第 5 章 自然语言处理
5.1 如何用Python做情感分析?
商品评论挖掘、电影推荐、股市预测……情感分析大有用武之地。本文帮助你一步步用Python做出自己的情感分析结果,难道你不想试试看?

5.1.1 需求
如果你关注数据科学研究或是商业实践,“情感分析”(sentiment analysis)这个词你应该不陌生吧?
维基百科上,情感分析的定义是:
文本情感分析(也称为意见挖掘)是指用自然语言处理、文本挖掘以及计算机语言学等方法来识别和提取原素材中的主观信息。
听着很高大上,是吧?如果说得具体一点呢?
给你一段文本,你就可以用情感分析的自动化方法获得这一段内容里包含的情感色彩是什么。
神奇吧?
情感分析不是炫技工具。它是闷声发大财的方法。早在2010年,就有学者指出,可以依靠Twitter公开信息的情感分析来预测股市的涨落,准确率高达87.6%!
在这些学者看来,一旦你能够获得大量实时社交媒体文本数据,且利用情感分析的黑魔法,你就获得了一颗预测近期投资市场趋势的水晶球。

这种用数据科学碾压竞争者的感受,是不是妙不可言啊?
大数据时代,我们可以获得的文本数据实在太多了。仅仅是大众点评、豆瓣和亚马逊上海量的评论信息就足够我们挥锹抡镐,深挖一通了。
你是不是疑惑,这么高深的技术,自己这个非计算机专业的文科生,如何才能应用呢?
不必担心。从前情感分析还只是实验室或者大公司的独门秘籍。现在早已飞入寻常百姓家。门槛的降低使得我们普通人也可以用Python的几行代码,完成大量文本的情感分析处理。
是不是摩拳擦掌,打算动手尝试了?
那我们就开始吧。
5.1.2 安装
为了更好地使用Python和相关软件包,你需要先安装Anaconda套装。详细的流程步骤请参考《 如何用Python做词云(3.1) 》一文。
到你的系统“终端”(macOS, Linux)或者“命令提示符”(Windows)下,进入我们的工作目录demo,执行以下命令。
pip install snownlp
pip install -U textblob
python -m textblob.download_corpora好了,至此你的情感分析运行环境已经配置完毕。
在终端或者命令提示符下键入:
jupyter notebook你会看到目录里之前的那些文件,忽略他们就好。
好了,下面我们就可以愉快地利用Python来编写程序,做文本情感分析了。
5.1.3 英文
我们先来看英文文本的情感分析。
这里我们需要用到的是 TextBlob包 。
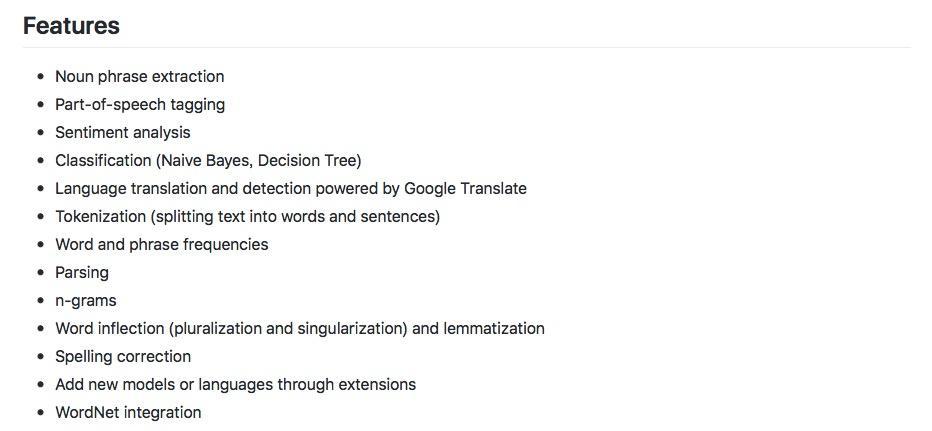
其实,从上图可以看出,这个包可以做许许多多跟文本处理相关的事情。本文我们只专注于情感分析这一项。其他功能以后有时间我们再介绍。
我们新建一个Python 2笔记本,并且将其命名为“sentiment-analysis”。
先准备一下英文文本数据。
text = "I am happy today. I feel sad today."这里我们输入了两句话,把它存入了text这个变量里面。学了十几年英语的你,应该立即分辨出这两句话的情感属性。第一句是“我今天很高兴”,正面;第二句是“我今天很沮丧”,负面。
下面我们看看情感分析工具TextBlob能否正确识别这两句话的情感属性。
首先我们呼唤TextBlob出来。
from textblob import TextBlob
blob = TextBlob(text)
blob按Shift+Enter执行,结果好像只是把这两句话原封不动打印了出来而已嘛。

别着急,TextBlob已经帮我们把一段文本分成了不同的句子。我们不妨看看它的划分对不对。
blob.sentences执行后输出结果如下:

划分无误。可是你能断句有啥了不起?!我要情感分析结果!
你怎么这么着急啊?一步步来嘛。好,我们输出第一句的情感分析结果:
blob.sentences[0].sentiment执行后,你会看到有意思的结果出现了:

情感极性0.8,主观性1.0。说明一下,情感极性的变化范围是[-1, 1],-1代表完全负面,1代表完全正面。
既然我说自己“高兴”,那情感分析结果是正面的就对了啊。
趁热打铁,我们看第二句。
blob.sentences[1].sentiment执行后结果如下:

“沮丧”对应的情感极性是负的0.5,没毛病!
更有趣的是,我们还可以让TextBlob综合分析出整段文本的情感。
blob.sentiment执行结果是什么?
给你10秒钟,猜猜看。
不卖关子了,是这样的:

你可能会觉得没有道理。怎么一句“高兴”,一句“沮丧”,合并起来最后会得到正向结果呢?
首先不同极性的词,在数值上是有区别的。我们应该可以找到比“沮丧”更为负面的词汇。而且这也符合逻辑,谁会这么“天上一脚,地下一脚”矛盾地描述自己此时的心情呢?
5.1.4 中文
试验了英文文本情感分析,我们该回归母语了。毕竟,互联网上我们平时接触最多的文本,还是中文的。
中文文本分析,我们使用的是 SnowNLP包 。这个包跟TextBlob一样,也是多才多艺的。

我们还是先准备一下文本。这次我们换2个形容词试试看。
text = u"我今天很快乐。我今天很愤怒。"注意在引号前面我们加了一个字母u,它很重要。因为它提示Python,“这一段我们输入的文本编码格式是Unicode,别搞错了哦”。至于文本编码格式的细节,有机会我们再详细聊。
好了,文本有了,下面我们让SnowNLP来工作吧。
from snownlp import SnowNLP
s = SnowNLP(text)我们想看看SnowNLP能不能像TextBlob一样正确划分我们输入的句子,所以我们执行以下输出:
for sentence in s.sentences:
print(sentence)执行的结果是这样的:

好的,看来SnowNLP对句子的划分是正确的。
我们来看第一句的情感分析结果吧。
s1 = SnowNLP(s.sentences[0])
s1.sentiments执行后的结果是:

看来“快乐”这个关键词真是很能说明问题。基本上得到满分了。
我们来看第二句:
s2 = SnowNLP(s.sentences[1])
s2.sentiments执行结果如下:

这里你肯定发现了问题——“愤怒”这个词表达了如此强烈的负面情感,为何得分依然是正的?
这是因为SnowNLP和textblob的计分方法不同。SnowNLP的情感分析取值,表达的是“这句话代表正面情感的概率”。也就是说,对“我今天很愤怒”一句,SnowNLP认为,它表达正面情感的概率很低很低。
这么解释就合理多了。
5.1.5 小结
学会了基本招式,很开心吧?下面你可以自己找一些中英文文本来实践情感分析了。
但是你可能很快就会遇到问题。例如你输入一些明确的负面情绪语句,得到的结果却很正面。
不要以为自己又被忽悠了。我来解释一下问题出在哪儿。
首先,许多语句的情感判定需要上下文和背景知识,因此如果这类信息缺乏,判别正确率就会受到影响。这就是人比机器(至少在目前)更强大的地方。
其次,任何一个情感分析工具,实际上都是被训练出来的。训练时用的是什么文本材料,直接影响到模型的适应性。
例如SnowNLP,它的训练文本就是评论数据。因此,你如果用它来分析中文评论信息,效果应该不错。但是,如果你用它分析其他类型的文本——例如小说、诗歌等,效果就会大打折扣。因为这样的文本数据组合方式,它之前没有见过。
解决办法当然有,就是用其他类型的文本去训练它。见多识广,自然就“见惯不怪”了。至于该如何训练,请和相关软件包的作者联系咨询。
5.2 如何用Python做舆情时间序列可视化?

如何批量处理评论信息情感分析,并且在时间轴上可视化呈现?舆情分析并不难,让我们用Python来实现它吧。
5.2.1 痛点
你是一家连锁火锅店的区域经理,很注重顾客对餐厅的评价。从前,你苦恼的是顾客不爱写评价。最近因为餐厅火了,分店越来越多,写评论的顾客也多了起来,于是你新的痛苦来了——评论太多了,读不过来。
从我这儿,你了解到了情感分析(5.1)这个好用的自动化工具,一下子觉得见到了曙光。
你从某知名点评网站上,找到了自己一家分店的页面,让助手把上面的评论和发布时间数据弄下来。因为助手不会用爬虫,所以只能把评论从网页上一条条复制粘贴到Excel里。下班的时候,才弄下来27条。(注意这里我们使用的是真实评论数据。为了避免对被评论商家造成困扰,统一将该餐厅的名称替换为“A餐厅”。特此说明。)
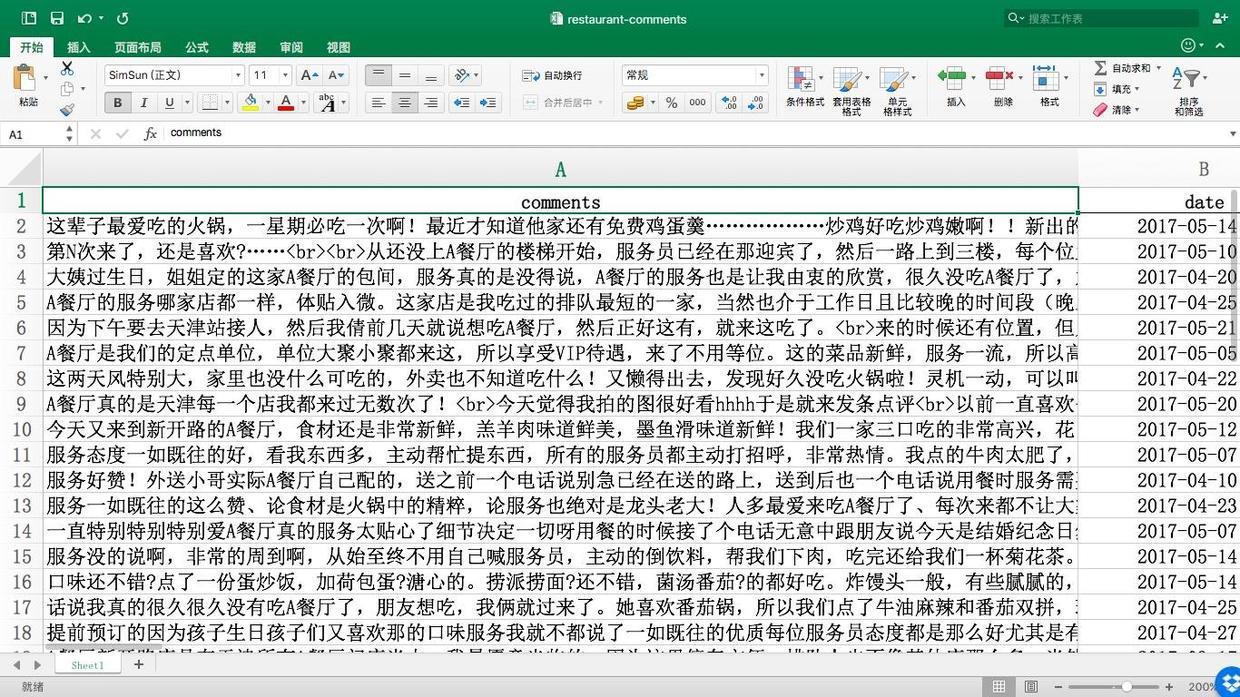
好在你只是想做个试验而已,将就了吧。你用我之前介绍的中文信息情感分析工具,依次得出了每一条评论的情感数值。刚开始做出结果的时候,你很兴奋,觉得自己找到了舆情分析的终极利器。
可是美好的时光总是短暂的。很快你就发现,如果每一条评论都分别运行一次程序,用机器来做分析,还真是不如自己挨条去读省事儿。
怎么办呢?
5.2.2 序列
办法自然是有的。我们可以利用《贷还是不贷:如何用Python和机器学习帮你决策?》(6.1)一文介绍过的数据框,一次性处理多个数据,提升效率。
但是这还不够,我们还可以把情感分析的结果在时间序列上可视化出来。这样你一眼就可以看见趋势——近一段时间里,大家是对餐厅究竟是更满意了,还是越来越不满意呢?
我们人类最擅长处理的,就是图像。因为漫长的进化史逼迫我们不断提升对图像快速准确的处理能力,否则就会被环境淘汰掉。因此才会有“一幅图胜过千言万语”的说法。

5.2.3 准备
首先,你需要安装Anaconda套装。详细的流程步骤请参考《 如何用Python做词云(3.1) 》一文。
助手好不容易做好的Excel文件restaurant-comments.xlsx,请从这里下载。
用Excel打开,如果一切正常,请将该文件移动到咱们的工作目录demo下。
因为本例中我们需要对中文评论作分析,因此使用的软件包为SnowNLP。情感分析的基本应用方法,请参考《如何用Python做情感分析?》(5.1)。
到你的系统“终端”(macOS, Linux)或者“命令提示符”(Windows)下,进入我们的工作目录demo,执行以下命令。
pip install snownlp
pip install ggplot运行环境配置完毕。
在终端或者命令提示符下键入:
jupyter notebook
如果Jupyter Notebook正确运行,下面我们就可以开始编写代码了。
5.2.4 代码
我们在Jupyter Notebook中新建一个Python 2笔记本,起名为time-series。
首先我们引入数据框分析工具Pandas,简写成pd以方便调用。
接着,读入Excel数据文件:
我们看看读入内容是否完整:
结果如下:
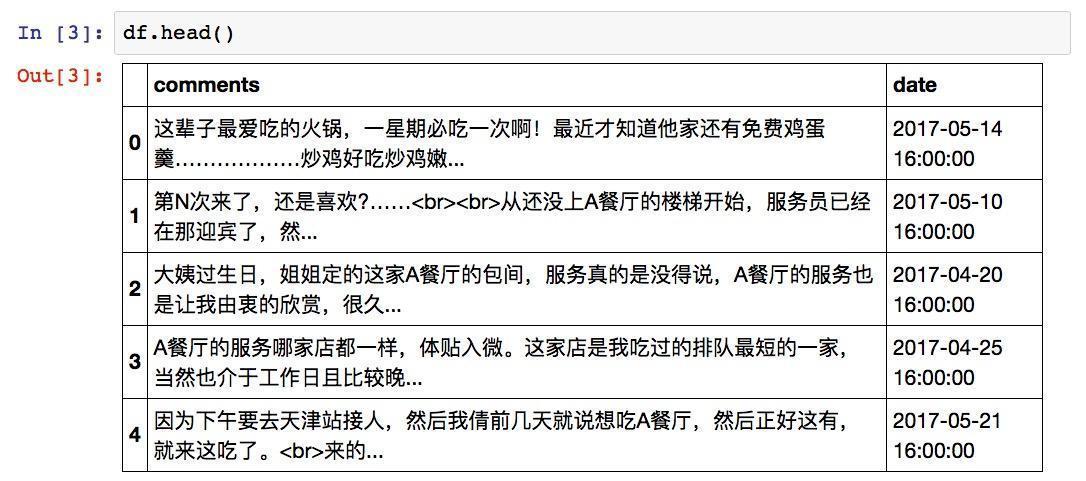
注意这里的时间列。如果你的Excel文件里的时间格式跟此处一样,包含了日期和时间,那么Pandas会非常智能地帮你把它识别为时间格式,接着往下做就可以了。
反之,如果你获取到的时间只精确到日期,例如“2017-04-20”这样,那么Pandas只会把它当做字符串,后面的时间序列分析无法使用字符串数据。解决办法是在这里加入以下两行代码:
这样,你就获得了正确的时间数据了。
确认数据完整无误后,我们要进行情感分析了。先用第一行的评论内容做个小实验。
然后我们调用SnowNLP情感分析工具。
显示一下SnowNLP的分析结果:
结果为:
0.6331975099099649情感分析数值可以正确计算。在此基础上,我们需要定义函数,以便批量处理所有的评论信息。
然后,我们利用Python里面强大的apply语句,来一次性处理所有评论,并且将生成的情感数值在数据框里面单独存为一列,称为sentiment。
我们看看情感分析结果:

新的列sentiment已经生成。我们之前介绍过,SnowNLP的结果取值范围在0到1之间,代表了情感分析结果为正面的可能性。通过观察前几条数据,我们发现点评网站上,顾客对这家分店评价总体上还是正面的,而且有的评论是非常积极的。
但是少量数据的观察,可能造成我们结论的偏颇。我们来把所有的情感分析结果数值做一下平均。使用mean()函数即可。
结果为:
0.7114015318571119结果数值超过0.7,整体上顾客对这家店的态度是正面的。
我们再来看看中位数值,使用的函数为median()。
结果为:
0.9563139038622388我们发现了有趣的现象——中位数值不仅比平均值高,而且几乎接近1(完全正面)。
这就意味着,大部分的评价一边倒表示非常满意。但是存在着少部分异常点,显著拉低了平均值。
下面我们用情感的时间序列可视化功能,直观查看这些异常点出现在什么时间,以及它们的数值究竟有多低。
我们需要使用ggplot绘图工具包。这个工具包原本只在R语言中提供,让其他数据分析工具的用户羡慕得流口水。幸好,后来它很快被移植到了Python平台。
我们从ggplot中引入绘图函数,并且让Jupyter Notebook可以直接显示图像。
这里可能会报一些警告信息。没有关系,不理会就是了。
下面我们绘制图形。这里你可以输入下面这一行语句。
你可以看到ggplot的绘图语法是多么简洁和人性化。只需要告诉Python自己打算用哪个数据框,从中选择哪列作为横轴,哪列作为纵轴,先画点,后连线,并且可以指定连线的颜色。然后,你需要让X轴上的日期以何种格式显示出来。所有的参数设定跟自然语言很相似,直观而且易于理解。
执行后,就可以看到结果图形了。
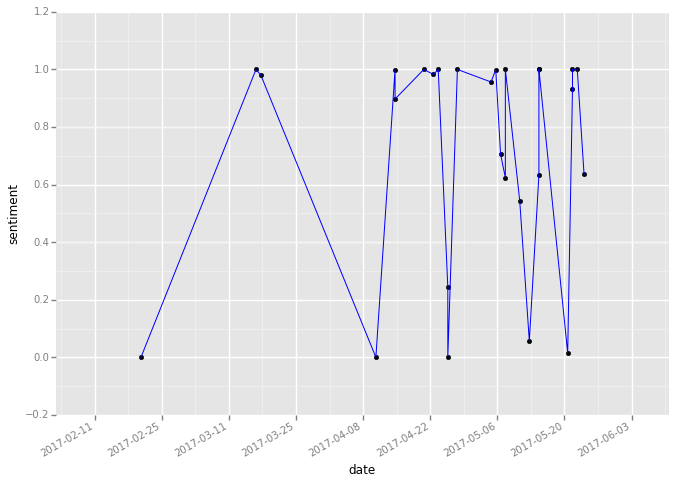
在图中,我们发现许多正面评价情感分析数值极端的高。同时,我们也清晰地发现了那几个数值极低的点。对应评论的情感分析数值接近于0。这几条评论,被Python判定为基本上没有正面情感了。
从时间上看,最近一段时间,几乎每隔几天就会出现一次比较严重的负面评价。
作为经理,你可能如坐针毡。希望尽快了解发生了什么事儿。你不用在数据框或者Excel文件里面一条条翻找情感数值最低的评论。Python数据框Pandas为你提供了非常好的排序功能。假设你希望找到所有评论里情感分析数值最低的那条,可以这样执行:
结果为:
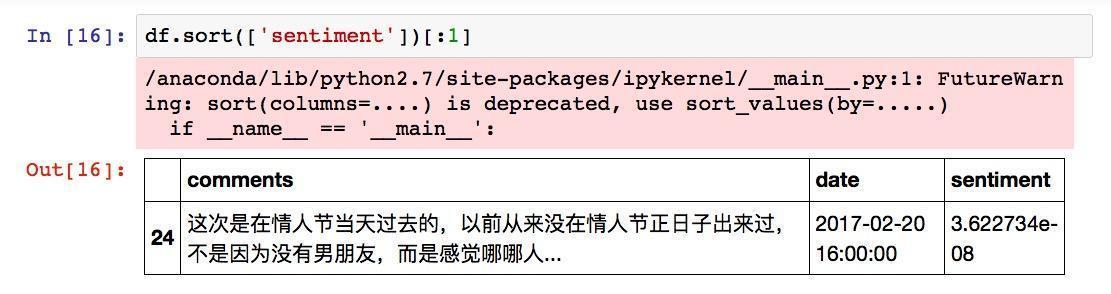
情感分析结果数值几乎就是0啊!不过这里数据框显示评论信息不完全。我们需要将评论整体打印出来。
评论完整信息如下:
这次是在情人节当天过去的,以前从来没在情人节正日子出来过,不是因为没有男朋友,而是感觉哪哪人都多,所以特意错开,这次实在是馋A餐厅了,所以赶在正日子也出来了,从下午四点多的时候我看排号就排到一百多了,我从家开车过去得堵的话一个小时,我一看提前两个小时就在网上先排着号了,差不多我们是六点半到的,到那的时候我看号码前面还有才三十多号,我想着肯定没问题了,等一会就能吃上的,没想到悲剧了,就从我们到那坐到等位区开始,大约是十分二十分一叫号,中途多次我都想走了,哈哈,哎,等到最后早上九点才吃上的,服务员感觉也没以前清闲时周到了,不过这肯定的,一人负责好几桌,今天节日这么多人,肯定是很累的,所以大多也都是我自己跑腿,没让服务员给弄太多,就虾滑让服务员下的,然后环境来说感觉卫生方面是不错,就是有些太吵了,味道还是一如既往的那个味道,不过A餐厅最人性化的就是看我们等了两个多小时,上来送了我们一张打折卡,而且当次就可以使用,这点感觉还是挺好的,不愧是A餐厅,就是比一般的要人性化,不过这次就是选错日子了,以后还是得提前预约,要不就别赶节日去,太火爆了!
通过阅读,你可以发现这位顾客确实有了一次比较糟糕的体验——等候的时间太长了,以至于使用了“悲剧”一词;另外还提及服务不够周到,以及环境吵闹等因素。正是这些词汇的出现,使得分析结果数值非常低。
好在顾客很通情达理,而且对该分店的人性化做法给予了正面的评价。
从这个例子,你可以看出,虽然情感分析可以帮你自动化处理很多内容,然而你不能完全依赖它。
自然语言的分析,不仅要看表达强烈情感的关键词,也需要考虑到表述方式和上下文等诸多因素。这些内容,是现在自然语言处理领域的研究前沿。我们期待着早日应用到科学家们的研究成果,提升情感分析的准确度。
不过,即便目前的情感分析自动化处理不能达到非常准确,却依然可以帮助你快速定位到那些可能有问题的异常点(anomalies)。从效率上,比人工处理要高出许多。
你读完这条评论,长出了一口气。总结了经验教训后,你决定将人性化的服务贯彻到底。你又想到,可以收集用户等候时长数据,用数据分析为等待就餐的顾客提供更为合理的等待时长预期。这样就可以避免顾客一直等到很晚了。
祝贺你,经理!在数据智能时代,你已经走在了正确的方向上。
下面,你该认真阅读下一条负面评论了……
5.3 如何用Python和R对故事情节做情绪分析?
想知道一部没看过的影视剧能否符合自己口味,却又怕被剧透?没关系,我们可以用情绪分析来了解故事情节是否足够跌宕起伏。本文一步步教你如何用Python和R轻松愉快完成文本情绪分析。一起来试试吧。

5.3.1 烦恼
追剧是个令人苦恼的事情。
就拿刚刚播完第7季的《权力的游戏》来说,每周等的时候那叫一个煎熬,就盼着周一能提早到来。
可是最后一集播完,你紧张、兴奋、激动和过瘾之后呢?是不是又觉得很失落?
因为——下面我该看什么剧啊?
现在的影视作品,不是太少,而是太多。如果你有选择困难症,更会有生不逢时的感觉。
Netflix, Amazon和豆瓣等推荐引擎可以给你推荐影视作品。但是它们的推荐,只是把观众划分成了许多个圈子。你的数据,如果足够真实准确的话,可能刚好和某一个圈子的特性比较接近,于是就给你推荐这个圈子更喜欢的作品。
但是这不一定靠谱。有可能你的观影和评价信息分散在不同的平台上。不完整、不准确的观影数据,会导致推荐的效果大打折扣。
即便有了推荐的影视剧,它是否符合你的口味呢?毕竟看剧也是有机会成本的。放着《绝命毒师》不看,去看了一部烂剧,你的生命中的数十小时就这样被浪费了。
可除了从头到尾看一遍,又如何能验证一部剧是否是自己喜欢的呢?
你可能想到去评论区看剧评。那可是个危险区域,因为随时都有被剧透的风险。
你觉得还是利用社交媒体吧,在万能的朋友圈问问好友。有的好友确实很热心,但有的时候,也许会过于热心。
例如下面这位(图片来自于网络):
你可能抓狂了,觉得这是个不可能完成的任务,就如同英谚所云:
You can’t have your cake and eat it too.
真的是这样吗?不一定。在这个大数据泛滥,数据分析工具并不稀缺的时代,你完全可以利用技术帮自己选择优秀的影视作品。
故事情节的文本,你可以到互联网上找剧本,或者是字幕。当然,不是让你把剧本从头读到尾,那样还不如直接看剧呢。你需要用技术来对文本进行分析。
5.3.2 情绪
我们提到的这个技术,叫做情绪分析(emotional analysis)。它和情感分析(sentiment analysis)有相似之处。都是通过对内容的自动化分析,来获得结果。
情感分析的结果一般分为正向(positive)和负向(negative),而情绪分析包含的种类就比较多了。
加拿大国家研究委员会(National Research Council of Canada)官方发布的情绪词典包含了8种情绪,分别为:
- 愤怒(anger)
- 期待(anticipation)
- 厌恶(disgust)
- 恐惧(fear)
- 喜悦(joy)
- 悲伤(sadness)
- 惊讶(surprise)
- 信任(trust)
有了这些情绪的标记,你可以轻松地对一段文本的情绪变化进行分析。
这时候,你可以回忆起中学语文老师讲作文时说过的那句话:
文如看山不喜平。
故事情节会伴随着各种情绪的波动。通过分析这些情绪的起伏,我们可以看出故事的基调是否符合自己的口味,情节是否紧凑等。这样,你可以根据自己的偏好,甚至是当前的心境,来选择合适的作品观看了。
我们需要用到Python和R。这两种语言在目前数据科学领域里最受欢迎。Python的优势在于通用,而R的优势在于统计学家组成的社区。这些统计学家真是高产,也很酷,经常制造出令人惊艳的分析包。
咱们这里就用Python来做数据清理,然后用R做情绪分析,并且把结果可视化输出。
5.3.3 准备
5.3.3.1 数据
我们首先需要找到的是来源数据。作为例子,我们选择了《权利的游戏》第三季的第9集,名字叫做“The Rains of Castamere”。
你可以到这个网址下载这一集的剧本。
你只需要全选页面拷贝,然后打开一个文本编辑器,把内容粘贴进去。好了,现在你就有可供分析的文本了。
请建立一个工作目录。后面的操作都在这个目录里进行。例如我的工作目录是~/Downloads/python-r-emotion。
把刚刚获得的文本文件放到这个目录中。
5.3.3.2 Python
我们需要用到Jupyter Notebook,请安装Anaconda套装。具体的安装方法请参考《 如何用Python做词云(3.1) 》一文。

5.3.4 清理
我们首先需要清理文本数据,完成以下这两个任务:
- 把与剧情正文无关的内容去除;
- 将数据转换成R可以直接做情绪分析的结构化数据格式。
到你的系统“终端”(macOS, Linux)或者“命令提示符”(Windows)下,进入我们的工作目录,执行以下命令。
jupyter notebook这时候工作目录下还只有那个文本文件。
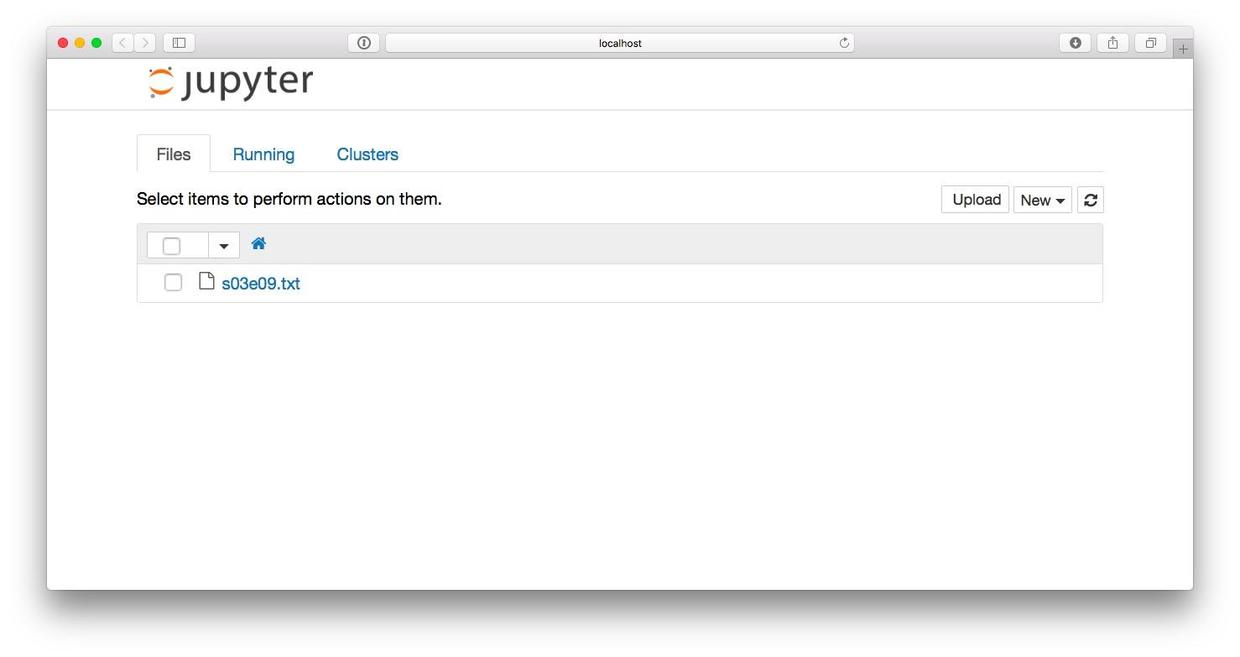
我们打开看看内容。
往下翻页,我们找到了剧本正文正式开始的标记Opening Credits。
翻到文本的结尾,我们可以看到剧本结束的标记End Credits。
我们回到主页面下,新建一个Python的Notebook。点击右方的New按钮,选择Python 2。
有了全新的Notebook后,我们首先引入需要用到的包。
然后读取当前目录下的文本文件。
看看内容:
结果如下:
数据正确读入。下面我们依照刚才浏览中发现的标记把正文以外的文本内容去掉。
先去掉开头的非剧本正文内容。
再次打印,可以看见现在从正文开头了。
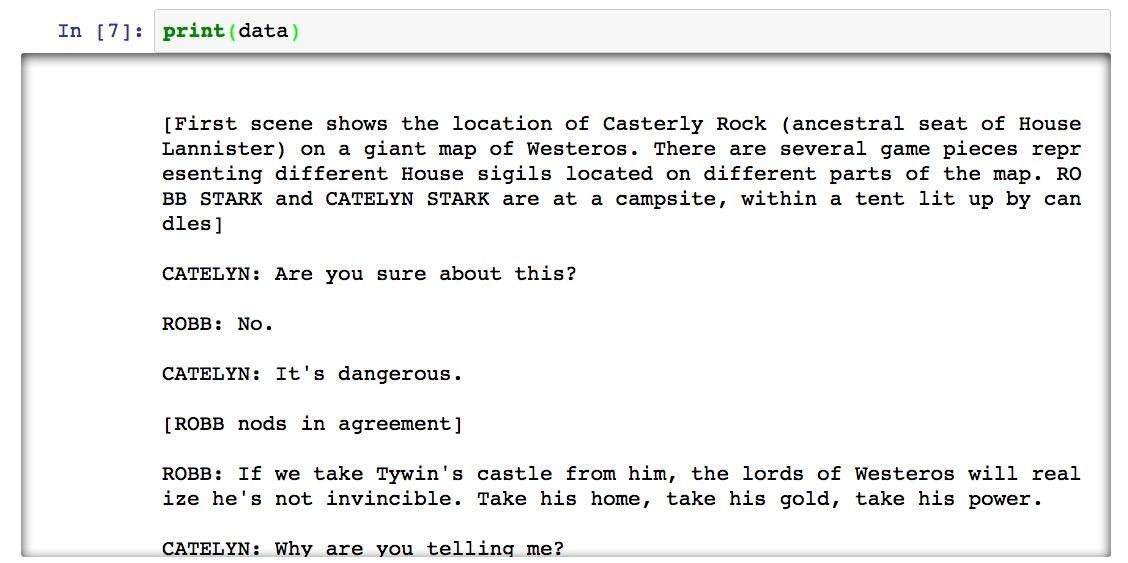
下面我们同样处理结尾部分。
打印出来试试看。
拖动到尾部。

移除了开头和结尾的多余内容后,我们来移除空行。这里我们需要用到正则表达式。
然后我们再次打印。
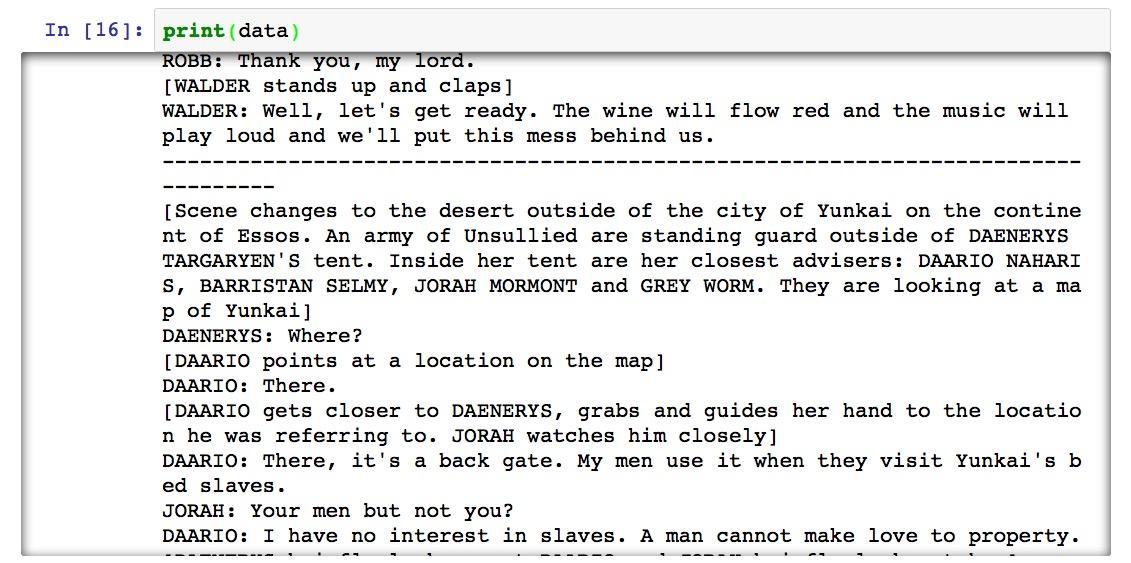
空行都已经成功挪走了。可是我们注意到还有一些分割线组成的行,也需要去除掉。
至此,清理工作已经完成了。下面我们把文本整理成数据框,每一行分别加上行号。
利用换行符把原本完整的文本分割成行。
然后给每一行加上行号。
我们看看前三行的行号是否已经正常添加。
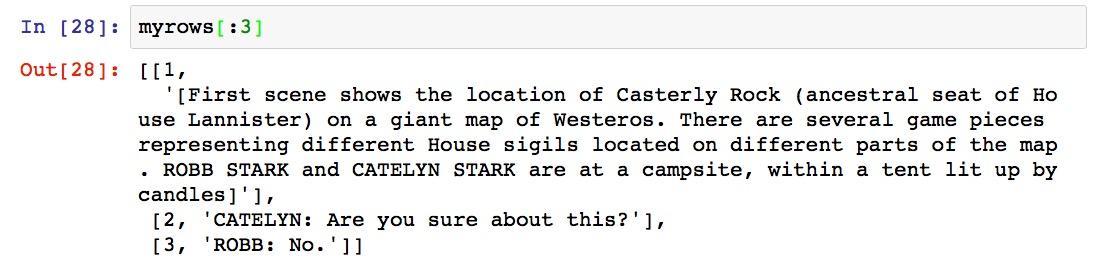
一切正常,下面我们把目前的数组转换成数据框。如果你对数据框的概念不太熟悉,请参考《贷还是不贷:如何用Python和机器学习帮你决策?》(6.1)一文。
我们来看看执行结果:
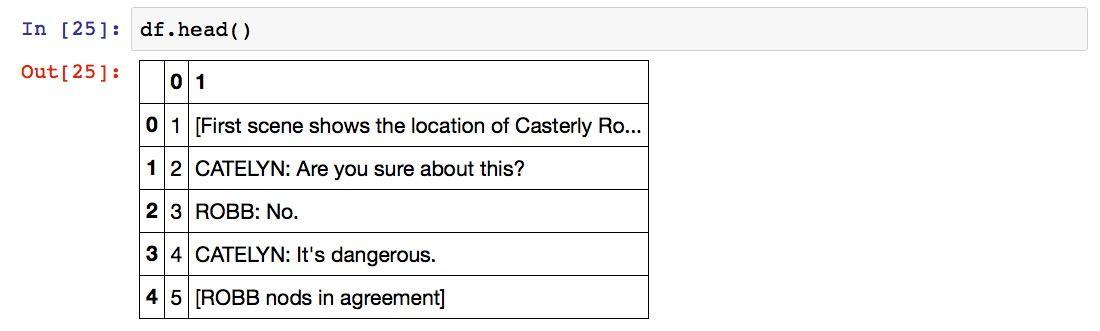
数据是正确的,不过表头不对。我们给表头重新命名。
再来看看:
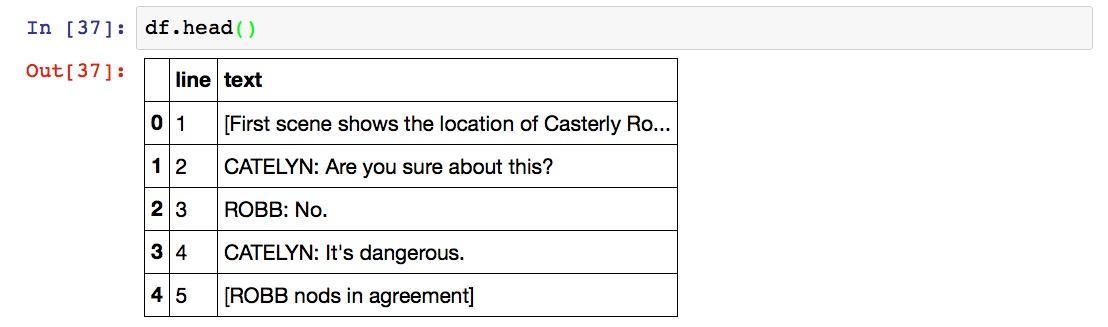
好了,既然数据框已经做好了。下面我们把它转换成为csv格式,以便于R来读取和处理。
我们打开data.csv文件,可以看到数据如下:
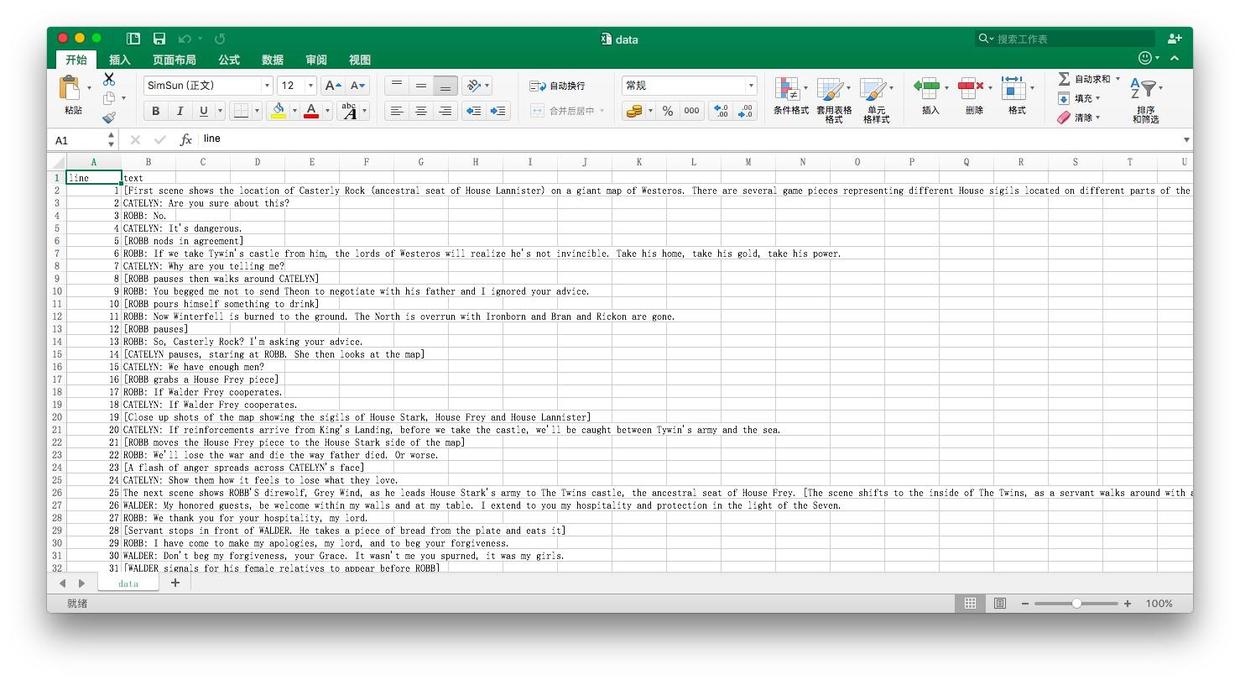
数据清理和准备工作结束,下面我们用R进行分析。
5.3.5 分析
RStudio可以提供一个交互环境,帮我们执行R命令并即时反馈结果。
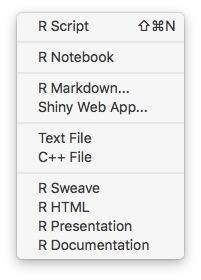
打开RStudio之后,选择File->New,然后从以下界面中选择 R Notebook。
然后,我们就有了一个R Notebook的模板。模板附带一些基础使用说明。
我们尝试点击编辑区域(左侧)代码部分(灰色)的运行按钮。
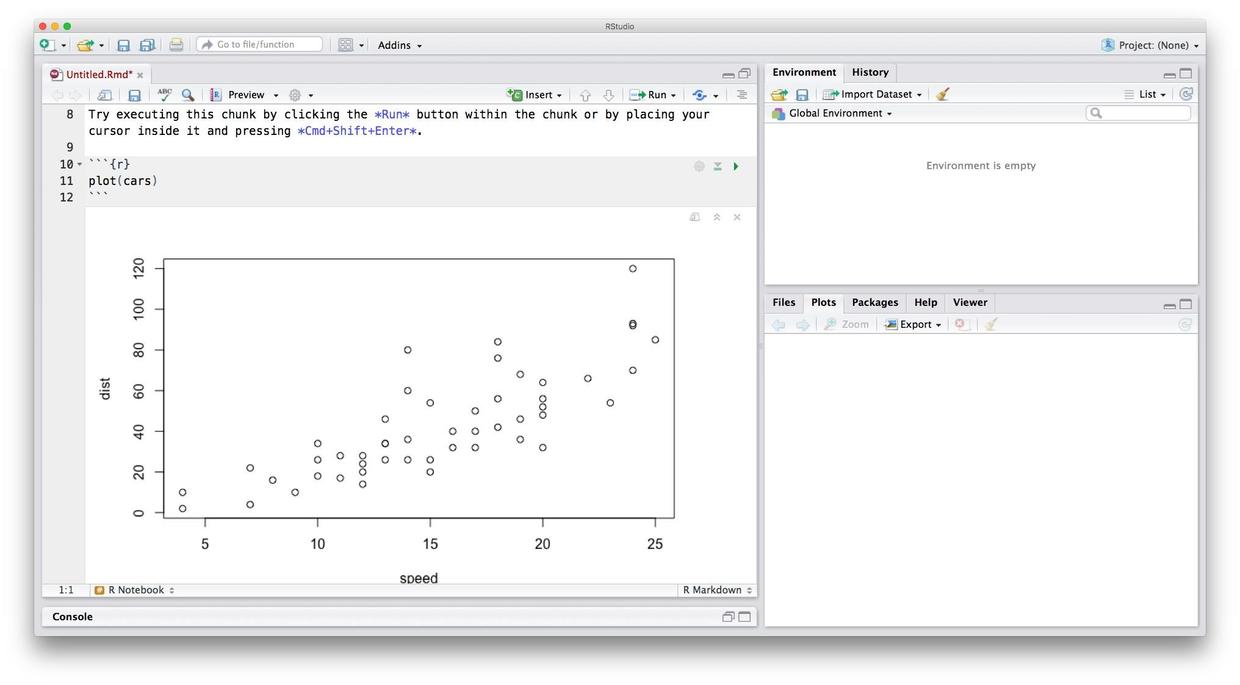
立即就可以看到绘图的结果了。
另外我们还可以点击菜单栏上的Preview按钮,来看整个儿代码的运行结果。
RStudio为我们生成了HTML文件,我们的文字说明、代码和运行结果图文并茂呈现出来。
好了,熟悉了环境后,我们该实际操作运行自己的代码了。咱们把左侧编辑区的开头说明区保留,把全部正文删除,并且把文件名改成有意义的名字,例如emotional-analysis。
这样就清爽多了。
下面我们读入数据。
读入的时候一定要注意设置stringsAsFactors=FALSE,不然R在读取字符串数据的时候,会默认转换为level,后面的分析就做不成了。读取之后,在右侧的数据区域你可以看到script这个变量,双击它,可以看到内容。

数据有了,下面我们需要准备分析用的包。这里我们需要用到4个包,请执行以下语句安装。
install.packages("dplyr")
install.packages("tidytext")
install.packages("tidyr")
install.packages("ggplot2")注意安装新软件包这种操作只需要执行一次。可是我们每次预览结果的时候,文件里所有语句都会被执行一遍。为了避免安装命令被反复执行。当安装结束后,请你删除或者注释掉上面几条语句。
安装了包,并不意味着就可以直接用其中的函数了。使用之前,你需要执行library语句调用这些包。
好了,万事俱备。我们需要把一句句的文本拆成单词,这样才能和情绪词典里的单词做匹配,从而分析单词的情绪属性。
在R里面,可以采用Tidy Text方式来做。执行的语句是unnest_token,我们把原先的句子拆分成为单词。
#### line word
#### 1 1 first
#### 1.1 1 scene
#### 1.2 1 shows
#### 1.3 1 the
#### 1.4 1 location
#### 1.5 1 of
这里原先的行号依然被保留。我们可以看到每一个词来自于哪一行,这有利于下面我们对行甚至段落单位进行分析。
我们调用加拿大国家研究委员会发布的情绪词典。这个词典在tidytext包里面内置了,就叫做nrc。
我们只显示前10行的内容:
#### Joining, by = "word"
#### line word sentiment
#### 1 1 rock positive
#### 2 1 ancestral trust
#### 3 1 giant fear
#### 4 1 representing anticipation
#### 5 1 stark negative
#### 6 1 stark trust
#### 7 1 stark negative
#### 8 1 stark trust
#### 9 4 dangerous fear
#### 10 4 dangerous negative
可以看到,有的词对应某一种情绪属性,有的词同时对应多种情绪属性。注意nrc包里面不仅有情绪,而且还有情感(正向和负向)。
我们对单词的情绪已经清楚了。下面我们来综合判断每一行的不同情感分别含有几个词。
tidy_script %>%
inner_join(get_sentiments("nrc")) %>%
count(line, sentiment) %>%
arrange(line) %>%
head(10)还是只显示结果的前10行。
#### Joining, by = "word"
#### # A tibble: 10 x 3
#### line sentiment n
#### <int> <chr> <int>
#### 1 1 anticipation 1
#### 2 1 fear 1
#### 3 1 negative 2
#### 4 1 positive 1
#### 5 1 trust 3
#### 6 4 fear 1
#### 7 4 negative 1
#### 8 5 positive 1
#### 9 5 trust 1
#### 10 6 positive 1
以第1行为例,包含“期待”的词有1个,包含“恐惧”的有1个,包含“信任”的有3个。
如果我们以1行为单位分析情感变化,粒度过细。鉴于整个剧本包含了几百行文字,我们以5行作为一个基础单位,来进行分析。
这里我们使用index来把原先的行号处理一下,分成段落。%/%代表整除符号,这样0-4行就成为了第一段落,5-9行成为第二段落,以此类推。
tidy_script %>%
inner_join(get_sentiments("nrc")) %>%
count(line, sentiment) %>%
mutate(index = line %/% 5) %>%
arrange(index) %>%
head(10)#### Joining, by = "word"
#### # A tibble: 10 x 4
#### line sentiment n index
#### <int> <chr> <int> <dbl>
#### 1 1 anticipation 1 0
#### 2 1 fear 1 0
#### 3 1 negative 2 0
#### 4 1 positive 1 0
#### 5 1 trust 3 0
#### 6 4 fear 1 0
#### 7 4 negative 1 0
#### 8 5 positive 1 1
#### 9 5 trust 1 1
#### 10 6 positive 1 1
可以看出,第一段包含的情感还真是很丰富。
只是如果让我们把结果表格从头读到尾,那也真够难受的。我们还是用可视化的方法,把图绘制出来吧。
绘图我们采用ggplot包。这个包我们在《 如何用Python做舆情时间序列可视化?(5.2) 》一文中介绍过,欢迎查阅复习。
我们使用geom_col指令,让R帮我们绘制柱状图。对不同的情绪,我们用不同颜色表示出来。
tidy_script %>%
inner_join(get_sentiments("nrc")) %>%
count(line, sentiment) %>%
mutate(index = line %/% 5) %>%
ggplot(aes(x=index, y=n, color=sentiment)) %>%
+ geom_col()#### Joining, by = "word"
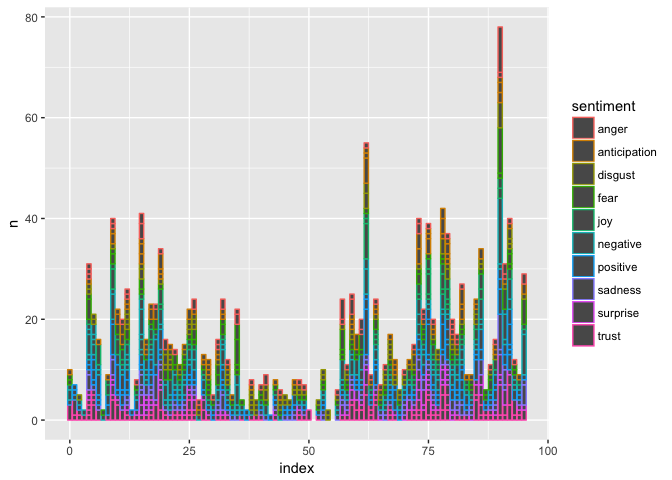
结果是丰富多彩的,可惜看不大清楚。为了区别不同情绪,我们调用facet_wrap函数,把不同情绪拆开,分别绘制。
tidy_script %>%
inner_join(get_sentiments("nrc")) %>%
count(line, sentiment) %>%
mutate(index = line %/% 5) %>%
ggplot(aes(x=index, y=n, color=sentiment)) %>%
+ geom_col() %>%
+ facet_wrap(~sentiment, ncol=3)#### Joining, by = "word"
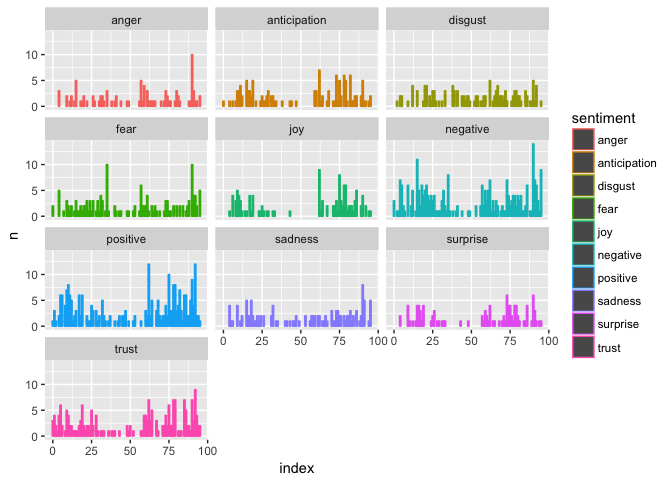
嗯,这张图看着就舒服多了。
不过这张图也会给我们造成一些疑惑。按照道理来说,每一段落的内容里,包含单词数量大致相当。结尾部分情感分析结果里面,正向和负向几乎同时上升,这就让人很不解。是这里的几行太长了,还是出了什么其他的问题呢?
数据分析的关键,就是在这种令人疑惑的地方深挖进去。
我们不妨来看看,出现最多的正向和负向情感词都有哪些。
先来看看正向的。我们这次不是按照行号,而是按照词频来排序。
tidy_script %>%
inner_join(get_sentiments("nrc")) %>%
filter(sentiment == "positive") %>%
count(word) %>%
arrange(desc(n)) %>%
head(10)#### Joining, by = "word"
#### # A tibble: 10 x 2
#### word n
#### <chr> <int>
#### 1 lord 13
#### 2 good 9
#### 3 guard 9
#### 4 daughter 8
#### 5 shoulder 7
#### 6 love 6
#### 7 main 6
#### 8 quiet 6
#### 9 bride 5
#### 10 king 5
看到这个词频,我们不禁有些失落——看来分析结果是有问题的。许多词汇都是名词,而且在《权力的游戏》故事中,这些词根本就没有明确的情感指向。例如lord这个词,剧中的lord有的正直善良,但也有很多不是什么好人;king也一样,虽然Robb和Jon是国王,但别忘了Joffrey也是国王啊。
我们再来看看负向情感词汇吧。
tidy_script %>%
inner_join(get_sentiments("nrc")) %>%
filter(sentiment == "negative") %>%
count(word) %>%
arrange(desc(n)) %>%
head(10)#### Joining, by = "word"
#### # A tibble: 10 x 2
#### word n
#### <chr> <int>
#### 1 stark 16
#### 2 pig 14
#### 3 lord 13
#### 4 worm 12
#### 5 kill 11
#### 6 black 9
#### 7 dagger 8
#### 8 shot 8
#### 9 killing 7
#### 10 afraid 4
看了这个结果,就更令人沮丧不已了——同样的一个lord,竟然既被当成了正向,又被当成了负向词汇。词典标注者太不负责任了吧!
别着急。出现这样的情况,是因为我们做分析时少了一个重要步骤——处理停用词。对于每一个具体场景,我们都需要使用停用词表,把那些可能干扰分析结果的词扔出去。
tidytext提供了默认的停用词表。我们先拿来试试看。这里使用的语句是anti_join,就可以把停用词先去除,再进行情绪词表连接。
我们看看停用词去除后,正向情感词汇的高频词有没有变化。
tidy_script %>%
anti_join(stop_words) %>%
inner_join(get_sentiments("nrc")) %>%
filter(sentiment == "positive") %>%
count(word) %>%
arrange(desc(n)) %>%
head(10)#### Joining, by = "word"
#### Joining, by = "word"
#### # A tibble: 10 x 2
#### word n
#### <chr> <int>
#### 1 lord 13
#### 2 guard 9
#### 3 daughter 8
#### 4 shoulder 7
#### 5 love 6
#### 6 main 6
#### 7 quiet 6
#### 8 bride 5
#### 9 king 5
#### 10 music 5
结果令人失望。看来停用词表里没有包含我们需要去除的那一堆名词。
没关系,我们自己来修订停用词表。使用R中的bind_rows语句,我们就能在基础的预置停用词表基础上,附加上我们自己的停用词。
custom_stop_words <- bind_rows(stop_words,
data_frame(word = c("stark", "mother", "father", "daughter", "brother", "rock", "ground", "lord", "guard", "shoulder", "king", "main", "grace", "gate", "horse", "eagle", "servent"),
lexicon = c("custom")))我们加入了一堆名词和关系代词。因为它们和情绪之间没有必然的关联。但是名词还是保留了一些。例如“新娘”总该是和好的情感和情绪相连吧。
用了定制的停用词表后,我们来看看词频的变化。
tidy_script %>%
anti_join(custom_stop_words) %>%
inner_join(get_sentiments("nrc")) %>%
filter(sentiment == "positive") %>%
count(word) %>%
arrange(desc(n)) %>%
head(10)#### Joining, by = "word"
#### Joining, by = "word"
#### # A tibble: 10 x 2
#### word n
#### <chr> <int>
#### 1 love 6
#### 2 quiet 6
#### 3 bride 5
#### 4 music 5
#### 5 rest 5
#### 6 finally 4
#### 7 food 3
#### 8 forward 3
#### 9 hope 3
#### 10 hospitality 3
这次好多了,起码解释情绪可以自圆其说了。我们再看看那些负向情感词汇。
tidy_script %>%
anti_join(custom_stop_words) %>%
inner_join(get_sentiments("nrc")) %>%
filter(sentiment == "negative") %>%
count(word) %>%
arrange(desc(n)) %>%
head(10)#### Joining, by = "word"
#### Joining, by = "word"
#### # A tibble: 10 x 2
#### word n
#### <chr> <int>
#### 1 pig 14
#### 2 worm 12
#### 3 kill 11
#### 4 black 9
#### 5 dagger 8
#### 6 shot 8
#### 7 killing 7
#### 8 afraid 4
#### 9 fear 4
#### 10 leave 4
比起之前,也有很大进步。
做好了基础的修订工作,下面我们来重新作图吧。我们把停用词表加进去,并且还用filter语句把情感属性删除掉了。因为我们分析的对象是情绪(emotion),而不是情感(sentiment)。
tidy_script %>%
anti_join(custom_stop_words) %>%
inner_join(get_sentiments("nrc")) %>%
filter(sentiment != "negative" & sentiment != "positive") %>%
count(line, sentiment) %>%
mutate(index = line %/% 5) %>%
ggplot(aes(x=index, y=n, color=sentiment)) %>%
+ geom_col() %>%
+ facet_wrap(~sentiment, ncol=3)#### Joining, by = "word"
#### Joining, by = "word"
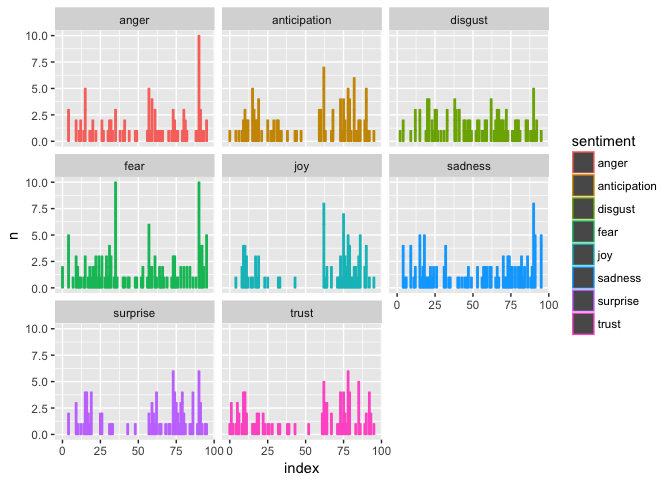
这幅图一下子变得清晰,也值得琢磨。
在这一集的结尾,多种情绪混杂交织——欢快的气氛陡然下降,期待与信任在波动,厌恶在不断上涨,恐惧与悲伤陡然上升,愤怒突破天际,交杂着数次的惊讶……
你可能会纳闷儿,情绪怎么可能这么复杂?是不是分析又出问题了?
还真不是,这一集的故事,有个另外的名字,叫做《红色婚礼》。
5.3.6 收获
通过本文的学习,希望你已初步掌握了如下技能:
- 如何用Python对网络摘取的文本做处理,从中找出正文,并且去掉空行等内容;
- 如何用数据框对数据进行存储、表示与格式转换,在Python和R中交换数据;
- 如何安装和使用RStudio环境,用R Notebook做交互式编程;
- 如何利用tidytext方式来处理情感分析与情绪分析;
- 如何设置自己的停用词表;
- 如何用ggplot绘制多维度切面图形。
掌握了这些内容后,你是否觉得用这么强大的工具分析个剧本找影视作品,有些大炮轰蚊子的感觉?
5.4 如何用Python提取中文关键词?
本文一步步为你演示,如何用Python从中文文本中提取关键词。如果你需要对长文“观其大略”,不妨尝试一下。

5.4.1 需求
好友最近对自然语言处理感兴趣,因为他打算利用自动化方法从长文本里提取关键词,来确定主题。
他向我询问方法,我推荐他阅读我的那篇《如何用Python从海量文本提取主题?》。
看过之后,他表示很有收获,但是应用场景和他自己的需求有些区别。
《如何用Python从海量文本提取主题?》一文面对的是大量的文档,利用主题发现功能对文章聚类。而他不需要处理很多的文档,也没有聚类的需求,但是需要处理的每篇文档都很长,希望通过自动化方法从长文提取关键词,以观其大略。
我突然发现,之前居然忘了写文,介绍单一文本关键词的提取方法。
虽然这个功能实现起来并不复杂,但是其中也有些坑,需要避免踩进去的。
通过本文,我一步步为你演示如何用Python实现中文关键词提取这一功能。
5.4.2 环境
5.4.2.1 Python
第一步是安装Python运行环境。我们使用集成环境Anaconda。
请到这个网址 下载最新版的Anaconda。下拉页面,找到下载位置。根据你目前使用的系统,网站会自动推荐给你适合的版本下载。我使用的是macOS,下载文件格式为pkg。
下载页面区左侧是Python 3.6版,右侧是2.7版。请选择2.7版本。
双击下载后的pkg文件,根据中文提示一步步安装即可。
5.4.2.2 样例
我专门为你准备了一个github项目,存放本文的配套源代码和数据。请从这个地址下载压缩包文件,然后解压。
解压后的目录名称为demo-keyword-extraction-master,样例目录包含以下内容:
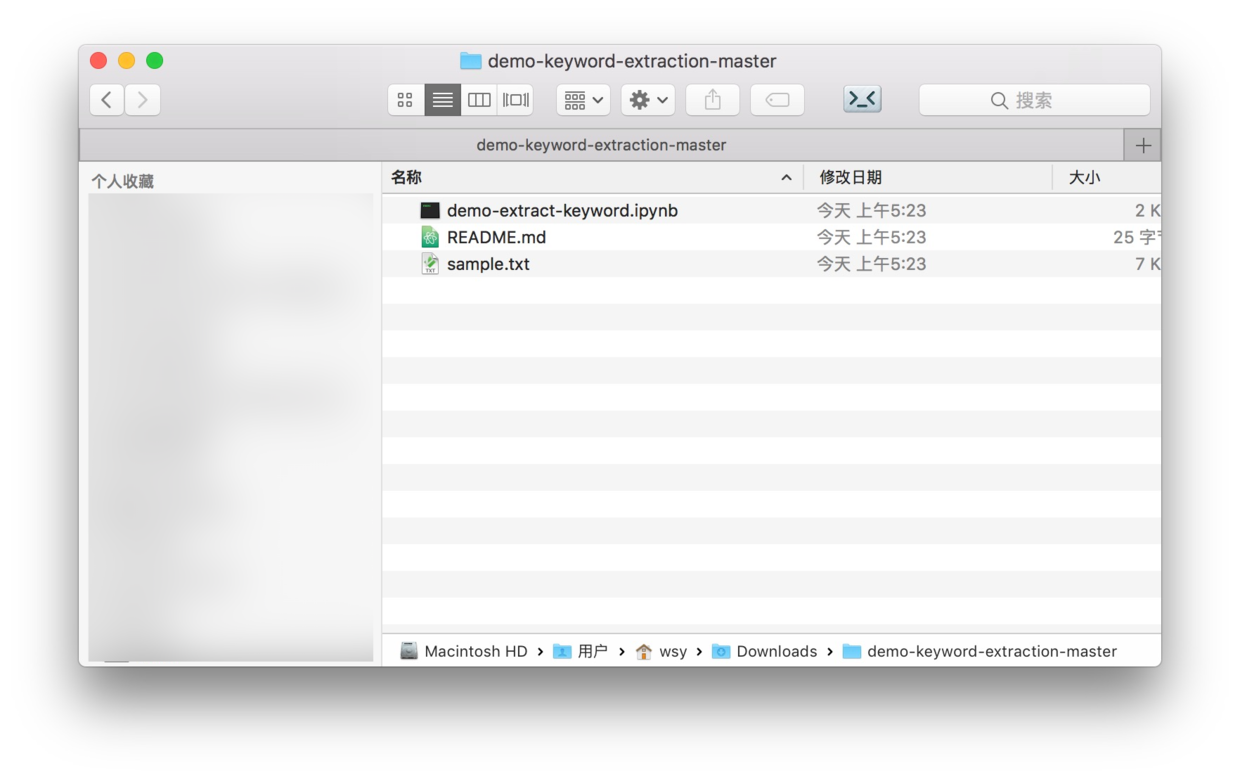
除了README.md这个github项目默认说明文件外,目录下还有两个文件,分别是数据文件sample.txt和程序源代码文件demo-extract-keyword.ipynb。
5.4.3 数据
一开始,我还曾为寻找现成的中文文本发愁。
网上可以找到的中文文本浩如烟海。
但是拿来做演示,是否会有版权问题,我就不确定了。万一把哪位大家之作拿来做了分析,人家可能就要过问一句“这电子版你是从哪里搞到的啊?”
万一再因此提出诉讼,我可无法招架。
后来发现,我这简直就是自寻烦恼——找别人的文本干什么?用我自己的不就好了?
这一年多以来,我写的文章已有90多篇,总字数已经超过了27万。
我特意从中找了一篇非技术性的,以避免提取出的关键词全都是Python命令。
我选取的,是去年的那篇《网约车司机二三事》。

这篇文章,讲的都是些比较有趣的小故事。
我从网页上摘取文字,存储到sample.txt中。
注意,这里是很容易踩坑的地方。在夏天的一次工作坊教学中,好几位同学因为从网上摘取中文文本出现问题,卡住很长时间。
这是因为不同于英语,汉字有编码问题。不同系统都有不同的默认编码,不同版本的Python接受的编码也不同。你从网上下载的文本文件,也可能与你系统的编码不统一。
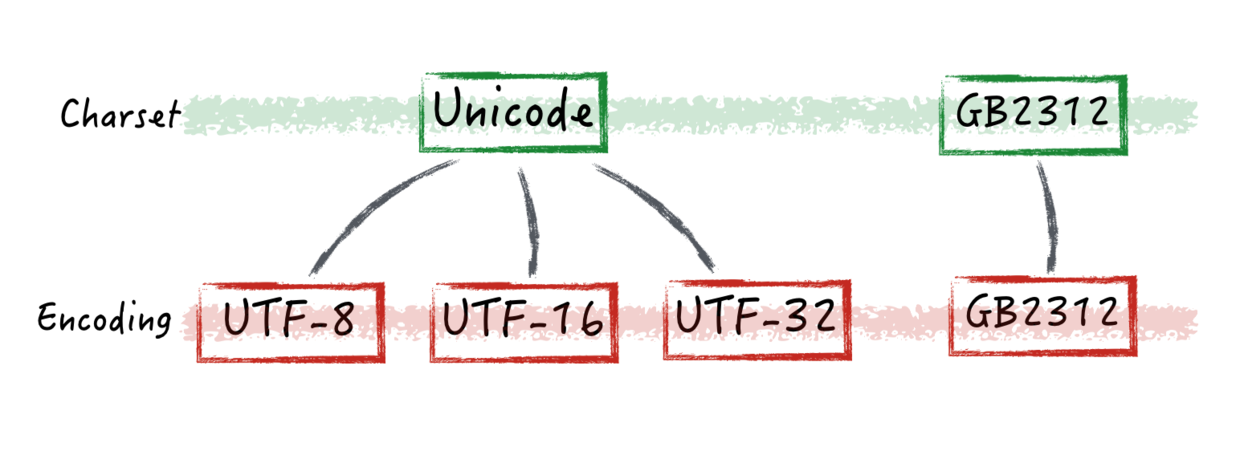
不论如何,这些因素都有可能导致你打开后的文本里,到处都是看不懂的乱码。
因而,正确的使用中文文本数据方式,是你在Jupyter Notebook里面,新建一个文本文件。
然后,会出现以下的空白文件。
把你从别处下载的文本,用任意一种能正常显示的编辑器打开,然后拷贝全部内容,粘贴到这个空白文本文件中,就能避免编码错乱。
避开了这个坑,可以为你节省很多不必要的烦恼尝试。
好了,知道了这个窍门,下面你就能愉快地进行关键词提取了。
5.4.4 执行
回到Jupyter Notebook的主界面,点击demo-extract-keyword.ipynb,你就能看到源码了。
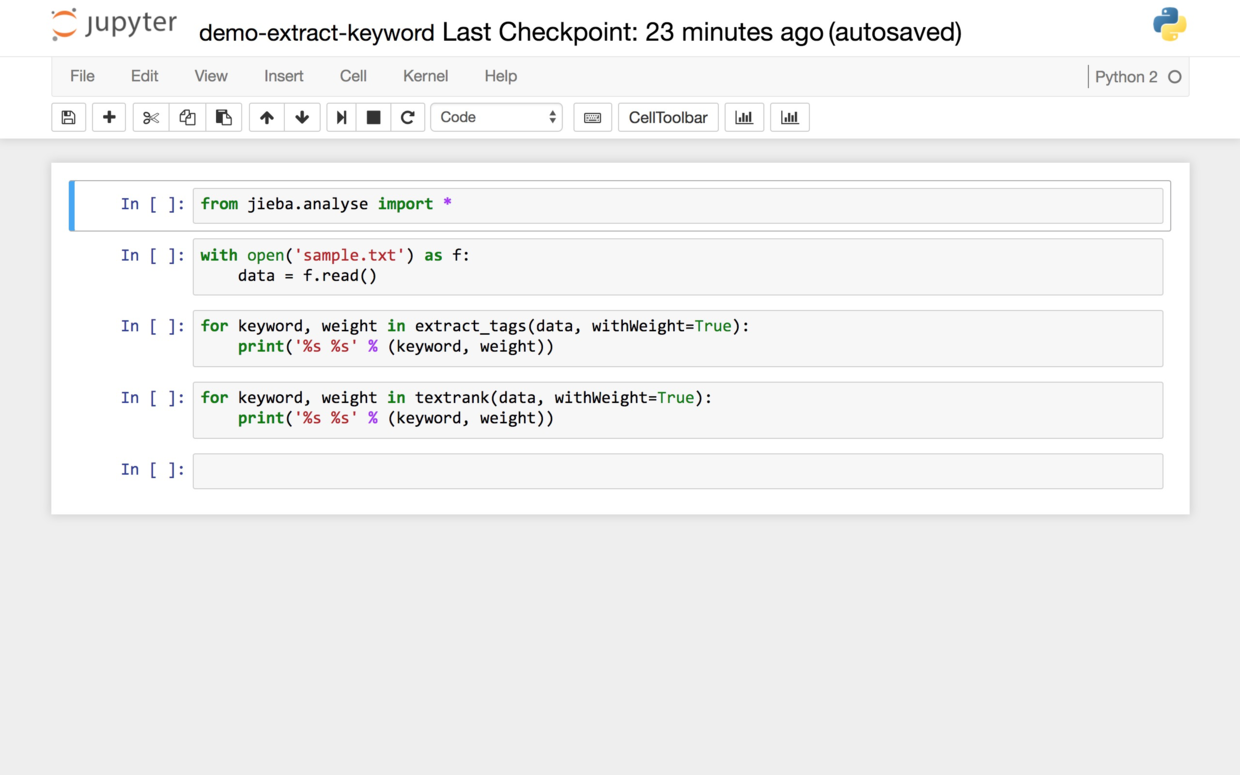
对,你没看错。只需要这短短的4个语句,就能完成两种不同方式(TF-idf与TextRank)的关键词提取。
本部分我们先讲解执行步骤。不同关键词提取方法的原理,我们放在后面介绍。
首先我们从结巴分词的分析工具箱里导入所有的关键词提取功能。
在对应的语句上,按下Shift+Enter组合按键,就可以执行语句,获取结果了。
然后,让Python打开我们的样例文本文件,并且读入其中的全部内容到data变量。
使用TF-idf方式提取关键词和权重,并且依次显示出来。如果你不做特殊指定的话,默认显示数量为20个关键词。
显示内容之前,会有一些提示,不要管它。
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/8s/k8yr4zy52q1dh107gjx280mw0000gn/T/jieba.cache
Loading model cost 0.547 seconds.
Prefix dict has been built succesfully.然后列表就出来了:
优步 0.280875594782
司机 0.119951947597
乘客 0.105486129485
师傅 0.0958888107815
张师傅 0.0838162334963
目的地 0.0753618512886
网约车 0.0702188986954
姐姐 0.0683412127766
自己 0.0672533110661
上车 0.0623276916308
活儿 0.0600134354214
天津 0.0569158056792
10 0.0526641740216
开优步 0.0526641740216
事儿 0.048554456767
李师傅 0.0485035501943
天津人 0.0482653686026
绕路 0.0478244723097
出租车 0.0448480260748
时候 0.0440840298591我看了一下,觉得关键词提取还是比较靠谱的。当然,其中也混入了个数字10,好在无伤大雅。
如果你需要修改关键词数量,就需要指定topK参数。例如你要输出10个关键词,可以这样执行:
for keyword, weight in extract_tags(data, topK=10, withWeight=True):
print('%s %s' % (keyword, weight))下面我们尝试另一种关键词提取方式——TextRank。
关键词提取结果如下:
优步 1.0
司机 0.749405996648
乘客 0.594284506457
姐姐 0.485458741991
天津 0.451113490366
目的地 0.429410027466
时候 0.418083863303
作者 0.416903838153
没有 0.357764515052
活儿 0.291371566494
上车 0.277010013884
绕路 0.274608592084
转载 0.271932903186
出来 0.242580745393
出租 0.238639889991
事儿 0.228700322713
单数 0.213450680366
出租车 0.212049665481
拉门 0.205816713637
跟着 0.20513470986注意这次提取的结果,与TF-idf的结果有区别。至少,那个很突兀的“10”不见了。
但是,这是不是意味着TextRank方法一定优于TF-idf呢?
这个问题,留作思考题,希望在你认真阅读了后面的原理部分之后,能够独立做出解答。
如果你只需要应用本方法解决实际问题,那么请跳过原理部分,直接看讨论吧。
5.4.5 原理
我们简要讲解一下,前文出现的2种不同关键词提取方式——TF-idf和TextRank的基本原理。
为了不让大家感到枯燥,这里咱们就不使用数学公式了。后文我会给出相关的资料链接。如果你对细节感兴趣,欢迎按图索骥,查阅学习。
先说TF-idf。
它的全称是 Term Frequency - inverse document frequency。中间有个连字符,左右两侧各是一部分,共同结合起来,决定某个词的重要程度。
第一部分,就是词频(Term Frequency),即某个词语出现的频率。
我们常说“重要的事说三遍”。
同样的道理,某个词语出现的次数多,也就说明这个词语重要性可能会很高。
但是,这只是可能性,并不绝对。
例如现代汉语中的许多虚词——“的,地,得”,古汉语中的许多句尾词“之、乎、者、也、兮”,这些词在文中可能出现许多次,但是它们显然不是关键词。
这就是为什么我们在判断关键词的时候,需要第二部分(idf)配合。
逆文档频率(inverse document frequency)首先计算某个词在各文档中出现的频率。假设一共有10篇文档,其中某个词A在其中10篇文章中都出先过,另一个词B只在其中3篇文中出现。请问哪一个词更关键?
给你一分钟思考一下,然后继续读。
公布答案时间到。
答案是B更关键。
A可能就是虚词,或者全部文档共享的主题词。而B只在3篇文档中出现,因此很有可能是个关键词。
逆文档频率就是把这种文档频率取倒数。这样第一部分和第二部分都是越高越好。二者都高,就很有可能是关键词了。
TF-idf讲完了,下面我们说说TextRank。
相对于TF-idf,TextRank要显得更加复杂一些。它不是简单做加减乘除运算,而是基于图的计算。
下图是原始文献中的示例图。
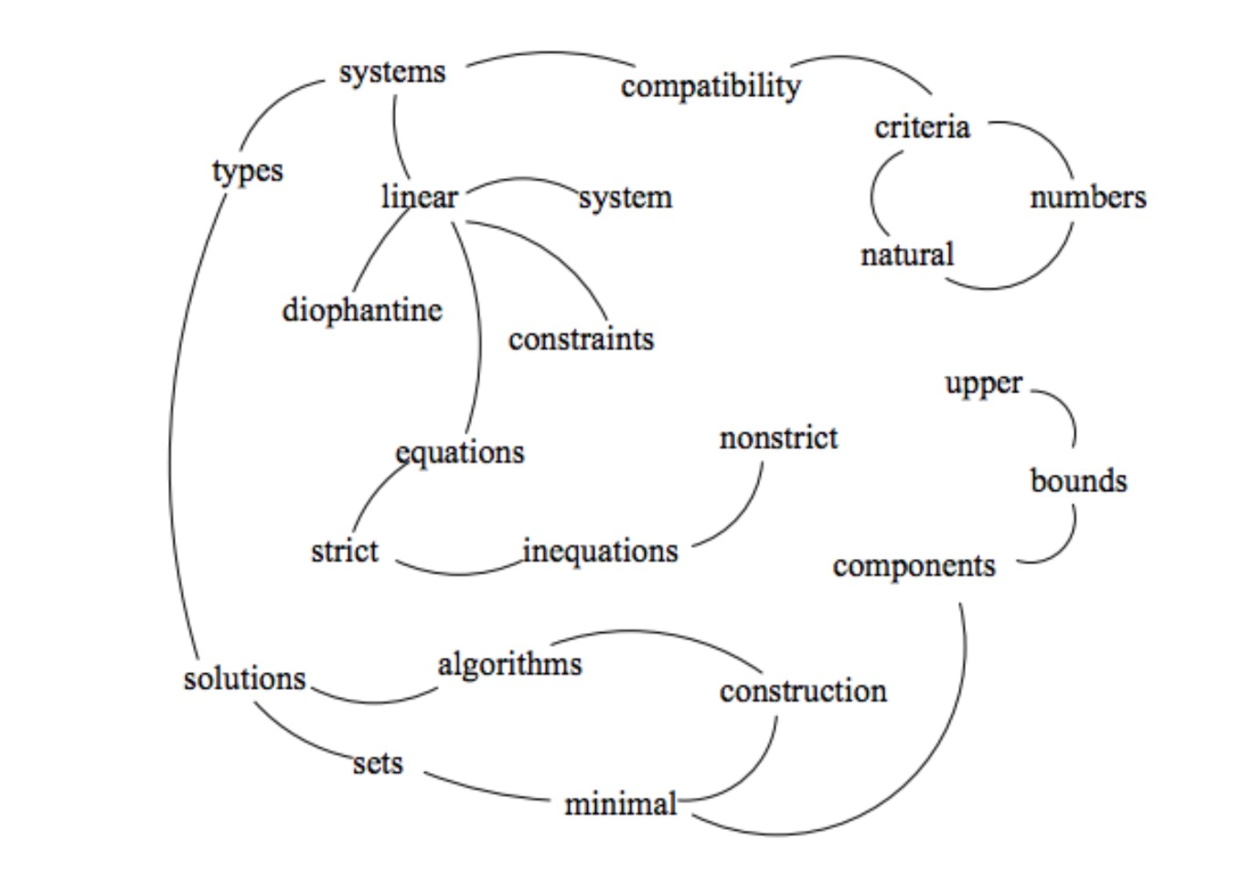
TextRank首先会提取词汇,形成节点;然后依据词汇的关联,建立链接。
依照连接节点的多少,给每个节点赋予一个初始的权重数值。
然后就开始迭代。
根据某个词所连接所有词汇的权重,重新计算该词汇的权重,然后把重新计算的权重传递下去。直到这种变化达到均衡态,权重数值不再发生改变。这与Google的网页排名算法PageRank,在思想上是一致的。

根据最后的权重值,取其中排列靠前的词汇,作为关键词提取结果。
如果你对原始文献感兴趣,请参考以下链接:
5.5 如何用Python处理自然语言?(Spacy与Word Embedding)
本文教你用简单易学的工业级Python自然语言处理软件包Spacy,对自然语言文本做词性分析、命名实体识别、依赖关系刻画,以及词嵌入向量的计算和可视化。
5.5.1 盲维
我总爱重复一句芒格爱说的话:
To the one with a hammer, everything looks like a nail. (手中有锤,看什么都像钉)
这句话是什么意思呢?
就是你不能只掌握数量很少的方法、工具。
否则你的认知会被自己能力框住。不只是存在盲点,而是存在“盲维”。
你会尝试用不合适的方法解决问题(还自诩“一招鲜,吃遍天”),却对原本合适的工具视而不见。
结果可想而知。
所以,你得在自己的工具箱里面,多放一些兵刃。
最近我又对自己的学生,念叨芒格这句话。
因为他们开始做实际研究任务的时候,一遇到自然语言处理(Natural Language Processing, NLP),脑子里想到的就是词云](#word-cloud-with-python3-video-tutorial)、情感分析和[LDA主题建模(6.2)。
为什么?
因为我的专栏和公众号里,自然语言处理部分,只写过这些内容。
你如果认为,NLP只能做这些事,就大错特错了。
看看这段视频,你大概就能感受到目前自然语言处理的前沿,已经到了哪里。

当然,你手头拥有的工具和数据,尚不能做出Google展示的黑科技效果。
但是,现有的工具,也足可以让你对自然语言文本,做出更丰富的处理结果。
科技的发展,蓬勃迅速。
除了咱们之前文章中已介绍过的结巴分词、SnowNLP和TextBlob,基于Python的自然语言处理工具还有很多,例如 NLTK 和 gensim 等。
我无法帮你一一熟悉,你可能用到的所有自然语言处理工具。
但是咱们不妨开个头,介绍一款叫做 Spacy 的 Python 工具包。
剩下的,自己举一反三。
5.5.2 工具
Spacy 的 Slogan,是这样的:
Industrial-Strength Natural Language Processing. (工业级别的自然语言处理)
这句话听上去,是不是有些狂妄啊?
不过人家还是用数据说话的。
数据采自同行评议(Peer-reviewed)学术论文:
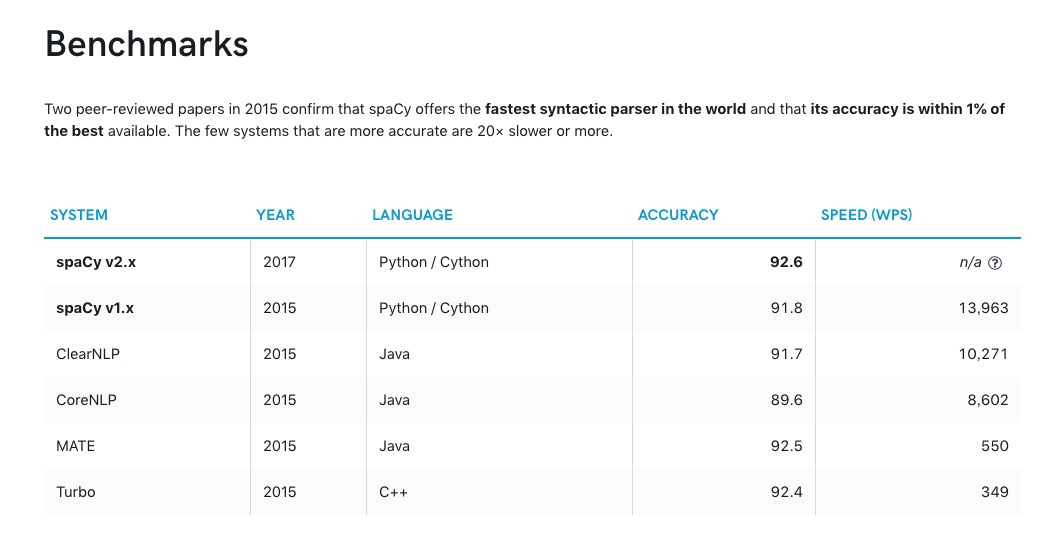
看完上述的数据分析,我们大致对于Spacy的性能有些了解。
但是我选用它,不仅仅是因为它“工业级别”的性能,更是因为它提供了便捷的用户调用接口,以及丰富、详细的文档。
仅举一例。
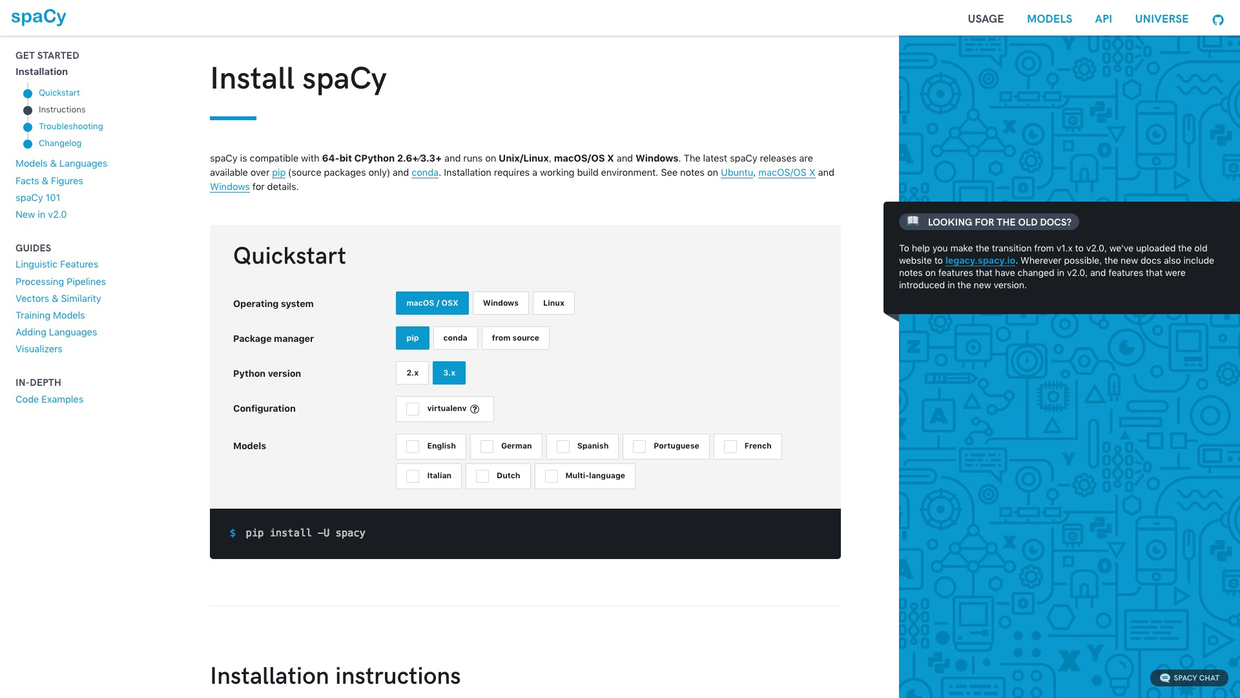
上图是Spacy上手教程的第一页。
可以看到,左侧有简明的树状导航条,中间是详细的文档,右侧是重点提示。
仅安装这一项,你就可以点击选择操作系统、Python包管理工具、Python版本、虚拟环境和语言支持等标签。网页会动态为你生成安装的语句。
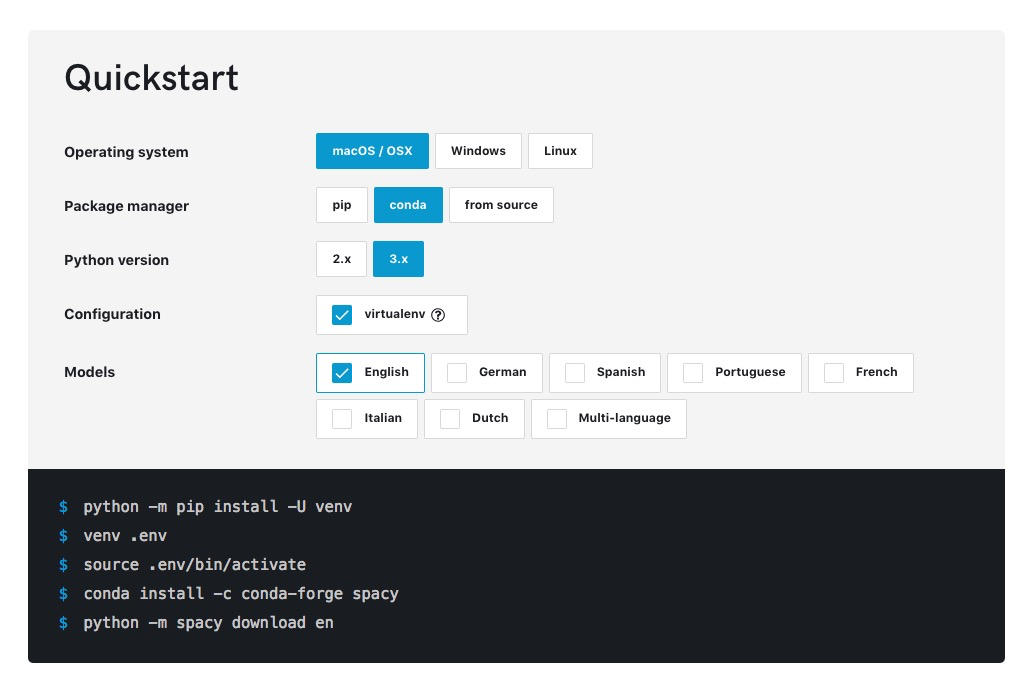
这种设计,对新手用户,很有帮助吧?
Spacy的功能有很多。
从最简单的词性分析,到高阶的神经网络模型,五花八门。
篇幅所限,本文只为你展示以下内容:
- 词性分析
- 命名实体识别
- 依赖关系刻画
- 词嵌入向量的近似度计算
- 词语降维和可视化
学完这篇教程,你可以按图索骥,利用Spacy提供的详细文档,自学其他自然语言处理功能。
我们开始吧。
5.5.3 环境
请点击这个链接(http://t.cn/R35fElv),直接进入咱们的实验环境。
对,你没看错。
你不需要在本地计算机安装任何软件包。只要有一个现代化浏览器(包括Google Chrome, Firefox, Safari和Microsoft Edge等)就可以了。全部的依赖软件,我都已经为你准备好了。
打开链接之后,你会看见这个页面。
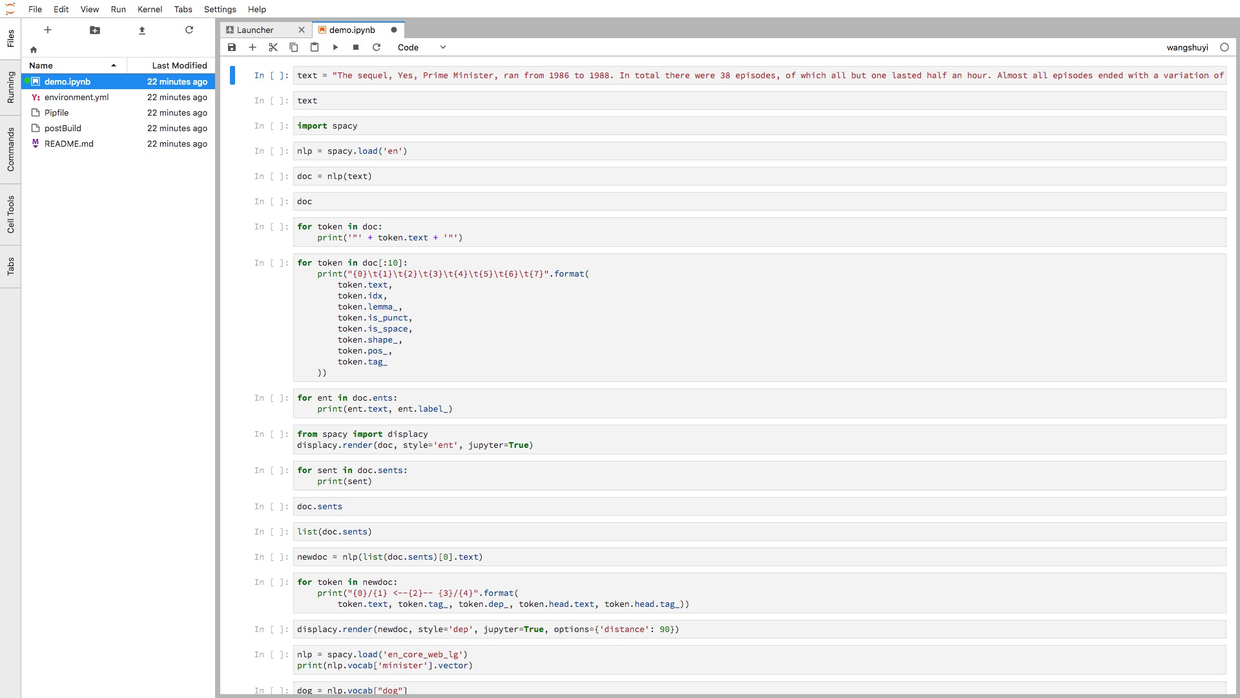
不同于之前的 Jupyter Notebook,这个界面来自 Jupyter Lab。
你可以将它理解为 Jupyter Notebook 的增强版,它具备以下特征:
- 代码单元直接鼠标拖动;
- 一个浏览器标签,可打开多个Notebook,而且分别使用不同的Kernel;
- 提供实时渲染的Markdown编辑器;
- 完整的文件浏览器;
- CSV数据文件快速浏览
- ……
图中左侧分栏,是工作目录下的全部文件。
右侧打开的,是咱们要使用的ipynb文件。
根据咱们的讲解,请你逐条执行,观察结果。
我们说一说样例文本数据的来源。
如果你之前读过我的其他自然语言处理方面的教程,应该记得这部电视剧。

对,就是“Yes, Minister”。
出于对这部80年代英国喜剧的喜爱,我还是用维基百科上“Yes, Minister”的介绍内容,作为文本分析样例。
下面,我们就正式开始,一步步执行程序代码了。
我建议你先完全按照教程跑一遍,运行出结果。
如果一切正常,再将其中的数据,替换为你自己感兴趣的内容。
之后,尝试打开一个空白 ipynb 文件,根据教程和文档,自己敲代码,并且尝试做调整。
这样会有助于你理解工作流程和工具使用方法。
5.5.4 实践
我们从维基百科页面的第一自然段中,摘取部分语句,放到text变量里面。
显示一下,看是否正确存储。
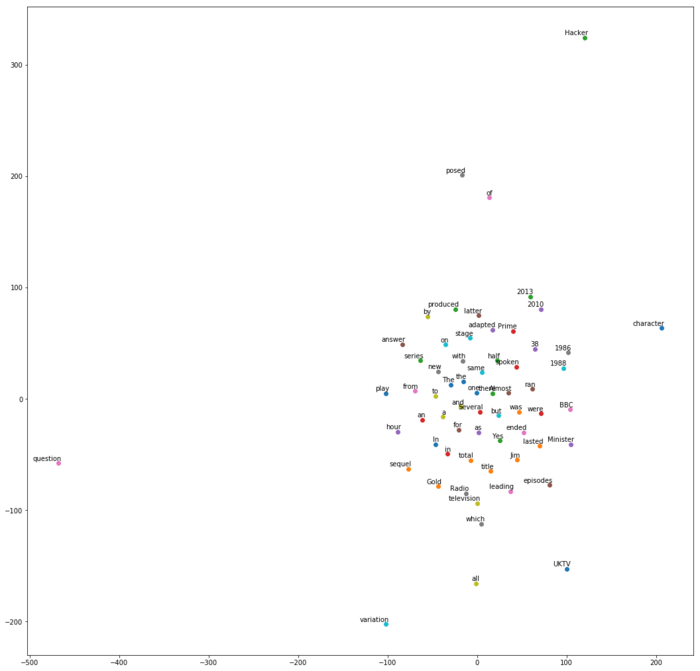
'The sequel, Yes, Prime Minister, ran from 1986 to 1988. In total there were 38 episodes, of which all but one lasted half an hour. Almost all episodes ended with a variation of the title of the series spoken as the answer to a question posed by the same character, Jim Hacker. Several episodes were adapted for BBC Radio, and a stage play was produced in 2010, the latter leading to a new television series on UKTV Gold in 2013.'没问题了。
下面我们读入Spacy软件包。
我们让Spacy使用英语模型,将模型存储到变量nlp中。
下面,我们用nlp模型分析咱们的文本段落,将结果命名为doc。
我们看看doc的内容。
The sequel, Yes, Prime Minister, ran from 1986 to 1988. In total there were 38 episodes, of which all but one lasted half an hour. Almost all episodes ended with a variation of the title of the series spoken as the answer to a question posed by the same character, Jim Hacker. Several episodes were adapted for BBC Radio, and a stage play was produced in 2010, the latter leading to a new television series on UKTV Gold in 2013.好像跟刚才的text内容没有区别呀?不还是这段文本吗?
别着急,Spacy只是为了让我们看着舒服,所以只打印出来文本内容。
其实,它在后台,已经对这段话进行了许多层次的分析。
不信?
我们来试试,让Spacy帮我们分析这段话中出现的全部词例(token)。
你会看到,Spacy为我们输出了一长串列表。
"The"
"sequel"
","
"Yes"
","
"Prime"
"Minister"
","
"ran"
"from"
"1986"
"to"
"1988"
"."
"In"
"total"
"there"
"were"
"38"
"episodes"
","
"of"
"which"
"all"
"but"
"one"
"lasted"
"half"
"an"
"hour"
"."
"Almost"
"all"
"episodes"
"ended"
"with"
"a"
"variation"
"of"
"the"
"title"
"of"
"the"
"series"
"spoken"
"as"
"the"
"answer"
"to"
"a"
"question"
"posed"
"by"
"the"
"same"
"character"
","
"Jim"
"Hacker"
"."
"Several"
"episodes"
"were"
"adapted"
"for"
"BBC"
"Radio"
","
"and"
"a"
"stage"
"play"
"was"
"produced"
"in"
"2010"
","
"the"
"latter"
"leading"
"to"
"a"
"new"
"television"
"series"
"on"
"UKTV"
"Gold"
"in"
"2013"
"."你可能不以为然——这有什么了不起?
英语本来就是空格分割的嘛!我自己也能编个小程序,以空格分段,依次打印出这些内容来!
别忙,除了词例内容本身,Spacy还把每个词例的一些属性信息,进行了处理。
下面,我们只对前10个词例(token),输出以下内容:
- 文本
- 索引值(即在原文中的定位)
- 词元(lemma)
- 是否为标点符号
- 是否为空格
- 词性
- 标记
for token in doc[:10]:
print("{0}\t{1}\t{2}\t{3}\t{4}\t{5}\t{6}\t{7}".format(
token.text,
token.idx,
token.lemma_,
token.is_punct,
token.is_space,
token.shape_,
token.pos_,
token.tag_
))结果为:
The 0 the False False Xxx DET DT
sequel 4 sequel False False xxxx NOUN NN
, 10 , True False , PUNCT ,
Yes 12 yes False False Xxx INTJ UH
, 15 , True False , PUNCT ,
Prime 17 prime False False Xxxxx PROPN NNP
Minister 23 minister False False Xxxxx PROPN NNP
, 31 , True False , PUNCT ,
ran 33 run False False xxx VERB VBD
from 37 from False False xxxx ADP IN看到Spacy在后台默默为我们做出的大量工作了吧?
下面我们不再考虑全部词性,只关注文本中出现的实体(entity)词汇。
1986 to 1988 DATE
38 CARDINAL
one CARDINAL
half an hour TIME
Jim Hacker PERSON
BBC Radio ORG
2010 DATE
UKTV Gold ORG
2013 DATE在这一段文字中,出现的实体包括日期、时间、基数(Cardinal)……Spacy不仅自动识别出了Jim Hacker为人名,还正确判定BBC Radio和UKTV Gold为机构名称。
如果你平时的工作,需要从海量评论里筛选潜在竞争产品或者竞争者,那看到这里,有没有一点儿灵感呢?
执行下面这段代码,看看会发生什么:

如上图所示,Spacy帮我们把实体识别的结果,进行了直观的可视化。不同类别的实体,还采用了不同的颜色加以区分。
把一段文字拆解为语句,对Spacy而言,也是小菜一碟。
The sequel, Yes, Prime Minister, ran from 1986 to 1988.
In total there were 38 episodes, of which all but one lasted half an hour.
Almost all episodes ended with a variation of the title of the series spoken as the answer to a question posed by the same character, Jim Hacker.
Several episodes were adapted for BBC Radio, and a stage play was produced in 2010, the latter leading to a new television series on UKTV Gold in 2013.注意这里,doc.sents并不是个列表类型。
<generator at 0x116e95e18>所以,假设我们需要从中筛选出某一句话,需要先将其转化为列表。
[The sequel, Yes, Prime Minister, ran from 1986 to 1988.,
In total there were 38 episodes, of which all but one lasted half an hour.,
Almost all episodes ended with a variation of the title of the series spoken as the answer to a question posed by the same character, Jim Hacker.,
Several episodes were adapted for BBC Radio, and a stage play was produced in 2010, the latter leading to a new television series on UKTV Gold in 2013.]下面要展示的功能,分析范围局限在第一句话。
我们将其抽取出来,并且重新用nlp模型处理,存入到新的变量newdoc中。
对这一句话,我们想要搞清其中每一个词例(token)之间的依赖关系。
for token in newdoc:
print("{0}/{1} <--{2}-- {3}/{4}".format(
token.text, token.tag_, token.dep_, token.head.text, token.head.tag_))The/DT <--det-- sequel/NN
sequel/NN <--nsubj-- ran/VBD
,/, <--punct-- sequel/NN
Yes/UH <--intj-- sequel/NN
,/, <--punct-- sequel/NN
Prime/NNP <--compound-- Minister/NNP
Minister/NNP <--appos-- sequel/NN
,/, <--punct-- sequel/NN
ran/VBD <--ROOT-- ran/VBD
from/IN <--prep-- ran/VBD
1986/CD <--pobj-- from/IN
to/IN <--prep-- from/IN
1988/CD <--pobj-- to/IN
./. <--punct-- ran/VBD很清晰,但是列表的方式,似乎不大直观。
那就让Spacy帮我们可视化吧。
结果如下:

这些依赖关系链接上的词汇,都代表什么?
如果你对语言学比较了解,应该能看懂。
不懂?查查字典嘛。
跟语法书对比一下,看看Spacy分析得是否准确。
前面我们分析的,属于语法层级。
下面我们看语义。
我们利用的工具,叫做词嵌入(word embedding)模型。
之前的文章《如何用Python从海量文本抽取主题?》(6.2)中,我们提到过如何把文字表达成电脑可以看懂的数据。

文中处理的每一个单词,都仅仅对应着词典里面的一个编号而已。你可以把它看成你去营业厅办理业务时领取的号码。
它只提供了先来后到的顺序信息,跟你的职业、学历、性别统统没有关系。
我们将这样过于简化的信息输入,计算机对于词义的了解,也必然少得可怜。
例如给你下面这个式子:
? - woman = king - queen只要你学过英语,就不难猜到这里大概率应该填写“man”。
但是,如果你只是用了随机的序号来代表词汇,又如何能够猜到这里正确的填词结果呢?
幸好,在深度学习领域,我们可以使用更为顺手的单词向量化工具——词嵌入(word embeddings )。
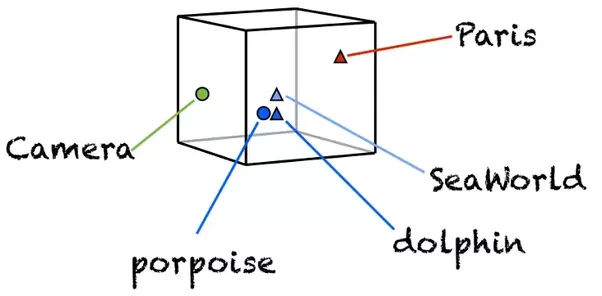
如上图这个简化示例,词嵌入把单词变成多维空间上面的向量。
这样,词语就不再是冷冰冰的字典编号,而是具有了意义。
使用词嵌入模型,我们需要Spacy读取一个新的文件。
为测试读取结果,我们让Spacy打印“minister”这个单词对应的向量取值。
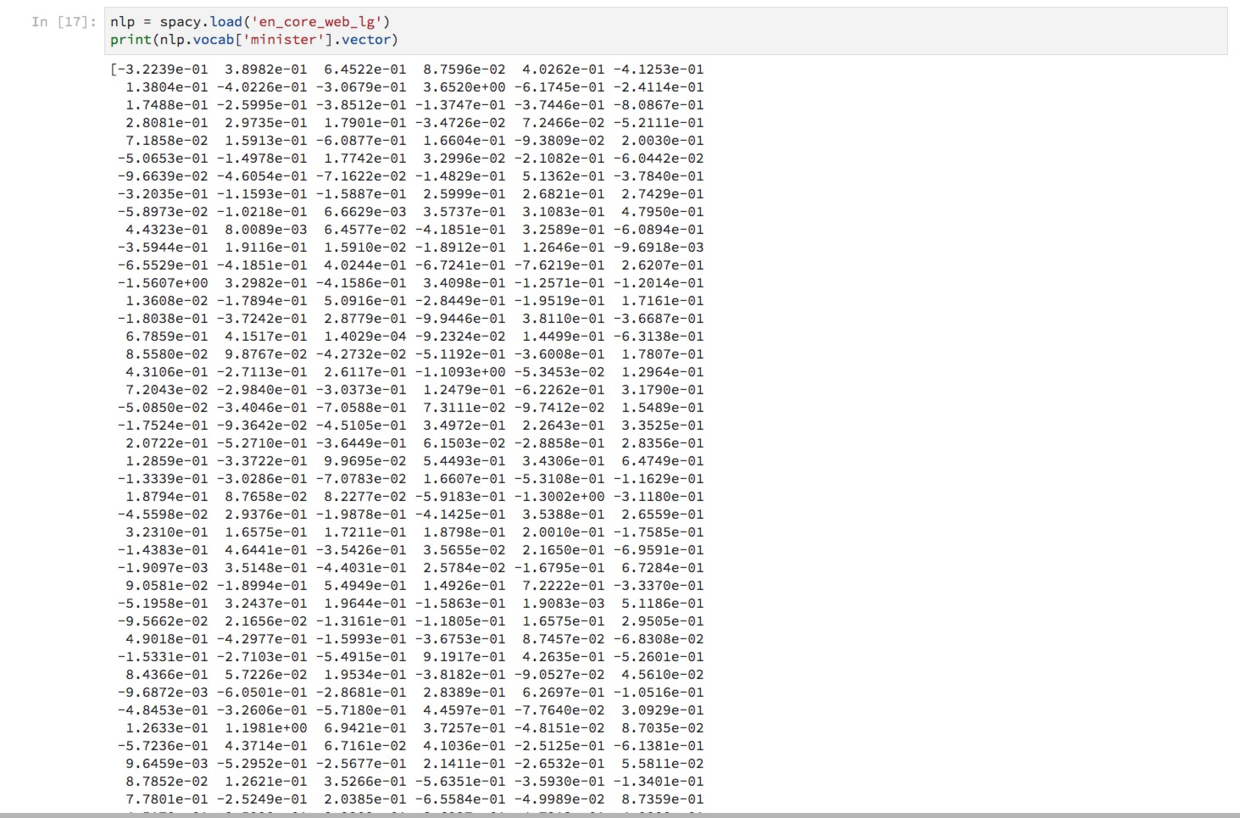
可以看到,每个单词,用总长度为300的浮点数组成向量来表示。
顺便说一句,Spacy读入的这个模型,是采用word2vec,在海量语料上训练的结果。
我们来看看,此时Spacy的语义近似度判别能力。
这里,我们将4个变量,赋值为对应单词的向量表达结果。
dog = nlp.vocab["dog"]
cat = nlp.vocab["cat"]
apple = nlp.vocab["apple"]
orange = nlp.vocab["orange"]我们看看“狗”和“猫”的近似度:
0.80168545嗯,都是宠物,近似度高,可以接受。
下面看看“狗”和“苹果”。
0.26339027一个动物,一个水果,近似度一下子就跌落下来了。
“狗”和“橘子”呢?
0.2742508可见,相似度也不高。
那么“苹果”和“橘子”之间呢?
0.5618917水果间近似度,远远超过水果与动物的相似程度。
测试通过。
看来Spacy利用词嵌入模型,对语义有了一定的理解。
下面为了好玩,我们来考考它。
这里,我们需要计算词典中可能不存在的向量,因此Spacy自带的similarity()函数,就显得不够用了。
我们从scipy中,找到相似度计算需要用到的余弦函数。
对比一下,我们直接代入“狗”和“猫”的向量,进行计算。
0.8016855120658875除了保留数字外,计算结果与Spacy自带的similarity()运行结果没有差别。
我们把它做成一个小函数,专门处理向量输入。
用我们自编的相似度函数,测试一下“狗”和“苹果”。
0.2633902430534363与刚才的结果对比,也是一致的。
我们要表达的,是这个式子:
? - woman = king - queen我们把问号,称为 guess_word
所以
guess_word = king - queen + woman我们把右侧三个单词,一般化记为 words。编写下面函数,计算guess_word取值。
def make_guess_word(words):
[first, second, third] = words
return nlp.vocab[first].vector - nlp.vocab[second].vector + nlp.vocab[third].vector下面的函数就比较暴力了,它其实是用我们计算的 guess_word 取值,和字典中全部词语一一核对近似性。把最为近似的10个候选单词打印出来。
def get_similar_word(words, scope=nlp.vocab):
guess_word = make_guess_word(words)
similarities = []
for word in scope:
if not word.has_vector:
continue
similarity = vector_similarity(guess_word, word.vector)
similarities.append((word, similarity))
similarities = sorted(similarities, key=lambda item: -item[1])
print([word[0].text for word in similarities[:10]])好了,游戏时间开始。
我们先看看:
? - woman = king - queen即:
guess_word = king - queen + woman输入右侧词序列:
然后执行对比函数:
这个函数运行起来,需要一段时间。请保持耐心。
运行结束之后,你会看到如下结果:
['MAN', 'Man', 'mAn', 'MAn', 'MaN', 'man', 'mAN', 'WOMAN', 'womAn', 'WOman']原来字典里面,“男人”(man)这个词汇有这么多的变形啊。
但是这个例子太经典了,我们尝试个新鲜一些的:
? - England = Paris - London即:
guess_word = Paris - London + England对你来讲,绝对是简单的题目。左侧国别,右侧首都,对应来看,自然是巴黎所在的法国(France)。
问题是,Spacy能猜对吗?
我们把这几个单词输入。
让Spacy来猜:
['france', 'FRANCE', 'France', 'Paris', 'paris', 'PARIS', 'EUROPE', 'EUrope', 'europe', 'Europe']结果很令人振奋,前三个都是“法国”(France)。
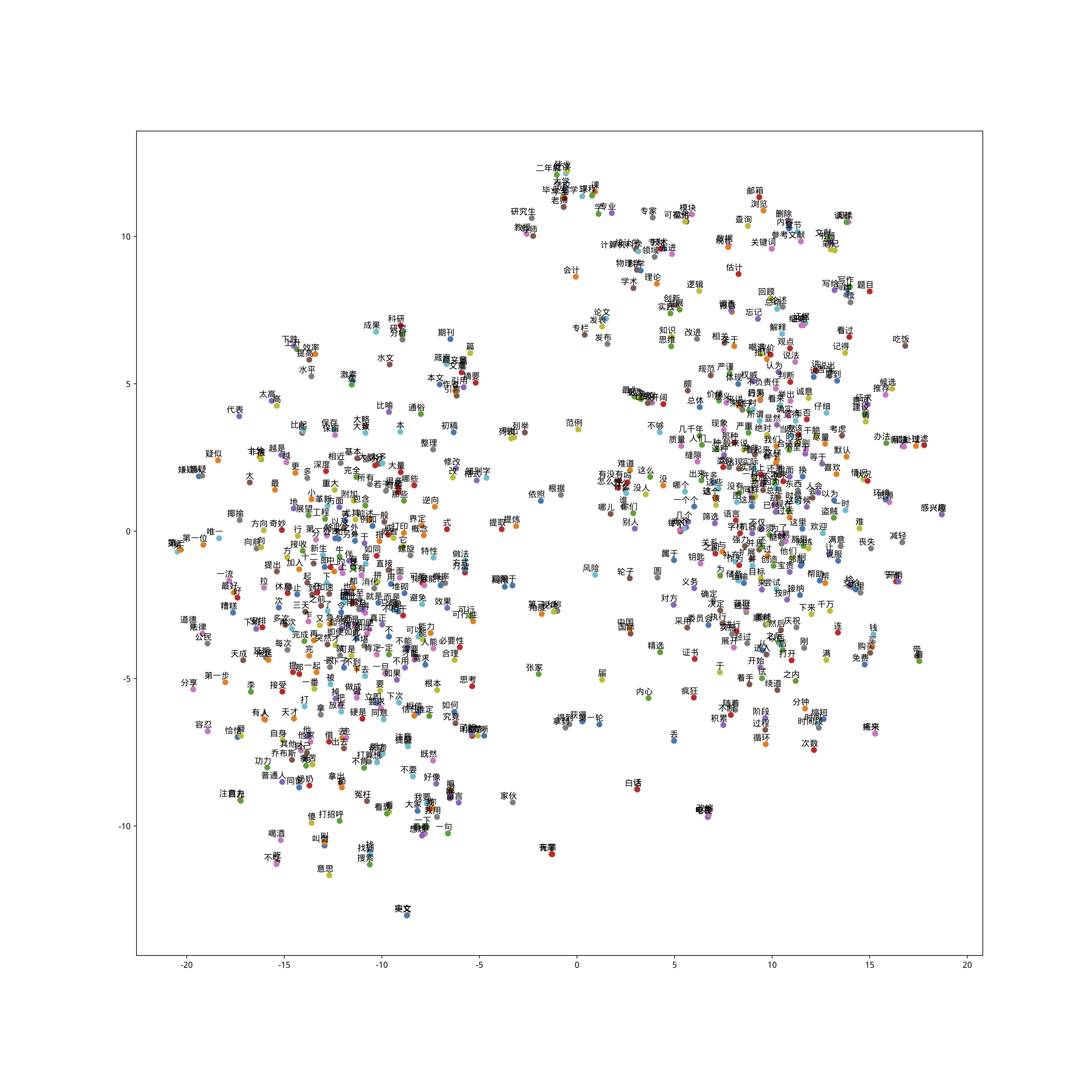
下面我们做一个更有趣的事儿,把词向量的300维的高空间维度,压缩到一张纸(二维)上,看看词语之间的相对位置关系。
首先我们需要读入numpy软件包。
我们把词嵌入矩阵先设定为空。一会儿慢慢填入。
需要演示的单词列表,也先空着。
我们再次让Spacy遍历“Yes, Minister”维基页面中摘取的那段文字,加入到单词列表中。注意这次我们要进行判断:
- 如果是标点,丢弃;
- 如果词汇已经在词语列表中,丢弃。
for token in doc:
if not(token.is_punct) and not(token.text in word_list):
word_list.append(token.text)看看生成的结果:
['The',
'sequel',
'Yes',
'Prime',
'Minister',
'ran',
'from',
'1986',
'to',
'1988',
'In',
'total',
'there',
'were',
'38',
'episodes',
'of',
'which',
'all',
'but',
'one',
'lasted',
'half',
'an',
'hour',
'Almost',
'ended',
'with',
'a',
'variation',
'the',
'title',
'series',
'spoken',
'as',
'answer',
'question',
'posed',
'by',
'same',
'character',
'Jim',
'Hacker',
'Several',
'adapted',
'for',
'BBC',
'Radio',
'and',
'stage',
'play',
'was',
'produced',
'in',
'2010',
'latter',
'leading',
'new',
'television',
'on',
'UKTV',
'Gold',
'2013']检查了一下,一长串(63个)词语列表中,没有出现标点。一切正常。
下面,我们把每个词汇对应的空间向量,追加到词嵌入矩阵中。
看看此时词嵌入矩阵的维度。
(18900,)可以看到,所有的向量内容,都被放在了一个长串上面。这显然不符合我们的要求,我们将不同的单词对应的词向量,拆解到不同行上面去。
再看看变换后词嵌入矩阵的维度。
(63, 300)63个词汇,每个长度300,这就对了。
下面我们从scikit-learn软件包中,读入TSNE模块。
我们建立一个同名小写的tsne,作为调用对象。
tsne的作用,是把高维度的词向量(300维)压缩到二维平面上。我们执行这个转换过程:
现在,我们手里拥有的 low_dim_embedding ,就是63个词汇降低到二维的向量表示了。
我们读入绘图工具包。
下面这个函数,用来把二维向量的集合,绘制出来。
如果你对该函数内容细节不理解,没关系。因为我还没有给你系统介绍过Python下的绘图功能。
好在这里我们只要会调用它,就可以了。
def plot_with_labels(low_dim_embs, labels, filename='tsne.pdf'):
assert low_dim_embs.shape[0] >= len(labels), "More labels than embeddings"
plt.figure(figsize=(18, 18)) # in inches
for i, label in enumerate(labels):
x, y = low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label,
xy=(x, y),
xytext=(5, 2),
textcoords='offset points',
ha='right',
va='bottom')
plt.savefig(filename)终于可以进行降维后的词向量可视化了。
请执行下面这条语句:
你会看到这样一个图形。
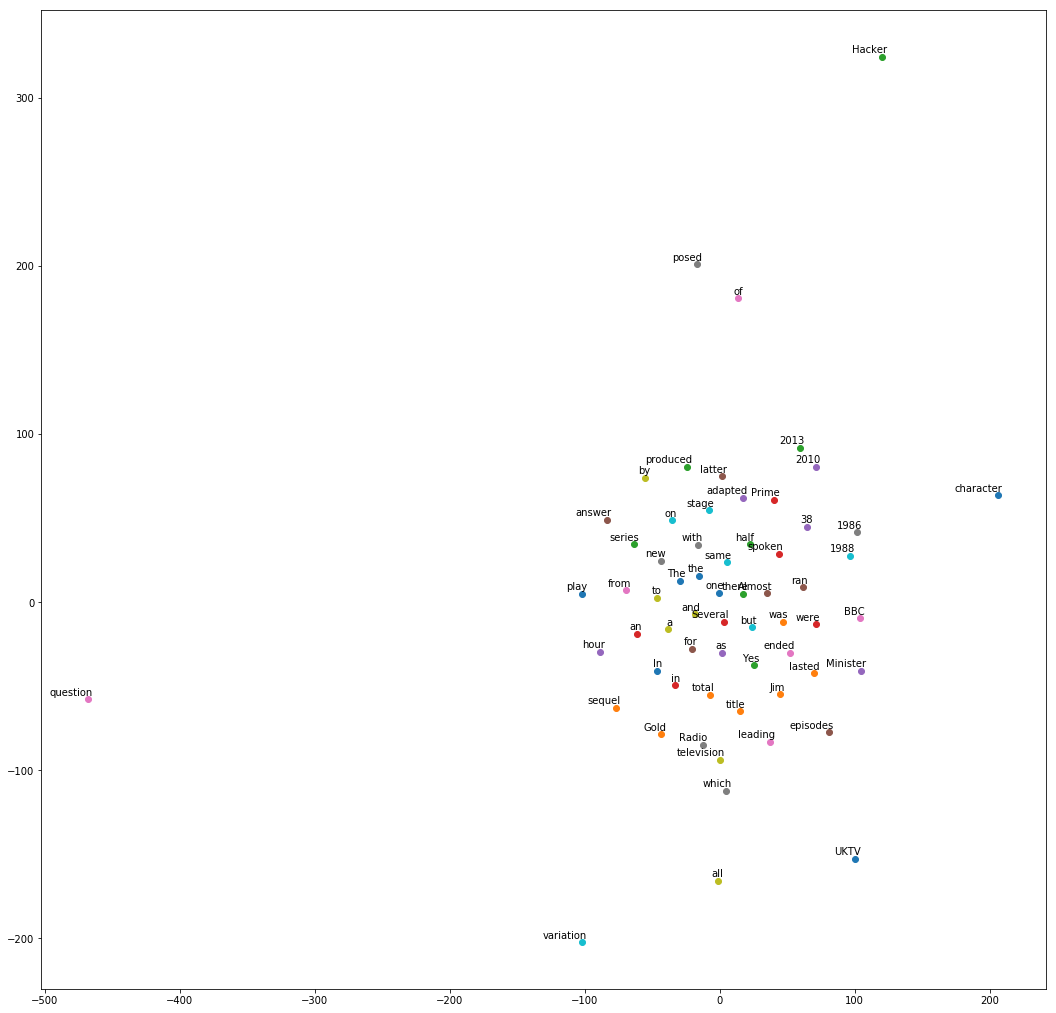
请注意观察图中的几个部分:
- 年份
- 同一单词的大小写形式
- Radio 和 television
- a 和 an
看看有什么规律没有?
我发现了一个有意思的现象——每次运行tsne,产生的二维可视化图都不一样!
不过这也正常,因为这段话之中出现的单词,并非都有预先训练好的向量。
这样的单词,被Spacy进行了随机化等处理。
因此,每一次生成高维向量,结果都不同。不同的高维向量,压缩到二维,结果自然也会有区别。
问题来了,如果我希望每次运行的结果都一致,该如何处理呢?
这个问题,作为课后思考题,留给你自行解答。
细心的你可能发现了,执行完最后一条语句后,页面左侧边栏文件列表中,出现了一个新的pdf文件。
这个pdf,就是你刚刚生成的可视化结果。你可以双击该文件名称,在新的标签页中查看。
看,就连pdf文件,Jupyter Lab也能正确显示。
下面,是练习时间。
请把ipynb出现的文本内容,替换为你感兴趣的段落和词汇,再尝试运行一次吧。
5.5.5 源码
执行了全部代码,并且尝试替换了自己需要分析的文本,成功运行后,你是不是很有成就感?
你可能想要更进一步挖掘Spacy的功能,并且希望在本地复现运行环境与结果。
没问题,请使用这个链接(http://t.cn/R35MIKh)下载本文用到的全部源代码和运行环境配置文件(Pipenv)压缩包。
如果你知道如何使用github(10.3,也欢迎用这个链接(http://t.cn/R35MEqk))访问对应的github repo,进行clone或者fork等操作。
当然,要是能给我的repo加一颗星,就更好了。
谢谢!
5.5.6 小结
本文利用Python自然语言处理工具包Spacy,非常简要地为你演示了以下NLP功能:
- 词性分析
- 命名实体识别
- 依赖关系刻画
- 词嵌入向量的近似度计算
- 词语降维和可视化
希望学过之后,你成功地在工具箱里又添加了一件趁手的兵器。
愿它在以后的研究和工作中,助你披荆斩棘,马到成功。
加油!
5.6 如何用 Python 和 gensim 调用中文词嵌入预训练模型?
利用 Python 和 Spacy 尝试过英文的词嵌入模型后,你是不是很想了解如何对中文词语做向量表达,让机器建模时捕捉更多语义信息呢?这份视频教程,会手把手教你操作。
5.6.1 疑问
写过《如何用Python处理自然语言?(Spacy与Word Embedding)》(5.5)一文后,不少同学留言或私信询问我,如何用 Spacy 处理中文词语,捕捉更多语义信息。
回顾一下, 利用词嵌入预训练模型,Spacy 可以做许多很酷的事情。
例如计算词语之间的相似程度:
这是“狗”和“猫”的相似度:
0.80168545这是“狗”和“橘子”的相似度:
0.2742508还可以利用特征语义,计算结果。
例如做个完形填空:
? - woman = king - queen你一眼就看出来了,应该填写“man”(男人),对吧?
把式子变换一下:
guess_word = king - queen + woman输入右侧词序列:
执行对比函数后,你会看到如下结果:
['MAN', 'Man', 'mAn', 'MAn', 'MaN', 'man', 'mAN', 'WOMAN', 'womAn', 'WOman']这证明了词嵌入模型捕获到了性别的差异,并且知道“男人”与“女人”、“国王”与“女王”在其他特征维度上的相似性。
另外,我们还可以把词语之间的关系,压缩到一个二维平面查看。
令人略感遗憾的是,以上的例子,都是英文的。
那么中文呢?
中文可不可以也这样做语义计算,和可视化?
答案是:
可以。
可惜 Spacy 这个软件包内置支持的语言列表,暂时还不包括中文。

但谁说用 Python 做词嵌入,就一定得用 Spacy ?
我们可以使用其他工具。
5.6.2 工具
我们这次使用的软件包,是 Gensim 。
它的 slogan 是:
Topic modelling for humans.

如果你读过我的《如何用Python爬数据?(一)网页抓取](#crawl-the-web-data-with-python)》和《[如何用 pipenv 克隆 Python 教程代码运行环境?(含视频讲解)》(2.3),那你应该记得,我非常推崇这些适合于人类使用的软件包。
Gensim 包很强大,甚至可以直接用来做情感分析和主题挖掘(关于主题挖掘的含义,可以参考我的《如何用Python从海量文本抽取主题?》(6.2)一文)。
而且,实现这些功能, Gensim 用到的语句非常简洁精炼。
这篇教程关注中文词嵌入模型,因而对其他功能就不展开介绍了。
如何使用 Gensim 处理中文词嵌入预训练模型呢?
我做了个视频教程给你。
5.6.3 视频教程
教程中,我们使用的预训练模型来自于 Facebook ,叫做 fasttext 。
它的 github 链接在这里。
视频里,我一步步为你展示语义计算与可视化功能的实现步骤,并且进行了详细的解释说明。
我采用 Jupyter Notebook 撰写了源代码,然后调用 mybinder ,把教程的运行环境扔到了云上。
请点击这个链接(http://t.cn/RBSyEhp),直接进入咱们的实验环境。
你不需要在本地计算机安装任何软件包。只要有一个现代化浏览器(包括Google Chrome, Firefox, Safari和Microsoft Edge等)就可以了。全部的依赖软件,我都已经为你准备好了。
如果你对这个代码运行环境的构建过程感兴趣,欢迎阅读我的《如何用iPad运行Python代码?》(8.4)一文。
浏览器中开启了咱们的环境后,请你观看我给你录制的视频教程。
视频教程的链接在这里。
希望你能跟着教程,实际操作一遍。这样收获会比较大。
通过本教程,希望你已经掌握了以下知识:
- 如何用 gensim 建立语言模型;
- 如何把词嵌入预训练模型读入;
- 如何根据语义,查找某单词近似词汇列表;
- 如何利用语义计算,进行查询;
- 如何用字符串替换与结巴分词对中文文本做预处理;
- 如何用 tsne 将高维词向量压缩到低维;
- 如何可视化压缩到低维的词汇集合;
如果你希望在本地,而非云端运行本教程中的样例,请使用这个链接(http://t.cn/R1T4400)下载本文用到的全部源代码和运行环境配置文件(Pipenv)压缩包。
然后,请你参考《如何用 pipenv 克隆 Python 教程代码运行环境?》(2.3)一文的说明,利用 Pipenv ,在本地构建代码运行环境。
如果你知道如何使用github(10.3,也欢迎用这个链接(http://t.cn/RBS4Ljo))访问对应的github repo,进行clone或者fork等操作。
当然,要是能给我的repo加一颗星,就更好了。

5.7 本章小结
如果你喜欢本章的内容,欢迎扫描下面二维码,请我喝杯咖啡。

如果你需要答疑,咱们的问答社区在这里: