第 3 章 上手
这一部分,主要包括两节内容。
3.1 节手把手教你做出一个英文词云。如果你希望把它应用到中文上,3.3 节的内容会对你很有帮助。
3.1 如何用 Python 做词云?
临渊羡鱼,不如退而结网。我们步步为营,从头开始帮助你用 Python 做出第一张词云图来。
在大数据时代,你经常可以在媒体或者网站上看到一些非常漂亮的信息图。
例如这个样子。
看过之后你有什么感觉?想不想自己做一张出来?
如果你的答案是肯定的,我们就不要拖延了,现在就开始,做个词云分析图。当然,做为基础的词云图,肯定比不上刚才那两张信息图酷炫。不过不要紧,好的开始是成功的一半。食髓知味,后面你就可以自己升级技能,进入你开挂的成功之路。
网上教你做信息图的教程很多。许多都是利用了专用工具。这些工具好是好,便捷而强大。只是它们功能都太过专一,适用范围有限。今天我们要尝试的,是用通用的编程语言 Python 来做词云。
Python 是一种时下很流行的编程语言。你不仅可以用它做数据分析和可视化,还能用来做网站、爬取数据、做数学题、写脚本替你偷懒……
知道豆瓣吗?它一开始就是用 Python 写的。
在目前的编程语言热度排序里,Python 屈居第四(当然,很多人不同意,所以编程语言的排行榜有许多,你懂的)。但看问题要用发展眼光。随着数据科学的发展,Python 有爆发的趋势。早点儿站上风口,很有益处。
如果你之前没有编程基础,没关系。从零开始,意味着我会教你如何安装Python运行环境,一步步完成词云图。希望你不要限于浏览,而是亲自动手尝试一番。到完成的那一步,你不仅可以做出第一张词云图,而且这还将是你的第一个有用的编程作品。
心动了?那咱们就开始吧。
3.1.1 安装
首先,我们需要安装 Python 运行环境。请参考第2章的介绍。
进行下一步之前,请确保你已经安装好了 Anaconda ,并且已经进入了终端。
请键入以下命令:
如果你用的操作系统是苹果的 macOS ,系统就会提示你先安装 XCode 命令行工具,你按照默认设置一步步进行就可以了。
如果你用的是 Windows,那么为了使用这个词云包,就稍微麻烦一些。好在我为你录制了在 Windows 下用 Python 制作词云的完整视频教程,请点击这个链接查看。
3.1.2 数据
安装了 Python 的运行环境,我们还需要数据。
词云分析的对象,是文本。
理论上讲,文本可以是各种语言的。英文、中文、法文、阿拉伯文……
为了简便,我们这里以英文文本为例。你可以随意到网上找一篇英文文章作为分析对象。我特别喜欢英剧“Yes, minister”,所以到维基百科上找到了这部剧的介绍词条。
我把其中的正文文字部分拷贝了下来,存储为一个文本文件,叫做 yes-minister.txt 。
请你点击这个网址链接,下载压缩包。并且把压缩包解压,将其中的 yes-minister.txt 文件挪动到工作目录 demo 里。
好了,文本数据已经准备好了。开始进入编程的魔幻世界吧!
3.1.3 代码
你会注意到,刚才压缩包里面其实还有一个文件,就是咱们词云绘制的完整代码 ipynb 文件。
不过我建议你还是自己跟着教程做一遍。这样印象更深刻,不是吗?
在命令行下,执行:
浏览器会自动开启,并且显示如下界面。
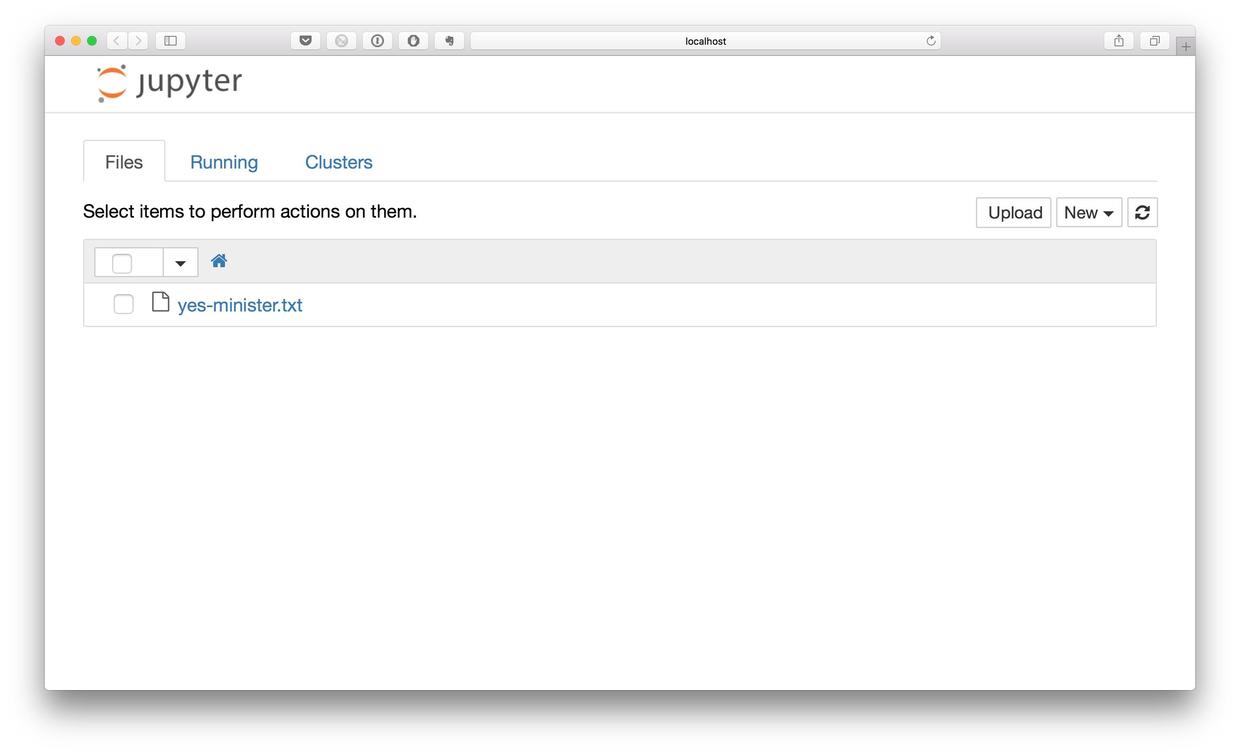
这就是咱们刚才的劳动成果——安装好的运行环境了。我们还没有编写程序,目录下只有一个刚才生成的文本文件。
打开这个文件,浏览一下内容。
回到 Jupyter 笔记本的主页面。我们点击 New 按钮,新建一个笔记本(Notebook)。在 Notebooks 里面,请选择 Python 3 选项。
系统会提示我们输入 Notebook 的名称。程序代码文件的名称,你可以随便起。但是我建议你起一个有意义的名字,将来好方便查找。由于我们要尝试词云,就叫它 wordcloud 好了。
然后就出现了一个空白的笔记本,供我们使用了。我们在网页里唯一的代码文本框里,输入以下3条语句。请务必逐字根据示例代码输入,空格数量都不可以有差别。尤其注意第三行,用4个空格,或者1个 Tab 开始。输入后,按 Shift+Enter 键,就可以执行了。
filename = "yes-minister.txt"
with open(filename) as f:
mytext = f.read()没有任何结果啊。
对,因为我们这里没有任何输出动作,程序只是打开了你的 yes-minister.txt 文本文件,把里面的内容都读了出来,存储到了一个叫做mytext 的变量里面。
然后我们尝试显示 mytext 的内容。输入以下语句之后,还是得按 Shift+Enter 键,系统才会实际执行该语句。
mytext之后的步骤里,也千万不要忘了这一确认执行动作。
显示的结果如下图所示。

嗯,看来 mytext 变量里存储的文本就是我们从网上摘来的文字。到目前为止,一切正常。
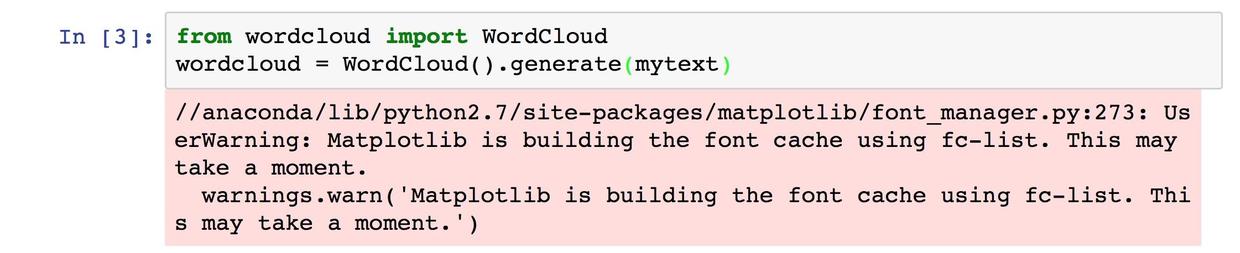
然后我们呼唤(import)词云包,利用 mytext 中存储的文本内容来制造词云。
from wordcloud import WordCloud
wordcloud = WordCloud().generate(mytext)这时程序可能会报警。别担心。警告(warning)不影响程序的正常运行。
此时词云分析已经完成了。你没看错,制作词云的核心步骤只需要这2行语句,而且第一条还只是从扩展包里找外援。但是程序并不会给我们显示任何东西。
说好了的词云呢?折腾了这么半天,却啥也没有,你蒙人吗?!
别激动。输入下面4行语句后,就是见证奇迹发生的时刻了。
%pylab inline
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")运行结果如图所示:
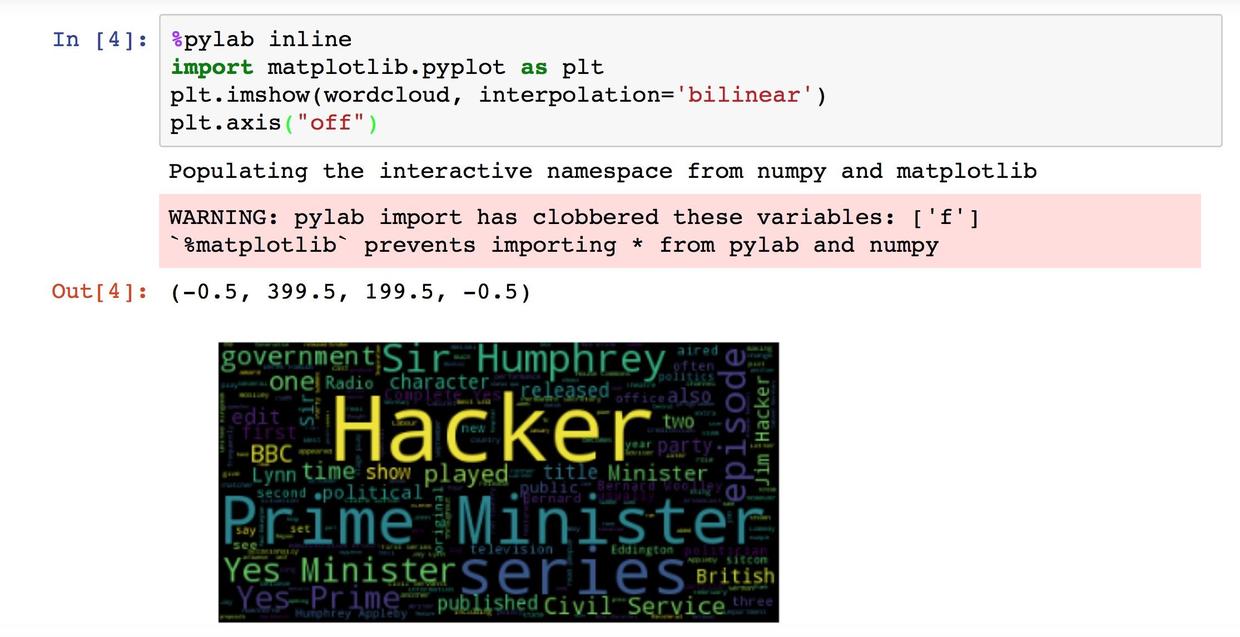
不用那么兴奋嘛。
你可以在词云图片上单机鼠标右键,用“图片另存为”功能导出。

通过这张词云图,我们可以看到不同单词和词组出现的频率高低差别。高频词的字体明显更大,而且颜色也很醒目。值得说明的是,最显眼的单词 Hacker 并不是指黑客,而是指这部剧的主角之一——哈克首相。
希望你在尝试过程中一切顺利。对自己生成的词云图满意吗?如果你不满意,也不要紧,可以挖掘 wordcloud 软件包的其他高级功能。尝试一下,看自己能不能做出这样的词云图来?
3.2 如何用 Python 3 做词云?(基础篇视频教程)
只需要花10几分钟,跟着教程完整做一遍,你就能自己用Python做出词云了。

《如何用Python做词云?》(3.1)图文版发布于2017年6月,是我数据科学系列教程中的第一篇。
目前仅简书一个平台,阅读数量就已经超过2万。

我一直不断收到读者的留言和来信,询问自己动手尝试过程中遇到的问题。
大部分的疑问,来自于Windows平台用户。
有时候,因为一个软件包选择错误,就会遇到各种报错。
错误也许是因为新版本的推出,也许是因为32位和64位平台没有正确区分……初学者如果得不到帮助,很容易迅速丧失完成的信心和兴趣。
为了让大家花费更少的时间试错,更高效地掌握词云制作基本方法,我制作了对应的视频教程。
视频以Windows平台上,基于Python 3.6的32位版本Anaconda为工作环境录制。
注意你需要先安装好Anaconda环境。安装的方法请参考我的另一份视频教程《如何安装Python运行环境Anaconda?(视频教程)》(2.2)。
我把数据和附加软件包的安装文件都打包提供了给你。可以访问这个链接来下载。
只需要花10几分钟,跟着教程完整做一遍,你就能自己用Python做出词云了。
视频链接在这里。
注意视频播放默认选择“高清”,但其实是支持1080P的。你可以在各种不同的屏幕上以最高分辨率清晰播放,以看清细节。
3.3 如何用Python做中文分词?
打算绘制中文词云图?那你得先学会如何做中文文本分词。跟着我们的教程,一步步用Python来动手实践吧。

3.3.1 需求
在《如何用Python做词云》(3.1)一文中,我们介绍了英文文本的词云制作方法。大家玩儿得可还高兴?
文中提过,选择英文文本作为示例,是因为处理起来最简单。但是很快就有读者尝试用中文文本做词云了。按照前文的方法,你成功了吗?
估计是不成功的。因为这里面缺了一个重要的步骤。
观察你的英文文本。你会发现英文单词之间采用空格作为强制分隔符。
例如:
Yes Minister is a satirical British sitcom written by Sir Antony Jay and Jonathan Lynn that was first transmitted by BBC Television between 1980 and 1984, split over three seven-episode series.
但是,中文的文本就没有这种空格区隔了。为了做词云,我们首先需要知道中文文本里面都有哪些“词”。
你可能觉得这根本不是问题——我一眼就能看出词和词之间的边界!
对,你当然可以。你可以人工处理1句、100句,甚至是10000句话。但是如果给你100万句话呢?
这就是人工处理和电脑自动化处理的最显著区别——规模。
别那么急着放弃啊,你可以用电脑来帮忙。
你的问题应该是:如何用电脑把中文文本正确拆分为一个个的单词呢?
这种工作,专业术语叫做分词。
在介绍分词工具及其安装之前,请确认你已经阅读过《如何用Python做词云》(3.1)一文,并且按照其中的步骤做了相关的准备工作,然后再继续依照本文的介绍一步步实践。
3.3.2 分词
中文分词的工具有很多种。有的免费,有的收费。有的在你的笔记本电脑里就能安装使用,有的却需要联网做云计算。
今天给大家介绍的,是如何利用Python,在你的笔记本电脑上,免费做中文分词。
我们采用的工具,名称很有特点,叫做“ 结巴分词 ”。
为什么叫这么奇怪的名字?
读完本文,你自己应该就能想明白了。
我们先来安装这款分词工具。回到你的“终端”或者“命令提示符”下。
进入你之前建立好的demo文件夹。
输入以下命令:
pip install jieba好了,现在你电脑里的Python已经知道该如何给中文分词了。
3.3.3 数据
在《如何用Python做词云》(3.1)一文中,我们使用了英剧”Yes, minister“的维基百科介绍文本。这次我们又从维基百科上找到了这部英剧对应的中文页面。翻译名称叫做《是,大臣》。
将网页正文拷贝下来之后,存入文本文件yes-minister-cn.txt,并且将这个文件移动到我们的工作目录demo下面。
好了,我们有了用于分析的中文文本数据了。
先别忙着编程序。正式输入代码之前,我们还需要做一件事情,就是下载一份中文字体文件。
请到 这个网址 下载simsun.ttf。
下载后,将这个ttf字体文件也移动到demo目录下,跟文本文件放在一起。
3.3.4 代码
在命令行下,执行:
jupyter notebook浏览器会自动开启,并且显示如下界面。
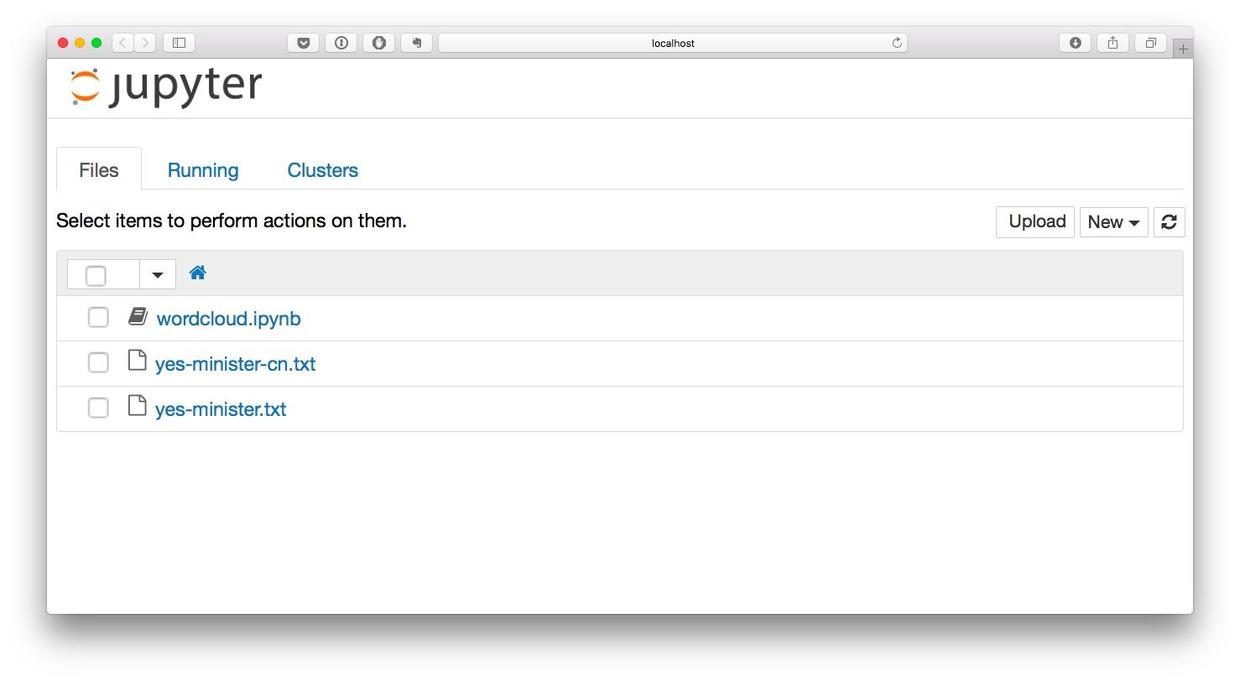
这里还有上一次词云制作时咱们的劳动成果。此时目录下多了一个文本文件,是“Yes, Minister”的中文介绍信息。
打开这个文件,浏览一下内容。
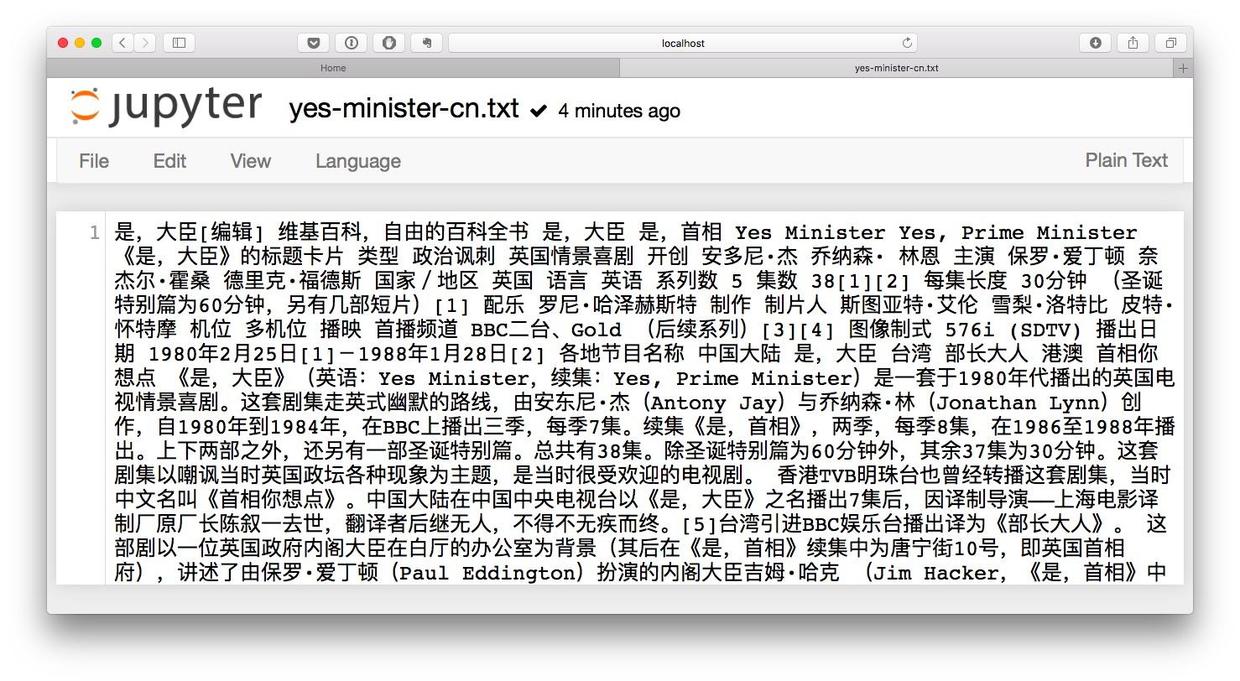
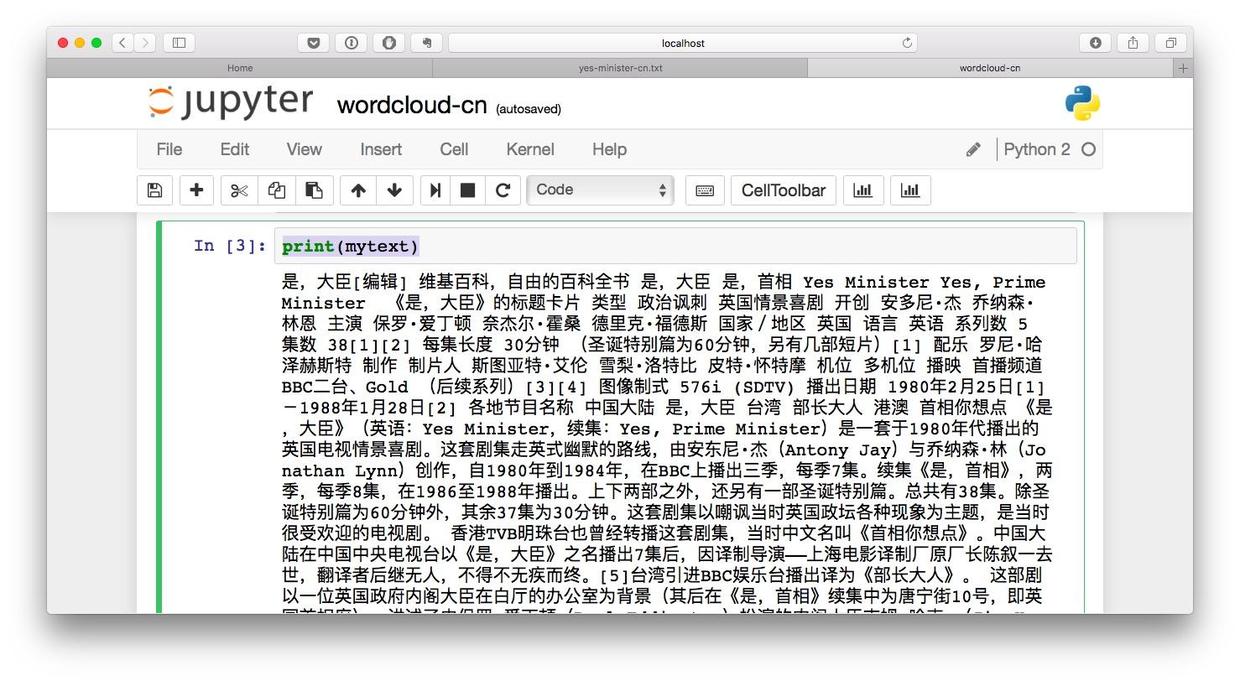
我们确认中文文本内容已经正确存储。
回到Jupyter笔记本的主页面。点击New按钮,新建一个笔记本(Notebook)。在Notebooks里面,请选择Python 2选项。
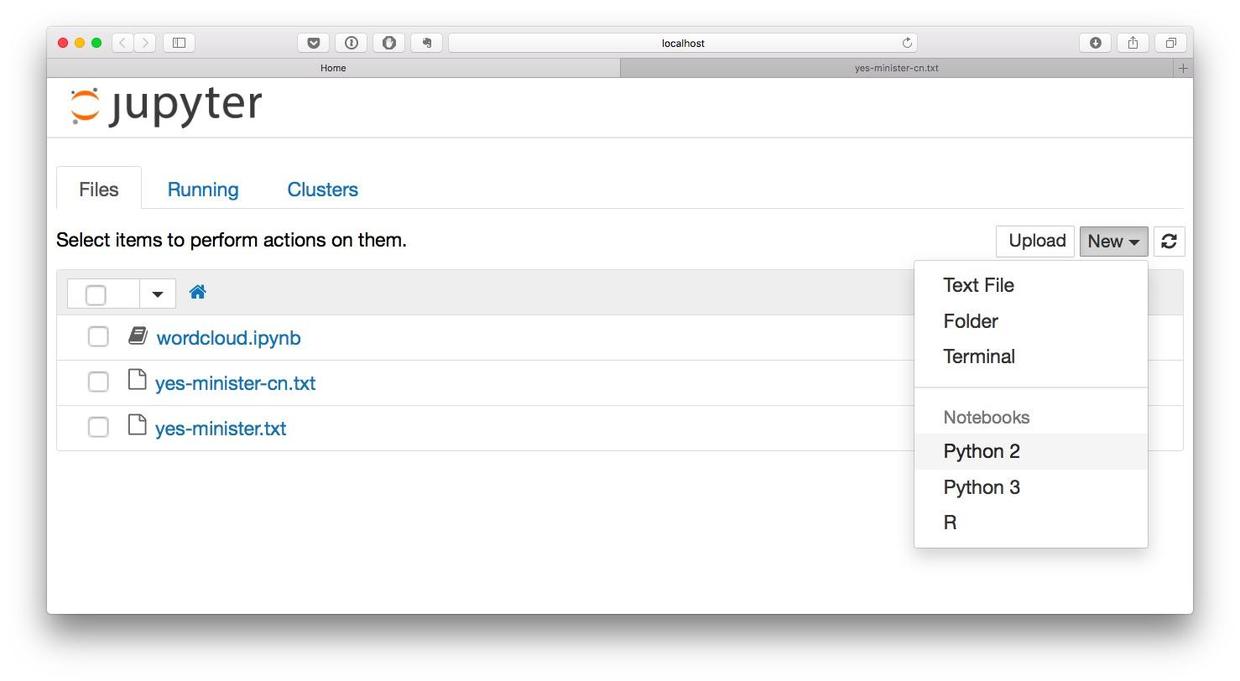
系统会提示我们输入Notebook的名称。为了和上次的英文词云制作笔记本区别,就叫它wordcloud-cn好了。
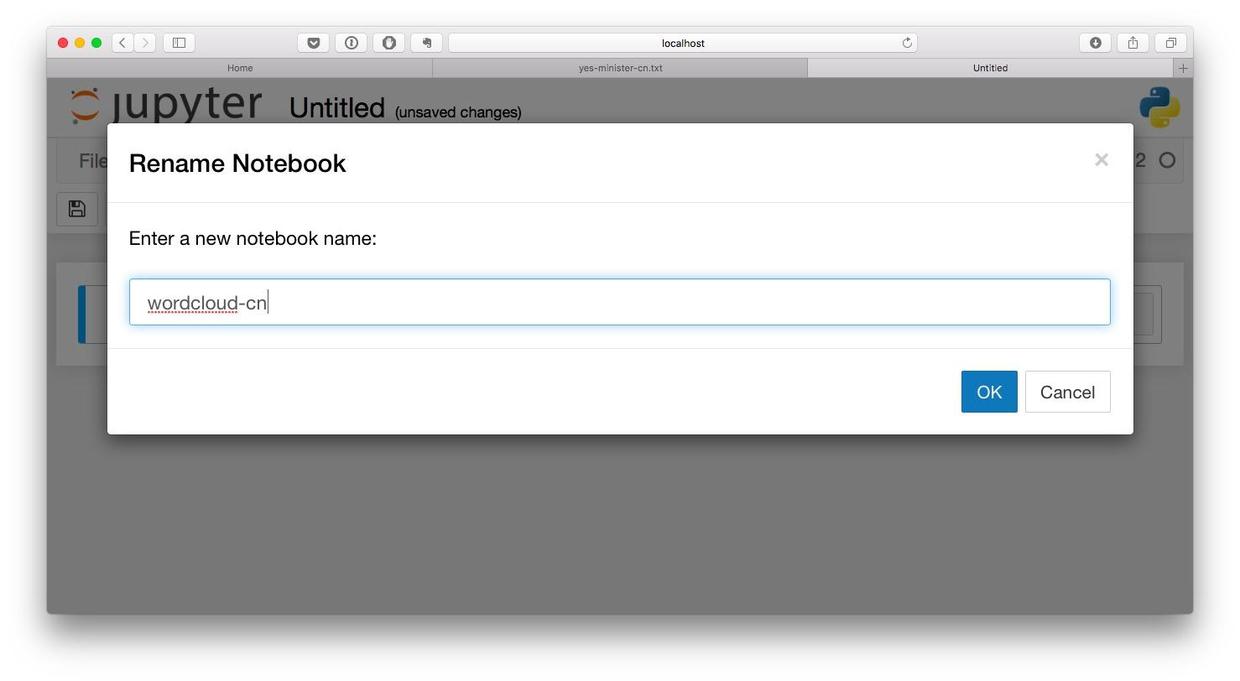
我们在网页里唯一的代码文本框里,输入以下3条语句。输入后,按Shift+Enter键执行。
filename = "yes-minister-cn.txt"
with open(filename) as f:
mytext = f.read()然后我们尝试显示mytext的内容。输入以下语句之后,还是得按Shift+Enter键执行。
print(mytext)显示的结果如下图所示。
既然中文文本内容读取没有问题,我们就开始分词吧。输入以下两行语句:
import jieba
mytext = " ".join(jieba.cut(mytext))系统会提示一些信息,那是结巴分词第一次启用的时候需要做的准备工作。忽略就可以了。
分词的结果如何?我们来看看。输入:
print(mytext)你就可以看到下图所示的分词结果了。
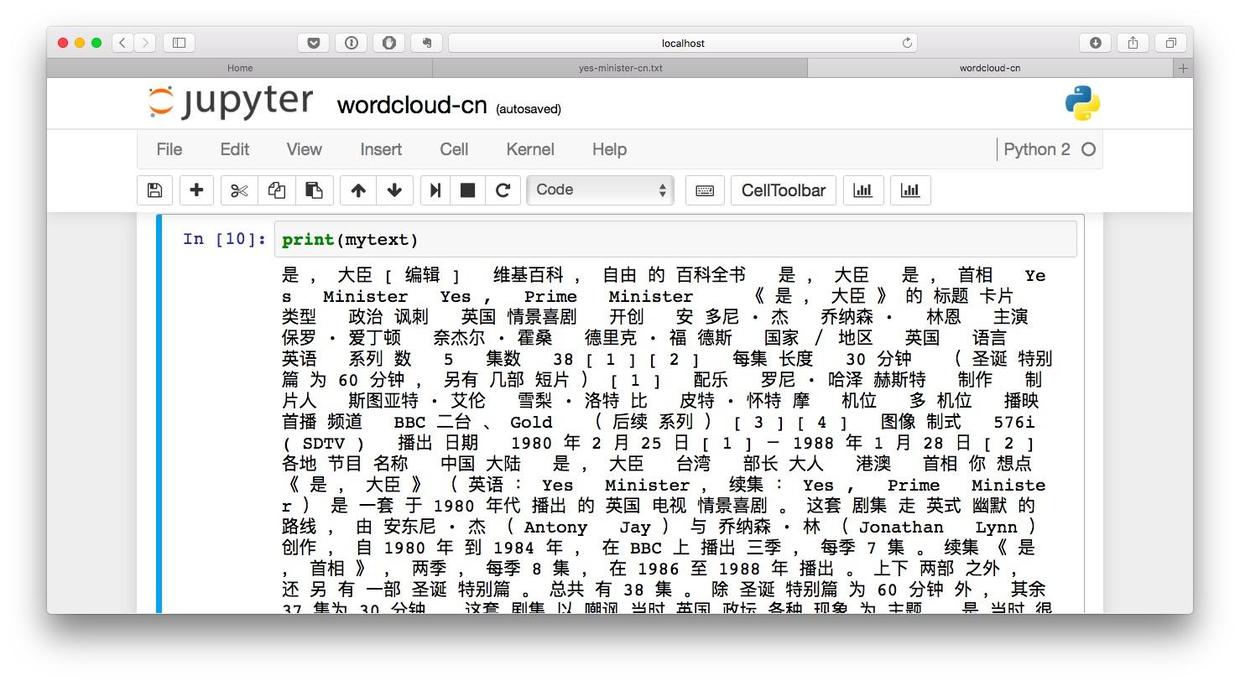
单词之间已经不再紧紧相连,而是用空格做了区隔,就如同英文单词间的自然划分一样。
你是不是迫不及待要用分词后的中文文本作词云了?
可以,输入以下语句:
from wordcloud import WordCloud
wordcloud = WordCloud().generate(mytext)
%pylab inline
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off"激动地期待着中文词云的出现?
可惜,你看到的词云是这个样子的。

你是不是非常愤怒,觉得这次又掉坑里了?
别着急,出现这样的结果,并不是分词或者词云绘制工具有问题,更不是因为咱们的教程步骤有误,只是因为字体缺失。词云绘制工具wordcloud默认使用的字体是英文的,不包含中文编码,所以才会方框一片。解决的办法,就是把你之前下载的simsun.ttf,作为指定输出字体。
输入以下语句:
from wordcloud import WordCloud
wordcloud = WordCloud(font_path="simsun.ttf").generate(mytext)
%pylab inline
import matplotlib.pyplot as plt
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")这次你看到的输出图形就变成了这个样子:

这样一来,我们就通过中文词云的制作过程,体会到了中文分词的必要性了。
这里给你留个思考题,对比一下此次生成的中文词云,和上次做出的英文词云:

这两个词云对应的文本都来自维基百科,描述的是同样一部剧,它们有什么异同?从这种对比中,你可以发现维基百科中英文介绍内容之间,有哪些有趣的规律?
3.4 本章小结
如果你喜欢本章的内容,欢迎扫描下面二维码,请我喝杯咖啡。

如果你需要答疑,咱们的问答社区在这里: