第 8 章 云端环境
8.1 如何免费云端运行Python深度学习框架?
想运行TuriCreate,却没有苹果电脑,也没有Linux使用经验,怎么办?用上这款云端应用,让你免安装Python运行环境。一分钱不用花,以高性能GPU,轻松玩儿转深度学习。

8.1.1 痛点
《如何用Python和深度神经网络识别图像?》(7.2)一文发布后,收到了很多读者的留言。大家对从前印象中高不可攀的深度神经网络图片识别来了兴趣,都打算亲自动手,试用一下简单易用的TuriCreate框架。
有的读者尝试之后,很开心。

有的读者却遇到了问题:
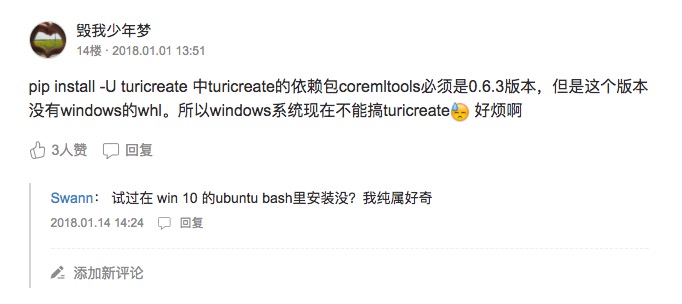
我在《如何用Python和深度神经网络寻找近似图片?》(7.3)一文中,对这个疑问做了回应——TuriCreate目前支持的操作系统有限,只包括如下选项:
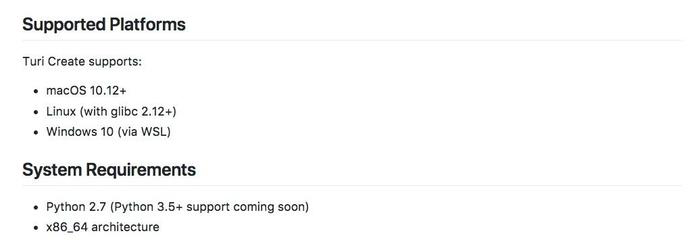
如果你用的操作系统是Windows 7及以下版本,目前TuriCreate还不支持。
解决办法有两种:
第一种,升级到Windows 10,并且使用WSL。
第二种,采用虚拟机安装好Linux。
这两种解决方法好不好?
不好。
它们都是没有办法的办法。
因为都需要用户接触到Linux这个新系统。
对于IT专业人士来说,Linux确实是个好东西。
首先,它免费。因此可以把软硬件的综合使用成本降到最低;
其次,它灵活。从系统内核到各种应用,你都可以随心所欲定制。不像Windows或者macOS,管你用不用西班牙语和文本语音朗读功能,统统默认一股脑给你装上;
第三,它结实。Linux虽然免费,但是从创生出来就是以UNIX作为参考对象,完全可以胜任运行在一年都不关机一回的大型服务器上。
但是,Linux这些优点,放到我专栏的主要阅读群体——“文科生(10.2)”——那里,就不一定是什么好事儿了。
因为Linux的学习曲线,很陡峭。
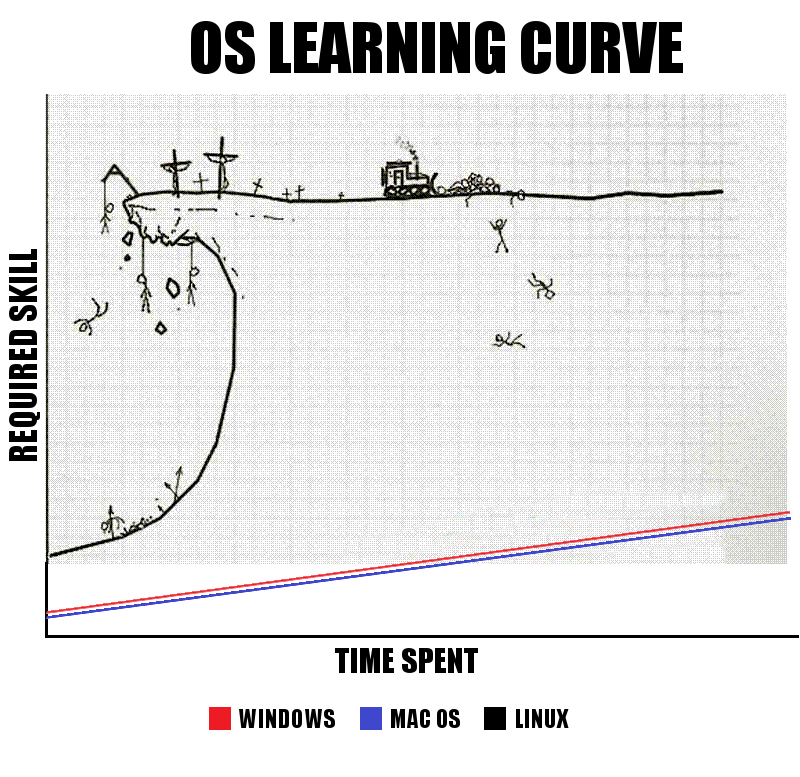
所以,如果你固执地坚持在自己的电脑上运行TuriCreate,又不愿意学Linux,那可能就得去买台Macbook了。
但是,谁说运行代码一定要在自己的机器上呢?
8.1.2 云端
你可以把TuriCreate安装在云端——只要云端的主机是Linux就好。
你可能怒了,觉得我是在戏耍你——我要是会用Linux,就直接本地安装了!本地的Linux我都不会用,还让我远程使用Linux?!你什么意思嘛?
别着急,听我把话说完。
云端的Linux主机,大多是只给你提供个操作系统,你可以在上面自由安装软件,执行命令。
这样的云端系统,往往需要你具备相当程度的IT专业知识,才能轻松驾驭。
更要命的是,这种租用来的云主机,要么功能很弱,要么很贵。
那种几十块钱一个月的主机,往往只有一个CPU核心。跑深度学习项目?只怕你还没获得结果,别人的论文都发出来了。
有没有高性能主机?当然有。
例如亚马逊的AWS,就提供了p2.xlarge这样的配置供你选择。有了它,运行深度学习任务游刃有余。
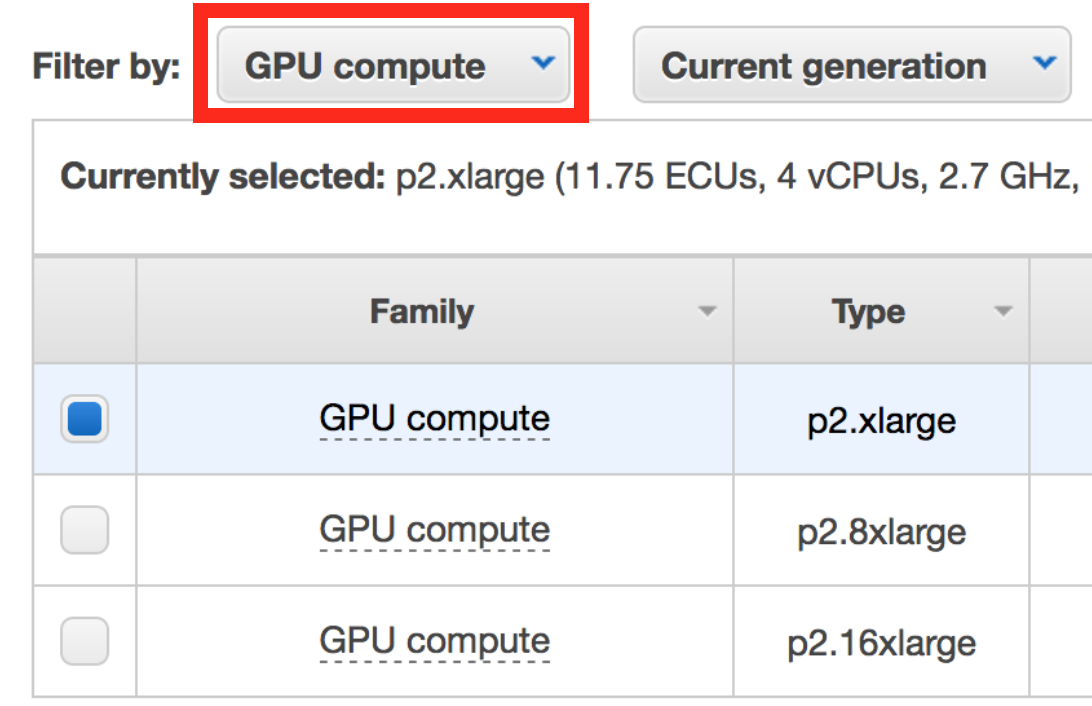
但是它很贵。
有人计算过,如果你需要长期使用深度学习功能,还是本地组装一台高性能电脑比较划算。
另外,虽然亚马逊已经帮你做了很多准备工作。你从开始折腾这台云主机到真正熟练掌握使用,还是要花些功夫。
从网上找一篇靠谱的教程后,经过自己的反复实践,不断求助,最终你会掌握以下技能:
- 硬件配置含义;
- 云平台信用卡支付方式;
- 控制面板使用;
- 计费原理;
- 竞价规则;
- 实例使用限制;
- 定制实例类型选择;
- 安全规则设定;
- 公钥私钥的使用;
- 加密通讯ssh连接;
- 文件权限设定;
- 其他……
了解了如何最省钱地运行高配置AWS虚拟主机,知道该在何时启动和关闭实例。一个月下来,你看着账单上的金额如此之少,会特别有成就感吧。
问题是,你最初是想要干什么来着?
你好像只是打算把手头的照片,利用TuriCreate上的卷积神经网络快速做个分类模型出来吧?
所以,这种折腾不是正道。
在某些时刻,做出正确的选择比盲目付出努力重要得多。
你应该选择一个云平台,它得具有如下特色:
你不必会Linux,也不用从头装一堆基础软件。打开就能用,需要哪个额外的功能,一条指令就搞定。提供高性能GPU用来运行深度学习代码……最好还免费。
你是不是觉得我在做梦?犹豫着要不要赶紧喊我醒过来?
这不是做梦,真的有这样的好事儿。
8.1.3 发现
本文推荐给你的云运行环境,是由Google提供的Colaboratory,下文简称Colab。
其实这个工具已经存在了好几年了。
最初版本由Google和Jupyter团队合作开发。只是最近才迭代到渐入佳境的状态。经过这篇Medium文章的推广,吸引了很多研究者和学习者的关注。
官方的介绍是:
Colaboratory 是一款研究工具,用于进行机器学习培训和研究。它是一个 Jupyter 笔记本环境,不需要进行任何设置就可以使用。
请用Google Chrome浏览器打开这个链接,你可以看到这份“Colaboratory简介”。
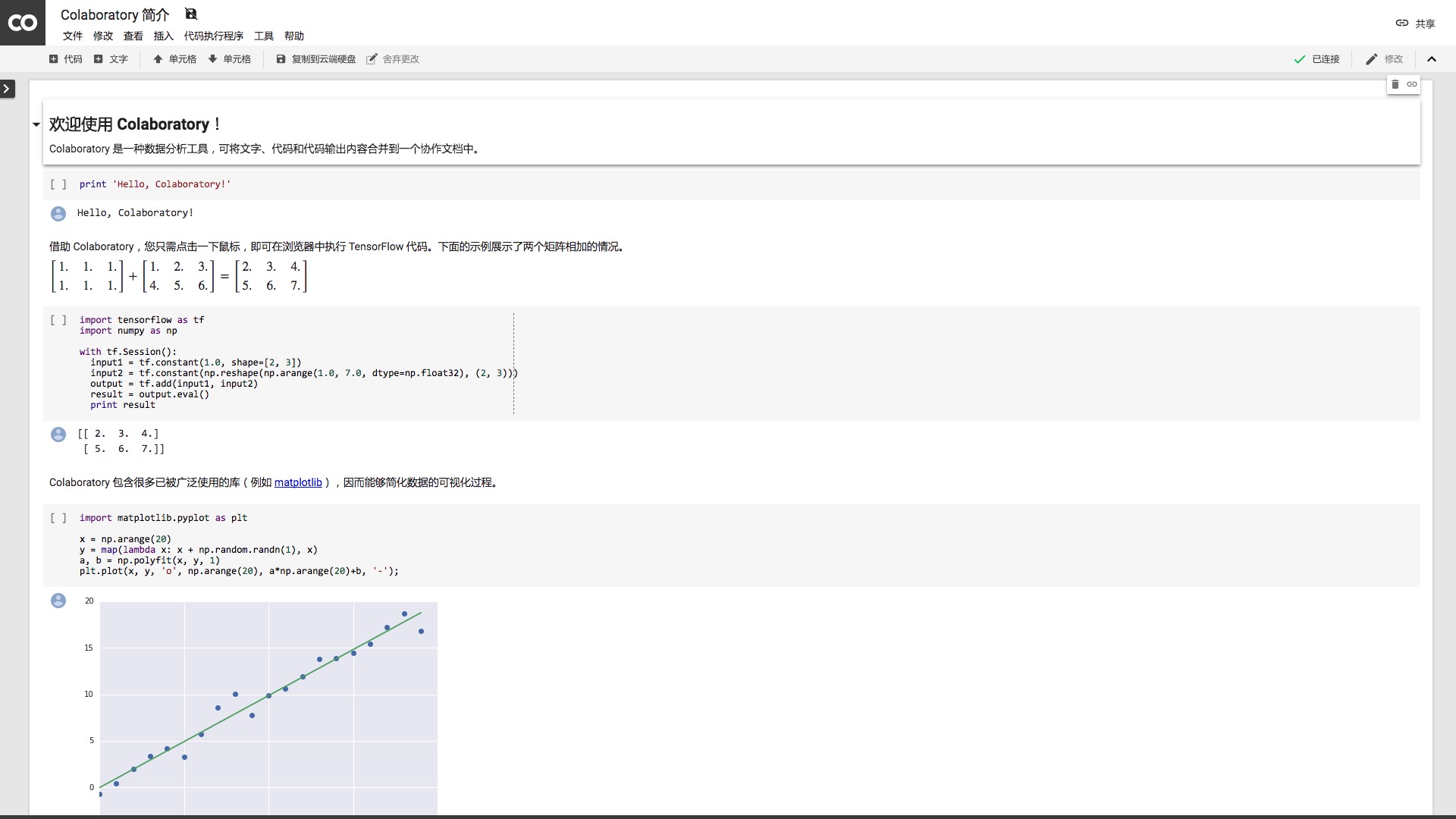
虽然外观不同,但是它实际上就是一份Jupyter Notebook笔记本。
我们尝试运行一下其中的语句。
注意这个笔记本里面的语句,其实是Python 2格式。但是默认笔记本的运行环境,是Python 3。
所以,如果你直接执行第一句(依然是用Shift+Enter),会报错。
解决办法非常简单,打开上方工具栏中的“代码执行程序”标签页。
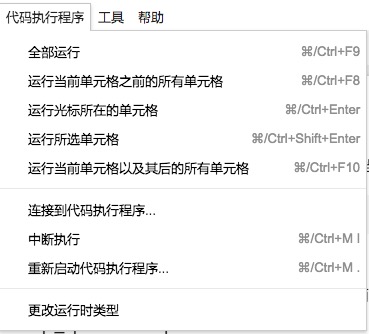
选择最下方的“更改运行时类型”。
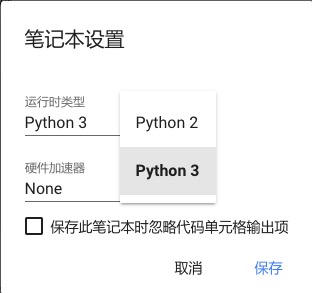
将默认的Python 3改成Python 2之后,点击右下角的保存按钮。
然后我们重新运行第一个代码区块的语句。这次就能正常输出了。

语句区块2就更有意思了。它直接调用Google自家的深度学习框架——tensorflow软件包。

我曾经专门为tensorflow的安装写过教程。但是在这里,你根本就没有安装tensorflow,它却实实在在为你工作了。
不仅是tensorflow,许多常用的数据分析工具包,例如numpy, matplotlib都默认安装好了。
对于这些基础工具,你一概不需要安装、配置、管理,只要拿过来使用就行。
我们运行最后一个代码单元。
看,图片输出都毫无问题。
编程环境领域的即插即用啊!太棒了!
可是兴奋过后,你可能觉得不过如此——这些软件包,我本地机器都正确安装了。执行起来,再怎么说也是本地更方便一些啊。
没错。
但是安装TuriCreate时,你的Windows操作系统不支持,对不对?
下面我为你展示如何用Colab运行TuriCreate,进行深度学习。
8.1.4 数据
我把需要分类的图像数据以及ipynb文件都放到了这个github项目中。请点击这个链接下载压缩包。
下载后解压到本地硬盘。
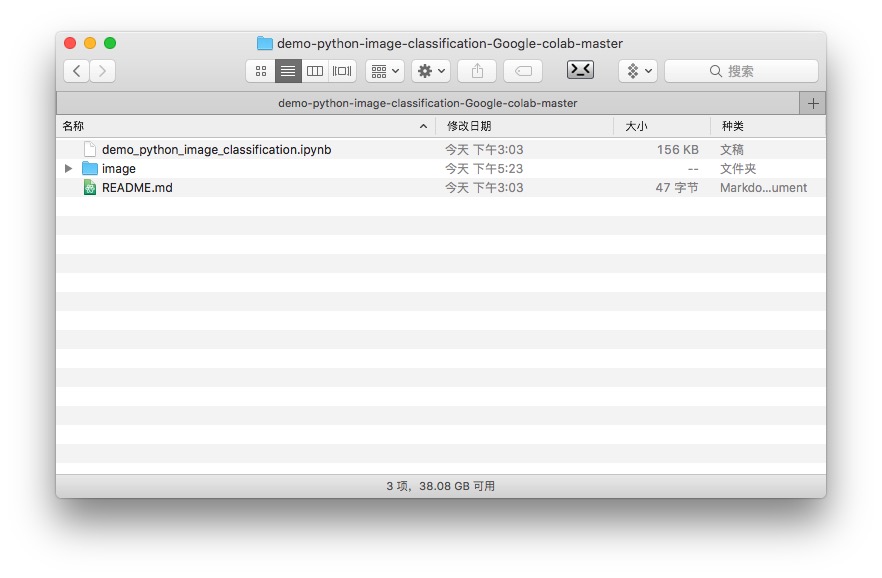
可以看到,其中包含一个ipynb文件和一个image目录。
image目录内容,就是你之前在《如何用Python和深度神经网络寻找近似图片?》(7.3)一文中已经见过的哆啦a梦和瓦力的图片。
这是蓝胖子的图片:
这是瓦力的图片:
请用Google Chrome浏览器(目前Colab尚不支持其他浏览器)打开这个链接,开启你的Google Drive。
当然,如果你还没有Google账号,需要注册一个,然后登录使用。
下面,把你刚刚解压的那个文件夹拖拽到Google Drive的页面上,系统自动帮你上传。
上传完成后,在Google Drive里打开这个文件夹。
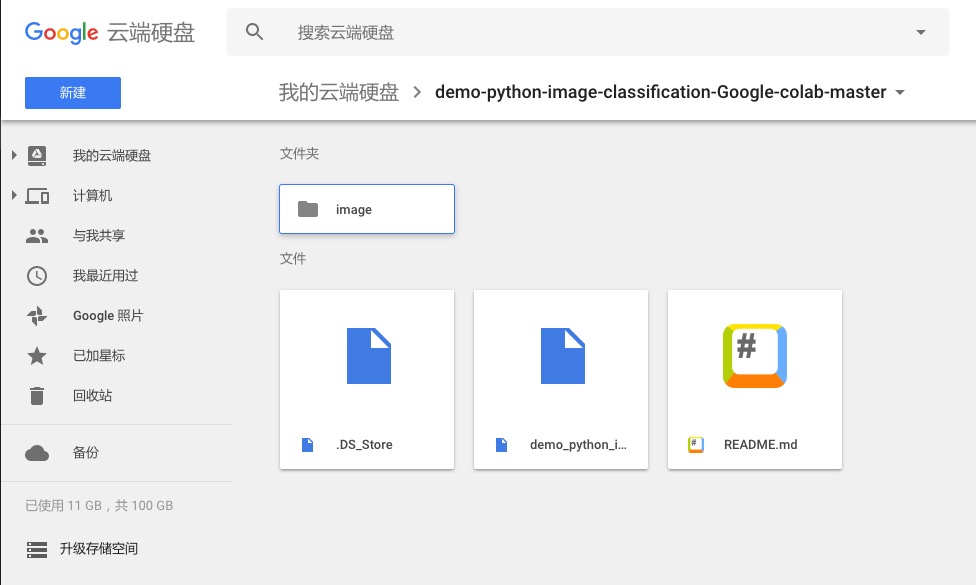
在demo_python_image_classification.ipynb文件上单击鼠标右键。选择打开方式为Colaboratory。
Colab打开后的ipynb文件如下图所示。
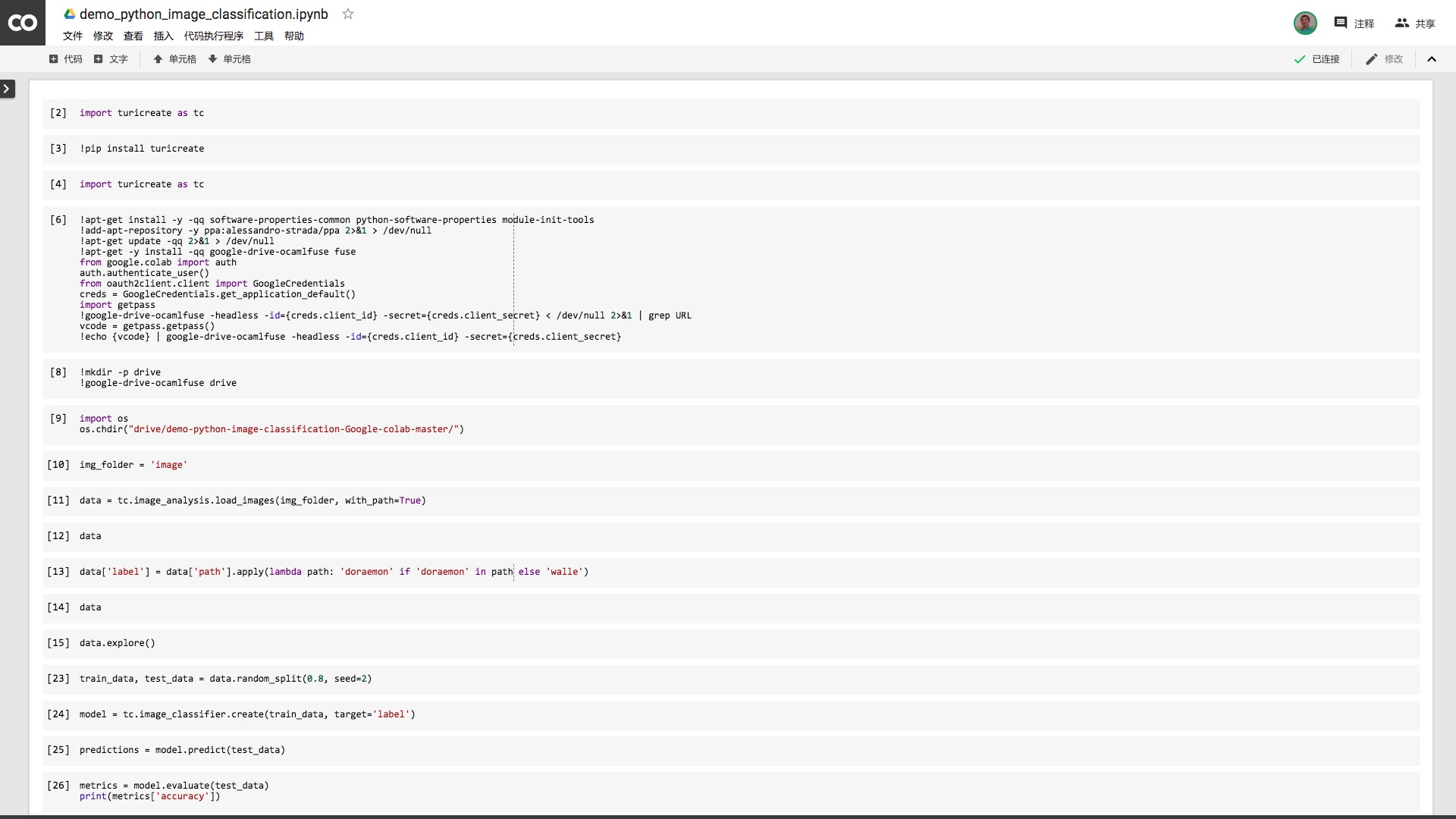
我们首先需要确定运行环境。点击菜单栏里面的“修改”,选择其中的“笔记本设置”。
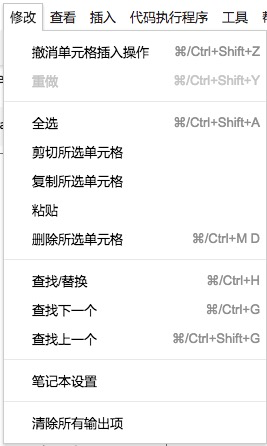
确认运行时类型为Python 2,硬件加速器为GPU。如果不是这样的设置,请修改。然后点击保存。
数据有了,环境也已配置好。下面我们正式开始运行代码了。
8.1.5 代码
我们尝试读入TuriCreate软件包。
结果会有如下报错。
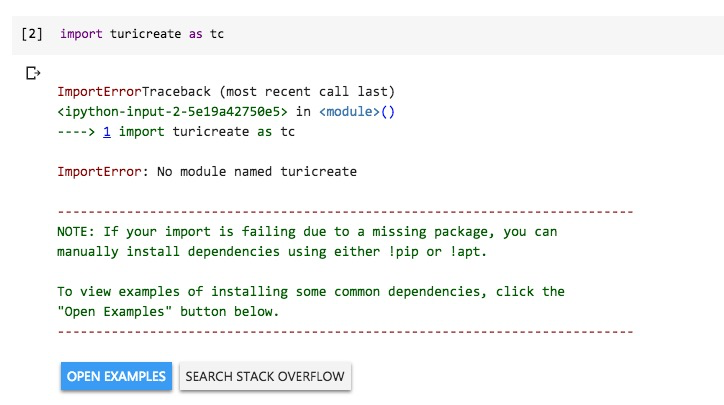
遇到这个报错很正常。
因为我们还没有安装TuriCreate。
不是说不需要安装深度学习框架吗?
那得看是谁家的深度学习框架了。
Colab默认安装Tensorflow,因为它是Google自家开发的深度学习框架。
而TuriCreate是苹果的产品,所以需要咱们手动安装。
手动安装很麻烦吗?
才不会。
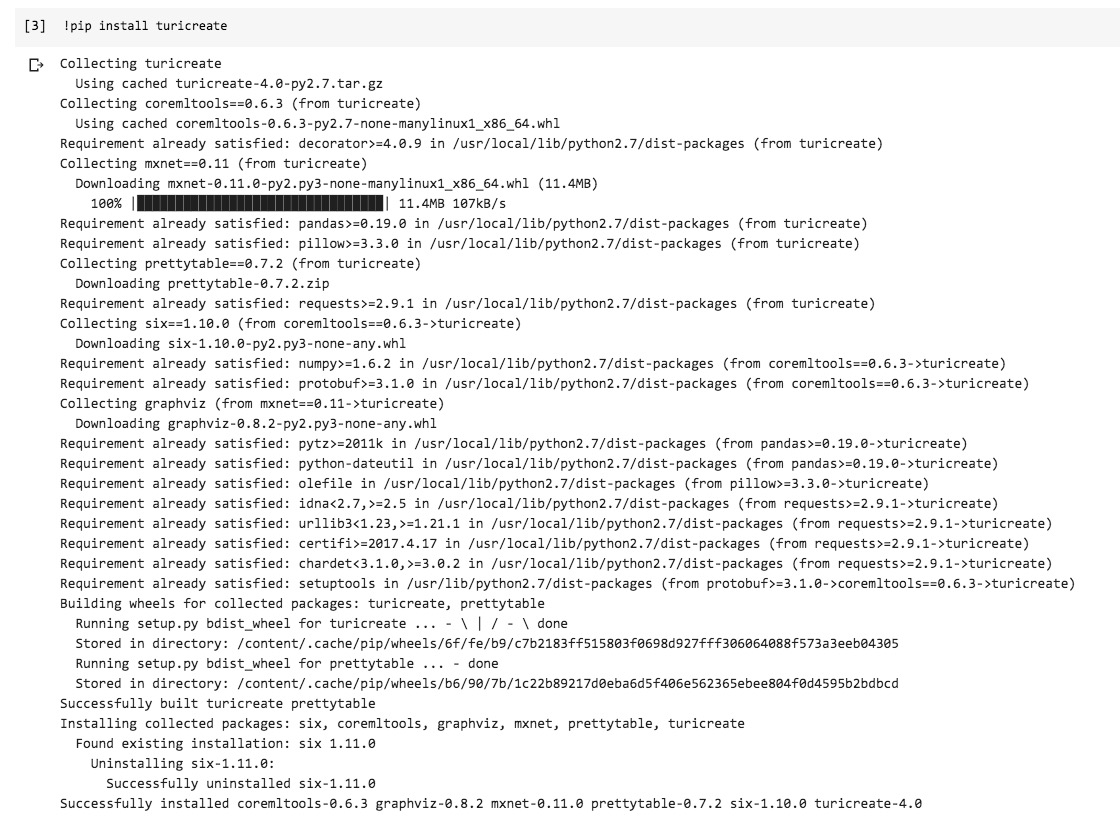
新开一个代码单元,然后输入以下一行语句:
你就可以看到Colab帮你辛勤地安装TuriCreate以及全部依赖包了,根本不用自己操心。瞬间就安装好了。
我们重新调用TuriCreate。
这次成功执行,再没有出现报错。
下面我们需要做一件事情,就是让Colab可以从我们的数据文件夹里面读取内容。
可是默认状态下,Colab根本就不知道我们的数据文件夹在哪里——即便我们本来就是从Google Drive的演示文件夹下面打开这个ipynb文件的。
我们首先要让Colab找到Google Drive的根目录。
这原本是一个相对复杂的问题。但是好在我们有现成的代码,可以拿来使用。
请执行下面这个单元格的代码。看不懂不要担心。因为你不需要调整其中的任何语句。
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}执行刚开始,你会看到下面的运行状态。
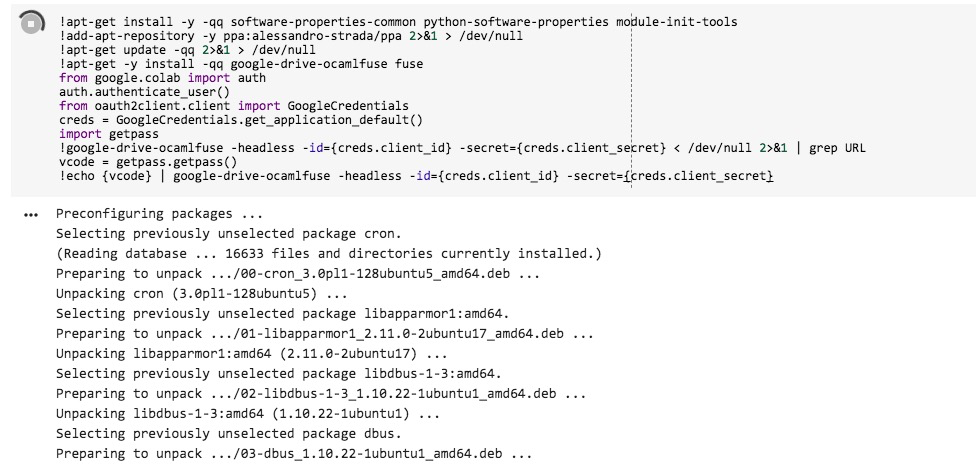
过了一小会儿,你会发现程序停了下来。给你一个链接,让你点击。并且嘱咐你把获得的结果填入下面的文本框。

点击链接,你会看到下图。
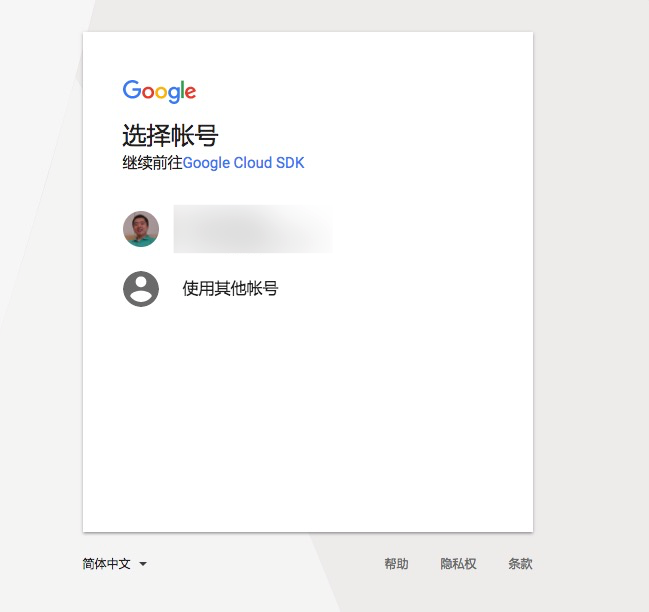
点击你自己的Google账号。
然后会提示你Google Cloud SDK的权限请求。
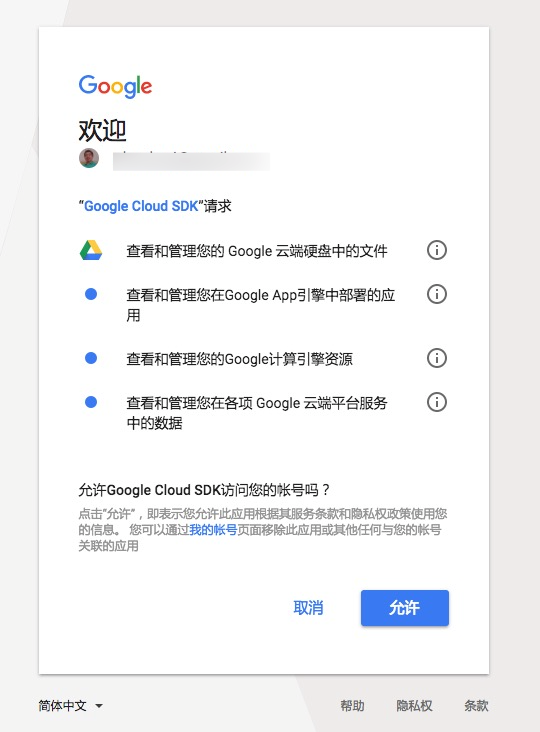
点击允许后,你就获得了一长串字符了。复制它们。

回到Colab页面上,把这一长串字符粘贴进去,回车。

你可能认为运行完毕。不对,还需要第二步验证。
又出来了一个链接。

点击之后,还是让你选择账号。
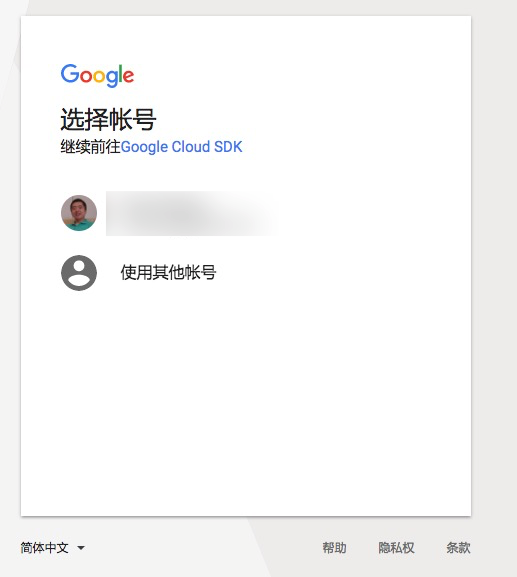
然后Google Cloud SDK又提出了权限要求。注意和上次的请求权限数量不一样。
你需要再复制另外的一串新字符。

粘贴回去,回车。这次终于执行完毕。

好了,现在Colab已经接管了你的Google Drive了。我们给Google Drive云端硬盘的根目录起个名字,叫做drive。
然后,我们告诉Colab,请把我们当前的工作目录设定为Google Drive下的demo-python-image-classification-Google-colab-master文件夹。
好了,准备工作完毕,我们继续。
我们需要告诉TuriCreate,图像数据文件夹在哪里。
然后,我们读入全部图像文件到数据框data。
这里,你会发现读入速度比较慢。这确实是个问题,是否是因为TuriCreate的SFrame数据框在Colab上有些水土不服?目前我还不能确定。
好在咱们样例中的文件总数不多,还能接受。

终于读取完毕了。
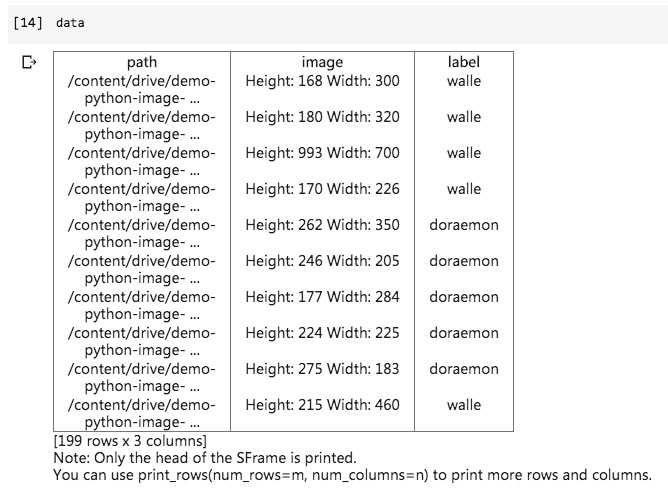
我们看看data中包含哪些数据吧。
跟Jupyter Notebook本地运行结果一致,都是文件路径,以及图片的尺寸信息。

下面,我们还是给图片打标记。
来自哆啦a梦文件夹的,标记为doraemon;否则标记为walle。
再看看data数据框内容。
可见,标记已经成功打好。
我们尝试用explore()函数浏览data数据框,查看图片。
但是很不幸,TuriCreate提示我们,该功能暂时只支持macOS.
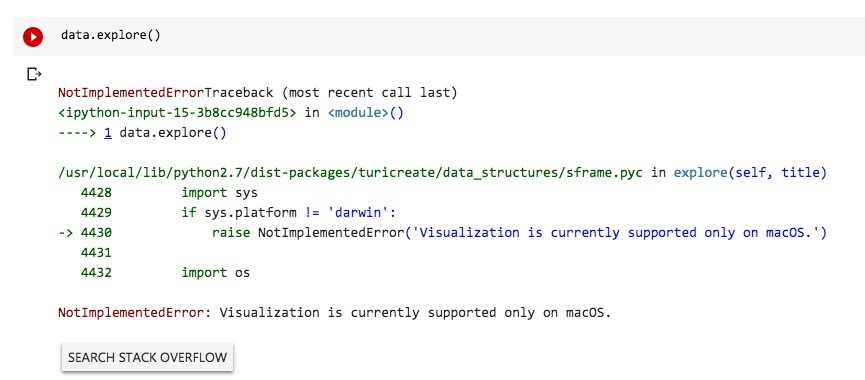
别忘了,我们现在使用的,是Linux操作系统,所以无法正常使用explore()函数。不过这只是暂时的,将来说不定哪天就支持了。
幸好,这个功能跟我们的图像分类任务关系不大。我们继续。
把数据分成训练集与测试集,我们使用统一的随机种子取值,以保证咱们获得的结果可重复验证。
下面我们正式建立并且训练模型。
运行的时候,你会发现,原本需要很长时间进行的预训练模型参数下载,居然瞬间就能完成。
这是怎么回事儿?作为思考题,留给你自行探索解答。给你一个小提示:云存储。
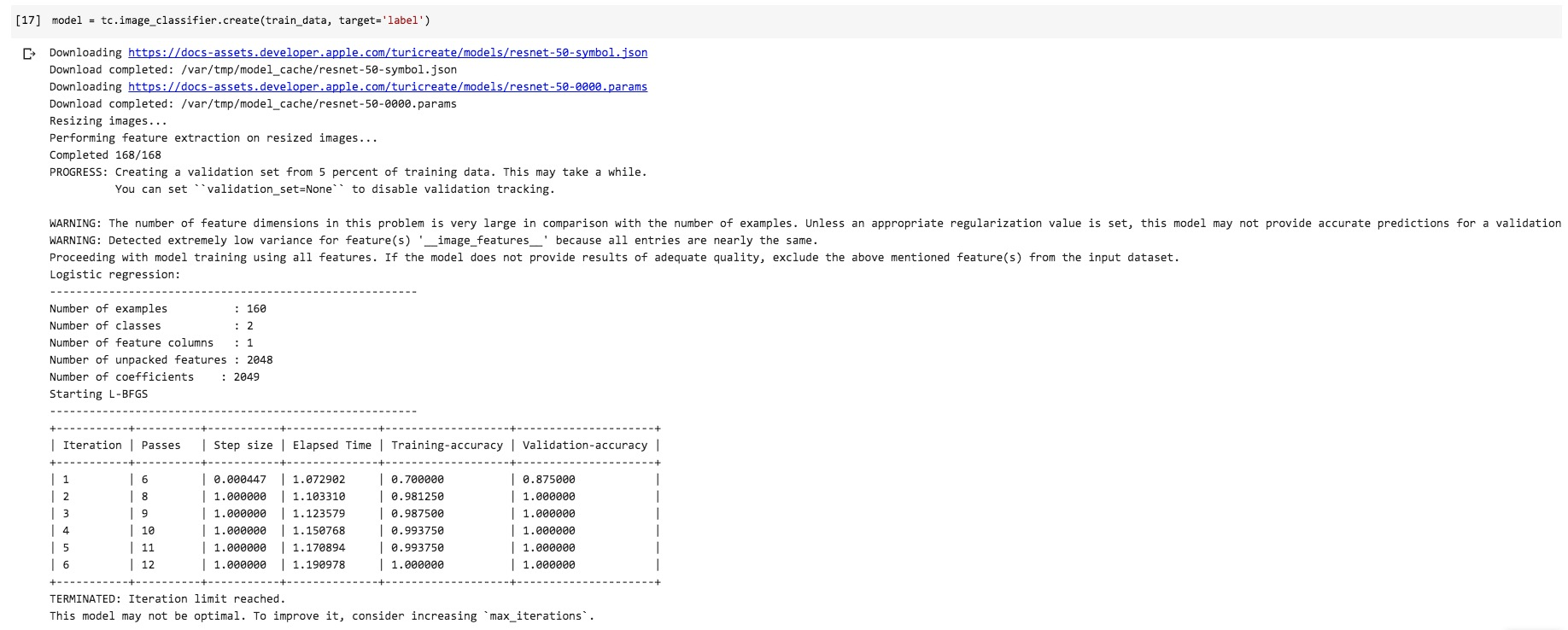
TuriCreate自动帮我们处理了图像尺寸归一化,并且进行了多轮迭代,寻找合适的超参数设置结果。
好了,我们尝试用训练集生成的模型,在测试集上面预测一番。
预测结果如何?我们用evaluate()函数来做个检验。
结果如下:
0.935483870968我们看看预测的结果:
dtype: str
Rows: 31
['doraemon', 'walle', 'walle', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle']再看看实际的标记:
dtype: str
Rows: 31
['walle', 'walle', 'walle', 'walle', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle', 'walle', 'doraemon', 'doraemon', 'doraemon', 'walle', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'doraemon', 'walle']两相比对,我们希望找出那些错误预测的图片存储位置:

下面我们需要直观浏览一下预测错误的图像。
读入Jupyter的Image模块,用于展示图像。
我们先来展示第一幅图像:
结果如下:

还是老样子,50层的深度神经网络模型,已经无法让人直观理解。所以我们无法确切查明究竟是哪个判定环节上出了问题。
然而直观猜测,我们发现在整个照片里,方方正正的瓦力根本就不占主要位置。反倒是圆头圆脑的机器人成了主角。这样一来,给图片形成了比较严重的噪声。
我们再来看看另一幅图:
结果是这样的:

这幅图里面,同样存在大量的干扰信息,而且就连哆啦a梦也做了海盗cosplay。
好了,到这里,我们的代码迁移到Colab工作顺利完成。
如你所见,我们不需要在本地安装任何软件包。只用了一个浏览器和一个从github下载的文件夹,就完成了TuriCreate深度学习的(几乎)全部功能。
比起虚拟机安装Linux,或者自己设定云端Linux主机,是不是轻松多了呢?
8.1.6 小结
通过阅读本文,希望你已经掌握了以下知识点:
- 某些深度学习框架,例如TuriCreate,会有平台依赖;
- 除了本地安装开发环境外,云端平台也是一种选择;
- 选择云端平台时,特别要注意设置的简便性与性价比;
- 如何将数据和代码通过Google Drive迁移到Colab中;
- 如何在Colab中安装缺失的软件包;
- 如何让Colab找到数据文件路径。
另外,请你在为需求选择工具的时候,记住哈佛大学营销学教授莱维特(Theodore Levitt)的那句经典名言:
人们其实不想买一个1/4英寸的钻头。他们只想要一个1/4英寸的洞。
这句话不仅对学习者和开发者有用。
对于产品的提供者,意义只怕更为重大。
8.2 如何用云端 GPU 为你的 Python 深度学习加速?

8.2.1 负荷
下午,我用 Python 深度学习框架 Keras 训练了一个包含3层神经网络的回归模型,预测波士顿地区房价。
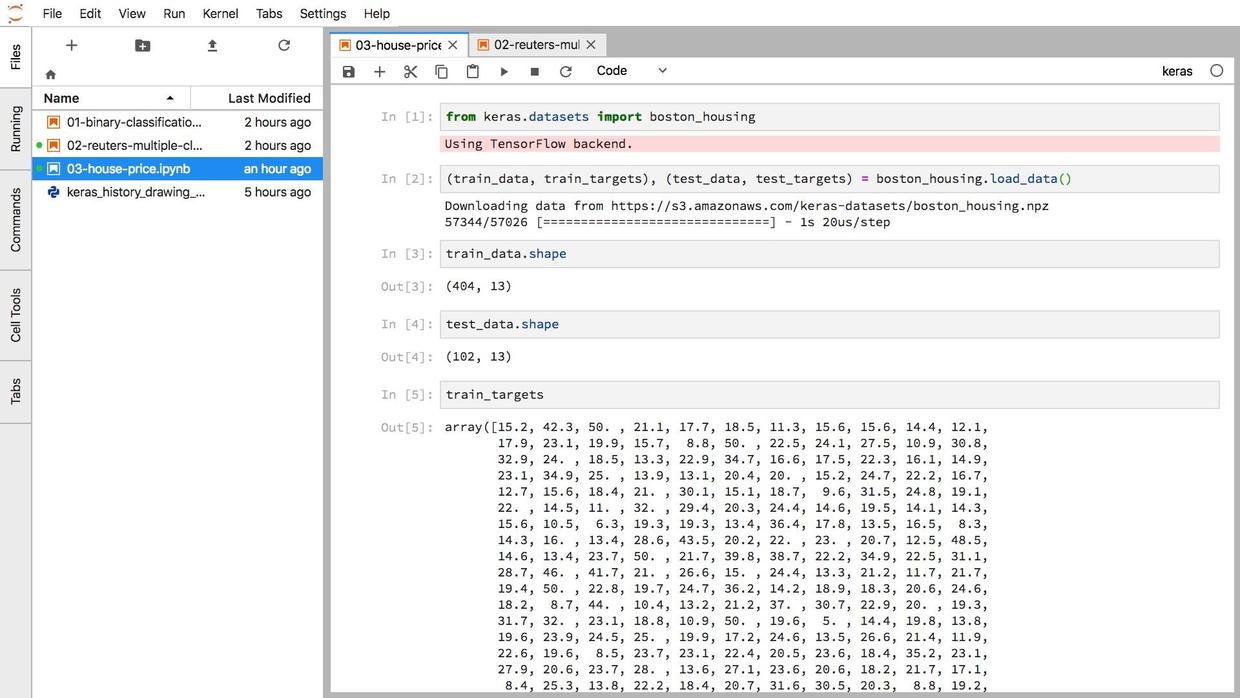
这是来自于 “Deep Learning with Python” 书上的一个例子。

运行的时候,代码有两个大循环。
第一个把数据跑100遍(epochs),第二个把数据跑500遍。
我的笔记本电脑算起来很吃力,风扇一直在响。
大热天的,看着好可怜。
用笔记本电脑进行机器学习,还是不大合适的。
我要是有一块 GPU 就好了……
此时,突发奇想。
我虽然没有带 nVidia GPU 的设备,不过谁说非要在本地机器运行代码了?
早已是云时代了啊!
能否用云端 GPU 跑机器学习代码,让我的笔记本少花些力气呢?
8.2.2 偶遇
有这个想法,是因为最近在 Youtube 上面,我看到了 Siraj Raval 的一段新视频。
这段视频里,他推荐了云端 GPU 提供平台 FloydHub。

我曾经试过 AWS GPU 产品。
那是在一门深度学习网课上。
授课老师跟 AWS 合作,为全体学生免费提供若干小时的 AWS 计算能力,以便大家顺利完成练习和作业。
我记得那么清楚,是因为光如何配置 AWS ,他就专门录了数十分钟的视频。
AWS 虽然已经够简单,但是对于新手来说,还是有些门槛。
FloydHub 这个网站,刚好能解决用户痛点。
首先它能够包裹 AWS ,把一切复杂的选择都过滤掉。
其次它内置了几乎全部主流深度学习框架,自带电池,开箱即用;
另外,它提供了丰富而简明的文档,用户可以快速上手。
正如它的主页宣称的:
Focus on what matters. Let FloydHub handle the grunt work.
翻译过来就是:
关注你想做的事儿。脏活累活,扔给 FloydHub 吧。
凡是设计给懒人用的东西,我都喜欢。
我于是立即注册了账户,并且做了邮件验证。
之后,我免费获得了2个小时的 GPU 时间,可以自由尝试运行机器学习任务。
为了能把珍贵的 GPU 运算时间花在刀刃上,我认真地阅读了快速上手教程。
几分钟后,我确信自己学会了使用方法。
8.2.3 尝试
首先,我到 FloydHub 的个人控制面板上,新建了一个任务,起名叫做 “try-keras-boston-house-regression”。
然后,我在本地的 Jupyter Notebook 里,把代码导出为 Python 脚本文件,如下图所示。
我新建了一个目录,把脚本文件拷贝了进来。
这个 Python 脚本,我仅仅在最后加了3行代码:
加入这几行代码,是因为我们需要记录运行中的一些数据(即 all_scores 和 all_mae_histories)。
然后,进入终端,利用 cd 命令,进入到这个文件夹。
执行:
pip install floyd-cli这样,本地的 FloydHub 命令行工具就安装好了。
执行下面命令登录进去:
floyd login系统会提示你,输入 FloydHub 上的账号信息。
输入正确后,执行:
floyd init try-keras-boston-house-regression注意这个名称,必须和刚才在控制面板新建的任务名称一致。
配置都完成了,下面直接运行就可以了。
输入:
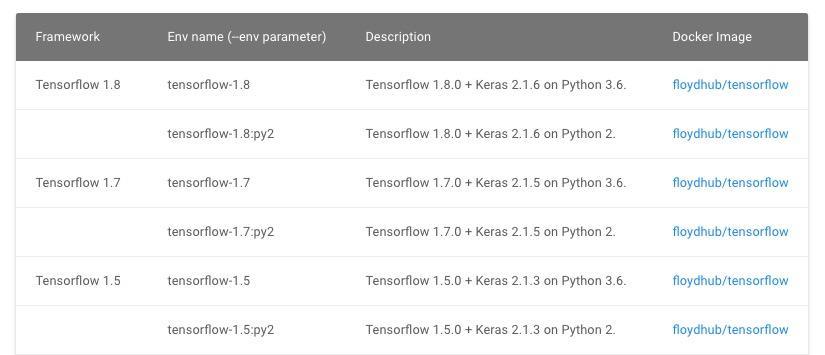
floyd run --gpu --env tensorflow-1.8 "python 03-house-price.py"这句话的意思是:
- 使用 GPU 计算;
- 运行环境选用 Tensorflow 1.8 版本,及对应的 Keras (2.1.6)。
如果你希望使用其他深度学习框架或版本,可以参考这个链接。
FloydHub 对我们的命令,是这样回应的:
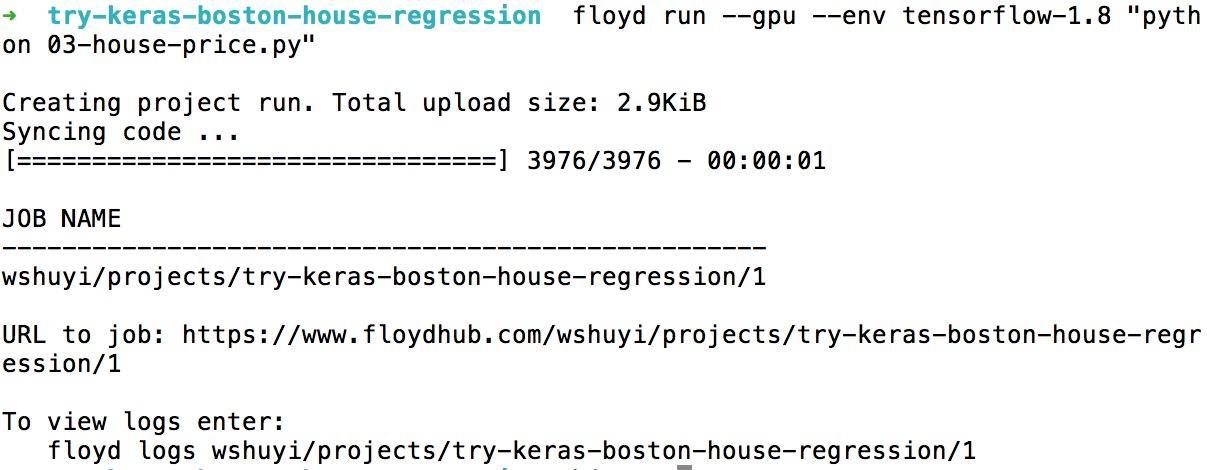
操作结束?
对,就这么简单。
你的任务,已在云端运行了。
8.2.4 结果
然后,我就忙自己的事儿去了。
喝茶,看书,还扫了几眼微信订阅号。
虽然是按时计费,但你不用因为怕多算钱,就死死盯住云端运行过程。
一旦任务结束,它自己会退出运行,不会多扣你一分钟珍贵的 GPU 运行时间。
等我回到电脑前面,发现任务已完成。
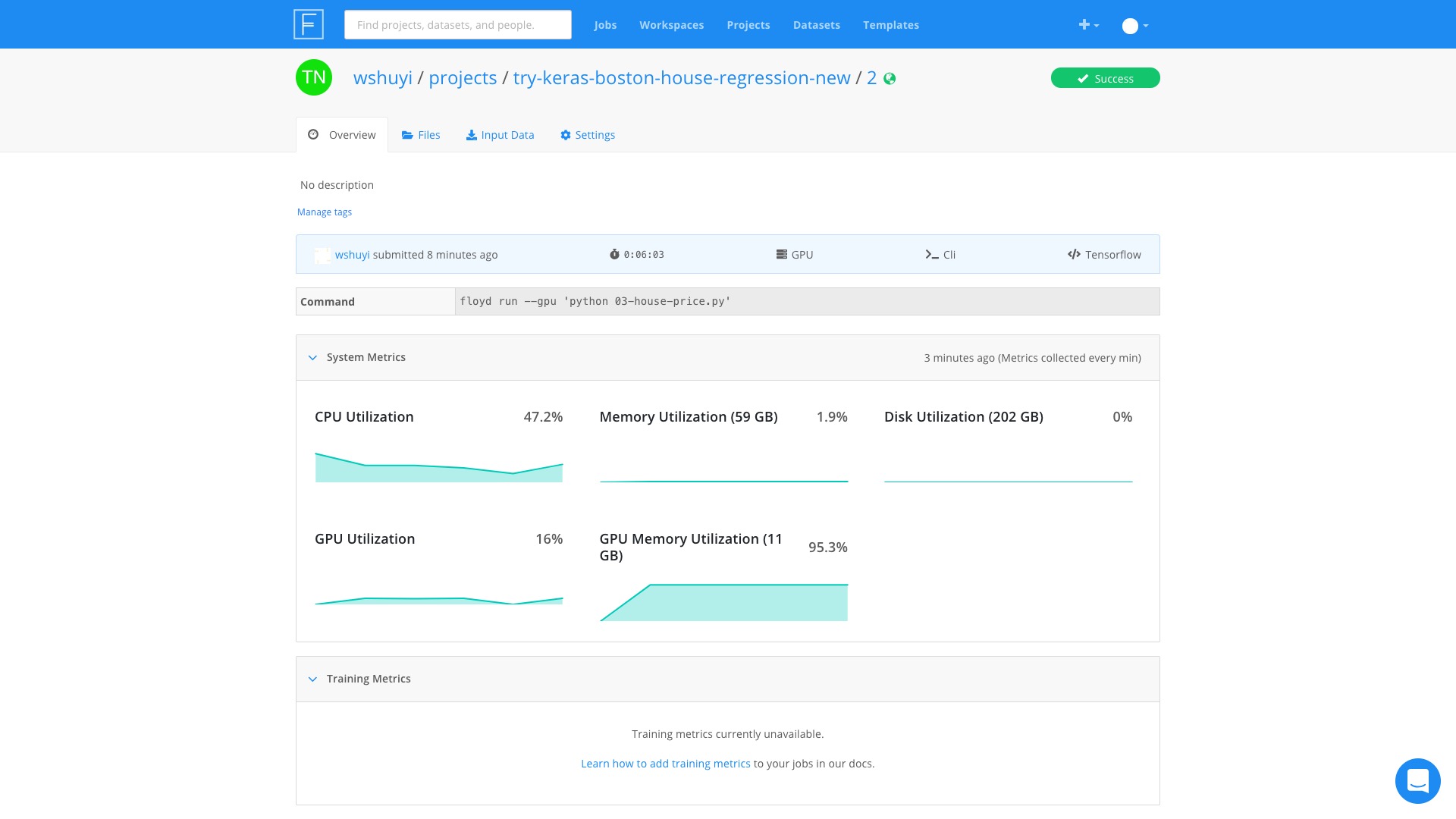
整个儿过程中,GPU 内存着实够忙碌的(占用率一直超过90%)。
不过 GPU 好像很清闲的样子,一直在百分之十几晃悠。
看来,我们的神经网络,层数还是太少了,结构不够复杂。
GPU 跑起来,很不过瘾。
往下翻页,看看输出的结果。
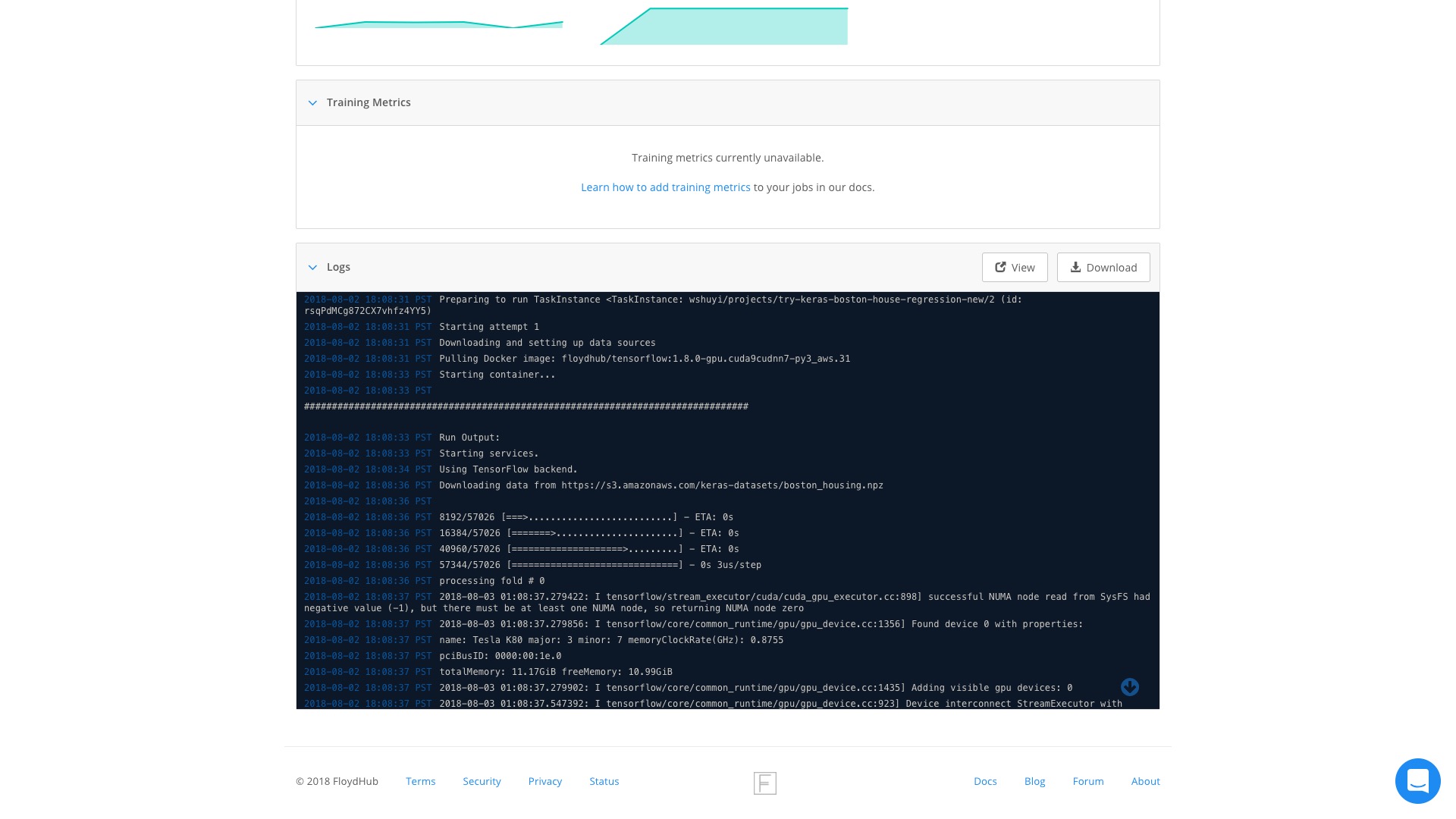
程序的输出,包括 GPU 资源创建、调用的一些记录,这里都有。
打开 Files 标签页,咱们看看结果。
之前追加3行代码,生成的 pickle 记录文件,就在这里了。
看来,FloydHub 确实帮我们完成了繁复的计算过程。
我的笔记本电脑,一直凉凉快快,等着摘取胜利果实。
选择下载,把这个 pickle 文件下载到本地。跟我们的 Jupyter Notebook 放在一个目录下。
回到 Jupyter Lab 运行界面。
新开一个 ipynb 文件。
我们输入以下代码,查看运行记录是否符合我们的需要。
import pickle
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
with open('data.pickle', 'rb') as f:
[all_scores, all_mae_histories] = pickle.load(f)
num_epochs = 500
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)
]
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()这些代码,只是为了绘图,本身没有任何复杂运算。
这是运行结果:
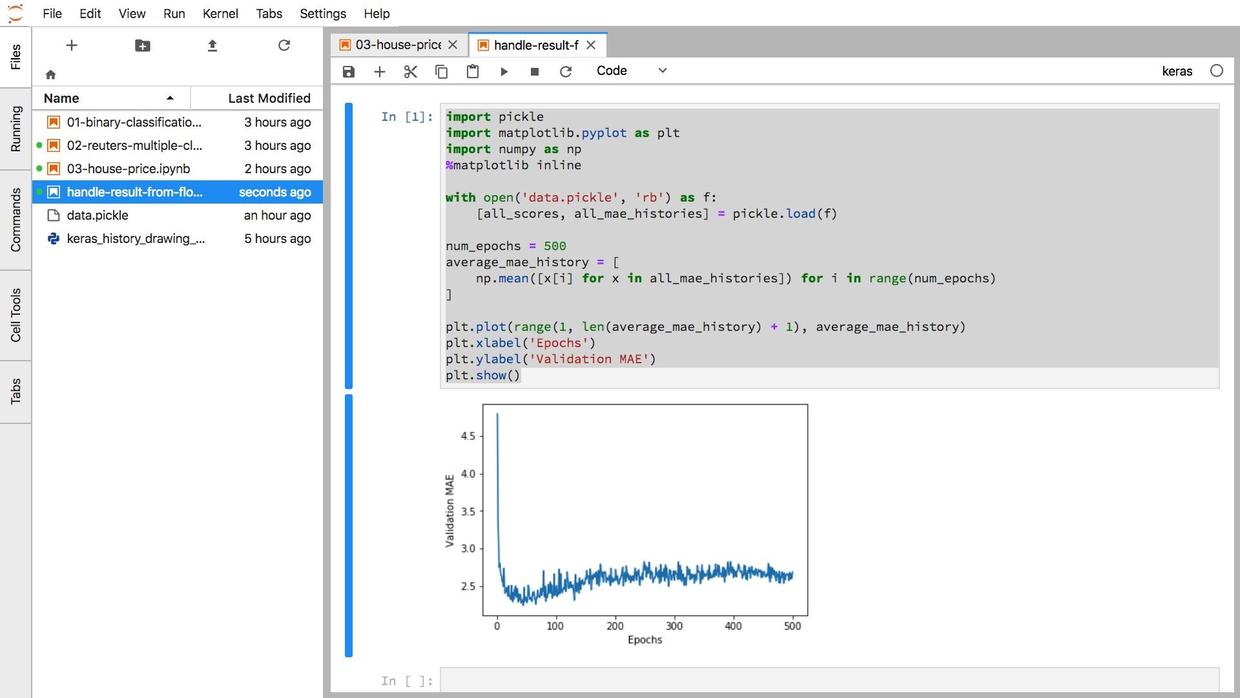
可视化结果与书上的一致。
证明机器学习代码在云端运行过程一切顺利。
我们还可以查看剩余的可用免费时长。
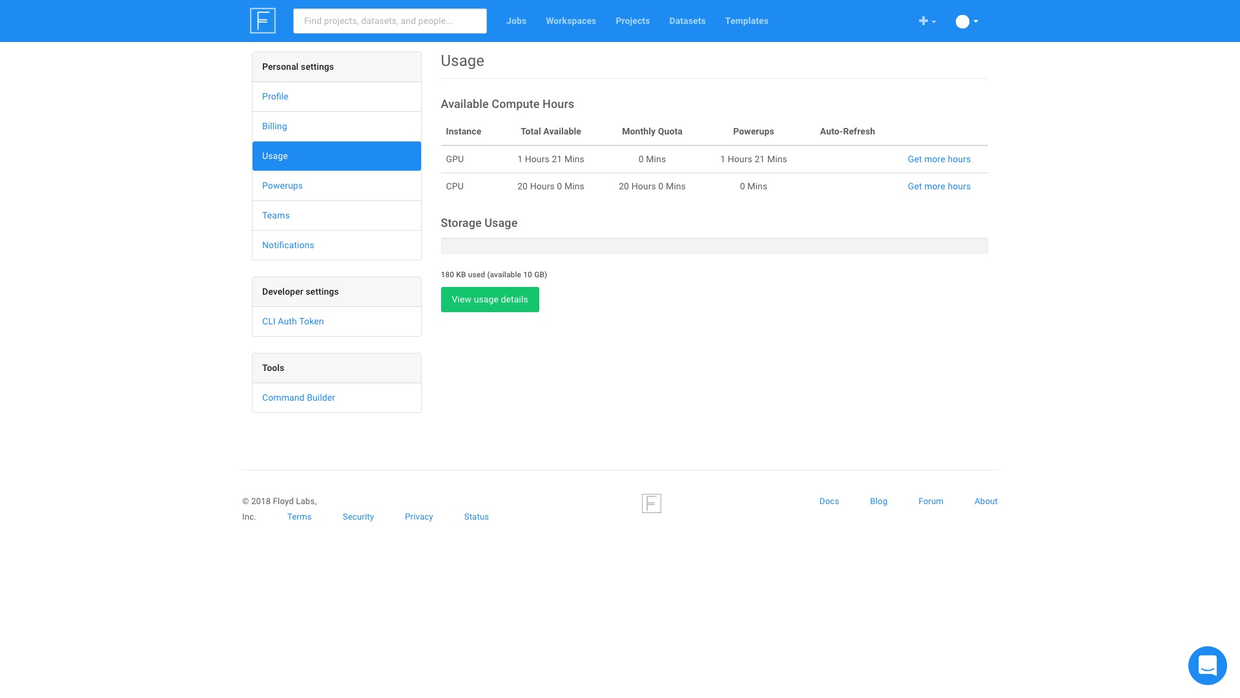
嗯,还剩下1个多小时 GPU 运算时间呢,回头接着玩儿。
8.2.5 Workspace
刚才咱们展示的,是命令行下的使用方法。如果你对于命令行操作很熟悉,建议你使用这种方式。因为控制感更强一些。
但是对于初学者,我推荐你使用另外一种更为简便的方法。
在主页点击上方的 Workspace 标签。
你会看到已有的2个样例 Workspace 。
尝试打开其中第一个,看看内容。
点击右上方的 Resume 绿色按钮,你会看到系统在认真地为我们准备环境。
准备工作结束后,你会看到出现了熟悉的 Jupyter lab 界面。
双击左侧文件区域的 dog-breed-classification.ipynb ,打开。
这里是个猫狗分辨的完整样例。
咱们执行一下。方式是执行菜单栏里面的 Run -> Restart Kernel and Run All Cells:
你会发现,跟在本地执行起来,没有什么区别。
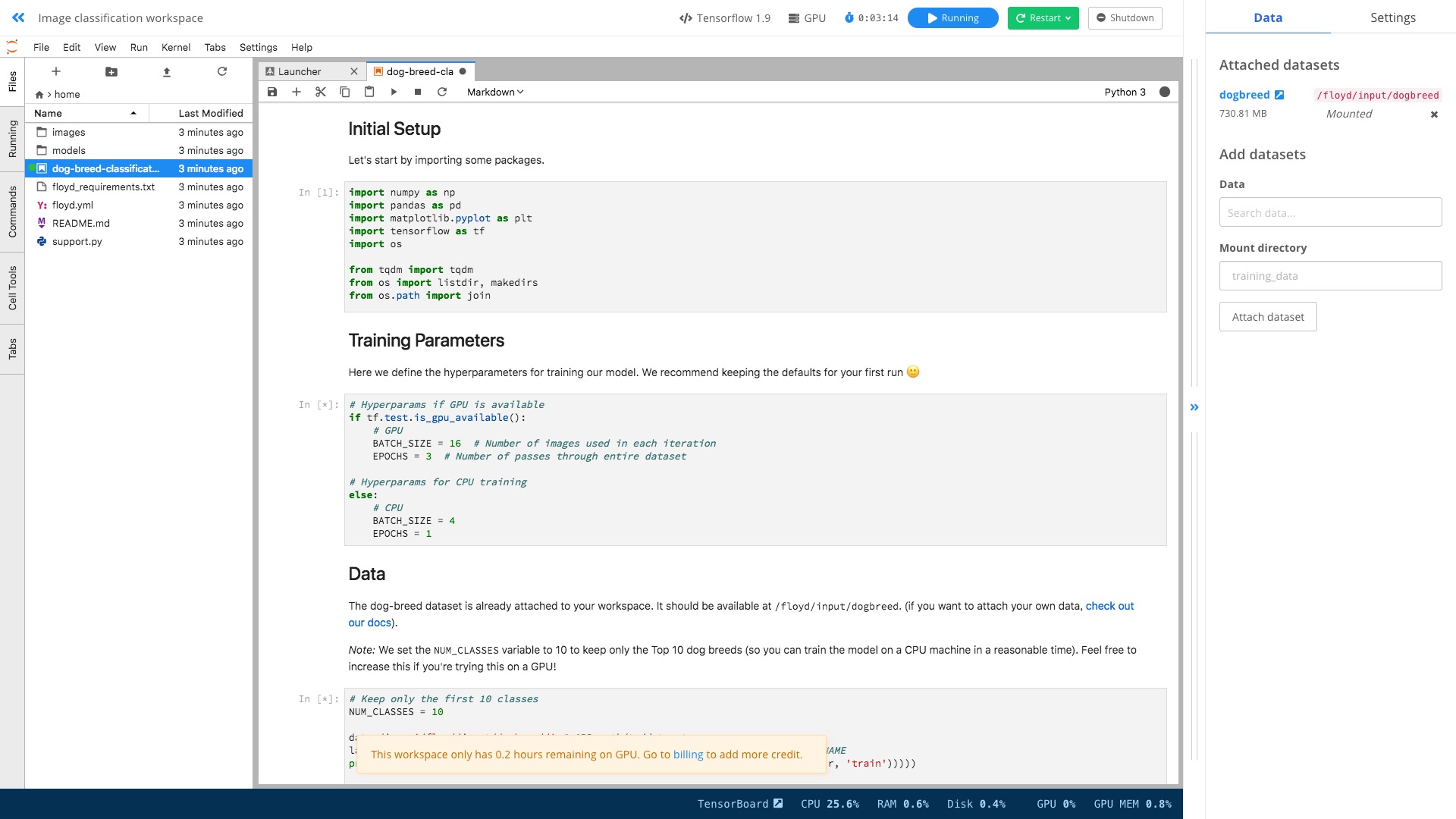
唯一的差别,是你在用 GPU 加速哦!
如果想建立自己的 Workspace ,该怎么办呢?
很简单,回到咱们的 Project 页面下,本例是这个链接。
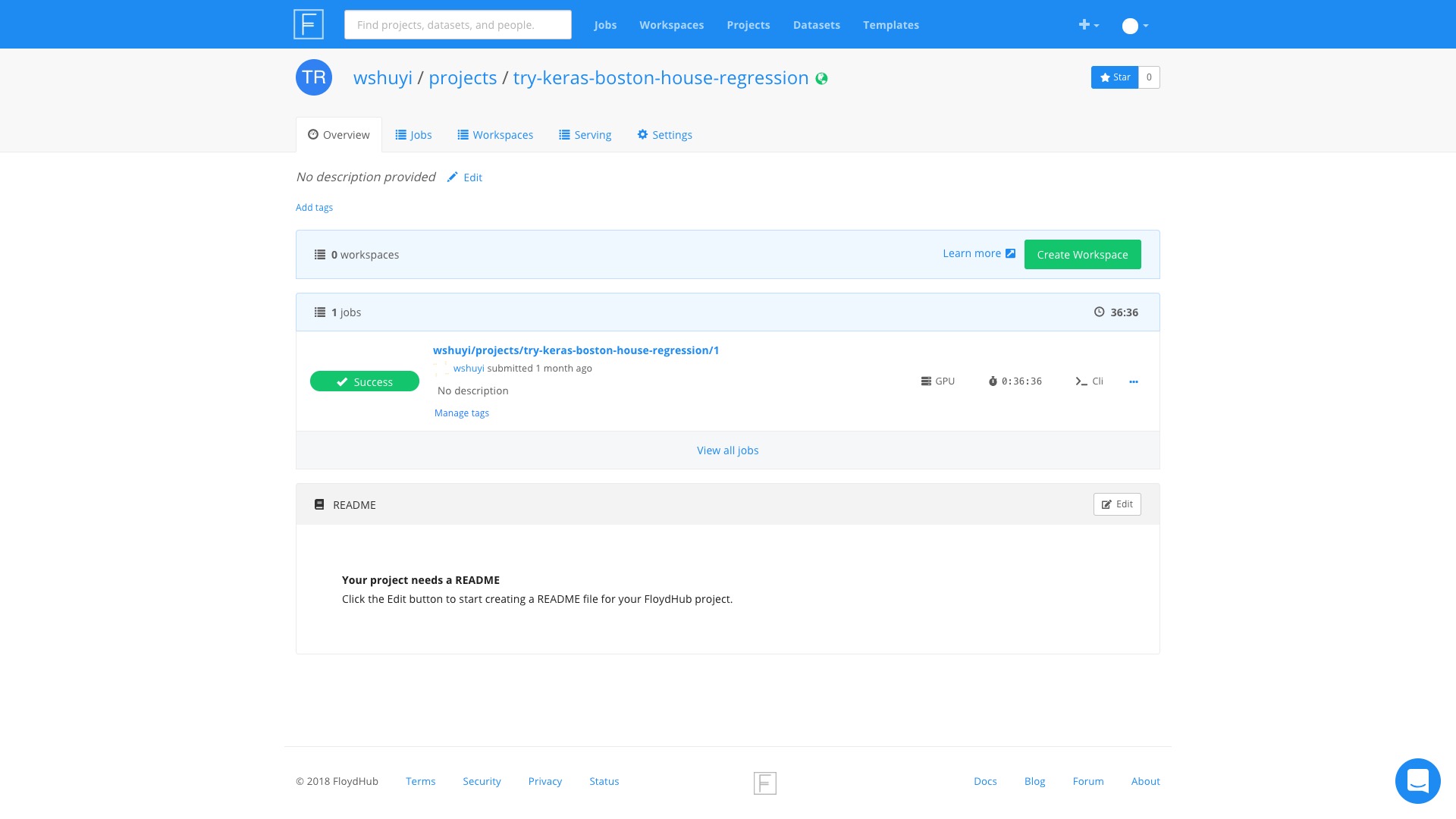
你会看到,每个项目下,都可以使用 Create Workspace 这个按钮创建新的 Workspace 。
Floydhub 会询问你,使用哪种方式建立新的 Workspace 。
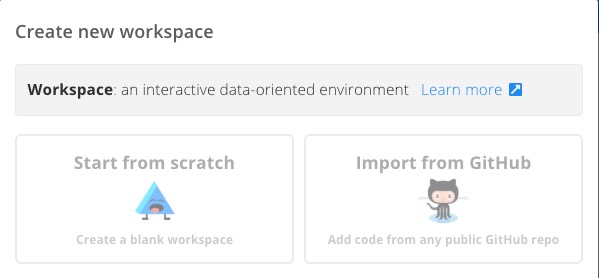
这里咱们选择左侧的 Start from scratch 。
下面选择使用的环境。
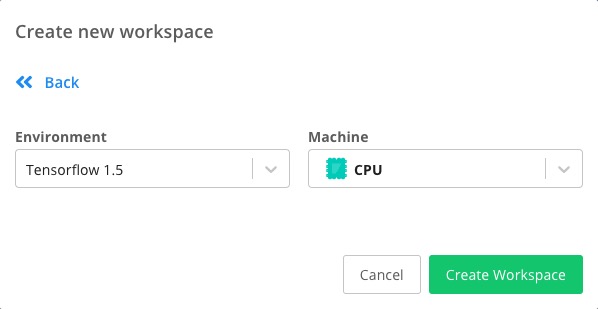
我们将其改成 Tensorflow 1.9 和 GPU 环境。
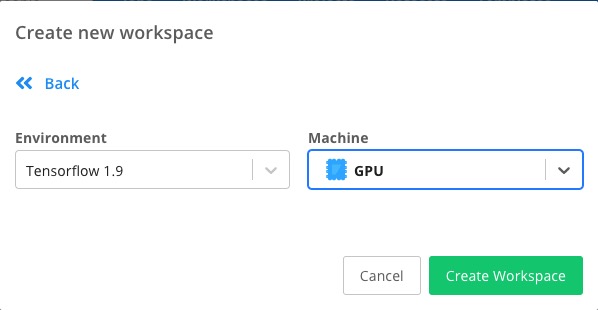
点击 Create Workspace 按钮,就创建完毕了。
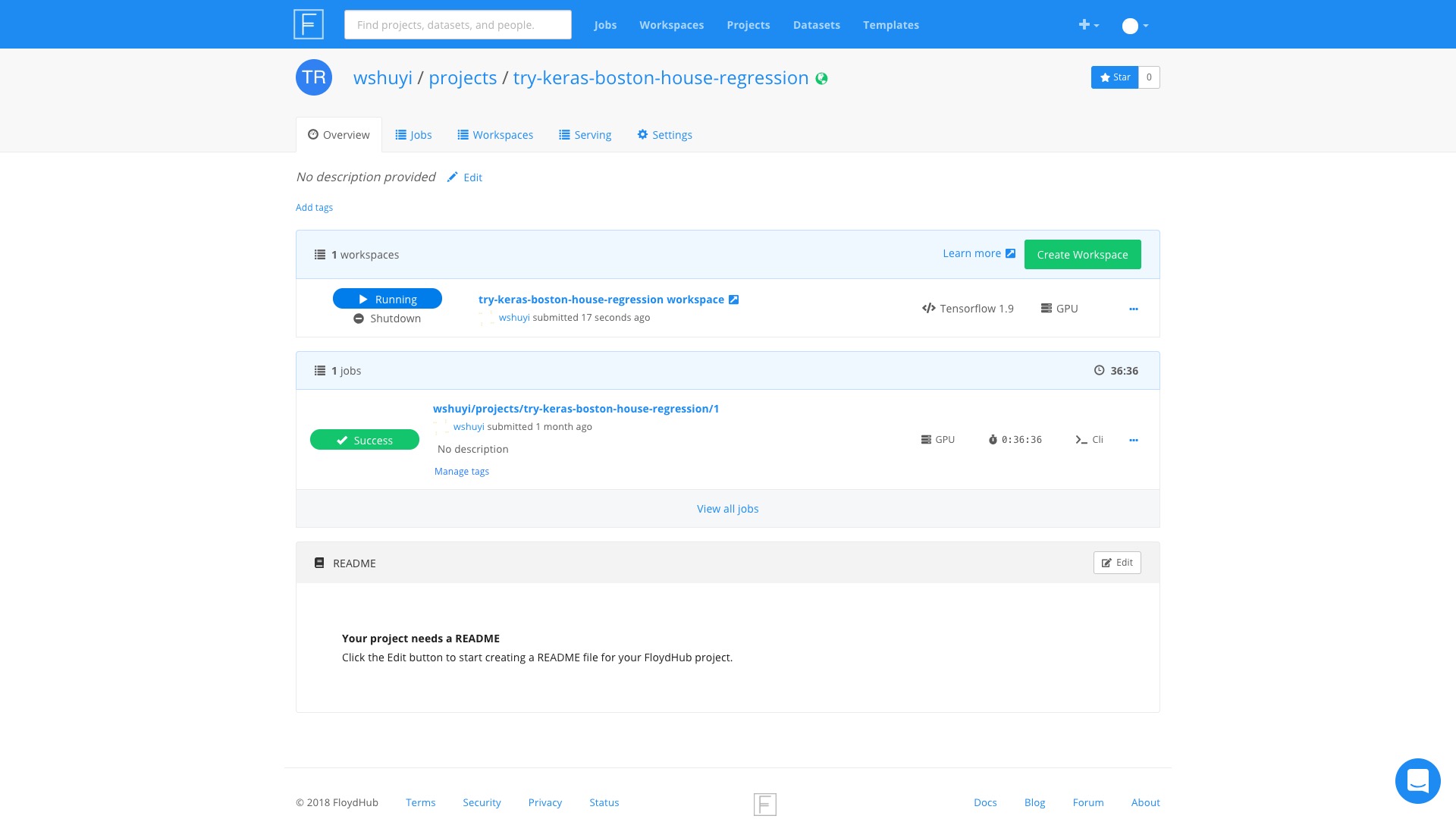
点击 try-keras-boston-house-regression workspace 这个链接。
我们就可以看到,一个 Jupyter Lab 界面为我们准备好了。
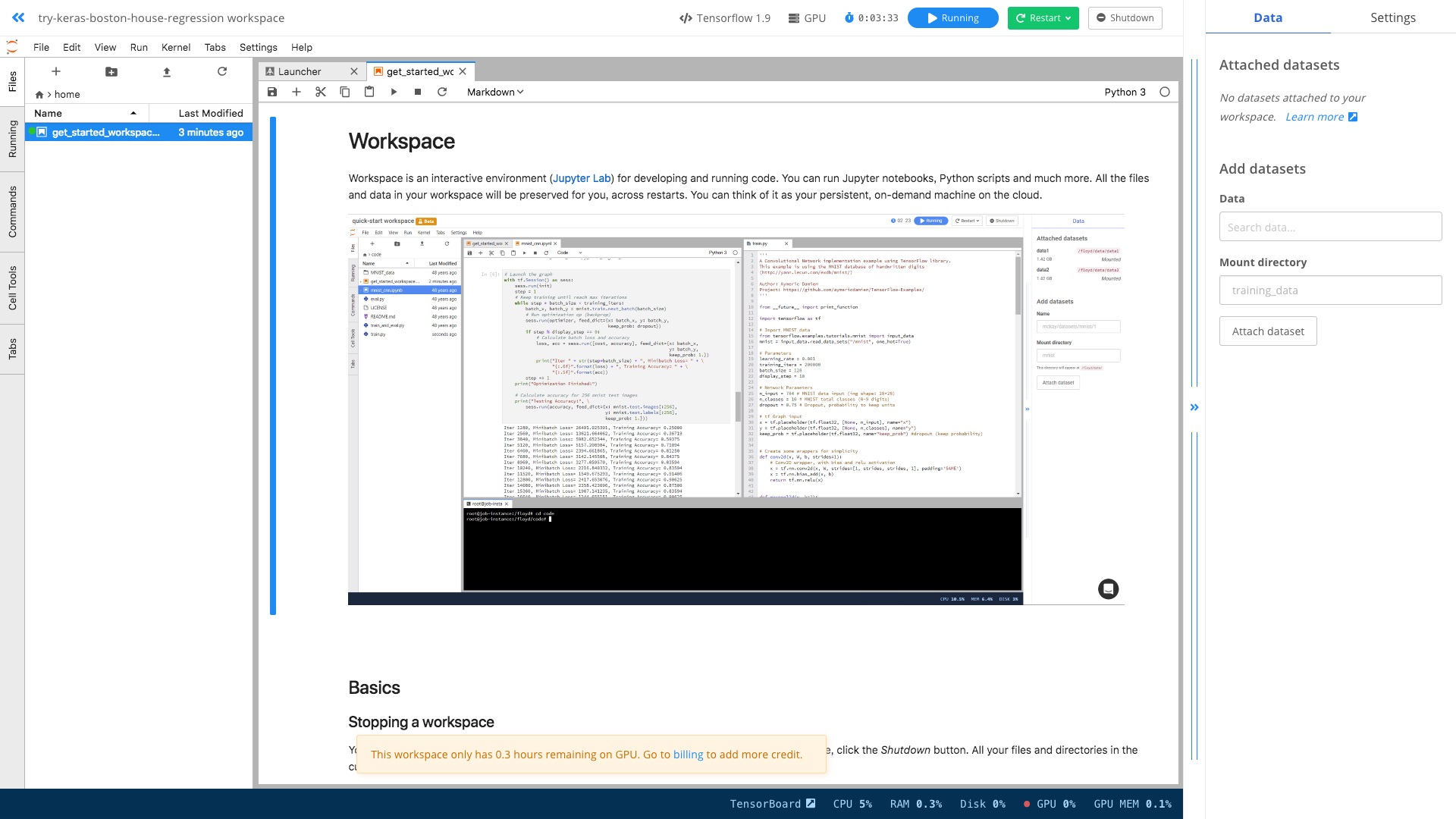
这个环境里面,Tensorflow 和 GPU 的配置都是现成的。
你不用去考虑如何执行 CLI 命令,只需要在其中像平时一样输入 Python 代码,调用 Keras 与 Tensorflow 命令就可以了。
是不是更方便呢?
利用 Floydhub ,开始你的深度学习之旅吧。
8.2.6 小结
做深度学习任务,不一定非得自己购置设备。主要看具体需求。
假如你不需要全天候运行深度学习代码,只是偶尔才遇到计算开销大的任务,这种云端 GPU ,是更为合适的。
你花钱买了深度学习硬件设备,就只有贬值的可能。而且如果利用率低,也是资源浪费。
而同样的租赁价格,你可以获得的计算能力,却是越来越强的。
这就是摩尔定律的威力吧。
8.3 如何在 GPU 深度学习云服务里,使用自己的数据集?

本文为你介绍,如何在 GPU 深度学习云服务里,上传和使用自己的数据集。
8.3.1 疑问
《如何用云端 GPU 为你的 Python 深度学习加速?》(8.2)一文里,我为你介绍了深度学习环境服务 FloydHub 。
文章发布后,有读者在后台提出来两个问题:
- 我没有外币信用卡,免费时长用完后,无法续费。请问有没有类似的国内服务?
- 我想使用自己的数据集进行训练,该怎么做?
第一个问题,有读者替我解答了。
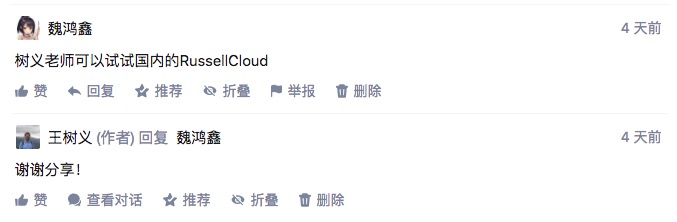
我看了一下,这里的 Russell Cloud ,确实是一款跟 FloydHub 类似的 GPU 深度学习云服务。
可是感谢之后,我才发现原来他是 Russell Cloud 的开发人员。
于是这几天,使用中一遇到问题,我就直接找他答疑了。
因为有这种绿色通道,响应一直非常迅速。用户体验很好。
这款国内服务的优势,有以下几点:
首先是可以支付宝与微信付款,无需 Visa 或者 Mastercard 信用卡,很方便;
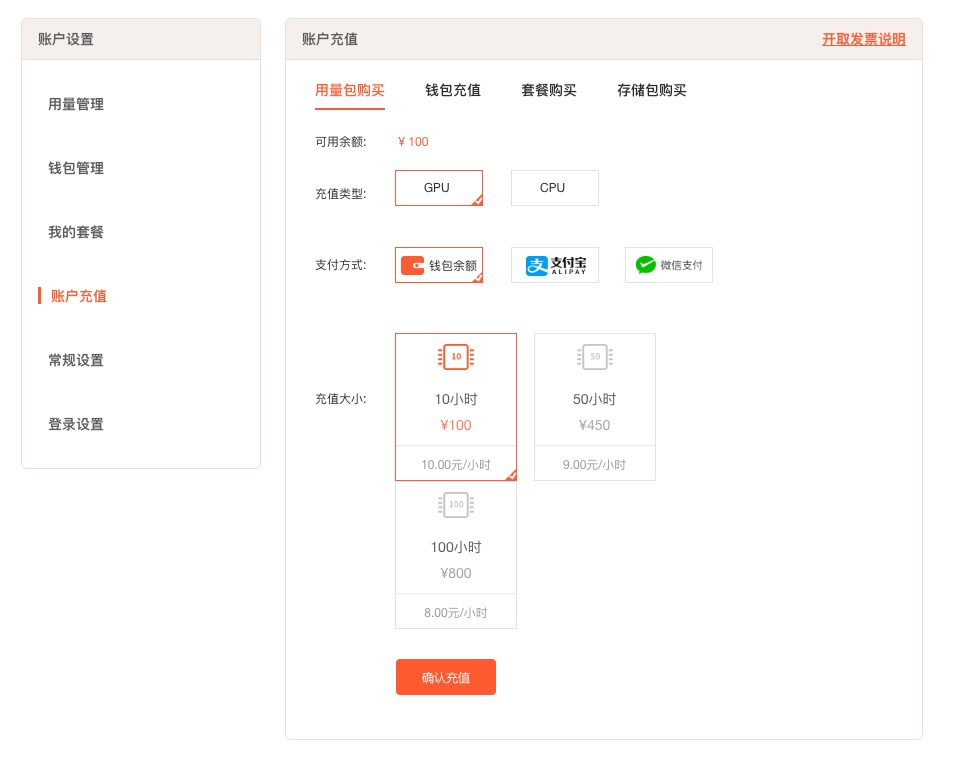
其次是 Russell Cloud 基于阿里云,访问速度比较快,而且连接稳定。在上传下载较大规模数据的时候,优势比较明显。与之相比,FloydHub 上传500MB左右数据的时候,发生了两次中断。
第三是文档全部用中文撰写,答疑也用中文进行。对英语不好的同学,更友好。
第四是开发团队做了微创新。例如可以在微信小程序里面随时查看运行结果,以及查询剩余时长信息。

解决了第一个问题后,我用 Russell Cloud 为你演示,如何上传你自己的数据集,并且进行深度学习训练。
8.3.2 注册
使用之前,请你先到 Russell Cloud 上注册一个免费账号。
因为都是中文界面,具体步骤我就不赘述了。
注册成功后,你就拥有了1个小时的免费 GPU 使用时长。
如果你用我的邀请链接注册,可以多获得4个小时免费 GPU 使用时间。
我手里只有这5个可用的邀请链接。你如果需要,可以直接输入。
看谁手快吧。
注册之后,进入控制台,你可以看到自己的相关信息。
其中有个 Token 栏目,是你的登录信息。下面我给你讲讲怎么用。
你需要下载命令行工具,方法是进入终端,执行:
然后你需要登录:
这时候根据提示,把刚才的 Token 输入进去,登录就完成了。
与 FloydHub 不同,大多数情况下 Russell Cloud 的身份与项目验证,用的都是这种 Token 的方式。
如果你对终端命令行操作还不是很熟悉,欢迎参考我的《如何安装Python运行环境Anaconda?(视频教程)》(2.2),里面有终端基本功能详细执行步骤的视频讲解。
8.3.3 环境
下文用到的数据和执行脚本,我都已经放到了这个 gitlab 链接。
你可以直接点击这里下载压缩包,之后解压。
解压后的目录里,包含两个子文件夹。
cats_dogs_small_vgg16 包含我们的运行脚本。只有一个文件。
它的使用方法,我们后面会介绍。
先说说,你最关心的数据集上传问题。
8.3.4 数据
解压后目录中的另一个文件夹,cats_and_dogs_small,就包含了我们要使用和上传的数据集。
如上图所示,图像数据被分成了3类。
这也是 Keras 默认使用的图像数据分类标准规范。
打开训练集合 train ,下面包含两个目录,分别是“猫”和“狗”。
当你使用 Keras 的图片处理工具时,拥有这样的目录结构,你就可以直接调用 ImageDataGenerator 下的flow_from_directory 功能,把目录里的图片数据,直接转化成为模型可以利用的张量(tensor)。
打开 test 和 validation 目录,你会看到的目录结构和 train 相同。
请你先在 Russell Cloud 上建立自己的第一个数据集。
主页上,点击“控制台”按钮。
在“数据集”栏目中选择“创建数据集”。
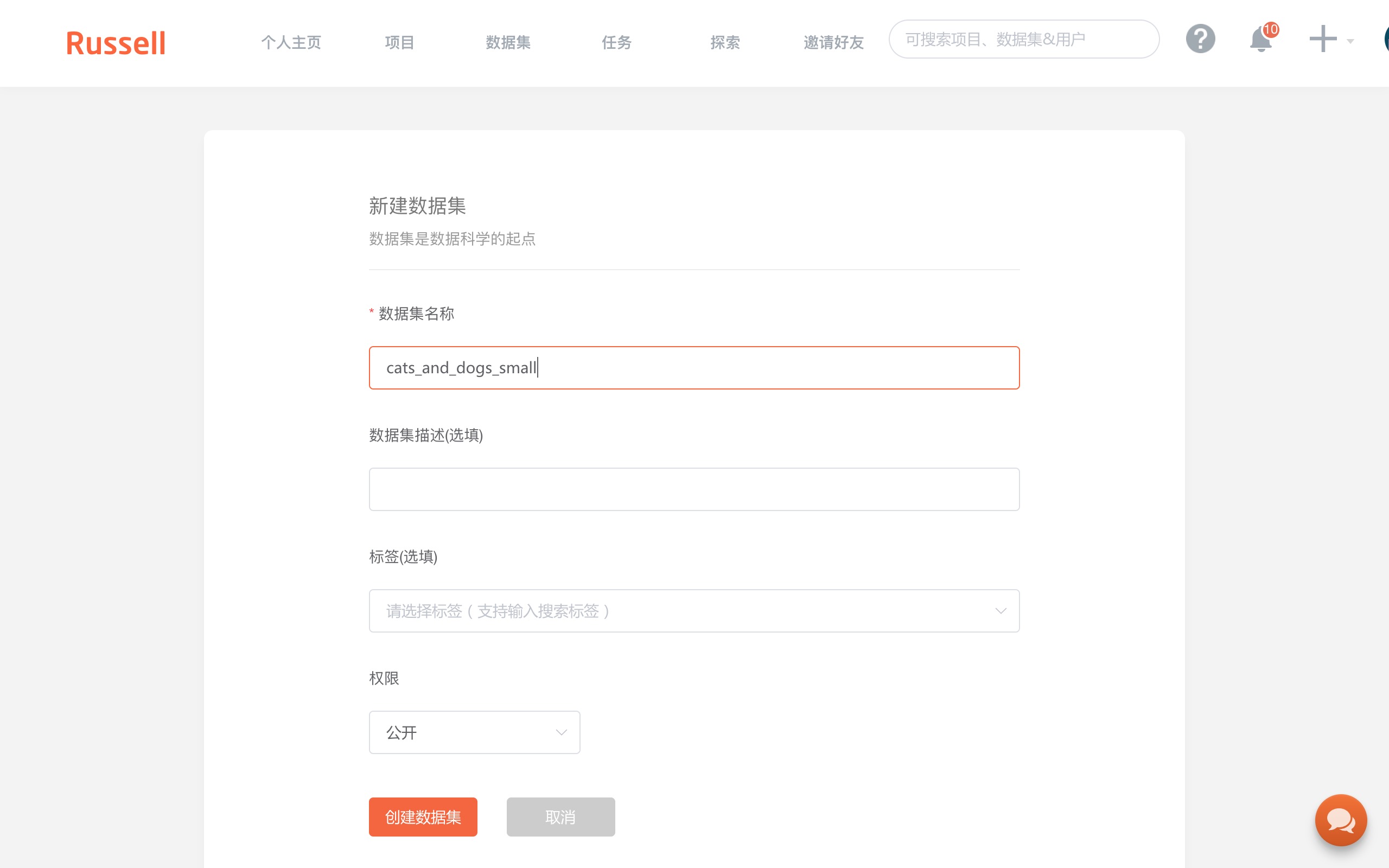
如上图,填写数据集名称为“cats_and_dogs_small”。
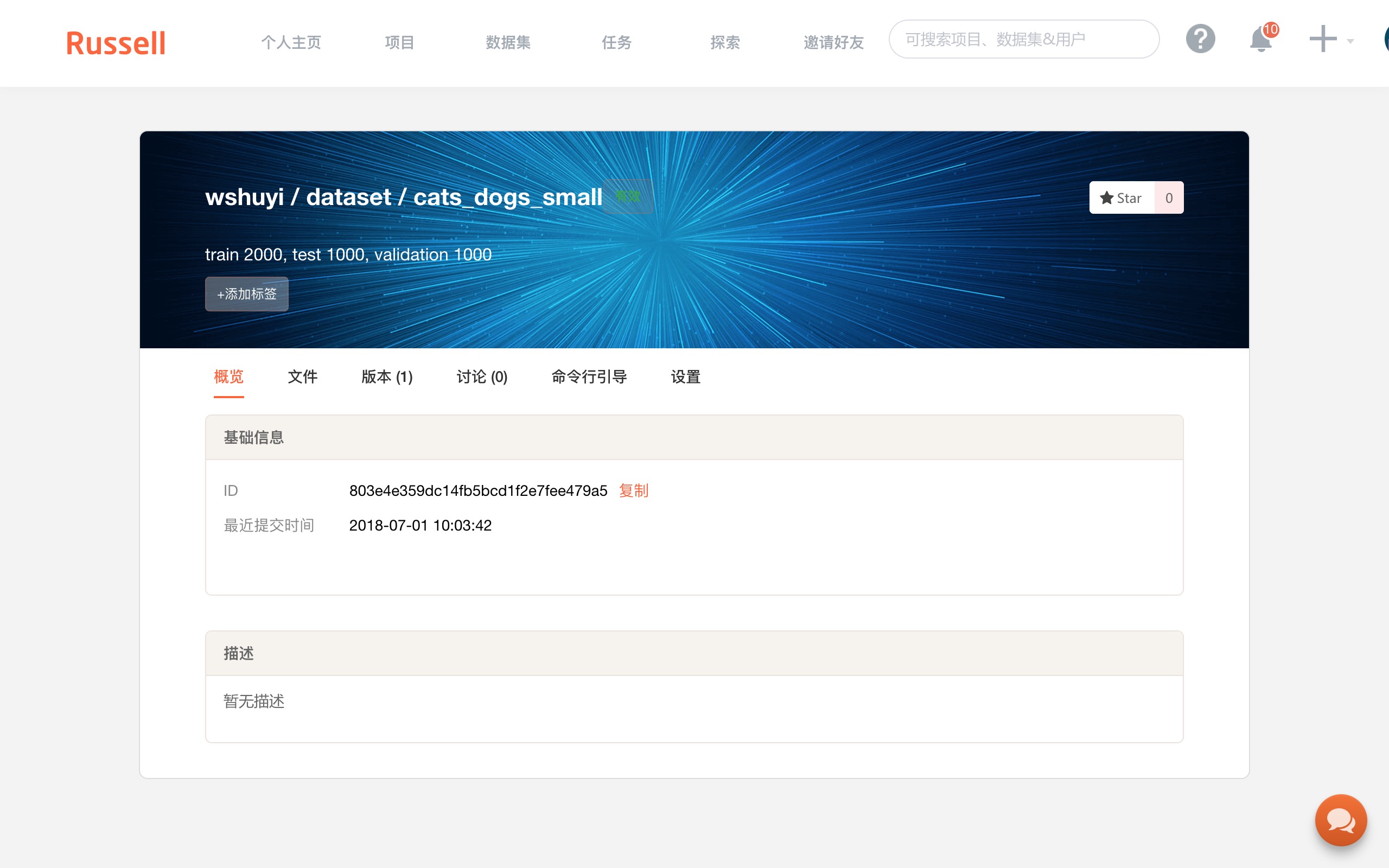
这里会出现数据集的 ID ,我们需要用它,将云端的数据集,跟本地目录连接起来。
回到终端下面,利用 cd 命令进入到解压后文件夹的 cats_and_dogs_small 目录下,执行:
请把上面“你的数据集ID”替换成你真正的数据集ID。
执行这两条命令,数据就被上传到了 Russell Cloud。
上传成功后,回到 Russell Cloud 的数据集页面,你可以看到“版本”标签页下面,出现了1个新生成的版本。
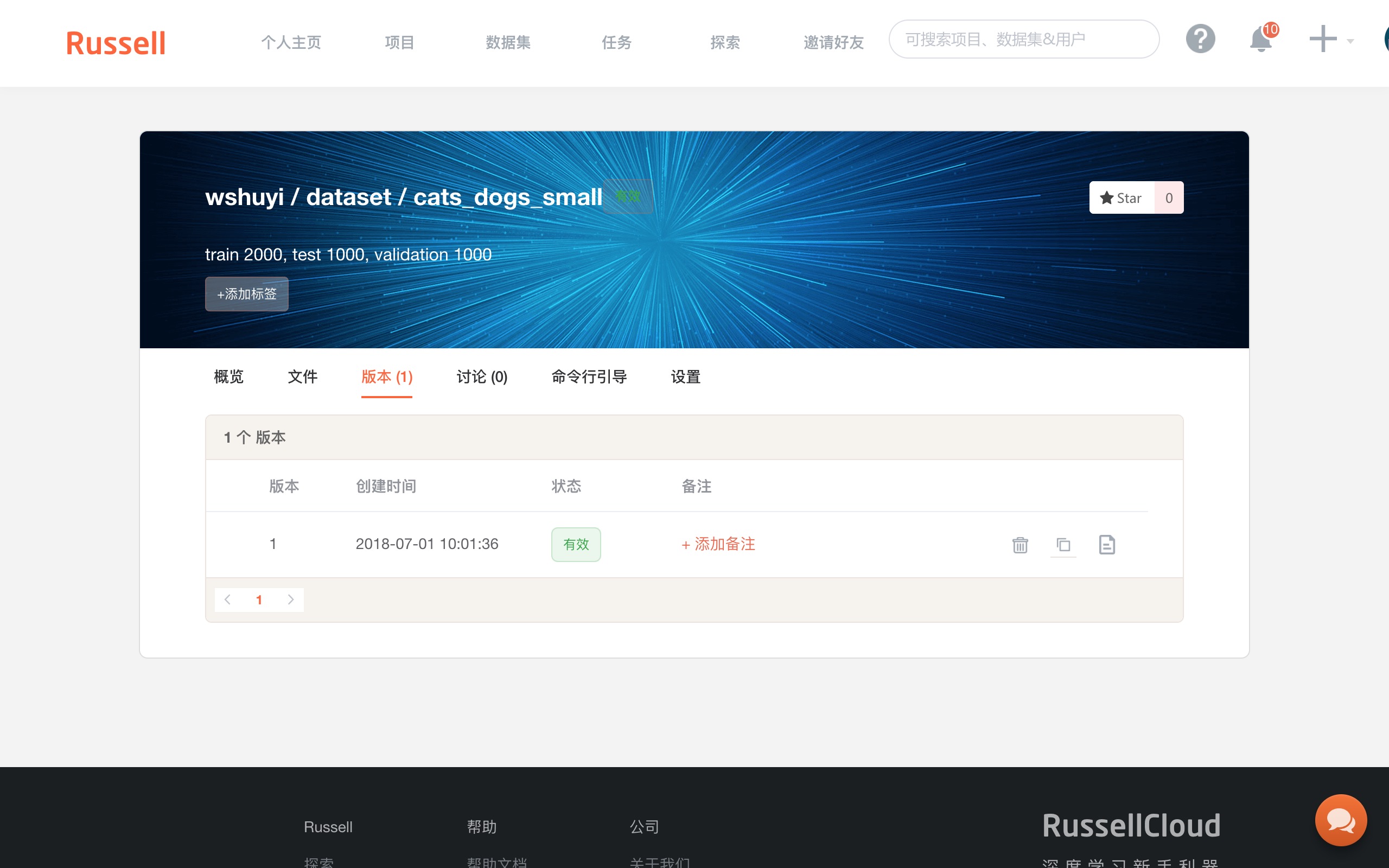
注意上图右侧,有一个“复制”按钮,点击它,复制数据集该版本的 Token 。
一定要注意,是从这里复制信息,而不是数据集首页的 ID 那里。
之前因为搞错了这个事儿,浪费了我很长时间。
8.3.5 运行
要执行你自己的深度学习代码,你需要在 Russell Cloud 上面,新建一个项目。
你得给项目起个名称。
可以直接叫做 cats_dog_small_vgg16。
其他项保持默认即可,点击“创建项目”。
出现下面这个页面,就证明项目新建成功。
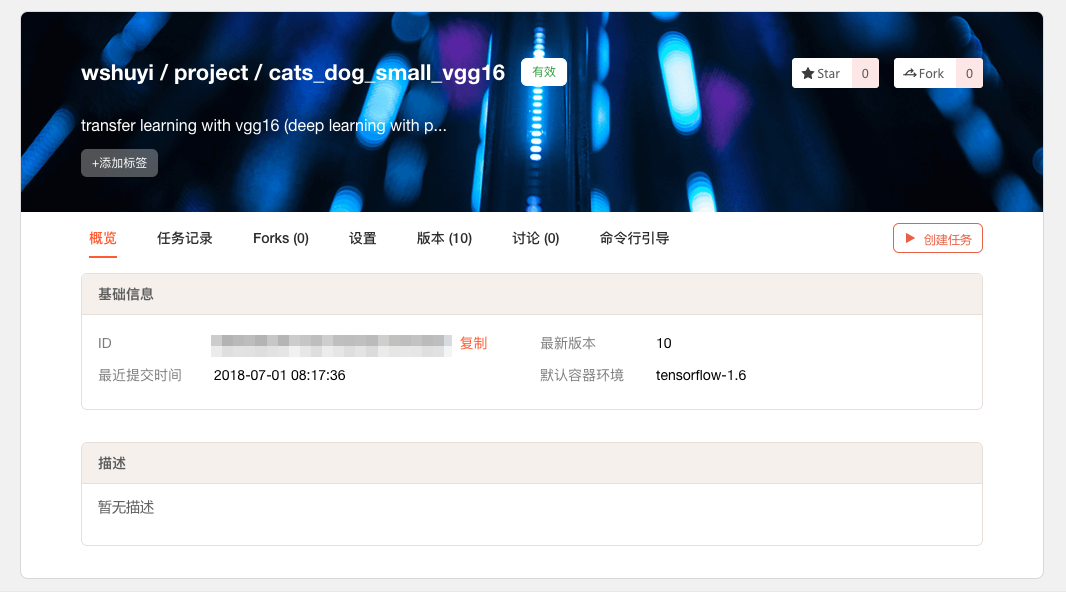
同样,你需要把本地的代码文件夹,和刚刚新建的项目连接起来。
方法是这样的:
复制上图页面的 ID 信息。
回到终端下,利用 cd 命令进入到解压后文件夹的 cats_dogs_small_vgg16 目录下,执行:
这样,你在本地的修改,就可以被 Russell Cloud 记录,并且更新任务运行配置了。
执行下面这条命令,你就可以利用 Russell Cloud 远端的 GPU ,运行卷积神经网络训练脚本了。
解释一下这条命令中的参数:
run后面的引号包括部分,是实际执行的命令;gpu是告诉 Russell Cloud,你选择 GPU 运行环境,而不是 CPU;data后面的数字串(冒号之前),是你刚刚生成的数据集版本的对应标识;冒号后面,是你给这个数据集挂载目录起的名字。假设这里挂载目录名字叫“potato”,那么在代码里面,你的数据集位置就是“/input/potato”;env是集成深度学习库环境名称。我们这里指定的是 Tensorflow 1.4。更多选项,可以参考文档说明。
输入上述命令后, Russell Cloud 就会把你的项目代码同步到云端,然后根据你指定的参数执行代码。
你在本地,是看不到执行结果的。
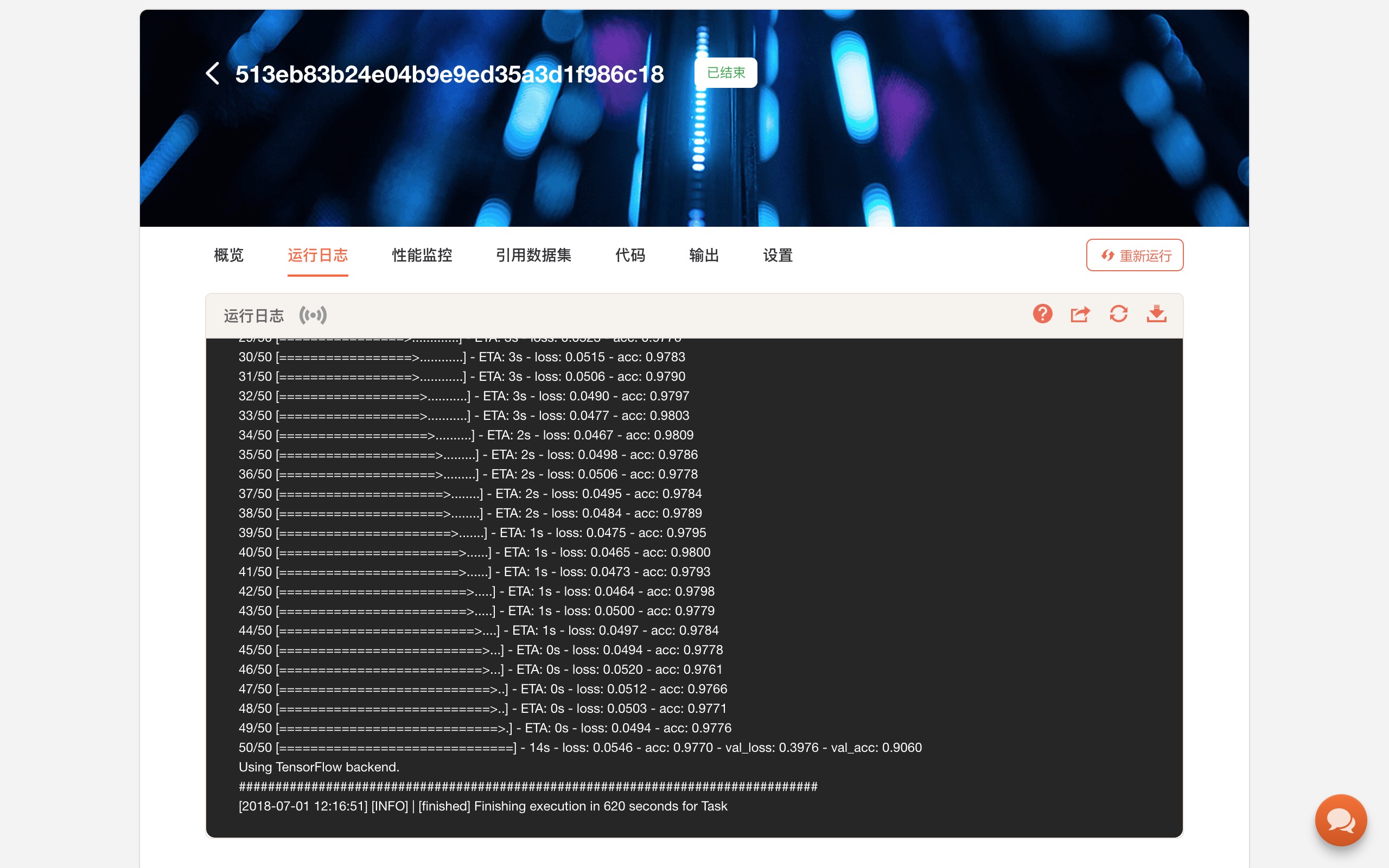
你需要到网页上,查看“任务”下“运行日志”,在系统提供的模拟终端下,查看运行输出结果。
为了把好不容易深度学习获得的结果保存下来,你需要用如下语句保存模型:
history.history 对象里,包含了训练过程中的一些评估数据,例如准确率(acc)和损失值(loss),也需要保存。
这里你可以采用 pickle 来完成:
import pickle
with open(Path(output_dir, 'data.pickle'), 'wb') as f:
pickle.dump(history.history, f)细心的你,一定发现了上述代码中,出现了一个 output_dir, 它的真实路径是 output/。
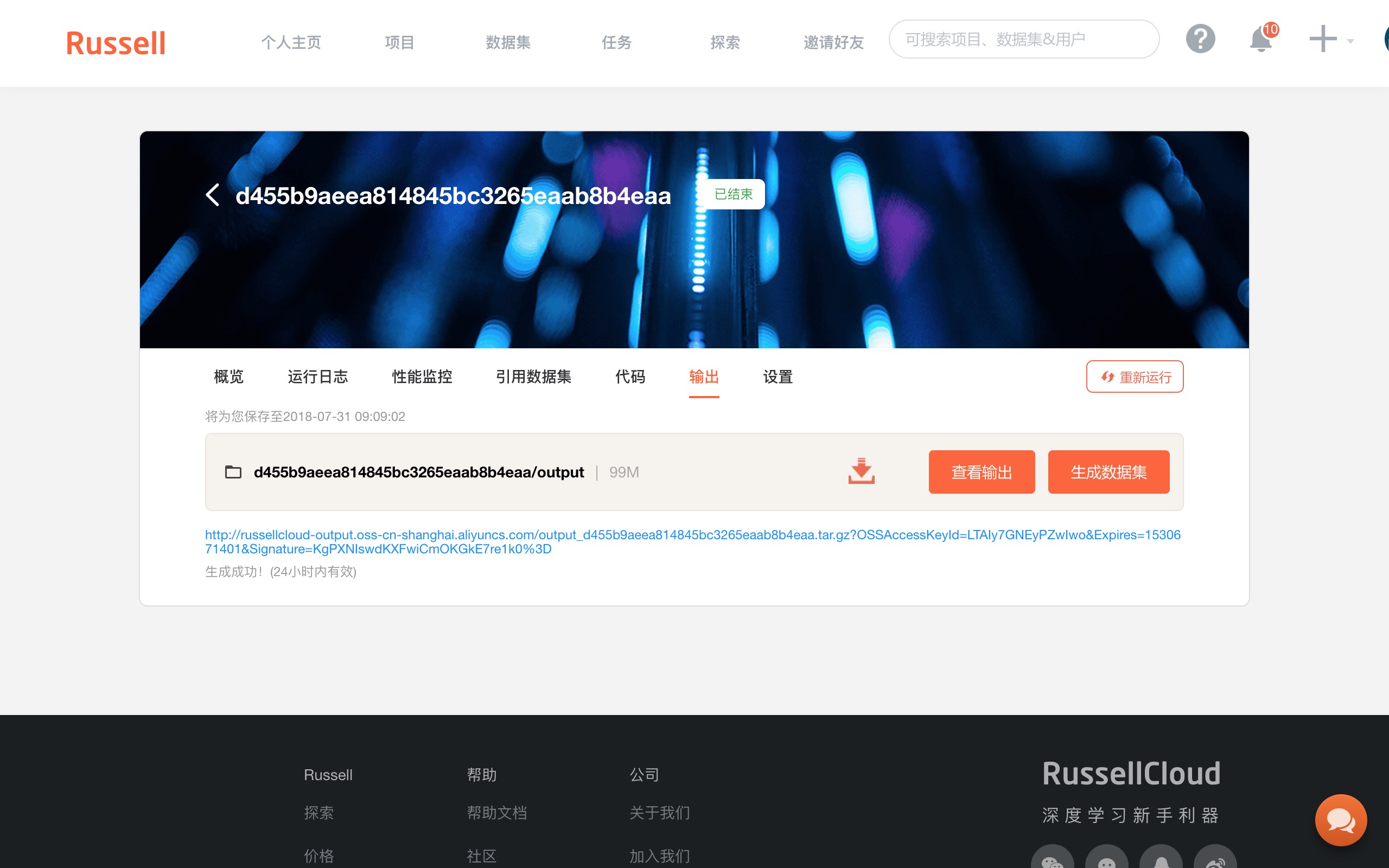
它是 Russell Cloud 为我们提供的默认输出路径。存在这里面的数据,在运行结束后,也会在云端存储空间中保存下来。
你可以在“任务记录”的“输出”项目下看到保存的数据。它们已被保存成为一个压缩包。
下载下来并解压后,你就可以享受云端 GPU 的劳动果实了。
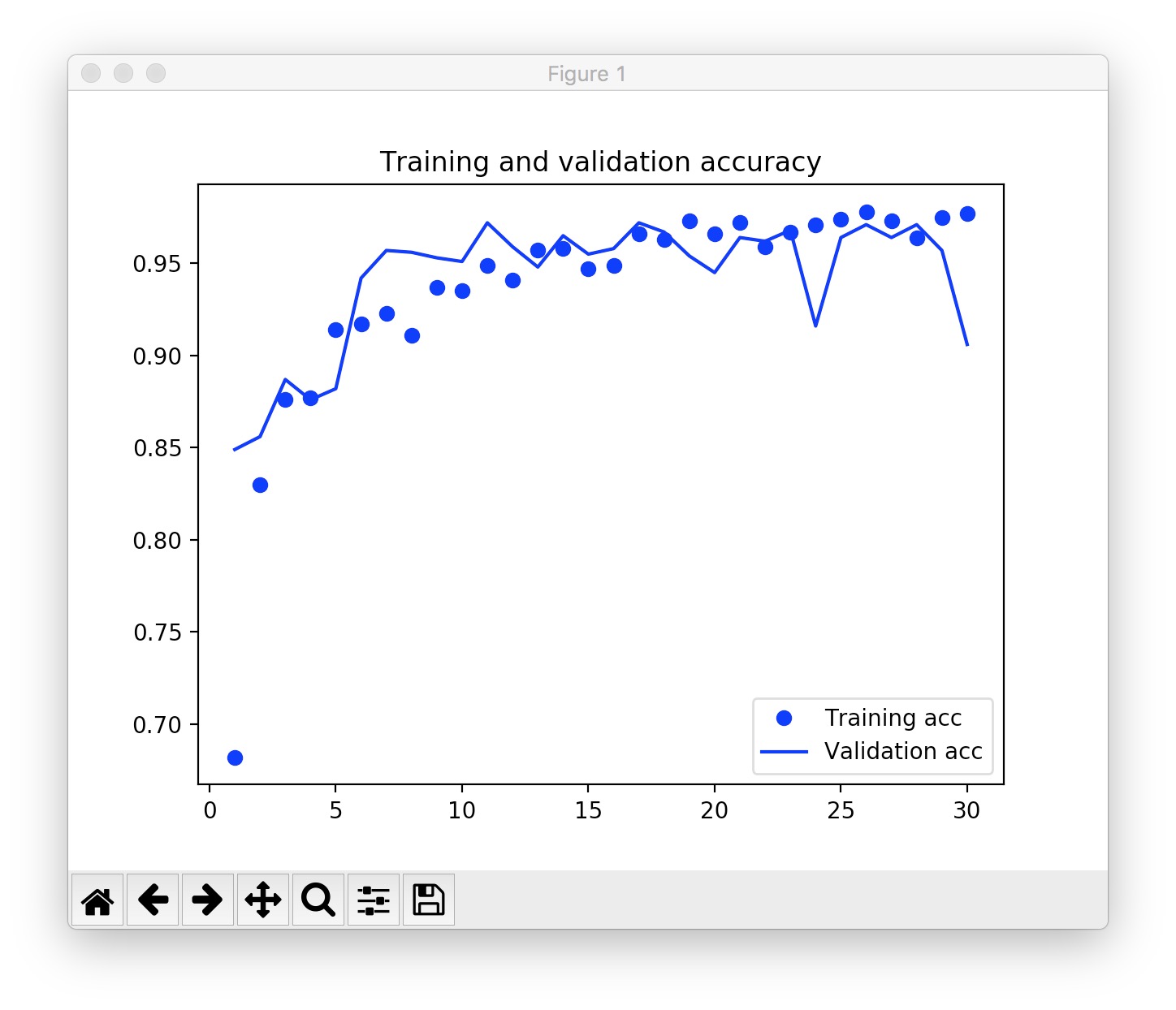
你可以用 history 保存的内容绘图,或者进一步载入训练好的模型,对新的数据做分类。
8.3.6 改进
在实际使用Russell Cloud中,你可能会遇到一些问题。
我这里把自己遇到的问题列出来,以免你踩进我踩过的坑。
首先,深度学习环境版本更新不够及时。
本文写作时 Tensorflow 稳定版本已经是 1.8 版,而 Russell Cloud 最高支持的版本依然只有 1.6。文档里面的最高版本,更是还停留在 1.4。默认的 Keras,居然用的还是 Python 3.5 + Tensorflow 1.1。
注意千万别直接用这个默认的 Keras ,否则 Python 3.6 后版本出现的一些优秀特性无法使用。例如你将 PosixPath 路径(而非字符串)作为文件地址参数,传入到一些函数中时,会报错。那不是你代码的错,是运行环境过于老旧。
其次,屏幕输出内容过多的时候(例如我跑了 100 个 epoch, 每个显示 100 条训练进度),“运行日志”网页上模拟终端往下拉,就容易出现不响应的情况。变通的方法,是直接下载 log 文件,阅读和分析。
第三,Keras 和 Tensorflow 的许多代码库(例如使用预训练模型),都会自动调用下载功能,从 github 下载数据。但是,因为国内的服务器到 github 之间连接不够稳定,因此不时会出现无法下载,导致程序超时,异常退出。
上述问题,我都已经反馈给开发者团队。对方已表示,会尽快加以解决。
如果你看到这篇文章时,上面这些坑都不存在了,那就再好不过了。
8.3.7 小结
本文为你推荐了一款国内 GPU 深度学习云服务 Russell Cloud 。如果你更喜欢读中文文档,没有外币信用卡,或是访问 FloydHub 和 Google Colab 不是很顺畅,都可以尝试一下。
通过一个实际的深度学习模型训练过程,我为你展示了如何把自己的数据集上传到云环境,并且在训练过程中挂载和调用它。
你可以利用平台赠送的 GPU 时间,跑一两个自己的深度学习任务,并对比一下与本地 CPU 运行的差别。
8.4 如何用iPad运行Python代码?
其实,不只是iPad,手机也可以。 ### 痛点
我组织过几次线下编程工作坊,带着同学们用Python处理数据科学问题。
其中最让人头疼的,就是运行环境的安装。
实事求是地讲,参加工作坊之前,我已经做了认真准备。
例如集成环境,选用了对用户很友好的Anaconda。
代码在我的Macbook电脑上跑,没有问题。还拿到学生的Windows 7上跑,也没有问题。这才上传到了Github。
在我的文章里,我也提前把安装软件包的说明写得非常详细。
但是,现场遇见的情况,依然五花八门。
有的是操作系统。例如你可能用Windows 10,我确实没用过。拿着Surface端详,连Anaconda运行文件夹都不知道在哪儿。
有的是编码。不同操作系统,有的默认中文编码是UTF-8,有的是GBK。这样同样的一段中文文本,我这里一切正常,你那里就是乱码。
有的是套件路径。来参加工作坊前,你可能看过我一些教程,并安装了 Python 2.7 版本 Anaconda。来到现场,一看需要 Python 3.6 版本,你就又安装了一份。结果执行起来,你根本分不清运行的 Python, pip 来自哪一个套件,更搞不清楚软件包究竟安装到哪里去了。
还有的,甚至是网络拥塞问题。因为有时需要现场调用体积庞大的软件包,几十台电脑“预备——齐”一起争抢有限的Wifi带宽,后果可想而知。
痛定思痛,我决定改变一下现状。
只提供基础源代码,对于许多新手同学来说,是不够的。
我得给你提供一个直接可以运行的环境。
这不是录一段视频给你播放那样简单,你需要即时获得运行结果的反馈。在此基础上,你还得可以修改代码,对比执行的差别。
这个事儿可能吗?
我研究了一下,确认没问题。
只要你的设备上有个现代化浏览器(包括但不限于Google Chrome, Firefox, Safari和Microsoft Edge等)就行。
IE 8.0?那个不行,赶紧升级吧!
读到这里,你应该想明白了。别说你用Windows 10,你就是用iPad,都能运行代码。
8.4.1 尝试
请你打开浏览器,输入这个链接(http://t.cn/R35fElv)。
看看会发生什么?
一开始会有个启动界面出来。请你稍等10几秒钟。

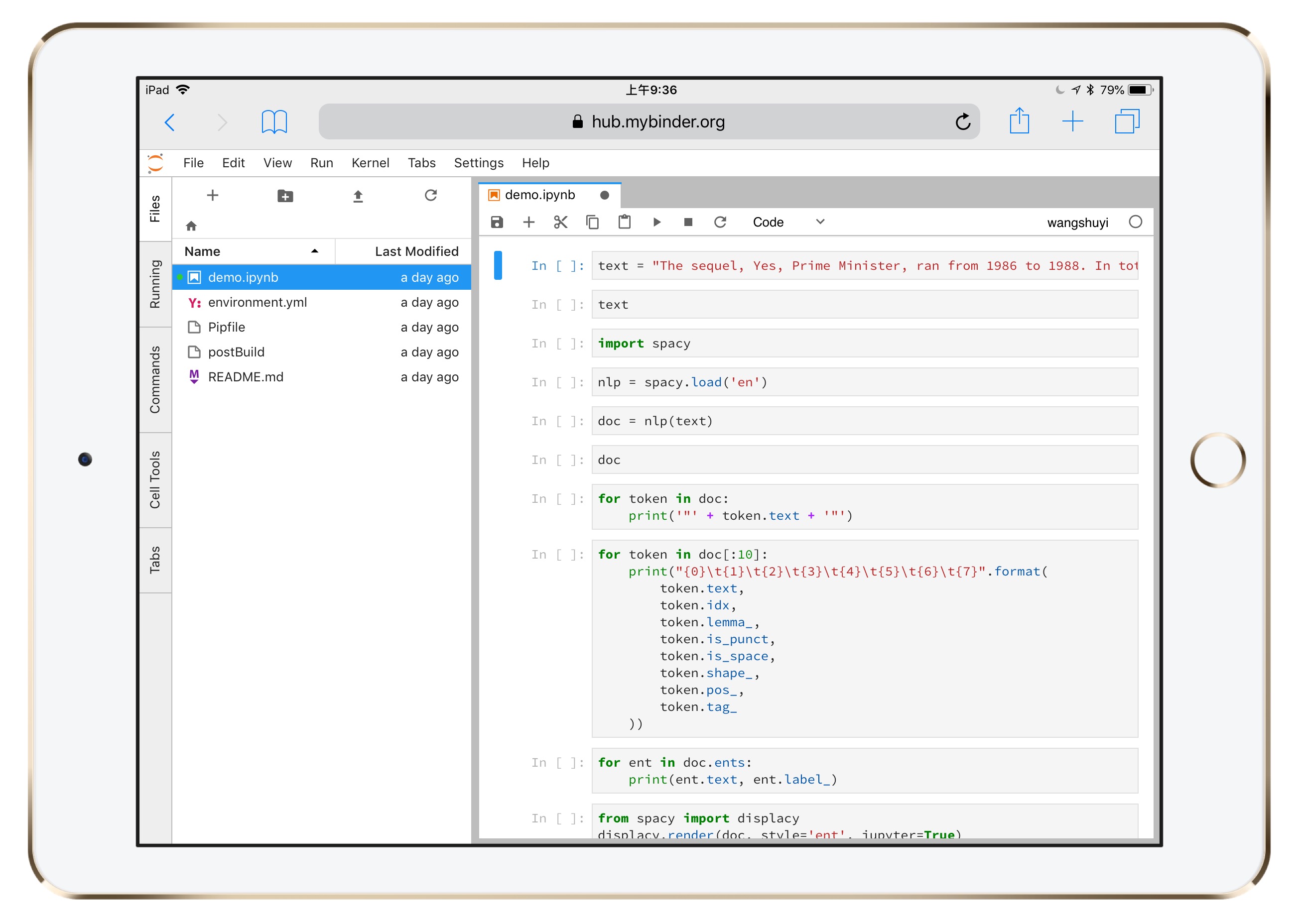
然后,你就能看到熟悉的Python代码运行界面了。
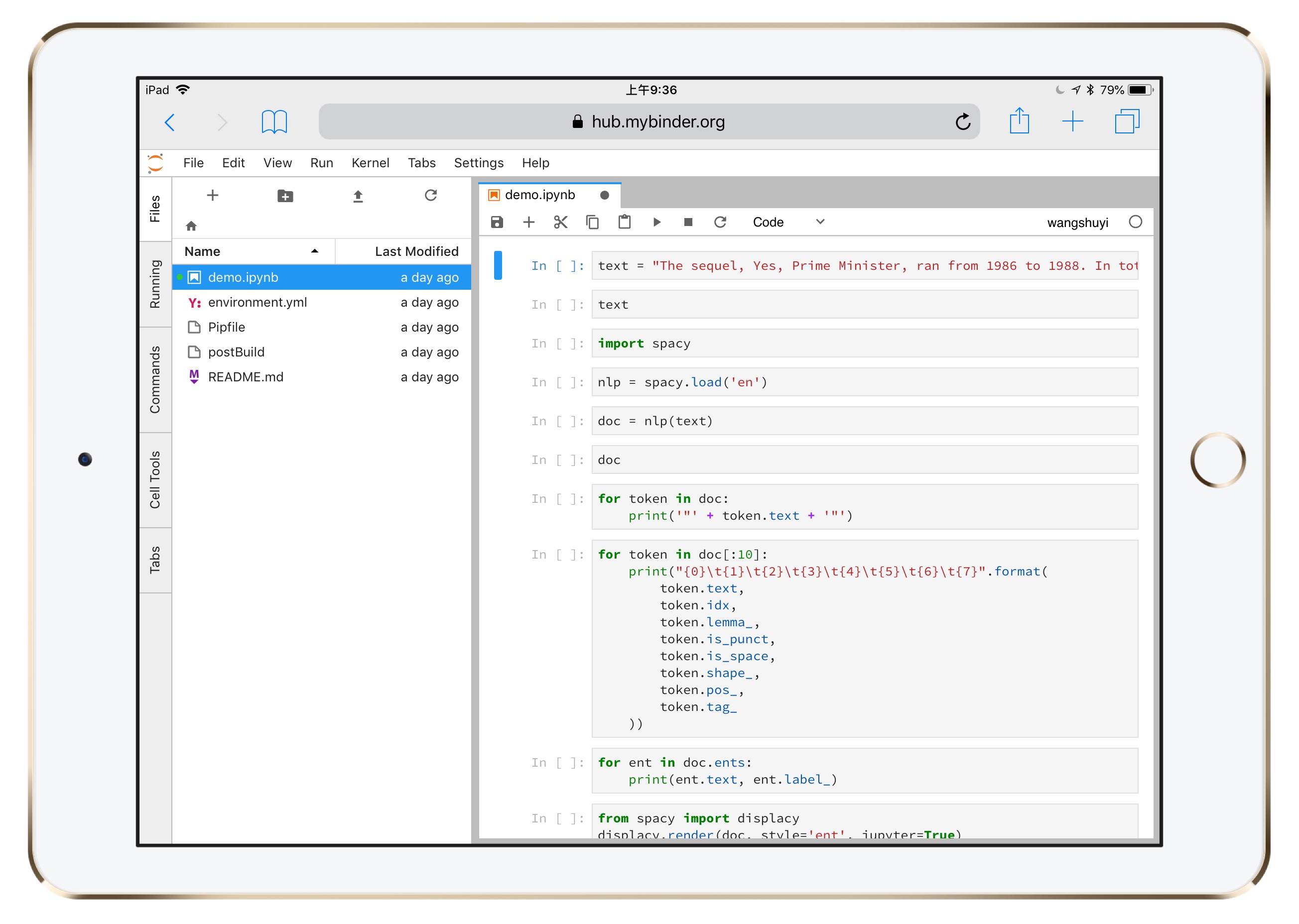
这个界面来自 Jupyter Lab。
你可以将它理解为 Jupyter Notebook 的增强版,它具备以下特征:
- 代码单元直接鼠标拖动;
- 一个浏览器标签,可打开多个Notebook,而且分别使用不同的Kernel;
- 提供实时渲染的Markdown编辑器;
- 完整的文件浏览器;
- CSV数据文件快速浏览
- ……
图中左侧分栏,是工作目录下的全部文件。
右侧打开的,是咱们要使用的ipynb文件。
为了证明这不是逗你玩儿,请你点击右侧代码上方工具栏的运行按钮。
点击一下,就会运行出当前所在代码单元的结果。
不断点击下来,你可以看见,结果都被正常渲染。
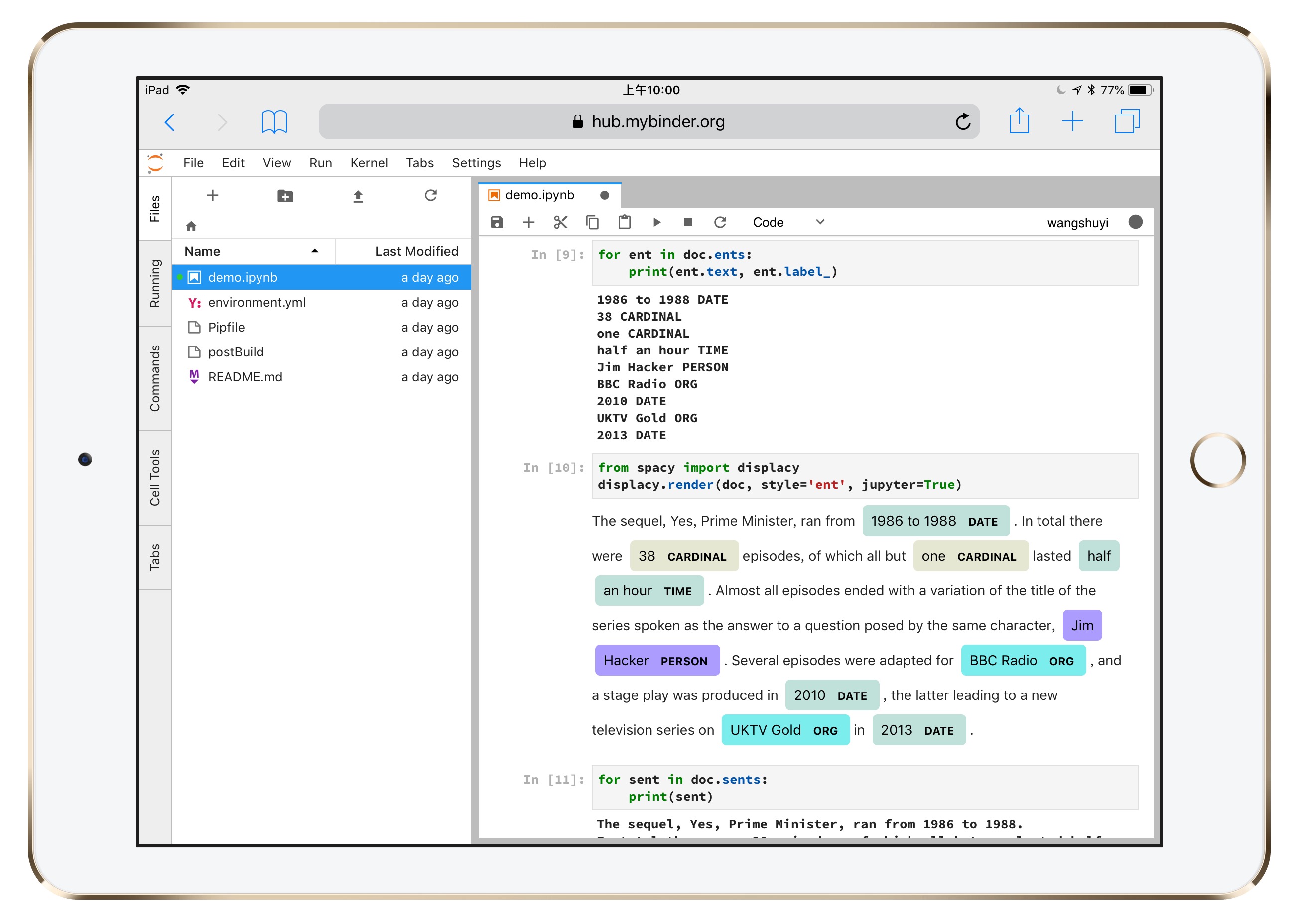
连图像也能正常显示。
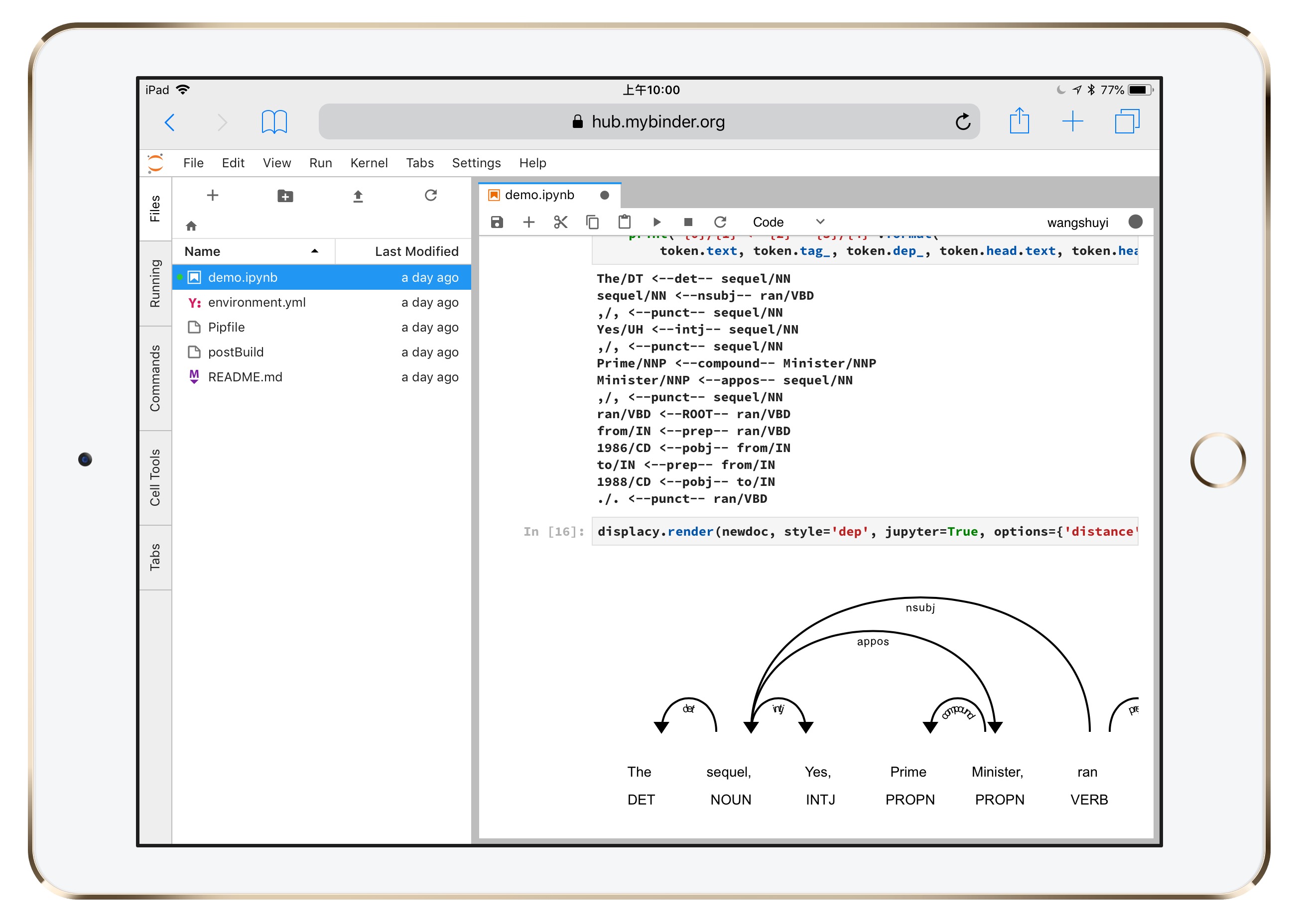
甚至连下面这种需要一定运算量的可视化结果,都没问题。
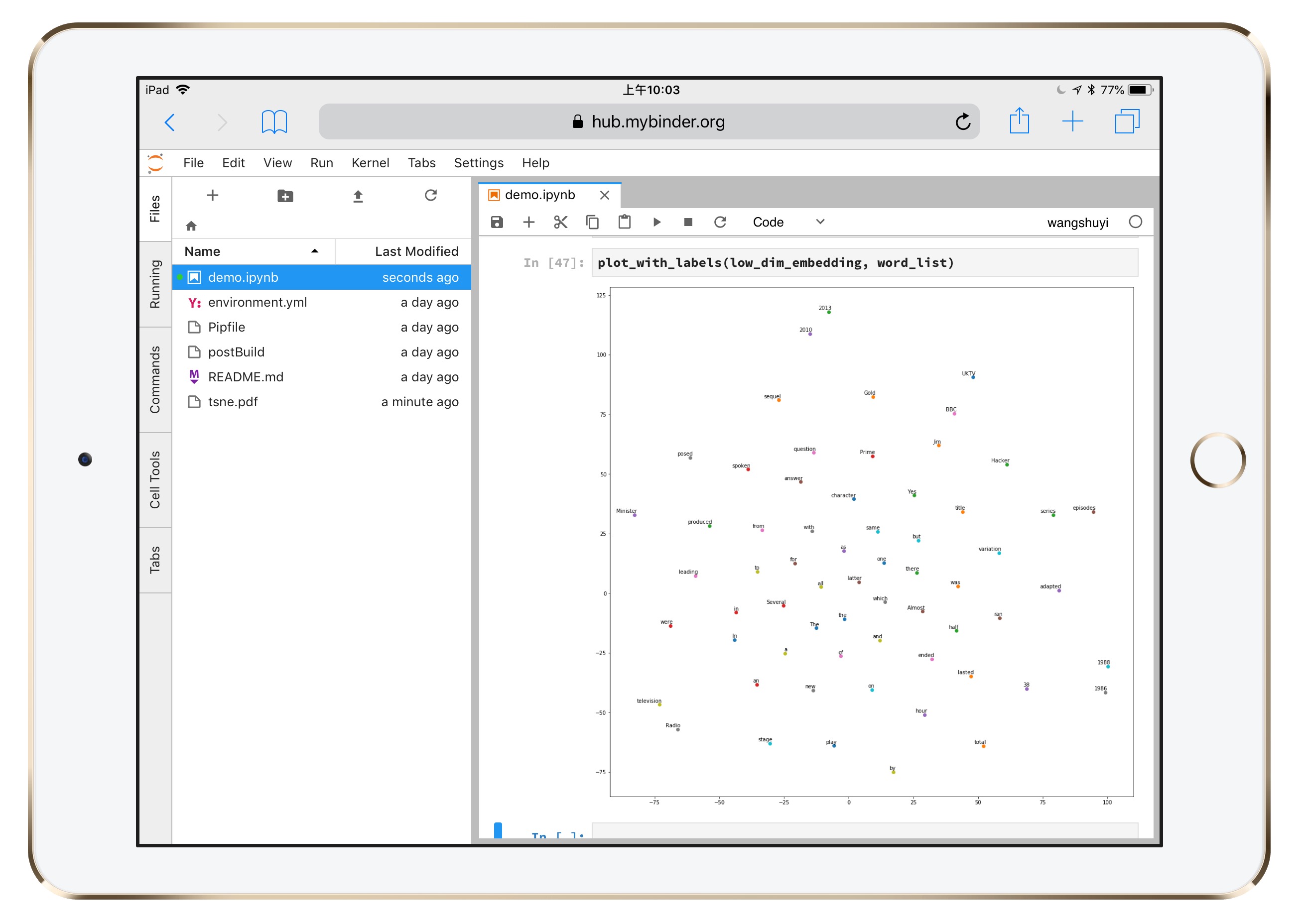
为了证明这不是魔术,你可以在新的单元格,写一行输出语句。
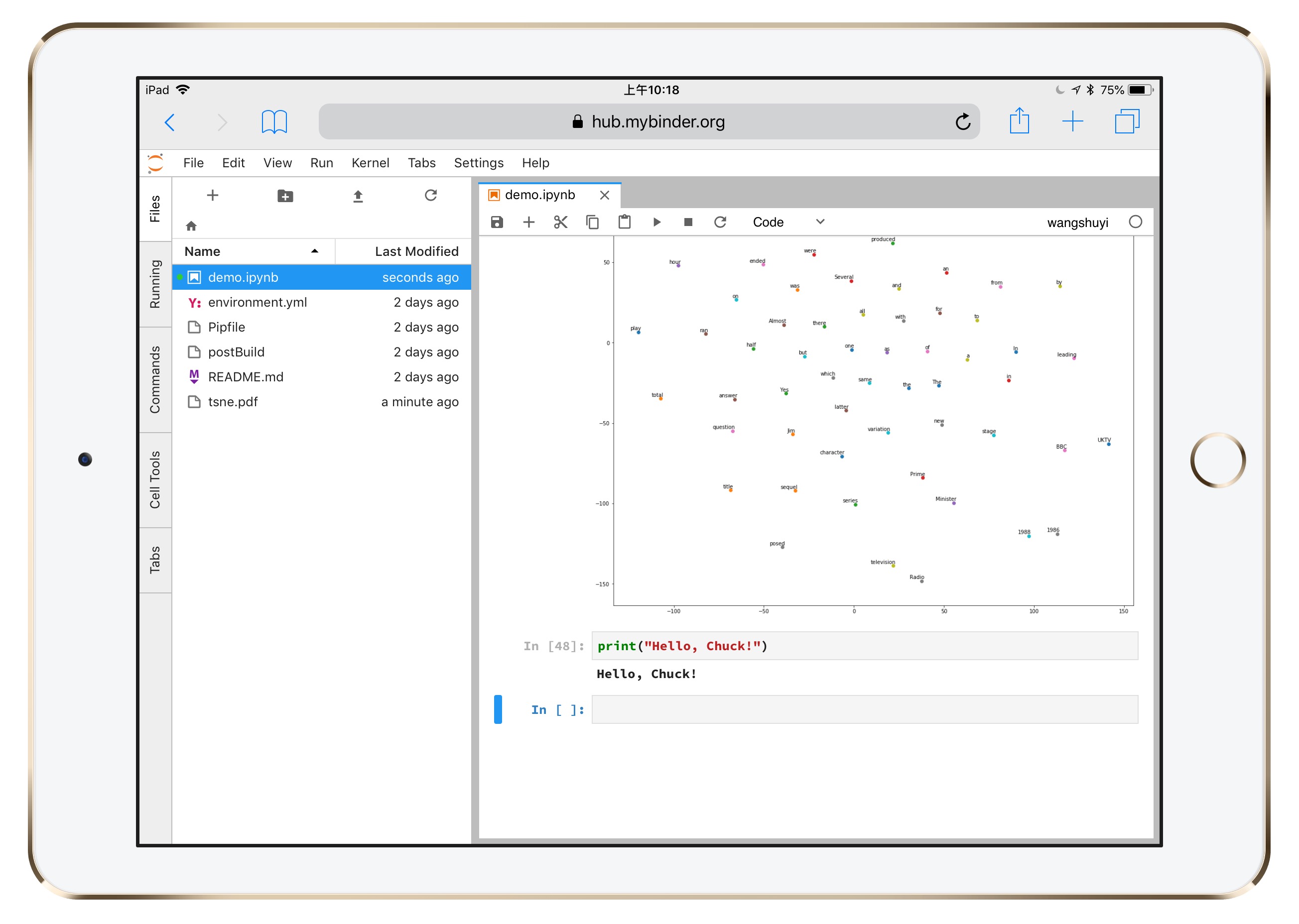
就让Python输出你的名字吧。
假如你叫 Chuck,就这样写:
print("Hello, Chuck!")把它替换成你自己的姓名,看看输出结果是否正确?
其实,又何止是iPad而已?
你如果足够孜(sang)孜(xin)以(bing)求(kuang),手机其实也是可以的。
就像这样。
 ### 流程
### 流程
下面我给你讲讲,这种效果是怎么做出来的。
我们需要用到一款工具,叫做 mybinder 。它可以帮助我们,把 github 上的某个代码仓库(repo),转换成为一个可运行的环境。许许多多的人同时在线使用,也不相冲突。
我们先来看看,怎么准备一个可供 mybinder 顺利转换的代码仓库。
我为你提供的样例在这里(http://t.cn/R35MEqk):
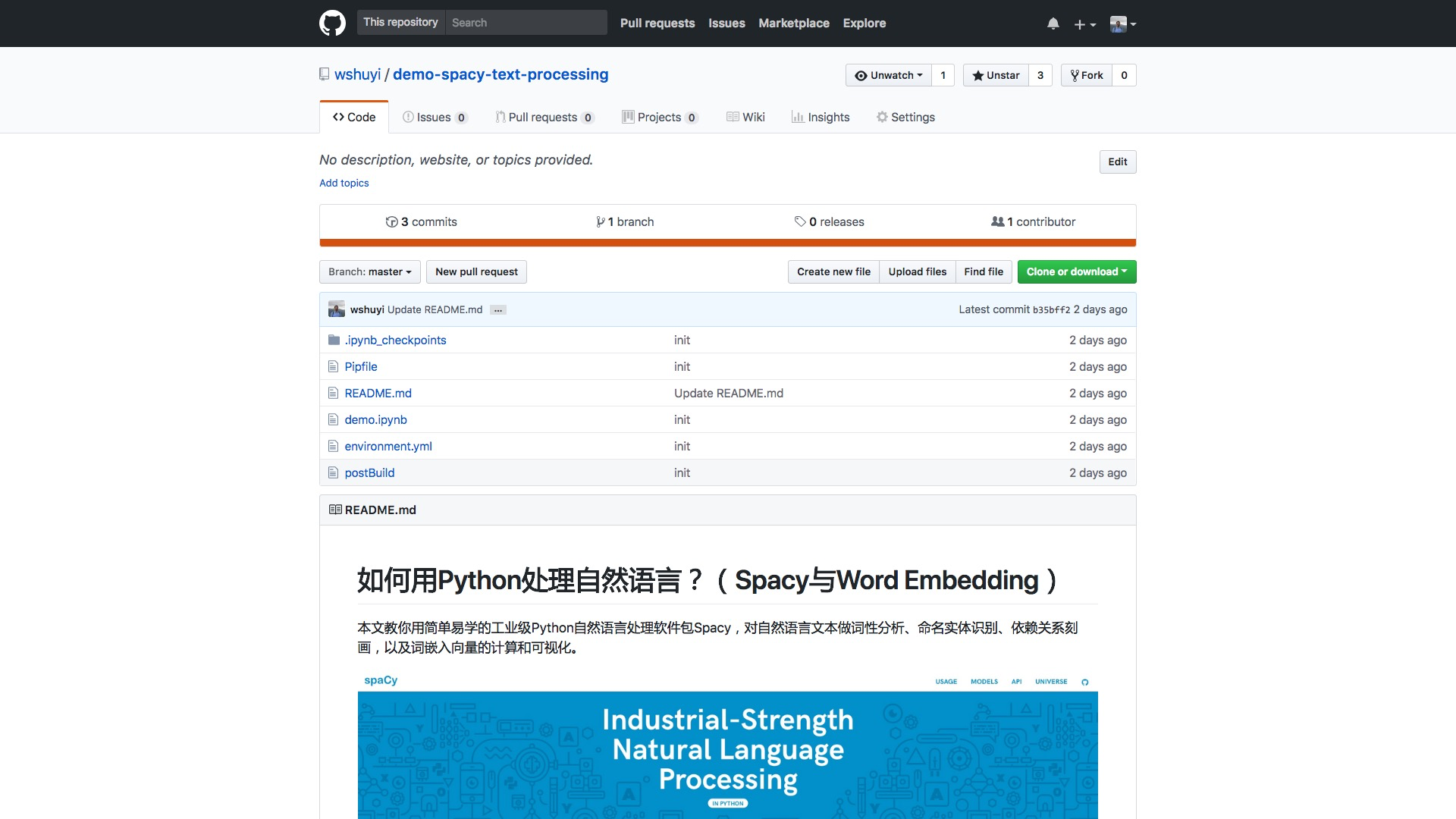
其中,你需要注意以下3个文件:
demo.ipynbenvironment.ymlpostBuild
其中demo.ipynb就是你在上一节看到的包含源代码的Jupyter Notebook文件。你需要首先在本地安装相关软件包,并且运行测试通过。
environment.yml文件非常重要,它来告诉 mybinder ,需要该如何为你的代码运行准备环境。
我们打开看看该文件的内容:
dependencies:
- python=3
- pip:
- spacy
- ipykernel
- scipy
- numpy
- scikit-learn
- matplotlib
- pandas
- thinc该文件首先告诉 mybinder ,你的 Python 版本。我们这里采用的是 3.6 。所以只需要指定 python=3 即可。
然后这个文件说明需要使用 pip 工具安装哪些软件包。我们需要把所有依赖的安装包都罗列出来。
这就是之前,我总在教程里给你说明的那些准备步骤。
但是这还没有完,因为 mybinder 只是为你安装好了一些软件依赖。
这里还有两个步骤需要处理:
- 为了分析语义,我们需要预训练的模型,这需要 mybinder 为我们下载好。
- Jupyter Notebook打开后,该使用的 kernel 名称为 wangshuyi ,这个 kernel 目前还没有在 Jupyter 里面注册。
为了完成上述两个步骤,你就需要准备postBuild文件。
它的内容如下:
python -m spacy download en
python -m spacy download en_core_web_lg
python -m ipykernel install --user --name=wangshuyi好了,至此你的准备工作就算结束了。
打开 mybinder 的网址(https://mybinder.org/)。
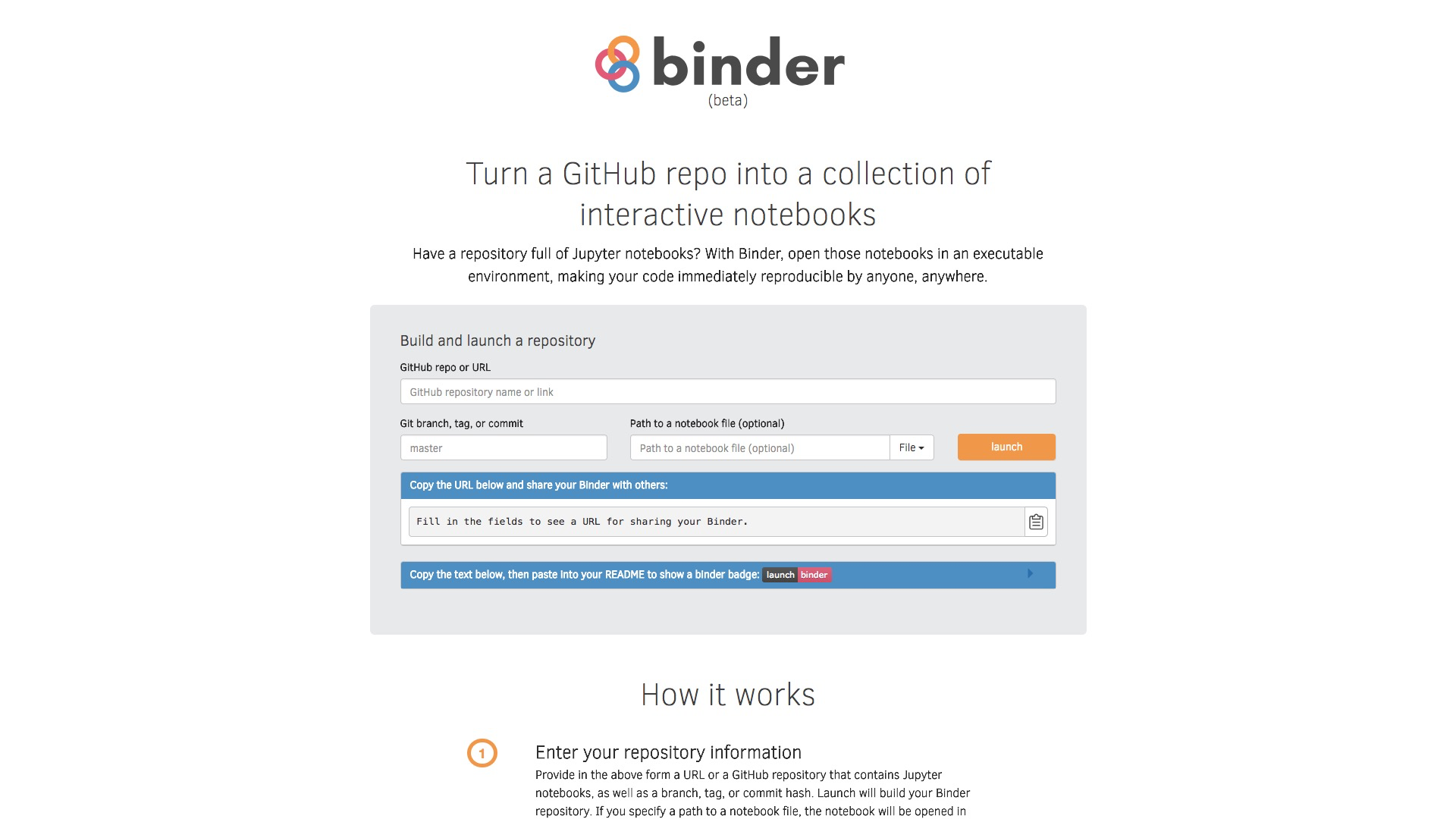
在 “GitHub repo or URL” 一栏,填写我们的 github 代码仓库链接,即
https://github.com/wshuyi/demo-spacy-text-processing我们希望一进入界面,就自动打开 demo.ipynb ,因此需要在“Path to a notebook file (optional)”一栏填写demo.ipynb 。
这时,你会发现“Copy the URL below and share your Binder with others:”一栏中,出现了你的代码运行环境网址。
点击右侧的“复制”按钮保存到你的记事本里面。将来找到你的运行环境,全靠它了。
保存地址后,点击“Launch”按钮。
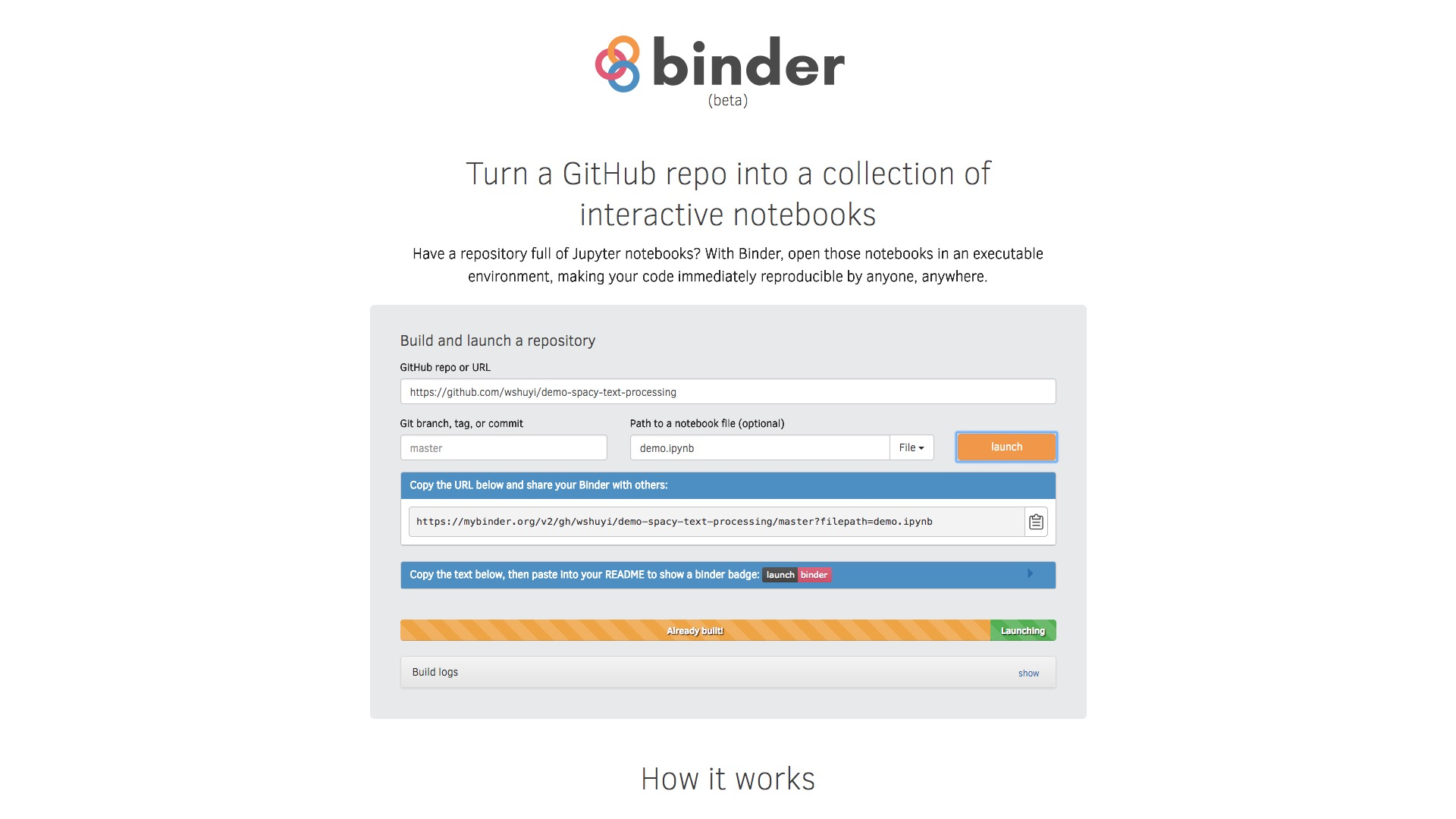
根据你的依赖安装包数量等因素,你需要等待的时间不一。但是只有构建的时候,需要花一些时间。
以后每一次执行,就会非常快了。
构建完毕后, mybinder 会自动为我们开启对应的运行环境。
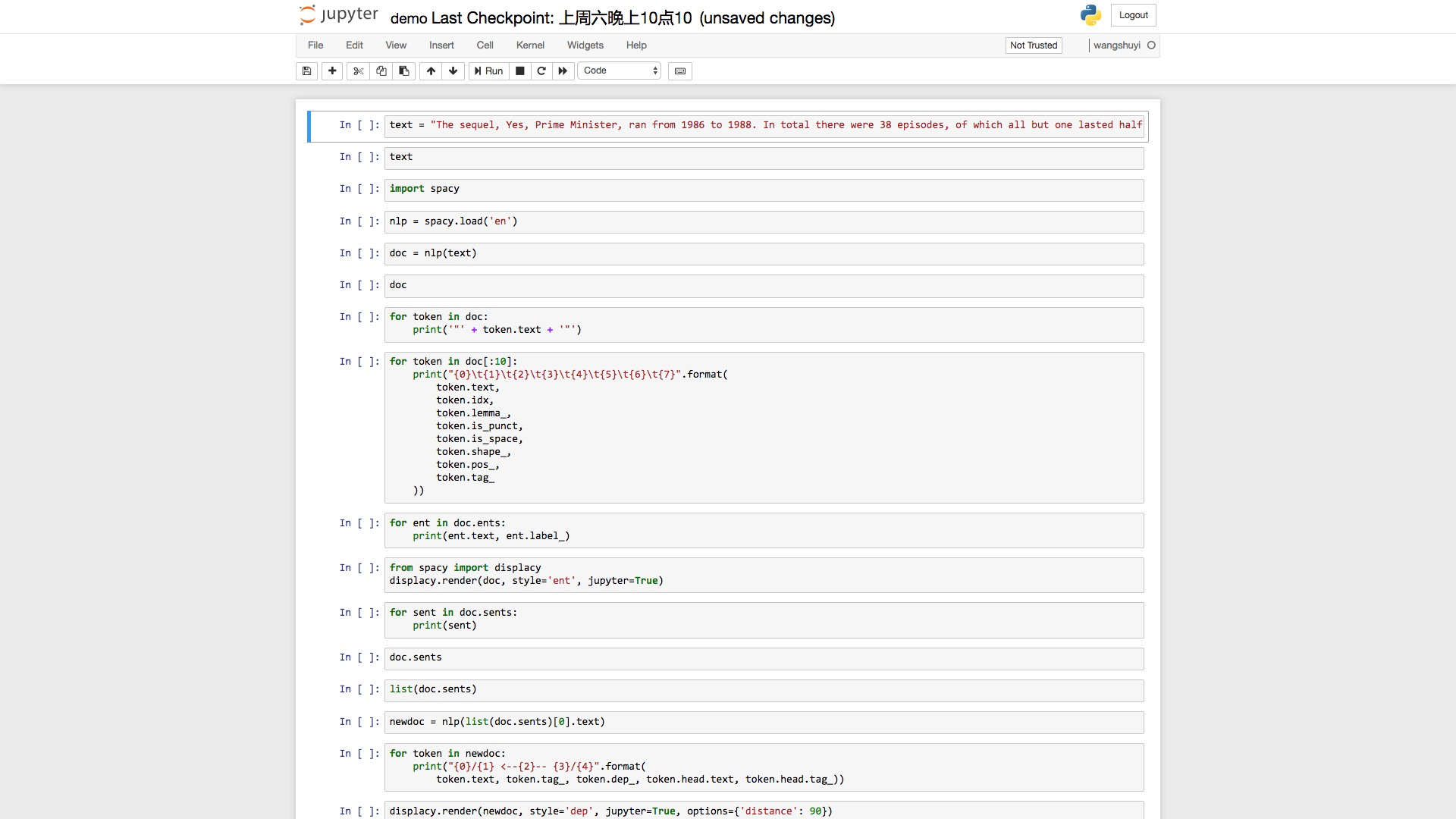
但是你会发现,不对啊!
老师你刚才展示的,不是高级版的 Jupyter Lab 吗?怎么又变成了 Jupyter Notebook 了?
我也想要高级版!
别着急。
看看你目前的链接地址:
https://mybinder.org/v2/gh/wshuyi/demo-spacy-text-processing/master?filepath=demo.ipynb你只需要做个小小的调整,将其中的:
?filepath=替换为:
?urlpath=lab/tree/替换后的链接为:
https://mybinder.org/v2/gh/wshuyi/demo-spacy-text-processing/master?urlpath=lab/tree/demo.ipynb把它输入到浏览器,看看出来的结果:
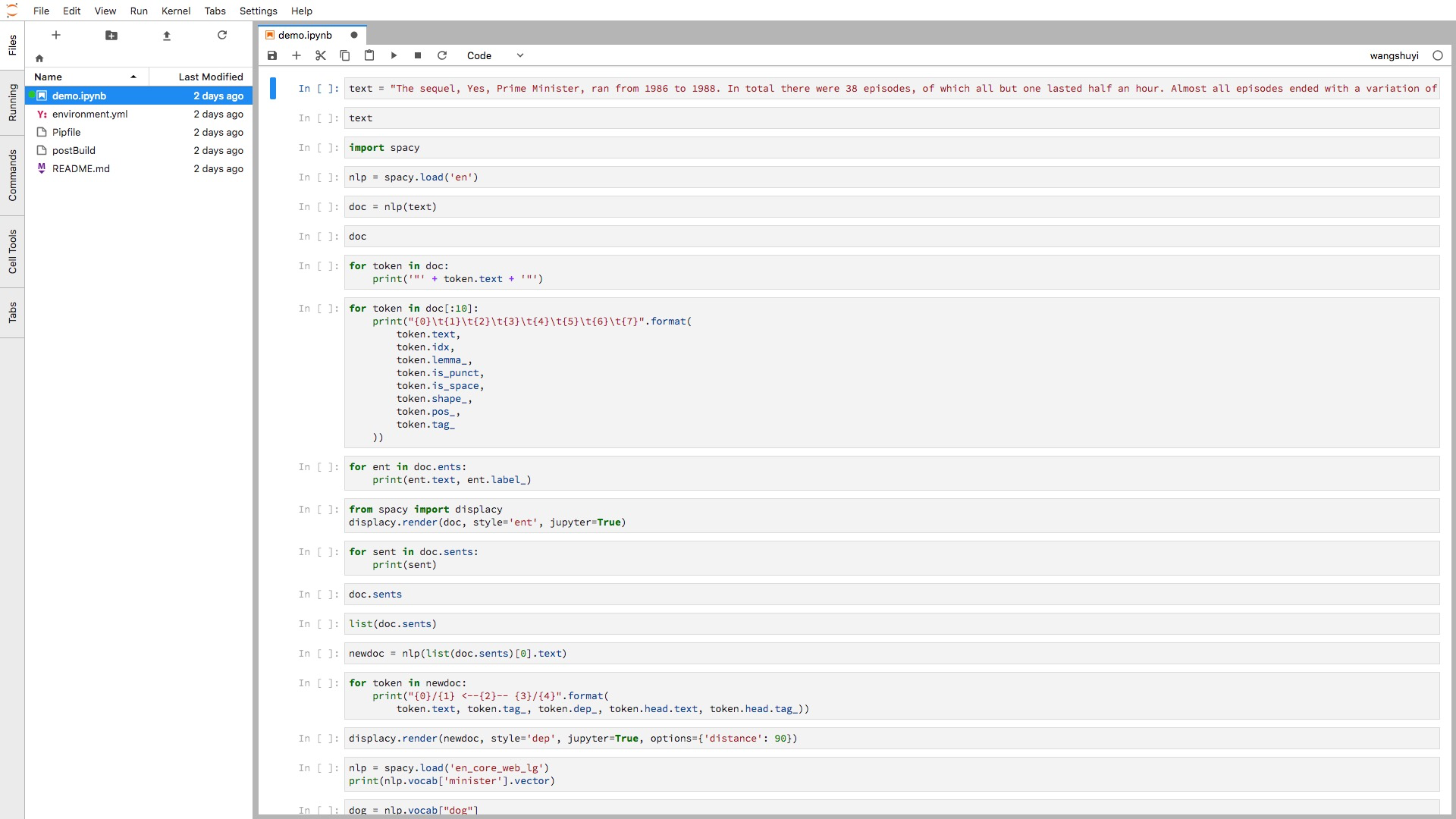
这下没问题了吧?
8.4.2 原理
你是不是觉得,mybinder 很黑科技?
其实,也不算。
它只是把之前的几项技术,链接了起来。
我们看看 mybinder 的说明:
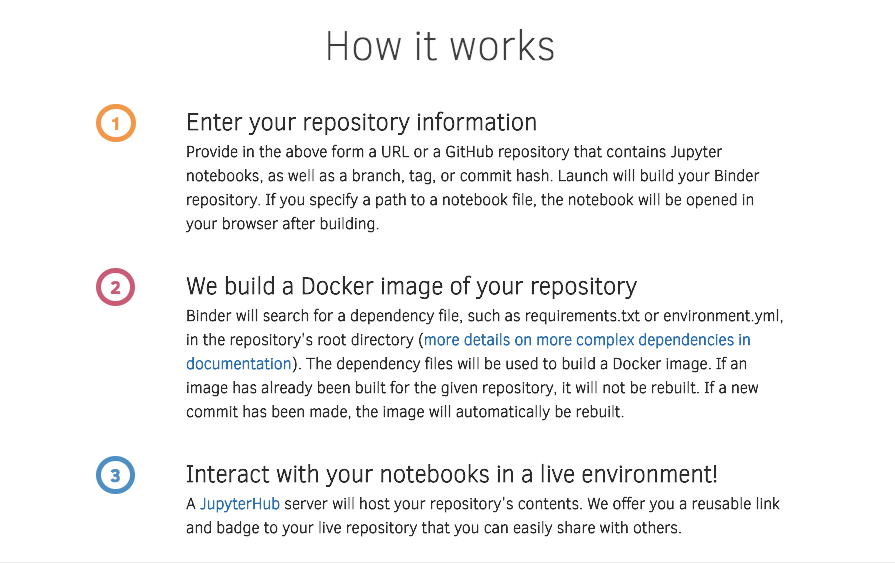
可以看到,其中最为关键的技术,是用了 docker 。
Docker 是个什么东西呢?
简单来说,Docker 就是为了不同平台上,都能够顺利执行同一份代码的保障工具。
你有些犹疑,这说的不是 Java 吗?
没错,Java 的宣传口号,就是一次编码,各处运行。
它利用虚拟机,来保障这种能力。
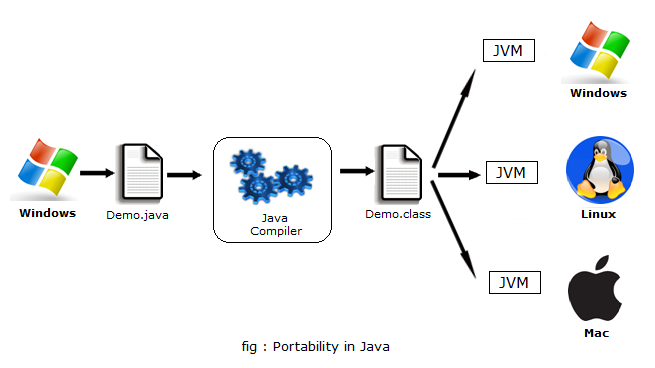
但是,如果你经常使用 Java 开发出来的工具,就应该了解痛点有哪些了。

上图中,左侧是虚拟机,右侧是Docker。
Docker 不但效率上要强过 Java 虚拟机,而且它支持的编程语言也不仅仅是一种。
至于其他好处,咱们就不展开了。否则听起来跟广告差不多。
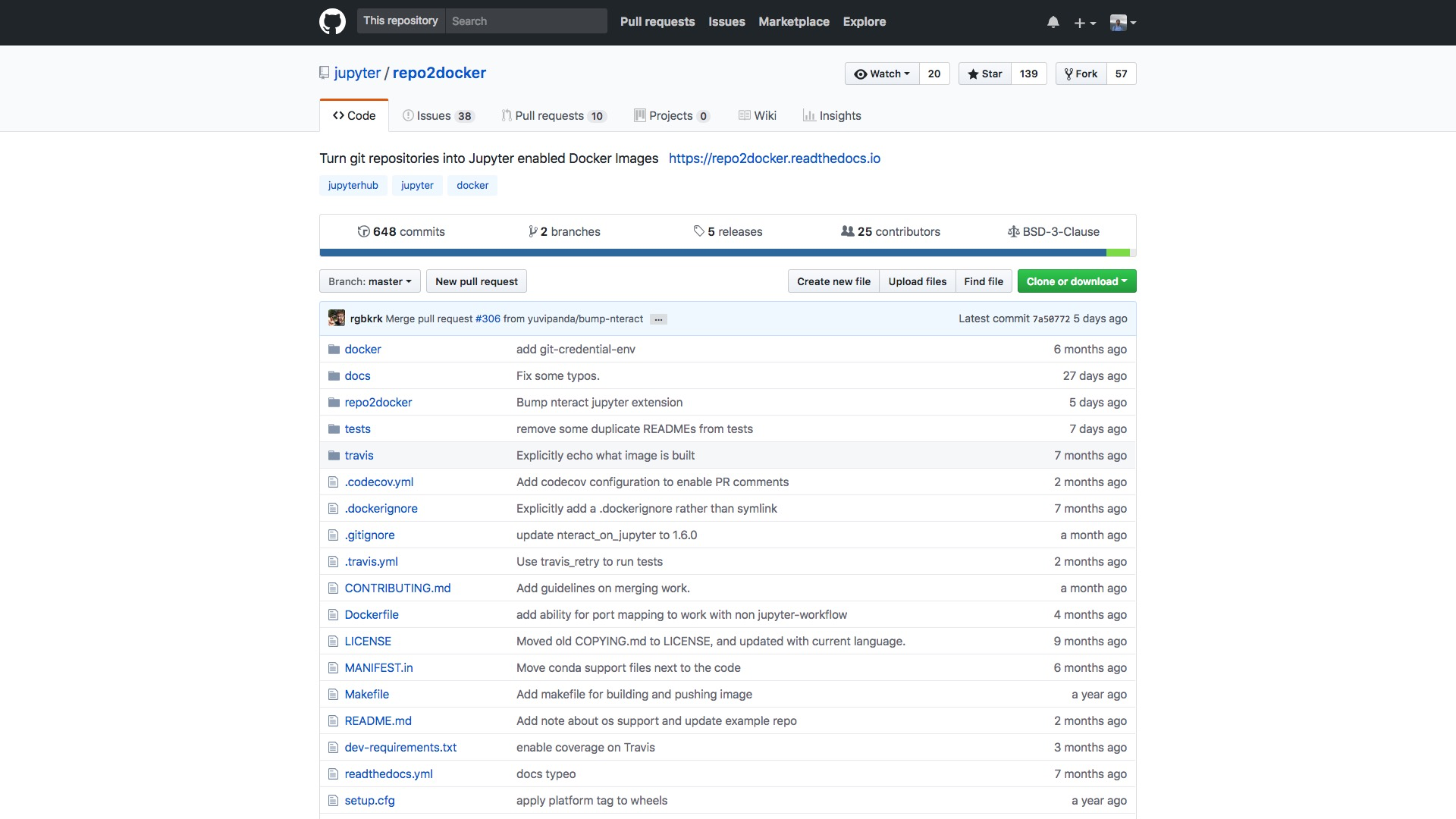
但其实,即便是把 github 代码仓库转换为 docker 镜像(image),也不是 mybinder 来做的。
它调用的,是另外的一个工具,叫做 repo2docker(https://github.com/jupyter/repo2docker) 。
至于你的浏览器能够执行 Python 代码,那是因为 Jupyter Notebook (或者Lab)本来就是建立在“浏览器/服务器”(Browser / Server, B/S)结构上。
看看你本地执行这个语句:
jupyter notebook会出现什么?
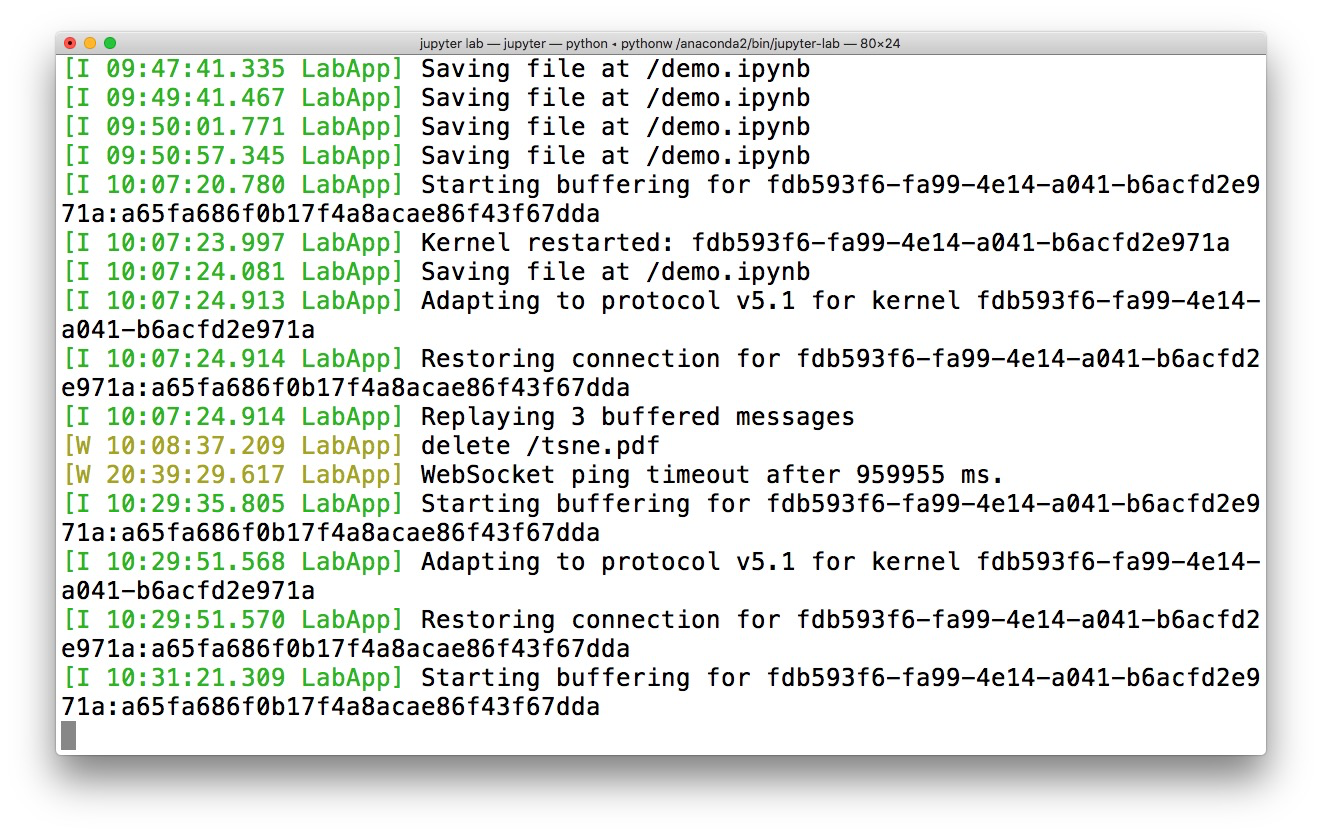
对,它开启了一个服务器,然后打开你的浏览器,跟这个服务器通讯。
Jupyter 的这种功能,本身就让它的扩展极为方便。
因为服务器摆在你的笔记本上,还是摆在另一个大洲的机房,对你执行代码来说,是没有实质区别的。 ### 小结
总结一下,本文为你讲述了以下内容:
- 如何利用 mybinder ,把一个 github repo 一键转换成 Jupyter Lab 运行环境;
- 如何在各种不同操作系统的浏览器上,运行该环境,编写、执行与修改代码;
- mybinder 转换 github repo 背后的基本原理。
我希望你能想到的,不仅仅是这点儿简单的用途。
提几个问题给你,作为思考题。
- 如果代码执行都在云端完成,教学实验室机房还有没有必要预装一大堆软件,且不定期更新维护?
- 练习、作业、考试有没有可能通过这种方式,直接远程进行,并且自动化评分?
- 既然应用的技术都是开源的,你有没有可能利用这些开源工具创业,例如提供深度学习环境,租赁给科研机构与小企业?
8.5 本章小结
如果你喜欢本章的内容,欢迎扫描下面二维码,请我喝杯咖啡。

如果你需要答疑,咱们的问答社区在这里: