Chapter 4 Data storage
As as been repeatedly mentioned, to the point of boredom, dbt transforms the data in your data warehouse. Now, before expanding the concept of a data warehouse, the following two are also terms you will hear mentioned quite often in the field of data engineering. They are data lake and data lakehouse.
4.1 Data warehouse
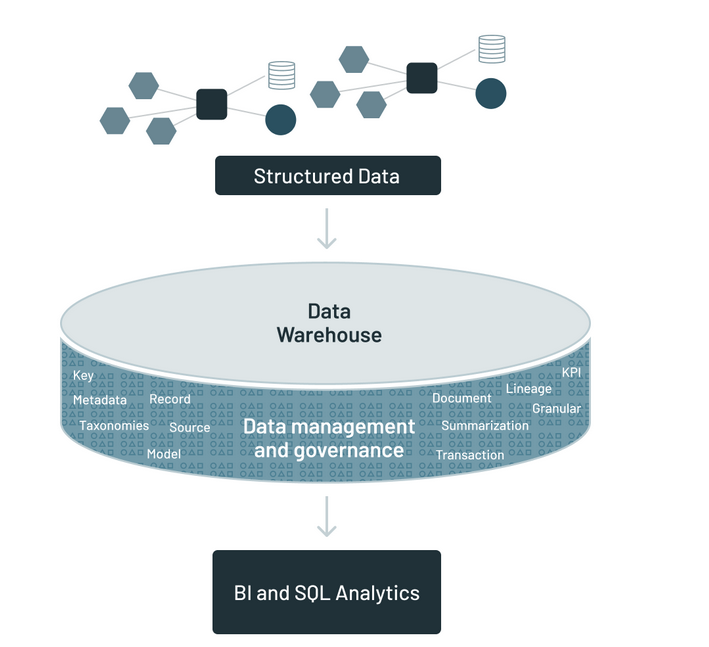
At the very beginning, when introduced to data engineering concepts with a test paper to boot in four weeks time, I thought that a data warehouse was some storage system akin to that found in Google Drive. I could have been partly right, but I was still far off the mark. A data warehouse is more than just a storage system. It is where data is not only stored but also queried, by means of SQL. It allows data from multiple sources such as internet of things, apps, from emails to social media and keeps a historical record of any changes. Examples of data warehouses are Snowflake, Google Big Query, Amazon Redshift and Azure Synapse Analytics.
The following are the components of a data warehouse.
Data sources - this refers to the origins of the data that lands in your data warehouse.
Extract, Transform and Load (ETL) Processes - these are the processes involved in extracting, transforming and loading the data into your data warehouse.
Data warehouse database - this is the central repository where the cleansed, integrated and historical data is stored.
Metadata repository - metadata is essentially data about data. Metadata will typically contain the source, usage, values and other features that comprise your data.
Access tools - imagine having to figure a way how to write a document in your computer without Microsoft Word. How hard would that be? Access tools are similar to Microsoft Word. They are the tools that enable a user to interact with the data. They include querying, reporting and visualization tools.
As you can see from above, a data warehouse is more than just a storage area for your data. It is like a whole community that will provide the services that you desire, so long as they are integrated into the data warehouse.
 Source: Reference
Source: Reference
4.2 Data lake
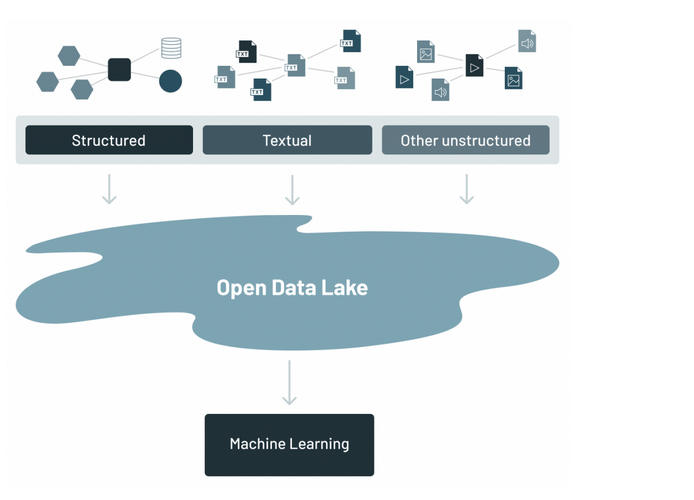
A data lake is a centralized repository that ingests and stores large volumes of data in its original form. Due to its open, scalable architecture, a data lake can store structured (database tables, excel sheets), semi-structured (xml, json and web pages) and unstructured data (images, audio, tweets) all in one place. Data in the data lake is stored in its original format.
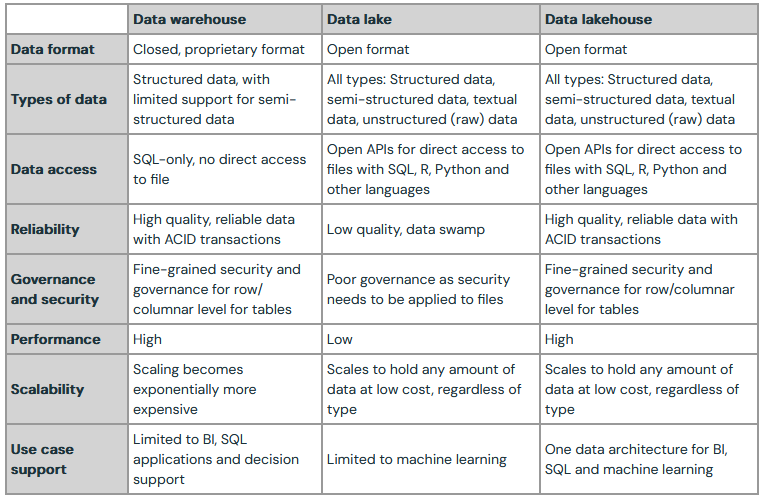
So if data lakes and data warehouses store data, then what is the difference? For one, a data lake can store data of any type, so long as it falls within the three classes of structured, semi-structured and unstructured data. On the other hand, data warehouses deal with more standardized data. That is, data in a data warehouse has undergone some refinement of some kind to be in a structure that fits the organizations’s goals.
 Source: Reference
Source: Reference
4.3 Data lakehouse
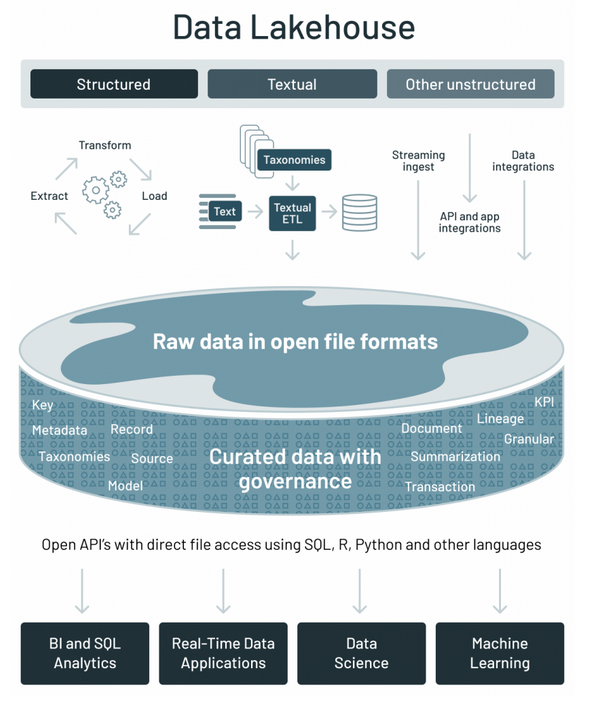
A data lakehouse is simply a hybrid of a data warehouse and data lake. It is like a product that combines the best of both worlds. A data lakehouse provides both scalability of large sums of data from the data lake and additionally, the application of a structural schema to data inherent in data warehouses.
Even with the above definition, it is still hard to decipher the advantage that a data lakehouse offers above that of a data warehouse. Apart from allowing the querying of unstructured data, storage costs are lower in a data lakehouse compared to a data warehouse.
Source: Reference
4.4 A brief history
At the very beginning, companies used to rely on relational databases and these were sufficient. However, they became too numerous as the needs and services of companies grew. Therefore, experts decided to look for a way of how they could merge all these single databases into one repository which would hold everything while allowing for permission controls to who gets access to what. Believe it or not, the concept of the data warehouse began in the 1960s but it is in the 1980s and 1990s that interest in this topic really began to get traction. That’s until the need for storing unstructured data from emails, images and audio began to grow. Data warehouses were not so efficient in storing this thanks to their strict schema enforcement (read, they store data in a structured format).
The beginning of 2000s saw the rise in the need to properly manage unstructured data with the growth of online platforms such as Google and Yahoo. Companies needed a way to store and retrieve unstructured data quickly and efficiently, which wasn’t possible with data warehouses. Data lakes excelled in storing all sorts of raw data, from structured to unstructured and everything in between. If you read on the history of data lakes, you willquite often come across the word ‘Hadoop’. Hadoop is the pioneer of the data lakes we use today.
However, despite being a good storage for any sort of data, the pesky question of maintaining some quality and order resurfaced again! How could we maintain some structure while allowing the data to be in any structure?!
From 2010s and onwards, after a decade of success with data lakes, companies wanted a better storage system from which to run their machine learning models but had the best capabilities of both a data warehouse and a data lake. Before lakehouses, companies would first ingest data into a data lake, then load into a data warehouse from where analytics would be done. But how could we just merge it into one place where storage and analytics could happen? This is how the data lakehouse concept came to be. Data lakehouses provide the following benefits:
ACID (Atomicity, Consistency, Isolation and Durability) transactions - ACID transactions promote integrity during data transfer.
Delta lake - initially developed by the Databricks team, this is a layer on top of your data in the data lake that provides a schema, keeps a record of changes in your data (versioning) and stores metadata.
Machine learning support - because a data lakehouse can store more data types than the data warehouse, it is a better place to perform machine learning modeling.
For more information on the evolution of data storage systems, this is a definitive guide.
 Source: Reference
Source: Reference