Chapter 1, Jolliffe, I. “Principal Component Analysis, 2nd Edition”.
Chapter 8 Mardia, K., and J. Kent and J. Bibbt. Multivariate Analysis.
A paper I really like, it is more advanced than we cover in this course: Tipping, M.E. \& Bishop C. M. (1999). Probabilistic principal component analysis. Journal of Royal Statistical Society: Series B. 61(3), 611-622.
Basic Concepts
Dimension Reduction
EVD, SVD, PCs
Principal component regression for correlated variables.
Big Goal: To find meaning from high dimensional data. In other words, find a low dimensional representation. This is referred to as dimensionality reduction.
PCA is a statistical technique used to reduce dimensionality of a data while retaining as much variability as possible.
Key Features:
Each PC captures maximum possible variance.
PCs are mutually orthogonal (uncorrelated)
PCA create components as linear combinations of the original variables.
PCA reduces number of dimensions by selecting top few that explain of the variance.
Suppose we have measurements on each of variables . Let .
Generate a set of uncorrelated variables .
Ways to think about PCA:
Approximate by the best rank matrix . This is the usual motivation for the Singular Value Decomposition (SVD).
Approximate the original set of points in by a sequence of best linear approximations to the data.
PCA in Practice
Applications Include
Dimension reduction
Factor Analysis
Data compression and reconstruction
Data Visualization
A way to address multicollinearity via PCA regression
A way to reduce .
Key Concept: when variables are correlated, there exists a lower dimensional reduction capturing most of the information.
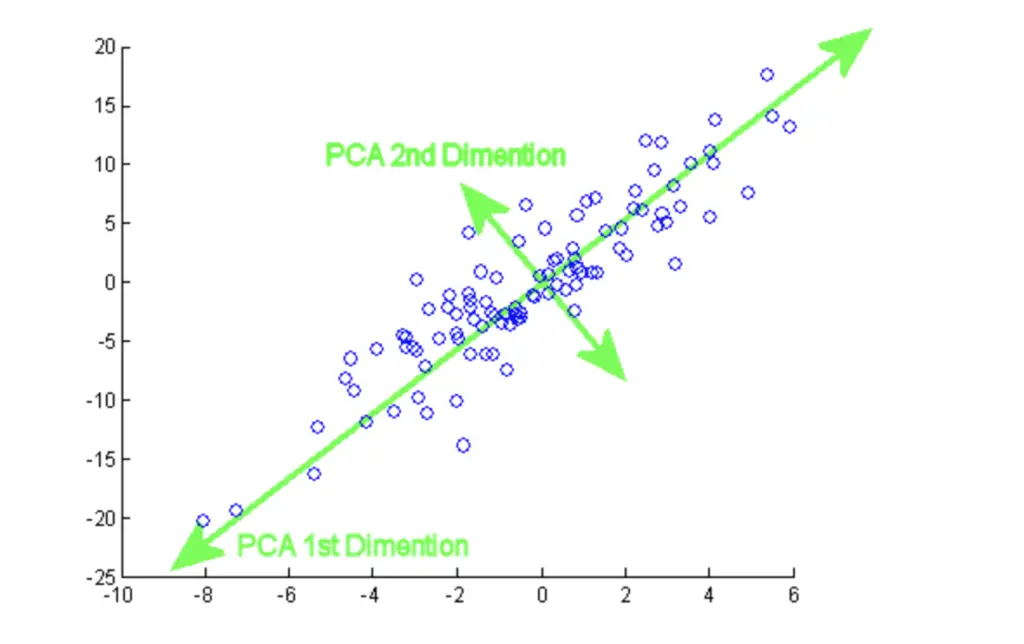
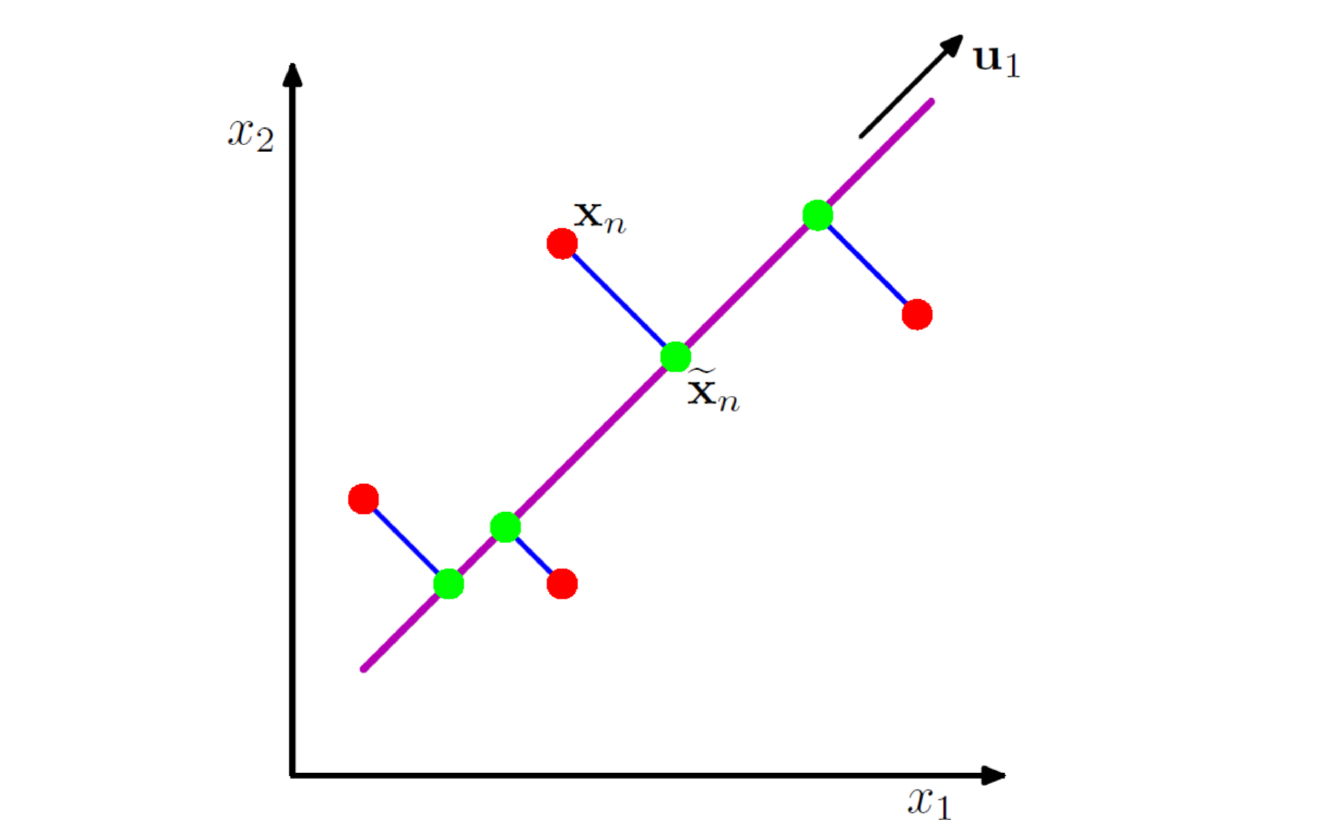
Example of PCA in two dimensions
is the projection of the data onto the longest direction, and has the largest variance among projections. It is the first principal component (PC1).
: The PC1 direction, a vector in the space of the original variables, determined to maximize the variance of the data along this direction.
: The projection of the data onto the PC1 direction . This new variable represents the data transformed into the PC1 space.
Consider a dataset with 4 observations and 2 variables:
2
1
4
3
6
5
8
7
Step 1: Center the Data: subtract the mean of each variable. This ensures that variance drives the analysis because the means are shifted to zero.
Mean of , mean of .
Centered data:
Step 2: Find the Principal Components Using Eigen Value Decomposition (EVD)
The first principal component () is the direction with the largest variance, roughly .
The second principal component () is orthogonal to .
Step 3: Project Data onto The projection of each centered data point onto is:
For example, for 1st observation :
Step 4: Interpretation The new variable (all values for each observation) captures the largest variance in the data. The original data can be approximated as:
providing a lower-dimensional representation.
Visualization
The first principal component represents the diagonal direction of greatest spread. Projections onto this line simplify the data into one dimension while retaining most of the information.
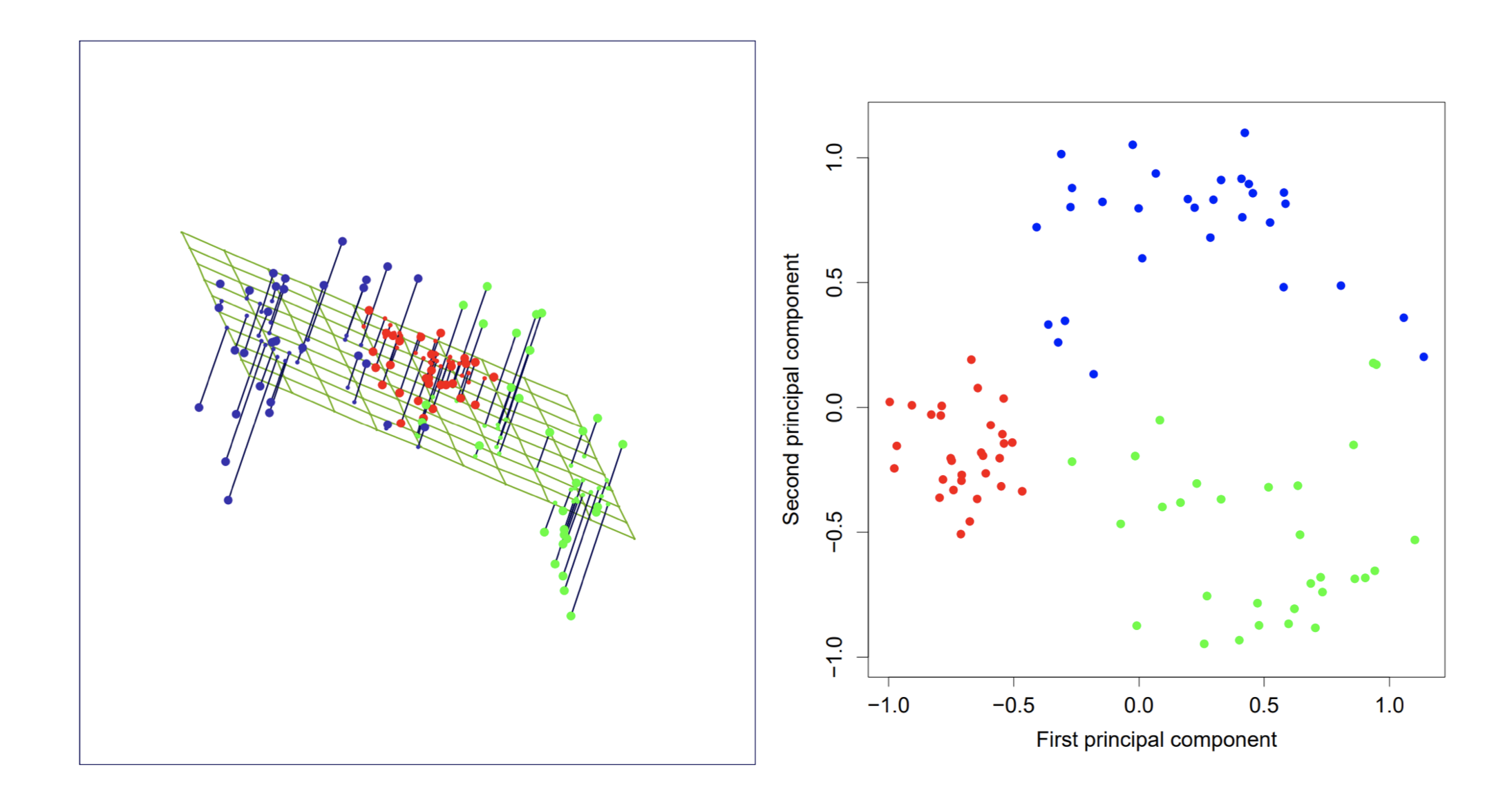
PCA in three dimensions
The best rank-two linear approximation to the half sphere data.
Figure: The left displays the projection from to . The right shows the points projected on the principal axes and , which are the subject scores .
Contrasting PCA and OLS: Supervised vs. Unsupervised Learning
PCA is an unsupervised learning problem.
For example, we have data in different categories and covariates; PCA finds “clusters” without knowing the categories.
And treats ALL variables as equal contributors to the overall variance.
PCA treats data symmetrically for i.e., what is the “best” representation of all variables.
In contrast OLS is a type of supervised learning problem.
Goal is to predict based on 1+ predictors.
Assumes is dependent on .
Prioritizes as the outcome variable, i.e., does not treat them symmetrically, and seeks to explain based on predictors.
Optimization Problem
In PCA, we will find a sequence of directions that successively maximize the variance explained in the data, given the previous directions.
Let’s first find the rank-1 projection of the data that captures the most variance:
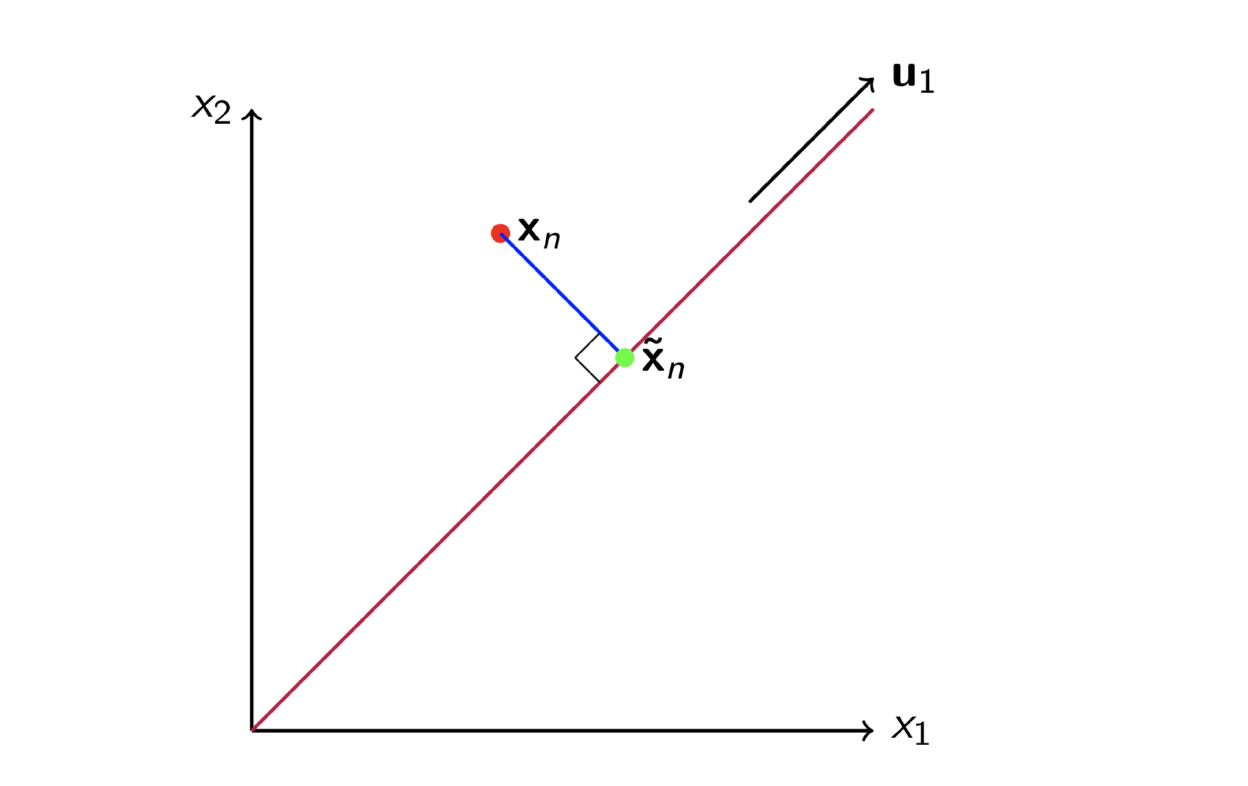
A rank-1 projection transforms data points (rows of ) onto the line spanned by , i.e., for each point, the projection is .
Note the constraint is necessary for this to be finite and for to be a unit vector.
Note how PCA treats data symmetrically, which contrasts with OLS which for tries to predict .
Projecting a Data Point
Finding PC 1
Let
where is the covariance matrix defined as :
The previous equation can be rewritten as:
We can solve this optimization problem using the method of Lagrange multipliers.
To reformulate the constraint into the objective function, we rewrite it such that the of the constrained objective function corresponds to a stationary point:
To find the optimal solution, we calculate the partial derivative of the objective function and set it equal to zero:
The partial derivative is given by:
Setting this equal to zero, we obtain:
where is an eigenvector of the covariance matrix and is the corresponding largest eigenvalue.
Finding PC2
Assume . We next aim to find , orthogonal to , that captures the most information. This can be formulated as:
subject to:
Using the method of Lagrange Multipliers, we formulate the objective function as:
The partial derivative is given by:
To solve for , we take the dot product with :
Since , this simplifies to:
Hence, .
So the Lagrangian equation simplifies to:
And as before, we have:
Hence, is the second largest eigenvalue, and is its corresponding eigenvector.
In , is simply the unique direction orthogonal to . This corresponds to the projection that minimizes the variance.
Spectral Decomposition of Positive Definite Symmetric Matrices
Any positive definite symmetric matrix can be decomposed using the eigenvalue decomposition (EVD), also known as the spectral decomposition:
where:
is a diagonal matrix with elements .
The last eigenvalue is strictly greater than when the matrix is positive definite, i.e., .
Intuitively, positive definite matrices generalize the notion of a positive integer to matrices.
, meaning is an orthogonal matrix (its rows are orthogonal and have unit norm).
Principal Component Scores and Loadings
This decomposition provides us with the principal component (PC) directions and their variances.
Let represent with the rows centered (i.e., for each variable, subtract its mean). Then:
We can compute the EVD of the using the decomposition
Let
where contains the first principal component directions, and represent the directions from to , which contain the remaining variance. Then:
The term is the rank- projection of with the highest variance among all linear projections.
Define . These are the principal component scores, representing a subspace of .
For the th subject, assuming is centered, , and the th component is:
In this projection, weights the variables, and these weights are referred to as the loadings, which form a subspace of .
Key Terminology
Subject Scores: The values represent the projection of a data point onto the principal components, summarizing its position in the principal subspace.
Variable Loadings: The columns of represent how much each variable contributes to the principal components.
The terminology can be confusing, as different authors may arrange the data matrix differently, such that the data matrix may be (variables by subjects) or (subjects by variables).
Variance of Principal Component Scores
Note that the covariance of the principal component scores, , is given by:
Substituting , we have:
Using the eigenvalue decomposition , this simplifies to:
where is the diagonal matrix containing the top eigenvalues.
Interpretation
The eigenvalues are the variances of the principal component scores.
Some treatments constrain the scores to have unit variance, in which case the loadings are adjusted to reflect the variance relationship.
Singular Value Decomposition (SVD) and its Relation to PCA
The singular value decomposition (SVD) of is closely related to PCA:
where:
are the left singular vectors (orthonormal),
are the singular values, and
are the right singular vectors.
Relationship to Covariance Decomposition
From the SVD, we observe:
Since is proportional to the eigenvalues of the covariance matrix, we rewrite this as:
where contains the eigenvalues of the covariance matrix.
The right singular vectors () of the SVD are identical to the eigenvectors from the covariance decomposition.
When (more variables than samples), it is computationally inefficient to calculate the covariance matrix. Instead, SVD provides a more practical alternative.
This is particularly important for working with high-dimensional data.
Principal Component Scores via SVD
We have:
and it follows that:
Interpretation
In words, the first principal component scores are the first left singular vectors, scaled by their corresponding singular values.
PCA as Minimizing Residual Error
We can also think of PCA as minimizing residual error. For notational simplicity, let be centered. For , PCA solves:
It turns out that the solution is the same as the one we previously derived!
This formulation provides motivation for PCA as a data compression technique.
Rank- Decomposition
Equivalently, for a rank- decomposition, we minimize the variance in the remaining directions:
Probabilistic PCA (PPCA)
The discussion so far has not explicitly involved statistics. We can formulate a population PCA model, as in probabilistic PCA (PPCA) by Tipping and Bishop (1999).
Let be latent variables (a random vector), where for . Let be a mixing matrix (fixed), and let represent measurement error, where . We assume isotropic noise.
The model is defined as:
where:
Key Assumptions
is a low-dimensional latent variable with a diagonal covariance structure, .
is independent of and represents isotropic noise with variance .
This model allows us to gain insight into the covariance structure of .
Let from the eigenvalue decomposition (EVD), and assume that the columns of are orthogonal. Define and let be the matrix formed by padding with zeros.
The covariance of is:
which simplifies to:
In terms of the full decomposition, this can be expressed as:
Interpretation
From this representation:
The largest eigenvalues and their corresponding eigenvectors are associated with the latent factors, as their variance is for .
The directions representing pure noise include only the variance , contributing no additional structure to the covariance matrix.
We typically look for an “elbow”, very roughly where the eignvalues go from exponential decay to a roughly linear trend, where a linear trend results in an isotropic nois model from the sorted sample estimates of the variance of the noise directions.
Warnings! - PCA is sensitive to scaling, eg, if you measured one variable in millimeters, and another in Km, the first variable would dominate the decomposition because numbers are much larger and hence has larger variance.
Motivating Example
PCA on a Wine Dataset
Here, we perform dimension reduction on a dataset with 178 wine samples. The dataset includes 13 variables measuring physicochemical properties:
Alcohol
Malic acid
Ash
Alkalinity
Magnesium
Phenols
Flavanoids
Non-flavonoid phenols
Proanthocyanins
Color intensity
Hue
OD280/OD315 of diluted wines
Proline
We also have a variable, “cultivar” (cultivated variety), which can be thought of as group labels. However, we will pretend we do not have access to this variable and examine whether patterns in the multivariate data from the 13 variables can be visualized in a lower-dimensional space.
Why PCA?
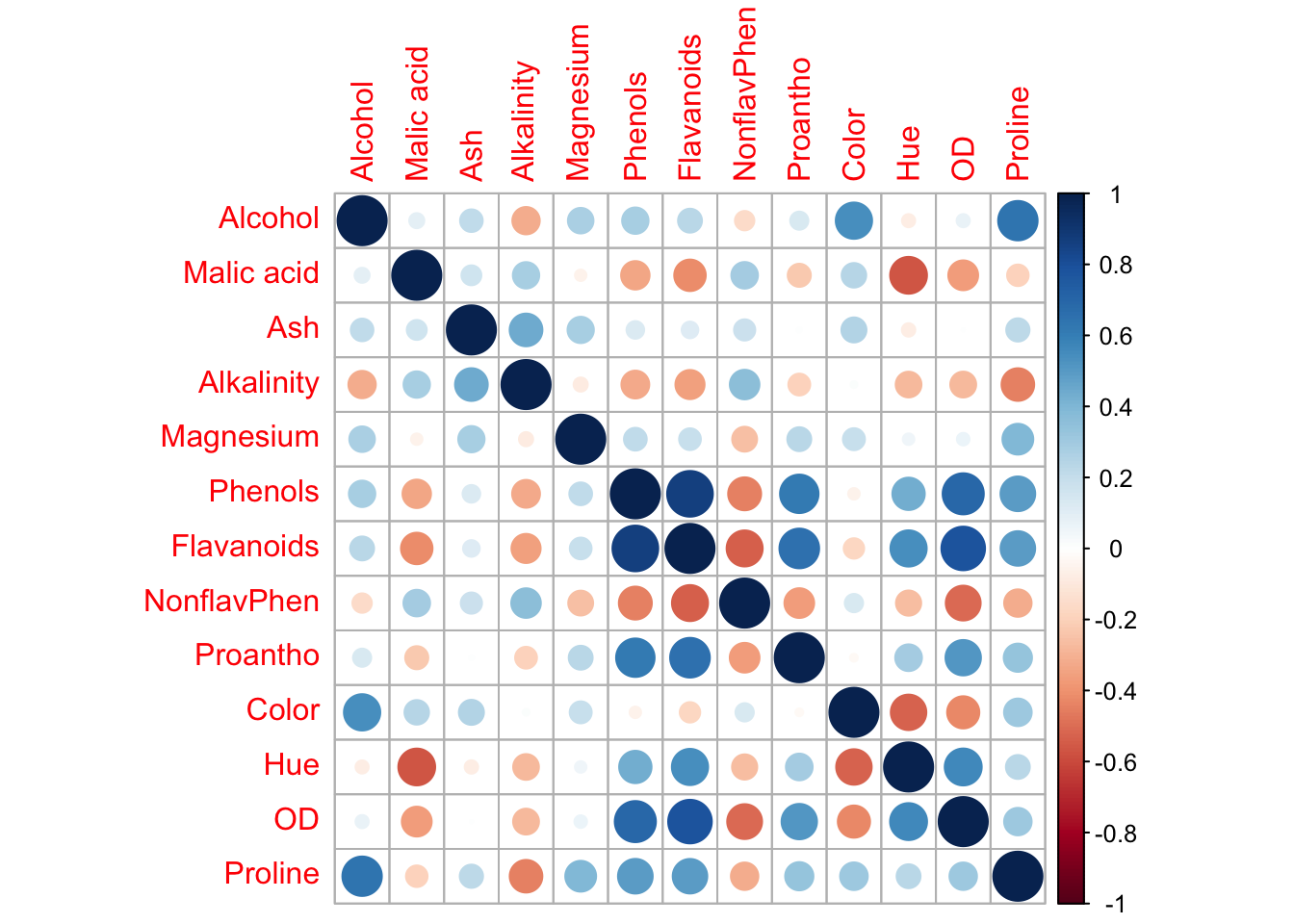
Many of the variables are highly correlated, making PCA a useful tool for this analysis. PCA will identify a smaller number of orthogonal variables (principal components) that capture most of the variance in the data. This allows us to reduce the dimensionality while preserving the structure and variability of the original dataset.
Goal
The goal is to transform the high-dimensional data into a lower-dimensional space (e.g., 2D or 3D) to visualize patterns or clusters, potentially corresponding to the different cultivars, without directly using the cultivar labels.
# citation: https://www.r-bloggers.com/principal-component-analysis-in-r/# http://archive.ics.uci.edu/ml/datasets/Winewine <-read.table("http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data", sep=",")# Name the variablescolnames(wine) <-c("Cvs","Alcohol","Malic acid","Ash","Alkalinity", "Magnesium", "Phenols", "Flavanoids", "NonflavPhen", "Proantho", "Color", "Hue", "OD", "Proline")# The first column corresponds to the cultivars (varieties)wineClasses <-factor(wine$Cvs)wine$Cvs = wineClasses# Use pairspairs(wine[,-1], col = wineClasses, upper.panel =NULL, pch =16, cex =0.5)legend("topright", bty ="n", legend =c("Cv1","Cv2","Cv3"), pch =16, col =c("black","red","green"),xpd = T, cex =2, y.intersp =0.5)
# cor(wine[,-1])corrplot(cor(wine[,-1]))
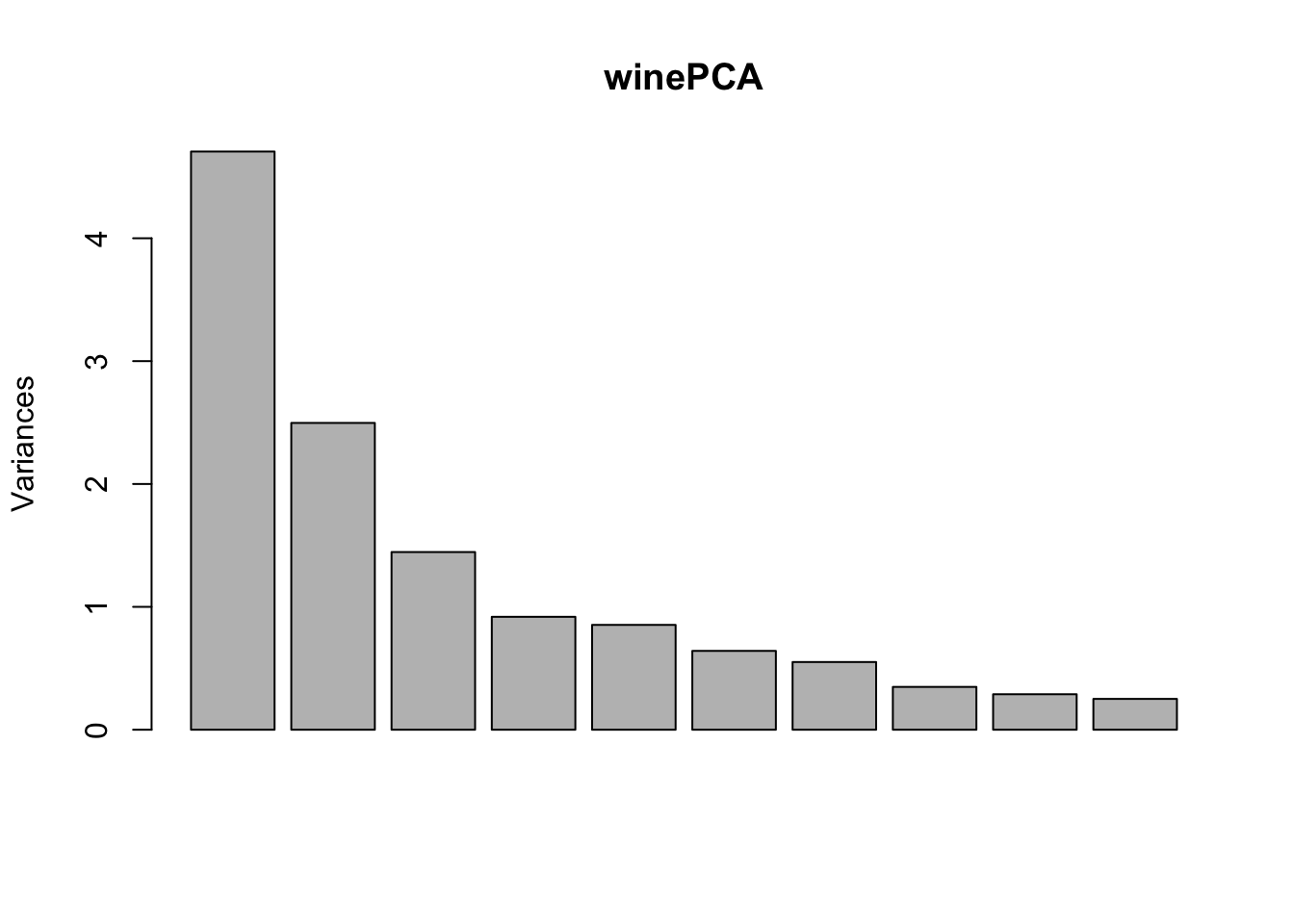
# a fair amount of correlation, so we can reasonably hope to capture most of the informations with some $q < 13$winePCA <-prcomp(wine[,-1],center =TRUE, scale. =TRUE)summary(winePCA)
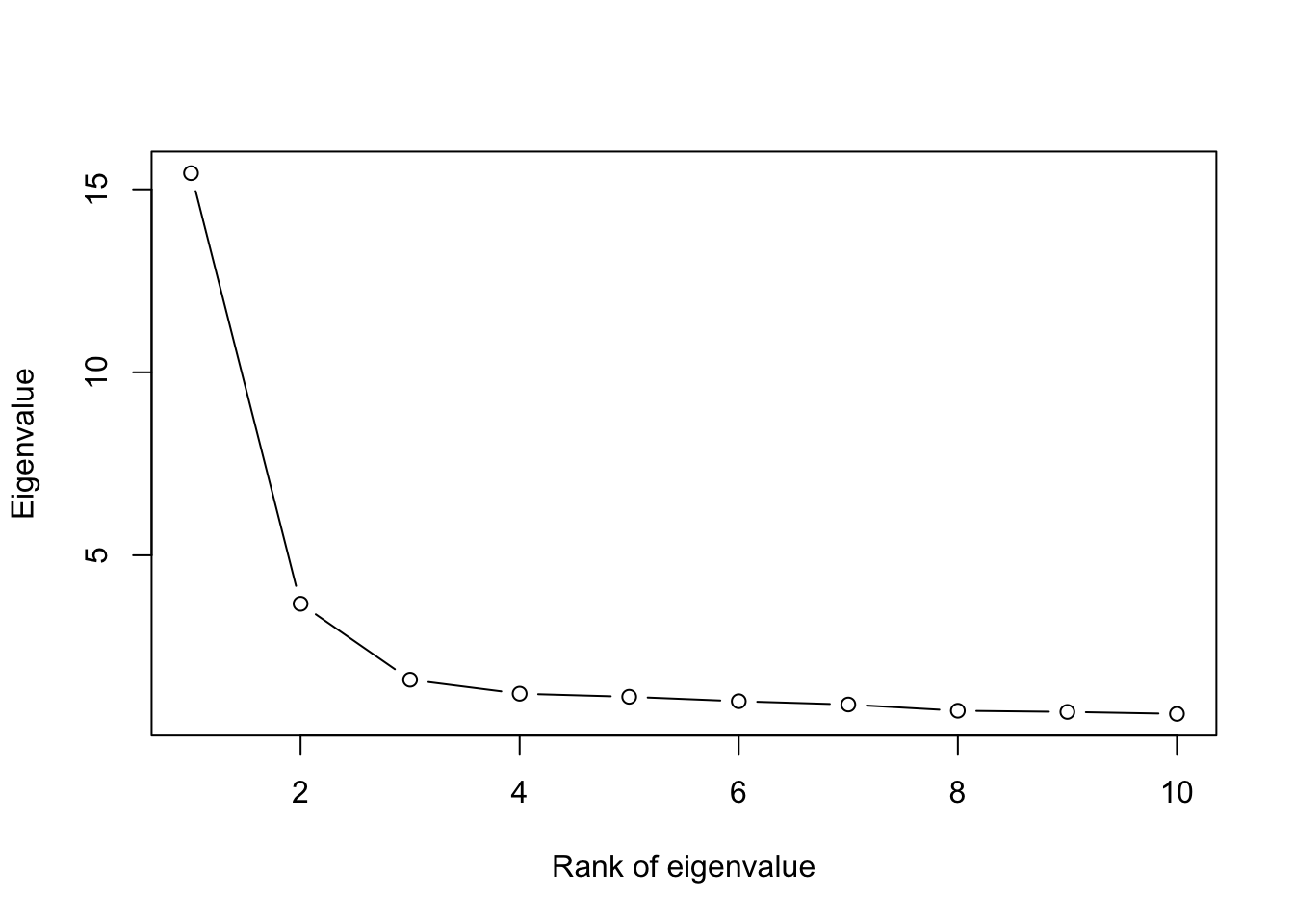
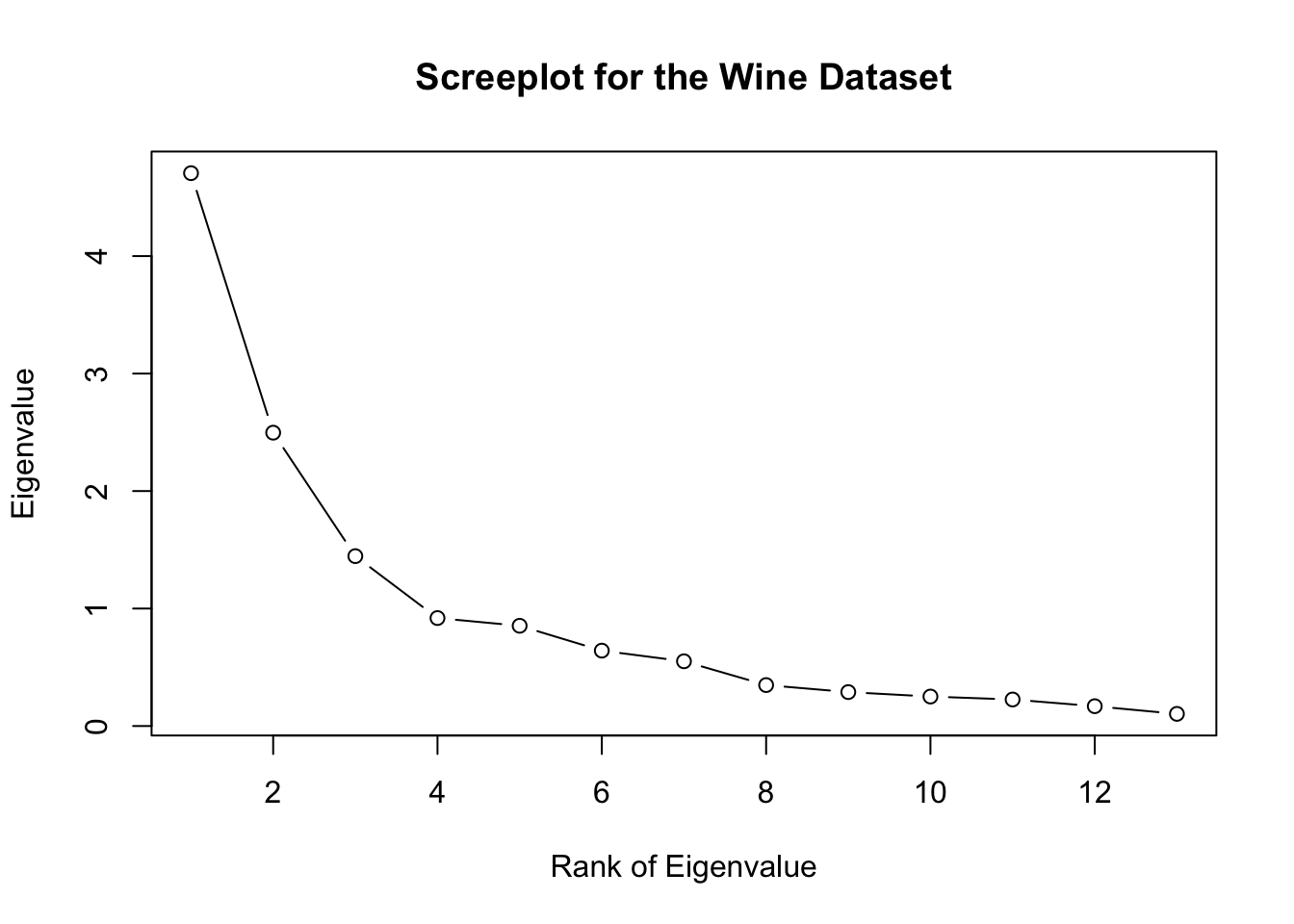
# I prefer the plot with points:#screeplot: the most important tool for selecting number of componentsplot(winePCA$sdev^2,xlab='Rank of Eigenvalue',ylab='Eigenvalue',main='Screeplot for the Wine Dataset',type='b')
# here, 3 would be a good option since ith corresponds to the "elbow"cumsum(winePCA$sdev^2)/sum(winePCA$sdev^2)
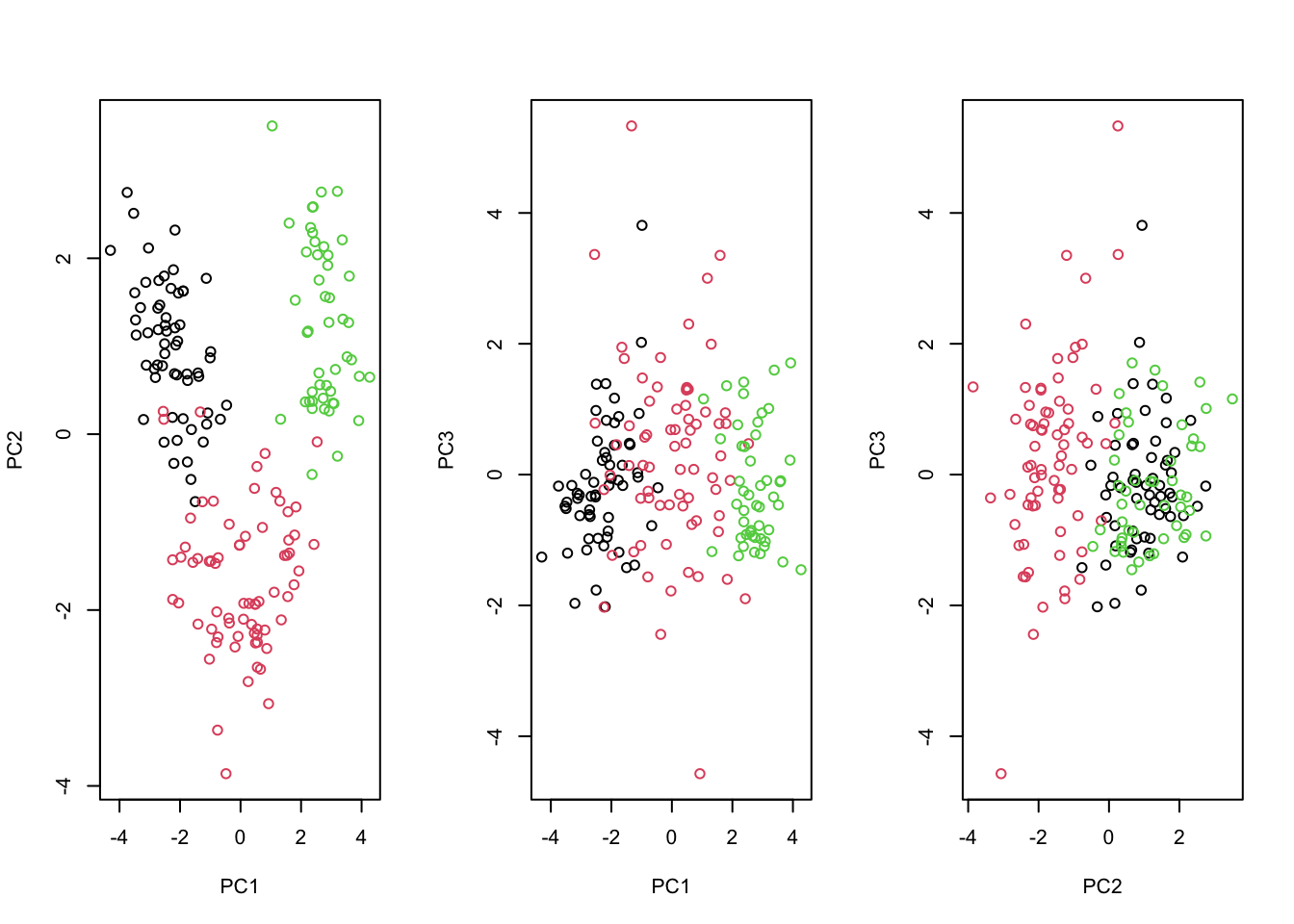
# 67% of variance with 3. 90% if often a rule of thumb for data compression; for latent variable representation, "elbow" is a useful heuristic# the scores can often be useful for visualizing differences between groups# plot the scores for the first two PCs and color the points by the categories:par(mfrow=c(1,3))plot(winePCA$x[,1:2], col = wineClasses)plot(winePCA$x[,c(1,3)], col = wineClasses)plot(winePCA$x[,c(2,3)], col = wineClasses)
# First two look seem to help the most with separating all three
PCA Regression
PCA regression involves estimating the first principal components and then using these components (subject scores) as predictors in linear regression:
Advantages of PCA Regression
Reduced Overfitting: By estimating coefficients, we reduce the risk of overfitting, especially in high-dimensional datasets.
Orthogonality of Predictors: The predictors (principal components) are orthogonal, which allows for more precise estimates of their standard errors compared to the original variables .
Limitation
The principal components can be more difficult to interpret because each component is a linear combination of the original variables:
where are the loadings for the th principal component.
Summary
While PCA regression improves model precision and reduces overfitting, the trade-off is a loss in interpretability since the predictors no longer correspond directly to the original variables.
When , PCA regression assumes that the directions containing the most variance in are the ones most closely associated with the response . However, this assumption may not always hold, as low-variance directions could still be strongly associated with .
When , the usual ordinary least squares (OLS) estimate is undefined. In such scenarios, one approach is to choose some such that , and then use principal component regression (PCR). This ensures a stable solution by reducing the number of predictors to fewer than the number of observations.
While PCA regression has limitations due to its independence from , it remains a practical method for dimensionality reduction, especially when and traditional regression methods are not feasible.
Motivating Example: PCA regression
Baseball example
Example 6.7: MLB Stats and Salary Prediction
Objective
The goal is to predict Salary of MLB players in 1987 based on performance and demographic statistics from 1986.
Dataset
The dataset contains MLB statistics for 1986, with the response variable being the player’s Salary in 1987. Below is a list of variables included in the dataset.
library(ISLR)library(pls)
Attaching package: 'pls'
The following object is masked from 'package:corrplot':
corrplot
The following object is masked from 'package:stats':
loadings
#Read in the datadata(Hitters)Hitters =na.omit(Hitters)names(Hitters)
# NOTE: make sure to scale=TRUE -- defaults to false:(# % variance explained: percent in X, second row is R^2 in PRC
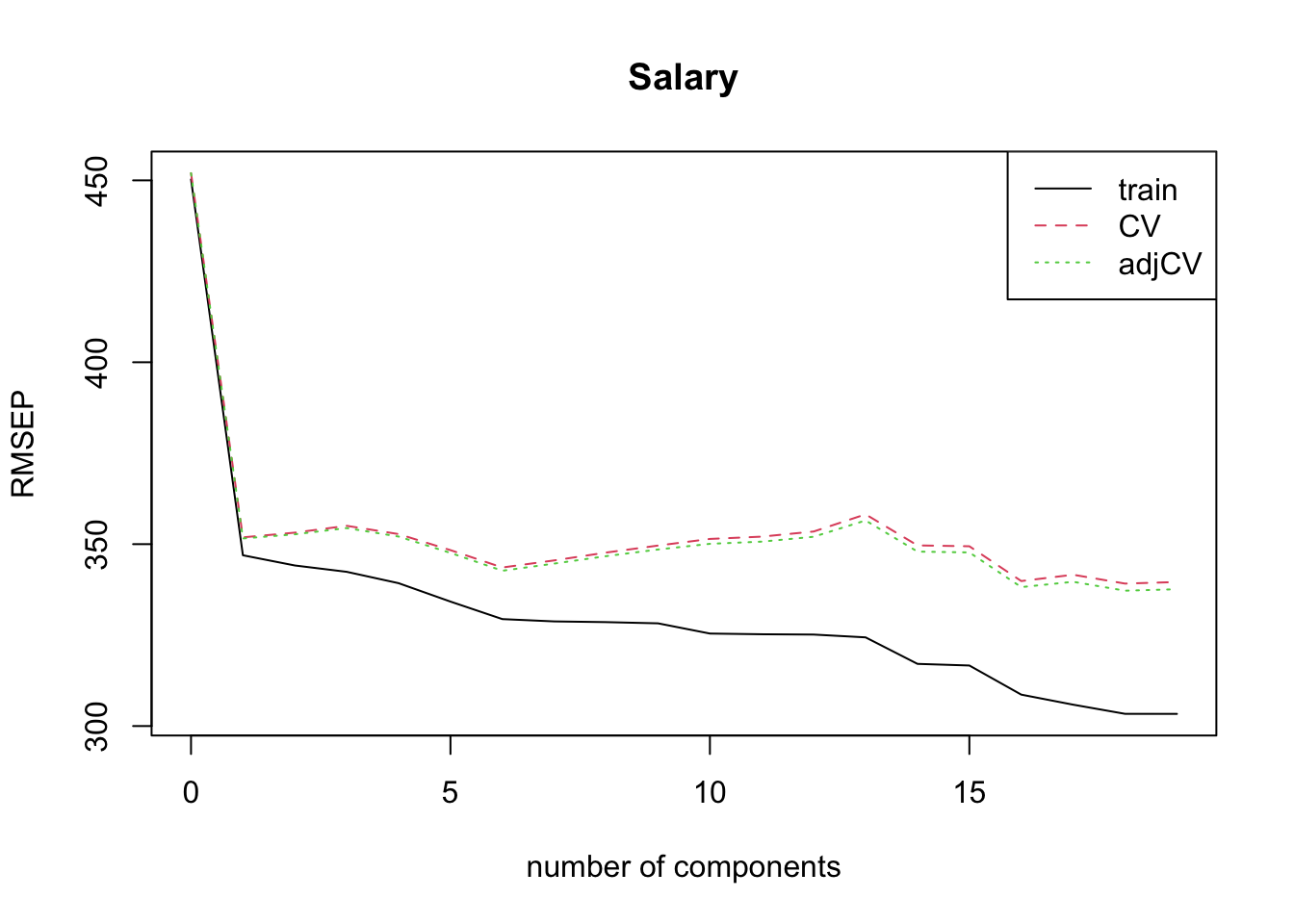
set.seed(2) # for cross-validation to determine number of componentspcr.fit =pcr(Salary~., data=Hitters, scale=TRUE, validation='CV')validationplot(pcr.fit,estimate='all',legendpos='topright')
In this example, cross validation is not very helpful.
Minimized at 16, not a clear minimum.
PC1 does fairly well.
Lets take a detailed look at what is happening in the regression:
# create a matrix that can be used by prcomp:hitters =model.matrix(Salary~.,data=Hitters)# now use prcomp and then lm:pca.hitters =prcomp(x=hitters[,-1],center =TRUE, scale. =TRUE)# if we used the 95% rule of thumb, choose 9 components# Let's try four, since these eigenvalues stand outpcr.fit.v2 =lm(Hitters$Salary~pca.hitters$x[,1:4])summary(pcr.fit.v2)
Call:
lm(formula = Hitters$Salary ~ pca.hitters$x[, 1:4])
Residuals:
Min 1Q Median 3Q Max
-905.49 -173.80 -24.63 115.75 2163.36
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 535.926 21.122 25.373 <2e-16 ***
pca.hitters$x[, 1:4]PC1 106.571 7.843 13.587 <2e-16 ***
pca.hitters$x[, 1:4]PC2 21.645 10.388 2.084 0.0382 *
pca.hitters$x[, 1:4]PC3 -24.341 14.852 -1.639 0.1024
pca.hitters$x[, 1:4]PC4 -37.056 16.962 -2.185 0.0298 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 342.5 on 258 degrees of freedom
Multiple R-squared: 0.4322, Adjusted R-squared: 0.4234
F-statistic: 49.1 on 4 and 258 DF, p-value: < 2.2e-16
# look what happens with 16:tempdata =data.frame('Salary'=Hitters$Salary,pca.hitters$x[,1:16])pcr.fit.v3 =lm(Salary~PC1+PC2+PC3+PC4+PC5+PC6+PC7+PC8+PC9+PC10+PC11+PC12+PC13+PC14+PC15+PC16,data=tempdata)summary(pcr.fit.v3)
We see that career numbers (CRBI, CRuns, CHits, CAtBats. CHmRun, CWalks) tend to have larger loadings thatn 1986 numbers.
Interpretation
Cross-validation insights:
Cross-validation suggests minimizing prediction error using 16 principal components, but no clear minimum is observed.
PC1 (the first principal component) explains a significant proportion of variance and performs well on its own.
Regression with PCA:
Using 4 principal components (pcr.fit.v2) provides a concise model, but only partially explains salary variation.
A model with all 16 components (pcr.fit.v3) includes later components that are surprisingly significant.
Driving factors of PC1:
The loadings for the first principal component show career statistics (e.g., CRBI, CRuns, CHits, CAtBats, CHmRun, CWalks) have higher weights compared to the 1986 season-specific statistics.
This suggests that career performance metrics are stronger predictors of player salary than short-term (single-season) performance.
Significance of later components:
While higher-order components explain less variance in predictors, some have significant contributions to predicting salary, highlighting that less dominant patterns in data can still be relevant.
Implications:
Career statistics provide more consistent and predictive value for salaries.
Dimensionality reduction using PCA helps simplify the model but may risk excluding later components with predictive importance.
Compare these results to OLS fitting the following model
# ols.fit <- lm(Salary ~., data = Hitters)
Look at the VIFs using . What are the findings?
Is it correct to use OLS in this case based on VIFs and based on significant coefficients from the OLS output?