Capítulo 6 Funções e loops
6.1 Funções
Uma função recebe alguns dados de entrada, faz algumas operações e devolve os dados de saída.
funcao<-function(x, y) #criando uma função
{ #inicio
result<- x^2+y^2 #calculando
return(result) #valor a ser retornado
} #fimUsando a função:
## [1] 136Quando ativamos um pacote, estamos ativando as funções daquele pacote. Podemos ver o conteúdo das funções digitando e executando o nome da função.
## function(x, y) #criando uma função
## { #inicio
## result<- x^2+y^2 #calculando
## return(result) #valor a ser retornado
## }Outro exemplo, podemos transformar em uma função aquele script que faz um histograma e sobrepõe a curva da distribuição normal:
curva<-function(x){
m<-mean(x,na.rm=TRUE)
std<-sd(x,na.rm=TRUE)
hist(x, prob=TRUE)
curve(dnorm(x, mean=m, sd=std),
col="darkblue", lwd=2, add=TRUE, yaxt="n")
}Usando a função:
library(openxlsx)
dados<-read.xlsx("dados/pinguim.xlsx", sheet = 1, colNames = T)
curva(dados$bill_length_mm)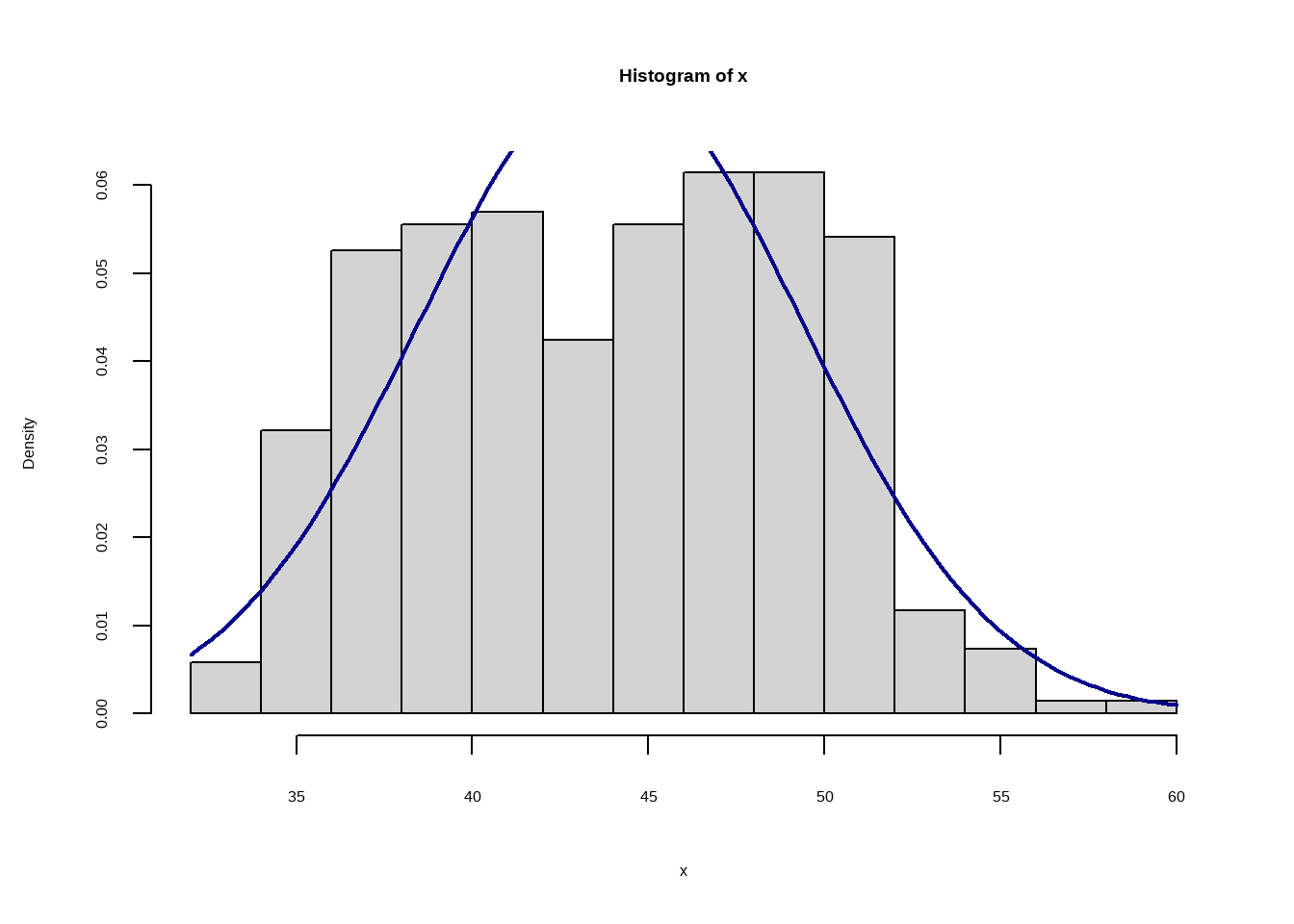
Porque escrever funções?
Uma função te força a escrever tudo em termos gerais. As funções são criadas para tarefas que serão repetidas várias vezes. Em vez de copiar e colar o código várias vezes fazendo as alterações necessárias, usar funções é uma maneira muito mais razoável de resolver o problema e, uma vez criada e debbugada, é muito mais prático de usar.
Um desafio é que o return só aceita um único objeto, ou seja, funções no R só retornam uma única coisa.
Quando precisa retornar mais de uma coisa, uma opção é o list(), recebe qualquer coisa.
Outra coisa que pode ser feita é quebrar uma função grande em funções menores. O R permite que uma função chame outra, o que facilita em muito o processo de criação de funções complicadas (Wickham, Çetinkaya-Rundel, and Grolemund 2023).
6.2 Loops
São processos interativos para realizar uma sequências de comandos até uma condição predeterminada.
6.2.1 for
Uma comando para isso é o for() Para esse comando usamos um contador. Exemplo:
## [1] 1
## [1] 2
## [1] 3
## [1] 4
## [1] 5Podemos vários comandos. Nesse os comandos são colocados entre{}
## [1] 1
## [1] 1
## [1] "teste"
## [1] 2
## [1] 4
## [1] "teste"
## [1] 3
## [1] 9
## [1] "teste"
## [1] 4
## [1] 16
## [1] "teste"
## [1] 5
## [1] 25
## [1] "teste"6.3 if e else
Com os comandos if e else se uma condição for atendida é executada uma ação.
Por exemplo:
## [1] "não"Podemos usar o if e else dentro de um loop:
## [1] "sim"
## [1] "sim"
## [1] "sim"
## [1] "sim"
## [1] "sim"
## [1] "não"
## [1] "não"
## [1] "não"
## [1] "não"
## [1] "não"Agora vamos usar um loop para fazer o teste de chi-quadrado e torná-lo mais funcional. Nesse exemplo temos que montar um arquivo de entrada com as seguintes características: - o arquivo de entrada deve ter a primeira coluna identificando a comparação - os valores das duas colunas seguintes são os valores do primeiro grupo em seguida os valores do outro grupo - exemplo: grupo 1 tem 200 ind. com alelo 1 e 300 com alelo 2 e o grupo 2 tem 250 com alelo 1 350 com alelo 2, então: comp1 200 300 250 350
Vamos rodar um exemplo para isso vamos carregar o arquivo, transformar em matriz:
dados4<-read.xlsx("dados/quiquadrado.xlsx", sheet = 1, colNames = F,rowNames = T)
dados5<-as.matrix(dados4)
dados5## X1 X2 X3 X4
## comp1 372 950 244 450
## comp2 244 850 260 780
## comp3 510 970 490 950Vamos criar um objeto (nomes) com os nomes das linhas. Agora vamos criar o loop, usando o comando for. O número de repetições do loop vai ser definido pelo número de elementos em nomes. Vamos armazenar os resultados em um arquivo txt:
## [1] "comp1" "comp2" "comp3"i<-1
for (i in nomes) {
a<-dados5[i,1] # linha i, coluna 1
b<-dados5[i,2] # linha i, coluna 2
c<-dados5[i,3] # linha i, coluna 3
d<-dados5[i,4] # linha i, coluna 4
quadrado<-rbind(c(a,c),c(b,d))
res_qui<-chisq.test(quadrado,correct=F)
write(i,file="resultados/resultado_quiquadrado.txt", append = T)
capture.output(res_qui, file="resultados/resultado_quiquadrado.txt", append = T)
}6.4 Funções apply, lapply, sapply, tapply, mapply
A família Apply representa um conjunto de funções básicas do R que permite realizar operações sobre os dados contidos nas várias estruturas disponíveis (vetor, data frame, listas).
A utilização destas funções permitem automatizar a aplicação das operações desejadas, permitindo assim ganhos de velocidade durante procedimentos que necessitam ser repetidos sobre todos os dados.
A função apply é para matriz
library(dplyr)
dados3<-dados%>%
select(bill_length_mm:body_mass_g)
dados3<-as.matrix(dados3)
apply(dados3, 2, mean, na.rm=T) # 2 indica colunas, 1 indica linhas## bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
## 43.92193 17.15117 200.91520 4201.75439A função lapply é para lista:
## $a
## [1] 1 2 3 4
##
## $b
## [1] -0.1462363 1.1329913 2.4079264 0.8440802 1.8885291 -1.5309676
## [7] 0.7304055 -1.2286932 1.8829656 0.5071695
##
## $c
## [1] 1.1307528 0.1606436 -0.0783188 1.6592956 2.5304673 -0.7101490
## [7] 0.3305488 0.3119459 0.2144906 0.5243890 -0.3594519 -0.9596989
## [13] 1.1986835 1.7080799 1.0791402 1.1761097 0.7434128 -0.2957054
## [19] 0.7377619 0.4087309
##
## $d
## [1] 4.987162 5.926693 5.123900 4.378592 4.231536 6.553934 3.703266 4.146679
## [9] 3.682711 4.529510 4.878990 5.071106 5.428486 5.024510 3.286090 3.776374
## [17] 4.367179 6.075260 6.586768 5.191323 4.959922 4.710876 6.579611 5.190614
## [25] 4.349555 6.711560 7.670846 5.056228 5.651544 5.481577 5.418695 5.314562
## [33] 3.749451 6.650012 4.480169 3.967190 3.340270 6.305455 5.190831 4.959075
## [41] 5.124409 6.011343 4.396762 4.833261 3.975135 6.206448 3.437240 6.350211
## [49] 4.110012 6.236525 8.267206 5.628478 5.075394 4.609689 5.738808 4.983893
## [57] 5.240769 5.594473 6.245396 4.209579 5.379996 4.838167 6.219653 5.428798
## [65] 6.390918 5.222443 3.840240 5.770810 4.687458 4.711948 3.464836 5.814927
## [73] 3.223144 6.755132 5.154703 5.021050 6.232634 5.366411 5.533100 6.266400
## [81] 5.635938 5.896446 5.166291 4.976217 6.404555 5.893115 5.587616 5.360103
## [89] 4.356734 5.684694 2.997125 4.673638 4.378489 4.450108 7.401493 5.236328
## [97] 5.062635 4.463701 5.840819 5.813454## $a
## [1] 2.5
##
## $b
## [1] 0.648817
##
## $c
## [1] 0.5755564
##
## $d
## [1] 5.195654A função sapply é parecida com lapply, mas retorna vetor ou matriz:
## a b c d
## 2.5000000 0.6488170 0.5755564 5.1956540A função tapply é utilizada para aplicar um procedimento a diferentes partes dos dados dentro de um array, matriz ou data frame. Ela difere das demais funções vistas até aqui por exigir a existência de uma variável categórica, a qual servirá para agrupar os dados aos diferentes níveis.
## female male
## 42.09697 45.85476A função mapply é uma versão multivariada da função lapply. As funções lapply e sapply atuam somente sobre os elementos de uma única lista. No caso da função mapply a função é aplicada sobre o primeiro elemento de cada um dos argumentos, em seguida ao segundo elemento, seguindo ao terceiro, e assim por diante.
## [1] 57.8 56.9 58.3 NA 56.0 59.9 56.7 58.8 52.2 62.2 54.9 55.1 58.7 59.8 55.7
## [16] 54.4 57.7 63.2 52.8 67.5 56.1 56.4 55.1 56.3 56.0 54.2 59.2 58.4 56.5 59.4
## [31] 56.2 55.3 57.3 59.8 53.4 60.3 58.8 60.7 56.9 58.9 54.5 59.2 54.5 63.8 53.9
## [46] 58.4 60.1 56.4 53.9 63.5 57.3 59.0 52.9 61.5 52.6 60.0 56.5 59.4 53.1 56.7
## [61] 52.6 62.4 54.6 59.3 53.5 59.6 51.7 60.2 52.5 61.2 52.5 58.1 56.8 64.7 53.0
## [76] 61.3 57.7 56.6 52.3 61.2 51.8 60.5 55.5 54.5 55.1 61.6 55.8 55.5 57.5 57.7
## [91] 53.7 59.2 51.1 57.7 53.5 59.7 56.7 58.8 49.2 61.7 52.9 61.0 53.7 57.8 56.5
## [106] 58.6 55.8 58.2 55.1 62.2 54.6 65.9 57.4 61.7 60.3 61.0 55.6 57.8 52.7 59.7
## [121] 53.4 57.5 57.2 59.9 51.1 59.6 56.4 59.8 56.1 62.1 56.4 62.3 55.3 56.0 55.7
## [136] 58.6 53.1 60.3 53.5 57.6 57.3 57.8 47.6 57.7 54.1 57.7 57.8 55.0 53.8 55.9
## [151] 53.1 60.0 59.3 66.3 62.8 65.2 62.1 60.0 60.0 62.0 56.7 62.2 54.6 65.1 59.2
## [166] 63.0 60.4 65.0 55.5 64.4 60.7 63.8 64.5 59.6 61.0 62.1 56.0 61.2 58.8 62.8
## [181] 62.5 65.3 62.6 57.0 59.6 76.6 63.9 64.7 56.3 61.7 57.6 64.4 56.4 65.6 59.0
## [196] 64.6 66.4 57.5 59.4 66.4 58.2 61.0 60.8 62.6 59.5 65.1 60.9 60.4 57.7 60.5
## [211] 57.7 65.7 59.1 61.1 59.6 70.0 60.0 66.6 60.6 65.7 57.7 65.7 62.7 62.0 63.8
## [226] 61.3 61.4 64.6 61.7 67.4 59.0 61.6 63.6 68.1 62.0 65.9 58.7 68.1 57.8 65.5
## [241] 61.5 69.1 62.5 69.3 60.0 65.6 59.2 66.5 65.2 61.5 62.8 67.6 63.5 72.9 62.7
## [256] 64.1 61.1 62.9 56.4 69.2 57.3 63.2 65.7 65.7 58.7 67.8 60.3 71.1 60.2 65.0
## [271] 60.9 NA 61.1 66.1 60.0 66.0 64.4 69.5 70.5 64.1 72.5 63.0 64.3 69.5 64.9
## [286] 71.2 64.4 72.0 64.3 70.1 63.0 70.1 70.3 75.8 65.0 67.4 59.7 66.0 59.8 70.0
## [301] 64.6 71.0 68.9 68.5 64.2 72.8 57.5 75.0 59.2 69.8 68.3 64.3 65.9 72.7 63.5
## [316] 73.4 68.5 63.7 70.0 62.5 68.8 69.3 68.0 68.6 70.2 67.1 64.5 70.4 63.0 70.4
## [331] 59.8 71.0 61.8 69.2 69.0 65.0 71.4 63.3 62.7 75.6 61.6 67.8 69.8 68.9