C Other useful R functions
C.1 General functions
-
seq()produces a sequence of integers:-
seq(1, 4)produces the list: \(1\), \(2\), \(3\), \(4\). -
seq(0, 10, by = 2)produces a list going up by two each time: \(0\), \(2\), \(4\), \(6\), \(8\), \(10\). -
seq(0, 10, length = 3)produces a list of length three: \(0\), \(5\), \(10\). - A colon can also be used in special cases:
3 : 7produces: \(3\), \(4\), \(5\), \(6\), \(7\).
-
-
c()is used to concatenate (join together) a series of values:-
c("fred", "martha")creates a vector with two text elements. -
c(1, 8, 3.14, -2)create a vector with four numerical elements.
-
-
cat()is often used to print information. -
array( dim = c(2, 4))produces an empty \(2\times 3\) array (which is like a matrix). -
array( data = c(1, 2, 3, 4, 5, 6), dim = c(2, 3))produces the \(2\times 3\) array \[ \left[ \begin{array}{ccc} 1 & 3 & 5\\ 2 & 4 & 6\\ \end{array} \right]. \] -
array( data = c(1, 2, 3, 4, 5, 6), byrow = TRUE, dim = c(2, 3))produces the \(2\times 3\) array \[ \left[ \begin{array}{ccc} 1 & 2 & 3\\ 4 & 5 & 6\\ \end{array} \right]. \] -
t()transposes a matrix or array.
Logical comparison in R are possible (notice the use of ==):
DaysOfWeek <- c("Mon", "Tues", "Wed", "Thurs", "Fri", "Sat", "Sun")
HoursSleep <- c(8, 8, 8, 8, 6, 6, 10)
HoursSleep == 8
#> [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE
HoursSleep > 8
#> [1] FALSE FALSE FALSE FALSE FALSE FALSE TRUE
HoursSleep >= 8
#> [1] TRUE TRUE TRUE TRUE FALSE FALSE TRUE
HoursSleep == 6 | HoursSleep == 10 # | means "OR"
#> [1] FALSE FALSE FALSE FALSE TRUE TRUE TRUE
HoursSleep > 6 & HoursSleep < 10 # & means "AND"
#> [1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE
which(HoursSleep == 8)
#> [1] 1 2 3 4
which(HoursSleep > 8)
#> [1] 7
which(HoursSleep >= 8)
#> [1] 1 2 3 4 7
which(HoursSleep == 6 | HoursSleep == 10 ) # | means "OR"
#> [1] 5 6 7
which(HoursSleep > 6 & HoursSleep < 10 ) # & means "AND"
#> [1] 1 2 3 4
WeekEnd <- DaysOfWeek == "Sat" | DaysOfWeek == "Sun"
WeekDay <- !WeekEnd # ! means "NOT"
HoursSleep[WeekDay]
#> [1] 8 8 8 8 6
HoursSleep[WeekEnd]
#> [1] 6 10
cat("These are the hours of sleep on weekdays:", HoursSleep[WeekDay], "\n")
#> These are the hours of sleep on weekdays: 8 8 8 8 6
# Notice that \n is used to create a new line.Specific elements of a vector can be accessed using square brackets:
HoursSleep[1]
#> [1] 8
HoursSleep[3:5]
#> [1] 8 8 6
HoursSleep[WeekEnd]
#> [1] 6 10C.2 Statistical functions
Because R is primarily a statistical package and environment, all the basic statistical functions are available, including
-
mean(): Find the mean of a sample of values. Example:mean( c(1, 2, 3, 4)). -
median(): Find the median of a sample of values. Example:median( c(1, 2, 3, 4)). -
sd(): Finds the standard deviation of a sample of values. Example:sd( c(1, 2, 3, 4)). -
var(): Finds the variance of a sample of values. Example:var( c(1, 2, 3, 4)). -
lm(): To fit a linear regression model:
x <- c(1, 2, 3, 4, 5)
y <- c(12, 10, 9, 7, 4)
out <- lm(y ~ x) # Read: 'y as a function of x'
coef(out)
#> (Intercept) x
#> 14.1 -1.9
summary(out)
#>
#> Call:
#> lm(formula = y ~ x)
#>
#> Residuals:
#> 1 2 3 4 5
#> -0.2 -0.3 0.6 0.5 -0.6
#>
#> Coefficients:
#> Estimate Std. Error t value Pr(>|t|)
#> (Intercept) 14.1000 0.6351 22.202 0.00020
#> x -1.9000 0.1915 -9.922 0.00218
#>
#> (Intercept) ***
#> x **
#> ---
#> Signif. codes:
#> 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> Residual standard error: 0.6055 on 3 degrees of freedom
#> Multiple R-squared: 0.9704, Adjusted R-squared: 0.9606
#> F-statistic: 98.45 on 1 and 3 DF, p-value: 0.002178C.3 Probability and counting functions
- the number of combinations of
nelements takenkat a time is found usingchoose(n, k). -
\(n!\) is given by
factorial(n). - the number of permutations of
nelements takenkat a time is found usingchoose(n, k) * factorial(k). - a list of all combinations of
nelements,mat a time, is given bycombn(x, m). -
\(\Gamma(x)\) is given by
gamma(x).
C.4 Vector operations
R is a vectorised system; that is, operations work on all elements of a vector:
x <- 0 : 10
x
#> [1] 0 1 2 3 4 5 6 7 8 9 10
x + 3
#> [1] 3 4 5 6 7 8 9 10 11 12 13
2 * x
#> [1] 0 2 4 6 8 10 12 14 16 18 20
sqrt(x) # The square root function
#> [1] 0.000000 1.000000 1.414214 1.732051 2.000000
#> [6] 2.236068 2.449490 2.645751 2.828427 3.000000
#> [11] 3.162278
cos(x) # The cosine function
#> [1] 1.0000000 0.5403023 -0.4161468 -0.9899925
#> [5] -0.6536436 0.2836622 0.9601703 0.7539023
#> [9] -0.1455000 -0.9111303 -0.8390715
exp( -x ) # The exponential function
#> [1] 1.000000e+00 3.678794e-01 1.353353e-01
#> [4] 4.978707e-02 1.831564e-02 6.737947e-03
#> [7] 2.478752e-03 9.118820e-04 3.354626e-04
#> [10] 1.234098e-04 4.539993e-05C.5 Plotting functions
Three systems exists for plotting in R, believe it or not. Here, we discuss the base system.
plot() is the basic function for plotting, with many options:
-
plot(x, y)andplot(y ~ x)both produce a scatterplot, withyon the vertical axis andxon the horizontal axis. -
plot(..., type = "l")plots with lines rather than points. -
plot(..., lwd = "3")plots with a line width thrice as thick. -
plot(..., xlab = "text", ylab = "Info")adds an label to the x and y axes respectively. -
plot(..., main = "Title")adds a main title to the plot. -
plot(..., col = "green")plots in green rather than the default (black).
plot() starts a new canvas every time it is called.
lines() and points() add lines and points respectively to an existing plot.
legend() adds a legend to an existing plot.
x <- seq(0, 4, length = 100)
y1 <- dexp(x, rate = 2) # Probability function for an exponential distn
plot(y1 ~ x,
type = "l", # Use lines, not points
lwd = 2, # Make lines a bit thicker
xlab = "Values of x",
ylab = "Probability function",
main = "Probability function for\nexponential distribution",
# NOTE: using \n adds a line break, and # is used for comments
col = "red",
las = 1, # Makes the axis labels all horizontal
xlim = c(0, 4.5), # Changes the displayed limits of the x-axis
ylim = c(0, 3) ) # Changes the displayed limits on the y-axis
y2 <- dexp(x, rate = 3)
lines( y2 ~ x, # ADD a line to existing point
lwd = 2,
col = "blue")
legend("topright", # The location
lwd = 2,
col = c("red", "blue"),
legend = c("Rate = 2",
"Rate = 3")
)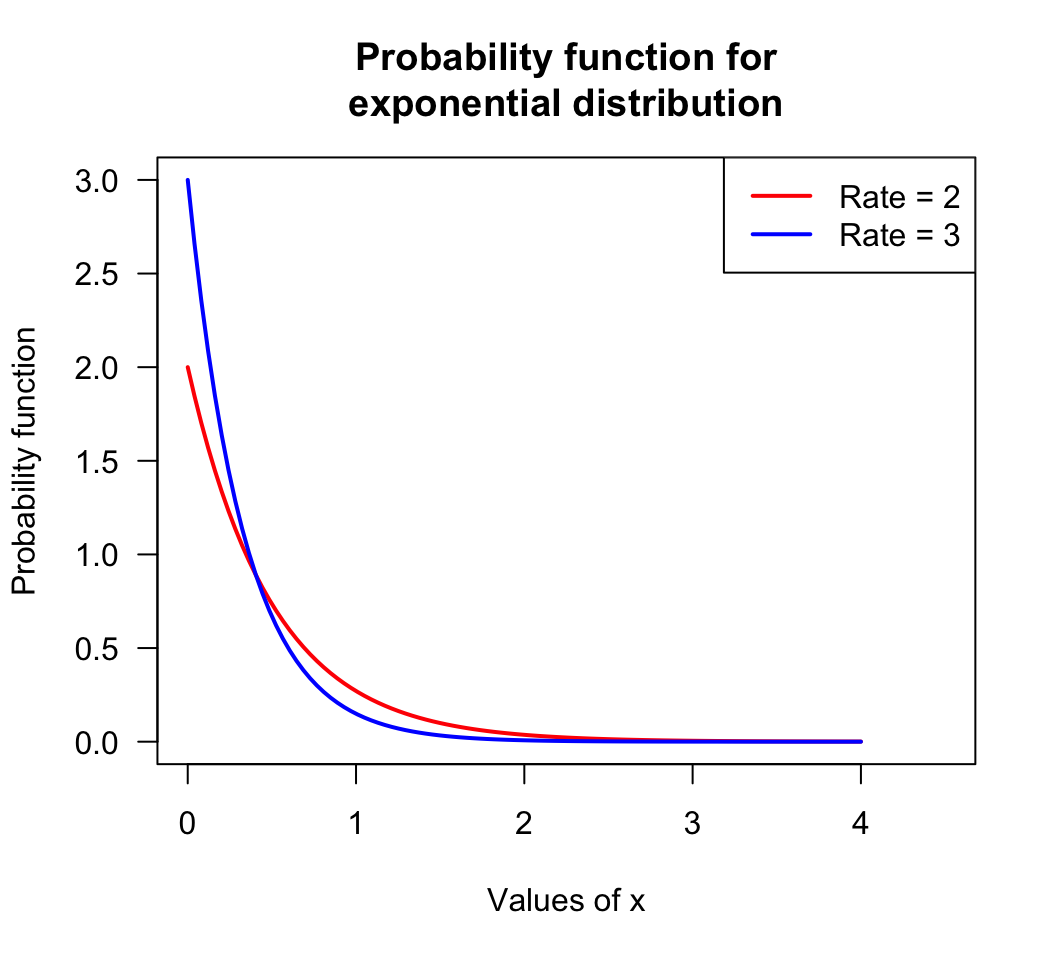
FIGURE C.1: An example plot: the probability function for two exponential distributions