Simulation in R: Below gives the design matrix and response outcome length 3.
Write code to compute .
solution: see below
What are the properties of the OLS Estimator , hint: also review theorems and when is OLS = MLE?
Interpret the coefficients based on your calculation.
solution:
Intercept (): When both and are 0, the expected value of is approximately .
Slope for (): For every one-unit increase in , is expected to increase by approximately , holding constant.
Slope for (): For every one-unit increase in , is expected to increase by approximately , holding constant.
Inference for Coefficients: Write out the covariance of and add code to calculate the covariance.
solution: where . is number of observations and is number of predictors including the intercept. See code below for result
Explain what the diagonal and off-diagonal elements of represent and how they relate to confidence intervals for the coefficients.
solution:
Each diagonal element corresponds to the variance of an individual coefficient estimate, e.g., . A smaller value indicates a more precise estimate of the coefficient. The off-diagonal elements capture the covariance between and . The standard error is used to compute confidence intervals for each coefficient. For a 95% confidence level, the interval is: where is the critical value from the -distribution with degrees of freedom.
# Example Databeta_true <-c(-0.5, 2, 1)N =100set.seed(1232)X <-cbind(1, rnorm(N, 0, 0.1), rnorm(N, 0, 0.1)) # Design matrix (with intercept)Y <- X %*% beta_true +rnorm(N, 0, sd =10) # Response vector# Compute beta-hatbeta_hat <-solve(t(X) %*% X) %*%t(X) %*% Y# Variance of beta-hat?# Calculate predicted valuesY_hat <- X %*% beta_hat# Residualsresiduals <- Y - Y_hat# Number of observations and predictorsn <-nrow(X)p <-ncol(X)# Estimate of sigma^2sigma2 <-sum(residuals^2) / (n - p)# Variance of beta hatvar_beta <- sigma2 *solve(t(X) %*% X)var_beta
solution: is an estimate of the true variance of the error term () in the underlying population, which captures the overall variability of the observed data . It is calculated as: But this estimated variance is biased because it does not account for the estimated coefficients in the calculation of . is an unbiased estimate of the population variance , adjusted for the loss of degrees of freedom due to estimating parameters. It is calculated as: where is the number of parameters (including the intercept) in the model. The adjustment by accounts for the degrees of freedom used to estimate the model parameters, making an unbiased estimator.
Interactions and Effect Modification
Interactions allow the effect of one predictor to depend on the value of another. The model:
Example:
set.seed(123)# Simulated databeta <-c(1,2,4,3)X1 =rnorm(N, 0, 10)X2 =rnorm(N, 0, 10)Y = beta[1] + beta[2] * X1 + beta[3] * X2 + beta[4] * X1* X2 +rnorm(N, 0, 1)# Fit a model with interactionmodel <-lm(Y ~ X1 * X2)summary(model)
Call:
lm(formula = Y ~ X1 * X2)
Residuals:
Min 1Q Median 3Q Max
-1.8719 -0.6777 -0.1086 0.5897 2.3166
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.140983 0.095777 11.91 <2e-16 ***
X1 1.990719 0.010834 183.75 <2e-16 ***
X2 4.003434 0.009881 405.15 <2e-16 ***
X1:X2 3.001591 0.001145 2621.64 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9468 on 96 degrees of freedom
Multiple R-squared: 1, Adjusted R-squared: 1
F-statistic: 2.406e+06 on 3 and 96 DF, p-value: < 2.2e-16
Interpretation: The coefficient for quantifies the interaction effect. If significant, it means the effect of on depends on .
Write the derivation for the prediction interval for a new observation.
solution Let be a new observation. The variance of is given by which is the sum of the plus the uncertainty due to measurement error . The 95% prediction interval is given by:
Write the code to calculate the 95% prediction interval using the results above.
X <-cbind(1, X1, X2, X1 * X2)# Fit the linear modelbeta_hat <-solve(t(X) %*% X) %*%t(X) %*% Y # Coefficients SHOULD BE THE SAME IN MODEL FIT.Y_hat <- X %*% beta_hat # Predicted valuesinvXtX =solve(t(X) %*% X)# Residual variance (s^2)n <-nrow(X)p <-ncol(X)residuals <- Y - Y_hatsigmahat <-sum(residuals^2) / (n - p) #use the unbiased estimate of sigma^2V= sigmahat * invXtX # Create New observationX_new <-c(1, 0.5, -0.2, 0.5*-0.2) # Example new observation#variance of the predicted value for new obsvar_pred =diag(X%*% V %*%t(X)) + sigmahatse_pred <-sqrt(var_pred)# Predicted value for the new observationY_tilde <-sum(X_new * beta_hat)# Prediction intervalt_value <-1.96# Approximate critical value for 95% confidence levellower_bound <- Y_tilde - t_value * se_predupper_bound <- Y_tilde + t_value * se_pred# Output resultslist(Predicted_Value = Y_tilde,Lower_Bound = lower_bound,Upper_Bound = upper_bound)
A variable is a confounder if it influences both the predictor and the outcome, potentially biasing the estimated relationship.
Example:
# Example datasetdata <-data.frame(smoking =c(0, 1, 0, 1),age =c(20, 30, 40, 50),disease =c(0, 1, 1, 1))# Fit a model without adjusting for agemodel1 <-glm(disease ~ smoking, family = binomial, data = data)# Fit a model adjusting for agemodel2 <-glm(disease ~ smoking + age, family = binomial, data = data)
Warning: glm.fit: fitted probabilities numerically 0 or 1 occurred
summary(model1)
Call:
glm(formula = disease ~ smoking, family = binomial, data = data)
Deviance Residuals:
1 2 3 4
-1.17741 0.00008 1.17741 0.00008
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.238e-16 1.414e+00 0.000 1.000
smoking 1.957e+01 7.604e+03 0.003 0.998
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 4.4987 on 3 degrees of freedom
Residual deviance: 2.7726 on 2 degrees of freedom
AIC: 6.7726
Number of Fisher Scoring iterations: 18
summary(model2)
Call:
glm(formula = disease ~ smoking + age, family = binomial, data = data)
Deviance Residuals:
1 2 3 4
-1.197e-05 1.197e-05 1.197e-05 2.110e-08
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -70.078 160246.558 0 1
smoking 23.359 87770.712 0 1
age 2.336 5067.441 0 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 4.4987e+00 on 3 degrees of freedom
Residual deviance: 4.2978e-10 on 1 degrees of freedom
AIC: 6
Number of Fisher Scoring iterations: 23
Compare the coefficient for smoking in both models to see how controlling for age effects the relationship. Interpret the findings for this coefficient in both settings.
solution: In the first model, the coefficient represents the effect of smoking on the odds of disease, without considering age. The confounding effect of age can potentially bias the results in model 1. The results show there is a 19.57 unit increase in the log-odds of disease for smokers compared to non-smokers. In the second model, the coefficient for smoking reflects the relationship between smoking and disease, accounting for age as a confounder. The results show there again is a 23.36 unit increase in log-odds of disease comparing smokers to non-smokers after accounting for age. The results between models 1 and 2 are show an increase in the effect of smoking after accounting for age. If results are similar with respect to the smoking effect this indicates age does not confound the relationship between smoking and disease. But here we see a change.
Compare the models to find the optimal model using a F-test statistic.
solution: The Analysis of Deviance Table compares two models: the unadjusted model (Model 1), which includes only smoking as a predictor, and the adjusted model (Model 2), which includes both smoking and age. The residual deviance for Model 1 is 2.7726 with 2 degrees of freedom, while the residual deviance for Model 2 is reduced to 0.0000 with 1 degree of freedom. The difference in deviance is 2.7726, with a corresponding p-value of 0.09589. This result indicates that adding age to the model explains additional variability in the outcome (disease), reducing the deviance. However, the p-value of 0.09589 is not significant, suggesting trivial improvement in model fit.
In conclusion, while age appears to contribute to the model, its effect is not strong enough to confidently reject the null hypothesis that it has no additional impact on the outcome beyond smoking. Depending on the context, further investigation or a larger sample size may be warranted to clarify its role.
# Perform F-test to compare modelsanova_result <-anova(model1, model2, test ="Chisq")# Display the resultanova_result
Analysis of Deviance Table
Model 1: disease ~ smoking
Model 2: disease ~ smoking + age
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 2 2.7726
2 1 0.0000 1 2.7726 0.09589 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Module 2 Linear Mixed Models
Linear mixed models (LMMs) are designed to handle correlated data. This arises when: -
Multiple measurements are taken on the same individuals (e.g., repeated measures).
Data are grouped into clusters (e.g., students nested within schools).
The general structure of a mixed model is: Where:
: Response for individual in group .
: Fixed effects (global trends or population-level effects).
: Random effect for group , .
: Residual error, .
Fixed vs. Random Effects
Fixed Effects:
Parameters of interest (e.g., , ).
Represent the population-level effects.
Random Effects:
Account for variability between clusters or groups.
Allow for partial pooling of information across groups.
Example: In a study of students’ test scores:
Fixed effect: Average effect of study hours on scores.
Random effect: Variation in scores across schools.
Variance Components
Mixed models decompose variability into:
1. Between-cluster variability (): How much clusters differ.
2. Within-cluster variability (): How much individuals within a cluster differ.
Example Dataset: Sleep study with repeated measures of reaction times for individuals under sleep deprivation. 1. Fit a linear mixed model regressing on and a random intercept for
# Load the lme4 packagelibrary(lme4)
Loading required package: Matrix
# Example: Sleep study datasetdata("sleepstudy", package ="lme4")# Fit a mixed-effects model# Reaction time ~ Days of sleep deprivation + (Random intercept for Subject)model <-lmer(Reaction ~ Days + (1| Subject), data = sleepstudy)summary(model)
Linear mixed model fit by REML ['lmerMod']
Formula: Reaction ~ Days + (1 | Subject)
Data: sleepstudy
REML criterion at convergence: 1786.5
Scaled residuals:
Min 1Q Median 3Q Max
-3.2257 -0.5529 0.0109 0.5188 4.2506
Random effects:
Groups Name Variance Std.Dev.
Subject (Intercept) 1378.2 37.12
Residual 960.5 30.99
Number of obs: 180, groups: Subject, 18
Fixed effects:
Estimate Std. Error t value
(Intercept) 251.4051 9.7467 25.79
Days 10.4673 0.8042 13.02
Correlation of Fixed Effects:
(Intr)
Days -0.371
Write out the interpretation of the fixed effects in this model.
solution: represents the predicted reaction time when Days = 0 (baseline reaction time without sleep deprivation). represents the average change in reaction time per additional day of sleep deprivation. A positive indicates that reaction time increases (worsens) with more days of sleep deprivation.
What is the estimates for the between-subject variability and the within-subject variability?
solution: The between subject variance is given by:
The within subject variance is given by:
Calculate and interpret the Intraclass Correlation.
solution: : The intraclass correlation coefficient (ICC) measures the proportion of total variability in the outcome (reaction time) that is attributable to between-subject variability. It is calculated as:
Substituting the values:
The ICC is approximately 0.59, meaning that about 59% of the total variability in reaction time is attributable to differences between subjects, while the remaining 41% is due to variability within subjects.
Extend this model to include both random intercepts AND slopes. Write out the model, fit the model with the code below, and interpret.
solution:
The extended model includes both random intercepts and random slopes. This allows each subject to have: 1. A unique baseline reaction time (random intercept). 2. A unique effect of Days on reaction time (random slope).
The model can be written as:
Where: - : Fixed intercept (average reaction time when Days = 0 across all subjects). - : Fixed slope (average effect of Days across all subjects). - : Random intercept for subject , accounting for individual baseline differences. - : Random slope for subject , accounting for individual differences in the effect of Days. - : Residual error for observation in subject .
# Random slope and intercept modelmodel2 <-lmer(Reaction ~ Days + (Days | Subject), data = sleepstudy)summary(model2)
Linear mixed model fit by REML ['lmerMod']
Formula: Reaction ~ Days + (Days | Subject)
Data: sleepstudy
REML criterion at convergence: 1743.6
Scaled residuals:
Min 1Q Median 3Q Max
-3.9536 -0.4634 0.0231 0.4634 5.1793
Random effects:
Groups Name Variance Std.Dev. Corr
Subject (Intercept) 612.10 24.741
Days 35.07 5.922 0.07
Residual 654.94 25.592
Number of obs: 180, groups: Subject, 18
Fixed effects:
Estimate Std. Error t value
(Intercept) 251.405 6.825 36.838
Days 10.467 1.546 6.771
Correlation of Fixed Effects:
(Intr)
Days -0.138
Comparing both models, the estimated fixed effects do not change. However, there is a large decrease in the between subject variability from 1378 to 612.10 due to the inclusion of random slopes. The between subject variability in slopes is 35.07. This shows the effect of sleep depriovation on reaction time varies between subjects, but the variability in slopes is smaller than the variability in random intercepts. The correlation between random intercepts and slopes is 0.07, indicating a weak positive relationship between baseline reaction times and the effect of sleep deprivation.
Is the random intercept or random intercept and slope model preferred? To compare models, we use the . Calculate the AICS and determine which model is better.
solution: Comparing AIC values between models, there is very slight change, however, there is a smaller AIC associated with model 2, indicating that model 2 results in a slightly better fit compared to model 1.
AIC(model, model2)
df AIC
model 4 1794.465
model2 6 1755.628
Module 3 Generalized Linear Models
GLMs extend linear regression to handle response variables that are not normally distributed.
A GLM consists of three components:
A probability distribution in the Exponential Family (e.g., Binomial, Poisson).
Systematic Component: A linear model , where is the design matrix and are the coefficients.
Link Function: Transforms the expected value of the response variable to the scale of the linear predictor, .
The probability distribution must be in the Exponential Family.
Write out the general form of the Exp Family and show that the Poisson distribution fits this form.
solution: The general form of a distribution in the exponential family is written as:
Where: - : Observed data (response variable). - : Canonical (natural) parameter. - : Dispersion parameter (often fixed to 1 for distributions like Poisson). - : A function of the dispersion parameter. - : A function that normalizes the distribution (ensures a proper probability distribution). - : A function involving the observed data and dispersion parameter.
The probability mass function (PMF) of the Poisson distribution is:
Start with the PMF:
Rewrite in terms of the natural parameter . For the Poisson distribution:
, so .
Substitute into the PMF:
Rearrange terms to match the exponential family form:
Identify the components of the exponential family:
: Canonical (natural) parameter, .
: Normalizing function, .
: Dispersion function, (fixed for Poisson).
: Function of , .
Thus, the Poisson distribution can be written in the general form of the exponential family as:
Where: and
Common GLMs:
Logistic Regression:
Used for binary data.
Link function: (logit link).
Response variable .
Probit Regression:
Also for binary data.
Link function: , where is the standard normal cumulative distribution function.
Poisson Regression:
Used for count data.
Link function: .
Response variable .
Consider a study on whether students pass an exam ( if pass, otherwise). The model is:
Write the logistic regression model where outcomes regress on the number of hours spent studying .
solution:
where .
Write out the expectation.
solution: The expectation is written as:
4. Interpret the coefficient in the context of the study.
solution:: The slope, representing the change in the log-odds of passing for each additional hour of studying.
If , compute the odds of passing for a student who studies 4 hours compared to one who studies 2 hours.
solution:
The odds ratio (OR) quantifies the change in odds for a one-unit increase in the predictor. For two students with and , the odds ratio is:
The odds of passing are calculated as:
However, the intercept () cancels when comparing odds for the same model. Thus, the odds ratio simplifies to:
Substituting Values , ,
The odds of passing for a student who studies 4 hours are approximately 2.718 times the odds of passing for a student who studies 2 hours.
Calculate the 95% CIs for the OR. (Assume )
solution:
The odds ratio (OR) is calculated from the coefficient of the logistic regression model. The 95% confidence interval (CI) for the OR is derived as:
Where: (log-odds per unit increase in hours), : The standard error of , : The critical value for a 95% confidence level (from the standard normal distribution).
Lower Bound:
Upper Bound:
The 95% confidence interval for the odds ratio is approximately:
Load the mtcars dataset in R and fit a logistic regression model to predict whether a car has an automatic transmission (am) using mpg and hp as predictors.
Write the R code to fit the model using the glm() function.
solution
data(mtcars)# Fit the logistic regression modelmodel <-glm(am ~ mpg + hp, data = mtcars, family = binomial)# Display the summary of the modelsummary(model)
Call:
glm(formula = am ~ mpg + hp, family = binomial, data = mtcars)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.41460 -0.42809 -0.07021 0.16041 1.66500
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -33.60517 15.07672 -2.229 0.0258 *
mpg 1.25961 0.56747 2.220 0.0264 *
hp 0.05504 0.02692 2.045 0.0409 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 43.230 on 31 degrees of freedom
Residual deviance: 19.233 on 29 degrees of freedom
AIC: 25.233
Number of Fisher Scoring iterations: 7
Interpret the coefficients of mpg and hp in the output.
solution: 1. mpg (1.25961): - For each one-unit increase in mpg, the log-odds of having an automatic transmission increase by 1.25961, holding hp constant. - In terms of odds, the odds of having an automatic transmission multiply by for every additional mile per gallon. 2. hp (0.05504): - For each one-unit increase in hp, the log-odds of having an automatic transmission increase by 0.05504, holding mpg constant. - In terms of odds, the odds of having an automatic transmission multiply by for every additional unit of horsepower.
Use the model to predict the probability of an automatic transmission for a car with mpg = 25 and hp = 100.
solution: Predicting log-odds for a car with mpg = 25 and hp = 100 are calculated as:
Compute the log-odds:
Convert log-odds to probability:
The predicted probability of the car having an automatic transmission is approximately 96.7% for a car with mpg = 25 and hp = 100.
Poisson Regression with Random Intercept
A hospital administrator is analyzing the number of patients admitted to different wards each day. The number of daily admissions is modeled as a Poisson-distributed outcome. The wards are suspected to have differing baseline admission rates, so a random intercept is included in the model.
The model for daily admissions in ward on day is given by:
is the random intercept for ward .
is a binary indicator (0 = weekday, 1 = weekend).
is the overall fixed intercept.
is the fixed effect of the day type.
Identify the fixed and random components of this model.
solution:
Fixed effects:
: The fixed intercept represents the log of the baseline admission rate on weekdays across all wards.
: The fixed effect of represents the change in the log of the admission rate when moving from a weekday () to a weekend (). This captures the overall effect of day type across all wards.
Random Effects:
: The random intercept for ward accounts for differences in baseline admission rates between wards. Each ward has its own unique offset from the overall baseline admission rate (), modeled as a random draw from a normal distribution with mean 0 and variance .
Write the expected value of in terms of .
solution:
For the Poisson distribution, the expected value of the outcome is equal to its mean, . Therefore:
The relationship between and the predictors is defined by the model:
Exponentiating both sides to express :
Substituting this into the expectation:
Interpret the meaning of in this model.
solution: represents the fixed effect of day type on the log of the expected number of daily admissions.
What does tell you about the variability across wards?
solution: quantifies how much the baseline log admission rates vary between wards.
Write R code to simulate data from this model. Assume the estimated coefficients are , , and
solution:
set.seed(123)# Parametersbeta_0 <-2.5# Fixed interceptbeta_1 <--0.3# Fixed effect of DayTypesigma_u <-sqrt(0.2) # Standard deviation of random interceptsn_wards <-15# Number of wardsn_days <-30# Number of days per ward# Simulate random intercepts for wardsrandom_intercepts <-rnorm(n_wards, mean =0, sd = sigma_u)# Create data framedata <-expand.grid(Ward =1:n_wards, Day =1:n_days)data$DayType <-sample(0:1, size =nrow(data), replace =TRUE) # Randomly assign weekdays/weekendsdata$u_i <- random_intercepts[data$Ward] # Assign random intercepts to wards# Calculate the log mean (linear predictor)data$log_mu <- beta_0 + beta_1 * data$DayType + data$u_i# Calculate the mean (expected number of admissions)data$mu <-exp(data$log_mu)# Simulate Poisson outcomesdata$y <-rpois(nrow(data), lambda = data$mu)# View a sample of the simulated datahead(data)
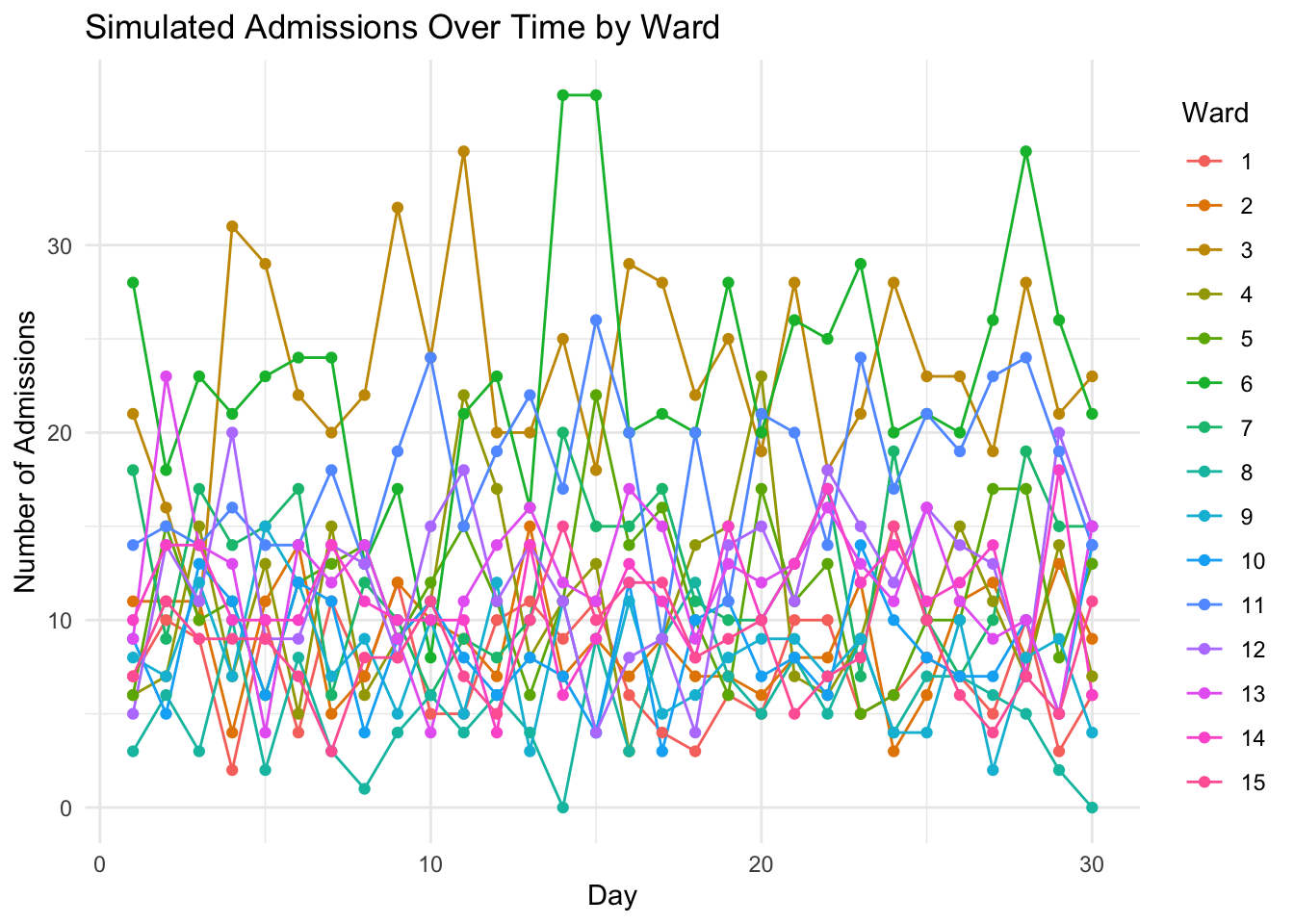
library(ggplot2)# Plot: Admissions over Days for Each Wardggplot(data, aes(x = Day, y = y, color =factor(Ward))) +geom_line() +geom_point() +labs(title ="Simulated Admissions Over Time by Ward",x ="Day",y ="Number of Admissions",color ="Ward" ) +theme_minimal() +theme(legend.position ="right")
Predict the expected number of admissions for: A weekday () in Ward A, where .
solution:
The expected number of admissions is:
Substituting the values:
Compute by exponentiating:
The expected number of admissions for a weekday () in Ward A, where , is approximately 13.46 admissions.
Module 4: Generalized Estimating Equations (GEEs)
GEEs are an extension of GLMs used for correlated or clustered data, such as repeated measures.
Unlike random-effects models, GEEs estimate population-averaged (marginal) effects rather than subject-specific effects.
Key features include:
Estimating Equation: An iterative method for parameter estimation.
Correlation Structures: Specify the within-cluster correlation (e.g., exchangeable, autoregressive, unstructured).
Robust Standard Errors: Account for misspecification of the correlation structure.
Correlation Structures
Exchangeable: Equal correlation among all observations within a cluster.
Autoregressive (AR1): Correlation decreases with increasing time separation.
Unstructured: No specific structure; each correlation is estimated.
The respiratory dataset includes longitudinal data from a respiratory study. The main variables are: - outcome: Binary outcome indicating the presence or absence of infection. - age: Age of the subject. - visit: Time of the visit. - treatment: Treatment group (placebo or drug).
Load the dataset and fit a GEE with an exchangeable correlation structure:
library(geepack)library(gee)set.seed(1232)# Load the respiratory datasetdata("respiratory", package ="geepack")# Fit the GEEfit_gee <-gee(outcome ~ age + visit + treat, data = respiratory, id = id, corstr ="exchangeable", family = binomial)
(Intercept) age visit treatP
1.31881870 -0.01217949 -0.06244781 -0.98377461
# Summary of the modelsummary(fit_gee)
GEE: GENERALIZED LINEAR MODELS FOR DEPENDENT DATA
gee S-function, version 4.13 modified 98/01/27 (1998)
Model:
Link: Logit
Variance to Mean Relation: Binomial
Correlation Structure: Exchangeable
Call:
gee(formula = outcome ~ age + visit + treat, id = id, data = respiratory,
family = binomial, corstr = "exchangeable")
Summary of Residuals:
Min 1Q Median 3Q Max
-0.7445718 -0.4523645 0.2814629 0.3964276 0.6710428
Coefficients:
Estimate Naive S.E. Naive z Robust S.E. Robust z
(Intercept) 1.31321054 0.47893788 2.7419225 0.47503342 2.7644593
age -0.01205922 0.01143541 -1.0545504 0.01160090 -1.0395071
visit -0.06245418 0.06350982 -0.9833784 0.06561084 -0.9518882
treatP -0.98039084 0.31316711 -3.1305677 0.31275820 -3.1346607
Estimated Scale Parameter: 1.010102
Number of Iterations: 2
Working Correlation
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
[1,] 1.0000000 0.4890786 0 0 0 0 0 0
[2,] 0.4890786 0.4890786 0 0 0 0 0 0
[3,] 0.4890786 1.0000000 0 0 0 0 0 0
[4,] 0.4890786 0.4890786 0 0 0 0 0 0
[5,] 0.4890786 0.4890786 0 0 0 0 0 0
[6,] 1.0000000 0.4890786 0 0 0 0 0 0
[7,] 0.4890786 0.4890786 0 0 0 0 0 0
[8,] 0.4890786 1.0000000 0 0 0 0 0 0
Interpret the coefficients for age and smoking.
solution: Coefficient for age () which represents the change in the log-odds of the outcome for a one-unit increase in age.The odds ratio is given by , which quantifies how the odds of the outcome change with age. , older individuals have lower odds of the outcome.
The coefficient for treat () represents the change in the log-odds of the outcome for individuals receiving treatment compared to those not receiving treatment. The odds ratio is , which quantifies the effect of treatment on the odds of the outcome.
Compare the robust and model-based standard errors in the output. What do they indicate about model assumptions?
solution:
Since the naive and robust standard errors are very similar, it suggests that the assumed correlation structure (exchangeable) aligns well with the actual data structure. There is little evidence of misspecification in the correlation structure.
Choice of S.E.: The robust standard errors are generally preferred as they are consistent even if the correlation structure is misspecified. In this case, the similarity between the two types of standard errors implies that either can be used with confidence.
Explain how misspecifying the correlation structure affects the model’s results.
solution: If the correlation structure is misspecified, model-based standard errors (which assume the correct correlation structure) will likely be biased. This leads to over- or underestimation of the variability of the coefficient estimates. Robust (sandwich) standard errors, which are less sensitive to misspecification of the correlation structure, may still provide reliable estimates, even when the assumed correlation structure is incorrect.
Consider a study on school performance, where test scores are modeled as a function of teacher experience and classroom size, clustered by school.
Write the general form of a GEE for this scenario, using for test scores, for teacher experience, and for classroom size.
solution:
Here is an example GEE formula. You may have chosen a different model which can be fine as long as you justify it:
Where: is the test score for student in school , is the teacher experience, is the classroom size, is the random intercept for school , is the residual error for student in school .
The general form of the working correlation structure for GEE is specified as:
How does the interpretation of coefficients differ between a GEE and a mixed-effects model?
Simulate data for a Poisson GEE: Run the code below to simulate clustered count data where the response variable represents the number of tasks completed by workers in teams, with predictors for experience (exp) and workload (load).
library(geepack)library(gee)# Simulate clustered Poisson dataset.seed(123)n_teams <-10n_workers <-5exp <-rnorm(n_teams * n_workers, mean =5, sd =2)load <-rpois(n_teams * n_workers, lambda =10)team <-rep(1:n_teams, each = n_workers)tasks <-rpois(n_teams * n_workers, lambda =exp(0.5+0.3* exp -0.1* load))# Create a data framedata <-data.frame(team, exp, load, tasks)# Fit a Poisson GEEfit_pois_gee <-gee(tasks ~ exp + load, data = data, id = team, corstr ="exchangeable", family = poisson)
GEE: GENERALIZED LINEAR MODELS FOR DEPENDENT DATA
gee S-function, version 4.13 modified 98/01/27 (1998)
Model:
Link: Logarithm
Variance to Mean Relation: Poisson
Correlation Structure: Exchangeable
Call:
gee(formula = tasks ~ exp + load, id = team, data = data, family = poisson,
corstr = "exchangeable")
Summary of Residuals:
Min 1Q Median 3Q Max
-2.5792704 -0.9928465 -0.2308147 0.8542432 3.1320614
Coefficients:
Estimate Naive S.E. Naive z Robust S.E. Robust z
(Intercept) 0.68090576 0.30291226 2.247865 0.33007871 2.062859
exp 0.25262895 0.03879274 6.512274 0.04602186 5.489325
load -0.09397882 0.02651737 -3.544047 0.01494948 -6.286427
Estimated Scale Parameter: 0.6964406
Number of Iterations: 2
Working Correlation
[,1] [,2] [,3] [,4] [,5]
[1,] 1.0000000 0.1138303 0.1138303 0.1138303 0.1138303
[2,] 0.1138303 1.0000000 0.1138303 0.1138303 0.1138303
[3,] 0.1138303 0.1138303 1.0000000 0.1138303 0.1138303
[4,] 0.1138303 0.1138303 0.1138303 1.0000000 0.1138303
[5,] 0.1138303 0.1138303 0.1138303 0.1138303 1.0000000
Interpret the coefficients for exp and load.
solution: represents the change in the log of the expected number of tasks for a one-unit increase in experience (exp), holding workload (load) constant. - The exponentiated value of gives the relative change in the expected number of tasks for each additional unit of experience. $_2 = -0.0940 $represents the change in the log of the expected number of tasks for a one-unit increase in workload (load), holding experience (exp) constant. The exponentiated value of gives the relative change in the expected number of tasks for each additional unit of workload.
Change the correlation structure to unstructured and compare the results. What differences do you observe?
solution:
# Fit a Poisson GEEfit_pois_gee2 <-gee(tasks ~ exp + load, data = data, id = team, corstr ="AR-M", family = poisson)
GEE: GENERALIZED LINEAR MODELS FOR DEPENDENT DATA
gee S-function, version 4.13 modified 98/01/27 (1998)
Model:
Link: Logarithm
Variance to Mean Relation: Poisson
Correlation Structure: AR-M , M = 1
Call:
gee(formula = tasks ~ exp + load, id = team, data = data, family = poisson,
corstr = "AR-M")
Summary of Residuals:
Min 1Q Median 3Q Max
-2.6058032 -0.9899380 -0.2396283 0.8584646 3.1402227
Coefficients:
Estimate Naive S.E. Naive z Robust S.E. Robust z
(Intercept) 0.64257506 0.30582240 2.101138 0.29645731 2.167513
exp 0.25799275 0.03980350 6.481660 0.04290350 6.013326
load -0.09305641 0.02690561 -3.458625 0.01584915 -5.871382
Estimated Scale Parameter: 0.6984726
Number of Iterations: 2
Working Correlation
[,1] [,2] [,3] [,4] [,5]
[1,] 1.0000000000 0.074917778 0.005612673 0.000420489 0.0000315021
[2,] 0.0749177775 1.000000000 0.074917778 0.005612673 0.0004204890
[3,] 0.0056126734 0.074917778 1.000000000 0.074917778 0.0056126734
[4,] 0.0004204890 0.005612673 0.074917778 1.000000000 0.0749177775
[5,] 0.0000315021 0.000420489 0.005612673 0.074917778 1.0000000000
solution: Between the two models estimates of fixed effects change very litte. The working correlation matrix shows a decrease in correlation with observations that are farther apart and an increase in correlation with observations that are closer. The robust standard errors for and are larger than the naive SEs indicating a more conservative estimate, i.e., the naive SEs are misleading and could be underestimated.
Robust Standard Errors
GEEs provide robust standard errors to account for potential misspecification of the working correlation structure.
These standard errors are derived using a sandwich estimator, ensuring valid inference even if the assumed correlation structure is incorrect.
Formula for Robust Variance-Covariance Matrix: The robust variance-covariance matrix of the estimated coefficients is given by:
where:
is the sensitivity matrix.
is the variability of the score function .
Compare the implications of using model-based standard errors versus robust standard errors when the working correlation structure is misspecified.
solution: In the above model we include an AR covariance structure which account for correlations that decrease over time or distance within groups. The exchangeable structure in the first model assumes constant correlation among all observations. If data exhibit temporal or sequential patterns, the AR structure is more appropriate. If the model is misspecified, ie you assume exach when AR is the true model, the naive SEs would severly under-estimate the covariance structure. Robust SE are larger and account for additional noise or covariance thereby being robust to model misspecification.
Based on the output above compare and interpret the model-based and Robust SEs for the covariate coefficients. What do differences indicate about the correlation structure?
solution: The Robust S.E. is slightly larger than the Naive S.E., indicating that the model accounts for more uncertainty in the presence of potential misspecification of the correlation structure. The AR model assumes that correlations decay over time, and the robust standard errors correct for any potential issues in this assumption.
For exp (Experience): The larger difference between the naive and robust standard errors suggests that the assumed correlation structure (exchangeable) may not fully capture the true dependencies between observations. The AR1 model, which accounts for decaying correlations over time, provides more reliable estimates of the coefficient for exp, as reflected by the smaller robust standard errors.
For load (Workload): The robust standard errors being smaller than the naive standard errors suggests that the AR1 structure better accounts for the correlation between observations within teams, leading to more precise estimates of the effect of load.
Variance-Covariance Derivation in GEEs
GEEs handle within-cluster correlations using a working correlation matrix, denoted by , where is a parameter that specifies the correlation structure (e.g., exchangeable, AR1).
The total variance-covariance matrix is derived as:
where:
is the variance function (e.g., for Poisson, for Binomial).
is the dispersion parameter.
Module 5: Smoothing Functions
Basis Expansion and Parametric Splines
Consider the regression model below:
Write out the model cubic spline
solution For cubic splines, the basis functions are typically piecewise cubic polynomials that are continuous and have continuous first and second derivatives. The number of basis functions depends on the number of knots and the degree of the spline (in this case, cubic, so degree 3).
The cubic spline basis functions, , are designed to: - Interpolate the data at certain values of called knots, - Ensure that the spline is smooth at the knots (i.e., the first and second derivatives are continuous).
The cubic spline model can be written as:
Where each is a cubic polynomial that takes different forms depending on the location of the knots. The typical cubic spline basis function for a given knot is defined in such a way that:
Where and are the adjacent knots
This gives a piecewise smooth function for , ensuring flexibility in modeling the relationship between and while maintaining smoothness at the knots.
Using the splines package, fit a piecewise cubic spline model to the GAbirth dataset.
Interpret the coefficients for age and explain how the knots affect the model fit.
solution:
The estimated intercept is 3111.8, which represents the estimated value of the dependent variable (bw, birth weight) when age is at the reference level (below 20 years, since the first knot is at 20). Significance: The intercept is highly significant with a p-value of < 2e-16, suggesting that the baseline birth weight when age is below 20 is statistically different from zero.
This coefficient, 291.7, represents the change in birth weight for an increase in age between 20 and 30 years compared to the reference group (below 20 years). Significance: The coefficient is highly significant (p-value < 2e-16), indicating a strong positive effect of age between 20 and 30 years on birth weight.
The coefficient, 231.4, represents the change in birth weight for an increase in age between 30 and 40 years compared to the reference group (below 20 years). Significance: The coefficient is highly significant (p-value = 2.7e-09), suggesting a positive effect of age between 30 and 40 years on birth weight, although the effect is slightly smaller than the previous age range (20-30 years).
The coefficient, 300.2, represents the change in birth weight for an increase in age between 40 and 50 years compared to the reference group (below 20 years). Significance: This effect is also highly significant (p-value = 5.6e-06), suggesting a strong positive effect of age between 40 and 50 years on birth weight, even though the sample size in this age range may be smaller.
The coefficient, 146.3, represents the change in birth weight for an increase in age between 50 and 60 years compared to the reference group (below 20 years). Significance: This effect is statistically significant (p-value = 0.018), though the magnitude of the effect is smaller than the previous age ranges.
Use the AIC function to compare this model to a simple linear regression of bw ~ age.
solution:
Based on the AIC values, the spline model has a slightly better fit than the linear model on age.
fit_linear <-lm(bw ~ age, data = GAbirth)AIC(fit_spline, fit_linear)
We pre-defined the knots in the above code. Now let’s use automatic knot selection with the L2-penalty.
a. Write out the objective function with the penalty constraint.
solution: In the context of cubic splines with automatic knot selection using an L2-penalty, the objective function consists of two parts: the least squares term (fit) and the L2-penalty term (smoothing penalty).
The least squares term measures how well the model fits the data:
Where is the observed value for the -th observation, is the cubic spline function fitted to , is the number of observations.
The L2-penalty term controls the smoothness of the spline by penalizing the total curvature:
Where: is the penalty parameter that controls the strength of the penalty (larger leads to smoother splines), is the -th basis function of the spline, The second derivative measures the curvature, and the penalty term encourages less curvature, meaning fewer knots or smoother splines.
The total objective function combines both the fit and the penalty:
Where: - The first term is the sum of squared residuals, which measures the fit of the model to the data. - The second term is the L2-penalty, which penalizes excessive curvature in the spline. - controls the trade-off between fitting the data well and keeping the spline smooth.
b. Derive the closed form solution for and describe the impact of the penalty term.
solution:
Given the objective function for the cubic spline with an L2-penalty, we aim to derive the closed-form solution for and describe the effect of the penalty term on the model.
The total objective function becomes:
To minimize the objective function with respect to , we take the derivative and set it equal to zero:
First, compute the derivative of the least squares term:
Then, compute the derivative of the penalty term:
Set the sum of these two derivatives equal to zero:
Simplifying, we get the closed-form solution for :
Thus, the closed-form solution for the coefficients is:
The Generalized Cross-Validation Error (GCV) is defined as
Fitting GAM with : Fit two models where (1) default , and (2) . Compare GCV values and determine the model with best fit.
solution: There is little difference between GCV values when using vs knots. In the first model (k=10), the GCV 95836, the second model (K=30) has a GCV 95835. Therefore, the addition of more knots does not greatly improve model fit.
library(mgcv)
Loading required package: nlme
Attaching package: 'nlme'
The following object is masked from 'package:lme4':
lmList
This is mgcv 1.8-42. For overview type 'help("mgcv-package")'.
fit_spline10 <-gam(bw ~s(age), data = GAbirth)fit_spline30 <-gam(bw ~s(age, k=30), data = GAbirth)
Check the diagnostic plots using for the most optimal model from (6). Interpret the findings from the diagnostic plot.
solution:
gam.check(fit_spline30)
Method: GCV Optimizer: magic
Smoothing parameter selection converged after 7 iterations.
The RMS GCV score gradient at convergence was 0.08232834 .
The Hessian was positive definite.
Model rank = 30 / 30
Basis dimension (k) checking results. Low p-value (k-index<1) may
indicate that k is too low, especially if edf is close to k'.
k' edf k-index p-value
s(age) 29.0 3.5 1.01 0.68
Using the optimal model chosen from (6), interpret the parametric coefficients.
Solution:
The estimated intercept is 3288.82, which represents the estimated birth weight when the age (age) is at the reference level (the baseline age, likely the minimum value or center point of the age variable).
The standard error of 4.38 indicates the precision of the estimate. Since the standard error is small relative to the coefficient, we can be confident in the intercept estimate.
The t-value of 752 and the p-value of < 2e-16 indicate that the intercept is statistically significant at the highest level, meaning the baseline birth weight (when age is at the reference level) is significantly different from zero.
Generalized Additive Models for Non-Normal Data.
Generalized Additive Models (GAMs): Extend GLMs by allowing additive non-linear relationships between predictors and the response.
Bivariate Splines: Used for modeling interactions between two continuous variables.
Interpreting Non-Linear Effects: GAMs provide smooth terms () that capture non-linear patterns in the data.
Use the gam() function from the mgcv package to fit a model predicting binary outcomes (e.g., infection status) from age and time of visit.
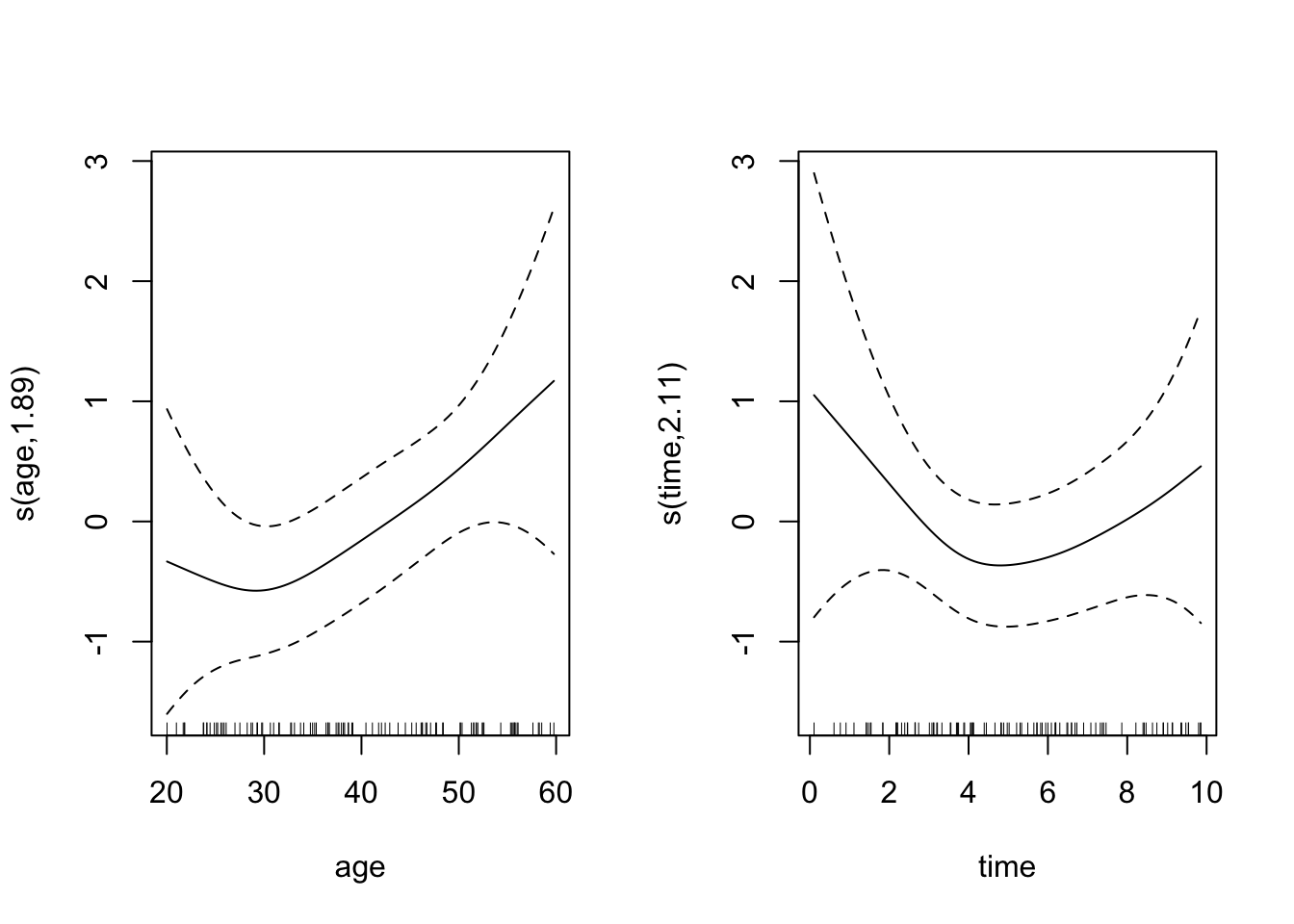
library(mgcv)# Simulate binary dataset.seed(123)age <-runif(100, 20, 60)time <-runif(100, 0, 10)outcome <-rbinom(100, 1, plogis(0.5+0.03* age -0.1* time))# Fit GAMfit_gam <-gam(outcome ~s(age) +s(time), family = binomial, method ="REML")# Summarize and plotsummary(fit_gam)
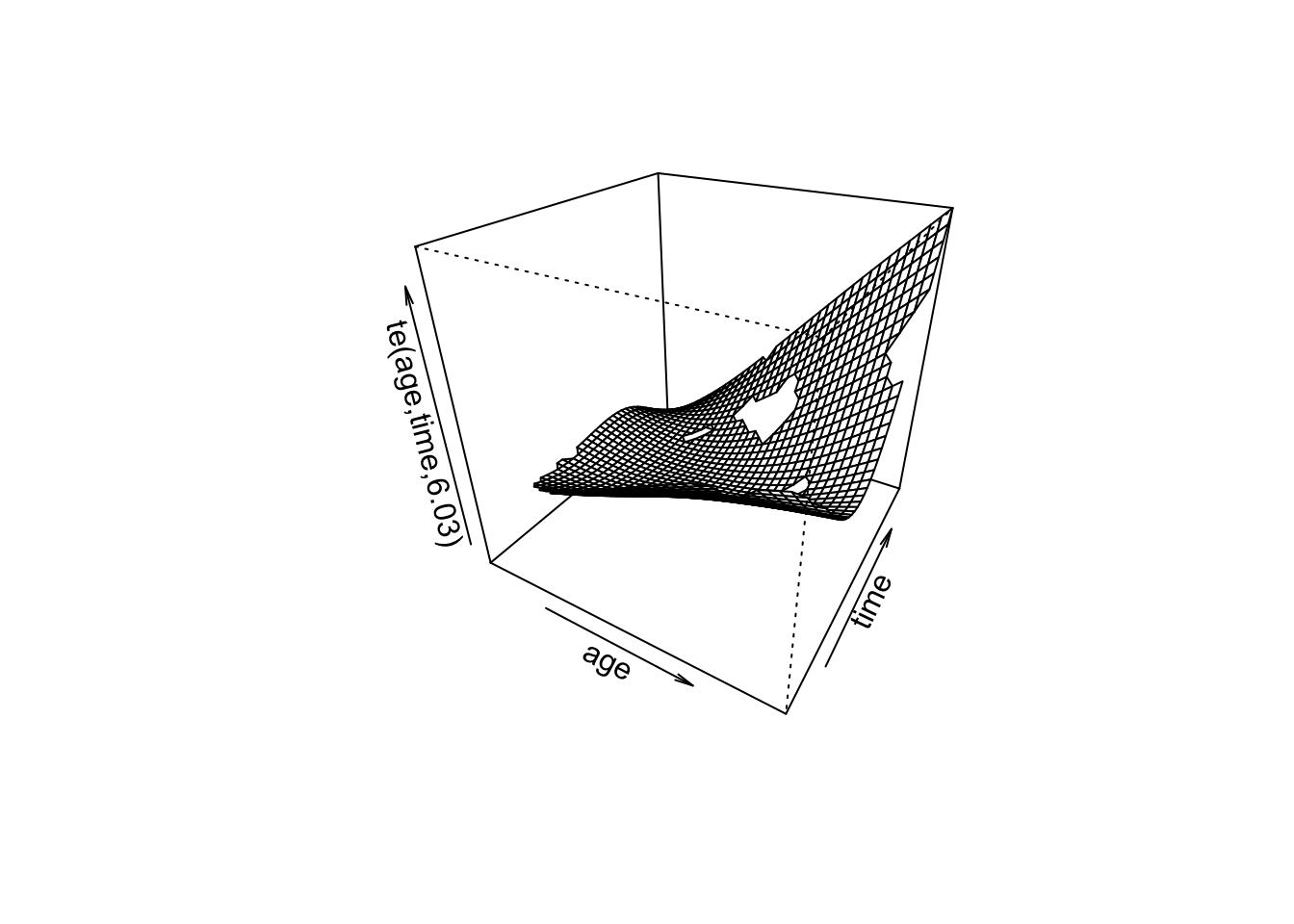
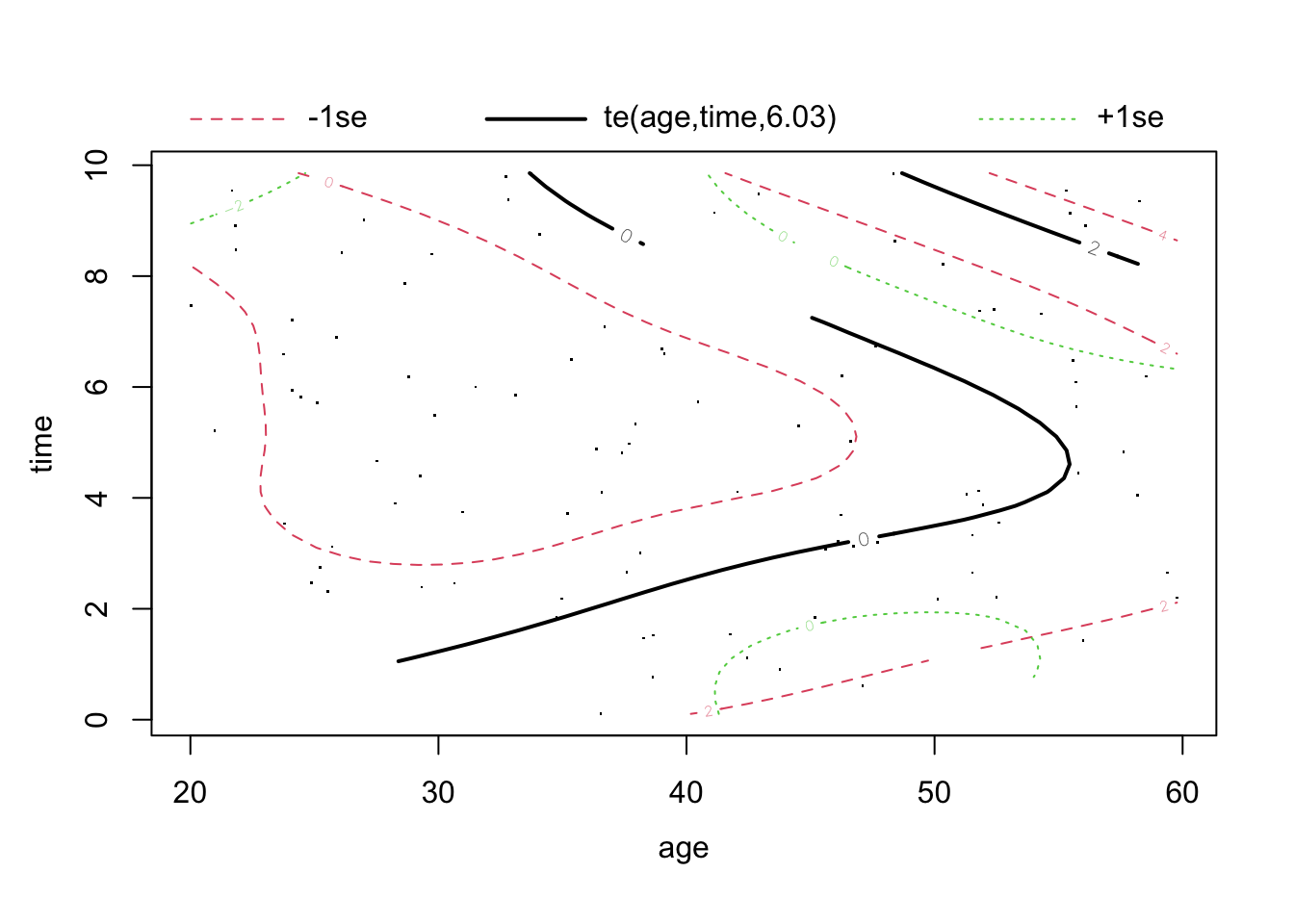
What does the bivariate spline capture that separate univariate smooths do not?
solutioin: The bivariate splinete(age, time) captures the interaction effect between age and time. Specifically, it allows for nonlinear relationships between both variables, considering how changes in age and time together influence the outcome. In contrast, separate univariate smooths for age and time would capture the individual nonlinear effects of each variable on the outcome, but they do not account for the interaction between the two variables. A univariate smooth would look at how age affects the outcome without considering how that effect changes over time (or vice versa for time).
Visualize the interaction between age and time using the plot() function.
# Visualize the interaction between age and time using the plot functionplot(fit_gam_bivariate, pages =1, scale =0)
Module 6: Principal Component Analysis
PCA is a method for dimensionality reduction that identifies principal components (PCs), which are uncorrelated linear combinations of the original variables. These PCs are ordered by the amount of variance they explain in the data.
Steps in PCA
Standardize the data if variables are measured on different scales.
Compute the covariance matrix or correlation matrix.
Perform eigenvalue decomposition (EVD) or singular value decomposition (SVD).
Eigenvalues () represent the variance explained by each PC.
Eigenvectors () define the weights for each variable in the PCs.
Transform the data into the principal component space.
Variance Explained by PCs
The proportion of variance explained (PVE) by the th PC is given by: where is the eigenvalue corresponding to the th PC.
Principal Component Regression (PCR)
PCR uses PCs as predictors in regression models instead of the original variables. This approach is particularly useful when predictors are highly correlated.
Consider a dataset with three variables , , and . The covariance matrix is:
Compute the eigenvalues and eigenvectors of (use R if needed).
solution:
# Define the covariance matrixSigma <-matrix(c(2, 1, 0.5, 1, 2, 0.3, 0.5, 0.3, 1), nrow =3, byrow =TRUE)# Compute eigenvalues and eigenvectorseig <-eigen(Sigma)# Display eigenvalues and eigenvectorseig$values
Write the first principal component as a linear combination of , , and .
solution:
Given the eigenvalues and eigenvectors of the covariance matrix , we can write the first principal component (PC1) as a linear combination of the original variables , , and . The first eigenvector corresponding to the largest eigenvalue () represents the weights for the first principal component.
From the output of eig$vectors, the first eigenvector is:
Thus, the first principal component (PC1) can be written as a linear combination of , , and :
This expression shows that the first principal component is a weighted sum of the original variables, where the coefficients represent the contribution of each variable to the overall component.
Interpretation of the First Principal Component: - (corresponding to the first coefficient -0.695) has the largest negative weight, meaning it contributes most negatively to PC1. - (coefficient -0.672) also contributes negatively, but slightly less than . - (coefficient -0.256) has the smallest negative weight, indicating a smaller negative contribution to PC1.
Perform PCA on the numerical variables in the mtcars dataset:
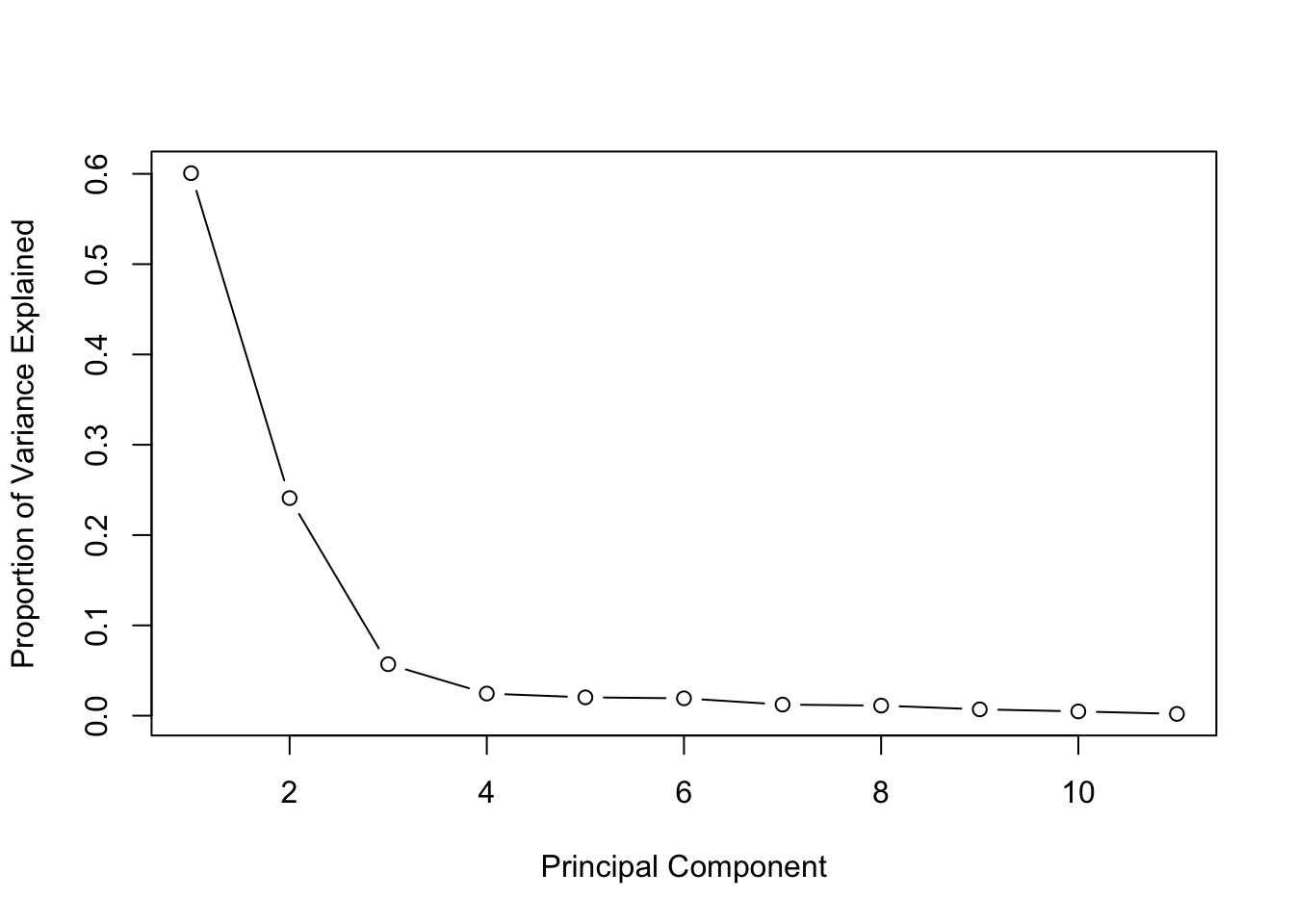
How many PCs explain at least 90% of the variance?
solution:To find how many principal components (PCs) explain at least 90% of the variance, check the cumulative proportion of variance explained. The first 3 components explain 90% of the variance.
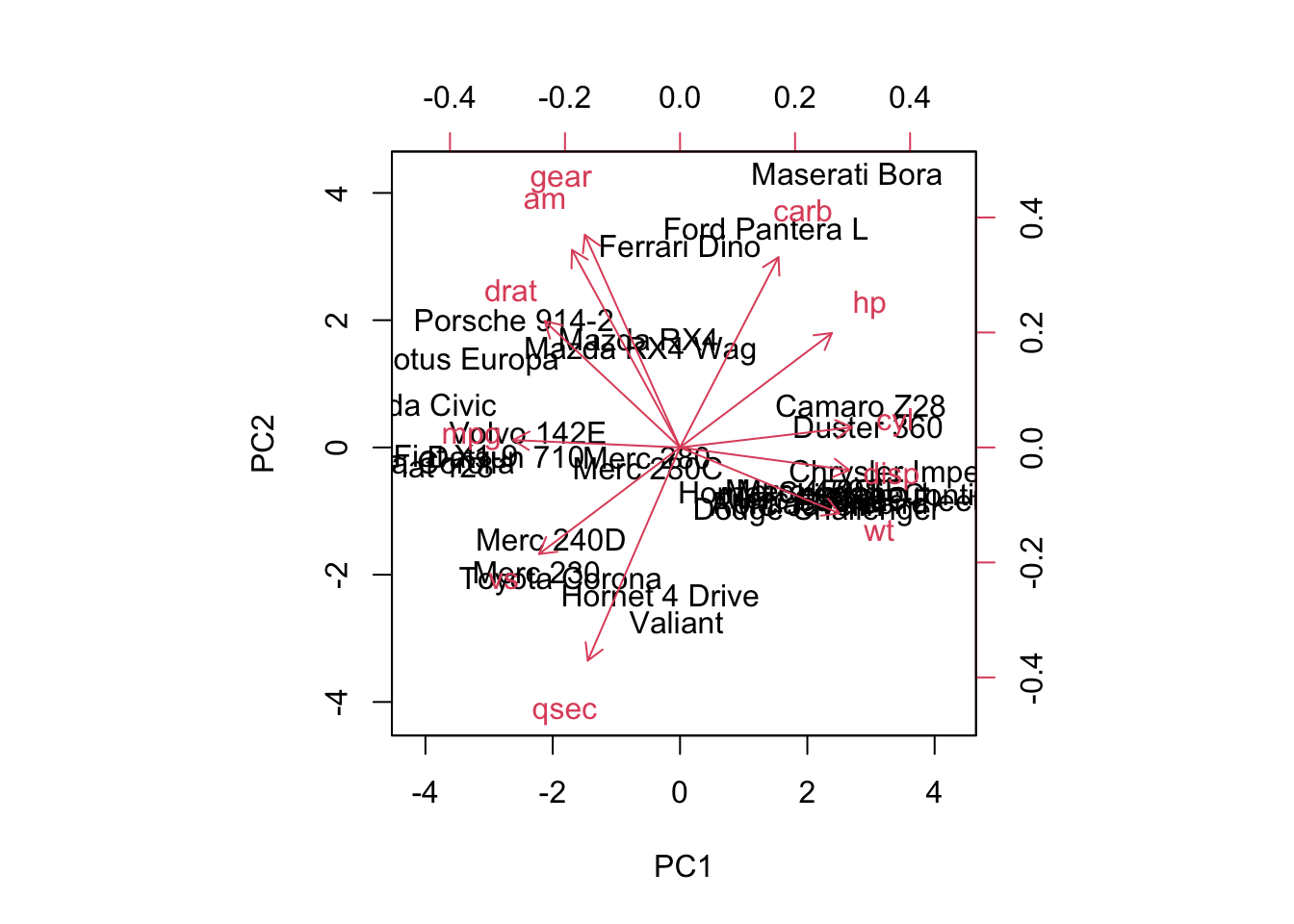
Variables with positive loadings (such as cyl, disp, hp, wt) have a positive relationship with PC1, while variables with negative loadings (such as mpg, drat, qsec, vs, am, gear) have a negative relationship with PC1.
PC1 seems to capture a general measure of vehicle performance or size, as variables like cyl, disp, and hp (which are related to engine size and power) have positive loadings, and variables like mpg (miles per gallon), drat (rear axle ratio), and qsec (quarter-mile time) have negative loadings, which are inversely related to performance.
PC2 appears to capture a different aspect of the data, possibly related to the vehicle’s weight, performance, and transmission type.
Variables such as am (automatic transmission), gear, and carb (carburetor count) have positive loadings, suggesting a relationship with these factors in PC2. Specifically, am and gear suggest that the second component might be related to transmission type and gear configuration.
Variables like qsec and wt have negative loadings, indicating a negative relationship with these components.
The relatively small loadings for mpg, cyl, disp, and hp suggest that PC2 is less sensitive to these variables compared to PC1.
Calculate the proportion of variance explained (PVE) for the first three PCs.
solution: The proportion of variance explained (PVE) can be computed as the square of the standard deviations of the principal components divided by the total variance:
# Calculate the proportion of variance explainedpve <- (pca_mtcars$sdev)^2/sum((pca_mtcars$sdev)^2)# Display the PVE for the first three PCspve[1:3]
[1] 0.60076366 0.24095163 0.05701793
Create a scree plot to visualize the PVE for all components.
pve <- (pca_mtcars$sdev)^2/sum((pca_mtcars$sdev)^2)plot(pve, type ="b", xlab ="Principal Component", ylab ="Proportion of Variance Explained")
Write out the model for a PCA regression of mpg (miles per gallon) on the first 3 PCs from the mtcars dataset.
Solution:
Perform this regression in R
# PCA for regressionpca_data <-data.frame(pca_mtcars$x[, 1:3], mpg = mtcars$mpg)# Regression on PCsfit_pcr <-lm(mpg ~ PC1 + PC2 + PC3, data = pca_data)summary(fit_pcr)
Call:
lm(formula = mpg ~ PC1 + PC2 + PC3, data = pca_data)
Residuals:
Min 1Q Median 3Q Max
-3.5769 -1.1683 -0.1571 1.0958 4.1058
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 20.09062 0.35240 57.010 < 2e-16 ***
PC1 -2.18495 0.13928 -15.688 2.12e-15 ***
PC2 0.09718 0.21992 0.442 0.66197
PC3 -1.36055 0.45210 -3.009 0.00549 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.993 on 28 degrees of freedom
Multiple R-squared: 0.9012, Adjusted R-squared: 0.8906
F-statistic: 85.12 on 3 and 28 DF, p-value: 3.496e-14
Compare the results to a regression using all original predictors.
solution:
fit_reg <-lm(mpg ~., data= mtcars)
PCA Regression:
PC1 and PC3 are both significant predictors of mpg, while PC2 is not significant. This suggests that the first and third principal components capture most of the meaningful variation in mpg, and the second principal component does not contribute much.
Regular Regression:
The original predictors such as cyl, disp, hp, drat, and others show little to no significance, with wt being the only variable that is close to significant with a p-value of 0.063.
Interpret the coefficients of the PCs and discuss why they differ from coefficients in a regression on the original variables.
solution:
PCA Regression:
PC1: The coefficient for PC1 is -2.1850, which is statistically significant (p-value = 2.1e-15), indicating that the first principal component has a strong negative effect on mpg.
PC2: The coefficient for PC2 is 0.0972, but it is not significant (p-value = 0.6620), suggesting that PC2 does not contribute significantly to explaining mpg.
PC3: The coefficient for PC3 is -1.3605, and it is statistically significant (p-value = 0.0055), suggesting that PC3 has a significant negative effect on mpg.
Regular Regression:
The coefficient for cyl is -0.1114, indicating a small negative relationship between cyl and mpg, though it is not statistically significant (p-value = 0.916).
The coefficient for disp is 0.0133, suggesting a small positive relationship with mpg, but it is also not statistically significant (p-value = 0.463).
The coefficient for hp is -0.0215, indicating a slight negative relationship with mpg, though it is not significant (p-value = 0.335).
The coefficient for wt is -3.7153, showing a significant negative effect on mpg with a p-value of 0.063, though it’s slightly above the 0.05 significance threshold.
am, gear, and carb also show positive relationships with mpg, but none are statistically significant (p-values > 0.05).
Interpretation of Coefficients
PCA Regression:
The coefficients in the PCA regression represent how the principal components (combinations of the original variables) contribute to explaining mpg. These components capture the most variance in the data and summarize the relationships between the variables.
PC1 and PC3 have significant coefficients, indicating that they explain important aspects of the variance in mpg. PC2, however, does not contribute significantly, suggesting that it represents noise or less important variation.
Regular Regression:
The coefficients in the regular regression are the direct effects of the original variables on mpg. Some variables (e.g., wt) show a meaningful negative effect on mpg, but many of the other predictors are not statistically significant. This could be due to multicollinearity between the original predictors, which makes it harder to isolate the individual effects.
The regular regression model’s coefficients are directly tied to the individual variables, while in PCA, the coefficients correspond to the principal components, which are uncorrelated and can better capture the underlying structure in the data.