A useful reference: Halekoh, I., S. Hojsgaard, and J. Yan. The R Package geepack for Generalized Estimating Equations. Journal of Statistical Software. 2006.
Generalized Estimating Equations (GEEs) are a statistical technique used primarily for analyzing correlated data, such as repeated measures or clustered observations.
Key Features:
Population-Averaged Estimates: GEEs focus on estimating the average effects across all subjects rather than individual-level effects.
Handling Correlation: GEEs are designed to handle correlated data, such as measurements taken from the same subject over time or from subjects within the same group. GEEs provide more robust estimates and standard errors.
Flexibility: GEEs can be applied to various types of data, including binary, count, and continuous outcomes.
Robustness: One of the strengths of GEEs is their ability to produce valid statistical inferences even when the specified correlation structure is incorrect.
Motivating Example
Consider data and from
and come from the same cluster and may be correlated, i.e.,
have the same expectation . The average of will give an unbiased estimator.
This assigns equal weight, i.e., .
To find the variance-covariance note .
The above estimator has variance given by
As R increases, variance also increases
Our aim is to find a set of weights such that:
is unbiased
What is the variance for ?
When , minimum variance when (the simple sample average).
Consider the following set of weights:
Simple average: .
Average and first; then average with : .
Use only one of or : .
Secret: assuming and are known: .
Estimator Weights
(1/3, 1/3, 1/3)
(1/4, 1/4, 1/2)
(1/2, 0, 1/2)
The secret (optimal) weights
have the smallest standard error for the complete range of values.
become a simple average when (independence).
gives weight 1/4 to and when .
Estimating Equations
All four estimators are solutions to the estimating equation. We will define an equation to produce a class of unbiased estimators of .
We know for all .
Combining the three equations, an unbiased estimator can be obtained by solving:
The above gives:
Therefore, the weights for are
An estimating equation is a very general approach. Equation (1) is an example where we set up an equation, set it to zero, and solve for . Methods of moments and maximum likelihood (setting the 1st deriv of the log-lik to zero) are examples of estimating equations.
Important
An estimating equation is a mathematical expression used to derive parameter estimates in statistical models. Unlike methods that maximize likelihoods (e.g., maximum likelihood estimation), estimating equations focus on finding parameters that satisfy certain conditions.
Key Features:
Estimating equations often arise in generalized estimating equations (GEE), which are commonly used to handle correlated data, like repeated measures or clustered data.
The solution to an estimating equation gives the parameter estimates that “best” explain the observed data, based on the chosen model.
These equations are particularly useful when the likelihood function is complex or unknown.
Regression with Heteroscedastic Errors
Now consider the linear regression problem with heteroscedastic errors:
Here we assume the residual covariance matrix is known and diagonal.
How can we find the least squares estimate of?
Weighted Least Squares
In WLS, we extend the methods we learned in regular OLS to account for heteroscedasticity (unqeual variance) . Each observation is given a weight based on how much reliability we place on it. This allows a better fit to data where some points have more variability than others.
let be a diagonal matrix with . Notand e that .
Now consider the transformed and transformed :
We now have a regression problem with EQUAL variance:
Reminder the OLS estimator .
Derive the weighted least squares estimator for , i.e., .
The WLS estimate is unbiased (for ANY ).
- What if we used regular ordinary least squares estimate?
Still unbiased!
The OLS estimator of is still unbiased and it is also consistent. So what is the problem?
Inference: p-values will be wrong.
Efficiency: we can define an estimator with lower variance.
What does this mean?
The estimate of the covariance for is given by .
We found the WLS covariance to be
Then if the OLS covariance is not correct, i.e., inference is incorrect.
Summary I
The OLS estimate of the SE of can lead to invalid inference.
The true variance of is larger than so OLS is inefficient. WLS improves accuracy.
Example: Fixed Effect Meta Analysis
Let be the effect size from study with estimated variance . We will assume the model
This can be expressed as:
Therefore:
.
the inverse-variance weighted average!.
What do we do if is not diagonal, meaning the errors are not independent?
Generalized Least Squares
For non-diagonal , this means that the errors are not independent. So there is heteroscedasticity (non-constant variance) AND correlated errors.
Derivation of the covariance, i.e.,:
Error Structure: We assume that the error term has the following structure: where is the variance-covariance matrix of the errors.
Substituting into the expression for
This can be expanded to: The first term simplifies to :
To find the covariance of , we need the covariance of the error term. The error term is zero-mean and has variance-covariance matrix :
Using the property that for any constant matrix and random vector Substituting : This simplifies to: Finally, since the middle terms cancel out:
Generalized Least Squares: Homoscedastic
For a normal (Gaussian) regression model, we often assume the observations are homoscedastic (equal variance). The model can be expressed as:
where .
The Generalized Least Squares (GLS) estimator is given by:
Substituting for homoscedasticity, we have:
- The covariance matrix of the GLS estimator is given by:
Later on this is called the naive SE in .
Motivating Example
Back to the motivating example assume , the assumed model for the outcome :
where .
The inverse of the variance-covariance matrix given by:
Calculating :
The inverse of :
Generalized Least Squares: Robust Regression
Handling Unknown Variance-Covariance Matrix
If we know and , we have:
The generalized least squares estimate :
Accounts for the correlation between observations, resulting in an estimator with lower variance.
The variance allows for valid inference.
However, what if is unknown (as is often the case)?
Initial Approach:
Use the Ordinary Least Squares (OLS) estimator:
because it is unbiased and consistent.
However,when heteroskedasticity is present,OLS estimates of standard errors may be biased. To correct for this, we use robust standard errors, also known as the sandwich estimator.
Robust Standard Error
For standard errors, recall:
So we can estimate and plug it in:
One estimate of is simply the empirical residual covariance:
Thus, the robust covariance matrix is:
Important
This is commonly referred to as the sandwich estimator because of its “bread-meat-bread” structure, with the covariance matrix being “sandwiched” between terms involving the design matrix .
The robust standard error provides an estimate of the covariance matrix given by:
However, the empirical estimate of the “meat” component uses only one observation for each element.
Thus it is a poor estimator of , i.e., inaccurate. We can have a better estimate if we have some idea about what is the structure of .
Tradeoffs in Modeling
When assumptions are true:
stronger assumptions = more accurate estimates.
weaker assumptions = less accurate if there is more structure to exploit.
When assumptions are false:
stronger assumptions = incorrect inference.
weaker assumptions = more robust.
For example, we see this is non-parametric tests, which are generally less powerful when parametric assumptions hold.
Simulation Exercise: Robust Standard Errors
In this exercise, you will simulate data with heteroskedasticity, fit an OLS model, and compare the standard errors from the OLS with the robust standard errors using the sandwich estimator.
Objective
Simulate data where the error variance depends on an explanatory variable (i.e., heteroskedasticity).
Fit an OLS model to the data.
Calculate both the usual OLS standard errors and the heteroskedasticity-robust (sandwich) standard errors.
Observe the differences in the standard errors.
Step 1: Simulate Heteroskedastic Data
We will simulate a dataset where the variance of the error term depends on the value of an independent variable, creating heteroskedasticity.
library(sandwich)library(lmtest)
Warning: package 'lmtest' was built under R version 4.0.5
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
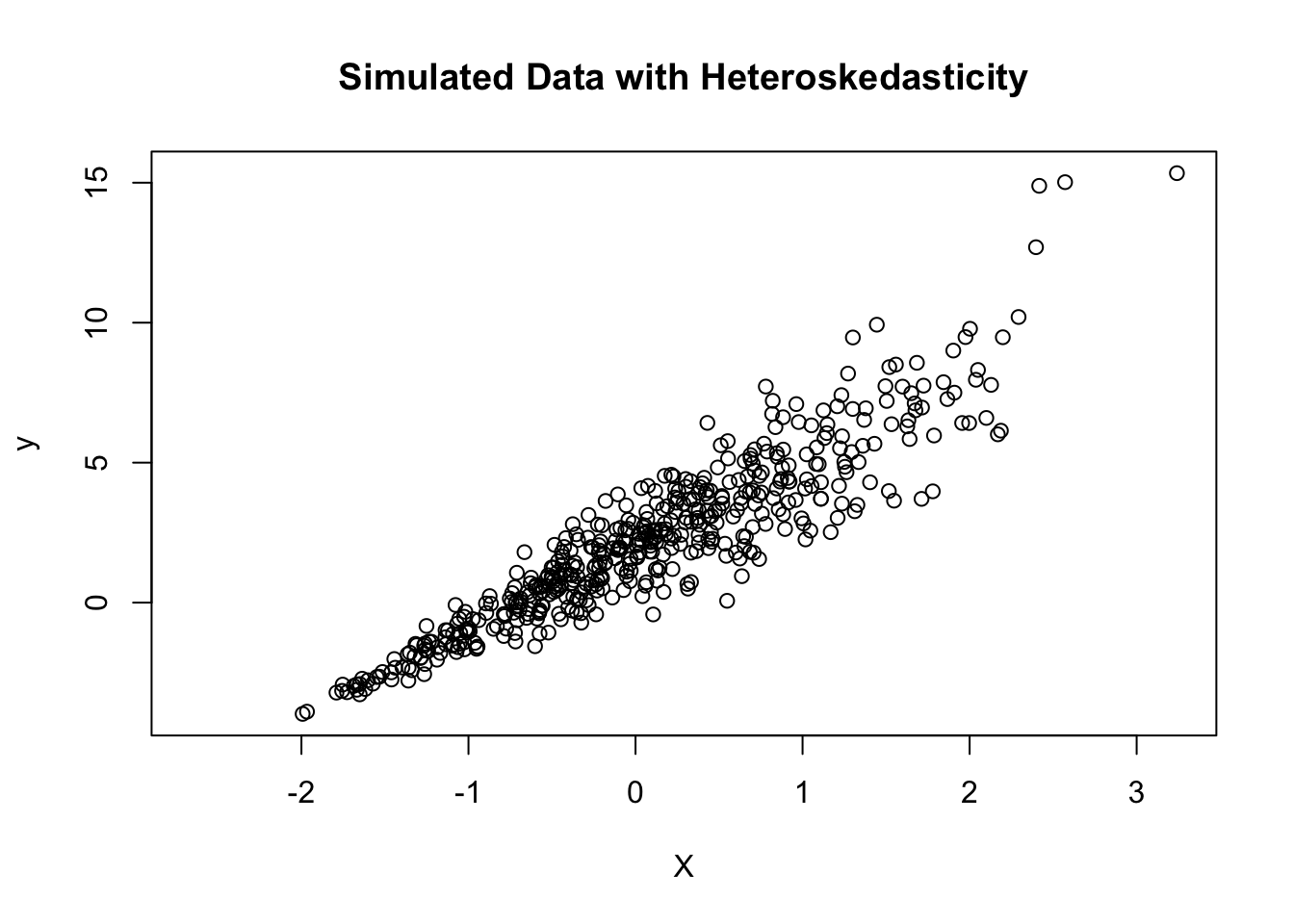
# Set seed for reproducibilityset.seed(123)# Number of observationsn <-500# Generate the independent variableX <-rnorm(n)# Generate heteroskedastic errors (variance depends on X)errors <-rnorm(n, mean =0, sd =1+0.5* X)
Warning in rnorm(n, mean = 0, sd = 1 + 0.5 * X): NAs produced
# Generate the dependent variable (y = 2 + 3*X + error)y <-2+3* X + errors# Create a data framedata <-data.frame(y, X)# Visualize the data and heteroskedasticityplot(X, y, main ="Simulated Data with Heteroskedasticity",xlab ="X", ylab ="y")
Step 2: Fit an OLS Model
# Fit an OLS modelols_model <-lm(y ~ X, data = data)# Summary of the OLS modelsummary(ols_model)
Call:
lm(formula = y ~ X, data = data)
Residuals:
Min 1Q Median 3Q Max
-3.5643 -0.5815 0.0211 0.5905 5.6468
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.98200 0.05315 37.29 <2e-16 ***
X 3.00384 0.05734 52.39 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 1.172 on 488 degrees of freedom
(10 observations deleted due to missingness)
Multiple R-squared: 0.849, Adjusted R-squared: 0.8487
F-statistic: 2744 on 1 and 488 DF, p-value: < 2.2e-16
Step 3: Calculate Standard Errors
Next we calculate both the usual OLS SEs and the robust SEs using the package. You can repeat this simulation with different levels of heteroskedasticity by adjusting the relationship between the variance of the errors and .
# OLS standard errorsols_se <-sqrt(diag(vcov(ols_model)))# Robust standard errors (using the HC3 estimator)robust_se <-sqrt(diag(vcovHC(ols_model, type ="HC3")))# Display the resultsresults <-data.frame(Coefficient =coef(ols_model),OLS_SE = ols_se,Robust_SE = robust_se)print(results)
Heteroskedasticity Impact: The data was simulated to have heteroskedastic errors.
This violates one of the key assumptions of the OLS model—that errors are homoscedastic (i.e., have constant variance).
As a result, the OLS standard errors become unreliable (underestimated) when heteroskedasticity is present.
OLS Standard Errors: These standard errors may be too small, leading to incorrect conclusions about the significance of predictors.
Robust Standard Errors: The robust (sandwich) standard errors account for heteroskedasticity and provide more accurate estimates of the variability in the coefficient estimates.
They adjust for the unequal error variance, resulting in larger standard errors vs OLS.
By using robust standard errors, the true variability is captured more accurately, which may increase the standard errors, lowering the t-values and thus reducing the likelihood of falsely identifying significant relationships.
The key takeaway is that OLS standard errors cannot be trusted when heteroskedasticity is present. The robust standard errors are a better reflection of the uncertainty in the coefficient estimates in this situation.
Next steps… assuming some structure on .
Introducing structure to
Lets call this .
Step 1: Generalized Least Squares (GLS): Use because it is unbiased and consistent
Step 2: Use the sandwich estimator, which adjusts for potential misspecification of . The robust covariance matrix for the GLS estimator is given by:
Idea: even if is misspecified, the SEs are valid for inference (confidence intervals, hypothesis testing)!
If we get the structure correct, we get more accurate estimate of .
Summary II
Heteroskedasticity Correction:
OLS assumes homoscedasticity (constant variance of errors). When this assumption is violated (heteroskedasticity), OLS standard errors are biased and unreliable.
Robust regression adjusts standard errors to account for heteroskedasticity, providing more reliable inference.
Robust Standard Errors:
Robust standard errors (sandwich estimators), provide a consistent estimate of the variance even when the errors have non-constant variance or are heteroskedastic.
Bias in OLS Standard Errors:
In the presence of heteroskedasticity, OLS tends to underestimate the standard errors, leading to (false positives for significance).
Robust standard errors correct this issue, leading to more accurate p-values and confidence intervals.
Generalization to Misspecified Models:
Even if model is misspecified (e.g., the structure of the errors is not correctly modeled), robust SEs yield valid inference.
Advantages of Robust Regression:
Reduces the influence of outliers and high-leverage points that might skew OLS estimates.
It is more flexible in the face of violations of assumptions, making it suitable for datasets with heteroskedasticity, outliers, or non-normal error distributions.
Marginal Model for Pig Data
Motivating Example
Let be the weight (kg) at the week for the pig.
For , we wish to model weight as a function of week:
We assume independence between pigs:
We will estimate and using Generalized Estimating Equations (GEE), which is a marginal approach. This differs from the random effects approach in the following ways:
We do not specify pig-specific intercepts or slopes; instead, we focus on how the within-group data are correlated .
Advantages:
The correlation structure can be very flexible.
Even if we specify incorrectly, we still obtain robust standard errors.
Disadvantages:
The marginal model does not provide subject-specific predictions since there are no random effects to balance subject-specific information with population information.
It can be less powerful compared to mixed models.
library(gee)
Warning: package 'gee' was built under R version 4.0.5
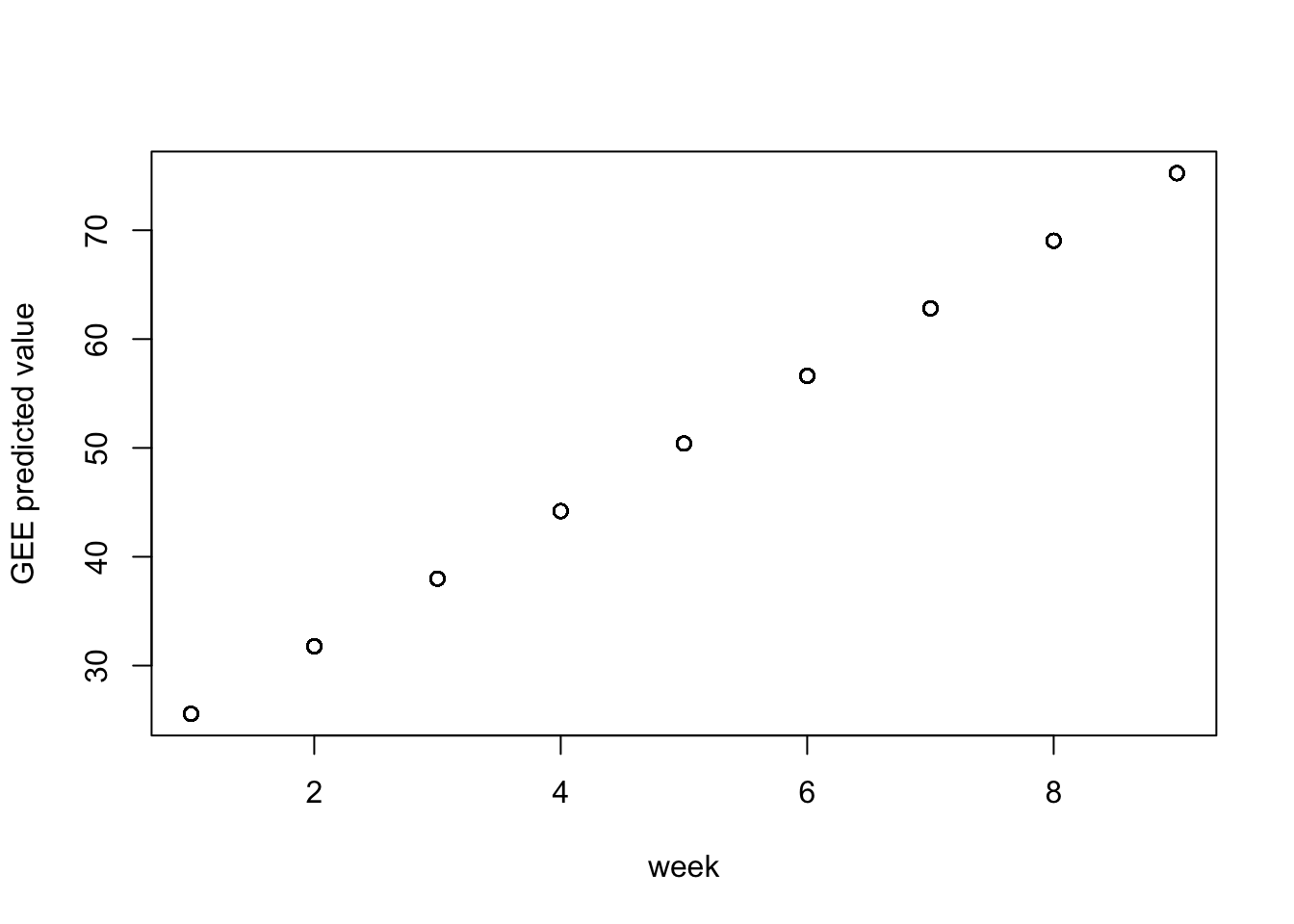
meaning there is a 6.21 unit change in weight per one unit change in week.
Naive S.E. shows standard errors of coefficient estimates assuming NO correlation. - Robust S.E. shows shows standard errors of coefficient estimates adjusted for correlation among observations within clusters.
The Robust SE is higher compared to Naive S.E., 0.09 vs. 0.04, respectively.
Week is significant using both Naive and Robust methods.
In GEEs you can only estimate effects averaged across ALL subjects: Meaning GEEs are designed to estimate the avg effects of predictors across all subjects. This is in contrast to mixed models which can estimate both fixed and subject specific effects.
Subject-Specific Predictions
In GEEs you can only estimate effects averaged across all subject:
Advantages:
can be very flexible.
Even if we get wrong, we still have robust standard error.
Disadvantages:
Marginal model does not provide subject
specific prediction
no random effect to balance subject-specific information with population-level information.
Can be less powerful than mixed models.
Compared to Random Intercept Model
library(lme4)
Loading required package: Matrix
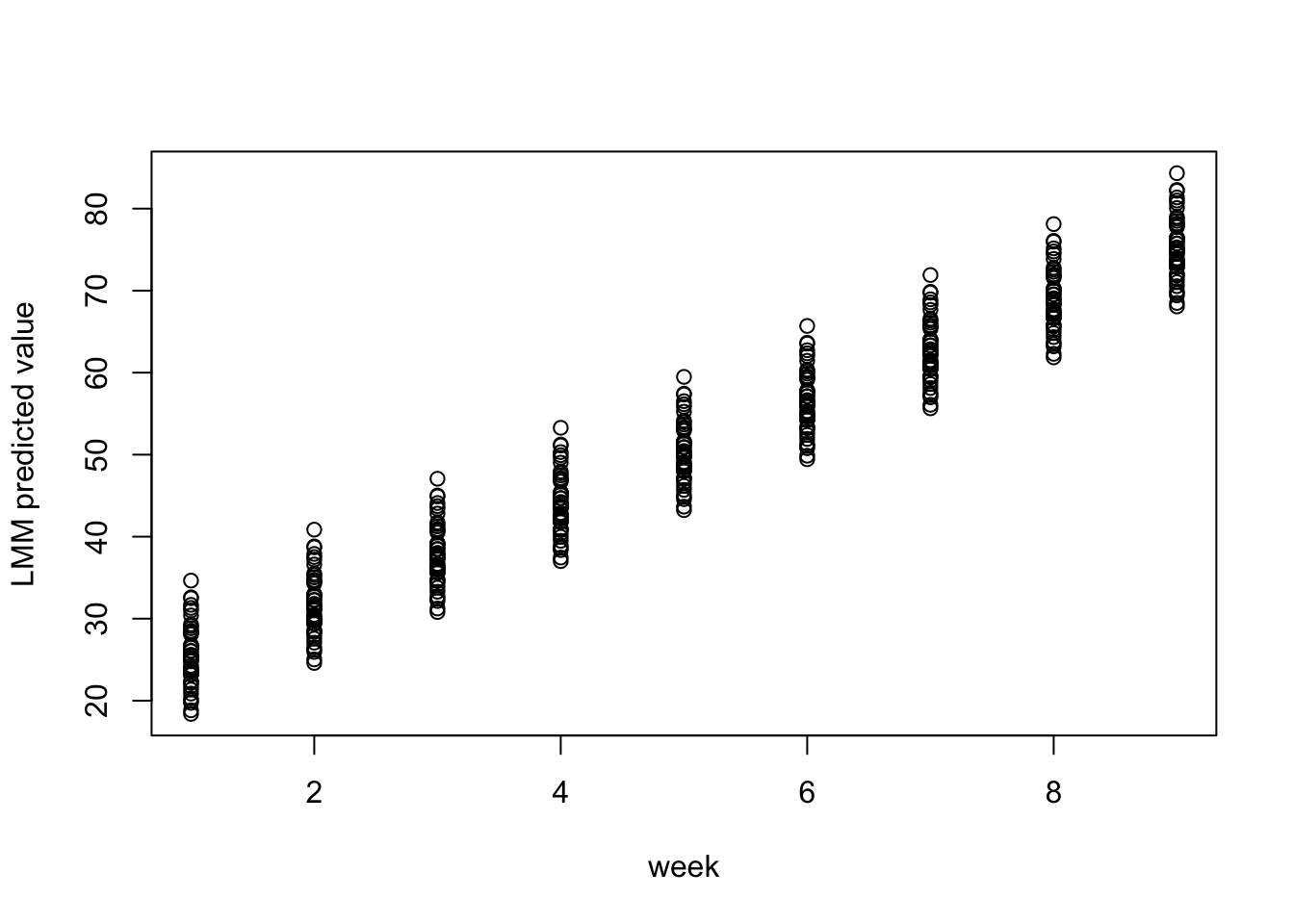
fit.mixed <-lmer(weight ~ weeks + (1|id), data = pigdata)summary(fit.mixed)
Linear mixed model fit by REML ['lmerMod']
Formula: weight ~ weeks + (1 | id)
Data: pigdata
REML criterion at convergence: 2033.8
Scaled residuals:
Min 1Q Median 3Q Max
-3.7390 -0.5456 0.0184 0.5122 3.9313
Random effects:
Groups Name Variance Std.Dev.
id (Intercept) 15.142 3.891
Residual 4.395 2.096
Number of obs: 432, groups: id, 48
Fixed effects:
Estimate Std. Error t value
(Intercept) 19.35561 0.60314 32.09
weeks 6.20990 0.03906 158.97
Correlation of Fixed Effects:
(Intr)
weeks -0.324
with . Here, equal tp GEE wtih exchangeable working correlation matrix and its naive SE.
The estimated intra-class correlation is , same as the estimated exchangeable working correlation.
Recall that the random intercept model induces exchanggeable correlation
Subject prediction in LMMs are more accurate for subject specific predictions.
Extending the definition of GEE for non-normal data
Important
Generalized Estimating Equations
For normal regression, the GEE approach corresponds nicely to a generalized regression.
However, GEEs are commonly used to analyze count data, binary outomes, and other data modeled using a distribution from an exponential family.
GEEs are a general method for analyzing grouped data when:
observations within a cluster may be correlated.
observations in separate clusters are independent.
a monotone transformation of the expectation is linearly related to the explanatory variables, i.e., the link function in GLM.
the variance is a function of the expectation. Note: Robust SEs allows for departures from this.
Model Residual Variance in Poisson or Bernoulli Regression
One challenge is that for Poisson or Bernoulli regression, the residual variance depends on the mean structure. For example, consider a logistic regression model. We have:
where:
The variance-covariance matrix is then given by:
Even without clustering, the marginal covariance has unequal variances that depend on.
To see how GEE work for Generalized Linear Models (GLMs), we need to examine in more detail how these models are fitted.
Revisit GLMs: Estimation for independent data
** Normal Regression**
Consider the linear regression model :
The likelihood function is:
If we assume is diagonal, the data likelihood simplifies to:
Therefore, the maximum likelihood estimate of can be obtained by minimizing the function:
This is equivalent to solving the system of linear equations:
The above expression represents an estimating equation too.
** Logistic Regression Model**
For a single observation , the log-likelihood is given by:
The score function is:
Therefore, the maximum likelihood estimate (MLE) of is obtained by solving equations with unknowns:
** Poisson Regression**
For a single observation , the log-likelihood is given by:
The score function with respect to is:
Therefore, the MLE of is obtained by solving a system of regression equations:
Commonality Among Score Equations for Different Models
Consider the score equations for different models:
Gaussian:
Logistic:
Poisson:
It can be shown that, for any GLM, the score equations needed to solve for the MLE are given by:
Let’s verify it for a single data point:
Gaussian:
Logistic:
where
Thus,
Poisson:
Estimating Equations for Generalized Linear Models
For a generalized linear model (e.g., logistic, Poisson), assuming independent samples, we can estimate by solving the estimating equations:
where:
is an vector of .
is an diagonal matrix.
is an matrix.
It can be shown that the resulting estimate is:
consistent, and
asymptotically normal with covariance:
Extending the definition of GEE for Grouped data
(for logistic regression)
We now assume the non-Gaussian observations may be correlated.
Let be the vector of observations from group $ i$.
We want to model the mean trend with a logistic link and account for dependence:
We can write the covariance structure as:
where is a diagonal matrix of the marginal variance and is a working correlation matrix.
In GLMs, all elements of depend on through the link function!
With a logistic link, for the -th observation on the -th subject, we have:
Also, the dependence structure is specified directly on the observations. This approach gives a marginal interpretation.
Marginal Model and GEE Estimation
Denote as the -th observation in group , with . Also, let
We are interested in the marginal model: where in the link function.
In the GEE approach, let’s forget the complicated data likelihood induced by the within-group correlation and work directly with the estimating equations.
The GEE estimate of is obtained by solving the system of equations with unknowns:
where is the total number of groups.
represents the mean function,
is the variance-covariance structure for the observations,
the sum extends over all groups from 1 to .
Covariance Estimates for
The naive covariance (assuming the model is correct) of is given by:
The sandwich (robust) covariance of is given by:
Scale Parameter
When modeling data in a GLM, the marginal variance is completely determined by the mean.
Often, this assumption does not hold; e.g., we may observe more variability in the data.
One approach to account for this is by assuming:
where is known as the scale (or dispersion) parameter for a GLM. Here, indicates no excess residual variation.
As before, GEE estimates can be found by solving the estimating equations.
Note that there is no density generating the estimating equation; therefore, the GEE estimation methodology is also known as a quasi-likelihood approach.
Summary III
Weighted Least Squares: Extension of OLS that accounts for differing/unequal variances. Each observation is weighted based on the inverse variance, i.e., larger variance yields less reliability.
Generalized Least Squares: Extension of WLS to account for both unequal variance and correlated errors.
Naive SE vs Robust SE:
Naive assumes working correlation matrix is correct.
Robust Sandwich SE adjusts for potential misspecification of correlation structure. Conservatively more reliable with larger SE’s.
where is the score function.
GEE extends GLMs to account for clustering/grouping, i.e., non-Gaussian data. where is covariance matrix for unit across observations . is a diagonal marginal variance and depends on the link function. is the unit specific correlation matrix. is an overdispersion parameter.
Example: 2 × 2 Crossover Trial
Data were obtained from a crossover trial on the disease cerebrovascular deficiency. The goal is to investigate the side effects of a treatment drug compared to a placebo.
Design:
34 patients: Active drug (A) followed by a placebo (B).
33 patients: Placebo (B) followed by an active drug (A).
Outcome: Electrocardiogram determined as normal (0) or abnormal (1). Each patient has two binary observations for period 1 or period 2.
Data:
Responses
Period
Group
(1,1)
(0,1)
(1,0)
(0,0)
Period 1
Period 2
Total
A-B
22
0
6
6
28
22
33
B-A
18
4
2
9
20
22
34
Marginal GEE?
Conditional (Random intercept model)?
Notes on marginal vs. conditional models:
The marginal approach models the exchangeable correlation directly on the observed binary outcomes.
The conditional approach induces an exchangeable correlation on the logit-transformed mean trend. This approach models group-specific baseline log-odds explicitly.
Marginal:
Conditional (Random intercept model): GLMM
Let .
Note:
Conclusion: Coefficient estimates and their interpretations differ.
library(gee)library(lme4)dat =read.table(paste0(getwd(), "/data/2by2.txt"), header=T)### GLMfit.glm <-glm(outcome ~ trt*period, data = dat, family = binomial)### Marginal GEE model with exch working corrfit.exch <-gee(outcome ~ trt*period, id = ID, data =dat, family =binomial(link ="logit"), corstr ="exchangeable")
(Intercept) trt period trt:period
-1.5404450 1.1096621 0.8472979 -1.0226507
### GLMM (conditional) model with (exch corr)fit.re <-glmer(outcome ~ trt*period + (1|ID), data = dat, family = binomial, nAGQ =25)
summary(fit.exch)
GEE: GENERALIZED LINEAR MODELS FOR DEPENDENT DATA
gee S-function, version 4.13 modified 98/01/27 (1998)
Model:
Link: Logit
Variance to Mean Relation: Binomial
Correlation Structure: Exchangeable
Call:
gee(formula = outcome ~ trt * period, id = ID, data = dat, family = binomial(link = "logit"),
corstr = "exchangeable")
Summary of Residuals:
Min 1Q Median 3Q Max
-0.3939394 -0.3529412 -0.1764706 0.6060606 0.8235294
Coefficients:
Estimate Naive S.E. Naive z Robust S.E. Robust z
(Intercept) -1.5404450 0.4567363 -3.372723 0.4498677 -3.424218
trt 1.1096621 0.5826118 1.904634 0.5738502 1.933714
period 0.8472979 0.5909040 1.433901 0.5820177 1.455794
trt:period -1.0226507 0.9997117 -1.022946 0.9789663 -1.044623
Estimated Scale Parameter: 1.030769
Number of Iterations: 1
Working Correlation
[,1] [,2]
[1,] 1.0000000 0.6401548
[2,] 0.6401548 1.0000000
very slight over-dispersion.
(note this is on the binary outcomes).
Results Comparison
Table of Log Odds Treatment Effect in
Approach
Naive SE
Robust SE
GLM
1.11
0.57
NA
GEE, Independent
1.11
0.58
0.57
GEE, Exchangeable
1.11
0.58
0.57
Random Intercept
3.60
2.14
NA
The three marginal approaches give the same point estimates. In this analysis, accounting for between-subject correlation gives very similar standard errors compared to standard GLM. (Usually will differ)
The conditional effect is larger than the marginal estimates.