第 1 章 导读
1.1 如何高效入门数据科学?
链接散落的教程文章,做个详细的导读,助你更高效入门数据科学。

1.1.1 问题
2017年6月以来,我陆续在自己的简书专栏《玉树芝兰》里,写了一系列数据科学教程。
这源于一次研究生课编程工作坊尝试。受阎教练的创新思维训练营启发,我在课后把词云制作流程详细记录转述,分享给了大家。
没想到,这篇《如何用Python做词云?》(3.1)受到了读者们非常热烈的欢迎。
此后,一发不可收拾。
应读者的要求,结合我自己的学习、科研和教学实践,我陆续分享了更多与数据科学相关的文章。
读者越来越多,我收到的问题也愈发五花八门。
许多读者的问题,我其实都已经在其他的文章里面讲解过了,因此有时用“请参考我的另一篇文章《……》,链接为……”来答复,也帮助读者解决了问题。
在建构同理心(empathy)之前,估计我会问出这样的问题:
他们为什么不翻翻我的其他文章呢?
但现在,我能感受到他们的疑惑:
我哪里知道你写过另一篇文章?
散落在各处的文章,不容易系统学习和检索。于是我在2017年11月,把写过的数据科学系列教程汇集到了一起,做了个索引贴。
我把这个索引贴链接置于每篇新教程的末尾,并不断更新维护。
然而,这样简单的标题索引,依然无法满足许多读者的需求。
有的读者跟着教程(3.1)做完了词云,发现如果对中文文本做分析,就会出现乱码:

这时候,你该怎么办呢?
更进一步,如果你希望把词云的外边框变成指定的形状,又该如何操作?

光看标题,你可能不容易发现哪一篇文章会帮助自己解决这些问题,甚至可能会选择放弃。
我决定做这个导读。
这篇文章,不再是从任务出发,简单罗列文章标题和链接;而是从先易后难的认知习惯,重新组织文章顺序,简要介绍内容,提示可能遇到的问题。
希望对你的学习能有帮助。
1.1.2 基础环境
大部分的教程,都是在 Python 运行环境 Jupyter Notebook 下运行和演示。
安装这个运行环境,最简单的方法,就是安装 Anaconda 集成套件。
请先收看这个视频教程《如何安装Python运行环境Anaconda?(视频教程)》(2.2),自己尝试安装Anaconda,运行起第一个Jupyter Notebook,输出一个“Hello world!”出来。
有了这个基础,你就可以尝试不同的数据科学任务了。
我的建议是先做词云。
因为简单,而且有成就感。
1.1.3 词云
跟着图文教程《如何用Python做词云?》(3.1)一步步执行。用几行Python代码,你就可以做出这样的词云来。

我还专门把它升级做成了视频教程《如何用Python做词云?(基础篇视频教程)》(3.2),供你观看。
参看这篇文章《如何用Python做中文分词?》(3.3),你就能做出这样的中文词云。

如果你希望改变词云边框外观,就参考这篇文章《Python编程遇问题,文科生怎么办?》(10.1)的最后部分。
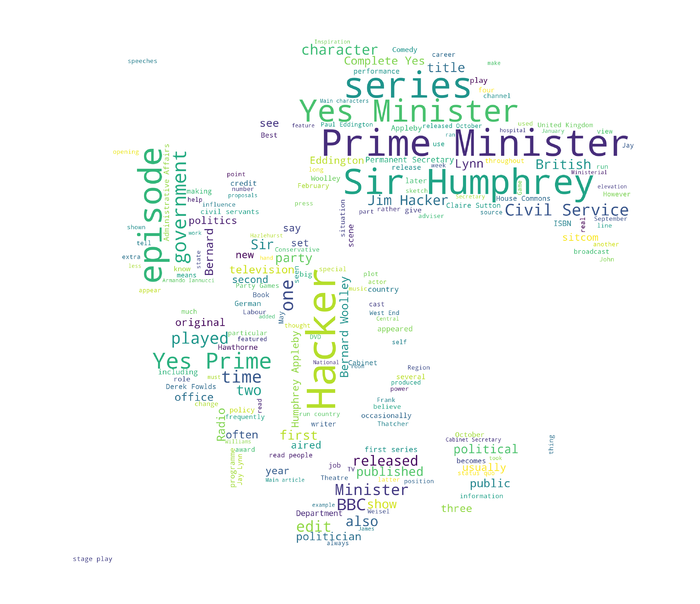
到这里,你已掌握Python运行环境安装、文本文件读取、常见软件包调用、可视化分析与结果呈现和中文分词等基本功夫了。
回头望去,是不是成就感爆棚呢?
1.1.4 虚拟环境
细心的你,可能已经发现,图文教程和视频内容并不完全一致。
视频教程目前全系列采用Python 3.6版本,未来得及重新整理的词云图文教程,展示的确实2.7版本Python。
为什么呢?
因为随着技术的发展,Python已经逐步要过渡到3.X版本了。
许多第三方软件包都已经宣布了时间表,尽快支持3.X,放弃2.X版本的支持。
才半年,你就可以感受到技术、社群和环境的变化之快。
可是目前某些软件包,依然只能支持2.X版本Python。虽然这样的软件包越来越少了。
你需要暂时做个“两栖动物”,千万不要束缚自己,因为“立场原因”固执着不肯用低版本Python。这样吃亏的是自己。
怎样才能做个“两栖动物”呢?
办法之一,就是使用Anaconda的虚拟环境。可以参考《如何在Jupyter Notebook中使用Python虚拟环境?》。
你初始安装版本针对Python 2.7的Anaconda,并不妨碍你快速建立一个3.6版本Python的虚拟环境。
有了这个秘籍,你就可以在不同版本的Python之间左右逢源,游刃有余了。
1.1.5 自然语言处理
下一步,我们来尝试自然语言处理(Natural Language Processing, NLP)。
情感分析,是NLP在许多社会科学领域热门的应用之一。
《如何用Python做情感分析?》(5.1)这篇文章,分别从英文和中文两个案例,分别采用不同的软件包,针对性地解决应用需求。
你只需要几行代码,就能让Python告诉你情感的取向。是不是很厉害?
有了情感分析做基础,你可以尝试增加维度,对更大体量的数据做分析。
增加时间维度,就可以持续分析变化的舆情。
《如何用Python做舆情时间序列可视化?》(5.2)这篇文章,一步步指引你在时间刻度上可视化情感分析结果:
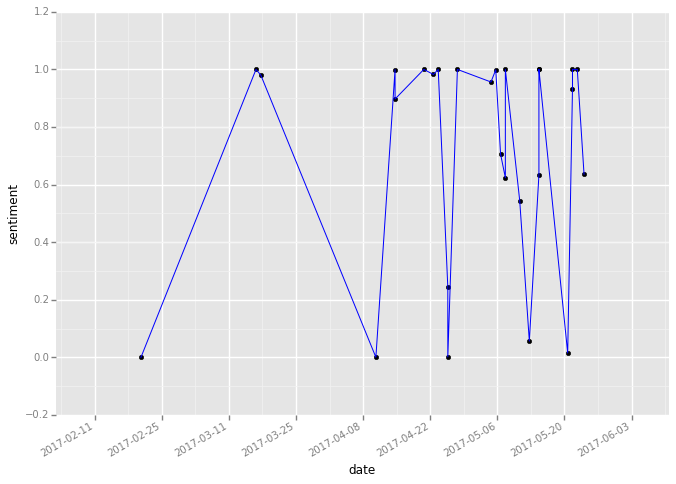
这图难看了一些。
不过我们需要容忍自己起步时的笨拙,不断迭代与精进。
希望一出手就满分,对极少数天才,确实无非是日常。
但对大多数人,是拖延症的开始。
你可能迫不及待,尝试换自己的数据做时间序列可视化分析。
不过日期数据如果与样例有出入,可能会出现问题。
这时候,不要慌,请参考《Python编程遇问题,文科生怎么办?》(10.1)的第二部分,其中有详细的错误原因分析与对策展示。
看过后,分析结果图也会迭代成这个样子:
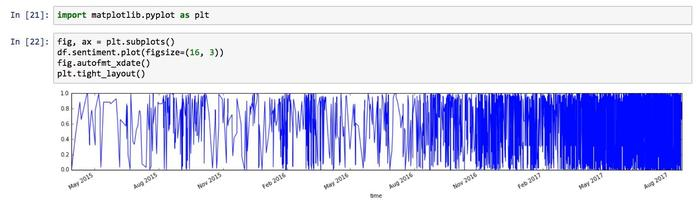
到这里,你对情感分析有点儿感觉了吧?
如果你不打算使用第三方提供的情感分类算法,打算自己动手训练一个更为精确的情感分类模型,可以参考《如何用Python和机器学习训练中文文本情感分类模型?》(6.3)一文。
刚刚这些情感分析,其实只是极性分析(正面vs负面)。但是我们都知道,人的情感其实是多方面共同构成的。

如何从文本中,分解出多维度的情感特征变化呢?
《如何用Python和R对《权力的游戏》故事情节做情绪分析?》(5.3)一文分析了《权力的游戏》中某一集剧本,你会获得这样的结果:
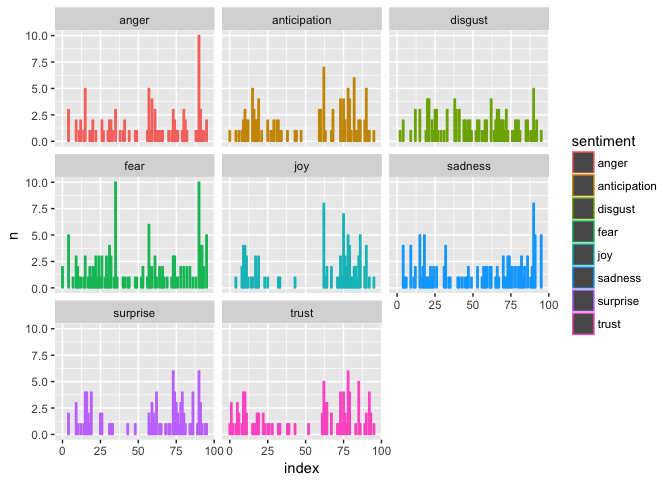
如果你是《权力的游戏》剧迷,请告诉我,这张图描绘的是哪一集?
先猜猜看,然后再打开文章(5.3),跟结尾做对比。
这篇文章的可视化分析部分,用的是R。
R也是数据科学领域一个非常受欢迎的开源工具。它的通用性和热度可能不如Python(毕竟Python除了数据科学,还能干许多其他的事儿),但是因为有统计学界诸多科学家的拥护和添砖加瓦,因此有非常好的一套生态系统。
如果你希望对单一长文本提取若干重要关键词,该怎么办呢?
请你阅读《如何用Python提取中文关键词?》(5.4)一文。它采用词汇向量化、TextRank等成熟的关键词提取算法来解决问题。
1.1.6 课间答疑
随着知识、技能和经验的积累,你的疑问可能也逐渐增多了吧?
有的同学对这种教学方式有疑问——案例挺有意思,也很简单易学,但是怎么把它用到我自己的学习、工作和科研中呢?
我为你写了一篇答疑说明,叫做《文科生如何高效学数据科学?》(10.2)。文中提到了以下几个方面:
- 如何指定目标?
- 如何确定深度?
- 如何加强协作?
提到协作,就不能不说Github这个全球最大的开源代码托管仓库了。
在咱们的教程里,也多次使用Github来存储代码和数据,以便你能够重复运行教程中的结果。
《如何高效入门Github?》(10.3)一文提供了文档和视频教程资源,希望能对你掌握这个数据富矿提供帮助。
不少读者在这个阶段常提出这个问题:老师,想学Python,推荐本书呗。
看来,你已经明白了Python的好处了,对吧?
《如何高效学Python?》(10.4)帮助你给自己的学习特性做出了分类。根据分类的结果,你可以选择更适合自己的学习路径。
推荐的教材,不仅包括书籍,还包括MOOC。希望这种充满互动的教学方式,对你入门数据科学有帮助。
1.1.7 机器学习
你可以尝试做更进一步的分析了。
例如机器学习(Machine Learning)。

机器学习的妙用,就是在那些你(其实是人类)无法准确描述解决步骤的问题上,让机器通过大量案例(数据)的观察、试错,构建一个相对有用的模型,来自动化处理问题,或者为人类的决策提供辅助依据。
大体上,机器学习主要分为3类:
- 监督学习(Supervised Learning)
- 非监督学习(Unsupervised Learning)
- 强化学习(Reinforcement Learning)
目前本专栏介绍了前两类的一些例子。
监督学习与非监督学习最大的差别,在于数据。
数据已有标注(一般是人工赋予标签),一般用监督学习;
数据没有标注,一般只能用非监督学习。
监督学习部分,我们举了分类(classification)任务的例子。
《贷还是不贷:如何用Python和机器学习帮你决策?》(6.1)中的案例,选择了贷款审批辅助决策。
具体的机器学习算法,是决策树(decision tree)。
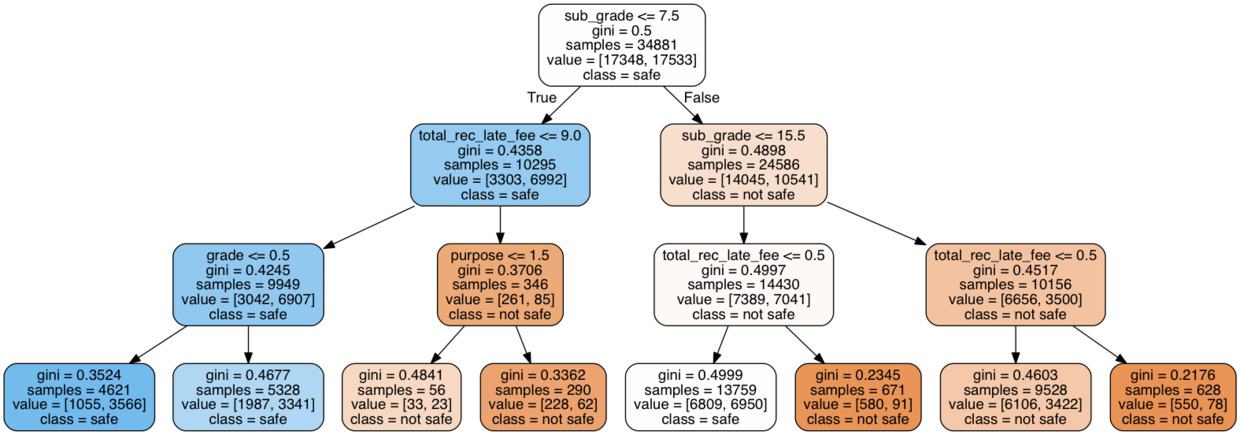
有同学表示,绘制这棵决策树的时候,遇到了问题。
这主要是因为运行环境的差异和依赖工具的安装没有正确完成。
《Python编程遇问题,文科生怎么办?》(10.1)的第一部分,对这些问题做了详细的阐述,请根据列出的步骤尝试解决。
不仅如此,这篇文章(10.1)展示给你了一种任务导向的学习方式,期望它可以提升你Python语言和数据科学学习效率。
非监督学习部分,我们讲述了《如何用Python从海量文本抽取主题?》(6.2)。
文中用一种叫做LDA的聚类(clustering)方法,帮你从可能感兴趣的浩如烟海文档中,提取出可能的类别,对应的主要关键词,并且做可视化处理。
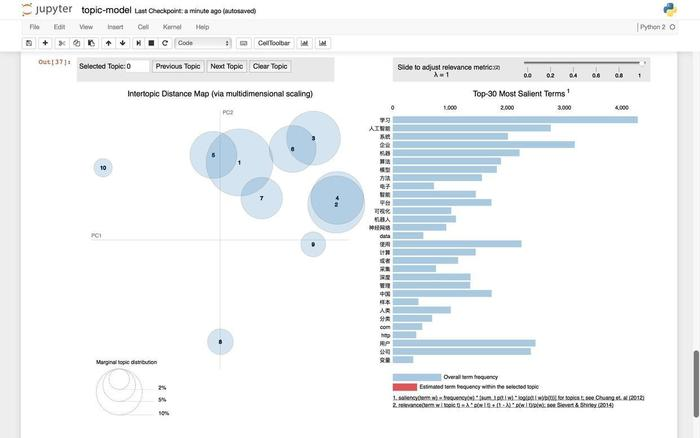
文中提及了停用词(stopwords)的处理,但是没有给出中文停用词的具体应用方法。
《如何用Python和机器学习训练中文文本情感分类模型?》(6.3)一文中,我不仅对停用词处理方式进行了详细的介绍,而且把监督学习Naive Bayes模型应用于情感分析,手把手教你如何训练自己的情感分类模型。
1.1.8 深度学习
深度学习,指用深度神经网络(Deep Neural Network)进行机器学习。
相对于传统机器学习方法,它使用的模型结构更为复杂,需要更多的数据支持,并且训练起来要消耗更多的计算资源和时间。
常见的深度学习应用,包括语音识别、计算机视觉和机器翻译等。
当然,新闻里面最爱提的,是下围棋这个事儿:

我们提供的案例,没有那么挑战人类智能极限,而是跟日常工作和生活更加相关。
《如何用Python和深度神经网络发现即将流失的客户?》(7.1)为你介绍了深度神经网络的基本结构。
这篇文章通过客户流失预警的例子,讲述了使用前馈神经网络进行监督式学习的基本样例。
实际操作部分,我们采用Tensorflow作为后端,tflearn作为前段,构造你自己的第一个深度神经网络。
《如何用Python和深度神经网络发现即将流失的客户?》(7.1)一文末尾还为你提供了进一步掌握深度学习的相关资源。
如果你需要安装Tensorflow深度学习框架(Google出品哦),欢迎先阅读这篇《Tensorflow执行pip升级安装的坑》。
有了深度神经网络的基础知识,我们折腾计算机视觉。
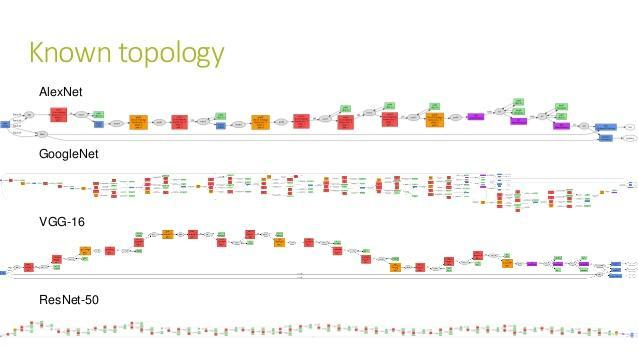
《如何用Python和深度神经网络识别图像?》(7.2)一文,举例分类哆啦a梦和瓦力这两个机器人的各种花式图像集合。
卷积神经网络(Convolutional Neural Network, CNN)这时就大放异彩了。
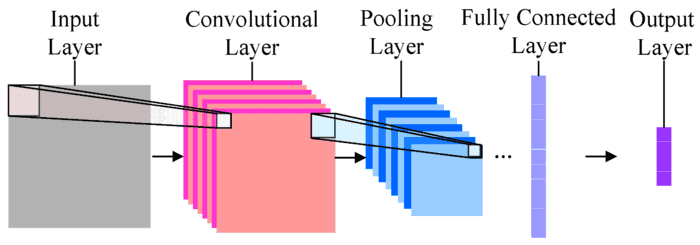
这篇文章,帮你分析了卷积神经网络中,不同层次(Layer)的作用。
我们尽量避免用公式,而是用图像、动图和平实简洁的语言描述来为你解释概念。
我们使用的深度学习框架,是苹果的TuriCreate。你会调用一个非常深层次的卷积神经网络,帮我们迁(tou)移(ji)学(qu)习(qiao),用很少的训练数据,获得非常高的分类准确率。
有的读者自己尝试,测试集准确率居然达到100%(视运行环境不同,有差异),大呼过瘾。可同时又觉得不可思议。
为了解释这种“奇迹”,同时解答读者“如何在私有数据集上以图搜图”的疑问,我写了《如何用Python和深度神经网络寻找近似图片?》(7.3)。
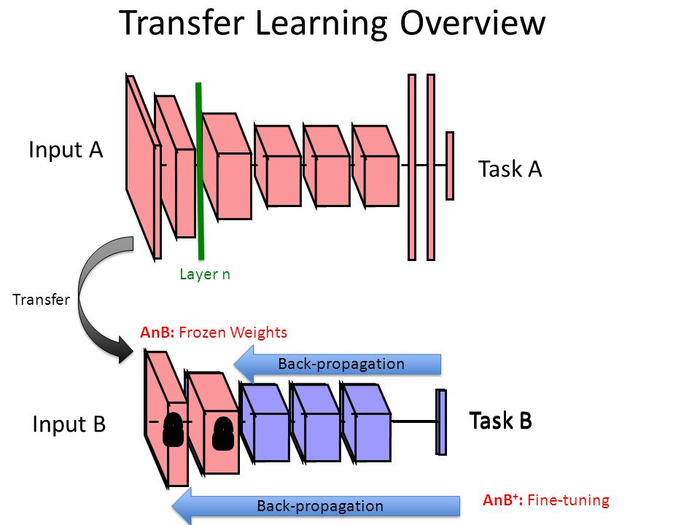
希望读过此文,你对迁移学习(Transfer Learning)有了更深入的认识。
如果这两篇文章学完,你对卷积神经网络的基础知识依然不是很清晰,也没关系,因为我的研究生们遭遇了同样的问题。
为此,我专门录制了一段讲解答疑视频(7.4)。

这段视频(7.4)里,我主要谈及了以下几个方面:
- 深度神经网络的基本结构;
- 神经元的计算功能实现;
- 如何对深度神经网络做训练;
- 如何选择最优的模型(超参数调整);
- 卷积神经网络基本原理;
- 迁移学习的实现;
- 疑问解答。
希望看过之后,你再从论文里读到计算机视觉的神经网络模型,就可以游刃有余了。
另一批作者又来发问了:
老师,我用Windows,死活就是装不上TuriCreate,可怎么办?
我替他们着急的时候,恰好找到了一个宝贝。于是写了《如何免费云端运行Python深度学习框架?》(8.1)。
免费使用GPU,用极为简易的操作,就可以在Google云端Linux主机上部署和执行苹果深度学习框架……
听着是不是像做梦啊?
感谢Google这家为人类知识积累做出贡献的企业。

1.1.9 数据获取
学完深度学习之后,你会发现自己变成了“数据饥渴”症患者。
因为如果没有大量的数据,就无法支撑你的深度神经网络。
如何获取数据呢?
我们先要区分数据的来源。
数据来源很多。但是对于研究者来说,网络数据和文献数据比较常用。
目前主流(合法)的网络数据方法,主要分为3类:
- 开放数据集下载;
- API读取;
- 爬虫爬取(Crawling)。
《如何用Python读取开放数据?》(9.1)一文中,我为你讲解了如何把开放数据集下载并且在Python中使用。
这篇文章介绍了常见的CSV/Excel, JSON和XML等开放数据文件格式的读取、初步处理和可视化方法与流程。
如果没有开放数据集整理好供你下载,网站只提供API接口,你该怎么办呢?
《如何用R和API免费获取Web数据?》(9.2)一文,我们使用R读取维基百科API,获得指定条目的访问数量记录,并且做了可视化。
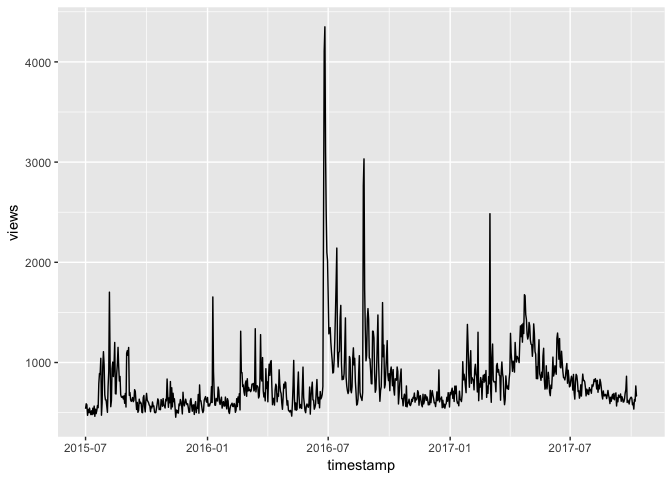
如果没有人为你整理好数据,网站也没有开放API给你,那你就得“直接上大锤”了。
《如何用Python爬数据?(一)网页抓取》(9.4)一文为你介绍了非常人性化、易用的网页抓取软件包 requests_html,你可以尝试抓取网页内的指定类型链接。

文献数据可能存储为各种格式,但其中pdf格式较为常见。
应诸多读者的要求,我写了《如何用Python批量提取PDF文本内容?》(9.6)。

你可以批量提取pdf文档的文本内容,并且进行各种分析。
文中的分析相对简单,我们只是统计了文档字符数量。
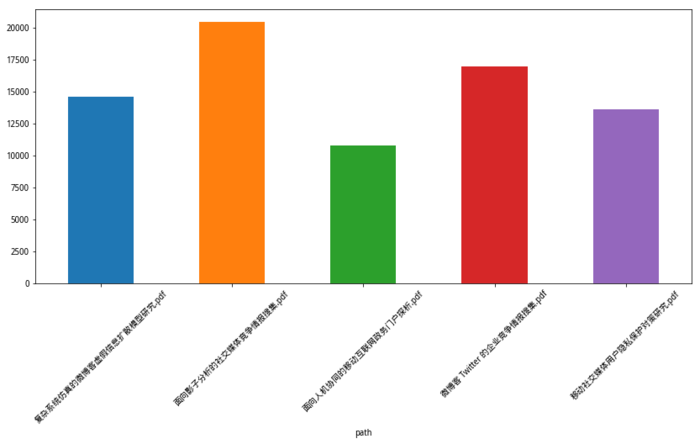
但是发挥想象力,你可能会做出非常有价值的分析结果。
希望这些文章可以帮助你高效获得优质数据,支撑起你自己的机器学习模型。