Chapter 1 From Science to Data
If you are a scientist or scientist in training, have you ever stopped and asked yourself what is science? Or what is not science? And if you know what science is, do you think about What defines good or bad science? These are large, philosophical questions that won’t be answered in this text, but there is still value in thinking about them and returning to the fundamentals of what constitutes science and how we best conduct science.

Figure 1.1: Source: XKCD
While many deep and philosophical answers exist to the question of what is science, one very practical answer is that science is culture’s answer to epistemology. If you are now wondering what epistemology is, epistemology is just a term that refers to the theory of knowledge; in other words, how we know things. So science is one way that societies and cultures generate knowledge and information about the material reality. Following this idea, we might think of science as an objective message about the nature of reality. This is true enough to not cause much disagreement, with the addition that our objective message changes as we learn more. In this case, science is also the last (or most recent) survivor of the contest of ideas. Obviously our first explanation of reality is almost never our last one as intellect and technology work to advance and refine our understanding of reality. We may get focused enough to think that some explanations are final, and practically speaking they may be, but technically speaking science always leaves the door open for possible alternative explanations.
Once we assume there is a material reality and we can discover it—a safe enough assumption for most people—science becomes what we discover and agree on. A discovery alone does not constitute science, but when that discovery is accompanied by some explanation of pattern and process, and when it is generally accepted, it may become science. Even if it is generally accepted, it is healthy for scientific ideas to be pushed and tested through replication and other means. Repeated results can help to confirm and support the agreement on that particular scientific phenomena, while results in disagreement may help push ideas in new directions to better understand the underlying science.
Figure 1.2: Two views may be equally valid.
What are the limits to scientific discovery? Primarily the human mind and technology. We are not able to discover things we are (generally) not looking for or do not predict, so human intellect and creativity are absolutely fundamental in opening the doors of perception and possibility. In parallel to the human mind, we also need technology and ways to test and measure the scientific discoveries and ideas we are generating. You might be able to see how either intellect or technology alone is not enough to advance scientific understanding. However, when both intellect and technology are advancing great discoveries can be made. It is also worth noting that scientific advances are then made when the science is replicated and understanding is improved. Although it is not often emphasized, good writing and communication are critical for the ability of others to replicate science. The clearer that an experiment or study can be followed, the less likely it is to come under scrutiny and the more likely it is to be replicated in the future.
1.1 Multiple Working Hypotheses
We all learn early in school that science is about making observations, creating a hypothesis that explains what we are observing, and then testing that hypothesis to generate support for our against our idea. While in principle this is a good practice, in the late 19th century T.C. Chamberlin pointed out that whether we acknowledge it or not, we all fall in love with out own ideas and hypotheses (Chamberlin 1890). OK, maybe we don’t fall in love with them, but by virtue of the fact that we have developed a hypothesis, it can become personal when we search for evidence to support that hypothesis—this is called confirmation bias. This reality removes some objectivity from the scientific process, which can result in bad outcomes. One solution to this issue, Chamberlin proposed, is to developed multiple working (or competing) hypotheses. In other words, when you observe something and want to hypothesize what might be going on, the best approach is to come up with several different explanations. Not only is this good because it exercises the human mind (which we said was a limit to discovery), but it creates a competition of ideas in which a scientist is much less likely to advocate for one hypothesis over another. Evidence can be weighed for each hypothesis, and an objective conclusion may be made about what mechanisms are at play in the study system.

Figure 1.3: T.C. Chamberlin (Source: Wikipedia)
1.2 Falsifiability
Several decades after Chamberlin, another important milemarker on the epistemological journey was made by philosopher Karl Popper. Popper was not a practicing scientist like Chamberlin, but rather a philospher of science—and one of the most well-known of all time. Among Popper’s contributions to the philosphy of science was the idea of falsifiability (Popper 1959). In a nutshell, falsifiability is the idea that ideas can be proven wrong (falsified), but can never be proven to be true. Although we think of proof in a discipline like math, in the field of science, we can never really prove something because there is always an unknown alternative. Even well studied and understood phenomena that we accept as practically true (e.g., the earth is round) are never proven in science. Thinking about this too much can be confusing, but on the other end, it may be comforting to know that we can prove things to be false. Another component to falsifiability is that if we can demonstrate something is false, then it falls in the category of science. This may seem obvious, but falsifiabilty can be a useful test to determine whether something is science or not. (For example, consider religion. Can anyone ever disprove a creator? No, and as such the principle of falsifiability establishes that religion is not a science.)

Figure 1.4: Source: XKCD
1.3 Strong Inference
The last stop on our brief history of epistemolgy comes from John Platt in the mid 1960s. Building on Chamberlin and Popper, you might say that we now have many hypotheses to choose from and ways to select or falsify them, and that this is how we advance science. While this is true, Platt pointed out that even with this recipe, not all scientific disciplines advance at the same rate. What is it that allows a discipline like molecular biology to seemingly advance all the time, while a discipline like geology never makes the headlines? Platt’s answer was strong inference (Platt 1964). Strong inference directly builds on Chamberlin’s multiple hypotheses ideas and adds on the notion that when you have multiple hypotheses, you can repeated experiments and either support your findings or move in the direction of hypotheses with more support. Platt was supportive of iterating experiments through having a wide range of explanations to investigate.
Platt held that the disciplines that iterate faster would tend to make more rapid discoveries, but what is it about a discipline that allows fast or slow iteration? The primary factor controlling scientific iteration is the nature of the discipline. In other words, disciplines that can iterate quickly, like molecular biology, tend to use experimental designs in which controls and treatments are used and experiment times are fast. On the other side are disciplines that cannot iterate, like geology—we cannot run experiments on many geological phenomena because we cannot replication, randomized, control, etc. Rather, these slow or non-iterative sciences rely on observations, which can still be incredibly powerful but may not be as fast as other experimentally-driven disciplines. Therefore, it can be said that the disciplines that use experiments to rapidly advance understanding are benefiting from strong inference, while those disciplines that typically cannot run experiments and need to rely on observations, do not benefit from strong inference.
1.4 Experiments and Observations
Aside from strong inference, experiments and observations are an important comparison to make when thinking about science. Chances are you will operate more within one approach than the other, so it is important to understand their strengths and weaknesses.
Experiments Experiments are the hallmark of strong inference, because they isolate experimental units, manipulate treatments, and include randomization, replication, and controls. This ability to engineer and isolate factors of interest tends to advance understanding by decluttering from other potential factors.
Observations Observations take place when a patter or process is observed and often parsed apart into some measured outcome (or response) and measured input(s). Outcomes and inputs can really only be measured and no manipulated in an expermental sense.
It is worth mentioning that while many sciences and scientists operate largely with either experiments or observations, there are hybrid approaches. For example, in natural resource work we may seek to control, manipulate, and randomize as much as we can for a given system, while also not being able to completely isolate factors of interest from background dynamics.
1.5 Epistemological Domains
In a short aside it is worth mentioning epistemological domains, which can be thought of as larger spaces in which experiments, observations, and scientific inquiry take place. Naive realism, instrumentalism, metaphysical realism, and rationalism are four well accepted epistemological domains. Although these four domains can be considered independently the figure below presents a relationship among them that suggests naive realism occurs first and scientific advances often develop into one of the remaining three domains (Midway and Hodge 2012). In other words, observations take place first. After initial ideas are born from observations, scientists may then subject their ideas to create a testable model or deconstruct into individual components or develop an abstract non testable theory. These domains are not something most practicing scientists consider in their daily activities however they can be useful concepts when thinking about how you and your discipline approach the generation of knowledge.
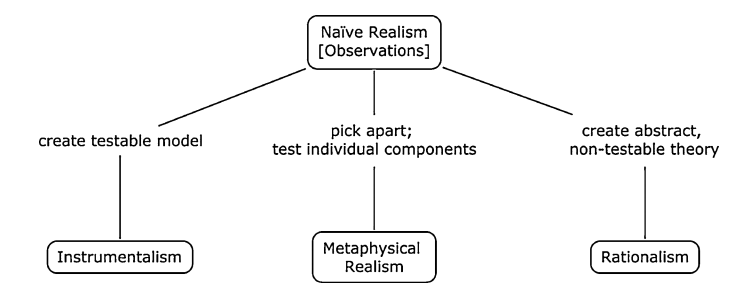
Figure 1.5: Epistemological domains (Midway and Hodge 2012)
1.6 Error
Error is an important underlying concept throughout science. So often we focus on what we know or what we think we know while ignoring the error and what we can learn from it. Consider a simple linear regression. The error term is the component of the model that makes this model statistical and not mathematical. For example if we were just converting a Celsius measurement to Fahrenheit we would know the answer without any error. If we know one we know the other and the measurements are considered perfectly correlated. However most of the time we understand some input or predictor variables in an attempt to understand how they influence a response variable yet this relationship always exists with error. Consider an example of measuring tree height. We might think that sunlight determines tree height yet some error would certainly be involved in that relationship because sunlight does not perfectly predict tree height. We know that water, nutrients, and other factors also influence tree height.
What is most important at this point from a very high level perspective is to think about the two types or sources of error that you may encounter. The first is process error, which is the error we tend to assume most errors will be. Process error concerns the errors that arise from imperfections in our understanding of the system we are trying to model. Returning to our tree height example process error would be accounted for because thinking that only sunlight influences tree height ignores the fact that tree height may also be influenced by water, nutrients, and another important factors. Yet by not knowing these factors all of their effects get bundled into the error term when the effects are excluded. As such, that error term is enlarged by our limited understanding of the process we are studying.
A second type of error is observation error. Observation error are those errors resulting from imperfections in how we measure and record the systems and relationships we seek to describe. Returning to our tree height example if we assume that sunlight did almost perfectly determine tree height, yet we had no tool to measure sunlight beyond a simple guess of how cloudy the atmosphere was, we would likely introduce error from our imperfect observations. Simply stating that one day was partly cloudy or partly sunny, for instance, is a general expression with lack of certainty about the driving variable (which may be Watts of solar radiation).
Process and observation error are often unavoidable. Therefore, the objective should be to recognize them and minimize them.
1.7 Replication and Reproducibility

Figure 1.6: Source: Sidney Harris
A final consideration about how we advance science regards our ability to communicate and share science. There is always a need to independently replicate the science that’s done in order to approach some asymptote of certainty regarding the results. If you aren’t convinced about the importance of replication consider medical science. Few of us would be interested in taking a drug that Whose results have not been independently replicated–or worse, could not be replicated. However, there are challenges to replication. First, there are often no funds to replicate work. Scientific funding bodies often want to fund new science–not work that has already been done. Second, there are often logistical challenges especially when studies are large and complex. Some large and complex studies may not even be able to be replicated. A final challenge to replication is when you cannot figure out what was done in the original study. Not being able to figure out what a study did can be a reality; however, it is not a necessary challenge because we all have the ability to effectively communicate our work.
In lieu of replication, reproducibility has emerged as a compromise between true replication and doing nothing. Reproducibility concerns the ability of a reader to reproduce the analysis of a study. Another way to think about reproducibility would be validating the data analysis. Obviously this is not a full replication; however, including code, data, and even linked code and data can create the opportunity for the reader to reproduce the analysis that the authors have shared (R. D. Peng 2011). Sharing code and data not only serves to allow others to evaluate your work, but it create the opportunity for others to build off your work and advance science.
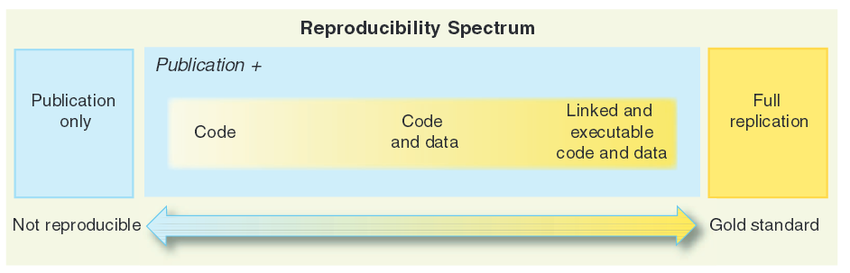
Figure 1.7: Roger Peng’s Reproducibility Spectrum
Decades ago it was common for a reader to only see a study as a published article, which may include text, figures, and tables but typically nothing more. Roger Peng’s research pipeline ideas have popularized the idea that the author should bring the reader farther back in the creation of the analysis. This includes not only sharing figures and tables and text but also making available computational results, analytic data, analytic code, processing code, and measured data in or associated with the publication.
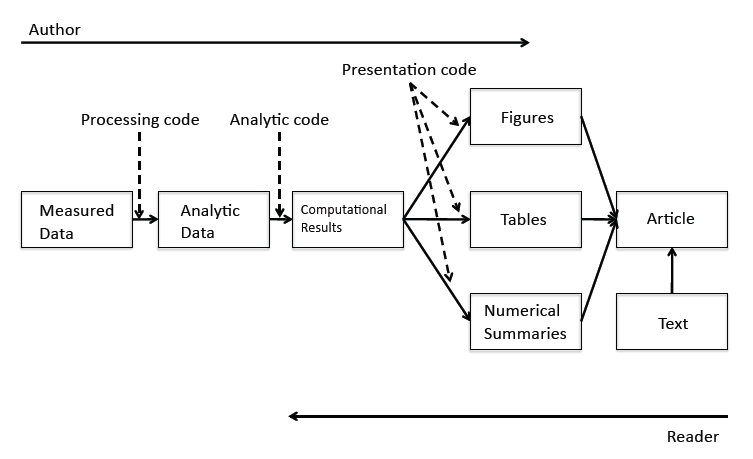
Figure 1.8: Research Pipeline to improve reproducibility
1.8 Recipe for Adult Science
In this chapter, we conclude with a recipe for doing science. We all might remember that page in our elementary or middle school math book that contained the steps for the scientific process. The below list is very similar, but infused with ideas and approaches that should only improve how you do science.
- Agree we can discover and agree on knowledge
- Make observations of how something works
- Develop multiple competing hypotheses
- Falsify or support hypotheses until agreement
- Use strong inference when possible to support leading hypotheses
- Further refine knowledge experiments and descriptions of error
- Share your work so that the study could be replicated and the analysis could be reproduced