第 9 章 数据获取
9.1 如何用Python读取开放数据?
当你开始接触丰富多彩的开放数据集时,CSV、JSON和XML等格式名词就会奔涌而来。如何用Python高效地读取它们,为后续的整理和分析做准备呢?本文为你一步步展示过程,你自己也可以动手实践。

9.1.1 需求
人工智能的算法再精妙,离开数据也是“巧妇难为无米之炊”。
数据是宝贵的,开放数据尤其珍贵。无论是公众号、微博还是朋友圈里,许多人一听见“开放数据”、“数据资源”、“数据链接”这些关键词就兴奋不已。
好不容易拿到了梦寐以求的数据链接,你会发现下载下来的这些数据,可能有各种稀奇古怪的格式。
最常见的,是以下几种:
- CSV
- XML
- JSON
你希望自己能调用Python来清理和分析它们,从而完成自己的“数据炼金术”。
第一步,你先得学会如何用Python读取这些开放数据格式。
这篇文章,咱们就用实际的开放数据样例,分别为你介绍如何把CSV、XML和JSON这三种常见的网络开放数据格式读取到Python中,形成结构化数据框,方便你的后续分析操作。
是不是跃跃欲试了?
9.1.2 数据
我们选择的开放数据平台,是Quandl。
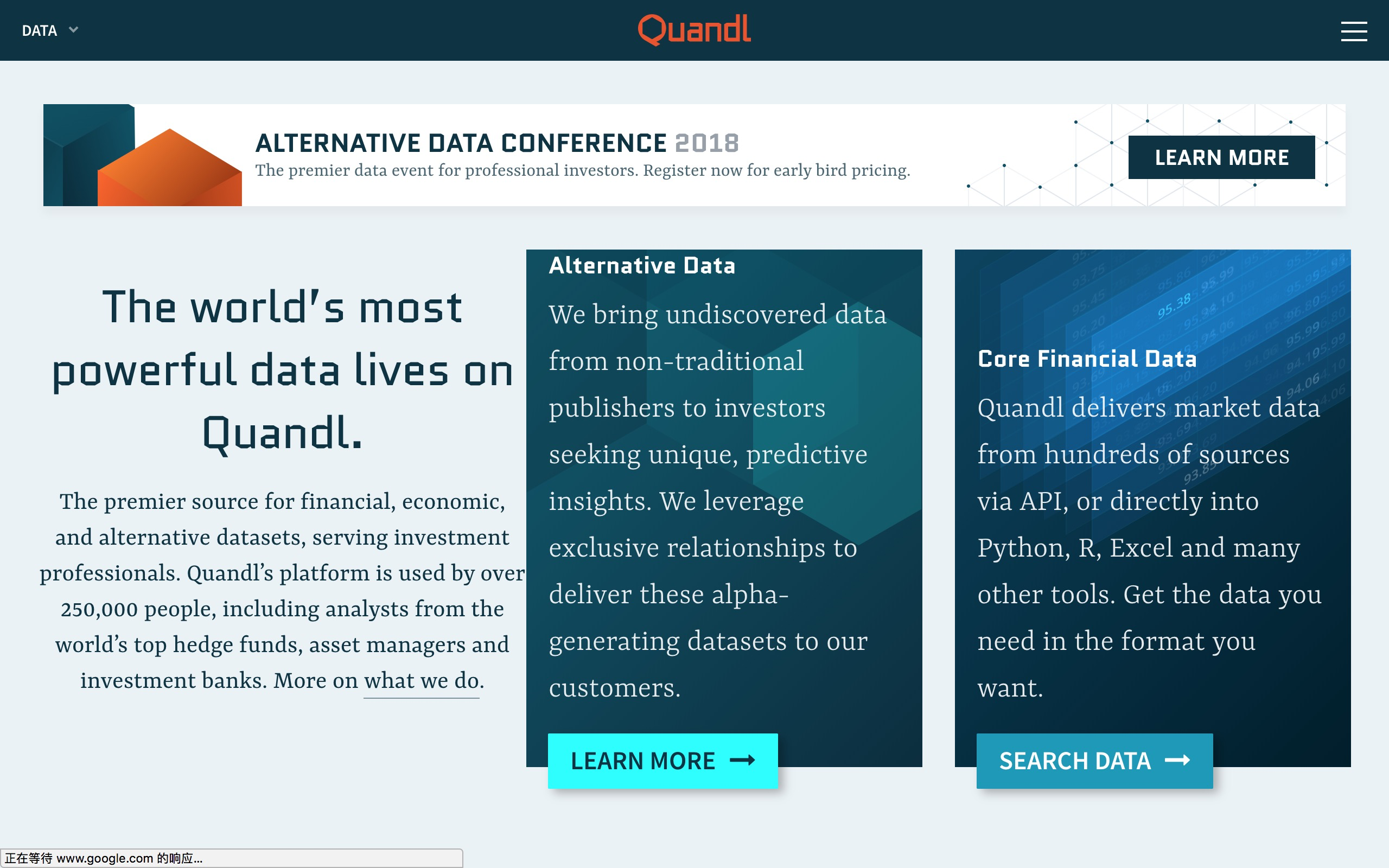
Quandl是一个金融和经济数据平台。其中既包括价格不菲的收费数据,也有不少免费开放数据。
你需要在Quandl免费注册一个账户,这样才可以正常访问其免费数据集合。
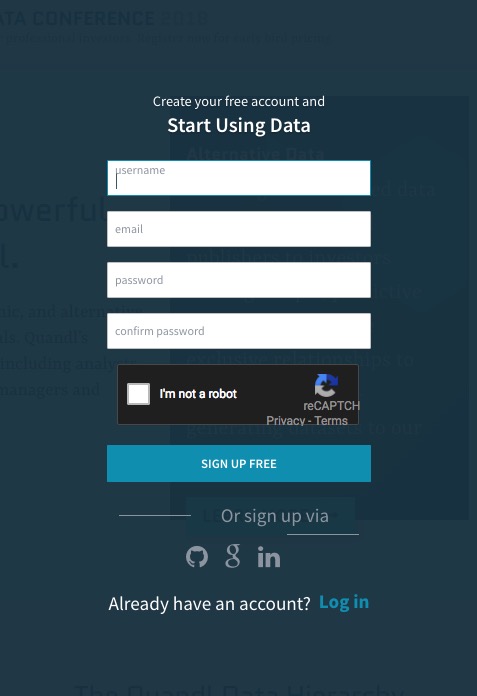
注册过程,只需要填写上面这个表格。注册完毕后,用新账户和密码登录。
登录后,点击首页上的“Core Financial Data”栏目中的“Search Data”。
你马上就看到让你眼花缭乱的数据集合了。
不要高兴得太早。仔细看数据集合右侧的标签,第一页里基本上都是“Premium”(只限会员),只有付费用户才能使用的。
你不需要自己翻页去查找免费开放数据。点击页面左侧上方的过滤器(Filter)下的“免费”(Free)选项。
这次显示的全都是免费数据了。
这些数据都包含什么内容?如果你感兴趣的话,欢迎自己花点儿时间浏览一下。
咱们使用其中的“Zillow Real Estate Research”,这是一个非常庞大的房地产数据集。
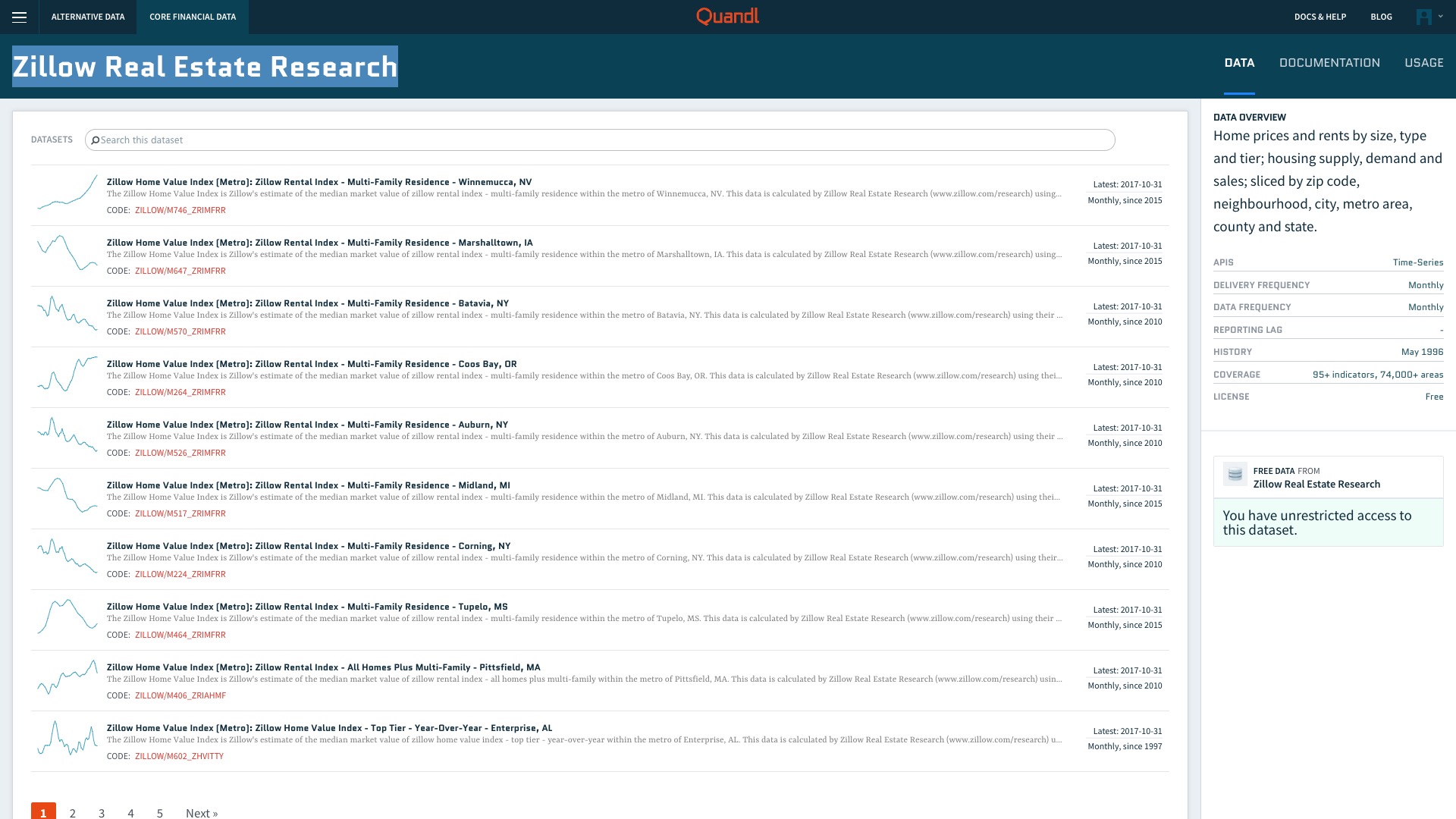
Zillow房地产数据都来自于美国城市。你可以根据自己的爱好,选择感兴趣的城市。我选择的是肯塔基州的莱克星顿(Lexington)市。
为什么不选纽约、洛杉矶,却要选它呢?
因为我在美国访学的时候,周末经常去那里。
我访问的大学坐落在村子里。本地没有华人超市,一些常见的食品和调料都买不到。
要想去华人超市,就得到最近的“大城市”莱克星顿。

从学校到那里地距离,跟天津到北京差不多。
我自己没有买车,公共交通又不方便,一开始很是苦恼。
好在留学生同胞们周末时常要去莱克星顿逛商场。我总是跟着蹭车。
一个半小时开车进城,我们先去真正的中餐馆吃一顿自助午餐,然后去商场。他们逛2个小时左右,我找个咖啡馆或者休息区闭目养神,戴着耳机听罗胖讲故事。

等他们逛完了,我们一起去华人超市采购。
这个有大商场、有正牌中餐馆、有多路公交,甚至还有华人超市的“大城市”当初给我留下了难忘的美好回忆。
就拿它当样例吧。
9.1.3 获取
搜索“lexington ky”,返回的结果还真不少。
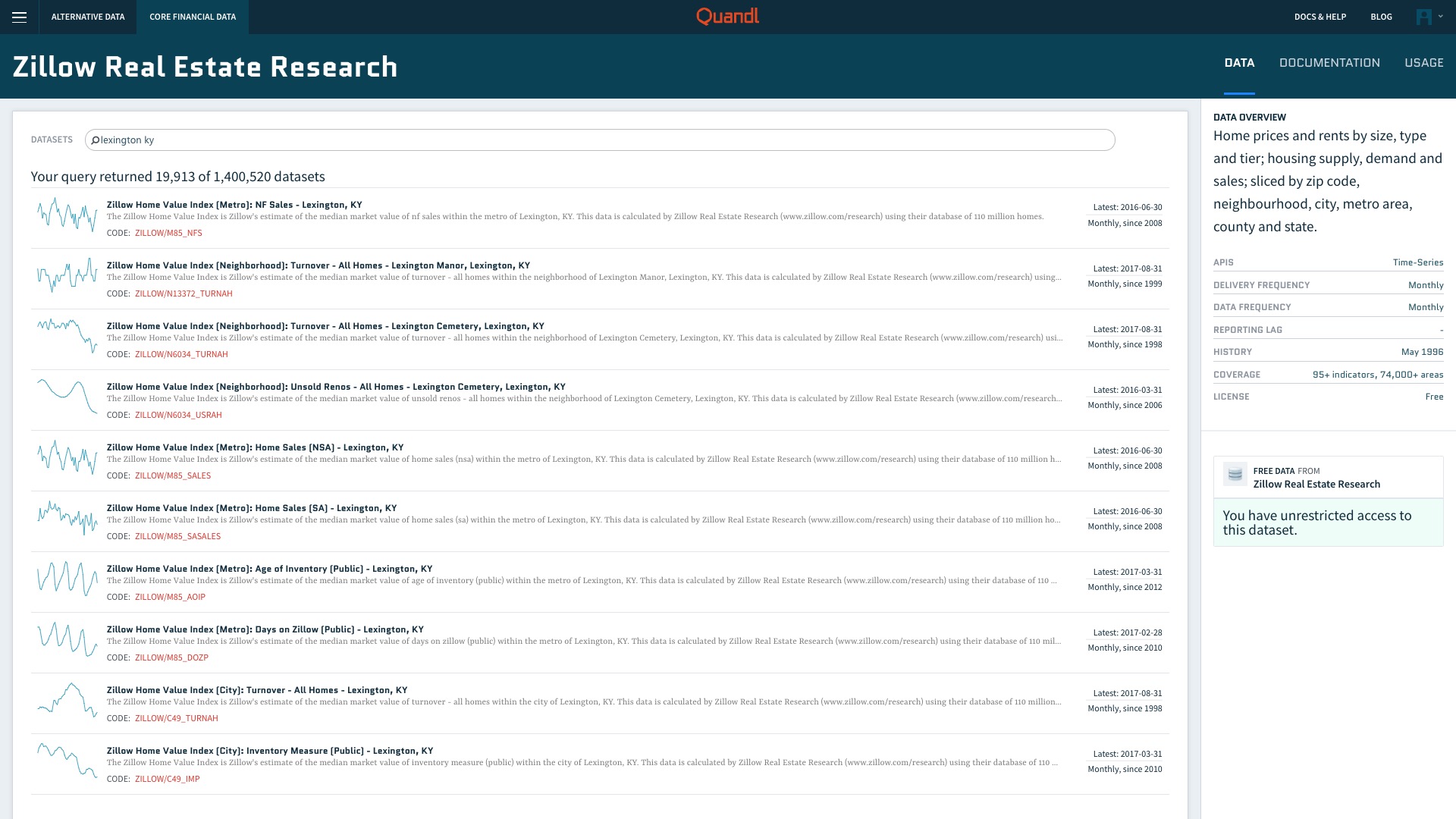
我们选择其中的“Zillow Home Value Index (Metro): Home Sales (SA) - Lexington, KY”,点击后可以看到这个数据集的页面。

这是莱克星顿房屋销售价格的中位数(median)在不同时间的记录。
Quandl已经很周到地帮我们用折线图绘制了历史价格信息的变化。选择“TABLE”标签页,我们可以查看原始数据。
下面我们把数据下载到本地。右上方有个Download按钮,我们点击它。
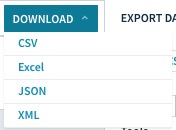
可以看到,Quandl提供了我们4种格式的数据,分别是
- CSV
- Excel
- JSON
- XML
这里咱们先不讲Excel(因为它是微软的专属格式),只依次下载其他3个类别的数据。
我们在对应的数据类别上点击鼠标右键,在弹出的浏览器菜单中选择“链接另存为”,然后存储到本地。
我已经为你下载好了相关的3种数据格式,并且存储在了一个Github项目中。请访问这个链接,下载压缩包后,解压查看。
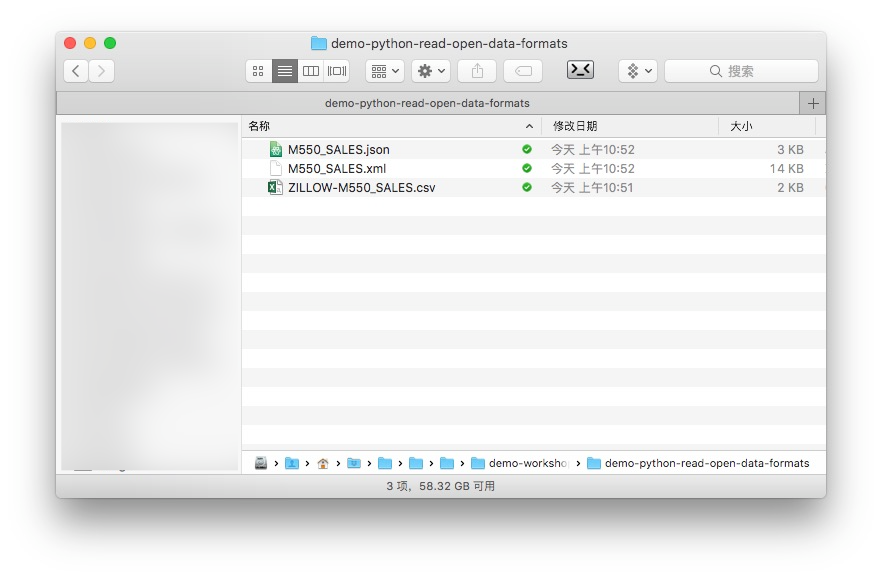
压缩包里,就是莱克星顿市房地产交易信息的三种不同格式了。从这张图里,可以看到同样的数据内容,csv文件占用空间最小,JSON次之;占空间最大的格式是XML。
数据有了,下面我们准备一下Python编程环境。
9.1.4 环境
我们使用Python集成运行环境Anaconda。
请到这个网址 下载最新版的Anaconda。下拉页面,找到下载位置。根据你目前使用的系统,网站会自动推荐给你适合的版本下载。我使用的是macOS,下载文件格式为pkg。
下载页面区左侧是Python 3.6版,右侧是2.7版。请选择2.7版本。
双击下载后的pkg文件,根据中文提示一步步安装即可。
安装好Anaconda后,我们还需要确保安装几个必要的软件包。
请到你的“终端”(Linux, macOS)或者“命令提示符”(Windows)下面,进入咱们刚刚下载解压后的样例目录。
执行以下命令:
pip install json
pip install bs4安装完毕后,执行:
jupyter notebook
这样就进入到了Jupyter笔记本环境。我们新建一个Python 2笔记本。
这样就出现了一个空白笔记本。
点击左上角笔记本名称,修改为有意义的笔记本名“demo-python-read-open-data-formats”。
至此,准备工作做完,下面我们就可以开始用Python读取不同格式的数据了。
9.1.5 CSV
我们先从最为简单的CSV格式开始。
所谓CSV,是英文“Comma Separated Values”(逗号分割数值)的简写。
我们先回到Jupyter Notebook的根目录。
打开咱们的样例csv文件,ZILLOW-M550_SALES.csv 来看看。
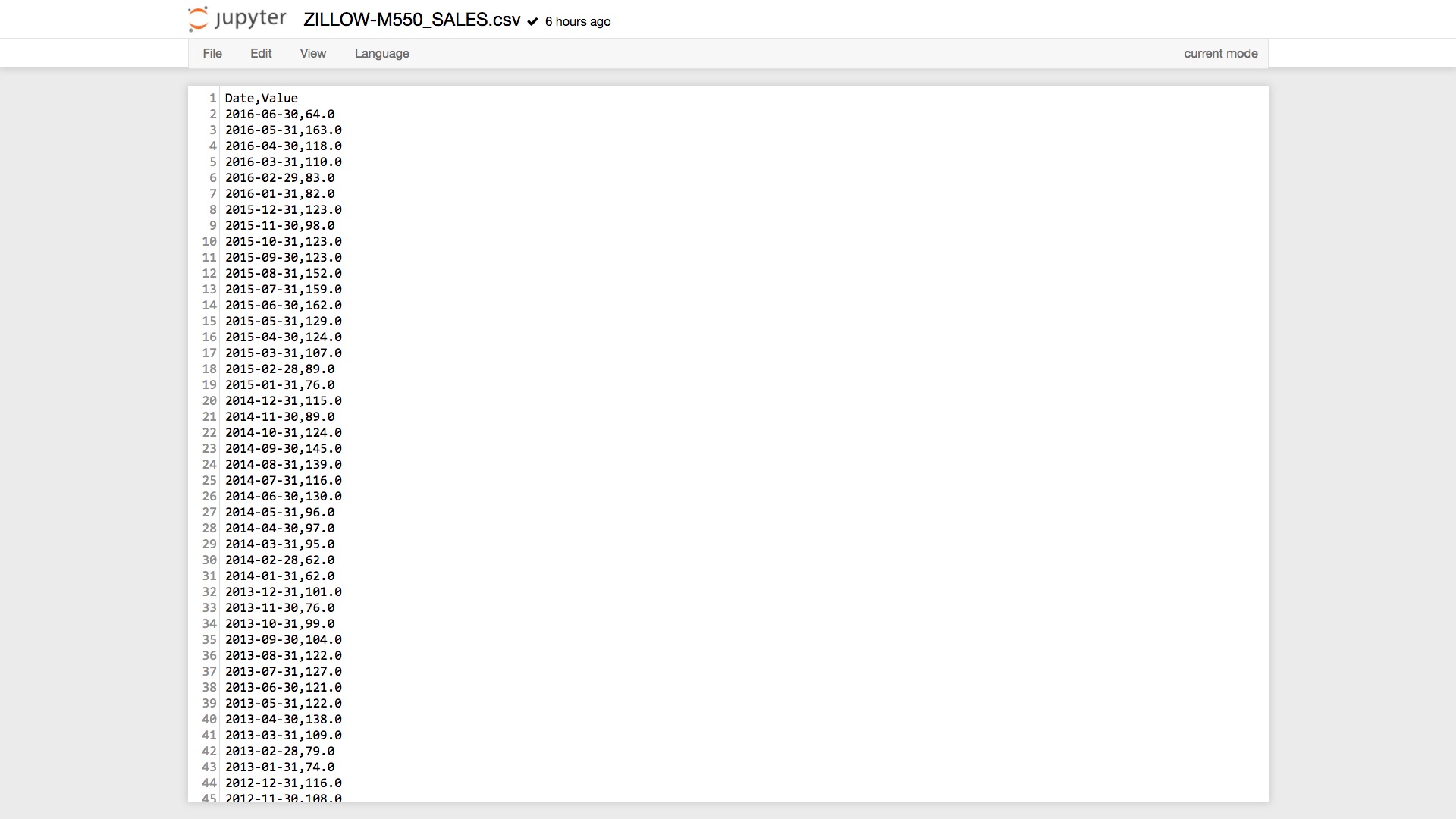
可以看到,第一行是表头,说明每一列的名称。之后每一行都是数据,分别是日期和对应的售价中位数取值。
每一行的两列数据,都是用逗号来分割的。
我们可以用Excel来打开csv数据,更直观来看看效果。

如图所示,当我们用Excel打开csv数据时,Excel自动将其识别为数据表单。逗号不见了,变成了分割好的两列若干行数据。
下面我们使用Python,将该csv数据文件读入,并且可视化。
读入Pandas工具包。它可以帮助我们处理数据框,是Python数据分析的基础工具。
然后,为了让图像可以在Jupyter Notebook上正确显示,我们使用以下语句,允许页内嵌入图像。
下面我们读入csv文件。Pandas对csv数据最为友好,提供了read_csv命令,可以直接读取csv数据。
我们把csv数据存储到了数据框变量df。下面显示一下数据读取效果。
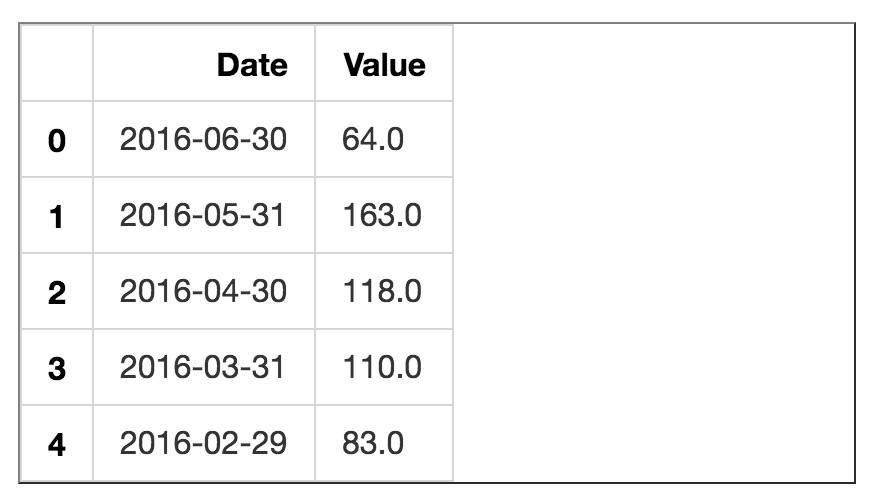
可以看到,日期和交易价格中位数记录都正确读入。
下面我们编制一个函数,帮我们整理数据框。它主要实现以下功能:
- 把列名变成小写的“date”和“value”;
- 按照时间顺序,排列数据。把最旧的日期和对应的数值放在第一行,最新的日期和对应的数值置于末尾;
- 把时间设置为数据框的索引,这主要是便于后面绘图的时候,横轴正确显示日期数据。
def arrange_time_dataframe(df):
df.columns = ['date', 'value']
df.sort_values(by='date', inplace=True)
df.set_index('date', inplace=True)
return df下面我们调用这个函数,整理数据框变量df。
我们展示一下df的前5行。

你会看到,日期数据变成了索引,而且按照升序排列。
下面我们该绘图了。数据框工具Pandas给我们提供了非常方便的时间序列图形绘制功能。
为了显示更为美观,我们把图形的长宽比例做了设置。
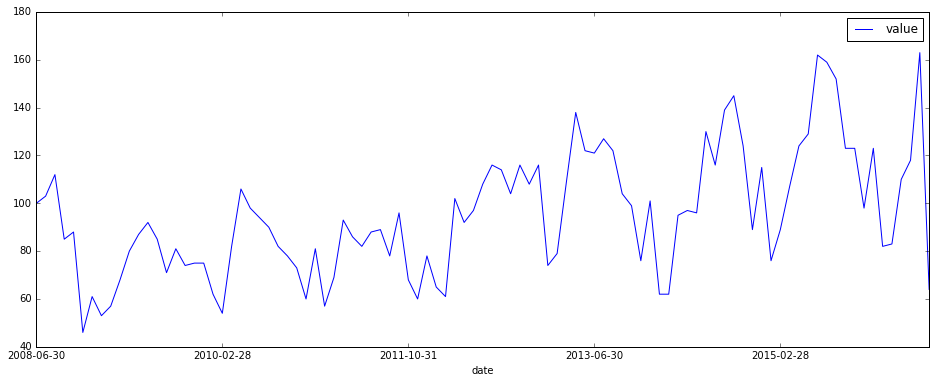
对比一下我们自己绘制的图像和Quandl的示例图形,是不是一致呢?
9.1.6 JSON
JSON是JavaScript Object Notation(JavaScript对象标记)的缩写,是一种轻量级的数据交换格式。它跟CSV一样,也是文本文件。
我们在Jupyter Notebook中打开下载的JSON文件,检视其内容:
我们需要的数据都在里面,下面我们回到Python笔记本文件ipynb中,尝试读取JSON数据内容。
首先我们读取json工具包。
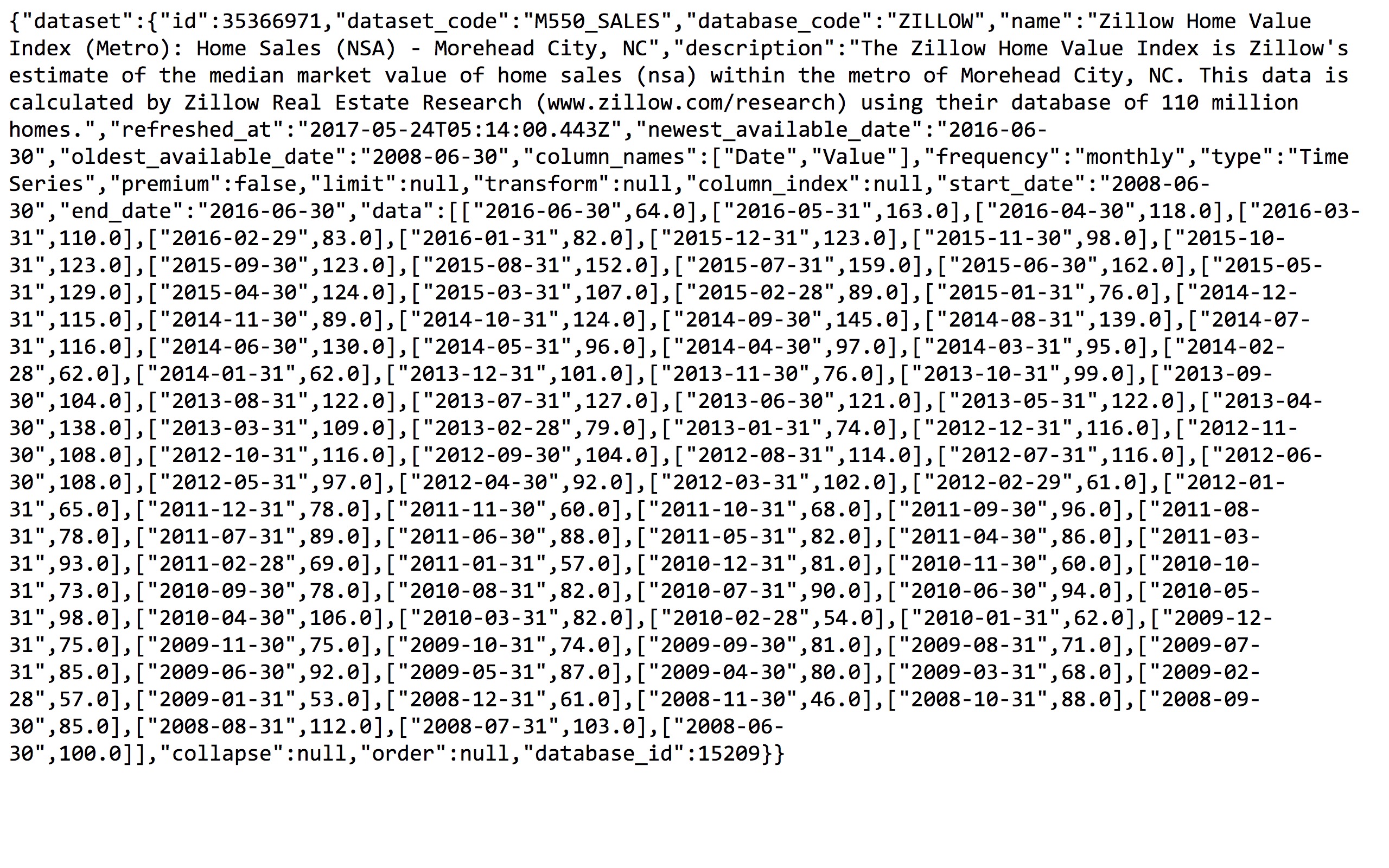
打开咱们下载的M550_SALES.json文件,读取数据到变量data。
为了看得更为直观,咱们把JSON正确缩进后输出。这里我们只展示前面的一些行。
{
"dataset": {
"dataset_code": "M550_SALES",
"column_names": [
"Date",
"Value"
],
"newest_available_date": "2016-06-30",
"description": "The Zillow Home Value Index is Zillow's estimate of the median market value of home sales (nsa) within the metro of Morehead City, NC. This data is calculated by Zillow Real Estate Research (www.zillow.com/research) using their database of 110 million homes.",
"end_date": "2016-06-30",
"data": [
[
"2016-06-30",
64.0
],
[
"2016-05-31",
163.0
],可以看到,JSON文件就像是一个大的字典(dictionary)。我们选择其中的某个索引,就能获得对应的数据。
我们选择“dataset”:
下面是结果的前几行。
{u'collapse': None,
u'column_index': None,
u'column_names': [u'Date', u'Value'],
u'data': [[u'2016-06-30', 64.0],
[u'2016-05-31', 163.0],
[u'2016-04-30', 118.0],我们关心的数据在“data”下面。继续来:
还是只展示前几行:
[[u'2016-06-30', 64.0],
[u'2016-05-31', 163.0],
[u'2016-04-30', 118.0],这不就是我们想要读取的数据吗?
为了和csv数据做出区分,我们这次将数据读取后存储在df1变量。
显示一下前几行:
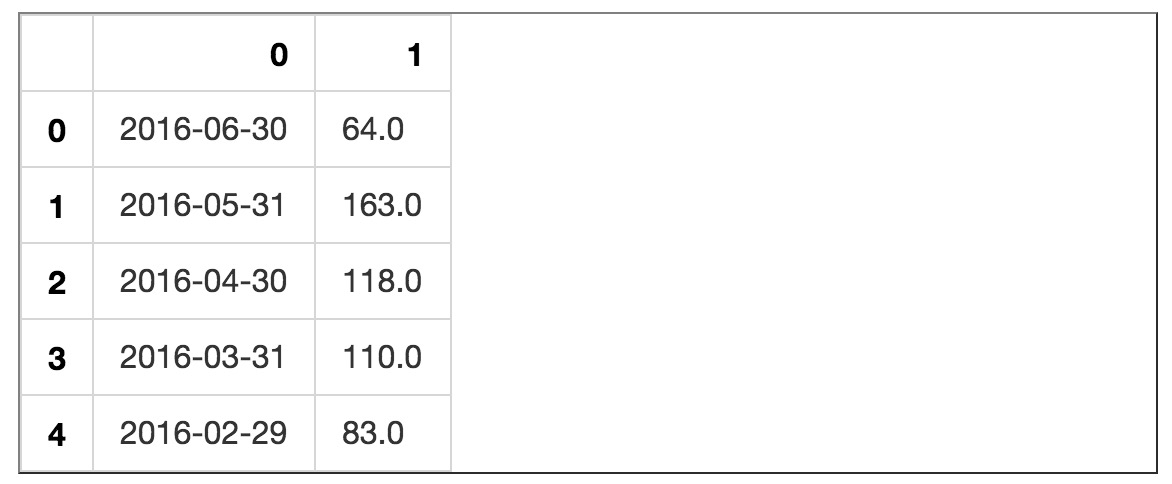
数据都对,可是列名称怪怪的。
没关系,我们刚才不是编制了整理函数吗?不管多么奇怪的列名称,都可以整理好。
整理之后,咱们再次调用绘图函数,绘制df1的数据:

绘图正确,证明我们的JSON数据读取成功。
9.1.7 XML
XML是扩展标记语言(eXtensible Markup Language)的缩写。它看起来有些像我们上网时每天都要用到的HTML源码,但是有区别。它的设计初衷,不是为了展示Web页面,而是为了数据交换。
我们在Jupyter Notebook中打开下载的XML文件。

在页面下方,我们看到了自己感兴趣的数据部分,但是数据是用很多标签来包裹的。
下面我们尝试使用Python来提取和整理XML数据。
首先,我们读入网页分析工具Beautifulsoup。
这是一个非常重要的网页信息提取工具,是Python爬虫编写的基础技能之一。
本文只会用到Beautifulsoup的一些简单命令。所以即便你之前从未接触过Beautifulsoup,也没有关系,跟着先做一遍,获得一些感性认知和经验。后面再系统学习。
我建议的系统学习方法,是到Beautifulsoup的文档页面认真阅读和学习。

如果你阅读英文文档有一些困难,可以看翻译好的中文文档,地址在这里。
然后,我们读入下载好的XML数据,存入变量data。
下面我们用“lxml”工具分析解析data数据,并且存储到soup变量里面。
解析之后,我们就可以利用Beautifulsoup的强大搜索功能了。
这里我们观察XML文件:

可以看到,我们关心的日期和交易中位数记录存放在datum标签下。
其中,日期数据的类型为“date”,交易价格中位数的类型为“float”。
我们先来尝试使用Beautifulsoup的find_all函数,提取所有的日期数据:
我们看看提取结果的前5行:
[<datum type="date">2016-06-30</datum>,
<datum type="date">2016-05-31</datum>,
<datum type="date">2016-04-30</datum>,
<datum type="date">2016-03-31</datum>,
<datum type="date">2016-02-29</datum>]很好,数据正确提取出来。问题是还有标签数据在前后,此时我们不需要它们。
我们处理一下。对列表每一项,使用Beautifulsoup的text属性提取内容。
再看看这次的提取结果:
[u'2016-06-30', u'2016-05-31', u'2016-04-30', u'2016-03-31', u'2016-02-29']好的,没问题了。
下面我们用同样的方式处理交易价格中位数记录:
显示一下结果:
[<datum type="float">64.0</datum>,
<datum type="float">163.0</datum>,
<datum type="float">118.0</datum>,
<datum type="float">110.0</datum>,
<datum type="float">83.0</datum>]这次还是有标签,需要去掉。
注意这里我们希望把结果存储为浮点数,所以除了用text属性提取数值以外,还用float()函数做了转换。
显示一下前5行:
[64.0, 163.0, 118.0, 110.0, 83.0]数据被正确转换成了浮点数。
我们手里,分别有了日期和交易价格中位数记录列表。下面我们将其转换成为Pandas数据框,并且存储于df2变量里。
看看df2的前几行:

数据我们有了,下面也用我们的自编函数整理一下:
然后我们尝试对df2绘图:
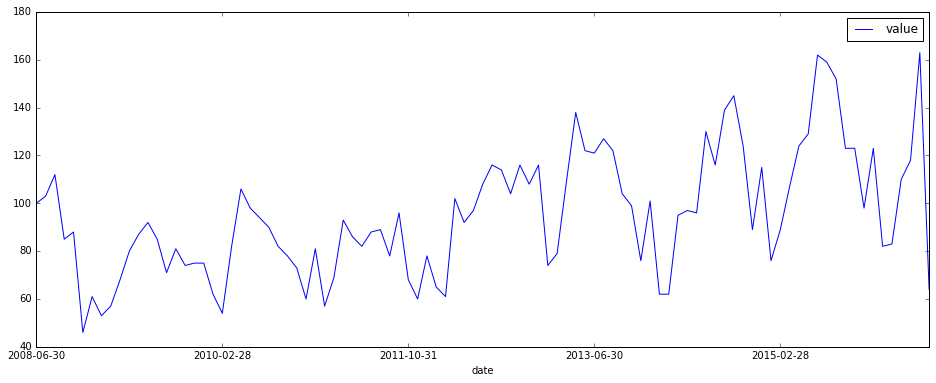
XML数据读取和检视成功。
9.1.8 小结
至此,你已经尝试了如何把CSV、JSON和XML数据读入到Pandas数据框,并且做最基本的时间序列可视化展示。
你可能会有以下疑问:
既然CSV文件这么小巧,Pandas读取起来也方便,为什么还要费劲去学那么难用的JSON和XML数据读取方法呢?
这是个好问题!
我能想到的,至少有两个原因。
首先,咱们找到的Quandl平台,全方位提供数据的下载格式,几乎涵盖了全部常见数据格式类别。但这只是特例。大多数的开放数据平台,是不提供这么多种数据格式供你下载的。因此,当你拿到的数据只有JSON或者XML格式时,了解如何读取它们,就很重要。
其次,JSON或XML附加的那些内容,绝不是无意义的。它们可以帮助你检查数据的完整性和合法性。你甚至还可以自行定义语义标准,以便和他人进行高效的数据交换。
如果你对JSON和XML格式感兴趣,希望系统学习,那我推荐你到Stanford Online这个MOOC平台上学习数据库课程。
祝进步!
9.2 如何用R和API免费获取Web数据?
API是获得Web数据的重要途径之一。想不想了解如何用R调用API,提取和整理你需要的免费Web数据呢?本文一步步为你详尽展示操作流程。

9.2.1 权衡
俗话说“巧妇难为无米之炊”。即便你已经掌握了数据分析的十八般武艺,没有数据也是苦恼的事情。“拔剑四顾心茫然”说的大概就是这种情境吧。
数据的来源有很多。Web数据是其中数量庞大,且相对容易获得的类型。更妙的是,许多的Web数据,都是免费的。
在这个号称大数据的时代,你是如何获得Web数据的呢?
许多人会使用那些别人整理好并且发布的数据集。
他们很幸运,工作可以建立在别人的基础上。这样效率最高。
但是不见得每个人都有这样的幸运。如果你需要用到的数据,偏巧没有人整理和发布过,怎么办?
其实,这样的数据数量更为庞大。我们难道对它们视而不见吗?
如果你想到了爬虫,那么你的思考方向是对的。爬虫几乎可以把一切看得见的(甚至是看不见的) Web数据,都统统帮你弄下来。然而编写和使用爬虫是有很高的成本的。包括时间资源、技术能力等。如果面对任何Web数据获取问题,你都不假思索“上大锤”,有时候很可能是“杀鸡用了牛刀”。
在“别人准备好的数据”和“需要自己爬取的数据”之间,还有很宽广的一片地带,这里就是API的天地。
API是什么?
它是Application Programming Interface的缩写。具体而言,就是某个网站,有不断积累和变化的数据。这些数据如果整理出来,不仅耗时,而且占地方,况且刚刚整理好就有过期的危险。大部分人需要的数据,其实都只是其中的一小部分,时效性的要求却可能很强。因此整理储存,并且提供给大众下载,是并不经济划算的。
可是如果不能以某种方式把数据开放出来,又会面对无数爬虫的骚扰。这会给网站的正常运行带来很多烦恼。折中的办法,就是网站主动提供一个通道。当你需要某一部分数据的时候,虽然没有现成的数据集,却只需要利用这个通道,描述你自己想要的数据,然后网站审核(一般是自动化的,瞬间完成)之后,认为可以给你,就立刻把你明确索要的数据发送过来。双方皆大欢喜。
今后你找数据的时候,也不妨先看看目标网站是否提供了API,以避免做无用功。
这个github项目里,有一份非常详尽的列表,涵盖了目前常见的主流网站API资源状况。作者还在不断整理修订,你可以把它收藏起来,慢慢看。
如果我们得知某个网站提供API,并且通过看说明文档,知道了我们需要的数据就在其中,那问题就变成了——该如何通过API来获得数据呢?
下面我们用一个实际的例子,为你全程展示操作步骤。
9.2.2 来源
我们找的样例,是维基百科。
维基百科的API总览,请参考这个页面。
假设我们关心的,是某一个时间段内,指定维基百科文章页面的访问量。
维基百科专门为我们提供了一类数据,叫做度量数据(metrics),其中就涵盖了页面访问次数这个关键值。对应API的介绍页面,在这里。
页面里有一个样例。假设你需要获得2015年10月,爱因斯坦这个词条页面的访问数量,就可以这样调用:
GET http://wikimedia.org/api/rest_v1/metrics/pageviews/per-article/en.wikipedia/all-access/all-agents/Albert_Einstein/daily/2015100100/2015103100我们可以把GET后面这一长串的网址,输入到浏览器的地址栏,然后回车,看看会得到什么结果。
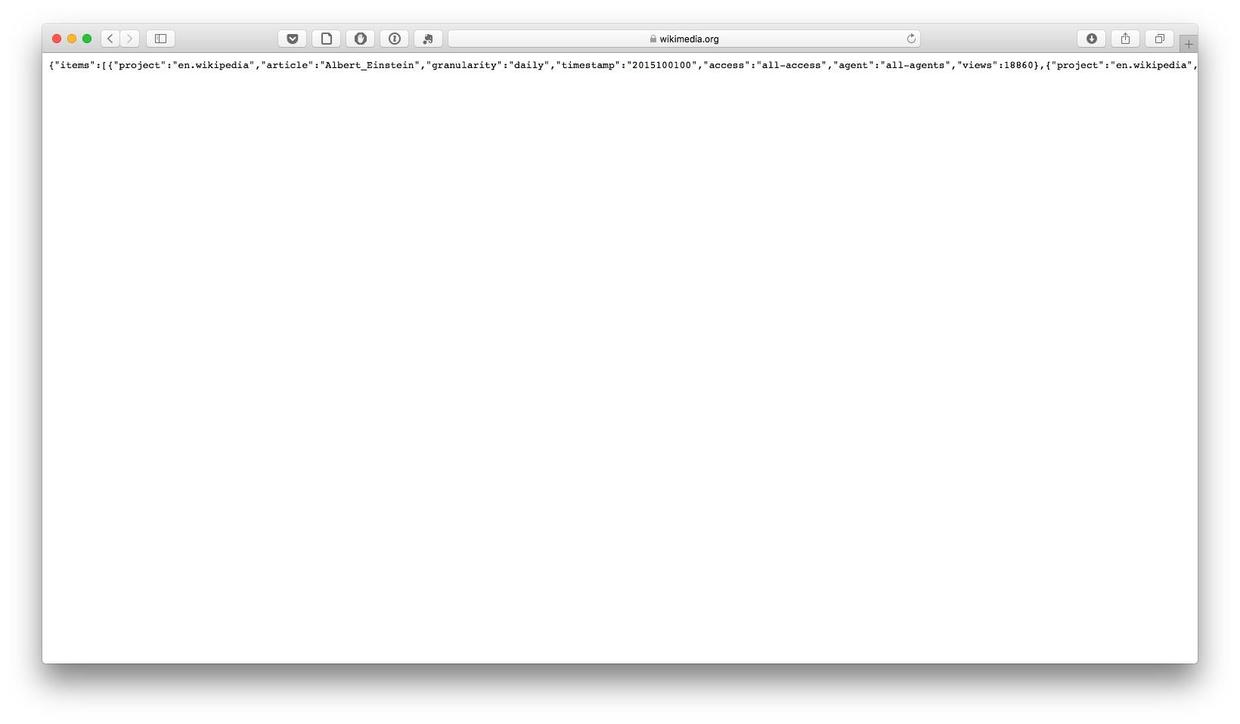
我们在浏览器里,看到上图中那一长串文字。你可能感觉很奇怪——这是什么玩意儿?
恭喜你,这就是我们需要获得的数据了。只不过,它使用了一种特殊的数据格式,叫做JSON。
JSON是目前互联网上数据交互的主流格式之一。如果你想搞清楚JSON的含义和用法,可以参考这个教程。
我们在浏览器里,初始只能看到数据最开头的一部分。但是里面已经包含了很有价值的内容:
{"items":[{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015100100","access":"all-access","agent":"all-agents","views":18860}这一段里,我们看到项目名称(en.wikipedia),文章标题(Albert Einstein),统计粒度(天),时间戳(2015年10月1日),访问类型(全部),终端类型(全部),以及访问数量(18860)。
我们用滑动条拖拽返回的文本到最后,会看到如下的信息:
{"project":"en.wikipedia","article":"Albert_Einstein","granularity":"daily","timestamp":"2015103100","access":"all-access","agent":"all-agents","views":16380}]}与10月1日的数据对比,只有时间戳(2015年10月31日)和访问数量(16380)发生了变化。
中间我们跳过的,是10月2日到10月30日之间的数据。存储格式都是一样的,也只是日期和访问量两项数据值在变化。
需要的数据都在这里,你只需要提取出相应的信息,就可以了。但是如果让你手动来做(例如拷贝需要的项,粘贴到Excel中),显然效率很低,而且很容易出错。下面我们来展示一下,如何用R编程环境来自动化完成这一过程。
9.2.3 准备
在正式用R调用API前,我们需要进行一些必要的准备工作。
首先是安装R。
请先到这个网址下载R基础安装包。

R的下载位置有很多。建议你选择清华大学的镜像,可以获得比较高的下载速度。
请根据你的操作系统平台,选择其中对应的版本下载。我用的是macOS版本。
下载得到pkg文件。双击就可以安装。
安装了基础包之后,我们继续安装集成开发环境RStudio。它可以帮助你轻松地以交互方式和R沟通。RStudio的下载地址在这里。
依据你的操作系统情况,选择对应的安装包。macOS安装包为dmg文件。双击打开后,把其中的RStudio.app图标拖动到Applications文件夹中,安装就完成了。
下面我们从应用目录中,双击运行RStudio。
我们先在RStudio的Console中,运行如下语句,安装一些需要用到的软件包:
install.packages("tidyverse")
install.packages("rlist")安装完毕后,选择菜单里的File->New,从以下界面中选择 R Notebook。

R Notebook默认提供给我们一个模板,附带一些基础使用说明。

我们尝试点击编辑区域(左侧)代码部分(灰色)的运行按钮。

立即就可以看到绘图的结果了。
我们点击菜单栏上的Preview按钮,来看整个儿代码的运行结果。运行结果会以图文并茂的HTML文件方式展示出来。
熟悉了环境后,我们该实际操作运行自己的代码了。我们把左侧编辑区的开头说明区保留,把其余部分删除,并且把文件名改成有意义的web-data-api-with-R。

至此,准备工作就绪。下面我们就要开始实际操作了。
9.2.4 操作
实际操作过程中,我们从维基百科上换另外一篇维基文章作为样例,以证明本操作方法的通用性。选择的文章是我们在介绍词云制作时使用过的,叫做“Yes, Minisiter”。这是一部1980年代的英国喜剧。

我们首先在浏览器里尝试一下,能否修改API样例里的参数,来获得“Yes, Minister”文章访问统计数据。作为测试,我们暂时只收集2017年10月1日到2017年10月3日 ,共3天的数据。
相对样例,我们需要替换的内容包括起止时间和文章标题。
我们在浏览器的地址栏输入:
https://wikimedia.org/api/rest_v1/metrics/pageviews/per-article/en.wikipedia/all-access/all-agents/Yes_Minister/daily/2017100100/2017100300返回结果如下:

数据能够正常返回,下面我们在RStudio中采用语句方式来调用。
注意下面的代码中,程序输出部分的开头会有##标记,以便和执行代码本身相区别。
一上来,我们就需要设置一下时区。不然后面处理时间数据的时候,会遇到错误。
Sys.setenv(TZ="Asia/Shanghai")然后,我们调用tidyverse软件包,它是个合集,一次性加载许多我们后面要用到的功能。
library(tidyverse)
## Loading tidyverse: ggplot2
## Loading tidyverse: tibble
## Loading tidyverse: tidyr
## Loading tidyverse: readr
## Loading tidyverse: purrr
## Loading tidyverse: dplyr
## Conflicts with tidy packages ----------------------------------------------
## filter(): dplyr, stats
## lag(): dplyr, stats这里可能会遇到一些警告内容,不要理会就可以。对咱们的操作毫不影响。
根据前面的例子,我们定义需要查询的时间跨度,并且指定要查找的维基文章名称。
注意与Python不同,R语言中,赋值采用<-标记,而不是=。不过R语言其实挺随和,你要是非得坚持用=,它也能认得,并不会报错。
starting <- "20171001"
ending <- "20171003"
article_title <- "Yes Minister"根据已经设定的参数,我们就可以生成调用的API地址了。
url <- paste("https://wikimedia.org/api/rest_v1/metrics/pageviews/per-article/en.wikipedia/all-access/all-agents",
article_title,
"daily",
starting,
ending,
sep = "/")这里我们使用的是paste函数,它帮助我们把几个部分串接起来,最后的sep指的是链接几个字符串部分时,需要使用的连接符。因为我们要形成的是类似于目录格式的网址数据,所以这里用的是分隔目录时常见的斜线。
我们检查一下生成的url地址是不是正确:
url
## [1] "https://wikimedia.org/api/rest_v1/metrics/pageviews/per-article/en.wikipedia/all-access/all-agents/Yes Minister/daily/20171001/20171003"检查完毕,结果正确。下面我们需要实际执行GET函数,来调用API,获得维基百科的反馈数据。
要执行这一功能,我们需要加载另外一个软件包,httr。它类似于Python中的request软件包,类似于Web浏览器,可以完成和远端服务器的沟通。
library(httr)然后我们开始调用。
response <-GET(url, user_agent="my@email.com this is a test")我们看看调用API的结果:
response
## Response [https://wikimedia.org/api/rest_v1/metrics/pageviews/per-article/en.wikipedia/all-access/all-agents/Yes Minister/daily/20171001/20171003]
## Date: 2017-10-13 03:10
## Status: 200
## Content-Type: application/json; charset=utf-8
## Size: 473 B注意其中的status一项。我们看到它的返回值为200。以2开头的状态编码是最好的结果,意味着一切顺利;如果状态值的开头是数字4或者5,那就有问题了,你需要排查错误。

既然我们很幸运地没有遇到问题,下面就打开返回内容看看里面都有什么吧。因为我们知道返回的内容是JSON格式,所以我们加载jsonlite软件包,以便用清晰的格式把内容打印出来。
library(jsonlite)
##
## Attaching package: 'jsonlite'
## The following object is masked from 'package:purrr':
##
## flatten然后我们打印返回JSON文本的内容。
toJSON(fromJSON(content(response, as="text")), pretty = TRUE)
## {
## "items": [
## {
## "project": "en.wikipedia",
## "article": "Yes_Minister",
## "granularity": "daily",
## "timestamp": "2017100100",
## "access": "all-access",
## "agent": "all-agents",
## "views": 654
## },
## {
## "project": "en.wikipedia",
## "article": "Yes_Minister",
## "granularity": "daily",
## "timestamp": "2017100200",
## "access": "all-access",
## "agent": "all-agents",
## "views": 644
## },
## {
## "project": "en.wikipedia",
## "article": "Yes_Minister",
## "granularity": "daily",
## "timestamp": "2017100300",
## "access": "all-access",
## "agent": "all-agents",
## "views": 578
## }
## ]
## }可以看到,3天的访问数量统计信息,以及包含的其他元数据,都正确地从服务器用API反馈给了我们。
我们把这个JSON内容存储起来。
result <- fromJSON(content(response, as="text"))检查一下存储的内容:
result
## $items
## project article granularity timestamp access agent
## 1 en.wikipedia Yes_Minister daily 2017100100 all-access all-agents
## 2 en.wikipedia Yes_Minister daily 2017100200 all-access all-agents
## 3 en.wikipedia Yes_Minister daily 2017100300 all-access all-agents
## views
## 1 654
## 2 644
## 3 578我们看看解析之后,存储的类型是什么:
typeof(result)
## [1] "list"存储的类型是列表(list)。可是为了后续的分析,我们希望把其中需要的信息提取出来,组成数据框(dataframe)。方法很简单,使用rlist这个R包,就可以轻松办到。
library(rlist)我们需要使用其中的两个方法,一个是list.select,用来把指定的信息抽取出来;一个是list.stack,用来把列表生成数据框。
df <- list.stack(list.select(result, timestamp, views))我们看看结果:
df
## timestamp views
## 1 2017100100 654
## 2 2017100200 644
## 3 2017100300 578数据抽取是正确的,包括了日期和浏览数量。但是这个日期格式不是标准格式,后面分析会有问题。我们需要做转化。
处理时间日期格式,最好的办法是用lubridate软件包。我们先调用它。
library(lubridate)
##
## Attaching package: 'lubridate'
## The following object is masked from 'package:base':
##
## date由于日期字符串后面还有表示时区的两位(这里都是0),我们需要调用stringr软件包,将其截取掉。然后才能正确转换。
library(stringr)然后我们开始转换,先用str_sub函数(来自于stringr软件包)把日期字符串的后两位抹掉,然后用lubridate软件包里面的ymd函数,将原先的字符串转换为标准日期格式。修改后的数据,我们存储回df$timestamp。
df$timestamp <- ymd(str_sub(df$timestamp, 1, -3))我们再来看看此时的df内容:
df
## timestamp views
## 1 2017-10-01 654
## 2 2017-10-02 644
## 3 2017-10-03 578至此,我们需要的数据都格式正确地保留下来了。
不过,如果为了处理每一篇文章的阅读数量,我们都这样一条条跑语句,效率很低,而且难免会出错。我们把刚才的输入语句整理成函数,后面使用起来会更加方便。
整理函数的时候,我们顺便采用dplyr包的“管道”(即你会看到的%>%符号)格式改写一下前面的内容,这样可以省却中间变量,而且看起来更为清晰明确。
get_pv <- function(article_title, starting, ending){
url <- paste("https://wikimedia.org/api/rest_v1/metrics/pageviews/per-article/en.wikipedia/all-access/all-agents",
article_title,
"daily",
starting,
ending,
sep = "/")
df <- url %>%
GET(user_agent="my@email.com this is a test") %>%
content(as="text") %>%
fromJSON() %>%
list.select(timestamp, views) %>%
list.stack() %>%
mutate(timestamp = timestamp %>%
str_sub(1,-3) %>%
ymd())
df
}我们用新定义的函数,重新尝试一下刚才的API数据获取:
starting <- "20171001"
ending <- "20171003"
article_title <- "Yes Minister"
get_pv(article_title, starting, ending)
## timestamp views
## 1 2017-10-01 654
## 2 2017-10-02 644
## 3 2017-10-03 578结果正确。
不过如果只是抓取3天的数据,我们这么大费周章就没有意思了。下面我们扩展时间范围,尝试抓取自2014年初至2017年10月10日的数据。
starting <- "20141001"
ending <- "20171010"
article_title <- "Yes Minister"
df <- get_pv(article_title, starting, ending)我们看看运行结果:
head(df)
## timestamp views
## 1 2015-07-01 538
## 2 2015-07-02 588
## 3 2015-07-03 577
## 4 2015-07-04 473
## 5 2015-07-05 531
## 6 2015-07-06 500有意思的是,数据的统计并不是从2014年开始,而是2015年7月。这究竟是由于“Yes, Minister”维基文章是2015年7月才发布?还是因为我们调用的API对检索时间范围有限制?抑或是其他原因?这个问题留作思考题,欢迎把你的答案和分析过程分享给大家。
下面,我们把获得的数据用ggplot2软件包绘制图形。用一行语句,看看几年之内,“Yes,
Minister”维基文章访问数量的变化趋势。
ggplot(data=df, aes(timestamp, views)) + geom_line()
作为一部30多年前的剧集,今天还不断有人访问其维基页面,可见它的魅力。从图中可以非常明显看到几个峰值,你能解释它们出现的原因吗?这将作为今天的另外一道习题,供你思考。
9.2.5 小结
简单回顾一下,本文我们接触到了以下重要知识点:
- 获取Web数据的三种常见方式及其应用场景;
- 常见API的目录资源获取地址和使用方法;
- 如何用R来调用API,并且从服务器反馈结果中抽取关心的数据。
希望读过本文,你能初步掌握上述内容,并且根据文中提供的链接和教程资源拓展学习相关知识。
9.3 如何用 Python 和 API 收集与分析网络数据?

本文以一款阿里云市场历史天气查询产品为例,为你逐步介绍如何用 Python 调用 API 收集、分析与可视化数据。希望你举一反三,轻松应对今后的 API 数据收集与分析任务。
9.3.1 雷同
上周的研究生课,学生分组展示实践环节第二次作业,主题是利用 API 获取、分析与可视化数据。
大家做的内容,确实五花八门。
例如这个组,调查对象是动画片《小猪佩奇》(英文名 “Peppa Pig”,又译作《粉红猪小妹》)。这部片子据说最近很火。

猜猜看,下面这一组调查对象是什么?

没错,是《权力的游戏》(Game of Thrones)。一部很好看的美剧。
主题丰富多彩,做得有声有色。
作为老师,我在下面,应该很开心吧?
不,我简直哭笑不得。
14个组中,有一多半都和他们一样,做的是维基百科页面访问量分析。
为什么会这样呢?
因为我在布置作业的时候,很贴心地给了一个样例,是我之前写的一篇教程《如何用R和API免费获取Web数据?》(9.2)。
于是,他们就都用 R 语言,来分析维基百科页面访问量了。
这些同学是不是太懒惰了?
听了他们的讲述,我发觉,其中不少同学,是非常想做些新东西的。
他们找了国内若干个云市场,去找 API 产品。
其中要价过高的 API ,被他们自动过滤了。
可即适合练手的低价或免费 API ,也不少。
问题是,他们花了很长时间,也没能搞定。
考虑到作业展示日程迫近,他们只好按照我的教程,去用 R 分析维基百科了。
于是,多组作业,都雷同。
讲到这里,他们一副不好意思的表情。
我却发觉,这里蕴藏着一个问题。
几乎所有国内云市场的 API 产品,都有丰富的文档。不少还干脆给出了各种编程语言对应调用代码。
既然示例代码都有了,为什么你还做不出来呢?
下课后,我让有疑问的同学留下,我带着他们实际测试了一款 API 产品,尝试找到让他们遭遇困境的原因。
9.3.2 市场
我们尝试的,是他们找到的阿里云市场的一款 API 产品,提供天气数据。
它来自于易源数据,链接在这里。

这是一款收费 API ,100次调用的价格为1分钱。
作为作业练习,100次调用已经足够了。
这价格,他们表示可以接受。
我自己走了一遍流程。
点击“立即购买”按钮。
你会被引领到付费页面。如果你没有登录,可以根据提示用淘宝账号登录。
支付1分钱以后,你会看到如下的成功提示。

之后,系统会提示给你一些非常重要的信息。
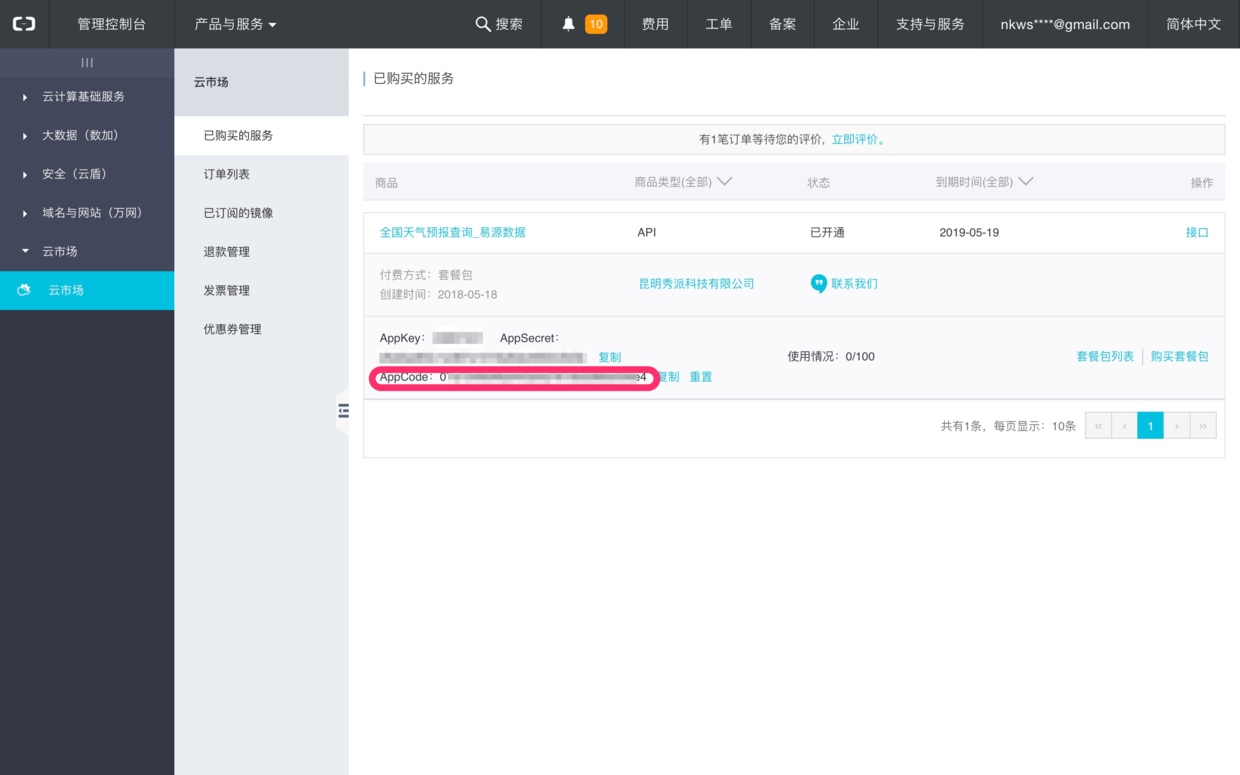
注意上图中标红的字段。
这是你的AppCode,是后面你调用 API 接口获取数据,最为重要的身份认证手段,请点击“复制”按钮把它存储下来。
点击上图中的商品名称链接,回到产品介绍的页面。
这个产品的 API 接口,提供多种数据获取功能。
学生们尝试利用的,是其中“利用id或地名查询历史天气”一项。

请注意这张图里,有几样重要信息:
- 调用地址:这是我们访问 API 的基本信息。就好像你要去见朋友,总得知道见面的地址在哪里;
- 请求方式:本例中的 GET ,是利用 HTTP 协议请求传递数据的主要形式之一;
- 请求参数:这里你要提供两个信息给 API 接口,一是“地区名称”或者“地区id”(二选一),二是月份数据。需注意格式和可供选择的时间范围。
我们往下翻页,会看到请求示例。
默认的请求示例,是最简单的 curl 。
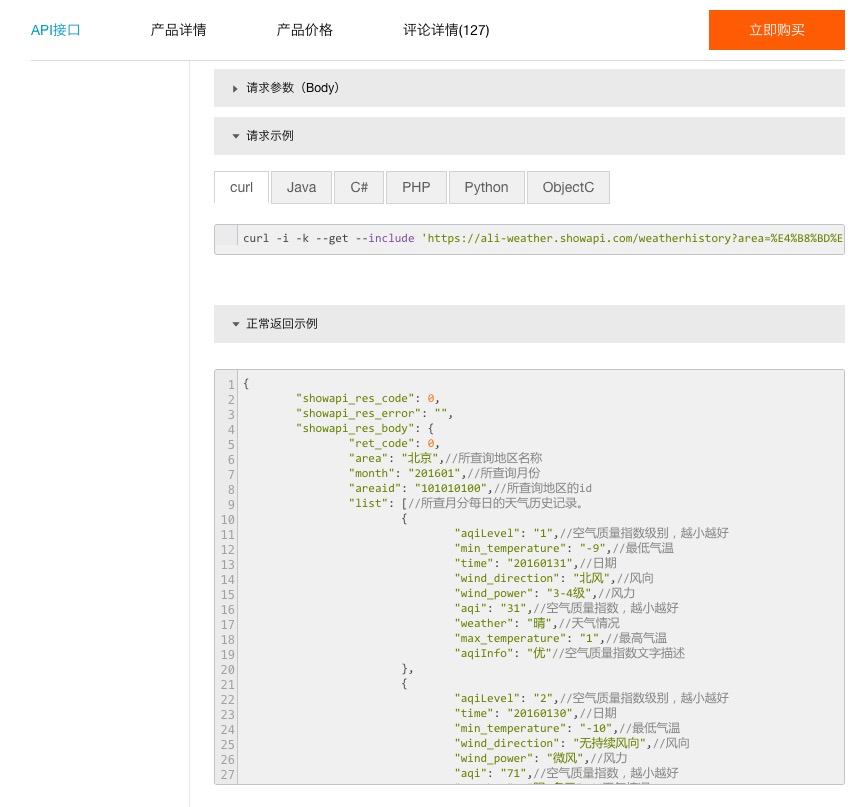
如果你的操作系统里面已经安装了 curl (没有安装的话,可以点击这个链接,寻找对应的操作系统版本下载安装),尝试把上图中 curl 开头的那一行代码拷贝下来,复制到文本编辑器里面。
就像这样:
curl -i -k --get --include 'https://ali-weather.showapi.com/weatherhistory?area=%E4%B8%BD%E6%B1%9F&areaid=101291401&month=201601' -H 'Authorization:APPCODE 你自己的AppCode'然后,一定要把其中的“你自己的AppCode”这个字符串,替换为你真实的 AppCode 。
把替换好的语句复制粘贴到终端窗口里面运行。
运行结果,如下图所示:
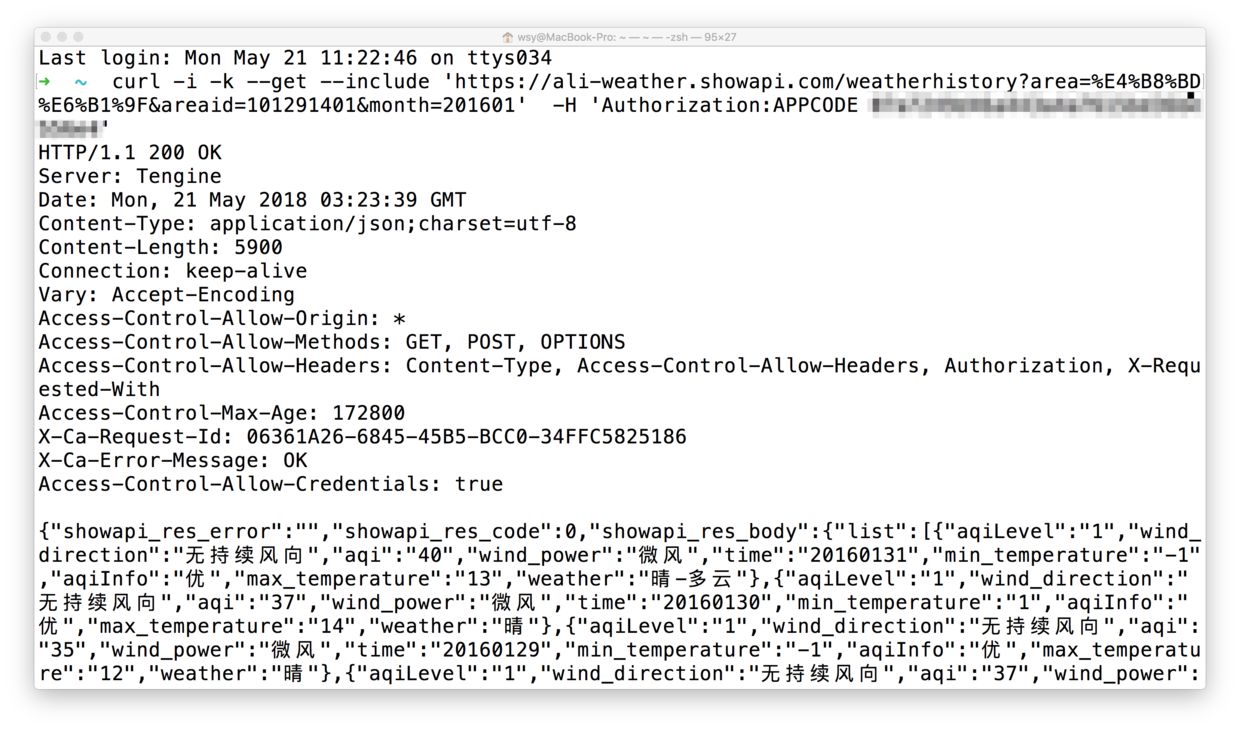
看见窗口下方包含中文的数据了吗?
利用 API 获取数据,就是这么简单。
既然终端执行一条命令就可以,那我们干嘛还要编程呢?
好问题!
因为我们需要的数据,可能不是一次调用就能全部获得。
你需要重复多次调用 API ,而且还得不断变化参数,积累获得数据。
每次若是都这样手动执行命令,效率就太低了。
API 的提供方,会为用户提供详细的文档与说明,甚至还包括样例。
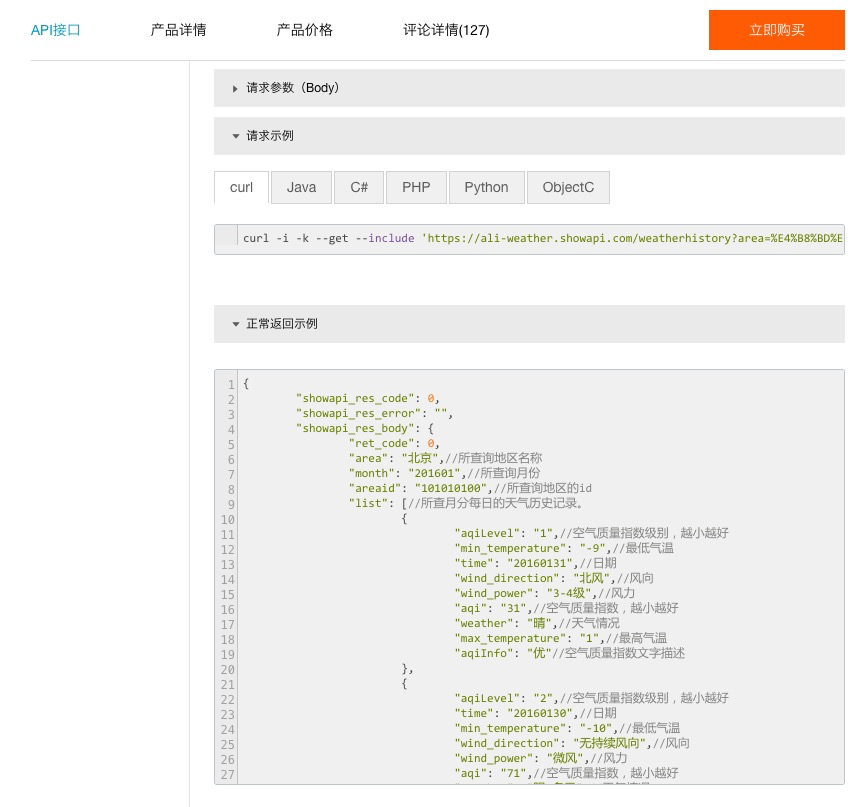
上图中,除了刚才我们使用的 curl ,还包括以下语言访问 API 接口的样例说明:
- Java
- C\#
- PHP
- Python
- Object C
我们以 Python 作为例子,点开标签页看看。

你只需要把样例代码全部拷贝下来,用文本编辑器保存为“.py”为扩展名的 Python 脚本文件,例如 demo.py 。

再次提醒,别忘了,把其中“你自己的AppCode”这个字符串,替换为你真实的 AppCode,然后保存。
在终端下,执行:
python demo.py如果你用的是 2.7 版本的 Python ,就立即可以正确获得结果了。

为什么许多学生做不出来结果呢?
我让他们实际跑了一下,发现确实有的学生粗心大意,忘了替换自己的 AppCode 。
但是大部分同学,由于安装最新版本的 Anaconda (Python 3.6版),都遇到了下面的问题:
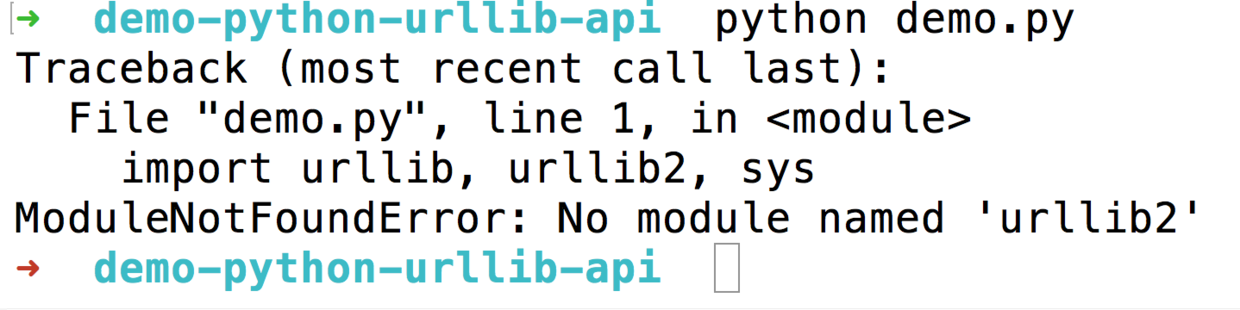
你可能会认为这是因为没有正确安装 urllib2 模块,于是执行
pip install urllib2你可能会看到下面的报错提示:

你也许尝试去掉版本号,只安装 urllib,即:
pip install urllib但是结果依然不美妙:

有些 Python 开发者看到这里,可能会嘲笑我们:Python 3版本里面,urllib 被拆分了啊!地球人都知道,你应该……
请保持一颗同理心。
想想一个普通用户,凭什么要了解不同版本 Python 之间的语句差异?凭什么要对这种版本转换的解决方式心里有数?
在他们看来,官方网站提供的样例,就应该是可以运行的。报了错,又不能通过自己的软件包安装“三板斧”来解决,就会慌乱和焦虑。
更进一步,他们也不太了解 JSON 格式。
虽然,JSON已是一种非常清晰的、人机皆可通读的数据存储方式了。
他们想了解的,是怎么把问题迁移到自己能够解决的范围内。
例如说,能否把 JSON 转换成 Excel 形式的数据框?
如果可以,他们就可以调用熟悉的 Excel 命令,来进行数据筛选、分析与绘图了。
他们还会想,假如 Python 本身,能一站式完成数据读取、整理、分析和可视化全流程,那自然更好。
但是,样例,样例在哪里呢?
在我《Python编程遇问题,文科生怎么办?》(10.1)一文中,我曾经提到过,这种样例,对于普通用户的重要性。
没有“葫芦”,他们又如何“照葫芦画瓢”呢?
既然这个例子中,官方文档没有提供如此详细的代码和讲解样例,那我就来为你绘制个“葫芦”吧。
下面,我给你逐步展示,如何在 Python 3 下,调用该 API 接口,读取、分析数据,和绘制图形。
9.3.3 环境
首先我们来看看代码运行环境。
前面提到过,如果样例代码的运行环境,和你本地的运行环境不一,计时代码本身没问题,也无法正常执行。
所以,我为你构建一个云端代码运行环境。(如果你对这个代码运行环境的构建过程感兴趣,欢迎阅读我的《如何用iPad运行Python代码?》(8.4)一文。)
请点击这个链接(http://t.cn/R3us4Ao),直接进入咱们的实验环境。
你不需要在本地计算机安装任何软件包。只要有一个现代化浏览器(包括Google Chrome, Firefox, Safari和Microsoft Edge等)就可以了。全部的依赖软件,我都已经为你准备好了。
打开链接之后,你会看见这个页面。
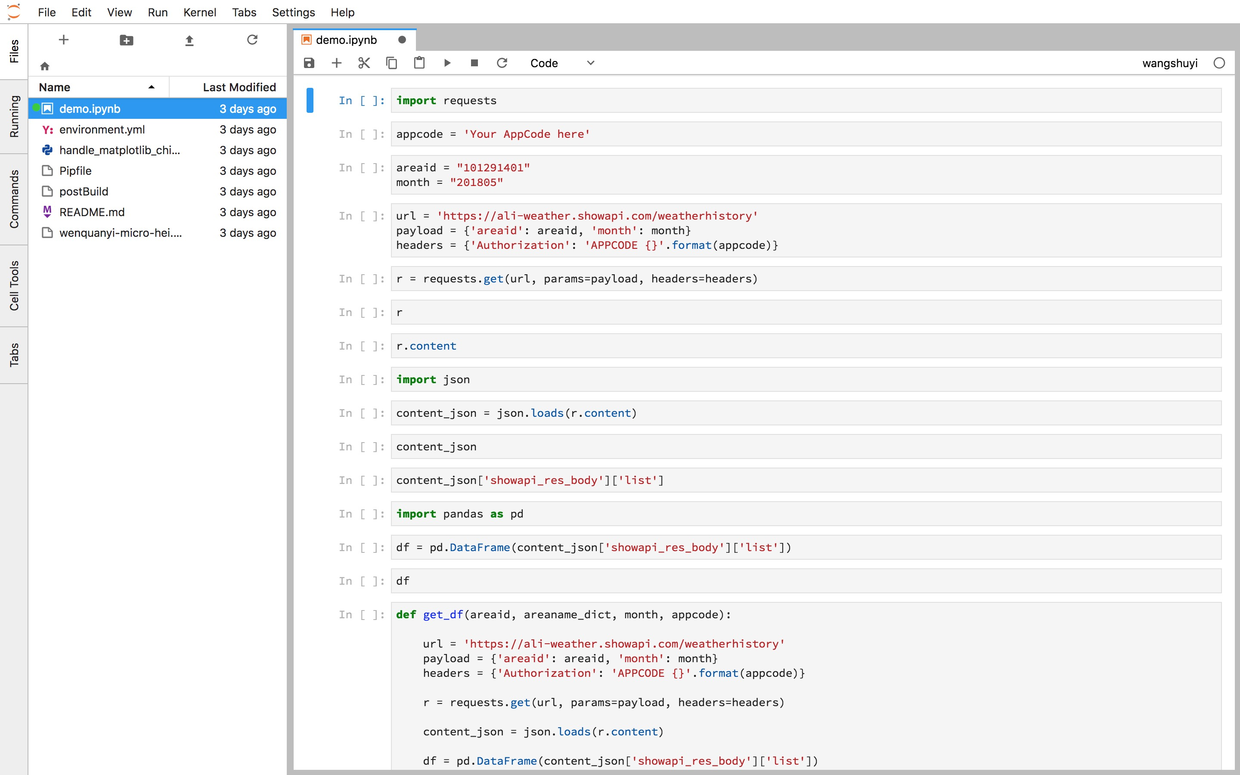
这个界面来自 Jupyter Lab。
图中左侧分栏,是工作目录下的全部文件。
右侧打开的,是咱们要使用的ipynb文件。
根据我的讲解,请你逐条执行,并仔细观察运行结果。
本例中,我们主要会用到以下两个新的软件包。
首先是号称“给人用”(for humans)的HTTP工具包requests。
这款工具,不仅符合人类的认知与使用习惯,而且对 Python 3 更加友好。作者 Kenneth Reitz 甚至在敦促所有的 Python 2 用户,赶紧转移到 Python 3 版本。
The use of Python 3 is highly preferred over Python 2. Consider upgrading your applications and infrastructure if you find yourself still using Python 2 in production today. If you are using Python 3, congratulations — you are indeed a person of excellent taste. —Kenneth Reitz
我们将用到的一款绘图工具,叫做 plotnine 。
它实际上本不是 Python 平台上的绘图工具,而是从 R 平台的 ggplot2 移植过来的。
要知道,此时 Python 平台上,已经有了 matplotlib, seaborn, bokeh, plotly 等一系列优秀的绘图软件包。
那为什么还要费时费力地,移植 ggplot2 过来呢?
因为 ggplot2 的作者,是大名鼎鼎的 R 语言大师级人物 Hadley Wickham 。
他创造 ggplot2,并非为 R 提供另一种绘图工具,而是提供另一种绘图方式。
ggplot2 完全遵守并且实现了 Leland Wilkinson 提出的“绘图语法”(Grammar of Graphics),图像的绘制,从原本的部件拆分,变成了层级拆分。

这样一来,数据可视化变得前所未有地简单易学,且功能强大。
我会在后文的“代码”部分,用详细的叙述,为你展示如何使用这两个软件包。
我建议你先完全按照教程跑一遍,运行出结果。
如果一切正常,再将其中的数据,替换为你自己感兴趣的内容。
之后,尝试打开一个空白 ipynb 文件,根据教程和文档,自己敲代码,并且尝试做调整。
这样会有助于你理解工作流程和工具使用方法。
下面我们来看代码。
9.3.4 代码
首先,读入HTTP工具包requests。
第二句里面,有“Your AppCode here”字样,请把它替换为你自己的AppCode,否则下面运行会报错。
我们尝试获取丽江5月份的天气信息。
在API信息页面上,有城市和代码对应的表格。
位置比较隐蔽,在公司简介的上方。

我把这个 Excel 文档的网址放在了这里(http://t.cn/R3T7e39),你可以直接点击下载。
下载该 Excel 文件后打开,根据表格查询,我们知道“101291401”是丽江的城市代码。

我们将其写入areaid变量。
日期我们选择本文写作的月份,即2018年5月。
下面我们就设置一下 API 接口调用相关的信息。
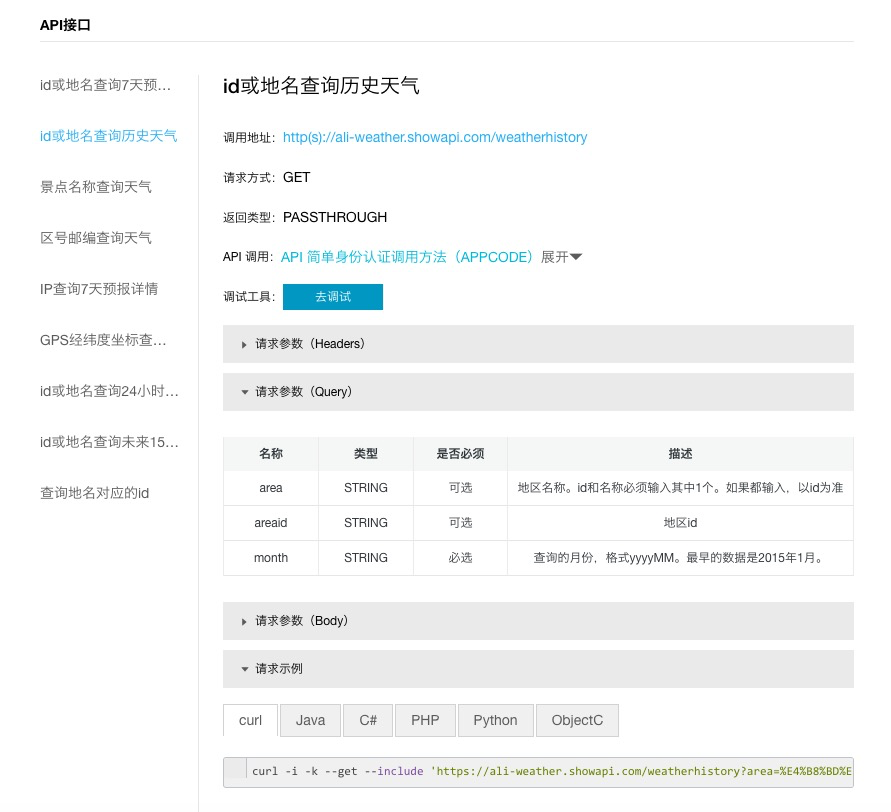
根据API信息页面上的提示,我们的要访问的网址为:https://ali-weather.showapi.com/weatherhistory,需要输入的两个参数,就是刚才已经设置的areaid和month。
另外,我们需要验证身份,证明自己已经付费了。
点击上图中蓝色的“API 简单身份认证调用方法(APPCODE)”,你会看到以下示例页面。

看来我们需要在HTTP数据头(header)中,加入 AppCode。
我们依次把这些信息都写好。
url = 'https://ali-weather.showapi.com/weatherhistory'
payload = {'areaid': areaid, 'month': month}
headers = {'Authorization': 'APPCODE {}'.format(appcode)}下面,我们就该用 requests 包来工作了。
requests 的语法非常简洁,只需要指定4样内容:
- 调用方法为“GET”
- 访问地址 url
- url中需要附带的参数,即 payload (包含
areaid和month的取值) - HTTP数据头(header)信息,即 AppCode
执行后,好像……什么也没有发生啊!
我们来查看一下:
Python 告诉我们:
<Response [200]>返回码“200”的含义为访问成功。
回顾一下,《如何用R和API免费获取Web数据?》(9.2)一文中,我们提到过:
以2开头的状态编码是最好的结果,意味着一切顺利;如果状态值的开头是数字4或者5,那就有问题了,你需要排查错误。
既然调用成功,我们看看 API 接口返回的具体数据内容吧。
调用返回值的 content 属性:

这一屏幕,密密麻麻的。
其中许多字符,甚至都不能正常显示。这可怎么好?
没关系,从 API 信息页上,我们得知返回的数据,是 JSON 格式。

那就好办了,我们调用 Python 自带的 json 包。
用 json 包的字符串处理功能(loads)解析返回内容,结果存入 content_json。
看看 content_json 结果:
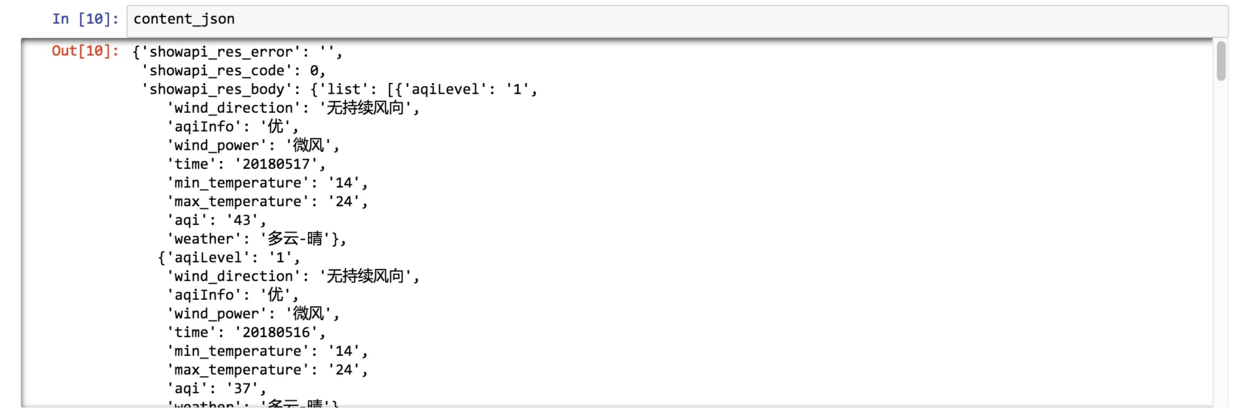
可以看到,返回的信息很完整。而且刚刚无法正常显示的中文,此时也都显现了庐山真面目。
下一步很关键。
我们把真正关心的数据提取出来。
我们不需要返回结果中的错误码等内容。
我们要的,是包含每一天天气信息的列表。
观察发现,这一部分的数据,存储在 ‘list’ 中,而 ‘list’ ,又存储在 'showapi_res_body’ 里面
所以,为选定列表,我们需要指定其中的路径:
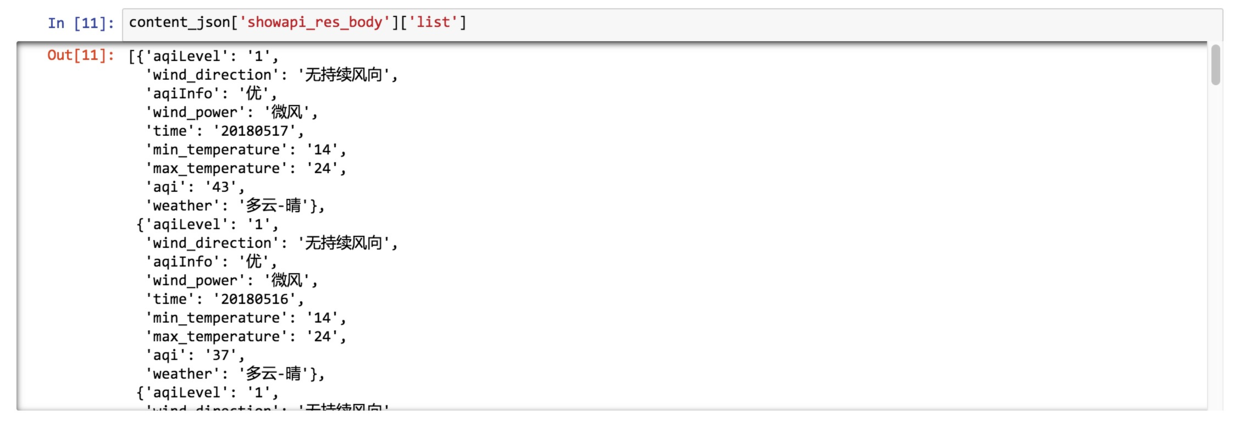
冗余信息都被去掉了,只剩下我们想要的列表。
但是对着一个列表操作,不够方便与灵活。
我们希望将列表转换为数据框。这样分析和可视化就简单多了。
大不了,我们还可以把数据框直接导出为 Excel 文件,扔到熟悉的 Excel 环境里面,去绘制图形。
读入 Python 数据框工具 pandas 。
我们让 Pandas 将刚刚保留下来的列表,转换为数据框,存入 df 。
看看内容:
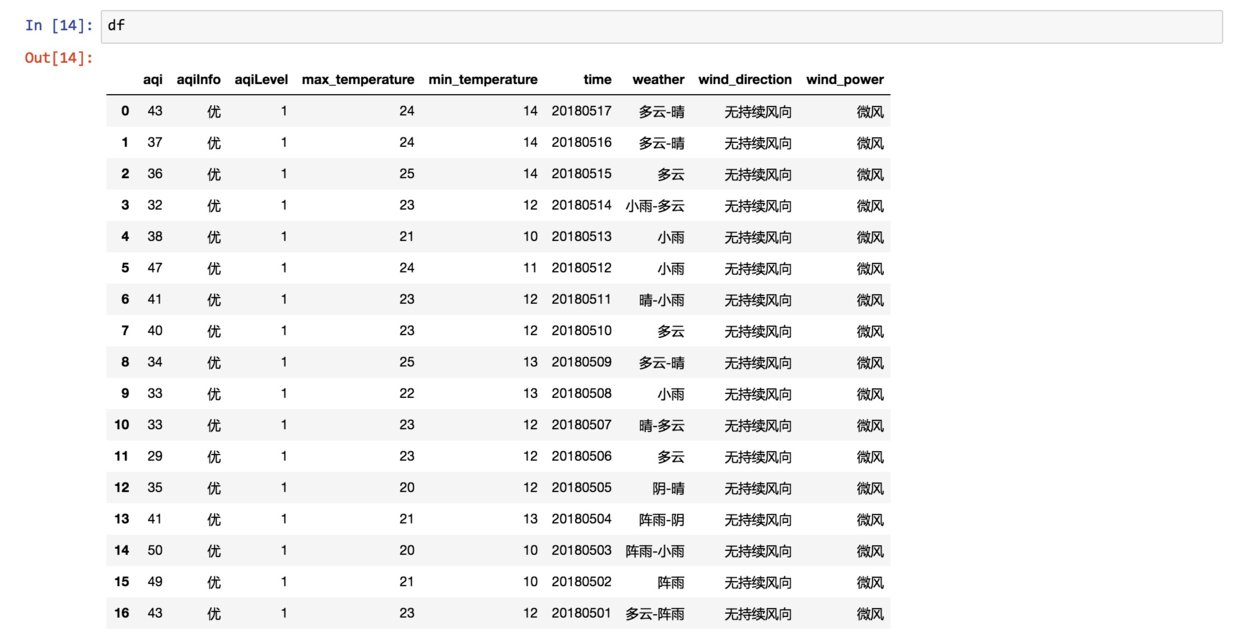
此时,数据显示格式非常工整,各项信息一目了然。
写到这里,你基本上搞懂了,如何读取某个城市、某个月份的数据,并且整理到 Pandas 数据框中。
但是,我们要做分析,显然不能局限在单一月份与单一城市。
每次加入一组数据,如果都得从头这样做一遍,会很辛苦。而且语句多了,执行起来,难免顾此失彼,出现错误。
所以,我们需要把刚刚的代码语句整合起来,将其模块化,形成函数。
这样,我们只需要在调用函数的时候,传入不同的参数,例如不同的城市名、月份等信息,就能获得想要的结果了。
综合上述语句,我们定义一个传入城市和月份信息,获得数据框的完整函数。
def get_df(areaid, areaname_dict, month, appcode):
url = 'https://ali-weather.showapi.com/weatherhistory'
payload = {'areaid': areaid, 'month': month}
headers = {'Authorization': 'APPCODE {}'.format(appcode)}
r = requests.get(url, params=payload, headers=headers)
content_json = json.loads(r.content)
df = pd.DataFrame(content_json['showapi_res_body']['list'])
df['areaname'] = areaname_dict[areaid]
return df注意除了刚才用到的语句外,我们为函数增加了一个输入参数,即areaname_dict。
它是一个字典,每一项分别包括城市代码,和对应的城市名称。
根据我们输入的城市代码,函数就可以自动在结果数据框中添加一个列,注明对应的是哪个城市。
当我们获取多个城市的数据时,某一行的数据说的是哪个城市,就可以一目了然。
反之,如果只给你看城市代码,你很快就会眼花缭乱,不知所云了。
但是,只有上面这一个函数,还是不够高效。
毕竟我们可能需要查询若干月、若干城市的信息。如果每次都调用上面的函数,也够累的。
所以,我们下面再编写一个函数,帮我们自动处理这些脏活儿累活儿。
def get_dfs(areaname_dict, months, appcode):
dfs = []
for areaid in areaname_dict:
dfs_times = []
for month in months:
temp_df = get_df(areaid, areaname_dict, month, appcode)
dfs_times.append(temp_df)
area_df = pd.concat(dfs_times)
dfs.append(area_df)
return dfs说明一下,这个函数接受的输入,包括城市代码-名称字典、一系列的月份,以及我们的 AppCode。
它的处理方式,很简单,就是个双重循环。
外层循环负责遍历所有要求查询的城市,内层循环遍历全部指定的时间范围。
它返回的内容,是一个列表。
列表中的每一项,都分别是某个城市一段时间(可能包含若干个月)的天气信息数据框。
我们先用单一城市、单一月份来试试看。
还是2018年5月的丽江。
我们将上述信息,传入 get_dfs 函数。
看看结果:
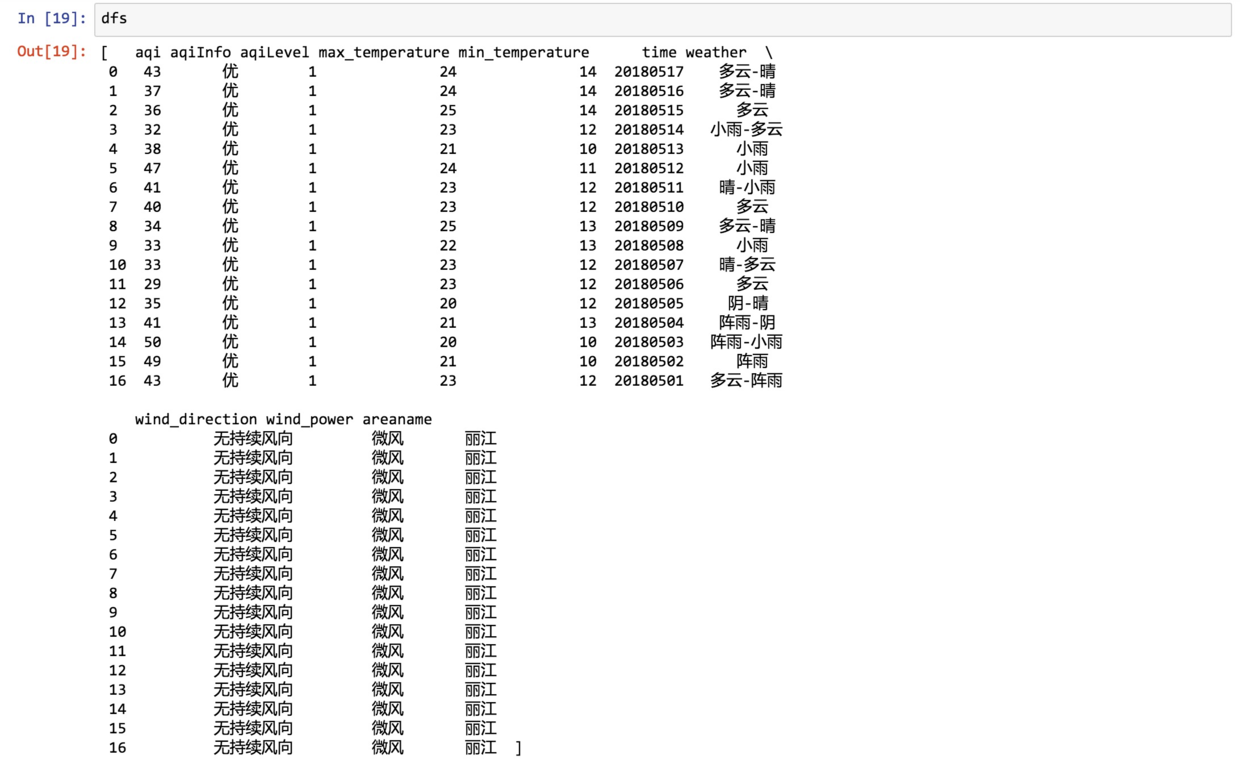
返回的是一个列表。
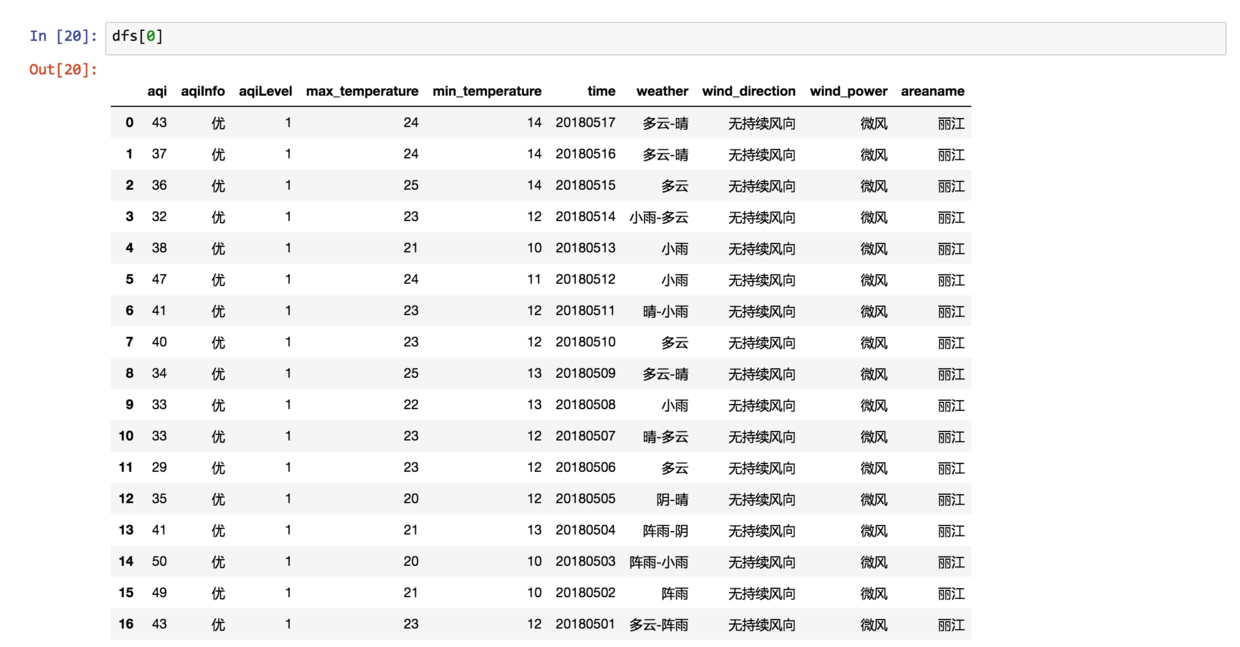
因为列表里面只有一个城市,所以我们只让它返回第一项即可。
这次显示的,就是数据框了:
测试通过,下面我们趁热打铁,把天津、上海、丽江2018年初至今所有数据都读取出来。
先设定城市:
再设定时间范围:
咱们再次执行 get_dfs 函数。
看看这次的结果:
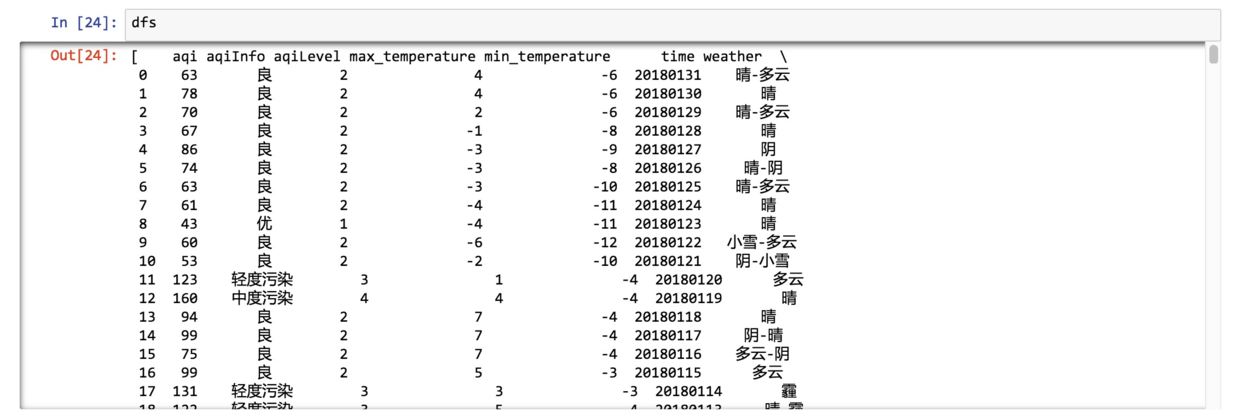
结果还是一个列表。
列表中的每一项,对应某个城市2018年年初到5月份本文写作时,这一段时间范围天气数据。
假设我们要综合分析几个城市的天气信息,那么就可以把这几个数据框整合在一起。
用到的方法,是 Pandas 内置的 concat 函数。
它接收一个数据框列表,把其中每一个个数据框沿着纵轴(默认)连接在一起。
看看此时的总数据框效果:
这是开头部分:

这是结尾部分:

3个城市,4个多月的数据都正确读取和整合了。
下面我们尝试做分析。
首先,我们得搞清楚数据框中的每一项,都是什么格式:
aqi object
aqiInfo object
aqiLevel object
max_temperature object
min_temperature object
time object
weather object
wind_direction object
wind_power object
areaname object
dtype: object所有的列,全都是按照 object 处理的。
什么叫 object ?
在这个语境里,你可以将它理解为字符串类型。
但是,咱们不能把它们都当成字符串来处理啊。
例如日期,应该按照日期类型来看待,否则怎么做时间序列可视化?
AQI的取值,如果看作字符串,那怎么比较大小呢?
所以我们需要转换一下数据类型。
先转换日期列:
再转换 AQI 数值列:
看看此时 df 的数据类型:
aqi int64
aqiInfo object
aqiLevel object
max_temperature object
min_temperature object
time datetime64[ns]
weather object
wind_direction object
wind_power object
areaname object
dtype: object这次就对了,日期和 AQI 都分别变成了我们需要的类型。其他数据,暂时保持原样。
有的是因为本来就该是字符串,例如城市名称。
另一些,是因为我们暂时不会用到。
下面我们绘制一个简单的时间序列对比图形。
读入绘图工具包 plotnine 。
注意我们同时读入了 date_breaks,用来指定图形绘制时,时间标注的间隔。
import matplotlib.pyplot as plt
%matplotlib inline
from plotnine import *
from mizani.breaks import date_breaks正式绘图:
(ggplot(df, aes(x='time', y='aqi', color='factor(areaname)')) + geom_line() +
scale_x_datetime(breaks=date_breaks('2 weeks')) +
xlab('日期') +
theme_matplotlib() +
theme(axis_text_x=element_text(rotation=45, hjust=1)) +
theme(text=element_text(family='WenQuanYi Micro Hei'))
)我们指定横轴为时间序列,纵轴为 AQI,用不同颜色的线来区分城市。
绘制时间的时候,以“2周”作为间隔周期,标注时间上的数据统计量信息。
我们修改横轴的标记为中文的“日期”。
因为时间显示起来比较长,如果按照默认样式,会堆叠在一起,不好看,所以我们让它旋转45度角,这样避免重叠,一目了然。
为了让图中的中文正常显示,我们需要指定中文字体,这里我们选择的是开源的“文泉驿微米黑”。
数据可视化结果,如下图所示。
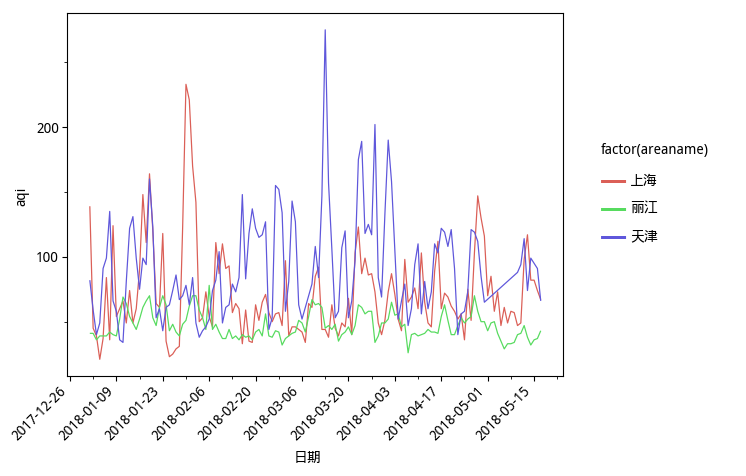
怎么样,这张对比图,绘制得还像模像样吧?
从图中,你可以分析出什么结果呢?
反正我看完这张图,很想去丽江。
9.3.5 小结
读过本教程,希望你已经掌握了以下知识:
- 如何在 API 云市场上,根据提示选购自己感兴趣的产品;
- 如何获取你的身份验证信息 AppCode ;
- 如何用最简单的命令行 curl 方式,直接调用 API 接口,获得结果数据;
- 如何使用 Python 3 和更人性化的 HTTP 工具包 requests 调用 API 获得数据;
- 如何用 JSON 工具包解析处理获得的字符串数据;
- 如何用 Pandas 转换 JSON 列表为数据框;
- 如何将测试通过后的简单 Python 语句打包成函数,以反复调用,提高效率;
- 如何用 plotnine (ggplot2的克隆)绘制时间序列折线图,对比不同城市 AQI 历史走势;
- 如何在云环境中运行本样例,并且照葫芦画瓢,自行修改。
希望这份样例代码,可以帮你建立信心,尝试自己去搜集与尝试 API 数据获取,为自己的科研工作添砖加瓦。
如果你希望在本地,而非云端运行本样例,请使用这个链接(http://t.cn/R3usDi9)下载本文用到的全部源代码和运行环境配置文件(Pipenv)压缩包。
如果你知道如何使用github(10.3,也欢迎用这个链接(http://t.cn/R3usEti))访问对应的github repo,进行clone或者fork等操作。

当然,要是能给我的repo加一颗星,就更好了。
9.4 如何用Python爬数据?
你期待已久的Python网络数据爬虫教程来了。本文为你演示如何从网页里找到感兴趣的链接和说明文字,抓取并存储到Excel。

9.4.1 需求
我在公众号后台,经常可以收到读者的留言。
很多留言,是读者的疑问。只要有时间,我都会抽空尝试解答。
但是有的留言,乍看起来就不明所以了。
例如下面这个:

一分钟后,他可能觉得不妥(大概因为想起来,我用简体字写文章),于是又用简体发了一遍。

我恍然大悟。
这位读者以为我的公众号设置了关键词推送对应文章功能。所以看了我的其他数据科学教程后,想看“爬虫”专题。
不好意思,当时我还没有写爬虫文章。
而且,我的公众号暂时也没有设置这种关键词推送。
主要是因为我懒。
这样的消息接收得多了,我也能体察到读者的需求。不止一个读者表达出对爬虫教程的兴趣。
之前提过,目前主流而合法的网络数据收集方法,主要分为3类:
- 开放数据集下载;
- API读取;
- 爬虫。
前两种方法,我都已经做过一些介绍,这次说说爬虫。

9.4.2 概念
许多读者对爬虫的定义,有些混淆。咱们有必要辨析一下。
维基百科是这么说的:
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。 这问题就来了,你又不打算做搜索引擎,为什么对网络爬虫那么热心呢?
其实,许多人口中所说的爬虫(web crawler),跟另外一种功能“网页抓取”(web scraping)搞混了。
维基百科上,对于后者这样解释:
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. Web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol, or through a web browser. 看到没有,即便你用浏览器手动拷贝数据下来,也叫做网页抓取(web scraping)。是不是立刻觉得自己强大了很多?
但是,这定义还没完:
While web scraping can be done manually by a software user, the term typically refers to automate processes implemented using a bot or web crawler. 也就是说,用爬虫(或者机器人)自动替你完成网页抓取工作,才是你真正想要的。
数据抓下来干什么呢?
一般是先存储起来,放到数据库或者电子表格中,以备检索或者进一步分析使用。
所以,你真正想要的功能是这样的:
找到链接,获得Web页面,抓取指定信息,存储。
这个过程有可能会往复循环,甚至是滚雪球。
你希望用自动化的方式来完成它。
了解了这一点,你就不要老盯着爬虫不放了。爬虫研制出来,其实是为了给搜索引擎编制索引数据库使用的。你为了抓取点儿数据拿来使用,已经是大炮轰蚊子了。
要真正掌握爬虫,你需要具备不少基础知识。例如HTML, CSS, Javascript, 数据结构……
这也是为什么我一直犹豫着没有写爬虫教程的原因。
不过这两天,看到王烁主编的一段话,很有启发:
我喜欢讲一个另类二八定律,就是付出两成努力,了解一件事的八成。 既然我们的目标很明确,就是要从网页抓取数据。那么你需要掌握的最重要能力,是拿到一个网页链接后,如何从中快捷有效地抓取自己想要的信息。
掌握了它,你还不能说自己已经学会了爬虫。
但有了这个基础,你就能比之前更轻松获取数据了。特别是对“文科生”的很多应用场景来说,非常有用。这就是赋能。
而且,再进一步深入理解爬虫的工作原理,也变得轻松许多。
这也算“另类二八定律”的一个应用吧。
Python语言的重要特色之一,就是可以利用强大的软件工具包(许多都是第三方提供)。你只需要编写简单的程序,就能自动解析网页,抓取数据。
本文给你演示这一过程。
9.4.3 目标
要抓取网页数据,我们先制订一个小目标。
目标不能太复杂。但是完成它,应该对你理解抓取(Web Scraping)有帮助。
就选择我最近发布的一篇简书文章作为抓取对象好了。题目叫做《如何用《玉树芝兰》入门数据科学?》(1.1)。
这篇文章里,我把之前的发布的数据科学系列文章做了重新组织和串讲。
文中包含很多之前教程的标题和对应链接。例如下图红色边框圈起来的部分。

假设你对文中提到教程都很感兴趣,希望获得这些文章的链接,并且存储到Excel里,就像下面这个样子:
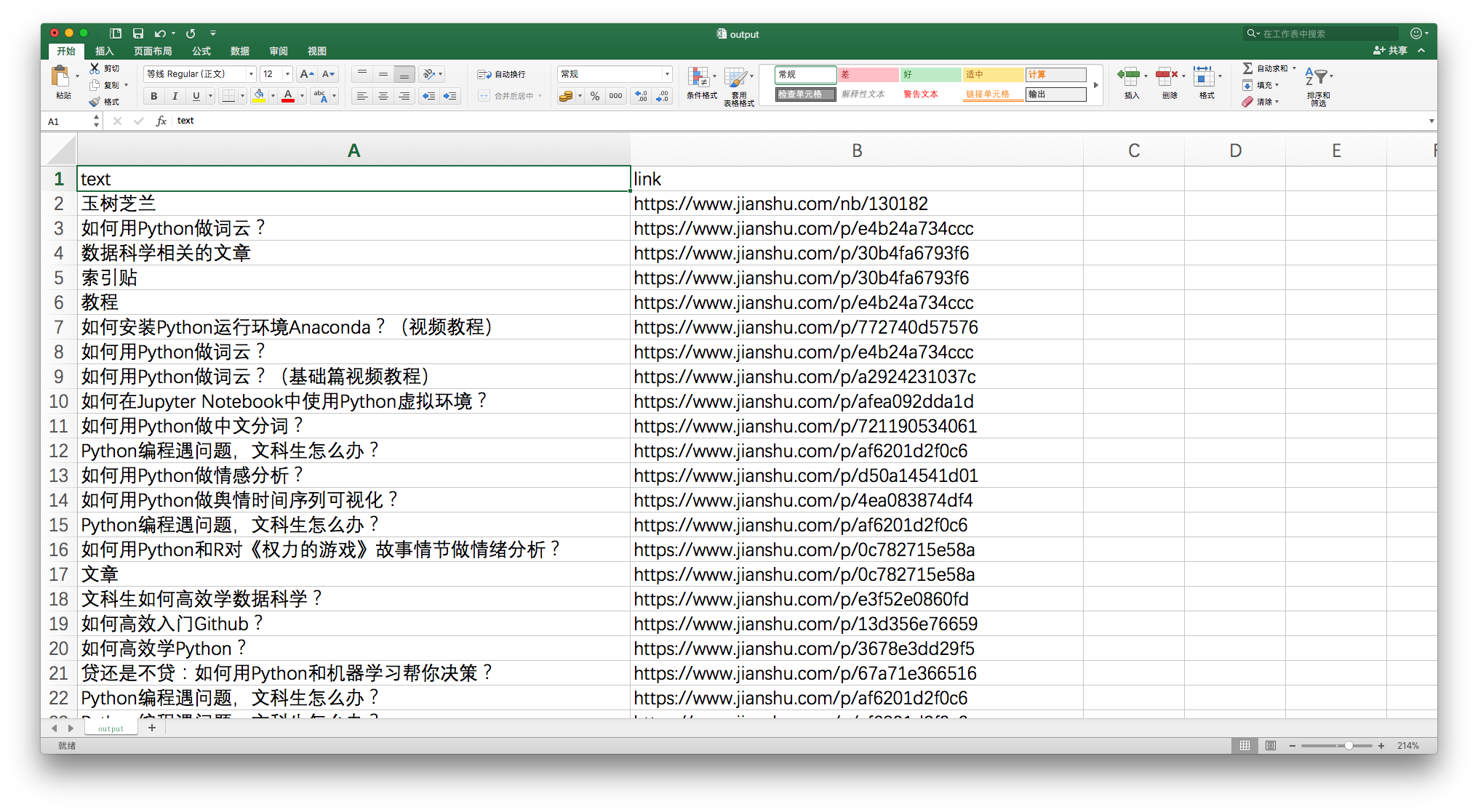
你需要把非结构化的分散信息(自然语言文本中的链接),专门提取整理,并且存储下来。
该怎么办呢?
即便不会编程,你也可以全文通读,逐个去找这些文章链接,手动把文章标题、链接都分别拷贝下来,存到Excel表里面。
但是,这种手工采集方法没有效率。
我们用Python。
9.4.4 环境
要装Python,比较省事的办法是安装Anaconda套装。
请到这个网址下载Anaconda的最新版本。
请选择左侧的 Python 3.6 版本下载安装。
如果你需要具体的步骤指导,或者想知道Windows平台如何安装并运行Anaconda命令,请参考我为你准备的视频教程(2.2)。
安装好Anaconda之后,请到这个网址下载本教程配套的压缩包。
下载后解压,你会在生成的目录(下称“演示目录”)里面看到以下三个文件。

打开终端,用cd命令进入该演示目录。如果你不了解具体使用方法,也可以参考视频教程(2.2)。
我们需要安装一些环境依赖包。
首先执行:
pip install pipenv这里安装的,是一个优秀的 Python 软件包管理工具 pipenv 。
安装后,请执行:
pipenv install看到演示目录下两个Pipfile开头的文件了吗?它们就是 pipenv 的设置文档。
pipenv 工具会依照它们,自动为我们安装所需要的全部依赖软件包。
上图里面有个绿色的进度条,提示所需安装软件数量和实际进度。
装好后,根据提示我们执行:
pipenv shell此处请确认你的电脑上已经安装了 Google Chrome 浏览器。
我们执行:
jupyter notebook默认浏览器(Google Chrome)会开启,并启动 Jupyter 笔记本界面:
你可以直接点击文件列表中的第一项ipynb文件,可以看到本教程的全部示例代码。
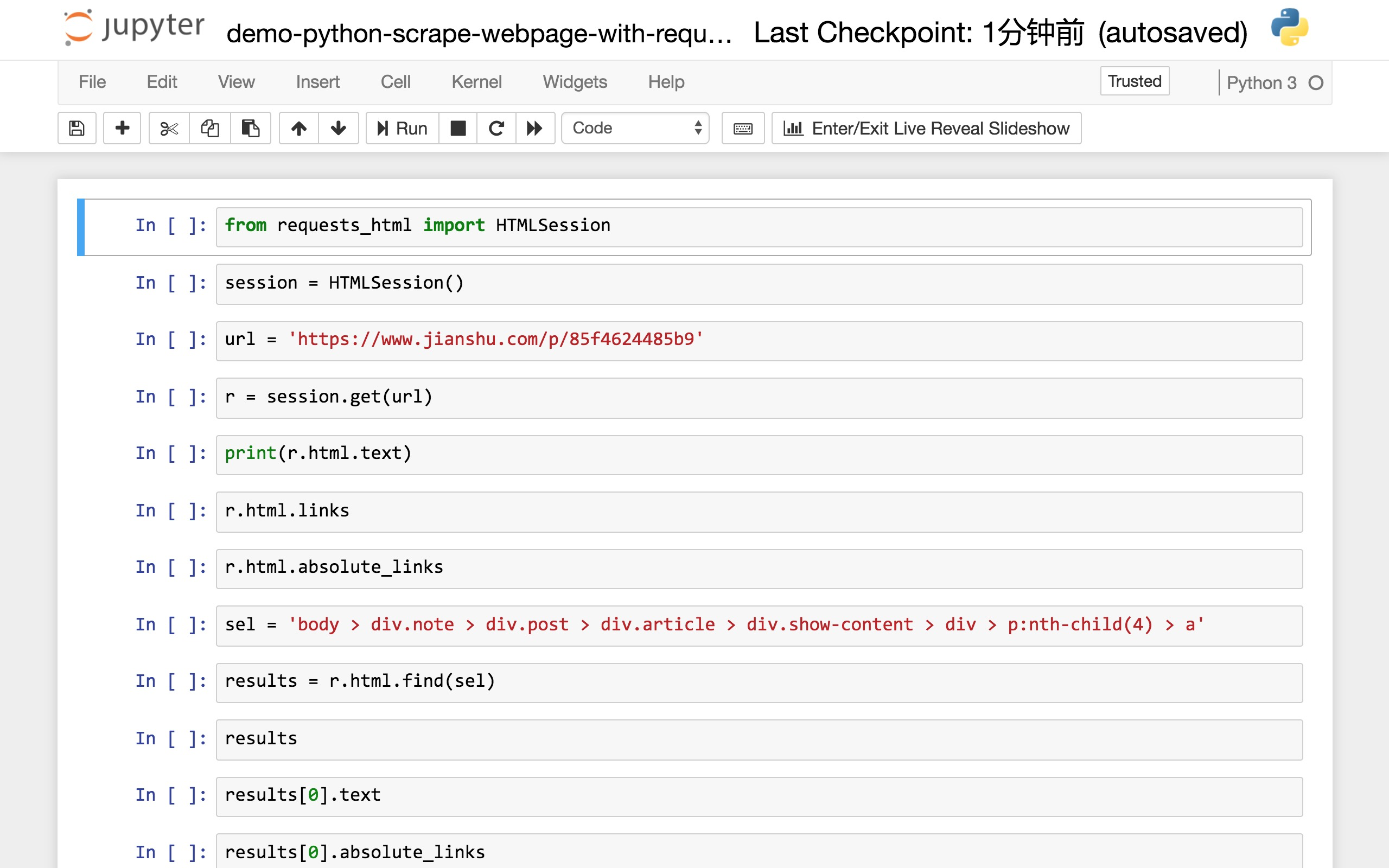
你可以一边看教程的讲解,一边依次执行这些代码。
但是,我建议的方法,是回到主界面下,新建一个新的空白 Python 3 笔记本。
请跟着教程,一个个字符输入相应的内容。这可以帮助你更为深刻地理解代码的含义,更高效地把技能内化。
准备工作结束,下面我们开始正式输入代码。
9.4.5 代码
读入网页加以解析抓取,需要用到的软件包是 requests_html 。我们此处并不需要这个软件包的全部功能,只读入其中的 HTMLSession 就可以。
然后,我们建立一个会话(session),即让Python作为一个客户端,和远端服务器交谈。
前面说了,我们打算采集信息的网页,是《如何用《玉树芝兰》入门数据科学?》(1.1)一文。
我们找到它的网址,存储到url变量名中。
下面的语句,利用 session 的 get 功能,把这个链接对应的网页整个儿取回来。
网页里面都有什么内容呢?
我们告诉Python,请把服务器传回来的内容当作HTML文件类型处理。我不想要看HTML里面那些乱七八糟的格式描述符,只看文字部分。
于是我们执行:
这就是获得的结果了:
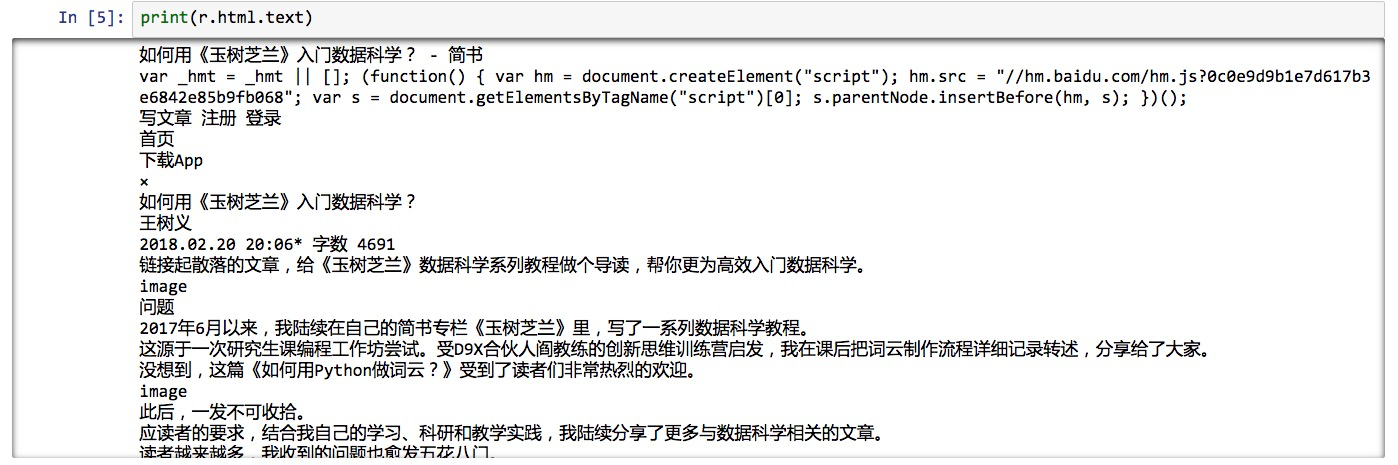
我们心里有数了。取回来的网页信息是正确的,内容是完整的。
好了,我们来看看怎么趋近自己的目标吧。
我们先用简单粗暴的方法,尝试获得网页中包含的全部链接。
把返回的内容作为HTML文件类型,我们查看 links 属性:
这是返回的结果:
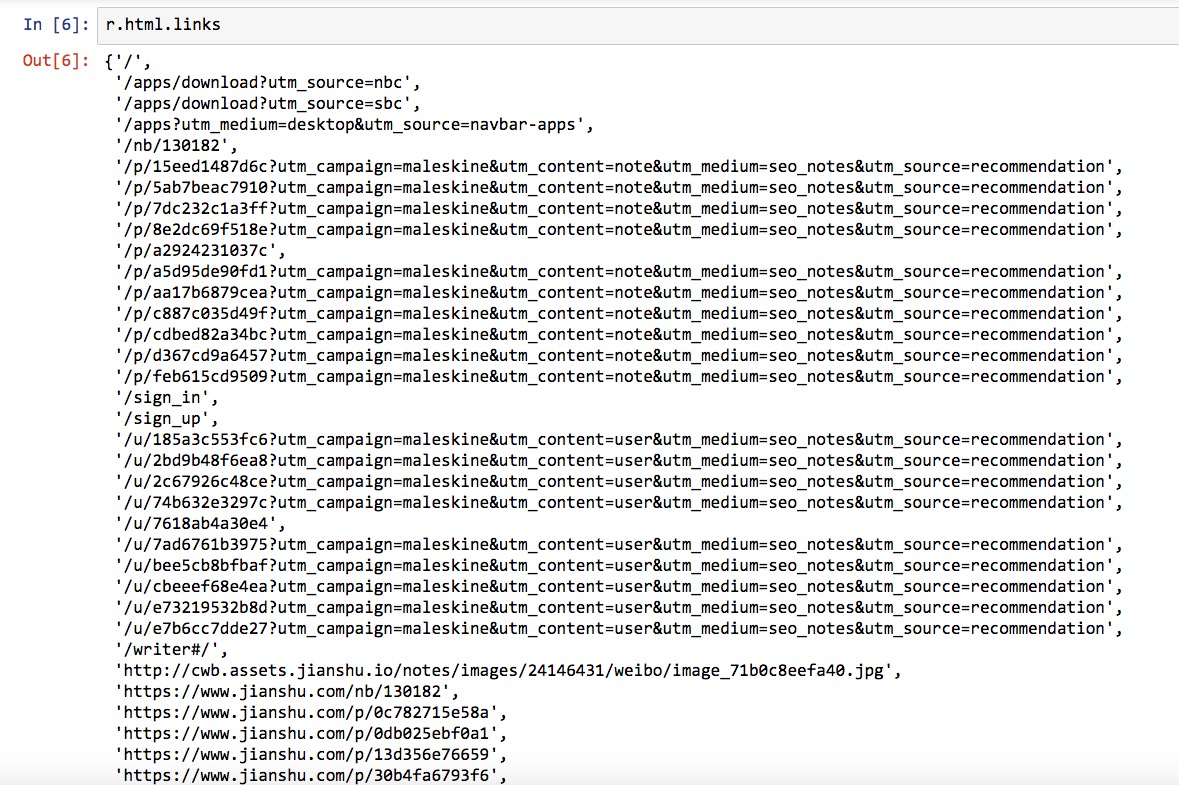
这么多链接啊!
很兴奋吧?
不过,你发现没有?这里许多链接,看似都不完全。例如第一条结果,只有:
'/'这是什么东西?是不是链接抓取错误啊?
不是,这种看着不像链接的东西,叫做相对链接。它是某个链接,相对于我们采集的网页所在域名(https://www.jianshu.com)的路径。
这就好像我们在国内邮寄快递包裹,填单子的时候一般会写“XX省XX市……”,前面不需要加上国家名称。只有国际快递,才需要写上国名。
但是如果我们希望获得全部可以直接访问的链接,怎么办呢?
很容易,也只需要一条 Python 语句。
这里,我们要的是“绝对”链接,于是我们就会获得下面的结果:

这回看着是不是就舒服多了?
我们的任务已经完成了吧?链接不是都在这里吗?
链接确实都在这里了,可是跟我们的目标是不是有区别呢?
检查一下,确实有。
我们不光要找到链接,还得找到链接对应的描述文字呢,结果里包含吗?
没有。
结果列表中的链接,都是我们需要的吗?
不是。看长度,我们就能感觉出许多链接并不是文中描述其他数据科学文章的网址。
这种简单粗暴直接罗列HTML文件中所有链接的方法,对本任务行不通。
那么我们该怎么办?
我们得学会跟 Python 说清楚我们要找的东西。这是网页抓取的关键。
想想看,如果你想让助手(人类)帮你做这事儿,怎么办?
你会告诉他:
“寻找正文中全部可以点击的蓝色文字链接,拷贝文字到Excel表格,然后右键复制对应的链接,也拷贝到Excel表格。每个链接在Excel占一行,文字和链接各占一个单元格。”
虽然这个操作执行起来麻烦,但是助手听懂后,就能帮你执行。
同样的描述,你试试说给电脑听……不好意思,它不理解。
因为你和助手看到的网页,是这个样子的。

电脑看到的网页,是这个样子的。

为了让你看得清楚源代码,浏览器还特意对不同类型的数据用了颜色区分,对行做了编号。
数据显示给电脑时,上述辅助可视功能是没有的。它只能看见一串串字符。
那可怎么办?
仔细观察,你会发现这些HTML源代码里面,文字、图片链接内容前后,都会有一些被尖括号括起来的部分,这就叫做“标记”。
所谓HTML,就是一种标记语言(超文本标记语言,HyperText Markup Language)。
标记的作用是什么?它可以把整个的文件分解出层次来。

(图片来源:https://goo.gl/kWCqS6)
如同你要发送包裹给某个人,可以按照“省-市-区-街道-小区-门牌”这样的结构来写地址,快递员也可以根据这个地址找到收件人。
同样,我们对网页中某些特定内容感兴趣,可以依据这些标记的结构,顺藤摸瓜找出来。
这是不是意味着,你必须先学会HTML和CSS,才能进行网页内容抓取呢?
不是的,我们可以借助工具,帮你显著简化任务复杂度。
这个工具,Google Chrome浏览器自带。
我们在样例文章页面上,点击鼠标右键,在出现的菜单里面选择“检查”。
这时,屏幕下方就会出现一个分栏。
我们点击这个分栏左上角(上图红色标出)的按钮。然后把鼠标悬停在第一个文内链接(《玉树芝兰》)上面,点击一下。

此时,你会发现下方分栏里面,内容也发生了变化。这个链接对应的源代码被放在分栏区域正中,高亮显示。
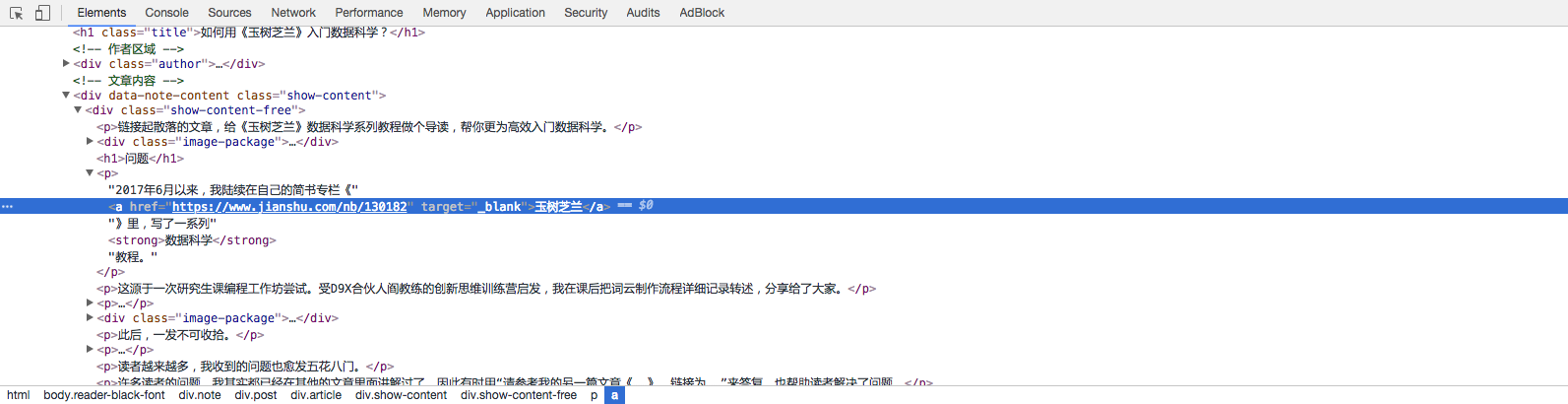
确认该区域就是我们要找的链接和文字描述后,我们鼠标右键选择高亮区域,并且在弹出的菜单中,选择 Copy -> Copy selector。
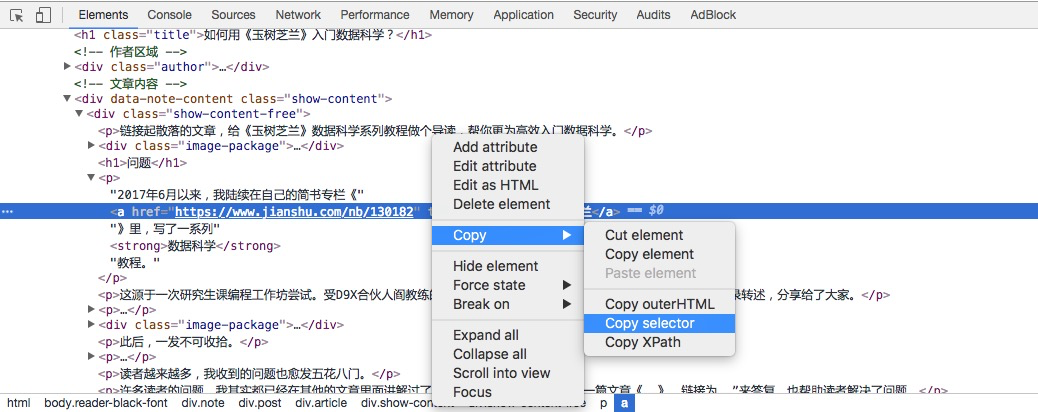
找一个文本编辑器,执行粘贴,就可以看见我们究竟复制下来了什么内容。
这一长串的标记,为电脑指出了:请你先找到 body 标记,进入它管辖的这个区域后去找 div.note 标记,然后找……最后找到 a 标记,这里就是要找的内容了。
回到咱们的 Jupyter Notebook 中,用刚才获得的标记路径,定义变量sel。
我们让 Python 从返回内容中,查找 sel 对应的位置,把结果存到 results 变量中。
我们看看 results 里面都有什么。
这是结果:
[<Element 'a' href='https://www.jianshu.com/nb/130182' target='_blank'>]results 是个列表,只包含一项。这一项包含一个网址,就是我们要找的第一个链接(《玉树芝兰》)对应的网址。
可是文字描述“《玉树芝兰》”哪里去了?
别着急,我们让 Python 显示 results 结果数据对应的文本。
这是输出结果:
'玉树芝兰'我们把链接也提取出来:
显示的结果却是一个集合。
{'https://www.jianshu.com/nb/130182'}我们不想要集合,只想要其中的链接字符串。所以我们先把它转换成列表,然后从中提取第一项,即网址链接。
这次,终于获得我们想要的结果了:
'https://www.jianshu.com/nb/130182'有了处理这第一个链接的经验,你信心大增,是吧?
其他链接,也无非是找到标记路径,然后照猫画虎嘛。
可是,如果每找一个链接,都需要手动输入上面这若干条语句,那也太麻烦了。
这里就是编程的技巧了。重复逐条运行的语句,如果工作顺利,我们就要尝试把它们归并起来,做个简单的函数。
对这个函数,只需给定一个选择路径(sel),它就把找到的所有描述文本和链接路径都返回给我们。
def get_text_link_from_sel(sel):
mylist = []
try:
results = r.html.find(sel)
for result in results:
mytext = result.text
mylink = list(result.absolute_links)[0]
mylist.append((mytext, mylink))
return mylist
except:
return None我们测试一下这个函数。
还是用刚才的标记路径(sel)不变,试试看。
输出结果如下:
[('玉树芝兰', 'https://www.jianshu.com/nb/130182')]没问题,对吧?
好,我们试试看第二个链接。
我们还是用刚才的方法,使用下面分栏左上角的按钮点击第二个链接。

下方出现的高亮内容就发生了变化:

我们还是用鼠标右键点击高亮部分,拷贝出 selector。
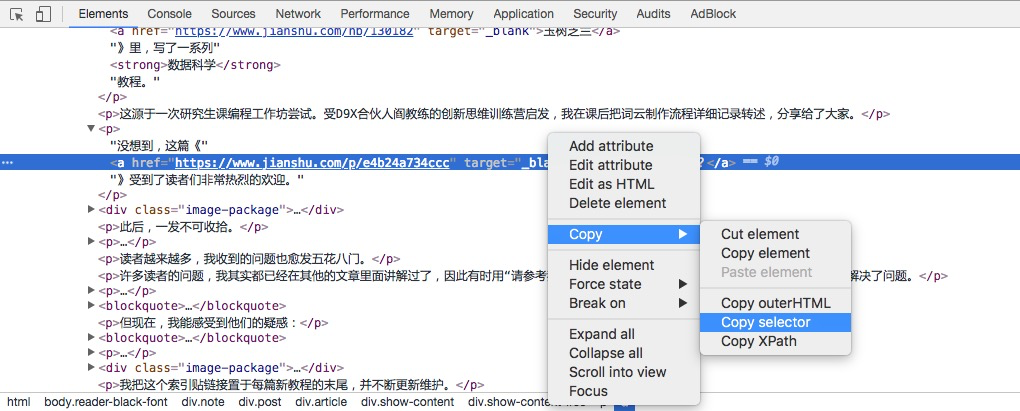
然后我们直接把获得的标记路径写到 Jupyter Notebook 里面。
用我们刚才编制的函数,看看输出结果是什么?
输出如下:
[('如何用Python做词云?', '#make-wordcloud-with-python')]检验完毕,函数没有问题。
下一步做什么?
你还打算去找第三个链接,仿照刚才的方法做?
那你还不如全文手动摘取信息算了,更省事儿一些。
我们要想办法把这个过程自动化。
对比一下刚刚两次我们找到的标记路径:
以及:
发现什么规律没有?
对,路径上其他的标记全都是一样的,唯独倒数第二个标记(“p”)后冒号后内容有区别。
这就是我们自动化的关键了。
上述两个标记路径里面,因为指定了在第几个“子”(nth-child)文本段(paragraph,也就是“p”代表的含义)去找“a”这个标记,因此只返回来单一结果。
如果我们不限定“p”的具体位置信息呢?
我们试试看,这次保留标记路径里面其他全部信息,只修改“p”这一点。
再次运行我们的函数:
这是输出结果:

好了,我们要找的内容,全都在这儿了。
但是,我们的工作还没完。
我们还得把采集到的信息输出到Excel中保存起来。
还记得我们常用的数据框工具 Pandas 吗?又该让它大显神通了。
只需要这一行命令,我们就能把刚才的列表变成数据框:
让我们看看数据框内容:

内容没问题,不过我们对表头不大满意,得更换为更有意义的列名称:
再看看数据框内容:

好了,下面就可以把抓取的内容输出到Excel中了。
Pandas内置的命令,就可以把数据框变成csv格式,这种格式可以用Excel直接打开查看。
注意这里需要指定encoding(编码)为gbk,否则默认的utf-8编码在Excel中查看的时候,有可能是乱码。
我们看看最终生成的csv文件吧。
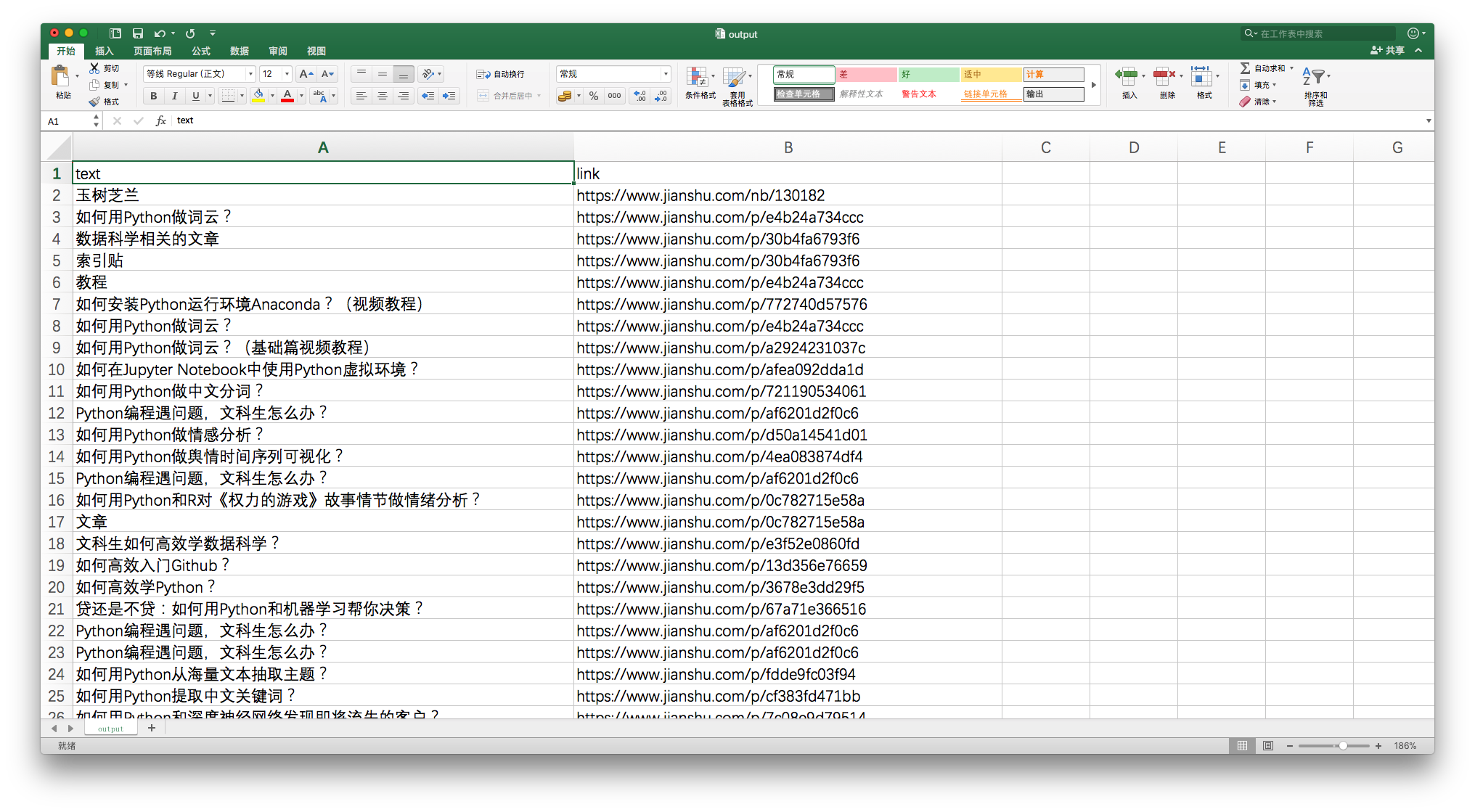
很有成就感,是不是?
9.4.6 小结
本文为你展示了用Python自动网页抓取的基础技能。希望阅读并动手实践后,你能掌握以下知识点:
- 网页抓取与网络爬虫之间的联系与区别;
- 如何用 pipenv 快速构建指定的 Python 开发环境,自动安装好依赖软件包;
- 如何用 Google Chrome 的内置检查功能,快速定位感兴趣内容的标记路径;
- 如何用 requests-html 包来解析网页,查询获得需要的内容元素;
- 如何用 Pandas 数据框工具整理数据,并且输出到 Excel。
或许,你觉得这篇文章过于浅白,不能满足你的要求。
文中只展示了如何从一个网页抓取信息,可你要处理的网页成千上万啊。
别着急。
本质上说,抓取一个网页,和抓取10000个网页,在流程上是一样的。
而且,从咱们的例子里,你是不是已经尝试了抓取链接?
有了链接作为基础,你就可以滚雪球,让Python爬虫“爬”到解析出来的链接上,做进一步的处理。
将来,你可能还要应对实践场景中的一些棘手问题:
- 如何把抓取的功能扩展到某一范内内的所有网页?
- 如何爬取Javascript动态网页?
- 假设你爬取的网站对每个IP的访问频率做出限定,怎么办?
- ……
这些问题的解决办法,我希望在今后的教程里面,一一和你分享。
需要注意的是,网络爬虫抓取数据,虽然功能强大,但学习与实践起来有一定门槛。
当你面临数据获取任务时,应该先检查一下这个清单:
- 有没有别人已经整理好的数据集合可以直接下载?
- 网站有没有对你需要的数据提供API访问与获取方式?
- 有没有人针对你的需求,编好了定制爬虫,供你直接调用?
如果答案是都没有,才需要你自己编写脚本,调动爬虫来抓取。
为了巩固学习的知识,请你换一个其他网页,以咱们的代码作为基础修改后,抓取其中你感兴趣的内容。
如果能把你抓取的过程记录下来,在评论区将记录链接分享给大家,就更好了。
因为刻意练习是掌握实践技能的最好方式,而教是最好的学。
祝顺利!
9.4.7 思考
本文主要内容讲解完毕。
这里给你提一个疑问,供你思考:
我们解析并且存储的链接,其实是有重复的:
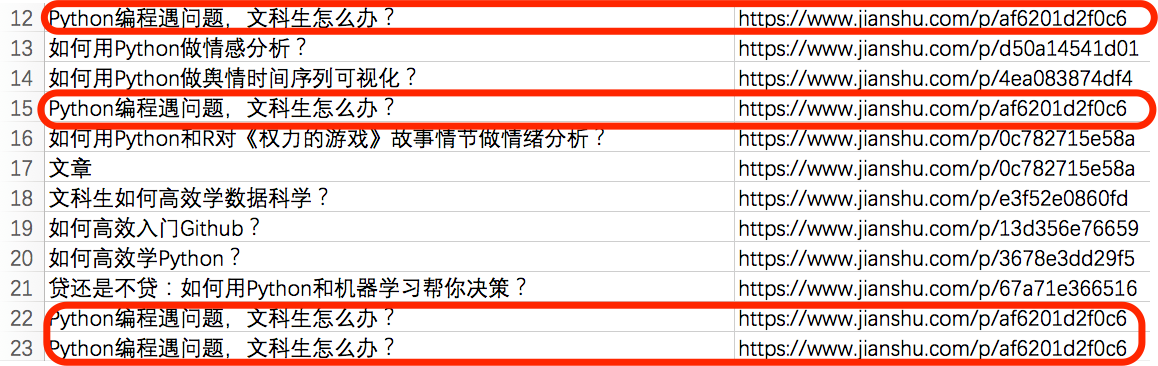
这并不是我们的代码有误,而是在《如何用《玉树芝兰》入门数据科学?》(1.1)一文里,本来就多次引用过一些文章,所以重复的链接就都被抓取出来了。
但是你存储的时候,也许不希望保留重复链接。
这种情况下,你该如何修改代码,才能保证抓取和保存的链接没有重复呢?
9.4.8 思考题答案
答案请参考这个网址(9.4)。
9.5 如何用 Python 脚本批量下载 Google 图像?

分不清谭卓和郝蕾?各来200张照片,让深度学习帮我们识别吧。
9.5.1 问题
有读者问:
老师,我想自己训练一个图片分类器,到哪里去批量下载带标注的训练图像呢?
我写教程的时候,是在 Google 图像栏目下,键入“Walle”。
搜索的结果,合乎我们的要求,Google 不但给了咱们图片,而且标记也已经做好了。但是,当需要把图片下载下来的时候,出了问题。显然挨个儿去点击一张张图片,再“图片另存为”,效率不够高。我于是尝试了以下几款 Chrome 中的 Google 图像下载插件。例如广受好评的 Canvas 。
安装了这个插件以后,鼠标悬停在某张图片的缩略图上方,就会出现下载按钮。

点一下就能下载图片,确实比原先的“点开-右键-另存”方式好一些,但是效率还是太低。于是,我进一步,在 Chrome Web Store 搜索图片下载扩展,发现大部分搜索结果的评分都不够高。

我尝试了搜索结果中评分最高的 Bulk Image Downloader 。安装之后,在 Walle 图片搜索结果的页面上,点击 Bulk Image Downloader 扩展的按钮。
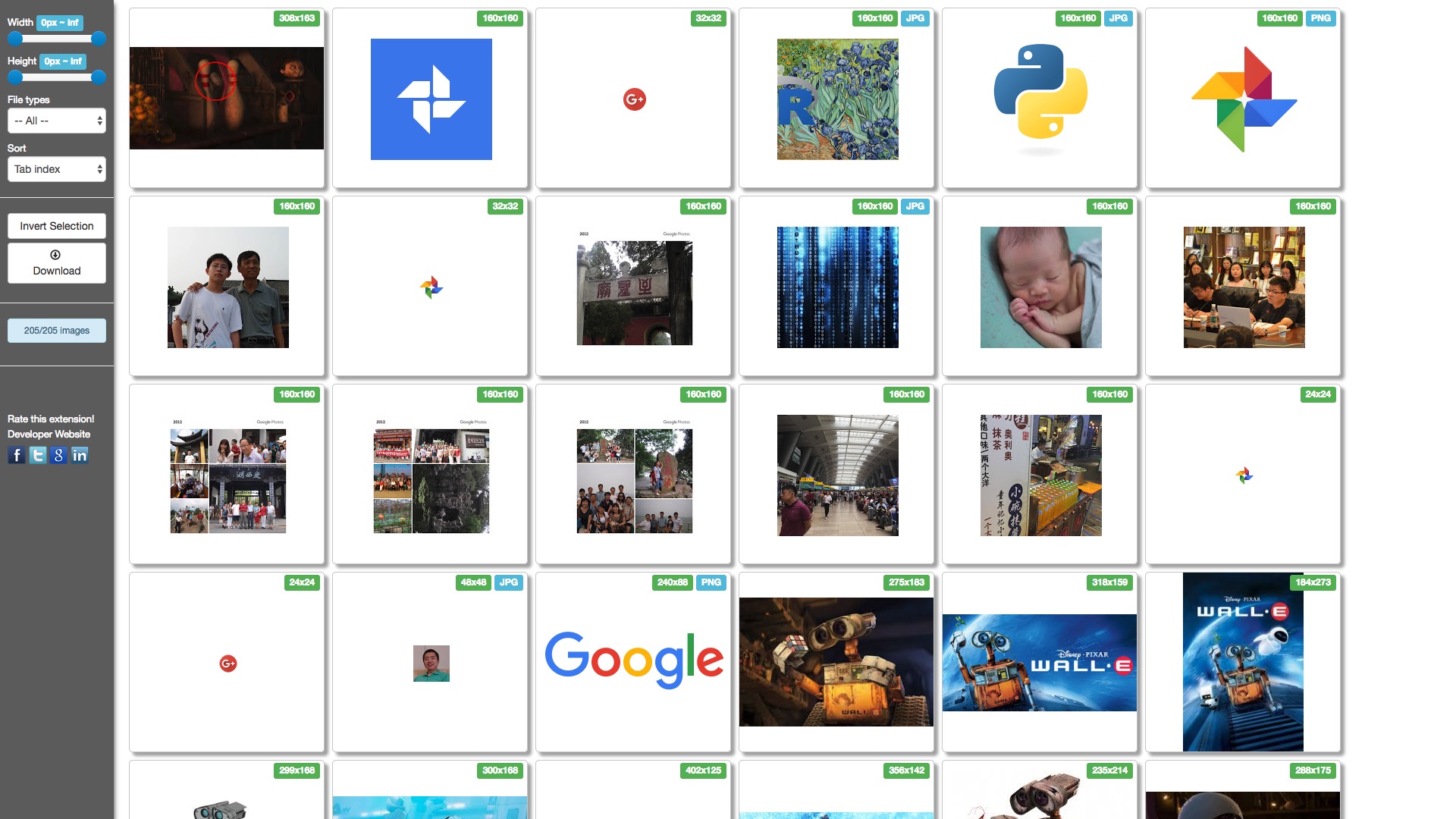
出来的图片列表结果让我大失所望。前面3行半的内容,跟瓦力毫无关系。许多居然都是我自己 Google 相册里面的图片。看来,对于 Google Image 搜索结果页面, Bulk Image Downloader 的智能筛选功能还有待增强。虽然我们可以手动对结果进行调整筛选,但是每一次图片数据采集都这样来一次,也很恼人。
9.5.2 发现
一个偶然的机会,我发现了一个特别棒的 Github 项目,叫做 google-images-download。链接在这里。
项目发布至今,只有短短5个月的时间,星标数量居然已经上了2000,看来确实非常受欢迎。
google-images-download 是个 Python 脚本。使用它,你可以一条命令,就完成 Google 图片搜索和批量下载功能。而且,这工具还跨平台运行,Linux, Windows 和 macOS 都支持。简直是懒人福音。
9.5.3 安装
google-images-download 安装很简单。以 macOS 为例,只需要在终端下,执行以下命令:
安装就算完成了。当然,这需要你系统里已经安装了 Python 环境。如果你还没有安装,或者对终端操作命令不太熟悉,可以参考我的《如何安装Python运行环境Anaconda?(视频教程)》(2.2)一文,学习如何下载安装 Anaconda ,和进行终端命令行操作。
9.5.4 尝试
在终端下,进入下载目录:
这次我们尝试下载什么图片呢?想起《我不是药神》里面有个叫谭卓的女演员,演的不错。可是我一开始,把她当成郝蕾了。咱们就尝试下载一些谭卓的图片吧。

在终端里执行:
解释一下,这里的 -k 指的是 “keyword”,也就是“关键词”,后面用双引号括起来要查找的关键词。你可以看出,使用中文关键词,也没问题。
后面的 -l ,指的是“limit”,也就是图片数量限定,你需要指定自己要下载多少张图像。本例中,我们要20张。下面是执行过程:

下载过程中,发生了一个错误。但程序依然锲而不舍,帮我们把下载流程运行完毕。我们看看结果。下载的图片都存放在 ~/Downloads/downloads/谭卓 下面,google-images-download 非常贴心地,为我们建立子目录。

看了半天,有的照片,还是跟郝蕾分不大清楚。为了彻底分清两位女演员,我们再下载 200 张郝蕾的照片吧。仿照刚才的命令,我们执行:
然后……就报错了:

9.5.5 解决
遇到问题,不要慌。你得认真看看错误提示。注意其中出现了一个关键词:chromedriver。这是个什么东西呢?
我们回到 google-images-download 的 github 页面,以 chromedriver 为关键词进行检索。你会立即找到如下结果:
原来如果你要的图片数量超过100张,那么程序就必须调用 Selenium 和 chromedriver 才行。Selenium 在你安装 google-images-download 的时候,已经自动安装好了。你只需要下载 chromedriver ,并且指定路径。下载链接在这里。
请根据你的操作系统类型,选择合适的版本:

我选的是 macOS 版本。下载后,压缩包里面只有一个文件,把它解压,放在 ~/Downloads 目录下。
然后,执行以下命令:
这里 --chromedriver 参数,用来告诉 google-images-download ,解压后 chromedriver 所在路径。
这回机器勤勤恳恳,帮我们下载郝蕾的照片了。

200张图片,需要下载一会儿。请耐心等待。
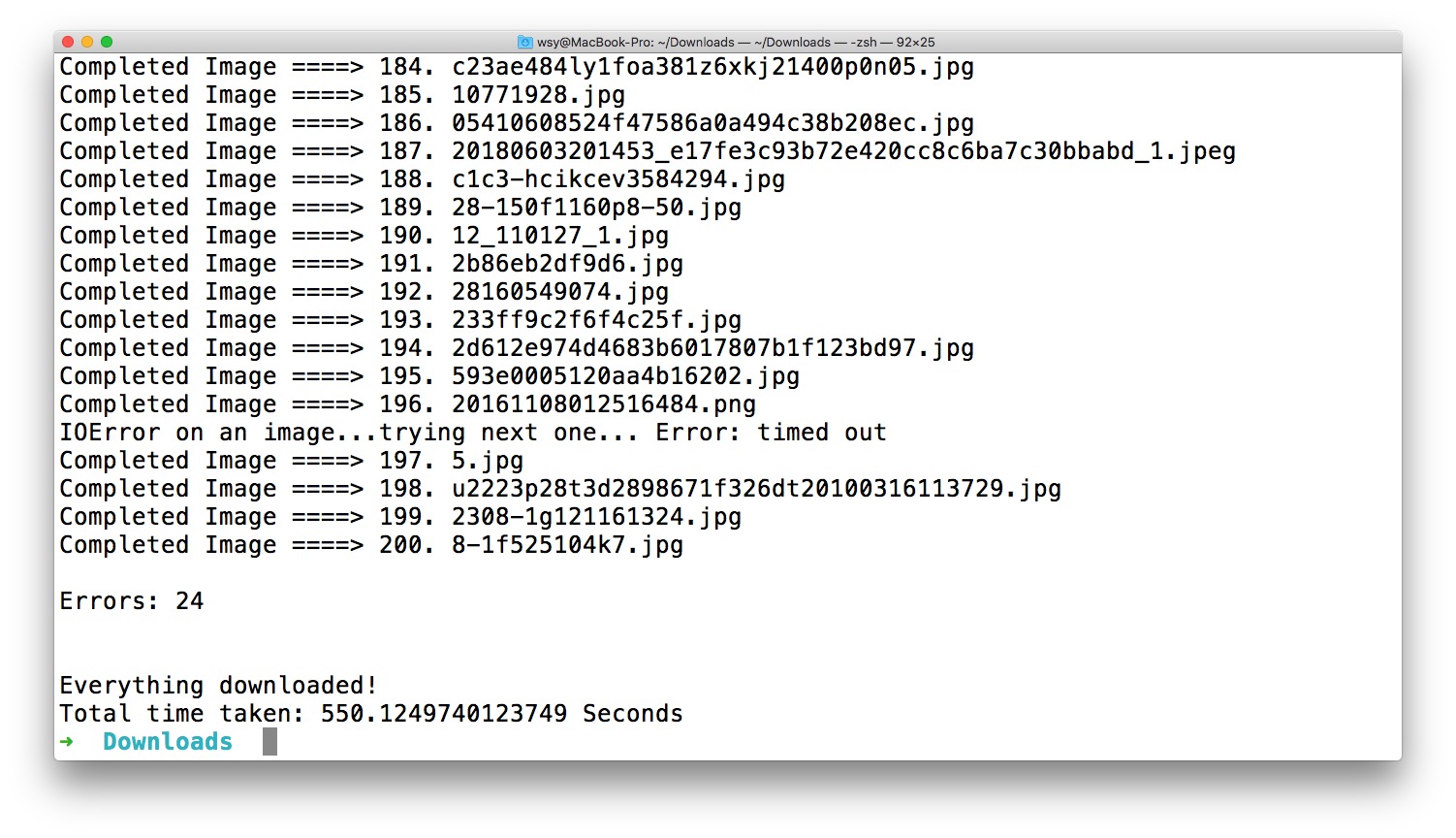
中间也有一些报错,部分图片没有正确下载。好在,这对总体结果没有太大影响。为了保险起见,建议你设置下载数量时,多设置一些。给自己留出安全边际嘛。
咱们打开下载后的目录 ~/Downloads/downloads/郝蕾 看看:

这回,你能分清楚她俩不?
9.5.6 补充
评分这么高的 google-images-download ,自然不可能只有上例中这两三个参数选项。如果你对它感兴趣,可以用这个链接查看全部可用参数列表。
我数了一下,一共有39项。篇幅所限,这里就不给你一一展开罗列了,否则就真成了汉译版使用手册。但是其中几个特色参数,我还是希望提示你一下,因为你在实际工作中,很可能会觉得它们有用处。
--format: 选择图片格式,例如jpg,png,gif和svg等;--usage_rights:选择图片版权,例如labeled-for-nocommercial-reuse等。如果你希望建立自己发布内容用的图片素材库,可以用这个选项,避免踩到版权的坑上,被人家狮子大开口要钱;--size:选择图片大小。假如说你对于图片分辨率有要求,可以用>10MP,只下载像素数量超过 10M 的那些图片;--type:选择图片类型。例如只想要照片,可以用photo,只想要动漫形象,可以用animated;--time:选择图片被检索的时间。假如想要过去一周的图片,可以使用past-7-days;--specific_site:指定图片存储网站。可以将搜索结果,限定在某个网站域名范围内;--safe_search:启用安全搜索。保证搜索结果中,不会出现不利于精神文明建设的内容。
9.5.7 作业
给你留个作业。
你已经学会如何一行命令,下载谭卓和郝蕾的照片。能否活学活用咱们之前介绍的卷积神经网络知识](#how-liberal-art-student-understand-convolutional-neural-networks),用 [TuriCreate(8.1) (或者 Tensorflow) ,建立模型识别两个人的照片?
完成作业后,欢迎把你的测试准确率结果告诉我。当然,如果你能举一反三,利用咱们今天介绍的脚本,下载其他图像集合,并且进行深度学习训练,就更好了。
9.6 如何用Python批量提取PDF文本内容?
本文为你展示,如何用Python把许多PDF文件的文本内容批量提取出来,并且整理存储到数据框中,以便于后续的数据分析。
9.6.1 问题
最近,读者们在后台的留言,愈发五花八门了。
写了几篇关于自然语言处理的文章后,一种呼声渐强:
老师,pdf中的文本内容,有没有什么方便的方法提取出来呢?
我能体会到读者的心情。
我展示的例子中,文本数据都是直接可以读入数据框工具做处理的。它们可能来自开放数据集合、网站API,或者爬虫。
但是,有的时候,你会遇到需要处理指定格式数据的问题。
例如pdf。
许多的学术论文、研究报告,甚至是资料分享,都采用这种格式发布。
这时候,已经掌握了诸多自然语言分析工具的你,会颇有“拔剑四顾心茫然”的感觉——明明知道如何处理其中的文本信息,但就是隔着一个格式转换的问题,做不来。
怎么办?
办法自然是有的,例如专用工具、在线转换服务网站,甚至还可以手动复制粘贴嘛。
但是,咱们是看重效率的,对不对?
上述办法,有的需要在网上传输大量内容,花费时间较多,而且可能带来安全和隐私问题;有的需要专门花钱购买;有的干脆就不现实。
怎么办?
好消息是,Python就可以帮助你高效、快速地批量提取pdf文本内容,而且和数据整理分析工具无缝衔接,为你后续的分析处理做好基础服务工作。
本文给你详细展示这一过程。
想不想试试?
9.6.2 数据
为了更好地说明流程,我为你准备好了一个压缩包。
里面包括本教程的代码,以及我们要用到的数据。
请你到 这个网址 下载本教程配套的压缩包。
下载后解压,你会在生成的目录(下称“演示目录”)里面看到以下内容。

演示目录里面包含:
- Pipfile: pipenv 配置文件,用来准备咱们变成需要用到的依赖包。后文会讲解使用方法;
pdf_extractor.py: 利用pdfminer.six编写的辅助函数。有了它你就可以直接调用pdfminer提供的pdf文本内容抽取功能,而不必考虑一大堆恼人的参数;demo.ipynb: 已经为你写好的本教程 Python 源代码 (Jupyter Notebook格式)。
另外,演示目录中还包括了2个文件夹。
这两个文件夹里面,都是中文pdf文件,用来给你展示pdf内容抽取。它们都是我几年前发表的中文核心期刊论文。
这里做2点说明:
- 使用我自己的论文做示例,是因为我怕用别人的论文做文本抽取,会与论文作者及数据库运营商之间有知识产权的纠纷;
- 分成2个文件夹,是为了向你展示添加新的pdf文件时,抽取工具会如何处理。
pdf文件夹内容如下:
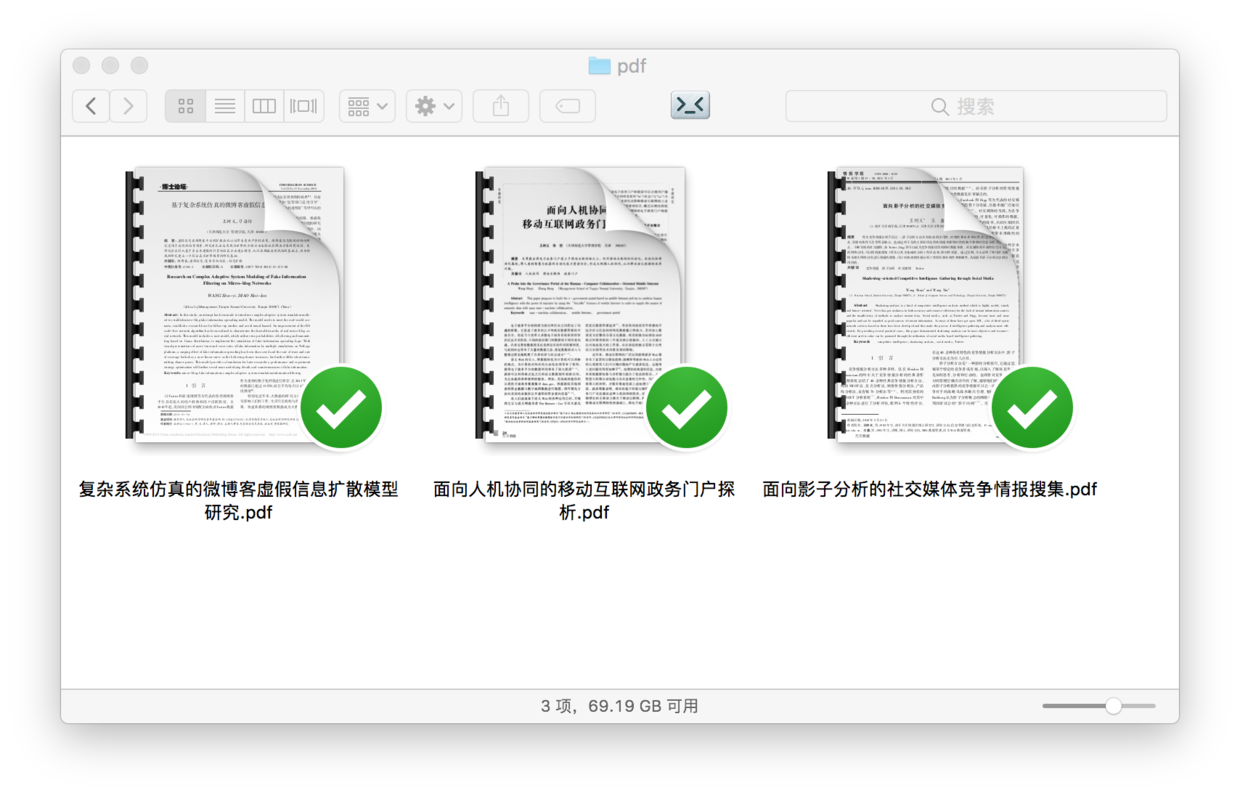
newpdf文件夹内容如下:
数据准备好了,下面我们来部署代码运行环境。
9.6.3 环境
要安装Python,比较省事的办法是装Anaconda套装。
请到 这个网址 下载Anaconda的最新版本。
请选择左侧的 Python 3.6 版本下载安装。
如果你需要具体的步骤指导,或者想知道Windows平台如何安装并运行Anaconda命令,请参考我为你准备的 视频教程(2.2) 。
安装好Anaconda之后,打开终端,用cd命令进入演示目录。
如果你不了解具体使用方法,也可以参考 视频教程(2.2) 。
我们需要安装一些环境依赖包。
首先执行:
pip install pipenv这里安装的,是一个优秀的 Python 软件包管理工具 pipenv 。 安装后,请执行:
pipenv install --skip-lockpipenv 工具会依照Pipfile,自动为我们安装所需要的全部依赖软件包。
终端里面会有进度条,提示所需安装软件数量和实际进度。
装好后,根据提示我们执行:
pipenv shell这样,我们就进入本教程专属的虚拟运行环境了。
注意一定要执行下面这句:
python -m ipykernel install --user --name=py36只有这样,当前的Python环境才会作为核心(kernel)在系统中注册,并且命名为py36。
此处请确认你的电脑上已经安装了 Google Chrome 浏览器。
我们执行:
jupyter notebook默认浏览器(Google Chrome)会开启,并启动 Jupyter 笔记本界面:
你可以直接点击文件列表中的第一项ipynb文件,可以看到本教程的全部示例代码。
你可以一边看教程的讲解,一边依次执行这些代码。
但是,我建议的方法,是回到主界面下,新建一个新的空白 Python 3 笔记本(显示名称为 py36 的那个)。
请跟着教程,一个个字符输入相应的内容。这可以帮助你更为深刻地理解代码的含义,更高效地把技能内化。
当你在编写代码中遇到困难的时候,可以返回参照 demo.ipynb 文件。
准备工作结束,下面我们开始正式输入代码。
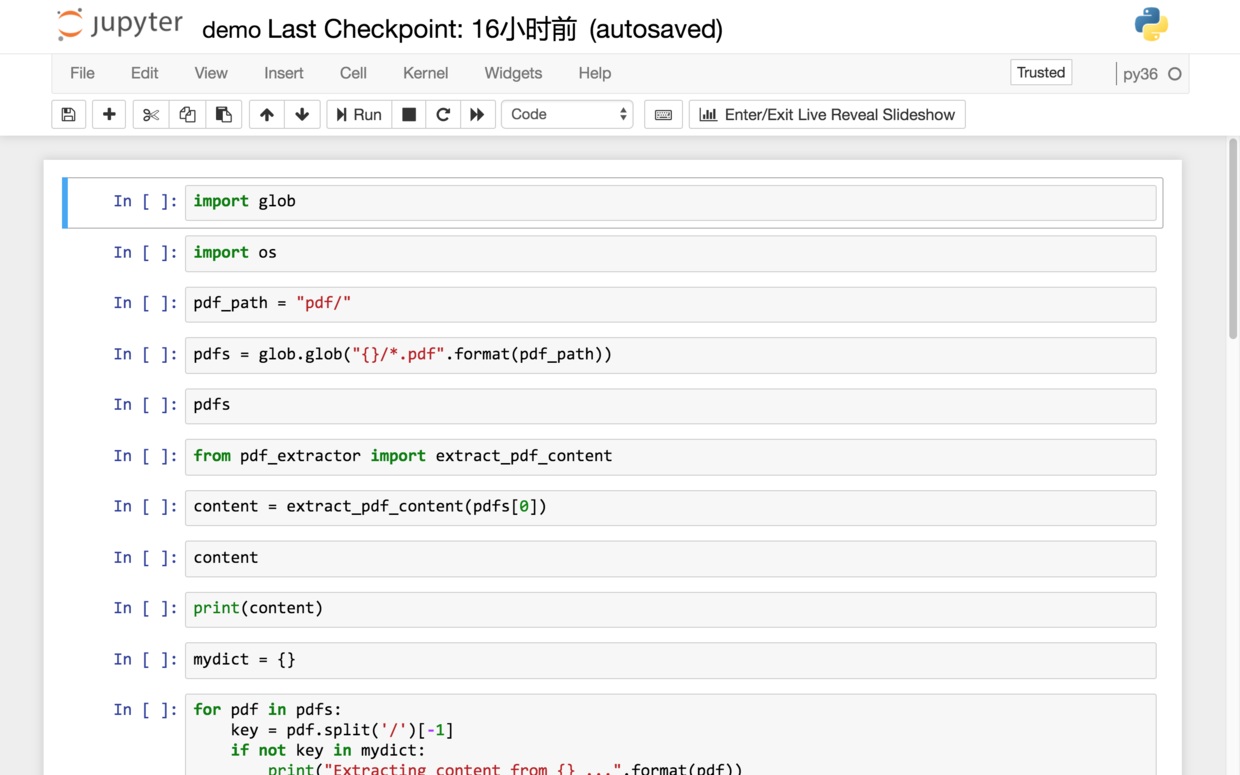
9.6.4 代码
首先,我们读入一些模块,以进行文件操作。
前文提到过,演示目录下,有两个文件夹,分别是pdf和newpdf。
我们指定 pdf 文件所在路径为其中的pdf文件夹。
我们希望获得所有 pdf 文件的路径。用glob,一条命令就能完成这个功能。
看看我们获得的 pdf 文件路径是否正确。
['pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf',
'pdf/面向影子分析的社交媒体竞争情报搜集.pdf',
'pdf/面向人机协同的移动互联网政务门户探析.pdf']经验证。准确无误。
下面我们利用 pdfminer 来从 pdf 文件中抽取内容。我们需要从辅助 Python 文件 pdf_extractor.py 中读入函数 extract_pdf_content。
用这个函数,我们尝试从 pdf 文件列表中的第一篇里,抽取内容,并且把文本保存在 content 变量里。
我们看看 content 里都有什么:

显然,内容抽取并不完美,页眉页脚等信息都混了进来。
不过,对于我们的许多文本分析用途来说,这无关紧要。
你会看到 content 的内容里面有许多的 \n,这是什么呢?
我们用 print 函数,来显示 content 的内容。

可以清楚看到,那些 \n 是换行符。
通过一个 pdf 文件的抽取测试,我们建立了信心。
下面,我们该建立辞典,批量抽取和存储内容了。
我们遍历 pdfs 列表,把文件名称(不包含目录)作为键值。这样,我们可以很容易看到,哪些pdf文件已经被抽取过了,哪些还没有抽取。
为了让这个过程更为清晰,我们让Python输出正在抽取的 pdf 文件名。
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)抽取过程中,你会看到这些输出信息:
Extracting content from pdf/复杂系统仿真的微博客虚假信息扩散模型研究.pdf ...
Extracting content from pdf/面向影子分析的社交媒体竞争情报搜集.pdf ...
Extracting content from pdf/面向人机协同的移动互联网政务门户探析.pdf ...看看此时字典中的键值都有哪些:
dict_keys(['复杂系统仿真的微博客虚假信息扩散模型研究.pdf', '面向影子分析的社交媒体竞争情报搜集.pdf', '面向人机协同的移动互联网政务门户探析.pdf'])一切正常。
下面我们调用pandas,把字典变成数据框,以利于分析。
下面这条语句,就可以把字典转换成数据框了。注意后面的reset_index()把原先字典键值生成的索引也转换成了普通的列。
然后我们重新命名列,以便于后续使用。
此时的数据框内容如下:

可以看到,我们的数据框拥有了pdf文件信息和全部文本内容。这样你就可以使用关键词抽取、情感分析、相似度计算等等诸多分析工具了。
篇幅所限,我们这里只用一个字符数量统计的例子来展示基本分析功能。
我们让 Python 帮我们统计抽取内容的长度。
此时的数据框内容发生以下变化:

多出的一列,就是 pdf 文本内容的字符数量。
为了在 Jupyter Notebook 里面正确展示绘图结果,我们需要使用以下语句:
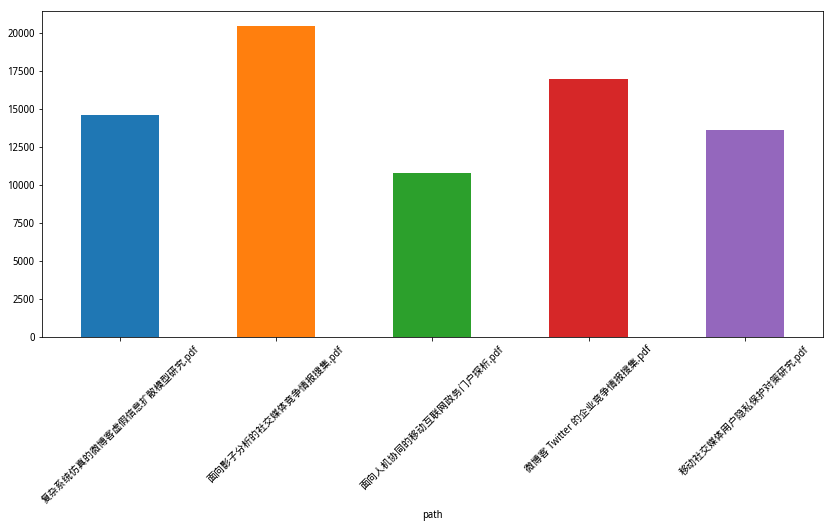
下面,我们让 Pandas 把字符长度一列的信息用柱状图标示出来。为了显示的美观,我们设置了图片的长宽比例,并且把对应的pdf文件名称以倾斜45度来展示。
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)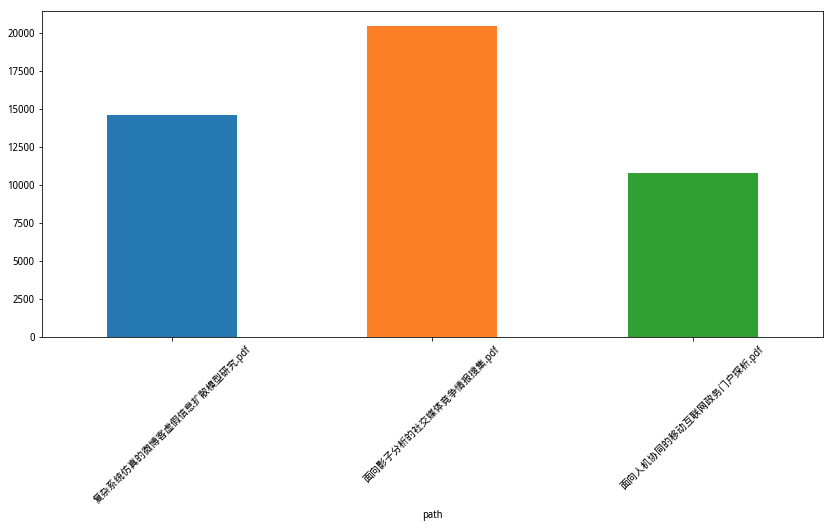
可视化分析完成。
下面我们把刚才的分析流程整理成函数,以便于将来更方便地调用。
我们先整合pdf内容提取到字典的模块:
def get_mydict_from_pdf_path(mydict, pdf_path):
pdfs = glob.glob("{}/*.pdf".format(pdf_path))
for pdf in pdfs:
key = pdf.split('/')[-1]
if not key in mydict:
print("Extracting content from {} ...".format(pdf))
mydict[key] = extract_pdf_content(pdf)
return mydict这里输入是已有词典和pdf文件夹路径。输出为新的词典。
你可能会纳闷为何还要输入“已有词典”。别着急,一会儿我用实际例子展示给你看。
下面这个函数非常直白——就是把词典转换成数据框。
def make_df_from_mydict(mydict):
df = pd.DataFrame.from_dict(mydict, orient='index').reset_index()
df.columns = ["path", "content"]
return df最后一个函数,用于绘制统计出来的字符数量。
def draw_df(df):
df["length"] = df.content.apply(lambda x: len(x))
plt.figure(figsize=(14, 6))
df.set_index('path').length.plot(kind='bar')
plt.xticks(rotation=45)函数已经编好,下面我们来尝试一下。
还记得演示目录下有个子目录,叫做newpdf对吧?
我们把其中的2个pdf文件,移动到pdf目录下面。
这样pdf目录下面,就有了5个文件:
我们执行新整理出的3个函数。
首先输入已有的词典(注意此时里面已有3条记录),pdf文件夹路径没变化。输出是新的词典。
Extracting content from pdf/微博客 Twitter 的企业竞争情报搜集.pdf ...
Extracting content from pdf/移动社交媒体用户隐私保护对策研究.pdf ...注意这里的提示,原先的3个pdf文件没有被再次抽取,只有2个新pdf文件被抽取。
咱们这里一共只有5个文件,所以你直观上可能无法感受出显著的区别。
但是,假设你原先已经用几个小时,抽取了成百上千个pdf文件信息,结果你的老板又丢给你3个新的pdf文件……
如果你必须从头抽取信息,恐怕会很崩溃吧。
这时候,使用咱们的函数,你可以在1分钟之内把新的文件内容追加进去。
这差别,不小吧?
下面我们用新的词典,构建数据框。
我们绘制新的数据框里,pdf抽取文本字符数量。结果如下:
至此,代码展示完毕。
9.6.5 小结
总结一下,本文为你介绍了以下知识点:
- 如何用glob批量读取目录下指定格式的文件路径;
- 如何用pdfminer从pdf文件中抽取文本信息;
- 如何构建词典,存储与键值(本文中为文件名)对应的内容,并且避免重复处理数据;
- 如何将词典数据结构轻松转换为Pandas数据框,以便于后续数据分析。
- 如何用matplotlib和pandas自带的绘图函数轻松绘制柱状统计图形。
9.7 本章小结
如果你喜欢本章的内容,欢迎扫描下面二维码,请我喝杯咖啡。

如果你需要答疑,咱们的问答社区在这里: