1 はじめに

科 学は一般に、蓄積されたプロセスであると考えられている。研究者は、何世代も前の科学者が積み上げてきた証拠を基に、科学的な努力を積み重ねている。アイザック・ニュートンの有名な言葉に「巨人の肩の上に立つことで、より遠くを見ることができる」というのがある。多くの人が科学に魅了されるのは、科学が進歩的であり、世界への理解を深めたり、より良い決断を下すのに役立つからである。
これは直感的な考えであるが、少なくとも数字上は正当化される。歴史上、今日ほど研究論文の発表という形で多くの証拠にアクセスできる時代はなかった。ペタバイト級の研究成果が、世界中で毎日生み出されているのである。生物医学だけでも、毎年100万件以上の査読付き論文が出版されている (Björk, Roos, and Lauri 2008)。
発表される研究成果の量は、ほぼ指数関数的に増加している。最大の書誌データベースの一つである PubMed の各年度の索引論文数は、このことを模範的に象徴しているといえるだろう。20世紀の半ばまで、各年度の研究論文は数百件しか掲載されていなかった。それが、その後の数十年で大幅に増え、21世紀に入ってから急増している(Figure 1.1 参照)。
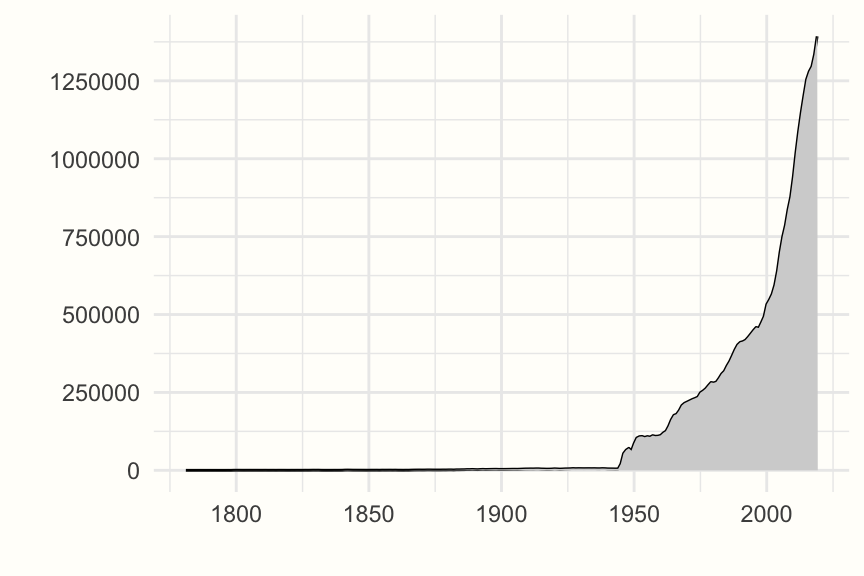
Figure 1.1: PubMed にインデックスされた論文数(年別)、1781年~2019年
原理的には、科学の発展により、科学の将来性が加速されるはずである。科学が蓄積されるものであるならば、より多くの研究が発表されるということは、より多くの証拠が得られることに等しい。そうすれば、より強力な理論を構築し、過去の誤謬を取り除くことができるはずである。
しかし、もちろん、そう簡単にはいかない。スタンフォード大学の John Ioannidis は、非常に影響力のある論文の中で、科学は自動的に蓄積され、常に改善されるという考え方を批判した。彼の論文には、「科学は、なぜ必ずしも自己修正しないのか」 (“Why Science Is Not Necessarily Self-Correcting”) という分かりやすいタイトルがつけられている (Ioannidis 2012)。彼は、研究分野では、特定のトピックや理論について膨大な研究成果が生み出される一方、根本的な誤謬に対しては検証されずに永続する状態が存在することもよくあると主張している。
1970年代にさかのぼるが、優れた心理学者である Paul Meehl は、ある研究分野において、理論とファッションのトレンドが酷似していることに気づき観察していた。Meehl は、多くの理論は継続的に改良されたり反論されたりするのではなく、人々が興味を失い始めると、単に「消えていく」のだと主張した (Meehl 1978)。
科学的なプロセスだけでは、自動的に最善の世界へと導かれることはない。これは、不都合な真実である。日々、前例のない量の研究結果が生み出される中、証拠となるものを全体として捉え、批判的に評価することがより一層重要になっている。メタ分析は、メタ分析自体の限界とバイアスを認識する限り、最善の世界に達するために非常に役立つものである。
1.1 メタ分析とは?
メタ分析の創始者の一人である Gene V. Glass は、メタ分析を「分析の分析」(Glass 1976) と表現した。この単純な定義が、すでに多くのことを物語っている。従来の研究では、分析の単位は、多数の人、標本、国、または物である。メタ分析では、一次研究そのものが分析の要素になるのである。
メタ分析の目的は、明確に定義された研究分野や研究課題に関連する利用可能なすべての証拠を組み合わせ、要約し、解釈することである (Lipsey and Wilson 2001, chap. 1)。しかし、メタ分析はこれを行うための1つの手法に過ぎない。複数の研究からのエビデンスを合成する方法には、少なくとも3つの異なる方法がある (Pim Cuijpers 2016)。
伝統的/ナラティブレビュー:1980年代に入るまで、研究分野を要約する方法としては、ナラティブレビュー (narrative review) が最も一般的であった。ナラティブ(訳注:「物語り」の意)レビューは、その分野の専門家や権威によって書かれることが多い。ナラティブレビューに含まれる研究をどのように選択しなければならないか、またレビューの範囲をどのように定義するかについて、厳密なルールはない。また、レビューされたエビデンスからどのように結論を出すかについても、決まったルールはない。全体として、これは著者の意見に有利なバイアスにつながる可能性がある。しかしながら、ナラティブレビューは、バランスの取れた方法で書かれていれば、読者が関連するリサーチクエスチョンや分野のエビデンスベースについて全体的な印象を得るのに役立つ方法となり得る。
システマティックレビュー:システマティックレビューは、明確に定義された透明性の高いルールでエビデンスをまとめようとするものである。システマティックレビューでは、研究課題を事前に決定し、研究を選択し、レビューするための明確で再現可能な方法論が存在する。その目的は、利用可能なすべてのエビデンスを網羅することである。また、あらかじめ定義された基準でエビデンスの妥当性を評価し、結果の統合を系統的に提示する。
メタ分析:メタ分析の多くは、システマティックレビューの発展型といえるだろう。メタ分析の範囲は事前に明確に定義され、一次研究も体系的かつ再現可能な方法で選択され、エビデンスの妥当性を評価する基準も明確になっている。そのため、「システマティックレビューとメタ分析」と名付けられた研究がよく見られるのである。メタ分析の目的は、先行研究の結果を定量的に組み合わせることで、この点がメタ分析を特別なものにしている。メタ分析の目的は、選択された研究で報告された定量的アウトカムを1つの数値的な推定値に統合することである。そしてこの推定値は、個々の結果をすべて要約したものである。メタ分析は、例えば、薬の効果、病気の流行、2つの性質の相関などを、すべての研究にわたって定量化する1 。したがって、定量的な結果を報告している研究にのみ適用することが可能である。システマティックレビューと比較して、メタ分析は、要約される証拠の種類に関してより限定的でなければならないことが多い。メタ分析を行うには、通常、同じデザイン、同じタイプの測定、同じ介入を行った研究が必要である (Chapter 1.3 参照)。
個別被験者データメタ分析 (Individual Participant Data Meta-Analysis)
定義によっては、第4のタイプのエビデンス合成法、いわゆる個別被験者データ (Individual Participant Data, IPD) メタ分析も存在する (Richard D. Riley, Lambert, and Abo-Zaid 2010; Richard D. Riley, Tierney, and Stewart 2021)。従来、メタ分析は、発表された文献にある研究の集計された結果(例えば、平均と標準偏差、または割合)に基づいている。IPD メタ分析では、代わりにすべての研究のオリジナルデータを収集し、1つの大きなデータセットにまとめる。
IPD メタ分析にはいくつかの利点がある。例えば、欠損データをインプットしたり、全ての研究に対して全く同じ方法で統計手法を適用することが可能である。さらに、関心のある結果に影響を与える変数の探索を容易にすることが可能である。従来のメタ分析では、いわゆる研究レベルの変数(例えば、発表年や研究で使用された集団など)のみを使用して、このようなことを行うことができることとする。しかし、結果の重要なモデレータとしての役割を果たすのは、しばしば参加者レベルの情報(例えば、個々の人の年齢や性別)である。このような変数は、IPD メタ分析を使ってのみ探索することが可能である。
IPD メタ解析は比較的新しい手法であり、現在行われているメタ解析の圧倒的多数は「従来の」メタ解析のままである。このことも、本ガイドで IPD メタ分析手法を取り上げない理由の一つである。
これは、従来のメタ分析が優れているということとは全く関係がなく、その逆である。これは単に、すべての研究データがオープンに利用可能であるという事実が、残念ながら最近までほとんどの分野で非常に稀であったためである。発表された研究報告から要約された結果を抽出することは比較的容易であるが、関連するすべての研究のオリジナルデータを入手することは、はるかに困難である。例えば、生物医学研究では、参加者個人のデータは、対象となる研究の約64%からしか得られない (Richard D. Riley, Simmonds, and Look 2007)。
1.2 “Exercises in Mega-Silliness” 歴史的な逸話
メタ分析は一人の人間によって発明されたのではなく、多くの創始者と父親によって発明されたのである。別々の、しかし類似した研究の効果を統計的に要約する最初の試みは約100年前にさかのぼり、史上最も重要な統計学者である Karl Pearson と Ronald A. Fisher の2人に結びつけることが可能である。
Pearson は20世紀初頭に、大英帝国全体での腸チフス接種の効果に関する知見を組み合わせて、プール推定値を計算した (Shannon 2016)。Fisher は、1935年の実験計画法の代表的な著書で、農業研究における複数の研究のデータを分析するアプローチを取り上げ、場所や時間によって研究結果が異なるという問題を既に認めている (R. A. Fisher 1935; O’Rourke 2007).
しかし、「メタ分析」という名称とその隆盛のきっかけは、20世紀半ばに起こったある学問的論争にさかのぼることが可能である。1952年、イギリスの著名な心理学者 Hans Jürgen Eysenck (Figure 1.2) が、心理療法(当時はフロイトの精神分析を指すことが多かった)は効果がないと主張する論文を発表したのである。もし患者が治療中に良くなったとしても、それは治療とは関係のない要因によるものであって、治療がなくとも状況が改善されたからである。さらに悪いことに、Eysenck は、心理療法は患者の回復を妨げることもよくあると主張した。
心理療法は大きな打撃を受け、1970年代後半までその評判は回復しなかった。この間、Gene V. Glass は「メタ分析」と呼ぶ技法を開発し、研究間で標準化平均差 (Standardized Mean Differences)2をプールできるようにした。この手法が初めて広範囲に適用されたのは、Mary L. Smith と Glass 自身 (Smith and Glass 1977) が書いた American Psychologist 誌に掲載された論文であった。この大規模な研究では、4000人以上が参加した375の研究の結果がメタ分析で統合された。
その結果、心理療法は 0.68 のプール効果を示し、これは非常に大きいと考えられる。Glass の研究は、Eysenck の評決が誤りであることを定量的に証明するものであり、そのインパクトは絶大であった。しかし、Eysenck 自身は納得しておらず、メタ分析を “Exercises in Mega-Silliness” と呼んでいる (Eysenck 1978) 。

Figure 1.2: Hans Jürgen Eysenck (Sirswindon/CC BY-SA 3.0)
今日、私たちは、Smith and Glass の研究が、対象研究のバイアスを制御しなかったために、心理療法の効果を過大評価した可能性があることを知っている (P. Cuijpers, Karyotaki, et al. 2019)。しかし、いくつかの心理療法が有効であるという主要な発見は、その後の数十年間で、他の無数のメタ分析によって裏付けらた。Eysenck の厳しい反応も、メタ分析がやがて様々な研究分野でよく使われる手法となるということを変えることはできなかった。この時代のことは、“meta-analytic Big Bang” に詳しく書かれている (Shadish and Lecy 2015)。
Glass がメタ分析の手法を開発したのとほぼ同時期に、Hunter and Schmidt は、測定誤差の補正に重点を置いた独自のメタ分析手法を作り始めた (Schmidt and Hunter 1977; Hunter and Schmidt 2004)。メタ分析が初めて医学の世界に登場したのは、Peter Elwood や Archie Cochrane らがメタ分析を用いた画期的な業績からである。このメタ分析で、アスピリンには、わずかではあるが心臓発作の再発を防ぐ効果が統計的にも臨床的にもあることを示した (Peto and Parish 1980; Elwood 2006; O’Rourke 2007)。
80年代半ば、Rebecca DerSimonian and Nan Laird がランダム効果メタ分析を計算するアプローチを紹介し(Chapter 4.1.2 参照)、今日まで使用されている (DerSimonian and Laird 1986)。その他にも数え切れないほどの技術革新があり、過去40年間にメタ分析手法の適用性、頑健性、汎用性を高めることに貢献してきた。
Cochrane と Campbellの共同研究
1993 年に設立され、Archie Cochrane にちなんで名付けられた コクラン共同計画 (Cochrane Collaboration, または単に Cochrane) は、応用メタ分析の発展において重要な役割を担っている。コクラン共同計画は、研究者、専門家、患者、その他関係者の国際的なネットワークで、「商業的なスポンサーシップやその他の利益相反のない、信頼性が高くアクセスしやすい健康情報を生み出すために協力し合う」ものである。
コクラン共同計画は、生物医学分野におけるエビデンスを統合するために、厳格な基準を用いている。ロンドンに本部を置くほか、世界数カ国に現地支部を置いている。
コクラン共同計画では、定期的に更新される Handbook for Systematic Reviews of Interventions (Julian Higgins et al. 2019) と Cochrane Risk of Bias Tool (Sterne et al. 2019) を発行している。どちらもシステマティックレビューやメタ分析に関するあらゆる技術的な詳細について、標準的な参考書として広く知られている(Chapter 1.4 参照)。
コクランに似た組織として、オスロに拠点を置くCampbell Collaboration があり、主に社会科学分野の研究に力を入れている。
1.3 りんごとオレンジ: メタ分析の落とし穴のクイックツアー
この数十年で、メタ分析は普遍的に受け入れられる研究ツールとなった。しかし、これにはそれなりのコストがかかる。質の高い一次研究を行うには多くの場合非常にコストがかかり、その結果を最終的に分析できるようになるまで何年もかかることがある。それに比べてメタ分析は、あまり多くのリソースを必要とせず、比較的短期間で作成することが可能である。それにもかかわらず、メタ分析はしばしば高い影響力を持ち、頻繁に引用されている (Patsopoulos, Analatos, and Ioannidis 2005)。
すなわち、科学雑誌はメタ分析を掲載する傾向が強く、たとえその品質や科学的メリットが限られていたとしても、掲載する傾向があるのである。残念ながら、このことは研究者に多くのメタ分析を作成する動機を与え、科学的動機は時として従属的になっている。
Ioannidis (2016) は、毎年膨大な量の冗長で誤解を招くメタ分析が生産されていると批判している。いくつかの「ホット」なトピックでは、最近のメタ分析が20以上ある。また、薬物療法研究などでは、企業の利益に大きく偏ったメタ分析もある(Ebrahim et al. 2016; Kirsch et al. 2002)。前にも述べたように、再現性は優れた科学の特徴である。しかし現実には、重要な情報が報告されないために、多くのメタ分析の再現性が制限されていることがあまりにも多い (Lakens et al. 2017)。
また、同じテーマ、あるいは重複するテーマについて、異なるメタ分析で異なる結論に至ることもよくある問題である。例えば、心理療法の研究では、すべてのタイプの心理療法が同等の結果をもたらすかどうかという問題に関連する議論が続いている。数え切れないほどのレビューが、どちらかの結論を支持する形で発表されている (Wampold 2013; Pim Cuijpers, Reijnders, and Huibers 2019) 。
こうした問題は、科学的プロセスの体系的な問題と関連しているかもしれないし、メタ分析自体の欠陥にさかのぼることが可能である。そこで、メタ分析の落とし穴を簡単に紹介する (Borenstein et al. 2011, chap. 40; Greco et al. 2013; Sharpe 1997)。
1.3.1 「りんごとオレンジ」問題
メタ分析とは、りんごとオレンジを混ぜることだ、と主張する人もいる。対象基準を最大限に厳格にしても、メタ分析における研究が完全に同一であることはない。含まれるサンプル、介入の実施方法、研究デザイン、研究で使用された測定の種類などには、常に大小の差が存在する。
これは問題になることもある。メタ分析とは、すべての研究の結果を表す数値的な推定値を計算することである。このような推定値は、統計学的な観点からは常に計算することが可能であるが、特定の研究課題に答えるために重要な特性を共有する研究がない場合には、意味がなくなる。
明らかにばかげたシナリオとして、仕事のパフォーマンスに対する仕事満足度の効果に関する研究と糖尿病患者の HbA1c 値に対する投薬の効果に関する利用可能なすべてのエビデンスを、1つのメタ分析にプールすることを決定した、と想像してみよう。その結果は、組織心理学者にとっても、糖尿病学者にとっても、無意味なものだろう。
さて、この無能なメタ分析者が、過去の失敗から学び過剰な補償をして、1990年から1999年の間に発表された、中程度の抑うつ症状を持つ60代のカナダ人男性に Fluoxetine を1日 40 mg、正確に6週間投与した研究のみを含むメタ分析を実施したとする。メタ分析は、研究の肯定的な結果を誇らしげに精神科医に報告することが可能である。しかし、精神科医は、「私の患者が45歳のフランス人だったらどうすればいいのか」と聞くだけだろう。
ここで重要なポイントがある。メタ分析の目的は、組み合わせられるものは何でも無造作に放り込むことではない。メタ分析は、個々の研究の特殊性を超えた、関連する研究課題に答えるために用いることが可能である (Borenstein et al. 2011, chap. 40)。したがって、メタ分析の範囲と特異性は、答えたい研究課題に基づくべきであり、この課題は実用的な関連性を持つものであるべきである(Chapter 1.4 参照)。
例えば、ある種のトレーニングプログラムが、様々な年齢層、文化的地域、環境において有効であるかどうかに関心がある場合、研究の対象者や出身国に制限を設けないことは非常に理にかなっている。しかし、その場合、評価する研修プログラムを限定し、一定の長さの研修や類似のトピックを扱った研修のみを対象とすることが望ましいと考えられる。
このようなメタ分析の結果は、トレーニングのプール効果を推定するだけでなく、この効果がどの程度変動しているのかを定量化することが可能である。メタ分析は、このような異質性に対応し、意味を持たせることができるのである。Chapter 5 では、この重要な概念について詳しく見ていく。
要約すると、「りんごとオレンジ」問題が実際に問題であるかどうかは、メタ分析が答えたい問題に大きく依存するということである。研究間のばらつきは、メタ分析の目的と問題の特定に正しく組み入れられれば、多くの場合問題にはならず、洞察的でさえある。
1.3.2 「Garbage In, Garbage Out」問題
メタ分析が生み出すエビデンスの質は、それが要約した研究の質に大きく依存する。もし、含まれる知見で報告された結果が偏っていたり、全く間違っていたりすれば、メタ分析の結果も同様に欠陥があることになる。これが「Garbage In, Garbage Out」問題の指すところである(訳注: 入力が無意味なら出力も無意味であることを指す。略して GIGO と書くこともある。)。これは、含まれる研究の質やバイアスのリスク(Chapter 1.4 と Chapter 15) 参照)を評価することである程度軽減することが可能である。
しかし、結果の多くまたは大部分が最適な品質ではなく、バイアスがある可能性が高い場合、最も厳密なメタ分析でもバランスを取ることはできない。このような場合、導き出される唯一の結論は、レビューしたテーマについて信頼できる証拠は存在せず、今後さらに質の高い研究を実施しなければならないということである。しかし、このような残念な結果であっても、将来の研究の指針として参考になることがある。
1.3.3 「ファイルの引き出し」問題
ファイルの引き出し問題とは、関連する研究結果がすべて発表されているわけではないため、メタ分析に欠落してしまうという問題である。メタ分析ですべてのエビデンスを統合できないことは望ましくないが、少なくとも、研究成果が発表された文献の中でランダムに欠落していると安全に仮定できるのであれば、許容範囲であろう。
しかし、残念ながら、そうではない。ポジティブで「革新的」な発見は、失敗した複製やネガティブで結論の出ない研究よりも話題を呼ぶことが多い。これに伴い、ここ数十年、多くの分野、特に社会科学や生物医学の分野で、否定的な知見が発表されることが少なくなっていることが調査で明らかになっている (Fanelli 2012)。
否定的な結果や「期待はずれ」の結果を出した研究は、発表された文献の中で体系的に過小評価されており、いわゆる発表バイアスがあると考える十分な根拠がある。このバイアスの正確な性質と程度は、メタ分析ではせいぜい「未知の知」(known unknown) である。
しかし、出版バイアスを最小化する方法はいくつかある。一つは、研究の検索・抽出の方法に関連する(Chapter 1.4 参照)。もう1つは、メタ分析において出版バイアスが存在するかどうか、またその影響がどの程度あるのかを推定しようとする統計的な方法である。これらの手法については、Chapter 9 でいくつか紹介する。
1.3.4 「研究者のアジェンダ」問題
メタ分析の範囲を定義し、研究を検索・選択し、最終的にアウトカム指標をプールする際、研究者は無数の選択を迫られる。メタ分析には多くの「研究者の自由度」(Wicherts et al. 2016) があり、時には恣意的であったり、公表されていない個人の好みの結果などの決定の余地が多く残されている。
メタ分析の運用法 (modus operandi) の自由度は、研究者が意識的または無意識的に自身のアジェンダに突き動かされている場合に特に問題となる。メタ分析は通常、応用研究者によって行われるが、レビュートピックに関する広範な主題固有の専門知識を持つことは諸刃の剣である。一方では、特定の分野における有意義なリサーチクエスチョンを導き出し、それに答えるのに役立つこともある。
また他方では、そのような専門家は、自分が調査している研究分野に深く関与していることも事実である。つまり、多くのメタ分析者は特定のテーマについて強い意見を持っており、意図的または無意識に自分の信念に合う方向に結果に影響を与える可能性がある。
同じデータセットが与えられると、最高の意図を持った経験豊富な分析者間でも、結論が大きく異なることがあるというエビデンスがある (Silberzahn et al. 2018) 。この問題は介入研究においてさらに深刻で、メタ分析者の中には、研究中の介入手法の開発に貢献したことがあるため、堅固な研究者としての忠誠心を持っている人もいる。そのような研究者はもちろん、メタ分析の結果を証拠によって示されるよりも肯定的に解釈する傾向が強いかもしれない。
研究者のアジェンダ問題を軽減する一つの方法として、メタ分析のデータ収集を開始する前に、事前登録を行い、詳細な解析計画を公開することが挙げられる(Chapter 1.4 と 16.3.5を参照)。
1.4 問題の特定、スタディ検索、コーディング
前章では、メタ分析の一般的な問題や限界について時間をかけて議論した。「りんごとオレンジ」問題、「ファイルの引き出し」問題、「研究者のアジェンダ」問題など、これらの問題の多くは、すべてのメタ分析者が取り組むことができ、また取り組むべきものである。
これは、最初の結果を計算し始めるずっと前から始まっている。メタ分析はデータがなければ実施できないため、当然ながらこのデータをどこからか持ってこなければならない。まず、計画中のメタ分析の研究課題と適格基準を特定し、研究を検索して関連するものを選び、計算に必要なデータを抽出し、後で報告したい重要な情報をコーディングする。
各ステップにおいて、従うことができる、または従うべき規則、基準、推奨事項がいくつかあり、高品質なメタ分析を作成するのに役立つ。このような高品質のメタ分析には、すべての適切なエビデンスが包括的に選択されており、その対象に関してバイアスがなく公平であり、その結果から有効かつ正当で、実際的に適切な結論が導き出されている。
しかし、「すべてのルールに従う」といっても、実際には具体的にどのような判断が最適なのか、必ずしも明らかでない場合もある。あなたが行った方法に対して、人々が反対することもあり得る。これは普通のことで、方法論の決定が透明かつ再現可能である限り、問題はない (Pigott and Polanin 2020)。
この章では、計算を始めるより前の段階で必要となる重要な構成要素を順番に説明する。この章は長いが、データ取得のプロセスが現実に要する時間を表すものではない。経験上、統計解析はメタ分析に費やす時間の最大15%を占めるに過ぎず、その前に行われるすべての作業と比較するとはるかに少ないものである。しかし、研究課題を特定し、系統的に研究を検索し、抽出されたデータを確実にコーディングすることは不可欠である。これが、優れたメタ分析の基礎となるのである。
1.4.1 リサーチクエスチョンの定義
研究をデザインするとき、最初にすることはリサーチクエスチョンの定義である。メタ分析も例外ではない。リサーチクエスチョンを問題指定の一形態として捉えると、適切に定義することができる。適切でインパクトのあるメタ分析を行うためには、問題を解決する必要がある。そのような問題を特定するためには、対象分野に特化した知識が必要である。
メタ分析のための良いリサーチクエスチョンを見つけるには、ある程度背景知識のある研究分野を選び、まずいくつかの基本的な質問を自分自身に問いかけることが有効だろう。この分野では、現在どのようなことが問題になっているのか?特定のテーマについて、現在の知識には欠如がないか?未解決の議論が残っていないか?また、対象となる読者について考えてみるのもよいだろう。他の研究者に関連する問題は何か?他の人々、例えば医療関係者、国家機関、学校、人事部などが直面しそうな問題は何か。
メタ分析は先行研究に依存する。研究課題の大まかな方向性が決まったら、現在の文献を見るのが効果的である。このテーマに関する先行研究は存在し、どのように問題に対処していたのか?どのような方法とアウトカム尺度を使用したのか?論文の背景や考察のセクションで、どのような制限に言及しているか?過去のレビューやメタ分析でこのテーマを扱ったことがあるか、またどのような問題が残されているか?
Cummings ら (2013) は、メタ分析の対象となる問題を特定するために使用できるいくつかの基準、FINERフレームワークを提案している。それは、リサーチクエスチョンが、実行可能 (Feasible)で、興味深く(Interesting)、新規性があり(Novel)、倫理的である( Ethical)、関連性がある(Relevant)べきである。
これらの質問を自分に投げかけることで、メタ分析で何を達成したいのかが、少しずつ明らかになってくるはずである。また、メタ分析が自分の問題に適していないことが明らかになる場合もある。例えば、そのテーマを扱った関連する研究がない、あるいは、その問題を十分に扱った質の高いメタ分析が既に文献に残っている、などである。
しかし、自分の問題が1つまたは複数のグループの人々に関連し、先行研究がこの問題に関連するデータを提供し、先行するレビューやメタ分析が十分にまたは適切に対処していないと感じた場合、それをリサーチクエスチョンに変えるために進むことが可能である。
どのようなことができるのか、例を挙げてみよう。医学研究においてジェンダーバイアスが存在することを示唆する証拠がある (Hamberg 2008; Nielsen et al. 2017)。以前は、多くの臨床試験で男性の参加者のみであるか、または大部分が男性であっタにもかかわらず、単純にアウトカムが女性にも一般化されると仮定されていた。このため、心臓疾患など一部の疾患では、女性の健康状態が悪くなることにつながったと考えられている (Kim and Menon 2009; Mosca et al. 2013) 3。
あなたが医学研究者であると仮定しよう。よく使われる薬である Chauvicepine には、これまでほとんど認識されていなかった女性への深刻な副作用があるのではないかという噂を耳にしたとする。これは、安全でない可能性のある薬が多くの女性に処方されていることになるので、もし噂が本当であれば非常に重要な問題であると判断した。
文献を見ると、Chauvicepine を調査した研究のほとんどが無作為化プラセボ対照試験であることがわかった。初期の試験では、男性のみ、あるいは男性が大半を占める集団で実施された。しかし、最近の試験では、性別の構成がよりバランスの取れたものもいくつか見受けられる。これらの試験の多くは、試験中に発生した否定的な副作用の数を、男女別に報告していた。また医学雑誌の最近の論評で、ある医師が、自分のクリニックでは、この薬で治療したときに多くの女性がネガティブな副作用を経験したと報告しているのも見つかった。
この問題をメタ分析で解決するのは面白いかもしれないと考えついた。そこで、今発見した問題をリサーチクエスチョンに変換した。「プラセボと比較して、Chauvicepine が女性における負の副作用を有意に増加させることを示す無作為化プラセボ対照試験からのエビデンスはあるだろうか?」。
リサーチクエスチョンの最初の定式化は、最初のステップに過ぎない。次に、それを具体的な適格性基準に変換する必要がある。これらの適格基準は、どの研究がメタ分析に含まれ、どの研究が含まれないかを決定する指針となりうる。したがって、この基準は非常に重要であり、絶対的に透明で再現可能でなければならない。
適格基準を指定し始める良い方法は、PICO フレームワークを使用することである (Mattos and Ruellas 2015)。このフレームワークは主に介入研究を対象としているが、他のタイプのリサーチクエスチョンにも役に立ちる。PICO の文字は、母集団(Population)、介入( Intervention)、対照群(Control group)または比較(Comparison)、アウトカム(Outcome)の頭文字をとったものである(訳注: P は、Patients, Problems とも)。
母集団 (P): どのような人々や研究対象者が含まれていれば、研究の対象となるのか。繰り返しになるが、この質問にはできるだけ正確に答え、それぞれの定義が持つ意味を考えることが重要であることを覚えておいてください。若年成人を対象とした研究のみを対象とするのであれば、「若年成人」とは何を意味するのだろうか。18歳から30歳までの人だけが対象なのだろうか?それは発表された論文から簡単に判断できることなのだろうか?それとも、大学や Cardi B のコンサートのような、若者がよく訪れる場所で募集されたことだけが重要なのだろうか?特定の病状を持つ患者に関する研究のみを対象とするのであれば、その病状はどのように診断されたのだろうか?訓練を受けた医療専門家によるものなのか、それとも自己報告式のアンケートで十分なのか?こうした質問は、FINER フレームワークの F と R の部分に頼ることによって答えられることが多い。発表された研究にこのような制限を加えることは可能なのか?また、それは適切な差別化なのだろうか。
介入 (I): どのような介入(または曝露)を研究する必要があるのか。介入の効果を研究したいのであれば、対象となる治療の種類を明確にすることが重要である。介入はどのくらいの期間でなければならないか?誰が介入を行うことが可能であるか?介入はどのような内容を含まなければならないか?介入に焦点を当てない場合、独立変数はどのように運用されなければならないか?変数は特定の測定機器や質問紙によって測定されなければならないか?例えば、仕事に対する満足度を研究する場合、この構成要素は研究においてどのように運用されなければならないか?
対照群または比較対象 (C): 試験結果は何と比較されたのか?情報提供プラセボ (Attention placebo) か、または錠剤のプラセボを受けた対照群か?待機者?別の治療法?それとも全く何もしないのか?例えば、異なる研究間での病気の有病率推定を研究したい場合や、異なる生息地にどれだけの種の標本があるのかを研究したい場合など、比較群や対照群が全くないこともあり得る。
アウトカム (O): 研究では、どのような成果や従属変数を測定しなければならないのだろうか?そして、その変数はどのように測定しなければならないのだろうか?質問票の点数の平均や標準偏差だろうか?それとも、死亡した患者や病気になった患者の数か?結果はいつ測定されなければならないのだろうか?治療期間には関係なく、単純に治療直後でよいのか?それとも1〜2年後か?
システマティックレビューとメタ分析のためのガイドライン
メタ分析の質が低いことが多いことから、メタ分析の実施方法について、いくつかのガイドラインや基準が設けられている。
生物医学研究または介入の効果に関するエビデンスをメタ分析する場合、Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) (Moher et al. 2009) に従うよう強く推奨する。PRISMA 声明には、メタ分析過程のほぼすべての側面についてどのように報告すべきかという推奨事項が含まれている。また、この声明はオンラインで見ることが可能である4。
心理・行動研究のメタ分析については、米国心理学会のメタ分析報告基準 (American Psychological Association’s Meta-Analysis Reporting Standards, MARS) (Appelbaum et al. 2018) に従うことが可能である。
これらの基準は、メタ分析がどのように報告されるべきかについて主にコメントしているが、メタ分析を行う際のベストプラクティスにも影響を及ぼしている。PRISMA とMARS はコアな要素を多数共有しており、本章で取り上げる多くの事柄は、両ガイドラインでも言及されている。
さらに詳細な資料として、Cochrane Handbook for Systematic Reviews of Interventions (Chapter 1.2) があり、システマティックレビューとメタ分析のほぼすべての側面に関する正確な推奨事項が記載されている。社会科学におけるメタ分析の方法論的基準の概要は、Pigott and Polanin (2020) で見ることが可能である。
PICO フレームワークはメタ分析の適格基準を指定する優れた方法であるが、関連する可能性のある情報すべてを網羅しているわけではない。他にも考慮すべき点がいくつかある (Lipsey and Wilson 2001)。
関連する詳細の1つは、対象となる研究デザインである。エビデンスに基づく医療では、無作為化化比較試験(参加者が偶然に治療群または対照群に割り付けられた研究を意味する)からのエビデンスのみを含めることが一般的であるが、これは必ずしも必要ではない (Borenstein et al. 2011、Chapter 40)。
また、対象となる研究の文化的および言語的範囲を指定することも有用だろう。ほとんどの研究は WEIRD 集団、つまり西洋(Western)、教育(Educated)、工業化(Industrialized)、豊か(Ric)、 民主主義国(Democratic societies)に基づいている (Henrich, Heine, and Norenzayan 2010) 。特に社会科学の分野では、ある効果や現象が他の社会規範を持つ国にはうまく一般化されない可能性が非常に高い。しかし、多くの研究者は、他の言語の論文を翻訳する手間を省くために、英語の論文のみをメタ分析の対象としている。
これは、異なる言語圏からのエビデンスが考慮されないことを意味する。英語はほとんどの分野で科学的発表の最も一般的な言語であるが、少なくともこの制限が存在することは適格基準において明らかにされるべきである。しかし、メタ分析の目的の一つが異文化間の差異を調べることであるならば、他のすべての基準を満たす限り、一般的に適格基準を他の言語にも拡大することが望ましい。
もう一つの重要な点は、メタ分析に許可される出版物の種類である。メタ分析には、査読付き科学雑誌に掲載された研究論文のみが含まれることがある。これは、その分野の専門家の厳しい目を通過した研究であるため、より高い基準を満たすという主張である。この正当化には欠点がないわけではない。Chapter 1.3 では、「ファイル引き出し」問題がメタ分析結果の妥当性を著しく制限する可能性があることをすでに取り上げた。
したがって、出版バイアスのリスクを軽減する方法として、灰色文献も含めることが挙げられる。灰色文献とは、従来の出版形式では入手できなかったあらゆるタイプの研究資料と定義することが可能である。これには、研究報告書、プレプリント、ワーキングペーパー、会議への投稿などが含まれる。学位論文も灰色文献に数えられることが多いが、その多くは今日、電子書誌データベースで索引付けされている (Schöpfel and Rasuli 2018)。
学位論文については、少なくともメタ分析には含めることが望ましいと思われる。他の種類の未発表資料と比較して、学位論文で提供される情報に大きなバイアスがあったり、明らかに不正であったりすることは、むしろ少ないだろう。さらに、科学雑誌に掲載されたかどうかにかかわらず、特定の方法論的要件を満たす研究のみを含めるよう、他の適格基準を定義することも可能である。
適格基準を定義する最後のステップは、適用する包含基準と除外基準のリストとして書き留めることである。大学生における不眠症の介入に関するメタ分析から、このような方法があることを示す例を紹介する (Saruhanjan et al. 2020)。
“We included: (a) RCTs [randomized controlled trials; authors’ note] in which (b) individuals enrolled at a tertiary education facility (university, college or comparable postsecondary higher education facility) at the time of randomization, (c) received a sleep-focused psychological intervention, (d) that was compared with a passive control condition, defined as a control condition in which no active manipulation was induced as part of the study (wait-list, treatment as usual).
For the purposes of this analysis, “sleep-focused” means that (e) effects on symptoms of sleep disturbances (global measures of sleep disturbances, sleep-onset latency […], fatigue and daytime functionality, pre-sleep behaviour and experiences) were assessed as a (f) target outcome (by declaring a sleep outcome as the primary outcome or by stating the intervention was primarily aimed at this outcome) using (g) standardized symptom measures (objective sleep measures, standardized sleep or fatigue questionnaires, sleep diaries, items recording sleep quantity, quality or hygiene).
Only studies (h) published in English or German were considered for inclusion.”
1.4.2 解析計画・事前登録
リサーチクエスチョンと適格基準を設定したら、解析計画 (Pigott and Polanin 2020; Tipton, Pustejovsky, and Ahmadi 2019) も書くのが賢明だろう。統計学では、a priori (先験的)な分析と post hoc (事後)な分析を明確に区別する。a priori 分析とは、データを見る前に指定される分析である。post hoc 分析あるいは探索的分析は、データを見た後、あるいはデータから示唆される結果に基づいて行われる。
a priori 分析の結果は、post hoc 分析よりもはるかに有効で信頼できると見なすことができる。post hoc 分析では、研究者の目標が達成されるまで、分析内容やデータそのものに手を加えることが容易になり得る。そのため、「研究者アジェンダ」の問題が発生しやすい。
解析計画では、メタ解析で行いたい重要な計算をすべて a priori に指定する。これには2つの目的がある。まず、実行した分析が本当に計画されたものであり、望ましい結果が得られるまでデータを操作しただけの結果ではないことを、他の人が確認することが可能である。つまり、メタ分析の各ステップで何をしたかを理解し、それを再現しようとすることができるのである。
R を使う場合は、分析の各ステップを他の人が再実行できるようなドキュメントを書くことができ、これによって解析の再現性を高めることが可能である(「各種ツール」の Chapter 16 参照)。しかし、これは分析が完了した後の話である。解析計画では、データを収集する前に、何をする予定なのかを指定する。
解析計画には、必ず明記すべきことが何点かある。どのような情報を抽出するのか、含まれる研究ごとにどのような効果量指標を算出するのかを明確にしておく必要がある(Chapter 3)。また、各研究の結果をプールする際に、研究間のばらつきの大きさを考慮して、固定効果モデルとランダム効果モデルのどちらを使用するかをあらかじめ決めておくとよいだろう(Chapter 4参照)。また、メタ分析で統計的に有意な効果を得るために必要な研究数を決定するために、先験的な検出力分析も役に立つ(「ツール」の Chapter 14 参照)。
さらに、サブグループ解析(Chapter 7)やメタ回帰(Chapter 8)を用いて、いくつかの変数が対象研究の結果の違いを説明しているかどうかを評価したいかを決定することが重要である。例えば、仮説として出版年が研究のアウトカムと関連している可能性があり、この関連をメタ分析で後で調べたい場合、解析計画にその旨を記載する。研究をサブグループに分類し、そのサブグループを別々に調査する予定であれば、特定のサブグループに属すると判断する正確な基準も報告する必要がある(Chapter 1.4.4 参照)。
本書の第II部(「 R でメタ分析」)では、メタ分析の一部として適用すべき様々な統計的技法について取り上げる。ここで学び、メタ分析で適用する予定の技法は、すべて解析計画書に記載する必要がある。
解析計画を書き終えたら、どこかに埋めてしまうのではなく、公開するようにしよう。研究者が自分の研究文書をオープンにするための優れた選択肢がいくつかある。例えば、オープンサイエンス・フレームワーク(OSF)のウェブサイトに新しいプロジェクトを作成し、そこに解析計画書をアップロードすることができる。また、研究内容によっては、medrxiv.org、biorxiv.org、psyarxiv.comなどのプレプリントサーバーに解析計画をアップロードすることも可能である。
研究課題、適格基準、解析計画、検索戦略(次章参照)が決まったら、メタ分析も登録する必要がある。メタ分析が広く健康に関連するアウトカムである場合、前向きシステマティックレビューとメタ分析の最大級の登録機関である PROSPERO を利用することが望ましい。OSF の事前登録サービスも良い選択肢である。
さらに一歩進んで、メタ分析用のプロトコル全体を書くことも可能である (Quintana 2015)。メタ分析プロトコルには、解析計画に加えて、研究の科学的背景の説明、より詳細な方法論、研究の潜在的な影響についての議論を含める。
また、PRISMA-P ステートメント (Moher et al. 2015) など、プロトコルの書き方に関するガイドラインも存在する。メタ分析のプロトコルは、多くの査読誌で受け入れられている。Büscher, Torok and Sander (2019) や Valstad and colleagues (2016) などは良い例である。
a priori な解析計画と事前登録は、よくできた信頼できるメタ分析には欠かせない特徴である。そして、このことで不安になる必要はない。方法論の決定一つ一つについて、事前に完璧な選択をすることは、不可能ではないにせよ、困難である。最初の計画をある時点で変更するのは、ごく普通のことである。計画したアプローチの変更について正直かつ明確に説明すれば、ほとんどの研究者はこれを失敗の印ではなく、プロ意識と信頼性の証と受け止めてくれることは間違いない。
1.4.3 研究の検索
適格基準や解析計画を決定した次のステップは、研究の検索である。本章では、ほとんどのメタ分析がシステマティックレビューの発展型であることを説明してきた。偏りのない包括的な事実の見方を得るために、研究課題に関する利用可能なエビデンスすべてを見つけることを目的としている。つまり、研究の検索も可能な限り包括的でなければならない。研究の検索には、1つだけでなく、複数の情報源を使用する必要がある。ここでは、重要かつ一般的に使用されている情報源の概要を説明する。
レビュー記事:同じトピックや類似のトピックに関する過去のレビューを精査し、関連する文献を探すことは非常に役に立つ。ナラティブレビューやシステマティックレビューでは、通常、レビューに含まれるすべての研究の引用が提供される。こうした研究の中には、自分の研究目的にも関連しているものも多くある可能性がある。
研究中の参照文献:メタ分析に関連する研究を見つけた場合、この研究が参照している論文もスクリーニングするのが賢明である。その研究が序論や考察のセクションで同じトピックに関する過去の文献を引用している可能性は非常に高く、これらの研究のいくつかもメタ分析に関連する可能性がある。
フォワードサーチ:フォワードサーチは、先行する一次研究やレビューの文献をスクリーニングすることの逆と見ることができる。メタ分析に関連する研究をベースとして、その研究が発表されてから引用された他の論文を検索することを意味する。これはインターネット上で非常に簡単に行うことが可能である。通常、その研究が掲載された雑誌のウェブサイトにある、その研究のオンラインエントリーを見つければいいのである。今日、ほとんどの雑誌のウェブサイトには、ある研究を引用した論文を表示する機能がある。また、Google Scholarで検索することもできる(Table 1.1 を参照)。Google Scholar では、引用されている研究を項目ごとに表示することが可能である。
関連する学術雑誌:多くの場合、あなたが注目している研究課題の種類に特化した科学雑誌がいくつもある。そのため、それらの雑誌に掲載されている研究を探すとよいだろう。現在では、ほぼすべての学術雑誌が検索機能を備えたウェブ サイトを持っており、それを使って対象となりそうな研究を選別することができ る。また、電子書誌データベースを利用し、1つまたは複数の雑誌からの結果のみが表示されるようにフィルタを使用することも可能である。
上で説明した方法は、かなり細かい戦略として見ることができる。この方法は、関連する論文がリストアップされる可能性が非常に高い場所を検索する方法である。欠点としては、本当にそこにあるすべての証拠を発見することができないことである。したがって、検索には電子書誌データベースも使用することが推奨される。重要なデータベースの概要は、Table 1.1 に記載している。
1つのデータベースだけでなく、常に複数のデータベースで検索する必要がある。多くの書誌データベースには、膨大な数の項目が含まれている。それでも、データベースの検索結果の重複が予想以上に少ないということはよくあることである。検索するデータベースは、テーマ別の焦点に基づいて選択することができる。例えば、メタ分析が健康に関連する結果に焦点を当てている場合、少なくとも PubMed と CENTRAL を検索する必要がある。
書誌データベースを検索する際には、検索文字列を作成することが重要になる。検索文字列には、異なる単語や用語を含め、AND や OR などの演算子を使って連結する。検索文字列の作成には、ある程度の時間と実験が必要である。まずは、PICO や適格基準(Chapter 1.4.1)をベースに、AND でつなげるのがよいだろう(簡単な例では、“college student” AND “psychotherapy” AND “randomized controlled trial” AND “depression” など)。
ほとんどの書誌データベースでは、切り捨てとワイルドカードも使用可能である。切り捨ては、語尾を記号で置き換えて、検索の一部として変化させることである。これは通常、アスタリスクを使用して行われる。たとえば、“sociolog*” を検索用語として使用すると、データベースは “sociology”、“sociological”、“sociologist” を同時に検索する。
ワイルドカードは、単語の中の文字が変化してもよいことを意味している。これは、単語の綴りに違いがある場合に便利である(例えば、アメリカ英語とイギリス英語の違いなど)。例えば、“randomized” という検索語を考えてみよう。この場合、アメリカ英語のスペルを使った研究のみが検索される。ワイルドカード(しばしばクエスチョンマークで象徴される)を使用する場合、代わりに “randomi?ed” と書くと、イギリス英語のスペルが使用された結果 (“randomised”) も得られる。
検索文字列を作成する際には、ヒット数にも注目する必要がある。検索文字列は、あまり特定しすぎて関連する記事が見落とされるようなことがあってはならない。例えば、検索文字列のヒット数が3000件程度であれば、後のステップで管理しやすく、重要な参考文献がすべて結果にリストアップされる可能性が高くなる。検索文字列が一般的に有効かどうかを確認するには、最初の数百件を検索して、少なくともいくつかの文献が研究課題と関係があるかどうかをチェックすると良いだろう。
選択したデータベースで使用する検索文字列の最終版を作成したら、どこかに保存する。検索文字列は、事前登録に含めておくのがベストプラクティスである。メタ分析のプロトコルを公開する場合や、メタ分析の最終結果を公開する場合は、検索文字列の報告(例えば、付録)が必要である。
結論として、書誌データベースの検索はそれ自体が技術であり、この段落では表面をわずかになぞった程度であることを強調しておきたい。このトピックに関しては、Cuijpers (2016) と Bramer and colleagues (2018) が より詳細な議論している。
| Database | Description |
|---|---|
| Core Database | |
| PubMed | 米国国立医学図書館の公開データベース。主に生物医学の研究成果を収録している。 |
| PsycInfo | 米国心理学会(American Psychological Association)のデータベース。主に社会科学、行動科学の研究をカバーする。30日間の無料トライアルが可能。 |
| Cochrane Central Register of Controlled Trials (CENTRAL) | コクラン共同計画のデータベースを公開。主に健康関連のトピックを扱う。 |
| Embase | 大手科学出版社エルゼビアが運営するバイオメディカル研究のデータベース。ライセンスが必要。 |
| ProQuest International Bibliography of the Social Sciences | 社会科学研究のデータベース。ライセンスが必要。 |
| Education Resources Information Center (ERIC) | 教育研究のデータベースを公開。 |
| Citation Database | |
| Web of Science | Clarivate Analyticsが運営する学際的な引用データベース。ライセンスが必要。 |
| Scopus | Elsevier 社が運営する学際的な引用データベース。ライセンスが必要。 |
| Google Scholar | Google が管理するオープンアクセスな引用データベース。検索・文献検索機能は限定的。 |
| Dissertations | |
| ProQuest Dissertations | 学位論文のデータベース。ライセンスが必要。 |
| Study Registries | |
| WHO International Clinical Trials Registry Platform (ICTRP) | 世界中の臨床試験登録のデータベースで、オープンにアクセスできる。まだ発表されていない試験の特定に利用できる。 |
| OSF Registries | 研究登録の学際的なデータベースで、オープンにアクセスできる。まだ発表されていない研究の特定に利用できる。 |
1.4.4 研究の選択
研究調査を終えれば、さまざまな情報源から何千もの参考文献を集めることができるはずである。次のステップは、自分の適格基準を満たすものを選択することである。そのためには、以下のように3つのステップを踏むことを勧める。
ステップ 1 では、重複している文献を削除する必要がある。特に、複数の電子書誌データベースで検索した場合、1つの文献が2回以上表示される可能性がある。これを行う簡単な方法は、まず、すべての参考文献を参考文献管理ソフトウェアにインポートして、一箇所に集めることである。優れた参考文献管理ツールはいくつかある。Zotero や Mendeley のようなものは、無料でダウンロードすることが可能である。また、EndNote のようなプログラムは、より多くの機能を提供したが、通常、ライセンスが必要である。
文献管理ソフトは、重複する論文を自動的に削除できる機能を備えている。最初に研究検索で見つけた文献の数と、重複を除去した後に残った文献の数を書き留めておくことが重要である。除外の詳細は、後にメタ分析を公開する際に報告する必要がある。
重複を除去した後は、タイトルとアブストラクトに基づいて、目的に合わない文献を除外する必要がある。研究検索をすると、研究課題とは全く関係のない結果が何百件も出てくる可能性が非常に高い5 。このような文献は、タイトルと要旨だけを見て、安全に削除することが可能である。このステップでも、文献管理ソフトが役に立つ。各参考文献を一つずつ調べていき、その論文が自分とは関係ないと確信したら、単に削除すればいい6。
タイトルとアブストラクトから、ある研究に興味深い情報が含まれているかもしれないと思った場合、たとえその研究が重要でないように思えても、削除しないほうがよい。せっかく時間と労力をかけて総合的な研究を検索したのに、次のステップで誤って関連する文献を削除してしまったら残念なことである。タイトルと抄録に基づく文献のスクリーニングでは、その研究を除外した具体的な理由を説明する必要はない。最終的には、次のステップのために、いくつの研究が残ったかを記録するだけでよいのである。
タイトルとアブストラクトのスクリーニングに基づくと、最初の参考文献の90%以上が削除される可能性がある。次のステップでは、各文献の全文を取得する必要がある。論文で報告されたすべての内容に基づいて、その研究が適格基準を満たすかどうかを最終的に判断する。この作業は、メタ分析に研究を含めるかどうかを決定する最終ステップなので、特に念入りに行う必要がある。さらに、単に「目的に合わないから外した」というだけでは不十分である。ここで理由を述べなければならない。削除する各研究について、定義した基準に従って、なぜその研究が適格でなかったのかを文書化する必要がある。適格性の基準以外に、ある研究を含めることができない理由がもう一つある。
論文全体に目を通すと、その研究が適格かどうかを判断するのに十分な情報が提供されていないことがわかるかもしれない。研究デザインに関する十分な情報が提供されていないだけということもあり得る。また別のよくあるシナリオは、メタ分析に必要な効果量メトリックを計算できるような形で研究結果が報告されていないことである。このような場合は、少なくとも2回、研究の責任著者に連絡を取り、必要な情報を求めるようにする。著者が応答しない場合、そして発表論文に欠けている情報が不可欠な場合のみ、その研究を除外することが可能である。
含めるべき研究の最終的な選択に到達したら、含めるプロセスのすべての詳細をフロー図に書き留める。フロー図のテンプレートとしてよく使われるのは、PRISMAガイドラインで提供されている7。このフローチャートは、上記で取り上げた必要な情報をすべて文書化したものである。
電子データベースを検索して、いくつの文献を特定できたか。
他の情報源から見つけた追加の参考資料の数。
重複排除後に残った参考文献の数。
タイトルとアブストラクトに基づいて削除した文献の数。
フル論文に基づいて削除した論文の数、特定の理由で除外した論文の数を含む。
定性的統合(つまりシステマティックレビュー)および定量的統合(つまりメタ分析)に含めた研究の数。
なお、(5)で除外しなかった論文の数と(6)で含めた研究の数は通常同じであるが、必ずしも同じである必要はない。例えば、1つの論文が2つ以上の独立した研究の結果を報告し、そのすべてがメタ分析に適していることもあり得る。その場合、研究の数は、含まれる論文の数より多くなる。
ダブルスクリーニング
関連するほぼすべてのガイドラインやコンセンサスステートメントは、研究選択プロセスにおいてダブルスクリーニングを用いるべきであると強調している (Tacconelli 2009; Julian Higgins et al. 2019; Campbell Collaboration 2016)。
つまり、誤りを避けるために、少なくとも2人が独立して各研究選択ステップを行う必要がある。タイトルとアブストラクトに基づく文献の削除は、2人以上の研究者が独立して行い、評価者が削除しなかったすべての記録の組み合わせを次のステップに転送する必要がある。
2人以上の評価者を使うことは、論文の全文をスクリーニングする最後のステップではさらに重要である。このステップでは、各人が独立して研究が適格であるかどうかを評価し、適格でない場合はその理由を述べなければならない。
その後、評価者同士でその結果を比較する必要がある。一部の研究の適格性に関して評価者が意見を異にすることはよくあることで、そのような意見の相違は通常、議論を通じて解決することが可能である。評価者が合意を見いだせない場合、そのような場合に最終決定を下すことができる上級研究者をあらかじめ決めておくと便利である。
2人以上の評価者を使用することは、研究の選択プロセスにおいてのみ望ましいわけではない。この方法は、データの抽出やコーディングの際にも有効である(Chapter 1.4.5 参照)。
1.4.5 データ抽出とコーディング
メタ分析に含める研究の選択が確定すると、データを抽出することができる。選択した論文から抽出すべき情報は、大きく分けて3種類ある (Pim Cuijpers 2016)。
- 研究の特徴。
- 効果量を算出するために必要なデータ。
- 研究の質またはバイアスのリスクの特性。
質の高いメタ分析では、対象となった研究の特徴を報告する表が用意されるのが通例である。この表で報告される正確な内容は、研究分野や研究課題によって異なる可能性がある。しかし、研究の筆頭著者とその発表時期は必ず抽出して報告する必要がある。また、各研究のサンプルサイズも報告する必要がある。
これとは別に、メタ分析の PICO で指定された特性、例えば、対象国、平均年齢または中央値、女性と男性の参加者の割合、介入または曝露の種類、対照群または比較(該当する場合)、および各研究の評価結果についての情報を含めることが可能である。1つまたは複数の研究で特性の1つが評価されていない場合は、その詳細が表で指定されていないことを示す必要がある。
また、プールする予定の効果量や結果指標を計算するために必要なデータを抽出・収集することも必要である。章では、効果量データを表計算ソフトで構成し、 R での計算に利用しやすくする方法について詳しく説明する。また、解析計画(Chapter 1.4.2 参照)にサブグループ解析やメタ回帰を計画している場合は、これらの分析に必要なデータも論文から抽出する必要がある。
メタ分析では、一次研究の質も評価して報告することが一般的である。そのために各研究から抽出する必要のある情報は、使用する評価システムの種類に依存する。一次研究の質を評価するツールは、この数十年で数え切れないほど開発されている (Sanderson, Tatt, and Higgins 2007)。
ランダム化比較試験のみが対象である場合、研究の質をコード化する方法として、コクランが開発した Risk of Bias Tool を用いるのが最適な方法の1つである (Julian Higgins et al. 2011; Sterne et al. 2019) 。タイトルにあるように、このツールは研究の質そのものを評価するのではなく、研究のバイアスのリスクを評価するものである。
研究の質とバイアスのリスクは関連しているが、同一の概念ではない。「バイアス」(あるいは「偏り」)とは、研究結果やその解釈における系統的な誤りを指す。バイアスのリスクとは、研究の実施方法やその結果が、そのような系統的な誤りを引き起こす可能性を高めるような側面である。たとえ、ある研究が「最先端」とされる方法のみを適用している場合でも、バイアスが存在する可能性はある。ある研究は、特定の研究分野で重要だと考えられている品質基準をすべて満たすことが可能であるが、時にはこれらのベストプラクティスでさえ、研究を歪みから守るには十分でない場合がある。このように、「バイアスのリスク」の概念は、研究の質の評価とは少し異なる焦点を持っている。それは主に介入研究のアウトプットが信じられるかという問題に関心があり、この目標に資する基準に焦点を当てている (Julian Higgins et al. 2019).
いくつかのドメインでは、バイアスリスクツールで研究のバイアスリスクを「高い」「低い」に分類できたり、「何らかの懸念がある」と判断できる。また、バイアスリスクをどのように視覚的にまとめるかについても慣例がある(Chapter 15 で R でどのようにできるかを説明している)。非無作為化研究のバイアスリスクを評価するための同様のリソースとして、Risk of Bias in Non-randomized Studies of Interventions または ROBINS-I, tool がある (Sterne et al. 2016)。
Cochrane Risk of Bias ツールは、(非)無作為化臨床試験におけるバイアスのリスクを評価するための標準的なアプローチとなっている (Jørgensen et al. 2016)。他の分野では、現在は残念ながらまだむしろ開拓時代である。例えば、心理学研究においては、研究の質の評価は一貫性がなく、不透明であるか、全く実施されていないことが多い (Hohn, Slaney, and Tafreshi 2019)。
臨床試験以外の研究のメタ分析を計画している場合、できることが2つある。まず、Risk of Bias または ROBINS-I ツールがまだ適用可能かどうかを確認しよう。例えば、健康に関連しない別の介入方法に焦点を当てている場合である。もう一つは、確かに最適とは言えないかもしれないが、類似のテーマに関する過去の高品質なメタ分析を検索し、これらの研究がどのように主要研究の品質を決定したかを確認することである。
これで、メタ分析の歴史、問題点、そしてデータを収集しエンコードする際にそれらをどのように回避するかについての考察を終えることとする。次の章は、このガイドの「ハンズオン」部分の始まりである。この章では、 R の最初のステップを自分で実施してみる。
\[\tag*{$\blacksquare$}\]
1.5 演習問題
知識を試そう!
- メタ分析はどのように定義することができるか?メタ分析と他の文献レビューの違いは何か?
- メタ分析の生みの親、生みの親を一人挙げることができるか?その人物はどのような功績を残したか?
- メタ分析のよくある問題点を3つ挙げ、1~2文で説明しなさい。
- メタ分析のための良いリサーチクエスチョンを定義する資質を挙げなさい。
- 大学生の睡眠介入に関するメタ分析の適格基準をもう一度見てみよう(Chapter 1.4.1章末)。この研究の適格基準、除外基準から PICO を抽出できるか。
- 研究を検索するために使用できるいくつかの重要なソースを挙げなさい。
- 「研究の質」と「バイアスのリスク」の違いを1~2文で説明しなさい。
1.6 概要
毎年、より多くの科学的研究が発表され、利用可能な証拠を追跡することが難しくなっている。しかし、研究成果が多いからといって、自動的に科学が進歩するわけではない。
メタ分析の目的は、過去の研究結果を定量的に組み合わせることである。ある研究課題に関する利用可能なすべての証拠を統合し、意思決定に利用することができる。
メタ分析の手法は、20世紀初頭にまで遡る。しかし、現代的なメタ分析手法は20世紀後半に開発され、それ以降、メタ分析は一般的な研究ツールとなった。
各メタ分析には、「りんごとオレンジ」問題、「Garbage In, Garbage Out」問題、「ファイルの引き出し」問題、「研究者のアジェンダ」問題などが関連する。
これらの問題の多くは、明確な研究課題と適格基準を定義し、解析計画を書き、メタ解析を事前に登録し、研究検索とデータ抽出を系統的かつ再現可能な方法で行うことによって軽減することが可能である。