第 6 章 机器学习
6.1 贷还是不贷:如何用Python和机器学习帮你决策?
耳闻目睹了机器学习的诸般神奇,有没有冲动打算自己尝试一下?本文我们通过一个贷款风险评估的案例,用最通俗的语言向你介绍机器学习的基础招式,一步步帮助你用Python完成自己的第一个机器学习项目。试过之后你会发现,机器学习真的不难。

6.1.1 任务
祝贺你,成功进入了一家金融公司实习。
第一天上班,你还处在兴奋中。这时主管把你叫过去,给你看了一个文件。
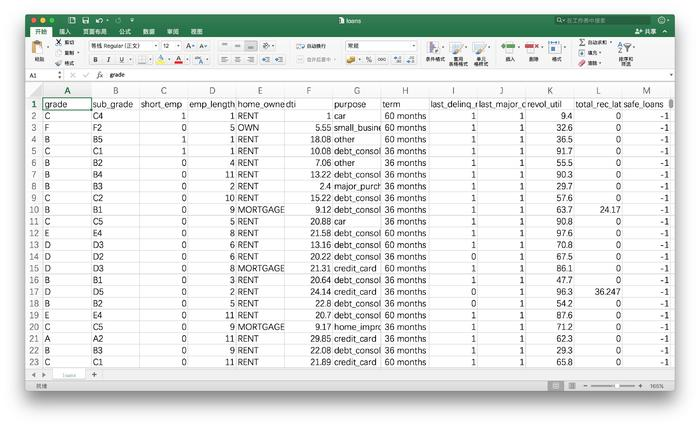
文件内容是这个样子的:
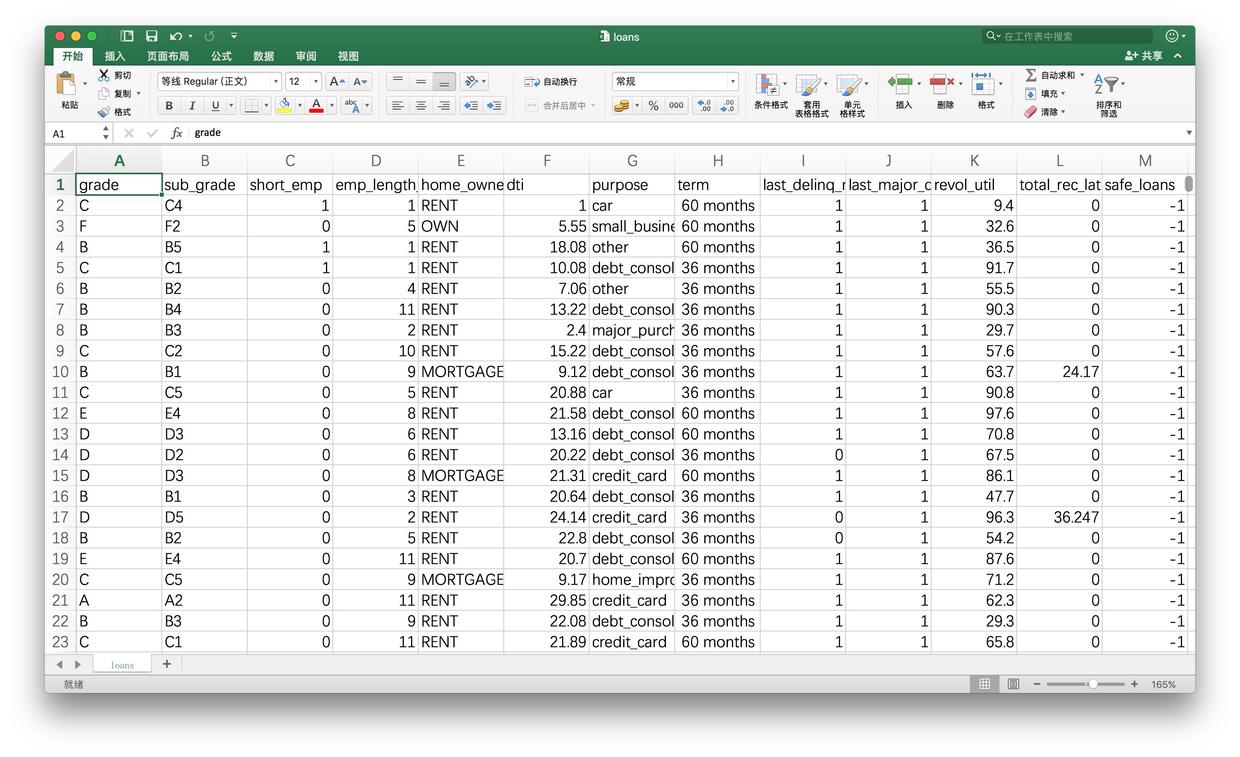
主管说这是公司宝贵的数据资产。嘱咐你认真阅读,并且从数字中找出规律,以便做出明智的贷款决策。
每一行数据,都代表了之前的一次贷款信息。你琢磨了很久,终于弄明白了每一列究竟代表什么意思:
- grade:贷款级别
- sub_grade: 贷款细分级别
- short_emp:一年以内短期雇佣
- emp_length_num:受雇年限
- home_ownership:居住状态(自有,按揭,租住)
- dti:贷款占收入比例
- purpose:贷款用途
- term:贷款周期
- last_delinq_none:贷款申请人是否有不良记录
- last_major_derog_none:贷款申请人是否有还款逾期90天以上记录
- revol_util:透支额度占信用比例
- total_rec_late_fee:逾期罚款总额
- safe_loans:贷款是否安全
最后一列,记录了这笔贷款是否按期收回。拿着以前的这些宝贵经验教训,主管希望你能够总结出贷款是否安全的规律。在面对新的贷款申请时,从容和正确应对。
主管让你找的这种规律,可以用决策树来表达。
6.1.2 决策
我们来说说什么是决策树。
决策树长得就像这个样子:
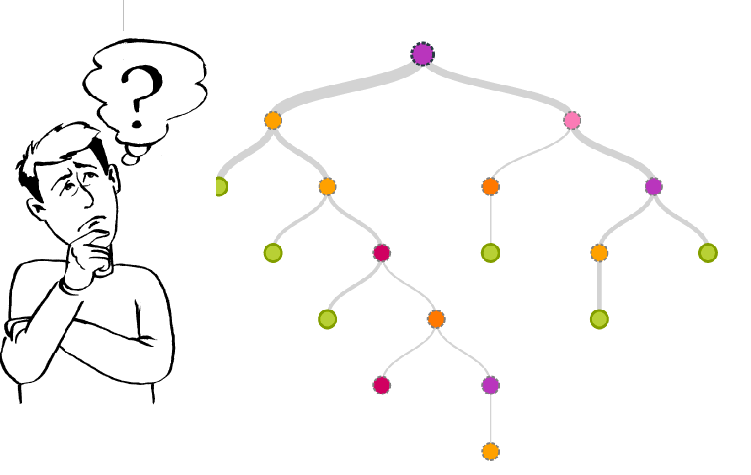
做决策的时候,你需要从最上面的节点出发。在每一个分支上,都有一个判断条件。满足条件,往左走;不满足,向右走。一旦走到了树的边缘,一项决策就完成了。
例如你走在街上,遇见邻居老张。你热情地打招呼:
“老张,吃了吗?”
好了,这里就是个分支。老张的回答,将决定你的决策走向,即后面你将说什么。
第一种情况。
老张:吃过了。
你:要不来我家再吃点儿?
第二种情况。
老张:还没吃。
你:那赶紧回家吃去吧。再见!
……
具体到贷款这个实例,你需要依次分析申请人的各项指标,然后判定这个贷款申请是否安全,以做出是否贷款给他的决策。把这个流程写下来,就是一棵决策树。
作为一名金融界新兵,你原本也是抱着积极开放的心态,希望多尝试一下的。但是当你把数据表下拉到最后一行的时候,你发现记录居然有46509条!
你估算了一下自己的阅读速度、耐心和认知负荷能力,觉得这个任务属于Mission Impossible(不可能完成),于是开始默默地收拾东西,打算找主管道个别,辞职不干了。
且慢,你不必如此沮丧。因为科技的发展,已经把一项黑魔法放在了你的手边,随时供你取用。它的名字,叫做机器学习。
6.1.3 学习
什么叫机器学习?
从前,人是“操作”计算机的。一项任务如何完成,人心里是完全有数的。人把一条条指令下达给电脑,电脑负责傻呵呵地干完,收工。
后来人们发现,对有些任务,人根本就不知道该怎么办。
前些日子的新闻里,你知道Alpha Go和柯洁下围棋。柯洁不仅输了棋,还哭了。

可是制造Alpha Go的那帮人,当真知道怎样下棋,才能赢过柯洁吗?你就是让他们放弃体育家精神,攒鸡毛凑掸子一起上,跟柯洁下棋……你估计哭的是谁?
一帮连自己下棋,都下不赢柯洁的人,又是如何制作出电脑软件,战胜了人类围棋界的“最强大脑”呢?
答案正是机器学习。
你自己都不知道如何完成的任务,自然也不可能告诉机器“第一步这么干,第二步那么办”,或者“如果出现A情况,打开第一个锦囊;如果出现B情况,打开第二个锦囊”。
机器学习的关键,不在于人类的经验和智慧,而在于数据。
本文我们接触到的,是最为基础的监督式学习(supervised learning)。监督式学习利用的数据,是机器最喜欢的。这些数据的特点,是都被打了标记。
主管给你的这个贷款记录数据集,就是打了标记的。针对每个贷款案例,后面都有“是否安全”的标记。1代表了安全,-1代表了不安全。
机器看到一条数据,又看到了数据上的标记,于是有了一个假设。
然后你再让它看一条数据,它就会强化或者修改原先的假设。
这就是学习的过程:建立假设——收到反馈——修正假设。在这个过程中,机器通过迭代,不断刷新自己的认知。
这让我想起了经典相声段子“蛤蟆鼓”里面的对话片段。
甲:那我问问你,蛤蟆你看见过吧?
乙:谁没见过蛤蟆呀。
甲:你说为什么它那么小的动物,叫唤出来的声音会那么大呢?
乙:那是因为它嘴大肚儿大脖子粗,叫唤出来的声音必然大。万物都是一个理。
甲:我家的字纸篓子也是嘴大脖子粗,为什么它不叫唤哪?
乙:字纸篓是死物,那是竹子编的,不但不叫,连响都响不了。
甲:吹的笙也是竹子的,怎么响呢?
乙:虽然竹子编的,因为它有窟窿有眼儿,有眼儿的就响。
甲:我家筛米的筛子尽是窟窿眼儿,怎么吹不响?
这里相声演员乙,就一直试图建立可以推广的假设。可惜,甲总是用新的例证摧毁乙的三观。
在四处碰壁后,可怜的机器跌跌撞撞地成长。看了许许多多的数据后,电脑逐渐有了自己对一些事情判断的想法。我们把这种想法叫做模型。
之后,你就可以用模型去辅助自己做出明智的判断了。
下面我们开始动手实践。用Python做个决策树出来,辅助我们判断贷款风险。
6.1.4 准备
使用Python和相关软件包,你需要先安装Anaconda套装。详细的流程步骤请参考《 如何用Python做词云(3.1) 》一文。
主管给你展示的这份贷款数据文件,请从 这里 下载。
文件的扩展名是csv,你可以用Excel打开,看看是否下载正确。
如果一切正常,请把它移动到咱们的工作目录demo里面。
到你的系统“终端”(macOS, Linux)或者“命令提示符”(Windows)下,进入我们的工作目录demo,执行以下命令。
pip install -U PIL运行环境配置完毕。
在终端或者命令提示符下键入:
jupyter notebook
Jupyter Notebook已经正确运行。下面我们就可以正式编写代码了。
6.1.5 代码
首先,我们新建一个Python 2笔记本,起名叫做loans-tree。
为了让Python能够高效率处理表格数据,我们使用一个非常优秀的数据处理框架Pandas。
然后我们把loans.csv里面的内容全部读取出来,存入到一个叫做df的变量里面。
我们看看df这个数据框的前几行,以确认数据读取无误。
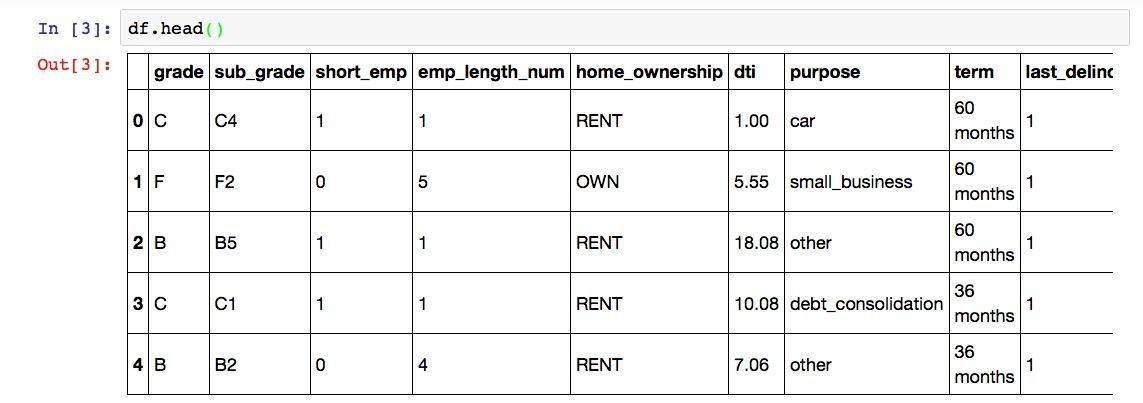
因为表格列数较多,屏幕上显示不完整,我们向右拖动表格,看表格最右边几列是否也正确读取。
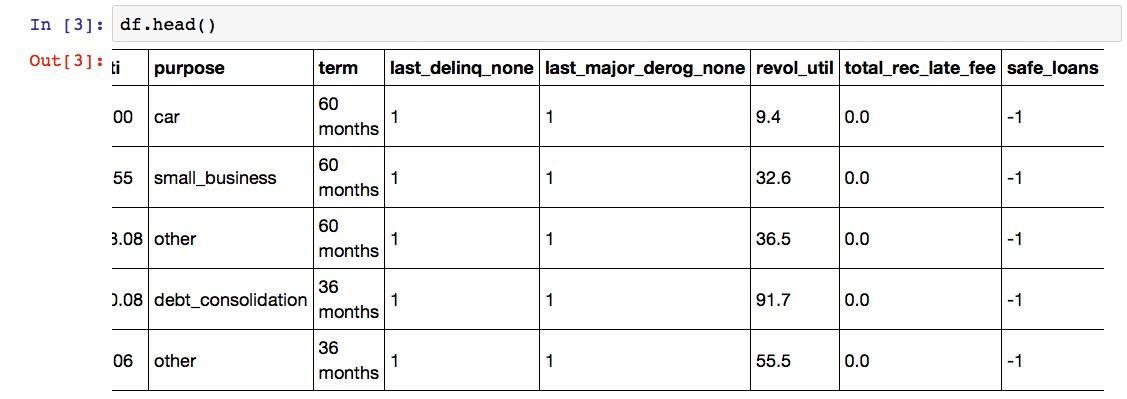
经验证,数据所有列都已读入。
统计一下总行数,看是不是所有行也都完整读取进来了。
运行结果如下:
(46508, 13)行列数量都正确,数据读取无误。
你应该还记得吧,每一条数据的最后一列safe_loans是个标记,告诉我们之前发放的这笔贷款是否安全。我们把这种标记叫做目标(target),把前面的所有列叫做“特征”(features)。这些术语你现在记不住没关系,因为以后会反复遇到。自然就会强化记忆。
下面我们就分别把特征和目标提取出来。依照机器学习领域的习惯,我们把特征叫做X,目标叫做y。
我们看一下特征数据X的形状:
运行结果为:
(46508, 12)除了最后一列,其他行列都在。符合我们的预期。我们再看看“目标”列。
执行后显示如下结果:
(46508,)这里的逗号后面没有数字,指的是只有1列。
我们来看看X的前几列。
运行结果为:
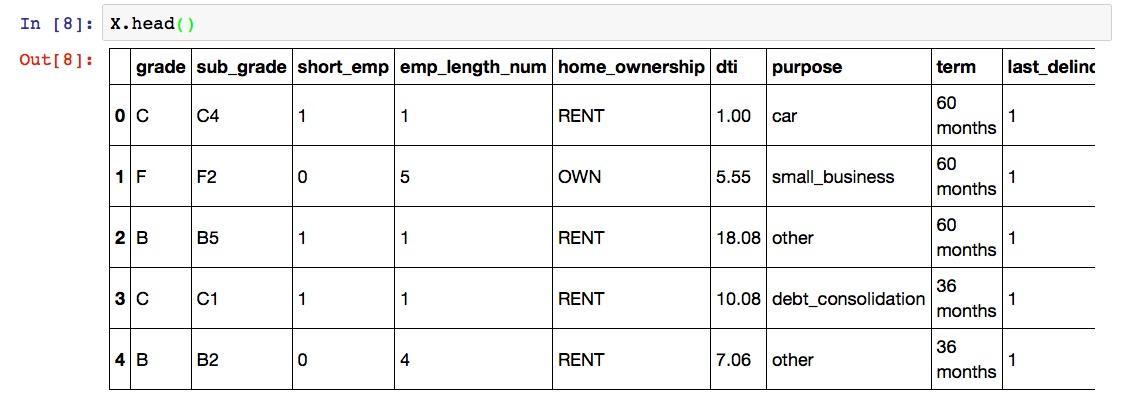
注意这里有一个问题。Python下做决策树的时候,每一个特征都应该是数值(整型或者实数)类型的。但是我们一眼就可以看出,grade, sub_grade, home_ownership等列的取值都是类别(categorical)型。所以,必须经过一步转换,把这些类别都映射成为某个数值,才能进行下面的步骤。
那我们就开始映射吧:
from sklearn.preprocessing import LabelEncoder
from collections import defaultdict
d = defaultdict(LabelEncoder)
X_trans = X.apply(lambda x: d[x.name].fit_transform(x))
X_trans.head()运行结果是这样的:
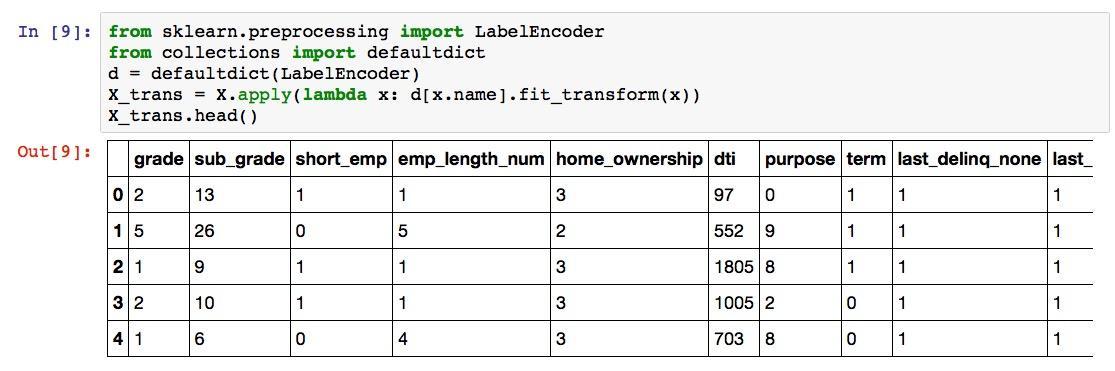
这里,我们使用了LabelEncoder函数,成功地把类别变成了数值。小测验:在grade列下面,B被映射成了什么数字?
请对比两个表格,思考10秒钟。
答案是1。你答对了吗?
下面我们需要做的事情,是把数据分成两部分,分别叫做训练集和测试集。
为什么这么折腾?
因为有道理。
想想看,如果期末考试之前,老师给你一套试题和答案,你把它背了下来。然后考试的时候,只是从那套试题里面抽取一部分考。你凭借超人的记忆力获得了100分。请问你学会了这门课的知识了吗?不知道如果给你新的题目,你会不会做呢?答案还是不知道。
所以考试题目需要和复习题目有区别。同样的道理,我们用数据生成了决策树,这棵决策树肯定对已见过的数据处理得很完美。可是它能否推广到新的数据上呢?这才是我们真正关心的。就如同在本例中,你的公司关心的,不是以前的贷款该不该贷。而是如何处理今后遇到的新贷款申请。
把数据随机拆分成训练集和测试集,在Python里只需要2条语句就够了。
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_trans, y, random_state=1)我们看看训练数据集的形状:
运行结果如下:
(34881, 12)测试集呢?
这是运行结果:
(11627, 12)至此,一切数据准备工作都已就绪。我们开始呼唤Python中的scikit-learn软件包。决策树的模型,已经集成在内。只需要3条语句,直接调用就可以,非常方便。
from sklearn import tree
clf = tree.DecisionTreeClassifier(max_depth=3)
clf = clf.fit(X_train, y_train)好了,你要的决策树已经生成完了。
就是这么简单。任性吧?
可是,我怎么知道生成的决策树是个什么样子呢?眼见才为实!
这个……好吧,咱们把决策树画出来吧。注意这一段语句内容较多。以后有机会咱们再详细介绍。此处你把它直接抄进去执行就可以了。
with open("safe-loans.dot", 'w') as f:
f = tree.export_graphviz(clf,
out_file=f,
max_depth = 3,
impurity = True,
feature_names = list(X_train),
class_names = ['not safe', 'safe'],
rounded = True,
filled= True )
from subprocess import check_call
check_call(['dot','-Tpng','safe-loans.dot','-o','safe-loans.png'])
from IPython.display import Image as PImage
from PIL import Image, ImageDraw, ImageFont
img = Image.open("safe-loans.png")
draw = ImageDraw.Draw(img)
img.save('output.png')
PImage("output.png")见证奇迹的时刻到了:
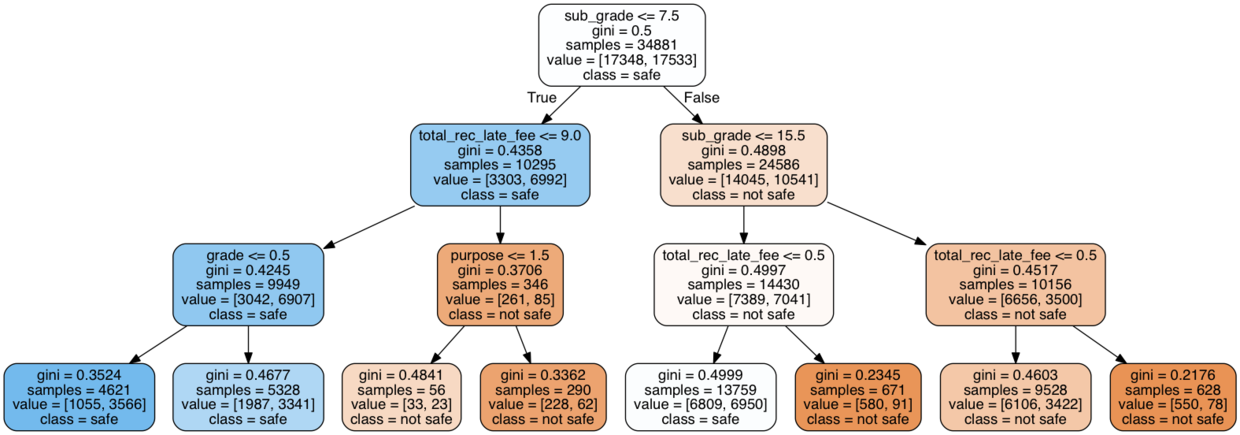
你是不是跟我第一次看到决策树的可视化结果一样,惊诧了?
我们其实只让Python生成了一棵简单的决策树(深度仅3层),但是Python已经尽职尽责地帮我们考虑到了各种变量对最终决策结果的影响。
6.1.6 测试
欣喜若狂的你,在悄悄背诵什么?你说想把这棵决策树的判断条件背下来,然后去做贷款风险判断?
省省吧。都什么时代了,还这么喜欢背诵?
以后的决策,电脑可以自动化帮你完成了。
你不信?
我们随便从测试集里面找一条数据出来。让电脑用决策树帮我们判断一下看看。
电脑告诉我们,它调查后风险结果是这样的:
array([1])之前提到过,1代表这笔贷款是安全的。实际情况如何呢?我们来验证一下。从测试集目标里面取出对应的标记:
结果是:
1经验证,电脑通过决策树对这个新见到的贷款申请风险判断无误。
但是我们不能用孤证来说明问题。下面我们验证一下,根据训练得来的决策树模型,贷款风险类别判断准确率究竟有多高。
虽然测试集有近万条数据,但是电脑立即就算完了:
0.61615205986066912你可能会有些失望——忙活了半天,怎么才60%多的准确率?刚及格而已嘛。
不要灰心。因为在整个儿的机器学习过程中,你用的都是缺省值,根本就没有来得及做一个重要的工作——优化。
想想看,你买一台新手机,自己还得设置半天,不是吗?面对公司的贷款业务,你用的竟然只是没有优化的缺省模型。可即便这样,准确率也已经超过了及格线。
关于优化的问题,以后有机会咱们详细展开来聊。
你终于摆脱了实习第一天就灰溜溜逃走的厄运。我仿佛看到了一颗未来的华尔街新星正在冉冉升起。
苟富贵,无相忘哦。
6.2 如何用Python从海量文本抽取主题?
你在工作、学习中是否曾因信息过载叫苦不迭?有一种方法能够替你读海量文章,并将不同的主题和对应的关键词抽取出来,让你谈笑间观其大略。本文使用Python对超过1000条文本做主题抽取,一步步带你体会非监督机器学习LDA方法的魅力。想不想试试呢?

6.2.1 淹没
每个现代人,几乎都体会过信息过载的痛苦。文章读不过来,音乐听不过来,视频看不过来。可是现实的压力,使你又不能轻易放弃掉。
假如你是个研究生,教科书和论文就是你不得不读的内容。现在有了各种其他的阅读渠道,微信、微博、得到App、多看阅读、豆瓣阅读、Kindle,还有你在RSS上订阅的一大堆博客……情况就变得更严重了。
因为对数据科学很感兴趣,你订阅了大量的数据科学类微信公众号。虽然你很勤奋,但你知道自己依然遗漏了很多文章。
学习了 Python爬虫课 以后,你决定尝试一下自己的屠龙之术。依仗着爬虫的威力,你打算采集到所有数据科学公众号文章。
你仔细分析了微信公众号文章的检索方式,制定了关键词列表。巧妙利用搜狗搜索引擎的特性,你编写了自己的爬虫,并且成功地于午夜放到了云端运行。
开心啊,激动啊……
第二天一早,天光刚亮,睡眠不足的你就兴冲冲地爬起来去看爬取结果。居然已经有了1000多条!你欣喜若狂,导出成为csv格式,存储到了本地机器,并且打开浏览。
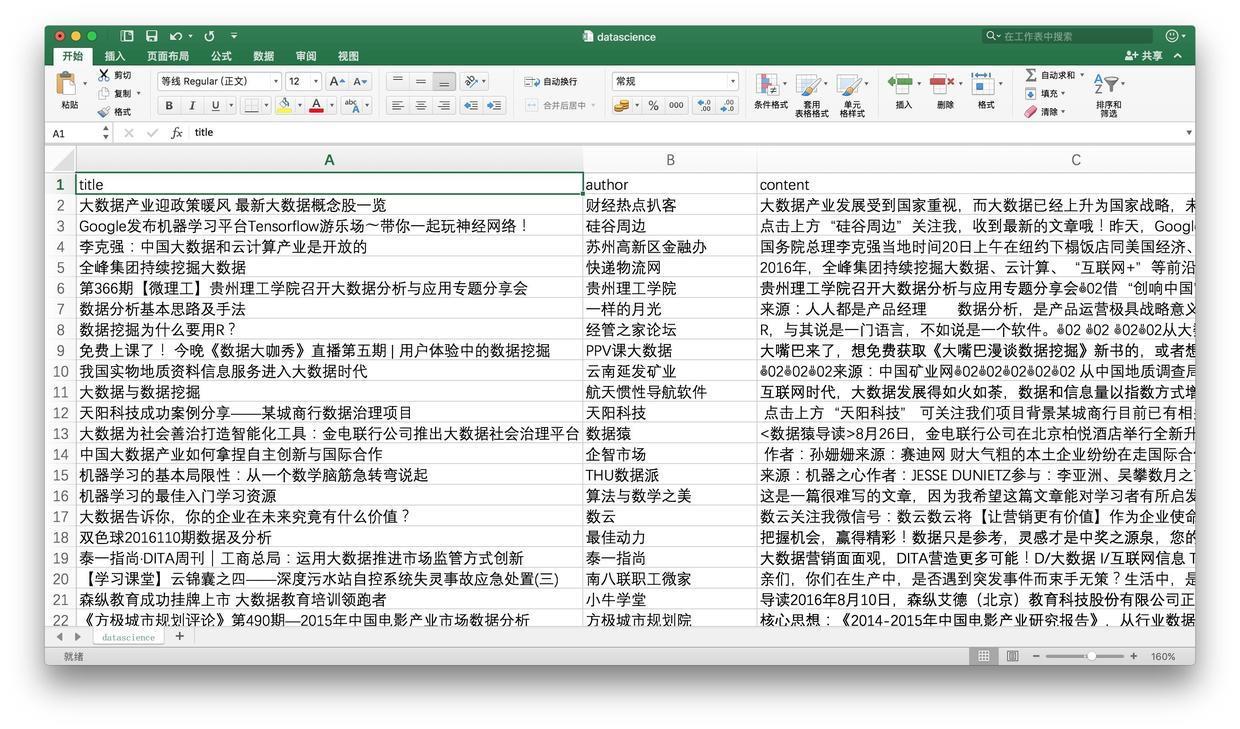
兴奋了10几分钟之后,你冷却了下来,给自己提出了2个重要的问题。 * 这些文章都值得读吗? * 这些文章我读得过来吗?
一篇数据科学类公众号,你平均需要5分钟阅读。这1000多篇……你拿出计算器认真算了一下。
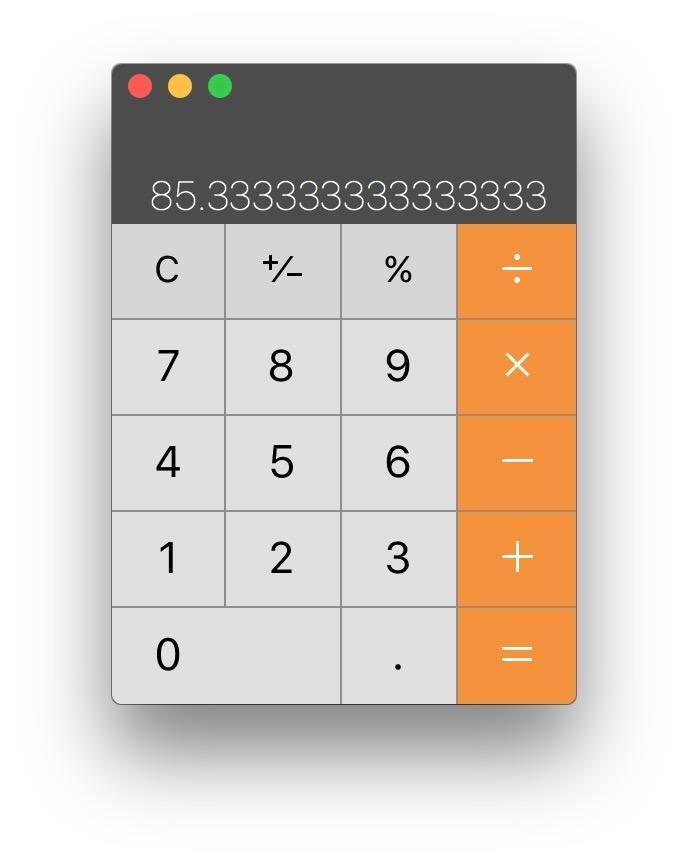
读完这一宿采集到的文章,你不眠不休的话,也需要85个小时。
在你阅读的这85个小时里面,许许多多的数据科学类公众号新文章还会源源不断涌现出来。
你感觉自己快被文本内容淹没了,根本透不过气……
学了这么长时间Python,你应该想到——我能否用自动化工具来分析它?
好消息,答案是可以的。
但是用什么样的工具呢?
翻了翻你自己的武器库,你发现了词云](#make-wordcloud-with-python)、情感分析(5.1和[决策树(6.1))。
然而,在帮你应对信息过载这件事儿上,上述武器好像都不大合适。
词云你打算做几个?全部文章只做一个的话,就会把所有文章的内容混杂起来,没有意义——因为你知道这些文章谈的就是数据科学啊!如果每一篇文章都分别做词云,1000多张图浏览起来,好像也没有什么益处。
你阅读数据科学类公众号文章是为了获得知识和技能,分析文字中蕴含的情感似乎于事无补。
决策树是可以用来做分类的,没错。可是它要求的输入信息是结构化的有标记数据,你手里握着的这一大堆文本,却刚好是非结构化的无标记数据。
全部武器都哑火了。
没关系。本文帮助你在数据科学武器库中放上一件新式兵器。它能够处理的,就是大批量的非结构无标记数据。在机器学习的分类里,它属于非监督学习(unsupervised machine learning)范畴。具体而言,我们需要用到的方法叫主题建模(topic model)或者主题抽取(topic extraction)。
6.2.2 主题
既然要建模,我们就需要弄明白建立什么样的模型。
根据维基百科的定义,主题模型是指:
在机器学习和自然语言处理等领域是用来在一系列文档中发现抽象主题的一种统计模型。
这个定义本身好像就有点儿抽象,咱们举个例子吧。
还是维基百科上,对一条可爱的小狗有这样一段叙述。
阿博(Bo;2008年10月9日-) 是美国第44任总统巴拉克·奥巴马的宠物狗,也是奥巴马家族的成员之一。阿博是一只已阉割的雄性黑色长毛葡萄牙水犬。奥巴马一家本来没有养狗,因为他的大女儿玛丽亚对狗过敏。但为了延续白宫主人历年均有养狗的传统,第一家庭在入主白宫后,花了多个月去观察各种犬种,并特地选择了葡萄牙水犬这一种掉毛少的低敏狗。
我们来看看这条可爱的小狗照片:

问题来了,这篇文章的主题(topic)是什么?
你可能脱口而出,“狗啊!”
且慢,换个问法。假设一个用户读了这篇文章,很感兴趣。你想推荐更多他可能感兴趣的文章给他,以下2段文字,哪个选项更合适呢?
选项1:
阿富汗猎狗(Afghan Hound)是一种猎犬,也是最古老的狗品种。阿富汗猎狗外表厚实,细腻,柔滑,它的尾巴在最后一环卷曲。阿富汗猎狗生存于伊朗,阿富汗东部的寒冷山上,阿富汗猎狗最初是用来狩猎野兔和瞪羚。阿富汗猎狗其他名称包含巴尔赫塔子库奇猎犬,猎犬,俾路支猎犬,喀布尔猎犬,或非洲猎犬。
选项2:
1989年夏天,奥巴马在西德利·奥斯汀律师事务所担任暑期工读生期间,结识当时已是律师的米歇尔·鲁滨逊。两人于1992年结婚,现有两个女儿——大女儿玛丽亚在1999年于芝加哥芝加哥大学医疗中心出生,而小女儿萨沙在2001年于芝加哥大学医疗中心出生。
给你30秒,思考一下。
你的答案是什么?
我的答案是——不确定。
人类天生喜欢把复杂问题简单化。我们恨不得把所有东西划分成具体的、互不干扰的分类,就如同药铺的一个个抽屉一样。然后需要的时候,从对应的抽屉里面取东西就可以了。

这就像是职业。从前我们说“三百六十行”。随便拿出某个人来,我们就把他归入其中某一行。
现在不行了,反例就是所谓的“斜杠青年”。
主题这个事情,也同样不那么泾渭分明。介绍小狗Bo的文章虽然不长,但是任何单一主题都无法完全涵盖它。
如果用户是因为对小狗的喜爱,阅读了这篇文章,那么显然你给他推荐选项1会更理想;但是如果用户关注的是奥巴马的家庭,那么比起选项2来,选项1就显得不是那么合适了。
我们必须放弃用一个词来描述主题的尝试,转而用一系列关键词来刻画某个主题(例如“奥巴马”+“宠物“+”狗“+”第一家庭“)。
在这种模式下,以下的选项3可能会脱颖而出:
据英国《每日邮报》报道,美国一名男子近日试图绑架总统奥巴马夫妇的宠物狗博(Bo),不惜由二千多公里远的北达科他州驱车往华盛顿,但因为走漏风声,被特勤局人员逮捕。奥巴马夫妇目前养有博和阳光(Sunny)两只葡萄牙水犬。
讲到这里,你大概弄明白了主题抽取的目标了。可是面对浩如烟海的文章,我们怎么能够把相似的文章聚合起来,并且提取描述聚合后主题的重要关键词呢?
主题抽取有若干方法。目前最为流行的叫做隐含狄利克雷分布(Latent Dirichlet allocation),简称LDA。
LDA相关原理部分,置于本文最后。下面我们先用Python来尝试实践一次主题抽取。如果你对原理感兴趣,不妨再做延伸阅读。
6.2.3 准备
准备工作的第一步,还是先安装Anaconda套装。详细的流程步骤请参考《 如何用Python做词云(3.1) 》一文。
从微信公众平台爬来的datascience.csv文件,请从 这里 下载。你可以用Excel打开,看看下载是否完整和正确。
如果一切正常,请将该csv文件移动到咱们的工作目录demo下。
到你的系统“终端”(macOS, Linux)或者“命令提示符”(Windows)下,进入我们的工作目录demo,执行以下命令。
pip install jieba
pip install pyldavis运行环境配置完毕。
在终端或者命令提示符下键入:
jupyter notebook
Jupyter Notebook已经正确运行。下面我们就可以正式编写代码了。
6.2.4 代码
我们在Jupyter Notebook中新建一个Python 2笔记本,起名为topic-model。
为了处理表格数据,我们依然使用数据框工具Pandas。先调用它。
然后读入我们的数据文件datascience.csv,注意它的编码是中文GB18030,不是Pandas默认设置的编码,所以此处需要显式指定编码类型,以免出现乱码错误。
我们来看看数据框的头几行,以确认读取是否正确。
显示结果如下:

没问题,头几行内容所有列都正确读入,文字显式正常。我们看看数据框的长度,以确认数据是否读取完整。
执行的结果为:
(1024, 3)行列数都与我们爬取到的数量一致,通过。
下面我们需要做一件重要工作——分词。这是因为我们需要提取每篇文章的关键词。而中文本身并不使用空格在单词间划分。此处我们采用“结巴分词”工具。这一工具的具体介绍和其他用途请参见《如何用Python做中文分词?》(3.3)一文。
我们首先调用jieba分词包。
我们此次需要处理的,不是单一文本数据,而是1000多条文本数据,因此我们需要把这项工作并行化。这就需要首先编写一个函数,处理单一文本的分词。
有了这个函数之后,我们就可以不断调用它来批量处理数据框里面的全部文本(正文)信息了。你当然可以自己写个循环来做这项工作。但这里我们使用更为高效的apply函数。如果你对这个函数有兴趣,可以点击这段教学视频查看具体的介绍。
下面这一段代码执行起来,可能需要一小段时间。请耐心等候。
执行过程中可能会出现如下提示。没关系,忽略就好。
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/8s/k8yr4zy52q1dh107gjx280mw0000gn/T/jieba.cache
Loading model cost 0.406 seconds.
Prefix dict has been built succesfully.执行完毕之后,我们需要查看一下,文本是否已经被正确分词。
结果如下:
0 大 数据 产业 发展 受到 国家 重视 , 而 大 数据 已经 上升 为 国家 战略 , 未...
1 点击 上方 “ 硅谷 周边 ” 关注 我 , 收到 最新 的 文章 哦 ! 昨天 , Goo...
2 国务院 总理 李克强 当地 时间 20 日 上午 在 纽约 下榻 饭店 同 美国 经济 、 ...
3 2016 年 , 全峰 集团 持续 挖掘 大 数据 、 云 计算 、 “ 互联网 + ” 等...
4 贵州 理工学院 召开 大 数据分析 与 应用 专题 分享 会 借 “ 创响 中国 ” 贵...
Name: content_cutted, dtype: object单词之间都已经被空格区分开了。下面我们需要做一项重要工作,叫做文本的向量化。
不要被这个名称吓跑。它的意思其实很简单。因为计算机不但不认识中文,甚至连英文也不认识,它只认得数字。我们需要做的,是把文章中的关键词转换为一个个特征(列),然后对每一篇文章数关键词出现个数。
假如这里有两句话:
I love the game. I hate the game.
那么我们就可以抽取出以下特征: * I * love * hate * the * game
然后上面两句话就转换为以下表格:

第一句表示为[1, 1, 0, 1, 1],第二句是[1, 0, 1, 1, 1]。这就叫向量化了。机器就能看懂它们了。
原理弄清楚了,让我们引入相关软件包吧。
处理的文本都是微信公众号文章,里面可能会有大量的词汇。我们不希望处理所有词汇。因为一来处理时间太长,二来那些很不常用的词汇对我们的主题抽取意义不大。所以这里做了个限定,只从文本中提取1000个最重要的特征关键词,然后停止。
下面我们开始关键词提取和向量转换过程:
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
max_features=n_features,
stop_words='english',
max_df = 0.5,
min_df = 10)
tf = tf_vectorizer.fit_transform(df.content_cutted)到这里,似乎什么都没有发生。因为我们没有要求程序做任何输出。下面我们就要放出LDA这个大招了。
先引入软件包:
然后我们需要人为设定主题的数量。这个要求让很多人大跌眼镜——我怎么知道这一堆文章里面多少主题?!
别着急。应用LDA方法,指定(或者叫瞎猜)主题个数是必须的。如果你只需要把文章粗略划分成几个大类,就可以把数字设定小一些;相反,如果你希望能够识别出非常细分的主题,就增大主题个数。
对划分的结果,如果你觉得不够满意,可以通过继续迭代,调整主题数量来优化。
这里我们先设定为5个分类试试。
n_topics = 5
lda = LatentDirichletAllocation(n_topics=n_topics, max_iter=50,
learning_method='online',
learning_offset=50.,
random_state=0)把我们的1000多篇向量化后的文章扔给LDA,让它欢快地找主题吧。
这一部分工作量较大,程序会执行一段时间,Jupyter Notebook在执行中可能暂时没有响应。等待一会儿就好,不要着急。
程序终于跑完了的时候,你会看到如下的提示信息:
LatentDirichletAllocation(batch_size=128, doc_topic_prior=None,
evaluate_every=-1, learning_decay=0.7,
learning_method='online', learning_offset=50.0,
max_doc_update_iter=100, max_iter=50, mean_change_tol=0.001,
n_jobs=1, n_topics=5, perp_tol=0.1, random_state=0,
topic_word_prior=None, total_samples=1000000.0, verbose=0)可是,这还是什么输出都没有啊。它究竟找了什么样的主题?
主题没有一个确定的名称,而是用一系列关键词刻画的。我们定义以下的函数,把每个主题里面的前若干个关键词显示出来:
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" % topic_idx)
print(" ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]))
print()定义好函数之后,我们暂定每个主题输出前20个关键词。
以下命令会帮助我们依次输出每个主题的关键词表:
tf_feature_names = tf_vectorizer.get_feature_names()
print_top_words(lda, tf_feature_names, n_top_words)执行效果如下:
Topic #0:
学习 模型 使用 算法 方法 机器 可视化 神经网络 特征 处理 计算 系统 不同 数据库 训练 分类 基于 工具 一种 深度
Topic #1:
这个 就是 可能 如果 他们 没有 自己 很多 什么 不是 但是 这样 因为 一些 时候 现在 用户 所以 非常 已经
Topic #2:
企业 平台 服务 管理 互联网 公司 行业 数据分析 业务 用户 产品 金融 创新 客户 实现 系统 能力 产业 工作 价值
Topic #3:
中国 2016 电子 增长 10 市场 城市 2015 关注 人口 检索 30 或者 其中 阅读 应当 美国 全国 同比 20
Topic #4:
人工智能 学习 领域 智能 机器人 机器 人类 公司 深度 研究 未来 识别 已经 医疗 系统 计算机 目前 语音 百度 方面
()在这5个主题里,可以看出主题0主要关注的是数据科学中的算法和技术,而主题4显然更注重数据科学的应用场景。
剩下的几个主题可以如何归纳?作为思考题,留给你花时间想一想吧。
到这里,LDA已经成功帮我们完成了主题抽取。但是我知道你不是很满意,因为结果不够直观。
那咱们就让它直观一些好了。
执行以下命令,会有有趣的事情发生。
import pyLDAvis
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
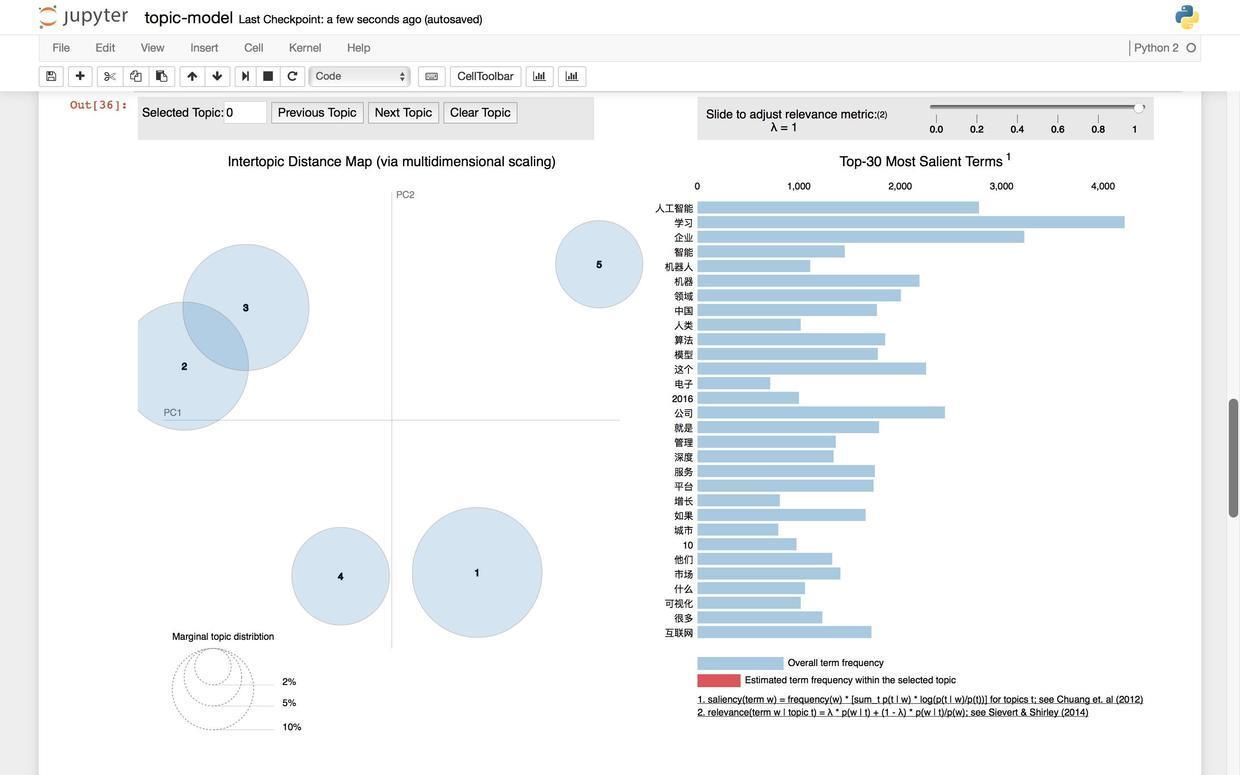
pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)对,你会看到如下的一张图,而且还是可交互的动态图哦。
需要说明的是,由于pyLDAvis这个包兼容性有些问题。因此在某些操作系统和软件环境下,你执行了刚刚的语句后,没有报错,却也没有图形显示出来。
没关系。这时候请你写下以下语句并执行:
Jupyter会给你提示一些警告。不用管它。因为此时你的浏览器会弹出一个新的标签页,结果图形会在这个标签页里正确显示出来。
如果你看完了图后,需要继续程序,就回到原先的标签页,点击Kernel菜单下的第一项Interrupt停止绘图,然后往下运行新的语句。
图的左侧,用圆圈代表不同的主题,圆圈的大小代表了每个主题分别包含文章的数量。
图的右侧,列出了最重要(频率最高)的30个关键词列表。注意当你没有把鼠标悬停在任何主题之上的时候,这30个关键词代表全部文本中提取到的30个最重要关键词。
如果你把鼠标悬停在1号上面:
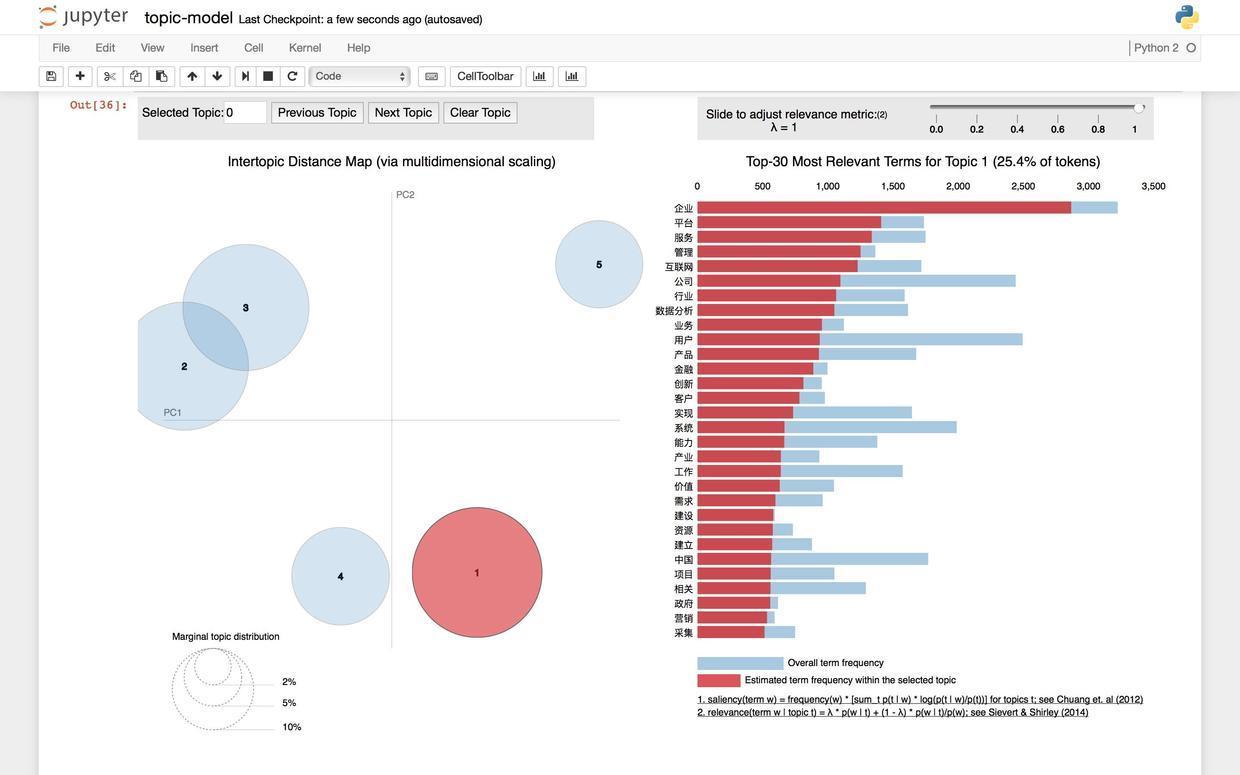
右侧的关键词列表会立即发生变化,红色展示了每个关键词在当前主题下的频率。
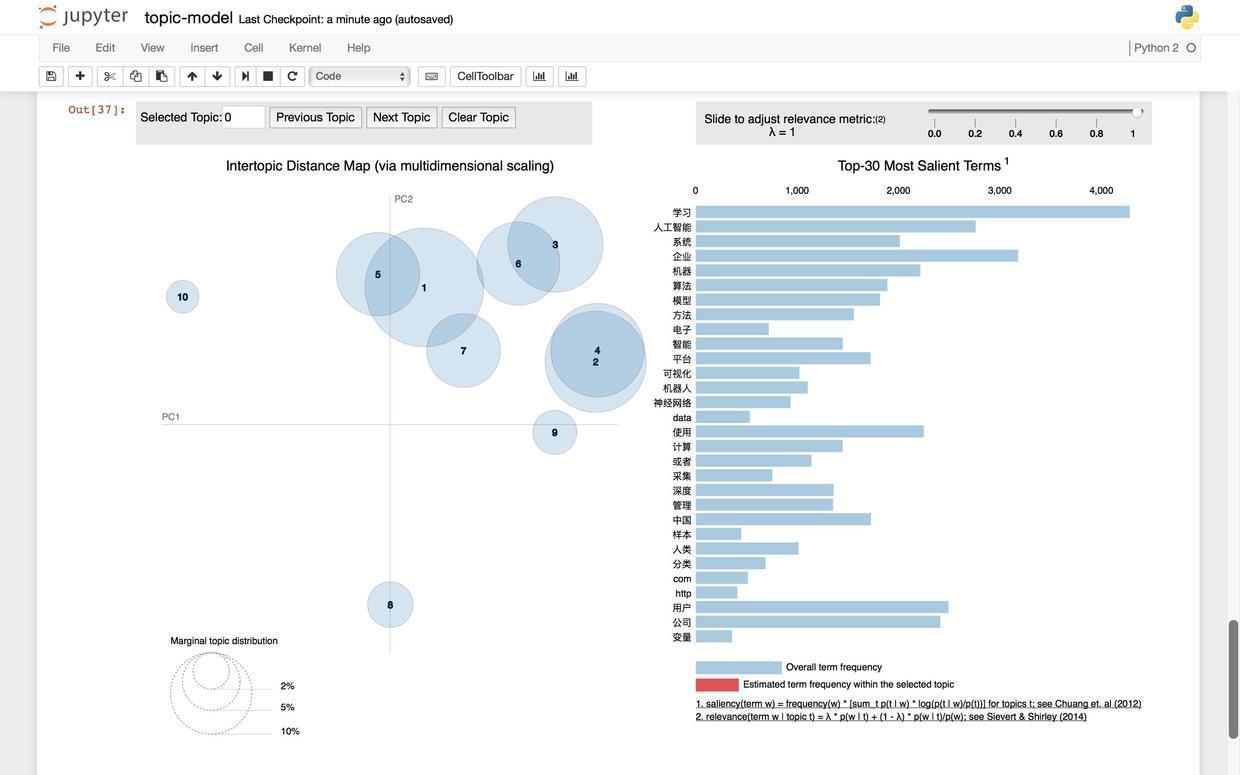
以上是认为设定主题数为5的情况。可如果我们把主题数量设定为10呢?
你不需要重新运行所有代码,只需要执行下面这几行就可以了。
这段程序还是需要运行一段时间,请耐心等待。
n_topics = 10
lda = LatentDirichletAllocation(n_topics=n_topics, max_iter=50,
learning_method='online',
learning_offset=50.,
random_state=0)
lda.fit(tf)
print_top_words(lda, tf_feature_names, n_top_words)
pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)程序输出给我们10个主题下最重要的20个关键词。
Topic #0:
这个 就是 如果 可能 用户 一些 什么 很多 没有 这样 时候 但是 因为 不是 所以 不同 如何 使用 或者 非常
Topic #1:
中国 孩子 增长 市场 2016 学生 10 2015 城市 自己 人口 大众 关注 其中 教育 同比 没有 美国 投资 这个
Topic #2:
data 变量 距离 http 样本 com www 检验 方法 分布 计算 聚类 如下 分类 之间 两个 一种 差异 表示 序列
Topic #3:
电子 采集 应当 或者 案件 保护 规定 信用卡 收集 是否 提取 设备 法律 申请 法院 系统 记录 相关 要求 无法
Topic #4:
系统 检索 交通 平台 专利 智能 监控 采集 海量 管理 搜索 智慧 出行 视频 车辆 计算 实现 基于 数据库 存储
Topic #5:
可视化 使用 工具 数据库 存储 hadoop 处理 图表 数据仓库 支持 查询 开发 设计 sql 开源 用于 创建 用户 基于 软件
Topic #6:
学习 算法 模型 机器 深度 神经网络 方法 训练 特征 分类 网络 使用 基于 介绍 研究 预测 回归 函数 参数 图片
Topic #7:
企业 管理 服务 互联网 金融 客户 行业 平台 实现 建立 社会 政府 研究 资源 安全 时代 利用 传统 价值 医疗
Topic #8:
人工智能 领域 机器人 智能 公司 人类 机器 学习 未来 已经 研究 他们 识别 可能 计算机 目前 语音 工作 现在 能够
Topic #9:
用户 公司 企业 互联网 平台 中国 数据分析 行业 产业 产品 创新 项目 2016 服务 工作 科技 相关 业务 移动 市场
()附带的是可视化的输出结果:
如果不能直接输出图形,还是按照前面的做法,执行:
你马上会发现当主题设定为10的时候,一些有趣的现象发生了——大部分的文章抱团出现在右上方,而2个小部落(8和10)似乎离群索居。我们查看一下这里的8号主题,看看它的关键词构成。
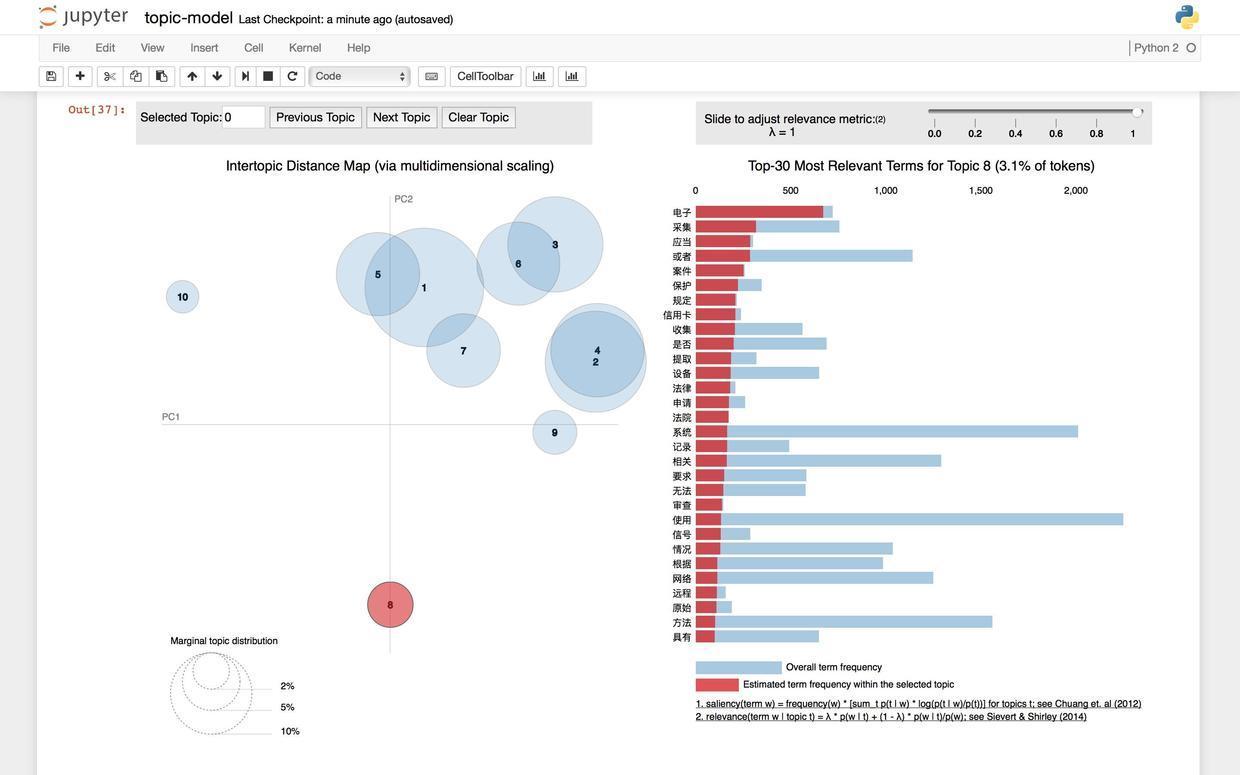
通过高频关键词的描述,我们可以猜测到这一主题主要探讨的是政策和法律法规问题,难怪它和那些技术、算法与应用的主题显得如此格格不入。
6.2.5 说明
前文帮助你一步步利用LDA做了主题抽取。成就感爆棚吧?然而这里有两点小问题值得说明。
首先,信息检索的业内专家一看到刚才的关键词列表,就会哈哈大笑——太粗糙了吧!居然没有做中文停用词(stop words)去除!没错,为了演示的流畅,我们这里忽略了许多细节。很多内容使用的是预置默认参数,而且完全忽略了中文停用词设置环节,因此“这个”、“如果”、“可能”、“就是”这样的停用词才会大摇大摆地出现在结果中。不过没有关系,完成比完美重要得多。知道了问题所在,后面改进起来很容易。有机会我会写文章介绍如何加入中文停用词的去除环节。
另外,不论是5个还是10个主题,可能都不是最优的数量选择。你可以根据程序反馈的结果不断尝试。实际上,可以调节的参数远不止这一个。如果你想把全部参数都搞懂,可以继续阅读下面的“原理”部分,按图索骥寻找相关的说明和指引。
6.2.6 原理
前文我们没有介绍原理,而是把LDA当成了一个黑箱。不是我不想介绍原理,而是过于复杂。
只给你展示其中的一个公式,你就能管窥其复杂程度了。
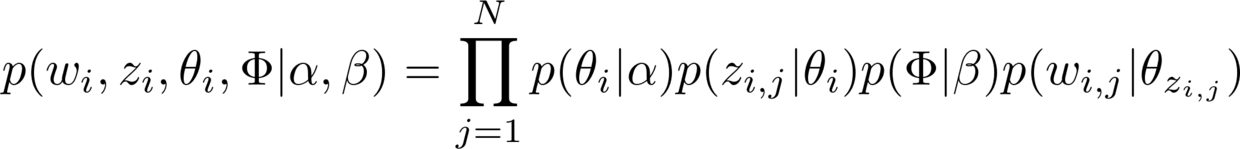
透露给你一个秘密:在计算机科学和数据科学的学术讲座中,讲者在介绍到LDA时,都往往会把原理这部分直接跳过去。
好在你不需要把原理完全搞清楚,再去用LDA抽取主题。
这就像是学开车,你只要懂得如何加速、刹车、换挡、打方向,就能让车在路上行驶了。即便你通过所有考试并取得了驾驶证,你真的了解发动机或电机(如果你开的是纯电车)的构造和工作原理吗?
但是如果你就是希望了解LDA的原理,那么我给你推荐2个学起来不那么痛苦的资源吧。
首先是教程幻灯。slideshare是个寻找教程的好去处。 这份教程 浏览量超过20000,内容深入浅出,讲得非常清晰。
但如果你跟我一样,是个视觉学习者的话,我更推荐你看 这段 Youtube视频。
讲者是Christine Doig,来自Continuum Analytics。咱们一直用的Python套装Anaconda就是该公司的产品。
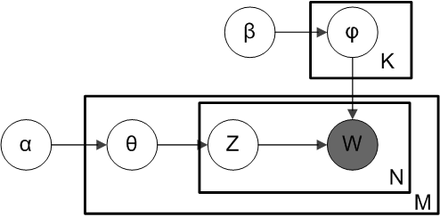
Christine使用的LDA原理解释模型,不是这个LDA经典论文中的模型图(大部分人觉得这张图不易懂):
她深入阅读了各种文献后,总结了自己的模型图出来:
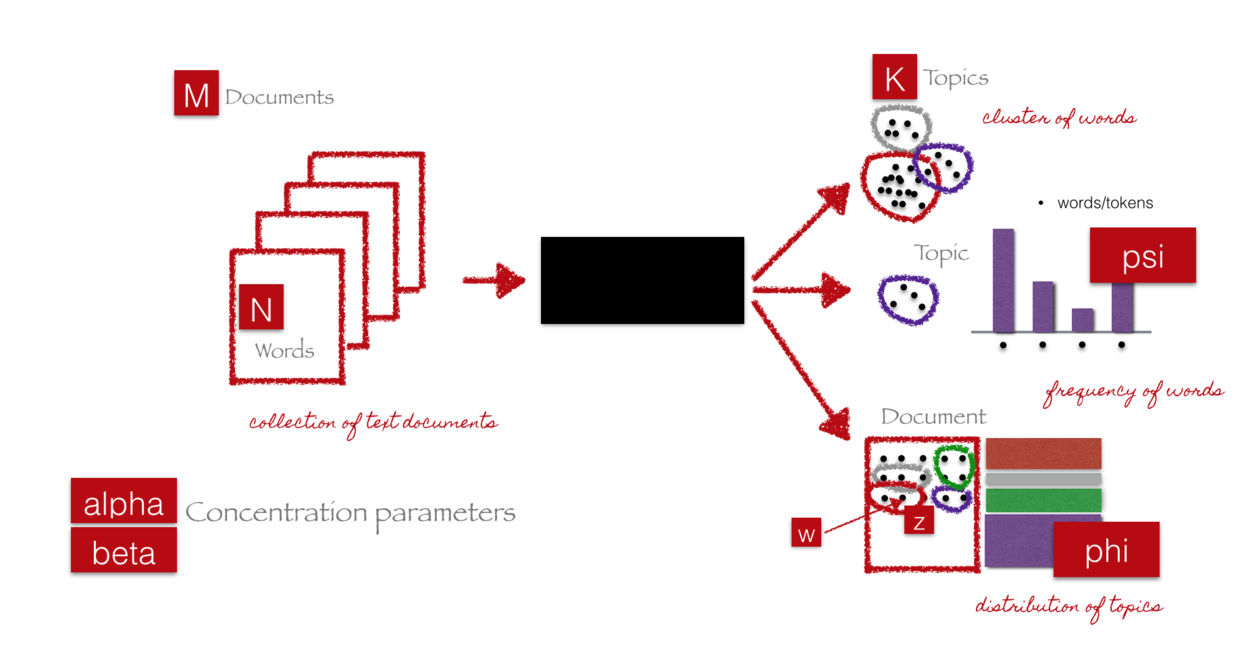
用这个模型来解释LDA,你会立即有豁然开朗的感觉。
祝探索旅程愉快!
6.3 如何用Python和机器学习训练中文文本情感分类模型?
利用Python机器学习框架scikit-learn,我们自己做一个分类模型,对中文评论信息做情感分析。其中还会介绍中文停用词的处理方法。

6.3.1 疑惑
前些日子,我在微信后台收到了一则读者的留言。

我一下子有些懵——这怎么还带点播了呢?
但是旋即我醒悟过来,好像是我自己之前挖了个坑。
之前我写过《 如何用Python从海量文本抽取主题?(6.2) 》一文,其中有这么一段:
为了演示的流畅,我们这里忽略了许多细节。很多内容使用的是预置默认参数,而且完全忽略了中文停用词设置环节,因此“这个”、“如果”、“可能”、“就是”这样的停用词才会大摇大摆地出现在结果中。不过没有关系,完成比完美重要得多。知道了问题所在,后面改进起来很容易。有机会我会写文章介绍如何加入中文停用词的去除环节。
根据“自己挖坑自己填”的法则,我决定把这一部分写出来。
我可以使用偷懒的办法。
例如在原先的教程里,更新中文停用词处理部分,打个补丁。
但是,最近我发现,好像至今为止,我们的教程从来没有介绍过如何用机器学习做情感分析。
你可能说,不对吧?
情感分析不是讲过了吗?老师你好像讲过《 如何用Python做情感分析?(5.1 》,《 如何用Python做舆情时间序列可视化?](#sentiment-series-vis-in-python) 》和《 [如何用Python和R对《权力的游戏》故事情节做情绪分析?(5.3)) 》。
你记得真清楚,提出表扬。
但是请注意,之前这几篇文章中,并没有使用机器学习方法。我们只不过调用了第三方提供的文本情感分析工具而已。
但是问题来了,这些第三方工具是在别的数据集上面训练出来的,未必适合你的应用场景。
例如有些情感分析工具更适合分析新闻,有的更善于处理微博数据……你拿过来,却是要对店铺评论信息做分析。
这就如同你自己笔记本电脑里的网页浏览器,和图书馆电子阅览室的网页浏览器,可能类型、版本完全一样。但是你用起自己的浏览器,就是比公用电脑上的舒服、高效——因为你已经根据偏好,对自己浏览器上的“书签”、“密码存储”、“稍后阅读”都做了个性化设置。
咱们这篇文章,就给你讲讲如何利用Python和机器学习,自己训练模型,对中文评论数据做情感分类。
\# 数据
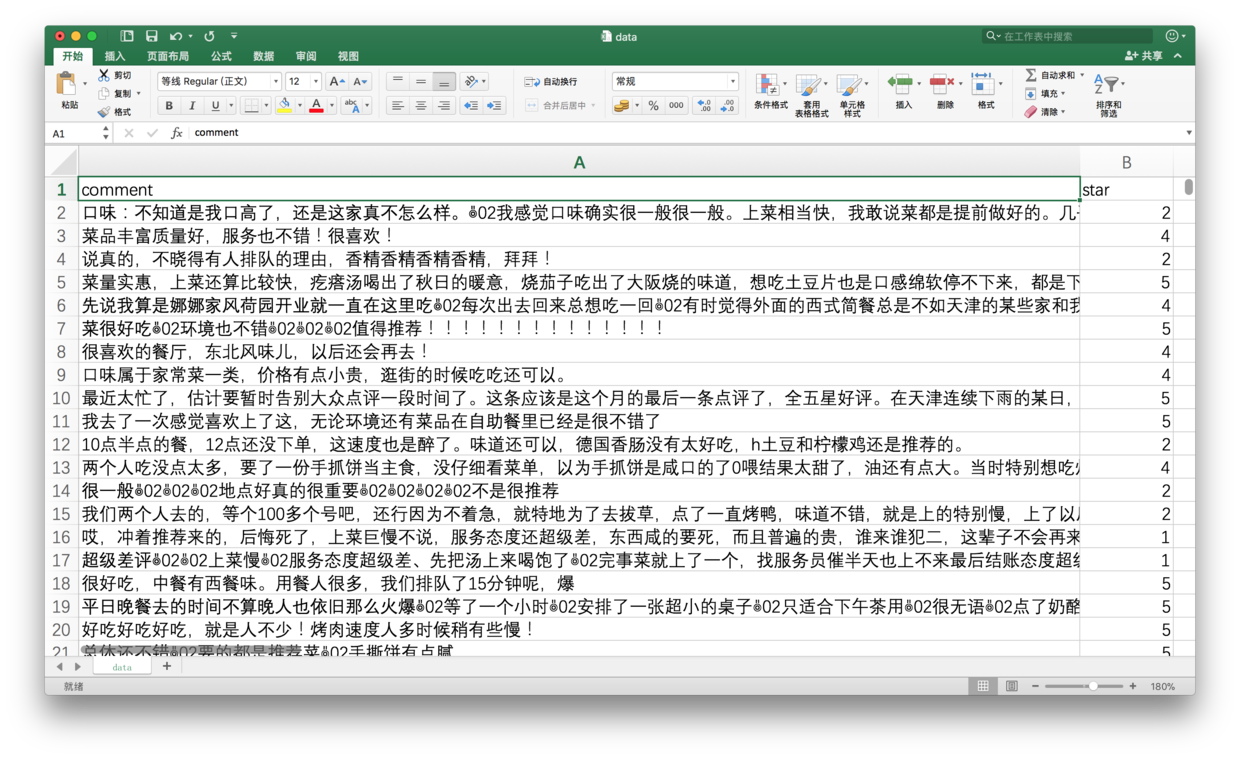
我的一个学生,利用爬虫抓取了大众点评网站上的数万条餐厅评论数据。
这些数据在爬取时,包含了丰富的元数据类型。
我从中抽取了评论文本和评星(1-5星),用于本文的演示。
从这些数据里,我们随机筛选评星为1,2,4,5的,各500条评论数据。一共2000条。
为什么只甩下评星数量为3的没有选择?
你先思考10秒钟,然后往下看,核对答案。
答案是这样的:
因为我们只希望对情感做出(正和负)二元分类,4和5星可以看作正向情感,1和2是负向情感……3怎么算?
所以,为了避免这种边界不清晰造成的混淆,咱们只好把标为3星的内容丢弃掉了。
整理好之后的评论数据,如下图所示。
我已经把数据放到了演示文件夹压缩包里面。后文会给你提供下载路径。
6.3.2 模型
使用机器学习的时候,你会遇到模型的选择问题。
例如,许多模型都可以用来处理分类问题。逻辑回归、决策树、SVM、朴素贝叶斯……具体到咱们的评论信息情感分类问题,该用哪一种呢?
幸好,Python上的机器学习工具包 scikit-learn 不仅给我们提供了方便的接口,供我们调用,而且还非常贴心地帮我们做了小抄(cheat-sheet)。
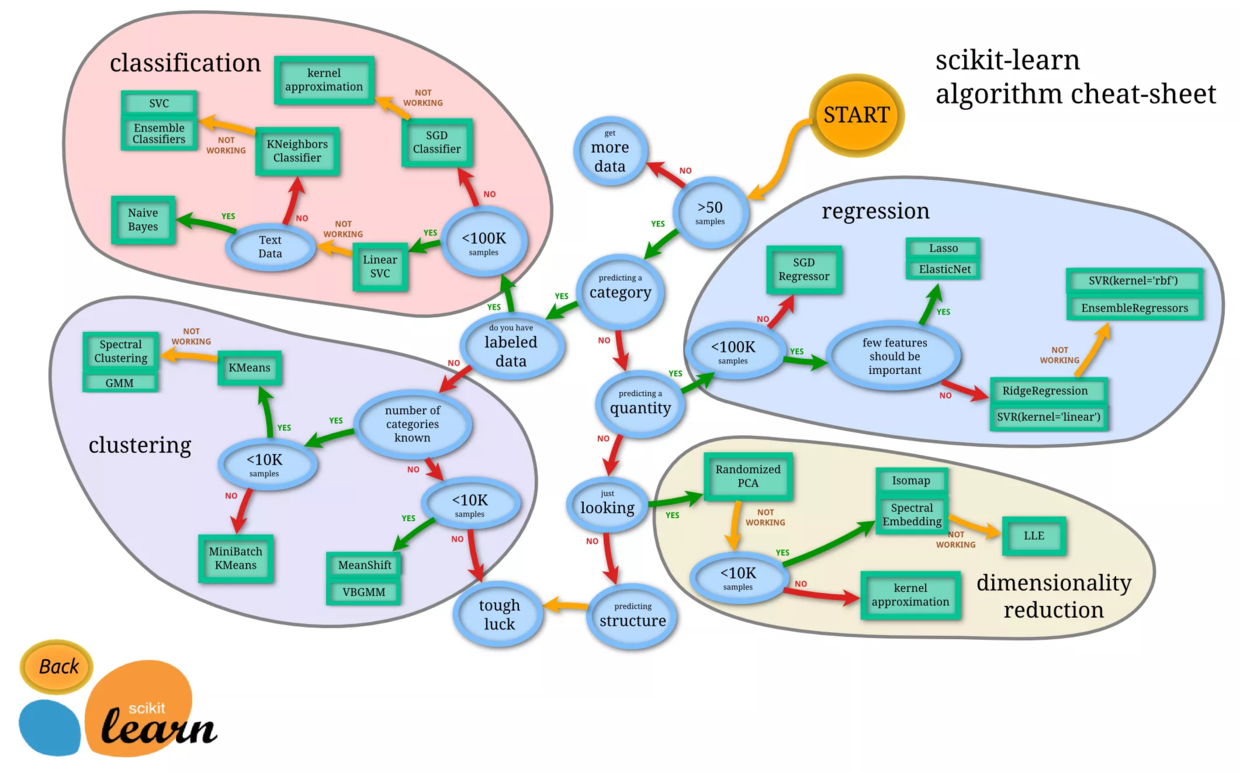
这张图看似密密麻麻,非常混乱,实际上是一个非常好的迷宫指南。其中绿色的方框,是各种机器学习模型。而蓝色的圆圈,是你做判断的地方。
你看,咱们要处理类别问题,对吧?
顺着往下看,会要求你判断数据是否有标记。我们有啊。
继续往下走,数据小于100K吗?
考虑一下,我们的数据有2000条,小于这个阈值。
接下来问是不是文本数据?是啊。
于是路径到了终点。
Scikit-learn告诉我们:用朴素贝叶斯模型好了。
小抄都做得如此照顾用户需求,你对scikit-learn的品质应该有个预期了吧?如果你需要使用经典机器学习模型(你可以理解成深度学习之外的所有模型),我推荐你先尝试scikit-learn 。
6.3.3 向量化
《 如何用Python从海量文本抽取主题?(6.2) 》一文里,我们讲过自然语言处理时的向量化。
忘了?
没关系。
子曰:
学而时习之,不亦乐乎?
这里咱们复习一下。
对自然语言文本做向量化(vectorization)的主要原因,是计算机看不懂自然语言。
计算机,顾名思义,就是用来算数的。文本对于它(至少到今天)没有真正的意义。
但是自然语言的处理,是一个重要问题,也需要自动化的支持。因此人就得想办法,让机器能尽量理解和表示人类的语言。
假如这里有两句话:
I love the game.
I hate the game.
那么我们就可以简单粗暴地抽取出以下特征(其实就是把所有的单词都罗列一遍):
- I
- love
- hate
- the
- game
对每一句话,都分别计算特征出现个数。于是上面两句话就转换为以下表格:

按照句子为单位,从左到右读数字,第一句表示为[1, 1, 0, 1, 1],第二句就成了[1, 0, 1, 1, 1]。
这就叫向量化。
这个例子里面,特征的数量叫做维度。于是向量化之后的这两句话,都有5个维度。
你一定要记住,此时机器依然不能理解两句话的具体含义。但是它已经尽量在用一种有意义的方式来表达它们。
注意这里我们使用的,叫做“一袋子词”(bag of words)模型。
下面这张图(来自 https://goo.gl/2jJ9Kp ),形象化表示出这个模型的含义。
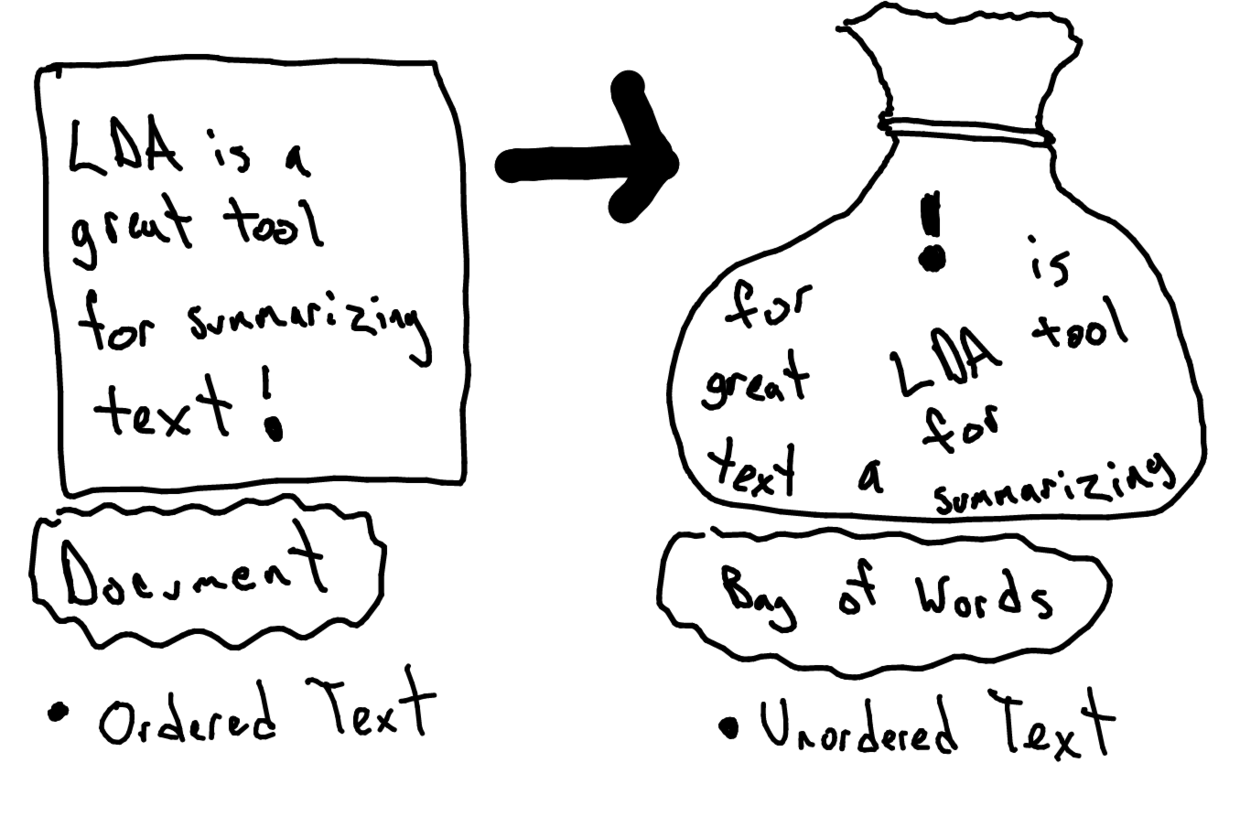 一袋子词模型不考虑词语的出现顺序,也不考虑词语和前后词语之间的连接。每个词都被当作一个独立的特征来看待。
一袋子词模型不考虑词语的出现顺序,也不考虑词语和前后词语之间的连接。每个词都被当作一个独立的特征来看待。
你可能会问:“这样不是很不精确吗?充分考虑顺序和上下文联系,不是更好吗?”
没错,你对文本的顺序、结构考虑得越周全,模型可以获得的信息就越多。
但是,凡事都有成本。只需要用基础的排列组合知识,你就能计算出独立考虑单词,和考虑连续n个词语(称作 n-gram),造成的模型维度差异了。
为了简单起见,咱们这里还是先用一袋子词吧。有空我再给你讲讲……
打住,不能再挖坑了。
6.3.4 中文
上一节咱们介绍的,是自然语言向量化处理的通则。
处理中文的时候,要更加麻烦一些。
因为不同于英文、法文等拉丁语系文字,中文天然没有空格作为词语之间的分割符号。
我们要先将中文分割成空格连接的词语。
例如把:
“我喜欢这个游戏”
变成:
“我 喜欢 这个 游戏”
这样一来,就可以仿照英文句子的向量化,来做中文的向量化了。
你可能担心计算机处理起中文的词语,跟处理英文词语有所不同。
这种担心没必要。
因为咱们前面讲过,计算机其实连英文单词也看不懂。
在它眼里,不论什么自然语言的词汇,都只是某种特定组合的字符串而已。 不论处理中文还是英文,都需要处理的一种词汇,叫做停用词。
中文维基百科里,是这么定义停用词的:
在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。
咱们做的,不是信息检索,而已文本分类。
对咱们来说,你不打算拿它做特征的单词,就可以当作停用词。
还是举刚才英文的例子,下面两句话:
I love the game.
I hate the game.
告诉我,哪些是停用词?
直觉会告诉你,定冠词 the 应该是。
没错,它是虚词,没有什么特殊意义。
它在哪儿出现,都是一个意思。
一段文字里,出现很多次定冠词都很正常。把它和那些包含信息更丰富的词汇(例如love, hate)放在一起统计,就容易干扰我们把握文本的特征。
所以,咱们把它当作停用词,从特征里面剔除出去。
举一反三,你会发现分词后的中文语句:
“我 喜欢 这个 游戏”
其中的“这个”应该也是停用词吧?
答对了!
要处理停用词,怎么办呢?当然你可以一个个手工来寻找,但是那显然效率太低。
有的机构或者团队处理过许多停用词。他们会发现,某种语言里,停用词是有规律的。
他们把常见的停用词总结出来,汇集成表格。以后只需要查表格,做处理,就可以利用先前的经验和知识,提升效率,节约时间。
在scikit-learn中,英语停用词是自带的。只需要指定语言为英文,机器会帮助你自动处理它们。
但是中文……
scikit-learn开发团队里,大概缺少足够多的中文使用者吧。
好消息是,你可以使用第三方共享的停用词表。
这种停用词表到哪里下载呢?
我已经帮你找到了 一个 github 项目 ,里面包含了4种停用词表,来自哈工大、四川大学和百度等自然语言处理方面的权威单位。
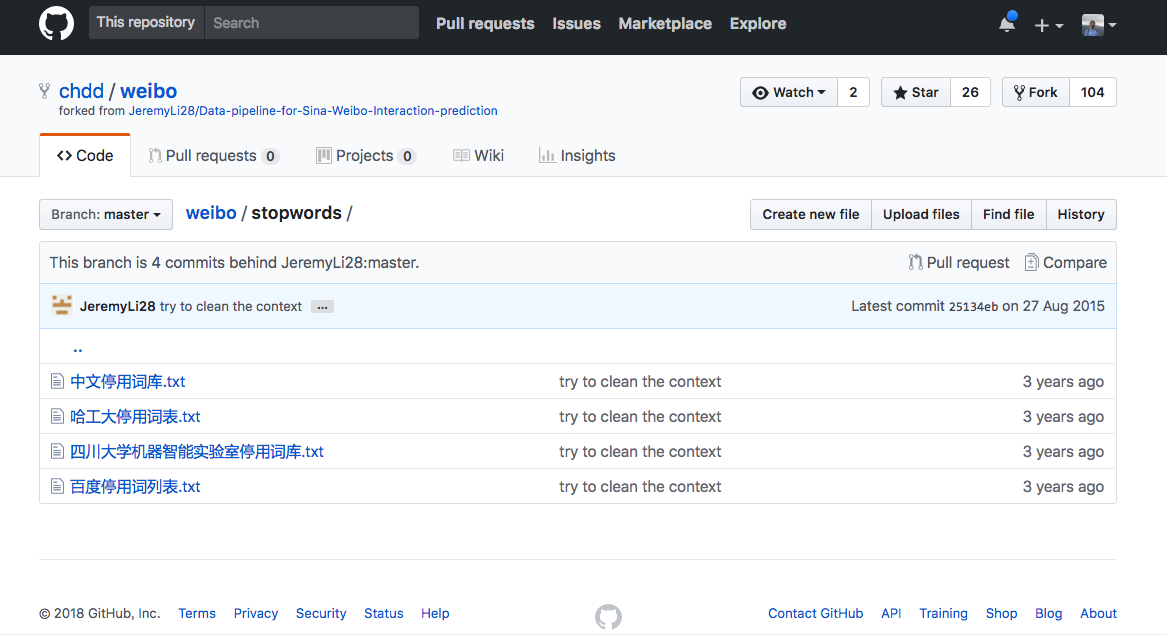
这几个停用词表文件长度不同,内容也差异很大。为了演示的方便与一致性,咱们统一先用哈工大这个停用词表吧。
我已经将其一并存储到了演示目录压缩包中,供你下载。 \# 环境
请你先到 这个网址 下载本教程配套的压缩包。
下载后解压,你会在生成的目录里面看到以下4个文件。
下文中,我们会把这个目录称为“演示目录”。
请一定注意记好它的位置哦。
要装Python,最简便办法是安装Anaconda套装。
请到 这个网址 下载Anaconda的最新版本。
请选择左侧的 Python 3.6 版本下载安装。
如果你需要具体的步骤指导,或者想知道Windows平台如何安装并运行Anaconda命令,请参考我为你准备的 视频教程(2.2) 。
打开终端,用cd命令进入演示目录。如果你不了解具体使用方法,也可以参考 视频教程(2.2) 。 我们需要使用许多软件包。如果每一个都手动安装,会非常麻烦。
我帮你做了个虚拟环境的配置文件,叫做environment.yaml ,也放在演示目录中。
请你首先执行以下命令:
conda env create -f environment.yaml
这样,所需的软件包就一次性安装完毕了。
之后执行,
source activate datapy3
进入这个虚拟环境。
注意一定要执行下面这句:
python -m ipykernel install –user –name=datapy3
只有这样,当前的Python环境才会作为核心(kernel)在系统中注册。 确认你的电脑上已经安装了 Google Chrome 浏览器。如果没有安装请到这里 下载 安装。
之后,在演示目录中,我们执行:
jupyter notebook
Google Chrome会开启,并启动 Jupyter 笔记本界面:
你可以直接点击文件列表中的demo.ipynb文件,可以看到本教程的全部示例代码。
你可以一边看教程的讲解,一边依次执行这些代码。
但是,我建议的方法,是回到主界面下,新建一个新的空白 Python 3 (显示名称为datapy3的那个)笔记本。
请跟着教程,一个个字符输入相应的内容。这可以帮助你更为深刻地理解代码的含义,更高效地把技能内化。
准备工作结束,下面我们开始正式输入代码。
6.3.5 代码
我们读入数据框处理工具pandas。
利用pandas的csv读取功能,把数据读入。
注意为了与Excel和系统环境设置的兼容性,该csv数据文件采用的编码为GB18030。这里需要显式指定,否则会报错。
我们看看读入是否正确。
前5行内容如下:

看看数据框整体的形状是怎么样的:
(2000, 2)我们的数据一共2000行,2列。完整读入。
我们并不准备把情感分析的结果分成4个类别。我们只打算分成正向和负向。
这里我们用一个无名函数来把评星数量>3的,当成正向情感,取值为1;反之视作负向情感,取值为0。
编制好函数之后,我们实际运行在数据框上面。
看看结果:
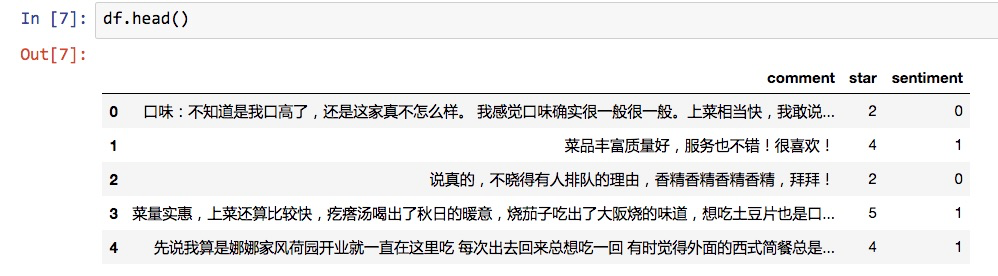
从前5行看来,情感取值就是根据我们设定的规则,从评星数量转化而来。
下面我们把特征和标签拆开。
X 是我们的全部特征。因为我们只用文本判断情感,所以X实际上只有1列。
(2000, 1)而y是对应的标记数据。它也是只有1列。
(2000,)我们来看看 X 的前几行数据。

注意这里评论数据还是原始信息。词语没有进行拆分。
为了做特征向量化,下面我们利用结巴分词工具来拆分句子为词语。
我们建立一个辅助函数,把结巴分词的结果用空格连接。
这样分词后的结果就如同一个英文句子一样,单次之间依靠空格分割。
有了这个函数,我们就可以使用 apply 命令,把每一行的评论数据都进行分词。
我们看看分词后的效果:
单词和标点之间都用空格分割,符合我们的要求。
下面就是机器学习的常规步骤了:我们需要把数据分成训练集和测试集。
为什么要拆分数据集合?
在《贷还是不贷:如何用Python和机器学习帮你决策?》(6.1)一文中,我已解释过,这里复习一下:
如果期末考试之前,老师给你一套试题和答案,你把它背了下来。然后考试的时候,只是从那套试题里面抽取一部分考。你凭借超人的记忆力获得了100分。请问你学会了这门课的知识了吗?不知道如果给你新的题目,你会不会做呢?答案还是不知道。所以考试题目需要和复习题目有区别。
同样的道理,假设咱们的模型只在某个数据集上训练,准确度非常高,但是从来没有见过其他新数据,那么它面对新数据表现如何呢?
你心里也没底吧?
所以我们需要把数据集拆开,只在训练集上训练。保留测试集先不用,作为考试题,看模型经过训练后的分类效果。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)这里,我们设定了 random_state 取值,这是为了在不同环境中,保证随机数取值一致,以便验证咱们模型的实际效果。
我们看看此时的 X_train 数据集形状。
(1500, 2)可见,在默认模式下,train_test_split函数对训练集和测试集的划分比例为 3:1。
我们检验一下其他3个集合看看:
(1500,)(500, 2)(500,)同样都正确无误。
下面我们就要处理中文停用词了。
我们编写一个函数,从中文停用词表里面,把停用词作为列表格式保存并返回:
def get_custom_stopwords(stop_words_file):
with open(stop_words_file) as f:
stopwords = f.read()
stopwords_list = stopwords.split('\n')
custom_stopwords_list = [i for i in stopwords_list]
return custom_stopwords_list我们指定使用的停用词表,为我们已经下载保存好的哈工大停用词表文件。
看看我们的停用词列表的后10项:

这些大部分都是语气助词,作为停用词去除掉,不会影响到语句的实质含义。
下面我们就要尝试对分词后的中文语句做向量化了。
我们读入CountVectorizer向量化工具,它依据词语出现频率转化向量。
我们建立一个CountVectorizer()的实例,起名叫做vect。
注意这里为了说明停用词的作用。我们先使用默认参数建立vect。
然后我们用向量化工具转换已经分词的训练集语句,并且将其转化为一个数据框,起名为term_matrix。
我们看看term_matrix的前5行:
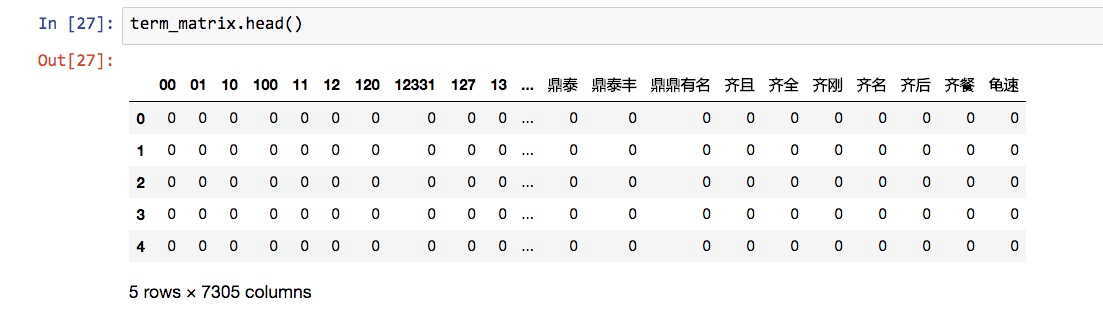
我们注意到,特征词语五花八门,特别是很多数字都被当作特征放在了这里。
term_matrix的形状如下:
(1500, 7305)行数没错,列数就是特征个数,有7305个。
下面我们测试一下,加上停用词去除功能,特征向量的转化结果会有什么变化。
下面的语句跟刚才一样:
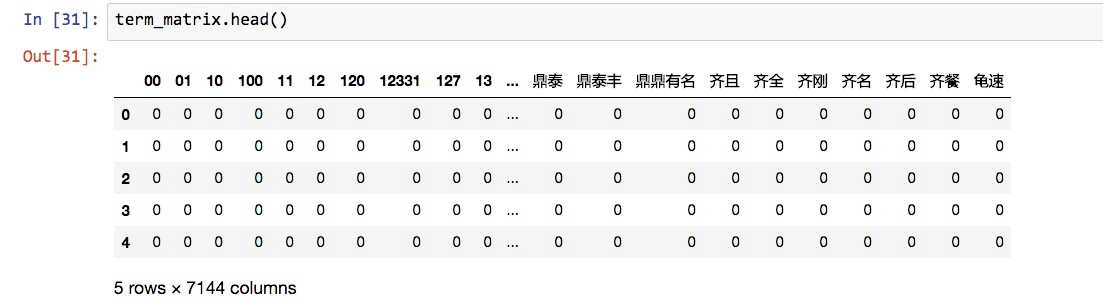
可以看到,此时特征个数从刚才的7305个,降低为7144个。我们没有调整任何其他的参数,因此减少的161个特征,就是出现在停用词表中的单词。
但是,这种停用词表的写法,依然会漏掉不少漏网之鱼。
首先就是前面那一堆显眼的数字。它们在此处作为特征毫无道理。如果没有单位,没有上下文,数字都是没有意义的。
因此我们需要设定,数字不能作为特征。
在Python里面,我们可以设定token_pattern来完成这个目标。
这一部分需要用到正则表达式的知识,我们这里无法详细展开了。
但如果你只是需要去掉数字作为特征的话,按照我这样写,就可以了。
另一个问题在于,我们看到这个矩阵,实际上是个非常稀疏的矩阵,其中大部分的取值都是0.
这没有关系,也很正常。
毕竟大部分评论语句当中只有几个到几十个词语而已。7000多的特征,单个语句显然是覆盖不过来的。
然而,有些词汇作为特征,就值得注意了。
首先是那些过于普遍的词汇。尽管我们用了停用词表,但是难免有些词汇几乎出现在每一句评论里。什么叫做特征?特征就是可以把一个事物与其他事物区别开的属性。
假设让你描述今天见到的印象最深刻的人。你怎么描述?
我看见他穿着小丑的衣服,在繁华的商业街踩高跷,一边走还一边抛球,和路人打招呼。
还是……
我看见他有两只眼睛,一只鼻子。
后者绝对不算是好的特征描述,因为难以把你要描述的个体区分出来。
物极必反,那些过于特殊的词汇,其实也不应该保留。因为你了解了这个特征之后,对你的模型处理新的语句情感判断,几乎都用不上。
这就如同你跟着神仙学了屠龙之术,然而之后一辈子也没有见过龙……
所以,如下面两个代码段所示,我们一共多设置了3层特征词汇过滤。
vect = CountVectorizer(max_df = max_df,
min_df = min_df,
token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b',
stop_words=frozenset(stopwords))这时候,再运行我们之前的语句,看看效果。
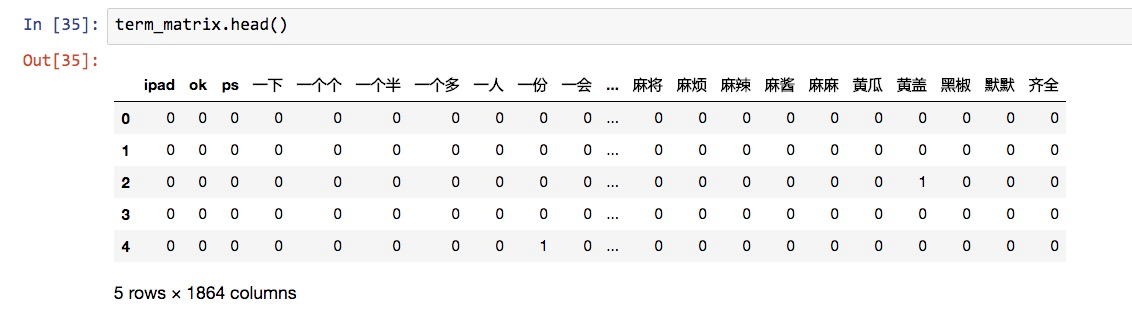
可以看到,那些数字全都不见了。特征数量从单一词表法去除停用词之后的7144个,变成了1864个。
你可能会觉得,太可惜了吧?好容易分出来的词,就这么扔了?
要知道,特征多,绝不一定是好事儿。
尤其是噪声大量混入时,会显著影响你模型的效能。
好了,评论数据训练集已经特征向量化了。下面我们要利用生成的特征矩阵来训练模型了。
我们的分类模型,采用朴素贝叶斯(Multinomial naive bayes)。
注意我们的数据处理流程是这样的:
- 特征向量化;
- 朴素贝叶斯分类。
如果每次修改一个参数,或者换用测试集,我们都需要重新运行这么多的函数,肯定是一件效率不高,且令人头疼的事儿。而且只要一复杂,出现错误的几率就会增加。
幸好,Scikit-learn给我们提供了一个功能,叫做管道(pipeline),可以方便解决这个问题。
它可以帮助我们,把这些顺序工作连接起来,隐藏其中的功能顺序关联,从外部一次调用,就能完成顺序定义的全部工作。
使用很简单,我们就把 vect 和 nb 串联起来,叫做pipe。
看看它都包含什么步骤:
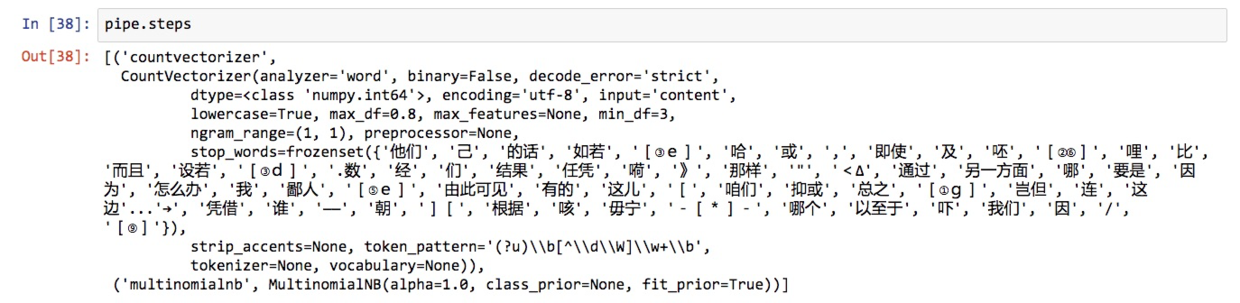
看,我们刚才做的工作,都在管道里面了。我们可以把管道当成一个整体模型来调用。
下面一行语句,就可以把未经特征向量化的训练集内容输入,做交叉验证,算出模型分类准确率的均值。
from sklearn.cross_validation import cross_val_score
cross_val_score(pipe, X_train.cutted_comment, y_train, cv=5, scoring='accuracy').mean()咱们的模型在训练中的准确率如何呢?
0.820687244673089这个结果,还是不错的。
回忆一下,总体的正向和负向情感,各占了数据集的一半。
如果我们建立一个“笨模型”(dummy model),即所有的评论,都当成正向(或者负向)情感,准确率多少?
对,50%。
目前的模型准确率,远远超出这个数值。超出的这30%多,其实就是评论信息为模型带来的确定性。
但是,不要忘了,我们不能光拿训练集来说事儿,对吧?下面咱们给模型来个考试。
我们用训练集,把模型拟合出来。
然后,我们在测试集上,对情感分类标记进行预测。
这一大串0和1,你看得是否眼花缭乱?
没关系,scikit-learn给我们提供了非常多的模型性能测度工具。
我们先把预测结果保存到y_pred。
读入 scikit-learn 的测量工具集。
我们先来看看测试准确率:
0.86这个结果是不是让你很吃惊?没错,模型面对没有见到的数据,居然有如此高的情感分类准确性。
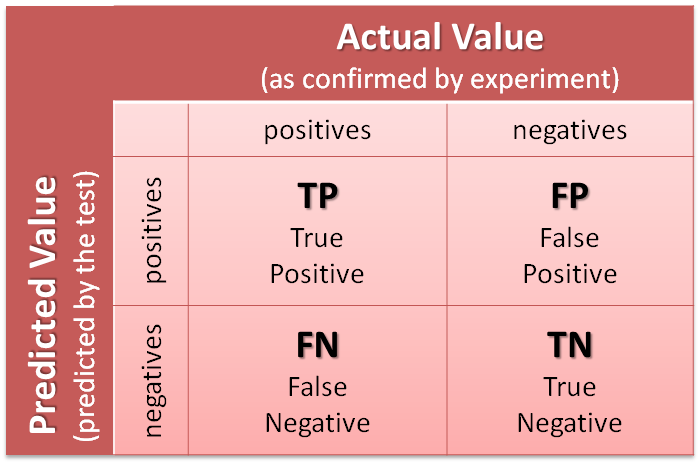
对于分类问题,光看准确率有些不全面,咱们来看看混淆矩阵。
array([[194, 43],
[ 27, 236]])混淆矩阵中的4个数字,分别代表:
- TP: 本来是正向,预测也是正向的;
- FP: 本来是负向,预测却是正向的;
- FN: 本来是正向,预测却是负向的;
- TN: 本来是负向,预测也是负向的。
下面这张图(来自 https://goo.gl/5cYGZd )应该能让你更为清晰理解混淆矩阵的含义:
写到这儿,你大概能明白咱们模型的性能了。
但是总不能只把咱们训练出的模型和无脑“笨模型”去对比吧?这也太不公平了!
下面,我们把老朋友 SnowNLP 呼唤出来,做个对比。
如果你把它给忘了,请复习《如何用Python做情感分析?》(5.1)
我们利用测试集评论原始数据,让 SnowNLP 跑一遍,获得结果。
注意这里有个小问题。 SnowNLP 生成的结果,不是0和1,而是0到1之间的小数。所以我们需要做一步转换,把0.5以上的结果当作正向,其余当作负向。
看看转换后的前5条 SnowNLP 预测结果:
好了,符合我们的要求。
下面我们先看模型分类准确率:
0.77与之对比,咱们的测试集分类准确率,可是0.86哦。
我们再来看看混淆矩阵。
array([[189, 48],
[ 67, 196]])对比的结果,是 TP 和 TN 两项上,咱们的模型判断正确数量,都要超出 SnowNLP。
6.3.6 小结
回顾一下,本文介绍了以下知识点:
- 如何用一袋子词(bag of words)模型将自然语言语句向量化,形成特征矩阵;
- 如何利用停用词表、词频阈值和标记模式(token pattern)移除不想干的伪特征词汇,降低模型复杂度。
- 如何选用合适的机器学习分类模型,对词语特征矩阵做出分类;
- 如何用管道模式,归并和简化机器学习步骤流程;
- 如何选择合适的性能测度工具,对模型的效能进行评估和对比。
希望这些内容能够帮助你更高效地处理中文文本情感分类工作。
6.4 如何用机器学习处理二元分类任务?

图像是猫还是狗?情感是正还是负?贷还是不贷?这些问题,该如何使用合适的机器学习模型来解决呢?
6.4.1 问题
暑假后,又有一批研究生要开题了。这几天陆续收到他们发来的研究计划大纲。
其中好几个,打算使用机器学习做分类。
但是,从他们的文字描述来看,不少人对机器学习进行分类的方法,还是一知半解。
考虑到之前分享机器学习处理分类问题的文章,往往针对具体的任务案例。似乎对分类问题的整体步骤与注意事项,还没有详细论述过。于是我决定写这篇文章,帮他们梳理一下。
他们和你一样,也是我专栏的读者。
如果你对机器学习感兴趣,并且实际遇到了分类任务,那我解答他们遇到的一些疑问,可能对于你同样有用。
所以,我把这篇文章也分享给你。希望能有一些帮助。
6.4.2 监督
监督式机器学习任务很常见。主要模型,是分类与回归。
就分类问题而言,二元分类是典型应用。
例如决策辅助,你利用结构化数据,判定可否贷款给某个客户;
例如情感分析,你需要通过一段文字,来区分情感的正负极性;
例如图像识别,你得识别出图片是猫,还是狗。
今天咱们就先介绍一下,二元分类,这个最为简单和常见的机器学习应用场景。
注意要做分类,你首先得有合适的数据。
什么是合适的数据呢?
这得回到我们对机器学习的大类划分。
分类任务,属于监督式学习。
监督式学习的特点,是要有标记。
例如给你1000张猫的图片,1000张狗的图片,扔在一起,没有打标记。这样你是做不了分类的。
虽然你可以让机器学习不同图片的特征,让它把图片区分开。
但是这叫做聚类,属于非监督学习。
天知道,机器是根据什么特征把图片分开的。
你想得到的结果,是猫放在一类,狗放在另一类。
但是机器抓取特征的时候,也许更喜欢按照颜色区分。
结果白猫白狗放在了一个类别,黄猫黄狗放在了另一个类别。跟你想要的结果大相径庭。
如果你对非监督学习感兴趣,可以参考《如何用Python从海量文本抽取主题?》(6.2)一文。
所以,要做分类,就必须有标记才行。
但是标记不是天上掉下来的。
大部分情况下,都是人打上去的。
6.4.3 标记
打标记(Labeling),是个专业化而繁复的劳动。
你可以自己打,可以找人帮忙,也可以利用众包的力量。
例如亚马逊的“土耳其机器人”(Amazon Mechanical Turk)项目。
别被名字唬住,这不是什么人工智能项目,而是普通人可以利用业余时间赚外快的机会。
你可以帮别人做任务拿佣金。任务中很重要的一部分,就是人工分类,打标记。

因此如果你有原始数据,但是没有标记,就可以把数据扔上去。
说明需求,花钱找人帮你标记。
类似的服务,国内也有很多。
建议找知名度比较高的平台来做,这样标记的质量会比较靠谱。
如果你还是在校学生,可能会觉得这样的服务价格太贵,个人难以负担。
没关系。假如你的研究是有基金资助项目的一部分,可以正大光明地找导师申请数据采集费用。
但若你的研究属于个人行为,就得另想办法了。
不少学生选择的办法,是依靠团队支持。
例如找低年级的研究生帮忙标记。
人家帮了忙,让你发表了论文,顺利毕业。你总得请大家吃一顿好吃的,是吧?
6.4.4 学习
有了标记以后,你就能够实施监督学习,做分类了。
这里我们顺带说一下,什么叫做“机器学习”。
这个名字很时髦。
其实它做的事情,叫做“基于统计的信息表征”。
先说信息表征(representation)。
你的输入,可能是结构化的数据,例如某个人的各项生理指标;可能是非结构化数据,例如文本、声音甚至是图像,但是最终机器学习模型看到的东西,都是一系列的数字。
这些数字,以某种形式排布。
可能是零维的,叫做标量(scalar);
可能是一维的,叫做向量(vector);
可能是二维的,叫做矩阵(Matrice);
可能是高维的,叫做张量(Tensor)。

但是,不论输入的数据,究竟有多少维度,如果你的目标是做二元分类,那么经过一个或简单、或复杂的模型,最后的输出,一定是个标量数字。
你的模型,会设置一个阈值。例如0.5。
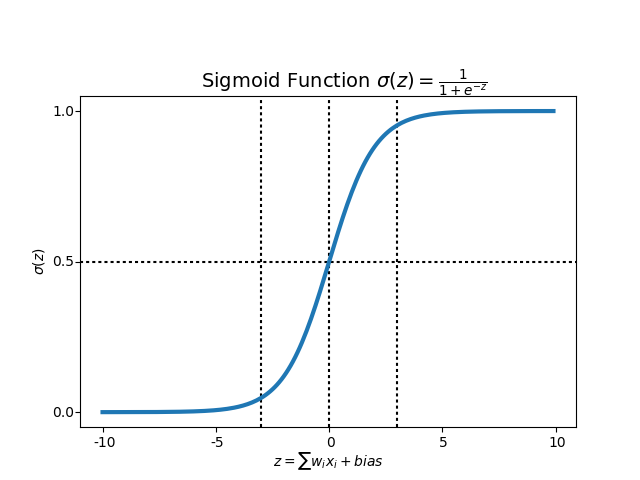
超出这个数字的,被分类到一处。
反之,被分类到另一处。
任务完成。
那么模型究竟在做什么呢?
它的任务,就是把输入的数据,表征成最终的这个标量。
打个不恰当的比方,就如同高考。
每一个考生,其实都是独特的。
每个人都有自己的家庭,自己的梦想,自己的经历,自己的故事。
但是高考这个模型,不可能完整准确表征上述全部细节。
它简单地以考生们的试卷答题纸作为输入,以一个最终的总成绩作为输出。
然后,划定一个叫做录取分数线的东西,作为阈值(判定标准)。
达到或超出了,录取。
否则,不录取。
这个分数,就是高考模型对每个考生的信息表征。
所谓分类模型的优劣,其实就是看模型是否真的达到了预期的分类效果。
什么是好的分类效果?
大学想招收的人,录取了(True Positive, TP);
大学不想招收的人,没被录取(True Negative, TN)。
什么是不好的分类效果?
大学想招收的人,没能被录取(False Negative, FN);
大学不想招收的人,被录取了(False Positive, FP)。
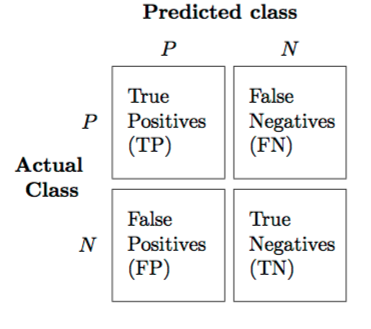
好的模型,需要尽力增大 TP 和 TN 的比例,降低 FN 和 FP 的比例。
评判的标准,视你的类别数据平衡而定。
数据平衡,例如1000张猫照片,1000张狗照片,可以使用 ROC AUC。
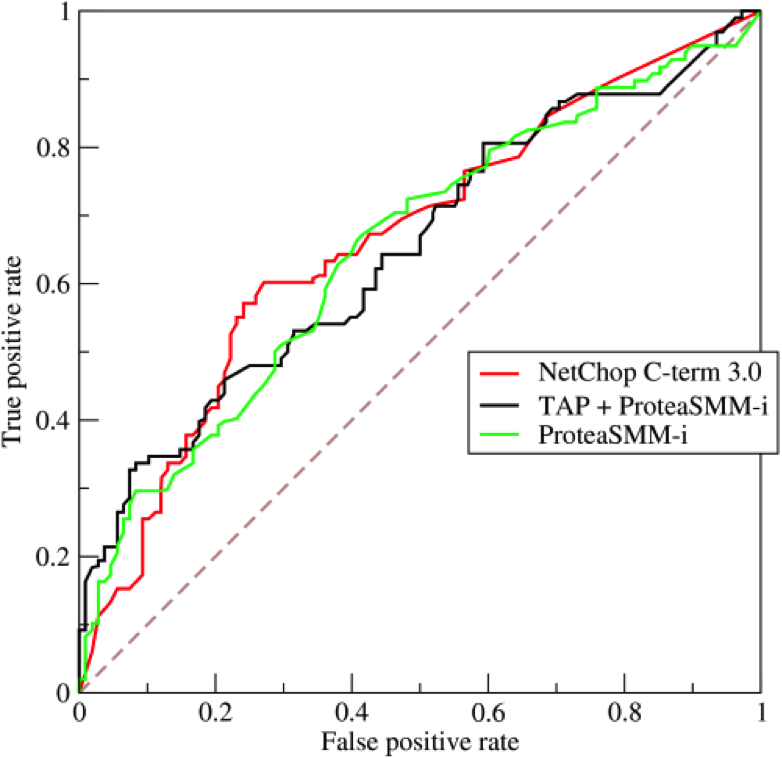
数据不平衡,例如有1000张猫的照片,却只有100张狗的照片,可以使用 Precision 和 Recall ,或者二者相结合的 F1 score。
因为有这样明确的评估标准,所以二元分类模型不能满足于“分了类”,而需要向着“更好的分类结果”前进。
办法就是利用统计结果,不断改进模型的表征方法。
所以,模型的参数需要不断迭代。
恢复高考后的40年,高考的形式、科目、分值、大纲……包括加分政策等,一直都在变化。这也可以看作是一种模型的迭代。
“表征”+“统计”+“迭代”,这基本上就是所谓的“学习”。
6.4.5 结构化
看到这里,希望你的头脑里已经有了机器学习做二元分类问题的技术路线概貌。
下面咱们针对不同的数据类型,说说具体的操作形式和注意事项。
先说最简单的结构化数据。
例如《贷还是不贷:如何用Python和机器学习帮你决策?》(6.1)一文中,我们见到过的客户信息。
处理这样的数据,你首先需要关注数据的规模。
如果数据量大,你可以使用复杂的模型。
如果数据量小,你就得使用简单的模型。
为什么呢?
因为越复杂的模型,表征的信息就越多。
表征的信息多,未必是好事。
因为你抓住的,既有可能是信号,也有可能是噪声。
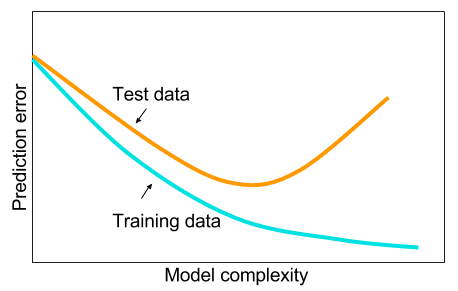
如果表征信息多,可是学习过的数据不多,它可能就会对不该记住的信息,形成记忆。
在机器学习领域,这是最恐怖的结果——过拟合(overfitting)。
翻译成人话,就是见过的数据,分类效果极好;没见过的数据,表现很糟糕。
举一个我自己的例子。
我上学前班后没多久,我妈就被请了家长。
因为我汉语拼音默写,得了0分。
老师嘴上说,是怀疑我不认真完成功课;心里想的,八成是这孩子智商余额不足。
其实我挺努力的。
每天老师让回家默写的内容,都默了。
但是我默写的时候,是严格按照“a o e i u ……”的顺序默的。
因为每天都这样默写,所以我记住的东西,不是每个读音对应的符号,而是它们出现的顺序。
结果上课的时候,老师是这样念的“a b c d e ……”
我毫无悬念没跟下来。
我的悲剧,源于自己的心智模型,实际上只反复学习了一条数据“a o e i u ……”。每天重复,导致过拟合,符号出现在顺序中,才能辨识和记忆。
因此,见到了新的组合方式,就无能为力了。
看,过拟合很糟糕吧。
确定了模型的复杂度以后,你依然需要根据特征多少,选择合适的分类模型。
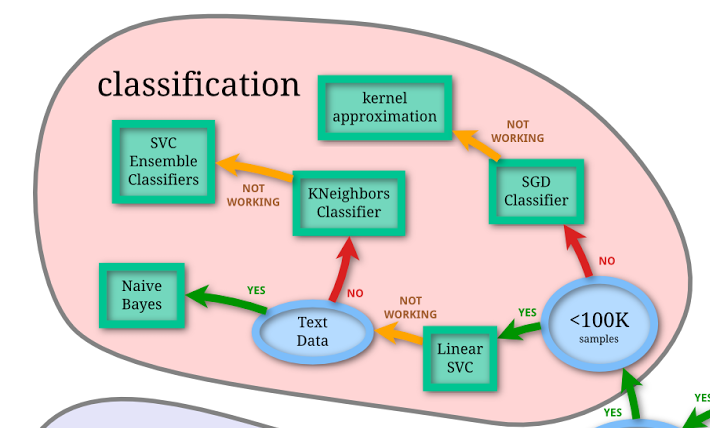
上图来自于 Scikit-learn ,我截取了其中“分类”模型部分,你可以做参考。
注意模型的效果,实际上是有等级划分的。
例如根据 Kaggle 数据科学竞赛多年的实践结果来看,Gradient Boosting Machine 优于随机森林,随机森林优于决策树。
这么比有些不厚道,因为三者的出现,也是有时间顺序的。
让爷爷跟孙子一起赛跑,公平性有待商榷。
因此,你不宜在论文中,将不同的分类模型,分别调包跑一遍,然后来个横向对比大测评。
许多情况下,这是没有意义的。
虽然显得工作量很大。
但假如你发现在你自己的数据集上面,决策树的效果就是明显优于 Gradient Boosting Machine ,那你倒是很有必要通过论文做出汇报。
尽管大部分审稿人都会认为,一定是你算错了。
另一个需要注意的事项,是特征工程(feature engineering)。
什么叫特征工程呢?
就是手动挑选特征,或者对特征(组合)进行转化。
例如《如何用Python和深度神经网络锁定即将流失的客户?》(7.1)一文中,我们就对特征进行了甄别。其中三列数据,我们直接剔除掉了:
- RowNumber:行号,这个肯定没用,删除
- CustomerID:用户编号,这个是顺序发放的,删除
- Surname:用户姓名,对流失没有影响,删除
正式学习之前,你需要把手头掌握的全部数据分成3类:
- 训练集
- 验证集
- 测试集
我在给期刊审稿的时候,发现许多使用机器学习模型的作者,无论中外,都似乎不能精确理解这些集合的用途。
训练集让你的模型学习,如何利用当前的超参数(例如神经网络的层数、每一层的神经元个数等)组合,尽可能把表征拟合标记结果。
就像那个笑话说的一样:
Machine Learning in a Nutshell:
Interviewer: what’s you biggest strength?
Me: I’m a quick learner.
Interviewer: What’s 11*11?
Me: 65.
Interviewer: Not even close. It’s 121.
Me: It’s 121.
而验证集的存在,就是为了让你对比不同的超参数选择,哪一组更适合当前任务。它必须用训练集没有用过的数据。
验证集帮你选择了合适的超参数后,它的历史任务也就结束了。
这时候,你可以把训练集、验证集合并在一起,用最终确定的超参数组合进行训练,获得最优模型。
这个模型表现怎么样?
你当然需要其他的数据来评判。这就是为什么你还要划分出另外的测试集。
6.4.6 图像
François Chollet 在自己的书中举过一个例子,我觉得很有启发,一并分享给你。
假如你看到了这样的原始数据:
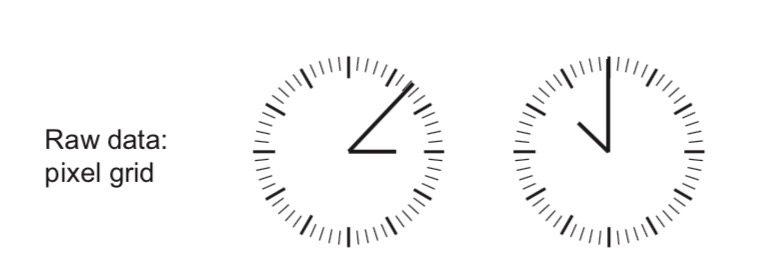
你该怎么做分类?
有的同学一看是图像,立刻决定,上卷积神经网络(7.4)!
别忙,想想看,真的需要“直接上大锤”吗?
别的不说,那一圈的刻度,就对我们的模型毫无意义。
你可以利用特征工程,将其表达为这样的坐标点:

你看,这样处理之后,你立刻就拥有了结构化数据。
注意这个转换过程,并不需要人工完成,完全可以自动化。
但是举一反三的你,估计已经想到了“更好的”解决方案:

对,这样一来,表达钟表时间的数据,就从原先的4个数字,变成了只需要2个。
一个本来需要用复杂模型解决的问题,就是因为简单的特征工程转化,复杂度和难度显著下降。
其实,曾经人们进行图片分类,全都得用特征工程的方法。
那个时候,图片分类问题极其繁琐、成本很高,而且效果还不理想。
手动提取的特征,也往往不具备良好的可扩展性和可迁移性。
于是,深度卷积神经网络就登场了。
如果你的图片数据量足够多的话,你就可以采用“端到端”的学习方式。
所谓“端到端”,是指不进行任何的特征工程,构造一个规模合适的神经网络模型,扔图片进去就可以了。
但是,现实往往是残酷的。
你最需要了解的,是图片不够多的时候,怎么办。
这时候,很容易出现过拟合。
因为深度神经网络,属于典型的复杂模型。
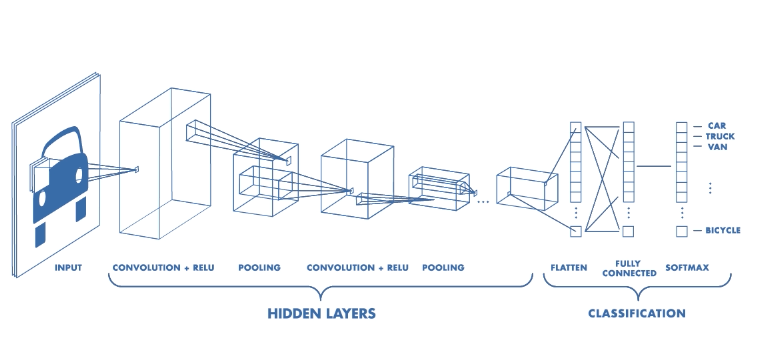
这个时候,可以尝试以下几个不同的方法:
首先,如果有可能,搜集更多的带标注图片。这是最简单的办法,如果成本可以接受,你应该优先采用。
其次,使用数据增强(Data Augmentation)。名字听起来很强大,其实无非是把原始的数据进行镜像、剪裁、旋转、扭曲等处理。这样“新的”图片与老图片的标注肯定还是一样的。但是图片内容发生的变化,可以有效防止模型记住过多噪声。

第三,使用迁移学习。
所谓迁移学习,就是利用别人训练好的模型,保留其中从输入开始的大多数层次(冻结保留其层次数量、神经元数量等网络结构,以及权重数值),只把最后的几层敲掉,换上自己的几层神经网络,对小规模数据做训练。
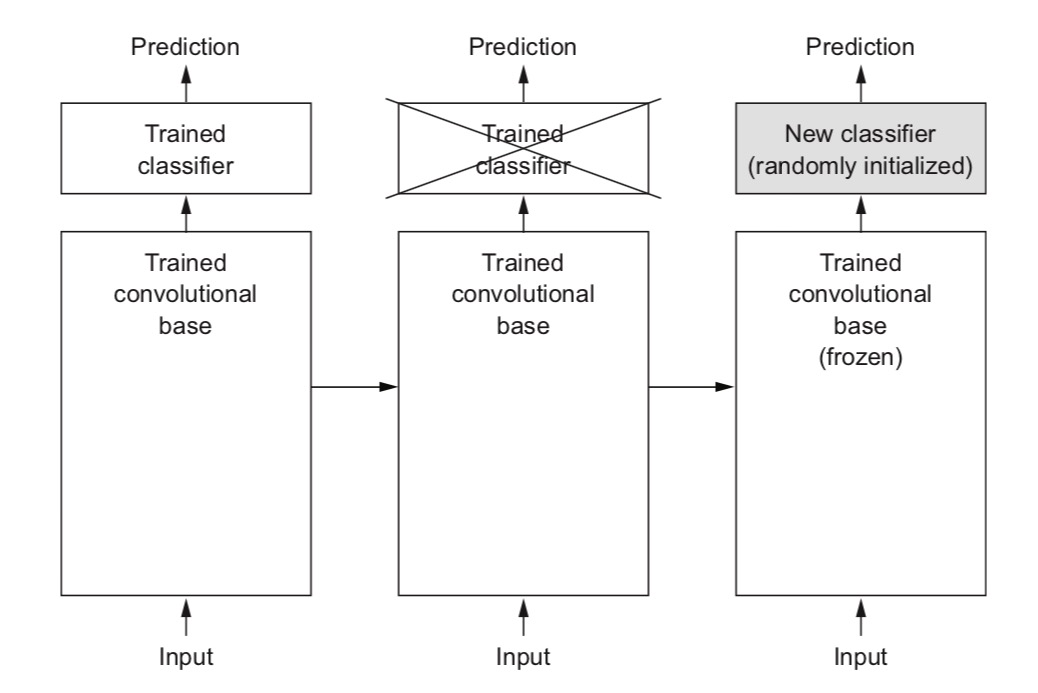
上图同样来自于 François Chollet 的著作。
这种做法,用时少,成本低,效果还特别好。如果重新训练,图片数少,就很容易过拟合。但是用了迁移学习,过拟合的可能性就大大降低。
其原理其实很容易理解。
卷积神经网络的层次,越是靠近输入位置,表达的特征就越是细节;越到后面,就越宏观。
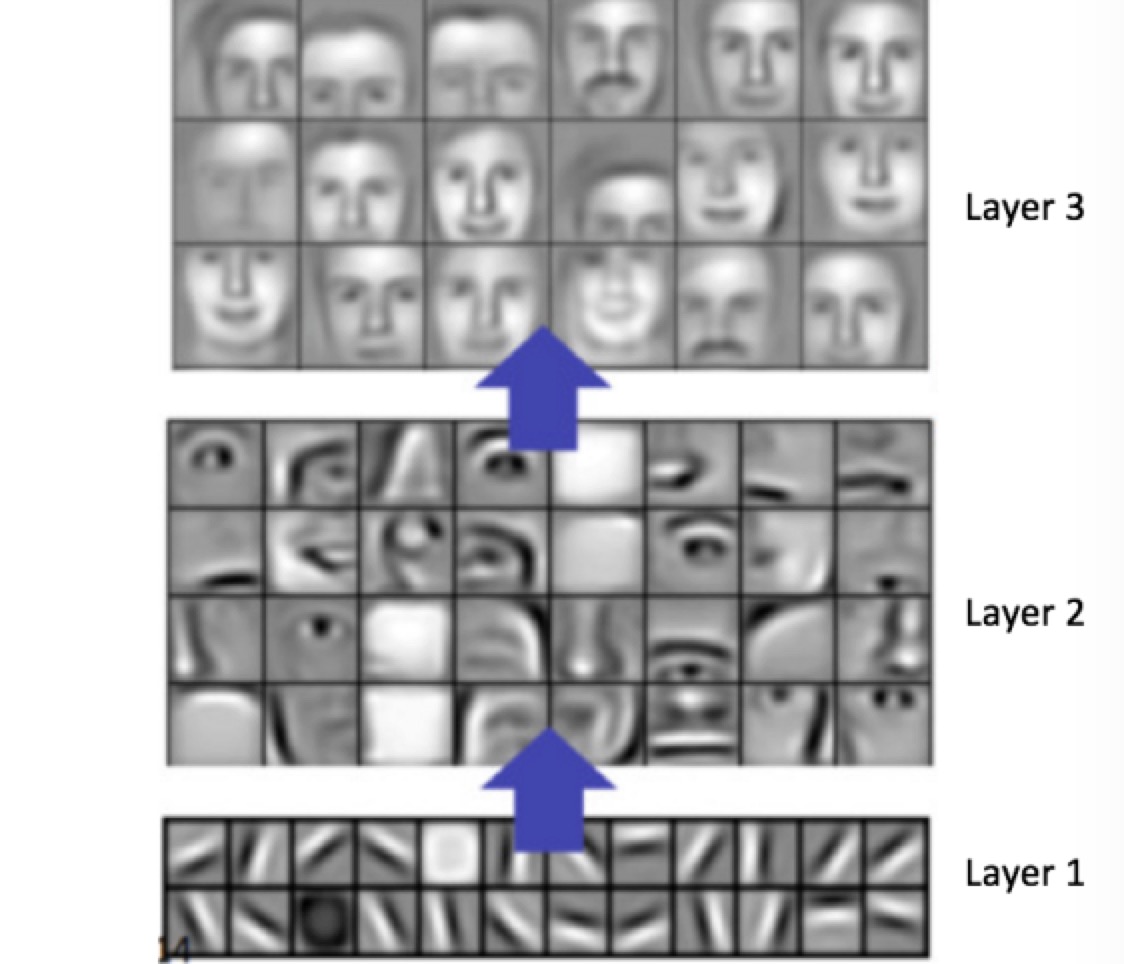
识别猫和狗,要从形状边缘开始;识别哆啦a梦和瓦力(7.2),也一样要从形状边缘开始。因此模型的底层,可以被拿来使用。
你训练的,只是最后几层表征方式。结构简单,当然也就不需要这么多数据了。
第四,引入 Dropout, Regularization 和 Early Stopping 等常规方法。注意这些方法不仅适用于图像数据。
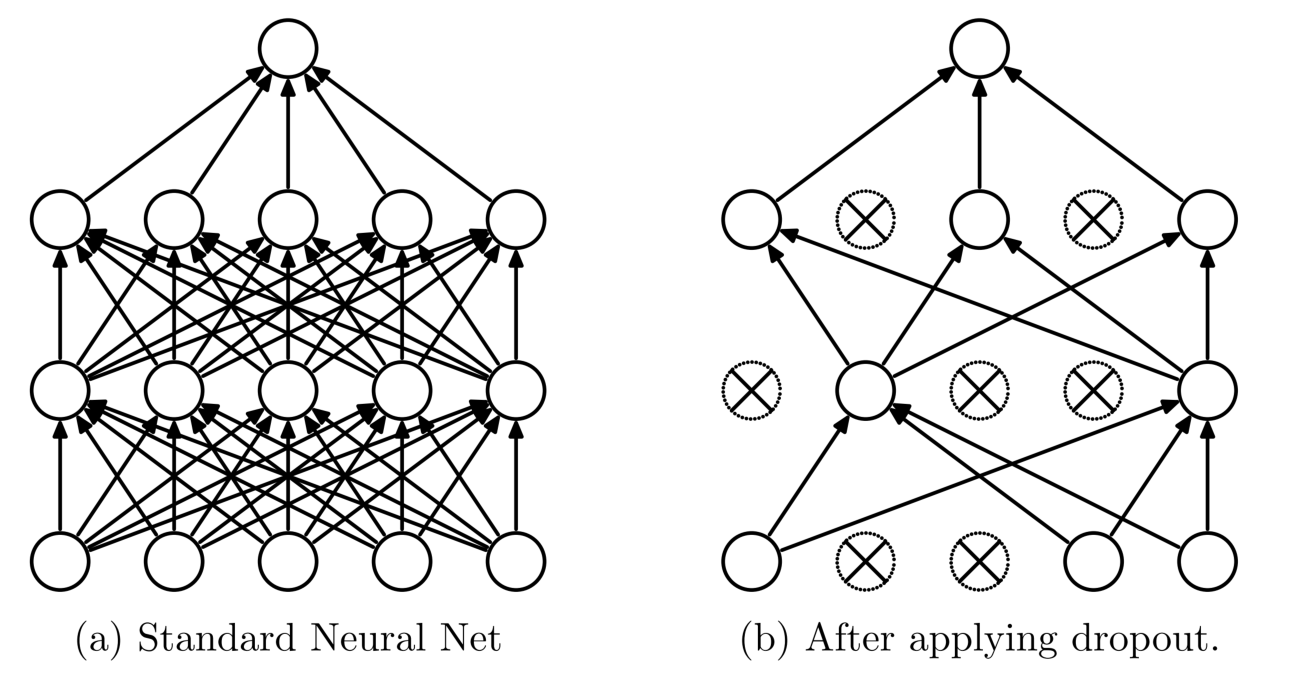
以 Dropout 为例。假如一个模型因为复杂,所以记住了很多噪声,那么训练的时候,每次都随机将一定比例的神经元“扔掉”(设置权重为0),那么模型的复杂度降低。而且因为随机,又比降低层数与神经元个数的固化模型适用性更高。
6.4.7 文本
前面说过了,机器不认得文本,只认得数字。
所以,要对文本做二元分类,你需要把文本转换成为数字。
这个过程,叫做向量化。
向量化的方式,有好几种。大致上可以分成两类:
第一类,是无意义转换。也就是转换的数字,只是个编号而已,本身并不携带其他语义信息。
这一类问题,我们在《如何用Python和机器学习训练中文文本情感分类模型?》(6.3)中,已经非常详细地介绍过了。
你需要做的,包括分词(如果是中文)、向量化、去除停用词,然后丢进一个分类模型(例如朴素贝叶斯,或者神经网络),直接获取结果,加以评估。
但是,这个过程,显然有大量的语义和顺序信息被丢弃了。
第二类,是有意义转换。这时候,每个语言单元(例如单词)转换出来的数字,往往是个高维向量。
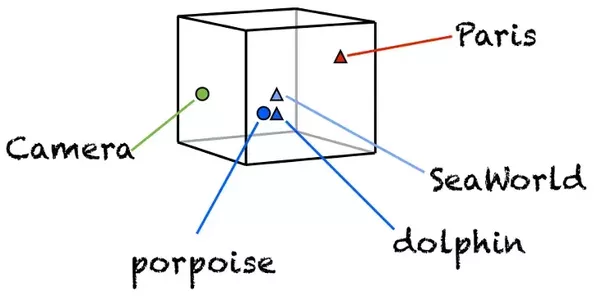
这个向量,你可以自己通过训练来产生。
但是这种训练,需要对海量语料进行建模。
建模的过程,成本很高,占用庞大存储空间,运算量极大。
因此更常见的做法,是使用别人通过大规模语料训练后的结果。也就是我们曾经介绍过的词嵌入预训练模型。
具体内容,请参见《如何用Python处理自然语言?(Spacy与Word Embedding)](#nlp-with-python-spacy-word-embedding)》和《[如何用 Python 和 gensim 调用中文词嵌入预训练模型?》(5.6)。
注意如果你有多个预训练模型可以选择,那么尽量选择与你要解决任务的文本更为接近的那种。
毕竟预训练模型来自于统计结果。两种差别很大的语料,词语在上下文中的含义也会有显著差异,导致语义的刻画不够准确。
如果你需要在分类的过程中,同时考虑语义和语言单元顺序等信息,那么你可以这样做:
第一步,利用词嵌入预训练模型,把你的输入语句转化为张量,这解决了词语的语义问题;
第二步,采用一维卷积神经网络(Conv1D)模型,或者循环神经网络模型(例如 LSTM),构造分类器。
注意这一步中,虽然两种不同的神经网络结构,都可以应用。但是一般而言,处理二元分类问题,前者(卷积神经网络)表现更好。
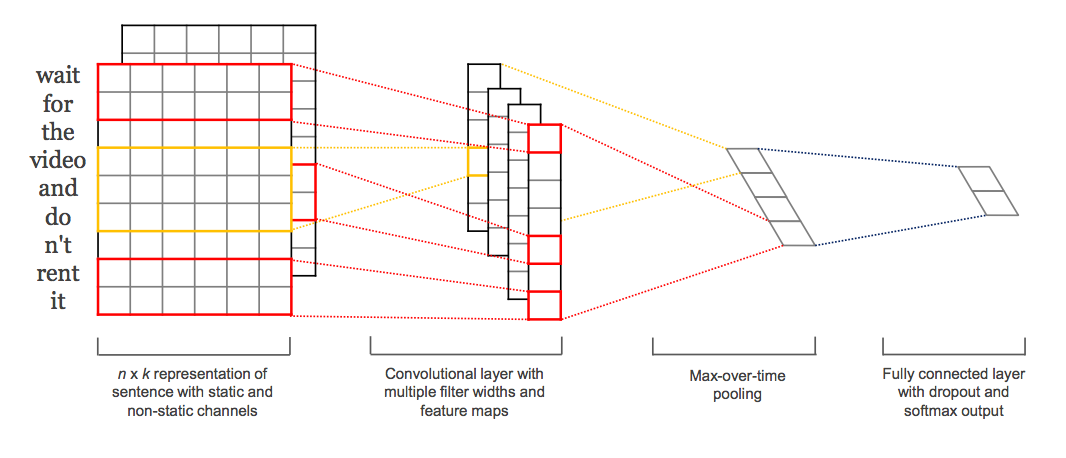
因为卷积神经网络实际上已经充分考虑了词语的顺序问题;而循环神经网络用在此处,有些“大炮轰蚊子”。很容易发生过拟合,导致模型效果下降。
6.4.8 实施
如果你了解二元分类问题的整体流程,并且做好了模型的选择,那么实际的机器学习过程,是很简单的。
对于大部分的普通机器学习问题,你都可以用 Scikit-learn 来调用模型。
注意其实每一个模型,都有参数设置的需要。但是对于很多问题来说,默认初始参数,就能带来很不错的运行结果。
Scikit-learn 虽好,可惜一直不能很好支持深度学习任务。
因而不论是图像还是文本分类问题,你都需要挑选一个好用的深度学习框架。
注意,目前主流的深度学习框架,很难说有好坏之分。
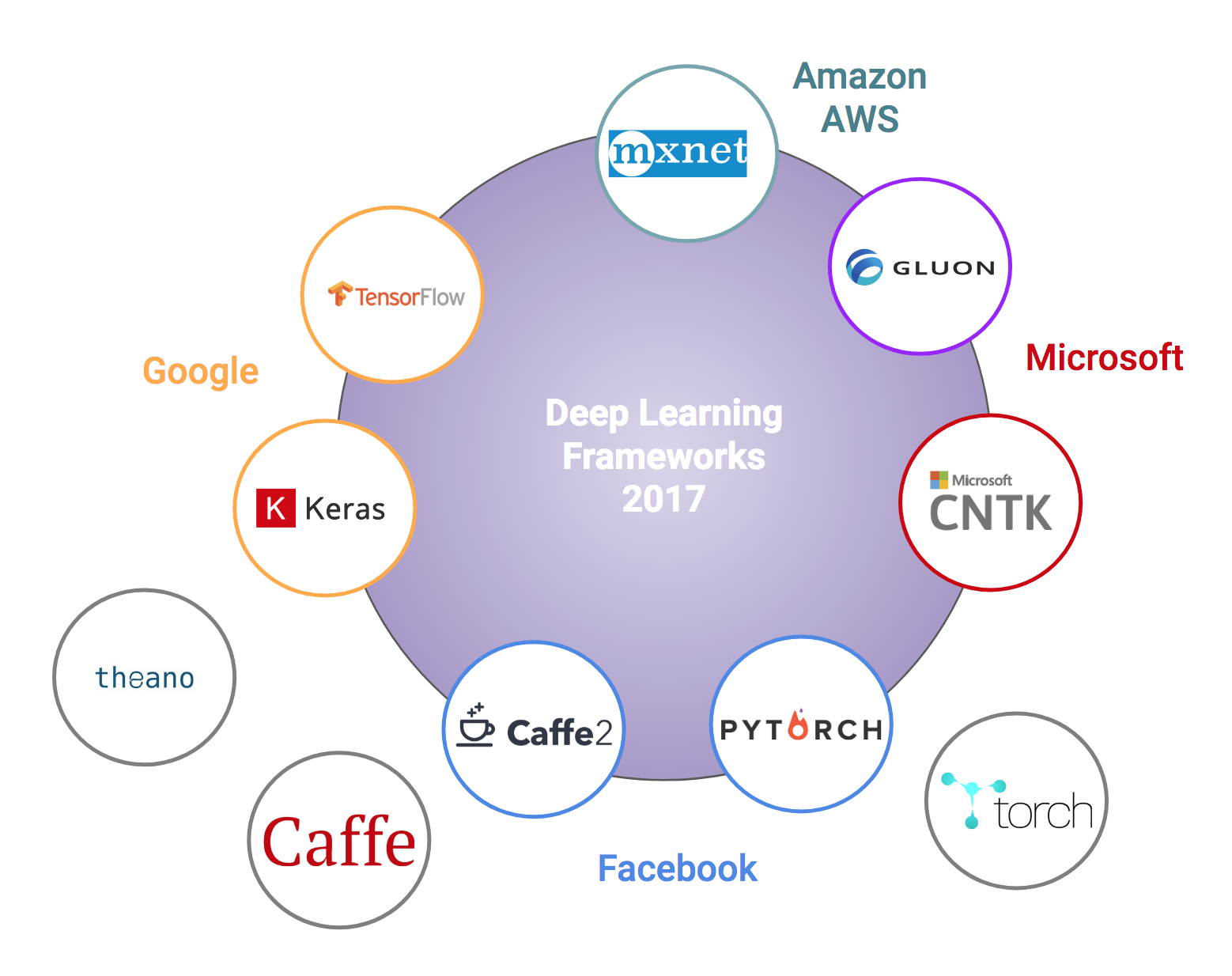
毕竟,在深度学习领域如此动荡激烈的竞争环境中,“坏”框架(例如功能不完善、性能低下)会很快被淘汰出局。
然而,从易用性上来说,框架之间确实有很大区别。
易用到了一种极致,便是苹果的 Turi Create 。
从《如何用Python和深度神经网络识别图像?](#image-classification-with-python-and-deep-learning)》和《[如何用Python和深度神经网络寻找近似图片?》(7.3)这两篇文章中,你应该有体会,Turi Create 在图像识别和相似度查询问题上,已经易用到你自己都不知道究竟发生了什么,任务就解决了。
但是,如果你需要对于神经网络的结构进行深度设置,那么 Turi Create 就显得不大够用了。
毕竟,其开发的目标,是给苹果移动设备开发者赋能,让他们更好地使用深度学习技术。

对于更通用的科研和实践深度学习任务,我推荐你用 Keras 。
它已经可以把 Theano, Tensorflow 和 CNTK 作为后端。
对比上面那张深度学习框架全家福,你应该看到,Keras 覆盖了 Google 和 微软自家框架,几乎占领了深度学习框架界的半壁江山。
照这势头发展下去,一统江湖也说不定哦。
为什么 Keras 那么厉害?
因为简单易学。
简单易学到,显著拉低了深度学习的门槛。
就连 Tensorflow 的主力开发人员 Josh Gordon,也已经认为你根本没必要去学习曾经的 Tensorflow 繁复语法了。
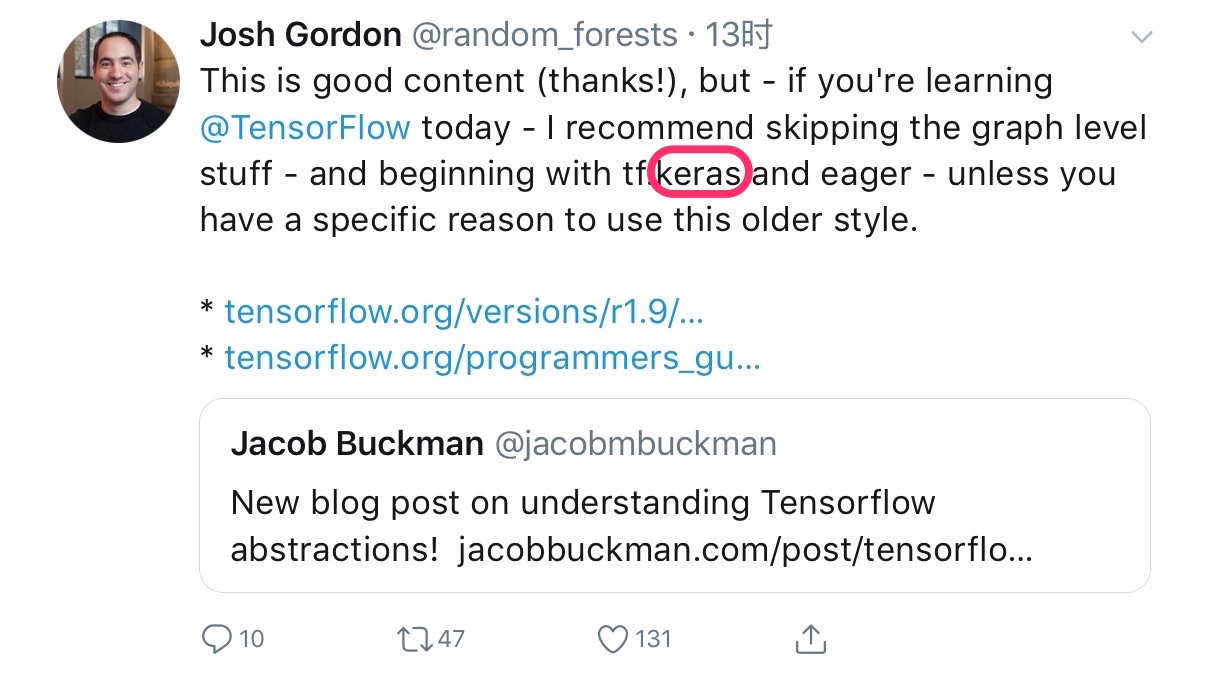
直接学 Keras ,用它完成任务,结束。
另外,使用深度学习,你可能需要 GPU 硬件设备的支持。这东西比较贵。建议你采用租用的方式。
《如何用云端 GPU 为你的 Python 深度学习加速?》(8.2)提到的 FloydHub,租赁一个小时,大概需要1美元左右。注册账号就赠送你2个小时;

至于《如何免费云端运行Python深度学习框架?》(8.1)中提到的 Google Colab ,就更慷慨了——到目前为止,一直是免费试用。
6.5 如何有效沟通你的机器学习结果?

多问自己一个“那又怎样?”,会很有用。
6.5.1 疑问
2018年7月初,我赴南京参会。 James Hendler 教授的演讲非常精彩。

其中一个片段,让我印象深刻。
他说,许多人跑模型,跑出来一个比别人都高的准确率,于是就觉得任务完成了。他自己做健康信息研究,通过各种特征判定病人是否需要住院治疗。很容易就可以构建一个模型,获得很好的分类效果。
但是,这其实远远不够。因为别人(例如他的医生客户们)非常可能会问出一个问题“so what?” (意即“那又怎样?”)
我听了深以为然。
因为模型准确率再高,有时也免不了会有运气的成分。能否在实际应用中发挥作用,并不能单单靠着一个数字来说明。
医生们都有自己作为专业人士的骄傲。如果计算机模型不能从理据上说服他们,那肯定是不会加以采纳的。同时,他们对于病患的健康和生命安全,也有足够重大的责任,因此无法简单接受机器模型的结果,而不加以自己的理解与思考。
对于机器学习模型研究的这种批评,之前我也听到一些。但是不少人仅仅是批评,却没有给出有效的解决方法。
该怎么办呢?Hendler 教授的解决办法,是给医生展示一些统计图表。例如描述年龄与二次入院关系的散点图。
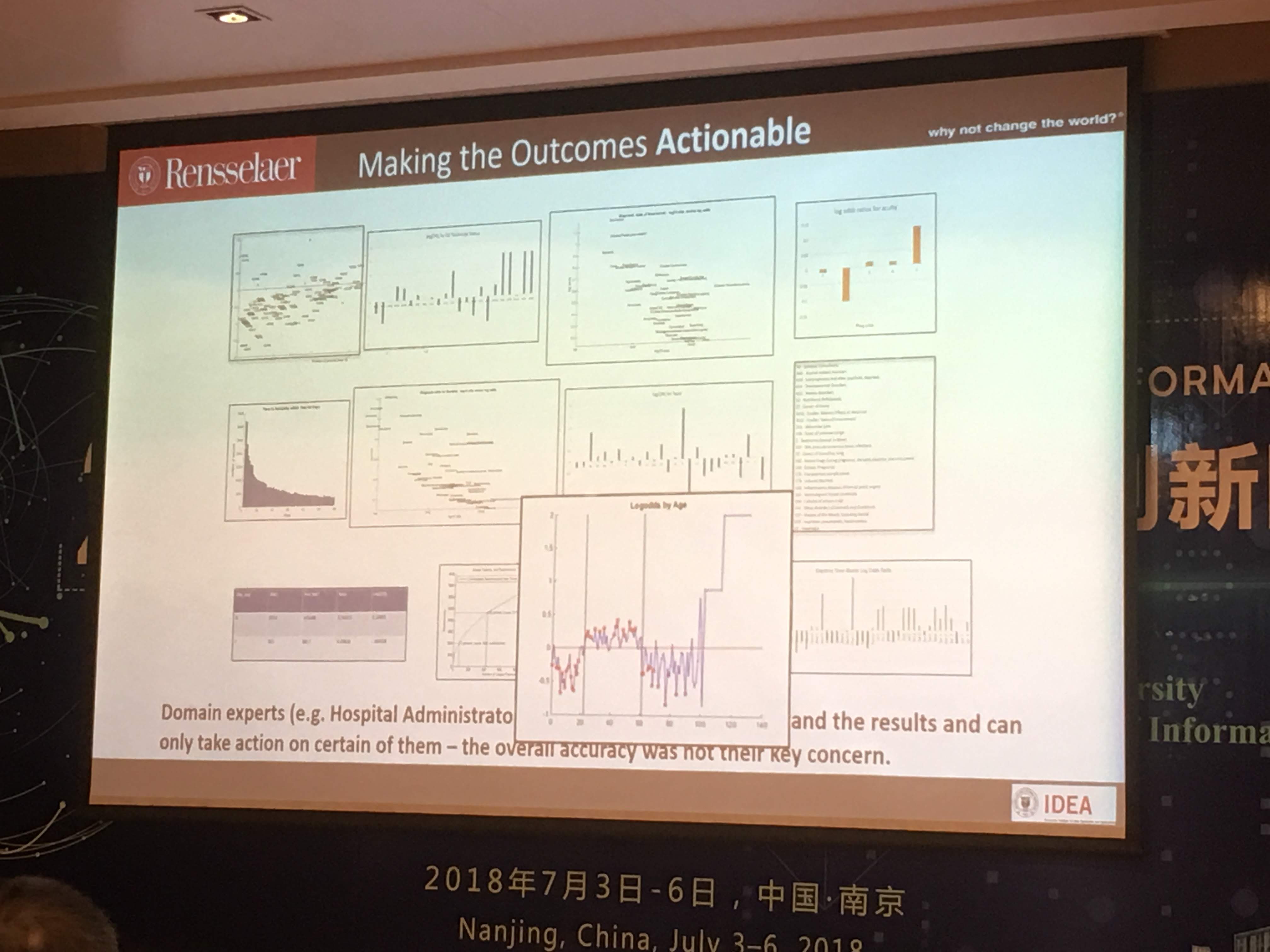
我听了大为惊诧,提问环节第一个就把话筒抢了过来,问:
这种图形,属于描述统计。难道不应该是正式进行模型训练之前,就做了的吗?如果把它作为沟通模型的结果,那还做什么机器学习呢?
6.5.2 解释
Hendler 教授耐心地给我解答了这个问题。

他说,没错,这个图形确实属于描述统计。然而,数百上千个特征里面,知道该汇报哪几个变量的统计图,就必须是机器学习之后才能做的。
实际上,医生们看了这个简单的统计图之后,非常震撼。
他们的刻板印象认为,老年人身体状况差,因此二次入院几率高;年轻人身体好,自愈能力强,因此不大容易“二进宫”。
就此,他们发现了一直以来决策上的失误——对于年轻病患,他们往往比较放心,因此缺乏足够的留院观察和治疗;反倒是对老年人,照顾得更加精细。造成的结果,是本以为没事儿的年轻人,再次重症发病入院;老年人却不少都治愈后健康回家了。
这种结果的传递沟通,有效地改进了医生的决策和行为方式。
其实,Hendler 教授的研究目的,不是去跟别人比拼一个数字,而是帮助医生更好地帮助病患。看似最为简单,没有技术含量的统计图,反倒比各种黑科技更能起到实际作用。
茶歇的时候,我们又聊了20分钟。
他给我讲,他的博士生,现在正在尝试在深度学习中找寻那些影响最后结果的关键要素,有的时候,甚至会选择跨过层级,来设计最简单明确的变量间关联设定。这样,深度学习的结果,可以最大限度(对别人)进行解释。即便会牺牲一些(当然不会很大)准确率,也在所不惜。
6.5.3 反思
为什么我们一直对准确率的数字,这么着迷,而忽略了模型的沟通解释呢?
其实道理也很简单,机器学习的最初广泛用途,给我们的思维带来了路径依赖。
还记得吗?机器学习逐渐受到世人重视的案例?
我说的不是 AlphaGo。
就是几乎每一本讲机器学习的书,都会用到的那个例子,MNIST。

专家们最初要解决的问题,无非是把原先需要人工分拣的邮件,变成机器自动分拣。关键在于手写数字的识别。
这个具体用例,有它的特点。
首先是任务目标单一,就是追求更高的准确率;
其次是分类数量确定,0-9,一共10个数字,不会更多,不会更少;
最后是犯错成本低,即便准确率达不到100%,也没有什么大问题——寄错了信,在人工分拣时代也是正常。
于是,这样的任务,就适合大家拼结果准确率数字。
但是,人们的思维惯性和路径依赖(包括各种竞赛的规则设置),导致了后面的机器学习任务,也都只关注数字,尤其是准确率。
但这其实是不对的。类似于决策支持,尤其是健康医疗的决策支持,就不适合单单比拼数字。
即便误判 0.1%,背后可能也是许许多多鲜活的生命,因此犯错成本极高。
医生并没有因为模型的准确率提升而被取代,反而在信息浪潮奔涌而来的场景下,充当把关人的角色,责任更加重大了。
一个模型要能说服医生,影响其决策行为,就必须解释清楚判断的依据,而不能递给他一个黑箱,告诉他:
你该这样做。
6.5.4 方法
原理想明白了,怎么实施呢?
如果每一个模型跑完,都只是拿出多张描述性统计图给用户,好像也不大合适。
通过文献阅读,我发现了其他机器学习研究人员为了解释结果所做的努力。
在深度学习领域,现在做得比较好的,是卷积神经网络。
在《文科生如何理解卷积神经网络?》(7.4)一文中,我给你解释过卷积神经网络的概念和使用方法。

但是,我们当时,还只是给你讲解如何用它进行分类等,没有涉及解释方案。
你看这样一幅图,机器模型可以很容易分辨它为“非洲象”。

但是,这到底是机器具有了辨别能力,还是只不过运气使然呢?
单看结果,不好分辨。但是我们可以对卷积神经网络训练的结果参数进行可视化,并且叠加到原图上,你一眼就可以看到,机器做出图像分类的依据,究竟是什么。

显然,在机器重点关注的区域里,象的鼻子和耳朵占了最大的决策比重。
由此可以看出,这不是简单的好运气。
以上例子,来自于 François Chollet 的《Deep Learning with Python》。书中附有详细的代码,供你用 Python 和 Keras 自己实现这种可视化结果。
6.5.5 小结
你训练出的模型表现好,这是成功的基础,但不是全部。
只展示一个数字给别人,在很多特定的应用场景下,是不够的。问题越是重要,犯错代价越高,这种方式就越不能被接受。这时候多问自己一个“那又怎样?”,没有坏处。
你需要明确自己用户的需求。与之有效沟通的关键在于用同理心,尊重对方。作为一个人,特别是一个专业人士,对方进行有效思考的要件,就是足够的理据支撑。
不管是用文中介绍的卷积神经网络可视化方法,还是 Hendler 教授所做的看似基础无比的描述性统计图,都可以根据问题的特点,加以采用。只要能够真正影响对方的决策,帮助他们更好地达成自己的目标,你的机器学习分析,便有了更佳的效果。
6.6 本章小结
如果你喜欢本章的内容,欢迎扫描下面二维码,请我喝杯咖啡。

如果你需要答疑,咱们的问答社区在这里: