The long run average value is just one feature of a distribution.
Random variables vary, and the distribution describes the entire pattern of variability.
Roughly, standard deviation measures overall degree of variability in a single number, as the average distance from the mean.
Technically, the variance is the long run average squared distance from the mean, and the standard deviation is the square root of the variance.
Example 8.1 A roulette wheel has 18 black spaces, 18 red spaces, and 2 green spaces, all the same size and each with a different number on it. Guillermo bets $1 on black. If the wheel lands on black, Guillermo wins his bet back plus an additional $1; otherwise he loses the money he bet. Let \(W\) be Guillermo’s net winnings (net of the initial bet of $1.)
Find the distribution of \(W\).
Compute \(\text{E}(W)\).
Interpret \(\text{E}(W)\) in context.
An expected profit for the casino of 5 cents per $1 bet seems small. Explain how casinos can turn such a small profit into billions of dollars.
The random variable \((W-\text{E}(W))^2\) represents the squared deviation from the mean. Find the distribution of this random variable and its expected value.
Standard deviation is the square root of the variance. Why would we want to take the square root of the variance? Compute and interpret the standard deviation of \(W\).
Compute \(\text{E}(W^2)\). (For this \(W\) you should be able to compute \(\text{E}(W^2)\) without any calculations; why?) Then compute \(\text{E}(W^2) - (\text{E}(W))^2\); what do you notice?
x =sample(c(-1, 1), size =10000, prob =c(20, 18) /38, replace =TRUE)data.frame(x, x -mean(x), (x -mean(x)) ^2) |>head() |>kbl(col.names =c("Value", "Deviation from mean", "Squared deviation")) |>kable_styling(fixed_thead =TRUE)
Value
Deviation from mean
Squared deviation
1
1.0406
1.0828484
1
1.0406
1.0828484
1
1.0406
1.0828484
-1
-0.9594
0.9204484
-1
-0.9594
0.9204484
1
1.0406
1.0828484
mean(x)
[1] -0.0406
mean((x -mean(x)) ^2)
[1] 0.9983516
var(x)
[1] 0.9984515
sqrt(var(x))
[1] 0.9992254
sd(x)
[1] 0.9992254
The variance of a random variable \(X\) is \[\begin{align*}
\text{Var}(X) & = \text{E}\left(\left(X-\text{E}(X)\right)^2\right)\\
& = \text{E}\left(X^2\right) - \left(\text{E}(X)\right)^2
\end{align*}\]
The standard deviation of a random variable is \[\begin{equation*}
\text{SD}(X) = \sqrt{\text{Var}(X)}
\end{equation*}\]
Variance is the long run average squared deviation from the mean.
Standard deviation measures, roughly, the long run average distance from the mean. The measurement units of the standard deviation are the same as for the random variable itself.
The definition \(\text{E}((X-\text{E}(X))^2)\) represents the concept of variance. However, variance is usually computed using the following equivalent but slightly simpler formula. \[
\text{Var}(X) = \text{E}\left(X^2\right) - \left(\text{E}\left(X\right)\right)^2
\]
That is, variance is the expected value of the square of \(X\) minus the square of the expected value of \(X\).
Variance has many nice theoretical properties. Whenever you need to compute a standard deviation, first find the variance and then take the square root at the end.
Example 8.2 Continuing with roulette, Nadja bets $1 on number 7. If the wheel lands on 7, Nadja wins her bet back plus an additional $35; otherwise she loses the money she bet. Let \(X\) be Nadja’s net winnings (net of the initial bet of $1.)
Find the distribution of \(X\).
Compute \(\text{E}(X)\).
How do the expected values of the two $1 bets — bet on black versus bet on 7 — compare? Explain what this means.
Are the two $1 bets — bet on black versus bet on 7 — identical? If not, explain why not.
Before doing any calculations, determine if \(\text{SD}(X)\) is greater than, less than, or equal to \(\text{SD}(W)\). Explain.
Compute \(\text{Var}(W)\) and \(\text{SD}(W)\).
Which $1 bet — betting on black or betting on 7 — is “riskier”? How is this reflected in the standard deviations?
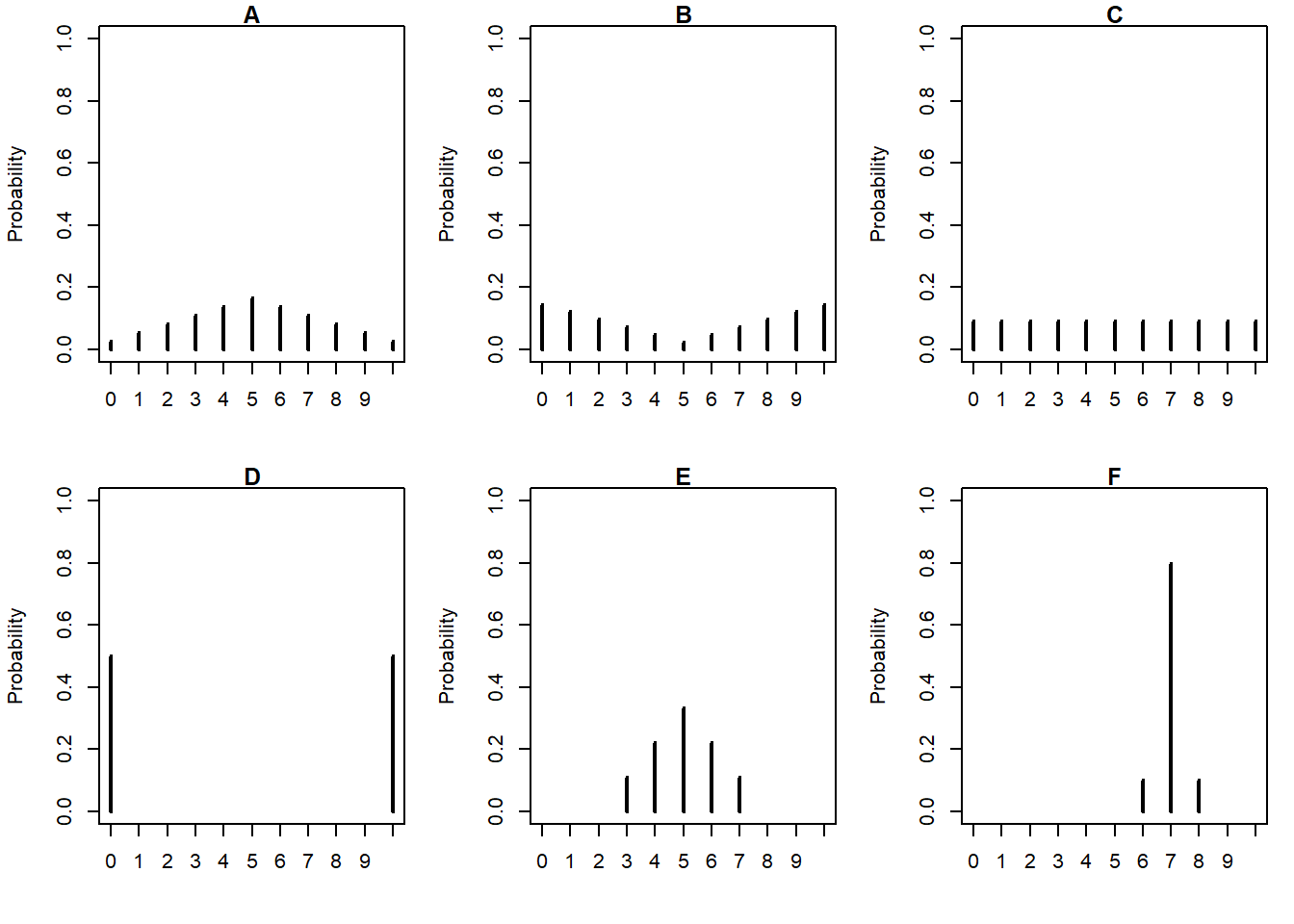
Example 8.3 The plots in Figure 8.1 summarize hypothetical distributions of quiz scores in six classes. All plots are on the same scale. Each quiz score is a whole number between 0 and 10 inclusive.
Figure 8.1: A few discrete distributions.
Donny Dont says that C represents the smallest SD, since there is no variability in the heights of the bars. Do you agree that C represents “no variability”? Explain.
What is the smallest possible value the SD of quiz scores could be? What would need to be true about the distribution for this to happen? (This scenario might not be represented by one the plots.)
Without doing any calculations, arrange the classes in order based on their SDs from smallest to largest.
In one of the classes, the SD of quiz scores is 5. Which one? Why?
Is the SD in F greater than, less than, or equal to 1? Why?
Provide a ballpark estimate of SD in each case.
8.1 Standardization
Standardization measures values in terms of “standard deviations away from the mean”
This idea is particularly useful when comparing random variables with different measurement units but whose distributions have similar shapes. \[
\text{Standardized value} = \frac{\text{Value - Mean}}{\text{Standard deviation}}
\]
If \(X\) is a random variable with expected value \(\text{E}(X)\) and standard deviation \(\text{SD}(X)\), then the standardized random variable is \[
Z = \frac{X - \text{E}(X)}{\text{SD}(X)}
\]
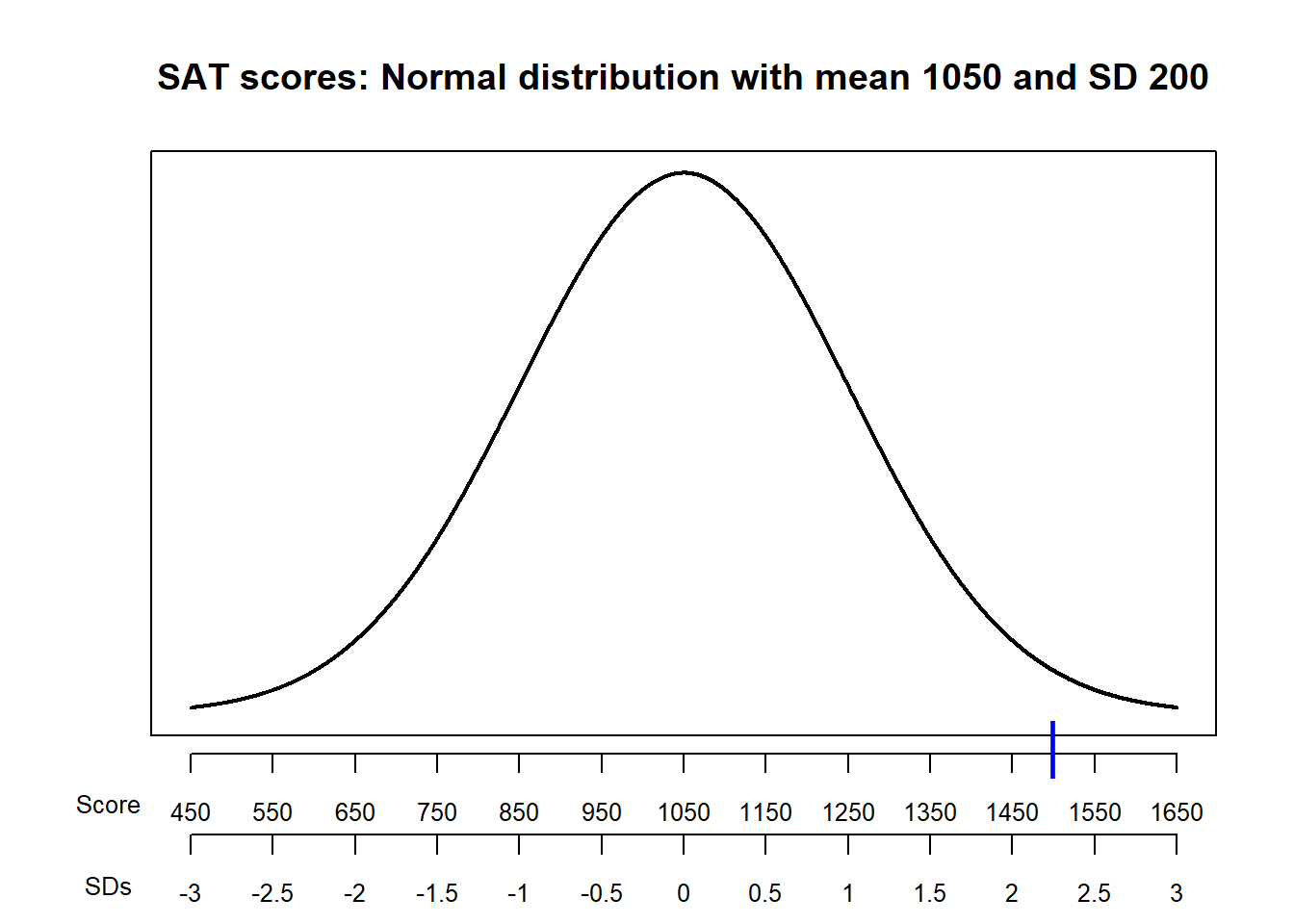
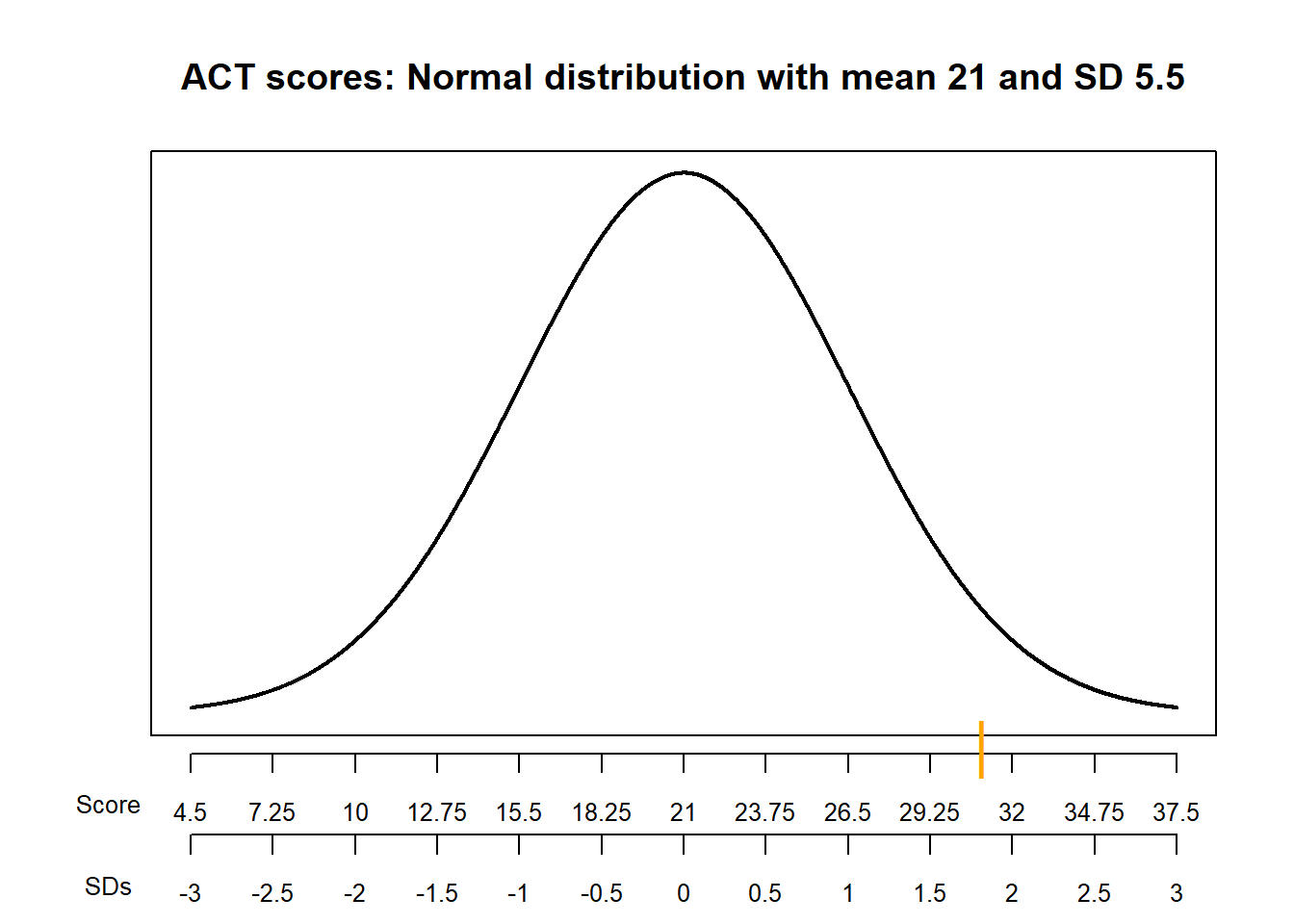
Example 8.4 SAT scores have, approximately, a symmetric bell-shaped distribution with a mean of 1050 and a standard deviation of 200. ACT scores have, approximately, a symmetric bell-shaped distribution with a mean of 21 and a standard deviation of 5.5. Darius’s score on the SAT is 1500. Alfred’s score on the ACT is 31. Who scored relatively better on their test?
Compute and interpret the standardized value for Darius’s SAT score.
Compute and interpret the standardized value for Alfred’s ACT score
Who scored relatively better on their test?
Figure 8.2: Comparison of the distributions in Example 8.4. The blue mark indicates Darius’s SAT score and the orange mark indicates Alfred’s ACT score.
Figure 8.3: Comparison of the distributions in Example 8.4. The blue mark indicates Darius’s SAT score and the orange mark indicates Alfred’s ACT score.