1.3.3 Konfidensinterval (praksis), “p-hat”
1.3.3.1 Beregning
Når vi skal estimere en ukendt sandsynlighed \(p\) i en binomialfordeling \(Bin(n,p)\), kan vi bruge det nedenstående resultat til at sige noget om, hvor præcist vores estimat \(\hat p\) af den ukendte sandsynlighed \(p\) er. Resultatet opsummerer overvejelserne i afsnit 1.3.2.
Det nedenstående interval kaldes et \(1-\alpha\) konfidensinterval for \(p\). Ofte anvendes \(\alpha=5\%\) ved beregning af intervallet (som dermed bliver et 95% (\(=1-\alpha\)) konfidensinterval).
Resultat: Konfidensinterval for \(p\)
Hvis \(X_1,...,X_n\) er indbyrdes uafhængige observationer af en variabel med to mulige udfald: 1 og 0, så vil den ukendte sandsynlighed \(p\) for at få udfaldet 1 ligge i intervallet \[\Bigl[\hat p+z_{\alpha/2}\cdot\sqrt{\frac{\hat p(1-\hat p)}{n}};\quad\hat p-z_{\alpha/2}\cdot\sqrt{\frac{\hat p(1-\hat p)}{n}}\Bigr]\] ca. med sandsynlighed \(1-\alpha\), hvor \(z_{\alpha/2}\) er \(\alpha/2\)-fraktilen i standardnormalfordelingen \(N(0,1)\).
Bemærk: For ethvert \(0<\alpha<1\) er \(z_{\alpha/2}<0\) og dermed \(-z_{\alpha/2}>0\), således at intervallet ovenfor altid er veldefineret.
Idéen bag at beregne et konfidensinterval for den ukendte sandsynlighed \(p\) er, at… * uanset hvordan vi beregner et estimat af (= gæt på) værdien af den ukendte størrelse \(p\), så vil estimatet variere lidt fra gang til gang alene på grund af tilfældig variation. Derfor giver det ikke mening kun at gætte på én bestemt værdi af \(p\). * et estimat af den ukendte værdi \(p\) ikke er meget værd, hvis ikke vi ved, hvor præcist det er. * vi beregner derfor et helt interval (= konfidensintervallet) af plausible værdier for \(p\). * værdierne i konfidensintervallet er de værdier, vi vil anse som fornuftige gæt på den sande værdi af \(p\) på baggrund af vores observationer i datamaterialet.
Eksempel: Skat
Vi ser igen på svarene på spørgmålet “Er topskatten for høj?” og antager som hidtil, at de indkomne svar kan beskrives ved en binomialfordeling \(Bin(n,p)\).
Hvis vi bruger de første \(n\) =10 personers svar som grundlag for at beregne et estimat af \(\hat p\), finder vi at \(\hat p=0,\!5\).
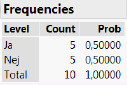
Det er klart, at vores gæt på \(\hat p\) = 0,5 som andelen af den voksne danske befolkning, der mener at topskatten er for høj, er behæftet med en vis usikkerhed, fordi det kun er baseret på svar fra 10 personer.
Vi kan derfor også beregne et konfidensinterval hørende til estimatet \(\hat p\) = 0,5. Hvis vi eksempelvis sætter \(\alpha\) = 10%, finder vi at et 90%-konfidensinterval for \(p\) er givet ved
\[\begin{align*} &\mathrel{\phantom{=}}\Bigl[\hat p+{z_{\alpha/2}}\cdot\sqrt{\frac{\hat p(1-\hat p)}{n}};\quad\hat p-z_{\alpha/2}\cdot\sqrt{\frac{\hat p(1-\hat p)}{n}}\Bigr]\\ &=\Bigl[0,\!5-1,\!64\cdot\sqrt{\frac{0,\!5\cdot(1-0,\!5)}{10}};\quad 0,\!5+1,\!64\cdot\sqrt{\frac{0,\!5\cdot(1-0,\!5)}{10}}\Bigr] = [0,\!27;\quad 0,\!73] \end{align*}\]
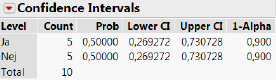
Figur 1.13: 90%-konfidensinterval for andelen \(p\) (med kun 10 observationer)
Med 90% sandsynlighed vil den sande (men for os ukendte) andel af befolkningen, som mener topskatten er for høj, ligge mellem 0,27 og 0,73.
Konfidensniveauet på 90% betyder, at hvis vi gentagne gange beregner et estimat af \(p\) baseret på 10 personers svar, så vil estimatet af \(p\) i det lange løb ligge i intervallet fra 0,27 til 0,73 90% af tiden (dvs. 9 ud af 10 gange).
Tegner vi alle 10-personers estimaterne op over tid og sammenligner med det fundne 90%-konfidensinterval (de røde linjer i figuren nedenfor) kan vi netop se, at intervallet indeholder de fleste – men ikke alle – af estimaterne.
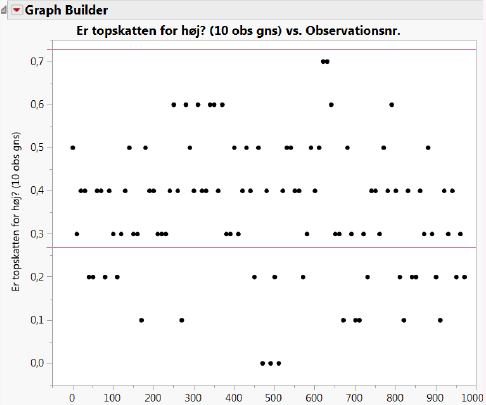
I princippet burde intervallet indeholde ca. 90% af estimaterne, men vi kan se, at i praksis indeholder det noget færre end 90% (helt præcist: 74 ud af 98 estimater).
Udover tilfældig variation skyldes det, at betingelserne \(n\hat p> 15\) og \(n(1-\hat p)>15\) ikke er opfyldt (idet \(n\hat p=10\cdot 0,\!5=5\) og \(n(1-\hat p)=10\cdot(1-0,\!5)=5\)), og vores metode derfor ikke fungerer, når vi kun baserer vores gæt på \(n=10\) observationer (NB: hvis \(n\) var større ville betingelserne formentlig være opfyldt).
Eksemplet med kun at anvende svar fra 10 personer til estimation af \(p\) er udelukkende medtaget for at vise, hvordan estimaterne ændrer sig i takt med, at der vælges data for nye grupper af 10 personer.
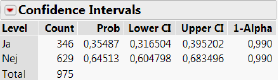
I praksis er der naturligvis ikke nogen grund til ikke at anvende hele datasættets 975 observationer til beregning af \(\hat p\). I det tilfælde finder vi at \(\hat p=346/975\) = 35,5%, og dermed at eksempelvis et 95%-konfidensinterval for \(p\) er givet som
\[\begin{align*} &\mathrel{\phantom{=}}\Bigl[\hat p+z_{\alpha/2}\cdot\sqrt{\frac{\hat p(1-\hat p)}{n}};\quad\hat p-z_{\alpha/2}\cdot\sqrt{\frac{\hat p(1-\hat p)}{n}}\Bigr]\\ &=\Bigl[0,\!355-1,\!96\cdot \sqrt{\frac{0,\!355(1-0,\!355)}{975}};\quad 0,\!35+1,\!96\cdot \sqrt{\frac{0,\!355(1-0,\!355)}{975}}\Bigr] = [0,\!325;\quad 0,\!385] \end{align*}\]
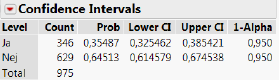
Tilsvarende er eksempelvis et 99%-konfidensinterval givet som \[\begin{align*} &\mathrel{\phantom{=}}\Bigl[\hat p+z_{\alpha/2}\cdot\sqrt{\frac{\hat p(1-\hat p)}{n}};\quad\hat p-z_{\alpha/2}\cdot\sqrt{\frac{\hat p(1-\hat p)}{n}}\Bigr]\\ &=\Bigl[0,\!355-2,\!58\cdot\sqrt{\frac{0,\!355(1-0,\!355)}{975}};\quad 0,\!355+2,\!58\cdot \sqrt{\frac{0,\!355(1-0,\!355)}{975}}\Bigr] = [0,\!317;\quad 0,\!395] \end{align*}\]