第 7 章 深度学习
7.1 如何用Python和深度神经网络锁定即将流失的客户?
Python深度学习简明实战教程来了。别犹豫了,赶紧从零开始,搭建你自己的第一个深度学习模型吧!
想不想了解如何用Python快速搭建深度神经网络,完成数据分类任务?本文一步步为你展示这一过程,让你初步领略深度学习模型的强大和易用。
7.1.1 烦恼
作为一名数据分析师,你来到这家跨国银行工作已经半年了。
今天上午,老板把你叫到办公室,面色凝重。
你心里直打鼓,以为自己捅了什么篓子。幸好老板的话让你很快打消了顾虑。
他发愁,是因为最近欧洲区的客户流失严重,许多客户都跑到了竞争对手那里接受服务了。老板问你该怎么办?
你脱口而出“做好客户关系管理啊!”
老板看了你一眼,缓慢地说“我们想知道哪些客户最可能在近期流失”。
没错,在有鱼的地方钓鱼,才是上策。
你明白了自己的任务——通过数据锁定即将流失的客户。这个工作,确实是你这个数据分析师分内的事儿。
你很庆幸,这半年做了很多的数据动态采集和整理工作,使得你手头就有一个比较完备的客户数据集。
下面你需要做的,就是如何从数据中“沙里淘金”,找到那些最可能流失的客户。
可是,该怎么做呢?
你拿出欧洲区客户的数据,端详起来。
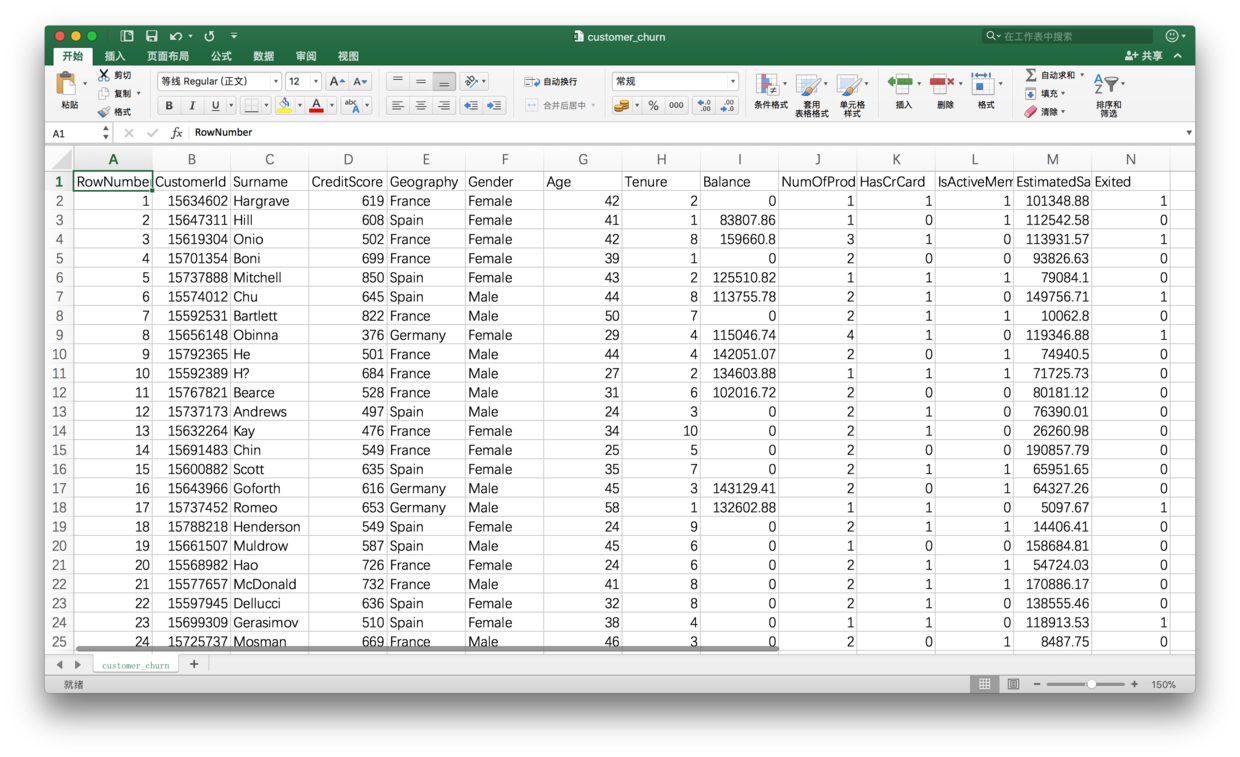
客户主要分布在法国、德国和西班牙。
你手里掌握的信息,包括他们的年龄、性别、信用、办卡信息等。客户是否已流失的信息在最后一列(Exited)。
怎么用这些数据来判断顾客是否会流失呢?
以你的专业素养,很容易就判断出这是一个分类问题,属于机器学习中的监督式学习。但是,你之前并没有做过实际项目,该如何着手呢?
别发愁,我一步步给你演示如何用Python和深度神经网络(或者叫“深度学习”)来完成这个分类任务,帮你锁定那些即将流失的客户。
7.1.2 环境
工欲善其事,必先利其器。我们先来安装和搭建环境。
首先是安装Python。
请到这个网址下载Anaconda的最新版本。
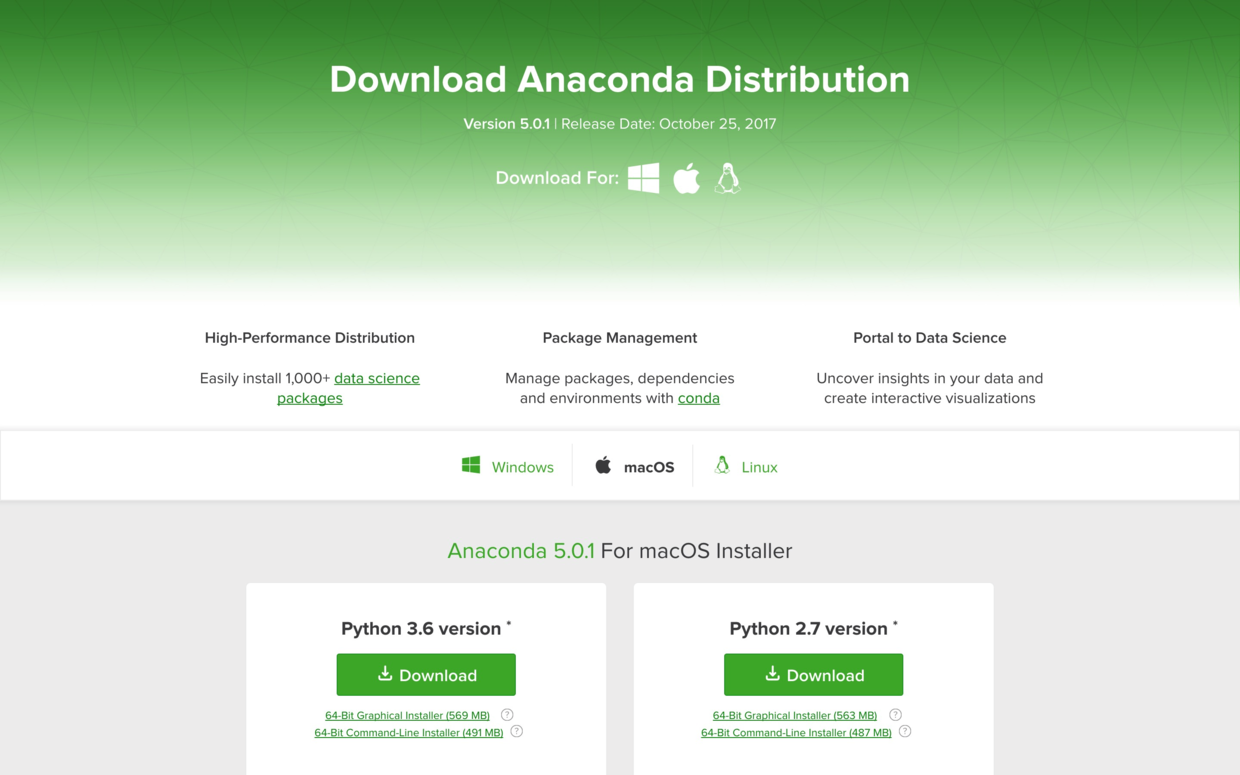
请选择左侧的Python 3.6版本下载安装。
其次是新建文件夹,起名为demo-customer-churn-ann,并且从这个链接下载数据,放到该文件夹下。
(注:样例数据来自于匿名化处理后的真实数据集,下载自superdatascience官网。)
打开终端(或者命令行工具),进入demo-customer-churn-ann目录,执行以下命令:
浏览器中会显示如下界面:
点击界面右上方的New按钮,新建一个Python 3 Notebook,起名为customer-churn-ann。
准备工作结束,下面我们开始清理数据。
7.1.3 清理
首先,读入数据清理最常用的pandas和numpy包。
从customer_churn.csv里读入数据:
看看读入效果如何:
这里我们使用了head()函数,只显示前5行。
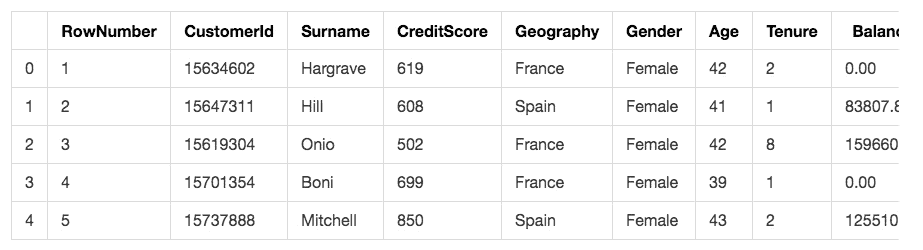
可以看到,数据完整无误读入。但是并非所有的列都对我们预测用户流失有作用。我们一一甄别一下:
- RowNumber:行号,这个肯定没用,删除
- CustomerID:用户编号,这个是顺序发放的,删除
- Surname:用户姓名,对流失没有影响,删除
- CreditScore:信用分数,这个很重要,保留
- Geography:用户所在国家/地区,这个有影响,保留
- Gender:用户性别,可能有影响,保留
- Age:年龄,影响很大,年轻人更容易切换银行,保留
- Tenure:当了本银行多少年用户,很重要,保留
- Balance:存贷款情况,很重要,保留
- NumOfProducts:使用产品数量,很重要,保留
- HasCrCard:是否有本行信用卡,很重要,保留
- IsActiveMember:是否活跃用户,很重要,保留
- EstimatedSalary:估计收入,很重要,保留
- Exited:是否已流失,这将作为我们的标签数据
上述数据列甄别过程,就叫做“特征工程”(Feature Engineering),这是机器学习里面最常用的数据预处理方法。如果我们的数据量足够大,机器学习模型足够复杂,是可以跳过这一步的。但是由于我们的数据只有10000条,还需要手动筛选特征。
选定了特征之后,我们来生成特征矩阵X,把刚才我们决定保留的特征都写进来。
看看特征矩阵的前几行:
显示结果如下:
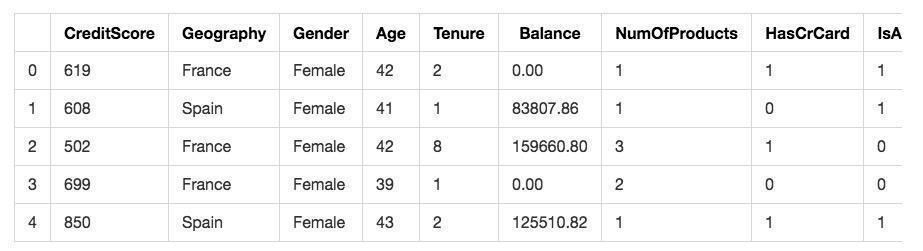
特征矩阵构建准确无误,下面我们构建目标数据y,也就是用户是否流失。
0 1
1 0
2 1
3 0
4 0
Name: Exited, dtype: int64此时我们需要的数据基本上齐全了。但是我们发现其中有几列数据还不符合我们的要求。
要做机器学习,只能给机器提供数值,而不能是字符串。可是看看我们的特征矩阵:
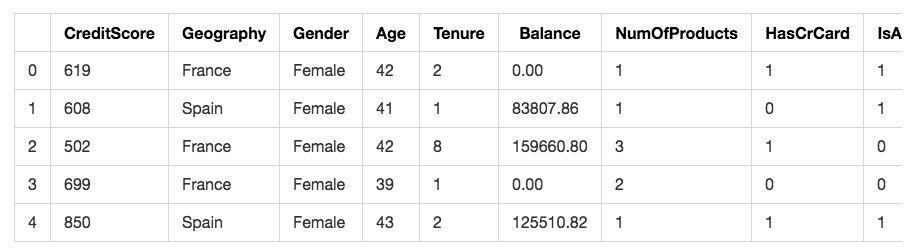
显然其中的Geography和Gender两项数据都不符合要求。它们都是分类数据。我们需要做转换,把它们变成数值。
在Scikit-learn工具包里面,专门提供了方便的工具LabelEncoder,让我们可以方便地将类别信息变成数值。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder1 = LabelEncoder()
X.Geography= labelencoder1.fit_transform(X.Geography)
labelencoder2 = LabelEncoder()
X.Gender = labelencoder2.fit_transform(X.Gender)我们需要转换两列,所以建立了两个不同的labelencoder。转换的函数叫做fit_transform。
经过转换,此时我们再来看看特征矩阵的样子:
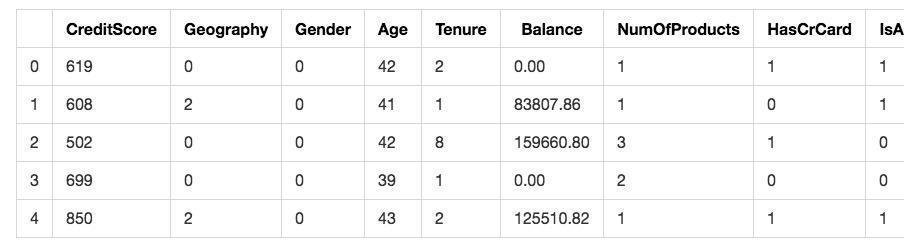
显然,Geography和Gender这两列都从原先描述类别的字符串,变成了数字。
这样是不是就完事大吉了呢?
不对,Gender还好说,只有两种取值方式,要么是男,要么是女。我们可以把“是男性”定义为1,那么女性就取值为0。两种取值只是描述类别不同,没有歧义。
而Geography就不同了。因为数据集里面可能的国家地区取值有3种,所以就转换成了0(法国)、1(德国)、2(西班牙)。问题是,这三者之间真的有序列(大小)关系吗?
答案自然是否定的。我们其实还是打算用数值描述分类而已。但是取值有数量的序列差异,就会给机器带来歧义。它并不清楚不同的取值只是某个国家的代码,可能会把这种大小关系带入模型计算,从而产生错误的结果。
解决这个问题,我们就需要引入OneHotEncoder。它也是Scikit-learn提供的一个类,可以帮助我们把类别的取值转变为多个变量组合表示。
咱们这个数据集里,可以把3个国家分别用3个数字组合来表示。例如法国从原先的0,变成(1, 0, 0),德国从1变成(0, 1, 0),而西班牙从2变成(0, 0, 1)。
这样,再也不会出现0和1之外的数字来描述类别,从而避免机器产生误会,错把类别数字当成大小来计算了。
特征矩阵里面,我们只需要转换国别这一列。因为它在第1列的位置(从0开始计数),因而categorical_features只填写它的位置信息。
onehotencoder = OneHotEncoder(categorical_features = [1])
X = onehotencoder.fit_transform(X).toarray()这时候,我们的特征矩阵数据框就被转换成了一个数组。注意所有被OneHotEncoder转换的列会排在最前面,然后才是那些保持原样的数据列。
我们只看转换后的第一行:
array([ 1.00000000e+00, 0.00000000e+00, 0.00000000e+00,
6.19000000e+02, 0.00000000e+00, 4.20000000e+01,
2.00000000e+00, 0.00000000e+00, 1.00000000e+00,
1.00000000e+00, 1.00000000e+00, 1.01348880e+05])这样,总算转换完毕了吧?
没有。
因为本例中,OneHotEncoder转换出来的3列数字,实际上是不独立的。给定其中两列的信息,你自己都可以计算出其中的第3列取值。
好比说,某一行的前两列数字是(0, 0),那么第三列肯定是1。因为这是转换规则决定的。3列里只能有1个是1,其余都是0。
如果你做过多元线性回归,应该知道这种情况下,我们是需要去掉其中一列,才能继续分析的。不然会落入“虚拟变量陷阱”(dummy variable trap)。
我们删掉第0列,避免掉进坑里。
再次打印第一行:
array([ 0.00000000e+00, 0.00000000e+00, 6.19000000e+02,
0.00000000e+00, 4.20000000e+01, 2.00000000e+00,
0.00000000e+00, 1.00000000e+00, 1.00000000e+00,
1.00000000e+00, 1.01348880e+05])检查完毕,现在咱们的特征矩阵处理基本完成。
但是监督式学习,最重要的是有标签(label)数据。本例中的标签就是用户是否流失。我们目前的标签数据框,是这个样子的。
0 1
1 0
2 1
3 0
4 0
Name: Exited, dtype: int64它是一个行向量,我们需要把它先转换成为列向量。你可以想象成把它“竖过来”。
array([[1],
[0],
[1],
...,
[1],
[1],
[0]])这样在后面训练的时候,他就可以和前面的特征矩阵一一对应来操作计算了。
既然标签代表了类别,我们也把它用OneHotEncoder转换,这样方便我们后面做分类学习。
此时的标签变成两列数据,一列代表顾客存留,一列代表顾客流失。
array([[ 0., 1.],
[ 1., 0.],
[ 0., 1.],
...,
[ 0., 1.],
[ 0., 1.],
[ 1., 0.]])总体的数据已经齐全了。但是我们不能把它们都用来训练。
这就好像老师不应该把考试题目拿来给学生做作业和练习一样。只有考学生没见过的题,才能区分学生是掌握了正确的解题方法,还是死记硬背了作业答案。
我们拿出20%的数据,放在一边,等着用来做测试。其余8000条数据用来训练机器学习模型。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)我们看看训练集的长度:
8000再看看测试集的长度:
2000确认无误。
是不是可以开始机器学习了?
可以,但是下面这一步也很关键。我们需要把数据进行标准化处理。因为原先每一列数字的取值范围都各不相同,因此有的列方差要远远大于其他列。这样对机器来说,也是很困扰的。数据的标准化处理,可以在保持列内数据多样性的同时,尽量减少不同类别之间差异的影响,可以让机器公平对待全部特征。
我们调用Scikit-learn的StandardScaler类来完成这一过程。
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)注意,我们只对特征矩阵做标准化,标签是不能动的。另外训练集和测试集需要按照统一的标准变化。所以你看,训练集上,我们用了fit_transform函数,先拟合后转换;而在测试集上,我们直接用训练集拟合的结果,只做转换。
array([[-0.5698444 , 1.74309049, 0.16958176, ..., 0.64259497,
-1.03227043, 1.10643166],
[ 1.75486502, -0.57369368, -2.30455945, ..., 0.64259497,
0.9687384 , -0.74866447],
[-0.5698444 , -0.57369368, -1.19119591, ..., 0.64259497,
-1.03227043, 1.48533467],
...,
[-0.5698444 , -0.57369368, 0.9015152 , ..., 0.64259497,
-1.03227043, 1.41231994],
[-0.5698444 , 1.74309049, -0.62420521, ..., 0.64259497,
0.9687384 , 0.84432121],
[ 1.75486502, -0.57369368, -0.28401079, ..., 0.64259497,
-1.03227043, 0.32472465]])你会发现,许多列的方差比原先小得多。机器学习起来,会更加方便。
数据清理和转换工作至此完成。
7.1.4 决策树
如果读过我的《贷还是不贷:如何用Python和机器学习帮你决策?》(6.1)一文,你应该有一种感觉——这个问题和贷款审批决策很像啊!既然在该文中,决策树很好使,我们继续用决策树不就好了?
好的,我们先测试一下经典机器学习算法表现如何。
从Scikit-learn中,读入决策树工具。然后拟合训练集数据。
然后,利用我们建立的决策树模型做出预测。
打印预测结果:
array([[ 1., 0.],
[ 0., 1.],
[ 1., 0.],
...,
[ 1., 0.],
[ 1., 0.],
[ 0., 1.]])这样看不出来什么。让我们调用Scikit-learn的classification_report模块,生成分析报告。
precision recall f1-score support 0 0.89 0.86 0.87 1595
1 0.51 0.58 0.54 405avg / total 0.81 0.80 0.81 2000经检测,决策树在咱们的数据集上,表现得还是不错的。总体的准确率为0.81,召回率为0.80,f1分数为0.81,已经很高了。对10个客户做流失可能性判断,它有8次都能判断正确。
但是,这样是否足够?
我们或许可以调整决策树的参数做优化,尝试改进预测结果。
或者我们可以采用深度学习。
7.1.5 深度
深度学习的使用场景,往往是因为原有的模型经典机器学习模型过于简单,无法把握复杂数据特性。
我不准备给你讲一堆数学公式,咱们动手做个实验。
请你打开这个网址。
你会看到如下图所示的深度学习游乐场:
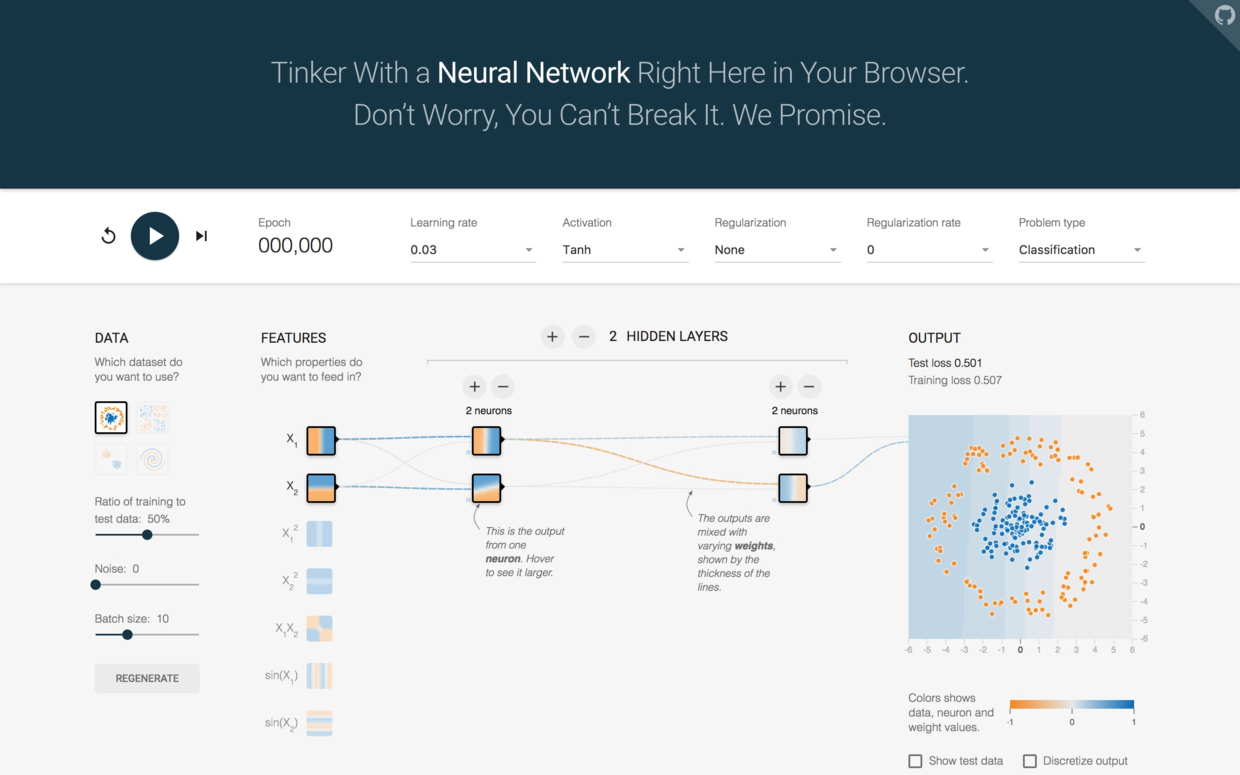
右侧的图形,里面是蓝色数据,外圈是黄色数据。你的任务就是要用模型分类两种不同数据。
你说那还不容易?我一眼就看出来了。
你看出来没有用。通过你的设置,让机器也能正确区分,才算数。
图中你看到许多加减号。咱们就通过操纵它们来玩儿一玩儿模型。
首先,点图中部上方的“2 HIDDEN LAYERS”左侧减号,把中间隐藏层数降低为1。
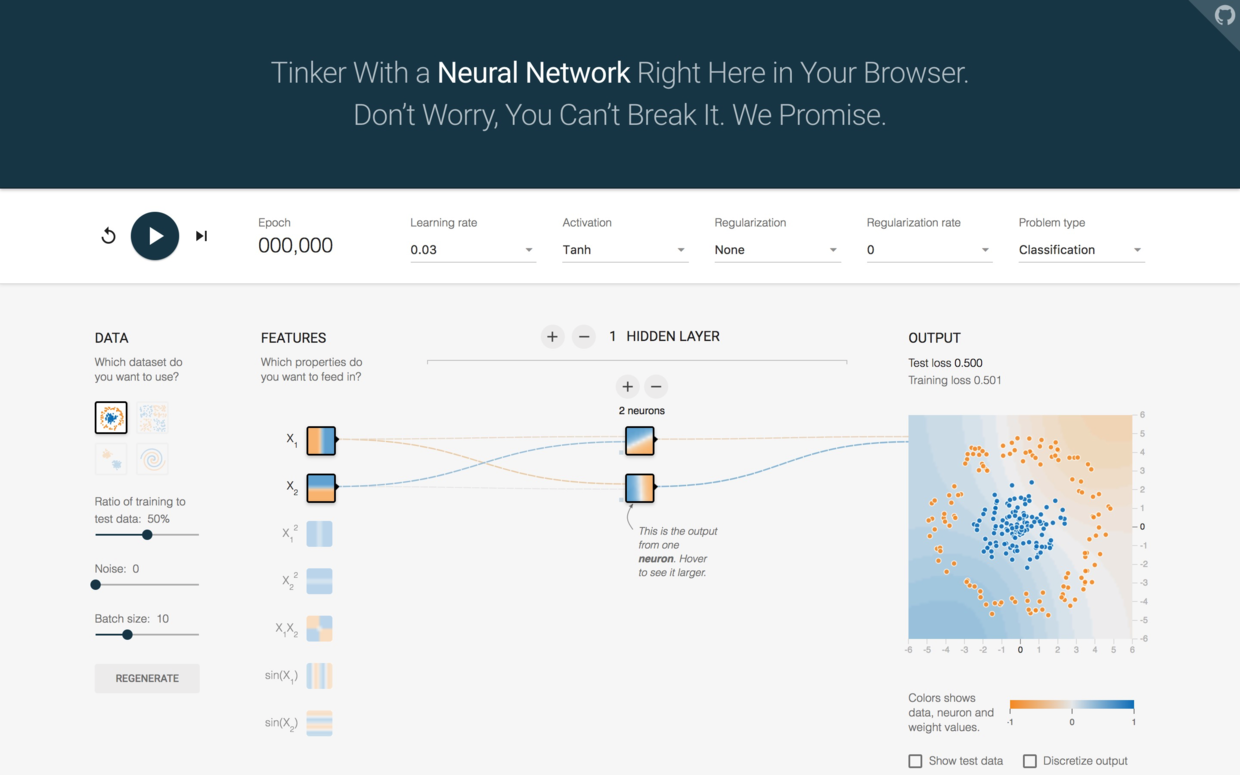
然后,点击“2 neurons”上面的减号,把神经元数量减少为1。
把页面上方的Activation函数下拉框打开,选择“Sigmoid”。
现在的模型,其实就是经典的逻辑回归(Logistic Regression)。
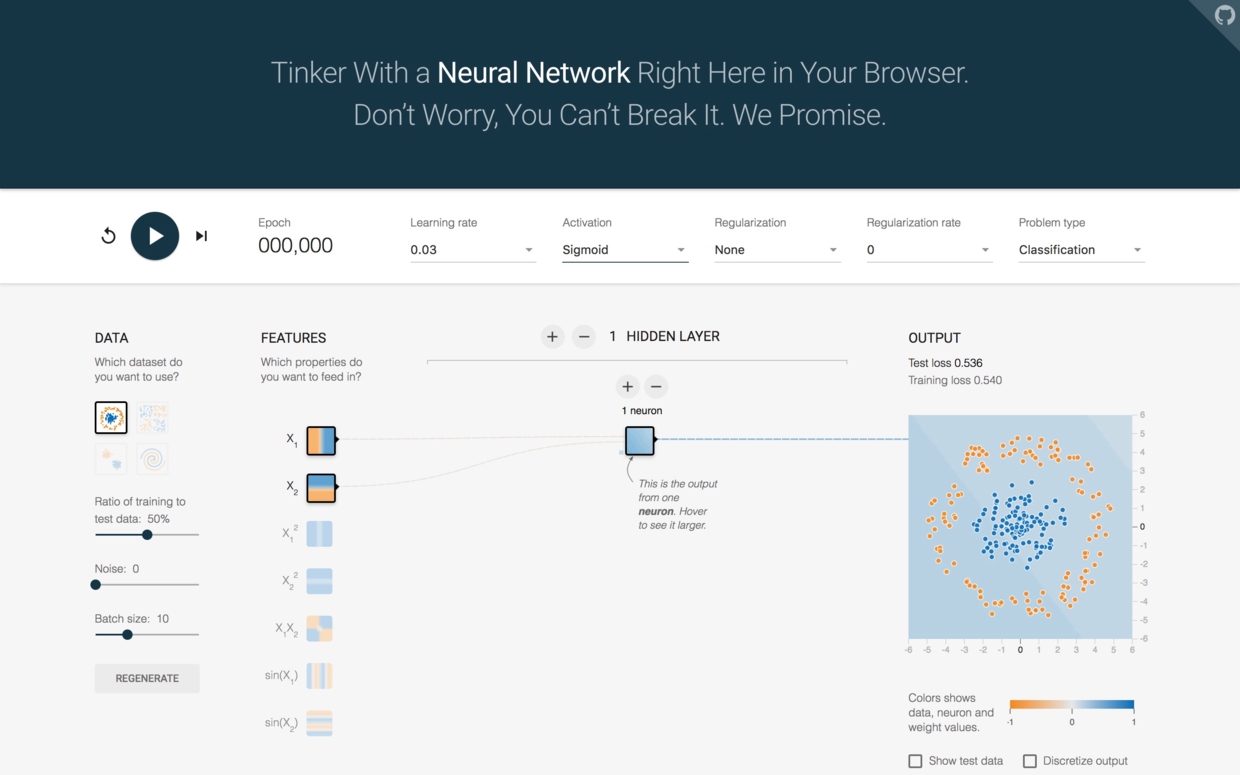
点击左上方的运行按钮,我们看看执行效果。
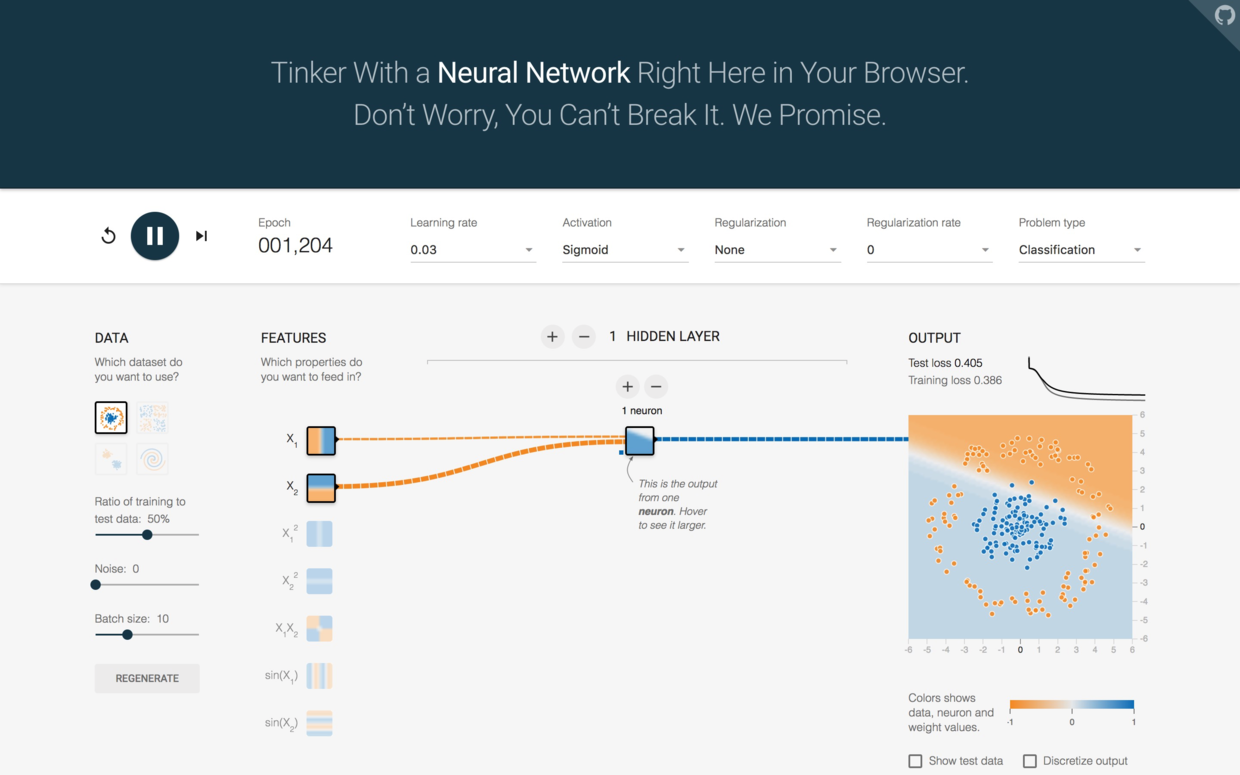
由于模型过于简单,所以机器绞尽脑汁,试图用一条直线切分二维平面上的两类节点。
损失(loss)居高不下。训练集和测试集损失都在0.4左右,显然不符合我们的分类需求。
下面我们试试增加层数和神经元数量。这次点击加号,把隐藏层数加回到2,两层神经元数量都取2。
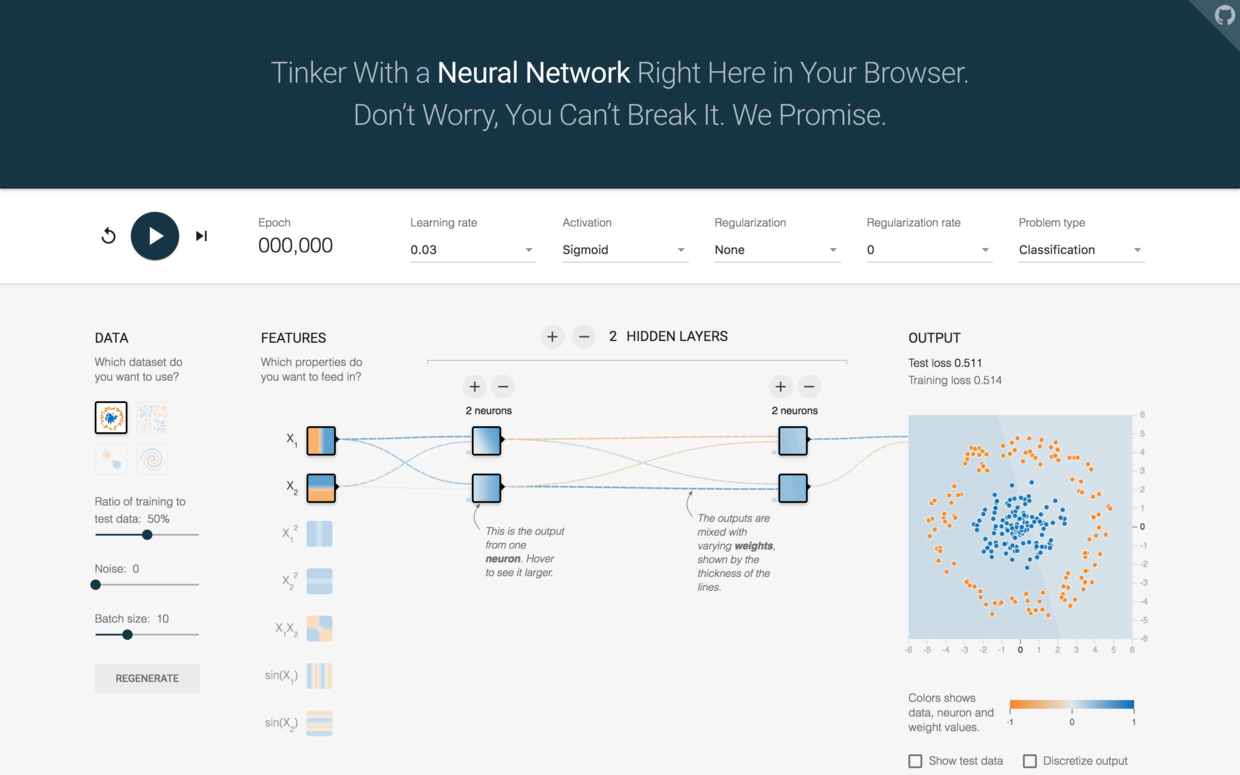
再次点击运行。
经过一段时间,结果稳定了下来,你发现这次电脑用了两条线,把平面切分成了3部分。
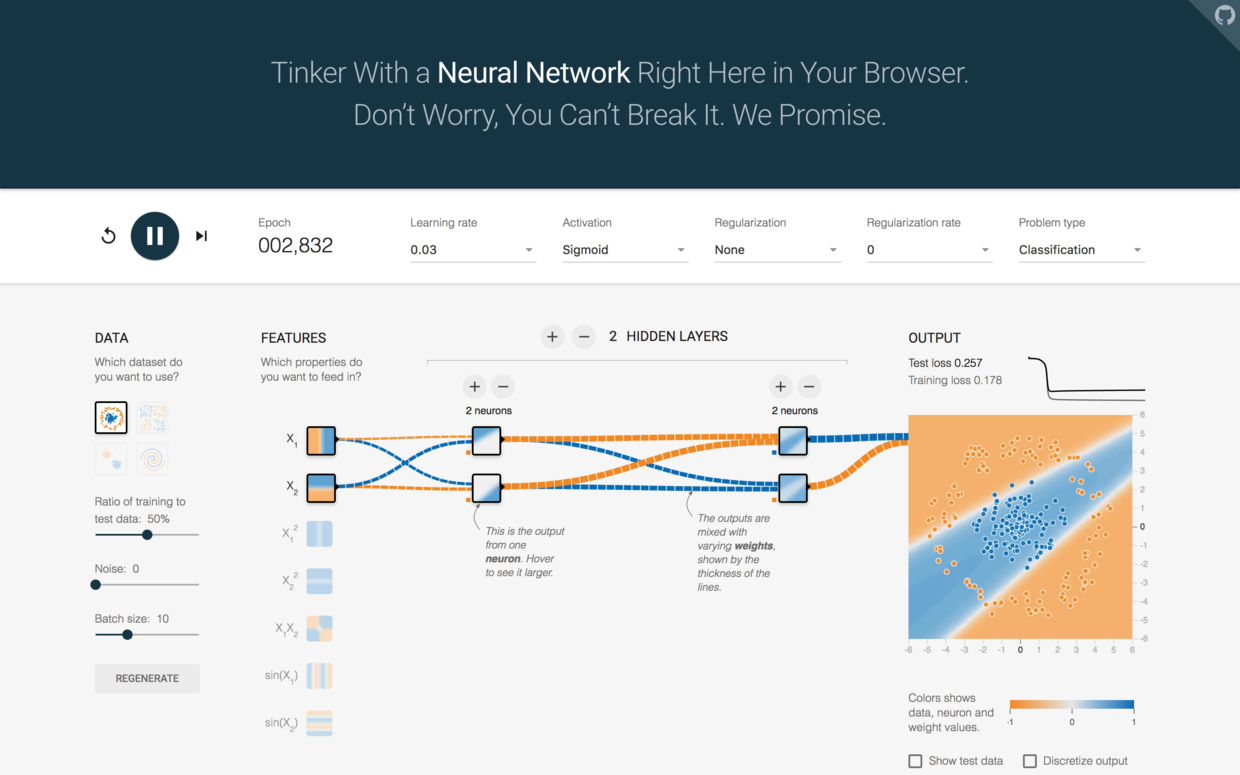
测试集损失下降到了0.25左右,而训练集损失更是降低到了0.2以下。
模型复杂了,效果似乎更好一些。
再接再厉,我们把第一个隐藏层的神经元数量增加为4看看。
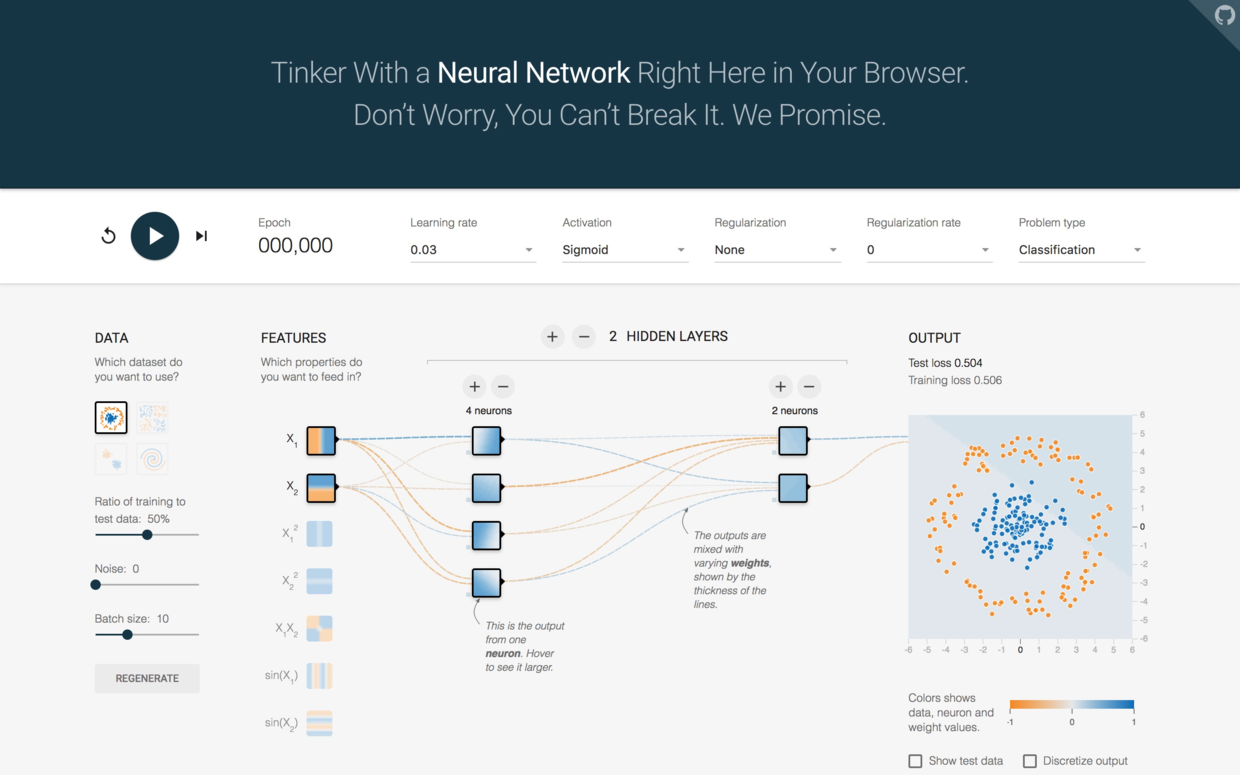
点击运行,不一会儿有趣的事情就发生了。
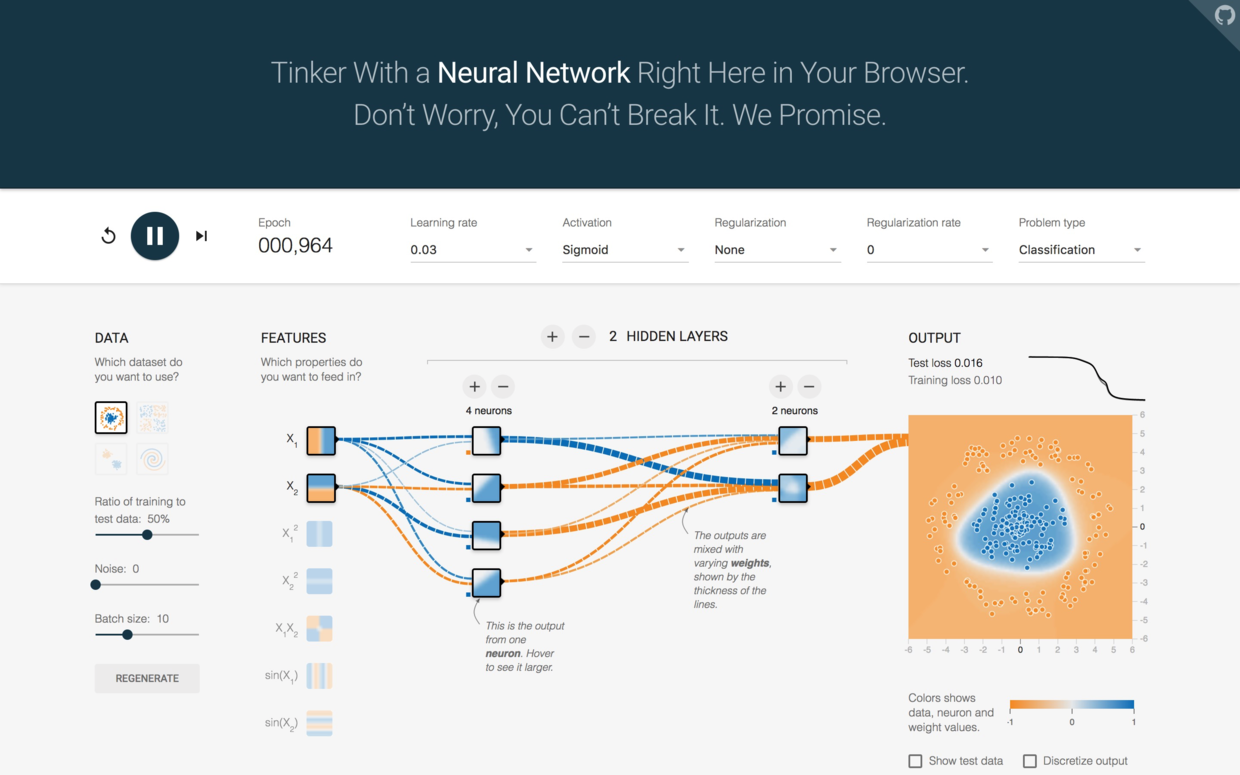
机器用一条近乎完美的曲线把平面分成了内外两个部分。测试集和训练集损失都极速下降,训练集损失甚至接近于0。
这告诉我们,许多时候模型过于简单带来的问题,可以通过加深隐藏层次、增加神经元的方法提升模型复杂度,加以改进。
目前流行的划分方法,是用隐藏层的数量多少来区分是否“深度”。当神经网络中隐藏层数量达到3层以上时,就被称为“深度神经网络”,或者“深度学习”。
久闻大名的深度学习,原来就是这么简单。
如果有时间的话,建议你自己在这个游乐场里多动手玩儿一玩儿。你会很快对神经网络和深度学习有个感性认识。
7.1.6 框架
游乐场背后使用的引擎,就是Google的深度学习框架Tensorflow。
所谓框架,就是别人帮你构造好的基础软件应用。你可以通过调用它们,避免自己重复发明轮子,大幅度节省时间,提升效率。
支持Python语言的深度学习的框架有很多,除了Tensorflow外,还有PyTorch, Theano和MXNet等。
我给你的建议是,找到一个你喜欢的软件包,深入学习使用,不断实践来提升自己的技能。千万不要跟别人争论哪个深度学习框架更好。一来萝卜白菜各有所爱,每个人都有自己的偏好;二来深度学习的江湖水很深,言多有失。说错了话,别的门派可能会不高兴哟。
我比较喜欢Tensorflow。但是Tensorflow本身是个底层库。虽然随着版本的更迭,界面越来越易用。但是对初学者来说,许多细节依然有些过于琐碎,不容易掌握。
初学者的耐心有限,挫折过多容易放弃。
幸好,还有几个高度抽象框架,是建立在Tensorflow之上的。如果你的任务是应用现成的深度学习模型,那么这些框架会给你带来非常大的便利。
这些框架包括Keras, TensorLayer等。咱们今天将要使用的,叫做TFlearn。
它的特点,就是长得很像Scikit-learn。这样如果你熟悉经典机器学习模型,学起来会特别轻松省力。
7.1.7 实战
闲话就说这么多,下面咱们继续写代码吧。
写代码之前,请回到终端下,运行以下命令,安装几个软件包:
执行完毕后,回到Notebook里。
我们呼叫tflearn框架。
然后,我们开始搭积木一样,搭神经网络层。
首先是输入层。
注意这里的写法,因为我们输入的数据,是特征矩阵。而经过我们处理后,特征矩阵现在有11列,因此shape的第二项写11。
shape的第一项,None,指的是我们要输入的特征矩阵行数。因为我们现在是搭建模型,后面特征矩阵有可能一次输入,有可能分成组块输入,长度可大可小,无法事先确定。所以这里填None。tflearn会在我们实际执行训练的时候,自己读入特征矩阵的尺寸,来处理这个数值。
下面我们搭建隐藏层。这里我们要使用深度学习,搭建3层。
net = tflearn.fully_connected(net, 6, activation='relu')
net = tflearn.fully_connected(net, 6, activation='relu')
net = tflearn.fully_connected(net, 6, activation='relu')activation刚才在深度学习游乐场里面我们遇到过,代表激活函数。如果没有它,所有的输入输出都是线性关系。
Relu函数是激活函数的一种。它大概长这个样子。
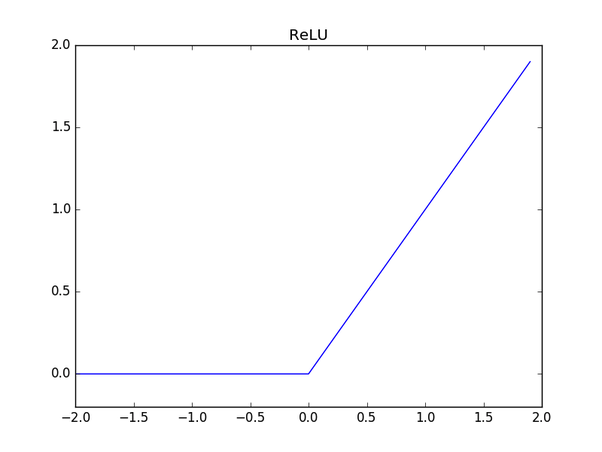
如果你想了解激活函数的更多知识,请参考后文的学习资源部分。
隐藏层里,每一层我们都设置了6个神经元。其实至今为之,也不存在最优神经元数量的计算公式。工程界的一种做法,是把输入层的神经元数量,加上输出层神经元数量,除以2取整。咱们这里就是用的这种方法,得出6个。
搭好了3个中间隐藏层,下面我们来搭建输出层。
这里我们用两个神经元做输出,并且说明使用回归方法。输出层选用的激活函数为softmax。处理分类任务的时候,softmax比较合适。它会告诉我们每一类的可能性,其中数值最高的,可以作为我们的分类结果。
积木搭完了,下面我们告诉TFlearn,以刚刚搭建的结构,生成模型。
有了模型,我们就可以使用拟合功能了。你看是不是跟Scikit-learn的使用方法很相似呢?
注意这里多了几个参数,我们来解释一下。
n_epoch:数据训练几个轮次。batch_size:每一次输入给模型的数据行数。show_metric:训练过程中要不要打印结果。
以下就是电脑输出的最终训练结果。其实中间运行过程看着更激动人心,你自己试一下就知道了。
Training Step: 7499 | total loss: [1m[32m0.39757[0m[0m | time: 0.656s
| Adam | epoch: 030 | loss: 0.39757 - acc: 0.8493 -- iter: 7968/8000
Training Step: 7500 | total loss: [1m[32m0.40385[0m[0m | time: 0.659s
| Adam | epoch: 030 | loss: 0.40385 - acc: 0.8487 -- iter: 8000/8000
--我们看到训练集的损失(loss)大概为0.4左右。
打开终端,我们输入
然后在浏览器里输入http://localhost:6006/
可以看到如下界面:
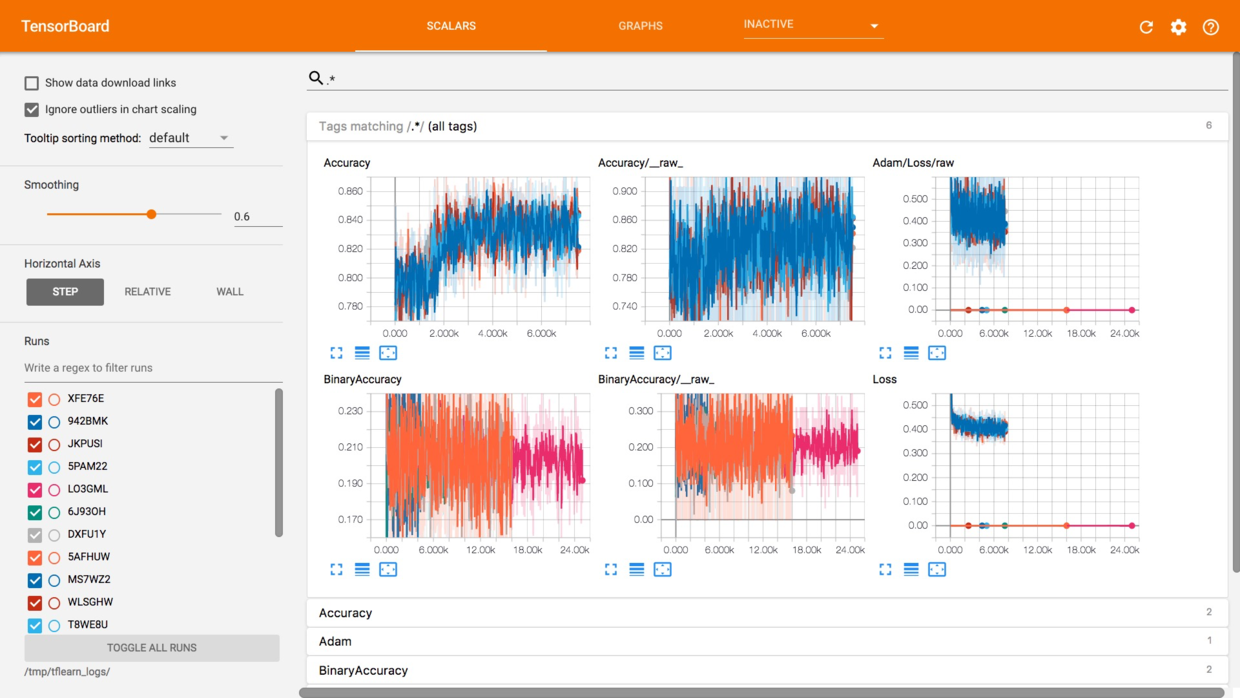
这是模型训练过程的可视化图形,可以看到准确度的攀升和损失降低的曲线。
打开GRAPHS标签页,我们可以查看神经网络的结构图形。
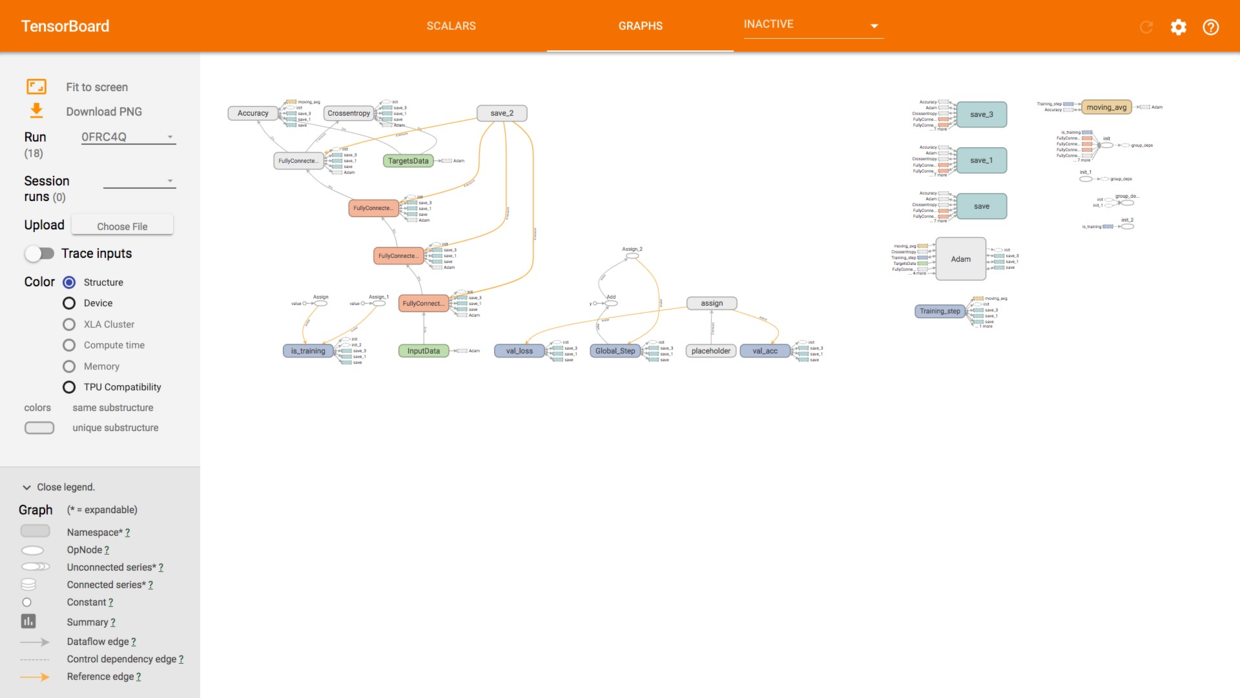
我们搭积木的过程,在此处一目了然。
7.1.8 评估
训练好了模型,我们来尝试做个预测吧。
看看测试集的特征矩阵第一行。
array([ 1.75486502, -0.57369368, -0.55204276, -1.09168714, -0.36890377,
1.04473698, 0.8793029 , -0.92159124, 0.64259497, 0.9687384 ,
1.61085707])我们就用它来预测一下分类结果。
打印出来看看:
array([ 0.70956731, 0.29043278], dtype=float32)模型判断该客户不流失的可能性为0.70956731。
我们看看实际标签数据:
array([ 1., 0.])客户果然没有流失。这个预测是对的。
但是一个数据的预测正确与否,是无法说明问题的。我们下面跑整个测试集,并且使用evaluate函数评价模型。
Test accuarcy: 84.1500%在测试集上,准确性达到84.15%,好样的!
希望在你的努力下,机器做出的准确判断可以帮助银行有效锁定可能流失的客户,降低客户的流失率,继续日进斗金。
7.1.9 说明
你可能觉得,深度学习也没有什么厉害的嘛。原先的决策树算法,那么简单就能实现,也可以达到80%以上的准确度。写了这么多语句,深度学习结果也无非只提升了几个百分点而已。
首先,准确度达到某种高度后,提升是不容易的。这就好像学生考试,从不及格到及格,付出的努力并不需要很高;从95分提升到100,却是许多人一辈子也没有完成的目标。
其次,在某些领域里,1%的提升意味着以百万美元计的利润,或者几千个人的生命因此得到拯救。
第三,深度学习的崛起,是因为大数据的环境。在许多情况下,数据越多,深度学习的优势就越明显。本例中只有10000条记录,与“大数据”的规模还相去甚远。
7.1.10 学习资源
如果你对深度学习感兴趣,推荐以下学习资源。
首先是教材。
第一本是Deep Learning,绝对的经典。

第二本是Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems,深入浅出,通俗易懂。

其次是MOOC。
推荐吴恩达(Andrew Ng)教授在Coursera上的两门课程。
一门是机器学习。这课推出有年头了,但是非常有趣和实用。具体的介绍请参考拙作《机器学习哪里有这么玄?》以及《如何用MOOC组合掌握机器学习?》。

一门是深度学习。这是个系列课程,包括5门子课程。今年推出的新课,自成体系,但是最好有前面那门课程作为基础。

7.2 如何用Python和深度神经网络识别图像?

只需要10几行Python代码,你就能构建自己的机器视觉模型,快速准确识别海量图片。快来试试吧!
7.2.1 视觉
进化的作用,让人类对图像的处理非常高效。
这里,我给你展示一张照片。

如果我这样问你:
你能否分辨出图片中哪个是猫,哪个是狗?
你可能立即会觉得自己遭受到了莫大的侮辱。并且大声质问我:你觉得我智商有问题吗?!
息怒。
换一个问法:
你能否把自己分辨猫狗图片的方法,描述成严格的规则,教给计算机,以便让它替我们人类分辨成千上万张图片呢?
对大多数人来说,此时感受到的,就不是羞辱,而是压力了。
如果你是个有毅力的人,可能会尝试各种判别标准:图片某个位置的像素颜色、某个局部的边缘形状、某个水平位置的连续颜色长度……
你把这些描述告诉计算机,它果然就可以判断出左边的猫和右边的狗了。
问题是,计算机真的会分辨猫狗图片了吗?
我又拿出一张照片给你。

你会发现,几乎所有的规则定义,都需要改写。
当机器好不容易可以用近似投机取巧的方法正确分辨了这两张图片里面的动物时,我又拿出来一张新图片……

几个小时以后,你决定放弃。
别气馁。
你遭遇到的,并不是新问题。就连大法官,也有过同样的烦恼。

1964年,美国最高法院的大法官Potter Stewart在“Jacobellis v. Ohio”一案中,曾经就某部电影中出现的某种具体图像分类问题,说过一句名言“我不准备就其概念给出简短而明确的定义……但是,我看见的时候自然会知道”(I know it when I see it)。
原文如下:
I shall not today attempt further to define the kinds of material I understand to be embraced within that shorthand description (“hard-core pornography”), and perhaps I could never succeed in intelligibly doing so. But I know it when I see it, and the motion picture involved in this case is not that.
考虑到精神文明建设的需要,这一段就不翻译了。
人类没法把图片分辨的规则详细、具体而准确地描述给计算机,是不是意味着计算机不能辨识图片呢?
当然不是。
2017年12月份的《科学美国人》杂志,就把“视觉人工智能”(AI that sees like humans)定义为2017年新兴技术之一。

你早已听说过自动驾驶汽车的神奇吧?没有机器对图像的辨识,能做到吗?
你的好友可能(不止一次)给你演示如何用新买的iPhone X做面部识别解锁了吧?没有机器对图像的辨识,能做到吗?

医学领域里,计算机对于科学影像(如X光片)的分析能力,已经超过有多年从业经验的医生了。没有机器对图像的辨识,能做到吗?

你可能一下子觉得有些迷茫了——这难道是奇迹?
不是。
计算机所做的,是学习。
通过学习足够数量的样本,机器可以从数据中自己构建模型。其中,可能涉及大量的判断准则。但是,人类不需要告诉机器任何一条。它是完全自己领悟和掌握的。
你可能会觉得很兴奋。
那么,下面我来告诉你一个更令你兴奋的消息——你自己也能很轻易地构建图片分类系统!
不信?请跟着我下面的介绍,来试试看。
7.2.2 数据
咱们就不辨识猫和狗了,这个问题有点不够新鲜。
咱们来分辨机器猫,好不好?
对,我说的就是哆啦a梦。

把它和谁进行区分呢?
一开始我想找霸王龙,后来觉得这样简直是作弊,因为他俩长得实在差别太大。

既然哆啦a梦是机器人,咱们就另外找个机器人来区分吧。
一提到机器人,我立刻就想起来了它。

对,机器人瓦力(WALLE)。
我给你准备好了119张哆啦a梦的照片,和80张瓦力的照片。图片已经上传到了这个Github项目。
请点击这个链接,下载压缩包。然后在本地解压。作为咱们的演示目录。
解压后,你会看到目录下有个image文件夹,其中包含两个子目录,分别是doraemon和walle。
打开其中doraemon的目录,我们看看都有哪些图片。
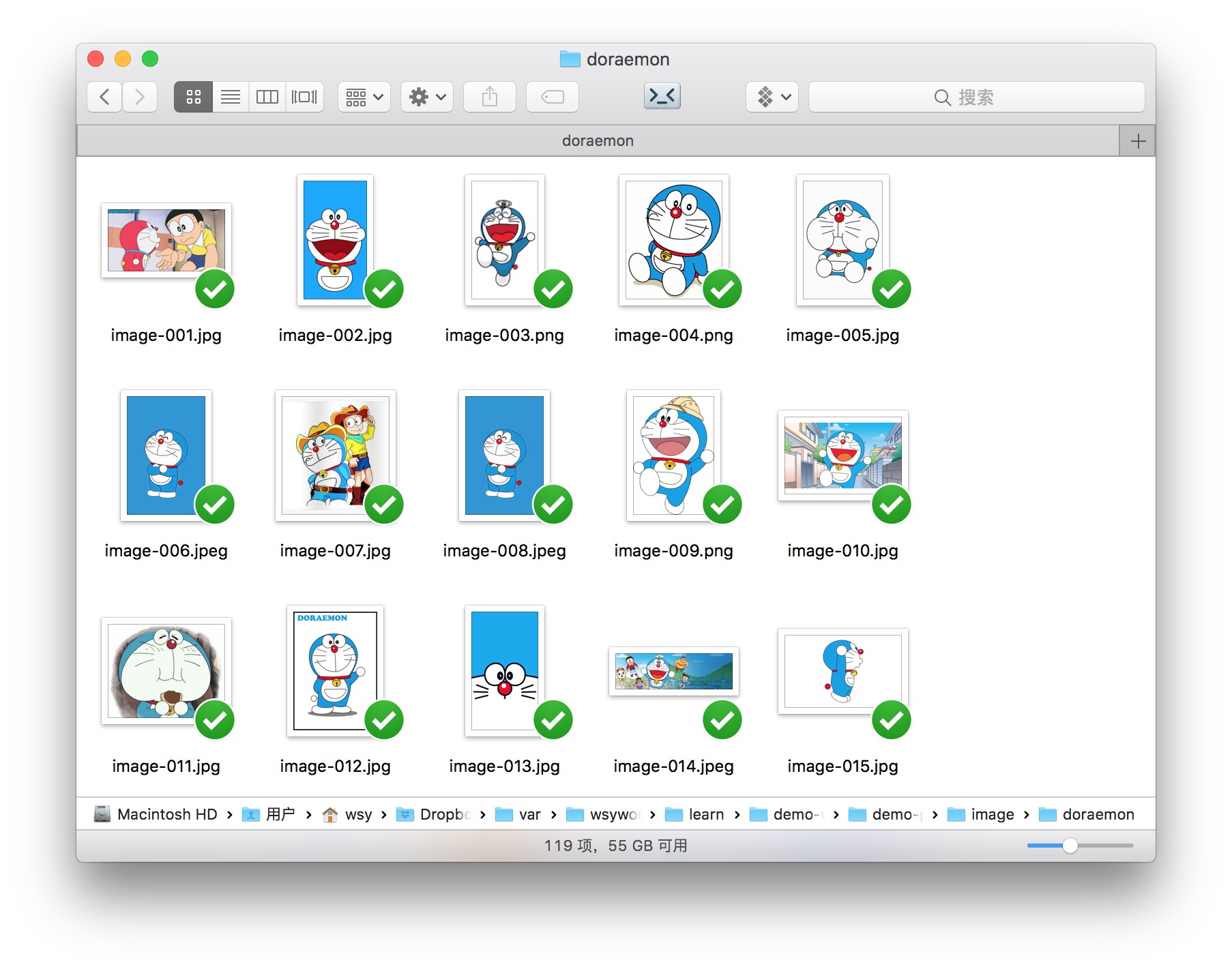
可以看到,哆啦a梦的图片真是五花八门。各种场景、背景颜色、表情、动作、角度……不一而足。
这些图片,大小不一,长宽比例也各不相同。
我们再来看看瓦力,也是类似的状况。
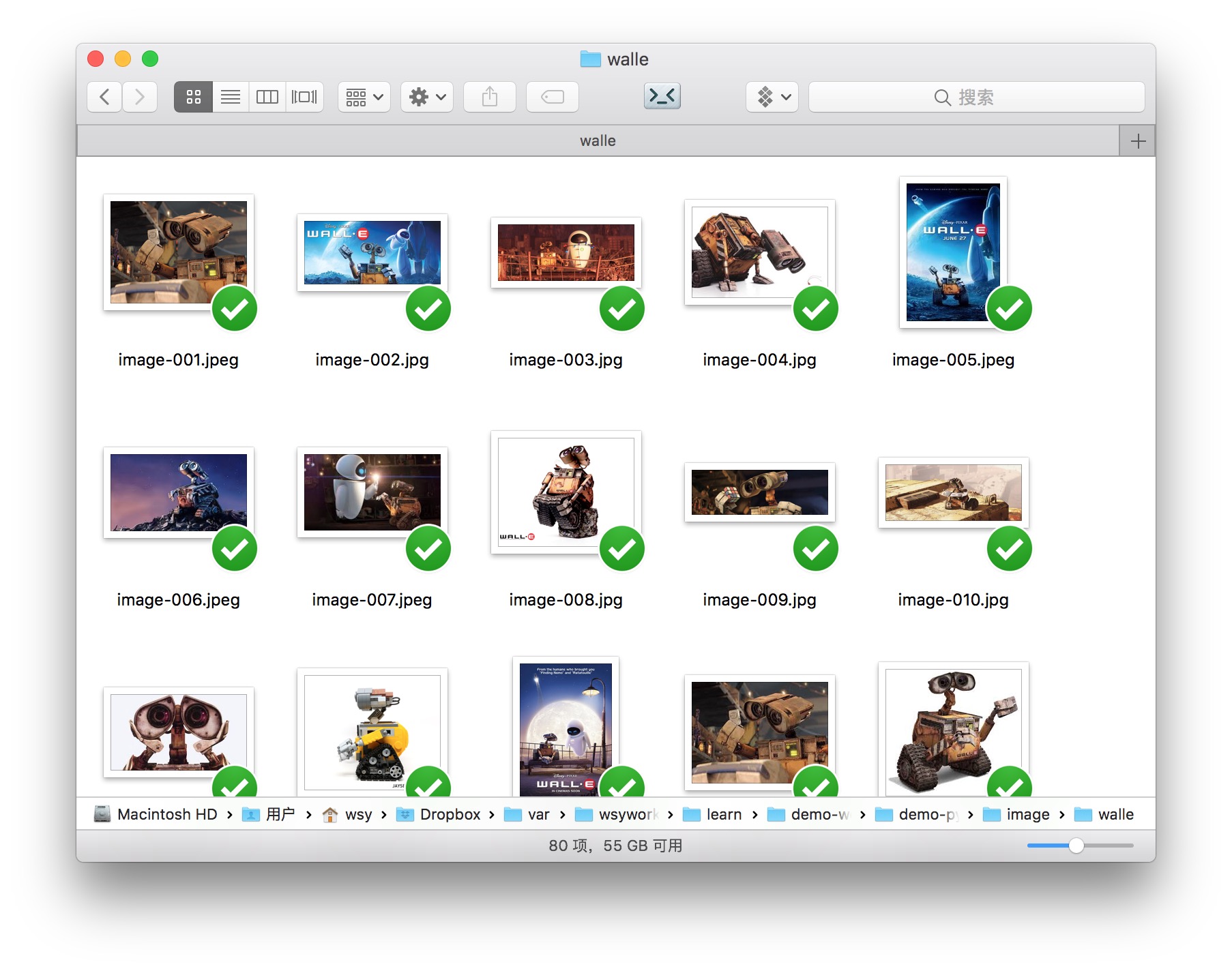
数据已经有了,下面我们来准备一下环境配置。
7.2.3 环境
我们使用Python集成运行环境Anaconda。
请到这个网址 下载最新版的Anaconda。下拉页面,找到下载位置。根据你目前使用的系统,网站会自动推荐给你适合的版本下载。我使用的是macOS,下载文件格式为pkg。
下载页面区左侧是Python 3.6版,右侧是2.7版。请选择2.7版本。
双击下载后的pkg文件,根据中文提示一步步安装即可。
安装好Anaconda后,我们需要安装TuriCreate。
请到你的“终端”(Linux, macOS)或者“命令提示符”(Windows)下面,进入咱们刚刚下载解压后的样例目录。
执行以下命令,我们来创建一个Anaconda虚拟环境,名字叫做turi。
conda create -n turi python=2.7 anaconda然后,我们激活turi虚拟环境。
source activate turi在这个环境中,我们安装最新版的TuriCreate。
pip install -U turicreate安装完毕后,执行:
jupyter notebook
这样就进入到了Jupyter笔记本环境。我们新建一个Python 2笔记本。
这样就出现了一个空白笔记本。
点击左上角笔记本名称,修改为有意义的笔记本名“demo-python-image-classification”。
准备工作完毕,下面我们就可以开始编写程序了。
7.2.4 代码
首先,我们读入TuriCreate软件包。它是苹果并购来的机器学习框架,为开发者提供非常简便的数据分析与人工智能接口。
我们指定图像所在的文件夹image。
前面介绍了,image下,有哆啦a梦和瓦力这两个文件夹。注意如果将来你需要辨别其他的图片(例如猫和狗),请把不同类别的图片也在image中分别存入不同的文件夹,这些文件夹的名称就是图片的类别名(cat和dog)。
然后,我们让TuriCreate读取所有的图像文件,并且存储到data数据框。
这里可能会有错误信息。
Unsupported image format. Supported formats are JPEG and PNG file: /Users/wsy/Dropbox/var/wsywork/learn/demo-workshops/demo-python-image-classification/image/walle/.DS_Store本例中提示,有几个.DS_Store文件,TuriCreate不认识,无法当作图片来读取。
这些.DS_Store文件,是苹果macOS系统创建的隐藏文件,用来保存目录的自定义属性,例如图标位置或背景颜色。
我们忽略这些信息即可。
下面,我们来看看,data数据框里面都有什么。
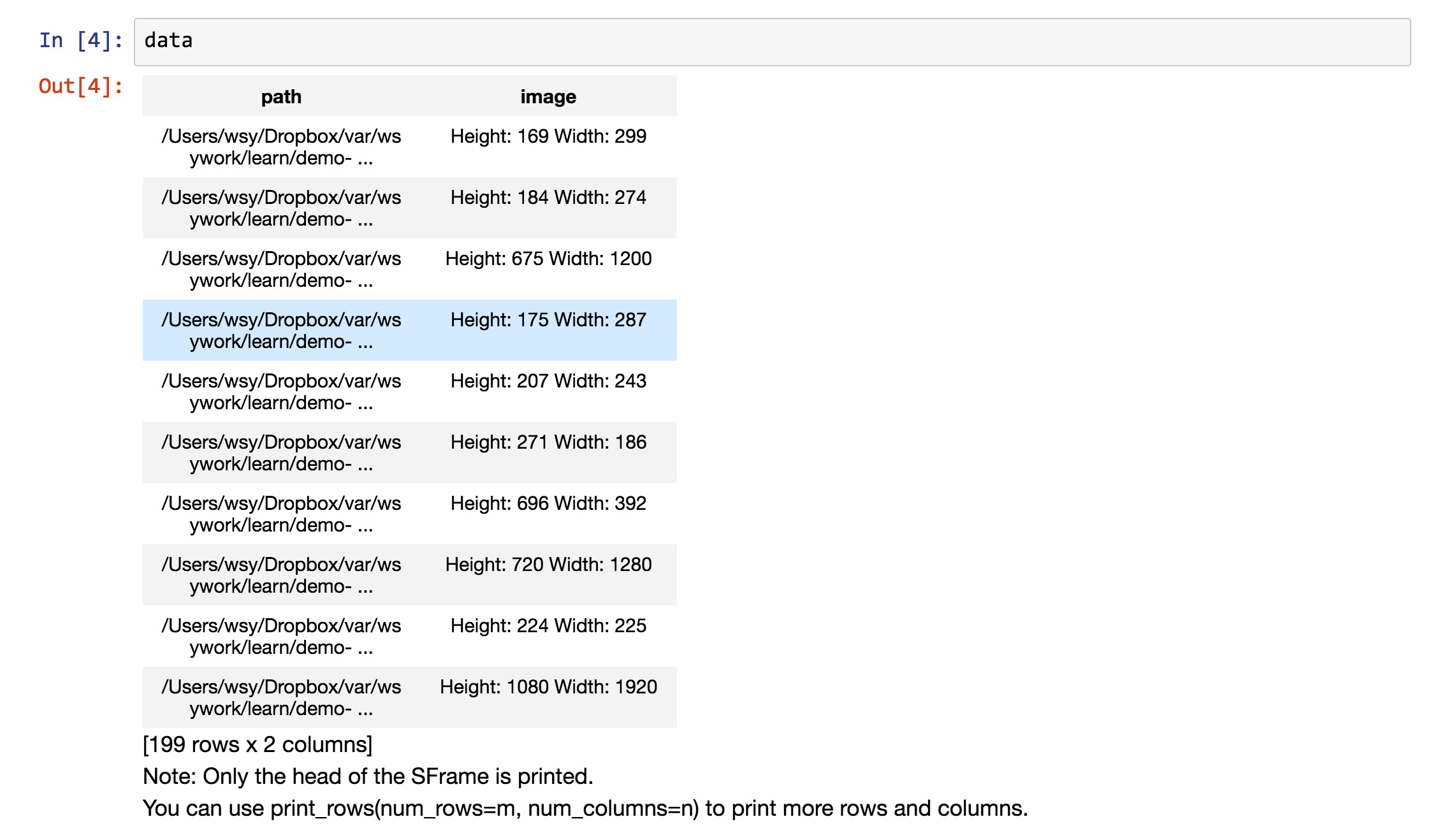
可以看到,data包含两列信息,第一列是图片的地址,第二列是图片的长宽描述。
因为我们使用了119张哆啦a梦图片,80张瓦力图片,所以总共的数据量是199条。数据读取完整性验证通过。
下面,我们需要让TuriCreate了解不同图片的标记(label)信息。也就是,一张图片到底是哆啦a梦,还是瓦力呢?
这就是为什么一开始,你就得把不同的图片分类保存到不同的文件夹下面。
此时,我们利用文件夹名称,来给图片打标记。
这条语句,把doraemon目录下的图片,在data数据框里打标记为doraemon。反之就都视为瓦力(walle)。
我们来看看标记之后的data数据框。
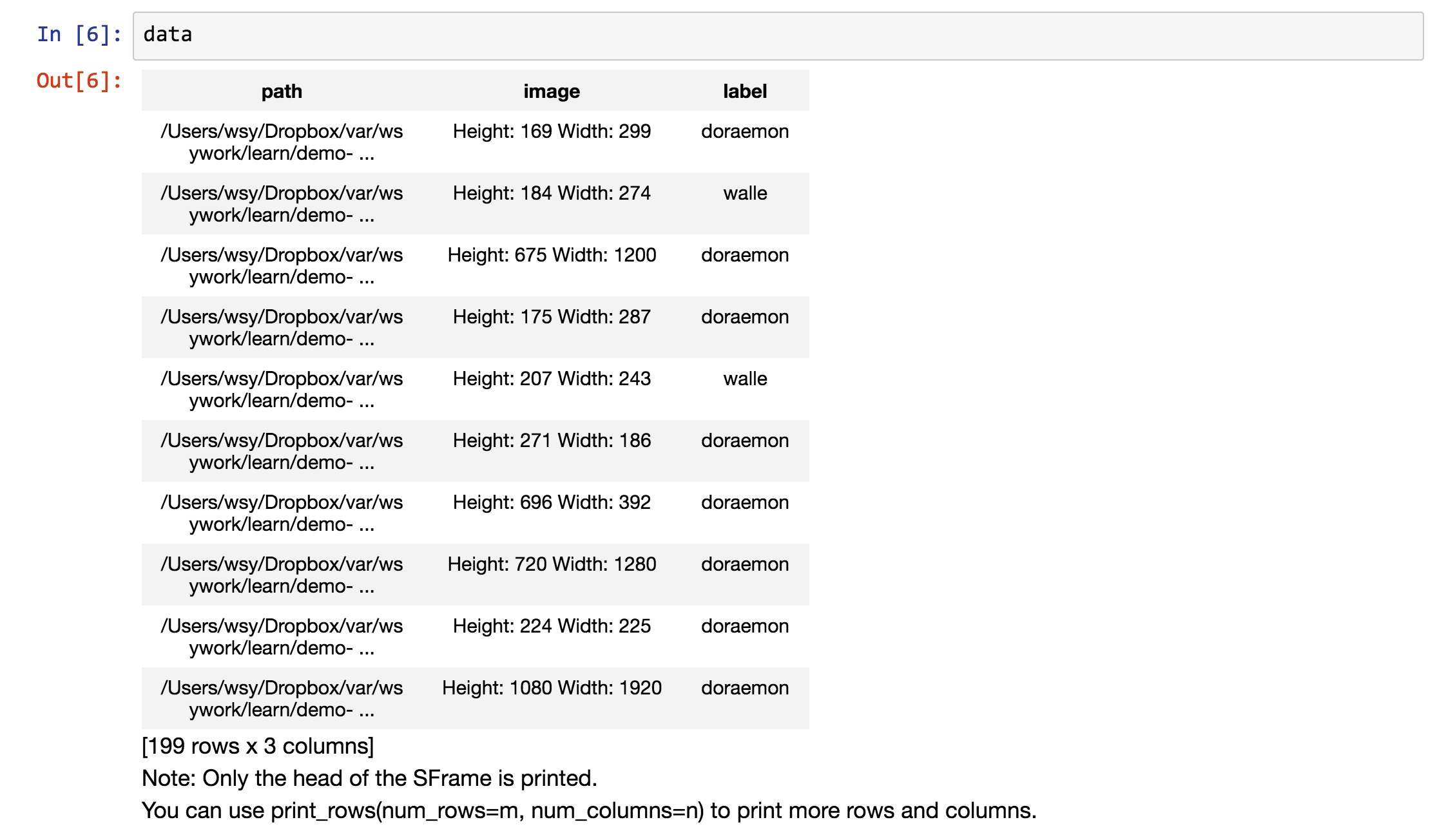
可以看到,数据的条目数量(行数)是一致的,只是多出来了一个标记列(label),说明图片的类别。
我们把数据存储一下。
这个存储动作,让我们保存到目前的数据处理结果。之后的分析,只需要读入这个sframe文件就可以了,不需要从头去跟文件夹打交道了。
从这个例子里,你可能看不出什么优势。但是想象一下,如果你的图片有好几个G,甚至几个T,每次做分析处理,都从头读取文件和打标记,就会非常耗时。
我们深入探索一下数据框。
TuriCreate提供了非常方便的explore()函数,帮助我们直观探索数据框信息。
这时候,TuriCreate会弹出一个页面,给我们展示数据框里面的内容。
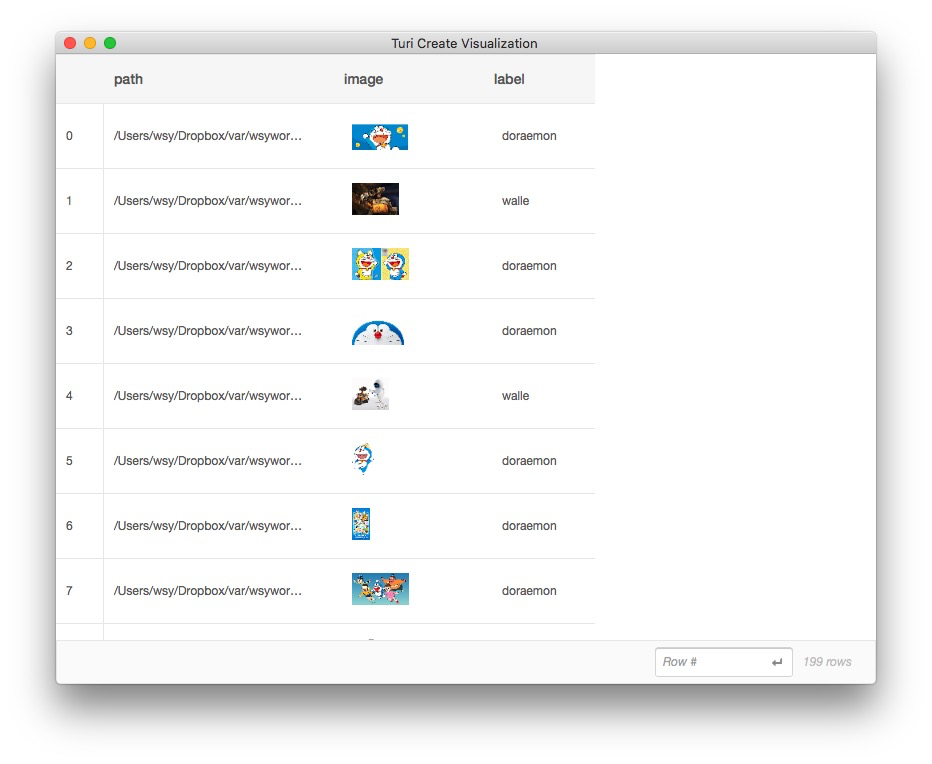
原先打印data数据框,我们只能看到图片的尺寸,此时却可以浏览图片的内容。
如果你觉得图片太小,没关系。把鼠标悬停在某张缩略图上面,就可以看到大图。
数据框探索完毕。我们回到notebook下面,继续写代码。
这里我们让TuriCreate把data数据框分为训练集合和测试集合。
训练集合是用来让机器进行观察学习的。电脑会利用训练集合的数据自己建立模型。但是模型的效果(例如分类的准确程度)如何?我们需要用测试集来进行验证测试。
这就如同老师不应该把考试题目都拿来给学生做作业和练习一样。只有考学生没见过的题,才能区分学生是掌握了正确的解题方法,还是死记硬背了作业答案。
我们让TuriCreate把80%的数据分给了训练集,把剩余20%的数据拿到一边,等待测试。这里我设定了随机种子取值为2,这是为了保证数据拆分的一致性。以便重复验证我们的结果。
好了,下面我们让机器开始观察学习训练集中的每一个数据,并且尝试自己建立模型。
下面代码第一次执行的时候,需要等候一段时间。因为TuriCreate需要从苹果开发者官网上下载一些数据。这些数据大概100M左右。
需要的时长,依你和苹果服务器的连接速度而异。反正在我这儿,下载挺慢的。
好在只有第一次需要下载。之后的重复执行,会跳过下载步骤。
下载完毕后,你会看到TuriCreate的训练信息。
Resizing images...
Performing feature extraction on resized images...
Completed 168/168
PROGRESS: Creating a validation set from 5 percent of training data. This may take a while.
You can set ``validation_set=None`` to disable validation tracking.你会发现,TuriCreateh会帮助你把图片进行尺寸变换,并且自动抓取图片的特征。然后它会从训练集里面抽取5%的数据作为验证集,不断迭代寻找最优的参数配置,达到最佳模型。
这里可能会有一些警告信息,忽略就可以了。
当你看到下列信息的时候,意味着训练工作已经顺利完成了。
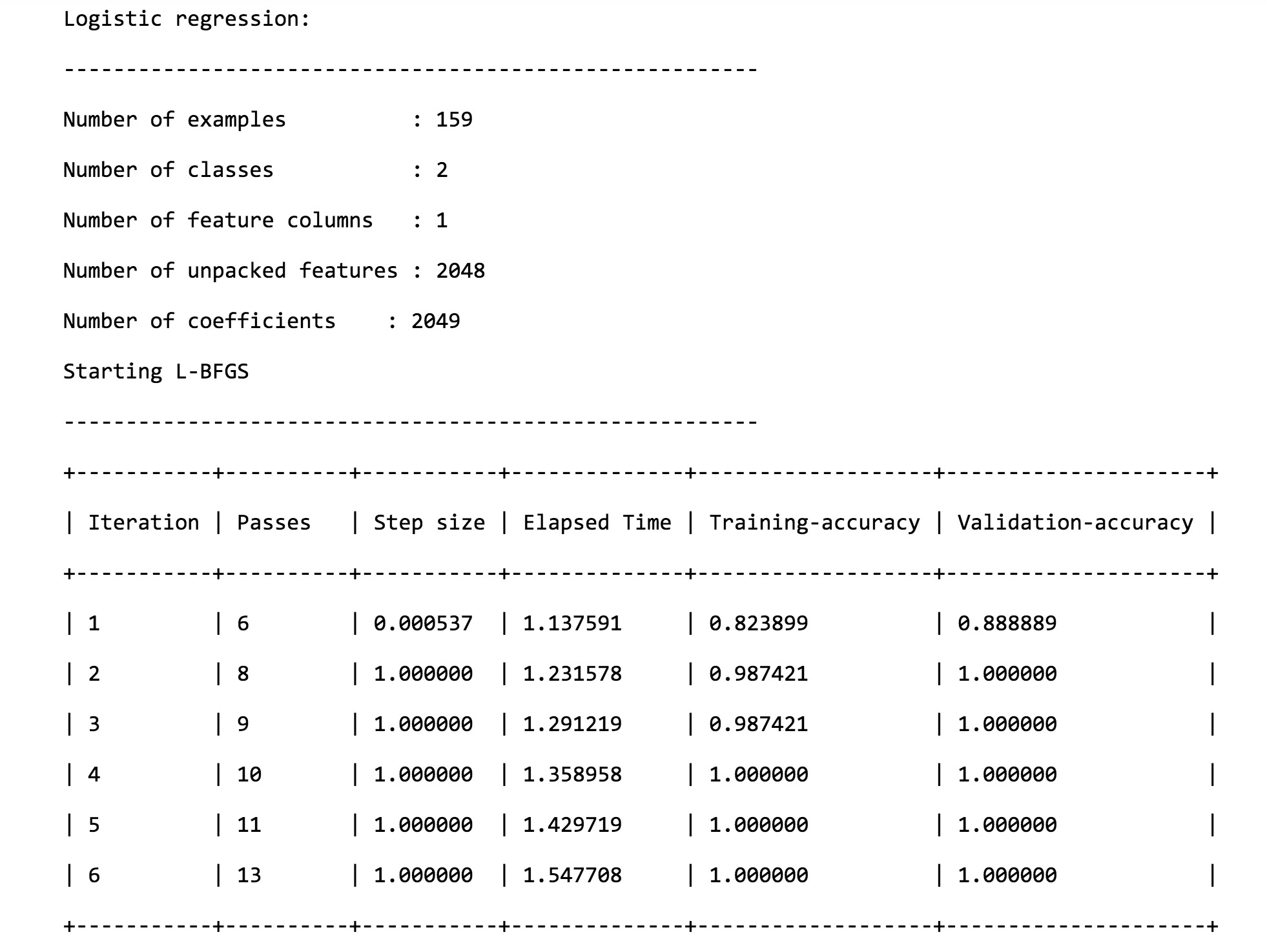
可以看到,几个轮次下来,不论是训练的准确度,还是验证的准确度,都已经非常高了。
下面,我们用获得的图片分类模型,来对测试集做预测。
我们把预测的结果(一系列图片对应的标记序列)存入了predictions变量。
然后,我们让TuriCreate告诉我们,在测试集上,我们的模型表现如何。
先别急着往下看,猜猜结果正确率大概是多少?从0到1之间,猜测一个数字。
猜完后,请继续。
这就是正确率的结果:
0.967741935484我第一次看见的时候,震惊不已。
我们只用了100多个数据做了训练,居然就能在测试集(机器没有见过的图片数据)上,获得如此高的辨识准确度。
为了验证这不是准确率计算部分代码的失误,我们来实际看看预测结果。
这是打印出的预测标记序列:
dtype: str
Rows: 31
['doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'walle', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'walle']再看看实际的标签。
这是实际标记序列:
dtype: str
Rows: 31
['doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'walle', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'walle']我们查找一下,到底哪些图片预测失误了。
你当然可以一个个对比着检查。但是如果你的测试集有成千上万的数据,这样做效率就会很低。
我们分析的方法,是首先找出预测标记序列(predictions)和原始标记序列(test_data['label'])之间有哪些不一致,然后在测试数据集里展示这些不一致的位置。

我们发现,在31个测试数据中,只有1处标记预测发生了失误。原始的标记是瓦力,我们的模型预测结果是哆啦a梦。
我们获得这个数据点对应的原始文件路径。
然后,我们把图像读取到img变量。
用TuriCreate提供的show()函数,我们查看一下这张图片的内容。
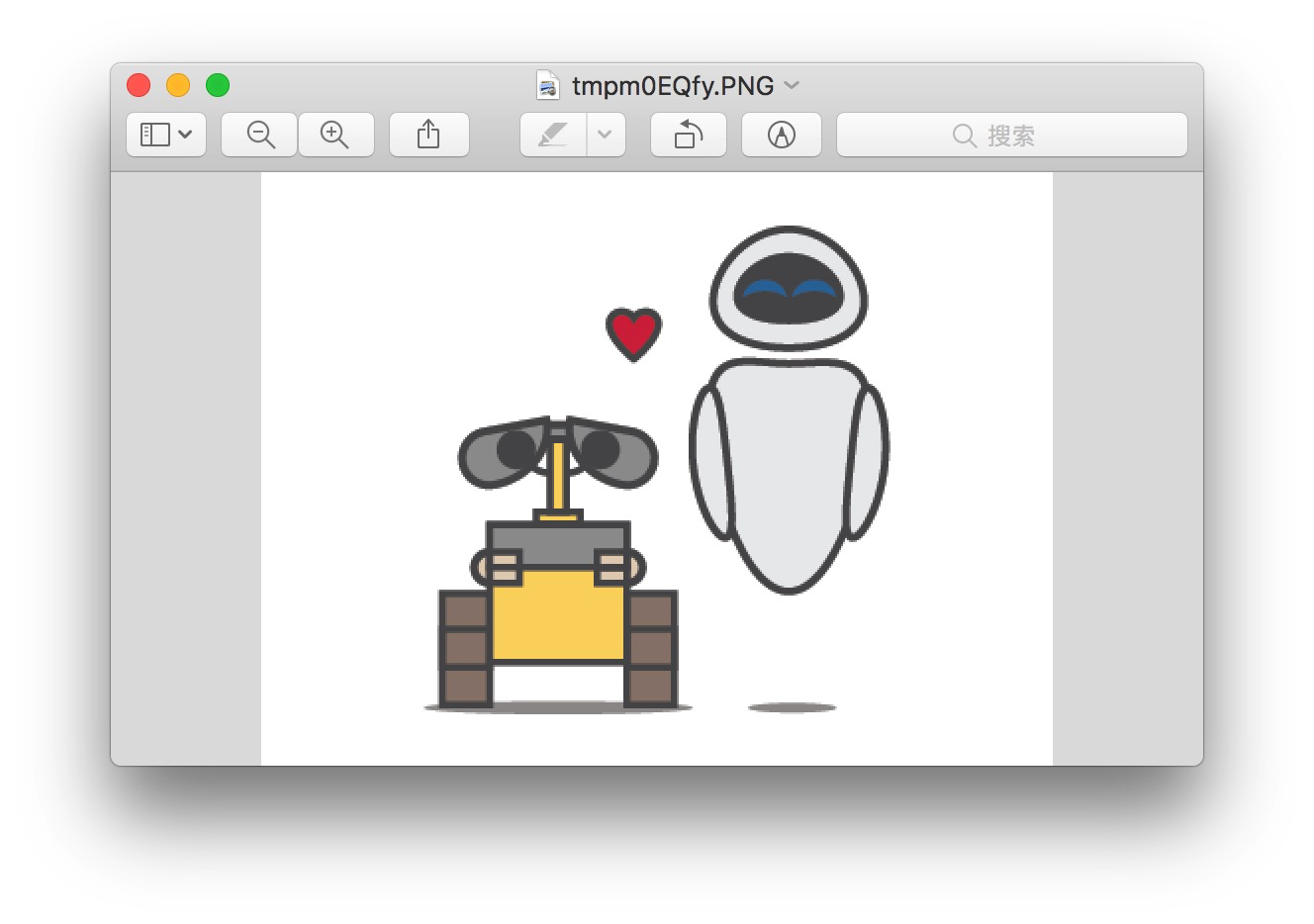
因为深度学习的一个问题在于模型过于复杂,所以我们无法精确判别机器是怎么错误辨识这张图的。但是我们不难发现这张图片有些特征——除了瓦力以外,还有另外一个机器人。
如果你看过这部电影,应该知道两个机器人之间的关系。这里我们按下不表。问题在于,这个右上方的机器人圆头圆脑,看上去与棱角分明的瓦力差别很大。但是,别忘了,哆啦a梦也是圆头圆脑的。
7.2.5 原理
按照上面一节的代码执行后,你应该已经了解如何构建自己的图片分类系统了。在没有任何原理知识的情况下,你研制的这个模型已经做得非常棒了。不是吗?
如果你对原理不感兴趣,请跳过这一部分,看“小结”。
如果你对知识喜欢刨根问底,那咱们来讲讲原理。
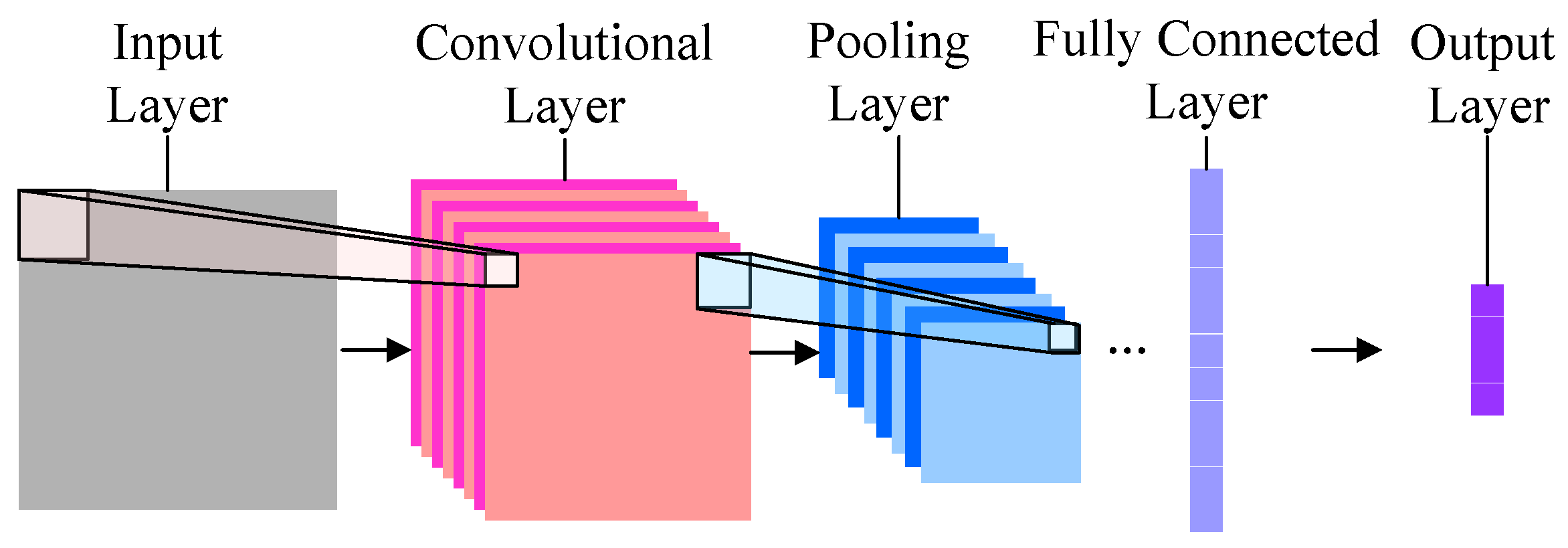
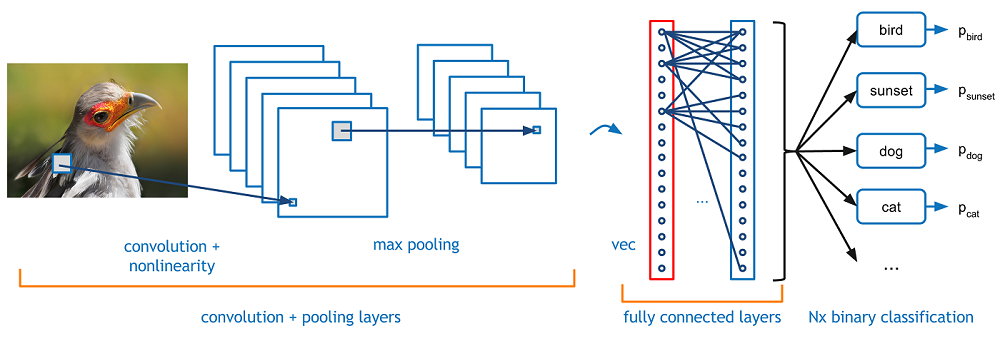
虽然不过写了10几行代码,但是你构建的模型却足够复杂和高大上。它就是传说中的卷积神经网络(Convolutional Neural Network, CNN)。
它是深度机器学习模型的一种。最为简单的卷积神经网络大概长这个样子:
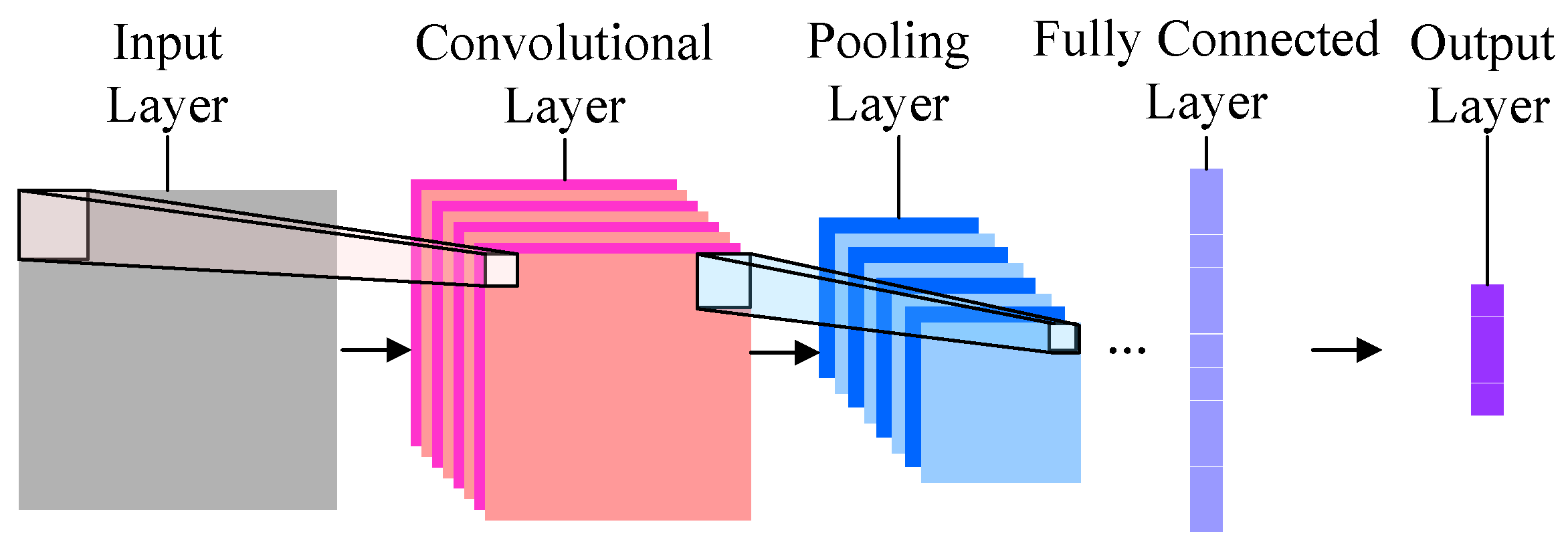
最左边的,是输入层。也就是咱们输入的图片。本例中,是哆啦a梦和瓦力。
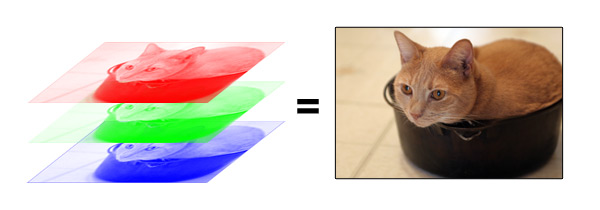
在计算机里,图片是按照不同颜色(RGB,即Red, Green, Blue)分层存储的。就像下面这个例子。
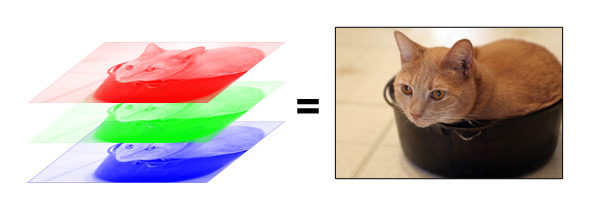
根据分辨率不同,电脑会把每一层的图片存成某种大小的矩阵。对应某个行列位置,存的就是个数字而已。
这就是为什么,在运行代码的时候,你会发现TuriCreate首先做的,就是重新设置图片的大小。因为如果输入图片大小各异的话,下面步骤无法进行。
有了输入数据,就顺序进入下一层,也就是卷积层(Convolutional Layer)。
卷积层听起来似乎很神秘和复杂。但是原理非常简单。它是由若干个过滤器组成的。每个过滤器就是一个小矩阵。
使用的时候,在输入数据上,移动这个小矩阵,跟原先与矩阵重叠的位置上的数字做乘法后加在一起。这样原先的一个矩阵,就变成了“卷积”之后的一个数字。
下面这张动图,很形象地为你解释了这一过程。
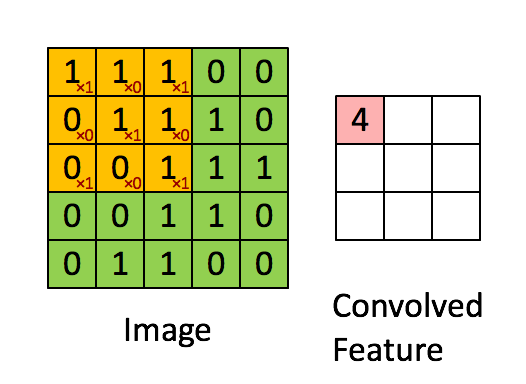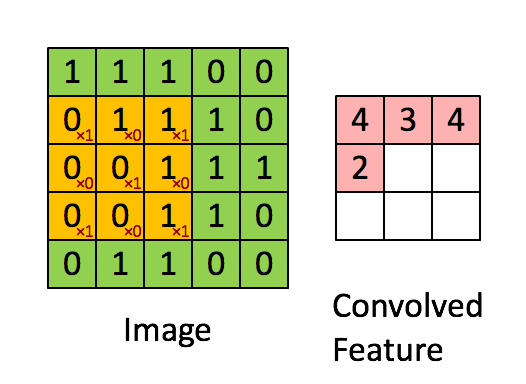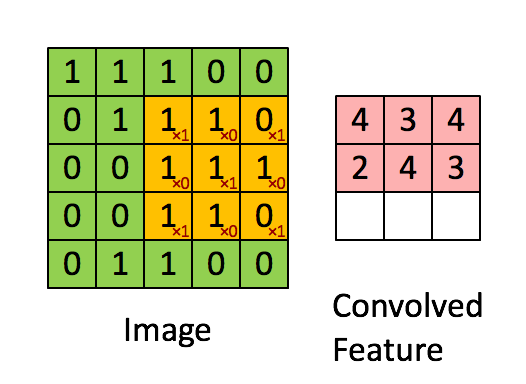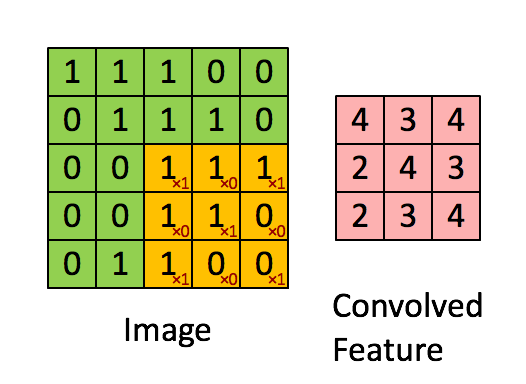
这个过程,就是不断从一个矩阵上去寻找某种特征。这种特征可能是某个边缘的形状之类。
再下一层,叫做“池化层”(Pooling Layer)。这个翻译简直让人无语。我觉得翻译成“汇总层”或者“采样层”都要好许多。下文中,我们称其为“采样层”。
采样的目的,是避免让机器认为“必须在左上角的方格位置,有一个尖尖的边缘”。实际上,在一张图片里,我们要识别的对象可能发生位移。因此我们需要用汇总采样的方式模糊某个特征的位置,将其从“某个具体的点”,扩展成“某个区域”。
如果这样说,让你觉得不够直观,请参考下面这张动图。
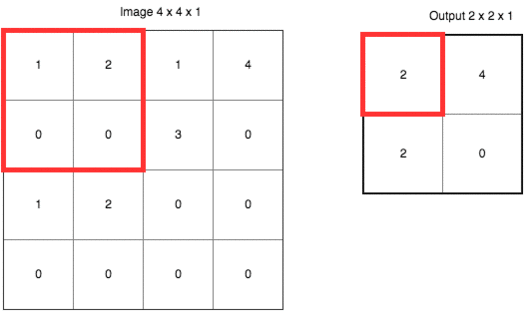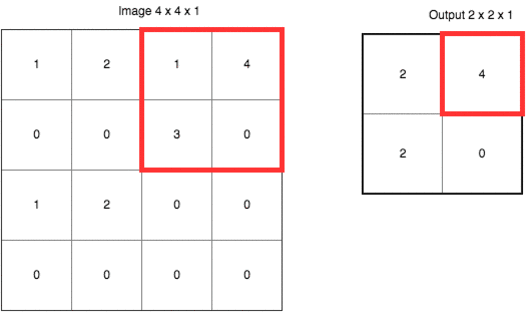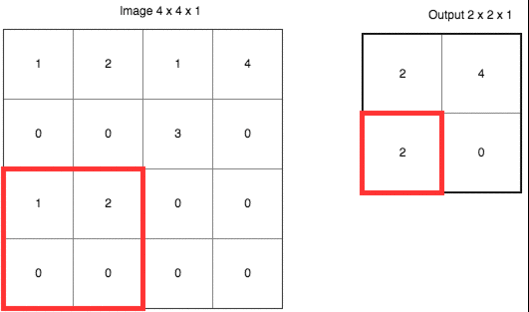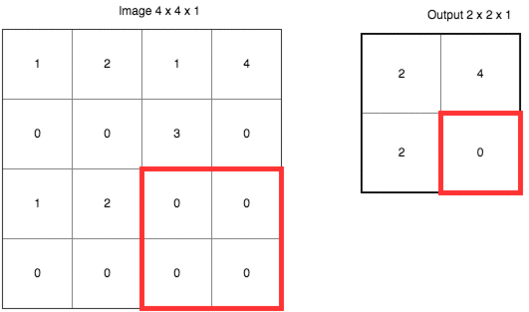
这里使用的是“最大值采样”(Max-Pooling)。以原先的2x2范围作为一个分块,从中找到最大值,记录在新的结果矩阵里。
一个有用的规律是,随着层数不断向右推进,一般结果图像(其实正规地说,应该叫做矩阵)会变得越来越小,但是层数会变得越来越多。
只有这样,我们才能把图片中的规律信息抽取出来,并且尽量掌握足够多的模式。
如果你还是觉得不过瘾,请访问这个网站。
它为你生动解析了卷积神经网络中,各个层次上到底发生了什么。

左上角是用户输入位置。请利用鼠标,手写一个数字(0-9)。写得难看一些也没有关系。
我输入了一个7。
观察输出结果,模型正确判断第一选择为7,第二可能性为3。回答正确。
让我们观察模型建构的细节。
我们把鼠标挪到第一个卷积层。停在任意一个像素上。电脑就告诉我们这个点是从上一层图形中哪几个像素,经过特征检测(feature detection)得来的。

同理,在第一个Max pooling层上悬停,电脑也可以可视化展示给我们,该像素是从哪几个像素区块里抽样获得的。

这个网站,值得你花时间多玩儿一会儿。它可以帮助你理解卷积神经网络的内涵。
回顾我们的示例图:
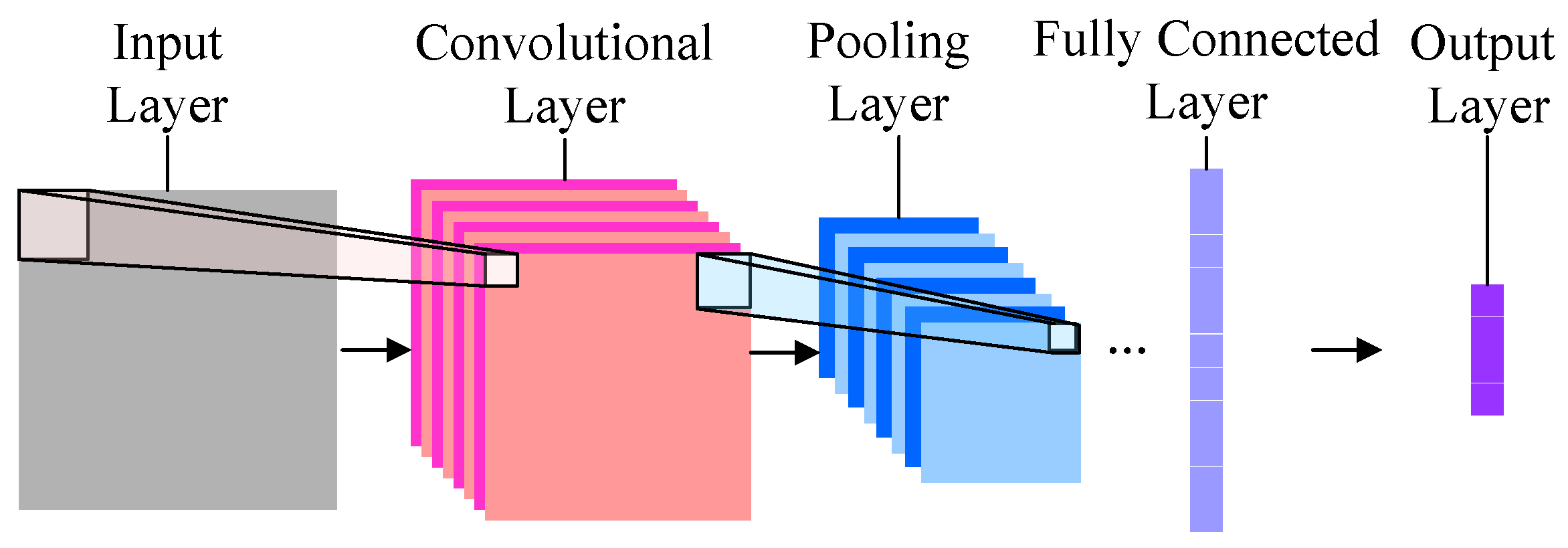
下一层叫做全连接层(Fully Connected Layer),它其实就是把上一层输出的若干个矩阵全部压缩到一维,变成一个长长的输出结果。
之后是输出层,对应的结果就是我们需要让机器掌握的分类。
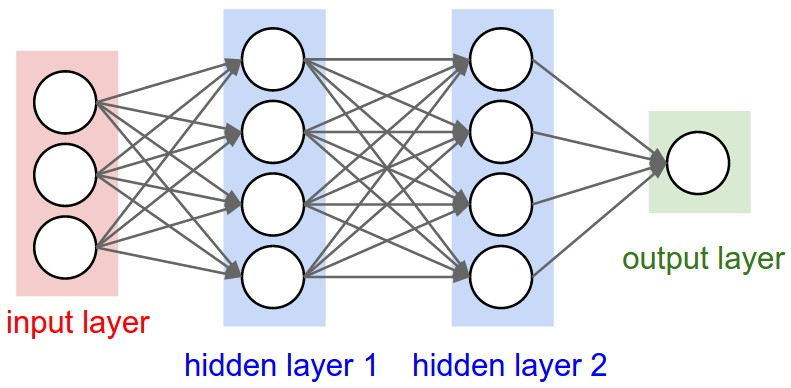
如果只看最后两层,你会很容易把它跟之前学过的深度神经网络(Deep Neural Network, DNN)联系起来。
既然我们已经有了深度神经网络,为什么还要如此费力去使用卷积层和采样层,导致模型如此复杂呢?
这里出于两个考虑:
首先是计算量。图片数据的输入量一般比较大,如果我们直接用若干深度神经层将其连接到输出层,则每一层的输入输出数量都很庞大,总计算量是难以想像的。
其次是模式特征的抓取。即便是使用非常庞大的计算量,深度神经网络对于图片模式的识别效果也未必尽如人意。因为它学习了太多噪声。而卷积层和采样层的引入,可以有效过滤掉噪声,突出图片中的模式对训练结果的影响。
你可能会想,咱们只编写了10几行代码而已,使用的卷积神经网络一定跟上图差不多,只有4、5层的样子吧?
不是这样的,你用的层数,有足足50层呢!
它的学名,叫做Resnet-50,是微软的研发成果,曾经在2015年,赢得过ILSRVC比赛。在ImageNet数据集上,它的分类辨识效果,已经超越人类。
我把对应论文的地址附在这里,如果你有兴趣,可以参考。
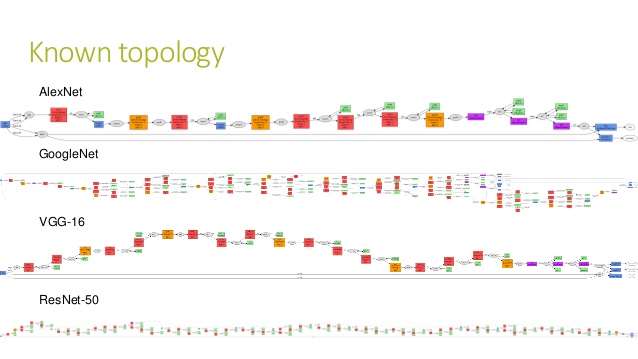
请看上图中最下面的那一个,就是它的大略样子。
足够深度,足够复杂吧。
如果你之前对深度神经网络有一些了解,一定会更加觉得不可思议。这么多层,这么少的训练数据量,怎么能获得如此好的测试结果呢?而如果要获得好的训练效果,大量图片的训练过程,岂不是应该花很长时间吗?
没错,如果你自己从头搭建一个Resnet-50,并且在ImageNet数据集上做训练,那么即便你有很好的硬件设备(GPU),也需要很长时间。
如果你在自己的笔记本上训练……算了吧。
那么,TuriCreate难道真的是个奇迹?既不需要花费长时间训练,又只需要小样本,就能获得高水平的分类效果?
不,数据科学里没有什么奇迹。
到底是什么原因导致这种看似神奇的效果呢?这个问题留作思考题,请善用搜索引擎和问答网站,来帮助自己寻找答案。
7.2.6 小结
通过本文,你已掌握了以下内容:
- 如何在Anaconda虚拟环境下,安装苹果公司的机器学习框架TuriCreate。
- 如何在TuriCreate中读入文件夹中的图片数据。并且利用文件夹的名称,给图片打上标记。
- 如何在TuriCreate中训练深度神经网络,以分辨图片。
- 如何利用测试数据集,检验图片分类的效果。并且找出分类错误的图片。
- 卷积神经网络(Convolutional Neural Network, CNN)的基本构成和工作原理。
但是由于篇幅所限,我们没有提及或深入解释以下问题:
- 如何批量获取训练与测试图片数据。
- 如何利用预处理功能,转换TuriCreate不能识别的图片格式。
- 如何从头搭建一个卷积神经网络(Convolutional Neural Network, CNN),对于模型的层次和参数做到完全掌控。
- 如何既不需要花费长时间训练,又只需要小样本,就能获得高水平的分类效果(提示关键词:迁移学习,transfer learning)。
请你在实践中,思考上述问题。欢迎留言和发送邮件,与我交流你的思考所得。
7.3 如何用Python和深度神经网络寻找近似图片?

给你10万张图片,让你找出与其中某张图片最为近似的10张,你会怎么做?不要轻言放弃,也不用一张张浏览。使用Python,你也可以轻松搞定这个任务。
7.3.1 疑问
《如何用Python和深度神经网络识别图像?》(7.2)一文写完后,我收到了不少读者的反馈。其中一个很普遍的疑问是:
识别相同或相似的图像,有什么好的方法么?
我虽然乐于帮助读者解决问题,但实话实说,一开始不太理解这种需求。
我文章里的样例图片(哆啦a梦和瓦力),都是从网络搜集来的。如果你需要从网上找到跟某张图片近似的图像,可以使用Google的“以图搜图”功能啊。
很快,我突然醒悟过来。
这种需求,往往不是为了从互联网上大海捞针,寻找近似图片。而是在一个私有海量图片集合中,找到近似图像。
这种图片集合,也许是你团队的科研数据。例如你研究鸟类。某天浏览野外拍摄设备传回来的图像时,突然发现一个新奇品种。

你于是很想搞清楚这种鸟类的出现时间、生活状态等。这就需要从大量图片里,找到与其近似的图片(最有可能是拍到了同一种鸟)。
这种图片集合,也许是社会安全数据。例如你在反恐部门,系统突然发现某个疑似恐怖分子出现在敏感区域。这家伙每一次现身,都伴随着恶性刑事案件的发生,给人民群众的生命财产安全带来严重威胁。

这时候无论对其衣着、外貌还是交通工具的相似度搜索,就显得至关重要了。
上述例子中,因为你都没有把图像上传到互联网,Google的“以图搜图”引擎功能再强大,也无能为力。
好吧,解决这个问题,很有意义。
下一个问题自然是:这种需求,解决起来复杂吗?
是不是需要跨过很高的技术门槛才能实现?是不是需要花大量经费雇佣专家才能完成?
本文,我为你展示如何用10几行Python代码,解决这个问题。
7.3.2 数据
为了讲解的方便,我们依然采用《如何用Python和深度神经网络识别图像?》(7.2)一文中使用过的哆啦a梦和瓦力图片集合。
我给你准备好了119张哆啦a梦的照片,和80张瓦力的照片。图片已经上传到了这个Github项目。
请点击这个链接,下载压缩包。然后在本地解压。作为咱们的演示目录。
解压后,你会看到目录下有个image文件夹,其中包含两个子目录,分别是doraemon和walle。
doraemon的目录下,都是各式各样的蓝胖子图片。
瓦力目录下的图片是这个样子的:
数据已经有了,下面我们来准备一下环境配置。
7.3.3 环境
本文中,我们需要使用到苹果公司的机器学习框架TuriCreate。
请注意TuriCreate发布时间不久,目前支持的操作系统列表如下:
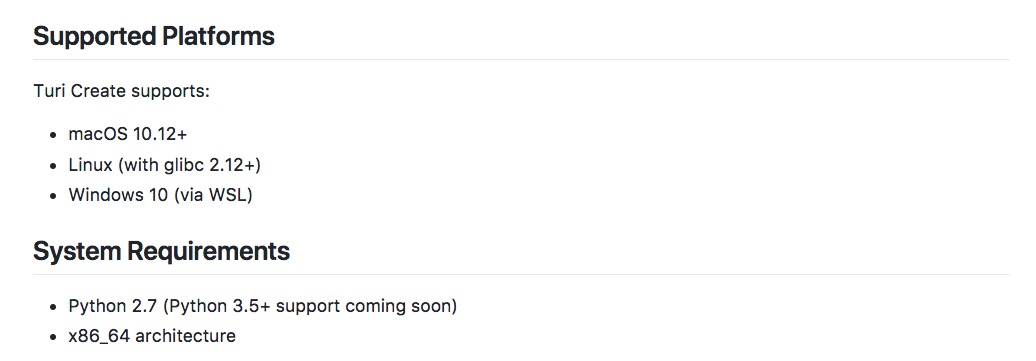
这就意味着,如果你用的操作系统是Windows 7及以下版本,那么目前TuriCreate还不支持。如需使用,有两种办法:
第一种,请升级到Windows 10,并且使用WSL。关于如何使用WSL,我帮你找到了一个中文教程。请按照教程一步步完成安装。
第二种,采用虚拟机。推荐采用Virtualbox虚拟机,开源免费。同样地,我也帮你找到了很详尽的Virtualbox安装Ubuntu Linux的中文教程。你可以参照它安装好Linux。
解决了系统兼容性问题,下面我们在TuriCreate支持的系统中,安装Python集成运行环境Anaconda。
请到这个网址 下载最新版的Anaconda。下拉页面,找到下载位置。根据你目前使用的系统,网站会自动推荐给你适合的版本下载。我使用的是macOS,下载文件格式为pkg。
下载页面区左侧是Python 3.6版,右侧是2.7版。请选择2.7版本。
双击下载后的pkg文件,根据中文提示一步步安装即可。
装好Anaconda后,我们安装TuriCreate。
请到你的“终端”下面,进入咱们刚刚下载解压后的样例目录。
执行以下命令,我们来创建一个Anaconda虚拟环境,名字叫做turi。如果你之前跟随我在《如何用Python和深度神经网络识别图像?》(7.2)一文中创立过这个虚拟环境,此处请跳过。
conda create -n turi python=2.7 anaconda然后,我们激活turi虚拟环境。
source activate turi在这个环境中,我们安装(或者升级到)最新版的TuriCreate。
pip install -U turicreate安装完毕后,执行:
jupyter notebook
这样就进入到了Jupyter笔记本环境。我们新建一个Python 2笔记本。
浏览器里出现了一个空白笔记本。
点击左上角笔记本名称,修改为有意义的笔记本名“demo-python-image-similarity”。
准备工作完毕,下面我们就可以开始编写程序了。
7.3.4 代码
首先,我们读入TuriCreate软件包。
我们指定图像所在的文件夹image。让TuriCreate读取所有的图像文件,并且存储到data数据框。
我们来看看,data数据框的内容:
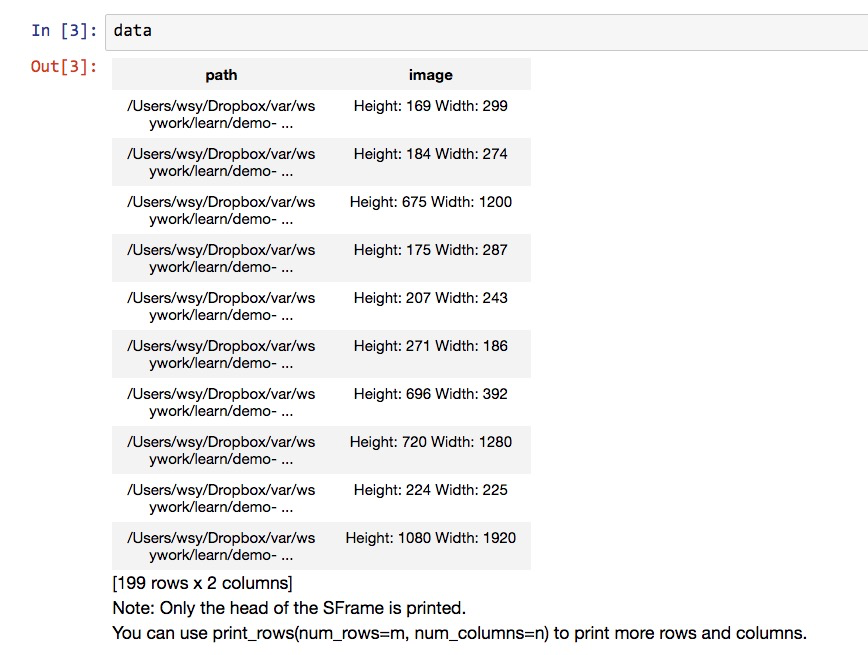
data包含两列信息,第一列是图片的地址,第二列是图片的长宽描述。
下面我们要求TuriCreate给数据框中每一行添加一个行号。这将作为图片的标记,好在后面查找图片时使用。
再看看此时的data数据框内容:
我们来看看数据框里面的这些信息对应的图片。
TuriCreate会弹出一个页面,给我们展示数据框里面的内容。
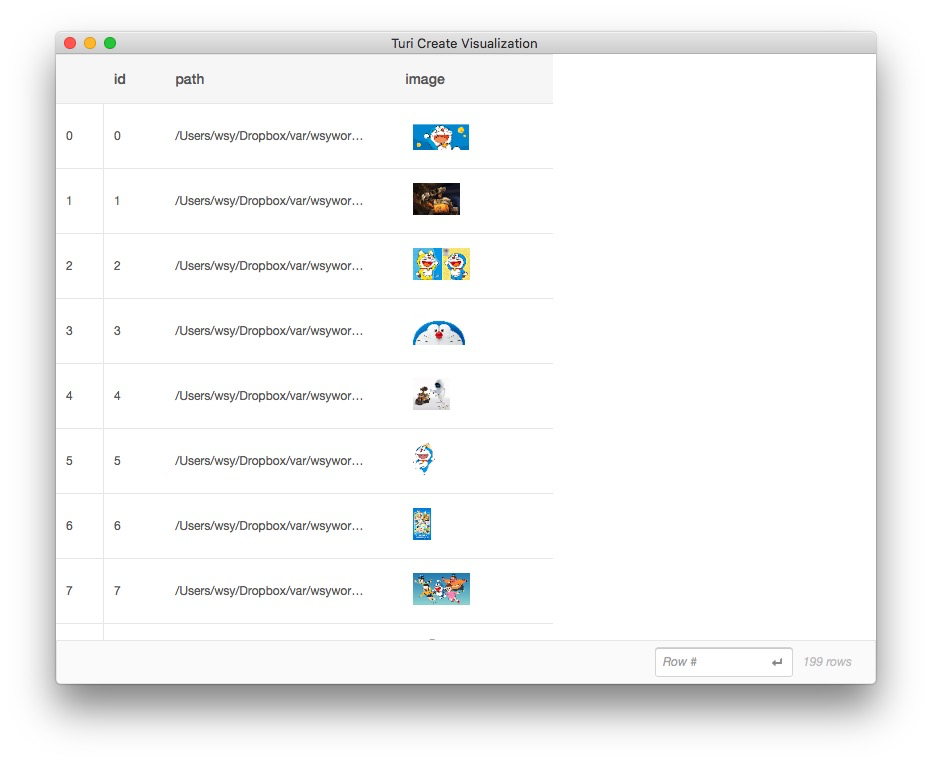
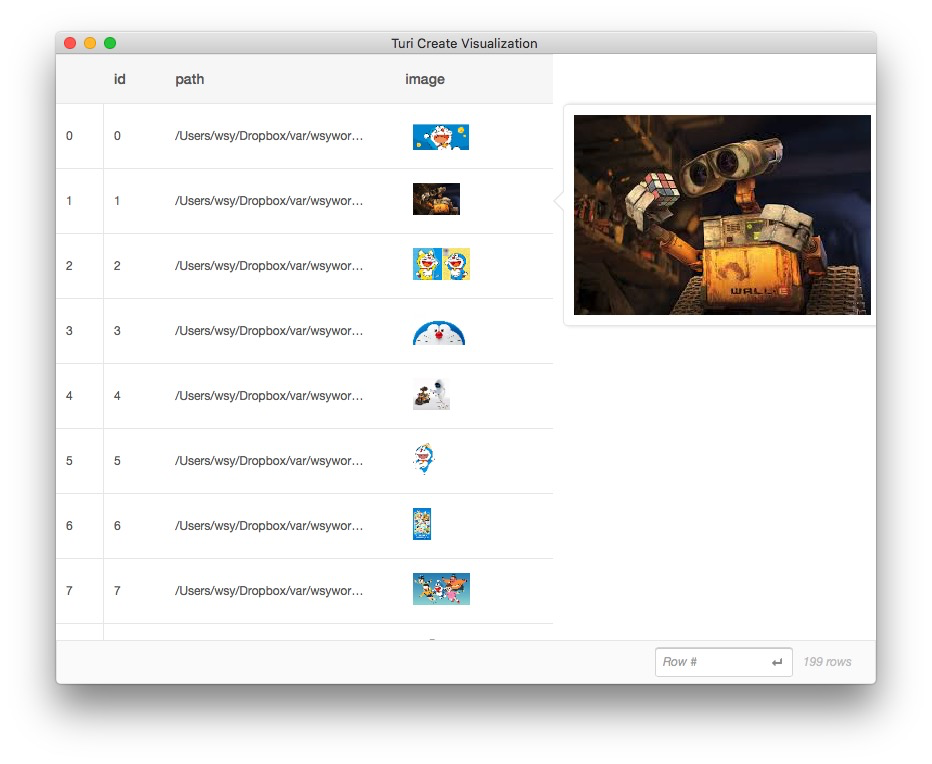
把鼠标悬停在某张缩略图上面,就可以看到对应清晰大图。
第一张图片,是哆啦a梦:
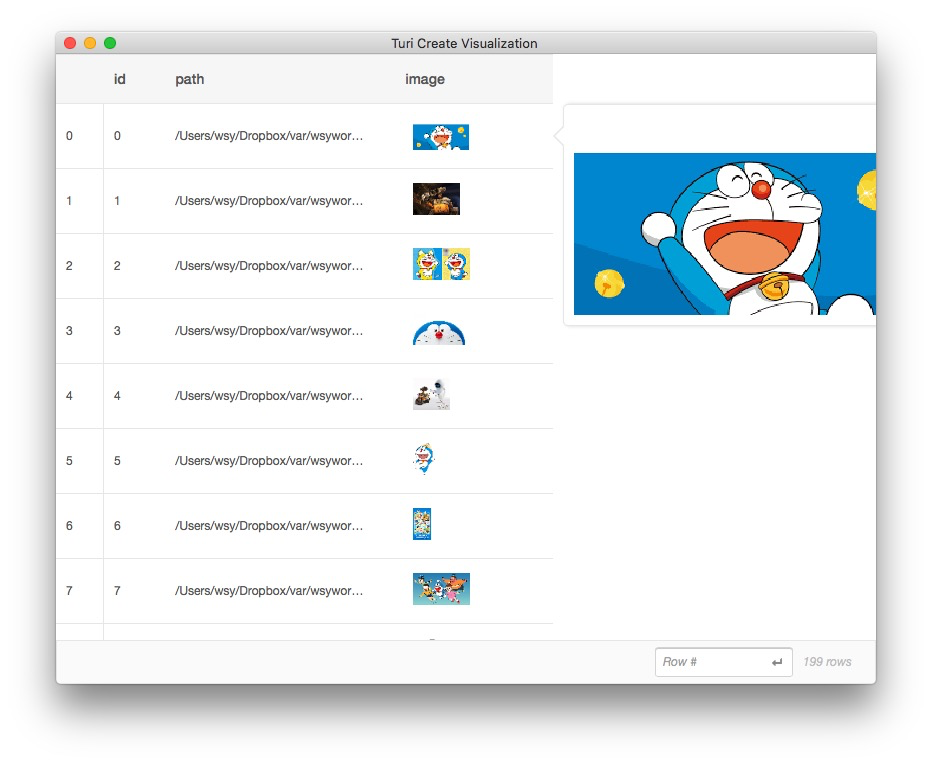
第二张图片,是瓦力:
下面,是重头戏。我们让TuriCreate根据输入的图片集合,建立图像相似度判别模型。
这个语句执行起来,可能需要一些时间。如果你是第一次使用TuriCreate,它可能还需要从网上下载一些数据。请耐心等待。
Resizing images...
Performing feature extraction on resized images...
Completed 199/199注意这里的提示,TuriCreate自动帮我们做了图片尺寸调整等预处理工作,并且对每一张图片,都做了特征提取。
经过或长或短的等待,模型已经成功建立。
下面,我们来尝试给模型一张图片,让TuriCreate帮我们从目前的图片集合里,挑出最为相似的10张来。
为了方便,我们就选择第一张图片作为查询输入。
我们利用show()函数展示一下这张图片。
确认无误,还是那张哆啦a梦。
下面我们来查询,我们让模型寻找出与这张图片最相似的10张。
很快,系统提示我们,已经找到了。
我们把结果存储在了similar_images变量里面,下面我们来看看其中都有哪些图片。
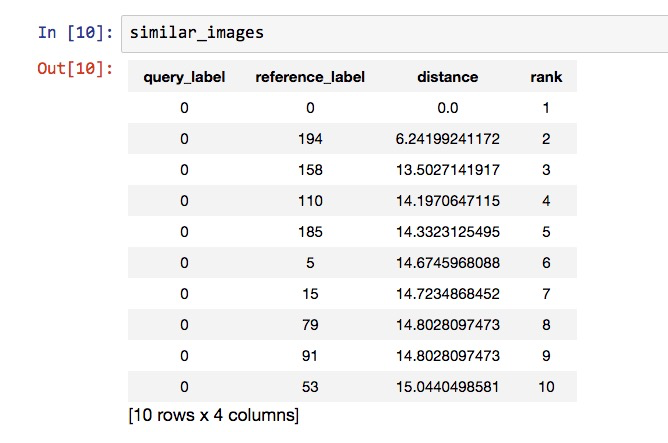
返回的结果一共有10行。跟我们的要求一致。
每一行数据,包含4列。分别是:
- 查询图片的标记
- 获得结果的标记
- 结果图片与查询图片的距离
- 结果图片与查询图片近似程度排序值
有了这些信息,我们就可以查看到底哪些图片与输入查询图片最为相似了。
注意其中的第一张结果图片,其实就是我们的输入图片本身。考虑它没有意义。
我们提取全部结果图片的标记(索引)值,忽略掉第一张(自身)。
剩余9张图片的标记都在结果中:
dtype: int
Rows: 9
[194, 158, 110, 185, 5, 15, 79, 91, 53]下面我们希望TuriCreate能够可视化帮我们展示这9张图片的内容。
我们要把上面9张图片的标记在所有图片的索引列表中过滤出来:
看看过滤后的索引结果:
dtype: int
Rows: 199
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, ... ]你可以自己数一数,其中标为1的那些图片位置,和我们存储在similar_image_index中的数字是否一致。
验证完毕以后,请执行以下语句。我们再次调用TuriCreate的explore()函数,展现相似度查询结果图片。
系统会弹出以下对话框:
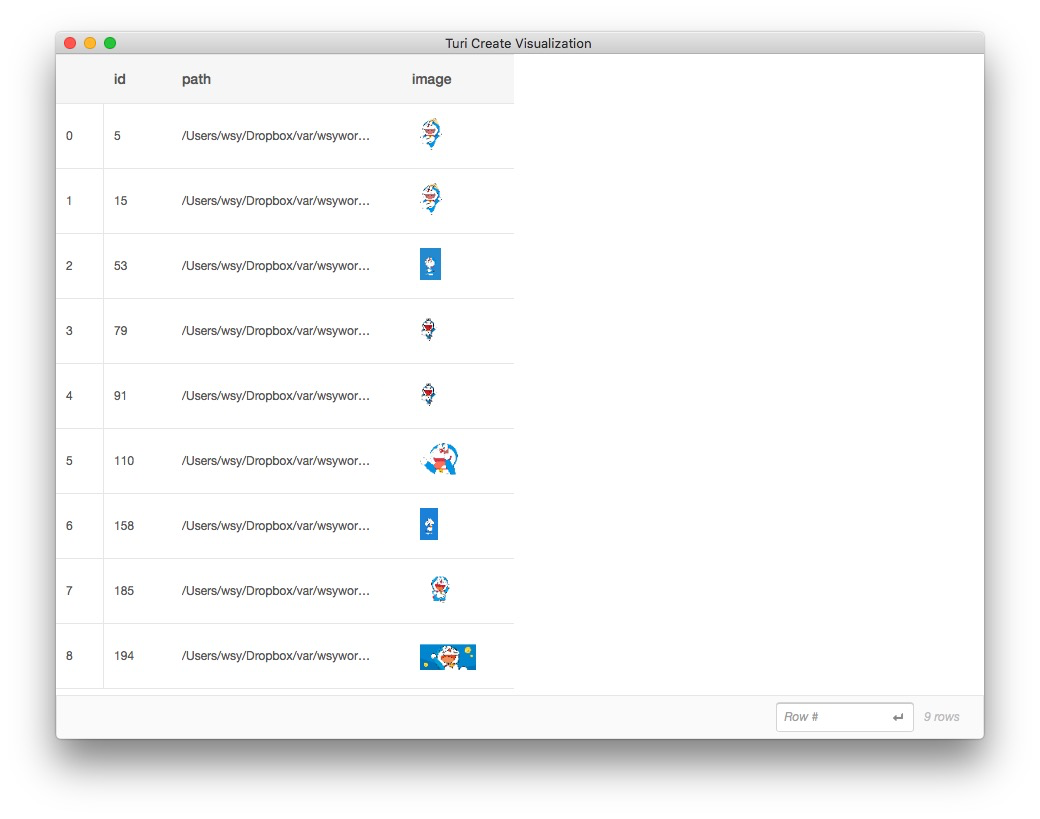
我们可以看到,全部查询结果图片中,只出现了哆啦a梦。瓦力的图片,一张都没有出现。
近似图片查找成功!
随着本文操作样例数据后,你不妨换用自己的数据,来动手尝试一番。
7.3.5 原理
展示了如何用10几行Python代码帮你查找相似图形后,我们来聊聊这种强大、简洁背后的原理。
如果你对原理不感兴趣,请跳过这一部分,看“小结”。
虽然我们刚刚只是用了一条语句构建模型:
然而实际上,TuriCreate在后台为我们做了很多事情。
首先,它调用了一个非常复杂的,在庞大数据集上训练好的模型。
《如何用Python和深度神经网络识别图像?》(7.2)一文中,我们介绍过,这个模型就是上图中的最后一行。它的名字叫做Resnet-50,足足有50层,训练的图片数以百万计,训练时长也很久。
这里,机智的你一定会问个问题:那些数以百万计的预训练图片里面,是否有哆啦a梦和瓦力呢?
没有。
那就怪了,不是吗?
如果这个复杂的模型之前根本就没有见过哆啦a梦和瓦力,那它怎么知道如何区分它们呢?又怎么能够判别两张哆啦a梦之间的差别,就一定比哆啦a梦和瓦力之间更小呢?
《如何用Python和深度神经网络识别图像?》(7.2)一文里,我已经提示给你一个关键词:迁移学习(transfer learning)。
这里咱们就不深入技术细节了。我只给你在概念层次讲解一下。
还记得这张描述计算机视觉(卷积神经网络)的示意图吗?
在全连接层(Fully Connected Layer)之前,你可能进行了多次的卷积、抽样、卷积、抽样……这些中间层次,帮我们描绘了图片的一些基本特征,例如边缘大概是个什么形状,某个区块主要的颜色是哪些等。
到了全连接层,你只剩下了一组数据,这组数据可能很长,它抽取了你输入数据的全部特征。

如果你的输入是一只猫,此时的全连接层里就描述了这只猫的各种信息,例如毛发颜色、面部组成部分排列方式、边缘的形状……
这个模型可以帮你提取猫的特征,但它并不知道“猫”的概念是什么。
你自然可以用它帮你提取一条狗的特征。
同理,哆啦a梦的照片,与猫咪的照片一样,都是二维图片,都是用不同颜色分层。
那用其他图片训练的模型,能否提取哆啦a梦照片里的特征呢?

当然也可以!
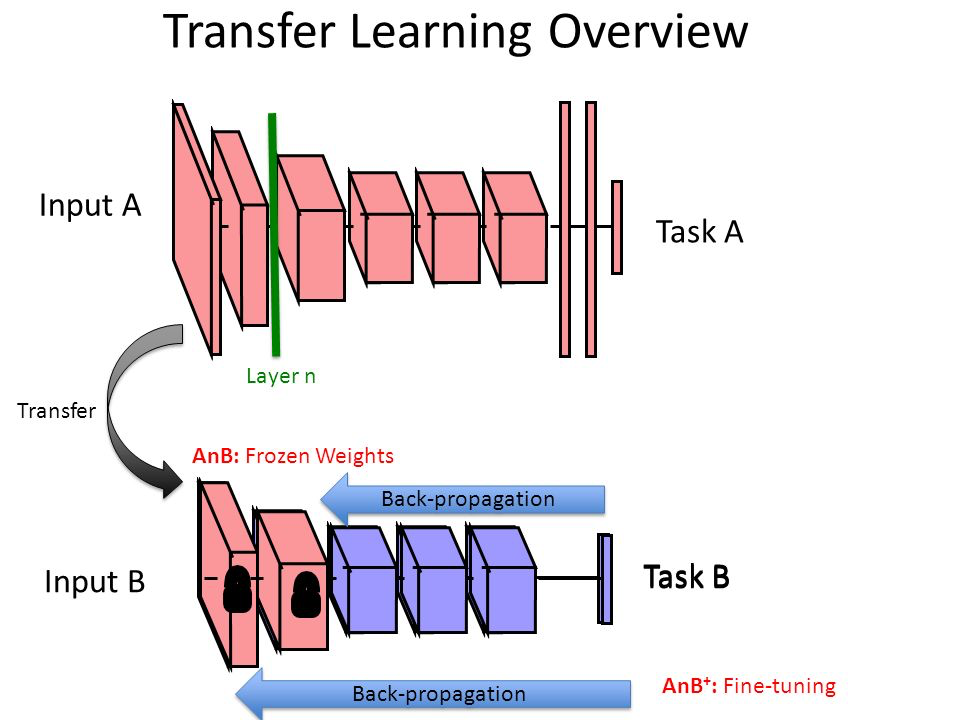
使用迁移学习的关键,在于冻结中间过程的全部训练结果,直接把一幅图,利用在其他图片集合上训练的模型,转化为一个特征描述结果。
后面的工作,只把这个最后的特征描述(全连接层),用来处理分类和相似度计算。
前面的好几十层参数迭代训练,统统都被省却了。
难怪可以利用这么小的数据集获得如此高的准确度;也难怪可以在这么短的时间里,就获得整合后的模型结果。
把在某种任务上积累下的经验与认知,迁移到另一种近似的新任务上,这种能力就叫做迁移学习。
比起机器来,人的迁移学习能力更为强大。
雨果奖作者郝景芳在最近的一篇文章里,描述了人的这种强大学习能力:
小孩子可以快速学习,进行小数据学习,而且可以得到「类」的概念。小孩子轻易分得清「鸭子」这个概念,和每一只具体不同的鸭子,有什么不同。前者是抽象的「类」,后者是具体的东西。小孩子不需要看多少张鸭子的照片,就能得到「鸭子」这个抽象「类」的概念。
用成语来描述,大概就是“触类旁通”吧。
如果人类不善于迁移学习,把生活中的所有事物,全都当成新的东西从头学起,那后果简直不堪设想。对比我们一生中所能处理的信息总量,这种认知负荷将是无法承受的。
回到我们的问题里,如果模型可以帮我们把每一张图片,都变成全连接层上的那一长串数字(特征),那么我们分辨这些图片的相似程度,就变得太简单了。因为这变成了一个简单的空间向量距离问题。
处理这种简单的数值计算,我们人类可能觉得很繁琐。但是计算机算起来,那就很欢快了。
根据距离大小排序,找出其中最小的几个向量,它们描述的图片,就被模型判定为相似度最高的。
7.4 文科生如何理解卷积神经网络?
不愿意看那一堆公式符号,却想知道卷积神经网络(Convolutional Neural Network)如何做图像分辨?分享一段我给自己研究生的讲解答疑视频,希望对你有帮助。
7.4.1 茫然
常有朋友问,我的Python和数据科学课程开在哪个学期,他们想过来蹭课。
不好意思,这个真没有。
我写了一系列的数据科学教程。但原本只是给我自己的研究生赋能,并非课程讲义。

他们有的人,本科学的专业,与技术毫不沾边。
但是情报学是个交叉学科。尤其是近几年,与数据科学融合愈发深入。
往周围看看,其他社会科学专业,例如新闻学、心理学、社会学、政治学等,都在利用开放互联网数据集,做以往无法想象的大规模信息分析。
在这种情况下,你一个情报学研究生,处在原本就有数据分析优势的学科,却一点儿也不掌握数据科学技能,出门好意思跟其他同学打招呼吗?
于是我给他们写教程,写尽量让文科生能看懂的教程。
事实证明,他们能跟着教程,做出来结果。
但是,我在《Python编程遇问题,文科生怎么办?》(10.1)中说过,“照葫芦画葫芦”,只是你入门数据科学的第一步。
你需要理解技术应用的前提和方法,这样才能应对自己的研究问题,利用适当工具,加以解决。
本周的组会上,我听一年级研究生论文翻译展示,明显感觉他们对于卷积神经网络结构与原理,依然不清楚。

我很奇怪。
因为我专门为他们写过至少2篇文章,都是讲如何利用卷积神经网络做图像处理的。
而且,他们还用自己的数据集,重新做过训练与测试。
在文章里,我还给他们介绍了深度学习模型的基本原理,并且在文末详细列出了参考资料,供延伸阅读。
这么长时间过去了,怎么还是懵懵懂懂?
倘在从前,我肯定要训人了。
因为怎么看,这都是学习态度不端正的问题。
但是,有了同理心训练基础,我突然能够理解他们的茫然与苦恼了。
7.4.2 同理
他们看到的延伸阅读材料,像一个黑洞。
这个黑洞吸收他们的时间和工作量,却看不到任何正反馈。
因为他们缺乏基础。
要学好深度神经网络,并不需要多么高人一等的智慧。但是一些基础要件却很重要。这些基础包括:
- 编程
- 数学
- 英语
如果有这3个基础,你根本无需导师帮助。自修 Coursera 上 Andrew Ng 《深度学习》这样的精品MOOC课程,就会让你成长迅速,大呼过瘾。
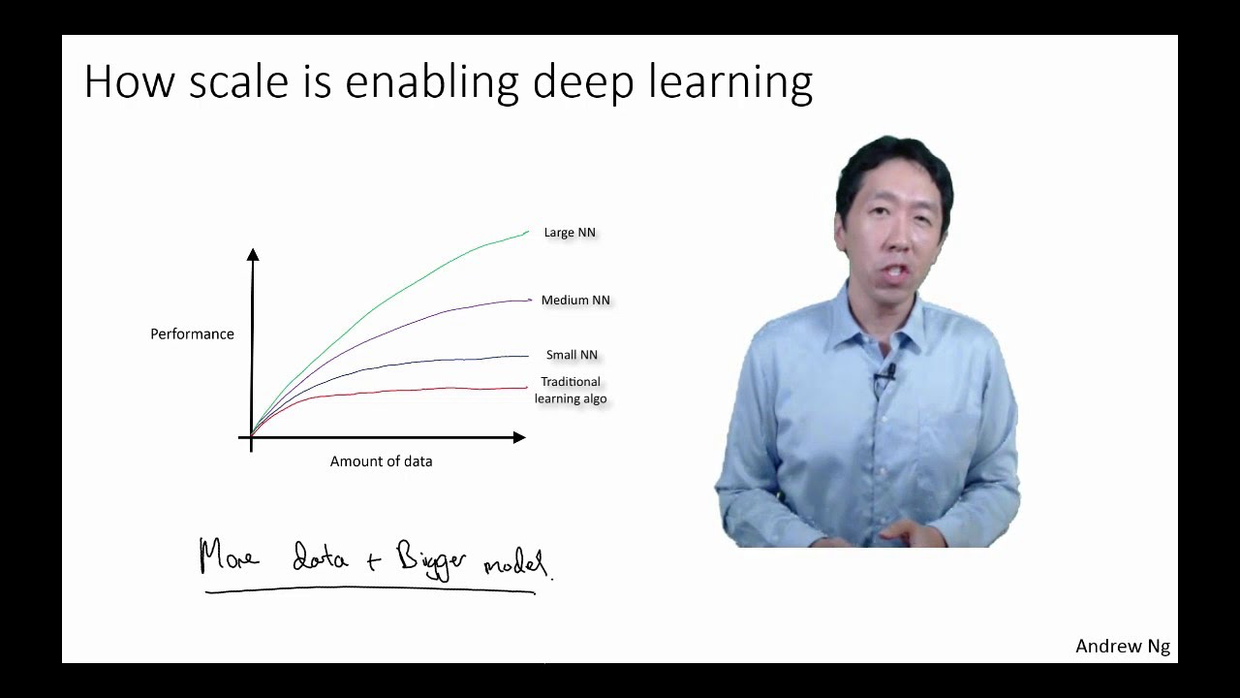
可是对国内的文科生来说,上面列出的几个基础要件,可谓是“三座大山”,能压得他们寸步难行。
编程没学过,数学早忘了,英语不过关。
你让他们一点一滴从头学起,全部补齐?
即便真补完整了,也该毕业了。
还做什么研究?
诚然,老师可以帮助他们精简学习模块。
编程不好,没关系。
不要去碰 Tensorflow 的神经网络结构搭建细节语句,只要会用最简单的 TuriCreate 调用迁移学习工具,几行代码搞定图像识别。
英语不好,没事儿。
我把教程给你用中文写出来。你直接照着做,就能出结果。
但是数学不好,理解不了神经网络模型的原理,怎么办?
从前我也是束手无策。
要么把整个工具当作黑箱,只知道输入输出,就能做出结果来。
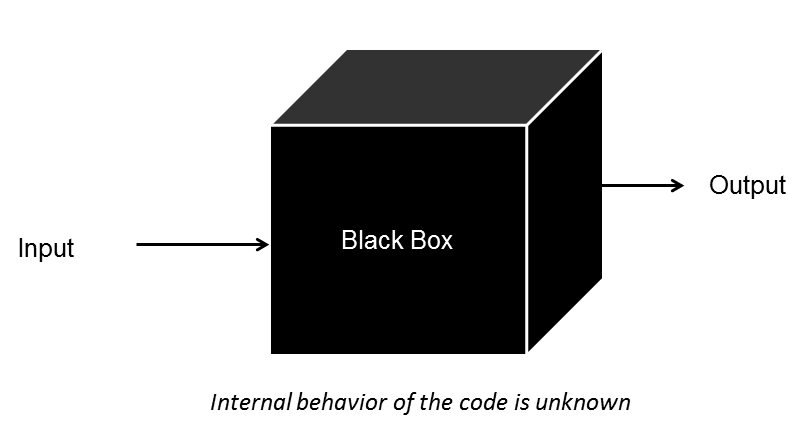
但这是用户的态度,不是研究者的态度。
这种低水准认知,可能让你有机会充分实践什么叫“垃圾进,垃圾出”。
很多对统计学一无所知的学生,不就是这么玩儿SPSS的吗?
想到这里,我突然灵光一闪。
7.4.3 借鉴
统计学对很多文科生,也很难学。
他们是通过什么途径学会的呢?
是一种“有限度拆解”。
只学会导入数据,点按钮出图表,显然不够用。
但是从头推各种分布的公式,讲解阈值设定(例如那个神奇的0.7)的原理……人早就跑掉了。
怎么办?
我想起来了李连江教授的这本书。

李老师的态度,是原理要讲清楚,不能让学生随便“拷打”数据。
但是又不能深入到底层数学原理,那样很多文科生根本就看不懂,甚至会很快丧失掉兴趣。
他的办法,简单而实际。
就是举例子和打比方。
用一个SPSS自带的雇员例子,他解释了好几章的内容。从数据的类型,一直到多元回归。
因为有了实际样例,学生充分代入,就好理解。
讲到因子分析,做旋转。这个怎么讲?
他用了两个比喻。
一个是三大男高音,代表3个因子。
三大男高音同台的演唱会,观众如潮。

有的观众爱听多明哥,有的爱听卡雷拉斯,有的是冲着帕瓦罗蒂来的。
但是观众们都坐在一起,你分不清哪个观众究竟是哪位歌唱家的粉丝。
怎么办?
让男高音们分开唱,唱对台戏。
这是第二个比喻。
一旦有对台戏,观众选择的座位,就明确代表了态度。
某个问项,归属于哪个因子,也同样可以通过因子唱对台戏(旋转)来分辨。
读了《戏说统计》,我觉得讲得真好。
但是我后来看了李老师的课程视频,觉得收获更大。
因为视频的信息传播更加丰富。
同样是刚才的例子,因为有了图像化解读,学生可以理解得更加透彻而深刻。

尤其是,每当讲到研究中统计结果出来,需要一些“不足为外人道”、“社会科学界有共识”的操作手法,李老师的笑容,总能让人跟着忍俊不禁。
7.4.4 讲解
有了李连江老师的例子做参考,我用组会的剩余时间,以板书的形式,一步步为研究生们讲解了以下内容:
- 深度神经网络的基本结构;
- 神经元的计算功能实现;
- 如何对深度神经网络做训练;
- 如何选择最优的模型(超参数调整);
- 卷积神经网络基本原理;
- 迁移学习的实现;
- 疑问解答。
我没有追求最大化的严谨,也没有对例子的通用性和实用性做更多的要求,只是从头到尾,把一个简化到极致的图像识别模型,与客户流失预判模型进行了对比讲解。
同样的,我用了样例,也用了打比方,尽力把听讲的认知负荷,降到最低。
过程中,我要求学生随时提问。因此交互很密切。
讲解完毕后,他们几个表示,这下终于弄懂了卷积神经网络的基础知识。

由于最近阎教练的工作坊训练了视觉记录行为,我讲了几分钟后,突然觉察到这一段可以录下来,分享给更多人。
于是我让坐在前排的杨文同学,帮我录制了视频。
视频中没有能包含最初的几分钟内容,即刚才列表的前两个部分。颇为遗憾。
不过没关系,过一段时间后,我准备组会时让研究生上讲台,把这一段复述一遍,作为学习效果检查。
如果他们做得好,我会录下来,分享给大家。
他们还不知道我的打算。
所以你看见后,别告诉他们。嘘!
这段视频时长接近30分钟,不算短。
如果你和他们一样,读过了我的《如何用Python和深度神经网络锁定即将流失的客户?](#customer-churn-detection-with-python-and-deep-learning)》、《如何用Python和深度神经网络识别图像?(7.2》和《[如何用Python和深度神经网络寻找近似图片?》(7.3))这几篇文章,但是对于深度神经网络的原理构造还是迷茫,建议你从头看到尾,可能会有一些收获。
欢迎点击这个链接,观看视频。
有言在先,因为是即兴讲解,没有任何准备。内容如有疏漏,在所难免。
欢迎各位高手帮助指出纰漏,我会在将来的讲解中,迭代改进。
提前谢过!
7.5 本章小结
如果你喜欢本章的内容,欢迎扫描下面二维码,请我喝杯咖啡。

如果你需要答疑,咱们的问答社区在这里: