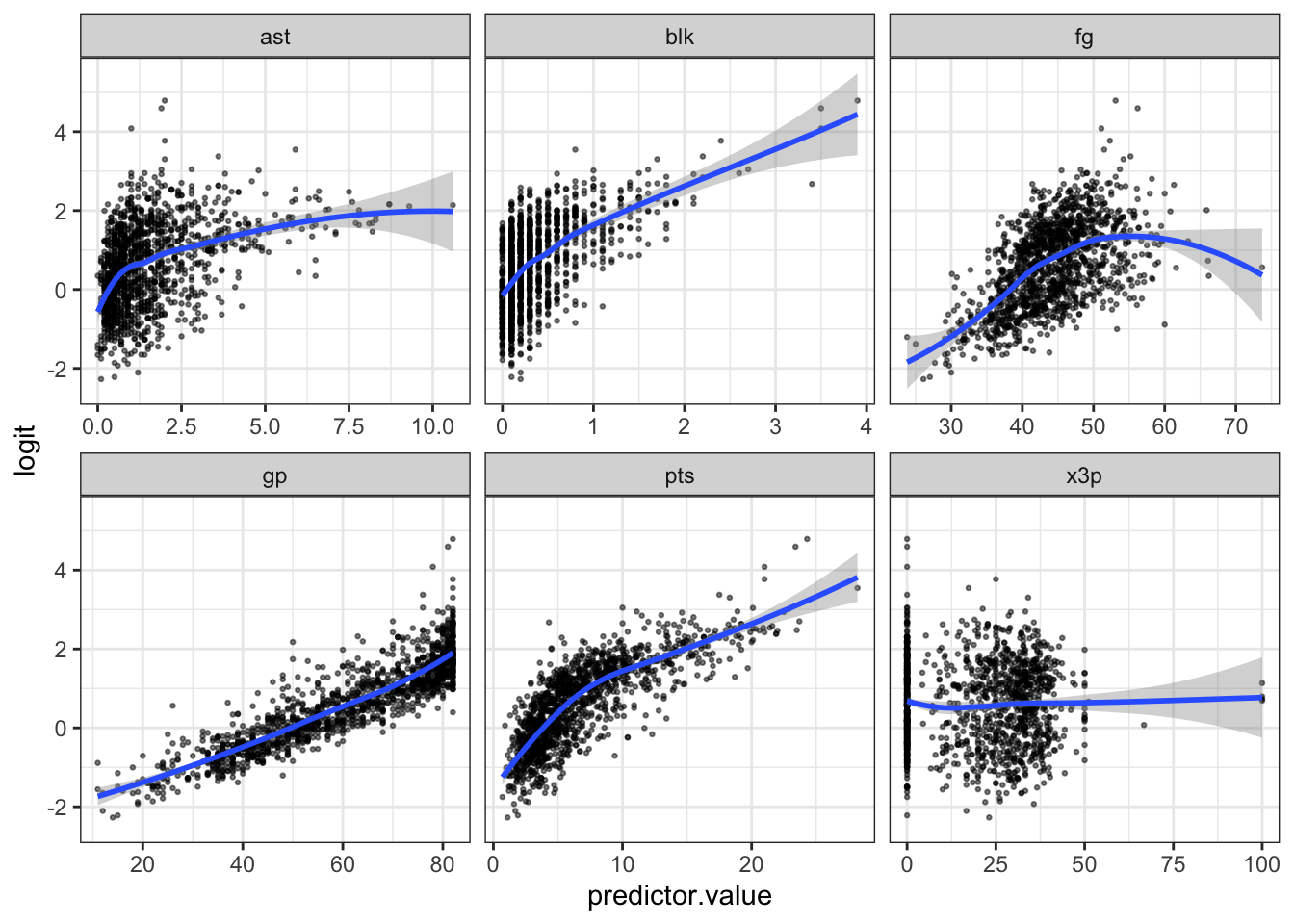
The relationship with fg might have a curve that you would need to address with transformations, but everything else looks pretty linear in terms of log-odds.
Errors are independent
This is another logic check. Do we have any clusters in this dataset? Well, if we had the team the player is on, that would be a cluster we would want to account for. Teams have the same schedule, the same teammates, and other potential similarities that would make their outcomes look more similar. Because we don’t have that variable in this dataset, we cannot account for it and have to decide how we think that clustering would change our results.
No severe multicolinearity
You may remember from linear regression that we can test for multicollinearity by calculating the variance inflation factor (VIF) for each covariate after the regression. We can do the same thing here!
vif(fit_full) pts gp fg x3p ast blk
2.113592 1.364052 1.357258 1.263372 1.805701 1.404371 We’re looking for any VIF over 10, and we are good!
A note on R-squared
We will discuss this more in our lab on comparing models, but R-squared statistics are more complicated with linear regression. They cannot be calculated in the same way as a linear regression because the estimation procedures are different. People have come up with many different ways to calculate an R-squared statistic. R shows “Pseudo R-squared” or Mcfadden’s R-squared, but there are other ways of evaluating how well your model fits the data for logistic regressions.
5.4 Apply this model on your own
Run a new regression using
target_5yrsas your outcome and three new independent variables. You can uselogitorlogistic.Calculate and plot the predicted probabilities at different levels of ONE independent variable, holding the other two at means.
Calculate the average marginal effect of ONE of your independent variables
You can look at the codebook for this dataset here: https://data.world/exercises/logistic-regression-exercise-1