Review matrix algebra, see materials in Module 0 on Canvas. For more advanced review see The Matrix Cookbook.
Review notes from Applied Linear Regression (BIOS 509)
Other useful materials:
Concepts
Linear regression model in matrix notation.
Inference for regression coefficient estimates, expected values, and predictions.
Dummy variables.
Effect modification, interactions, and confounding.
Acknowledgements
Lecture notes are build upon materials from Prof. Benjamin Risk and Howard Chang.
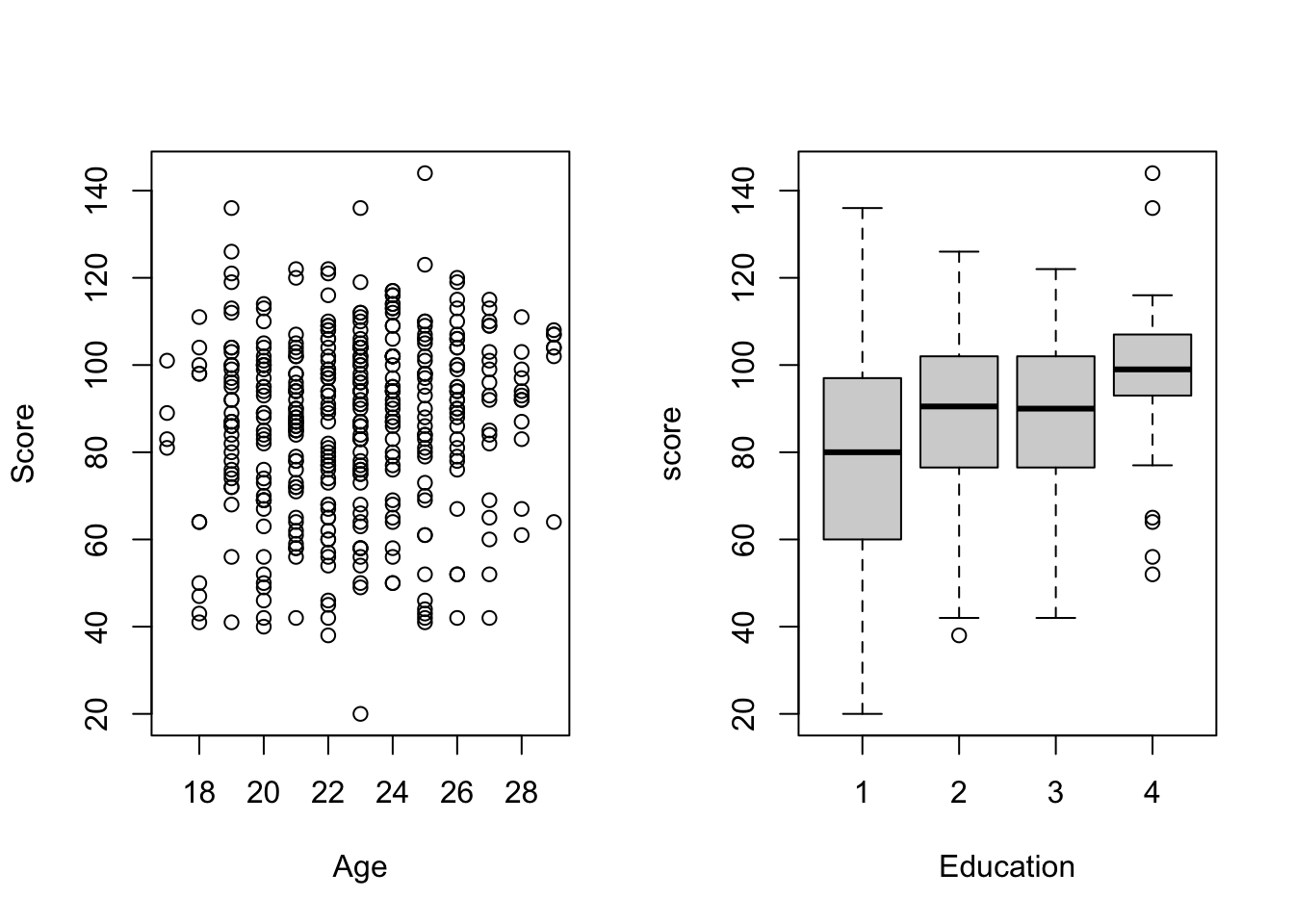
Motivating Example
We are interested in the maternal traits associated with children’s cognitive test scores at age 3. Using data from a survey of adult American women and their children from the National Longitudinal Survey of Youth.
Variables:
score: cognitive test score at age 3.
age: maternal age at delivery
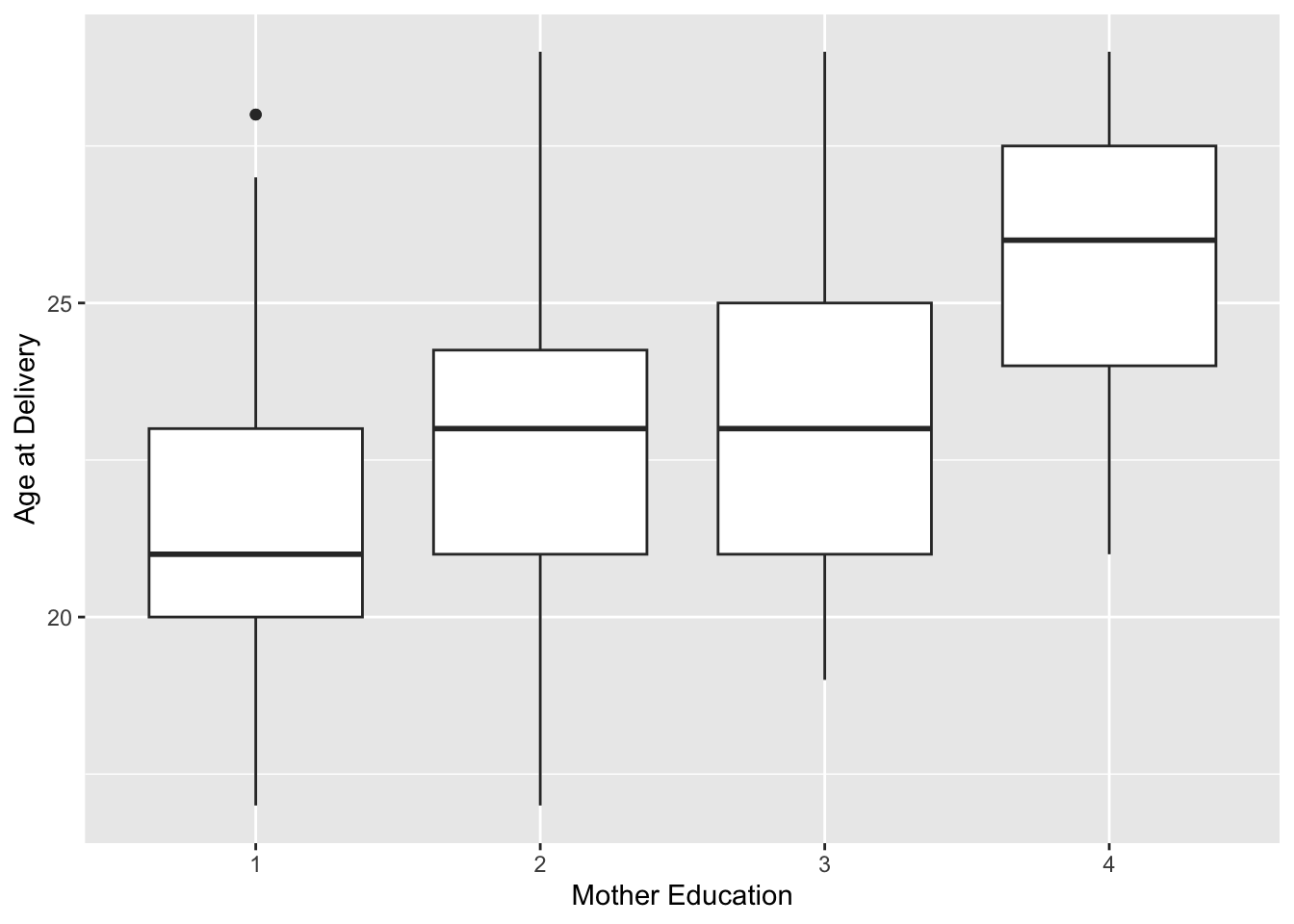
edu: maternal education (1) less than high school, (2) high school, (3) some college, (4) college and above.
Rows: 400 Columns: 3
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (3): score, edu, age
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Min. 1st Qu. Median Mean 3rd Qu. Max.
20.00 74.00 90.00 86.93 102.00 144.00
table(dat$edu)
1 2 3 4
85 212 76 27
summary(dat$age)
Min. 1st Qu. Median Mean 3rd Qu. Max.
17.00 21.00 23.00 22.79 25.00 29.00
par(mfrow =c(1,2))plot(score ~ age, data = dat, xlab ="Age", ylab ="Score")boxplot(score ~ edu, xlab ="Education", data = dat)
Simple Linear Regression
Linear regression is a method that summarizes how the average values of a numerical outcome variable vary over subpopulations defined by linear functions of predictors. Two goals of linear regression:
Prediction of outcome values given fixed predictor values.
Assessment of impact of predictors on the outcome (Estimation).
Let denote the test score for a given child . denotes the corresponding maternal age at delivery for mom corresponding to child , and denotes the error term. We will consider the following linear model:
We can write Eq. 1 in matrix form by stacking observations by row:
In-class exercise
Define the different components .
What is the expected value of ?
What is the variance of ?
What is the covariance of ?
Assumptions of the above model
is a linear function of , i.e, is linear.
the test score for a child born of a mother at age=0 (not meaningful!)
increase in test score associated with one year increase in maternal age.
Expectation of the errors in zero.
Least Squares Solution
Our aim is to find estimates ofandthat “best” fit the data, but what does “best” mean?
We seek that minimizes a loss function.
Our approach is to minimize the sum of squared differences between and , i.e., this defines the differences between and the predicted value based on a fixed set of .
Theorem
If then the value of that minimizes is .
is the fitted (predicted) value.
defines the residual error.
In-class exercise
Let’s show this!
For OLS, we have a nice closed-form solution.
Other loss functions or models often require iterative optimization routines.
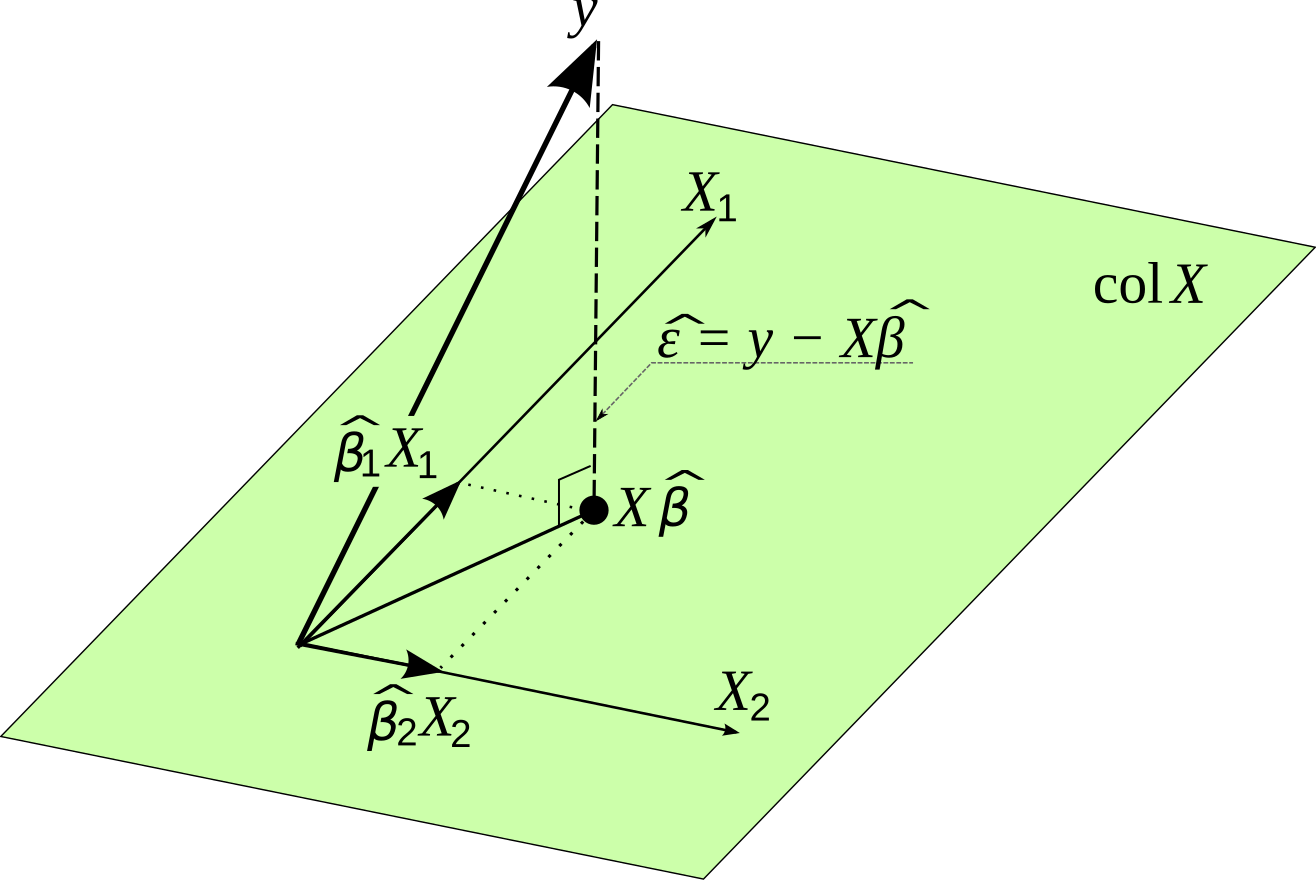
Geometric Interpretation of the OLS estimate
The fitted values are a linear transformation of . We in real space is projected on is model space.
The HATmatrix is defined as . It is a projection matrix that projects to .
The projection matrix is idempotent, i.e., .
The trace of the projection matrix is the number of covariates plus intercept, i.e, .
and are independent, i.e., orthogonal (perpendicular in model space).
A geometrical interpretation of least squares.
Properties of the OLS Estimator
If then is unbiased for .
is consistent estimation of under very general assumptions, i.e., .
is an unbiased estimator of the mean trend .
If , the covariance of the estimator .
In-class exercise
Find the .
Gauss-Markov Theorem
and
is the best (minimum variance) unbiased estimator (BLUE) for .
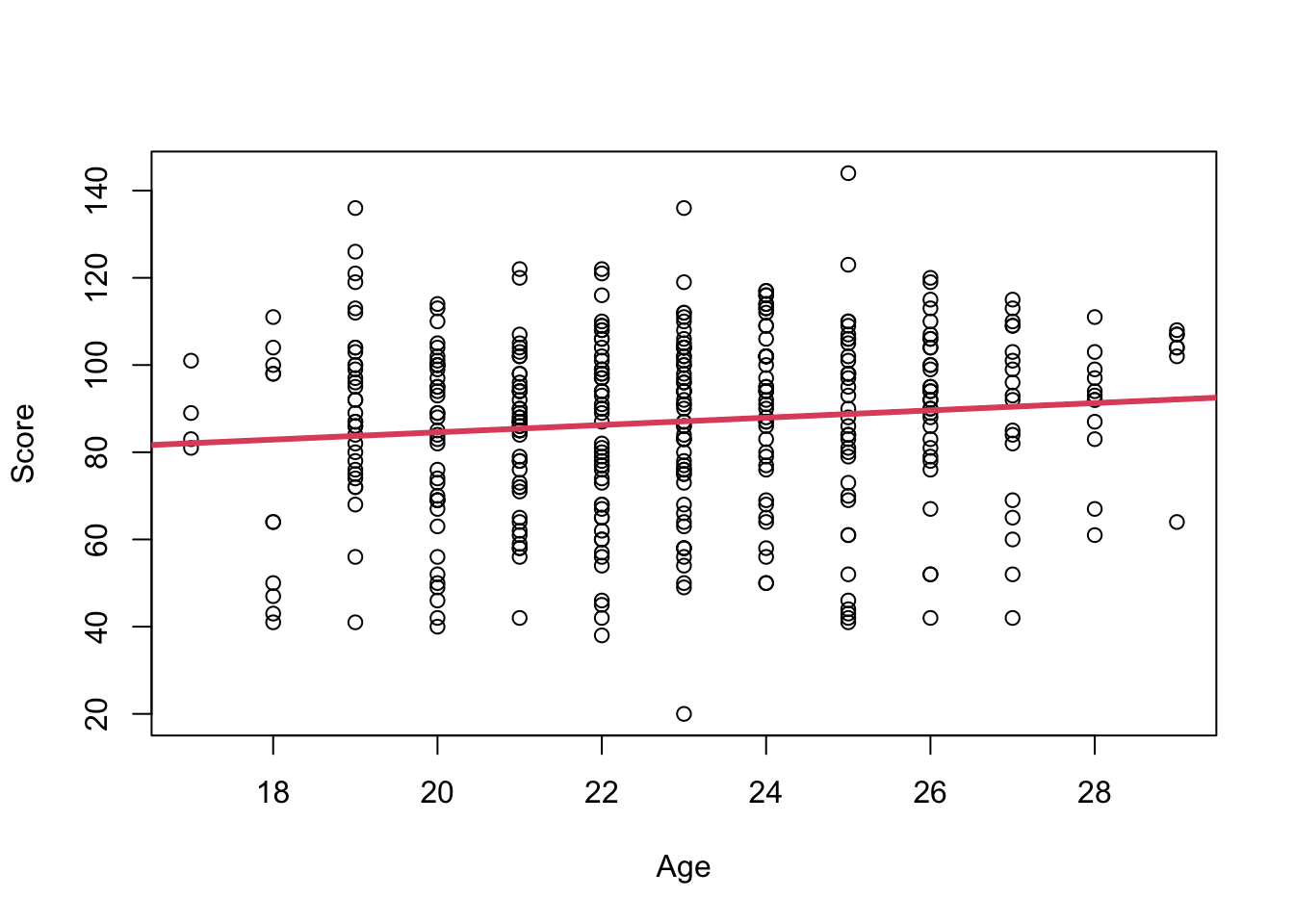
plot(score ~ age, data = dat, xlab ="Age", ylab ="Score")abline(beta, lwd =3, col =2)
Summary I
What is the model?
In simple linear regression, we regress a vector of outcomesvalues on a vector of predictor valueswith:
is avector of regression coefficients: (1) the intercept, and (2) the covariate coefficient.
Model Assumptions
global variance
is a linear function of
orthogonalityindependence
Least Squares Solution
is the best (smallest variance) linear unbiased estimator of the true
and
The HAT matrix is a projection matrix which projects to
Interpretation
the global value ofwhen
the global value of the change offor every one unit change of
captures the total variance across all observations
Statistical Linear Regression & Inference
The relation between OLS, Normality, and Maximum Likelihood
So far, we have not discussed the distribution of the errors. For OLS we did not need to make any distributional assumption. For inference, let’s now assume
where .
What does i.i.d mean? identically and independently distributed. This implies the following model:
is normally distributed.
This parametrization is equal to
.
where captures the trend
where captures the variability (uncertainty) around the trend. It is constant, i.e., the same across all observations.
In matrix form: where .
is unkown!
The Maximum Likelihood
The likelihood of the normal distribution is given by
Taking the log of the likelihood, we get:
To find Maximum Likelihood Estimators we take partial derivatives and set the equal to zero to find the estimators that maximize the log-likelihood.
What do we get?
so under normality.
.
so it is NOT unbiased.
An unbiased estimator for is given by .
Summary of OLS vs. MLE approaches
OLS
MLE
Distributional assumption
NONE
Normal
Estimator
Estimator
Cannot get
is biased
Residual Error
Above we determined that the unbiased estimator of is .
library(ggplot2)#Here p = 2fit =lm(score ~ age, data = dat)summary(fit)
Call:
lm(formula = score ~ age, data = dat)
Residuals:
Min 1Q Median 3Q Max
-67.109 -11.798 2.971 14.860 55.210
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 67.7827 8.6880 7.802 5.42e-14 ***
age 0.8403 0.3786 2.219 0.027 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 20.34 on 398 degrees of freedom
Multiple R-squared: 0.01223, Adjusted R-squared: 0.009743
F-statistic: 4.926 on 1 and 398 DF, p-value: 0.02702
#Can we confirm this manuallyyhat = fit$fitted.values #Predicted Valuesy = dat$score #Observed ValuesN =length(y)P=2#number columns in design matrixsq_error = (y-yhat)^2#Squared errorssigma_squared_est <-sum(sq_error)/(N-P) #Unbiased est of the variancesigma_est =sqrt(sigma_squared_est) #Unbiased est of the std. errorsigma_est
[1] 20.34027
#Include 95% confidence intervals in your summaryconfidence_intervals <-predict( fit, interval ="confidence", level =0.95)confidence_intervals[1:3,]
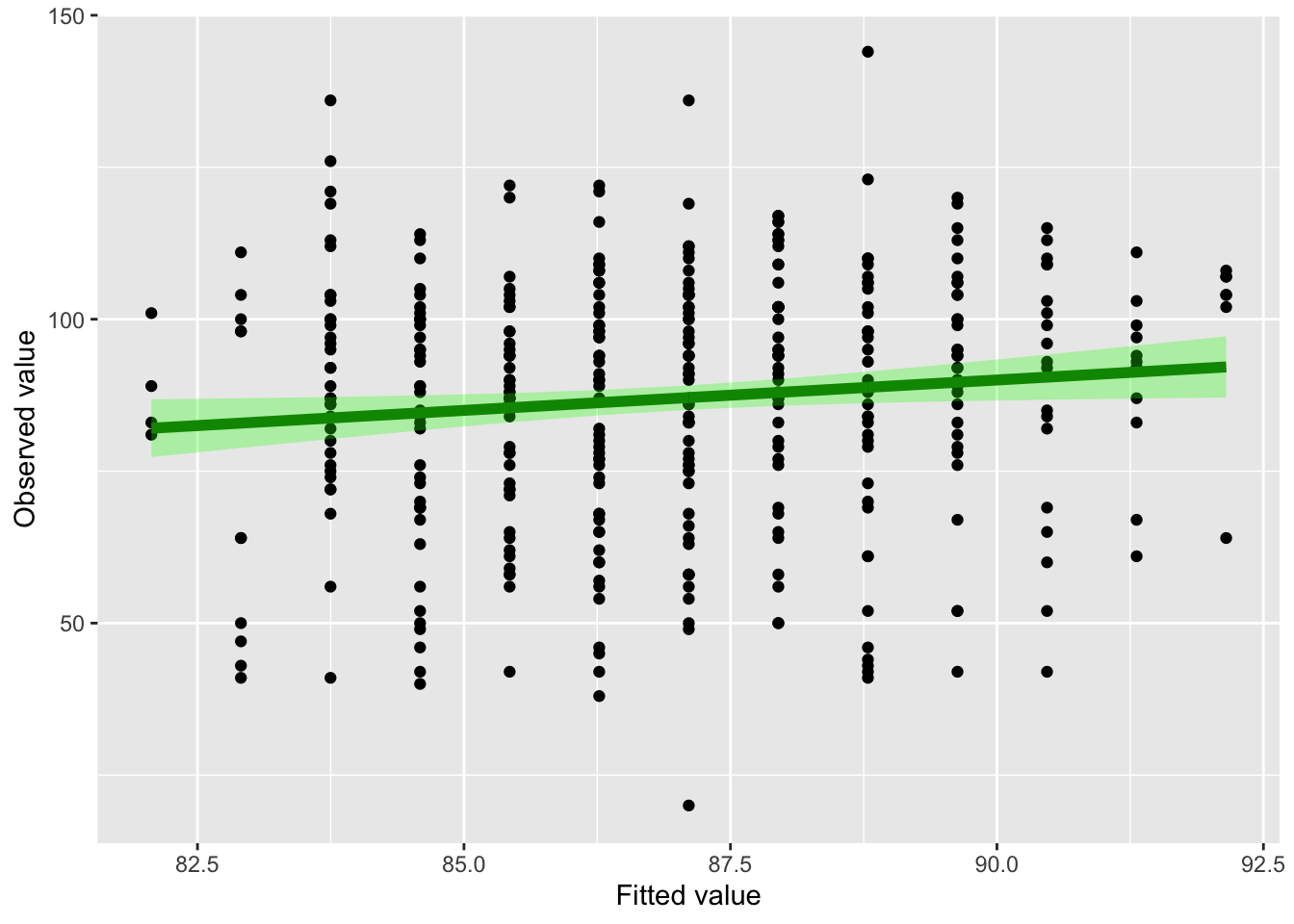
est <- fit$coefficients[1] + fit$coefficients[2] * dat$age#Now add the 95% confidence intervals surrounding the fitted valuesplot_data <-data.frame(dat$age, dat$score, confidence_intervals, est)ggplot(plot_data) +geom_point(aes(fit, dat.score)) +geom_line(aes(fit,est), col ="darkgreen", lwd=2) +geom_ribbon(aes(x=fit, ymin =lwr, ymax = upr ), fill ="green", alpha =0.3) +labs(x ="Fitted value", y ="Observed value")
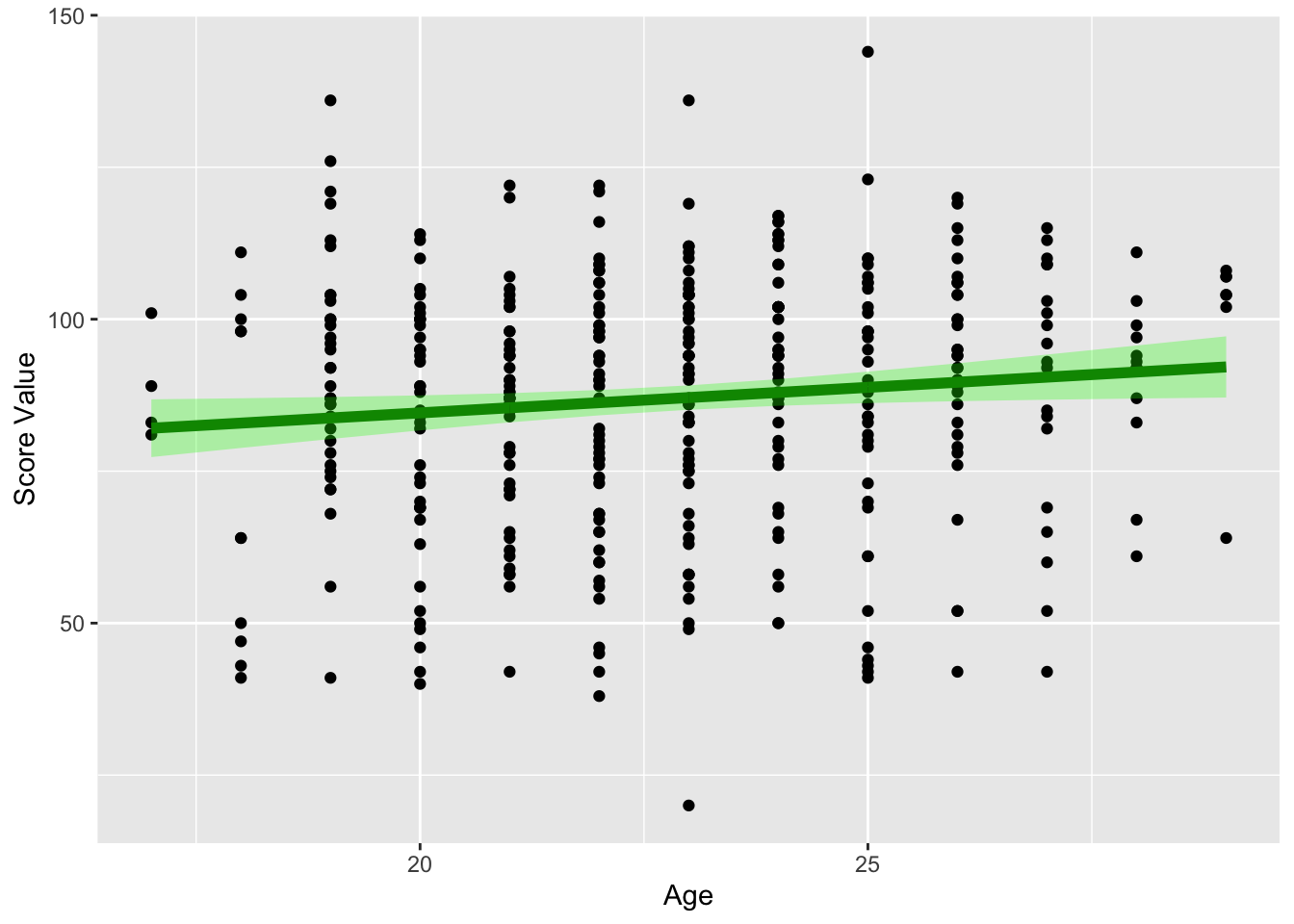
ggplot(plot_data) +geom_point(aes(dat.age, dat.score)) +geom_line(aes(dat.age,est), col ="darkgreen", lwd=2) +geom_ribbon(aes(x=dat.age, ymin =lwr, ymax = upr ), fill ="green", alpha =0.3) +labs(x ="Age", y ="Score Value")
Model Interpretation
fit =lm(score ~ age, data = dat)summary(fit)
Call:
lm(formula = score ~ age, data = dat)
Residuals:
Min 1Q Median 3Q Max
-67.109 -11.798 2.971 14.860 55.210
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 67.7827 8.6880 7.802 5.42e-14 ***
age 0.8403 0.3786 2.219 0.027 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 20.34 on 398 degrees of freedom
Multiple R-squared: 0.01223, Adjusted R-squared: 0.009743
F-statistic: 4.926 on 1 and 398 DF, p-value: 0.02702
Interpretation: A one year increase in mother’s age at delivery was associated with a X (95%CI = ) increase in the child’s average test score, where test score was measured at age 3. Th association was statistically signifianct at a type I error rate of 0.05.
There was considerable heterogeneity in test scores . Therefore, the regression model does not predict individual test scores well . 1.2% of variances is explained by mother’s age.
Prediction Interval for a New Observation
Let be a new observation with covariate value . How can you obtain its uncertainty? We want to capture the uncertainty in our predicted estimate of the expected value PLUS the uncertainty due to measurement error .
The total uncertainty surrounding the predicted value can be broken down as the sum of two components.
Taking the variance of Equation XX.
We know the first term on the right, and so .
We know the variance of the error term .
We plug in our estimators to get the predicted variance
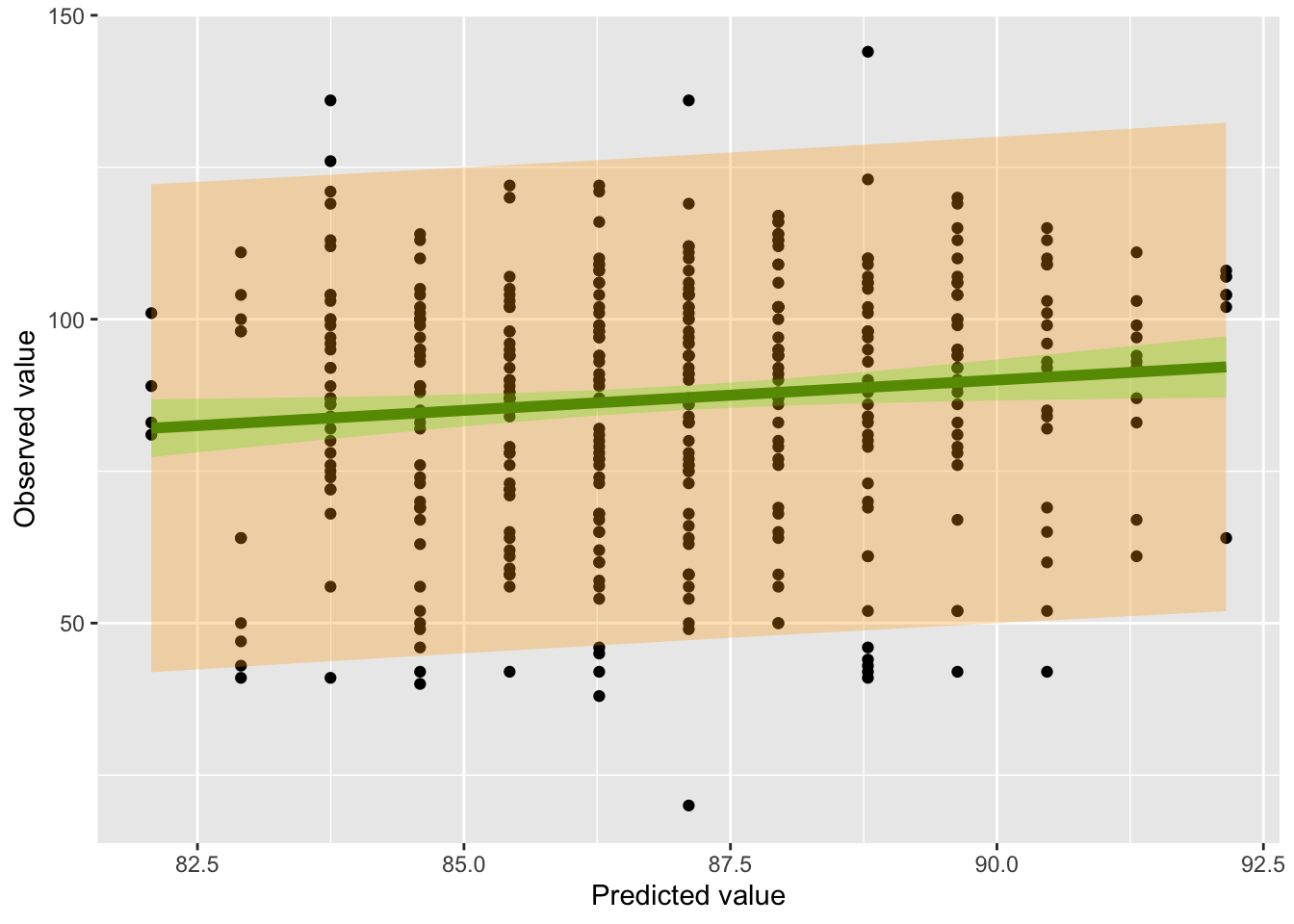
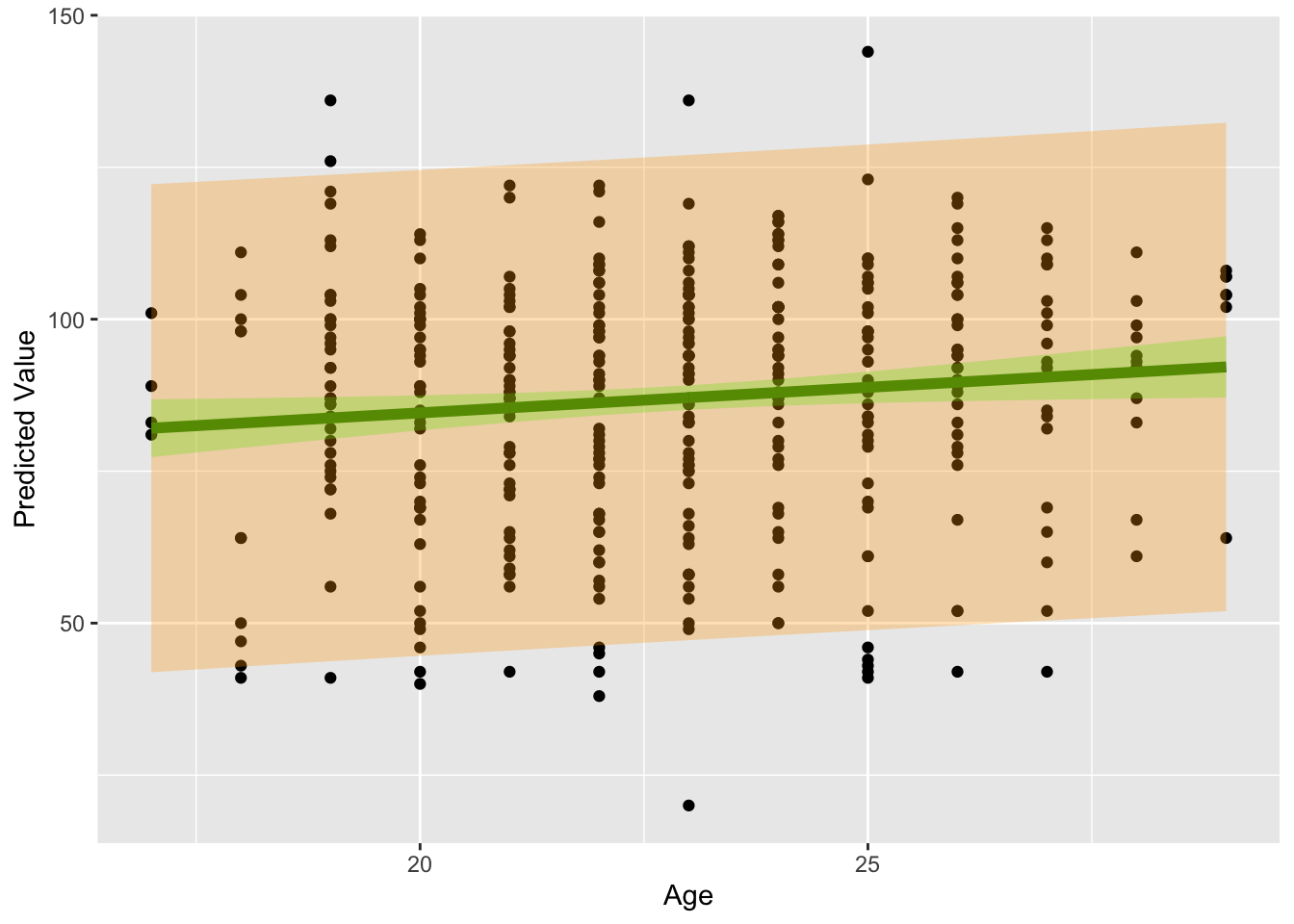
From this derivation we can see that . So the 95% prediction interval is going to be wider than the 95% confidence interval.
The approximate 95% prediction interval is given by .
X =cbind(1, dat$age)Y = dat$scoreinvXtX =solve(t(X) %*% X)beta = invXtX %*%t(X) %*% Ysigmahat =sum((Y- X%*%beta)^2)/(length(Y) -2)V = sigmahat * invXtXvar_pred =diag(X %*% V %*%t(X)) + sigmahatlwr_pred = fit$fitted.values -1.96*sqrt(var_pred)uppr_pred = fit$fitted.values +1.96*sqrt(var_pred)#Now add the 95% prediction intervals surrounding the fitted valuesplot_data2 <-data.frame(dat$age, dat$score, confidence_intervals, est, lwr_pred, uppr_pred)ggplot(plot_data2) +geom_point(aes(fit, dat.score)) +geom_line(aes(fit,est), col ="darkgreen", lwd=2) +geom_ribbon(aes(x=fit, ymin =lwr, ymax = upr ), fill ="green", alpha =0.3) +geom_ribbon(aes(x=fit, ymin =lwr_pred, ymax = uppr_pred ), fill ="orange", alpha =0.3) +labs(x ="Predicted value", y ="Observed value")
ggplot(plot_data) +geom_point(aes(dat.age, dat.score)) +geom_line(aes(dat.age,est), col ="darkgreen", lwd=2) +geom_ribbon(aes(x=dat.age, ymin =lwr, ymax = upr ), fill ="green", alpha =0.3) +geom_ribbon(aes(x=dat.age, ymin =lwr_pred, ymax = uppr_pred ), fill ="orange", alpha =0.3) +labs(x ="Age", y ="Predicted Value")
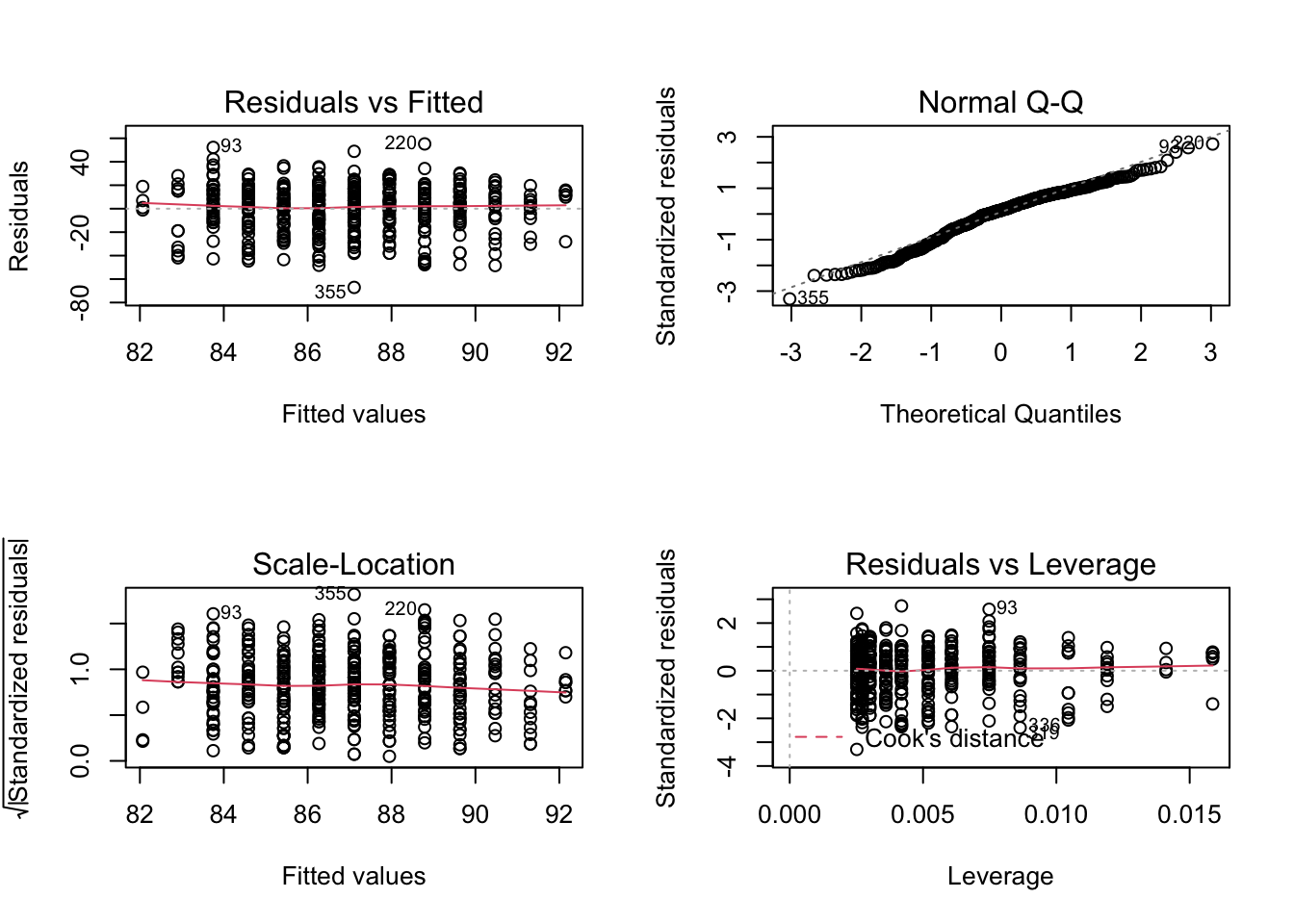
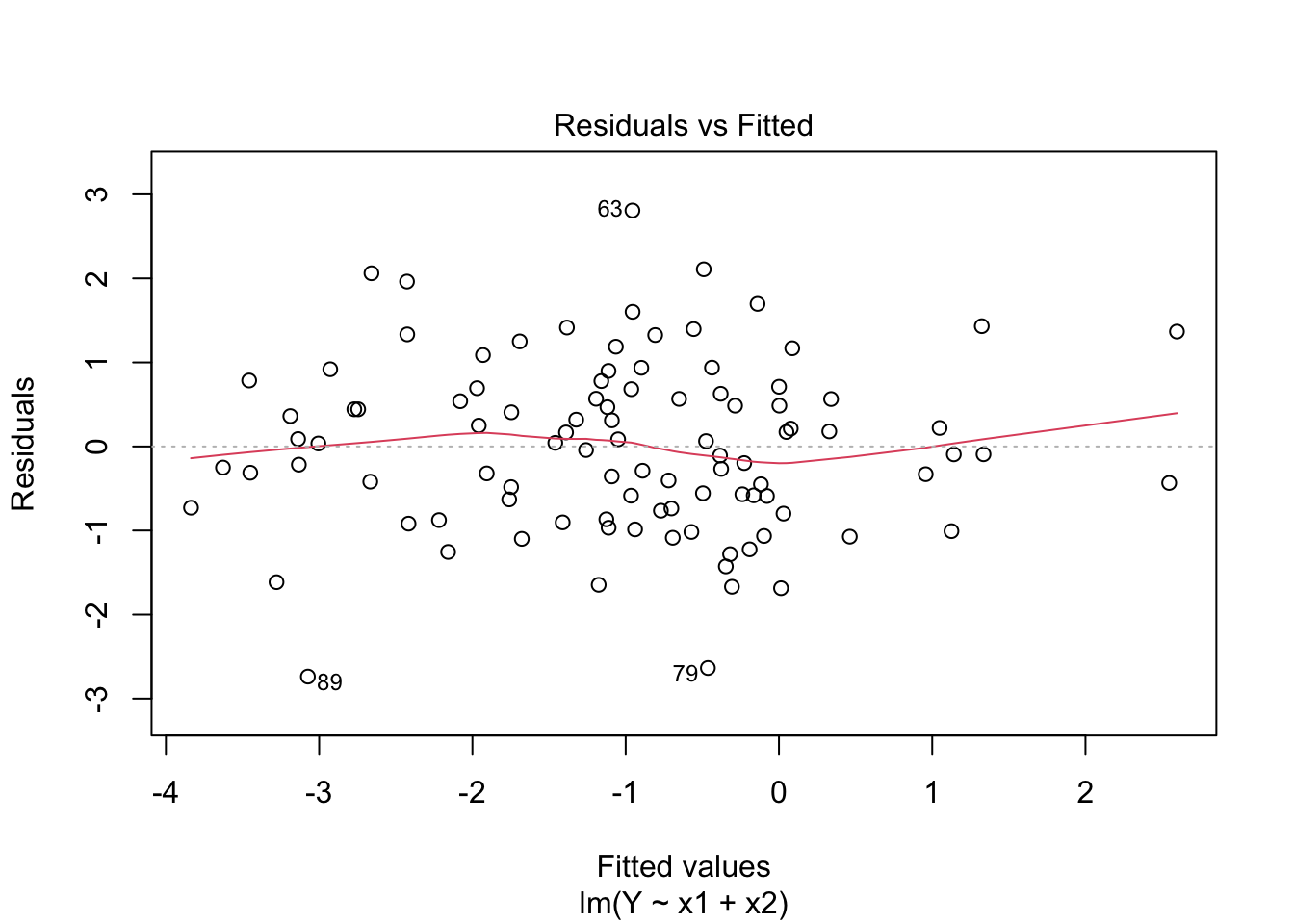
Model Diagnostics
Residual vs. Fitted
should be independent of , i.e., no patterns.
Linearity: Red line should be flat, ie banded around 0.
Constant variance (homoscedasticity).
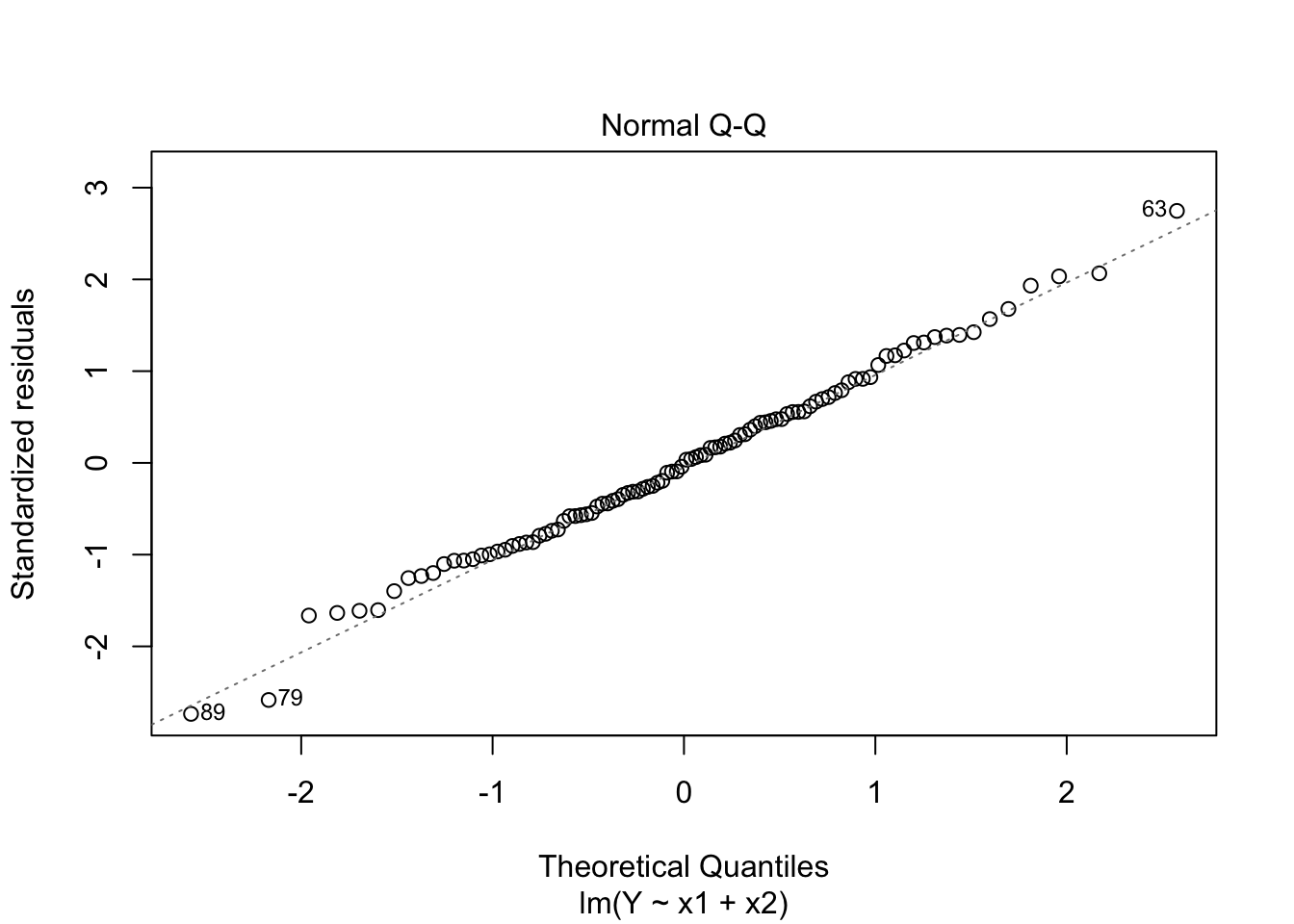
Normal Q-Q Plot
Standardized residual should be a standard normal.
We expect the points to follow a straight line, Check non-normality, particularly skewed tails.
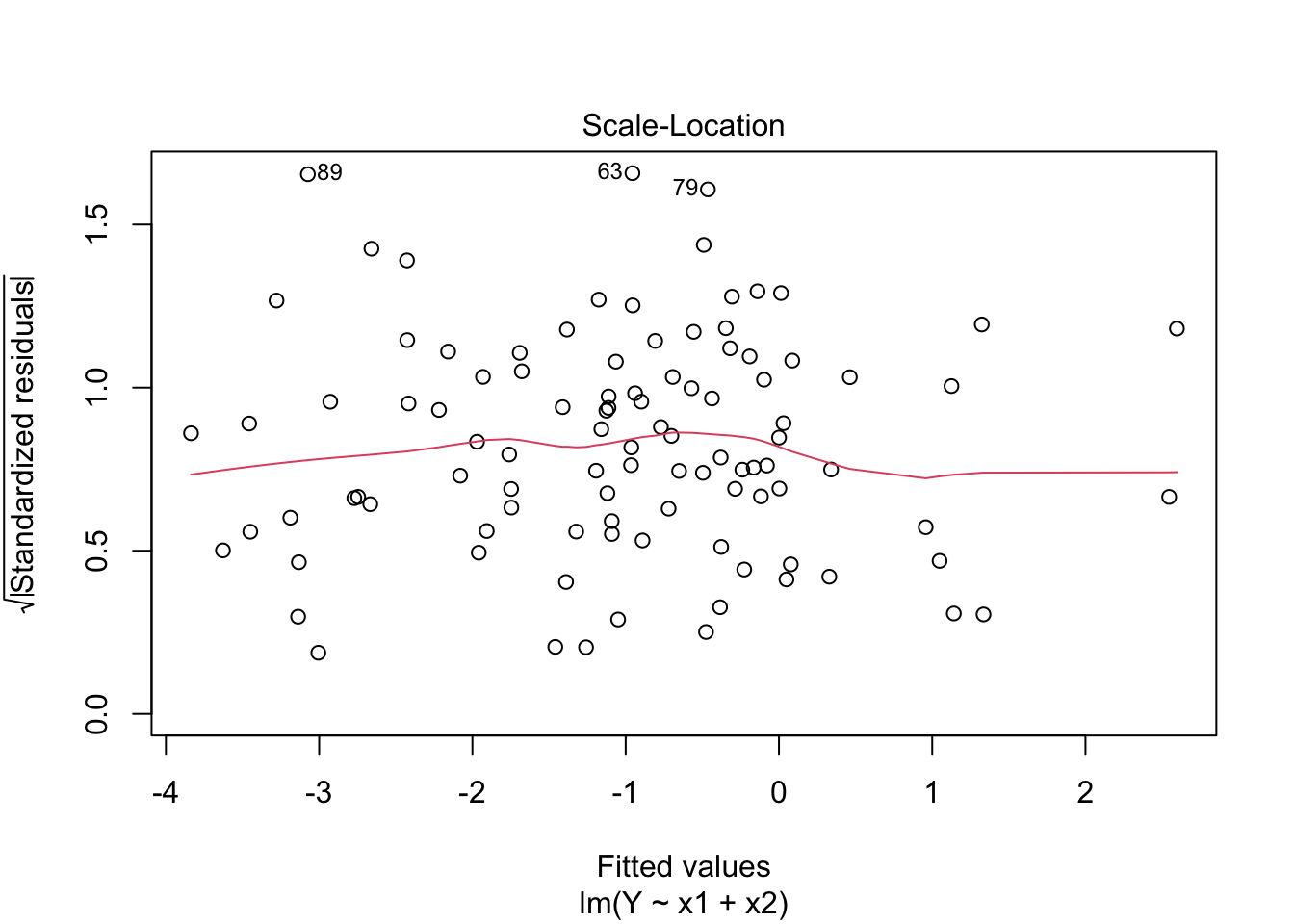
Scale-Location
Similar to residual vs fitted, but use standardized residual. Diagnose heteroscedasticity (eg red line increasing).
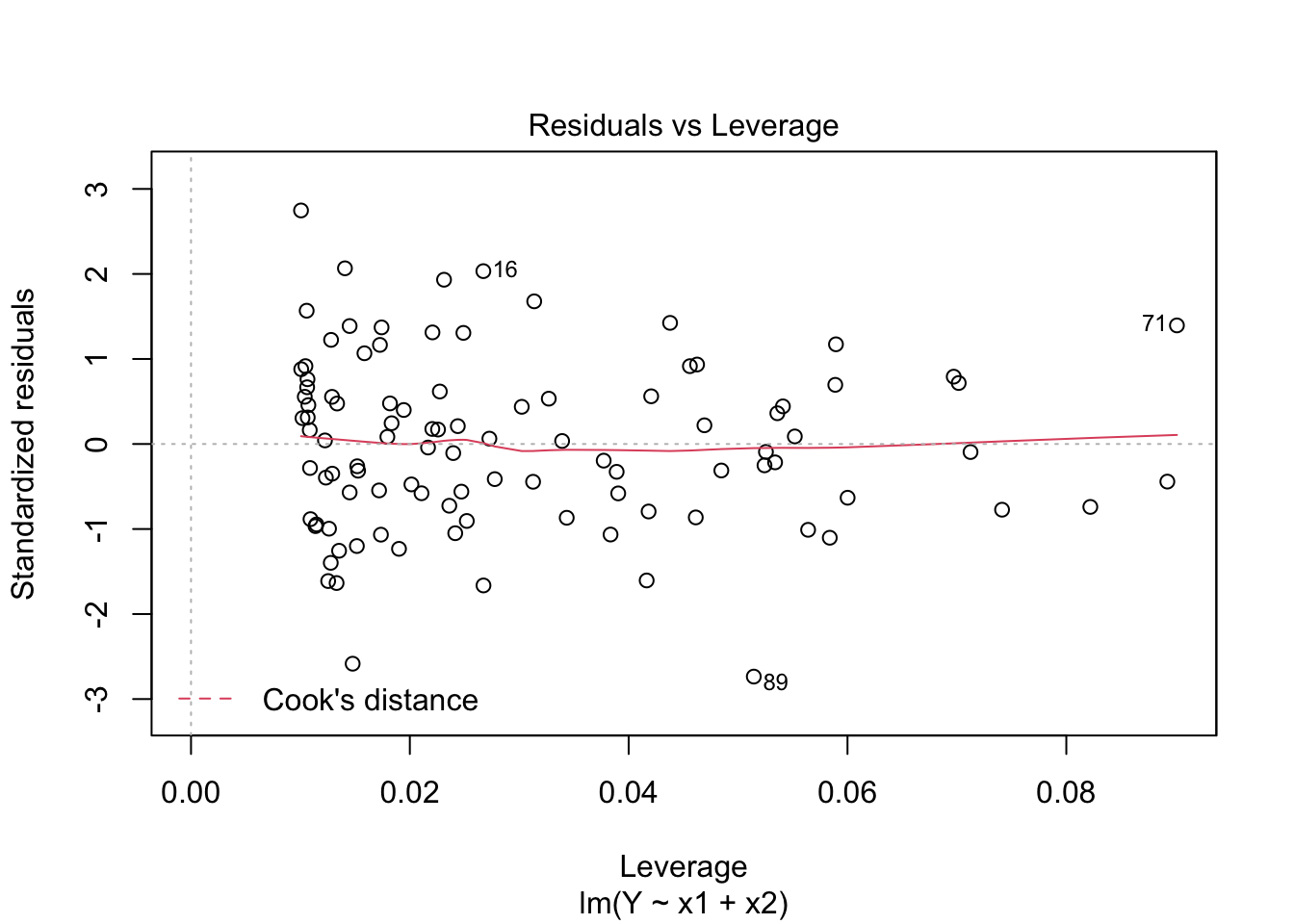
Residual vs Leverage
Leverage is how far away is from other where .
Cook’s Distance: measures how much model changes when remove point; >1 is problematic.
par(mfrow=c(2,2))plot(fit)
Hypothesis Testing
(Intercept): when . In other words test scores are equal to zero for a mother at versus .
Age: In words, the slope of age is equal to zero or there is no linear effect. if there is a significant linear effect.
summary(fit)
Call:
lm(formula = score ~ age, data = dat)
Residuals:
Min 1Q Median 3Q Max
-67.109 -11.798 2.971 14.860 55.210
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 67.7827 8.6880 7.802 5.42e-14 ***
age 0.8403 0.3786 2.219 0.027 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 20.34 on 398 degrees of freedom
Multiple R-squared: 0.01223, Adjusted R-squared: 0.009743
F-statistic: 4.926 on 1 and 398 DF, p-value: 0.02702
Tip
In class exercise:
What conclusions can we make about the intercept and the impact of age?
Summary II
What is the model?
In multiple linear regression, we regress a vector of outcomesvalues on multiple vector of predictor valueswith:
is a *vector of regression coefficients:
the intercept* , and (2) the covariate coefficients.
Model Assumptions
is i.i.d normally distributed .
global variance
is a linear function of
orthogonalityindependence
Maximum Likelihood
is the best (smallest variance) linear unbiased estimator of the true and is equal to under normality.
and
is biased
is an unbiased estimator
Interpretation
the global value ofwhen
the global value of the change offor every one unit change of
captures the total variance across all observations but is a biased estimator
Prediction
The predicted value is given by.
The uncertainty around the predicted value is equal to .
is the sum of the data varianceand the global variance, i.e.,
Diagnostics
Linearity: Residuals vs Fitted should be banded around 0 with constant variance, i.e., no patterns.
Normality: Normal QQ Plot should follow the straight line with slightly skewed tails.
Constant variance: Standardized residuals should show flat line
Residual vs Leverage: Shows impact of outlier values, Cook’s distance >1 is problematic.
Hypothesis Testing
is the null hypothesis of no effect.
is the alternative hypothesis of a significant effect not equal to zero.
BREAKOUT SESSION 1
Let and let . Then
Show the derivation for .
What is the unbiased estimator of ?
The unbiased estimator for contains a parameter . What does represent?
Below code is given to simulate data from a “true” model. Run the code to get simulated quantities of covariates and outcomes .
What is the “true” intercept in the below simulation?
What is the “true” covariate coefficient value in the below simulation?
Fit the linear model. Find the estimates of the and global variance .
Interpret the findings of the model in terms of null versus alternative hypotheses.
Create diagnostic plots and determine if model assumptions have been met.
fit =lm(dat$score ~ E1 + E2 + E3 + E4 -1) #use -1 to remove the interceptsummary(fit)
Call:
lm(formula = dat$score ~ E1 + E2 + E3 + E4 - 1)
Residuals:
Min 1Q Median 3Q Max
-58.45 -12.70 1.61 15.23 57.55
Coefficients:
Estimate Std. Error t value Pr(>|t|)
E1 78.447 2.159 36.33 <2e-16 ***
E2 88.703 1.367 64.88 <2e-16 ***
E3 87.789 2.284 38.44 <2e-16 ***
E4 97.333 3.831 25.41 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 19.91 on 396 degrees of freedom
Multiple R-squared: 0.9508, Adjusted R-squared: 0.9503
F-statistic: 1913 on 4 and 396 DF, p-value: < 2.2e-16
What does each element of vector mean?
is equivalent to taking the average of scores for kids with mother’s . So each is equivalent to calculating the mean IQ for each education group.
In class exercise
What is the estimated difference in average score between mothers without high school and mothers with college and above?
Approach 2: Intercept plus three indicators for groups 2,3, and 4.
fit =lm(dat$score ~factor(dat$edu))summary(fit)
Call:
lm(formula = dat$score ~ factor(dat$edu))
Residuals:
Min 1Q Median 3Q Max
-58.45 -12.70 1.61 15.23 57.55
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 78.447 2.159 36.330 < 2e-16 ***
factor(dat$edu)2 10.256 2.556 4.013 7.18e-05 ***
factor(dat$edu)3 9.342 3.143 2.973 0.00313 **
factor(dat$edu)4 18.886 4.398 4.294 2.21e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 19.91 on 396 degrees of freedom
Multiple R-squared: 0.05856, Adjusted R-squared: 0.05142
F-statistic: 8.21 on 3 and 396 DF, p-value: 2.59e-05
represents the difference in average score with respect to the group., i.e., 10.256 is the average difference between no high school group and high school group.
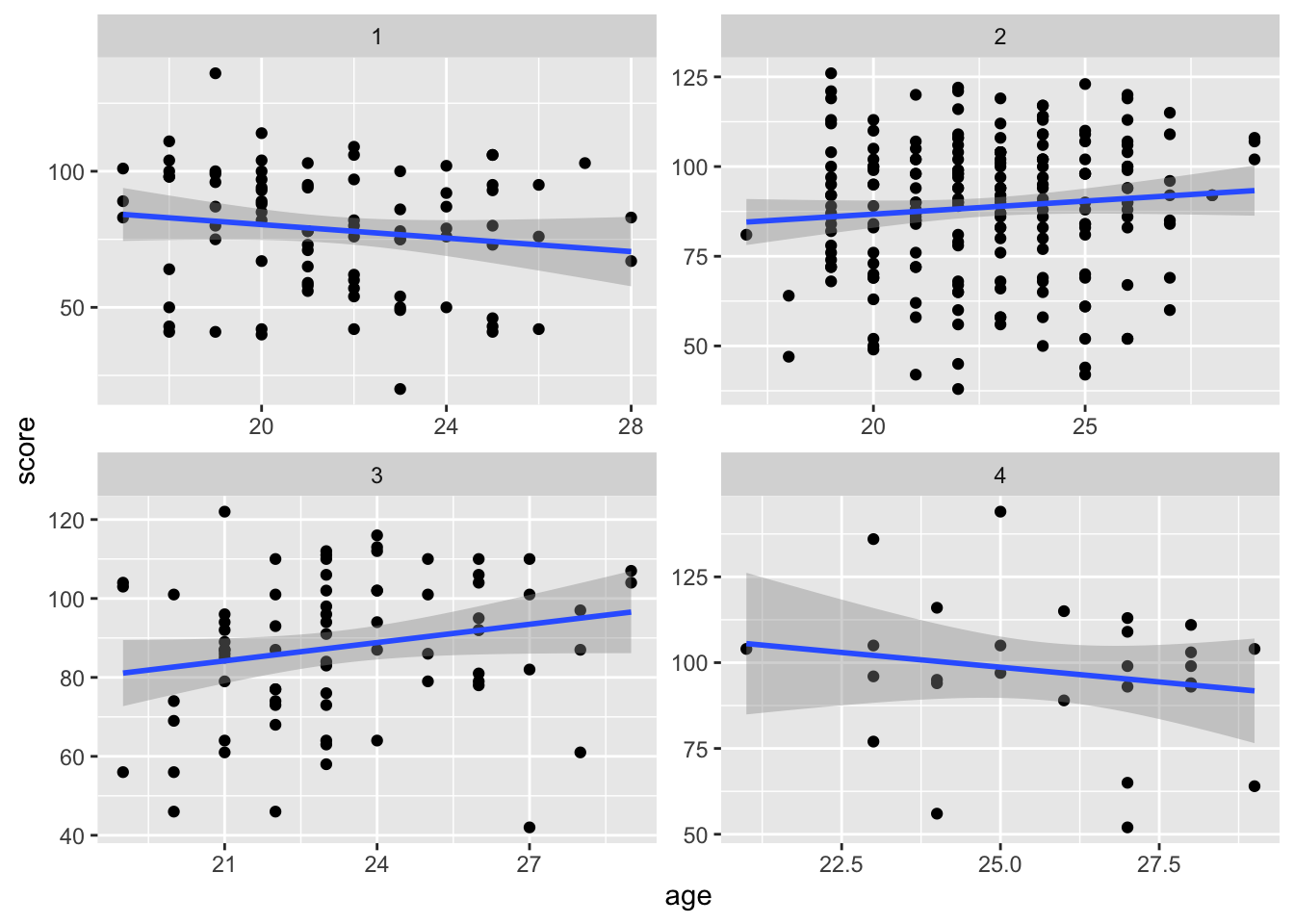
Adjusting for Confounding:
Consider the above model: .
Each education group has their own coefficient.
The slope of maternal age is constant across education groups (parallel lines).
is the association between score and age, accounting for different averages in score in different education groups.
fit =lm(score ~factor(edu) + age, data = dat)summary(fit)
Call:
lm(formula = score ~ factor(edu) + age, data = dat)
Residuals:
Min 1Q Median 3Q Max
-58.853 -12.112 1.779 14.687 58.298
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 72.2360 8.8700 8.144 5.07e-15 ***
factor(edu)2 9.9365 2.5953 3.829 0.000150 ***
factor(edu)3 8.8416 3.2203 2.746 0.006316 **
factor(edu)4 17.6809 4.7065 3.757 0.000198 ***
age 0.2877 0.3985 0.722 0.470736
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 19.92 on 395 degrees of freedom
Multiple R-squared: 0.0598, Adjusted R-squared: 0.05028
F-statistic: 6.28 on 4 and 395 DF, p-value: 6.59e-05
Age effect is no longer statistically significant after accounting for mother’s education level.
This model assumes an identical effect of age across ALL education groups.
Is this assumption realistic?
Variance Inflation Factors
One must always be on the lookout for issues with multicollinearity!
The general issues is that when two variables are highly correlated, it is hard to disentangle their effects.
Mathematically, the standard errors are inflated. Suppose we have a design matrix and we want to calculate the variance inflation factor (VIF). We regress against .