Capítulo 10 Dados não estruturados
Muitos dados estão apresentados de forma não estruturada, como por exemplo textos, imagens, vídeos e sons.
No entanto, também podemos analisar esse tipo de dados. Por exemplo, um texto pode ser utilizado em um processo de mineração de dados.
Nesse capítulo veremos com trabalhar com textos, imagens e sons no R.
10.1 Texto
Você pode usar qualquer texto, salve como um arquivo txt.
Vamos carregar um arquivo de texto. Para isso usaremos o pacote tm [feinerer2008]:
Mas o texto carregado não está em um formato que possa ser analisado, então usamos a função VectorSource que interpreta cada elemento do vetor x como um documento.
Mas um texto tem muitos elementos que não são tão relevantes para uma análise, como pontuação, espaços, stop words e números. Podemos resolver isso com as seguintes funções:
docs <- docs %>%
tm_map(removeNumbers) %>%
tm_map(removePunctuation) %>%
tm_map(stripWhitespace)
docs <- tm_map(docs, content_transformer(tolower))
docs <- tm_map(docs, removeWords, stopwords("english"))Agora transformamos em uma matriz:
## Docs
## Terms 1 2 3
## able 1 0 0
## accumulated 2 0 0
## accumulation 1 0 0
## acquired 1 0 0
## act 7 0 0
## acted 1 0 0Podemos criar um objeto com as palavras e organizamos as palavras por frequência:
words <- sort(rowSums(matrix),decreasing=TRUE)
df <- data.frame(word = names(words),freq=words)
head(df)## word freq
## selection selection 24
## natural natural 20
## can can 15
## life life 13
## nature nature 13
## far far 11Para procurar os termos mais frequentes usamos a função findFreqTerms, por exemplo, procurar os termos que ocorrem pelo menos 10 vezes:
## <<TermDocumentMatrix (terms: 628, documents: 3)>>
## Non-/sparse entries: 628/1256
## Sparsity : 67%
## Maximal term length: 14
## Weighting : term frequency (tf)
## Sample :
## Docs
## Terms 1 2 3
## can 15 0 0
## far 11 0 0
## life 13 0 0
## may 11 0 0
## natural 20 0 0
## nature 13 0 0
## selection 24 0 0
## structure 11 0 0
## variations 9 0 0
## will 10 0 0## [1] "can" "far" "life" "may" "natural" "nature"
## [7] "selection" "structure" "will"Uma das coisas que é possível fazer com esse objeto é uma nuvemn de palavras, para isso vamos usar o pacote wordcloud2 (Lang and Chien 2018):
10.1.1 Análise de sentimentos
A Análise de Sentimentos é o estudo computacional de opiniões, sentimentos e emoções expressas em um texto.
Na educação, ela é empregada como método para a obtenção do “feedback” dos alunos ou avaliação de professores.
Os professores as vezes têm que lidar com grandes quantidades de mídia textual, o que é trabalhoso e demanda tempo. Nesse cenário, a utilização de ferramentas computacionais que os auxiliem na tarefa de analisar textos é muito atrativa.
A ideia é que se possa identificar a tendência geral de uma turma em relação ao tema em discussão, sem a necessidade de ler todos os textos, que podem ser volumosos.
Como exemplo, vamos o mesmo texto, mas agora usaremos o pacote pdftools (Ooms 2023) para ler um arquivo pdf. (Obs. com o pacote pdftools é possível juntar ou dividir arquivos pdf, bem como extrair páginas do pdf)
E agora usaremos o pacote syuzhet (Jockers 2015) para fazer a análise de sentimentos.
library(syuzhet)
library(RColorBrewer)
sentimentos <- get_nrc_sentiment(texto2, lang="english", lowercase = T)E plotamos o resultado em um gráfico:
barplot(
colSums(prop.table(sentimentos[, 1:8])),
space = 0.2,
horiz = FALSE,
las = 1,
cex.names = 0.7,
col = brewer.pal(n = 8, name = "Set3"),
xlab=NULL, ylab = NULL)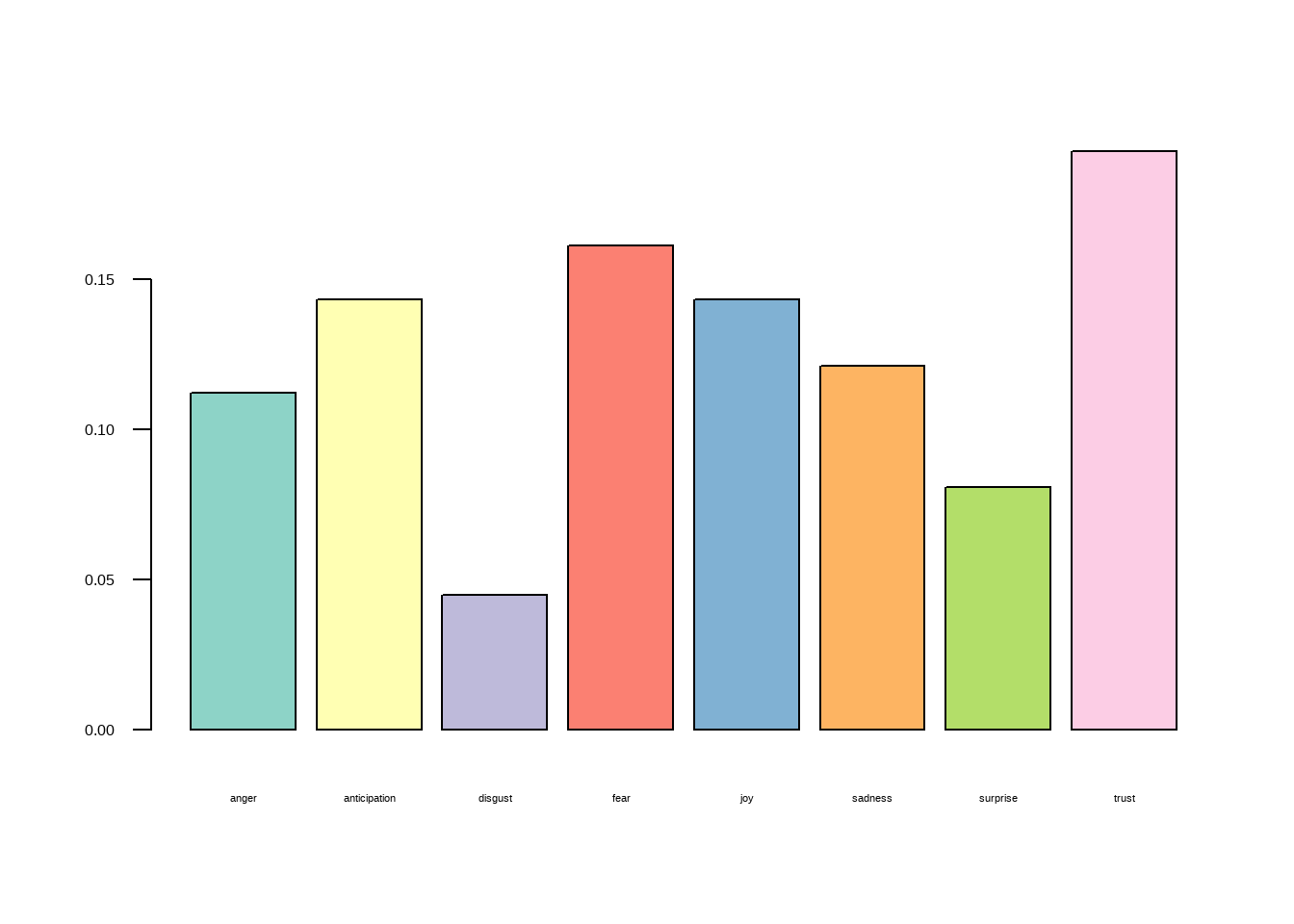
Também podemos resumir em sentimentos positivos e negativos:
barplot(
colSums(prop.table(sentimentos[, 9:10])),
space = 0.2,
horiz = FALSE,
las = 1,
cex.names = 0.7,
col = c("tomato","skyblue3"),
xlab=NULL, ylab = NULL)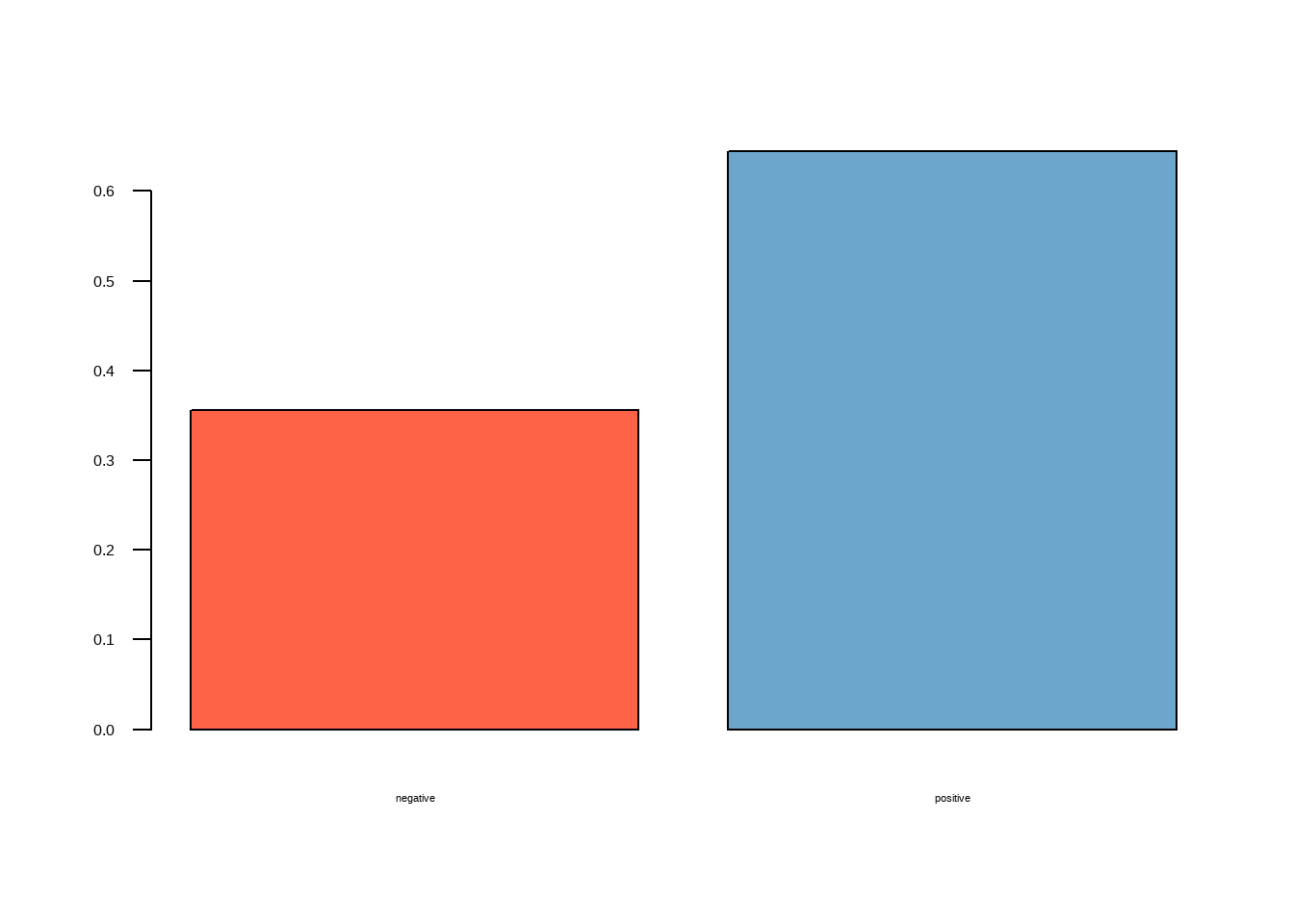
10.2 Imagens
As imagens são outro tipo de dado não estruturado e também podem ser carregadas e editadas. Como exemplo veremos o pacote magick.

Também podemos salvar em diferentes formatos:
10.2.1 Edição de imagens
Podemos cortar a imagem:
500px por350px começando na esquerda em +1550px:

Para redimensionar proporcionalmente à largura:

Para redimensionar proporcionalmente à altura:

Adicionar uma borda:

Vamos redimensionar a imagem para fazer outras alterações

Rotações de imagem:


Brilho, saturação e matiz:

Pintar a mesa de laranja:

Outros efeitos:




Adicionando texto:

Personalizando o texto;
image_annotate(foto2, "UFPR", size = 30, color = "red", boxcolor = "pink", degrees = -45, location = "+150+100",font = 'Times')
Usando pipes
Cada uma das funções de transformação de imagem retorna uma cópia modificada da imagem original. Não afeta a imagem original.
foto2 %>%
image_rotate(270) %>%
image_background("blue", flatten = TRUE) %>%
image_border("red", "10x10") %>%
image_annotate("Lab", color = "blue", size = 50)
Vamos carregar outra imagem:

E colocar as duas imagens em um vetor:
Um mosaico imprime imagens umas sobre as outras, expandindo a tela de saída de forma que tudo se encaixe:

O achatamento combina as camadas em uma única imagem que tem o tamanho da primeira imagem. O nivelamento e o mosaico permitem especificar operadores compostos alternativos:



Combinando imagens
Anexar significa simplesmente colocar os quadros um ao lado do outro:

A composição permite combinar duas imagens em uma posição específica:
logo2<-image_scale(image_rotate(image_background(logo, "none"), 300), "x200")
image_composite(image_scale(foto2, "x400"), logo2, offset = "+180+100")
Animação
Em vez de tratar os elementos vetoriais como camadas, também podemos transformá-los em quadros em uma animação.

Morphing cria uma sequência de n imagens que transformam gradualmente uma imagem em outra. Faz animações
newlogo <- image_scale(image_read("https://jeroen.github.io/images/Rlogo.png"))
oldlogo <- image_scale(image_read("https://jeroen.github.io/images/Rlogo-old.png"))
image_resize(c(oldlogo, newlogo), '200x150!') %>%
image_background('white') %>%
image_morph() %>%
image_animate(optimize = TRUE) 
10.3 Áudio
Assim como as imagens, também podemos trabalhar com arquivos de áudio. Para isso, utilizaremos o pacote tuneR. Vamos usar um arquivo de áudio em mp3.
##
## Wave Object
## Number of Samples: 95616
## Duration (seconds): 2.17
## Samplingrate (Hertz): 44100
## Channels (Mono/Stereo): Stereo
## PCM (integer format): TRUE
## Bit (8/16/24/32/64): 16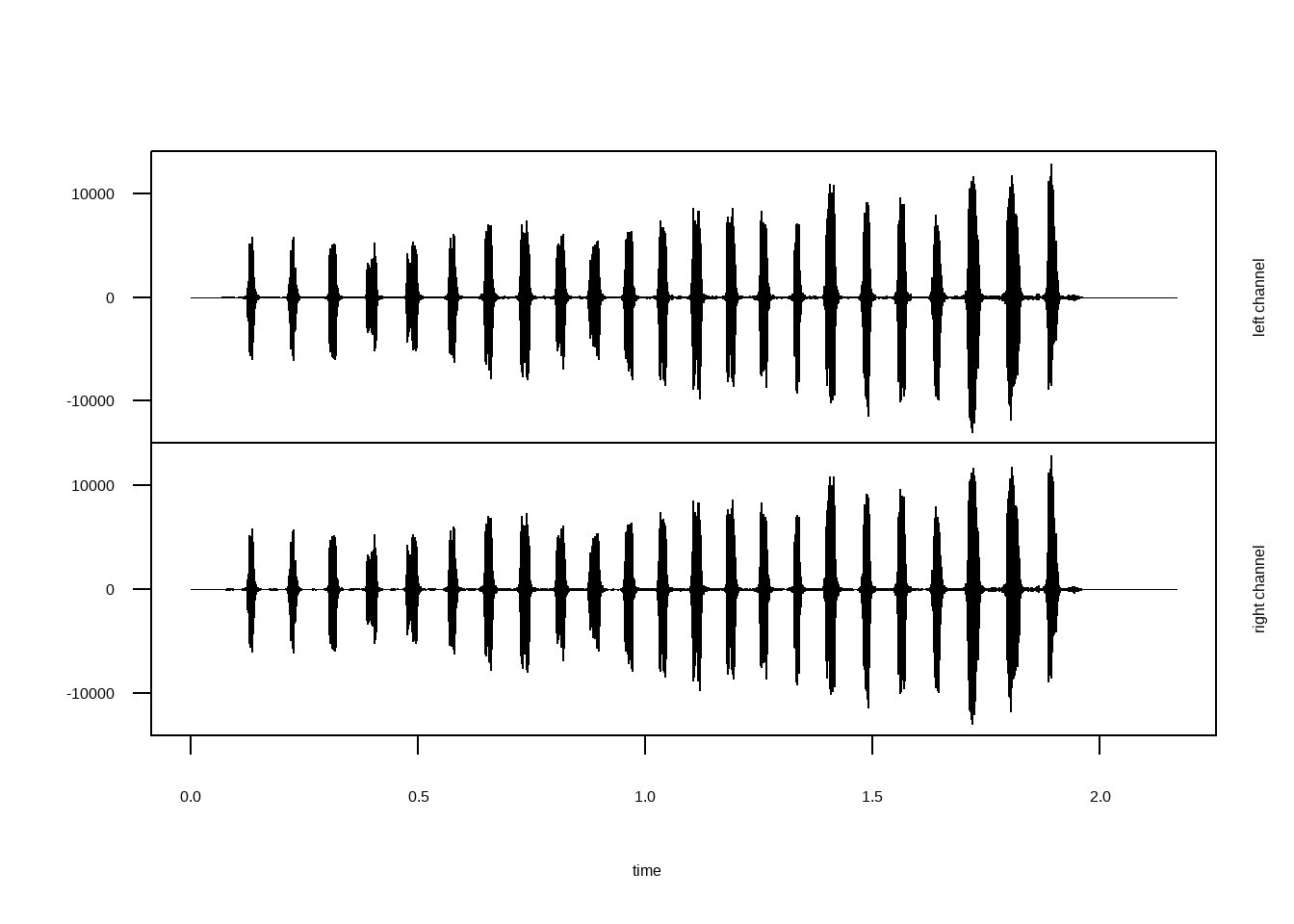 Usando:
play(bird)
será acionado um player de áudio para tocar o áudio.
Usando:
play(bird)
será acionado um player de áudio para tocar o áudio.
Pegaremos apenas um canal para extrair algumas informações do áudio.
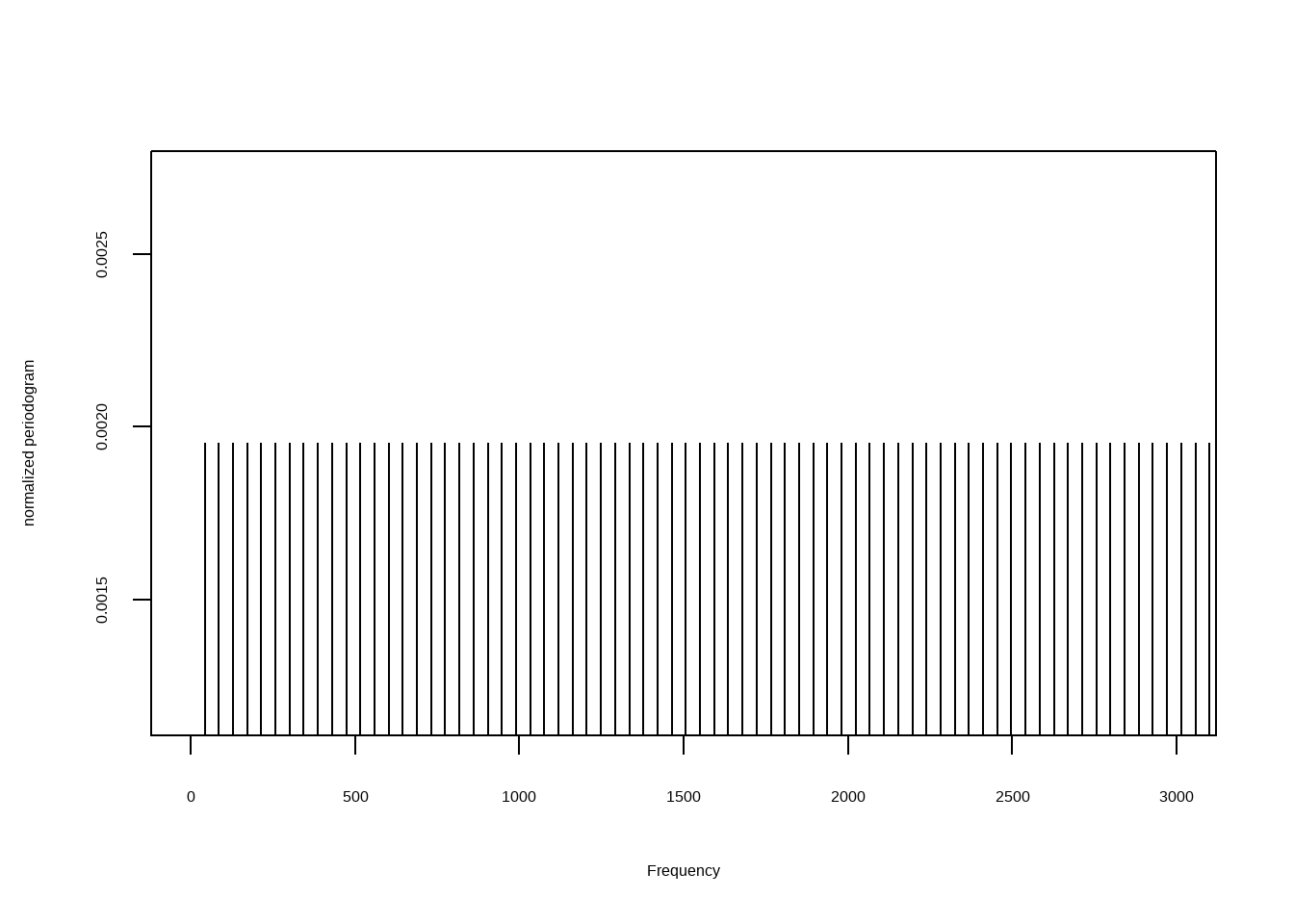
wobjm <- mono(bird, "left")
WspecObject <- periodogram(wobjm, normalize = TRUE, width = 1024, overlap = 512)Vejamos o primeiro periodograma:
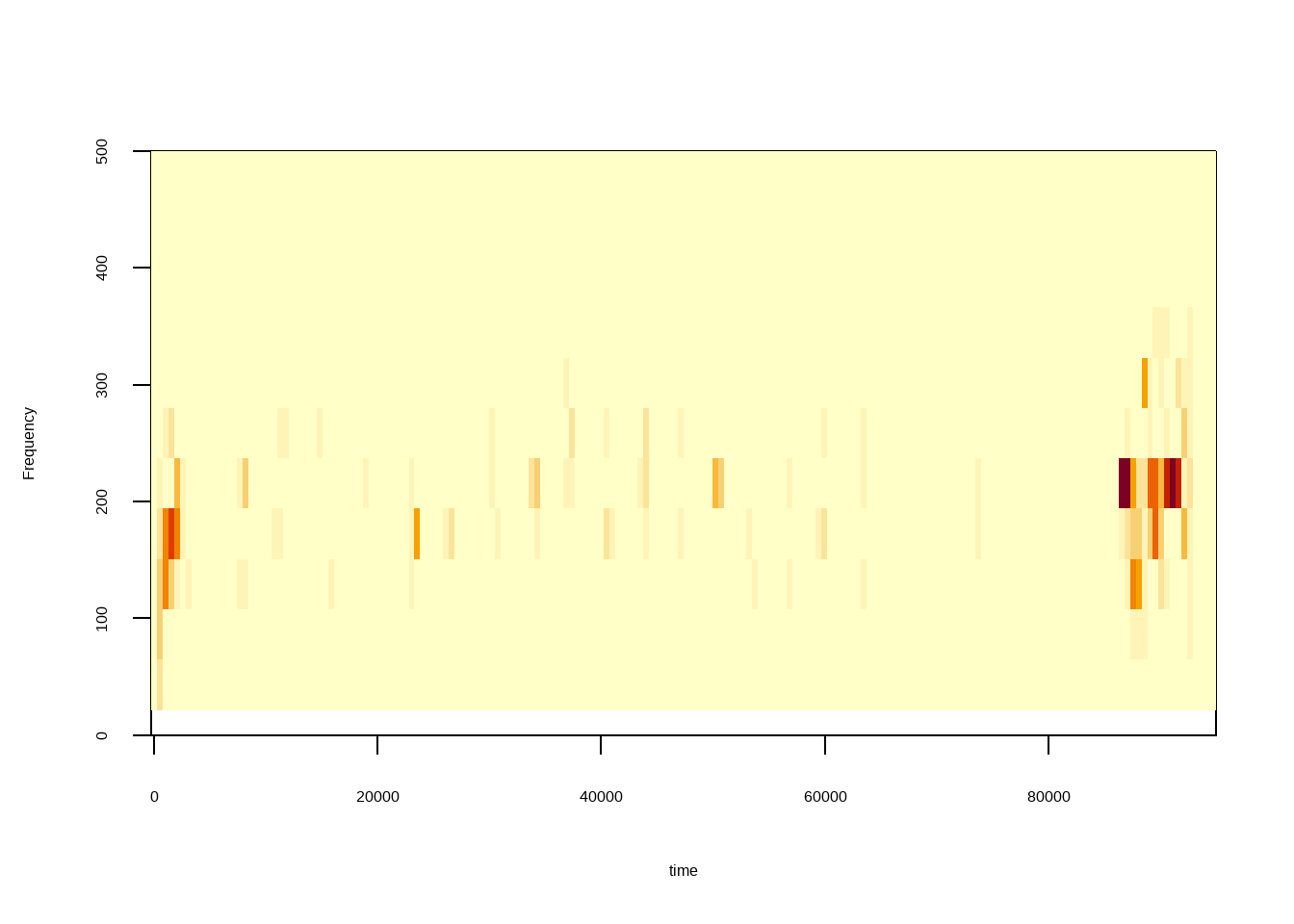
Ou o espectrograma:
Calculando a frequência fundamental
## [1] 64.59961 NA NA 157.61370 190.49718 NA
## [7] 122.38931 NA NA 68.65275 1307.25253 1304.91011
## [13] 186.36882 NA NA 208.51484 NA 239.47304
## [19] 1316.87812 1307.09008 203.61197 NA NA NA
## [25] 224.89103 1229.82436 1191.25743 1225.72103 115.94173 NA
## [31] 280.35222 136.92399 113.80207 1144.64054 1175.98917 450.59224
## [37] 228.69309 NA NA 247.74156 1135.16935 1138.56091
## [43] 1181.17227 111.98844 225.52343 193.87516 NA 141.20795
## [49] 1223.99605 1189.99512 239.65834 158.96104 162.50840 136.96878
## [55] 195.89302 1179.23405 1176.32140 279.89437 142.01919 234.51471
## [61] 184.57174 285.11695 1182.03568 1182.27814 240.39591 188.66432
## [67] 201.72665 201.73638 1145.25713 1171.13817 2347.22572 137.95489
## [73] 310.06133 239.62800 220.72491 1147.34294 1149.32670 1271.95231
## [79] 116.00928 NA 178.83420 191.57976 1190.65734 2388.42507
## [85] 191.24564 199.89378 236.02492 285.11982 1183.38516 1189.22560
## [91] 156.13566 250.04596 189.38153 107.84409 1179.68209 1177.59186
## [97] 1962.26711 223.28651 210.78742 224.84481 139.18888 1174.04464
## [103] 1178.07041 201.16565 192.20782 124.65268 179.78313 1185.21392
## [109] 1183.06218 189.63599 187.53263 146.04791 116.55402 315.08823
## [115] 2432.35358 2431.15224 169.64383 161.82987 234.15430 1143.98102
## [121] 2333.10267 1181.81971 1106.25765 151.89479 139.98791 275.27740
## [127] 497.53243 1229.88256 2046.93927 195.21948 281.09972 232.03905
## [133] 199.26075 2393.29052 2400.57146 322.29840 204.85652 194.56689
## [139] 269.21640 363.42894 2278.99300 2296.81342 239.29813 318.95594
## [145] 196.19900 159.64041 1224.43889 1225.66359 2432.01938 279.17197
## [151] 238.88824 271.84562 311.88075 2044.02861 1970.36983 1199.44922
## [157] 2398.11124 284.57293 283.13241 319.35321 157.07776 325.65761
## [163] 1787.00889 586.06028 196.28648 324.72040 335.16499 278.96700
## [169] 283.27520 NA 205.36409 144.30646 147.86967 NA
## [175] 200.75462 193.42870 196.70002 223.36453 209.97048 209.47188
## [181] NA NA 64.59961 64.59961 64.59961 64.59961Derivar nota de FF dado diapasão A=440
Suavizar as notas:
O resultado deve ser 0 para o A do diapasão e -12 (12 meios-tons abaixo) para A
## [1] 492.50 492.50 492.50 255.75 19.00 19.00 19.00 19.00 19.00 19.00
## [11] 19.00 19.00 19.00 19.00 19.00 19.00 19.00 19.00 19.00 19.00
## [21] 19.00 19.00 19.00 18.00 18.00 18.00 18.00 17.00 17.00 17.00
## [31] 0.00 0.00 0.00 0.00 0.00 0.00 16.00 16.00 16.00 16.00
## [41] 16.00 16.00 16.00 16.00 16.00 -10.00 -11.00 -12.00 -12.00 -12.00
## [51] -12.00 -14.00 -14.00 -14.00 -14.00 -11.00 -11.00 -11.00 -11.00 -11.00
## [61] -10.00 -10.00 -8.00 -10.00 -10.00 -10.00 -10.00 -10.00 -10.00 -8.00
## [71] -6.00 -6.00 -6.00 -6.00 -6.00 -6.00 17.00 -6.00 -6.00 -6.00
## [81] -11.00 -11.00 -8.00 -10.00 -11.00 -11.00 -11.00 -10.00 -10.00 -10.00
## [91] -10.00 -10.00 -11.00 -11.00 -10.00 -12.00 -12.00 -12.00 -12.00 -12.00
## [101] -12.00 -13.00 -14.00 -14.00 -14.00 -14.00 -14.00 -14.00 -15.00 -15.00
## [111] -15.00 -15.00 -15.00 -15.00 -11.00 -6.00 -11.00 -8.00 -6.00 2.00
## [121] 16.00 16.00 2.00 2.00 -8.00 -8.00 2.00 -5.00 -8.00 -8.00
## [131] -8.00 -8.00 -8.00 -8.00 -5.00 -6.00 -8.00 -9.00 -6.00 -6.00
## [141] -5.00 -6.00 -6.00 -6.00 -8.00 -6.00 -6.00 -6.00 -6.00 -6.00
## [151] -6.00 -6.00 -6.00 -6.00 -5.00 -5.00 -6.00 -6.00 -6.00 -5.00
## [161] -5.00 -5.00 -5.00 -5.00 -5.00 -5.00 -5.00 -8.00 -8.00 -8.00
## [171] -8.00 -13.00 -13.00 -13.00 -13.00 -13.00 -13.00 -13.00 -13.00 -13.00
## [181] -13.00 -13.00 -18.00 -23.00 -28.00 -33.00Plotar a melodia e energia do som:
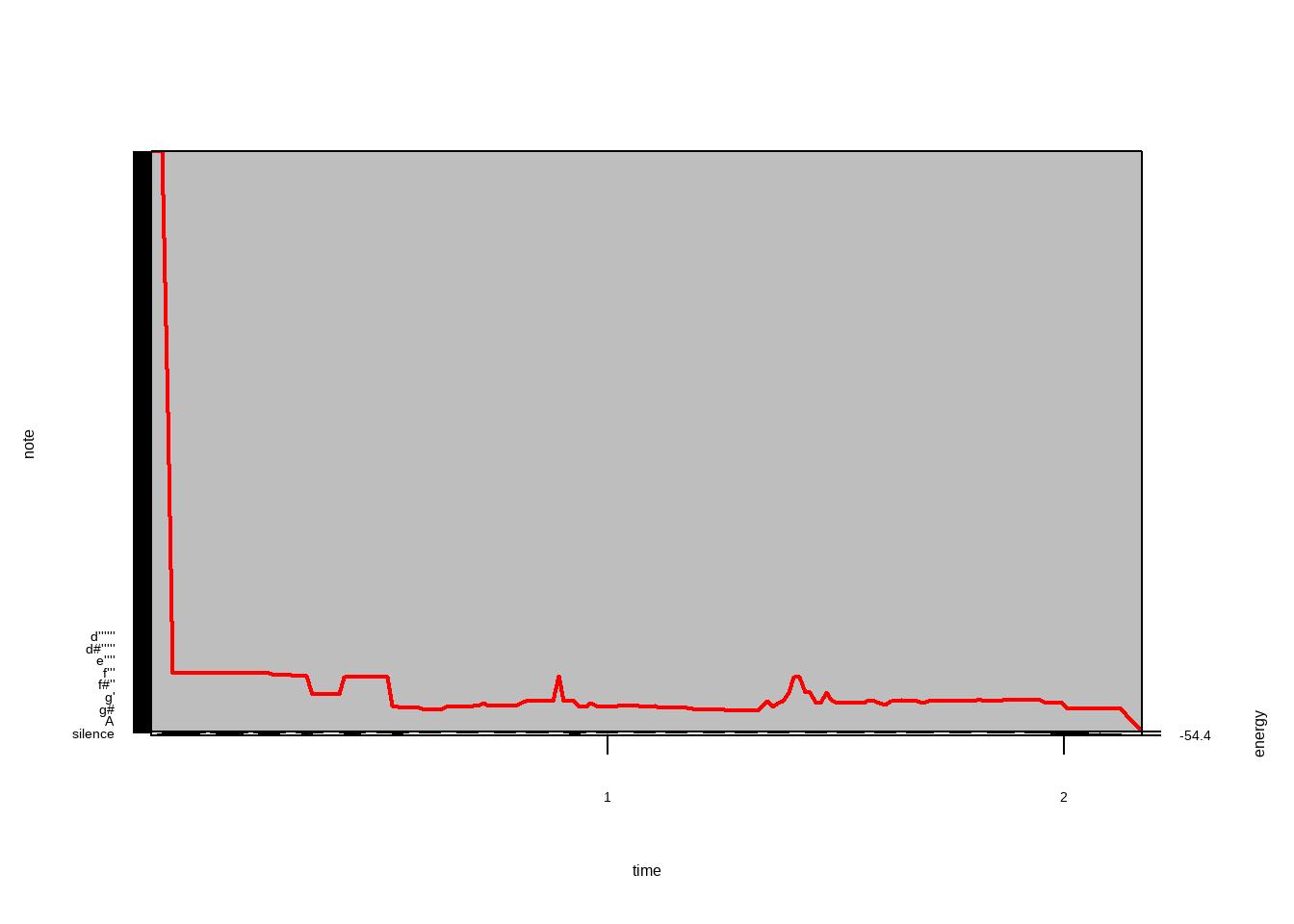
Aplique alguma quantização (em 8 partes) e um gráfico, 4 partes por barra:
qnotes <- quantize(snotes, WspecObject@energy, parts = 8)
quantplot(qnotes, expected = rep(c(0, -12), each = 4), bars = 2)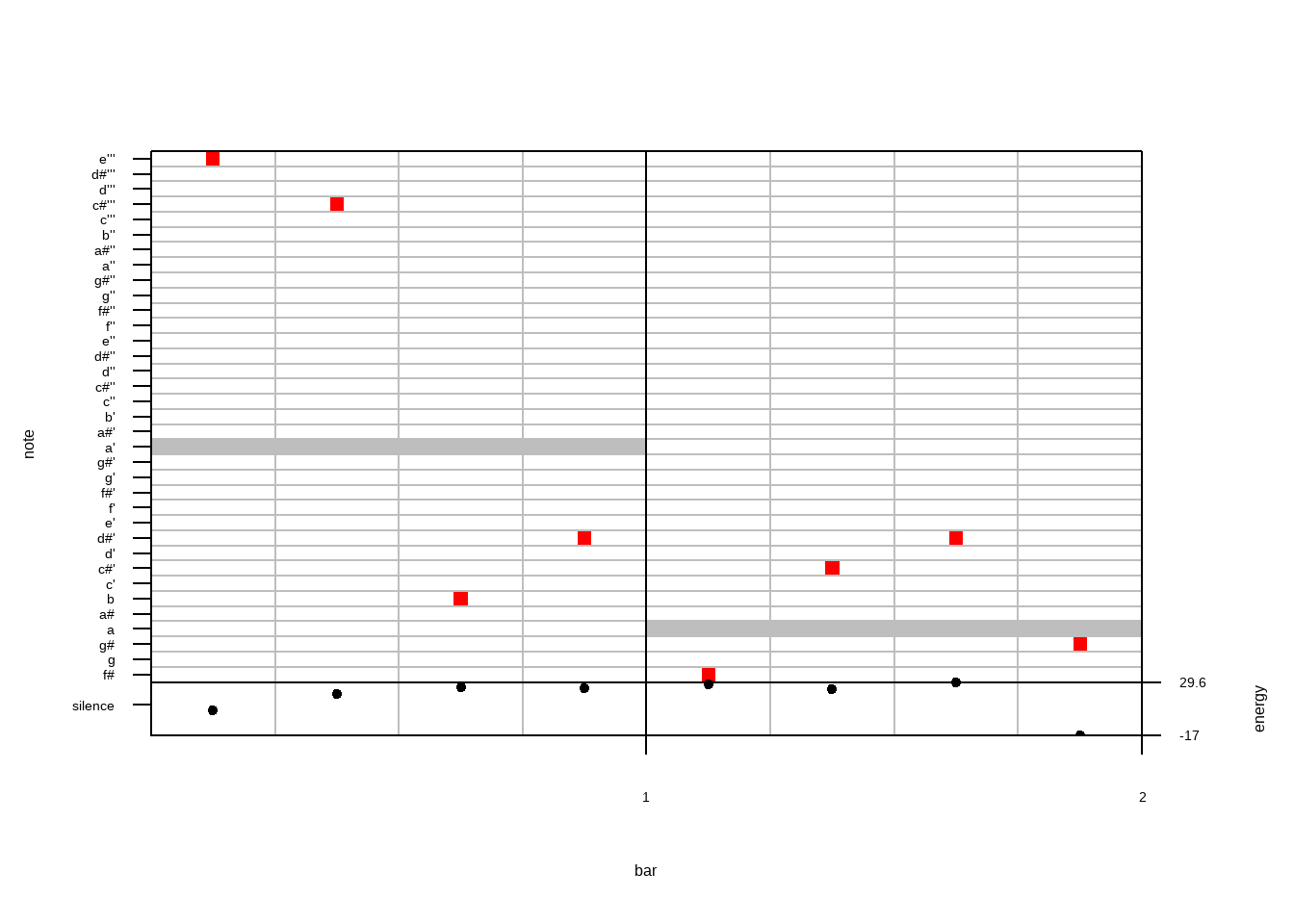
E preparando o objeto para o LilyPond. LilyPond é um programa de gravação de música, dedicado a produzir partituras de alta qualidade possíveis (http://lilypond.org/).
## note duration punctuation slur
## 1 19 4 FALSE FALSE
## 2 16 4 FALSE FALSE
## 3 -10 4 FALSE FALSE
## 4 -6 4 FALSE FALSE
## 5 -15 4 FALSE FALSE
## 6 -8 4 FALSE FALSE
## 7 -6 4 FALSE FALSE
## 8 -13 4 FALSE FALSE