第 10 章 答疑时间
10.1 Python编程遇问题,文科生怎么办?
敲黑板了啊,答疑时间到。如果你没有良好的Python编程基础,在尝试应用数据科学方法时遇到了问题和困难,又不知道该如何有效解决,那么这篇文章就是为你写的。请务必认真阅读哟。

10.1.1 错误
几个月以来,我一直在发布数据科学类的应用案例文章。我的目标是帮助初学者建立信心,激发兴趣。从反馈来看,确实吸引了不少“文科生”来尝试数据科学方法。
这里所谓文科生,就是没有编程经验,却又对数据科学感兴趣,甚至不得不实践数据科学(这种压力往往来自于导师、老板和同侪)的人。
我承认,这么定义“文科生”,有些利用刻板印象简化问题的成分。实际上,现在不少文科专业学生,都是高素质复合型人才,编程玩儿得比IT类专业都要熟练。如果你恰巧就是个复合型人才,觉得这个称呼冒犯了你,请你谅解。但至少你得承认,相当多的文科专业同学,还是对技术不够熟悉,有抵触甚至是恐惧心理的。
我收到了不少读者留言和来信,提出了许多疑问。其中有很大一部分,是在实践编程环节,遇到了错误提示,向我求助。
对于这一类的反馈,我秉持着“能帮就帮”的原则。一两句话能够说明的问题,我就旋即答复;对于那些需要深入调查的问题,我会让读者把Jupyter Notebook或者R notebook文件以及数据发给我。这里真得感谢文学化编程环境的提供者们,给我和读者这样便捷沟通、重现问题的方式。

但是,按照反馈的情况来看,还有不少读者遇到了问题,没有能够解决,就直接放弃了。
我这样确信,是因为前些日子给一年级的硕士研究生布置了同样的练习作业,重现我一系列文章中的结果。他们很快就遭遇到了问题,但是长时间自己瞎折腾,没有跟我及时沟通。直到最近的一次的工作坊,我用了几分钟的时间,消除了一直困扰他们的“疑难杂症”,做出了预期的结果。看他们一个个喜上眉梢的样子,很享受。
我能够理解他们的心情。我们总想留给别人聪明、勤奋和积极主动的印象。轻易提出看似异常简单的“傻问题”,可能会让我们的自我评价受挫,觉得自己没有能力,又被别人看作“懒惰”。所以许多情况下,我们遇到问题,喜欢自己先折腾一番。
动手折腾并不是坏事。以正确的方法尝试解决问题,会帮你积累认知。所谓的“编程经验”,很多就是从各种失败尝试中提炼出来的。但是如果你面对错误,尝试使用的方法低效,甚至根本不得其法,那就得不偿失了。我们时常揶揄的“从入门到放弃”,往往就是这么来的。
本着“授人以鱼不如授人以渔”的原则,我今天跟你谈谈,文科生该如何应对数据科学Python编程中可能出现的问题。
许多程序员和专业人士可能会对这样的主题不以为然,甚至嗤之以鼻——除错(debug)是一门专业的学问,你打算一篇文章讲清楚?吹吧!
诚然,我不可能用一篇文章讲清楚如何编程除错。我只想给文科生一些建议,因为他们的情况比较特殊。
对他们来说,直接列一个清单,说明如何除错是不够满足需求的。咱们得结合具体的场景来谈。
文科生遭遇Python编程问题的场景该如何分类呢?
我根据长期的观察和思考,认为可以分成3类:
- 照葫芦画葫芦;
- 照葫芦画瓢;
- 找葫芦画瓢。
你可能看得不知所云。简单解释一下。
文科生使用Python编程,往往没有程序设计的基础训练。他们不是从基础关键词、语法、数据结构、算法的路径学下来的。他们拿到一个任务,一般都有明确的时限,却没有解法清单,唯一的线索是“这个问题可以用Python (或者R)来解决”。
有人说,这就像是某人被塞了一把伞,然后推到台风中心。我觉得挺形象的。
所以,他们首先寻找的,不会是Python(或者R)的基础教科书,而是样例。
如果恰好有个样例,讲如何绘制词云](#make-wordcloud-with-python),如何做中文情感分析(5.2,如何用决策树分类,[如何抽取海量文本的主题(6.2))……恰好跟他们的任务一致,那他们自然如释重负。
于是他们就开始了第一步,照葫芦画葫芦,先把样例中的代码重复实践一遍,确定本地可以运行。
做好了第一步,出了正确的结果,他们也就来了信心。下面需要做的,是把自己的数据扔进去,看能否出预期的结果,这一部分,就算作“照葫芦画瓢”。
许多人只需要前两步,就能完成任务,高高兴兴收工了。但是如果很不幸,你的任务和样例有一些区别,那你就得在样例基础上,添加新的代码,调用新的软件包来尝试完成任务。你无法自己从头造瓢出来,这一部分就得“自己找葫芦画瓢”了。
对大部分“文科生”来说,场景就是这三类了。出离这样的要求,要么外包,要么自己从头学编程。等他扎扎实实学会了,也就不算文科生了。
下面咱们分别看看,在这三种不同的情境下,文科生遇到Python编程中的问题,该如何有效尝试解决。
说明一下,虽然本文以Python为例讲解方法,但是其中的原理同样使用于大部分数据科学类编程语言和工具,例如R等。学习时请举一反三。
10.1.2 画葫芦
我们先看第一种场景,也就是“照葫芦画葫芦”。
例如说,你打算用决策树做分类,于是找到了我这篇《贷还是不贷:如何用Python和机器学习帮你决策?》(6.1),开始实践,重现结果。
前面还好,一直很顺利。你的信心在逐渐积累。听说下面这段代码可以帮你绘制出决策树的图形,你异常欣喜,期待的心情,就如同小时候等着父母出差回家给你带来玩具一样。
with open("safe-loans.dot", 'w') as f:
f = tree.export_graphviz(clf,
out_file=f,
max_depth = 3,
impurity = True,
feature_names = list(X_train),
class_names = ['not safe', 'safe'],
rounded = True,
filled= True )
from subprocess import check_call
check_call(['dot','-Tpng','safe-loans.dot','-o','safe-loans.png'])
from IPython.display import Image as PImage
from PIL import Image, ImageDraw, ImageFont
img = Image.open("safe-loans.png")
draw = ImageDraw.Draw(img)
img.save('output.png')
PImage("output.png")可是事与愿违,运行后图形没有出来,却见到了一大堆错误信息。
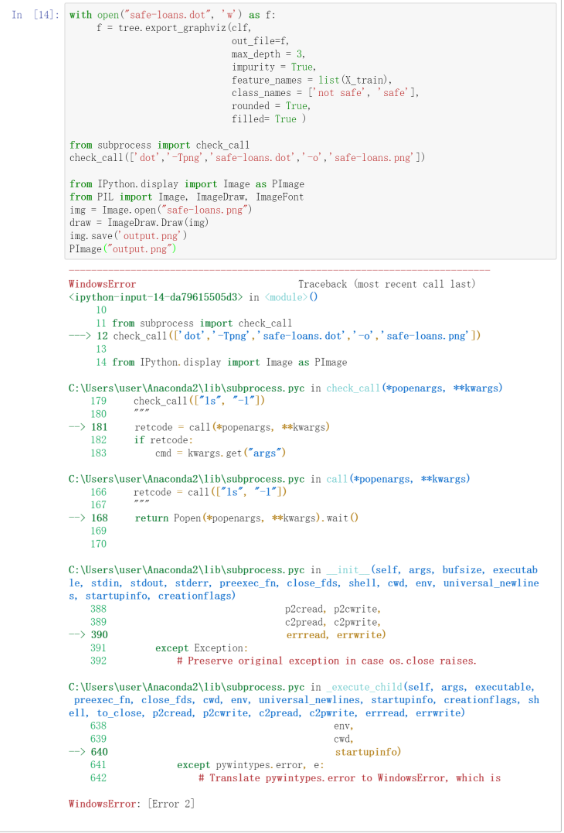
看到错误信息,你已经很紧张了。更要命的是,它们还是英文的。
于是,你一下子茫然无措了。
喝了一杯水,缓了口气,你往后翻文章,到了讨论区。发现其他人也遇到了同样的问题,你眼前一亮。

赶紧往后翻,看看有没有解决办法,你看到了作者的答复:
好像装了Graphviz,问题就可以解决。你赶紧搜索这个软件,并且下载安装了。
安装结束后,你的开始菜单里面,可以看到Graphviz目录。证明你安装成功。
你回到Jupyter Notebook下面,重新执行到这一步。按下“Shift+Enter”按键之前,你又激动不已了。
然而,你看到的执行结果,竟然还是这样子的:
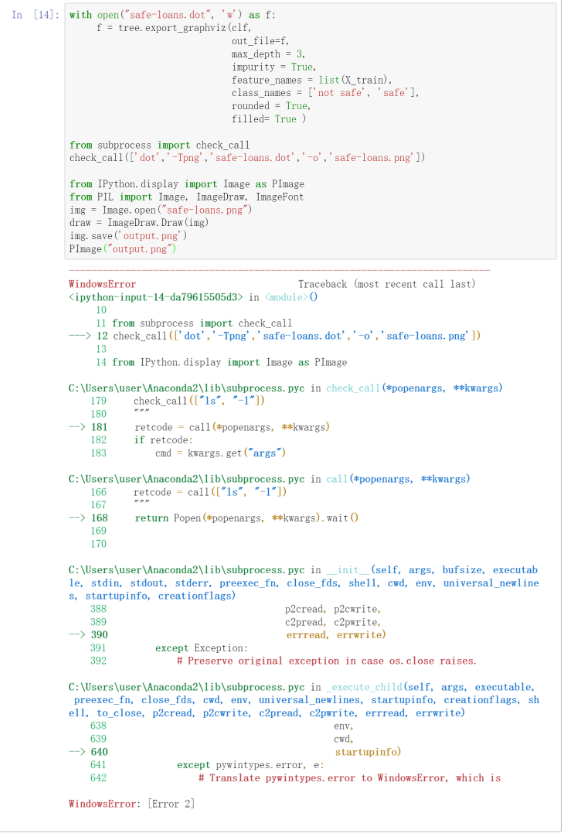
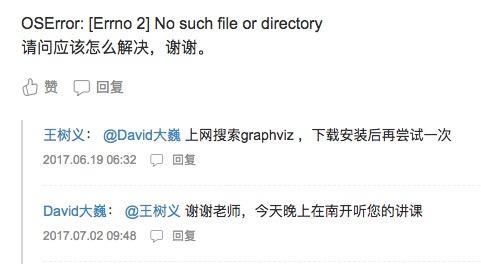
你后悔自己肯定遗漏了讨论区里面的一些重要信息,赶紧返回寻找,你看到了这样的对话:
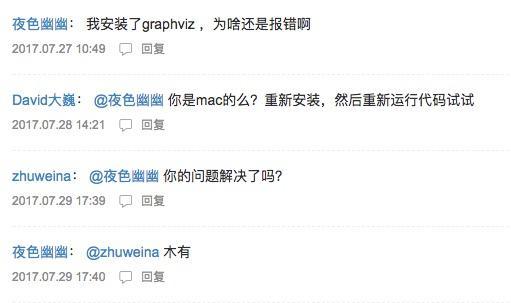
看到别人安装了Graphviz后,问题依然没有解决。你于是决定放弃了。而且可能还会怀疑,那个叫做大卫的家伙,应该是作者的托儿吧。
其实你冤枉大卫了。安装了Graphviz以后,他确实成功做出了结果。问题到底处在哪儿?请你往下看。
我先说说面对程序给你的这一大堆报错,你该怎么办?
首先你要看看,错误出现在哪里。
WindowsError Traceback (most recent call last)
<ipython-input-14-da79615505d3> in <module>()
10
11 from subprocess import check_call
---> 12 check_call(['dot','-Tpng','safe-loans.dot','-o','safe-loans.png'])
13
14 from IPython.display import Image as PImage错误提示的第一段已经告诉你了,问题发生在check_call这一行,行号为12。
这就意味着,前面11行,其实都没有问题。这一大段代码用空行分割,一共是3个部分。前面10行是第一部分。中间2行第二部分,后面是第三部分。我们把它拆分成3个Jupyter中的代码段落,单独执行。
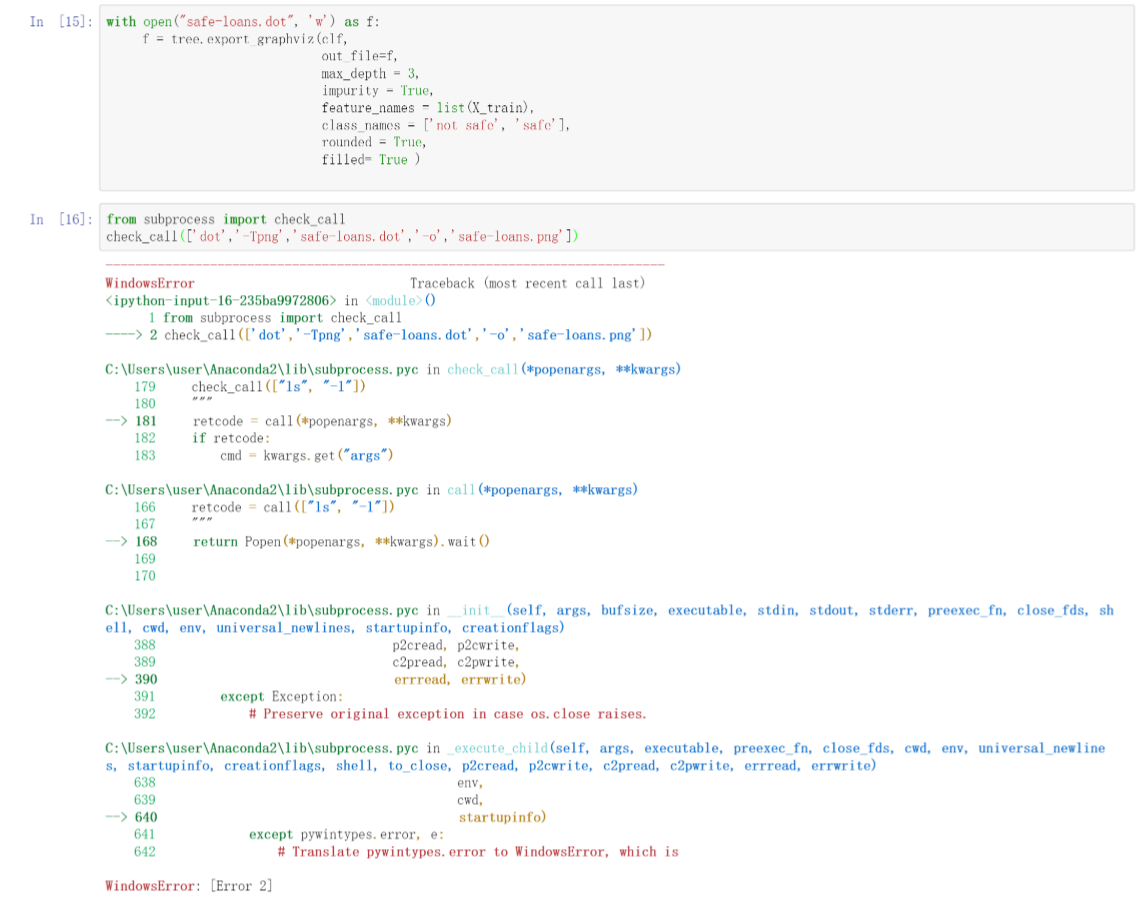
上面的运行结果,证明我们的猜测是对的。第一段运行起来没问题,第二段只有两句,第一句不报错,只有check_call这一行报错。这样问题就聚焦了。
这种拆分复杂问题到简单部分,然后各个击破的方法,可以追溯到笛卡尔。他老人家曾经说过:
Divide each difficulty into as many parts as is feasible and necessary to resolve it.
注意,这种方法适合于我们此处展示的线性环节。所谓线性,就是顺序执行的若干步骤。前面的改动会对后面有影响,但是后面的改动对前面没有影响。
如果你遭遇的是个循环问题,那就要小心了。这种解决方法可能会失效。
check_call这一行到底遇到了什么问题呢?我们还是要回到报错信息里,寻找线索。
这么长的报错信息,该看哪里呢?我的经验是,问题发生位置要看开头(我们刚才已经做完了),问题症结十有八九要看末尾。
我们看看报错信息的末尾是什么:
C:\Users\user\Anaconda2\lib\subprocess.pyc in _execute_child(self, args, executable, preexec_fn, close_fds, cwd, env, universal_newlines, startupinfo, creationflags, shell, to_close, p2cread, p2cwrite, c2pread, c2pwrite, errread, errwrite)
638 env,
639 cwd,
--> 640 startupinfo)
641 except pywintypes.error, e:
642 # Translate pywintypes.error to WindowsError, which is
WindowsError: [Error 2]你可能又晕了,这一大堆的术语,我如何懂得?
你不需要懂那些东西,看最后的报错信息,叫做“WindowsError: [Error 2] ”。
这是一个错误代码,但是包含信息不够。我们需要查询一下,2号Windows错误代码,究竟是什么意思。
这时候,就该搜索引擎出场了。我们搜索“WindowsError: [Error 2] ”,结果如下:
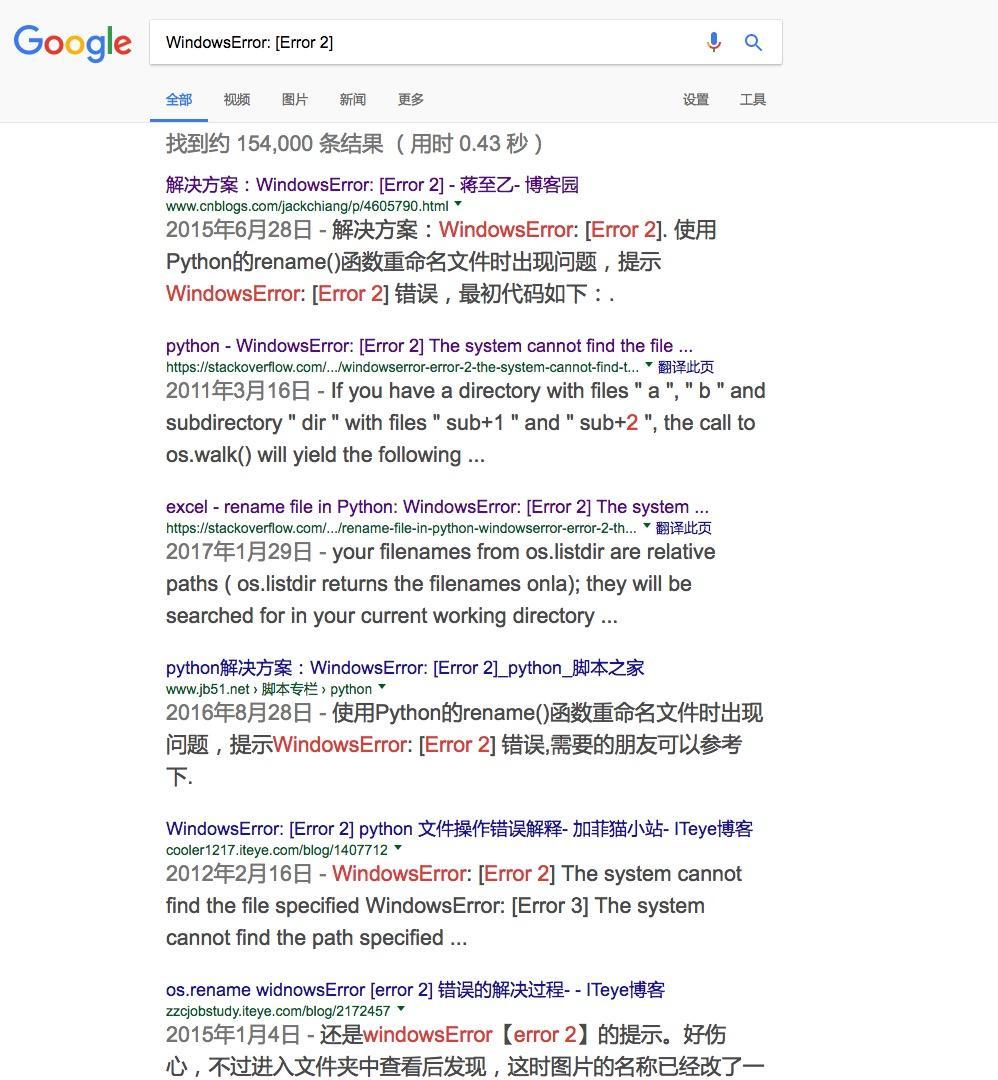
我知道,你的吸引力立刻就被图中的中文文字抓住了。但是我告诉你,更应该看的,不是语言种类,而是信息来源。你会注意到,其中一些搜索结果,来自于“stackoverflow.com”这个网站。
这个网站,汇集了全世界程序设计中遇到的各种问题和可能的解决办法。你可以把它想想成全球程序员的“知乎”。
打开其中的第二条搜索结果。
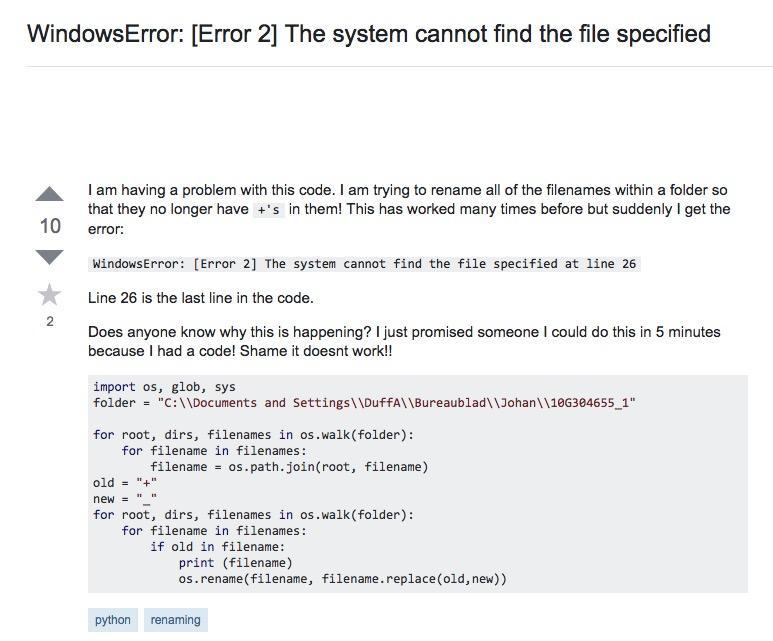
标题信息就已经非常清楚地告诉了你,所谓的“WindowsError: [Error 2] ”,是指“系统找不到你指定的文件”。
这样我们再次回头审视出问题的代码句:
check_call(['dot','-Tpng','safe-loans.dot','-o','safe-loans.png'])其实,我们是让Python调用一个Graphviz的命令,叫做dot,用它来把我们前面生成的 safe-loans.dot文件,转换成png格式的图片。
系统找不到什么文件呢?我们打开当前的demo目录,你会看到 safe-loans.dot文件赫然在目。而png文件此时还没有生成。因此,我们锁定了问题,系统找不到的,是dot这个命令。
这就是为什么你必须要先安装Graphviz包。你不安装的话,Python当然找不到dot文件。
但是为什么你明明装了Graphviz包,还会遭遇报错呢?
你确定这时候Python可以找到dot包了吗?
我们尝试一下。到命令提示符下面,执行dot试试看。

真相大白了。你在命令提示符下,自己都找不到dot命令,你能指望Python有多智能呢?
怎么办?方法其实并不难,只需要加上必要的路径,让电脑知道dot这个命令在哪里,就可以了。
我们到C盘的Program Files,或者Program Files(x86)目录下,去找Graphviz安装目录。
你会发现,路径为:
C:\Program Files(x86)\Graphviz2.38\bin\于是这次你执行:

你会看到,没有报错信息了。
再接再厉,这次你把完整的命令输入:
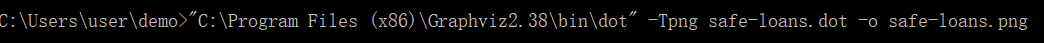
这次不但没有报错,而且你想要的png文件已经生成了。
不过,这些都是你手动完成的,咱们还是需要用程序来完成,不是吗?
于是我们回到Jupyter Notebook里,尝试给dot命令一样加上路径。
执行!

报错信息又来了!而且一模一样啊!
注意我们做了改动,但是改动并没有成功。我们就得想想原因是什么了。
这次我们搜索执行的Python命令( check_call ),以及输入路径中的特征部分(Program Files)。把这几个关键词放到搜索引擎里,结果如下:
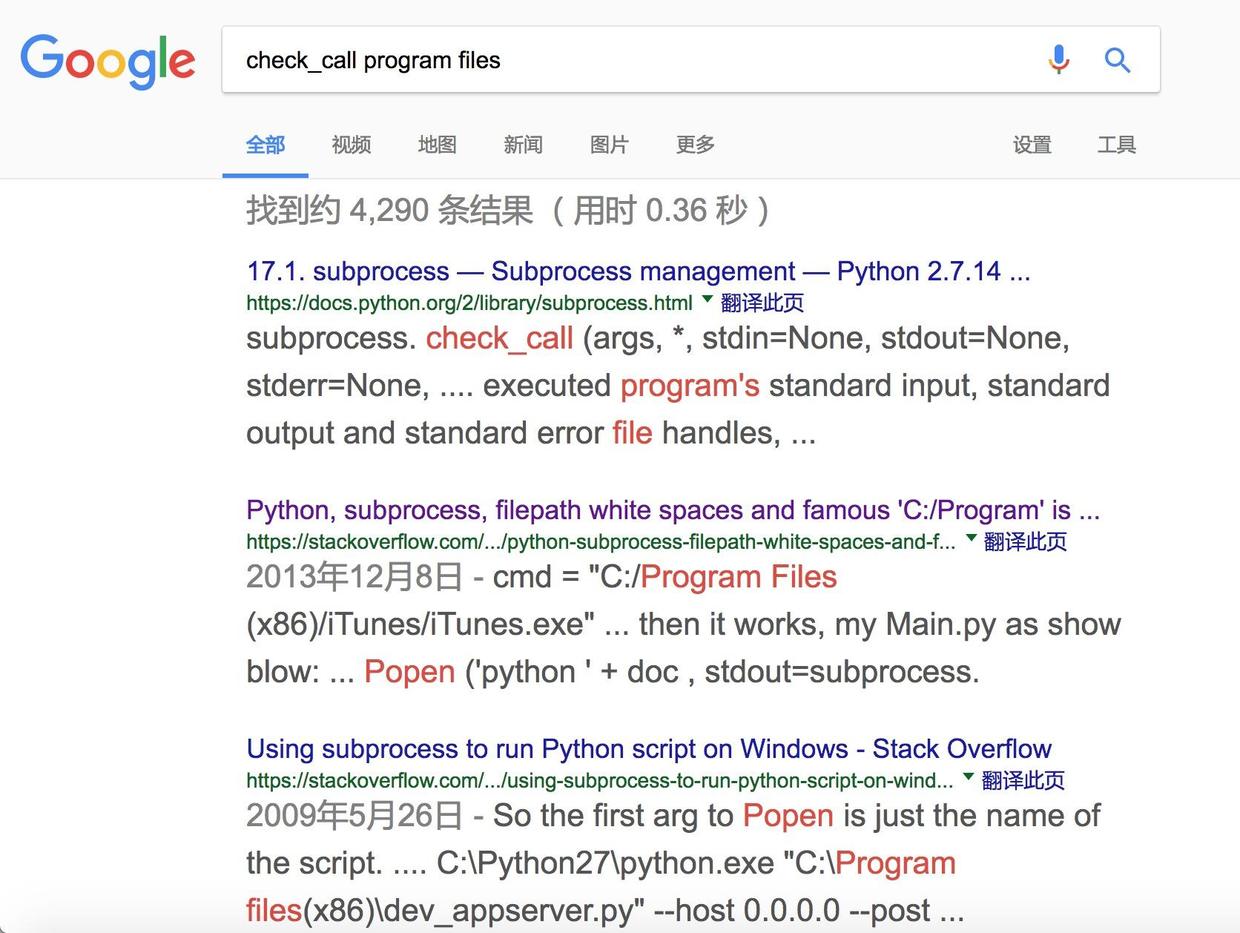
注意第一条结果是帮助文档,我们把目光聚焦在第二条搜索结果上。因为它依然来自stackoverflow.com。
我们点击打开这个链接。
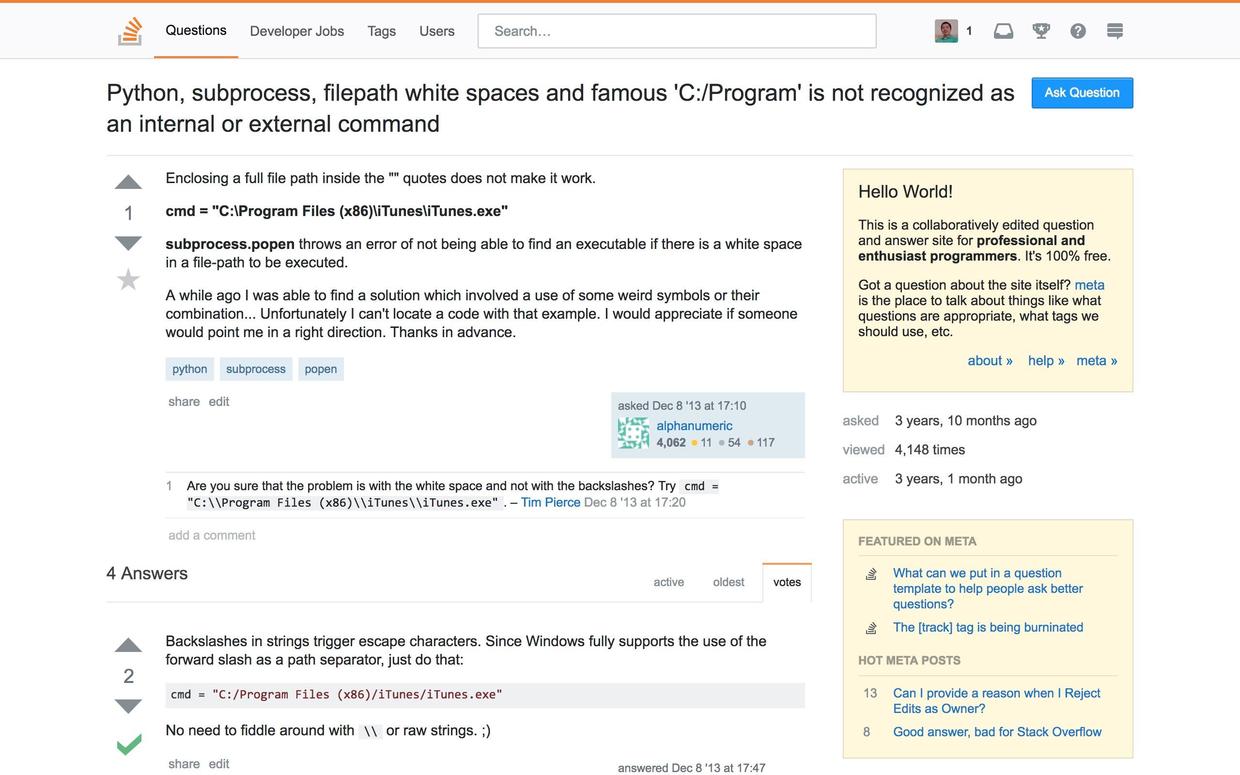
提问者问,为什么使用(跟我们类似的)完全路径,Python依然找不到命令。
被赞同的答题者回答:你应该用斜杠(/),而不是反斜杠()。
看了这个答案,你可能觉得恍然大悟了吧。于是回到Jupyter Notebook里面,把C:\Program Files(x86)\Graphviz2.38\bin\dot改成了C:/Program Files(x86)/Graphviz2.38/bin/dot。
再次运行,这部分不再报错了:

你战战兢兢,尝试一直就没能正确运行到的最后一段代码:
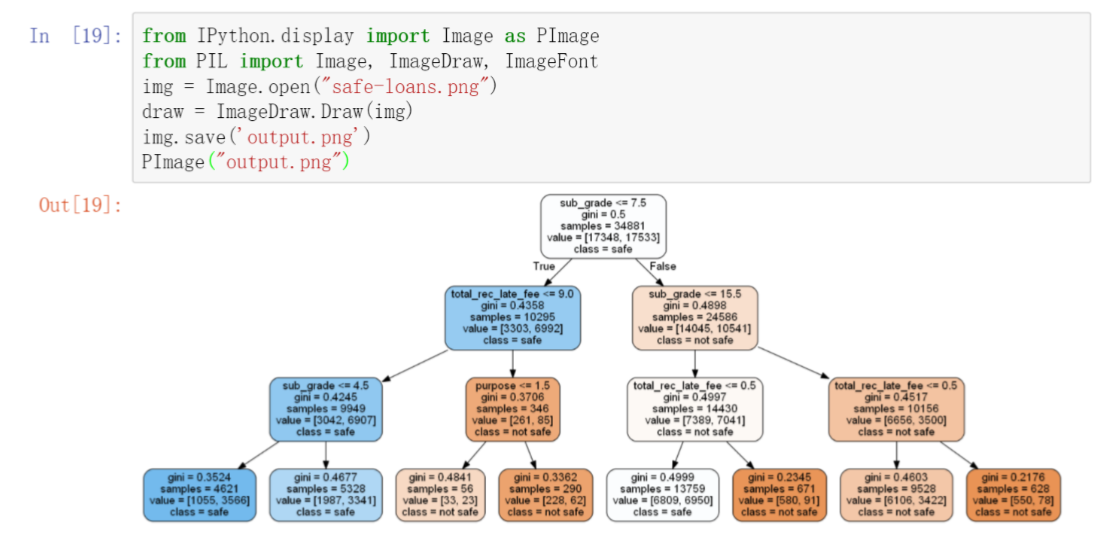
是不是有一种想要仰天大笑的感觉?
现在我们来回答一下,为什么评论里大卫的问题获得了解决,而其他读者似乎没能解决问题呢?
罪魁祸首在于操作系统环境差异。大卫用的是macOS。安装Graphviz之后,mac操作系统记录下来了Graphviz的各项可执行命令。Python因此也知道了dot这个命令在哪里。所以调用起来没有任何问题。
我写作该文的时候,操作系统也是macOS,所以并没有意识到Windows上运行环境的这种差异。甚至因为2年多以前我就安装了Graphviz,所以在初稿写作的时候甚至都没有把Graphviz作为环境准备的必要组成部分。
顺便说一句,根据部分读者反映,他们在Windows上安装了Graphviz后,只需要重启一遍,系统就会自动识别dot命令的完全路径,所以根本就不必修改代码内容。但是其他读者反映这样做了无效。你看,同样是Windows,环境差异都是如此之大的。
操作系统、Python软件版本、调用的相关软件包版本……这些环境差异可能直接导致你“照葫芦画葫芦”时候出现严重问题,也是最容易踩到的坑。不过通过咱们前面的叙述,相信你已经找到了从坑里爬起来,甚至是避开坑的方法了。
10.1.3 画瓢
当你完整重现样例或教程中的运行结果后,就该开始照着葫芦画瓢了。毕竟你需要分析的,是自己独特的数据。
但是一定要注意,务必在“画葫芦”完成后,开始画瓢。来信和留言中的许多问题,都是读者在没有完整重现教程结果时,就开始了改动,把不同层次的问题混杂在了一起,就很难发现和解决了。
这里咱们举的例子,是这位读者的来信。

他看了我那篇《如何用Python做舆情时间序列可视化?》(5.2)之后,完全重现了结果。然后灌入了自己的数据。我展示的样例用的是饭馆点评信息,他用的是外卖评论信息。
这是我原文中读入后数据的样例:
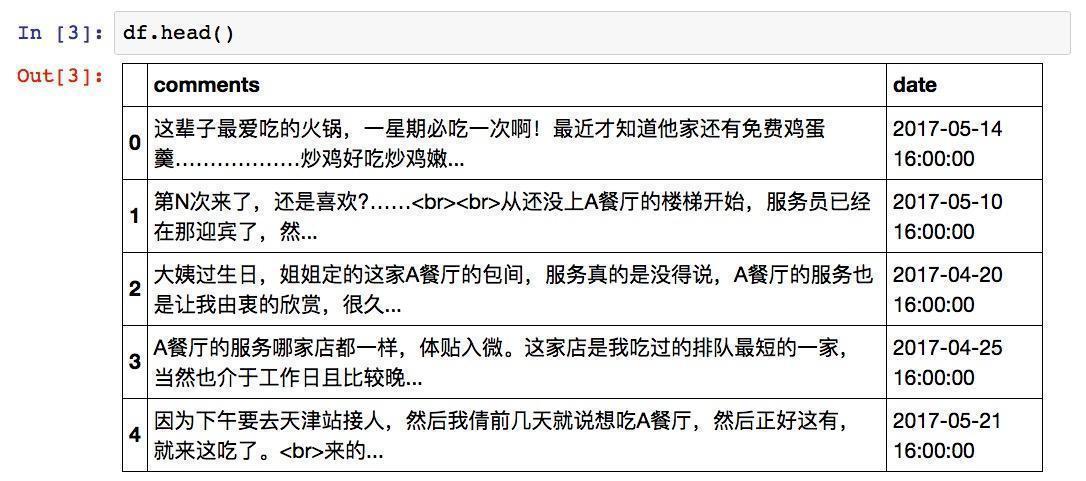
这是他的数据:

看起来很相似,不是吗?可是前面情感分析等环节都没有问题。到了最后的绘制图形,又是一堆报错信息。
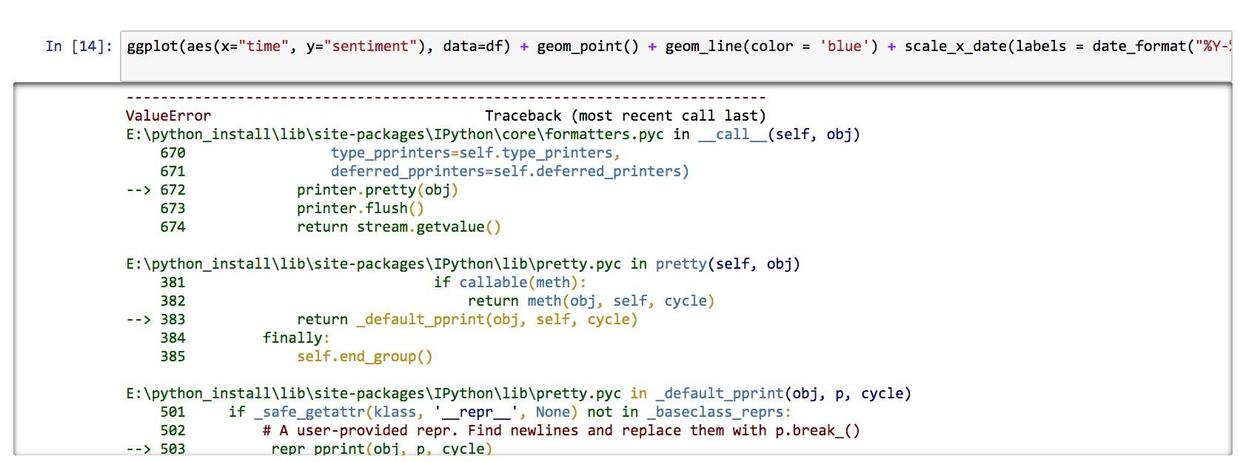
复习一下,我们说过报错信息的开头和结尾最为重要。开头是确定位置。因为这里本来就只有一行语句,所以可以忽略。那我们看看结尾吧。
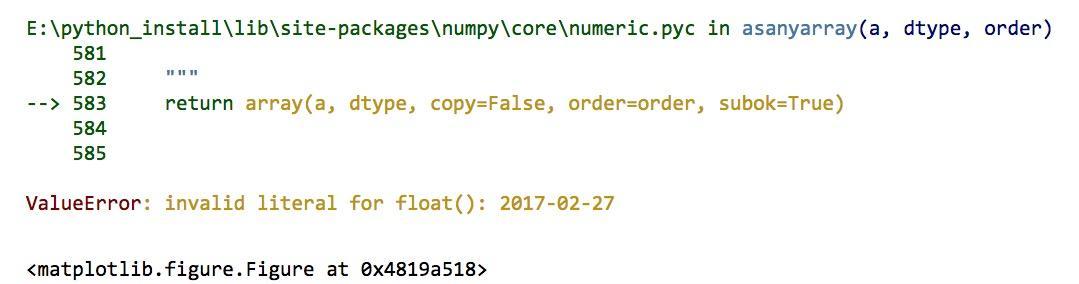
注意,这里提示的是取值错误(ValueError),并且标出了问题,就是评论时间,例如“2017-02-27”。
回顾一下,在原文中,评论时间的格式为Python可以识别的时间单位,这样最后绘出的图形才是这样的:
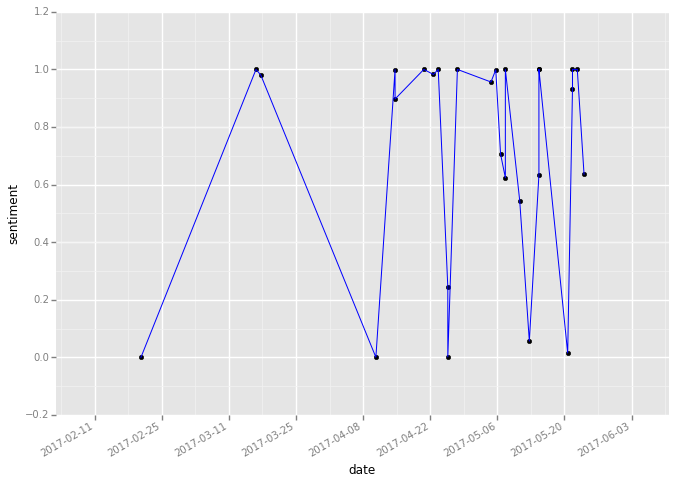
而这里,时间显示为“2017-02-27”,应该没错啊。
数据框中的时间是从新到旧排列的。我们显示最后一条数据,就是“2017-02-27”。
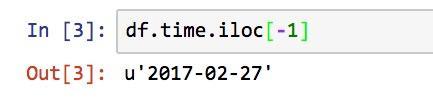
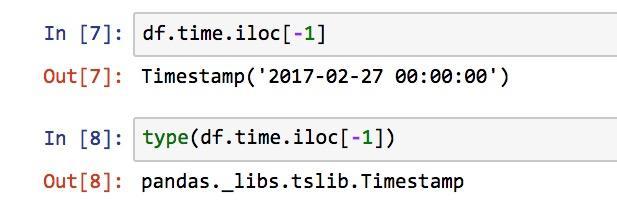
这里我们就需要记住一条非常重要的命令:
type()它可以帮助我们搞清楚取值的类型。

这一下子,原形毕露了。数据框里面的每一个时间条目,存储的格式都不是Python日期,而是简单的字符串!难怪当我们需要绘制时间序列图形的时候,会报错。
明白了问题,方法也就容易找到了。我们再次用搜索引擎,查找Pandas里,把字符串转换为日期的方法。
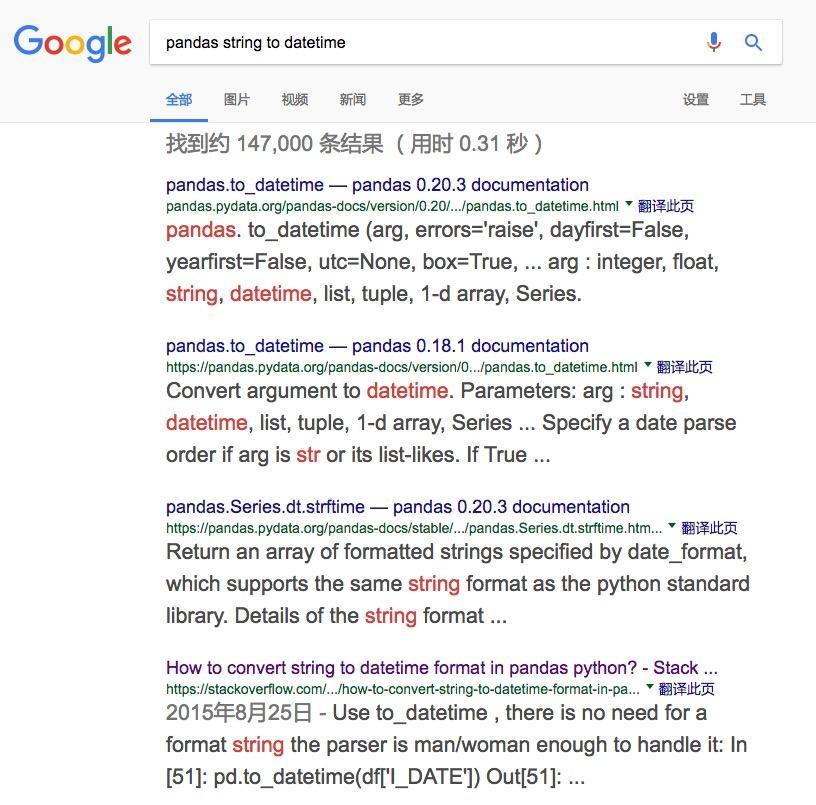
其实Google已经非常聪明地把最相关的结果摆在前面了。但是我们依然可以用老方法,找stackoverflow链接,并且点击进入。
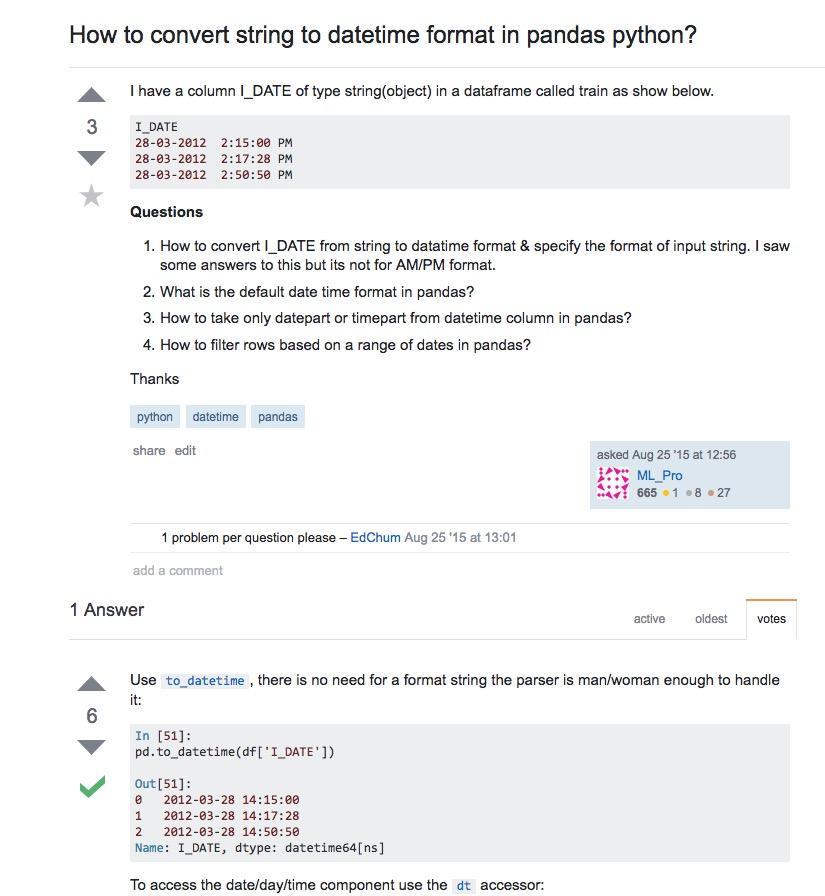
选定答案里面清晰明白地告诉我们——使用Pandas数据框的to_datetime函数,并且给出了详细的样例。
好的,我们试试看。
df.time = pd.to_datetime(df.time)然后我们重新执行刚才的两条语句:
看,这次Python正确识别出日期格式。
然后我们再绘图:
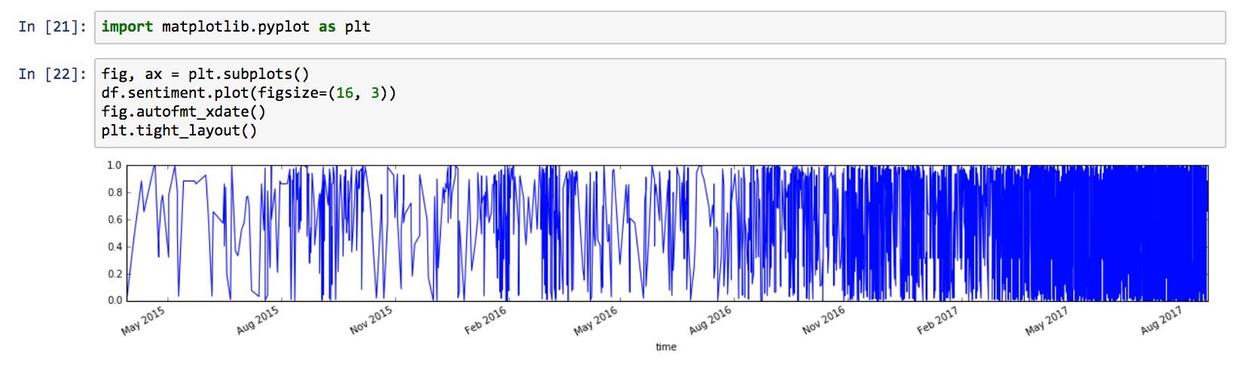
虽然由于数据量过大,后半部分看不大清楚。不过结果已经初步显现了。下面就是分段截取数据,细致地进行可视化的工作了。
问题出在哪里呢?对比一下原文使用的excel数据文件,和读者来信里面附带的数据文件,你就能看出端倪了。
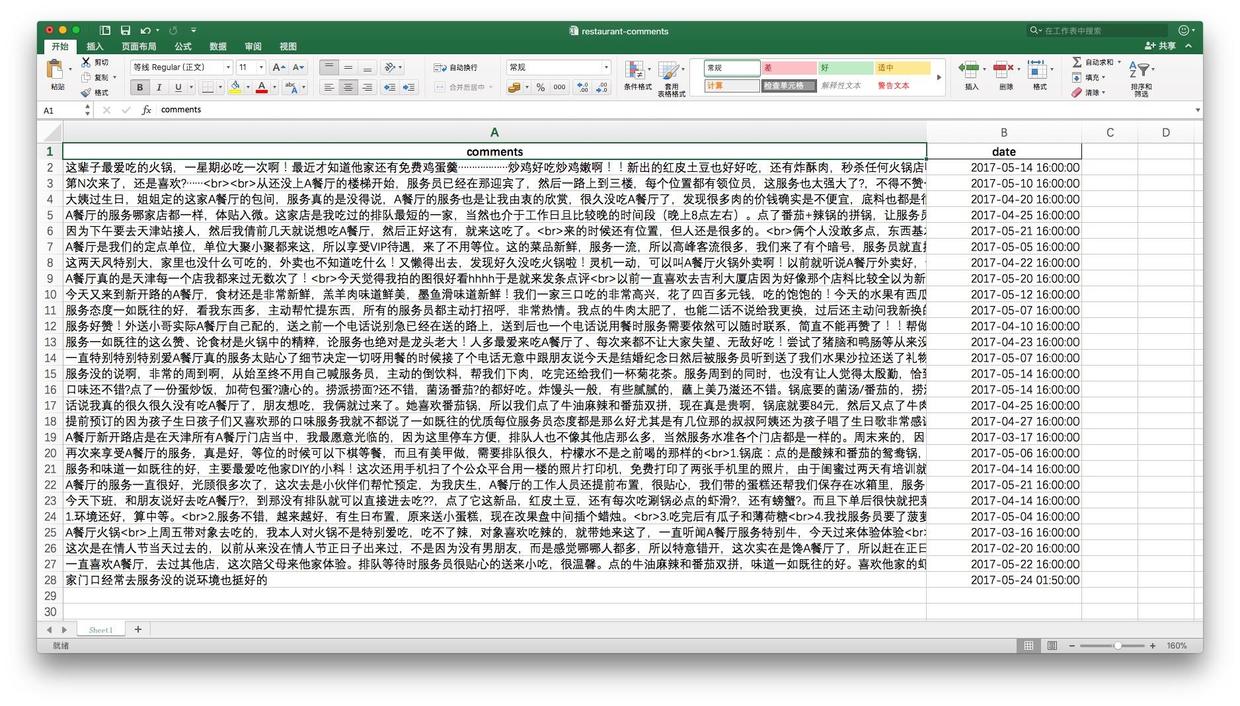
这是原文使用的餐馆评论原始数据:
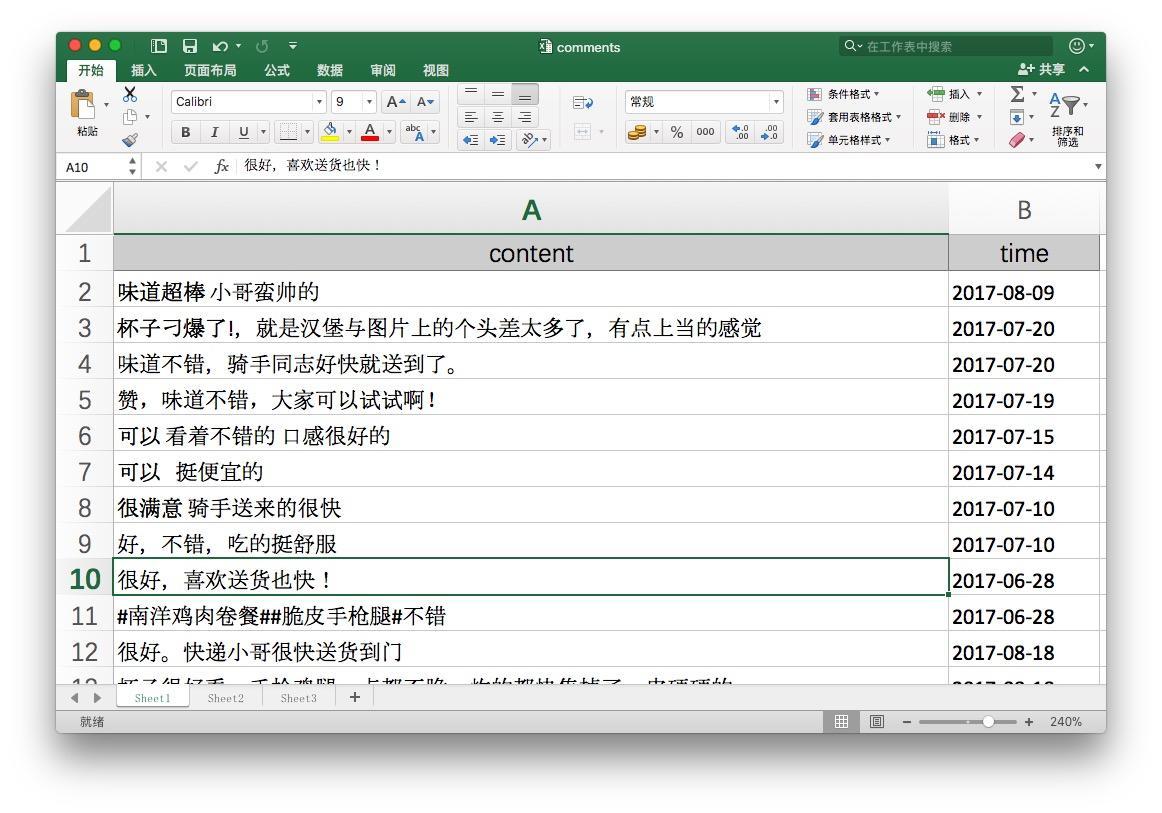
这是读者使用的外卖评论原始数据:
你会看到,原先数据里面不仅有日期,还有时间。虽然时间不过都是些“00:00:00”,但Pandas在读入的时候,会将其自动转化为日期时间格式。
然而读者数据里只有日期,没有具体的时间。Pandas读入数据时,不确定要不要做转化,默认就当成字符串来处理了。
所以你看,如果你需要“照葫芦画瓢”,一定要仔细对比数据格式,即便是这样微小的差异,都会造成后续运行结果的区别,乃至报错。
10.1.4 找葫芦
如果样例里面没有提供某个功能,但是你确实需要用到它,怎么办?
这个时候似乎手头没有葫芦可以照着画,你得自己找葫芦。
例如读完了我那篇《如何用Python做词云?》(3.1)后,有读者在微信公众号后台留言,询问我如何在绘制词云的时候,把词云变成需要的形状。
读者想要的,其实是这样的效果:
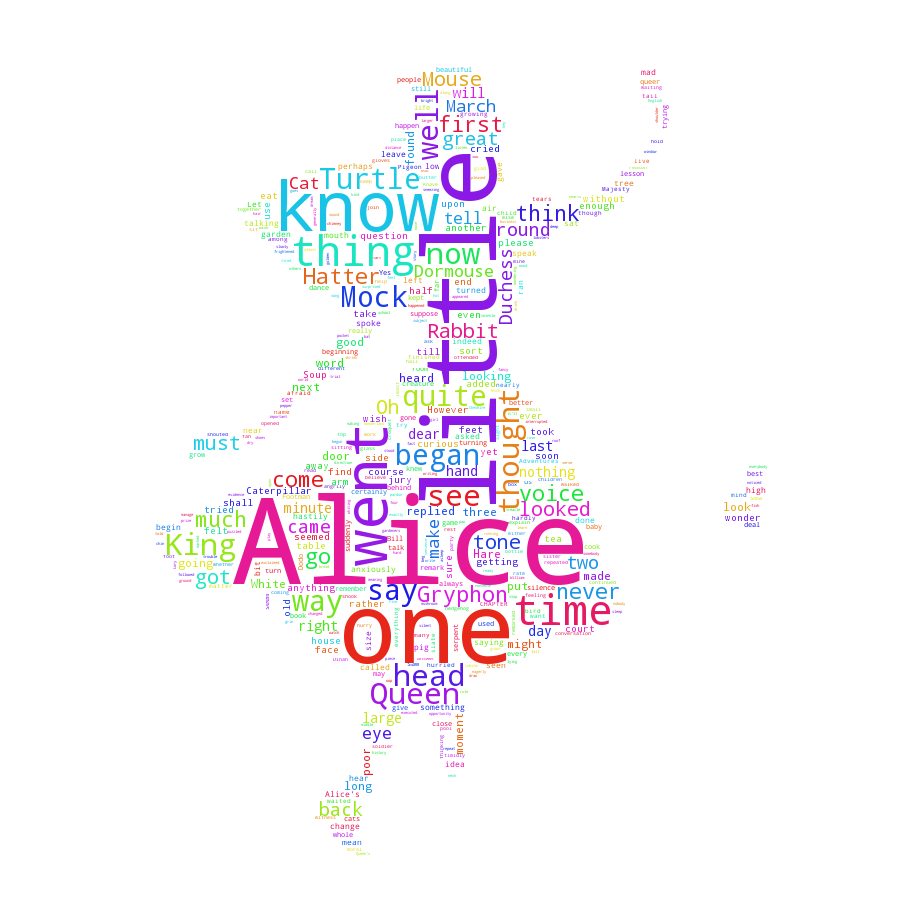
但是我那篇文章里,并没有提供这样的样例,只能做出下面这种四四方方的词云图。

如果你也遇到了类似的问题,我的建议是,按图索骥查询原始文档。
你先看看文中,我们究竟用了哪个词云绘制工具包。
from wordcloud import WordCloud
wordcloud = WordCloud().generate(mytext)这里,我们注意wordcloud这个关键词,然后结合python,到搜索引擎里面查找。
这回我们不再专门去找stackoverflow网站链接了。因为我们遇到的,不是报错信息,而是一项暂时还不懂得如何使用的功能。
搜索结果里的第一项,就是wordcloud词云包的官方github站点。我们点开看看。
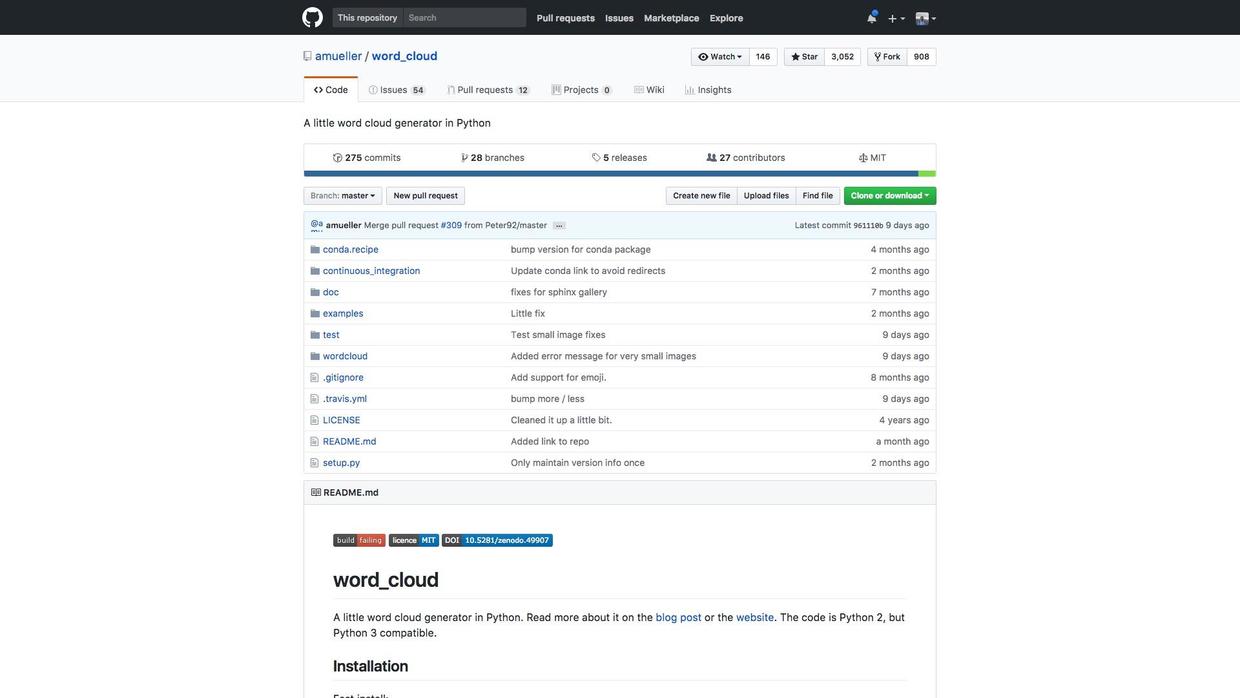
Github是目前全球最主要的代码托管与分享站点。我也曾经把思维导图秒变成幻灯(??的代码)发布在github上面。右上方几个统计数字很重要,尤其是Star,说明了该项目受欢迎程度。wordcloud软件包的受欢迎数字超过3000,可以说是非常棒的。相较之下,我的代码Star数量只有20,相形见绌啊。
我们把网页往下翻,可以找到Example部分。

你是不是眼前一亮啊?对,你需要的绘图结果就在这里,而且人家有专门链接直达使用方式。
点击一下,你就能看到官方的masked词云样例代码了。
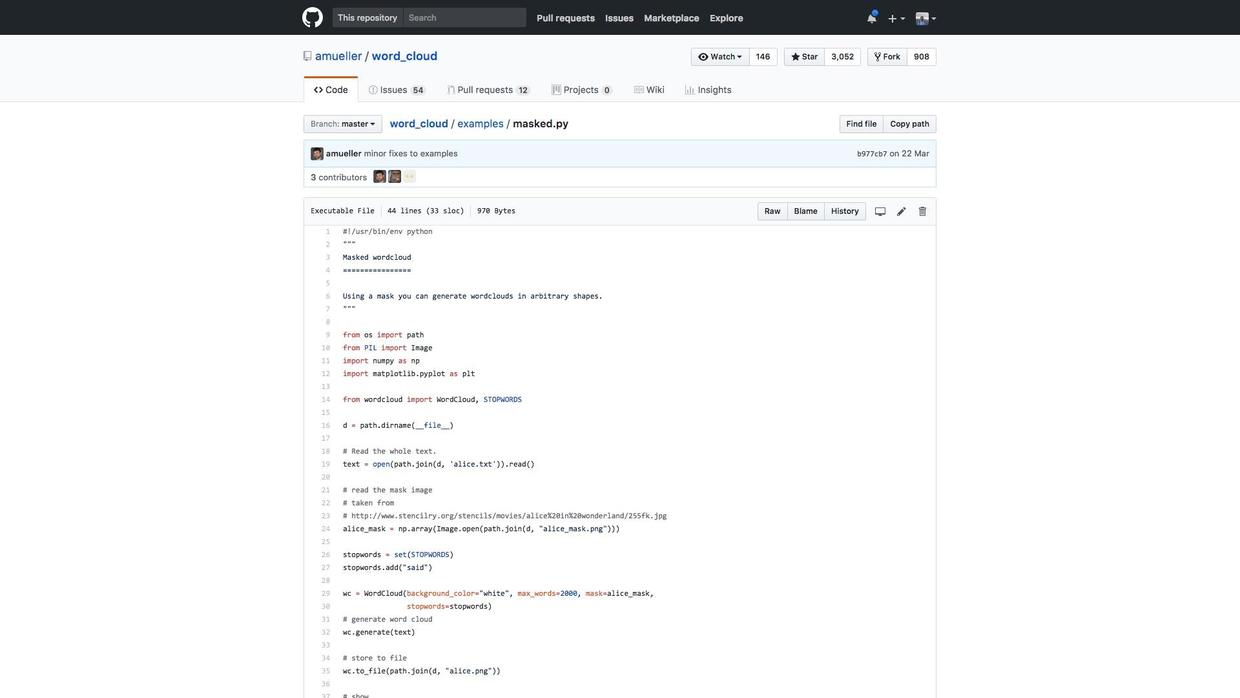
浏览代码,你会发现这一段有集中注释:
# read the mask image
# taken from
# http://www.stencilry.org/stencils/movies/alice%20in%20wonderland/255fk.jpg
alice_mask = np.array(Image.open(path.join(d, "alice_mask.png")))这里告诉你,如果打算把词云绘制成特殊的图形外观,你需要在这里指定一个mask图像文件。样例里面的文件叫做alice_mask.png。
我们来看看,这个文件是什么样子的。因为源代码就在这里,指定的文件也没有加入完全路径,因此它只可能放在样例代码文件的相同目录下。
我们点击页面上方的路径链接,返回到上层目录。
目录里面所有的文件都在这里了。我们找到alice_mask.png,点开看看。
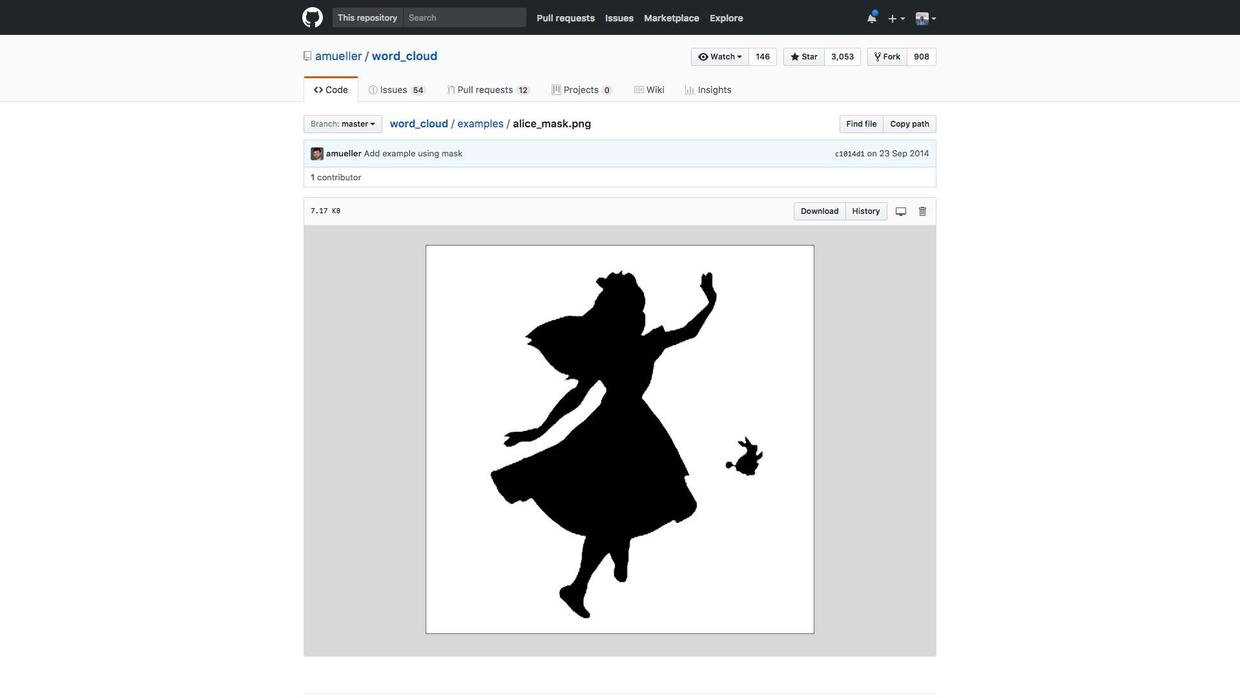
原来你需要提供这样一张黑白图像,词云会显示在其中的黑色区域内。
但是这样的图像需要我自己来绘制吗?
这就考验你看代码的时候是不是细致了。有没有注意到这一句?
# http://www.stencilry.org/stencils/movies/alice%20in%20wonderland/255fk.jpg这是alice_mask.png图像文件原始地址。我们点击看看。
原来这个网站上的文件直接就可以用来做词云图像设置。我们看到上方的路径按钮,点击上一层,进入“movies”。
居然有这么多的电影图像可以使用啊。
我们再进入到上一层,看看还有哪些其他类别图像可用。
看了之后,是不是有一种“芝麻开门”的感觉?
可惜的是,tv类别下面,并没有原文提到的“Yes, minister”可供选择。我们随便选一张世界地图来试试看。
回到Jupyter Notebook里面,按照我们从原始说明文档里找到的新葫芦,开始画瓢。
如果你做出了下面的结果,那么恭喜你,“找葫芦画瓢”工作圆满完成。
10.1.5 小结
小结一下,对文科生来说,编程中遇到的问题,需要依据不同的场景,分别采取不同的思考清单来尝试有效解决。
对于“照葫芦画葫芦”类场景,方法如下:
- 确认你的运行环境尽量和作者的运行环境一致(安装相同的软件版本)。如果环境不一致(例如操作系统差异),遇到问题的时候要时刻意识到这种差异可能是造成无法重复结果的元凶。
- 把遇到问题的代码拆解开。聚焦到实际产生了问题的代码片段上。这就是所谓的“分而治之”。
- 认真阅读报错信息,里面有非常重要的线索。尤其是开头和结尾部分。
- 善用搜索引擎,输入可以准确定义问题的关键字。
- 明白stackoverflow网站的重要性,其中被支持的答案可能一语道破你百思不得其解的问题。
对于“照葫芦画瓢”类场景,方法如下:
- 确认你已经圆满完成了“照葫芦画葫芦”过程。
- 确保你自己的数据格式与样例中数据格式一致。
- 认真阅读报错信息,从中找到问题的大致方向。
- 利用搜索引擎查找类似问题的已知有效解决方法。尤其要注意stackoverflow网站的相关链接。
对于“找葫芦画瓢”类场景,方法如下:
- 依照类似的功能,按图索骥找到提供相应功能的软件包。
- 阅读其官方说明文档,最好能找到特定功能的样例代码。
- 读代码的时候务必注意注释信息,其中包含了注意事项和重要资源。
- 自己实践的第一步,是用找到的“新葫芦”画出“葫芦”来,然后再尝试“画瓢”。
不论对于哪一类场景,你都要明白遇到的问题可能会成为你未来的财富。但前提是你必须把它们及时记录下来,并且养成定期回顾的好习惯。
如果实在解决不了问题,最后的一招,就是提问了。但是请你在发问之前,确定自己已经通过上述步骤和流程尝试了可能有效的方法。这不仅是《提问的智慧》里面要求的,更是为了你自己能够学有所得。提问的时候,要注意提供你的运行代码(最好是ipynb这样的格式,包含完整的报错信息)、用到的实际数据,以及你的尝试过程等。信息越详细,别人就越有能力帮助你。
向谁提问呢?当然可以问老师、问作者。但是别忘了你一直在使用的stackoverflow网站,本来就是一个让你提问的好地方啊。通过观察别人的问题和答案,你应该不难发现,网站上的高手们,大都非常热心助人。
另外,不要满足于永远当一个“文科生”。如果你打算在数据科学的路径上走得足够远、足够稳,夯实基础就是必要的。毕竟人工智能都要进入中小学课程体系了,不是吗?
如果你打算好好学习Python基础知识,欢迎阅读《如何高效学Python?》(10.4)一文。
10.2 文科生如何高效学数据科学?
看似无边无际、高深难懂而又时刻更新的数据科学知识,该怎样学才更高效呢?希望读过本文后,你能获得一些帮助。

10.2.1 疑惑
周五下午,我给自己的研究生开组会。主题是工作坊教学,尝试搭建自己的第一个深度神经网络。
参考资料是我的文章《如何用Python和深度神经网络发现即将流失的客户?》(7.1)。我带着学生们从下载最新版Anaconda安装包开始,直到完成第一个神经网络分类器。
过程涉及编程虚拟环境问题,他们参考了《如何在Jupyter Notebook中使用Python虚拟环境?》一文,比较顺利地掌握了如何在虚拟环境里安装软件包和执行命令。
我要求他们,一旦遇到问题就立即提出。我帮助解决的时候,所有人围过来一起看解决方案,以提升效率。

我给学生们介绍了神经网络的层次结构,并且用Tensorboard可视化展示。他们对神经网络和传统的机器学习算法(师兄师姐答辩的时候,他们听过,有印象)的区别不是很了解,我就带着他们一起玩儿了一把深度学习实验场。
看着原本傻乎乎的直线绕成了曲线,然后从开放到闭合,把平面上的点根据内外区分,他们都很兴奋。还录了视频发到了微信朋友圈。
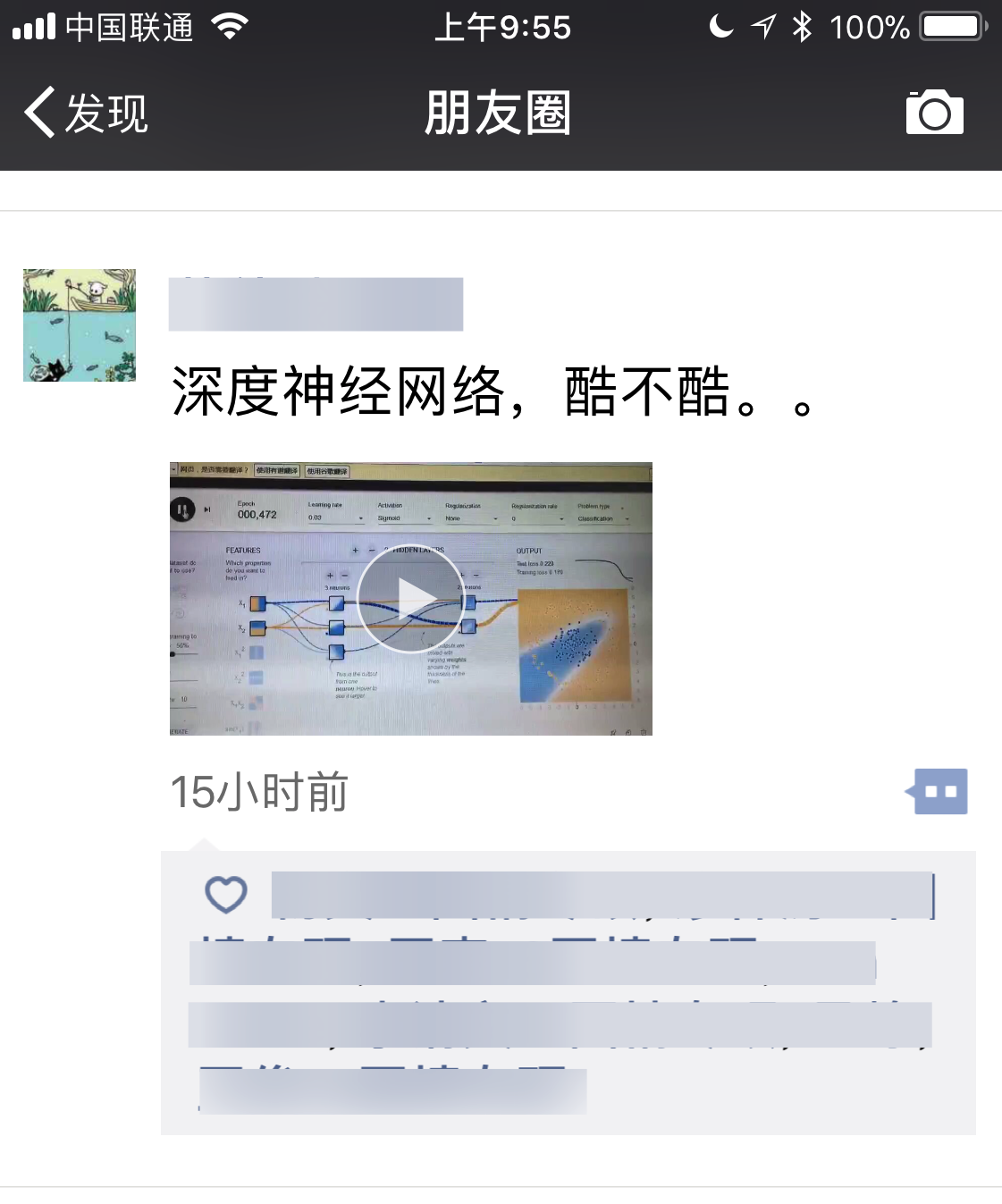
欣喜之余,一个学生不无担忧地问我:
老师,我现在能够把样例跑出来了,但是里面有很多内容现在还不懂。这么多东西该怎么学呢?
我觉得这是个非常好的问题。
对于非IT类本科毕业生,尤其是“文科生”(定义见这里(10.1)),读研阶段若要用到数据科学方法,确实有很多知识和技能需要补充。他们中不少人因此很焦虑。
但是焦虑是没有用的,不会给你一丝一毫完善和进步。学会拆解和处理问题,才是你不断进步的保证。
这篇文章,我来跟你谈一谈,看似无边无际、高深难懂而又时刻更新的数据科学知识,该怎样学才更高效。
许多读者曾经给我留言,询问过类似的问题。因此我把给自己学生的一些建议分享给你,希望对你也有一些帮助。
10.2.2 目标
你觉得自己在数据科学的知识海洋里面迷失,是因为套用的学习模式不对。
从上小学开始,你就习惯了把要学习的内容当成学科知识树,然后系统地一步步学完。前面如果学不好,必然会影响后面内容的理解消化。

知识树的学习,也必须全覆盖。否则考试的时候,一旦考察你没有掌握的内容,就会扣分。
学习的进程,有教学大纲、教材和老师来负责一步步喂给你,并且督促你不断预习、学习和复习。
现在,你突然独自面对一个新的学科领域。没了教学大纲和老师的方向与进度指引,教材又如此繁多,根本不知道该看哪一本,茫然无措。
其实如果数据科学的知识是个凝固的、静态的集合,你又有无限长的学习时间,用原先的方法来学习,也挺好。
可现实是,你的时间是有限的,数据科学的知识却是日新月异。今年的热点,兴许到了明年就会退潮。深度学习专家Andrej Karpathy评论不同的机器学习框架时说:
Matlab is so 2012. Caffe is so 2013. Theano is so 2014. Torch is so 2015. TensorFlow is so 2016. :D
怎么办呢?
你需要以目标导向来学习。
例如说,你手头要写的论文里,需要做数据分类。那你就研究分类模型。
分类模型属于监督学习。传统机器学习里,KNN, 逻辑回归,决策树等都是经典的分类模型;如果你的数据量很大,希望用更为复杂而精准的模型,那么可以尝试深度神经网络。
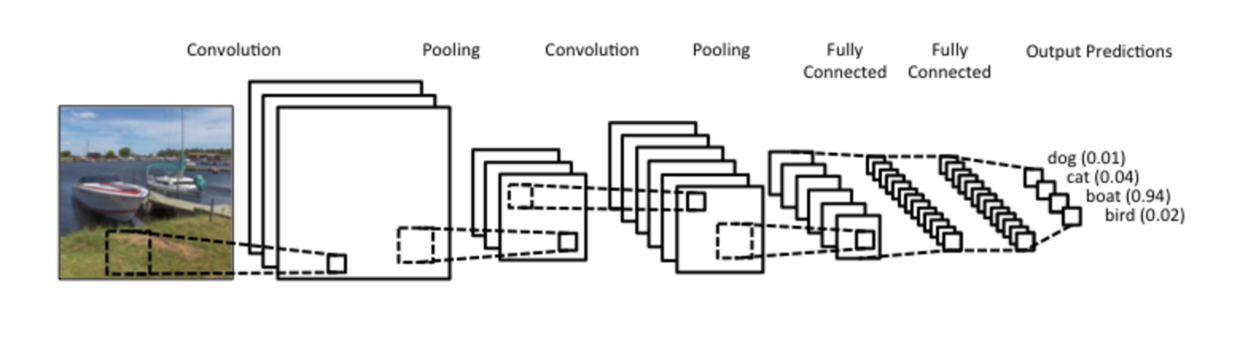
如果你要需要对图片进行识别处理,便需要认真学习卷积神经网络(Convolutional Neural Network),以便高效处理二维图形数据。
如果你要做的研究,是给时间序列数据(例如金融资产价格变动)找到合适的模型。那么你就得认真了解递归神经网络(recurrent neural network),尤其是长短期记忆(Long short-term memory, LSTM)模型。这样用人工智能玩儿股市水晶球才能游刃有余。

但如果你目前还没有明确的研究题目,怎么办?
不要紧。可以在学习中,以案例为单位,不断积累能力。
实践领域需求旺盛,数据科学的内容又过于庞杂,近年来MOOC上数据科学类课程的发展,越来越有案例化趋势。
一向以技术培训类见长的平台,如Udacity, Udemy等自不必说。就连从高校生长出来的Coursera,也大量在习题中加入实际案例场景。Andrew Ng最新的Deep Neural Network课程就是很好的例证。
我之前推荐过的华盛顿大学机器学习课程,更是非常激进地在第一门课中,通过案例完整展示后面若干门课的主要内容。
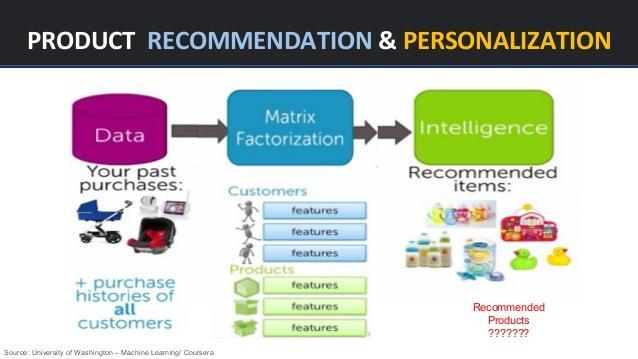
注意,学第一门课时,学员们对于相关的技术(甚至是术语)还一无所知呢!
然而你把代码跑完,出现了结果的时候,真的会因为不了解和掌握细节就一无所获吗?
当然不是。
退一万步说,至少你见识了可以用这样的方法成功解决该场景的问题。这就叫认知。
告诉你一个小窍门:在生活、工作和学习中,你跟别人比拼的,基本上都是认知。
你获得了认知后,可以快速了解整个领域的概况。知道哪些知识对自己目前的需求更加重要,学习的优先级更高。
比案例学习更高效的“找目标”方式,是参加项目,动手实践。
动手实践,不断迭代的原理,在《如何高效学Python?》(10.4》和《创新怎么教?)文中我都有详细分析,欢迎查阅。
这里我给你讲一个真实的例子。
我的一个三年级研究生,本科学的是工商管理。刚入学的时候按照我的要求,学习了密歇根大学的Python课程,并且拿到了系列证书。但是很长的一段时间里,他根本就不知道该怎么实际应用这些知识,论文自然也写不出来。
一个偶然的机会,我带着他参加了另一个老师的研究项目,负责技术环节,做文本挖掘。因为有了实际的应用背景和严格的时间限定,他学得很用心,干得非常起劲儿。之前学习的技能在此时真正被激活了。
等到项目圆满结束,他主动跑来找我,跟我探讨能否把这些技术方法应用于本学科的研究,写篇小论文出来。
于是我俩一起确定了题目,设计了实验。然后我把数据采集和分析环节交给了他,他也很完满地做出了结果。
有了这些经验,他意识到了自己毕业论文数据分析环节的缺失,于是又顺手改进了毕业论文的分析深度。
恰好是周五工作坊当天,我们收到了期刊的正式录用通知。
看得出来,他很激动,也很开心。
10.2.3 深度
确定目标后,你就明白了该学什么,不该学什么。
但是下一个问题就来了,该学的内容,要学到多深、多细呢?
在《贷还是不贷:如何用Python和机器学习帮你决策?》(6.1)一文里,我们尝试了决策树模型。
所谓应用决策树模型,实际上就是调用了一个包。
from sklearn import tree
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X_train_trans, y_train)只用了三行语句,我们就完成了决策树的训练功能。
这里我们用的是默认参数。如果你需要了解可以进行哪些参数调整设置,在函数的括号里使用shift+tab按键组合,就能看到详细的参数列表,并且知道了默认的参数取值是多少。
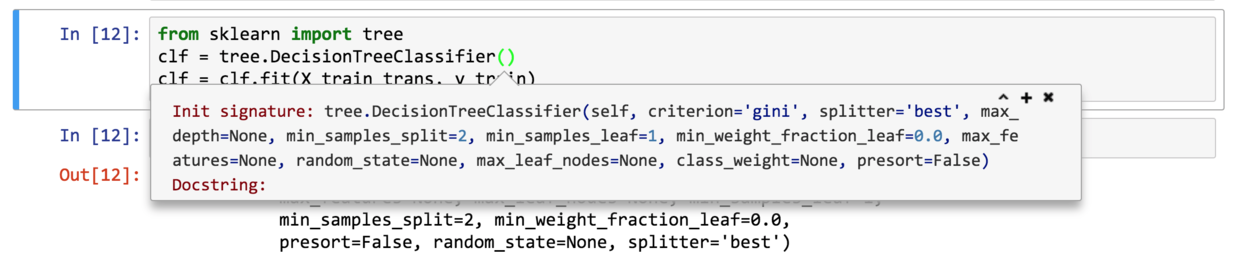
如果你需要更详细的说明,可以直接查文档。在搜索引擎里搜索sklearn tree DecisionTreeClassifier这几个关键词,你会看到以下的结果。
点击其中的第一项,就可以看到最新版本scikit-learn相关功能的官方文档。
当你明白了每个函数工作的方法、参数可以调整的类型和取值范围时,你是否可以宣称自己了解这个功能了?
你好像不太有信心。
因为你觉得这只是“知其然”,而没有做到“知其所以然”。
但是,你真的需要进一步了解这个函数/功能是如何实现的吗?
注意图中函数定义部分,有一个指向source的链接。

点开它,你就会导航到这个函数的源代码,托管在github上。

如果你是个专业人士,希望研究、评估或者修改该函数,认真阅读源代码就不仅必要,而且必须。
但是作为文科生的你,如果仅是为了应用,那完全可以不必深入到这样的细节。将别人写好的,广受好评的软件包当成黑箱,正确地使用就好了。
这就如同你不需要了解电路原理,就可以看电视;不需要了解川菜的技艺和传承,就可以吃麻婆豆腐。只要你会用遥控器,会使筷子,就能享受这些好处。
越来越多的优秀软件包被创造出来,数据科学的门槛也因此变得越来越低。甚至低到被声讨的地步。例如这篇帖子,就大声疾呼“进入门槛太低正在毁掉深度学习的名声!”
但是,不要高兴得太早。觉得自己终于遇到一门可以投机取巧的学问了。
你的基础必须打牢。
数据科学应用的基础,主要是编程、数学和英语。
数学(包括基础的微积分和线性代数)和英语许多本科专业都会开设。文科生主要需要补充的,是编程知识。
只有明白基础的语法,你才能和计算机之间无障碍交流。
一门简单到令人发指的编程语言,可以节省你大量的学习时间,直接上手做应用。
程序员圈子里,流行一句话,叫做:
人生苦短,我用Python。
Python有多简单?我的课上,一个会计学本科生,为了拿下证书去学Python基础语法,一门课在24小时内,便搞定了。这还包括做习题、项目和系统判分时间。
怎么高效入门和掌握Python呢?欢迎读读《如何高效学Python?》(10.4),希望对你快速上手能有帮助。
10.2.4 协作
了解了该学什么,学多深入之后,我们来讲讲提升学习效率的终极秘密武器。
这个武器,就是协作的力量。
协作的好处,似乎本来就是人人都知道的。
但是,在实践中,太多的人根本就没有这样做。
因为,我们都过于长期地被训练“独立”完成问题了。
例如考试的时候跟别人交流,那叫作弊。
但是,你即便再习惯一个人完成某些“创举”,也不得不逐渐面对一个真实而残酷的世界——一个人的单打独斗很难带来大成就,你必须学会协作。
这就像《权力的游戏》里史塔克家族的名言:
When the cold winds blow the lone wolf dies and the pack survives. (凛冬将至,独狼死,群狼活。)

文科生面对屏幕编程,总会有一种孤独无助的感觉,似乎自己被这个世界抛弃了。
这种错误的心态会让你变得焦虑、恐慌,而且很容易放弃。
正确的概念却能够拯救你——你正在协作。而且你需要主动地、更好地协作。
你面前这台电脑或者移动终端,就是无数人的协作成果。
你用的操作系统,也是无数人的协作成果。
你用的编程语言,还是无数人的协作成果。
你调用的每一个软件包,依然是无数人的协作成果。
并非只有你所在的小团队沟通和共事,才叫做协作。协作其实早已发生在地球级别的尺度上。
当你从Github上下载使用了某个开源软件包的时候,你就与软件包的作者建立了协作关系。想想看,这些人可能受雇于大型IT企业,月薪6位数(美元),能跟他们协作不是很难得的机会吗?
当你在论坛上抛出技术问题、并且获得解答的时候,你就与其他的使用者建立了协作关系。这些人有可能是资深的IT技术专家,做咨询的收费是按照秒来算的。
这个社会,就是因为分工协作,才变得更加高效的。
数据科学也是一样。Google, 微软等巨头为什么开源自己的深度学习框架,给全世界免费使用?正是因为他们明白协作的终极含义,知道这种看似吃亏的傻事儿,带来的回报无法估量。

这种全世界范围内的协作,使得知识产生的速度加快,用户的需求被刻画得更清晰透彻,也使得技术应用的范围和深度空前提高。
如果你在这个协作系统里,就会跟系统一起日新月异地发展。如果你不幸自外于这个系统,就只能落寞地看着别人一飞冲天了。
这样的时代,你该怎么更好地跟别人协作呢?
首先,你要学会寻找协作的伙伴。这就需要你掌握搜索引擎、问答平台和社交媒体。不断更新自己的认知,找到更适合解决问题的工具,向更可能回答你问题的人来提问。经常到Github(10.3)和Stackoverflow上逛一逛,收获可能大到令你吃惊。
其次,你要掌握清晰的逻辑和表达方式。不管是搜寻答案,还是提出问题,逻辑能力可以帮助你少走弯路,表达水平决定了你跟他人协作的有效性和深度。具体的阐释,请参考《Python编程遇问题,文科生怎么办?》(10.1)。
第三,不要只做个接受帮助者。要尝试主动帮助别人解决问题,把自己的代码开源在Github上,写文章分享自己的知识和见解。这不仅可以帮你在社交资本账户中储蓄(当你需要帮助的时候,相当于在提现),也可以通过反馈增长自己的认知。群体的力量可以通过“赞同”、评论等方式矫正你的错误概念,推动你不断进步。
可以带来协作的链接,就在那里。
你不知道它们的存在,它们对你来说就是虚幻。
你了解它们、掌握它们、使用它们,它们给你带来的巨大益处,就是实打实的。
10.2.5 小结
我们谈了目标,可以帮助你分清楚哪些需要学,哪些不需要学。你现在知道了找到目标的有效方法——项目实践或者案例学习。
我们聊了深度,你了解到大部分的功能实现只需要了解黑箱接口就可以,不需要深入到内部的细节。然而对于基础知识和技能,务必夯实,才能走得更远。
我们强调了协作。充分使用别人优质的工作成果,主动分享自己的认知,跟更多优秀的人建立链接。摆脱单兵作战的窘境,把自己变成优质协作系统中的关键节点。
愿你在学习数据科学过程中,获得认知的增长,享受知识和技能更新带来的愉悦。放下焦虑感,体验心流的美好感受。
10.3 如何高效入门Github?
如今的编程,早已不是单打独斗的模式了。优秀的编程人员,甚至是初学者,都必须学会如何与他人高效协作。Github是编程协作中须要掌握的基础知识。如何尽快入门,少走弯路呢?希望读过本文,你能获得一些帮助。

10.3.1 疑惑
前几天,有同学在知识星球留言,询问我如何学习Github的使用。

我觉得这个问题很重要。本打算写一篇教程,以最简化的样例作为基础,带着你从头到尾做一遍的。
然而在搜集资料的过程中,我发觉现有的Github教程已经非常全面了。因而不觉得还需要我动笔写一篇。
我把找到的比较好的教程和资源整理出来,发给你。如果你能直接学会,请告诉我。如果在实践中某个环节遇到问题,也欢迎反馈给我。我会针对性地写个教程出来,有的放矢解答疑惑,以帮助更多的同学。
10.3.2 教程
教程里面,最推荐的是官方的 Hello World教程 。这肯定是最权威的了。
阅读和实践这份教程,只需要10分钟。官方承诺不需要掌握编程基础知识就能学会。具体的方式,是在教程里使用文本文件,而非程序代码的编写作为样例。
学习完官方Hello World教程后,你可以进一步开启Github的 Help页面 ,探索github中的各项功能。
这里的 bootcamp 详细讲解Git, Github Repo的各种知识,建议探索。
这里需要辨析一下概念。Github是代码托管平台,是协作的工具;而Git是版本控制工具。Git不需要联网,在本机就可以使用,例如我经常用它来保存论文修改的中间状态文稿。Git也可以和其他的代码托管平台结合使用。
当然,Git和Github双剑合璧,是最顺畅的。这就如同macOS可以和安卓手机间交互信息,但是显然和iPhone交互信息用户体验更好。
如果你英文不达标,想找寻中文资源,那么我推荐你看这个 维基页面 。
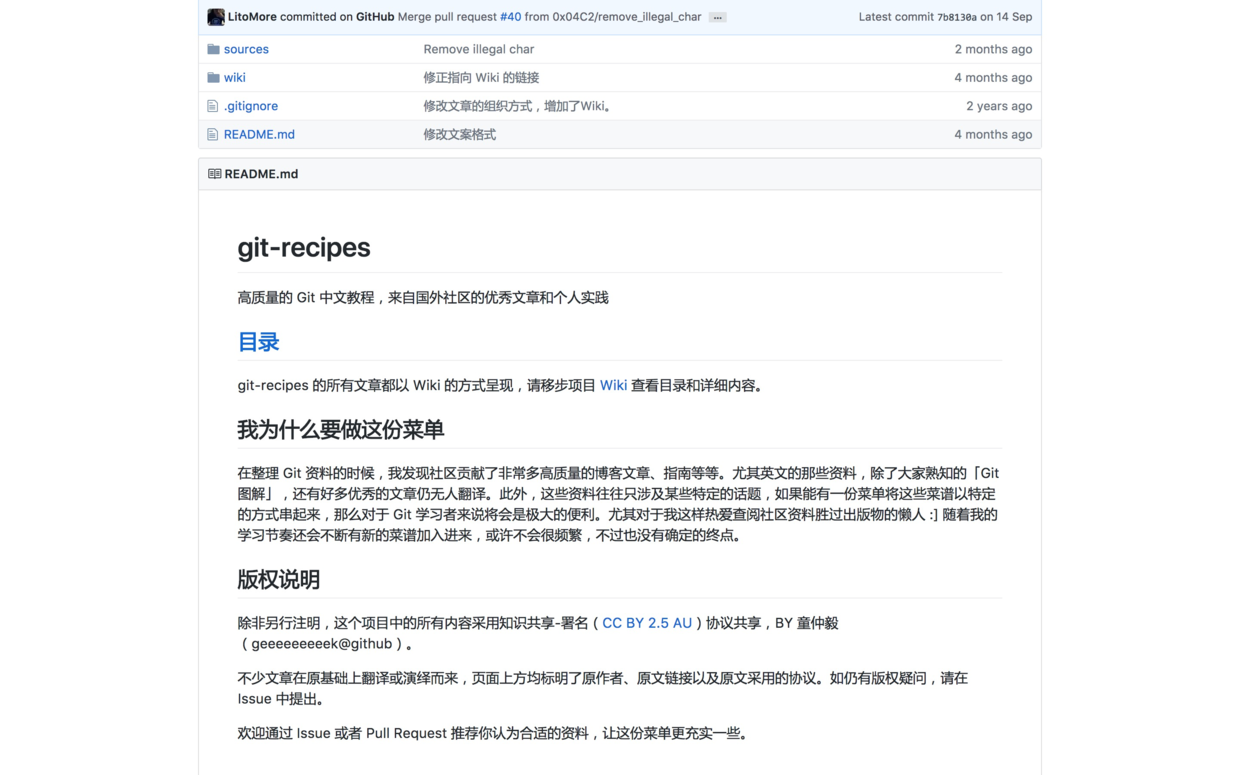
该Wiki的编者非常认真细致地总结和翻译了许多Github知识和技巧。4775颗星说明了该Wiki的受欢迎程度。
10.3.3 视频
如果你是个视觉学习者,希望获取Github的视频教程,那你可以参考 GitHub的官方Youtube频道 。各种应用类型的讲解可以满足你的个性化需求。
另外我个人推荐的Github视频教程为 LearnCode.academy的作品 。在Youtube平台上,该视频观看次数超过130万,点赞次数将近10000。
视频教程里,作者用一个分割窗口的编辑器,就把编程协作中常见的问题——拉取(pull)、推送(push)、冲突(conflicts)处理等讲得生动形象,一清二楚。
如果你访问Youtube不是很方便,请点击这个链接,查看我转存到腾讯视频的版本。可惜,视频清晰度不是很高。我下载来的视频,清晰度没问题,上传到腾讯视频的时候,也没有提示我选择清晰度的选项。如果你知道如何能改进上传视频的画质,欢迎留言告诉我。谢谢!
希望上述归纳总结的学习路径和资源对你有帮助。当然,光是看教程是不够的。你需要跟着教程,从最基本的命令开始练习。你的指尖会不断熟悉和记忆相关的命令,完成从入门到高手的进阶。
希望你能够早日与他人一起愉快地协作编程。祝顺利!
10.4 如何高效学Python?
如果你一直想学Python,但是不知道如何入手,那就别犹豫了。这篇文章就是为你写的。

10.4.1 疑问
随着数据科学概念的普及,Python这门并不算新的语言火得一塌糊涂。
因为写了几篇用Python做数据分析的文章,经常有读者和学生在留言区问我,想学习Python,该如何入手?
我经常需要根据他们的不同情况,提出对应的建议。这样针对性虽强,但效率不高。这个问题,我还是写出来,让更多的人一同看到吧。
有几位出版社的编辑,给我发私信,鼓励我赶紧写一本Python教材出来。
我暂时还没有写Python基础教程的计划。因为在我看来,现有的学习资源已经足够好了。
有现成的资源和路径,为什么许多人依然在为学Python犯愁呢?
因为学习有个效率问题。
Python语法清晰明快,简单易学。这是Python如此普及的重要原因。但是,选择合适的Python学习方式,需要跟你自身的特性相结合。
人群划分的标准是什么?不是你是否计算机相关专业,也不是你是否已经工作,而是一个重要的指标——你的自律能力。
你可能觉得我说的话没有信息含量。自律能力强,学得更好,地球人谁不知道?
可是,自律不够强的人,难道就注定什么也不能学了?
当然不是。
每个人的性格都有不同的特点,没有绝对的高下之分。不信你听听刘宝瑞先生的相声《日遭三险》,就明白了。

自律能力也是这样。只要你能清楚认识自己,就能以更高效的方法来学习新知识和技能。
下面我们分类探讨一下,不同自律能力的人,该如何学Python,才能更高效。
10.4.2 路径I
咱们先从自律能力最差的人说起。
这样的同学,往往是三分钟热度。偶然受到了刺激,发奋要学习Python,以便投入数据科学的事业中。
他会立即跑到图书馆或者书店抱回来一本《X天从入门到精通Python》的书开始啃。结果X天还没到,就顺利跑完了从入门到放弃的全过程。
你没能坚持下来,自己肯定是有责任的。但是最大的问题,在于过度高估自己的自律能力。
这样的同学,我推荐你到Coursera平台上,按部就班学习一门非常好的MOOC——“Programming for Everybody”。
推荐这门课,是因为课程质量真是太好了。
首先是教材好。这本教材的来源是有故事的。
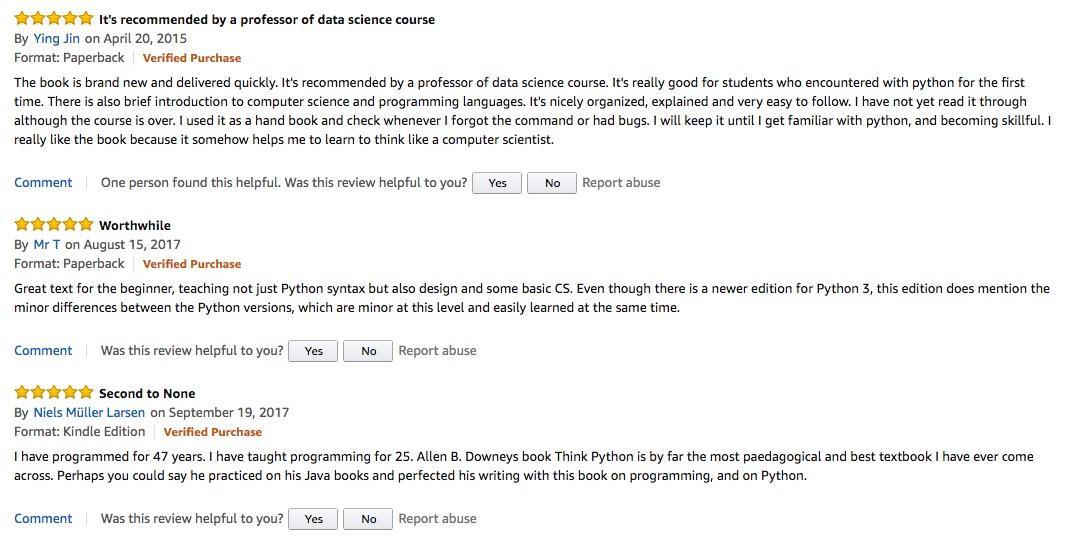
先是 Allen B. Downey 写了一本开放书籍 “Think Python: How to Think like a Computer Scientist”。

这本书在Amazon上的评价是这样的:
Charles Severance觉得这本书写得太好了,想把它作为教材。于是征得作者同意,大篇幅借鉴了这本书的内容架构,编写了一本 “Python for Informatics”。

Charles写作这本书的时候,同时开放推出了iBook格式。里面就包含了自己的授课视频,供学生直接观看学习。
后来,Charles用这本书扩展,做成了一门MOOC。2015年上线不久,硅谷资深工程师就都争相学习。
Charles深谙课程迭代的技艺。他不断添加内容,完善课程体系,将一门课发展成一个专项课程(Signature Track),并且将教材升级为 “Python for Everybody: Exploring Data In Python 3”

在目前全球MOOC口碑榜上,Charles的这门课一直名列前茅。

这个专项课程深入浅出讲解Python本来就很简单的语法,而且还用数据科学的一些基础工作任务,带动你去使用Python语言写简单项目。这种扎实的训练过程可以增强你的信心,激发兴趣。
对于自律程度低的同学来说,下面这个特性更重要——一切工作都有时限。
Coursera上的课程,每周的任务很明确。练习题正确率如果不能达到80%,就不能过关。到了截止日期,如果你不能完成全部练习和课程项目,就拿不到证书。

老师在前面引领你,助教在旁边督促你,平台用时间表提醒你,论坛上的同学们在用同侪压力推挤你……
想偷懒?想三天打鱼两天晒网?很难。
10.4.3 路径II
如果你的自律能力中等偏上,那么你可以选择的面就宽了。
这里我给你推荐另一个MOOC平台,叫做Datacamp。

我第一次接触Datacamp,是在2015年初。那时我在Coursera上选修杜克大学的统计学课程 “Statistical Inference”,配套的练习就在Datacamp上。
当时这个平台就给我留下了非常深刻的印象,因为代码的运行都采用了云环境。学习者不需要在本机安装任何环境,一个支持HTML5标准的浏览器就能带给你完整的学习体验。
对初学者来说,这种入门方式太好了。要知道,许多人的学习热情,就是被环境配置和依赖软件包安装的坑埋掉的。
两年之后,Datacamp已经迭代得更为强大。你可以打开首页的Data Scientist with Python这个学习路径,查看其中已经提供的20门课程。
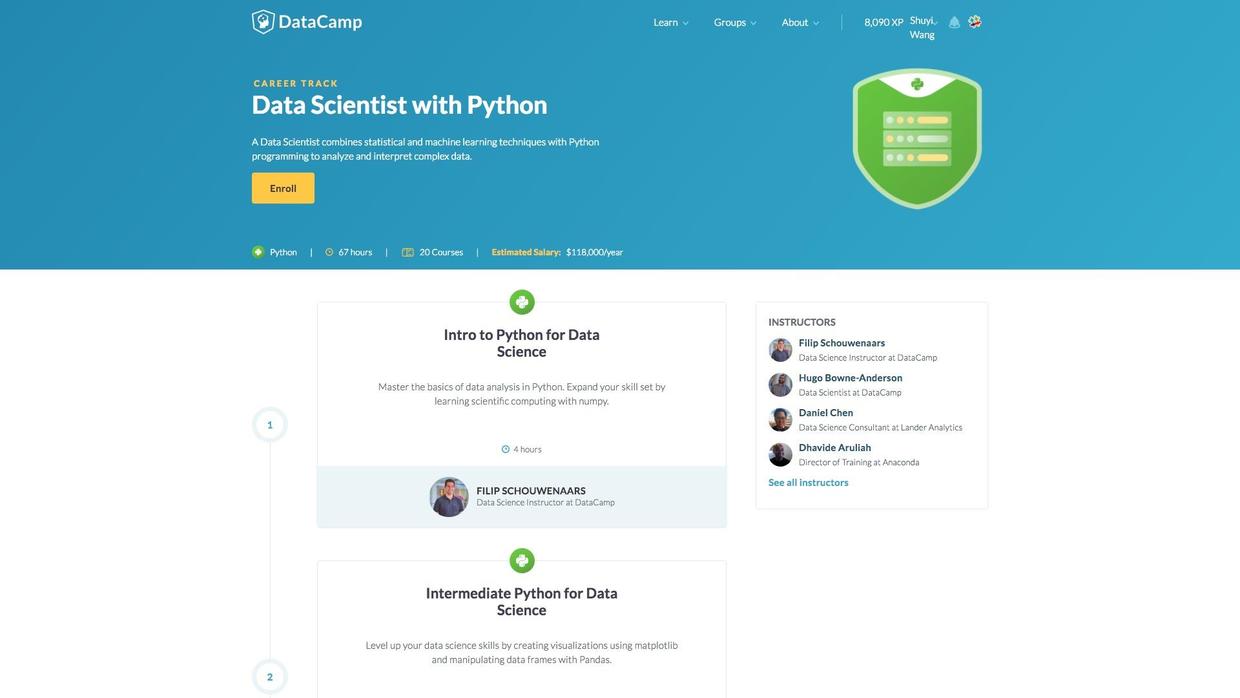
这些课程涵盖了从Python基础,到数据处理,直至人工智能和深度神经网络的方方面面。
所有的课程设计,都是短小精悍的。一般不超过4个小时,就可以完成某一主题的学习。这样你学起来毫不费力,可以在相当短的时间内获得反馈(练习题自动评分)和成就感(证书)。
这个平台的课程,进度完全由学习者自己掌控。所以我把它归纳为适合有一定自律能力的学习者。
它既可以给你即时的回馈,让你时刻了解自己所处的位置进度,不会迷失方向,又能充分体验自主学习的乐趣。
Datacamp的课程,一般都是第一部分免费开放。后面部分购买后才能解锁学习。如果你对自己的学习能力和毅力有信心,可以购买一个完整时间段(例如一年)的课程。在此期间,所有平台上的课程,你都可以学习,并且可以在通过后获取证书。这样的购买方案本身已经有优惠,而且每年都会有特定时段的大幅打折促销,非常划算。建议放到购物车里面多关注。

这是我在Datacamp拿到的深度学习框架Keras课程证书。确实只需要几个小时的时间就能学完。成就感还是蛮强的。
10.4.4 路径III
前面提到的课程费用不菲。Coursera上每门课平均价格在49美元左右。对来自发展中国家的学生群体,Coursera可以提供助学金。你可以根据自己的需求如实填写申请表,来获得资助。
对于自律能力强的同学来说,你的选择可以变得非常简单直接——可以用最受推崇的教材,自己看书学习。
最受推崇的教材,其实是没有的。正如西谚有云:
One man’s meat, is another man’s poison.
这个世界上,就没有哪件东西大家都说好。但口碑非常好的教材是存在的,例如这本起了个怪名字的《笨办法学Python》(Learn Python the Hard Way)。

千万不要被名称迷惑,望文生义觉得这是一本糟糕的Python入门教程。
恰恰相反,这本书的设计,非常适合人们的认知规律。
我们学东西,由浅入深,由易到难,逐步递进。如果一味追求新知,那么之前学的东西会很快遗忘。如果总是原地打转,会带来枯燥和无聊的感觉。还记得高三做的那一年卷子吧?
好的教科书,应该在每一个章节给学习者提供新的知识和内容,提出足够的挑战。但是挑战性不能高到让学习者产生挫败感而放弃。同时也不能忽视在后续内容中把前面所学知识改换面目不断螺旋上升式重复出现。只有这样才能巩固所学,让学习者感受到基础知识的作用,增强学习的愉悦感。
这么说有些抽象,实际上有一本英语教材非常符合上述认知规律。就是我在课堂上和文章里反复推荐过的这一套教材:

《笨办法学Python》也是一本这样的书。你需要做的就是把书打开,同时打开一个好用的代码编辑器,开始按书中要求敲代码、运行代码、改代码……
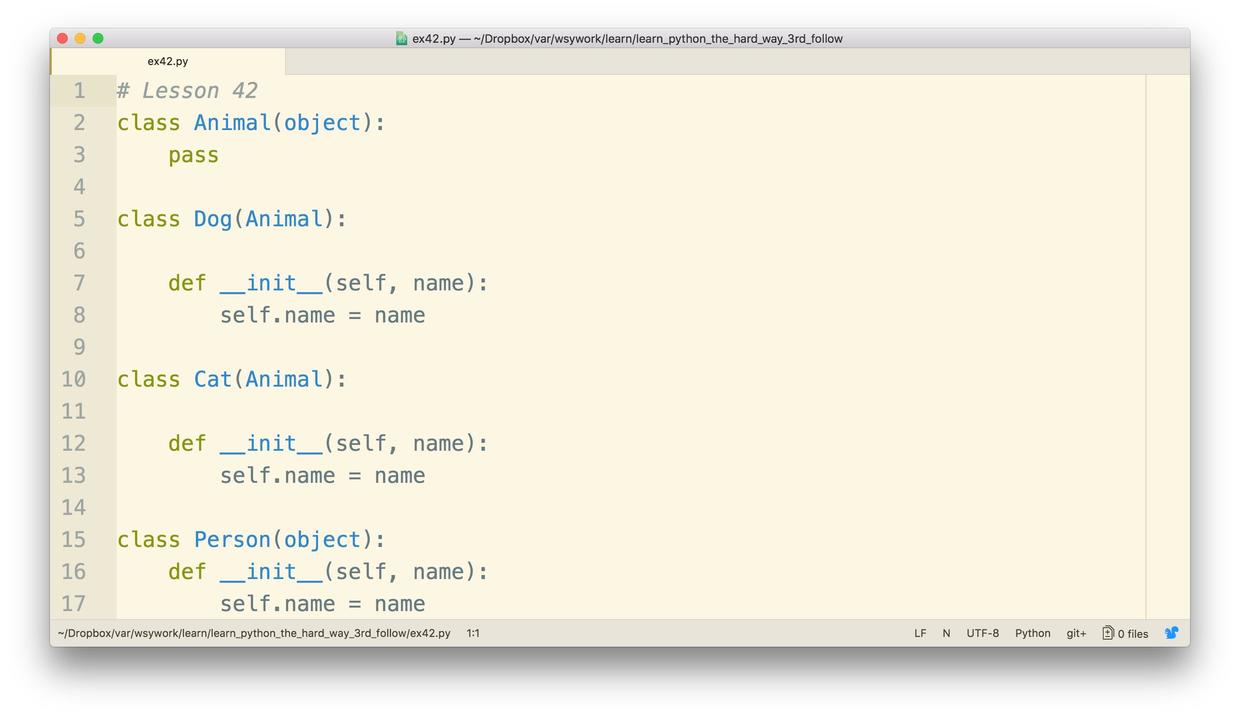
下图是我当初学习时,照着这本书敲的代码。
书中对Python基础内容训练的完备性,至今无出其右者。
顺便说一句,这本书有中文版哦。所以如果你英语不好,完全不用担心。
嘱咐一句,英语真该好好学。拓宽的不仅是你的眼界,也增加了你可能获得的机会。考虑到仔细阅读这部分的读者都是自律性很强的人,我就不用多说了。
10.4.5 挑战
三条基本的Python入门路径讲完了。通过对自己自律能力的清晰理解,相信你可以找到一种适合自己逐渐学习和掌握Python的方式。
但是完成了读书和听课,是不是就完事大吉了?
当然不是。
许多人在这里犯了错误。他们以为拿到了证书,或学完了教材,就算是真正掌握了Python。然后把这门语言丢弃在一旁,去刷美剧和小说了。
相信我,你会遗忘的。
如果你对于长期不接触的东西从不遗忘……去医院检查一下吧。
大部分人的记忆模式,都是这个样子的:
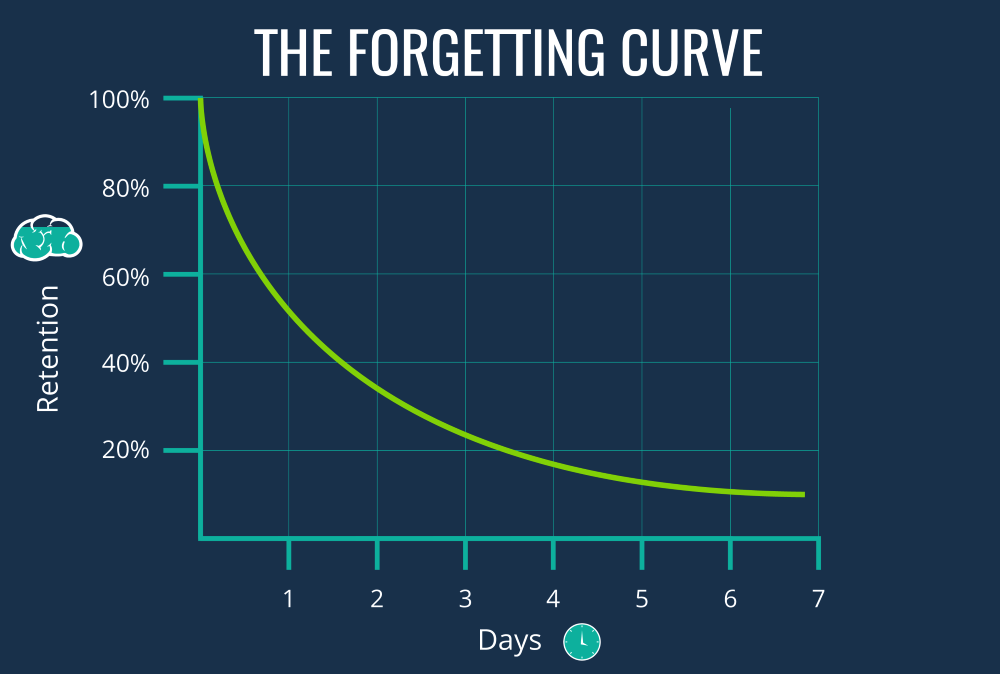
若不加以干涉,不出一个星期,你就能把学到的新知识几乎忘光。
如果你不希望自己辛苦学来的Python知识被如此轻易浪费掉,怎么办?
10.4.6 实践
你应该实践。
实践Python技能,未必一定要找个世界500强企业的核心技术部门,“996”工作N年才能完成。
你可以从生活中寻找各种有趣的问题,然后思考能否用Python编程来解决它。
我真正觉得自己初步掌握了Python,就是在完成了我的第一个github项目之后。
项目非常简单,就是用Python作为胶水语言,把一系列工具连接在一起。可以把Markdown撰写的内容随心所欲一键变化成各种格式。
格式包括而不限于:
- PDF/LaTeX;
- Word;
- Bitcron文稿;
- MarkEditor文稿;
- MWeb文稿;
- Bear文稿;
- TextBundle(可以导入MindNode, Ulysses等);
- Reveal.js幻灯;
- 发布版本Markdown(图片一键至七牛图床);
- 本地版本Markdown(简书等远程Markdown同步图片至本地);
- Day One日记。
其中部分功能我正陆续发布在github公开项目中,地址在这里](https://github.com/wshuyi/mindmap2slide)。相应地,我也[撰文(??)做了介绍。
这个小项目,我从2014年开始做。实话实说,现在回头看当时的代码,简直惨不忍睹。但是如果你逐渐对自己的代码有了这种感觉,证明你在进步。
不要指望自己一出手就能写出完美的代码,要把“迭代”两个字时刻装在心里。这样你才能容忍自己的笨拙,不断提高。正如古人说的那句:
勤学似春起之苗,不见其增,而日有所长。
我在做这个项目的过程中,曾经遇到了中文编码、隐私信息存储、文件名空格处理、绝对与相对路径、发布流程划分、功能解耦合、Web图片地址附带参数……等等一系列的问题。
通过回顾用git版本控制工具记载下来的日志,以及版本对比功能,你可以清楚看到自己是在何时利用什么方法解决了这些问题。然后别忘了,给自己工具箱里的新增小技能打个勾。
一个个小问题逐渐被你攻克的时候,你才能真正感受到所学技能的价值,并且点滴积累自信。
10.5 本章小结
如果你喜欢本章的内容,欢迎扫描下面二维码,请我喝杯咖啡。

如果你需要答疑,咱们的问答社区在这里: