Kapitel 1 Konfidensinterval (for én gruppe)
1.1 Emne i dette kapitel
I praksis kan en variabel i et datasæt i mange tilfælde beskrives ved hjælp af enten en normal- eller en binomialfordeling. Det betyder, at vi kan bruge enten en normal- eller en binomialfordeling som en teoretisk model for variablen. På baggrund af en sådan teoretisk model har vi mulighed for eksempelvis at sige noget om, hvad vi vil forvente omkring fremtidige værdier af variablen.
For at kunne lave den slags analyser skal vi først have estimeret parametrene i variablens teoretiske fordeling, dvs. have estimeret parametrene i en normal- eller binomialfordeling.
For en variabel, der kan beskrives ved en normalfordeling, er det først og fremmest middelværdien \(\mu\), vi er interesseret i at estimere. Et estimat af \(\mu\) udtrykker vores gæt på, hvad værdien af variablens ukendte (teoretiske) middelværdi er.
Som ethvert gæt er også vores gæt på værdien af \(\mu\) behæftet med usikkerhed. Spørgsmålet er derfor: Når vi gætter på en værdi af \(\mu\), hvor præcist er vores gæt så? Kunne vi ligeså godt gætte på en helt anden værdi? Eller kan vi føle os nogenlunde sikre på, at vores gæt er forholdsvis præcist? (tilsvarende overvejelser gælder for et estimat af den ukendte sandsynlighed \(p\) i en binomialfordeling)
Dette kapitel beskæftiger sig med, hvordan vi kan måle præcisionen af de gæt på ukendte parametre i en teoretisk fordeling, som vi har behov for at lave for at kunne bruge henholdsvis normal- eller binomialfordelingen til videre statistisk analyse.
Eksempel: Ølsalg
Ser vi på prisen for 1 stk. Grøn Tuborg (33 cl glasflaske) i supermarkedskæden Føtex (datafil: Ølsalg.jmp), får vi følgende histogram over variablens empiriske fordeling:
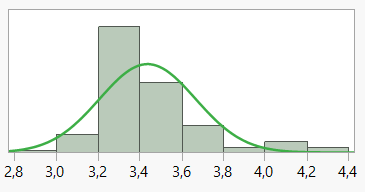
Figur 1.1: Fordeling af prisen på 1 stk. Tuborg i Føtex
Datamaterialet består af 157 ugers priser og kan med en vis rimelighed beskrives af en normalfordeling (den grønne kurve) med estimerede parametre \[\hat\mu=3,\!44\textsf{ og }\hat\sigma=0,\!23\]
Den ukendte teoretiske middelværdi \(\mu\) for prisen på Grøn Tuborg, gætter vi således på er 3,44 kr. Med andre ord: på baggrund af datamaterialet er vores bedste gæt, at vi skal forvente at prisen på Grøn Tuborg i Føtex er 3,44 kr.
Vores gæt på 3,44 kr. er baseret på samtlige 157 prisobservationer i datamaterialet (det er beregnet som gennemsnittet af alle 157 observationer), og er naturligvis kun et gæt, for vi ved godt at prisen kan variere lidt fra uge til uge.
Hvis vi nu i stedet nøjes med at gætte på værdien af \(\mu\) på baggrund af de første 4 prisobservationer i datamaterialet (svarende til priserne i perioden 30/12 2013 til 26/1 2014), så får vi i stedet et gæt på \(\hat\mu\) = 3,62. Gætter vi baggrund af de efterfølgende 4 prisobservationer (svarende til priserne i perioden 27/1 2014 til 23/2 2014), så får vi et gæt på \(\hat\mu\) = 3,47.
Hver gang vi vælger et nyt datasæt at basere vores gæt på, får vi en anden værdi af \(\hat\mu\). Det skyldes den almindelige variation i priserne fra uge til uge. Det betyder, at et gæt på værdien af \(\mu\) altid vil være behæftet med en vis usikkerhed. Det gælder, uanset hvor få eller hvor mange observationer vi baserer vores gæt på.
Hvis vi, som illustrativt eksempel, går igennem datasættet og regner et gæt på værdien af \(\mu\) ud for 4 ugers observationer ad gangen og herefter tegner de mange gæt op i en figur, så kommer det til at se således ud (datafil: Ølsalg_konfidens.jmp):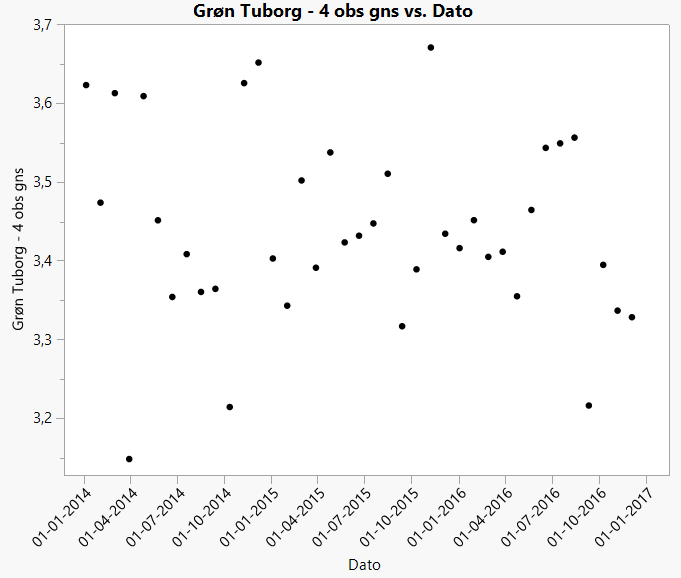
Figur 1.2: Estimater af prisen på 1 stk. Tuborg i Føtex
Der er tydeligvis stor variation på de mange forskellige gæt på værdien af \(\mu\), vi kan producere ud fra 4 observationer i datamaterialet.
Selv hvis vi baserer vores gæt på alle 157 prisobservationer, vil det være behæftet med en vis usikkerhed. Vi vil jo næppe forvente, at såfremt vi venter, til der er gået nye 157 uger, og vi dermed kan beregne et nyt gennemsnit af 157 ugers priser, at vi så vil få præcis samme gæt (3,44 kr.) én gang til.
Summa summarum: Når vi beregner et gæt på \(\hat\mu\)=3,44 på den ukendte middelværdi for prisen på Grøn Tuborg i Føtex, så er gættet behæftet med usikkerhed.
Det vi skal se på i dette kapitel er, hvordan vi kan måle denne usikkerhed, dvs. hvordan vi kan afgøre, hvor præcist vores gæt på 3,44 kr. for 1 stk. Grøn Tuborg i Føtex egentlig er. Kunne vi ligeså godt have gættet på en pris på 3,44 plus/minus 1 kr.? Eller er det mere rimeligt at tro, at den forventede pris ligger omkring 3,44 kr. plus/minus et par øre?
Eksempel: Skat
Ser vi på svarene på spørgsmålet “Er topskatten for høj?” fra en spørgeskemaundersøgelse vedr. velfærd og skat baseret på svar fra 975 respondenter (datafil: Skat.jmp), så får vi følgende nøgletal for datamaterialet: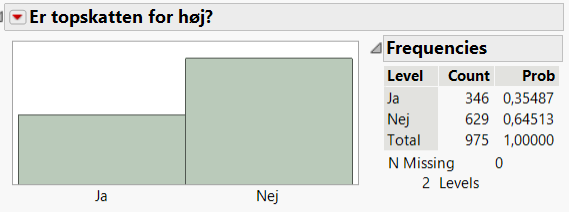
Figur 1.3: Svar på spørgsmålet: Er topskatten for høj?
Her kan vi bruge binomialfordelingen med de to parametre \(n\) og \(p\) som teoretisk model til at beskrive de afgivne svar, idet der kun er tilladt to svarmuligheder på det stillede spørgsmål: “Ja” eller “Nej”.
Antalsparameteren \(n\) er i dette tilfælde lig med antallet af indkomne svar (\(n\)=975). Sætter vi værdien 1 til at repræsentere svaret “Ja”, og 0 til at repræsentere “Nej”, så angiver sandsynlighedsparameteren \(p\) sandsynligheden for, at en given person svarer “Ja” på spørgsmålet, eller med andre ord: andelen af personer der svarer “Ja”,
346 ud af de 975 adspurgte personer har svaret “Ja” og vi estimerer derfor sandsynlighedsparameteren til \(\hat p=\frac{346}{975}\) = 35,5%. Men det er naturligvis kun et gæt på hvad den sande værdi af \(p\) er (for at kende den skulle vi have spurgt hele den danske befolkning) og er derfor behæftet med usikkerhed. Havde vi spurgt et andet udsnit af befolkningen havde vi formentlig fået en anden værdi af \(\hat p\).
Hvis vi, som illustrativt eksempel, nøjes med at basere vores gæt på \(p\) på svarene fra de 10 første personer i datamaterialet, så får vi en værdi på \(\hat p\) = 0,5. Ser vi i stedet på svarene fra de næste 10 personer, bliver værdien \(\hat p\) = 0,3. Går vi på denne måde igennem hele datasættet og beregner \(\hat p\) (et gæt på værdien af den sande parameter \(p\)) ved at se på svarene for 10 personer ad gangen, så får vi nedenstående resultat: (datafil: Skat_konfidens.jmp):
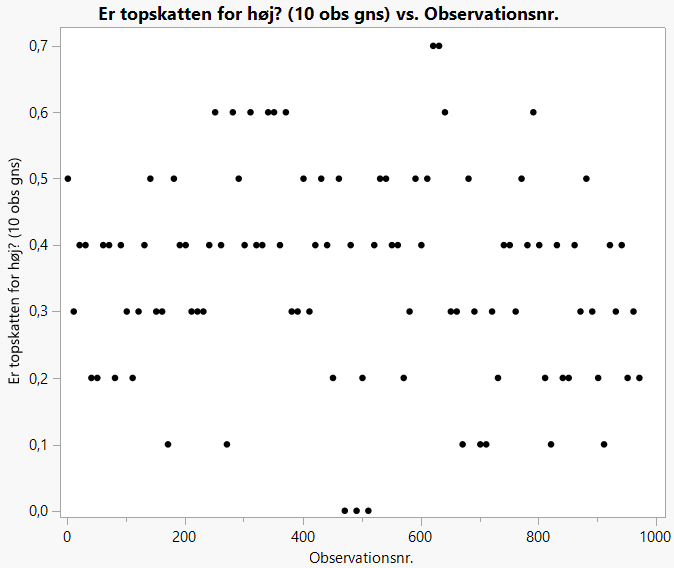
Figur 1.4: Estimater af andelen \(p\) af befolkningen, der synes topskatten er for høj
Der er helt tydeligt stor variation på de mange forskellige gæt på værdien af \(p\). Som i det foregående eksempel vedr. ølsalg, så er pointen også her, at ethvert gæt på en ukendt parameter vil være behæftet med usikkerhed, netop fordi det kun er et gæt.
Spørgsmålet her er, hvor præcist vi kan regne med, at vores gæt ovenfor på \(\hat p\) = 35,5% (= andelen af befolkningen der synes topskatten er for høj) egentlig er?