1.2 Normalfordeling
1.2.1 Fordeling, “my-hat”
Når vi skal estimere (dvs. gætte på) en værdi af de ukendte parametre \(\mu\) og \(\sigma\) i en normalfordeling, er det ikke på forhånd klart, hvordan vi gør det bedst muligt.
Der er imidlertid tungtvejende teoretiske argumenter for, at den bedste måde at estimere værdier for \(\mu\) og \(\sigma\) på er som angivet i nedenstående resultat.
Resultat: Fordeling af \(\hat\mu\) (“my-hat”)
Lad \(X_1,...,X_n\) være indbyrdes uafhængige observationer af en variabel, der er normalfordelt \(N(\mu,\sigma)\). Vi estimerer normalfordelingens parametre ved \[\hat\mu=\frac{1}{n}\sum_{i=1}^nX_i\hspace{2cm}\hat\sigma=\sqrt{\frac{1}{n-1}\sum_{i=1}^n\left(X_i-\hat\mu\right)^2}\] Estimatet af \(\mu\) bliver selv normalfordelt \[\hat\mu\sim N\left(\mu,\frac{\sigma}{\sqrt{n}}\right)\]
Bemærk: Symbolet \(\mu\) betegner en ukendt teoretisk værdi, som vi er interesseret i at estimere. Symbolet \(\hat\mu\) betegner vores gæt på den ukendte størrelse \(\mu\).
Forklaring af resultatet:
- Vi antager, at vi har et datamateriale med \(n\) observationer af en normalfordelt variabel \(N(\mu,\sigma)\)
- Den første observation i datamaterialet betegner vi med \(X_1\), den næste med \(X_2\) osv.
- Vi tænker på det, som om vi endnu ikke kender talværdierne af de enkelte observationer. Derfor skriver vi observationerne som store bogstaver (dvs. \(X_1\), \(X_2\) osv.). Det vi antager er, at alle observationer kan beskrives med den samme normalfordeling \(N(\mu,\sigma)\) (dvs. med de samme parametre \(\mu, \sigma\))
- Resultatet fortæller, at vores estimat \(\hat\mu\) af den ukendte middelværdi \(\mu\) i sig selv kan beskrives ved en normalfordeling (dvs. at hvis vi udregner en masse forskellige estimater, så vil estimaterne kunne beskrives ved en normalfordeling)
- Denne normalfordeling har parametre \(\mu\) (middelværdi) og \(\frac{\sigma}{\sqrt{n}}\) (standardafvigelse)
- Ideen er at udnytte resultatet til at sige noget om størrelsen af usikkerheden på vores estimat \(\hat\mu\)
Eksempel: Ølsalg
Fordelingen af de ugentlige observationer af prisen for 1 stk. Grøn Tuborg (33 cl glasflaske) i supermarkedskæden Føtex fremgår af nedenstående histogram:
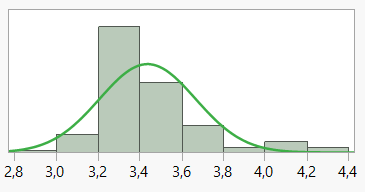
Figur 1.5: Fordeling af prisen på 1 stk. Tuborg i Føtex
Den indtegnede normalfordelingskurve viser, at prisen på Grøn Tuborg med en vis rimelighed kan beskrives ved en normalfordeling \(N(\mu,\sigma)\).
Hvis vi, for eksemplets skyld, vælger at estimere middelværdien \(\mu\) ud fra \(n=4\) ugers prisobservationer, så får vi en lang række forskellige estimater afhængig af præcis hvilke 4 ugers priser, vi vælger.
Tegner vi et histogram baseret på alle de forskellige estimater, får vi tegnet fordelingen af estimatet af \(\mu\) baseret på 4 observationer:
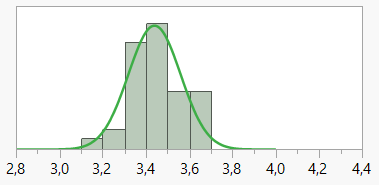
Figur 1.6: Estimater af prisen på 1 stk. Tuborg i Føtex
Det fremgår af histogrammet, at fordelingen af 4 ugers-estimatet har samme centrum (\(\mu\)) som den oprindelige variabel, men at det har en meget mindre standardafvigelse (\(\sigma/\sqrt{4}\)) end standardafvigelsen (\(\sigma\)) i fordelingen af den oprindelige variabel.
Når vi nu kan se, at vi kan bruge en normalfordeling til at beskrive fordelingen af \(\hat\mu\), så kan vi bruge denne viden til også at sige noget om usikkerheden på \(\hat\mu\).