10.3 Worked Example
Helene Wagner and Yessica Rico
1. Overview of Worked Example
a. Goals
This worked example shows:
- How to test regression residuals for spatial autocorrelation.
- How to fit a model with spatially autocorrelated errors (GLS).
- How to fit a spatial simultaneous autoregressive error model (SAR).
- How to perform spatial filtering with Moran eigenvector maps (MEM).
- How to fit a spatially varying coefficients model (SVC).
b. Data set
Here we analyze population-level data of the wildflower Dianthus carthusianorum (common name: Carthusian pink) in 65 calcareous grassland patches in the Franconian Jura, Germany (Rico et al. 2013):
- Dianthus: ‘sf’ object with population-level data (patch characteristics, grazing regime, genetic diversity, 15 alternative connectivity indices Si) for sampling locations, included in package ‘LandGenCourse’. To load the data, type (without quotes): ‘data(Dianthus)’. For a definition of the variables, type: ‘?Dianthus’.
c. Required R packages
Note: the function ‘library’ will always load the package, even if it is already loaded, whereas ‘require’ will only load it if it is not yet loaded. Either will work.
library(LandGenCourse)
#library(here)
#libraryspdep)
library(nlme)
#library(lattice)
#library(MuMIn)
#library(gridExtra)
library(dplyr)
library(spatialreg)
library(ggplot2)
library(tmap)
#library(sf)
source(system.file("extdata", "panel.cor.r",
package = "LandGenCourse"))Package ‘spmoran’ not automatically installed with ‘LandGenCourse’:
2. Explore data set
We will model allelic richness ‘A’ as a function of the following predictors:
- IBD: connectivity index Si (‘Eu_pj’) based on Euclidean distance between source and focal patch. This represents a hypothesis of isolation by distance (IBD).
- IBR: connectivity index Si (‘Sheint_pj’) based on the number of continuously or intermittently grazed patches between source and focal patch. This represents a hypothesis of isolation by resistance (IBR). Specifically, this model assumes connectivity via sheep-mediated seed dispersal, where seeds are likely to be transported from patch to patch within the same grazing system (shepherding route). Seeds are assumed to disperse most likely to the next patch (in either direction) along the grazing route, and less likely to more remote patches along the route.
- PatchSize: Logarithm of calcareous grassland patch size in ha.
Bonus Materials: The connectivity indices Si were calculated for each focal patch i, integrating over all other patches j where the species was present (potential source patches) using Hanski’s incidence function. See the Week 7 Bonus Material for how this was done!
a. Import data
Allelic richness ‘A’ was not calculate for populations with < 5 individuals. Here we extract only the patches with ‘A’ values, and the variables needed, and store them in a data frame ‘Dianthus.df’.
b. Create a map
With tmap (see Week 3 Worked Example), mapping the points is easy. Here, we use color to indicate allelelic richness.
Note that tmap internally converts the CRS to lat/long to plot the points on a basemap from the internet. See here for a list of available basemaps: https://leaflet-extras.github.io/leaflet-providers/preview/
## tmap mode set to interactive viewingtm_basemap(c("Esri.WorldTopoMap", "Esri.WorldStreetMap", "Esri.WorldShadedRelief")) +
tm_shape(Dianthus) + tm_sf(col="A")Toggle between the basemaps to visualize the topographic relief and forest cover.
As you can see from the shaded relief, most sites lie on the steep slopes between an upper and a lower Jurassic plateau. A few sites lie at the forest edge on the upper plateau, typically in areas where the soil is too shallow to allow crop farming. With in the study area, all known sites were sampled. Additional sites are expected to be found mainly in the valley system in the Southwest.
c. Explore correlations
When fitting linear models, it is always a good idea to look at the correlations first.
Dianthus.df <- data.frame(A=Dianthus$A, IBD=Dianthus$Eu_pj,
IBR=Dianthus$Sheint_pj,
PatchSize=log(Dianthus$Ha),
System=Dianthus$System,
Longitude=Dianthus$Longitude,
Latitude=Dianthus$Latitude,
st_coordinates(Dianthus))
# Define 'System' for ungrazed patches
Dianthus.df$System=as.character(Dianthus$System)
Dianthus.df$System[is.na(Dianthus.df$System)] <- "Ungrazed"
Dianthus.df$System <- factor(Dianthus.df$System,
levels=c("Ungrazed", "East", "South", "West"))
# Remove patches with missing values for A
Dianthus.df <- Dianthus.df[!is.na(Dianthus.df$A),]
dim(Dianthus.df)## [1] 59 9Create a scatterplot matrix. The variables are plotted against each other and labeled along the diagonal. You will find histograms on the diagonal, scatterplots and a smooth line in the lower triangle, and the linear correlation coefficient r (with p-value) in the upper triangle. Stronger correlations are indicated with a larger font. You may ignore any warnings about graphical parameters.
graphics::pairs(Dianthus.df[,-c(5:7)], lower.panel=panel.smooth,
upper.panel=panel.cor, diag.panel=panel.hist)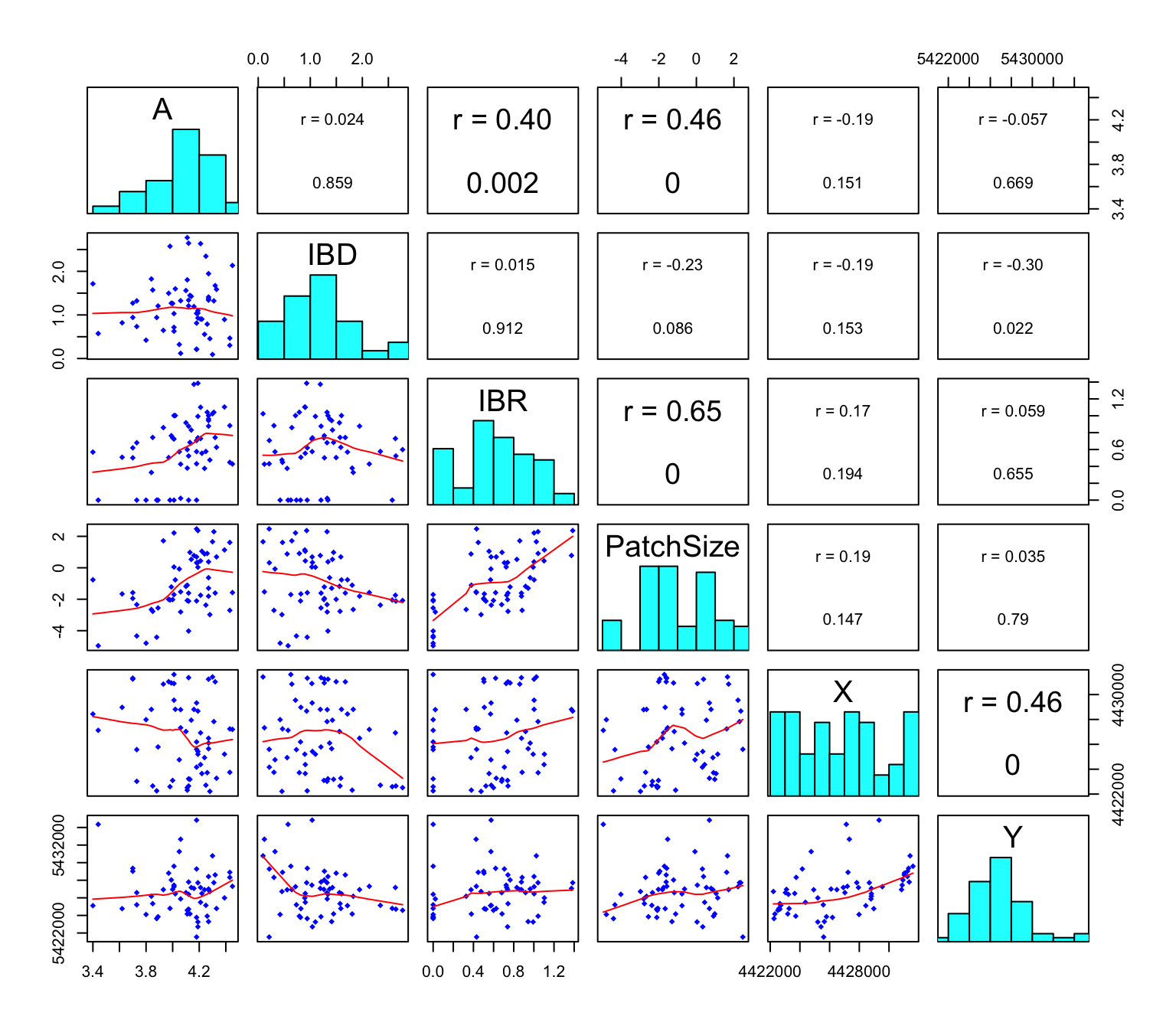
Questions:
- How strong is the linear relationship between ‘Eu_pj’ and ‘A’? What does this suggest about the hypothesis of IBD?
- How strong is the linear relationship between ‘Sheint_pj’ and ‘A’? What does this suggest about the hypothesis of sheep-mediated gene flow (IBR)?
- Which variable seems to be a better predictor of allelic richness: patch size ‘Ha’ or the logarithm of patch size, ‘PatchSize’?
- Is logHa correlated with ‘IBD’ or ‘IBR’?
- Are any of the variables correlated with the spatial coordinates X and Y?
Do the three grazing systems, and the ungrazed patches, differ in allelic richness A? Also, let’s check the association between patch size and population size. Here we create boxplots that show the individual values as dots. We add a horizontal jitter to avoid overlapping points.
Boxplot1 <- ggplot(Dianthus, aes(x=System, y=A)) +
geom_boxplot() + xlab("Grazing system") + ylab("Allelic richness (A)") +
geom_jitter(shape=1, position=position_jitter(0.1), col="blue")
Boxplot2 <- ggplot(Dianthus, aes(x=factor(pop09), y=log(Ha))) +
geom_boxplot() + xlab("Population size class") + ylab("PatchSize (log(Ha))") +
geom_jitter(shape=1, position=position_jitter(0.1), col="blue")
gridExtra::grid.arrange(Boxplot1, Boxplot2, nrow=1)## Warning: Removed 6 rows containing non-finite values (`stat_boxplot()`).## Warning: Removed 6 rows containing missing values (`geom_point()`).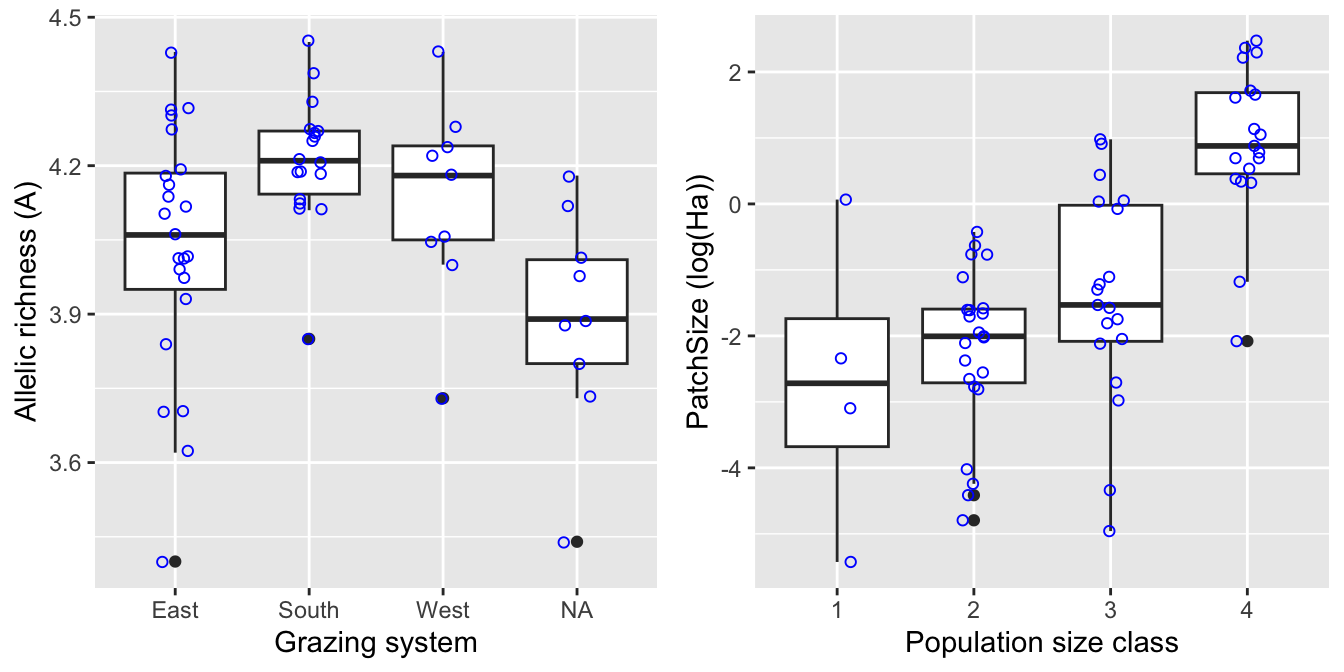
Even though the population size categories were very broad, there appears to be a strong relationship between populations size (category) and (the logarithm of) patch size.
Despite this relationship, connectivity models Si that only considered Dianthus carthusianorum presence/absence (‘pj’) in source patches ‘j’ were better supported than those Si models that took into account source patch area (‘Aj’) or population size (‘Nj’).
We can check this by calculating the correlation of allelelic richness ‘A’ with each of the 15 connectivity models ‘Si’ in the data set.
round(matrix(cor(Dianthus$A, st_drop_geometry(Dianthus)[,15:29],
use="pairwise.complete.obs"), 5, 3, byrow=TRUE,
dimnames=list(c("Eu", "Shecte", "Sheint", "Shenu", "Forest"),
c("pj", "Aj", "Nj"))),3)## pj Aj Nj
## Eu 0.024 0.207 0.098
## Shecte 0.375 0.273 0.369
## Sheint 0.403 0.196 0.369
## Shenu 0.135 -0.045 0.105
## Forest 0.137 0.168 0.138- Correlations with ‘A’ are highest for the two ‘IBR’ models that assume seed dispersal over a limited number of patches along shepherding routes (‘Shecte’ and ‘Sheint’. These two models include only continuously grazed, or both continuously and intermittently grazed patches, respectively.
- Correlations for models that take in to account population size (‘Nj’) are only slightly lower, whereas those that use patch size (‘Aj’) as a proxy for the size of the seed emigrant pool had lower correlations.
3. Test regression residuals for spatial autocorrelation
a. Fit regression models
Here we fit three multiple regression models to explain variation in allelic richness:
- mod.lm.IBD: IBD model of connectivity ‘Eu_pj’.
- mod.lm.IBR: IBR model shepherding connectivity ‘Sheint_pj’.
- mod.lm.PatchSize: log patch size and IBR model.
##
## Call:
## lm(formula = A ~ IBD, data = Dianthus.df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.68545 -0.10220 0.03883 0.16178 0.36100
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.070960 0.064061 63.549 <2e-16 ***
## IBD 0.008454 0.047460 0.178 0.859
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2324 on 57 degrees of freedom
## Multiple R-squared: 0.0005563, Adjusted R-squared: -0.01698
## F-statistic: 0.03173 on 1 and 57 DF, p-value: 0.8593This model does not fit the data at all!
##
## Call:
## lm(formula = A ~ IBR, data = Dianthus.df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.66844 -0.11251 0.03418 0.12219 0.41760
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3.92306 0.05499 71.348 < 2e-16 ***
## IBR 0.25515 0.07672 3.326 0.00155 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2128 on 57 degrees of freedom
## Multiple R-squared: 0.1625, Adjusted R-squared: 0.1478
## F-statistic: 11.06 on 1 and 57 DF, p-value: 0.001547This model fits much better. Let’s check the residuals plots.
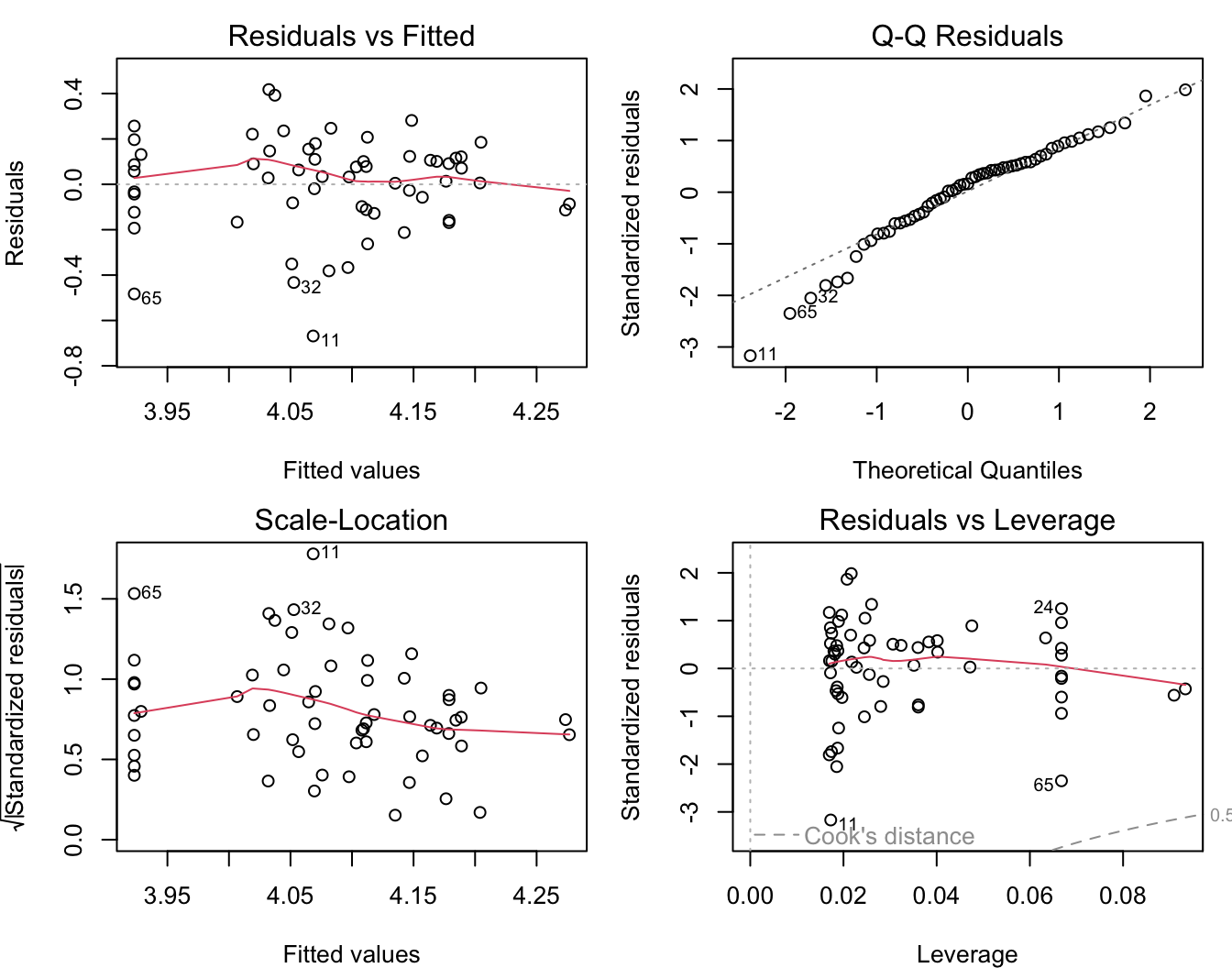
The residuals show some deviation from a normal distribution. Specifically, the lowest values are lower than expected.
##
## Call:
## lm(formula = A ~ PatchSize + IBR, data = Dianthus.df)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.68359 -0.08844 0.02538 0.11705 0.41705
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 4.05158 0.07781 52.069 <2e-16 ***
## PatchSize 0.04266 0.01888 2.260 0.0277 *
## IBR 0.11338 0.09709 1.168 0.2479
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2055 on 56 degrees of freedom
## Multiple R-squared: 0.2325, Adjusted R-squared: 0.2051
## F-statistic: 8.482 on 2 and 56 DF, p-value: 0.0006058This combinde model explains more variation in allelic richness than the IBR model alone. Moreover, after adding PatchSizes, the IBR term is no longer statistically significant!
Has the distribution of residuals improved as well?
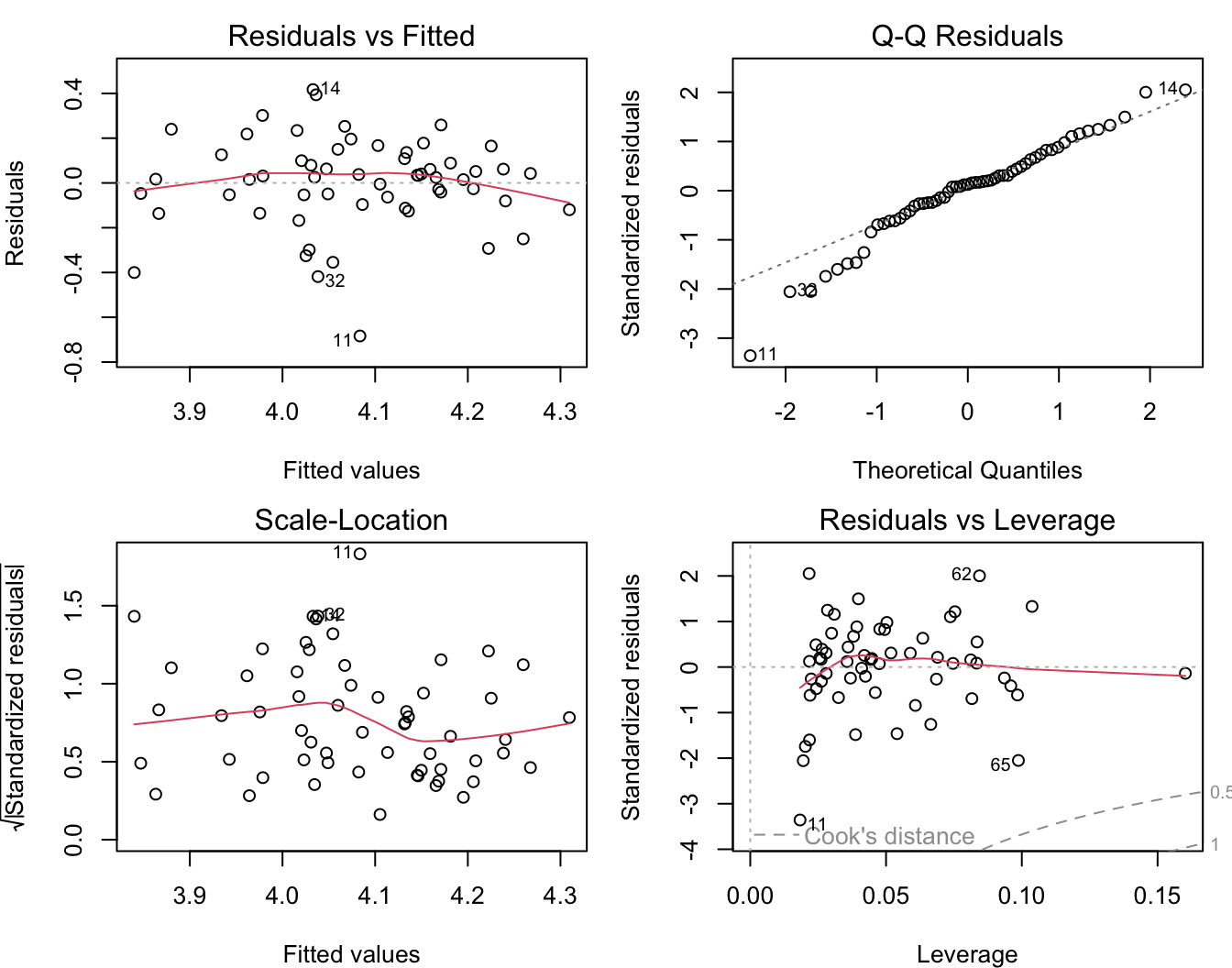
Not really!
b. Test for spatial autocorrelation (Moran’s I)
Before we interpret the models, let’s check whether the assumption of independent residuals is violated by spatial autocorrelation in the residuals.
To calculate and test Moran’s I, we first need to define neighbours and spatial weights. Here we use a Gabriel graph to define neighbours.
We define weights in three ways (see Week 5 video and tutorial for explanation of code):
- listw.gab: 1 = neighbour, 0 = not a neighbour.
- listw.d1: inverse distance weights: neighbour j with weight 1/dij
- listw.d2: inverse squared distance weights: neighbour j with weight 1/dij^2
In each case, we row-standardize the weights with the option ‘style = “W”’.
Note: when using ‘graph2nb’, make sure to use the argument ‘sym=TRUE’. This means that if A is a neighbour of B, B is also a neighbour of A. The default is ‘sym=FALSE’, which may result in some sites not having any neighbours assigned (though this would not be evident from the figure!).
xy <- data.matrix(Dianthus.df[,c("X", "Y")])
nb.gab <- spdep::graph2nb(spdep::gabrielneigh(xy), sym=TRUE)
par(mar=c(0,0,0,0))
plot(nb.gab, xy)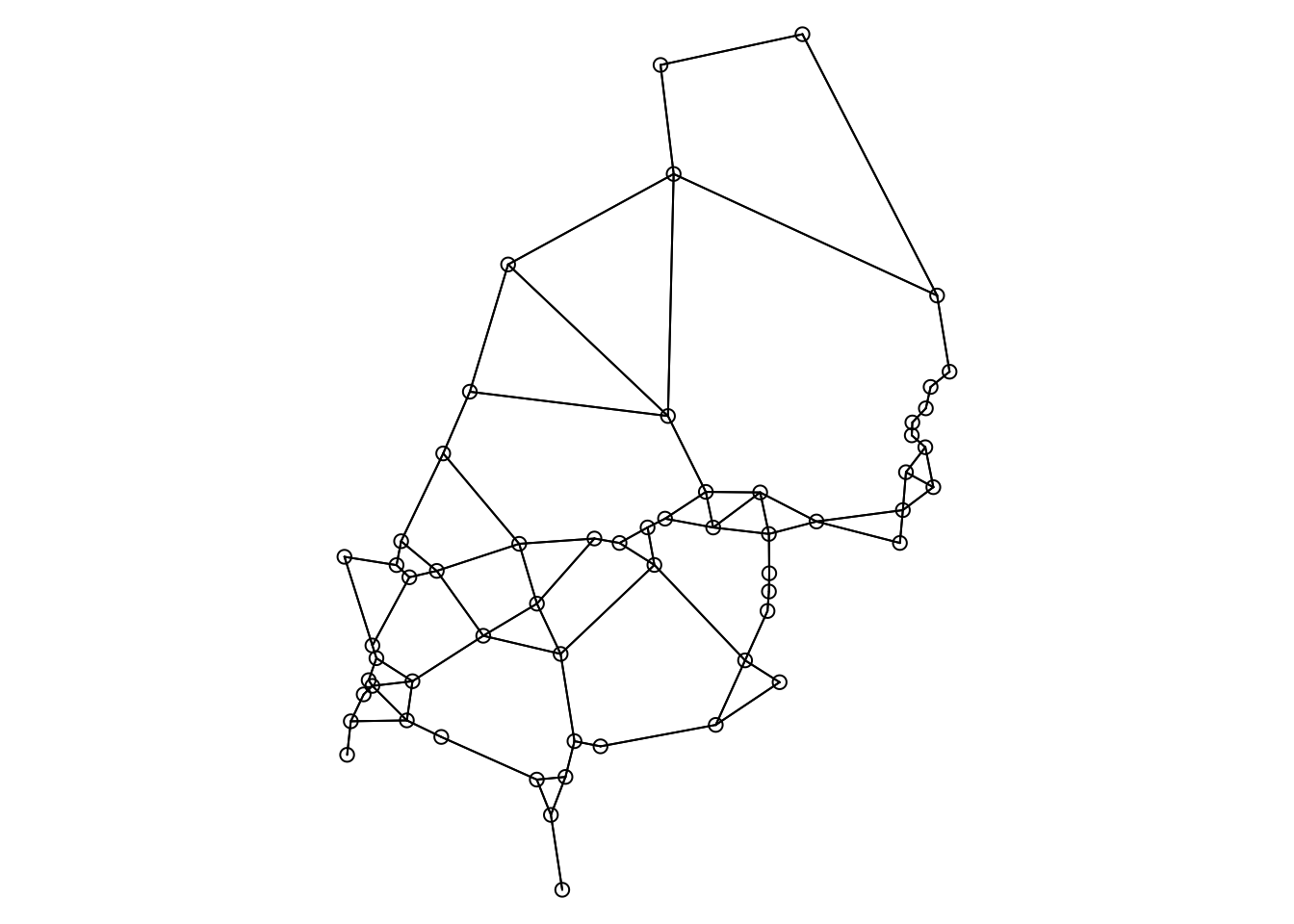
listw.gab <- spdep::nb2listw(nb.gab)
dlist <- spdep::nbdists(nb.gab, xy)
dlist <- lapply(dlist, function(x) 1/x)
listw.d1 <- spdep::nb2listw(nb.gab, style = "W", glist=dlist)
dlist <- lapply(dlist, function(x) 1/x^2)
listw.d2 <- spdep::nb2listw(nb.gab, style = "W", glist=dlist)Now we can quantify and test Moran’s I for each variable to test for spatial autocorrelation in response and predictor variables. For now, we’ll take the simple weights ‘listw.gab’.
Allelic richness A:
##
## Moran I test under randomisation
##
## data: Dianthus.df$A
## weights: listw.gab
##
## Moran I statistic standard deviate = 2.881, p-value = 0.001982
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.29180913 -0.01724138 0.01150691IBD:
##
## Moran I test under randomisation
##
## data: Dianthus.df$IBD
## weights: listw.gab
##
## Moran I statistic standard deviate = 5.9689, p-value = 1.194e-09
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.62709841 -0.01724138 0.01165320IBR:
##
## Moran I test under randomisation
##
## data: Dianthus.df$IBR
## weights: listw.gab
##
## Moran I statistic standard deviate = 3.008, p-value = 0.001315
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.30918167 -0.01724138 0.01177588PatchSize:
##
## Moran I test under randomisation
##
## data: Dianthus.df$PatchSize
## weights: listw.gab
##
## Moran I statistic standard deviate = 3.4257, p-value = 0.0003066
## alternative hypothesis: greater
## sample estimates:
## Moran I statistic Expectation Variance
## 0.35490160 -0.01724138 0.01180103Questions:
- Which variables showed statistically signficant spatial autocorrelation?
- Which variables showed the strongest autocorrelation? Is this surprising?
Next, let’s test each model for autocorrelation in the residuals:
IBD:
##
## Global Moran I for regression residuals
##
## data:
## model: lm(formula = A ~ IBD, data = Dianthus.df)
## weights: listw.gab
##
## Moran I statistic standard deviate = 2.9439, p-value = 0.00162
## alternative hypothesis: greater
## sample estimates:
## Observed Moran I Expectation Variance
## 0.28889983 -0.02854559 0.01162751IBR:
##
## Global Moran I for regression residuals
##
## data:
## model: lm(formula = A ~ IBR, data = Dianthus.df)
## weights: listw.gab
##
## Moran I statistic standard deviate = 1.883, p-value = 0.02985
## alternative hypothesis: greater
## sample estimates:
## Observed Moran I Expectation Variance
## 0.18032443 -0.02296810 0.01165614PatchSize:
##
## Global Moran I for regression residuals
##
## data:
## model: lm(formula = A ~ PatchSize + IBR, data = Dianthus.df)
## weights: listw.gab
##
## Moran I statistic standard deviate = 1.7484, p-value = 0.04019
## alternative hypothesis: greater
## sample estimates:
## Observed Moran I Expectation Variance
## 0.16223745 -0.02708922 0.01172530Quite a bit of the spatial autocorrelation in allelic richness can be explained by the spatial structure in the predictors IBR and PatchSize. There is still statistically significant spatial autocorrelation in the residuals, though it is not strong any more.
4. Fit models with spatially correlated error (GLS) with package ‘nlme’
One way to account for spatial autocorrelation in the residuals is to fit a Generalized Least Squares model (GLS) with a spatially autocorrelated error structure. See also: http://rfunctions.blogspot.ca/2017/06/how-to-identify-and-remove-spatial.html
a. Plot empirical variogram
The error structure in a GLS is defined in a geostatistical framework, based on a variogram and as a function of distance between observations. Hence we start with plotting an empirical variogram of the residuals, with a smooth line. Here we specify ’resType = “normalized”, which means that the variogram will be fitted to the normalized residuals of the model.
The expected value of the semivariance will be 1. Hence it would make sense to add a horizontal line at 1. However, this is cumbersome with the trellis graphics (using package ‘lattice’) used by ‘nlme’.
model.lm <- nlme::gls(A ~ IBR + PatchSize, data = Dianthus.df, method="REML")
semivario <- nlme::Variogram(model.lm, form = ~X + Y, resType = "normalized")If you want to create your own figure, e.g. with ‘ggplot2’, you can access the values stores in the data frame ‘semivario’ to plot the points, and add a smooth line yourself. Then we can add a horizontal line with ‘geom_hline’.
ggplot(data=semivario, aes(x=dist, y=variog)) + geom_point() + geom_smooth(se=FALSE) +
geom_hline(yintercept=1) + ylim(c(0,1.3)) + xlab("Distance") + ylab("Semivariance")## `geom_smooth()` using method = 'loess' and formula = 'y ~ x'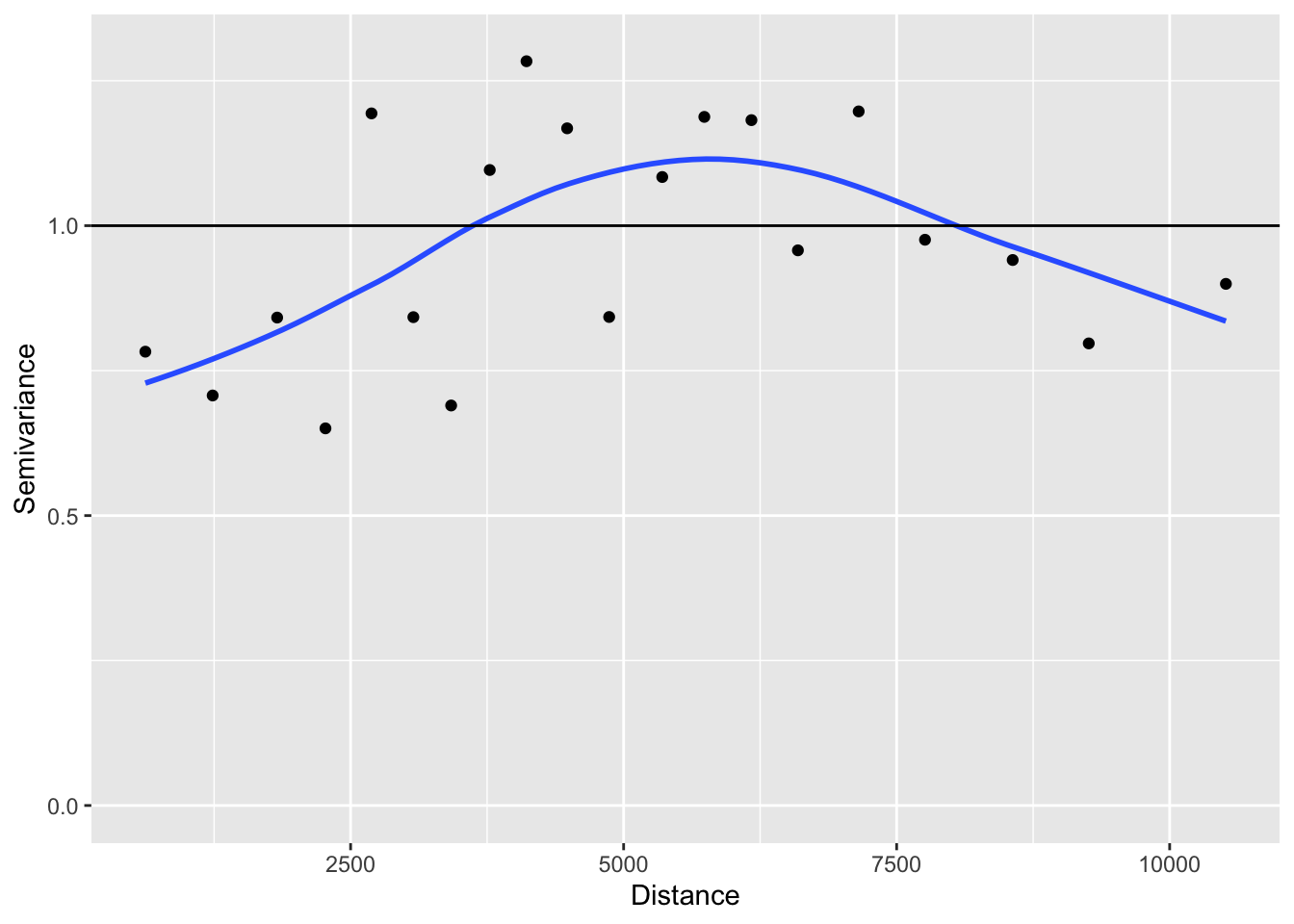
Question:
- What do you conclude from this empirical variogram?
- Estimate the range of the variogram from the intersection of the smooth line with the horizontal line.
- Estimate the nugget effect from the intercept at Distance = 0.
b. Fit variogram models
We can ask R to fit different types of variogram models to this empirical variogram. The model family (e.g., exponential, gaussian, spherical) determines the general shape of the curve that will be fitted. With ‘nugget=T’, we indicate that a nugget effect should be fitted.
Note: Here we want to compare mixed models with the same fixed effects but different random effect structures defined by correlation. For this, we use REML. If we wanted to compare models with the same random effects but different fixed effects (as in Week 6), we should use maximum likelihood.
- With function
lme4::lmer, we can setREML=TRUEfor REML andREML=FALSEfor ML. - Here with
nlme::gls, we setmethod="REML"for REML andmethod="ML"for ML. - For update to work here, you’ll need to load the library
nlme(or use this, with three coons to access a function ‘update’, for ‘lme’ objects, that is not ‘exported’ from the package:nlme:::update.lme)
model.lm <- nlme::gls(A ~ IBR + PatchSize, data = Dianthus.df, method="REML")
mod.corExp <- update(model.lm, correlation = nlme::corExp(form = ~ X + Y, nugget=T))
mod.corGaus <- update(model.lm, correlation = nlme::corGaus(form = ~ X + Y, nugget=T))
mod.corSpher <- update(model.lm, correlation = nlme::corSpher(form = ~ X + Y, nugget=T))
mod.corRatio <- update(model.lm, correlation = nlme::corRatio(form = ~ X + Y, nugget=T))
#mod.corLin <- update(model.lm, correlation = nlme::corLin(form = ~ X + Y, nugget=T))c. Select best-fitting model
Now we compare all models for which we did not get an error message:
## Model selection table
## (Intrc) IBR PtchS correlation df logLik AICc delta weight
## mod.corExp 4.044 0.08468 0.04269 n::cE(X+Y,T) 6 6.283 1.1 0.00 0.336
## mod.corRatio 4.032 0.09704 0.04129 n::cR(X+Y,T) 6 6.229 1.2 0.11 0.319
## model.lm 4.052 0.11340 0.04266 4 3.702 1.3 0.29 0.291
## mod.corGaus 4.047 0.11840 0.04247 n::cG(X+Y,T) 6 3.763 6.1 5.04 0.027
## mod.corSpher 4.048 0.11710 0.04242 n::cS(X+Y,T) 6 3.760 6.1 5.04 0.027
## Abbreviations:
## correlation: n::cE(X+Y,T) = 'nlme::corExp(~X+Y,T)',
## n::cG(X+Y,T) = 'nlme::corGaus(~X+Y,T)',
## n::cR(X+Y,T) = 'nlme::corRatio(~X+Y,T)',
## n::cS(X+Y,T) = 'nlme::corSpher(~X+Y,T)'
## Models ranked by AICc(x)The list sorts the models, with the best model on top. The last column ‘weight’ contains the model weight, which indicate how much support there is for each model, given all other models in the set (see Week 12). Here, the exponential model fitted best, though the ratio model and the model without a spatially correlated error structure fitted the data almost equally well. The top three models have delta values within 2 (in fact, close to 0).
We refit the best model with maximum likelihood to test the fixed effects.
mod.corExp.ML <- nlme::gls( A ~ PatchSize + IBR, data = Dianthus.df, method="ML",
correlation = nlme::corExp(form = ~ X + Y, nugget=T))
car::Anova(mod.corExp.ML) ## Analysis of Deviance Table (Type II tests)
##
## Response: A
## Df Chisq Pr(>Chisq)
## PatchSize 1 5.4912 0.01911 *
## IBR 1 0.8710 0.35067
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1The fitted model with the exponential error structure shows a significant effect for PatchSize but not for the IBR term.
We don’t get an R-squared value directly, but we can calculate a pseudo R-squared from a regression of the response ‘A’ on the fitted values (using the model fitted with REML). Let’s compare it to the R-squared from the lm model.
## [1] 0.2317629## [1] 0.2324922The pseudo R-squared is almost identical to the R-squared of the non-spatial lm model.
Let’s check the residual plots:
The normal probability plot still looks about the same.
Note that the function residplot recognized that we have a gls model and added a plot of the auto-correlation function, ACF. Here we have a value of 1 for the distance lag 0, which is the comparison of each value with itself. All other values are low. Recall that the autcorrelation is inversely related to the semivariogram (which does not report the value for lag = 0):
semivario <- nlme::Variogram(mod.corExp, form = ~ X + Y,
resType = "normalized")
plot(semivario, smooth = TRUE)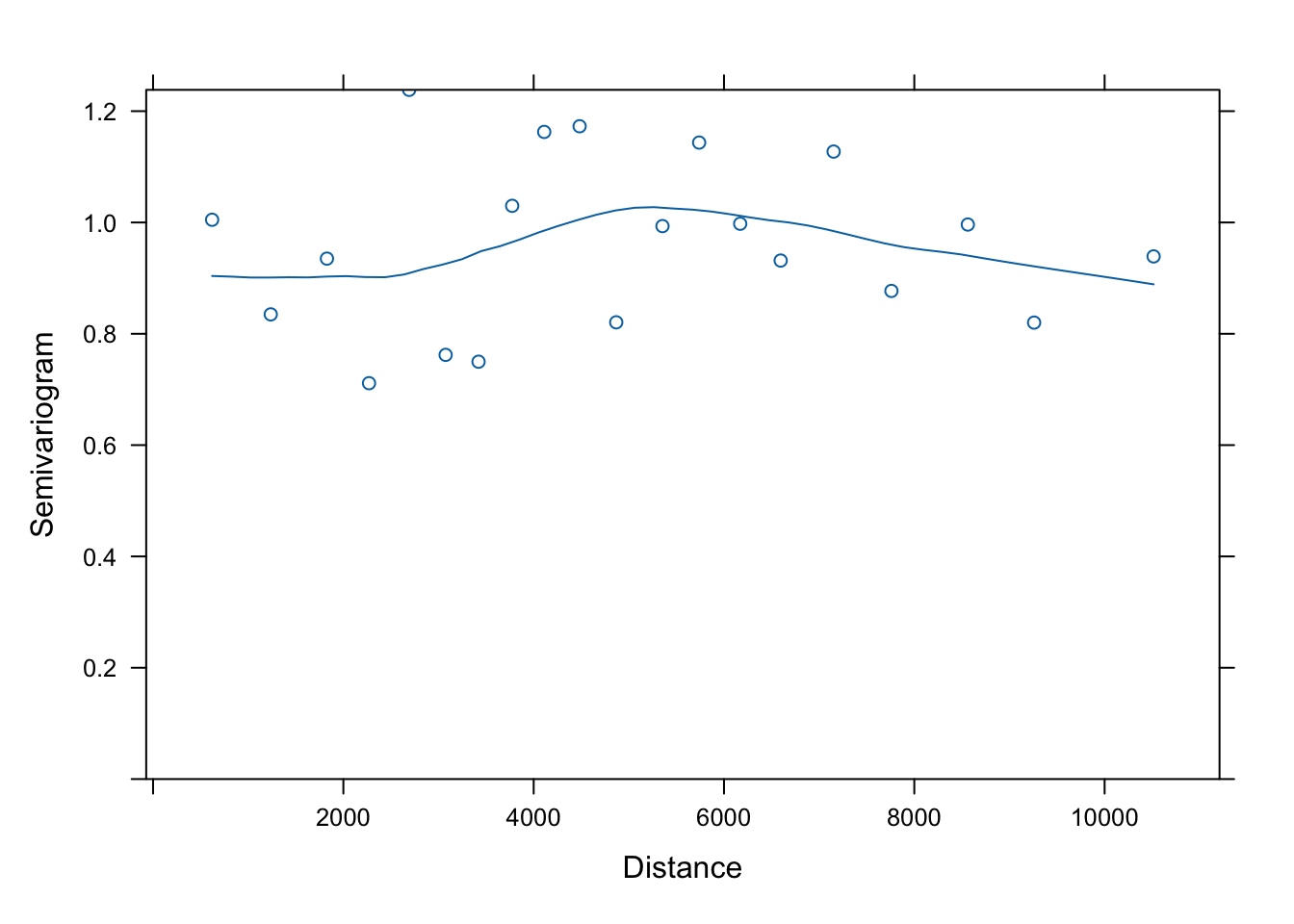
The variogram of the residuals (after accounting for spatial autocorrelation as modeled by the variogram model) does look better!
d. Plot fitted variogram model
How can we plot the fitted variogram? Let’s first store it in an object ‘Fitted.variog’, then plot it. Note that the fitted variogram itself has two classes, “Variogram” and “data.frame”. The plot created by plot(Fitted.variog) is a “trellis” object.
## [1] "Variogram" "data.frame"## [1] "trellis"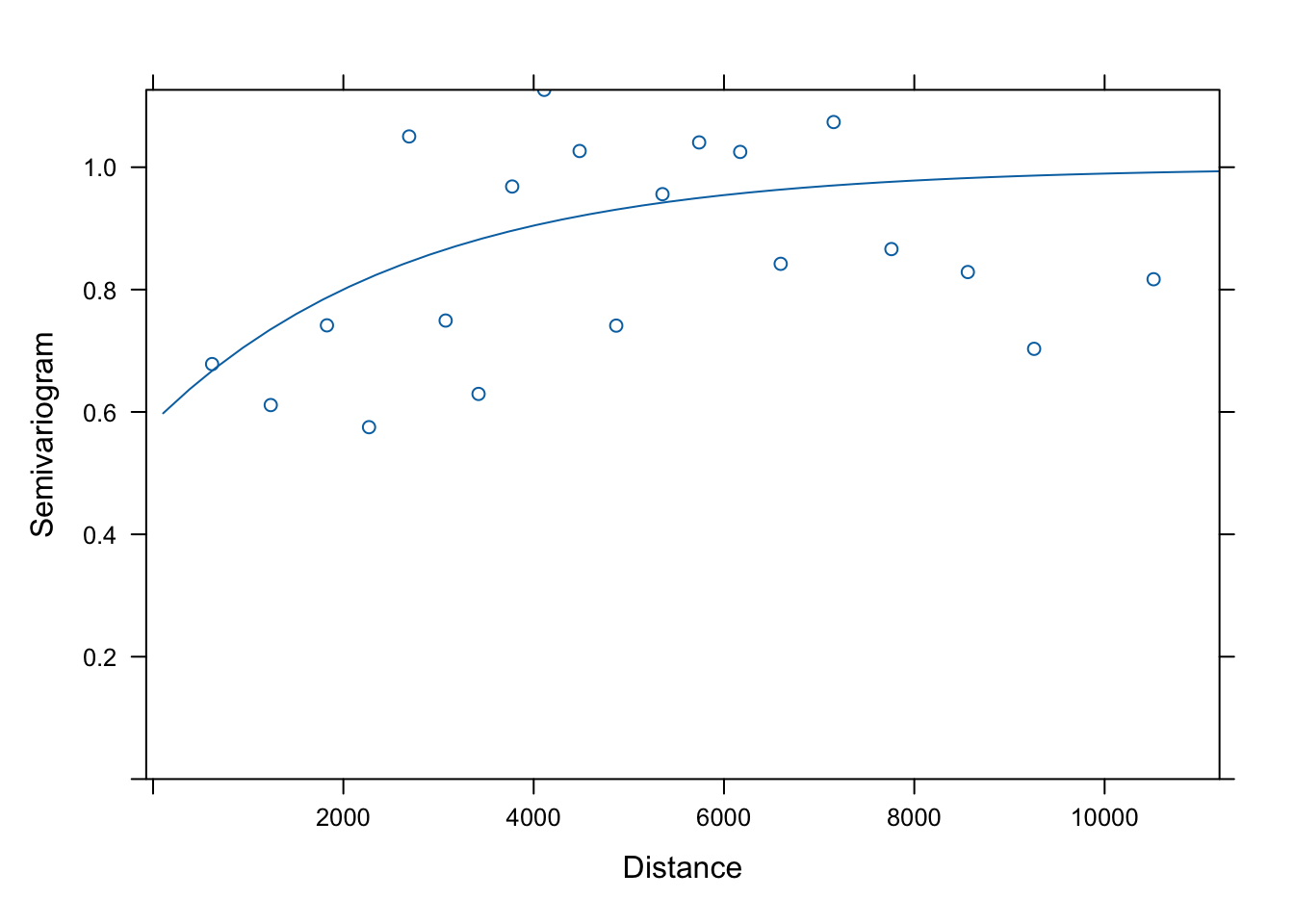
That was easy. However, trellis plots are difficult to tweak, and we may want to create our own plot with ggplot2. For this, we need to access the fitted variogram values (i.e. the exponential model curve values), which is a bit more involved.
The object ‘Fitted.variog’ is a data frame (S3) with additional attributes. This raises a challenge, because we access attributes of S3 objects with $, but we also use $ to access columns in a data frame.
If we just print Fitted.variog, we only see the data frame.
## variog dist n.pairs
## 1 0.6782704 620.5202 85
## 2 0.6112605 1236.8297 86
## 3 0.7415493 1827.3367 85
## 4 0.5751311 2269.6729 86
## 5 1.0503017 2691.2494 85
## 6 0.7493939 3074.7370 86We can see the attributes listed by using str:
## Classes 'Variogram' and 'data.frame': 20 obs. of 3 variables:
## $ variog : num 0.678 0.611 0.742 0.575 1.05 ...
## $ dist : num 621 1237 1827 2270 2691 ...
## $ n.pairs: int [1:20(1d)] 85 86 85 86 85 86 85 86 85 86 ...
## - attr(*, "modelVariog")=Classes 'Variogram' and 'data.frame': 50 obs. of 2 variables:
## ..$ variog: num [1:50] 0.598 0.637 0.673 0.705 0.734 ...
## ..$ dist : num [1:50] 106 385 665 945 1224 ...
## - attr(*, "collapse")= logi TRUEThe line we are looking for is: - attr(*, "modelVariog"). The attribute modelVariog has 50 rows (obs.) and 2 variables: $variog and $dist. These are the fitted values (i.e., values of the exponential variogram model for 50 distance values).
The notation attr(*, "modelVariog") is a cryptic way of telling us how to access the attribute: use the function attr and provide two arguments: the object names Fitted.variog (represented by the asterisk), and the name of the attribute, in quotes: attr(Fitted.variog, "modelVariog").
## # A tibble: 50 × 2
## variog dist
## <dbl> <dbl>
## 1 0.598 106.
## 2 0.637 385.
## 3 0.673 665.
## 4 0.705 945.
## 5 0.734 1224.
## 6 0.760 1504.
## 7 0.784 1783.
## 8 0.805 2063.
## 9 0.824 2342.
## 10 0.841 2622.
## # ℹ 40 more rowsThis is useful to know if you want to create your own figures, e.g. with ggplot2.
ggplot(data=Fitted.variog, aes(x=dist, y=variog)) + geom_point() +
ylim(c(0,1.3)) + xlab("Distance") + ylab("Semivariance") +
geom_line(data=attr(Fitted.variog, "modelVariog"), aes(x=dist, y=variog), color="blue") +
geom_hline(yintercept=1,linetype="dashed")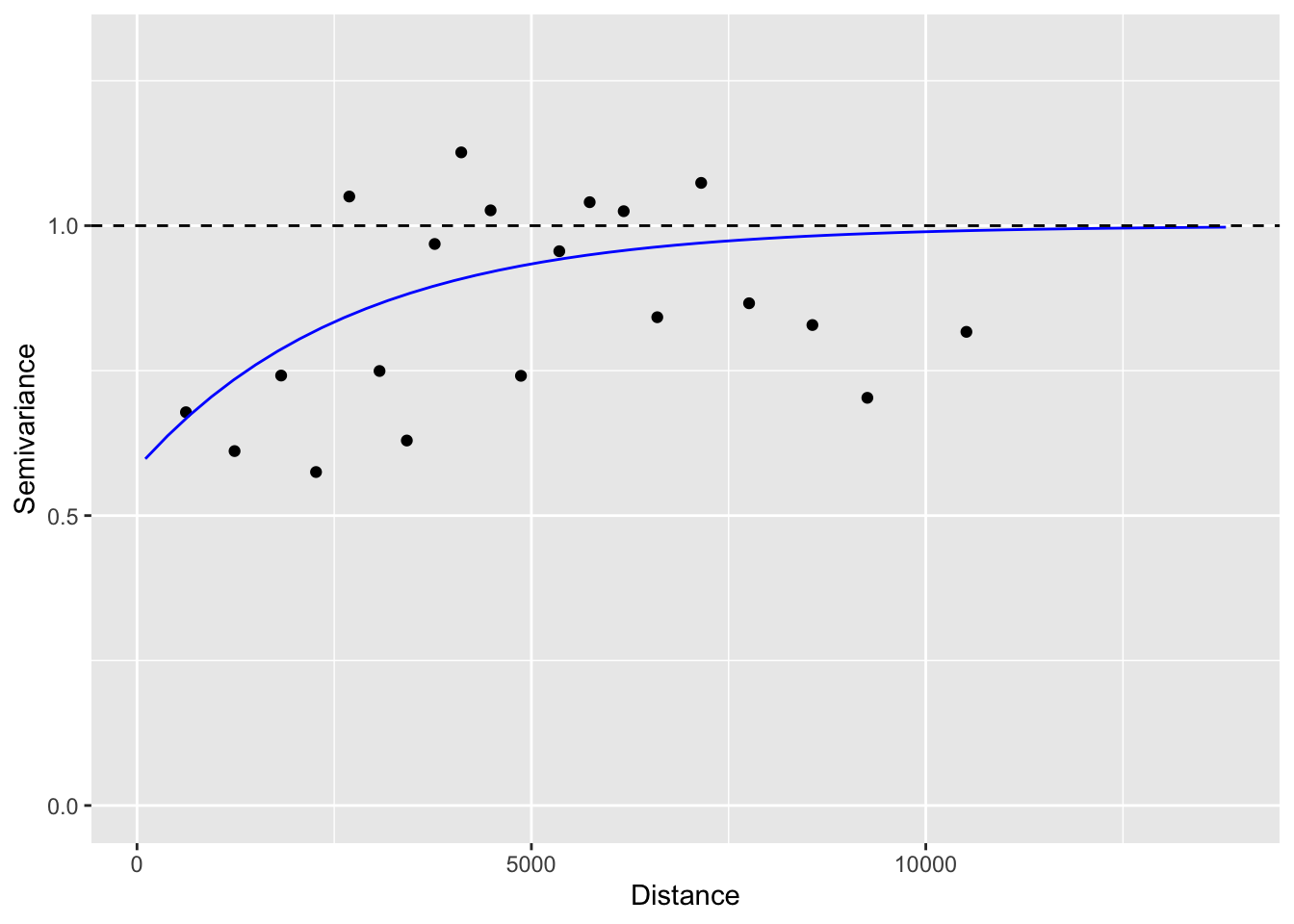
e. Add random factor
The package nlme allows us also to include random factors. Here we add System as a random factor and test whether this would improve the model fit.
- Instead of function
nlme::gls, we use the functionnlme::lme. - In
nlme, random effects are specified differently fromlmer::lme4(Week6):random = ~ 1 | System. - The correlation structure is specified exactly as with
gls.
mod.lme.corExp <- nlme::lme( A ~ PatchSize + IBR,
random = ~ 1 | System, data = Dianthus.df,
correlation = nlme::corExp(form = ~ X + Y, nugget=T),
method="REML")
summary(mod.lme.corExp)## Linear mixed-effects model fit by REML
## Data: Dianthus.df
## AIC BIC logLik
## -0.04236554 14.1351 7.021183
##
## Random effects:
## Formula: ~1 | System
## (Intercept) Residual
## StdDev: 0.08165681 0.1947089
##
## Correlation Structure: Exponential spatial correlation
## Formula: ~X + Y | System
## Parameter estimate(s):
## range nugget
## 385.7379489 0.1971837
## Fixed effects: A ~ PatchSize + IBR
## Value Std.Error DF t-value p-value
## (Intercept) 4.084490 0.08657381 53 47.17928 0.0000
## PatchSize 0.049722 0.01860186 53 2.67296 0.0100
## IBR 0.083831 0.10438753 53 0.80307 0.4255
## Correlation:
## (Intr) PtchSz
## PatchSize 0.560
## IBR -0.782 -0.485
##
## Standardized Within-Group Residuals:
## Min Q1 Med Q3 Max
## -3.15608775 -0.30381193 0.00663275 0.52443183 1.89376128
##
## Number of Observations: 59
## Number of Groups: 4The nature of the results did not change: PatchSize is still significant but IBR is not.
As in Week 6, we can obtain marginal (fixed effects) and conditional R-squared values (fixed + random):
## Warning: 'r.squaredGLMM' now calculates a revised statistic. See the help page.## R2m R2c
## [1,] 0.2294698 0.3447197Now we can include this model in the model comparison from above. Notes:
- As discussed in the Week 6 video, we should fit the mixed model with maximum likelihood (method = “ML”) to test fixed effects and to compare its AIC to the other models.
- The Week 6 video followed the philosphy that random effect should only be fitted for factors with >5 levels, whereas here, we are using a factor with 4 levels.
## Model selection table
## (Intrc) IBR PtchS class correlation random df logLik AICc
## mod.corExp 4.044 0.08468 0.04269 gls n::cE(X+Y,T) 6 6.283 1.1
## mod.corRatio 4.032 0.09704 0.04129 gls n::cR(X+Y,T) 6 6.229 1.2
## model.lm 4.052 0.11340 0.04266 gls 4 3.702 1.3
## mod.lme.corExp 4.084 0.08383 0.04972 lme n::cE(X+Y,T) S 7 7.021 2.2
## delta weight
## mod.corExp 0.00 0.295
## mod.corRatio 0.11 0.280
## model.lm 0.29 0.256
## mod.lme.corExp 1.10 0.170
## Abbreviations:
## correlation: n::cE(X+Y,T) = 'nlme::corExp(~X+Y,T)',
## n::cR(X+Y,T) = 'nlme::corRatio(~X+Y,T)'
## Models ranked by AICc(x)
## Random terms:
## S: 1 | SystemQuestions:
- How may degrees of freedom (df) were used for the random effect?
- How can you see from the table that System was fitted as a random effect, and what method was used (REML vs. ML)?
- Was the model with the random effect ranked higher than the model without it?
- Compare the estimates of the slope coefficients for IBR between the models. How did accounting for spatial autocorrelation affect the slope coefficient, compared to
model.lm? How large was the difference due to using different variogram models? And how much of a difference was related to including the random effect? - How about the slope estimate for PatchSize?
5. Fit spatial simultaneous autoregressive error models (SAR)
An alternative way to account for spatial autocorrelation in the residuals is spatial regression with a simultaneous autoregressive error model (SAR).
a. Fit and compare alternative SAR models
The method errorsarlm fits a simultaneous autoregressive model (‘sar’) to the error (‘error’) term of a ‘lm’ model.
This approach is based on spatial neighbours and weights. We have already defined them in three versions of a listw object. Let’s see which one fits the data best. First, we fit the three models:
mod.sar.IBR.gab <- spatialreg::errorsarlm(A ~ PatchSize + IBR, data = Dianthus.df,
listw = listw.gab)
mod.sar.IBR.d1 <- spatialreg::errorsarlm(A ~ PatchSize + IBR, data = Dianthus.df,
listw = listw.d1)
mod.sar.IBR.d2 <- spatialreg::errorsarlm(A ~ PatchSize + IBR, data = Dianthus.df,
listw = listw.d2)Due to some issues when using model.sel with these objects, here we manually compile AICc and delta values and sort the models by delta:
#MuMIn::model.sel(mod.lm.IBR, mod.sar.IBR.gab, mod.sar.IBR.d1, mod.sar.IBR.d2)
Models <- list(mod.lm.IBR=mod.lm.IBR, mod.sar.IBR.gab=mod.sar.IBR.gab,
mod.sar.IBR.d1=mod.sar.IBR.d1, mod.sar.IBR.d2=mod.sar.IBR.d2)
data.frame(AICc = sapply(Models, MuMIn::AICc)) %>%
mutate(delta = AICc - min(AICc)) %>%
arrange(delta)## AICc delta
## mod.sar.IBR.d1 -13.86736 0.0000000
## mod.sar.IBR.gab -13.29796 0.5694002
## mod.sar.IBR.d2 -11.96555 1.9018039
## mod.lm.IBR -10.77004 3.0973135The best model (‘mod.sar.IBR.d1’) is the one with (row-standardized) inverse-distance weights (‘listw.d1’). It is only slightly better than the model with the (row-standardized) binary weights (‘listw.gab’), whereas the nonspatial model and the one with (row-standardized) inverse squared distance weights have much less support.
b. Interpret best-fitting SAR model
Let’s have a look at the best model. With the argument Nagelkerke = TRUE, we request a pseudo R-squared.
##
## Call:spatialreg::errorsarlm(formula = A ~ PatchSize + IBR, data = Dianthus.df,
## listw = listw.d1)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.654613 -0.085961 0.016066 0.091687 0.389419
##
## Type: error
## Coefficients: (asymptotic standard errors)
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 4.067066 0.077809 52.2696 <2e-16
## PatchSize 0.041416 0.018554 2.2322 0.0256
## IBR 0.090578 0.094946 0.9540 0.3401
##
## Lambda: 0.22322, LR test value: 2.6442, p-value: 0.10393
## Asymptotic standard error: 0.13659
## z-value: 1.6343, p-value: 0.1022
## Wald statistic: 2.6708, p-value: 0.1022
##
## Log likelihood: 12.49972 for error model
## ML residual variance (sigma squared): 0.037595, (sigma: 0.19389)
## Nagelkerke pseudo-R-squared: 0.26613
## Number of observations: 59
## Number of parameters estimated: 5
## AIC: -14.999, (AIC for lm: -14.355)- Again, PatchSize is significant but not IBR.
- The section starting with ‘Lamba’ summarizes the fitted spatial autocorrelation term. It is not statistically significant (p-value = 0.1039 for the Likelihood Ratio test LR).
6. Spatial filtering with MEM using package ‘spmoran’
See tutorial for ‘spmoran’ package: https://arxiv.org/ftp/arxiv/papers/1703/1703.04467.pdf
Both GLS and SAR fitted a spatially correlated error structure of a relatively simple form to the data. Gene flow could be more complex and for example, could create spatial autocorrelation structure that is not the same in all directions or in all parts of the study area. Moran Eigenvector Maps (MEM) allows a more flexible modeling of spatial structure in the data. In spatial filtering, we use MEM spatial eigenvectors to account for any spatial structure while fitting and testing the effect of our predictors.
a. Default method
The new package spmoran makes this really easy. First, we create the MEM spatial eigenvectors. This implies defining neighbors and weights, but this is well hidden in the code below. The function meigen here takes the coordinates, calculates a minimum spanning tree (so that each site has at least one neighbour), and finds the maximum distance ‘h’ from the spanning tree. It then calculates neighbor weights as exp(-dij / h).
Note: if you have many sites (> 200), the function meigen_f may be used instead of meigen, it should even work for >1000 sites.
The function esf then performs the spatial filtering. Here it uses stepwise selection of MEM spatial eigenvectors using an R-squared criterion (fn = "r2").
# lm model: using truncated distance matrix (max of min spanning tree distance)
meig <- spmoran::meigen(coords=xy)## 9/59 eigen-pairs are extractedsfd.res <- spmoran::esf( y=Dianthus.df$A, x=Dianthus.df[,c("PatchSize", "IBR")],
meig=meig, fn = "r2" )## 5/9 eigenvectors are selectedThe objects created by functions ‘meigen’ and ‘esf’ contain a lot of information:
- meigW: a list returned by function ‘meigen’, with the following attributes:
- sf: Matrix of retained spatial eigenvectors.
- ev: Eigenvalues of retained spatial eigenvectors.
- ev_full: All (n - 1) eigenvalues.
- sfd.res: a list returned by function ‘esf’, with the following attributes:
- b: Table with regression results for predictors X.
- r: Table with regression results the selected MEM spatial eigenvectors (based on step-wise eigenvector selection).
- e: Summary statistics for the entire model.
- vif: Variance inflation factors.
- sf: Fitted spatially dependent component (i.e., fitted value based on significant MEM spatial eigenvectors)
- pred: Fitted values.
- resid: Residuals.
Let’s look at the table ‘b’ with regression results for the predictors first:
## Estimate SE t_value p_value
## (Intercept) 4.08678879 0.06759658 60.4585130 3.838659e-49
## PatchSize 0.03642554 0.01673612 2.1764625 3.417603e-02
## IBR 0.04687286 0.08602602 0.5448685 5.882188e-01Again, PatchSize is statistically significant but not IBR.
Next, we look at the table ‘r’ with regression results for MEM spatial eigenvectors:
## Estimate SE t_value p_value
## sf6 0.5938646 0.1782765 3.331144 0.001613967
## sf1 0.3962440 0.1788408 2.215624 0.031207615
## sf7 -0.4065267 0.1895836 -2.144313 0.036795842
## sf3 -0.3474148 0.1760289 -1.973624 0.053854181
## sf5 -0.3290397 0.1757533 -1.872168 0.066922529Five MEM spatial eigenvectors were important enough to be included in the model. Here they are ranked by their (absolute value of) slope coefficient, and thus by the strength of their association with the response variable. Eigenvector ‘sf6’ was by far the most important.
Note: some eigenvectors are included despite having a p-value > 0.05. This may have two reasons. First, the eigenvectors were selected without taking into account predictors X. Second, a different test was used in the stepwise eigenvector selection. The type of test can be specified with an argument fn (see ‘?esf’ helpfile and ‘spmoran’ tutorial).
Finally, let’s look at the summary results for the fitted model:
## stat
## resid_SE 0.1728755
## adjR2 0.4374576
## logLik 24.1369653
## AIC -30.2739307
## BIC -11.5760937Here, adjR2 is rather high (0.437), but this includes the selected MEM spatial eigenvectors!
b. Using a custom connectivity matrix
We know already that listw.d1 fit the data well, so let’s re-run the model with our own definition of spatial weights. With the funciton ‘listw2mat’, we convert from listw format to a full connnectivity matrix.
## Note: cmat is symmetrized by ( cmat + t( cmat ) ) / 2## 27/59 eigen-pairs are extractedsfw.res <- spmoran::esf( y=Dianthus.df$A, x=Dianthus.df[,c("PatchSize", "IBR")],
meig=meigw, fn = "r2" )## 15/27 eigenvectors are selected## Estimate SE t_value p_value
## (Intercept) 4.05985212 0.06875531 59.0478330 2.716097e-41
## PatchSize 0.02051541 0.01679035 1.2218572 2.287404e-01
## IBR 0.06583796 0.09048375 0.7276219 4.709800e-01## # A tibble: 15 × 4
## Estimate SE t_value p_value
## <dbl> <dbl> <dbl> <dbl>
## 1 -0.712 0.172 -4.14 0.000166
## 2 0.511 0.166 3.08 0.00369
## 3 -0.366 0.151 -2.43 0.0196
## 4 0.284 0.152 1.87 0.0693
## 5 -0.278 0.155 -1.79 0.0806
## 6 0.236 0.167 1.41 0.166
## 7 0.270 0.150 1.80 0.0787
## 8 0.309 0.159 1.94 0.0594
## 9 -0.289 0.160 -1.80 0.0786
## 10 0.227 0.152 1.49 0.143
## 11 0.233 0.151 1.55 0.130
## 12 0.217 0.151 1.43 0.159
## 13 -0.189 0.151 -1.25 0.217
## 14 0.196 0.152 1.29 0.204
## 15 0.166 0.161 1.03 0.309## stat
## resid_SE 0.1493144
## adjR2 0.5803455
## logLik 39.2199714
## AIC -40.4399428
## BIC -0.9667313Note: the messages tell us that ‘cmat’ has been made symmetric before analysis, that 27 out of 59 MEM spatial eigenvector (and their eigenvalues, hence ‘pairs’) were retained initially and subjected to stepwise selection, which then returned 15 statistically significant MEM eigenvectors that were included in the regression model with the predictor variables X (PatchSize and IBR).
Questions:
- Does this model fit the data better? Look for a lower AIC. In addition, you can compare the adjusted R-squared.
- What could cause a difference in model performance?
- Does this affect the results for PatchSize and IBR? Compare both parameter estimates and p-value between two two models.
c. Plot spatial eigenvectors
So far, we have treated the MEM spatial eigenvectors as a black box. What kind of patterns do they represent?
First, we plot all the selected (significant) eigenvectors. A convenient way to do so is converting to an sf object and then use the function plot.
Here we need tweak the column names of the eigenvectors, which are called “X1”, “X2” etc., to show which spatial eigenvectors (sf1, sf2, etc.) are being plotted. We will plot all 15 eigenvectors that were selected above, in order of importance.
- In the first line, we create a data frame ‘MEM’ that combines the coordinates from ‘xy’ with the eigenvectors from ‘meigw’, ordered by importance.
- We add the names for the eigenvectors.
sfw.res$other$sf_idcontains the numbers (ID’s) of the selected eigenvectors. - Then we convert the data frame
MEMto ansfobject withst_as_sf. - The plot function for
sfobjects will plot each attribute. Here we specify that the axes should be plotted (axes=TRUE), but no ticks along the axes (xaxt,yaxt) should be shown - thus, only a box will be drawn around each plot. By default, the first ten variables will be plotted. To show all variables, we use the argumentmax.plot = ncol(MEM) - 1.
MEM <- data.frame(xy, meigw$sf[,sfw.res$other$sf_id])
names(MEM)[-c(1,2)] <- paste0("sf", sfw.res$other$sf_id)
MEM <- st_as_sf(MEM, coords=c("X", "Y"))
plot(MEM, axes=TRUE, yaxt = "n", xaxt = "n", max.plot = ncol(MEM) - 1)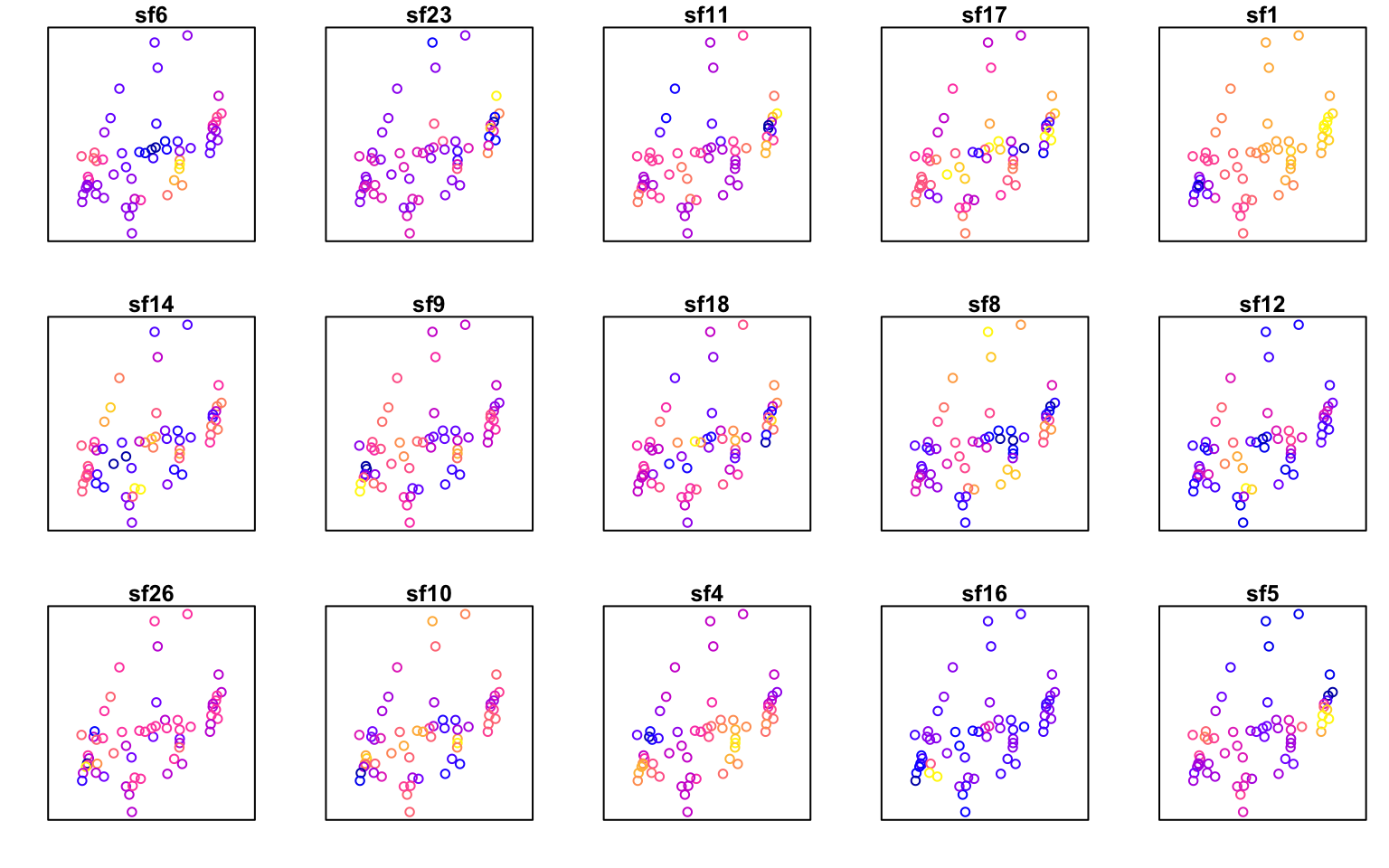
The most important spatial eigenvector (sf6) is plotted at the top left, the second most important (sf23) second from left, etc.
The smallest numbers are patterns with the largest spatial scale (sf1), which here shows a gradient from East to West. The most important eigenvector (sf6) shows a finer-scale pattern with the highest values (yellow) in the center, lowest values East and West, and intermediate values North and South.
However, these patterns individually are not meaningful. More importantly, we can plot the total spatial component in the response as a weighted sum of these component patterns (MEM$wmean), where the weights correspond to the regression coefficients (Estimate) in table sfw.res$r. Here we create a panel with two plots, the modeled spatial components MEM.w on the left and the response allelic richness A on the right (the mean has been removed to make values comparable).
Note: you could calculate the weighted mean sfw.res$sf yourself as follows: data.matrix(st_drop_geometry(MEM[,1:15])) %*% sfw.res$r$Estimate
MEM$wmean <- sfw.res$sf
#MEM$pred <- sfw.res$pred
MEM$A <- scale(Dianthus.df$A, scale = FALSE)
plot(MEM[c("wmean", "A")])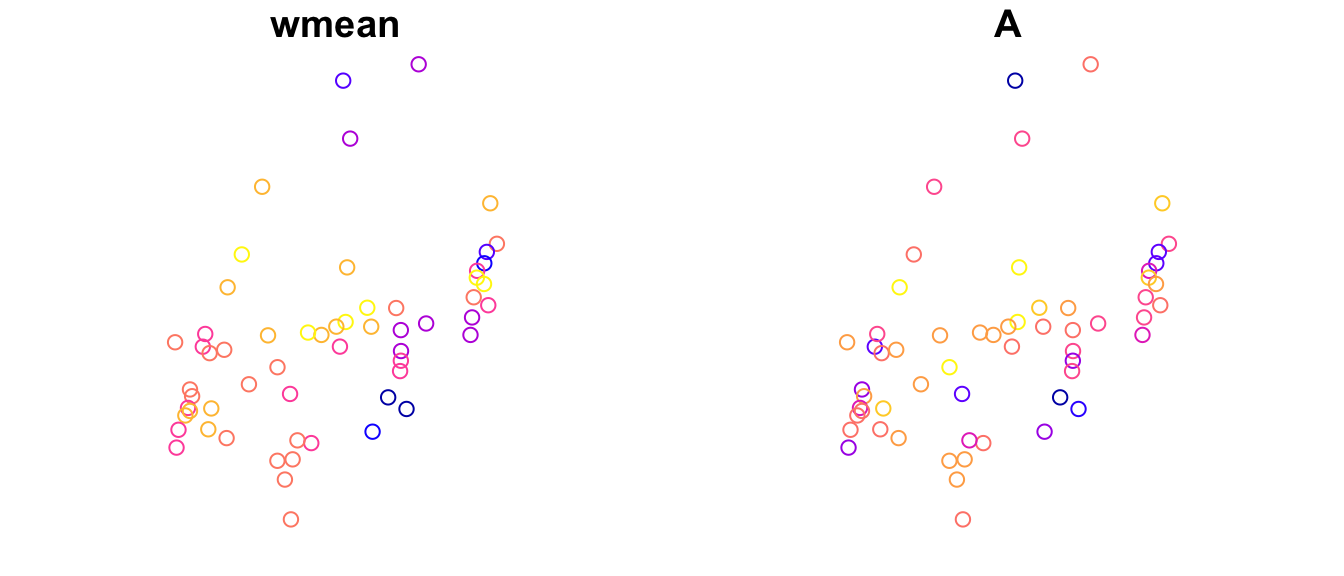
Obviously, a big part of the variation in allelic richness is already captured by the weighted mean MEM$wmean. In essence the model then tries to explain the difference between these two sets of values by the predictors “PatchSize” and “IBR”.
Let’s quantify the correlation of this spatial component with allelic richness, and compare the correlation between the two models:
## sfd sfw
## [1,] 0.6252594 0.8054356With the default method (defining neighbors based on a distance cut-off), the spatial component modeled by the significant MEM spatial eigenvectors showed a correlation of 0.625 with the response variable. Using a Gabriel graph with inverse distance weights increased this correlation to 0.805.
This means that the spatial eigenvectors derived from the Gabriel graph were more effective at capturing the spatial variation in allelic richness than the default method. This spatial component is then controlled for when assessing the relationship between allelic richness and the predictors (PatchSize and IBR).
d. Random effect model
The previous model selected 15 MEM spatial eigenvectors, and thus fitted 15 additional models. Just like the random effects for family and population in Week 6 lab, we can save a few parameters here by fitting the set of MEM eigenvectors as a random effect. This is done by the function ‘resf’.
sfr.res <- spmoran::resf( y=Dianthus.df$A, x=Dianthus.df[,c("PatchSize", "IBR")],
meig = meigw, method = "reml" )
sfr.res$b## Estimate SE t_value p_value
## (Intercept) 4.06902707 0.06645938 61.225772 0.00000000
## PatchSize 0.04247164 0.01652051 2.570843 0.01344639
## IBR 0.08489102 0.08467569 1.002543 0.32132725## # A tibble: 27 × 1
## value
## <dbl>
## 1 -0.191
## 2 -0.0314
## 3 -0.0601
## 4 -0.124
## 5 0.0640
## 6 -0.312
## 7 -0.0576
## 8 -0.113
## 9 0.128
## 10 0.105
## # ℹ 17 more rows## stat
## resid_SE 0.15643275
## adjR2(cond) 0.50394642
## rlogLik 5.99141269
## AIC 0.01717462
## BIC 12.48239928## (Intercept)
## random_SE 0.1785609
## Moran.I/max(Moran.I) 0.7742902As in Week 6 lab, the conditional R-squared is the variance explained by the fixed effects (PatchSize and IBR) and the random effects (significant MEM spatial eigenvectors) together. It is adjusted for the number of effects that were estimated.
Note: we can’t compare AIC with the previous models, as the model was fitted with ‘reml’.
We get an additional output ‘sfr.res$s’ with two variance parameters:
- random_SE: standard error of the random effect (spatial component).
- Moran.I/max(Moran.I): Moran’s I of the spatial component, rescaled by the maximum possible value. From the help file: “Based on Griffith (2003), the scaled Moran’I value is interpretable as follows: 0.25-0.50:weak; 0.50-0.70:moderate; 0.70-0.90:strong; 0.90-1.00:marked.”
7. Fit spatially varying coefficients model with package ‘spmoran’
See: https://arxiv.org/ftp/arxiv/papers/1703/1703.04467.pdf
Now comes the coolest part!
So far, we have fitted the same model for all sites. Geographically weighted regression (GWR) would allow relaxing this. Spatial filtering with MEM can be used to accomplish the same goal, and the ‘spmoran’ tutorial calls this a ‘Spatially Varying Coefficients’ model (SVC). The main advantage is that we can visualize how the slope parameter estimates, and their p-values, vary across the study area! This is a great exploratory tool that can help us better understand what is going on.
Model with PatchSize and IBR
We fit the model with ‘resf_vc’.
rv_res <- spmoran::resf_vc( y=Dianthus.df$A,
x = Dianthus.df[,c("PatchSize", "IBR")],
xconst = NULL, meig = meigw, method = "reml", x_sel = FALSE)## [1] "------- Iteration 1 -------"
## [1] "1/3"
## [1] "2/3"
## [1] "3/3"
## [1] "BIC: 25.57"
## [1] "------- Iteration 2 -------"
## [1] "1/3"
## [1] "2/3"
## [1] "3/3"
## [1] "BIC: 24.682"
## [1] "------- Iteration 3 -------"
## [1] "1/3"
## [1] "2/3"
## [1] "3/3"
## [1] "BIC: 24.641"
## [1] "------- Iteration 4 -------"
## [1] "1/3"
## [1] "2/3"
## [1] "3/3"
## [1] "BIC: 24.64"
## [1] "------- Iteration 5 -------"
## [1] "1/3"
## [1] "2/3"
## [1] "3/3"
## [1] "BIC: 24.64"Instead of one slope estimate for each predictor, we now get a different estimate for each combination of parameter and site (sounds like overfitting?). Here’s a summary of the distribution of these estimates.
## (Intercept) PatchSize IBR
## Min. :4.106 Min. :0.01704 Min. :-0.66583
## 1st Qu.:4.106 1st Qu.:0.03131 1st Qu.:-0.06980
## Median :4.106 Median :0.04139 Median : 0.07447
## Mean :4.106 Mean :0.04501 Mean : 0.01518
## 3rd Qu.:4.106 3rd Qu.:0.05195 3rd Qu.: 0.14467
## Max. :4.106 Max. :0.10383 Max. : 0.22945The slope estimate for PatchSize varied between 0.017 and 0.1, with a mean of 0.045. The slope estimate for the ‘IBR’ term varied between -0.66 and 0.23, with a mean close to 0! That is an astounding range of variation. Keep in mind that we really expect a positive relationship, there is no biological explanation for a negative relationship.
Here is a similar summary of the p-values:
## (Intercept) PatchSize IBR
## Min. :0 Min. :0.0000137 Min. :0.0000835
## 1st Qu.:0 1st Qu.:0.0351729 1st Qu.:0.0976874
## Median :0 Median :0.1301712 Median :0.2605918
## Mean :0 Mean :0.1605394 Mean :0.3356247
## 3rd Qu.:0 3rd Qu.:0.2605700 3rd Qu.:0.5327635
## Max. :0 Max. :0.5107902 Max. :0.9219282For both variables, most sites do not show a significant effect (i.e., only few sites show a p-value < 0.05).
We could print these results by site (type rv_res$b_vc or rv_res$p_vc). Even better, we can plot them in space. We start with combining the data (‘Dianthus.df’) and the results into one data frame ‘Results’. By specifying b=rv_res$b_vc and p=rv_res$p_vc, R will create column names that start with ‘b’ or ‘p’, respectively.
## [1] "A" "IBD" "IBR" "PatchSize"
## [5] "System" "Longitude" "Latitude" "X"
## [9] "Y" "b..Intercept." "b.PatchSize" "b.IBR"
## [13] "p..Intercept." "p.PatchSize" "p.IBR"Let’s start with PatchSize. Here, we first plot PatchSize in space, with symbol size as a function of patch size. In a second plot, we color sites by statistical significance and the size of the symbols represents the parameter estimate of the regression slope coefficient for Patch Size. The layer ‘coord_fixed’ keeps controls the aspect ratio between x- and y-axes.
require(ggplot2)
ggplot(as.data.frame(Result), aes(X, Y, size=PatchSize)) +
geom_point(color="darkblue") + coord_fixed()
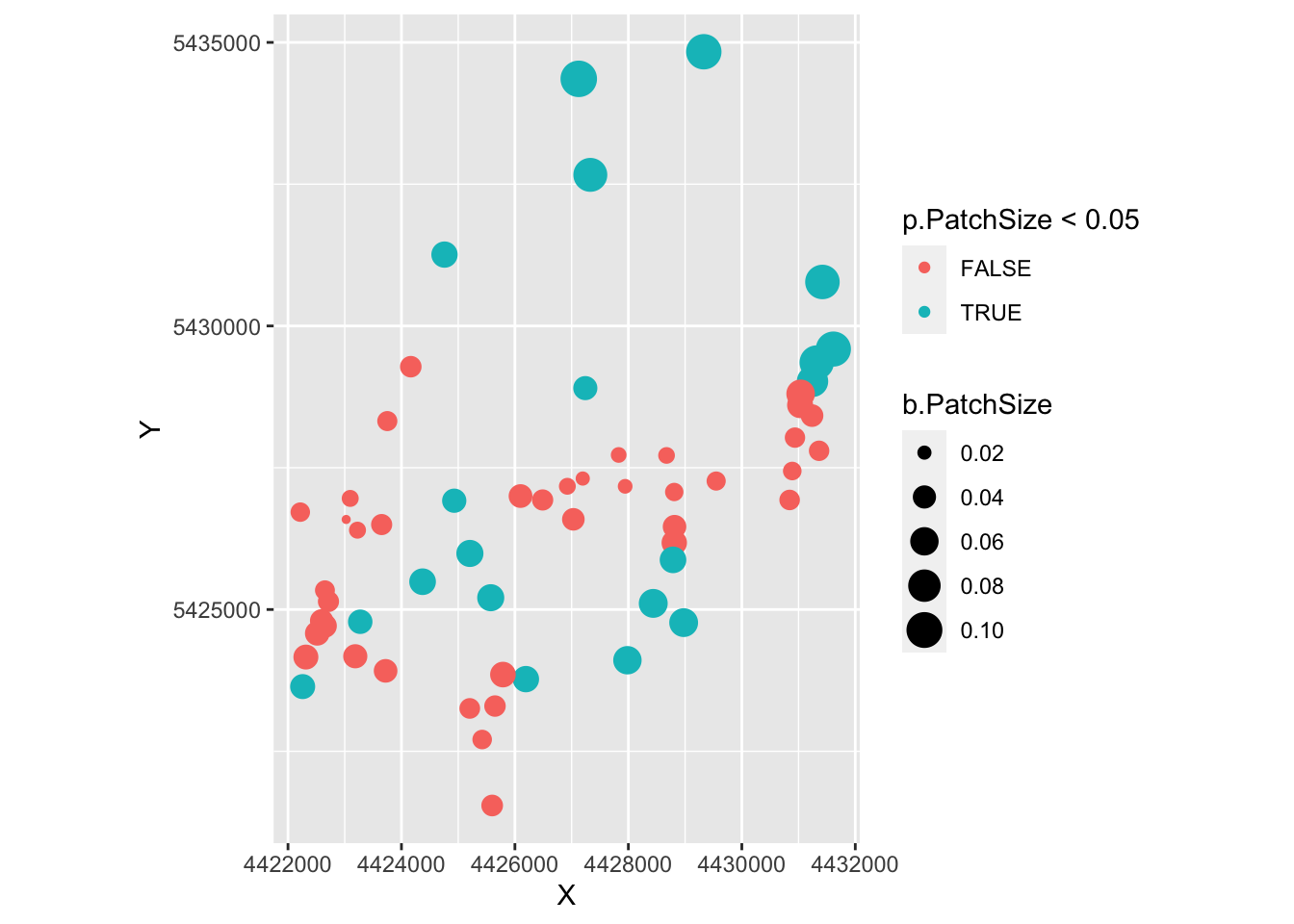
ggplot(as.data.frame(Result), aes(X, Y, col=p.PatchSize < 0.05, size=b.PatchSize)) +
geom_point() + coord_fixed()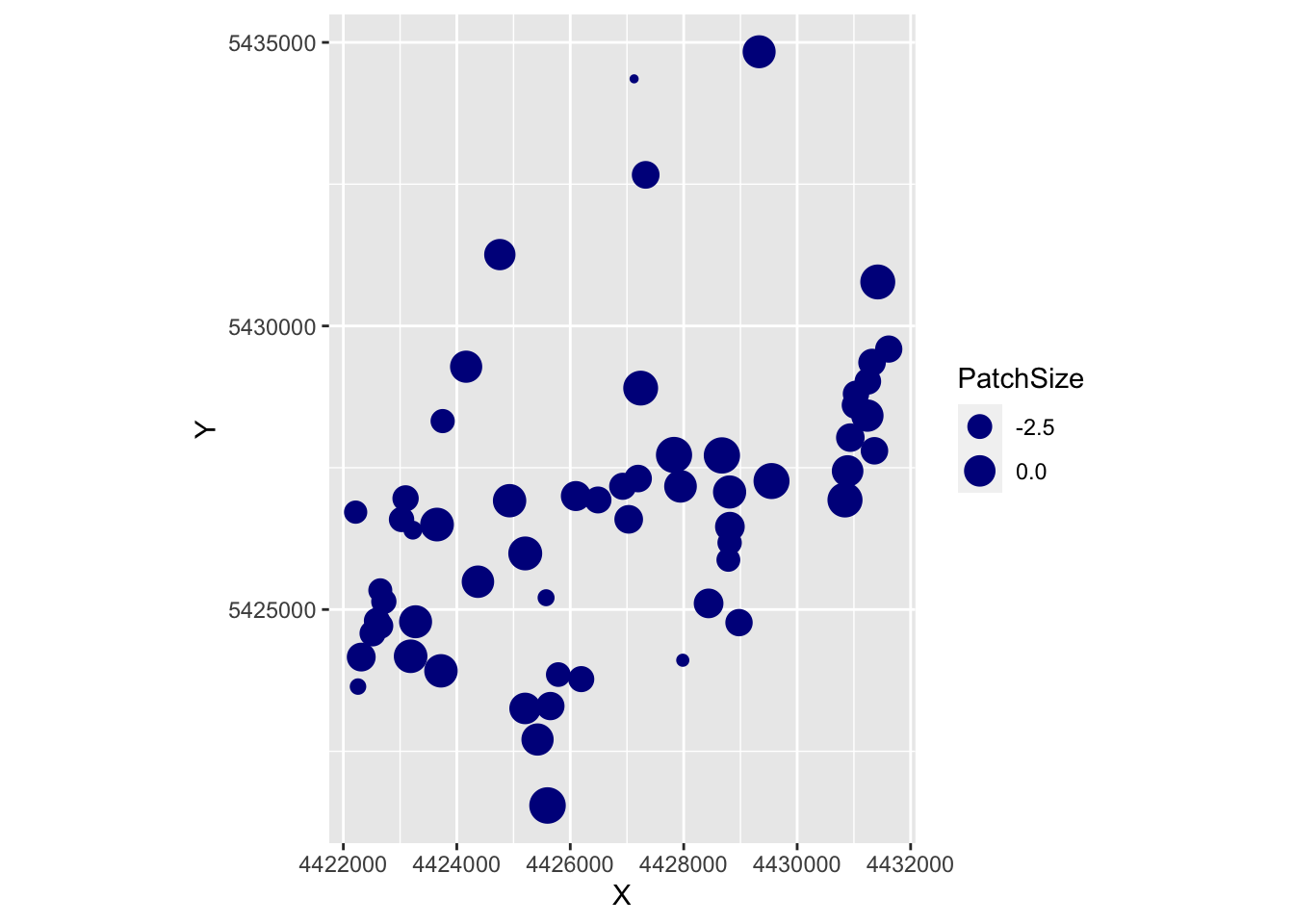
Let’s do the same for ‘IBR’:
require(ggplot2)
ggplot(as.data.frame(Result), aes(X, Y, size=IBR)) +
geom_point(color="darkgreen") + coord_fixed()
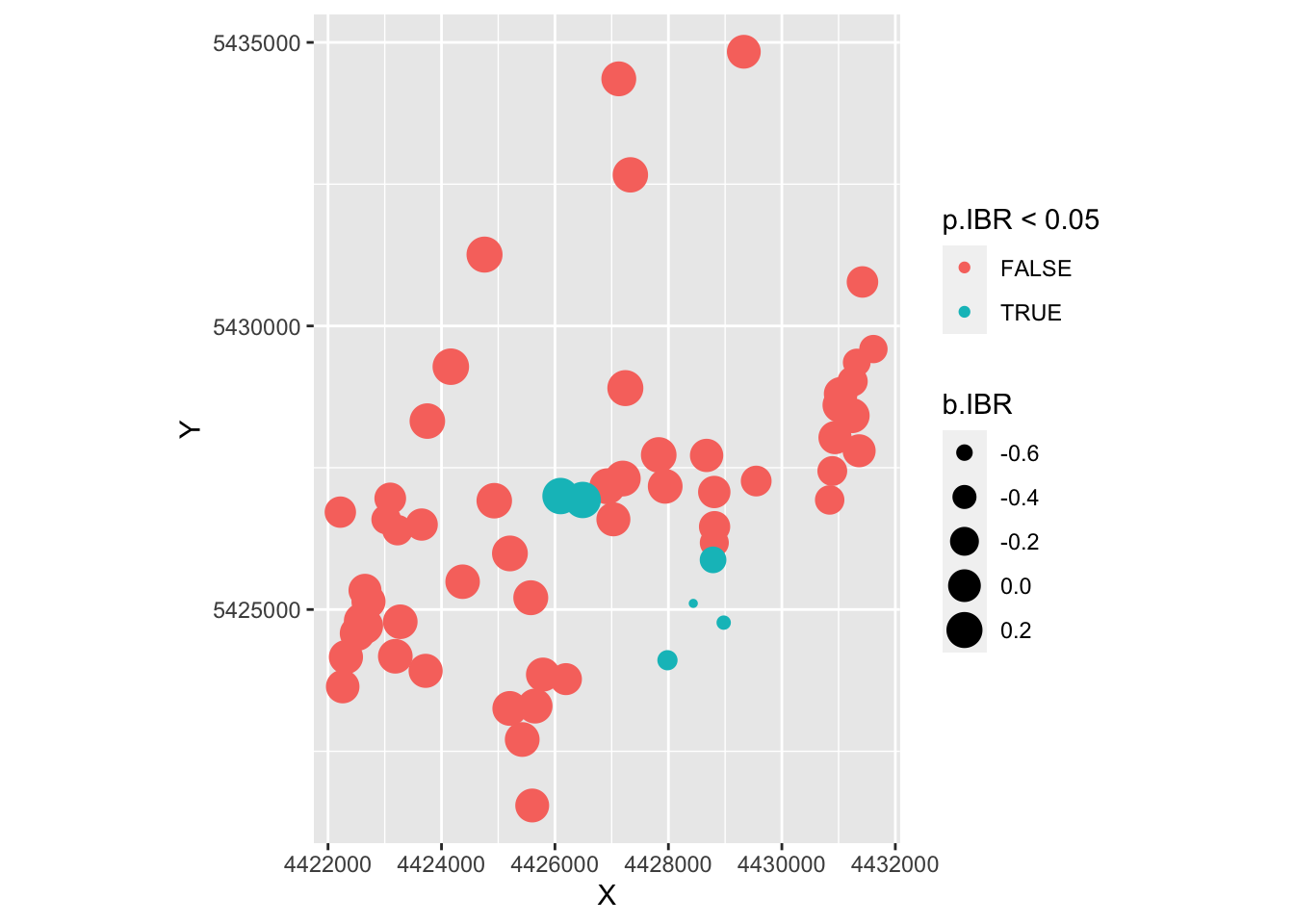
ggplot(as.data.frame(Result), aes(X, Y, col=p.IBR < 0.05, size=b.IBR)) +
geom_point() + coord_fixed()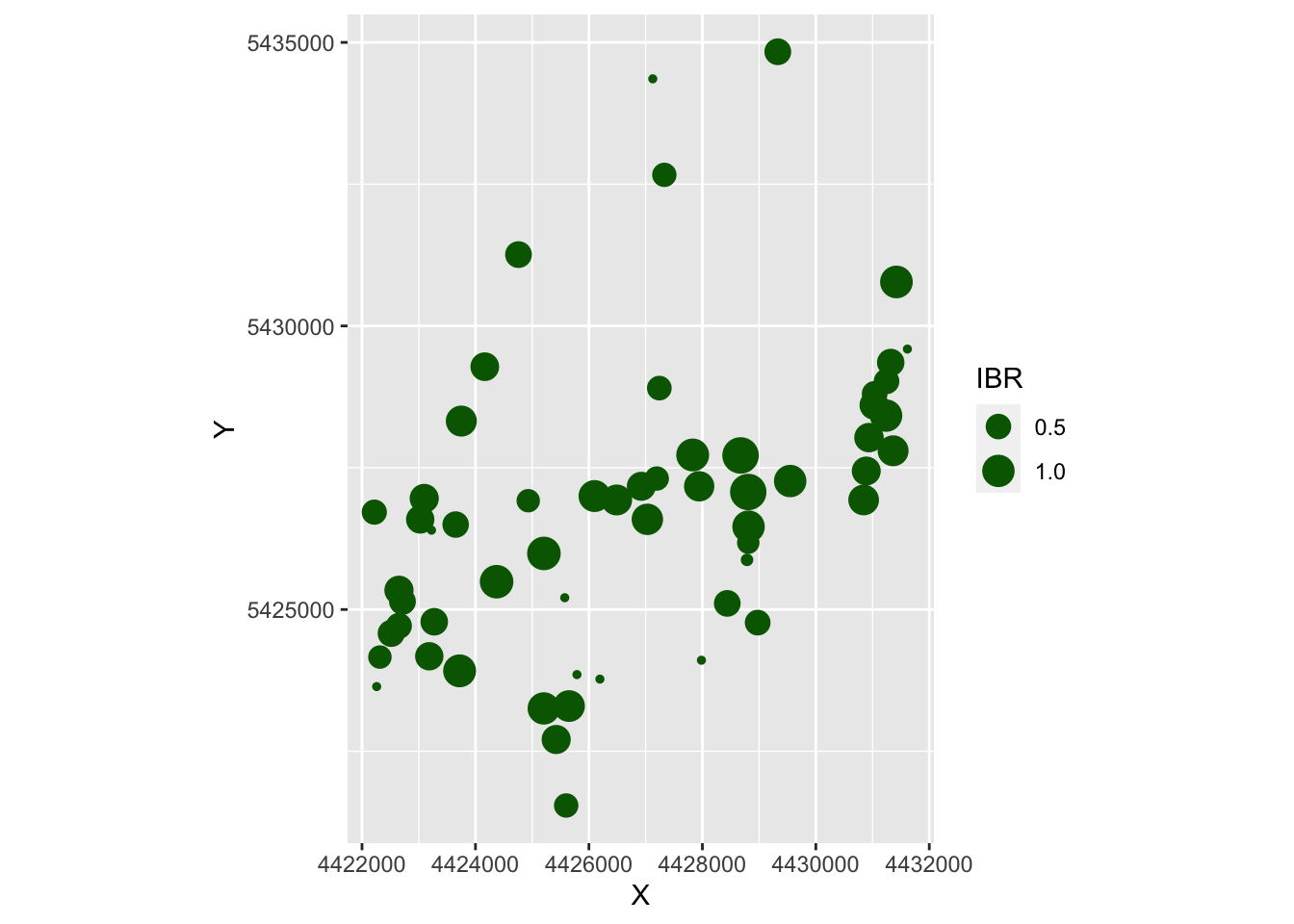
- The very small dots in the first map are the ungrazed patches.
- From the second map, it looks like the significant values were the one with negative slope estimates, for which we don’t have a biological interpretation.
Model with IBR only
Keep in mind that ‘IBR’ and ‘PatchSize’ showed a strong correlation. The parameter estimates could therefore depend quite a bit on the other variables. To help with the interpretation, let’s repeat the last analysis just with ‘IBR’, without ‘PatchSize’.
rv_res <- spmoran::resf_vc( y=Dianthus.df$A,
x = Dianthus.df[,c("IBR")],
xconst = NULL, meig = meigw, method = "reml", x_sel = FALSE)## [1] "------- Iteration 1 -------"
## [1] "1/2"
## [1] "2/2"
## [1] "BIC: 13.336"
## [1] "------- Iteration 2 -------"
## [1] "1/2"
## [1] "2/2"
## [1] "BIC: 13.278"
## [1] "------- Iteration 3 -------"
## [1] "1/2"
## [1] "2/2"
## [1] "BIC: 13.278"
## [1] "------- Iteration 4 -------"
## [1] "1/2"
## [1] "2/2"
## [1] "BIC: 13.278"## (Intercept) V1
## Min. :3.816 Min. :-0.2226
## 1st Qu.:3.924 1st Qu.: 0.1384
## Median :3.949 Median : 0.2480
## Mean :3.943 Mean : 0.2078
## 3rd Qu.:3.978 3rd Qu.: 0.3108
## Max. :4.043 Max. : 0.4084Now the range of slope estimates is smaller, most sites have a positive estimate, and the mean is approx. 0.21.
## (Intercept) V1
## Min. :0 Min. :0.0004291
## 1st Qu.:0 1st Qu.:0.0048915
## Median :0 Median :0.0572719
## Mean :0 Mean :0.1577143
## 3rd Qu.:0 3rd Qu.:0.2228429
## Max. :0 Max. :0.9073438Also, a larger proportion of sites nows has p-values < 0.05.
Let’s plot the results onto a gray-scale, stamen terrain map to facilitate interpretation. Note: here the zoom level zoom = 12 covers the entire study area, whereas the default value would actually cut off a large number of sites. We use the argument force=TRUE to force the map to be downloaded again (otherwise the argument color="bw" may not have an effect if we already downloaded the terrain map in color).
Result <- data.frame(Dianthus.df, b=rv_res$b_vc, p=rv_res$p_vc, resid=rv_res$resid)
ggplot(as.data.frame(Result), aes(X, Y, col=p.V1 < 0.05, size=b.V1)) +
geom_point() + coord_fixed()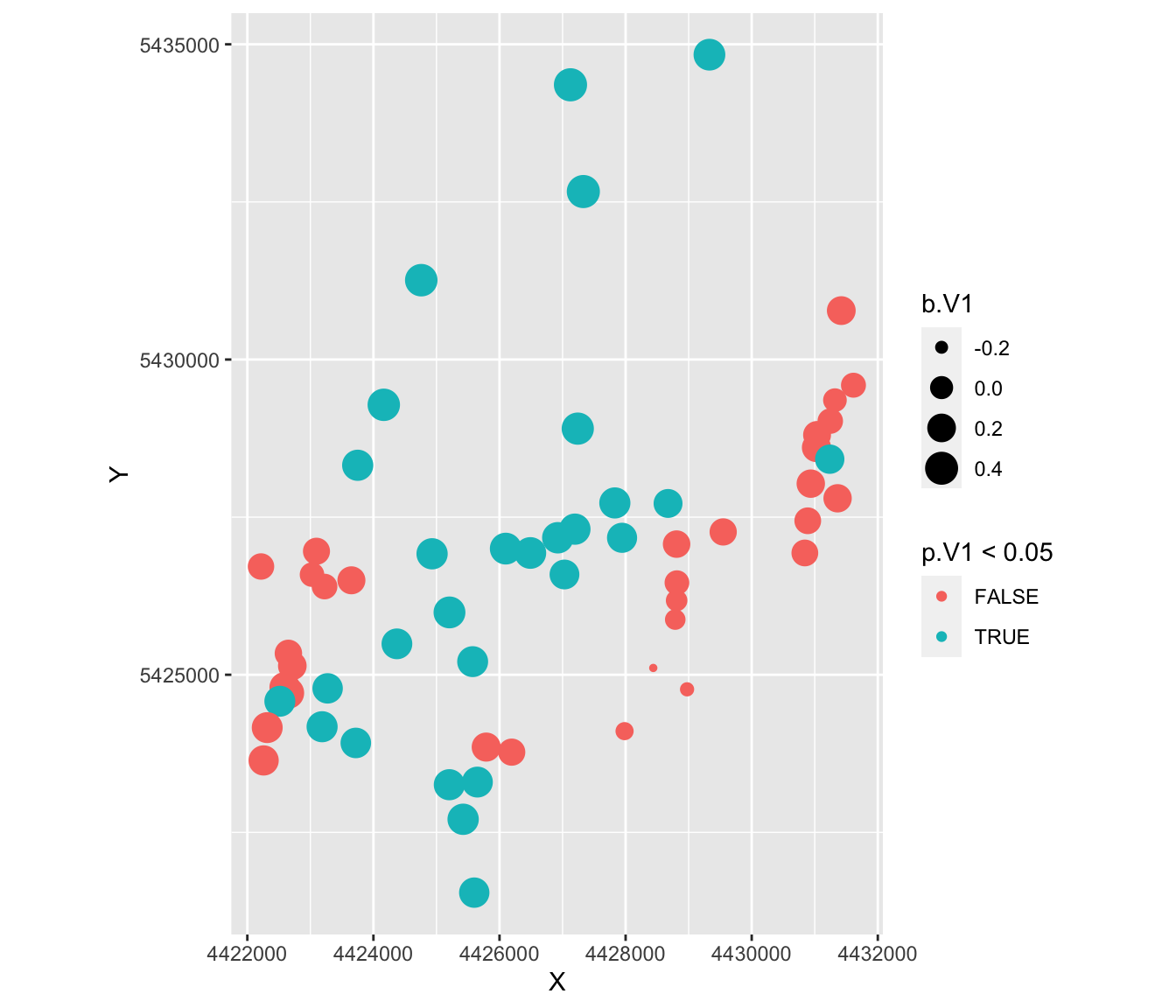
This is a very different map of results!
- Most sites now show significant effects.
- The sites with larger positive estimates show significant effects, whereas those with small or negative estimates show non-significant effects.
- There are 3 - 4 clusters of sites where the IBR models is not effective at explaining variation in allelic richness: in the very East, in the South-East, and one area in the South-West.
- Knowing the study area, these are distinct regions (e.g. valleys) that may suggest further biological explanations.
Result.sf <- st_as_sf(Result, coords=c("X", "Y"), crs=st_crs(Dianthus))
Result.sf$Significant <- Result.sf$p.V1 < 0.05
tmap_mode("view")
tm_shape(Result.sf) + tm_bubbles(size="b.V1", col="Significant")We can compare this to a model with fixed
8. Conclusions
- We moved from pair-wise distance matrices (link-based) to node-based analysis by integrating the explanatory distance matrices for IBD and IBR into patch-level connectivity indices Si (neighborhood analysis).
- We found no support for the IBD model, and strong support for the IBR model when tested without additional predictors.
- The site-level predictors ‘PatchSize’ (log(‘Ha’)) was strongly correlated with our IBR model, and when PatchSize was added to the model, ‘IBR’ was no long statistically significant and its slope estimate changed considerably.
- The MEM analogue to spatially weighted regression showed very different patterns for ‘IBR’ depending on whether or not ‘PatchSize’ was included in the model. Withouth ‘PatchSize’, ‘IBR’ showed significant positive correlation with allelic richness across the study area, except for three sub-areas.
- In practical terms, this may suggest that the management strategy of maintaining plant functional connectivity through shepherding seems to be working for this species overall, though there are three parts of the study area where this may not be sufficient to maintain gene flow.
- The evidence is not conclusive, however, the observed patterns could also be explained by population size, which in this species seems to be associated with patch size. This makes sense if smaller patches contain smaller populations with higher rates of genetic drift.