Capítulo 7 Diagnóstico da Doença
A palavra “diagnóstico” origina-se no grego e significa “conhecer através”. Nós Médicos Veterinários tentamos portanto conhecer a doença que está afetando os animais através da conhecimento do que é normal no animal em questão, tentando identificar o ele apresenta de alterado (vide Capítulo 2). Esta identificação do alterado pode ser feita de três formas básicas:
Diagnóstico Clínico: Quando o Médico Veterinário caracteriza uma doença através da identificação de um conjunto de sinais clínicos e anormalidades orgânicas e/ou comportamentais que estão associadas a tal enfermidade na literatura científica. Este tipo de diagnóstico é fortemente influenciado por alguns fatores:
- Experiência do Médico Veterinário: Quanto mais experiente e melhor treinado o Médico Veterinário maior sua probabilidade de identificar sinais e alterações clínicas no animal que sejam indicadoras de doença. Esta é uma parte inerente ao processo de aquisição de experiência, uma capacidade maior de identificação de anormalidades frente ao normal.
- Intensidade dos Sinais Clínicos: Quanto maior a severidade da doença e mais visíveis os sinais, mais fácil é a identificação da presença de doença.
- Localização dos Sinais Clínicos: Diarreias e sinais respiratórios são mais facilmente identificáveis do que alterações em qualidade e quantidade de urina. Ectoparasitas e miíases em animais de pelo curto são mais visíveis do que em animais de pelo longo. Estes dois pequenos exemplos podem ser expandidos para um variado número de situações em que o local do tecido orgânico afetado pode modificar sua probabilidade de caracterização pelo Médico Veterinário.
Diagnóstico Parasitológico:A segunda abordagem comum de diagnóstico ganhou importância principalmente depois do final do século XIX, após a Teoria da Higiene estabelecer o fato que microorganismos podem modificar a saúde de seus hospedeiros e são causa frequente de doenças. O Diagnóstico Parasitológico veio a tornar-se mais uma ferramenta de conhecimento da doença, permitindo associarmos muitas vezes a presença do parasito ao estabelecimento da doença. Este tipo de diagnóstico depende muito da:
- Intensidade da infestação: Quanto maior a quantidade dos parasitos maior é a probabilidade de encontro. Esta quantidade maior geralmente, com exceções, está associada a uma maior expoliação parasitária, a uma maior produção de formas ou estágios infectantes e a uma maior lesão tecidual e alteração da funcionalidade dos tecidos orgânicos. Todos estes fatores aumentam a probabilidade de identificação da presença do parasito dentro do hospedeiro. Eles também permitem o estabelecimento de uma escala de severidade da doença inferida a partir da intensidade de infestação parasitária determinada a partir de um teste diagnóstico. O Médico Veterinário deve estabelecer, preferencialmente para cada relação parasita-hospedeiro-ambiente, tal escala de relacionamente entre o grau de infestação e a provável severidade da doença naquele indivíduo.
- Localização do Parasito: O Médico Veterinário naturalmente tem facilidade para identificar uma teleógina de carrapato pela simples visualização à vista desarmada, enquanto que para caracterizar um ácaro de traquéia ele previsará recorrer à um lavado de traqueia ou exame de fezes com auxílio de um microscópio para poder diagnosticar tal infestação. Tal é a realidade para muitos parasitos, onde seu tamanho (que pode variar de macroscópico a microscópico), sua fase do ciclo ou mesmo sua localização podem modificar muito a taxa de sucesso no encontro e caracterização do microorganismo, bem como da adequação do teste àquele taxa parasitário em particular. Um outro exemplo simples é o diagnóstico parasitológico de fezes, onde a mera diferença de densidade e peso dos ovos entre as diferentes espécies de helmintos e protozoários provoca a necessidade do uso de técnicas diferentes para cada parasito em particular.
Diagnóstico Bioquímico: Por último, podemos também utilizar como forma de conhecer a doença uma análise dos tecidos orgânicos do animal afetado, procurando alterações na fisiologia que evidenciem aonde o animal tem problemas. É difícil na Medicina Veterinária moderna algum diagnóstico sem que se utilize alguma ferramenta laboratorial que avalie funções e mecanismos bioquímicos do animal em análise. Neste caso o diagnóstico vê-se complicado pela necessidade de estabelecermos faixas de referência de valores das variáveis bioquímicas que representam o animal ou tecido normal, para podermos, por comparação, identificar animais que estejam anormais. Tais faixas de referência devem ser estabelecidas com base em determinados critérios, que são matematicamente estabelecidos. Estes limites podem variar tremendamente entre espécies, sexos, idades e raças, devendo ser cuidadosamente escolhidos para que permitam uma correta seleção de animais doentes ou saudáveis no que tange a seus valores de bioquímica sanguínea ou de outros tecidos.
Na Medicina Veterinária moderna baseada em evidências, uma associação de resultados Clínicos, Parasitológicos e Bioquímicos é corriqueiramente utilizada para o estabelecimento do Diagnóstico definitivo sobre a causa da doença que está afetando o animal ou população animal. Outro produto da avaliação bioquímica da fisiologia de tecidos específicos no animal é a possibilidade de graduação da severidade da doença ou da infecção parasitária associada. Tal graduação advém do arrazoado de que quanto maior fôr a presença de determinadas enzimas na corrente sanguínea, mais células que contém taiz enzimas foram lesionadas, logo maior é o dano orgânico. Contudo, toda e qualquer forma de diagnóstico é sujeita a erros de classificação, erros que, como vimos acima, são inerentes ao processo de diagnóstico, e que variam de técnica para técnica.
7.1 Erros de classificação do diagnóstico
Nós vimos no capítulo 5 que em qualquer teste estatístico nós temos a possibilidade de termos uma hipótese Nula verdadeira ou falsa, e que nosso teste estatístico pode caracterizá-la como tal acertadamente ou não. No caso de testes ou procedimentos de diagnótico, estes erros de classificação são devidos a dois tipos de resultados: positivos ou negativos que são na realidade, falsos. Por “falso positivo” (ou “positivo falso”) entende-se o resultado positivo de um teste ou procedimento de diagnóstico, clínico, bioquímico ou parasitológico, relativo a um animal que é, na verdade, negativo para o agente, sinal clínico ou anormalidade bioquímica em questão. De forma inversa, um resultado “falso negativo” para um teste diagnóstico não foi capaz de identificar um animal que é positivo ou portador do agente ou sinal clínico em questão, classificando-o, erradamente, como negativo. Sendo assim, como nossa hipótese Nula em qualquer teste diagnóstico é “o animal é negativo para a presença do microorganismo, anormalidade ou sinal clínico em questão”, quando atribuimos um resultado positivo a um animal que é de fato negativo, cometemos um erro de Tipo I: refutar erradamente uma hipótese nula verdadeira (falsa descoberta). Já quando um animal é positivo para o aspecto a ser diagnosticado, e o teste ou procedimento diagnóstico não é capaz de caracterizá-lo, cometemos um erro de Tipo II: aceitar erradamente uma hipótese Nula falsa. A probabilidade de,erradamente, incluir negativos no grupo dos positivos (erro de tipo I) ou positivos no grupo dos negativos (erro de tipo II) são definidas pelos coeficientes α e β, respectivamente. Considere a Tabela 7.1; nela você pode observar os possíveis resultados de teste de hipóteses que a Tabela 5.1 apresenta foram convertidos para os possíveis resultados de um teste diagnóstico.
| Infectado | Não Infectado | Total | |
|---|---|---|---|
| Resultado do Teste Diagnóstico | |||
| Positivo | Positivo Verdadeiro | Positivo Falso (α) | Positivos Detectados |
| Negativo | Negativo Falso (β) | Negativo Verdadeiro | Negativos Detectados |
| Infectados, Total | Não Infectados, Total | Analisados, Total | |
Onde E: Especificidade; NV: Negativos Verdadeiros, animais que foram corretamente classificados pelo teste como negativos; NIT: Total de Não Infectados.
Conversamente, a Sensibilidade de um teste diagnóstico indica qual a proporção de testes realizados em animais infectados resultará em positivos. O restante serão resultados falsos negativos. Da mesma forma, o cálculo da Sensibilidade de um teste diagnóstico é conforme a Equação (7.2): S=PVTIOnde S: Sensibilidade; PV: Positivos Verdadeiros, animais que foram corretamente classificados pelo teste como positivos; IT: Total de Infectados.
Ambos os índices são comumente expressos como porcentagens. Por exemplo, uma Especificidade de 90% indica que 10% dos animais identificados como positivos, são na realidade falsos positivos, animais negativos que foram positivos no teste: são erros de classificação de Tipo I. Da mesma forma, um teste diagnóstico com 95% de Sensibilidade indica que 5% dos resultados negativos são relativos a animais falsos negativos. São animais positivos na realidade que não foram identificados pelo teste: são erros de classificação de Tipo II (Capítulo 5; (Zar 1996)).
Normalmente os dois índices tem uma certa competição entre si: quanto mais específico um teste diagnóstico, ele tende a perder em sensibilidade, aumentando o número de falsos negativos. De forma inversa, quanto mais sensível um teste diagnóstico, aumentam os falsos positivos. São considerados índices de Sensibilidade e Especificidade razoáveis valores acima de 80%, idealmente bons testes ou técnicas diagnósticas tem índices acima de 90%. Veja que com testes muito específicos (valores acima de 95%) mas pouco sensíveis (abaixo de 80%), podemos ter 95% de confiança que um positivo é realmente positivo. Mas entre os resultados negativos, devido a baixa sensibilidade do teste, podem existir muitos falsos negativos, animais positivos não caracterizados pelo teste (20% destes). O raciocínio inverso também deve ser considerado: testes muito sensíveis (mais do que 95%) perdem em especificidade; logo, dentre os resultados positivos, uma parcela maior será relativa a falsos positivos (Rifai 2008).
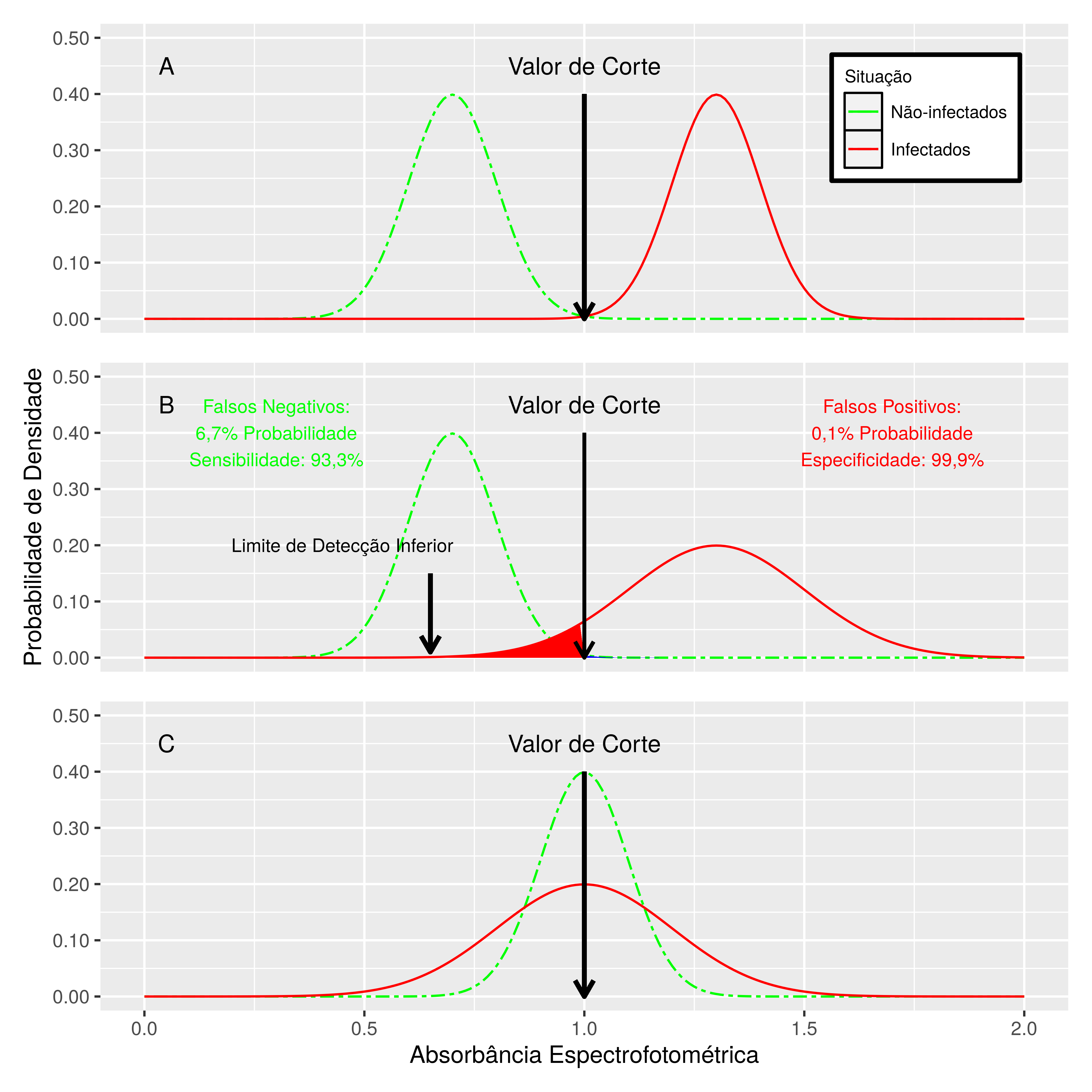
Figura 7.1: Resultados de leituras espectrofotométricas de três hipotéticos testes de diagnóstico. A) Teste próximo ao ideal. Há baixíssima probabilidade de cometer qualquer erro de classificação. B) Teste com maiores possibilidades de cometer erros de classificação de tipo II, e pequenas possibilidades de cometer erros de tipo I. C) Teste que não deve ser utilizado. Há sobreposição significativa das faixas de absorção espectrofotométrica, com grandes chances de cometer tanto erros de Tipo I quanto de Tipo II.
Para compreender melhor a competição entre Sensibilidade e Especificidade, considere a Figura 7.1. No painel A está exposta a situação ideal de um teste diagnóstico. Pode-se ver que os valores de absorção espectrofotométrica dos animais negativos e dos positivos no nosso teste fictício tem valores médios bem diferentes, mas mesma distribuição normal. Neste caso a superposição das caudas de distribuição dos valores de ELISA dos animais positivos e negativos é da ordem de 0,13%, ou seja, a cada 10000 animais testados seriam cometidos 13 erros de classificação. Neste caso o Limite de Detecção Inferior praticamente equivale-se ao Limite de Corte.
Já no painel B da mesma figura nosso teste fictício apresenta respostas dos níveis de absorção espectrofotométrica entre animais negativos e positivos já com maior superposição, gerando uma redução da Sensibilidade do teste (93,3%). Esta queda na sensibilidade foi devida a uma dispersão maior dos resultados positivos. Esta é situação comum no mundo real, já que animais positivos terão títulos diferentes entre animais e mais dispersos do que os resultados dos animais negativos, que tendem a apresentar-se mais concentrados. Destarte, os menores títulos dos animais positivos ficam abaixo do limite de discriminação estabelecido para o teste, gerando um percentual de 6,7% de falsos negativos. Quanto mais a média dos animais positivos fôr próxima da média dos animais negativos maior será a proporção de falsos negativos que o teste resultará. Caso fosse assumido o Limite de Detecção Inferior como valor de corte (maior sensibilidade, diminuindo os falsos negativos), muitos animais negativos seriam incluídos erradamente no grupo dos positivos (menor especificidade).
Finalmente na figura Já no painel C da Figura 7.1 apresenta-se resultados de um teste que deve ser descartado. Ele é incapaz de discriminar entre animais positivos e negativos, já que há quase completa superposição dos resultados da leitura entre os dois grupos. Os resultados deste teste não possuiriam confiabilidade alguma.
Nosso teste fictício do painel A acima poderia ser considerado o “padrão-ouro” para diagnóstico do parasito em questão, ou seja, a melhor técnica para se realizar aquele teste diagnóstico. Por melhor técnica considera-se aquela com os melhores índices de Especificidade e Sensibilidade, ou seja, aquela que resultará no menor índice de erros de classificação. Todos os outros testes diagnóstico terão sua Sensibilidade e Especificidade aferida EM COMPARAÇÃO ao padrão-ouro. Em muitas situações a inoculação experimental é utilizada como parâmetro para estabelecimento dos índices de Especificidade e Sensibilidade de testes diagnóstico.
Em termos de diagnóstico clínico, Sensibilidade e Especificidade de qualquer técnica são fortemente influenciadas pela experiência e o treinamento prévio do Clínico Médico Veterinário que realiza o diagnóstico. Neste caso, a escolha da técnica a ser utilizada em cada caso depende do(s) profissional(is) envolvido(s). Já no caso do diagnóstico parasitológico, depois do advento das técnicas de biologia molecular, o diagnóstico por PCR tornou-se o padrão-ouro em termos de diagnóstico de presença de microorganismos, contra o qual todos os outros testes são comparados. Lembre-se que presença do parasito não necessariamente implica que haja um doença clínica estabelecida no animal, já que tal estado depende de muitas outras variáveis, e não apenas a presença do parasito.
Por sua vez, as técnicas de diagnóstico sorológicas envolvem a detecção de anticorpos séricos. Elas permitem caracterizar o prévio contato do animal com o antígeno específico pesquisado. Entretanto, um resultado sorológico positivo não é garantia direta de que o animal era portador do microorganismo no momento da coleta do material biológico, nem tampouco que ele estava doente no momento da coleta do material biológico. Via de regra, títulos sorológicos muito altos indicam uma resposta intensa do organismo à uma infecção ativa e, por conseguinte, geralmente há uma doença clínica estabelecida ou um animal em recuperação clínica, dependendo da fase da infecção. Contudo o que é considerado um título “muito alto” varia sobremaneira entre métodos, técnicas e antígenos e espécies animais. Técnicas sorológicas são muito dependentes de um grande número de fatores que alteram tanto a afinidade dos anticorpos pelos antígenos procurados, quanto a capacidade de identificação pelo pesquisador de quando ocorre tal ligação. Dependendo da resultante da interação de tais fatores testes sorológicos podem variar muito seus índices de Sensibilidade e Especificidade.
7.2 Ajustando o teste diagnóstico
Como vimos no Capítulo 3 a prevalência é o indicador que relaciona o número de animais positivos no teste à população total analisada. Agora sabemos que nosso teste de diagnóstico pode cometer erros. É por isso que quando estabelecemos uma proporção de prevalência a partir de um teste diagnóstico, esta é denominada Prevalência Aparente (PA). A Prevalência é aparente porquê contém erros. A correção destes erros pela Sensibilidade e Especificidade do teste permite que agora ela seja denominada de Prevalência Verdadeira (PV). Este índice, caso tenhamos trabalhado corretamente, será agora estatisticamente indistinguível da Prevalência Real (PR).
A determinação dos índices de Sensibilidade e Especificidade de um determinado teste diagnóstico é feita através de experimentos controlados. Só assim podemos ter certeza do status infeccioso de cada animal, através da infecção experimental. Este status infeccioso conhecido é então comparado aos resultados obtidos no teste diagnóstico. Tal estratégia é demonstrada na Tabela 7.2, que contingencia os resultados de um experimento fictício de inoculação experimental e diagnóstico laboratorial:
| Infectados | Não_Infectados | Total | |
|---|---|---|---|
| Resultado Diagnóstico | |||
| Positivos | 250 | 20 | 270 |
| Negativos | 40 | 690 | 730 |
| Total | 290 | 710 | 1000 |
Na Tabela 7.2 você vai poder notar que 270 animais resultaram em um teste positivo.
A PA é, de acordo com a Equação (3.1):
PA=2701000=0,27×100=27%.
Destes animais, apenas 250 são verdadeiro positivos (ou positivo verdadeiros, à sua escolha); os outros 40 animais são erros de classificação, são falsos positivos.
Entretanto, 290 animais foram infectados e portanto são sabidamente positivos.
Sendo assim, a Prevalência Verdadeira é:
PV=2901000=0,29×100=29%.
Isso significa que os outros 40 animais que resultaram em um teste negativo são negativos falsos (eles deveriam ter um resultado positivo mas tal não aconteceu).
Da mesma forma, de todos os 710 animais que eram sabidamente naõ infectados, 690 destes resultaram em um teste diagnóstico negativo.
Estes são os negativos verdadeiros.
Como vimos, a Especificidade de nosso teste é a proporção de Negativos Verdadeiros em relação ao total de Não Infectados. Quanto maior a Especificidade, menor o número de Positivos Falsos, os erros de tipo I: refutar erradamente uma hipótese nula correta (de que o animal é negativo para o teste). Este índice é calculado conforme a Equação (7.1):
E=NVNIT=690710=0,972=97,2%
Igualmente, a definição de Sensibilidade é a proporção de Positivos Verdadeiros em relação ao total de Positivos Conhecidos. Quanto maior a Sensibilidade do teste, menor o número de Negativos Falsos. Assim, neste caso a Sensibilidade de nosso teste fictício, calculado conforme a (7.2) é:
S=PVIT=250290=0,862=86,2%
Baseado nestes índices sabemos que, de um conjunto de exames realizados com este mesmo teste, 86,2% dos animais positivos presentes na amostra serão efetivamente detectados. Uma proporção de 13,8% destes resultará, erradamente, em um teste negativo. São Erros de Tipo II: - hipóteses alternativa correta (de que são positivos) refutada erradamente. E podemos contar que dos animais negativos presentes em tal conjunto de exames, apenas 3,8% deles serão erradamente incluidos no grupo de positivos. De forma geral, é melhor testes com alta Especificidade, ou seja, baixa probabilidade de cometer Erros de Tipo I: atribuir positividade a um animal verdadeiramente negativo.
Quando utilizarmos nosso teste diagnóstico em nossos trabalhos experimentais, nós não podemos ter certeza quais dos animais negativos foram incluídos erradamente no grupo positivo (Erros de Tipo I), nem tampouco quais animais positivos passaram indetectados (Erros de Tipo II). Mas nós podemos corrigir a proporção, através do ajuste do valor da Prevalência Aparente a partir dos dados previamente caracterizados de Sensibilidade e Especificidade, para obtermos a Prevalência Verdadeira. Este ajuste é feito através de um mero re-arranjo dos valores da Tabela 7.2 resultando na Equação (7.3), a seguir: PV=(PA+e−1)(e+s−1)Onde PV: Prevalência Verdadeira; PA: Prevalência Aparente determinada pelo teste diagnóstico; s: Sensibilidade do teste diagnóstico; e: Especificidade do teste diagnóstico.
Baseados então na prevalência aparente (27%) e nos índices acima calculados de Especificidade e Sensibilidade do teste diagnóstico, nós poderíamos calcular a Prevalência Verdadeira, assim:
PV=(0,27+0,972)−1(0,972+0,862)−1=0,2420,834=0,2901≈29%, cqd.
Pequenas diferenças nos percentuais de prevalência podem ser criados por arredondamento, o que é justamente a causa da pequena diferença entre o valor acima calculado e o obtido diretamente na Tabela 7.2 (29%). Cuidados pois devem ser tomados para não utilizarmos um número reduzido de casas decimais nos cálculos, ainda mais quando os percentuais serão aplicados sobre populações animais grandes. Por exemplo, uma diferença de 0,1% em uma cálculo de prevalência, se aplicado sobre uma população de 100.000 animais, vai resultar em 1000 animais sendo incorretamente classificados, números que podem complicar alguma estratégia de controle que seja estabelecida baseada em tais percentuais.
7.3 Confiabilidade de resultados de diagnóstico
Outros dois índices que podemos obter a respeito de nosso teste diagnóstico hipotético em análise referem-se à qual a probabilidade de que um resultado negativo do teste seja efetivamente negativo, e seu índice complementar, qual a probabilidade que um resultado positivo seja efetivamente positivo. Denominamos respectivamente aos dois índices “Valor Preditivo Negativo” (VPN) (Equação (7.4)) e “Valor Preditivo Positivo” (VPP) do teste diagnóstico (Equação (7.5)).
VPN=NVTNDOnde NV: Negativos Verdadeiros que foram detectados no teste; TND: Total de Negativos Detectados no teste.
VPP=PVTPDOnde PV: Positivos Verdadeiros que foram detectados no teste; TPD: Total de Positivos Detectados no teste.
Ambos são calculados com base na proporção entre os resultados que são Verdadeiro Positivos (ou Verdadeiro Negativos) e o total de resultados Positivos Detectados (ou Negativos Detectados) no teste. Tal proporção é usualmente expressa em porcentagens. Em nosso caso de exemplo, o Valor Preditivo Positivo de nosso teste diagnóstico seria:
VPP=250270=0,9259×100=92,59%≈93%
Ou seja, pouco mais de 7% dos resultados Positivos Detectados no teste são Falsos Positivos.
Da mesma forma, o VPN seria:
VPN=690730=0,9452×100=94,52%≈95%
Cerca de 5% dos resultados Negativos Detectados no teste serão Falsos Negativos.
Estes dois índices são bons estimados de qual é a “seriedade” de um resultado Positivo ou Negativo Detectado no Teste. Estes índices são correlacionados à Sensibilidade e Especificidade do teste, obviamente. Quanto maior a Sensibilidade do Teste, maior o VPP dele. complementarmente, quanto maior a Especificidade do teste, maior o VPN do mesmo.
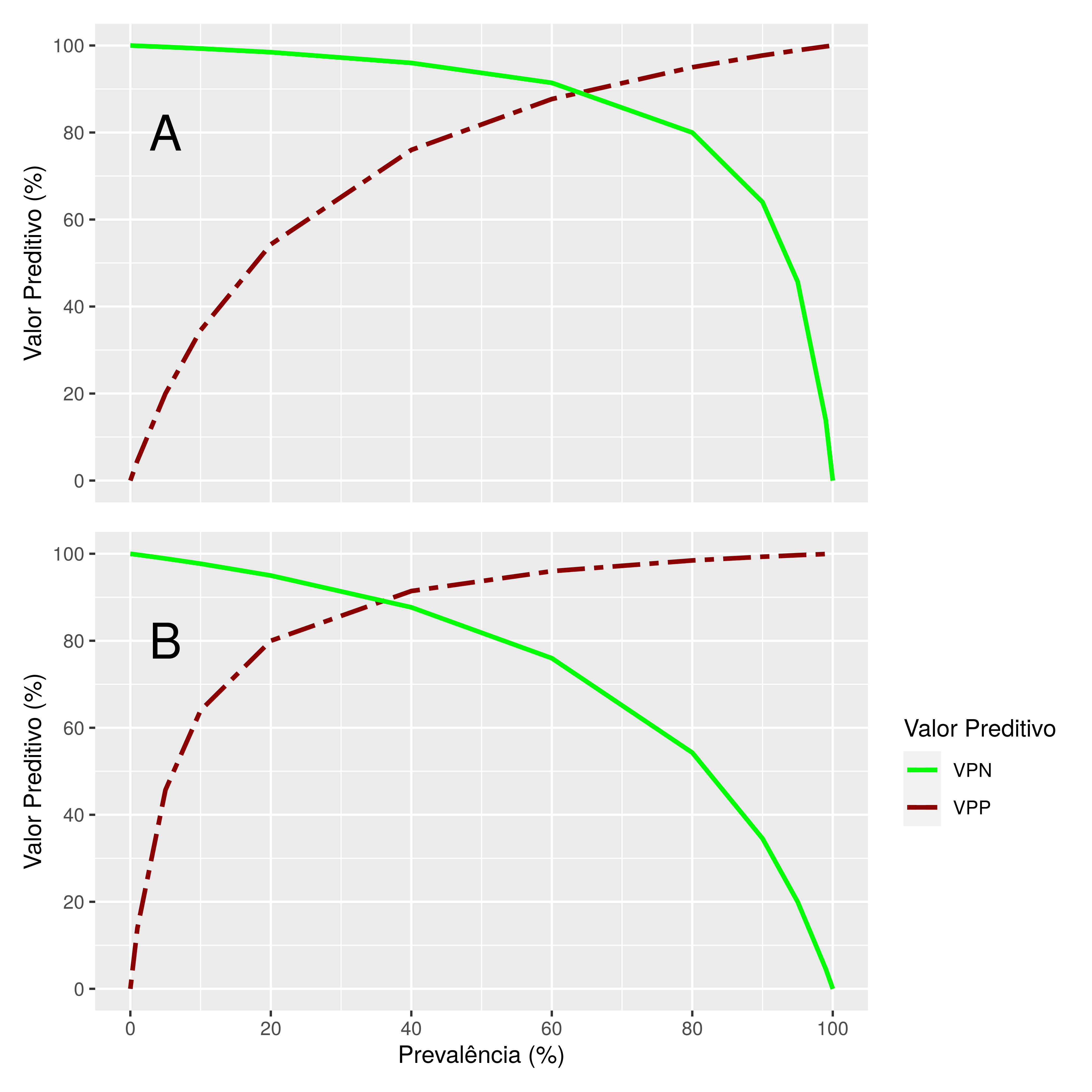
Figura 7.2: Relação entre a Prevalência e os Valores Preditivo Negativo e Positivo (VPN e VPP), de um teste com A) 95% de sensibilidade e 80% de Especificidade; B) 80% de Sensibilidade e 95% de Especificidade.
Outro fator que está relacionado ao VPP e VPN é a própria Prevalência Aparente do fator em análise. Observe na Figura 7.2 como comportam-se os valores de VPP e VPN frente a um teste com 95% de Sensibilidade e 80% de Especificidade em diferentes níveis de Prevalência Aparente. Enquanto a PA na população analisada estiver abaixo de 80% de prevalência, o VPN é máximo, pois soma-se a boa Sensibilidade do teste à probabilidade de encontro naturalmente baixa mantendo o VPN em níveis maiores do que 80%. A partir deste limite de 80% de PA o VPN cai abruptamente, já que poucos negativos realmente existirão na amostra, aumentando a possibilidade de que falsos negativos estejam entre eles. Por outro lado, enquanto a prevalência fôr baixa, devido à baixa Especificidade do teste, muitos falsos positivos se somarão à PA, diminuindo proporcionalmente o VPP. Este passa a subir gradativamente com a PA, atingindo níveis mais confiáveis (80% de VPP) quando a PA atinge 50% aproximadamente, estabilizando gradativamente até os 100% de Prevalência Aparente. Assim, em testes com Sensibilidade maior do que a Especificidade como foi o caso acima, são mais confiáveis os resultados negativos do que os positivos em PAs mais baixas. Já em em prevalências mais altas o inverso ocorrerá, com os resultados positivos sendo mais confiáveis do que os negativos. Uma inversão dos valores de Sensibilidade e Especificidade (80% e 95%, respectivamente), levam a uma inversão desta relação com os valores de VPN na faixa do confiável apenas com PA baixas, caindo abaixo do confiável (80%) já com PAs a partir dos 50%. Por outro lado, o VPP sobe subitamente já com prevalências aparentes da ordem de 20%, aumentando a confiabilidade nos resultados positivos gradativamente. Diferentes índices de Sensibilidades e Especificidade modificariam os limites de aumento/queda de VPN e VPP com a Prevalência Aparente proporcionalmente, de acordo com as equações (7.4) e (7.5).
7.4 Limites de detecção
Além dos índices acima aludidos, todo teste diagnóstico também tem seus Limites de Detecção, tanto superior quanto inferior. Tais limites representam a faixa de valores da variável analisada em que o teste diagnóstico desempenha adequadamente, e os resultados são compatíveis com a Sensibilidade e Especificidade que foi estabelecida no laboratório. Com relação ao Limite de Detecção Inferior, este seria a mínima quantidade do material biológico que o teste consegue assinalar em pelo menos 50% dos exames que tenham tal quantidade mínima. A Sensibilidade do Teste será a estabelecida nos experimentos desde que tal quantidade mínima esteja presente. Tal limite está demonstrado graficamente na Figura 7.1, painel B. Veja que estamos falando de quantidades mínimas de diferentes substâncias, dependendo do teste diagnóstico em análise: material genético (DNA/RNA) no caso de PCRs, imunoglobullinas no caso de testes sorológicos, o próprio parasito (ou suas formas infectantes) no caso dos testes parasitológicos. Testes moleculares são capazes de resultar positivo, em muitos casos, a partir da amplificação de apenas uma cópia de material genético a ser detectado, o que equivale a apenas um microorganismo unicelular.
Já testes sorológicos tipicamente tem limites de detecção inferiores mais altos, porquê dependem da quantidade presente inicialmente de imunoglobulinas, as quais não são amplificadas nos testes sorológicos, mas pelo contrário, tendem a degradar-se paulatinamente desde a coleta do material biológico. A conservação do soro e/ou plasma até o exame é pivotal para obtermos resultados confiáveis. Já o diagnóstico parasitológico pode ser afetado por fatores vários como local de infecção, tamanho do parasito, intensidade da infecção, fase do ciclo; em todos estes os limites de detecção inferiores podem ser modificados para cima ou para baixo. É mister que o pesquisador faça um experimento que permita-lhe identificar abaixo de qual limite de parasitismo ele não consegue mais identificar os animais positivos tendo em vista o parasito e modelo animal em questão. A determinação do Limite de Detecção Inferior é sempre feito experimentalmente. O animal é infectado experimentalmente com quantidades conhecidas e pequenas do antígeno ou parasito em questão, de forma a que um pesquisador possa saber a partir de qual limite inferior seu teste diagnóstico resultará em negativos por falha de detecção.
Já o Limite de Detecção Superior é geralmente estabelecido como o ponto na curva de relação entre a quantidade do analito e o resultado do teste que tal relação deixa de fazer sentido matemático. Quando os valores do analito estão acima do Limite de Detecção Inferior do Teste ele encontra-se na início da Faixa de Detecção. A partir deste ponto há uma relação matemática entre a quantidade do analito e o resultado do teste, relação esta que pode ser de ordem linear, quadrática, cúbica, exponencial, entre vários modelos de função que podem ser utilizadas para calculara um valor do analito a partir do resultado do teste, seja ele absorção óptica, densidade colorimétrica, ou contagem de células por campo de microscópio. Quando tal relação deixa de existir ou fazer sentido matemático, considera-se que o Teste atingiu seu Limite de Detecção Superior.
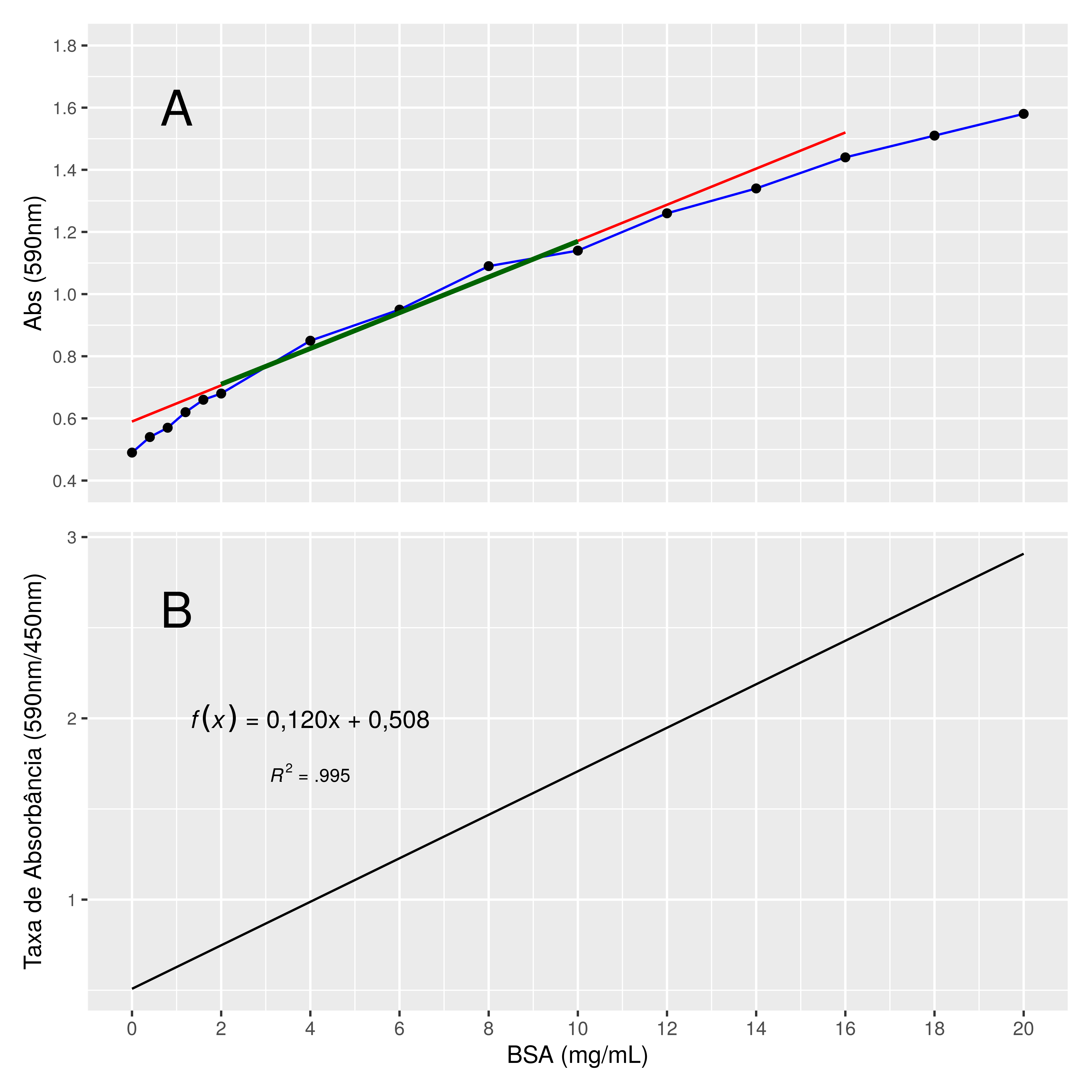
Figura 7.3: Curva de calibração do método de Bradford. A) Os resultados de absorbância só seguem um padrão linear dentro do limite de 2 a 12 mg/mL de Albumina Bovina (trecho demarcado em verde). Fora destes limites as variações de resposta não permitem inferências sobre qual a quantidade de Albumina (ou proteína em geral) estaria na amostra (trecho em vermelho). B) Gráfico gerado a partir de uma função de regressão que utiliza a razão entre a absorbância do solução de proteína em dois comprimentos de onda diferentes (450nm e 590nm) para corrigir a falta de linearidade apresentada no painel A do método de Bradford. Adaptado de Ernst and Zor (2010).
Como exemplo, considere a Figura 7.3, painel A, que apresenta a faixa de resultados de absorção Colorimétrica da curva de calibração do tradicional método de Bradford para quantificação de Albumina Bovina, nesse caso em particular. Pode ser visto que antes ou depois de determinados valores de concentração de Albumina, a curva de calibração do teste perde sua relação linear entre absorbância:quantidade de Albumina. A partir do momento que a relação entre albumina:absorbância perde sua relação linear, o teste não oferece mais a certeza de que a coloração registrada equivale à quantidade de Albumina existente no soro. Qualquer teste que depende de detecção por via luminosa ou colorimétrica pode passar por este efeito: saturação do meio de leitura por quantidade excessiva do analito. A solução nestes casos geralmente reside na diluição do material a ser analisado e/ou uma correção matemática posterior a ser aplicada no resultado obtido. Diluições maiores (ou menores) podem ser necessárias para ajustar os resultados diluidos à Faixa de Detecção do Teste. Neste caso particular do método de Bradford, podemos ver na mesma Figura 7.3, painel B, vemos que se aplicada uma correção às leituras espectrofotométricas, o método pode ser utilizado em uma faixa de valores mais ampla e com resultados mais acurados (Ernst and Zor 2010).
7.5 Acurácia (Verossimilhança)
A Acurácia de um determinado instrumento ou leitura analítica é uma expressão do quanto a leitura obtida (ou média de leituras) encontra-se próximo do valor real do analito em questão. No caso de testes diagnóstico, podemos calcular a Acurácia pela proporção dos resultados corretos tanto positivos como negativos em relação ao total de exames realizados. É o inverso da proporção dos erros de diagnóstico. Como exemplo, se examinarmos a Tabela 7.2 a acurácia do nosso teste diagnóstico hipotético seria:Acu=250+690990=0,9494≈95%
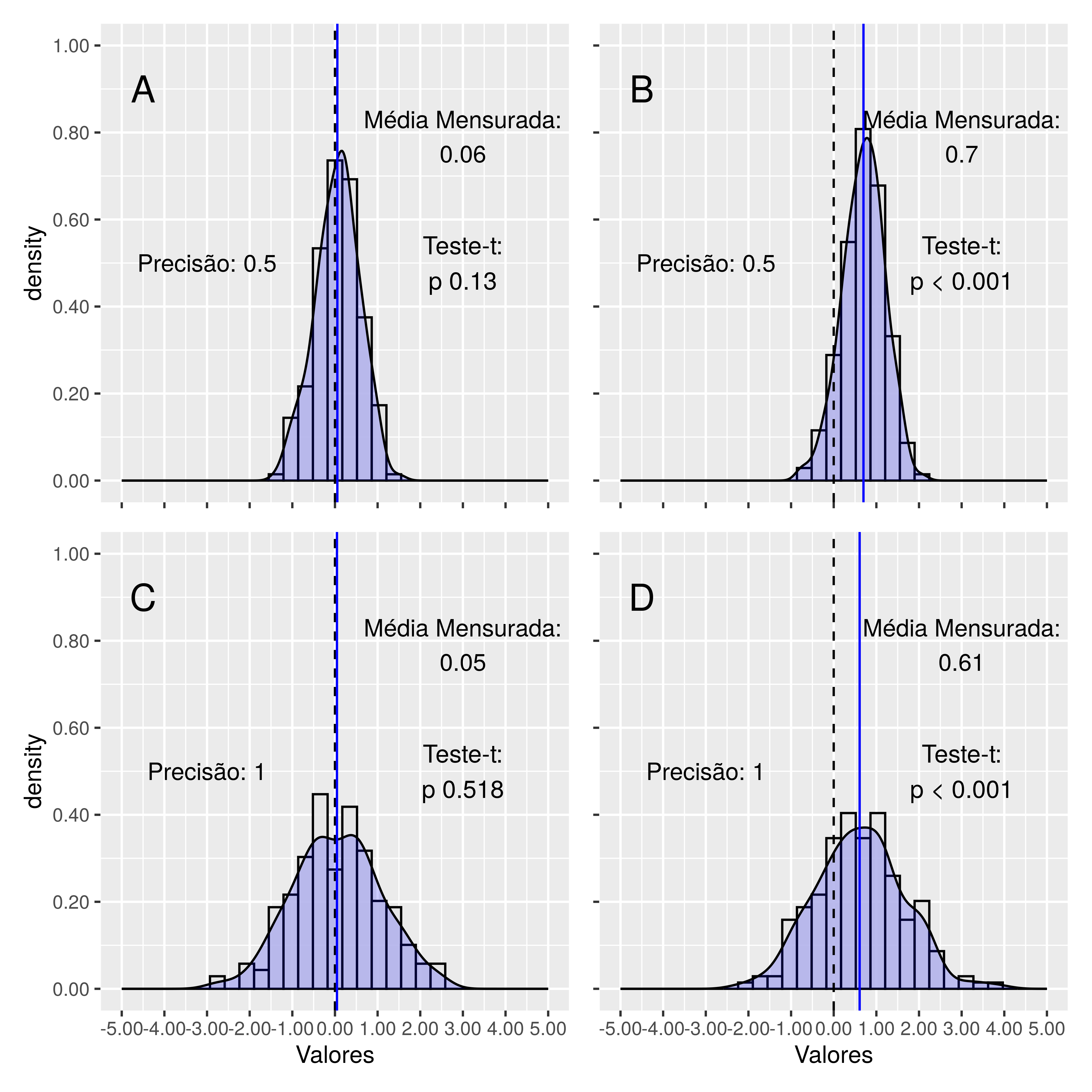
Figura 7.4: Gráficos representando resultados normalizados de diferentes métodos hipotéticos de dosagem de Albumina Sérica (g/L). A) Acurado e Preciso: o teste ideal; B) Inacurado e Preciso: pode ser corrigido para ganhar acurácia; C) Acurado e Impreciso: necessita de mais repetições para ser acurado; D) Inacurado e Impreciso: teste que não deve ser usado. Observe que nos métodos acurados ( A & C) o teste t não rejeita a hipótese Nula de que as médias verdadeiras e mensuradas são iguais, diferente do que acontece com os métodos inacurados ( B & D).
Instrumentos ou métodos inacurados podem ser corrigidos, se formos capazes de caracterizar a intensidade e direção do desvio. Tal processo de corrigir as leituras de um aparelho ou método para que ele reflita o valor real é conhecido como calibração ou aferição. A calibração de um instrumento é geralmente feita através da leitura ou mensuração de uma amostra com conteúdo ou concentração conhecidos, de forma a podermos gerar uma comparação linear entre a intensidade da leitura e o valor do analito a que tal leitura corresponde.
A figura do método de Bradford (Figura 7.3) é uma demonstração da utilização desta estratégia de calibração, no caso em questão concentrações diferentes de Albumina Bovina. Não é correto a estimativa de valores do analito que estejam situados fora da zona ou faixa de calibração, ou seja, a faixa de valores para qual o aparelho ou método foi calibrado. Novamente a diluição ou concentração da amostra pode ajudar a adequar a concentração do analito à faixa de calibração. Instrumentos ou métodos de análise que mesmo calibrados são inacurados devem ser abandonados para tal finalidade. É claro que para aferia tal inacurácia um valor conhecido deve ser estabelecido através de um método já consagrado ou que seja o Padrão Ouro do analito em questão. Observe que o erro total de uma medida ou análise será a soma dos erros aleatórios (geradores de imprecisão) com os erros sistemáticos (geradores de inacurácia).
7.6 Precisão (Repetibilidade)
A Precisão de um determinado instrumento de análise, aferido previamente, é uma estimativa de quão próximas entre si estarão sucessivas leituras efetuadas sobre um mesmo analito. Quanto mais preciso um instrumento menor a dispersão das leituras sucessivas, logo menos são necessárias para obter-se um valor médio correto. Testes diagnósticos frequentemente dependem de instrumentos de análise para identificação de alterações de cor, tamanho, forma ou conteúdo de materiais biológicos submetidos à examinação científica. Logo, tais testes também serão limitados pela precisão do instrumental analisado. A precisão de um determinado instrumento (e do método que o utiliza, por conseguinte) pode ser tremendamente afetada por variáveis que interfiram na sua capacidade de leitura. Por exemplo, métodos de análise de bioquímica sérica colorimétricos ou espectrofotométricos podem ser afetados de forma muito diferente e variável pela hemólise sanguínea. Imagens ultrassongráficas podem sofrer com artefatos gerados por gases, líquidos e outros fatores confundentes. Tempo e forma de conservação do material biológico até análise é um tremendo fator que pode modificar a precisão de variados métodos de diagnóstico.
Além de todos estes fatores ligados à amostra, outras fontes de imprecisão podem surgir devido a flutuações intrínsecas às leituras dos instrumentos, devido a interferências ópticas, eletro-eletrônicas, de temperatura, para citar os interferentes mais comuns. Estes erros são considerados aleatórios, randômicos, e como tal distribuem-se igualmente pelas amostras. Evidentemente tais erros devem sempre ser minimizados, mas eles não afetam as conclusões do teste das hipóteses. Note que mesmo um instrumento preciso pode resultar em resultados que estão longe do valor real do analito (vide Figura 7.4, se o instrumento ou método tem baixa acurácia (vide a seguir).
7.7 Comparando entre testes de diagnóstico
Em muitas situações, a comparação entre os resultados de dois tipos de teste diagnóstico se faz necessária, por motivos vários. Como dissemos anteriormente, há uma certa permuta entre os índices de Sensibilidade e Especificidade em qualquer teste diagnóstico: o aumento de um geralmente resulta na diminuição do outro. Quando utilizamos um teste de alta sensibilidade é inevitável aumentarem o número de falsos positivos. Em contrapartida, quando a especificidade é muito alta, aumentam o número de falsos negativos. Como forma de equalizar estas duas tendências, é praxe utilizar-se dois testes de diagnóstico de forma a contrabalançar tais efeitos. Em outras situações, por razões de precaução e/ou por exigências legais, a confirmação de uma diagnóstico positivo por um segundo teste diagnóstico é exigida. Nestes casos, um problema se estabelece: em qual dos resultados de cada teste confiar? Há uma concordância dos testes em análise em resultados positivos e negativos?
Note que embora que possa saber que determinado teste é mais ou menos sensível/específico que outro, esta informação só pode ser aplicada a uma população de resultados, não a um resultado em particular. O Valor Preditivo Positivo ou Negativo de cada teste pode até dar uma indicação de em qual resultado de cada teste confiar, mas novamente, cada resultado é uma incógnita em si. Embora não possamos saber qual resultado é o correto exame a exame em cada um dos testes, se estivermos comparando qualquer teste diagnóstico alternativo ao Padrão Ouro já estabelecido para a análise em questão, é do Padrão Ouro o resultado com maior confiabilidade. O desejável que haja uma concordância alta entre os dois para que o teste alternativo possa ser considerado adequado. Tendo isto em vista, considere a matriz de resultados apresentados na Tabela 7.3. Nela pode ser visto o resultado comum de acontecer quando da utilização de dois testes diagnósticos diferentes: resultados concordantes e discordantes podem acontecer.
| Teste_Z | Teste_W | Concordância | |
|---|---|---|---|
| 93 | 1 | 0 | |
| 94 | 0 | 0 | c |
| 95 | 0 | 1 | |
| 96 | 0 | 0 | c |
| 97 | 0 | 1 | |
| 98 | 1 | 1 | c |
| 99 | 0 | 0 | c |
| 100 | 0 | 0 | c |
| a A proporção de concordância entre os dois testes é de: 88% |
Para ajudar a dirimir tais dúvidas, existem alguns métodos matemáticos que comparam os resultados de dois (ou mais) testes diagnóstico, de forma a verificar qual a proporção de concordância entre os testes. O Teste Kappa de Cohen é um dos mais comuns destes testes McHugh (2012). Ele avalia o grau de concordância entre dois testes, gerando um índice que permite classificar tal grau de concordância entre inexistente até um máximo (Tabela 7.5), conforme a Equação (7.8).
O teste utiliza três parâmetros para calcular o Índice Kappa de Cohen: a Proporção Observada de resultados concordantes e discordantes, a proporção esperada calculada a partir dos resultados e o número de exames realizados. A Proporção Observada é calculada com base na razão entre a soma do número dos resultados positivos ou negativos que concordam entre si nos dois testes e o número total de testes realizados, conforme a Equação (7.6): Po=(Pc+Nc)NOnde Po: Proporção observada; Pc: Número de exames positivos concordantes no dois testes; Nc: Número de exames negativos concordantes no dois testes; N: Número total de exames realizados.
Já a Proporção Esperada é obtida pela razão entre a soma do produto entre os resultados negativos dos dois testes e do produto dos resultados positivos, e o número total de testes realizados. Dessta forma ela estima a proporção de resultados concordantes esperados se os dois testes fossem completamente independentes e aleatórios. A Proporção Esperada pode ser calculada através da Equação (7.7):Pe=(PT1∗PT2)+(NT1∗NT2)N2
Onde Pe: Proporção esperada; PT1, PT2: Número de exames positivos nos Testes 1 e 2, respectivamente; NT1, NT2: Número de exames negativos nos Testes 1 e 2, respectivamente; N: Número total de exames realizados.
O cálculo do Índice Kappa de Cohen então segue a formulação descrita na Equação (7.8):
k=Po−Pe1−PeOnde k: Índice Kappa de Cohen; Po: Proporção observada; Pe: Proporção esperada.
Tendo em vista os resultados discriminados na Tabela 7.3, para calcularmos o ìndice Kappa de Cohen eles devem ser devidamente contingenciados conforme exposto na Tabela 7.4.
| Negativos | Positivos | Total | |
|---|---|---|---|
| Teste W | |||
| Negativos | 48 | 5 | 53 |
| Positivos | 7 | 40 | 47 |
| Total | 55 | 45 | 100 |
| a O valor do Índice Kappa de Cohen entre estes dois testes é 0.759 | |||
Agora sim podemos calcular então o índice de Kappa de Cohen conforme a Equação (7.8) e compará-lo aos valores da Tabela 7.5 e tomar a decisão de utilizar ou não um ou os dois testes de diagnóstico em comparação.
| Índice Kappa | Grau de Concordância | Proporção dos resultados que é confiável |
|---|---|---|
| 0 - 0,20 | Pobre | < 4% |
| 0,21 - 0,40 | Baixo | 4% a 15% |
| 0,41 - 0,60 | Moderado | 15% a 35% |
| 0,61 - 0,80 | Alto | 35% a 63% |
| 0,81 - 0,90 | Muito Alto | 63% a 81% |
| > 0,90 | Quase Perfeito | >81% |
| a Adaptada a partir de McHugh (2012) |