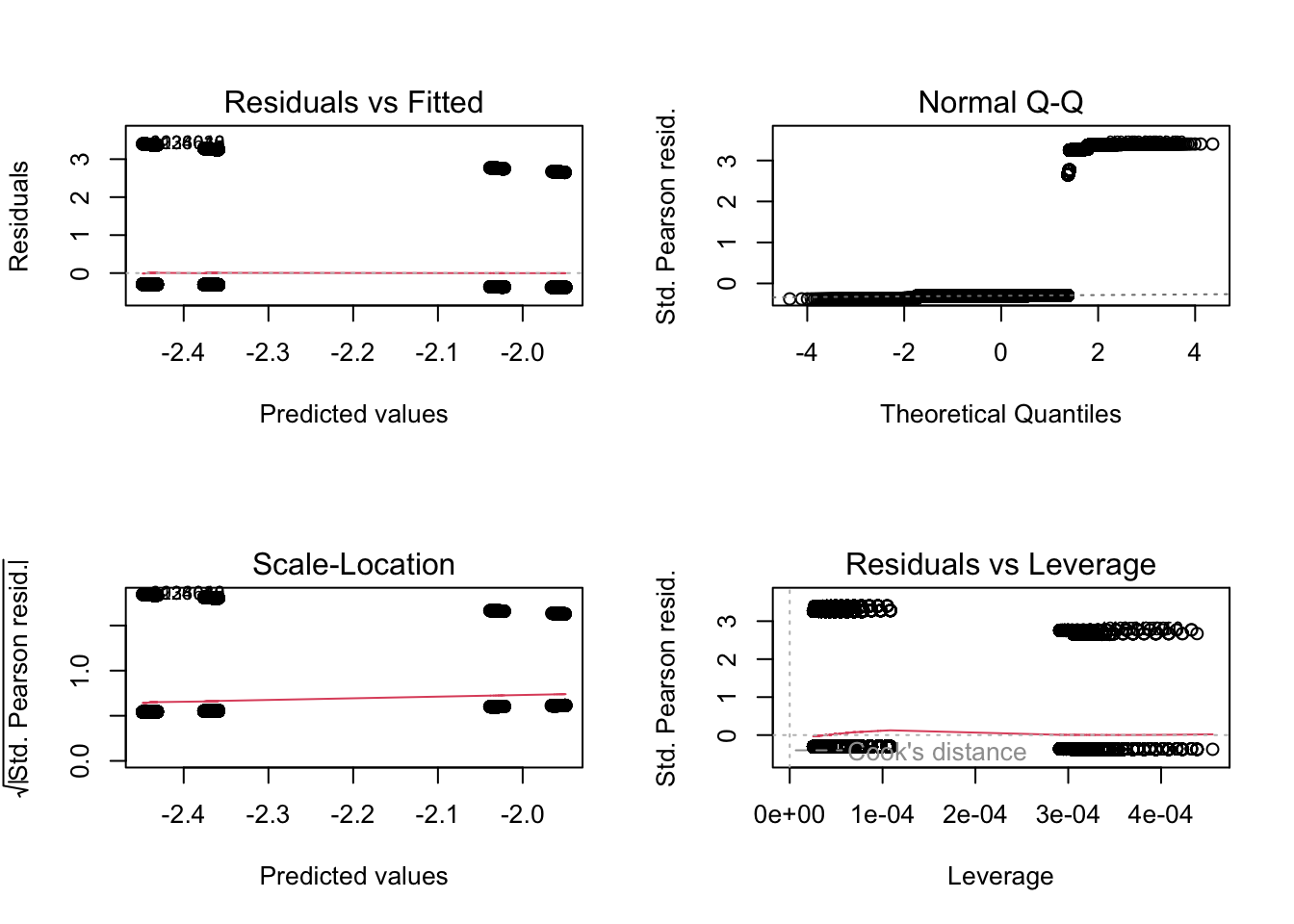
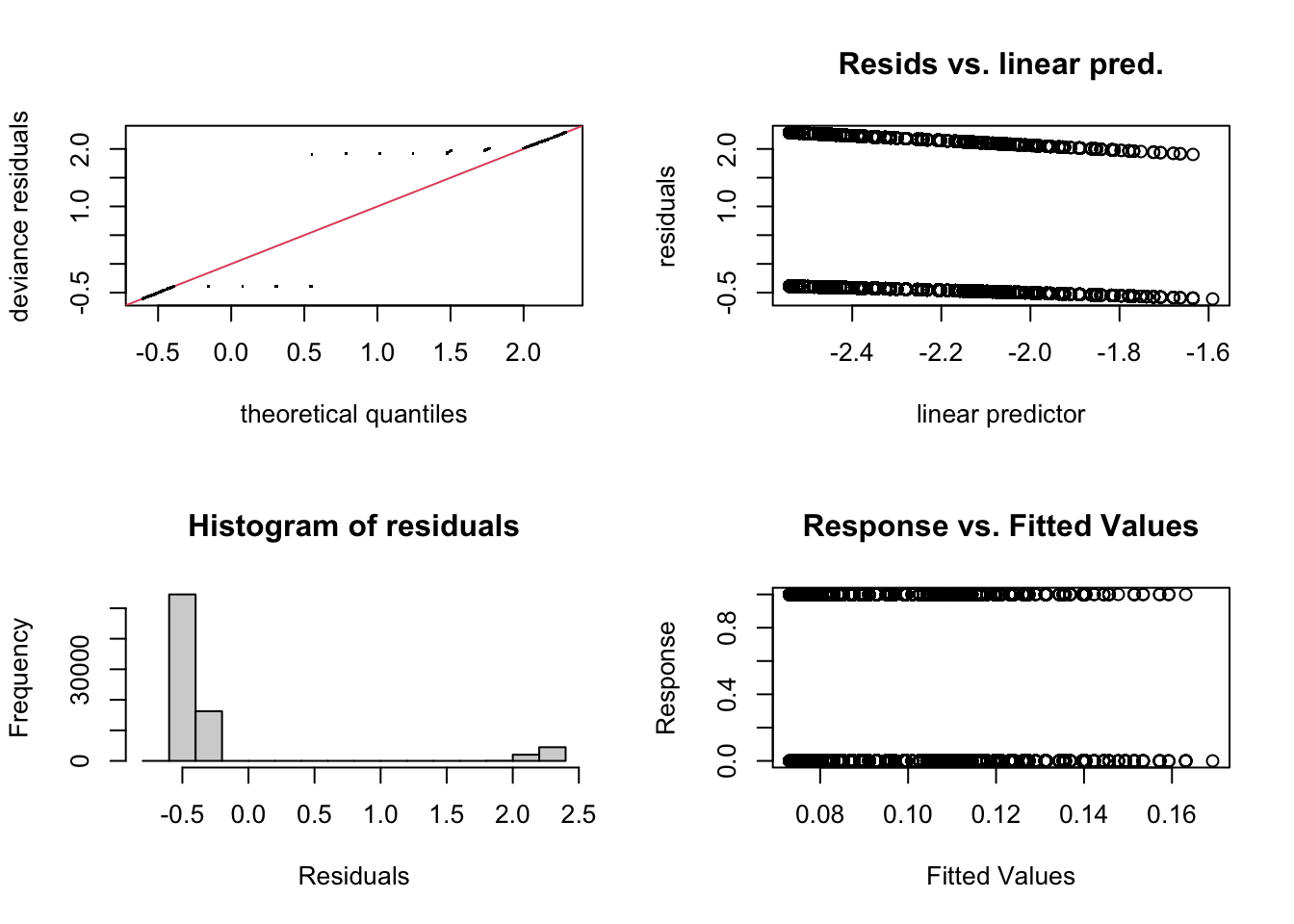
The response variable ptb is modeled using a binomial family with a logit link function.
The formula includes:
A smooth term for age (s(age)).
Linear terms for male and tobacco.
Coefficients
Intercept: The log-odds of ptb when all predictors are at their reference levels is estimated as (highly significant, ).
maleM (male effect): Being male is associated with a small but significant increase in the log-odds of ptb (estimate = , ). Tobacco use is associated with a significant increase in the log-odds of ptb (estimate = , ).
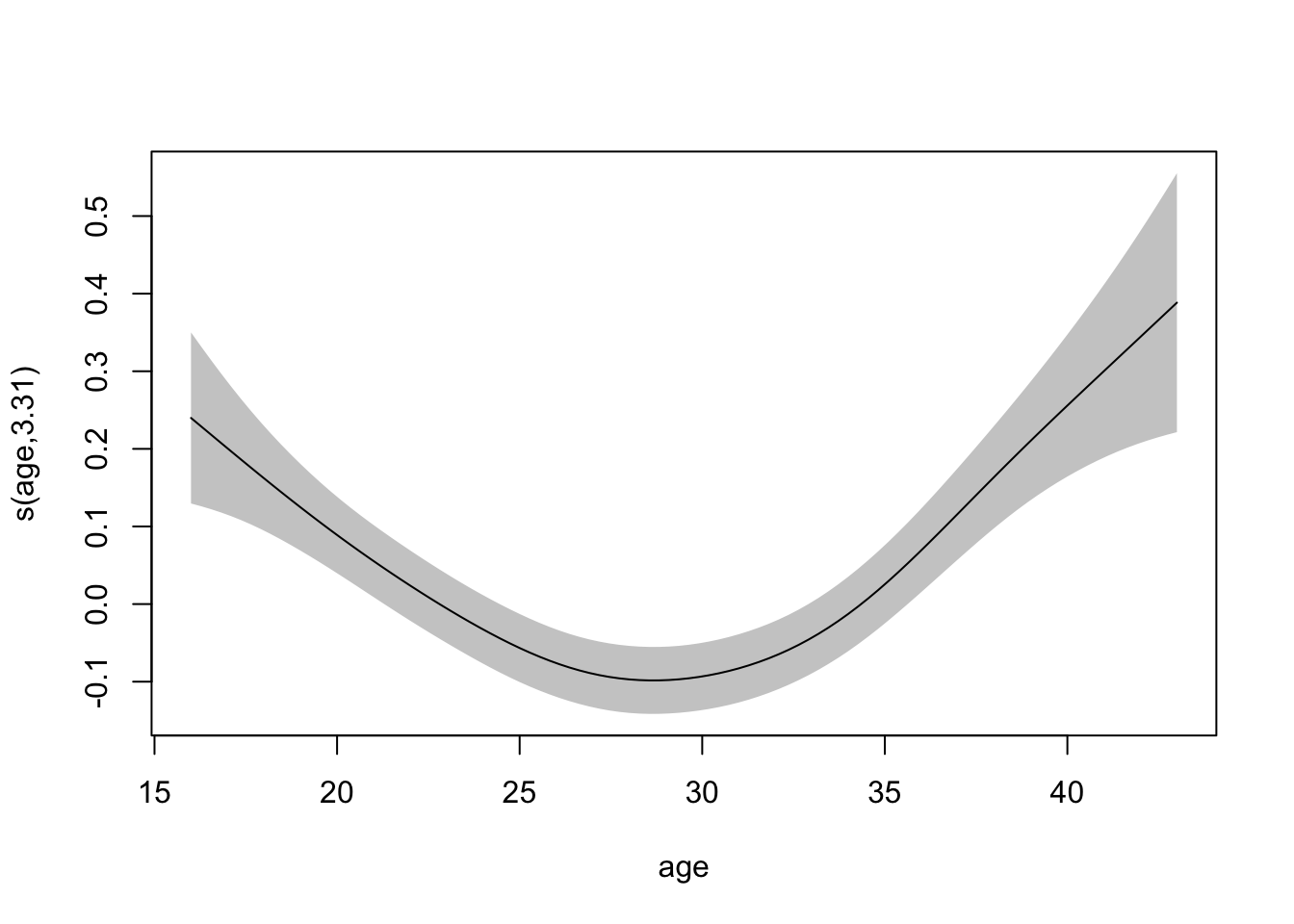
Smooth Term for Age (s(age)) : The smooth function for age has an estimated effective degrees of freedom (edf) of , indicating a moderately flexible relationship. Is highly significant (), suggesting a non-linear relationship between age and the log-odds of ptb.
Model Fit and Diagnostics
Adjusted: The model explains only of the variability in the response, indicating weak predictive power.
Deviance explained: The model accounts for of the total deviance, further supporting limited explanatory capability. -
UBRE score: - A measure of model fit, with a value of .
Sample size: - The model was fit on observations.
Conclusion: While the predictors (age, male, and tobacco) show significant associations with ptb, the overall model has limited explanatory power for predicting ptb.
Checking GAMs
mgcv::gam.check(fit.gam)
Method: UBRE Optimizer: outer newton
full convergence after 3 iterations.
Gradient range [9.816712e-07,9.816712e-07]
(score -0.4209495 & scale 1).
Hessian positive definite, eigenvalue range [1.285937e-05,1.285937e-05].
Model rank = 12 / 12
Basis dimension (k) checking results. Low p-value (k-index<1) may
indicate that k is too low, especially if edf is close to k'.
k' edf k-index p-value
s(age) 9.00 3.31 0.95 0.73
Looking at the plot below, what is the trend of age and preterm birth?
Biologically, log-odds of preterm birth is higher at very young ages, lowest around 29 years, and then increased again.
Bayesian Credible Intervals
We are assuming the underlying function is smooth. This assumption can be formalized as a prior in a Bayesian model.
In Bayesian statistics, the parameters are treated as random variables. A ridge penalty corresponds to an improper Gaussian prior:
For Gaussian data, this results in a posterior distribution:
where:
is the estimated parameter vector.
is the variance.
is the penalty parameter.
is the penalty matrix.
For a general likelihood, the Fisher Information matrix (Hessian of the negative log-likelihood at ) is used:
where is the Fisher Information matrix. For quasi-Poisson data, multiply the penalty by .
In particular, the “Bayesian credible intervals” plotted in mgcv::gam have Frequentist coverage probabilities. For more details, see Section 6.10 in Wood (2017).
Multiple Smoothers
Let’s consider the additive model for two continuous variables and :
where denote smooth relationships between response and predictors and the .
Again, extends to generalized linear models (binomial, Poisson, etc).
We again express non-linear functions using basis functions:
- Induce smoothing by penalizing regression coefficients. Note we also use smoothers to control for confounders flexibly.
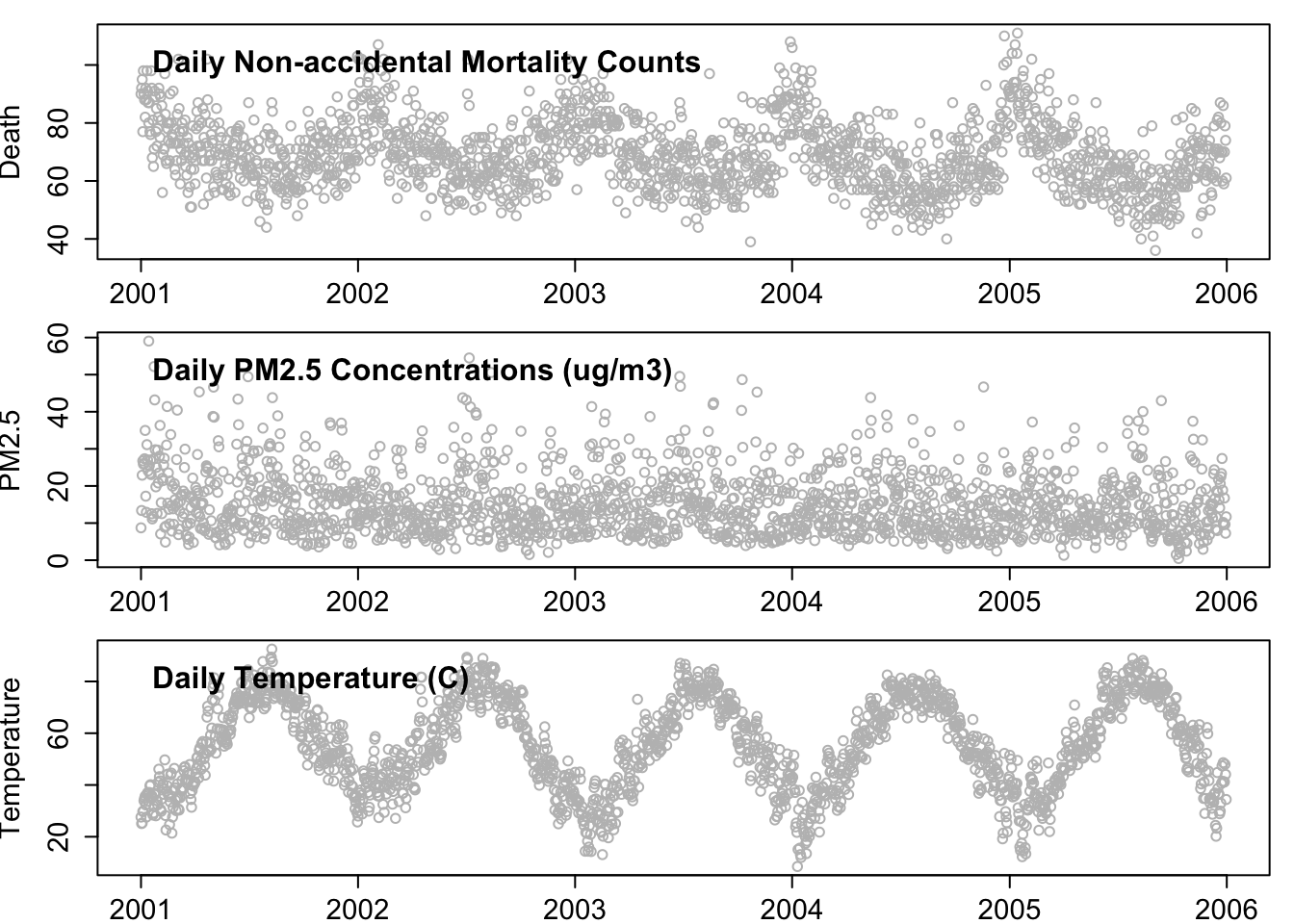
Motivating Example: Associations between Mortality and Fine Particulate Matter
Fine Particulate Matter (PM2.5)
Represents a mixture of solid and liquid particles in the air that are less than in diameter.
Mainly arises from combustion sources, including:
Power generation
Vehicle emissions
Industrial operations.
Scientific Question: What is the association between daily mortality counts and daily concentration of outdoor PM2.5 air pollution?
Data Sources:
Mortality Data: Daily counts of non-accidental deaths (age ) in the 5-county New York City area (2001–2005) obtained from the National Center for Health Statistics (CDC).
Air Pollution Data: Daily PM2.5 concentrations from the Environmental Protection Agency (EPA).
Meteorology Data: Daily meteorological conditions from the National Climatic Data Center (NOAA).
Time Series Health Model
We are interested in the association between daily variation in mortality counts and daily variation in exposure (PM2.5)
In a time-series design we view population as the unit of analysis, i.e., outcome = total mortality counts arising from the population.
Confounders that vary smoothly in time can be easily controlled for by including smoothers.
Let denote the death count on day , and be the corresponding PM2.5 level.
Temporal Delay
There is typically a temporal delay between exposure and outcome. To address this, let’s examine the association between daily mortality and previous-day exposure.
The model is given by:
Focus of Interest
We are particularly interested in , the smooth function of lagged PM2.5 (). Modeling log-transformed death counts helps improve the normality of residuals.
Confounders to Consider:
Day of the week.
Seasonality and long-term trends.
Same-day temperature.
Same-day dew point temperature.
Previous day’s temperature and dew point temperature.
Let’s model the joint effects:
# create lag variable of pm25: used later onhealth$pm25.lag1 =c(NA, health$pm25[1:1825])health$date2=order(health$date)health$fdow =factor(health$dow)health$fdow =relevel (health$fdow, ref ="Sunday")# use a more intuitive reference level:fit =gam(log(cr65plus)~s(pm25)+fdow+s(date2, k =100)+s(Temp)+s(DpTemp)+s(rmTemp)+s(rmDpTemp), data = health)summary(fit)
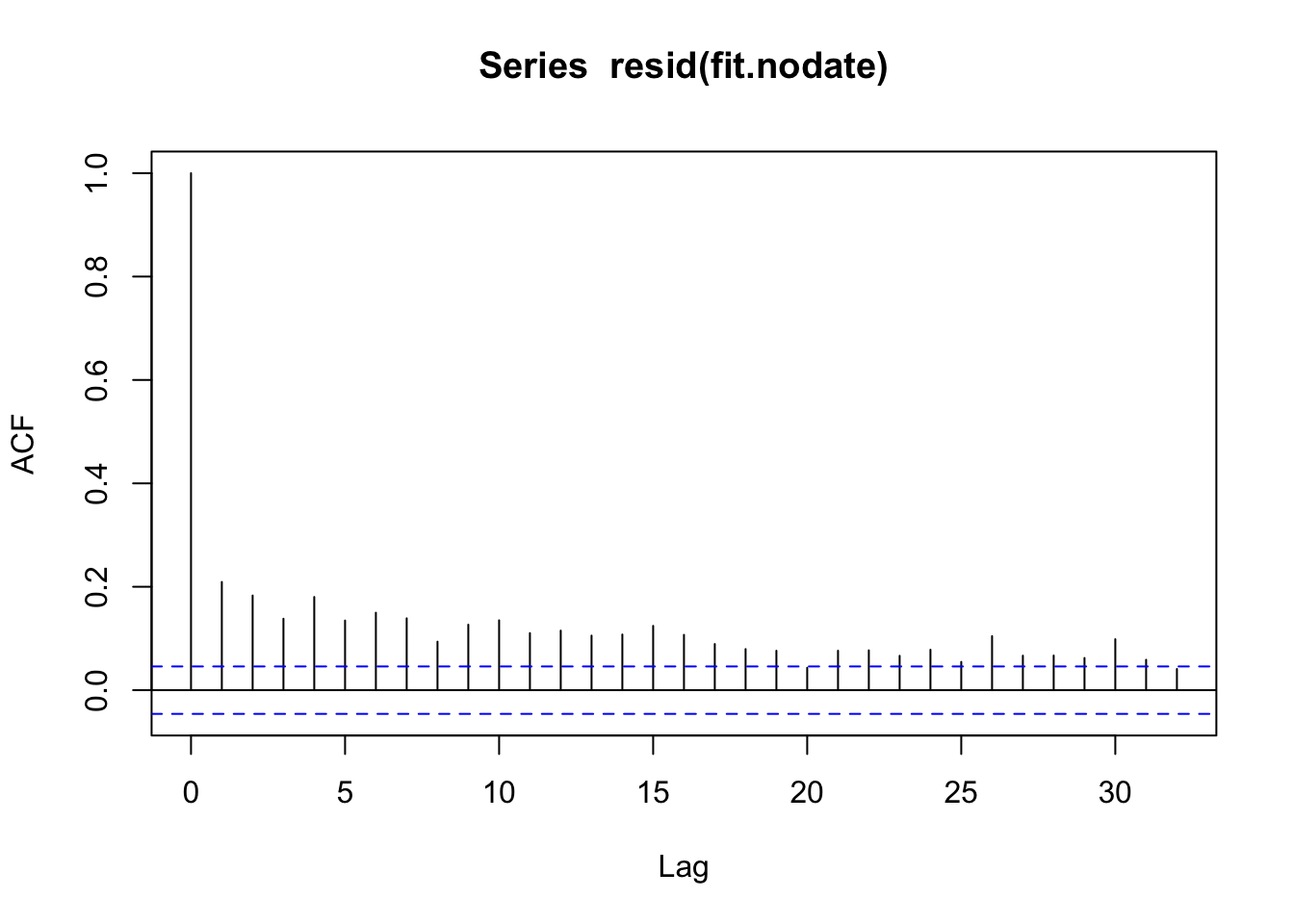
Run diagnostics on this model to determine if it is a good fit!
Run the function on the fit to get diagnostic to get model output.
What are the findings from this diagnostic checks?
It is always good to check the correlations between variables. VIFs are mode complicated due to expanding covariates with a spline basis. Here we will be concerned if there are high correlations with PM2.g.lag1. Run the code below to obtain VIFs:
Analyze residuals for evidence of autocorrelation. If residuals are correlated, inference is not valid and p-values tend to be small. Use ,
Family and Link Function: The model assumes a Gaussian distribution for the response variable with an identity link function, meaning predictions are on the same scale as the response variable .
Model Formula: The model includes:
A smooth function of date2 with (basis dimension for flexibility).
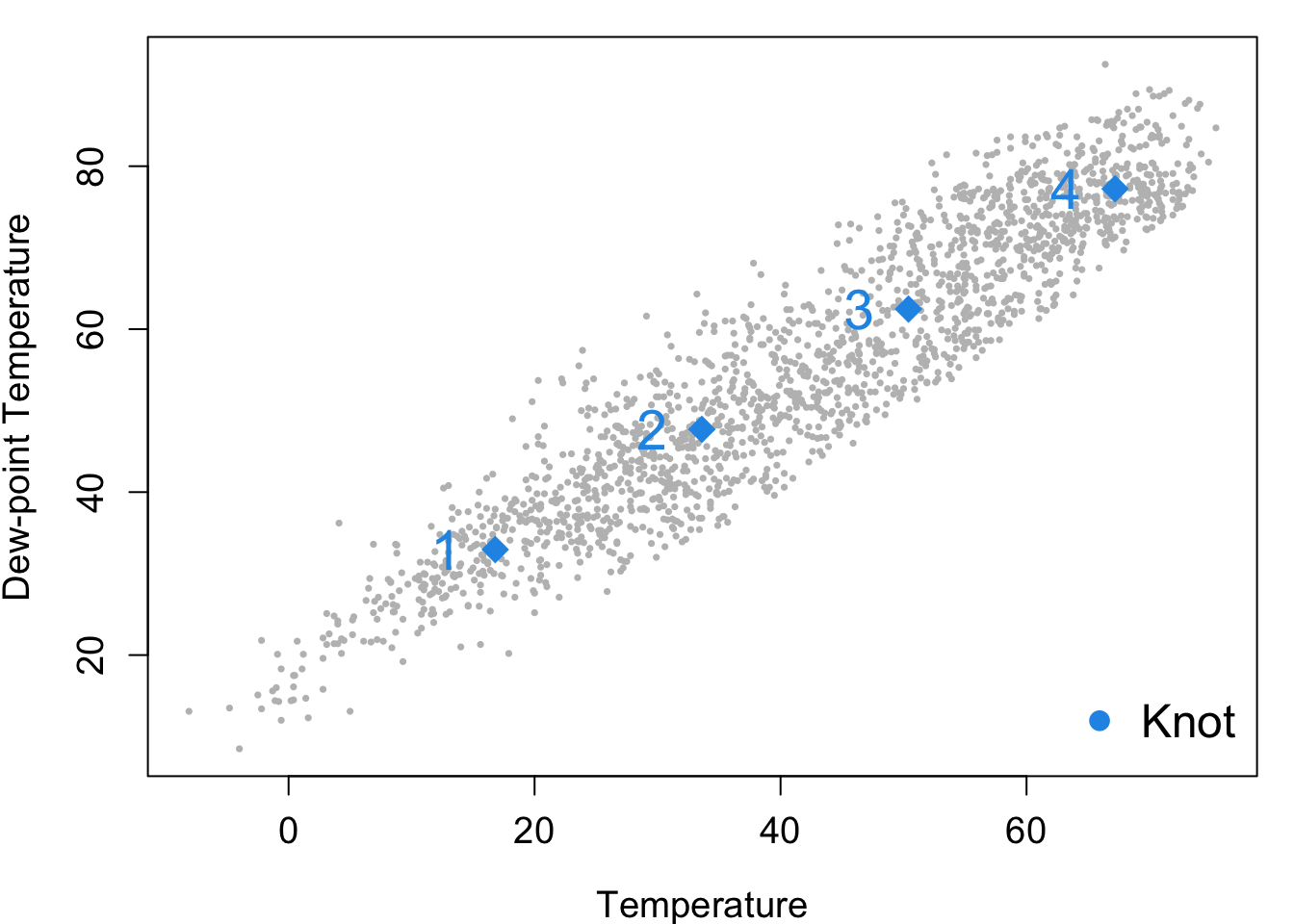
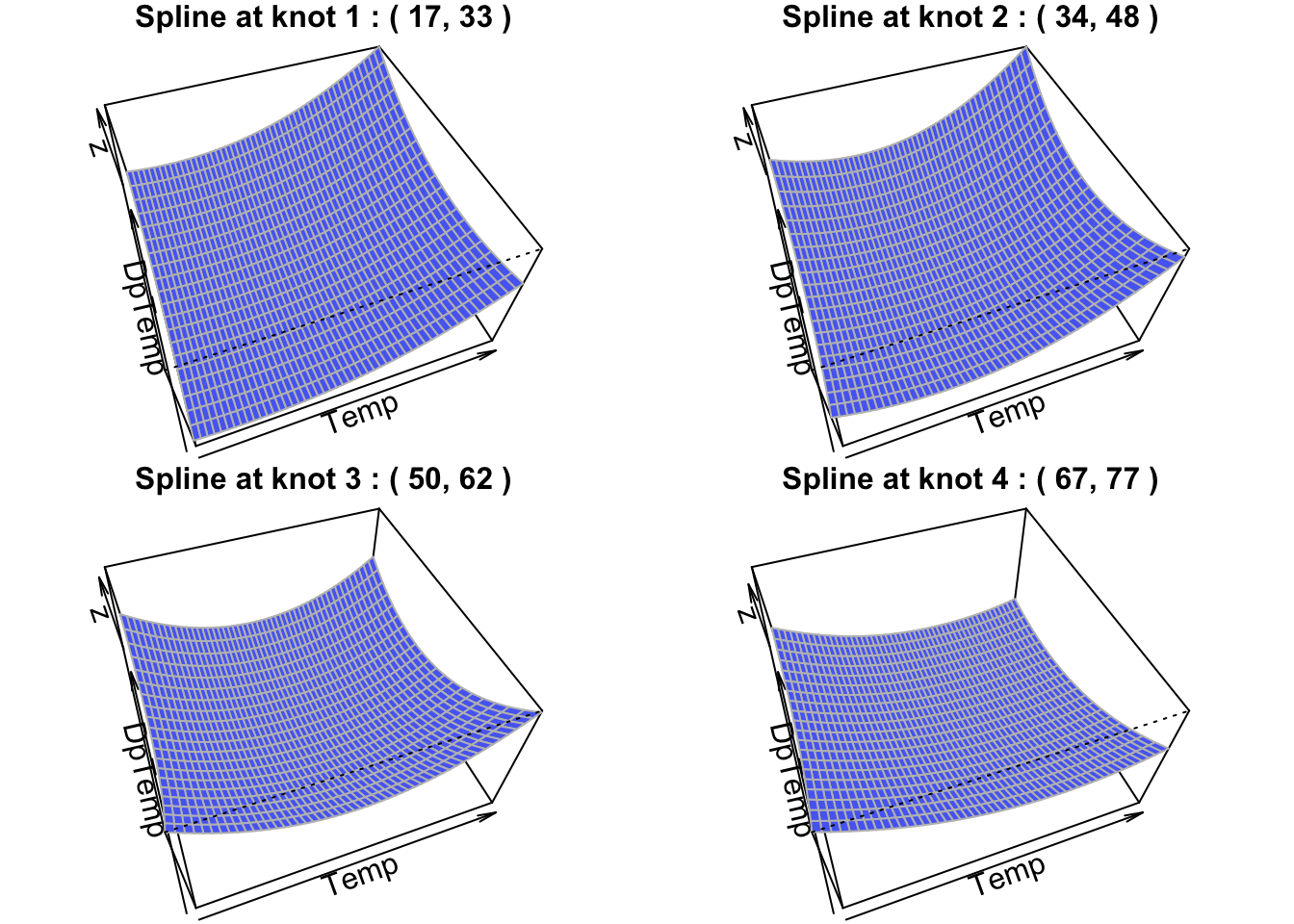
A bivariate smooth function of Temp and DpTemp with .
Parametric Coefficients:
The intercept is 4.962, representing the baseline log of deaths when all covariates are at their mean.
The intercept’s -value is extremely high (2422), and the associated -value is , indicating it is highly significant.
Smooth Terms:
s(date2):
Effective degrees of freedom (edf): 67.37 suggesting a highly flexible fit for the time trend.
-value: 9.597 with a -value , indicating that the temporal trend is highly significant.
s(Temp, DpTemp):
edf: 12.66 indicating a moderately flexible surface for the relationship between temperature and dew point temperature.
-value: 4.327 with a -value <2e-16, suggesting the smooth term for Temp and DpTemp is also highly significant.
Model Performance:
Adjusted : 0.464, meaning 46.4% of the variability in the response (log of deaths) is explained by the model.
Deviance Explained: 48.8%, similar to , indicating a good fit but room for improvement.
Generalized Cross-Validation (GCV) score: 0.008021 smaller is better! Mostly used for model comparison.
Scale Estimate : 0.0076651, indicating the residual variance.
Key Takeaways:
Both smooth terms (date2 and the bivariate smoother of Temp and DpTemp) are highly significant and contribute meaningfully to explaining variability in the log of deaths.
The model captures temporal trends and the effect of temperature and dew point interactions effectively, but the explained variance suggests other factors might also influence the response variable.