第 4 章 探索分析
4.1 如何用 Python 可视化《三国》人物与兵器出现频率?(视频教程)
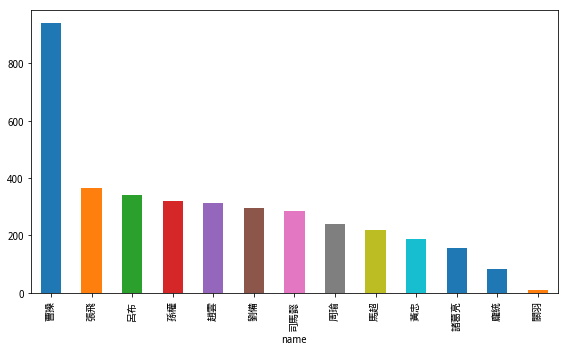
咱们以《三国演义》人名和兵器谱为例,尝试读取不同结构的文本文件,并且对其中的信息进行统计分析和可视化。
4.1.1 入门
如何帮助学生高效入门 Python ,一直是困扰我的问题。
总结经验后,我写下了《如何高效学Python?》(10.4)一文。
文中按照自律能力,我把学生分成了3个类别。
自律能力最高的,看书就行。文中推荐了我认为最好的 Python 书籍,有中文译本;
自律能力中等的,可以学各种轻量级课程组合。除了我当时推荐的课程平台外,最近我发现 Udemy 上的某些课程,也很不错;
自律能力较低的,可以学一门比较完整的专项课程。我推荐了经典 Python 入门课“Programming for Everybody”。
这篇文章很受欢迎,多个平台上阅读量都数以万计。
可是,有一个统计规律,我写作时,似乎没有考虑到。
直到后来,我收到了多名读者的留言反馈,才恍然大悟。
这个统计规律是:
自律能力,和英文能力,是显著正相关的。
仔细诼磨一下这句话,是不是能品出些滋味来?
如果一个学生自律能力较低,去尝试 “Programming for Everybody”,结果会发现英文听不懂,于是放弃……
读者的反馈,让我意识到了,找一门靠谱的、全面系统讲解 Python 基础的中文在线课程,是很重要的。
这样的课程,如果能够达到 “Programming for Everybody”的深度与广度,那么学过后,再进一步学数据挖掘、机器学习,乃至深度神经网络,就可以水到渠成了。
前几天,看到卖桃君(MacTalk,池建强老师的公众号)又重发了《人生苦短,我用 Python》的感言,我就知道又一门 Python 基础课程来了。
果不其然,池老师推荐的,是他们公司《极客时间》平台上的一门新 Python 课程《零基础学 Python》,主讲人是尹会生老师,金山软件西山居技术经理。

虽然我不需要“零基础”学 Python,但是我很想了解这门课,是否足够培训培训新入学的研究生,迅速掌握 Python 。
我很快就付费订阅了。
周末,我花了两个半天的时间,把目前已上线的27个视频(预计总视频数量50个),都从头到尾,完整看了一遍。
许多环节,我都实际跑了代码,还做了笔记。
我觉得,这门课对于我这个“非零基础”的学员,有不少帮助和启发。
如果你一直从事某一方面的工作或研究,即便是 Python 这么简单的语言,很多语法和技巧,你也不会经常用到。
用进废退。很多你学过的东西,也会遗忘掉。
系统地梳理知识体系,可以帮助自己补足漏洞,不至于经常“重新发明轮子”。
另外,我发现之前教程读者不断提出的一些问题,其实都跟 Python 基础命令的不熟悉有关系。
例如几乎每次教程,都要用到的文件操作,以读取外部数据。
你知道可以用 Pandas 读取与分析处理 csv 文件或者 Excel 文件。
但是那些非结构化的文本文件,你该如何读取与分析呢?
如果遇到编码问题,该怎么办?
尹老师在视频教程中,讲解了《三国演义》人名与兵器出现次数统计的例子,让我眼前一亮,觉得确实是很好的分析案例。
一个例子里面,不仅讲解了文件操作,还顺带复习了字符串、列表和字典等多项知识点。
而且我也是个《三国》迷,上中学的时候玩儿《三国志IV》非常上瘾。

为了修改武将技能和数值,还专门学会了16进制。
我在思考,如果换作自己授课,用同样的数据作为例子,给学生讲文件读取、字符串拆分、列表循环、字典生成……我会怎么讲呢?
作为行动派,我立刻就做了个视频教程出来。
4.1.2 视频教程
我采用 Jupyter Notebook 撰写了源代码,然后调用 mybinder ,把教程的运行环境扔到了云上。
请点击这个链接(http://t.cn/R1TLtxq),直接进入咱们的实验环境。
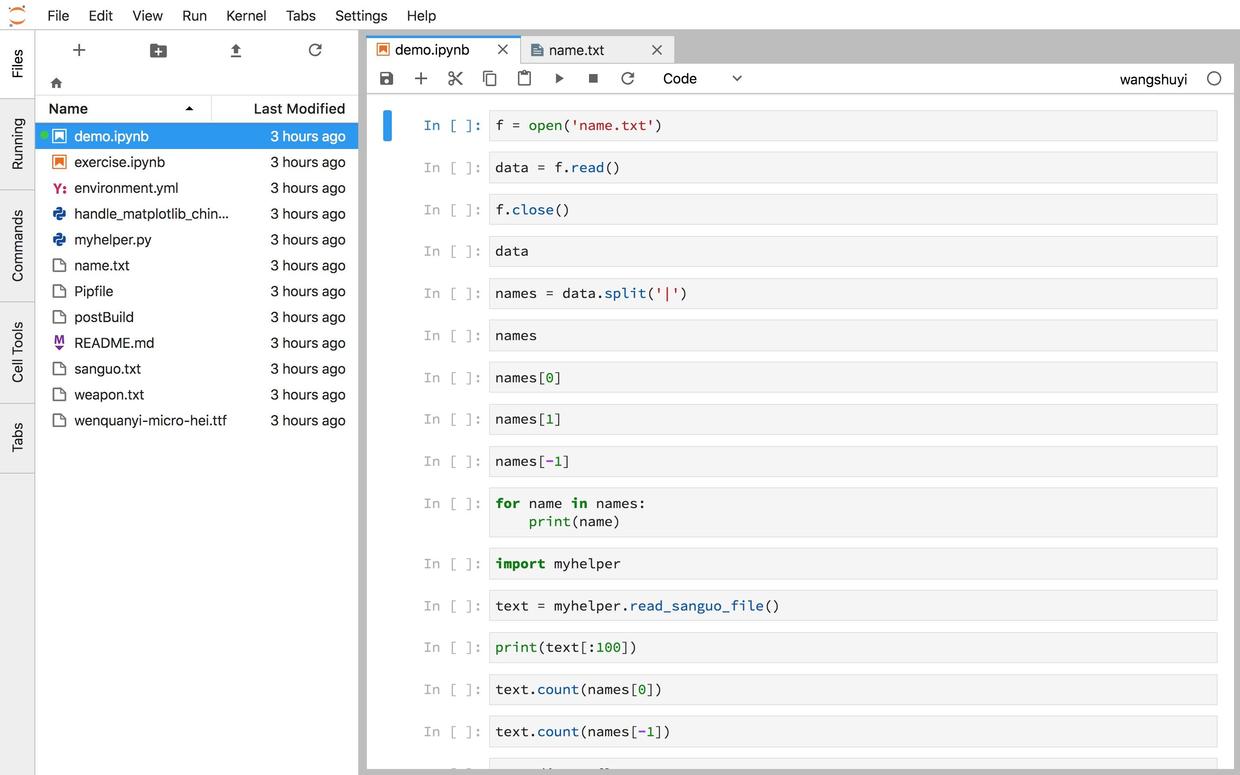
你不需要在本地计算机安装任何软件包。只要有一个现代化浏览器(包括Google Chrome, Firefox, Safari和Microsoft Edge等)就可以了。全部的依赖软件,我都已经为你准备好了。
如果你对这个代码运行环境的构建过程感兴趣,欢迎阅读我的《如何用iPad运行Python代码?》(8.4)一文。
浏览器中开启了咱们的环境后,请你观看我给你录制的视频教程。
视频教程的链接在这里。

希望你能跟着教程,实际操作一遍。这样收获会比较大。
教程的末尾,我给你留了一道练习题。说明了练习题的要求,还给出了辅助框架代码。
请你自行尝试解决该练习题,以巩固所学知识。
如果你解完了练习题,或者在解题过程中遇到了问题,欢迎参考我做的练习解答视频,核对参考答案。
这段视频的链接在这里。
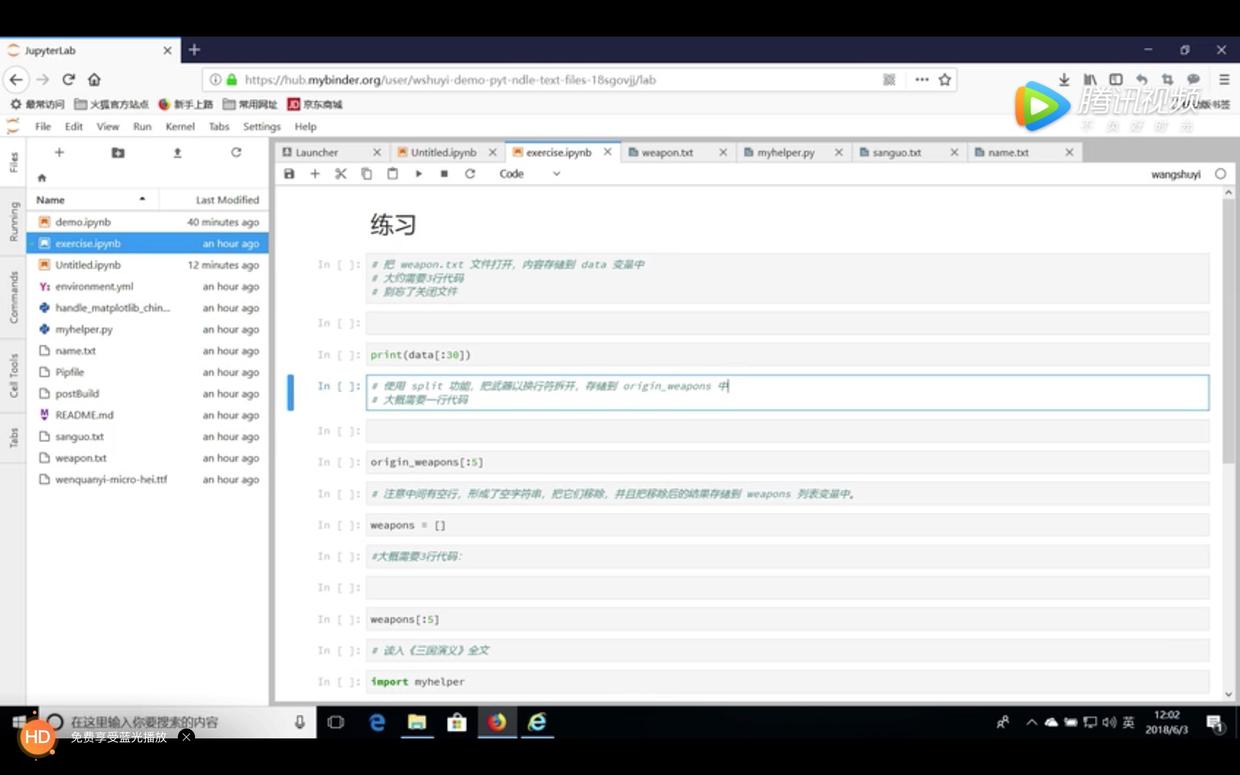
通过本教程,希望你已经掌握了以下知识:
- 如何读取文本文件;
- 如何把字符串分割成列表;
- 如何依据顺序,找出列表中的某一项内容;
- 如何遍历列表;
- 如何统计字符串a中,字符串b出现的次数;
- 如何新建,并用遍历方法,填充字典;
- 如何读入外部帮助函数模块,并调用其功能函数;
如果你希望在本地,而非云端运行本教程中的样例,请使用这个链接(http://t.cn/R1T4400)下载本文用到的全部源代码和运行环境配置文件(Pipenv)压缩包。
然后,请你参考《如何用 pipenv 克隆 Python 教程代码运行环境?》(2.3)一文的说明,利用 Pipenv ,在本地构建代码运行环境。
如果你知道如何使用github(10.3,也欢迎用这个链接(http://t.cn/R1T4iL5))访问对应的github repo,进行clone或者fork等操作。
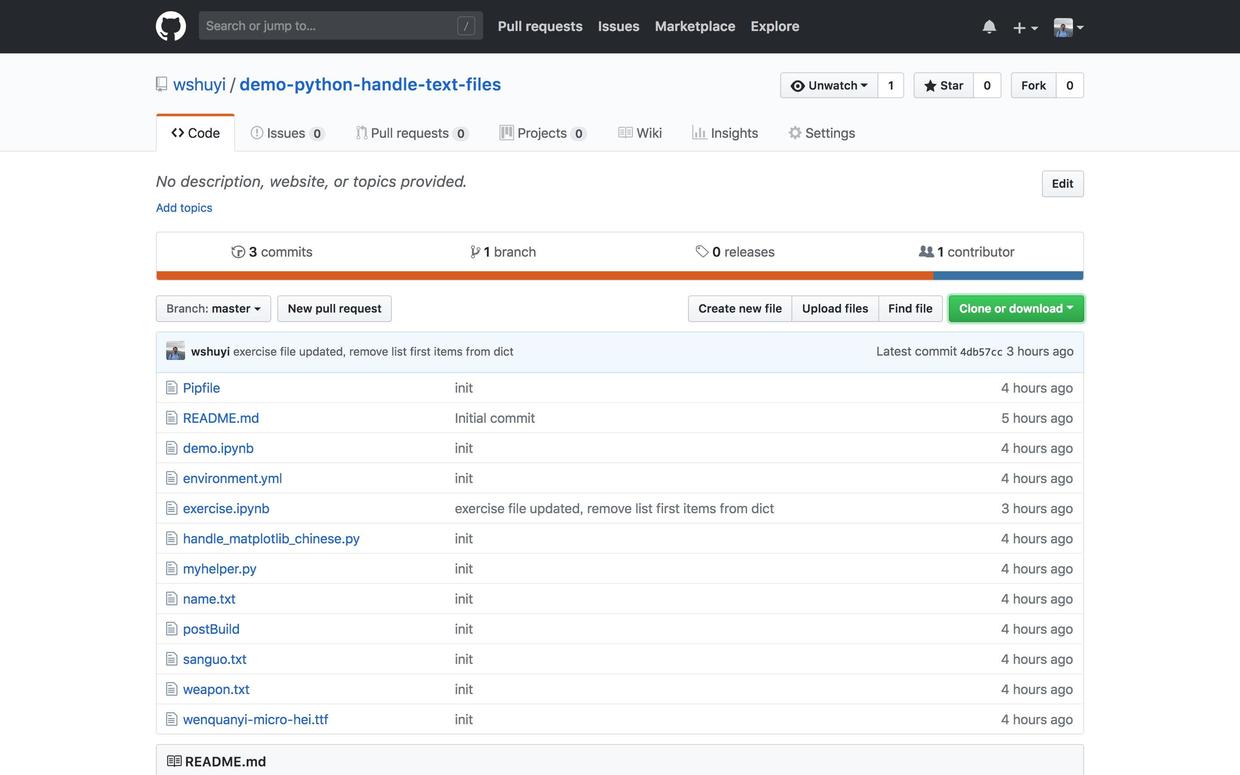
当然,要是能给我的repo加一颗星,就更好了。
4.1.3 建议
录完视频,我做个对比分析:
我俩的讲法,到底有哪些不同?
细节的差别,可能有很多。但是大多都不重要。
我只想给尹老师提一个建议——把握节奏。
这里的节奏,主要是为了学生和老师分别获得即时反馈用的。
编程不是一门看了,甚至听了,就能懂的课。
这就是为什么,得到App至今也没有上线编程课程。
编程必须要强调训练,注重实践。
训练该在什么时候做?
来自 Coursera, Udacity, 和 DataCamp 等平台的经验是:
间隔必须足够短。
老师得盯住学生在学完知识点后,旋即练习。
通过练习,把握知识和技能,提升应用能力。
学生在练习中遇到了疑惑,及时提问,加以解决,可以避免疑问的非线性积攒。
如果你不理解“疑问的非线性积攒”,可以回忆你学微积分或随机过程的遭遇。
学生不断积攒疑问,对老师也会有很大的不利影响。因为老师同样得不到有效反馈,还以为学生那边一切顺利呢。
在文件操作这一部分,尹老师确实也留了练习。
# 练习一 文件的创建和使用
1. 创建一个文件,并写入当前日期
2. 再次打开这个文件,读取文件的前4个字符后退出问题在于,有多少学生会主动去 GitHub 上面找到这个练习,而且不但做了,还反馈给老师呢?
他们会拖延,甚至忽略这些练习。
然后一味继续播放下一集。
看似懂了内容,实际上没有真正掌握。
一旦中途遇到了比较困难的题目,或者是最后来个“期末考试”(例如项目作业),学生刚刚建立起来的学习兴趣和信心,可能会彻底崩盘。
还是回到一开始那个问题——如果学生自律能力足够强,他也就不需要这门 MOOC 了。
我的视频教程,就是把尹老师原先直接讲解的内容(武器文件读取与统计)先作为练习题,布置给了学生。
刚学完知识后,大部分人,还是愿意在操作成本足够低的情况下,去尝试一下的。
什么叫“操作成本足够低”?
看看我采取的这些方法,你就能理解了:
- 不需要学生自行安装任何编程环境,有浏览器和网络就行;
- 不用离开 Jupyter Lab 界面,直接打开另外一个 ipynb 就行;
- 不需要面对空的文档,只需要在辅助代码基础上,做填空就行;
- 不需要猜测代码长度,已经给出了建议行数;
- 不需要接触过多新的知识点,例如数据框转化、排序和绘图等,只需要调用已封装的帮助函数即可。
而且,视频教程末尾,明确说明了,下一个视频就是讲解练习的。
这就指明了,本练习的截止日期,就是你播放下一个视频的时候。
对于自律能力差的学生,很多时候,只能靠这种前面铺路、后面推一把的方法。
尹老师的教程介绍里面,类似《三国》武将和兵器谱统计这样的有趣例子还有不少。
例如查找星座和属相,用机器学习分类鸢尾花,用爬虫爬图片等。
因此,我对后续即将上线的20几个视频,还是很期待的。
《零基础学 Python》课程对应的 github 项目链接在这里(http://t.cn/R1TGsnK)。
里面不仅包括课程已发布视频的全部对应代码,还包含了配套的练习和讲义等。你可以在订阅课程之前,先浏览一下。
如果你对这门课程感兴趣,可以点击 这个链接 ,扫码订阅。
{kind=link}
4.2 如何用4行 R 语句,快速探索你的数据集?

用最简单的方式,完成探索性分析。
4.2.1 痛点
实践中,大量数据分析时间,都会花在数据清洗与探索性数据分析(Exploratory Data Analysis, EDA)。即缺失值统计处理,和变量分布可视化。
数据采集过程中,可能有缺失。
你需要了解缺失数据的多少,以及它们可能对后续分析造成的影响。
如果某个变量的缺失数据少,干脆把含有缺失值的行(观测)扔掉就算了,免得影响分析精确程度。
但如果缺失数据太多,都扔掉就不可行了。你需要考虑如何进行填补。是用0,用 “unknown” ,还是使用均值或中位数?
另外,你可能还想看看每个特征变量的分布情况。
例如定量数据是正态分布,还是幂律分布?这对你后面合理进行研究假设,都是有影响的。
即便是对于分类数据,你也要了解独特取值(unique values)的个数,以便做到心中有数。
这些工作很有必要。但是实现起来,却一直很麻烦。即便是 R 这样专门给统计工作者使用的软件,从前也需要调用若干条命令(一般跟特征变量个数成正比),才能完成。
我最近发现了一款 R 包,可以非常方便地进行数据集总结概览。只要一条语句,就帮你完成探索性数据分析中的许多步骤。
通过本文,我把它分享给你。希望对你的数据分析工作有帮助。
4.2.2 演示
你不需要安装任何软件。只需要点击这个链接(http://t.cn/Rg1JFfo),就可以使用 R 编程环境了。

等准备工作完毕,你会看到,浏览器里面开启了一个 RStudio 界面。
点击左上角的 File -> New File ,选择菜单里面的第一项 R Script 。
此时,你会看到左侧分栏一个空白编辑区域开启,可以输入语句了。

输入之前,我们先给文件起个名字。点击 File -> Save 按钮。
在新出现的对话框里面,输入 demo ,回车。
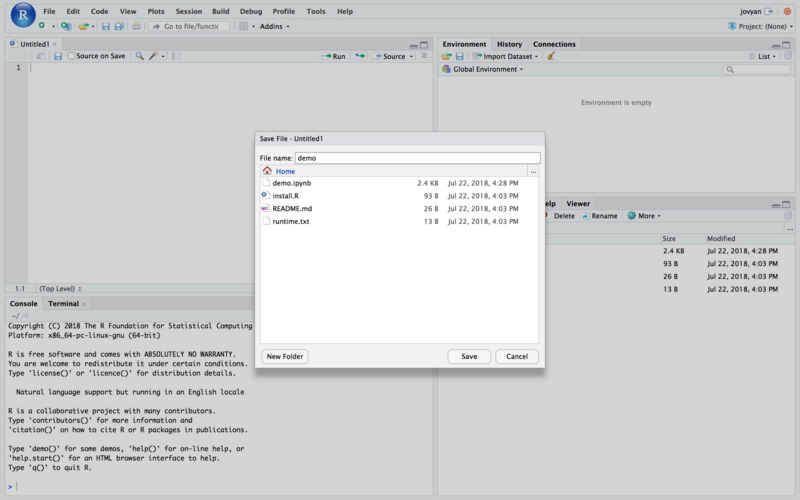
我们一共需要如下输入4条语句。你可以直接复制粘贴进编辑区域。
library(tidyverse)
library(summarytools)
flights <- read_csv("https://gitlab.com/wshuyi/demo-data-flights/raw/master/flights.csv")
view(dfSummary(flights))分别解释一下含义。其实前3行语句,都是准备工作。真正总结概览功能,只需第4条。
第一行: tidyverse 是一个非常重要的库。可以说它改进了 R 语言处理数据的生态环境。而这个库中的大部分工具,都是 Hadley Wickham 一己之力推动和完成的。

第二行: summarytools 是我们今天用来总结概览数据的软件包名称。
第三行: 使用 read_csv 做数据读入。我们是从这个网址读取的,并且把数据存储到 flights 变量中。
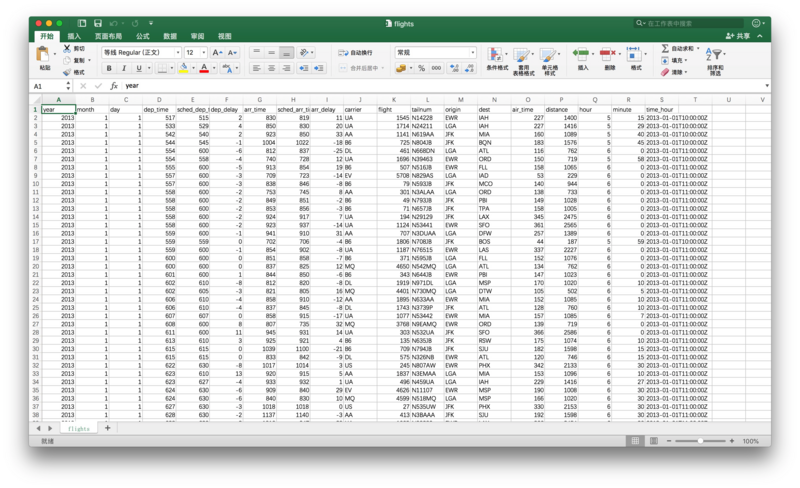
你可以点击该链接(http://t.cn/Rg1XCCN),下载原始数据 csv 文件,查看其内容。
这个数据集,来自于 Hadley Wickham 的 github 项目,名称叫做 nycflights13 。
它记录的是 2013 年,纽约市3大机场(分别为: JFK 肯尼迪国际机场、 LGA 拉瓜迪亚机场,和 EWR 纽瓦克自由国际机场)起飞的航班信息。
具体的记录信息(特征列),包括起飞时间、到达时间、延误时常、航空公司、始发机场、目的机场、飞行时长,和飞行距离等。
这个表格,看起来已经是很清晰的了。但是,由于观测(行)数量众多,我们很难直观分析出缺失值的情况,以及数据的分布等信息。
第4条语句,就是负责帮助我们更好地检视和探索数据用的。它用 dfSummary 函数处理 flights 数据框的内容,然后用 view 函数直观输出给用户。
点击 Code -> Run Region -> Run All 命令,运行代码。
运行中,可能会有一些警告信息。别理它就好。
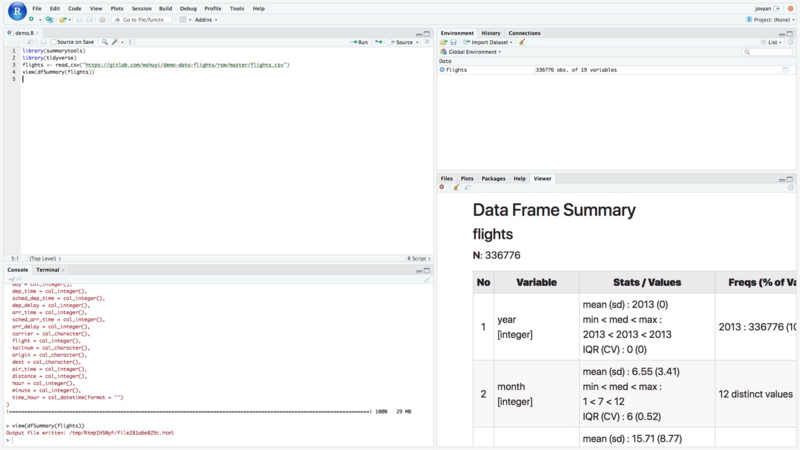
分析的结果,在右下方的显示区域。因为区域比较小,内容却很多,看不全面。
你可以点击这个区域左上方第三个按钮 Show in new window ,在浏览器新窗口打开完整的显示结果。
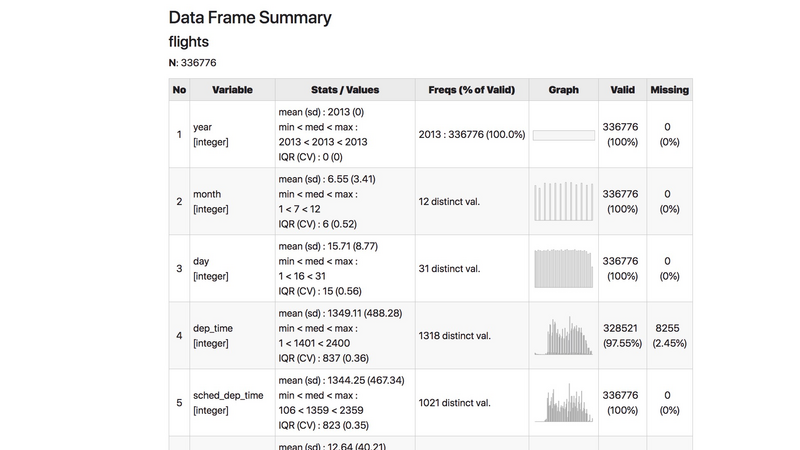
4.2.3 解读
因截图篇幅关系,一张图中,无法显示完整信息。就着第一屏,给你讲解一下都有哪些分析结果。
- 第一列是序号。不用理会。
- 第二列是变量名称,以及变量的类型。例如
integer指的是整数类型的定量数据;character是字符串类型,也就是分类数据。 - 第三列是统计结果。对于定量数据,直接汇报最大、最小、均值、中位数等信息。
- 第六列是有效值个数;与其互补,第七列是缺失值个数。
- 第四列是频数。显示每一个变量对应独特取值出现的情况。
- 第五列最有意思,直接绘制分布统计图形。
我们翻到下一页看看。
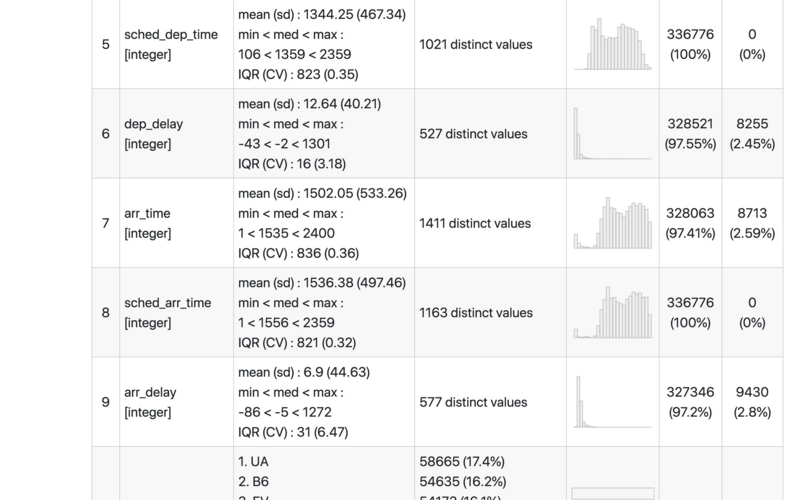
可以看出,起飞延误是个典型的幂律分布。
到达延误,和的起飞延误分布长得很像,想想似乎很有道理。
但到达延误的分布类别是什么呢?为什么二者会有差异呢?
这个问题,供你思考。
4.2.4 探索
本文介绍的 summarytools 包的功能,并不只是对数据集做总体总结概览。
它还可以进行变量之间的关系展示。例如你想知道3大机场起飞的航班,对应航空公司的比例是否有差别。可以用一条语句,就得到这样的一张分析表格:

想自己动手,做出这样一张分析表格?请你点击这个链接(https://github.com/dcomtois/summarytools),阅读文档,了解 summarytools 的更多功能。
4.3 如何用 R 绘制动态统计图?
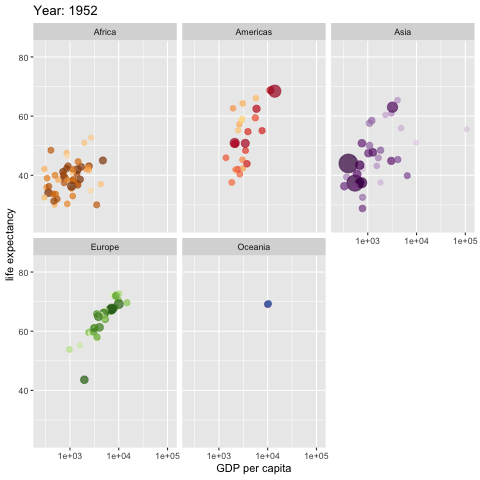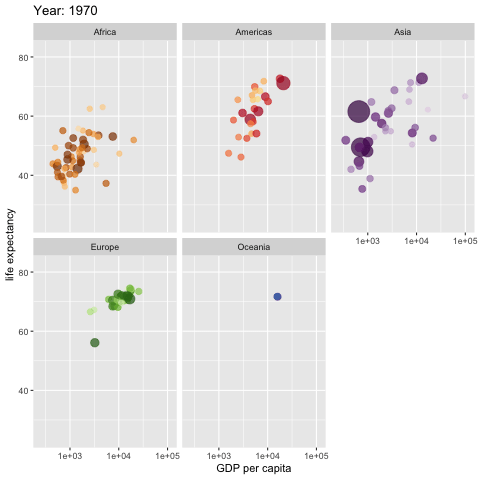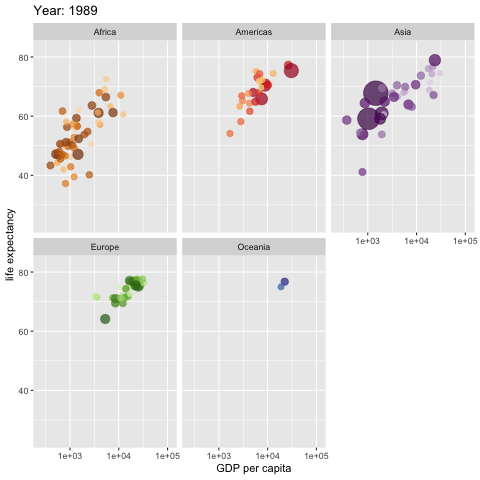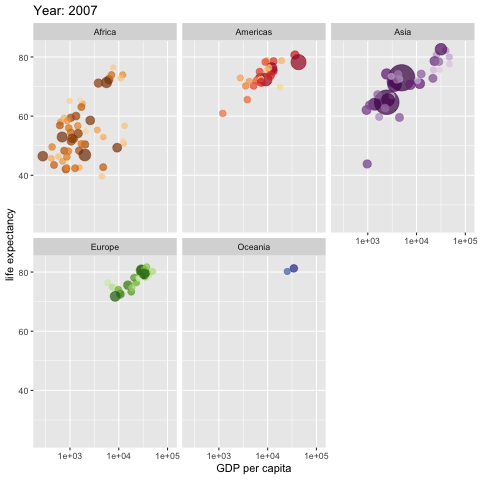
如果一幅图胜过千言万语,那么一幅会动的图呢?
4.3.1 需求
绘制统计图形,是为了给谁看?
显然不是给电脑看。因为它看不懂,也没必要看。给它数据就好了。它理解起来,更准确。
绘制统计图形,是给人看的。可以给别人看。例如合作者、读者、审稿人,或者演讲时的观众。但更多的情况,图也是给自己看的。
为什么要画图?因为密密麻麻的数字或符号,远不如一幅图像,看得清楚和舒服。人类中的大多数,目前还没有进化出对海量原始数据,条件反射一般的理解能力。
漫长的演化史上,人类的感官只要能有效发现食物(包含猎物),快速捕获危险信号(例如捕食者逼近),和同类高效交流(使用声音、表情或肢体语言)就大概率可以在残酷的自然淘汰赛里幸存下来。

不得不从财务报表这样的密集数据里,发现机会和风险,是最近几百年才有的事儿。

巴菲特和芒格这样的投资大家,也许有这种超能力。但这种能力,显然不是所有人的标配。对普通人来说,理解大量的数据,统计图形很必要。因此人们常说,“一幅图胜过千言万语”。
在《如何用Python从海量文本抽取主题?》(6.2)一文里,我给你展示过如何绘制主题挖掘图形。
而《如何用Python和R对故事情节做情绪分析?》(5.3)一文中,我给你介绍了如何绘制故事情绪时间序列。
如你所见,这些图很有用。但是它们只是静态的。那么,如果图是动态的呢?那至少,它能够给我们提供更多一个维度的信息。
这种功能,真的有用吗?我这里给你看一个例子。
这幅动态统计图,描绘了世界不同区域,人均 GDP 和预期寿命之间的关联。随着左上角年份的不断变化,你会看到几十年来,这个世界的发展变化。Hans Rosling 曾经用类似的数据和动画效果,做了非常精彩的 TED 演讲。我上课的时候,不止一次拿来作为演示样例,让学生揣摩学习。

如果你感兴趣的话,可以点击这个链接查看视频。
你知道吗?只需要短短10行语句,你也能自己绘制出这个图形。
不过我们学东西,不宜贪多求快。要绘制上图,你需要了解相关的基础知识。一下子摄入很多新知,可能造成认知负荷,对你的学习兴趣没有益处。本文中,我用一个更简单的例子,给你展现如何用 R 绘制动态统计图。有了它作为基础,结合我给你推荐的相关学习资源,你也能很快做出更为实用,甚至是令人惊艳的动图。
4.3.2 预览
实际动手之前,我想让你看一下,用 R 可以绘制出什么样的动态统计图效果。你不需要安装任何软件。只需要点击这个链接(http://t.cn/ReaP9Mk),就可以使用 R 编程环境了。
等准备工作完毕,你会看到,浏览器里面开启了一个 RStudio 界面。
点击左上角的 File -> Open File,并且从出现的文件列表中,选择 code.Rmd 。
你就能看见下图这样打开该文件后的结果。
Rmd 文件后缀,代表 R Markdown,是 RStudio 这个 IDE 上可以使用的一种特殊的 Markdown 文件。说它特殊,是因为其中的代码段落,可以直接运行出结果。
界面左上方这里,有一个毛线球形状的按钮,名称叫做 Knit ,点击一下,它会把这个 code.Rmd 文件,转换成 HTML ,并且其中全部的代码,都显示出运行结果来。这是第一页:
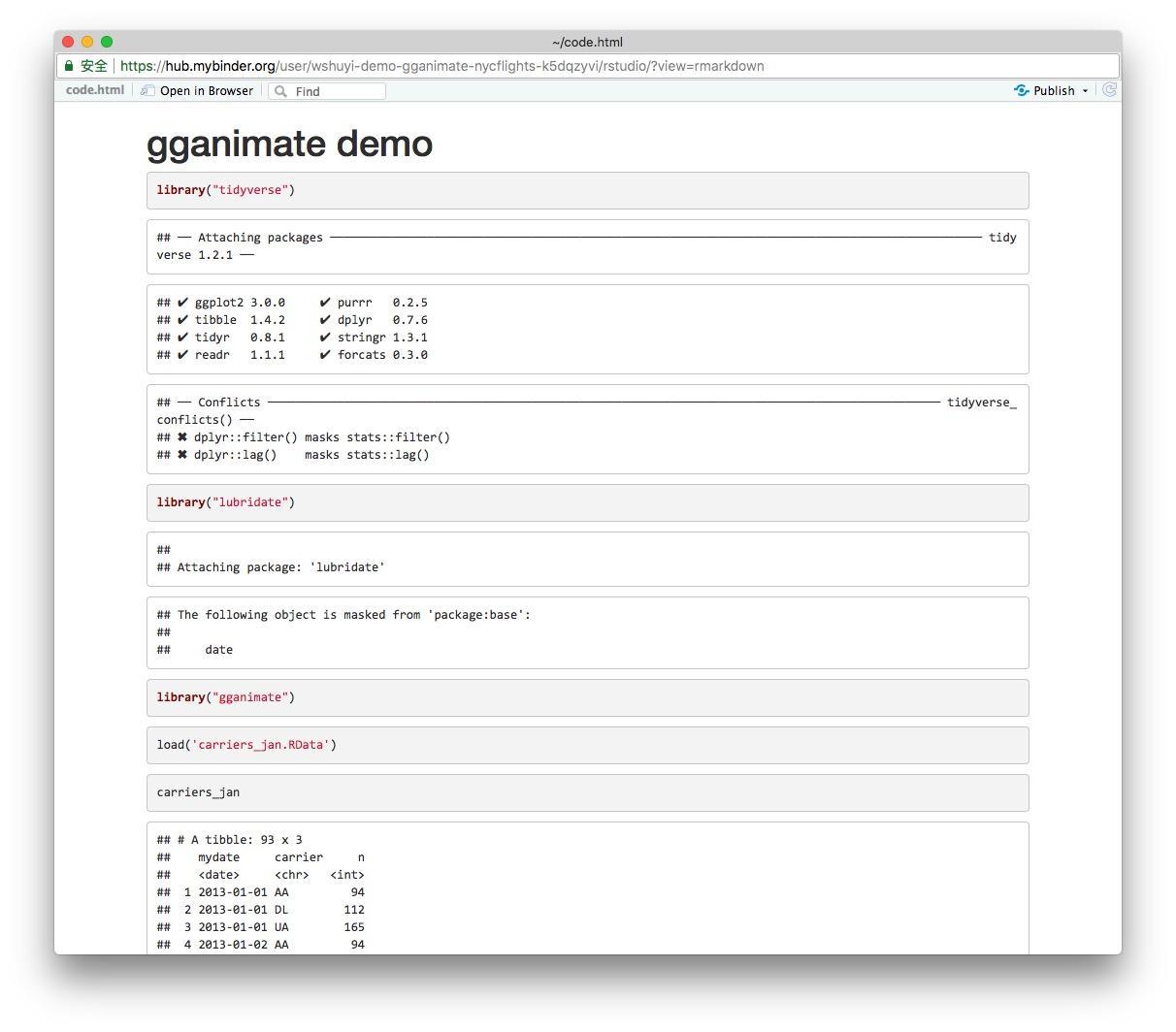
翻到最后一页,效果是这样的:

怎么样,挺有趣吧?想不想自己试试看?
4.3.3 上手
点击左上角的 File -> New File ,选择菜单里面的第一项 R Script 。
此时,你会看到左侧分栏一个空白编辑区域开启,可以输入语句了。
输入之前,我们先给文件起个名字。点击 File -> Save 按钮。
在新出现的对话框里面,输入 demo ,回车。
下面就可以输入并运行代码了。
其实我们下面输入的代码,就是刚才你在 code.Rmd 文件里见到的寥寥几个代码段落。而且,就连这几个代码段,也不是你将来绘制动态统计图都需要用到的。它们中的大多数内容,只是为了给你逐步展示方法,加入的中间过程而已。
如果你比较心急,只想获得最终的结果,那么你只需要录入以下这9行语句:
library("tidyverse")
library("lubridate")
library("gganimate")
load('carriers_jan.RData')
carriers_jan %>%
ggplot(aes(x=carrier, y=n, fill=carrier)) +
geom_bar(stat='identity', position='identity') +
transition_time(mydate) +
labs(title='{frame_time}')点击运行,就能做出你想要的结果了。
然而,这样一来,你还是不清楚具体语句的含义。将来没办法很好地应用到自己的实际工作和科研中去。所以如果你能抽出10分钟的时间,还是请按照我下面的说明来操作。根据教程,一步步手动输入语句。这样更有助于你的理解,收获会更大。
4.3.4 代码
首先,我们需要读入几个必要的软件包:
如果你看过我的《如何用R和API免费获取Web数据?》(9.2)一文,对于 tidyverse 应该并不陌生。它是大神 Hadley 等人共同开发的一系列 R 工具包合集。对我来说,它改变了之前 R 语言“难以学习”、“语法古怪”、“不好使用”等刻板印象。
lubridate 是用来处理时间数据的 R 软件包。如果没有这东西,你每次操作时间数据,都会麻烦许多。
gganimate 顾名思义,后面我们绘制动态图形,需要用到。
下面看看我们这次使用的数据。数据保存的格式是 .RData ,需要使用 load() 函数读入。
读入以后,保存在其中的一个数据框变量 carriers_jan 就复活了。下面我们看看其内容:
#### # A tibble: 93 x 3
#### mydate carrier n
#### <date> <chr> <int>
#### 1 2013-01-01 AA 94
#### 2 2013-01-01 DL 112
#### 3 2013-01-01 UA 165
#### 4 2013-01-02 AA 94
#### 5 2013-01-02 DL 152
#### 6 2013-01-02 UA 170
#### 7 2013-01-03 AA 95
#### 8 2013-01-03 DL 128
#### 9 2013-01-03 UA 159
#### 10 2013-01-04 AA 95
#### # ... with 83 more rows
这个数据实际上是从《如何用4行 R 语句,快速探索你的数据集?》(4.2)一文中的 nycflights13 数据集,通过转换得来的。转换后的数据,统计了不同航空公司在2013年1月,每一天从纽约三大机场起飞航班次数。
为了简便,我们在这个数据集里,只保留了3家航空公司,即:
- 美国航空(American Airlines,AA)
- 达美航空(Delta Air Lines, DL)
- 美联航(United Airlines, UA)
下面我们挑出1月1日的数据看看:
#### # A tibble: 3 x 3
#### mydate carrier n
#### <date> <chr> <int>
#### 1 2013-01-01 AA 94
#### 2 2013-01-01 DL 112
#### 3 2013-01-01 UA 165
可见,这一天里,美国航空起飞航班 94 架次,达美 112 ,美联航为 165 。
根据上表,我们绘制一张柱状图(bar chart)。横坐标是航空公司名称,是分类数据;纵坐标是航班次数,是量化数据。
carriers_jan %>%
filter(mydate == ymd('20130101')) %>%
ggplot(aes(x=carrier, y=n, fill=carrier)) +
geom_bar(stat='identity', position='identity')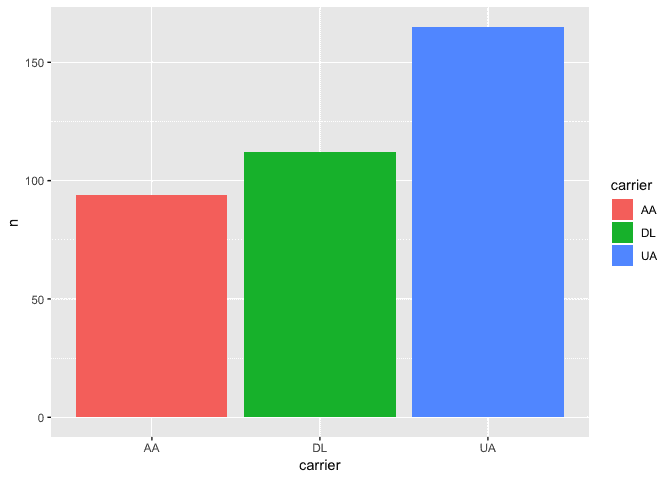
如上图所示,三家航空公司从纽约机场起飞次数,分别采用了不同颜色柱状图进行了可视化。红色是美国航空,绿色是达美航空,蓝色是美联航。
简单解释一下其中的 ggplot 语句。ggplot2 也是 Hadley Wickham 的作品,属于 tidyverse 软件包的一部分。它将 Leland Wilkinson 提出的“绘图语法”(Grammar of Graphics)在 R 语言上实现。
在《如何用 Python 和 API 收集与分析网络数据?》(9.3)一文中,我们已经介绍过 ggplot2 的 Python 克隆(plotnine),所以这里就不赘述背景了。你只要记住,它绘制图形的时候,采用的是“分层”机制就好。
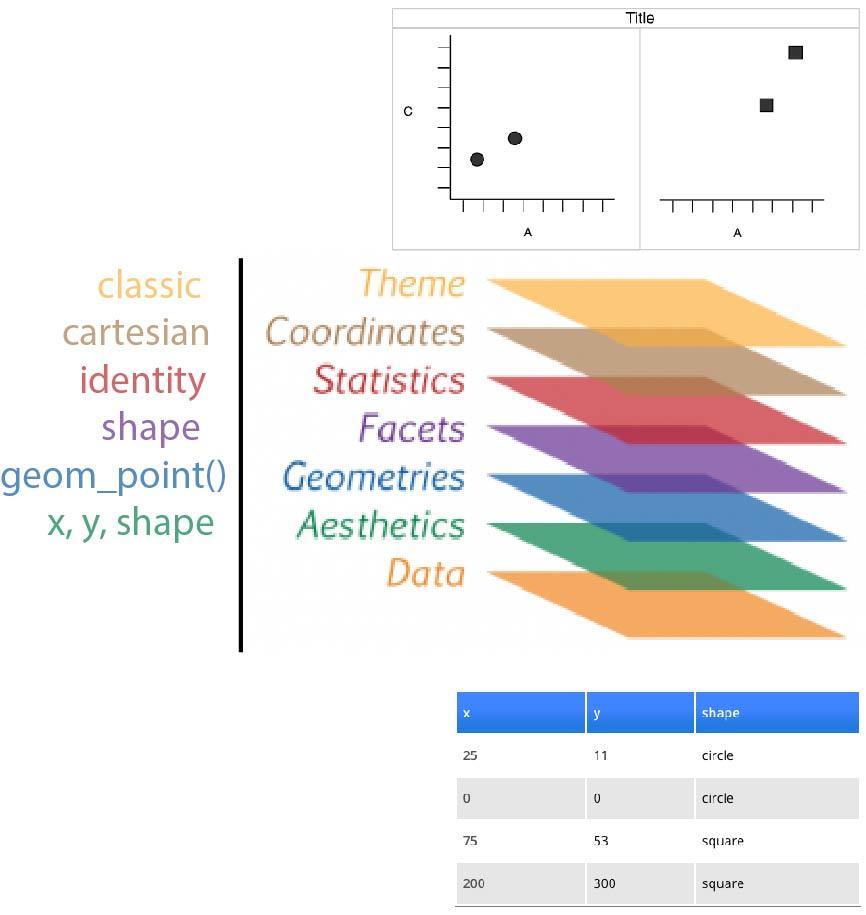
ggplot(aes(x=carrier, y=n, fill=carrier)) 这一句讲述映射(mapping)关系,指定了把 carrier 信息投射到 x 轴, n(航班次数)投射到 y 轴,用不同 carrier 类别填充不同的色彩。
但是单单这一句,实际上是绘制不出东西来的,不信你可以尝试执行一下:
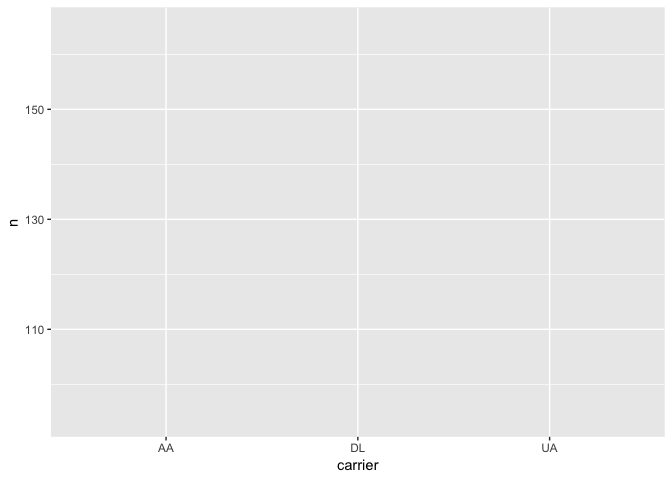
请注意这个图里, x 轴和 y 轴的设置,都与我们的预期一致。但是任何实质性内容,都没有绘制出来。因为咱们还没有告诉 ggplot ,打算画一个什么类别的统计图形。这就是下一句 geom_bar(stat='identity', position='identity') 的用处。
这句话告诉 ggplot ,请绘制柱状图,柱的高度按照 y 值设置,对应 x 上每一个取值(航空公司名称),分别绘制一根柱。
这张静态图,只能告诉我们2013年1月1日这一天,纽约机场这3个航空公司起飞航班数量信息。假如我们想多了解一个维度,也就是把时间加进去,怎么办?
这里办法并不唯一。
最简单的常规方法,是把三维信息压缩到二维平面里面去。因为我们看二维图像,除了能观察到位置区别之外,还可以辨识色彩。利用下列语句,你可以把这张图轻松做出来。
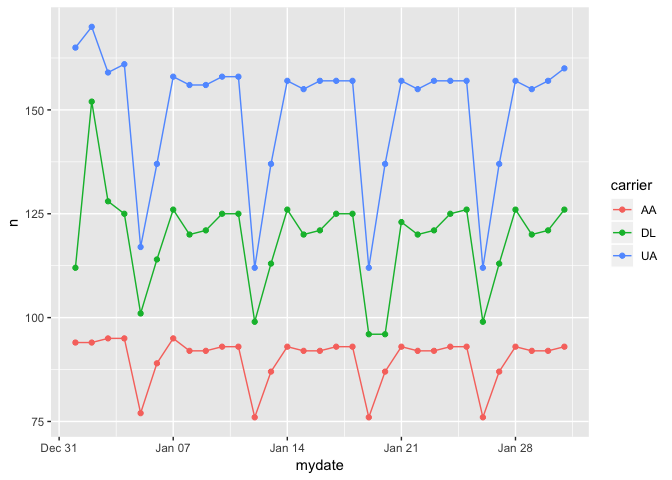
注意,这里因为我们不再把时间限定在1月1日了,因此你得把 filter(mydate == ymd('20130101')) 这一句去掉,使用全部1个月的时间。否则使用时间轴就没有意义了。
这里的 ggplot(aes(x=mydate, y=n, color=carrier)) ,你应该能观察到跟之前的图形间,映射关系的差别。不同于上一幅图,我们把 mydate ,而不是 carrier 映射到了 x 轴。 y 轴的映射关系没有变化。
我们此次不打算绘制柱状图了,而是描绘随时间变化趋势,所以选用的是散点图(geom_point())+折线图(geom_line())。这就意味着,再考虑柱状图里面的填充,就不恰当了,所以我们把 carrier 的信息,映射到颜色上去(color=carrier)。
从这张图里,你可以发现非常显著的规律性。假如你不想这样压缩信息,而希望用图形随时间的动态变化,来体现附加的时间维度,该怎么办?
这时,你就需要使用 gganimate 这个动画包的功能了。gganimate 目前的开发维护者,是 Thomas Lin Pedersen 。这是他的 github 页面地址。
他把原先的 gganimate 包接管了过来,仿照 ggplot 的风格,对语法进行了修改和补充,使其能够无缝融入到 ggplot 语句里,很方便地调用。因为可以用动态体现时间维度,所以我们这次依然绘制柱状图。语句如下:
carriers_jan %>%
ggplot(aes(x=carrier, y=n, fill=carrier)) +
geom_bar(stat='identity', position='identity') +
transition_time(mydate)
图动起来了,是吧?
解释一下语句。
与之前静态柱状图的区别,也是去掉了时间的限定那一句 filter(mydate == ymd('20130101')) ,以便描绘整个儿一月份的情况。另一个显著差别,是加入了最后一行语句, transition_time(mydate) ,这也是图像能够动起来的关键。
根据 gganimate 官方的说明,图形转换可以有多个不同类型语句来控制。因为我们恰好有 mydate 这个时间数据列,所以可以使用最自然而简单的 transition_time() 方法。transition_time(mydate) 根据时间信息对数据框进行切片,然后分别加以展示。图像因而动了起来。
不过,这里有个很严重的问题——你根本就看不清,当前的动态结果对应哪个时间。对不对?
咱们需要改进一下。改进的方法很简单:加入图片标题,显示时间,并且让标题对应着一起变化。修改后的代码如下:
carriers_jan %>%
ggplot(aes(x=carrier, y=n, fill=carrier)) +
geom_bar(stat='identity', position='identity') +
transition_time(mydate) +
labs(title='{frame_time}')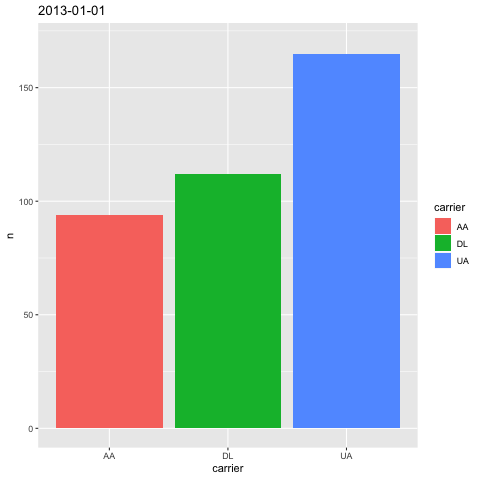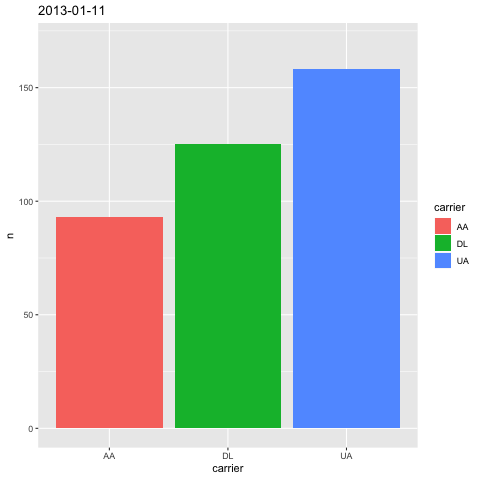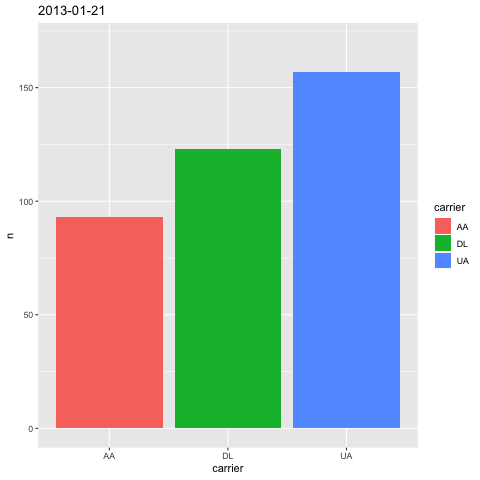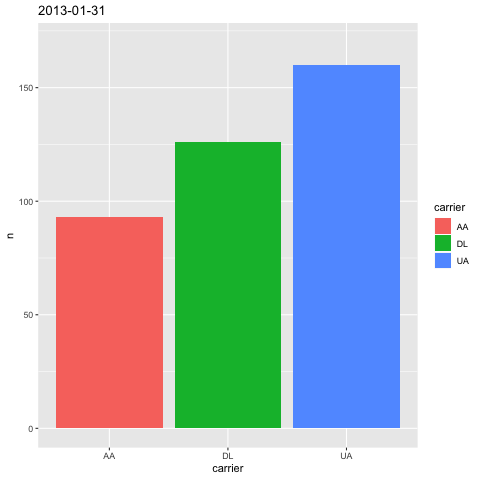
这下,你一眼就可以从标题中,看到当前动图对应的时间了。这里我们用到了 ggplot 的 labs() 函数,这个函数负责图片的标记设定,除了标题以外,你还可以设置横纵轴说明等内容。
我们用 title 参数设置标题内容。标题需要变化,所以我们得传入一个可以变化的量给 title 参数。我们传入的是 {frame_time} ,这就是我们刚才提到的, gganimate 自动切片所用的时间数据。 传入参数时,不要忘了需要将其包裹在双引号里,作为字符串类型传入。
4.3.5 小结
本文给你展示了 R 环境绘制动态统计图的方法,具体包含以下知识点:
- 如何读入
.RData格式的数据文件; - 如何利用
ggplot命令映射变量,选择统计图类型(包括柱状图、散点图和折线图等); - 如何使用
gganimate的transition_time()方法绘制基于时间数据的动态图; - 如何通过
labs设置,动态显示时间,以便于和图像的变化对应。
为了展示样例的最小化,本文的动态统计图非常简单,技术含量并不高。抛砖引玉。希望你举一反三,绘制出更有价值、内容也更加丰富的动态统计图来。
如果你对 ggplot2 绘图包感兴趣,想详细了解其语法,可以读作者 Hadley Wickham 自己写的书《ggplot2:数据分析与图形艺术》。

如果你想了解 gganimate 包的更多用法,可以阅读官方文档,或者看这段作者的演讲视频。

希望这些资源,能对你今后可视化沟通、展示自己的数据分析结果,有所帮助。
给你留个思考题:
本文中的数据,是从《如何用4行 R 语句,快速探索你的数据集?》(4.2)一文中的 nycflights13 数据集,通过转换(data manipulation)得来的。你能不能自己利用 R 或者 Python 语句,完成这一转化过程呢?
欢迎留言,把你的思考和解决过程分享给大家。
小提示:
- 如果你用 R ,可以参考 dplyr 包的文档;
- 如果你用 Python ,可以参考《推荐Python数据框Pandas视频教程》一文。
4.4 本章小结
如果你喜欢本章的内容,欢迎扫描下面二维码,请我喝杯咖啡。

如果你需要答疑,咱们的问答社区在这里: