6.3 Worked Example
Helene Wagner
1. Overview of Worked Example
a. Goals
This worked example shows how to:
- Check markers and populations (polymorphism, HWE, linkage, null alleles).
- Assess genetic diversity.
- Aggregate genetic data at the population level.
b. Data set
This is the same data set as used in Weeks 1 & 2.
Microsatellite data for 181 individuals of Colombia spotted frogs (Rana luteiventris) from 12 populations. Site-level spatial coordinates and attributes. The data are a subsample of the full data set analyzed in Funk et al. (2005) and Murphy et al. (2010). Please see the separate introduction to the data set.
- ralu.loci: Data frame with populations and genetic data (181 rows x 9 columns). Included in package ‘LandGenCourse’. To load it, type: data(ralu.loci)
- ralu.site: Spatial points data frame with spatial coordinates and site variables Included in package GeNetIt’. To load it, type: data(ralu.site)
2. Basic checking of markers and populations
Before we do landscape genetic analysis, we need to perform a basic population genetic analysis of the genetic data, in order to better understand the nature and quality of the data and to check for underlying assumptions of population genetic models and corresponding methods.
a. Re-create genind object
Adapted from Week 1 tutorial:
Note: we use the double colon notation ‘package::function(argument)’ to indicate, for each function, which package it belongs to (see Week 2 video).
data(ralu.loci, package="LandGenCourse")
Frogs <- data.frame(FrogID = paste(substr(ralu.loci$Pop, 1, 3),
row.names(ralu.loci), sep="."), ralu.loci)
Frogs.genind <- adegenet::df2genind(X=Frogs[,c(4:11)], sep=":", ncode=NULL,
ind.names= Frogs$FrogID, loc.names=NULL,
pop=Frogs$Pop, NA.char="NA", ploidy=2,
type="codom", strata=NULL, hierarchy=NULL)
Frogs.genind## /// GENIND OBJECT /////////
##
## // 181 individuals; 8 loci; 39 alleles; size: 55.5 Kb
##
## // Basic content
## @tab: 181 x 39 matrix of allele counts
## @loc.n.all: number of alleles per locus (range: 3-9)
## @loc.fac: locus factor for the 39 columns of @tab
## @all.names: list of allele names for each locus
## @ploidy: ploidy of each individual (range: 2-2)
## @type: codom
## @call: adegenet::df2genind(X = Frogs[, c(4:11)], sep = ":", ncode = NULL,
## ind.names = Frogs$FrogID, loc.names = NULL, pop = Frogs$Pop,
## NA.char = "NA", ploidy = 2, type = "codom", strata = NULL,
## hierarchy = NULL)
##
## // Optional content
## @pop: population of each individual (group size range: 7-23)b. Check that markers are polymorphic
The genetic resolution depends on the number of markers and their polymorphism. The table above and the summary function for genind objects together provide this information. Now we run the summary function:
##
## // Number of individuals: 181
## // Group sizes: 21 8 14 13 7 17 9 20 19 13 17 23
## // Number of alleles per locus: 3 4 4 4 9 3 4 8
## // Number of alleles per group: 21 21 20 22 20 19 19 25 18 14 18 26
## // Percentage of missing data: 10.64 %
## // Observed heterozygosity: 0.1 0.4 0.09 0.36 0.68 0.02 0.38 0.68
## // Expected heterozygosity: 0.17 0.47 0.14 0.59 0.78 0.02 0.48 0.74The output of the summary function shows us the following:
- 8 loci with 3 - 9 alleles (39 in total)
- Expected heterozygosity varies between 0.14 (locus C) and 0.78 (locus E)
- There’s a reasonable level of missing values (10.6%)
c. Check for deviations from Hardy-Weinberg equilibrium (HWE)
See also: http://dyerlab.github.io/applied_population_genetics/hardy-weinberg-equilibrium.html
For a very large population (no drift) with random mating and non-overlapping generations (plus a few more assumptions about the mating system), and in the absence of mutation, migration (gene flow) and selection, we can predict offspring genotype frequencies from allele frequencies of the parent generation (Hardy-Weinberg equilibrium). In general, we don’t expect all of these assumptions to be met (e.g., if we want to study gene flow or selection, we kind of expect that these processes are present). Note: plants often show higher levels of departure from HWE than animals.
Here are p-values for two alternative tests of deviation from HWE for each locus. Columns:
- chi^2: value of the classical chi-squared test statistic
- df: degrees of freedom of the chi-squared test
- Pr(chi^2 >): p-value of the chi-squared test (‘>’ indicates that the alternative is ‘greater’, which is always the case for a chi-squared test)
- Pr.exact: p-value from an exact test based on Monte Carlo permutation of alleles (for diploids only). The default is B = 1000 permutations (set B = 0 to skip this test). Here we use the function ‘round’ with argument ‘digits = 3’ to round all values to 3 decimals.
## chi^2 df Pr(chi^2 >) Pr.exact
## A 40.462 3 0.000 0.000
## B 17.135 6 0.009 0.036
## C 136.522 6 0.000 0.000
## D 83.338 6 0.000 0.000
## E 226.803 36 0.000 0.000
## F 0.024 3 0.999 1.000
## G 12.349 6 0.055 0.007
## H 76.813 28 0.000 0.000Both tests suggest that all loci except for locus “F” are out of HWE globally (across all 181 individuals). Next, we check for HWE of each locus in each population.
Notes on the code: The curly brackets ‘{ }’ below are used to keep the output from multiple lines together in the html file. Function ‘seppop’ splits the genind object by population. We use ‘sapply’ to apply the function ‘hw.test’ from package ‘pegas’ to each population (see this week’s video and tutorial). We set ‘B=0’ to specify that we don’t need any permutations right now. The function ‘t’ takes the transpose of the resulting matrix, which means it flips rows and columns. This works on a matrix, not a data frame, hence we use ‘data.matrix’ to temporarily interpret the data frame as a matrix.
# Chi-squared test: p-value
HWE.test <- data.frame(sapply(seppop(Frogs.genind),
function(ls) pegas::hw.test(ls, B=0)[,3]))
HWE.test.chisq <- t(data.matrix(HWE.test))
{cat("Chi-squared test (p-values):", "\n")
round(HWE.test.chisq,3)}## Chi-squared test (p-values):## A B C D E F G H
## Airplane 0.092 0.359 1.000 0.427 0.680 1.000 0.178 0.051
## Bachelor 1.000 0.557 0.576 0.686 0.716 1.000 0.414 0.609
## BarkingFox 0.890 0.136 0.005 0.533 0.739 0.890 0.708 0.157
## Bob 0.764 0.864 0.362 0.764 0.033 1.000 0.860 0.287
## Cache 1.000 0.325 0.046 0.659 0.753 1.000 0.709 0.402
## Egg 1.000 0.812 1.000 1.000 0.156 1.000 0.477 0.470
## Frog 1.000 0.719 0.070 0.722 0.587 1.000 0.564 0.172
## GentianL 0.809 0.059 1.000 0.028 0.560 0.717 0.474 0.108
## ParagonL 1.000 0.054 0.885 0.709 0.868 1.000 0.291 0.000
## Pothole 1.000 1.000 1.000 0.488 0.248 1.000 0.296 0.850
## ShipIsland 0.807 0.497 1.000 0.521 0.006 1.000 0.498 0.403
## Skyhigh 0.915 0.493 0.063 0.001 0.155 1.000 0.126 0.078Let’s repeat this with a Monte Carlo permutation test with B = 1000 replicates:
# Monte Carlo: p-value
HWE.test <- data.frame(sapply(seppop(Frogs.genind),
function(ls) pegas::hw.test(ls, B=1000)[,4]))
HWE.test.MC <- t(data.matrix(HWE.test))
{cat("MC permuation test (p-values):", "\n")
round(HWE.test.MC,3)}## MC permuation test (p-values):## A B C D E F G H
## Airplane 0.02 1.000 1.000 0.407 0.638 1 0.252 0.011
## Bachelor 1.00 0.467 1.000 1.000 0.854 1 0.470 0.614
## BarkingFox 1.00 0.223 0.085 1.000 0.731 1 1.000 0.182
## Bob 1.00 1.000 1.000 1.000 0.011 1 1.000 0.262
## Cache 1.00 0.409 0.132 1.000 1.000 1 1.000 0.632
## Egg 1.00 1.000 1.000 1.000 0.094 1 0.532 0.449
## Frog 1.00 1.000 0.085 1.000 0.435 1 1.000 0.172
## GentianL 1.00 0.055 1.000 0.057 0.665 1 0.661 0.155
## ParagonL 1.00 0.185 1.000 1.000 1.000 1 0.337 0.069
## Pothole 1.00 1.000 1.000 1.000 0.521 1 0.555 1.000
## ShipIsland 1.00 0.623 1.000 0.677 0.155 1 0.564 0.474
## Skyhigh 1.00 0.365 0.169 0.110 0.127 1 0.085 0.046To summarize, let’s calculate, for each locus, the proportion of populations where it was out of HWE. Here we’ll use the conservative cut-off of alpha = 0.05 for each test. There are various ways of modifying this, including a simple Bonferroni correction, where we divide alpha by the number of tests, which you can activate here by removing the ### i. front of the line.
We write the results into a data frame ‘Prop.loci.out.of.HWE’ and use ‘=’ to specify the name for each column.
alpha=0.05 # /96
Prop.loci.out.of.HWE <- data.frame(Chisq=apply(HWE.test.chisq<alpha, 2, mean),
MC=apply(HWE.test.MC<alpha, 2, mean))
Prop.loci.out.of.HWE # Type this line again to see results table## Chisq MC
## A 0.00000000 0.08333333
## B 0.00000000 0.00000000
## C 0.16666667 0.00000000
## D 0.16666667 0.00000000
## E 0.16666667 0.08333333
## F 0.00000000 0.00000000
## G 0.00000000 0.00000000
## H 0.08333333 0.16666667And similarly, for each population, the proportion of loci that were out of HWE:
Prop.pops.out.of.HWE <- data.frame(Chisq=apply(HWE.test.chisq<alpha, 1, mean),
MC=apply(HWE.test.MC<alpha, 1, mean))
Prop.pops.out.of.HWE ## Chisq MC
## Airplane 0.000 0.250
## Bachelor 0.000 0.000
## BarkingFox 0.125 0.000
## Bob 0.125 0.125
## Cache 0.125 0.000
## Egg 0.000 0.000
## Frog 0.000 0.000
## GentianL 0.125 0.000
## ParagonL 0.125 0.000
## Pothole 0.000 0.000
## ShipIsland 0.125 0.000
## Skyhigh 0.125 0.125The results suggest that:
- While most loci are out of HWE globally, this is largely explained by subdivision (variation in allele frequencies among local populations indicating limited gene flow).
- No locus is consistently out of HWE across populations (loci probably not affected by selection).
- No population is consistently out of HWE across loci (probably no recent major bottlenecks/ founder effects).
Let’s repeat this with ‘false discovery rate’ correction for the number of tests. Here we use the function ‘p.adjust’ with the argument ‘method=“fdr”’ to adjust the p-values from the previous tests. This returns a vector of length 96 (the number of p-values used), which we convert back into a matrix of 12 rows (pops) by 8 columns (loci). Then we procede as above.
Chisq.fdr <- matrix(p.adjust(HWE.test.chisq,method="fdr"),
nrow=nrow(HWE.test.chisq))
MC.fdr <- matrix(p.adjust(HWE.test.MC, method="fdr"),
nrow=nrow(HWE.test.MC))
Prop.pops.out.of.HWE <- data.frame(Chisq=apply(HWE.test.chisq<alpha, 1, mean),
MC=apply(HWE.test.MC<alpha, 1, mean),
Chisq.fdr=apply(Chisq.fdr<alpha, 1, mean),
MC.fdr=apply(MC.fdr<alpha, 1, mean))
Prop.pops.out.of.HWE ## Chisq MC Chisq.fdr MC.fdr
## Airplane 0.000 0.250 0.000 0
## Bachelor 0.000 0.000 0.000 0
## BarkingFox 0.125 0.000 0.000 0
## Bob 0.125 0.125 0.000 0
## Cache 0.125 0.000 0.000 0
## Egg 0.000 0.000 0.000 0
## Frog 0.000 0.000 0.000 0
## GentianL 0.125 0.000 0.000 0
## ParagonL 0.125 0.000 0.125 0
## Pothole 0.000 0.000 0.000 0
## ShipIsland 0.125 0.000 0.000 0
## Skyhigh 0.125 0.125 0.125 0After using false discovery rate correction for the 8 * 12 = 96 tests performed, very few combinations of locus and population were out of HWE based on the chi-squared test, and none with the MC test.
Note: exact results are likely to differ somewhat between runs due to the permutation tests.
d. Check for linkage disequilibrium (LD)
See also: https://grunwaldlab.github.io/Population_Genetics_in_R/Linkage_disequilibrium.html
For microsatellite markers, we typically don’t know where on the genome they are located. The closer together two markers are on a chromosome, the more likely they are inherited together, which means that they don’t really provide independent information. Testing for linkage disequilibrium assesses this, for each pair of loci, by checking whether alleles of two loci are statistically associated.
This step is especially important when developing a new set of markers. You may want to drop (the less informative) one marker of any pair of linked loci.
Here, we start with performing an overall test of linkage disequilibrium (the null hypothesis is that there is no linkage among the set of markers). Two indices are calculated and tested: an index of association (Ia; Brown et al. 1980) and a measure of correlation (rbarD; Agapow and Burt 2001), which is less biased (see URL above). The number of permutations is specified by ‘sample = 199’.
Overall, there is statistically significant association among the markers (p-value: prD = 0.005; also left figure). Recall that the power of a statistical test increases with sample size, and here we have n = 181, hence even a small effect may be statistically significant. Hence we look at effect size, i.e., the actual strength of the pairwise associations (right figure).
## Ia p.Ia rbarD p.rD
## 0.33744318 0.00500000 0.05366542 0.00500000## Ia rbarD
## A:B 0.0485 0.0492
## A:C -0.0314 -0.0335
## A:D 0.1886 0.1966
## A:E 0.0560 0.0569
## A:F -0.0272 -0.0452
## A:G 0.0931 0.0935
## A:H 0.0294 0.0304
## B:C -0.0329 -0.0375
## B:D 0.0903 0.0911
## B:E 0.0910 0.0910
## B:F -0.0013 -0.0025
## B:G 0.0451 0.0452
## B:H 0.0621 0.0623
## C:D -0.0859 -0.1049
## C:E 0.0247 0.0284
## C:F -0.0311 -0.0397
## C:G -0.0107 -0.0118
## C:H 0.0012 0.0015
## D:E 0.0455 0.0458
## D:F 0.0094 0.0199
## D:G 0.0069 0.0070
## D:H 0.0461 0.0462
## E:F 0.0013 0.0025
## E:G 0.0453 0.0454
## E:H 0.2153 0.2159
## F:G 0.0167 0.0299
## F:H 0.0296 0.0606
## G:H 0.0942 0.0953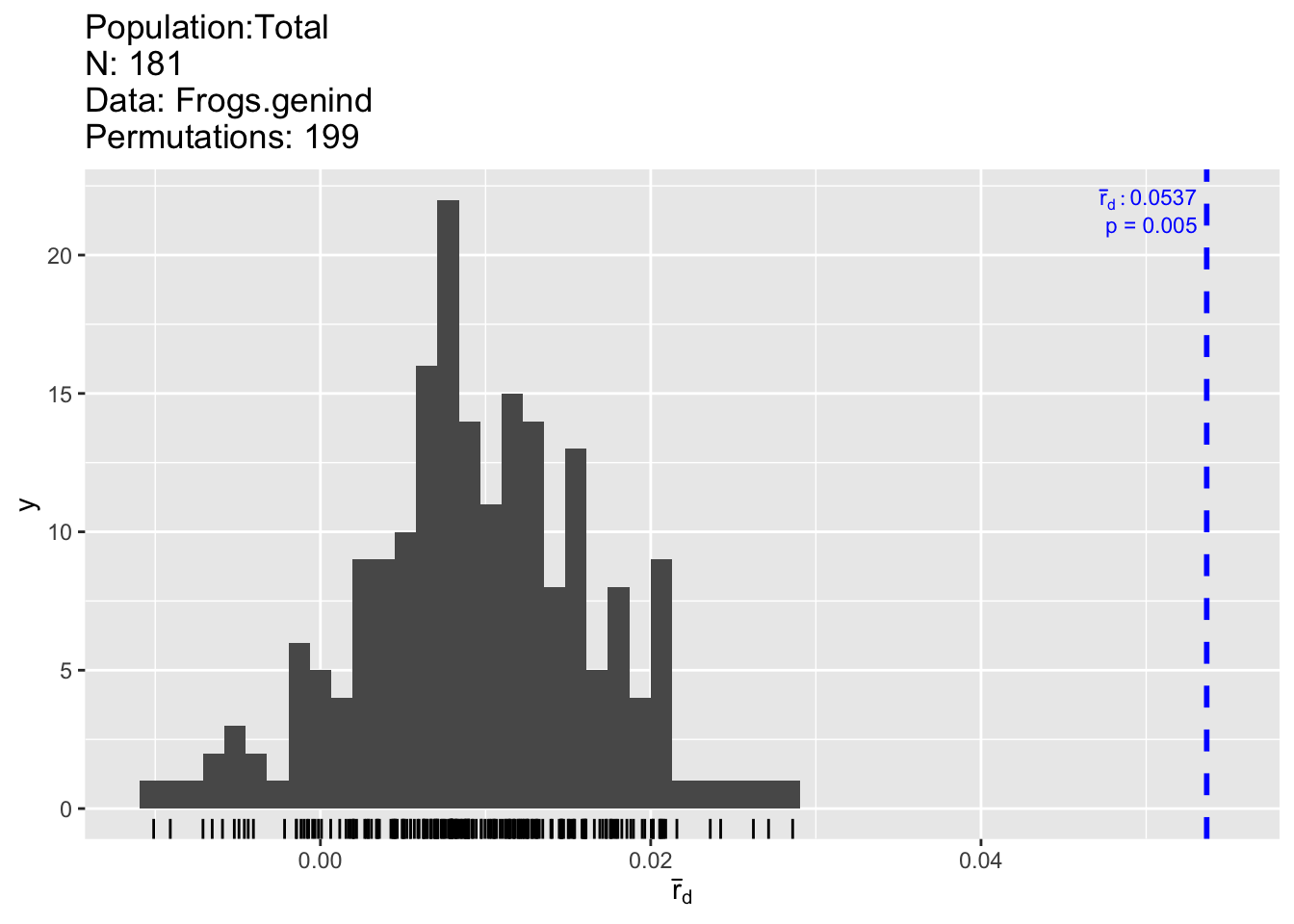
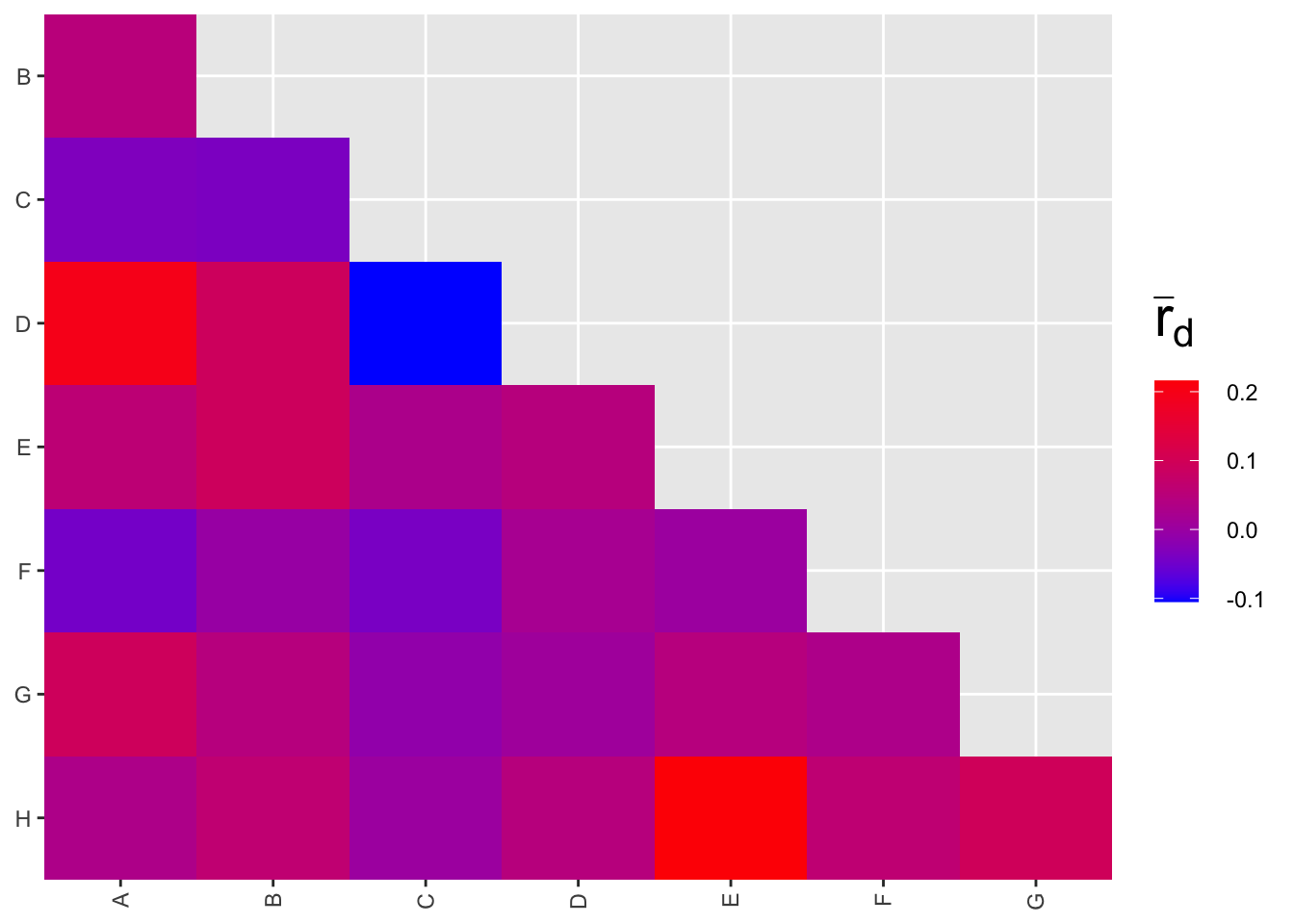
The strongest correlation is around 0.2, for markers E and H.
Effect size: If rbarD can be interpreted similarly to a linear correlation coefficient r, that would mean that less than 5% of the variation in one marker is shared with the other marker (recall from stats: the amount of variance explained in regression, Rsquared, is the square of the linear correlation coefficient). This is probably not large enough to worry about.
e. Check for null alleles
See also Dakin and Avise (2004): http://www.nature.com/articles/6800545
One potential drawback for microsatellites as molecular markers is the presence of null alleles that fail to amplify, thus they couldn’t be detected in the PCR assays.
The function ‘null.all’ takes a genind object and returns a list with two components (‘homozygotes’ and ‘null.allele.freq’), and each of these is again a list. See ‘?null.all’ for details and choice of method.
List ‘homozygotes’:
- homozygotes$observed: observed number of homozygotes for each allele at each locus
- homozygotes$bootstrap: distribution of the expected number of homozygotes
- homozygotes$probability.obs: probability of observing the number of homozygotes
Note: we are turning off warnings here (currently the code throws a warning for each sample, though results don’t seem to be affected).
# Null alleles: depends on method! See help file.
Null.alleles <- PopGenReport::null.all(Frogs.genind)## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2## Registered S3 method overwritten by 'genetics':
## method from
## [.haplotype pegas## Allele-1 Allele-2 Allele-3 Allele-4 Allele-5 Allele-6 Allele-7 Allele-8
## A 0.097 0.000 0.034 NA NA NA NA NA
## B 0.148 0.044 0.062 0.007 NA NA NA NA
## C 0.166 0.000 0.000 0.002 NA NA NA NA
## D 0.000 0.000 0.207 0.007 NA NA NA NA
## E 0.062 0.012 0.035 0.286 0.066 0.045 0.715 0.555
## F 0.436 0.002 0.013 NA NA NA NA NA
## G 0.077 0.082 0.019 0.004 NA NA NA NA
## H 0.448 0.101 0.019 0.023 0.256 0.334 0.008 0.000
## Allele-9
## A NA
## B NA
## C NA
## D NA
## E 0
## F NA
## G NA
## H NAList ‘null.allele.freq’:
- null.allele.freq$summary1: null allele frequency estimates based upon the forumulas of Chakraborty et al. (1994)
- null.allele.freq$summary2: null allele frequency estimates based upon the forumulas of Brookfield (1996)
From the help file: “Brookfield (1996) provides a brief discussion on which estimator should be used. In summary, it was recommended that Chakraborty et al. (1994)’s method (e.g. summary1) be used if there are individuals with no bands at a locus seen, but they are discounted as possible artefacts. If all individuals have one or more bands at a locus then Brookfield (1996)’s method (e.g. summary2) should be used.” In this case, we have many individuals with missing values for both alleles, hence better use summary1.
Each summary table contains a summary with observed, median, 2.5th percentile and 97.5the percentile. The percentiles form a 95% confidence interval. From the help file: “If the 95% confidence interval includes zero, it indicates that the frequency of null alleles at a locus does not significantly differ from zero.”
## summary1 (Chakraborty et al. 1994):## A B C D E F G H
## Observed frequency 0.24 0.08 0.23 0.25 0.06 0.00 0.11 0.04
## Median frequency 0.24 0.08 0.23 0.24 0.06 0.00 0.11 0.04
## 2.5th percentile 0.08 0.01 0.02 0.17 0.02 -0.01 0.01 0.00
## 97.5th percentile 0.42 0.15 0.48 0.33 0.10 0.00 0.22 0.09## summary2 (Brookfield et al. 1996):## A B C D E F G H
## Observed frequency 0.06 0.05 0.05 0.17 0.05 0 0.07 0.04
## Median frequency 0.06 0.05 0.05 0.17 0.05 0 0.07 0.04
## 2.5th percentile 0.02 0.01 0.01 0.12 0.01 0 0.01 0.00
## 97.5th percentile 0.11 0.09 0.11 0.22 0.09 0 0.13 0.08For this example, both methods suggest that there may be null alleles in most loci. However, the estimates of the frequency of null alleles differ a lot between the two methods.
A different approach for estimating null alleles at microsatellite loci, based on the Estimation-Maximization algorithm, is implemented in FreeNA (outside of the R environment). FreeNA will directly provide Fst values and some other measurements using the corrected allele frequencies: https://www1.montpellier.inra.fr/CBGP/software/FreeNA/
Relevant papers for the Estimation-Maximization algorithm:
- Kalinowski et al. (2006), Conservation Genetics 7:991–995, doi: 10.1007/s10592-006-9134-9.
- Chapuis and Estoup (2007), Mol. Biol. Evol. 24:621–631, doi: 10.1093/molbev/msl191.
f. Overall interpretation
- Spatial genetic structure: The Columbia spotted frog data used in this lab come from a study area with a great deal of genetic structure. If we use a population assignment test (see Week 9), each basin is a separate unit with significant substructure within basins. Testing for significant genetic distance, most pairs of ponds have a genetic distance that is significantly different from zero.
- HWE: Therefore, we expect global estimates (i.e., the whole dataset) of He to be out of HWE due to population substructure (HWE assumes panmictic populations). We would also expect data to be out of HWE when analyzing data by basin due to population substructure. We could, then, test HWE and linkage disequilibrium at the pond level (as shown here). However, some ponds have low sample sizes (which refleect a low number of individuals: based on repeated surveys of sites, most if not nearly all animals were captured).
- Linkage: These low samples sizes can result in deviations from HWE and in linkage disequilibrium as an artifact of sample size and/or breeding structure (if one male is responsible for all breeding, his genes would appear “linked” in offspring genotypes, even though they are not physically linked in the genome). In addition, each pond may not represent a “population”, but only a portion of a population.
So, what do we do? We can look for patterns. Are there loci that are consistently out of HWE across samples sites while other loci are not out of HWE suggesting that there are null alleles or other data quality control issues? With the full data set, this was not the case. Are there loci that are consistently linked across different ponds (while others are not), suggesting that they are linked? With the full dataset, this was not the case.
- Null alleles: Missing data can imply null (non-amplifying) alleles. In this case, while there are loci that have higher “drop-out” rates than others, this is more likely due to some loci being more difficult to call (the authors were very strict in removing any questionable data; equivocal calls resulting in no data). In addition, some of the samples used in this study were toe clips which with low yields of DNA, resulting in incomplete genotypes. While presence of null alleles is a possibility, genetic structure, breeding patterns at low population size and aggressive quality control of genotypes can all explain the results. Finally, with all of the structure in these data, there are examples (at the basin level and pond level) of unique alleles that are fixed or nearly fixed. When the data are assessed globally, this will result in a similar pattern to the presence of null alleles and will result in positive null allele tests.
3. Assess genetic diversity
These measures are typically quantified per population.
a. Rarefied allelic richness
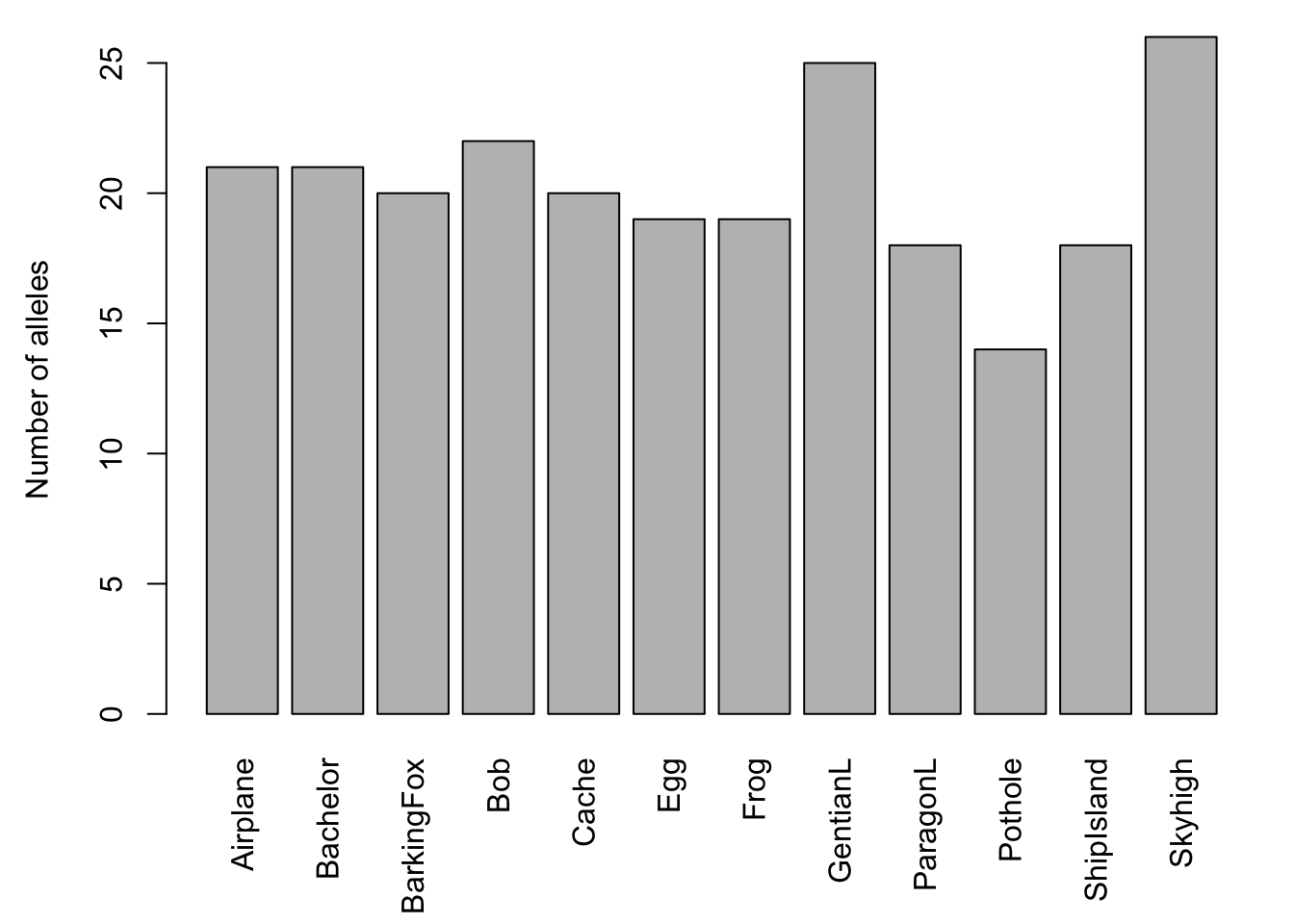
Both nominal sample size (number of frogs sampled) and valid sample size (e.g., for each locus, the number of frogs with non-missing genetic data) vary between sites. We would expect the number of alleles found in a population to increase with the number of individuals genotyped.
We can check this by plotting the number of alleles against sample size. Here we create an object ‘Sum’ that contains the summary of the genind object, then we can access its elements by ‘$’ to plot what we need. The function ‘names’ lists the names of the elements, which reduced the guesswork.
## [1] "n" "n.by.pop" "loc.n.all" "pop.n.all" "NA.perc" "Hobs"
## [7] "Hexp"The site names are quite long, hence we print the labels vertically by setting ‘las=3’, and we modify the margins (‘mar’). The four numbers give the size of each margin in the following order: bottom, left, top, right.
We add a regression line to the scatterplot with the function ‘abline’, where we specify the linear regression model with the function ‘lm’. In this case, we model the response ‘pop.n.all’ as a function of predictor ‘n.by.pop’.
The barchart (left) shows that there is considerable variation among ponds in the number of alleles observed across all loci. The scatterplot (right) with the red regression line shows that the number of alleles increases with sample size.
plot(Sum$n.by.pop, Sum$pop.n.all,
xlab = "Sample size", ylab = "Number of alleles")
abline(lm(Sum$pop.n.all ~ Sum$n.by.pop), col = "red")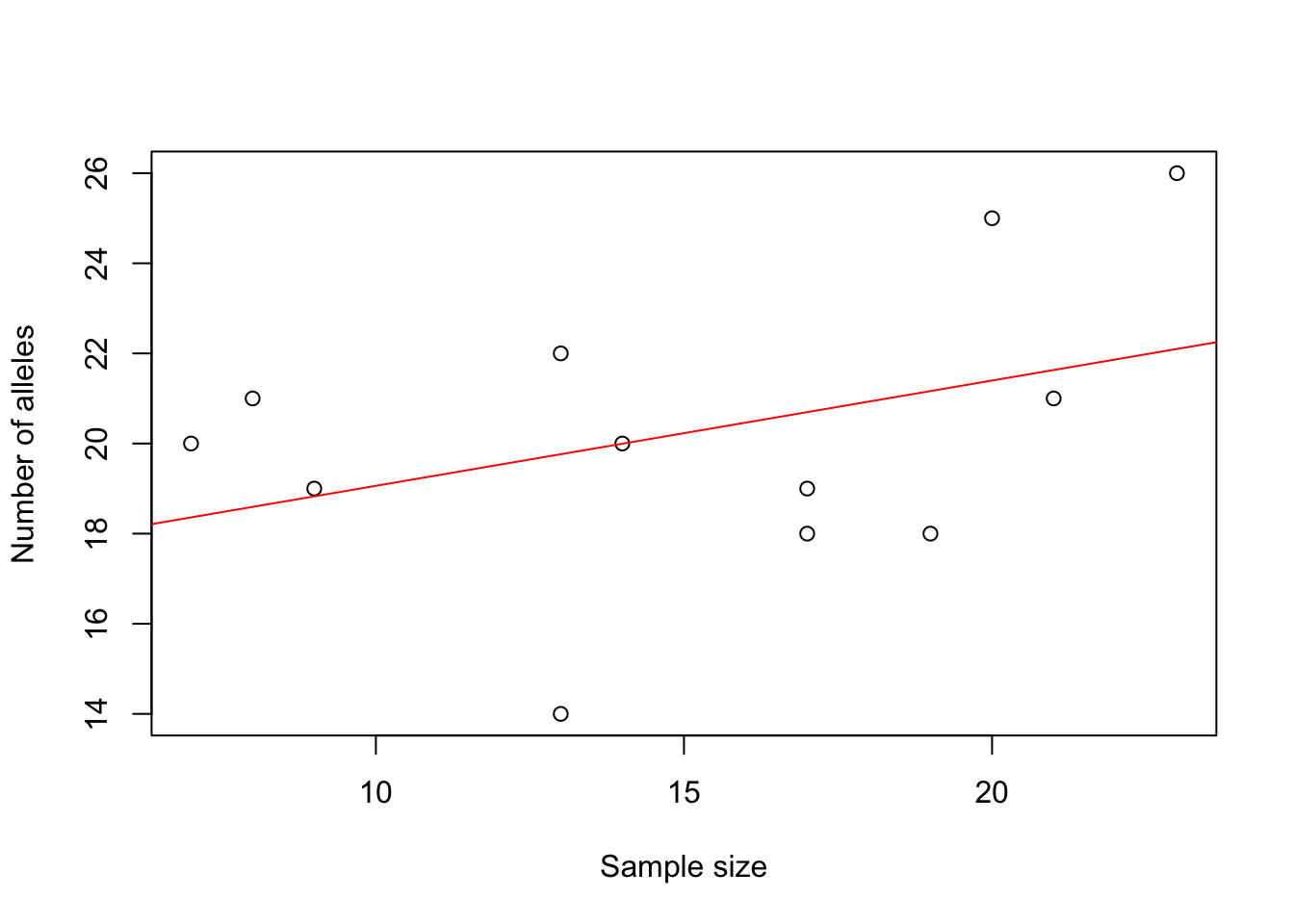
Hence we should not compare the number of alleles directly. Instead, we’ll use rarefied allelic richness (Ar).
By default, the function ‘allel.rich’ finds the lowest valid sample size across all populations and loci, and multiplies it by the ploidy level. The number is stored as ‘Richness$alleles.sampled’ (here: 3 individuals * 2 alleles = 6 alleles). Alternatively, this number can be set with the ‘min.alleles’ argument.
## [1] 6Populations with more alleles are resampled to determine the average allelic richness among the minimum number of alleles. Here, this means that 6 alleles are sampled from each population, allelic richness is calculated, and the process is repeated many times to determine the average).
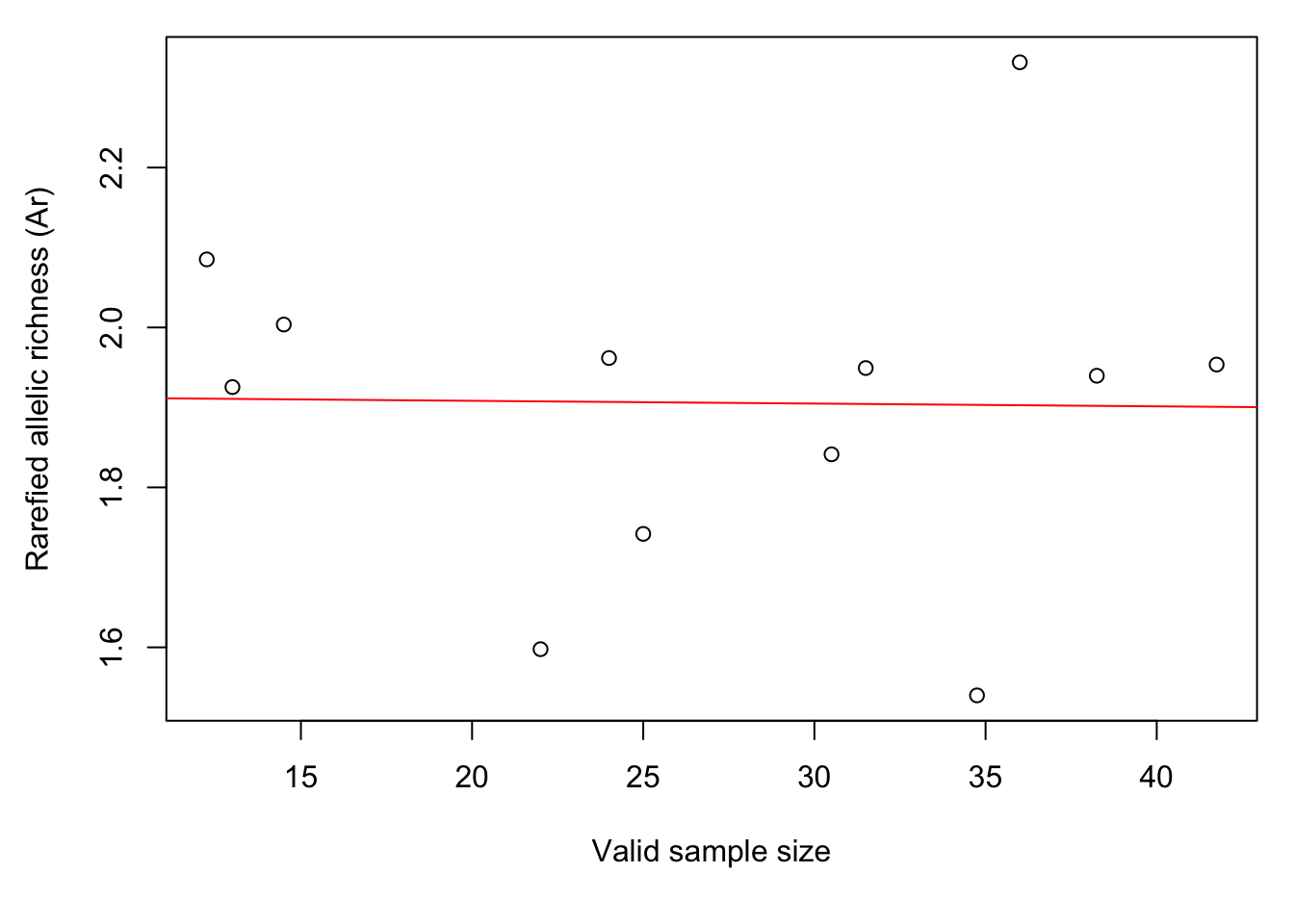
Let’s plot the results again. The barchart shows that there is considerable variation in genetic diversity among ponds. The scatterplot against sample size (here: for each population, the average number of valid alleles across loci) suggests that the variation is not related to sample size. The regression line (red) is almost horizontal.
Here we plot the average Ar across loci, so that the result does not depend on the number of loci used.
par(mar=c(5.5, 4.5,1,1))
barplot(Richness$mean.richness, las=3, ylab="Rarefied allelic richness (Ar)")
plot(colMeans(Richness$pop.sizes), Richness$mean.richness,
xlab="Valid sample size",
ylab="Rarefied allelic richness (Ar)")
abline(lm(Richness$mean.richness ~ colMeans(Richness$pop.sizes)), col="red")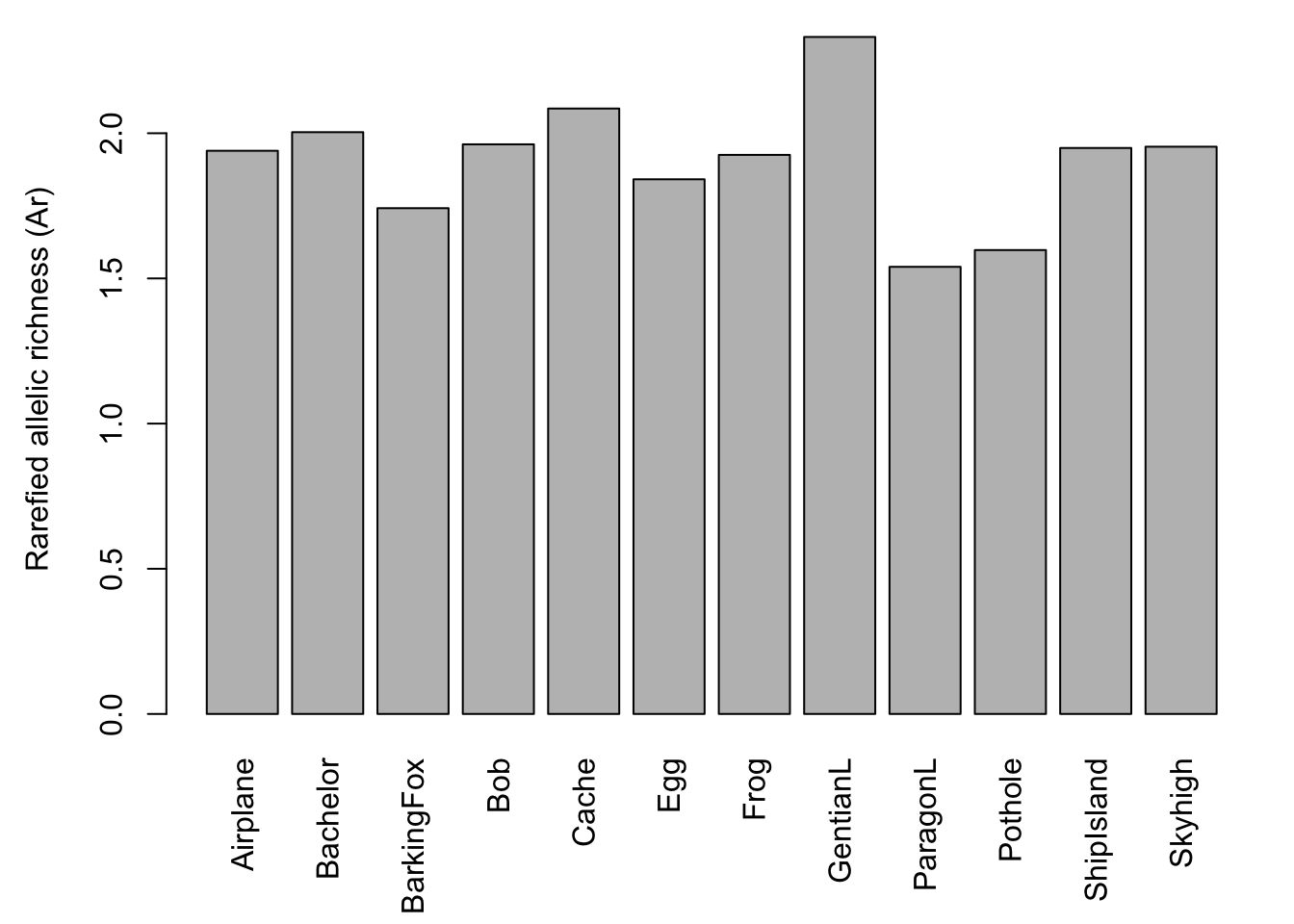
b. Observed and expected heterozygosity
Note: Writing the ‘genind’ summary into an object ‘Sum’ allows accessing its attributes by name.
## [1] "n" "n.by.pop" "loc.n.all" "pop.n.all" "NA.perc" "Hobs"
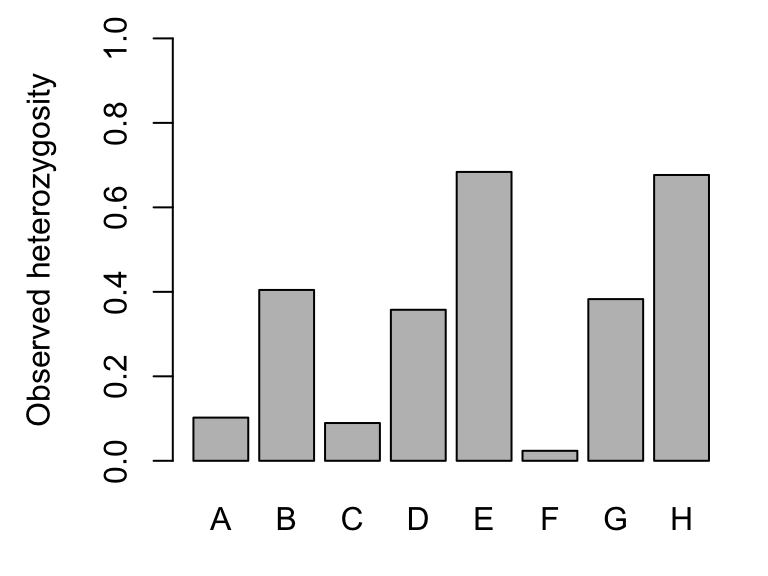
## [7] "Hexp"Expected heterozygosity (here: Hexp) is the heterozygosity expected in a population under HWE, and observed heterozygosity (here: Hobs) is the observed number of heterozygotes at a locus divided by the total number of genotyped individuals. Here are the global values (pooled across all populations):
par(mar=c(3, 4.5,1,1))
barplot(Sum$Hexp, ylim=c(0,1), ylab="Expected heterozygosity")
barplot(Sum$Hobs, ylim=c(0,1), ylab="Observed heterozygosity")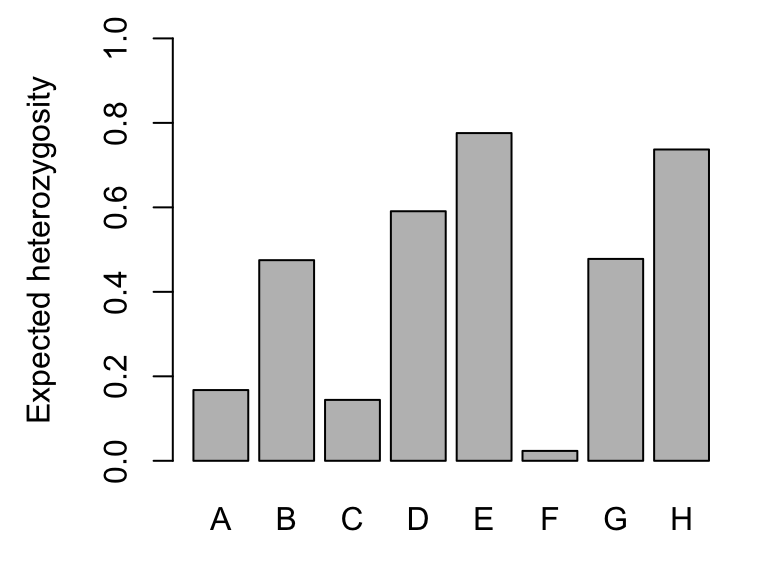
By locus and population:
Here we use ‘seppop’ to split the genind object by population, then ‘sapply’ to apply function ‘summary’ to each population.
Hobs <- t(sapply(seppop(Frogs.genind), function(ls) summary(ls)$Hobs))
Hexp <- t(sapply(seppop(Frogs.genind), function(ls) summary(ls)$Hexp))
{cat("Expected heterozygosity (Hexp):", "\n")
round(Hexp, 2)}## Expected heterozygosity (Hexp):## A B C D E F G H
## Airplane 0.49 0.28 0.00 0.36 0.67 0.00 0.23 0.72
## Bachelor 0.00 0.54 0.32 0.22 0.70 0.00 0.50 0.65
## BarkingFox 0.07 0.25 0.22 0.49 0.63 0.07 0.20 0.33
## Bob 0.14 0.33 0.33 0.14 0.79 0.00 0.10 0.70
## Cache 0.00 0.57 0.38 0.24 0.77 0.00 0.48 0.70
## Egg 0.00 0.39 0.00 0.00 0.79 0.00 0.46 0.72
## Frog 0.00 0.43 0.36 0.44 0.62 0.00 0.50 0.58
## GentianL 0.10 0.66 0.00 0.72 0.80 0.14 0.48 0.73
## ParagonL 0.00 0.19 0.07 0.15 0.29 0.00 0.50 0.57
## Pothole 0.00 0.00 0.00 0.28 0.38 0.00 0.58 0.63
## ShipIsland 0.44 0.49 0.00 0.51 0.60 0.00 0.44 0.66
## Skyhigh 0.04 0.49 0.20 0.34 0.63 0.00 0.52 0.62##
## Observed heterozygosity (Hobs):## A B C D E F G H
## Airplane 0.25 0.33 0.00 0.33 0.62 0.00 0.16 0.74
## Bachelor 0.00 0.38 0.40 0.25 0.88 0.00 0.33 0.75
## BarkingFox 0.07 0.14 0.00 0.57 0.79 0.07 0.22 0.23
## Bob 0.15 0.38 0.42 0.15 0.92 0.00 0.11 0.67
## Cache 0.00 0.83 0.00 0.29 1.00 0.00 0.40 0.86
## Egg 0.00 0.41 0.00 0.00 0.87 0.00 0.36 0.87
## Frog 0.00 0.38 0.14 0.56 0.86 0.00 0.33 1.00
## GentianL 0.11 0.95 0.00 0.74 0.90 0.15 0.56 0.84
## ParagonL 0.00 0.11 0.08 0.16 0.33 0.00 0.36 0.47
## Pothole 0.00 0.00 0.00 0.33 0.50 0.00 0.57 0.73
## ShipIsland 0.41 0.41 0.00 0.59 0.53 0.00 0.36 0.71
## Skyhigh 0.04 0.57 0.11 0.30 0.52 0.00 0.77 0.59Locus F shows variation only in two populations (i.e., Hexp = 0 in 10 populations).
Let’s plot the average across all loci for each population:
Here we use ‘apply’ to apply the function ‘mean’ to the rows (MARGIN = 1). For columns, use ‘MARGIN = 2’.
par(mar=c(5.5, 4.5, 1, 1))
Hobs.pop <- apply(Hobs, MARGIN = 1, FUN = mean)
Hexp.pop <- apply(Hexp, 1, mean)
barplot(Hexp.pop, ylim=c(0,1), las=3, ylab="Expected heterozygosity")
barplot(Hobs.pop, ylim=c(0,1), las=3, ylab="Observed heterozygosity")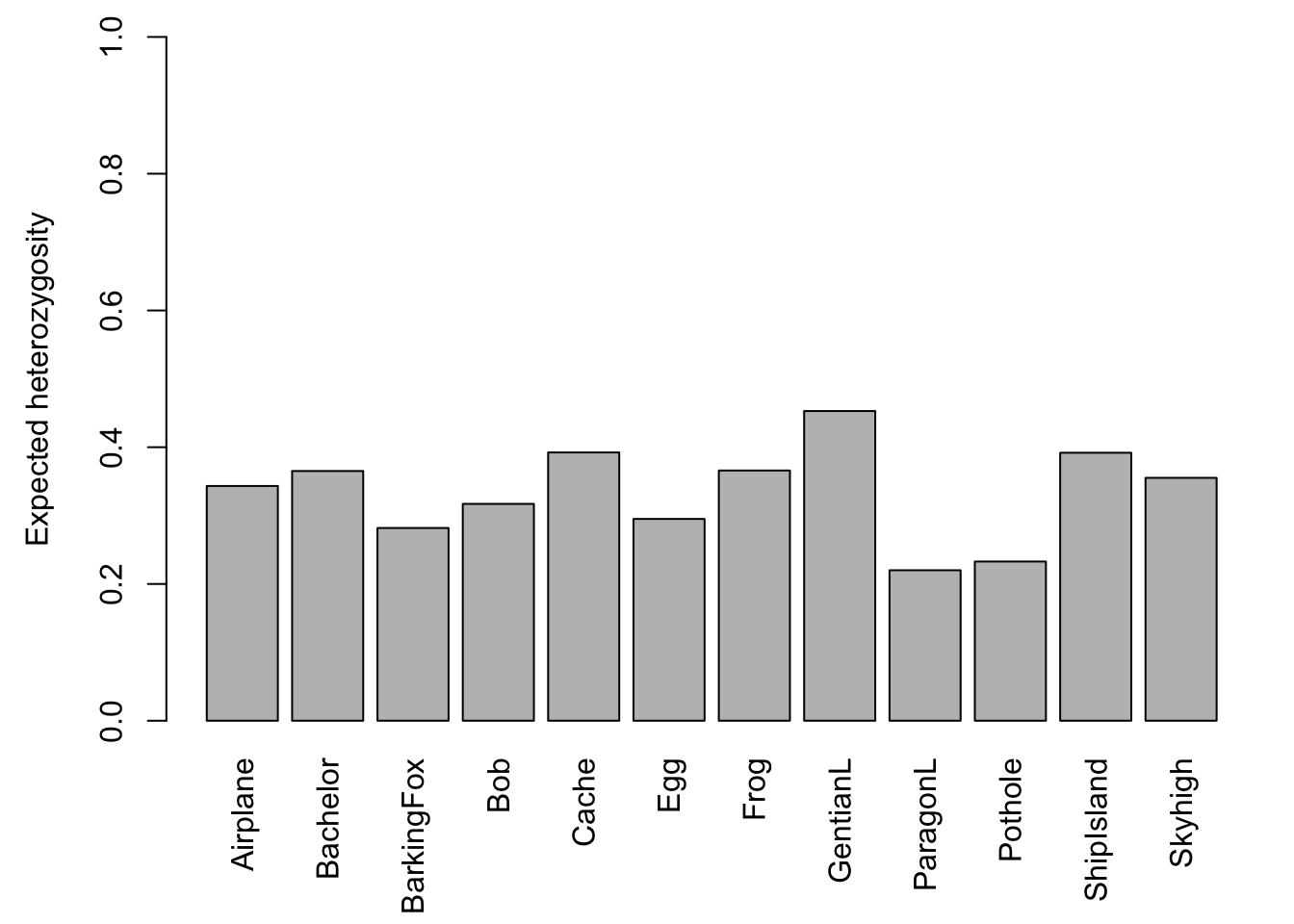
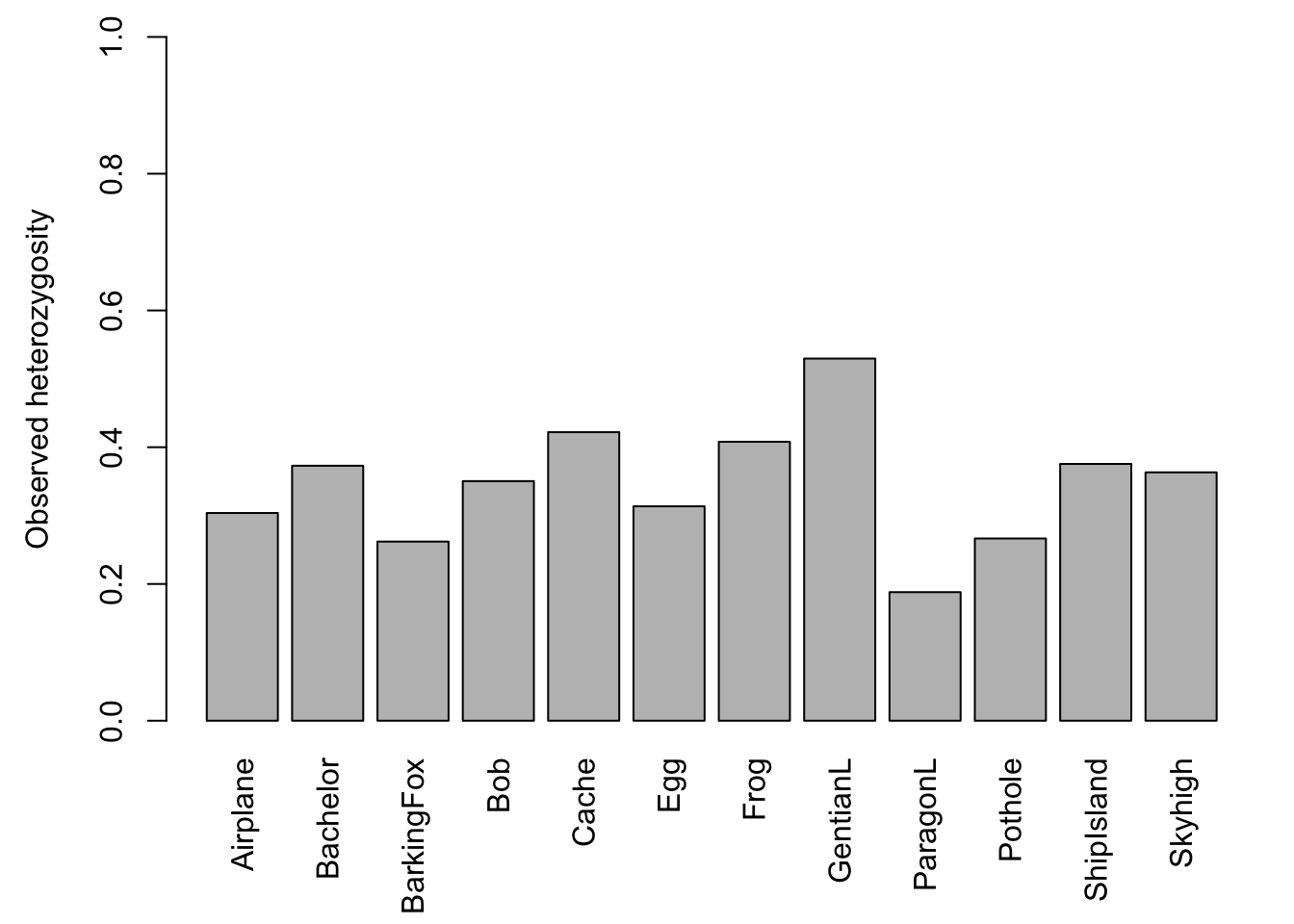
c. Create table with sitel-level genetic diversity measures
Frogs.diversity <- data.frame(Pop = names(Hobs.pop),
n = Sum$n.by.pop,
Hobs = Hobs.pop,
Hexp = Hexp.pop,
Ar = Richness$mean.richness)
Frogs.diversity## Pop n Hobs Hexp Ar
## Airplane Airplane 21 0.3038064 0.3433019 1.939629
## Bachelor Bachelor 8 0.3729167 0.3651953 2.003673
## BarkingFox BarkingFox 14 0.2619811 0.2818609 1.741904
## Bob Bob 13 0.3504274 0.3171011 1.961791
## Cache Cache 7 0.4220238 0.3923413 2.085115
## Egg Egg 17 0.3135918 0.2951215 1.841382
## Frog Frog 9 0.4079861 0.3659439 1.925469
## GentianL GentianL 20 0.5296418 0.4529000 2.331599
## ParagonL ParagonL 19 0.1880302 0.2200536 1.539923
## Pothole Pothole 13 0.2665043 0.2328137 1.597687
## ShipIsland ShipIsland 17 0.3755252 0.3918983 1.949255
## Skyhigh Skyhigh 23 0.3632542 0.3552167 1.953610You can save the R object ‘Frogs.diversity’ with the code below (need to uncomment by removing the hashtags ‘#’):
4. Aggregate genetic data at population level (allele frequencies)
For some analyses, we will need to aggregate data from the individual to the population level, e.g. as a table of allele frequencies per population.
Here we convert the ‘genind’ object to a ‘genpop’ object (NOT the same as a ‘genepop’ object!). This is defined in the package ‘adegenet’ to hold population-level genetic data. The function ‘genind2genpop’ obviously converts from ‘genind’ to ‘genpop’.
##
## Converting data from a genind to a genpop object...
##
## ...done.The function ‘makefreq’ extracts the table with allele frequencies from the ‘genpop’ object. We’ll plot just a few lines and alleles.
##
## Finding allelic frequencies from a genpop object...
##
## ...done.## A.1 A.2 A.3 B.1 B.3 B.2 B.4 C.1 C.2 C.4
## Airplane 0.62 0.35 0.03 0.83 0.17 0.00 0.00 1.00 0.00 0
## Bachelor 1.00 0.00 0.00 0.56 0.06 0.38 0.00 0.80 0.20 0
## BarkingFox 0.96 0.00 0.04 0.86 0.04 0.11 0.00 0.88 0.12 0
## Bob 0.92 0.00 0.08 0.81 0.00 0.12 0.08 0.79 0.21 0
## Cache 1.00 0.00 0.00 0.42 0.00 0.50 0.08 0.75 0.25 0
## Egg 1.00 0.00 0.00 0.74 0.00 0.26 0.00 1.00 0.00 0The allele frequencies of all alleles from the same locus (e.g., A.1, A.2 and A.3) should sum to 1 for each population. With eight loci, the row sums should thus add to 8.
## Airplane Bachelor BarkingFox Bob Cache Egg Frog
## 8 8 8 8 8 8 8
## GentianL ParagonL Pothole ShipIsland Skyhigh
## 8 8 8 8 8