2 R の発見

こ の章では、 R の世界への旅行を始めよう。初めてプログラミングに触れる読者、少し不安かもしれない。その気持ちはよく分かる。しかし、それほど心配する必要はない。この 20 年間、世界中の何千人もの知的な人々が、 R をより簡単に、より便利に使えるようにするための方法を提供してきた。また、 R のコードの記述と実行をより簡単にするために使用できる、非常に強力なコンピュータプログラムについても紹介する。
とはいえ、これまで使ってきた他のデータ解析プログラムと比べると、 R で作業するのはやはり難しいのも事実である。 R コミュニティの最も重要な人物の一人である Hadley Wickham は、かつて R は GUI (Graphical User Interface) ベースの統計用ソフトウェアとは根本的に異なることを強調した (Grolemund 2014, Foreword)。GUI では、いくつかのボタンをクリックするだけでデータ分析を行うことが可能であるが、最終的には開発者が重要と判断した機能に限定されてしまう。
一方、 R はこのような制限はない。しかし、より多くの背景知識を必要とする場合がある。他の言語と同様に、 R も学習が必要であり、熟練したユーザーになるためには練習が必要である。この過程では、不満が生じることもあるが、それは当然のことである。序章では、「行き詰まったら」という節で、できることをいくつか紹介している。
R には、学ぶ価値があることを保証しよう。 R は、最も汎用性が高く、包括的で、最も頻繁に使用されている統計プログラミング言語である。 R のコミュニティは毎年急速に拡大しており、 R の魅力は非常に大きいので、ニューヨークタイムズでさえもニュースとして報道する価値があると判断した (Vance 2009)。
大学や研究機関で働いていようが、一般企業で働いていようが、 R でできることは、他人から見れば超能力に見えることが多いだろう。しかし、多少の時間と努力さえあれば、誰でも習得できる超能力なのである。では、そろそろ始めよう。
2.1 R と R Studio のインストール
開始する前に、統計解析のために R を便利に使えるコンピュータ・プログラムをダウンロードし、用意しなければならない。現時点での最良の選択肢は、おそらく R Studio だろう。このプログラムは、データ、パッケージ、出力の取り扱いを容易にするユーザー・インタフェースを提供してくれる。R Studio は完全に無料で、インターネットからいつでもダウンロードできるのが最大の魅力である。最近では、R Studio のオンライン版もリリースされ (https://rstudio.cloud/)、ウェブブラウザを通してほぼ同じインターフェースと機能を利用できるようになった。しかし、本書では、コンピュータに直接インストールする R Studio のバージョンに焦点を当てる。
この章では、 R と R Studio 各自のコンピュータに インストールする方法に焦点を当てている。すでに R Studio をコンピュータにインストールしており、 R の経験豊富なユーザーであれば、どれも目新しいものではないだろう。その場合は、この章を読み飛ばしてよい。 R を使ったことがない人は、しばらくお付き合い願いたい。
それでは、初めてのコーディングに向けて、 R と R Studio の設定に必要なステップに進んでいこう。
R Studio は、 R のコードを書き、それを簡単に実行できるようにするインターフェイスである。しかし、R Studioは R と同一ではなく、 R のソフトウェアがすでにコンピュータにインストールされている必要がある。したがって、まず、 R の最新版をインストールする必要がある。R Studio と同様、 R は完全に無料である。Comprehensive R Archive Network (CRAN)というウェブサイトからダウンロード可能である。Windows PC か Mac かによって、ダウンロードする R の種類は異なる。 R の重要な点は、その バージョン である。 R は定期的に更新され、新しいバージョンが利用できるようになる。 R のバージョンが古くなりすぎると、一部の機能が動作しなくなることがある。そのため、 R を再インストールして、定期的(だいたい1年ごと)に R のバージョンを更新することが有効である。この本では 、 R のバージョン 4.0.3 を使用している。 R をインストールした時点で、すでに上位のバージョンがある可能性もあるので、常に最新のバージョンをインストールすることを勧める。
R をダウンロードしてインストールした後、R Studioのウェブサイトから “R Studio Desktop” をダウンロードする。R Studio にはライセンスを購入しなければならないバージョンもあるが、今回の目的では必要ではない。R Studio Desktop の無料版をダウンロードしてインストールするだけである。
R Studio を初めて開くと、Figure 2.1 のような画面になると思われる。R Studio には、3 つのペインがある。右上には Environment ペインがあり、 R で内部的に定義した(=保存した)オブジェクトが表示される。右下には、Files, Plots, Packages, Help ペインがある。このペインにはいくつかの機能があり、例えば、コンピュータ上のファイルを表示したり、プロットやインストールされたパッケージを表示したり、ヘルプページにアクセスするために使用される。しかし、R Studio の中心は左側の Console である。Console は、 R コードを入力し、実行する場所である。
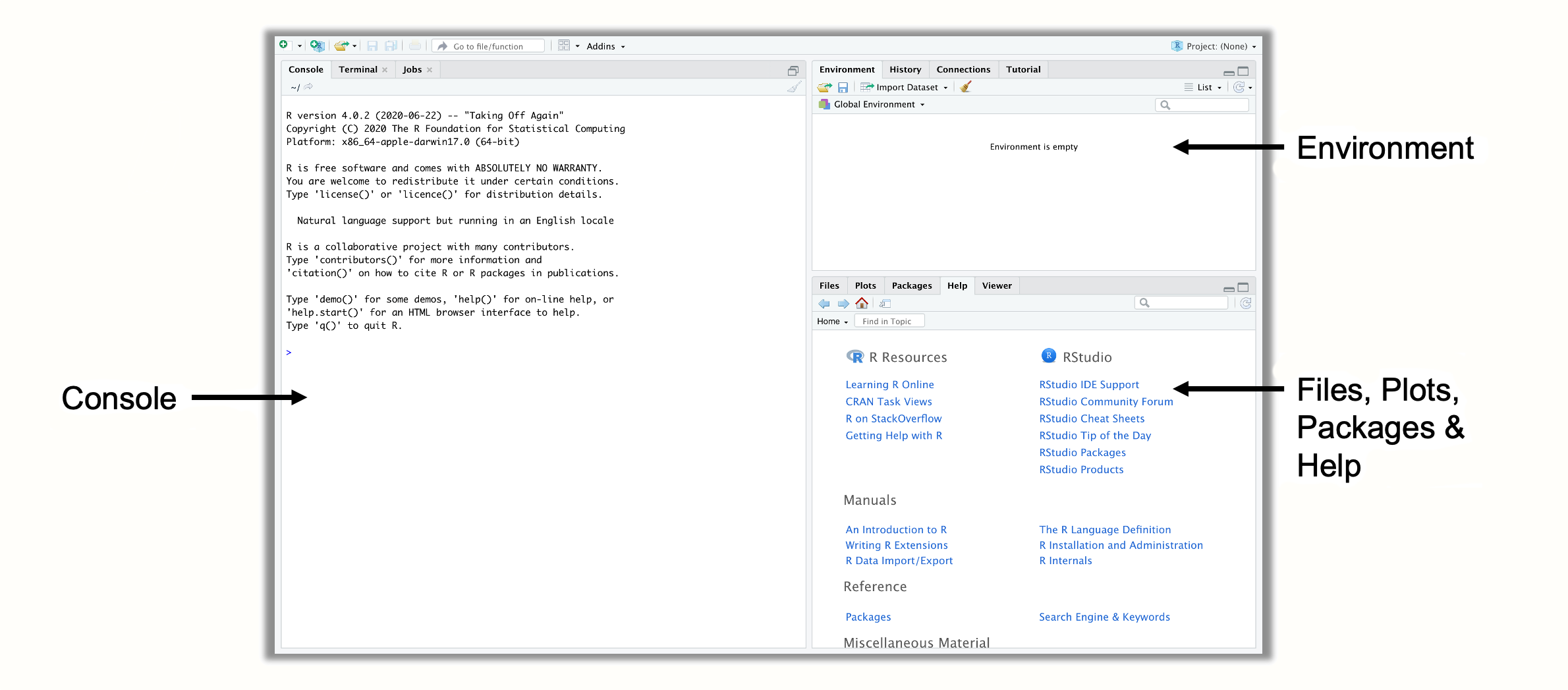
Figure 2.1: R Studio のペイン
- R Studioには、通常はじめに表示されない4番目のペインとして、Source ペインがある。メニューの File > New File > R Script をクリックすると、Source ペインを開くことが可能である。すると、左上に空の R スクリプトを含む新しいペインが開く。 R スクリプトは、コードを1つの場所に集めるのに最適な方法である。また、拡張子が “.R” のファイル (例: myscript.R) として、コンピュータに保存することも可能である。 R スクリプトのコードを実行するには、関連するすべての行にカーソルをドラッグして選択し、右側にある “Run” ボタンをクリックする。これにより、コードがコンソールに送信され、そこで評価される。ショートカットは、Ctrl + R (Windows) または Cmd + R (Mac)である。
2.2 パッケージ
ここでは、 R のコードを使用して、いくつかのパッケージをインストールする。パッケージは R が非常に強力である主な理由の1つである。パッケージによって、世界中の専門家が一連の関数を開発し、他の人がそれをダウンロードして R で使用できるようになる。関数は R の中核的な要素であり、事前に定義された種類の操作を、通常は自分のデータに対して実行できるようにする。
関数 \(f(x)\) の数学的定式化と R における関数の定義の仕方は並行している。 R では、関数はまずその名前を書き、その後に入力や関数の指定(いわゆる引数)を括弧で囲んでコーディングされる。
例えば、9の平方根が何であるかを知りたいとする。 R では、 sqrt 関数を使用することが可能である。結果を得るためには、関数への入力として 9 を与えるだけでよいのである。自分で試してみてみよう。コンソールの小さな矢印(>)の横に sqrt(9) と書いて、Enter キーを押してみてみよう。何が起こるか見てみよう。
sqrt(9)## [1] 3これで R から最初の出力が得られた。 R にはこれよりはるかに複雑な関数があるが、すべて同じ原理で支配されている。関数が必要とするパラメータの情報を提供すると、関数はその情報を使って計算を行い、最終的に出力を提供する。
R では、install.packages という関数を使って、パッケージのインストール を行う。この関数に伝えるべきことは、インストールしたいパッケージの名前だけである。とりあえず、後々役に立つ3つのパッケージをインストールしておこう。
{tidyverse}. {tidyverse} (Wickham et al. 2019) は単一のパッケージではなく、実際には R でのデータの操作と視覚化を容易にするパッケージのバンドルである。{tidyverse} パッケージをインストールすると、同時に {ggplot2}, {dplyr}, {tidyr}, {readr}, {purr}, {stringr}, {forcats} パッケージが提供される。tidyverse に含まれる関数は、近年 R コミュニティで非常に人気があり、多くの研究者、プログラマ、データ科学者に利用されている。tidyverse についてもっと知りたい方は、公式ウェブサイトを参照。
{meta}. このパッケージには、様々なタイプのメタアナリシスを簡単に実行するための関数が含まれている (Balduzzi, Rücker, and Schwarzer 2019)。このガイドでは主にこのパッケージに焦点を当てる。なぜなら、このパッケージは使いやすく、よく文書化されており、非常に汎用性が高いからである。{meta} パッケージの詳細については、 ウェブサイトを参照。
{metafor}. {metafor} パッケージ (Viechtbauer 2010) もメタアナリシスの実施に特化したパッケージで、機能面ではまさに強豪と言える。このパッケージは後の章で時々使用するし、{meta} パッケージが多くの応用で {metafor} を使用するため、インストールしておくとよいだろう(訳注: 通常、
metaをインストールすると自動的にmetaforもインストールされる。)。また、{metafor} パッケージには、メタ分析関連の様々なトピックに関する優れたドキュメントがある。
install.packages 関数は、インストールしたいパッケージの名前のみを入力として要求する。ひとつずつパッケージを追加するコードは次のようになるはずである。
install.packages("tidyverse")
install.packages("meta")
install.packages("metafor")コンソールに上記のコードを入力し、Enter キーを押すだけでインストールが開始される(Figure 2.1)。
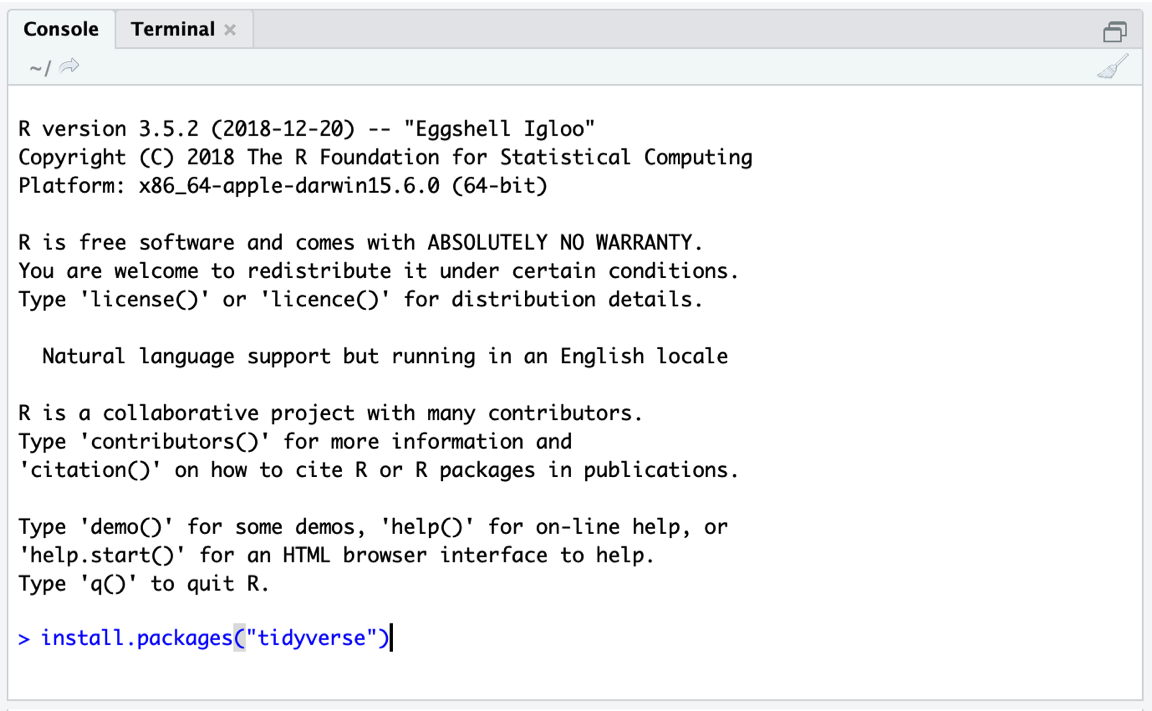
Figure 2.2: パッケージをインストールする。
"") で囲むことを忘れないように。これを忘れると、エラーメッセージが表示される。
Enter を押すと、 R はパッケージのインストールを開始し、インストールの進行状況についての情報を表示する。install.packages 関数が終了すると、そのパッケージを使用する準備が整ったことになる(訳注:この際のメッセージが赤字の英語で表示されるため、エラーが出たと勘違いする人が多い。じっくり読んで、successful とあれば成功である。)。インストールされたパッケージは、 R の システム・ライブラリ に追加される。このシステムライブラリは、R Studio の画面左下にあるパッケージペインでアクセス可能である。インストールされたパッケージを使いたいときは、library 関数を使ってライブラリから読み込むことが可能である。試しに、{tidyverse} パッケージをロードしてみよう。
2.3 {dmetar} パッケージ
このガイドでは、研究者としてメタアナリシスの実施をできるだけアクセスしやすく、簡単にできるようにしたい。メタ分析には {meta} や {metafor} パッケージのような素晴らしいパッケージがあり、ほとんどの重労働をこなしてくれるが、メタ分析にはまだいくつかの重要な側面があり、現在 R で行うのは簡単ではない。
不足している機能を補うため、我々は本書のコンパニオン R パッケージとして、{dmetar} パッケージを開発した。{dmetar} パッケージは独自のドキュメントを持っており、オンラインで見ることが可能である。{dmetar} パッケージの関数は、このガイドで頻繁に使用する {meta} と {metafor} パッケージ(と、より高度な他のいくつかのパッケージ)のための追加機能を提供している。{dmetar} パッケージに含まれる関数がどのようにメタ分析のワークフローを改善するかを、この本を通じて詳細に説明していこう。このガイドで使用するサンプルデータセットのほとんどは、{dmetar} に含まれている。
このガイドを読み進めていくためには、{dmetar} パッケージをインストールすることを強く推奨するが、必須ではない。パッケージの各関数について、ソースコード(関数をローカルに保存するために使用可能)と、それらの関数が依存する追加の R パッケージも提供している。また、パッケージに含まれるデータセットの補足的なダウンロードリンクも提供する。
しかし、あらかじめ {dmetar} パッケージをインストールしておくと、すべての機能、データセットがコンピュータにプリインストールされるので、より便利である。{dmetar} パッケージをインストールするには、 R のバージョンが 3.6 以降である必要がある。最近 R を(再)インストールしたのであれば、おそらく大丈夫だろう。 R のバージョンが十分に新しいかどうかを確認するには、次のコード行をコンソールに貼り付けて、Enterキーを押す。
R.Version()$version.stringこれにより、現在の R バージョンが表示される。もし、 R のバージョンが3.6以下であれば、アップデートする必要がある。この方法については、インターネット上に良いブログ記事があり、案内されている。
{dmetar} をインストールする場合、先にインストールしなければならないパッケージがある。このパッケージは {devtools} と呼ばれている。{devtools} がまだコンピュータにインストールされていない場合は、先程と同じようにインストールしておこう。
install.packages("devtools")そして、この行を使って {dmetar} をインストールすることが可能である。
devtools::install_github("MathiasHarrer/dmetar")これでインストールが開始される。{dmetar} パッケージが正しく機能するためには、他のパッケージも一緒にインストー ルする必要があるため、インストールに時間がかかる可能性がある。インストール中に、インストールマネージャが以下のように訪ねてくることがあるがこれは、すでにインストール済みの R パッケージを更新するかどうか尋ねている。
## These packages have more recent versions available.
## Which would you like to update?
##
## 1: All
## 2: CRAN packages only
## 3: None
## 4: ggpubr (0.2.2 -> 0.2.3) [CRAN]
## 5: zip (2.0.3 -> 2.0.4) [CRAN]
##
## Enter one or more numbers, or an empty line to skip updates:このメッセージが表示されたら、パッケージ更新をしたくないことをインストールマネージャに伝えるとよい。この例では、コンソールに 3 を貼り付けて Enter キーを押す。同じように、インストールマネージャが、
## There are binary versions available but the source versions are later:
##
## [...]
##
## Do you want to install from sources the package which needs compilation?
## y/n: このような質問をした場合、n (いいえ) を選ぶとよいだろう。この方法でインストールに失敗した場合(つまり Error が表示された場合)、もう一度インストールを実行し、今度はすべてのパッケージをアップデートする。
本書を執筆し、パッケージを開発する際には、誰もがエラーなくインストールできるように配慮した。とはいえ、初回でパッケージのインストールがうまくいかない可能性もある。それでもインストールに問題がある場合は、本書のまえがきにある「問い合わせ」の項を参照されたい。
2.4 データ準備とインポート
この章では、R Studio を使用してデータを R にインポートする方法について説明する。データの準備は、面倒で疲れるものではあるが、後のすべてのステップの基礎となる。したがって、先に進む前にデータを正しい形式にすることに細心の注意を払わなければならない。
通常、 R に取り込んだデータは、 Microsoft Excel のスプレッドシートに格納されている。インポートを非常に簡単に行うことができるため、データを Excel に保存することを勧める。 Excel でデータを準備する際には、いくつかの「すべきこと」と「してはいけないこと」がある。
Excel シートの列にどのように名前を付けるかは非常に重要である。列に正しく名前を付けておけば、 R を使用してデータを変換する必要がないため、後で時間を大幅に節約することが可能である。スプレッドシートの列に「名前を付ける」とは、単に変数の名前を列の最初の行に書き込むことである。(訳注: 日本では2行目以降にも列名を書くことがあるが、あまりよい習慣とは言えない。)
列名にはスペースを含めてはいけない。列名の2つの単語を区切るには、アンダースコアまたはポイントを使用した(例:“column_name”)。
Excel のスプレッドシートで列をどのように並べるかは重要ではない。ただ、正しくラベル付けされている必要がある。
また、列の書式設定も必要ない。スプレッドシートの最初の行に列名を入力すると、 R はそれを列名として自動的に検出する。
インポート時に、ä、ü、ö、á、é、ê などの特殊文字が文字化けする可能性があることも知っておくとよいだろう。インポートする前に、これらの文字を「通常の」文字に変換しておくとよいだろう。(訳注: 列名に日本語を使っても問題ないが、英語論文作成を意図している場合は英語にしておく方が良いだろう。)
Excel ファイルにシートが1つだけ入っていることを確認する。
もし、以前にデータを含んでいて現在空になっている行や列が1つまたはいくつかある場合、それらの列や行を完全に削除することを確認する。
まず、データセットの例から見てみよう。これから、自殺防止プログラムのメタアナリシスを実施する予定だとする。研究で注目したいアウトカムは、質問票によって評価された自殺念慮の重症度(すなわち、個人がどの程度、自分の人生を終わらせることを考え、検討し、計画するか)である。あなたはすでに研究の検索とデータ抽出を完了し、次に R でメタ分析データをインポートしたいと思っている。
したがって、次の作業は、関連するすべてのデータを含む Excel シートを準備することである。Table 2.1 は、インポートするすべてのデータを示している。この表の最初の行には、上で挙げたルールに基づき、 Excel ファイル内の列にどのような名前を付けるかも示されている。スプレッドシートには、各研究が1行にリストされていることがわかる。各研究について、介入群と対照群の両方のサンプルサイズ(\(n\))、平均値、標準偏差(\(SD\))が含まれている。これは効果の大きさを計算するために必要なアウトカムデータで、詳しくは Chapter 3 で説明する。次の3列は、後でメタ分析で分析したい変数である。
このデータをまとめた “SuicidePrevention.xlsx”という Excel ファイルを用意した。このファイルは、インターネットからダウンロードすることが可能である。
| Author | N | Mean | SD | N | Mean | SD | Year | Age Group | Control Group |
|---|---|---|---|---|---|---|---|---|---|
| Berry et al. | 90 | 14.98 | 3.29 | 95 | 15.54 | 4.41 | 2006 | general | WLC |
| DeVries et al. | 77 | 16.21 | 5.35 | 69 | 20.13 | 7.43 | 2019 | older adult | no intervention |
| Fleming et al. | 30 | 3.01 | 0.87 | 30 | 3.13 | 1.23 | 2006 | general | no intervention |
| Hunt & Burke | 64 | 19.32 | 6.41 | 65 | 20.22 | 7.62 | 2011 | general | WLC |
| McCarthy et al. | 50 | 4.54 | 2.75 | 50 | 5.61 | 2.66 | 1997 | general | WLC |
| … | … | … | … | … | … | … | … | … | … |
R Studioで Excel ファイルをインポートするには、まず作業ディレクトリを設定する必要がある。作業ディレクトリとは、 R がデータを使用することができ、出力が保存されるコンピュータ上のフォルダのことである。作業ディレクトリを設定するには、まず、メタアナリシスのデータと結果をすべて保存するフォルダをコンピュータ上に作成する必要がある。また、インポートしたい “SuicidePrevention.xlsx” ファイルもこのフォルダに保存する。
R Studio を起動し、左下の Files ペインに新しく作成したフォルダを開く。フォルダを開くと、先ほど保存した Excel ファイルが表示されているはずである。次に、ペイン上部の小さな歯車をクリックし、ポップアップメニューの Set as working directory をクリックして、このフォルダを作業ディレクトリとして設定する。これで、現在開いているフォルダが作業ディレクトリになる。
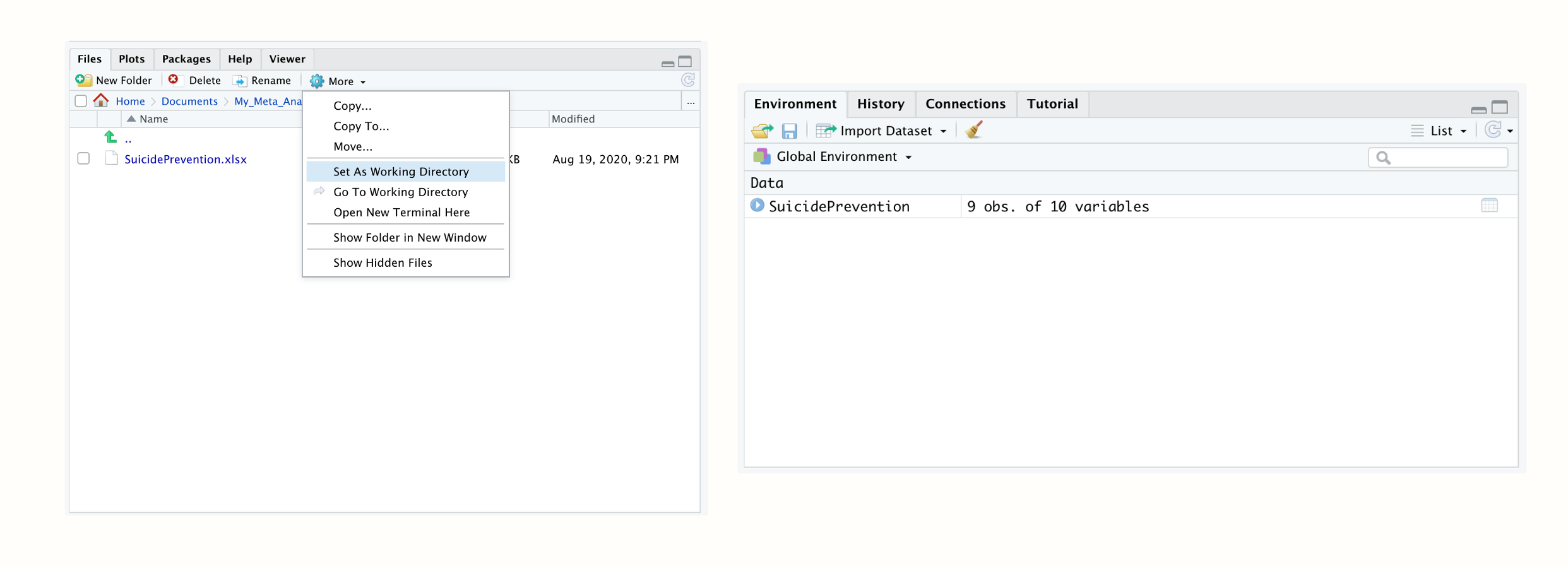
Figure 2.3: 作業ディレクトリを設定し、R 環境にデータセットを読み込む。
これで、 R にデータをインポートできるようになった。Files ペインで、“SuicidePrevention.xlsx” ファイルをクリックしよう。次に、Import Dataset… をクリックする。インポートアシスタントがポップアップ表示され、データのプレビューが読み込まれるはずである。これは時間がかかる場合があるので、このステップをスキップして、そのまま Import をクリックする。
すると、右上の Environment ペインに SuicidePrevention という名前でデータセットが表示されるはずである。これは、データが読み込まれ、 R コードで使用できるようになったことを意味している。今回インポートしたような表形式のデータセットは、 R では データフレーム (data.frame) と呼ばれている。データフレームは、先ほどインポートした Excel のシートのように、列と行を持つデータセットである。
{openxlsx}
また、コードを使用してデータファイルを直接インポートすることも可能である。このために使える良いパッケージは {openxslx} (Schauberger and Walker 2020) と呼ばれるものである。他の R パッケージと同様に、最初にこれをインストールする必要がある。それから read.xlsx 関数を使って Excel シートをインポートすることが可能である。
ファイルが作業ディレクトリに保存されている場合、関数にファイル名を与え、インポートしたデータを R のオブジェクトに代入するだけでよい。例えば、データセットが R 内で data という名前になるようにしたい場合は、次のようなコードを使用する。
library(openxlsx) data <- read.xlsx("SuicidePrevention.xlsx")
2.5 データ操作
R Studio を使って最初のデータセットをインポートしたので、いくつかの操作を行ってみよう。データ操作とは、さらなる分析に使えるようにデータを変換することであり、すべてのデータ分析に不可欠な作業である。データサイエンティストのような職業は、生の「整頓されていない」データを「整頓された」(tidy) データセットに変えることに大半の時間を費やしている。{tidyverse} の関数は、データ操作のための優れたツールボックスを提供している。もしまだパッケージをライブラリからロードしていないなら、次の例のために今ロードすべきである。
2.5.1 クラス変換
まず、前章でインポートした SuicidePrevention データセットを覗いてみよう。これを行うには、 {tidyverse} が提供する glimpse 関数を使用する。(訳注: あるいは Environment ペイン内の SuicidePrevention の左にある丸印をクリックすれば表示される。)
glimpse(SuicidePrevention)## Rows: 9
## Columns: 10
## $ author <chr> "Berry et al.", "DeVries et al.", "Fleming et al.", "Hunt & …
## $ n.e <chr> "90", "77", "30", "64", "50", "109", "60", "40", "51"
## $ mean.e <chr> "14.98", "16.21", "3.01", "19.32", "4.54", "15.11", "3.44", …
## $ sd.e <chr> "3.29", "5.35", "0.87", "6.41", "2.75", "4.63", "1.26", "0.7…
## $ n.c <dbl> 95, 69, 30, 65, 50, 111, 60, 40, 56
## $ mean.c <chr> "15.54", "20.13", "3.13", "20.22", "5.61", "16.46", "3.42", …
## $ sd.c <chr> "4.41", "7.43", "1.23", "7.62", "2.66", "5.39", "1.88", "1.4…
## $ pubyear <dbl> 2006, 2019, 2006, 2011, 1997, 2000, 2013, 2015, 2014
## $ age_group <chr> "general", "older adult", "general", "general", "general", "…
## $ control <chr> "WLC", "no intervention", "no intervention", "WLC", "WLC", "…これにより、データセットの各列に格納されているデータの種類の詳細を知ることができる。データの種類を示す略語はさまざまである。 R では、これらはクラスと呼ばれている(訳注: クラスではなく型である)。
<num>は numeric の略である。これは、数字として格納されているすべてのデータである(例:1.02)。(訳注: 実際はと表示されているはずである。) <chr>は character の略である。これは、単語として格納されているすべてのデータである。<log>は logical の略で、ある条件がTRUEまたはFALSEのいずれかであることを示すバイナリ変数である。<factor>は数値として保存され、各数値は変数の異なる水準を意味する。変数の因子水準は、1 = “low”、2 = “medium”、3 = “high” とすることができる。
また、 class 関数を使用して、列のクラスを確認することも可能である。データフレームの列の名前に $ 演算子を付けて、列の名前を指定すれば、データフレーム内の列に直接アクセスすることが可能である。これを試してみよう。まず、 R に n.e という列に含まれるデータを提供させる。その後、その列のクラスを確認する。
SuicidePrevention$n.e## [1] "90" "77" "30" "64" "50" "109" "60" "40" "51"
class(SuicidePrevention$n.e)## [1] "character"介入グループのサンプルサイズを含む列 n.e は、クラス character を持っていることがわかる。しかし、待ってみよう、これは間違ったクラスである。インポート時に、この列は誤って character 変数として分類されたが、実際には numeric クラスであるべきである。この間違いは、今後の分析段階に影響を与える。例えば、サンプルサイズの平均を計算したい場合、このような警告が表示される。
mean(SuicidePrevention$n.e)## Warning in mean.default(SuicidePrevention$n.e): argument is not numeric or
## logical: returning NA## [1] NAデータセットを使えるようにするためには、まず列を正しいクラスに変換しなければならないことがよくある。これを行うには、すべて “as.” で始まる一連の関数を使用することが可能である。すなわち、 as.numeric, as.character, as.logical そして as.factor である。それでは、いくつかの例を見てみよう。
先ほどの glimpse 関数の出力では、いくつかの列が numeric であるべきなのに character クラスに設定されていることがわかる。これは n.e, mean.e, sd.e, mean.c, sd.c という列に関係している。出版年 pubyear は <dbl> というクラスを持っていることがわかる。これは double の略で、列が数値ベクトルであることを意味する。 R では、数値データ型を参照するために double と numeric の両方が使用されるのは歴史的な例外である。しかし、通常、これは実際のところ何の意味もない。
しかし、このデータセットでは、いくつかの数値が文字 (character) としてコード化されているため、今後問題が発生することが予想される。したがって、 as.numeric 関数を使用してクラスを変更する必要がある。この関数に変更したい列を指定し、代入演算子 (<-) を使って出力を元の場所に保存する。これは次のようなコードになる。
SuicidePrevention$n.e <- as.numeric(SuicidePrevention$n.e)
SuicidePrevention$mean.e <- as.numeric(SuicidePrevention$mean.e)
SuicidePrevention$sd.e <- as.numeric(SuicidePrevention$sd.e)
SuicidePrevention$n.c <- as.numeric(SuicidePrevention$n.c)
SuicidePrevention$mean.c <- as.numeric(SuicidePrevention$mean.c)
SuicidePrevention$sd.c <- as.numeric(SuicidePrevention$sd.c)
SuicidePrevention$n.c <- as.numeric(SuicidePrevention$n.c)また、glimpse の出力では、データのサブグループである age_group と control が文字としてコード化されていることがわかる。しかし、実際には、それぞれ2つの因子水準を持つ因子としてエンコードする方が適切である。クラスを変更するには、 as.factor 関数を使用する。
SuicidePrevention$age_group <- as.factor(SuicidePrevention$age_group)
SuicidePrevention$control <- as.factor(SuicidePrevention$control)levels と nlevels 関数を使用すると、因子のラベルと因子の水準数を確認することも可能である。
levels(SuicidePrevention$age_group)## [1] "general" "older adult"
nlevels(SuicidePrevention$age_group)## [1] 2また、levels 関数を使用して、因子ラベルの名前を変更することが可能である。単に、元のラベルに新しい名前を割り当てるだけである。これを R で行うには、 concatenate または c 関数を使用する必要がある。この関数は2つ以上の単語や数字を結びつけて、1つの要素を作ることが可能である。これを試してみよう。
new.factor.levels <- c("gen", "older")
new.factor.levels## [1] "gen" "older"完璧である。これで、新しく作成した new.factor.levels オブジェクトを使用して、age_group 列の因子ラベルに割り当てることができるようになった。
levels(SuicidePrevention$age_group) <- new.factor.levelsリネームがうまくいったかどうか、確認してみよう。
SuicidePrevention$age_group## [1] gen older gen gen gen gen gen older older
## Levels: gen olderまた、as.logical を使用して論理値を作成することも可能である。例えば、 pubyear 列を再コード化し、2009年以降に発表された研究のみを表示するようにしたいとしよう。これを行うには、コードでイエス/ノーのルールを定義する必要がある。「以上」演算子 >= を使用し、as.logical 関数の入力として使用する。
SuicidePrevention$pubyear## [1] 2006 2019 2006 2011 1997 2000 2013 2015 2014
as.logical(SuicidePrevention$pubyear >= 2010)## [1] FALSE TRUE FALSE TRUE FALSE FALSE TRUE TRUE TRUEこれは pubyear の各要素を、出版年が2010年以上かそうでないかによって TRUE または FALSE としてエンコードしていることがわかる。
2.5.2 データのスライス
R では、データフレームの部分集合を抽出する方法がいくつかある。そのうちのひとつである $ 演算子を使って列を抽出する方法についてすでに説明した。データセットからスライスを抽出する、より一般的な方法は、角括弧を使用することである。角括弧を使用する一般的な形式は、 data.frame[rows, columns] である。行と列は、データセットに現れる番号を使って抽出することができる。例えば、データフレームの2行目のデータを取り出すには、以下のようなコードを使用する。
SuicidePrevention[2,]## author n.e mean.e sd.e n.c mean.c sd.c pubyear age_group
## 2 DeVries et al. 77 16.21 5.35 69 20.13 7.43 2019 older
## control
## 2 no interventionさらに具体的に、2行目の1列目の情報だけが欲しいと R に伝えることが可能である。
SuicidePrevention[2, 1]## [1] "DeVries et al."特定のスライスを選択するには、再び concatenate (c) 関数を使用する必要がある。たとえば、2行目と3行目、および4列目と6列目を抽出したい場合は、次のようなコードを使用する。
## sd.e mean.c
## 2 5.35 20.13
## 3 0.87 3.13通常、行は番号によってのみ選択することができる。しかし、列の場合は、番号の代わりに列の名前を指定することも可能である。
SuicidePrevention[, c("author", "control")]## author control
## 1 Berry et al. WLC
## 2 DeVries et al. no intervention
## 3 Fleming et al. no intervention
## 4 Hunt & Burke WLC
## 5 McCarthy et al. WLC
## 6 Meijer et al. no intervention
## 7 Rivera et al. no intervention
## 8 Watkins et al. no intervention
## 9 Zaytsev et al. no intervention別の方法として、行の値に基づいてデータセットにフィルタを行うこともできる。これを行うには、関数 filter を使用する。この関数では、データセット名とフィルタ条件を指定する必要がある。比較的簡単な例として、n.e が50以下である研究をすべてフィルタしてみよう。
filter(SuicidePrevention, n.e <= 50)## author n.e mean.e sd.e n.c mean.c sd.c pubyear age_group
## 1 Fleming et al. 30 3.01 0.87 30 3.13 1.23 2006 gen
## 2 McCarthy et al. 50 4.54 2.75 50 5.61 2.66 1997 gen
## 3 Watkins et al. 40 7.10 0.76 40 7.38 1.41 2015 older
## control
## 1 no intervention
## 2 WLC
## 3 no intervention名前によるフィルタも可能である。例えば、著者である Meijer と Zaytsev による研究を抽出したいとする。そのためには、%in%演算子と concatenate 関数を用いて、フィルタ条件を定義する必要がある。
## author n.e mean.e sd.e n.c mean.c sd.c pubyear age_group
## 1 Meijer et al. 109 15.11 4.63 111 16.46 5.39 2000 gen
## 2 Zaytsev et al. 51 23.74 7.24 56 24.91 10.65 2014 older
## control
## 1 no intervention
## 2 no intervention逆に、フィルタの論理式の前に感嘆符(!)をつけることで、Meijer と Zaytsev による研究を除くすべての研究を抽出することも可能である。
2.5.3 データ変換
もちろん、 R のデータフレーム内の特定の値を変更したり、拡張したりすることも可能である。 R で内部保存したデータを変更するには、代入演算子を使用する必要がある。以前、データスライスについて学んだことを再利用して、データセットの特定の値を変更することにしよう。私たちが間違いを犯し、DeVries et al. による研究の出版年が、2018であるべきところを2019と誤って報告されたとする。データセットを適宜スライスし、新しい値を割り当てることで、値を変更することが可能である。DeVries et al. の結果は、データセットの2行目に報告されていることを忘れないように。
SuicidePrevention[2, "pubyear"] <- 2018
SuicidePrevention[2, "pubyear"]## [1] 2018また、一度に複数の値を変更することもできる。例えば、データセットのすべての介入グループの平均に5を加えたい場合、次のコードで可能である。
SuicidePrevention$mean.e + 5## [1] 19.98 21.21 8.01 24.32 9.54 20.11 8.44 12.10 28.74また、2つ以上の列を使用して計算を行うこともできる。実用的な例としては、各研究の介入群の平均と対照群の平均の平均差 (mean difference) を計算したいとする。他のプログラミング言語と比較すると、 R では、これは驚くほど簡単である。
SuicidePrevention$mean.e - SuicidePrevention$mean.c## [1] -0.56 -3.92 -0.12 -0.90 -1.07 -1.35 0.02 -0.28 -1.17今見たように、これは各研究の介入群の平均から対照群の平均を引くが、毎回同じ行の値を使用する。この平均差 (mean difference) を後で利用することにしよう。そこで、これを md というオブジェクトとして保存し、 SuicidePrevention データフレームに新しい列として追加したいと思ったとする。どちらも代入演算子を使えば簡単にできる。
md <- SuicidePrevention$mean.e - SuicidePrevention$mean.c
SuicidePrevention$md <- SuicidePrevention$mean.e -
SuicidePrevention$mean.c最後に紹介するのは、パイプ演算子である。 R では、パイプは %>% と表記される(訳注: R 4.2 から、|> というパイプも導入された)。パイプを使うと、関数を呼び出す際にオブジェクト名を直接指定することなく、オブジェクトに関数を適用することが可能である。単に、オブジェクトと関数をパイプ演算子でつなげるだけである。簡単な例を挙げてみよう。対照群のサンプル数の平均を計算したい場合、mean 関数とパイプ演算子を次のように使用する。
## [1] 64この例では、パイプの価値を見ることは困難である。パイプの特別な強みは、多くの関数を連結することができる点にある。例えば、2009年以降に発表された研究のみを対象として、対照群サンプルサイズの平均値の平方根を知りたいとする。パイプを使えば、これを1ステップで簡単に行うことが可能である。
## [1] 7.615773パイプの中では、これまで取り上げていない関数として、pull 関数を使った。この関数は、パイプで使用できる $ 演算子と同等と見なすことができる。この関数は、関数内で指定した変数を単に「引き出す」だけで、パイプの次の部分に送り込むことが可能である。
R のドキュメントにアクセス
R の多くの関数は複数の引数を必要とし、全ての関数の使い方を正しく記憶することは不可能である。ありがたいことに、各関数の使い方を丸暗記する必要はない。R Studio では、 R のドキュメントに簡単にアクセスでき、各関数には詳細な説明ページが用意されている。
関数のドキュメントページを検索するには、2つの方法がある。一つは、R
Studio の左下(訳注:「右下」にあることの方が多い。)にある
Help
ペインにアクセスし、検索バーを使って特定の関数に関する情報を見つける方法である。もっと便利な方法は、コンソールで
? の後に関数名をつけて、例えば ?mean
のように実行することである。これで自動的にこの関数のドキュメントのエントリーが開かれる。
関数の R ドキュメントには通常、少なくとも使用法 (Usage)、引数 (Arguments)、例 (Examples) のセクションがある。特に、引数と例のセクションは、関数がどのように使用されるかを理解するのに役立つことが多いだろう。
2.5.4 データの保存
データを変換して R に内部保存した後、ある時点でエクスポートする必要がある。 R のデータフレームを保存する際には、2種類のファイル形式を使用することをお勧めする。 .rda と .csv である。
ファイルの末尾 .rda は、 R Data の略である。これは R 専用のファイル タイプで、すべての利点と欠点がある。 .rda ファイルの利点は、 R で簡単に再オープンできることと、エクスポート中にデータが歪む心配がないことである。また、汎用性が高く、表計算ソフトの形式に収まらないデータも保存可能である。欠点は、 R でしか開けないことであるが、プロジェクトによっては、これで十分である。
オブジェクトを .rda データファイルとして保存するには、 save 関数を使用する。この関数では、(1) オブジェクトの名前、(2) ファイルの末尾を含めた正確なファイル名、を指定する必要がある。この関数を実行すると、ファイルが作業ディレクトリに保存される。
save(SuicidePrevention, file = "suicideprevention.rda")ファイルの末尾 .csv は comma-separated values の略である。この形式は、一般的なデータで最もよく使用されるものの1つである。これは、Excel_を含む多くのプログラムで開くことが可能である。データを .csv_ として保存するには、 write.csv 関数を使用する。コードの構成や動作は save とほぼ同じであるが、提供するオブジェクトはデータフレームなどの表形式データオブジェクトである必要がある。そしてもちろん、ファイルタイプは “.csv” を指定する必要がある。
write.csv(SuicidePrevention, file = "suicideprevention.csv")ここでは、 R におけるデータ操作の戦略について簡単に説明する。特に、データの操作のように簡単だと思われるものを扱う場合、 R をゼロから学ぶのは疲れることがある。しかし、 R の動作に慣れるには、練習するのが一番である。しばらくすると、 R の一般的なコマンドは自然に使えるようになる。
学習を続けるには、Hadley Wickham and Garrett Grolemund の著書 R for Data Science (2016) に目を通しておくとよいだろう。このガイドと同様に、この本もオンラインで完全に無料で読むことが可能である 。さらに、次のページでいくつかの演習も集めたので、ここで学んだことを実践するために使うことを勧める。
\[\tag*{$\blacksquare$}\]
2.6 演習問題
データ操作の演習
この演習では、data
という新しいデータセットを使用する。このデータセットは、以下のコードを使って
R で直接作成することが可能である。
data <- data.frame("Author" = c("Jones", "Goldman",
"Townsend", "Martin",
"Rose"),
"TE" = c(0.23, 0.56,
0.78, 0.23,
0.33),
"seTE" = c(0.324, 0.235,
0.394, 0.275,
0.348),
"subgroup" = c("one", "one",
"two", "two",
"three"))このデータセットの演習を紹介する。
-
変数
Authorを表示しなさい。
-
subgroupを因子型 (factor) に変換しなさい。
- “Jones” と “Martin” の研究のデータをすべて選択しなさい。
- 研究名 “Rose” を “Bloom” に変更しなさい。
-
TEからseTEを引いて、新しい変数TE_seTE_diffを作成し、結果をdataに保存しなさい。
-
パイプを使用して、(1)
subgroupが”one” または “two” に属するすべての研究をフィルタし、(2) 変数TE_seTE_diffを選択し、(3) その変数の平均をとり、それにexp関数を適用しなさい。 R のドキュメントにアクセスして、exp関数が何をするのか調べてみなさい。
問題の解答は、本書の巻末 Appendix A にある。
2.7 概要
R は、世界で最も強力かつ頻繁に使用される統計プログラミング言語の1つとなっている。
R は、グラフィカル・ユーザー・インターフェースとあらかじめ定義された機能を持つコンピュータ・プログラムではない。世界中の人々が自由に利用できるアドオン、いわゆるパッケージを提供できる完全なプログラミング言語である。
R Studio は、 R を使った統計解析を便利に行うためのコンピュータ・プログラムである。
R の基本的な構成要素は関数である。これらの関数の多くは、インターネットからインストールできるパッケージを通じてインポートすることが可能である。
R を使ったデータの取り込み、操作、解析、保存に関数を使用することが可能である。