Chapter 5 Random Variables
5.1 Overview
In this Chapter we will introduce the concept of a random variable (Section 5.2). Random variables assign numerical values to outcomes from a sample space and these can be discrete (counts), continuous (measurements on the real-line) or mixed. Key summaries for random variables are their expectation (mean) and variance, concepts that we have already seen for summarising data and which in Section 5.3 we formalise for random variables. We introduce important classes of random variables (probability distributions), both discrete and continuous distributions. These include:
- Section 5.4 Bernoulli random variables and their extensions such as the Bernoulli, Binomial, Geometric and Negative Binomial distributions
- Section 5.5 Poisson distribution
- Section 5.6 Exponential random variables and their extensions such as the Exponential, Gamma, Chi-squared and Beta distributions
- Section 5.7 Normal (Gaussian) distribution
5.2 Random variables
Random variable.
A random variable (r.v.) \(X\) is a mapping from \(\Omega\) to \(\mathbb R\), that is
For example,
Let \(X\) be the number of heads observed when tossing a fair coin three times.
Let \(T\) be the length of time you wait to be serviced by a bank teller.
Note: Random variables can be either discrete (i.e. take a finite or countable number of values), continuous, or mixed.
An example of a mixed random variable is, \(R\), the amount of rain \((ml)\) on a given day.
Cumulative distribution function.
The cumulative distribution function (c.d.f.) of a random variable \(X\) is
Properties of the c.d.f include
\(P(X>x) = 1 - F_X(x)\).
\(P(x_1 < X \leq x_2) = F_X(x_2) - F_X(x_1)\).
Note the c.d.f. is defined for all random variables regardless of whether they are discrete, continuous or mixed.
Probability mass function.
If \(X\) is a discrete random variable, then we can define a function \(p_X(x)\), called the probability mass function (p.m.f.) such thatCoin toss.
Let \(X\) be the number of heads observed when tossing a fair coin three times. What is the p.m.f. of \(X\)?
Probability density function.
Let \(X\) be a continuous random variable. If there exists some non-negative function \(f_X\) on \(\mathbb R\) such that for any interval \(I\),the function \(f_X\) is called the probability density function (p.d.f.) of \(X\).
Note that if \(F_X(x)\) is the c.d.f. of a continuous random variable \(X\), then the p.d.f. of \(X\) is given by \[f_X(x) = \frac{d F_X(x)}{dx}.\]
Note that5.3 Expectation
In this Section we formally define the expectation (mean), variance, median and mode of a random variable. We can note the similarities with the definitions of the measures of location (mean, median and mode) and variance of summary statistics in Section 2.
Expectation.
The expectation of a random variable \(X\) is defined byNote that \(E[X]\) only exists if \(E[|X|]<\infty\) and that \(E[X]\) is a measure of the centre of the distribution, that is the centre of mass. We can also define expectations of functions of random variables.
If \(Y=g(X)\) then the expectation of \(Y\) is given by
For constants \(c\), \(c_i\) and \(d\), the following are properties of the expectation:
- \(E[c]=c\);
- \(E[c g(X) + d]= c E[g(X)] + d\);
- \(E \left[ \sum\limits_{i=1}^n c_i g_i(X_i) \right] = \sum\limits_{i=1}^n c_i E[g_i(X_i)]\);
- A special case of the above results is \(c_1 = \ldots =c_n =1\) and \(g_i (\cdot)\) is the identity transform, \(g_i (X_i) =X_i\). Then \(E \left[ \sum\limits_{i=1}^n X_i \right] = \sum\limits_{i=1}^n E \left[ X_i \right]\).
Variance.
The variance of \(X\) is
The standard deviation of \(X\) is \(\sqrt{\text{Var} (X)}\).
For constants \(c\), \(c_i\) and \(d\), the following are properties of the variance:
\(\text{Var}(X) = E[X^2] - (E[X])^2\);
\(\text{Var}(X) \geq 0\);
\(\text{Var}(cX + d) = c^2 \text{Var}(X)\);
If \(X_1,\dots,X_n\) are independent, then
\[\text{Var} \left( \sum_{i=1}^n c_i X_i \right) = \sum_{i=1}^n c_i^2 \text{Var} (X_i).\]
Median.
The median of \(X\) is defined as \(x_{0}\) such that \(F_X (x_{0}) =0.5\).
For a discrete random variable it is unlikely that there exists \(x_0\) such that \(F_X (x_{0}) =0.5\). Therefore for discrete random variables the median is defined to be the smallest \(x_0\) such that \(F_X (x_0) \geq 0.5\).
Mode.
The mode of \(X\) is the point at which \(f_X (x)\) is maximised, i.e. mode is \(x_{0}\) if and only if \(f_X(x_{0}) \geq f_X(x)\) for all \(x\).
Continuous distribution.
Suppose that the random variable \(X\) has probability density function: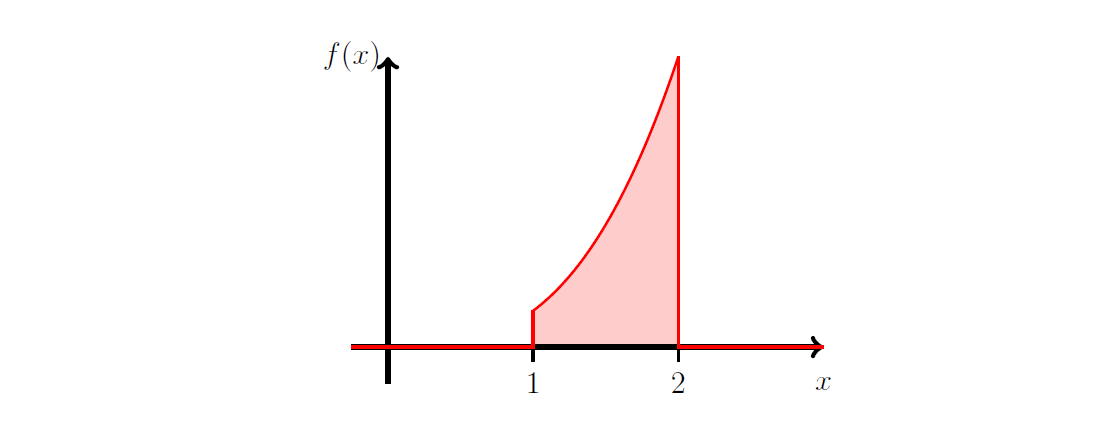
Figure 5.1: Plot of \(f_X (x)\).
- Show that \(k =4/15\);
- Find \(P (\frac{5}{4}\le X \le \frac{7}{4})\).
- Compute the standard deviation of \(X\).
Remember: Standard deviation is the square root of the variance.
- Find the median of \(X\).
Attempt Example 5.3.6 and then watch Video 10 for the solutions.
Video 10: Continuous random variable
Solution to Example 5.3.6.
- Remember \(\int_{-\infty}^\infty f_X (x) \, dx =1\) and therefore
\[\begin{eqnarray*} 1 &=& \int_{-\infty}^\infty f_X (x) \, dx \\ &=& \int_1^2 k x^3 \, dx \\ &=& k \left[ \frac{x^4}{4} \right]_1^2 \\ &=& k \left(\frac{2^4}{4} -\frac{1^4}{4} \right) = k \times \frac{15}{4}. \end{eqnarray*}\] Thus, \(k=\frac{4}{15}\).
- It follows from the above that the c.d.f of \(X\) is
\[ F_X (x) = \left\{ \begin{array}{ll} 0 & \mbox{for } x<1 \\ \int_1^x \frac{4}{15}y^3 \, dy = \frac{x^4-1}{15} & \mbox{for } 1 \leq x \leq 2 \\ 1 & \mbox{for } x>2 \end{array} \right. \] Thus\[\begin{eqnarray*} P \left(\frac{5}{4} \leq X \leq \frac{7}{4}\right) &=& \frac{(7/4)^4-1}{15} - \frac{(5/4)^4-1}{15} \\ &=& \frac{1}{15} \left[\left( \frac{7}{4}\right)^4 -\left( \frac{5}{4}\right)^4 \right] \\ &=& \frac{37}{80} (=0.4625). \end{eqnarray*}\] - Remember that the standard deviation of \(X\) is the square root of the variance. Therefore
\[ sd (X) = \sqrt{var(X)} = \sqrt{E[X^2]- E[X]^2}. \]
- The median of \(X\), \(m\), satisfies
\[\begin{eqnarray*} 0.5 &=& P (X \leq m) = \frac{m^4 -1}{15} \\ 7.5 &=& m^4 -1 \\ 8.5 &=& m^4. \end{eqnarray*}\]
5.4 Bernoulli distribution and its extension
In this section, we start with the Bernoulli random variable, which is the simplest non-trivial probability distribution taking two possible values (0 or 1). In itself the Bernoulli random variable might not seem particularly exciting, but it forms a key building block in probability and statistics. We consider probability distributions which arise as extensions of the Bernoulli random variable such as the Binomial distribution (sum of \(n\) Bernoulli random variables), the Geometric distribution (number of Bernoulli random variables until we get a 1) and the Negative Binomial distribution (number of Bernoulli random variables until we get our \(n^{th}\) 1).
5.4.1 Bernoulli distribution
Bernoulli trial.
A Bernoulli trial is a simple random experiment with two outcomes: success \((1)\) or failure \((0)\). The success probability is \(p\), so failure probability = \(1-p (=q)\). A Bernoulli random variable \(X\) describes this:[If \(x =1\), \(p_X (1) = p^1 q^0 = p\) and if \(x=0\), \(p_X (0) = p^0 q^1 = q\).]
We have that5.4.2 Binomial Distribution
Two discrete random variables \(X\) and \(Y\) are said to be independent and identically distributed (i.i.d.) if for all \(x, y \in \mathbb{R}\),
(identically distributed, i.e. have the same pmf.)
Binomial distribution.
Consider \(n\) independent Bernoulli trials, each with success probability \(p\). Let \(X\) be the total number of successes. Then \(X\) has a Binomial distribution, writtenTo see this: consider any particular sequence of \(k\) successes and \(n-k\) failures. Each such sequence has probability \(p^{k}(1-p)^{n-k}\), since the \(n\) trials are independent. There are \(\binom{n}{k}\) ways of choosing the positions of the \(k\) successes out of \(n\) trials.
Note:
1. \(n\) and \(p\) are called the parameters of the Binomial distribution.
2. The number of trials \(n\) is fixed.
3. There are only two possible outcomes: ‘success’ with probability \(p\) and ‘failure’ with probability \(q =1-p\).
4. The probability of success \(p\) in each independent trial is constant.
Binomial distribution: Expectation and variance.
Let \(X \sim {\rm Bin} (n,p)\), thenwhere \(X_1, X_2, \ldots, X_n\) are independent Bernoulli random variables each with success probability \(p\).
Therefore using properties of expectations
where \([x]\) is the greatest integer not greater than \(x\).
An R Shiny app is provided to explore the Binomial distribution.
R Shiny app: Binomial distribution
Twenty multiple choice questions, each with 5 options. Suppose that you guess at random, independently for each question. Then if \(X\) is the number of right answers,
5.4.3 Geometric Distribution
Geometric distribution.
Consider a sequence of independent Bernoulli trials each with success probability \(p\). Let \(Y\) denote the number of trials needed for the first success to appear. Then \(Y\) has a Geometric distribution with parameter \(p\), written \(Y \sim Geom(p)\), andTo see this: If the \(k^{th}\) trial is the first success then the first \(k-1\) trials must have been failures. Probability of this is \((1-p)^{k-1}p\).
Note thatso a success eventually occurs with probability \(1\).
Geometric distribution: Expectation and variance.
Let \(Y \sim {\rm Geom} (p)\), thensince \(\sum_{k=1}^\infty x^k = x/(1-x)\) if \(|x| <1\).
Therefore5.4.4 Negative binomial Distribution
Negative binomial distribution.
Consider a sequence of independent Bernoulli trials, each with success probability \(p\). If \(W\) is the number of trials needed until \(r\) successes have occurred then \(W\) has a Negative Binomial distribution, \(W \sim {\rm Neg Bin} (r,p)\), with probability mass functionTo see this: We must have the \(k^{th}\) trial is successful and that it is the \(r^{th}\) success. Therefore we have \(r-1\) successes in first \(k-1\) trials, the locations of which can be chosen in \(\binom{k-1}{r-1}\) ways.
Negative binomial distribution: Expectation and variance.
Let \(W \sim {\rm Neg Bin} (r,p)\), thenwhere \(Y_1\) is the number of trials until the first success and, for \(i=2,3,\dots,r\), \(Y_i\) is the number of trials after the \((i-1)^{st}\) success until the \(i^{th}\) success.
We observe that \(Y_1, Y_2,\dots,Y_r\) are independent \({\rm Geom}(p)\) random variables, so
The negative binomial distribution \(W \sim {\rm Neg Bin} (r,p)\) is the sum of \(r\) independent geometric, \(Y \sim {\rm Geom} (p)\) distributions in the same way that the binomial distribution \(X \sim {\rm Bin} (n,p)\) is the sum of \(n\) independent Bernoulli random variables with success probability \(p\).
An R Shiny app is provided to explore the Negative Binomial distribution.
R Shiny app: Negative Binomial distribution
Example 5.4.10 draws together the different Bernoulli-based distributions and demonstrates how they are used to answer different questions of interest.

Figure 5.2: Crazy golf picture.
A child plays a round of crazy golf. The round of golf consists of 9 holes. The number of shots the child takes at each hole is geometrically distributed with success probability 0.25.
- Calculate the probability that the child gets a ‘hole in
one’ on the first hole. (A ‘hole in one’ means the child only takes
one shot on that hole.)
- Calculate the probability that the child takes more than five shots on the first hole.
- Calculate the probability that the child gets three `hole in one’ during their round.
- Calculate the mean and variance for the total number of shots the child takes.
- Calculate the probability that the child takes 36 shots in completing their round.
Attempt Example 5.4.10 (Crazy golf) and then watch Video 11 for the solutions.
Video 11: Crazy Golf Example
Solution to Example 5.4.10.
Let \(X_i\) denote the number of shots taken on hole \(i\). Then \(X_i \sim {\rm Geom} (0.25)\).
- A ‘hole in one’ on the first hole is the event \(\{ X_1 =1\}\). Therefore
- More than five shots on the first hole is the event \(\{X_1 >5\}\). Therefore
- This is a binomial question since there are \(n=9\) holes and on each hole there is \(p=P(X_1 =1) =0.25\) of obtaining a hole in one. Let \(Y \sim {\rm Bin} (9,0.25)\) denote the number of holes in one in a round, then
- The total number of shots taken is
Thus the mean number of shots taken is \(E[Z] = \frac{9}{0.25} = 36\) and the variance of the number of shots is \(var (Z) = \frac{9 (1-0.25)}{0.25^2} =108\).
(e) The probability that the child takes exactly 36 (mean number of) shots is
5.5 Poisson distribution
The Poisson distribution is often used to model ‘random’ events - e.g. hits on a website; traffic accidents; customers joining a queue etc.
Suppose that events occur at rate \(\lambda > 0\) per unit time. Divide the time interval \([0,1)\) into \(n\) small equal parts of length \(1/n\).
Assume that each interval can have either zero or one event, independently of other intervals, and
![Four events (red crosses) in 50 sub-intervals of [0,1].](Images/pois1.png)
Figure 5.3: Four events (red crosses) in 50 sub-intervals of [0,1].
Poisson distribution
Let \(X\) be a discrete random variable with parameter \(\lambda >0\) and p.m.f.
Then \(X\) is said to follow a Poisson distribution with parameter \(\lambda\), denoted \(X \sim {\rm Po} (\lambda)\).
Poisson distribution: Expectation and variance.
Let \(X \sim {\rm Po} (\lambda)\), then
since \(0 \times P(X=0) =0\).
Now
Using a change of variable \(k=x-1\),
Therefore, as noted in Lemma 5.4.7 (5.2), we have that \(E[X^2]=E[X(X-1)] + E[X]\) giving
5.6 Exponential distribution and its extensions
In this section we start with the Exponential random variable which is an important continuous distribution that can take positive values (on the range \([0,\infty)\)). The Exponential distribution is the continuous analogue of the Geometric distribution. The sum of exponential distributions leads to the Erlang distribution which is a special case of the Gamma distribution. Another special case of the Gamma distribution is the \(\chi^2\) (Chi squared) distribution which is important in statistics. Finally, we consider the Beta distribution which is continuous distribution taking values on the range \((0,1)\) and can be constructed from Gamma random variables via a transformation. (See Section 14 for details on transformations.)
5.6.1 Exponential distribution
Let \(X\) denote the total number of hits on a website in time \(t\). Let \(\lambda\) - rate of hits per unit time, and so, \(\lambda t\) - rate of hits per time \(t\).
A suitable model as we have observed in Section 5.5 for \(X\) is \({\rm Po} (\lambda t)\).
Let \(T\) denote the time, from a fixed point, until the first hit. Note that \(T\) is continuous \(0 < T < \infty\) whilst the number of hits \(X\) is discrete. Then \(T > t\) if and only if \(X=0\). Hence,Exponential distribution
A random variable \(T\) is said to have an exponential distribution with parameter \(\lambda > 0\), written \(T \sim {\rm Exp} (\lambda)\) if its c.d.f. is given by \[ F_T (t) = \left\{ \begin{array}{ll} 1- e^{- \lambda t} & t>0 \\ 0 & t \leq 0, \end{array} \right. \] and its p.d.f. is \[ f_T (t) = \frac{d \;}{dt} F_T (t) = \left\{ \begin{array}{ll} \lambda e^{- \lambda t} & t>0 \\ 0 & t \leq 0 \end{array} \right. \]
Exponential distribution: Expectation and variance.
Let \(T \sim {\rm Exp} (\lambda)\), then \[ E[T]= \frac{1}{\lambda} \hspace{0.5cm} \mbox{and} \hspace{0.5cm} var(T) = \frac{1}{\lambda^2}. \]
5.6.2 Gamma distribution
Suppose that we want to know, \(W\), the time until the \(m^{th}\) \((m=1,2,\ldots)\) hit on a website. Then \[W=T_1 + T_2 + \ldots + T_m \] where \(T_i\) is the time from the \((i-1)^{st}\) hit on the website until the \(i^{th}\) hit on the website.
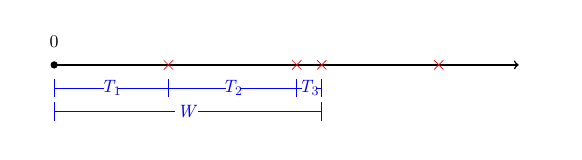
Figure 5.4: Illustration with \(m=3\), \(W=T_1 +T_2 +T_3\).
Note that \(T_1,T_2, \ldots\) are independent and identically distributed i.i.d. according to \(T \sim {\rm Exp} (\lambda)\). That is, \(W\) is the sum of \(m\) exponential random variables with parameter \(\lambda\). Then \(W\) follows a Gamma distribution with \(W \sim {\rm Gamma} (m,\lambda)\).
Gamma distribution
A random variable \(X\) is said to have a Gamma distribution with parameters \(\alpha, \beta > 0\), written \(X \sim {\rm Gamma} (\alpha, \beta)\) if its p.d.f. is given bywhere \(\Gamma (\alpha) = \int_0^\infty y^{\alpha -1} \exp(-y) \, dy\).
By definition, for \(\alpha =1\), \(X \sim {\rm Exp} (\beta)\) and for \(\alpha \in \mathbb{N}\), the Gamma distribution is given by the sum of \(\alpha\) exponential random variables. The special case where \(\alpha\) is integer is sometimes referred to as the Erlang distribution. However, the gamma distribution is defined for positive, real-valued \(\alpha\).
The \(\alpha\) parameter is known as the shape parameter and determines the shape of the Gamma distribution. In particular, the shape varies dependent on whether \(\alpha <1\), \(\alpha =1\) or \(\alpha >1\).
- \(\alpha <1\), the modal value of \(X\) is at 0 and \(f(x) \to \infty\) as \(x \downarrow 0\) (\(x\) tends to 0 from above).
- \(\alpha =1\), the exponential distribution. The modal value of of \(X\) is at 0 and \(f(0)=\beta\).
- \(\alpha >1\), \(f(0)=0\) and the modal value of \(X\) is at \(\frac{\alpha-1}{\beta}\).
Equality in distribution
Two random variables \(X\) and \(Y\) are said to be equal in distribution, denoted \(X \stackrel{D}{=} Y\), if for all \(x \in \mathbb{R}\),That is, \(X\) and \(Y\) have the same c.d.f., or equivalently, \(X\) and \(Y\) have the same p.d.f. (p.m.f.) if \(X\) and \(Y\) are continuous (discrete).
An R Shiny app is provided to explore the Gamma distribution.
R Shiny app: Gamma distribution
Gamma distribution: Expectation and variance.
If \(X \sim {\rm Gamma} (\alpha, \beta)\) thenThe proof is straightforward if \(\alpha =m \in \mathbb{N}\) since then \(X= T_1 +T_2 + \ldots +T_m\), where the \(T_i\) are i.i.d. according to \(T \sim {\rm Exp} (\beta)\). (Compare with the proof of Lemma 5.4.9 for the mean and variance of the negative binomial distribution.)
We omit the general proof for \(\alpha \in \mathbb{R}^+\), which can be proved by integration by parts.
5.6.3 Chi squared distribution
The chi squared (\(\chi^2\)) distribution is a special case of the Gamma distribution which plays an important role in statistics. For \(k \in \mathbb{N}\), ifwith \(E[X] =k\) and \(var(X) =2k\).
5.6.4 Beta distribution
Suppose that \(X\) and \(Y\) are independent random variables such that \(X \sim {\rm Gamma} (\alpha, \gamma)\) and \(Y \sim {\rm Gamma} (\beta, \gamma)\) for some \(\alpha, \beta, \gamma >0\). Note that both \(X\) and \(Y\) have the same scale parameter \(\gamma\). Letthe proportion of the sum of \(X\) and \(Y\) accounted for by \(X\). Then \(Z\) will take values on the range \([0,1]\) and \(Z\) follows a Beta distribution with parameters \(\alpha\) and \(\beta\).
Beta distribution
A random variable \(Z\) is said to have a Beta distribution with parameters \(\alpha, \beta > 0\), written \(Z \sim {\rm Beta} (\alpha, \beta)\) if its pdf is given byAn R Shiny app is provided to explore the Beta distribution.
R Shiny app: Beta distribution
Example 5.6.7 (Catching a bus) draws together the different Exponential-based distributions and demonstrates how they are used to answer different questions of interest.
Catching a bus.

Figure 5.5: Bus picture.
Suppose that the time (in minutes) between buses arriving at a bus stop follows an Exponential distribution, \(Y \sim {\rm Exp} (0.5)\). Given you arrive at the bus stop just as one bus departs:
- Calculate the probability that you have to wait more than 2
minutes for the bus.
- Calculate the probability that you have to wait more than 5
minutes for the bus given that you wait more than 3 minutes.
- Given that the next two buses are full, what is the probability you have to wait more than 6 minutes for a bus (the third bus to arrive)?
- What is the probability that the time until the third bus arrives is more than double the time until the second bus arrives?
Attempt Example 5.6.7 (Catching a bus) and then watch Video 12 for the solutions.
Video 12: Catching a bus
Solution to Example 5.6.7.
- Since \(Y \sim {\rm Exp} (0.5)\),
\[ P(Y >2) = \exp (-0.5(2)) = \exp(-1) =0.3679.\] - Note that \(\{Y>5\}\) implies that \(\{Y > 3\}\). Therefore
\[ P(Y>5|Y>3) = \frac{P(Y >5)}{P(Y>3)} = \frac{\exp(-0.5(5))}{\exp(-0.5(3))} = \exp(-1) =0.3679.\] Therefore\[ P(Y > 5 |Y >3) = P(Y>2). \] This property is known as the memoryless property of the exponential distribution, for any \(s,t>0\),\[ P(Y > s+t| Y>s) = P(Y >t).\] - The time, \(W\), until the third bus arrives is \(W \sim {\rm Gamma} (3,0.5)\). Therefore
\[ f_W (w) = \frac{0.5^3}{(3-1)!} w^{3-1} \exp(-0.5 w) \hspace{1cm} (w>0), \] and\[ F_W (w) = 1- \exp (-0.5 w) \left[ 1 + 0.5 w + \frac{(0.5w)^2}{2} \right]. \]
- This question involves the beta distribution. Let \(Z\) denote the time until the second bus arrives and let \(T\) denote the time between the second and third bus arriving. Then we want \[P(Z+T>2Z). \]
Rearranging \(Z+T >2 Z\), we have that this is equivalent to
\[\frac{1}{2}> \frac{Z}{Z+T},\] where\[\frac{Z}{Z+T} = U \sim {\rm Beta} (2,1)\] with \(U\) having p.d.f.\[ f_U (u) = \frac{(2+1-1)!}{(2-1)! (1-1)!} u^{2-1} (1-u)^{1-1} = 2u \hspace{1cm} (0<u<1).\] Hence\[\begin{eqnarray*} P(Z+T>2Z) &=&P(U < 0.5) \\ &=& \int_0^{0.5} 2 u \, du \\ &=& \left[ u^2 \right]_0^{0.5} =0.25. \end{eqnarray*}\]
5.7 Normal (Gaussian) Distribution
Normal (Gaussian) distribution.
\(X\) is said to have a normal distribution, \(X \sim N(\mu, \sigma^{2})\), if it has p.d.f.where \(\mu \in \mathbb{R}\) and \(\sigma > 0\).
The normal distribution is symmetric about its mean \(\mu\) with the p.d.f. decreasing as \([x-\mu]^2\) increases. Therefore the median and mode of the normal distribution are also equal to \(\mu\). See Figure 5.6 for the p.d.f. and c.d.f. of \(N(0,1)\).
The c.d.f. of the normal distribution \(X \sim N(\mu,\sigma^2)\) is
\[ F_X(x) = \int_{-\infty}^x f(y) \;dy = \int_{-\infty}^x \frac{1}{\sqrt{2 \pi} \sigma} \exp \left( - \frac{1}{2 \sigma^2} [y-\mu]^2 \right) \;dy, \]
and has no analytical solution. (i.e. We cannot solve the integral.)
How do we proceed with the Normal distribution if we cannot compute its c.d.f.?
The simplest solution is to use a statistical package such as R to compute probabilities (c.d.f.) for the Normal distribution. This can be done using the pnorm function. However, it is helpful to gain an understanding of the Normal distribution and how to compute probabilities (c.d.f.) for the Normal distribution using the good old-fashioned method of Normal distribution tables.
The starting point is to define the standard normal distribution, \(Z \sim N(0,1)\). We can then show that for any \(X \sim N(\mu,\sigma^2)\) and \(a, b \in \mathbb{R}\), \(P(a < X<b)\) can be rewritten as \[ P(a <X <b) = P(c <Z<d) = P(Z<d) - P(Z<c)\] where \(c\) and \(d\) are functions of \((a,\mu,\sigma)\) and \((b,\mu,\sigma)\), respectively. It is thus sufficient to know the c.d.f. of \(Z\). Note that when \(Z\) is used to define a normal distribution it will always be reserved for the standard normal distribution.
Traditionally, probabilities for \(Z\) are obtained from Normal tables, tabulated values of \(P(Z<z)\) for various values of \(z\). Typically, \(P(Z <z)\) for \(z=0.00,0.01,\ldots,3.99\) are reported with the observation \[P(Z <-z) = 1-P(Z<z)\] used to obtain probabilities for negative values.
A normal table will usually look similar to the table below.
| z | 0 | 1 | 2 | 3 | 4 | \(\cdots\) |
|---|---|---|---|---|---|---|
| 0.0 | 0.5 | 0.504 | 0.508 | 0.512 | 0.516 | \(\cdots\) |
| 0.1 | 0.5398 | 0.5438 | 0.5478 | 0.5517 | 0.5557 | \(\cdots\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\ddots\) |
| 1.2 | 0.8849 | 0.8869 | 0.8888 | 0.8907 | 0.8925 | \(\cdots\) |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\ddots\) |
The first column, labelled \(z\), increments in units of \(0.1\). Columns 2 to 11 are headed 0 through to 9. To find \(P(Z <z) = P(Z<r.st)\) where \(z=r.st\) and \(r,s,t\) are integers between 0 and 9, inclusive, we look down the \(z\) column to the row \(r.s\) and then look along the row to the column headed \(t\). The entry in row “\(r.s\)” and column “\(t\)” is \(P(Z<r.st)\). For example, \(P(Z <1.22) = 0.8888\).
Standard Normal distribution.
If \(\mu = 0\) and \(\sigma = 1\) then \(Z \sim N(0,1)\) has a standard normal distribution with p.d.f. \[ \phi(x) = \frac{1}{\sqrt{2 \pi}} \, {\rm e}^{-x^{2}/2 }, \; \; \; x \in \mathbb{R}, \] and c.d.f. \[ \Phi (x) = \int_{- \infty}^{x} \frac{1}{\sqrt{2 \pi}} \, {\rm e}^{-y^{2}/2 } \; dy \] Note the notation \(\phi (\cdot)\) and \(\Phi (\cdot)\) which are commonly used for the p.d.f. and c.d.f. of \(Z\).
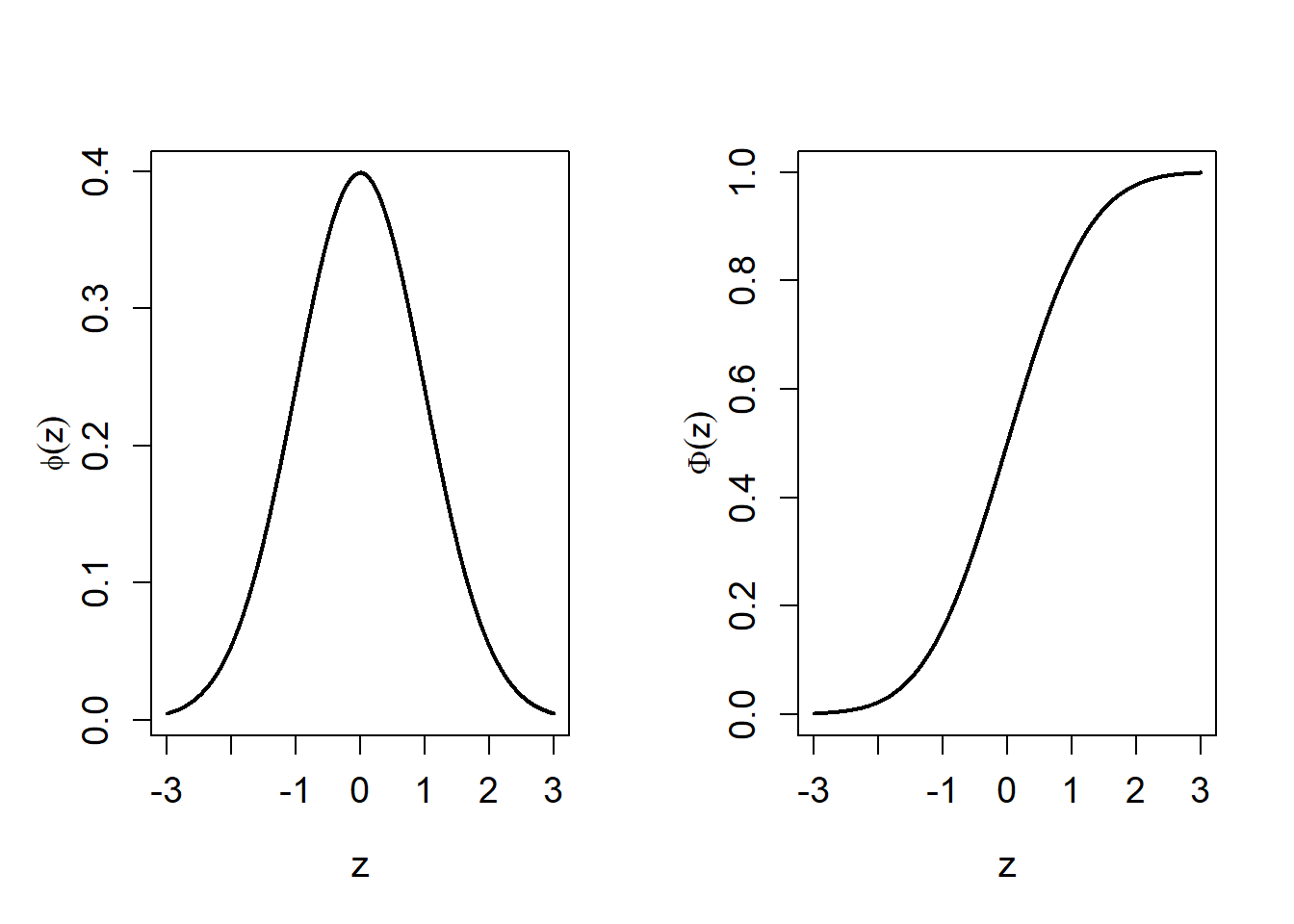
Figure 5.6: Standard normal, Z~N(0,1), p.d.f. and c.d.f.
Transformation of a Normal random variable.
If \(X \sim N(\mu, \sigma^2)\) and \(Y=aX+b\) then \[ Y \sim N (a \mu +b, a^2 \sigma^2).\]
An immediate Corollary of Lemma 5.7.4 is that if \(X \sim N(\mu, \sigma^2)\), then \[ \frac{X - \mu}{\sigma} = Z \sim N(0,1).\] This corresponds to setting \(a=1/\sigma\) and \(b=-\mu/\sigma\) in Lemma 5.7.4.
Hence, for any \(x \in \mathbb{R}\),Percentage points
The inverse problem of finding for a given \(q\) \((0<q<1)\), the value of \(z\) such that \(P(Z < z)=q\) is often tabulated for important choices of \(q\). The function qnorm in R performs this function for general \(X \sim N(\mu,\sigma^2)\).
Sums of Normal random variables
Suppose that \(X_1, X_2, \ldots, X_n\) are independent normal random variables with \(X_i \sim N(\mu_i, \sigma_i^2)\). Then for \(a_1, a_2, \ldots, a_n \in \mathbb{R}\),
Lemonade dispenser
Suppose that the amount of lemonade dispensed by a machine into a cup is normally distributed with mean \(250 \, ml\) and standard deviation \(5\, ml\). Suppose that the cups used for the lemonade are normally distributed with mean \(260 \, ml\) and standard deviation \(4 \, ml\).
- What is the probability that the lemonade overflows the cup?
- What is the probability that the total lemonade in 8 cups exceeds \(1970 ml\)?
Attempt Example 5.7.7 (Lemonade dispenser) and then watch Video 13 for the solutions.
Video 13: Lemonade dispenser
Solution to Example 5.7.7
- Let \(L\) and \(C\) denote the amount of lemonade dispensed and the size of a cup (in \(ml\)), respectively. Then \(L \sim N(250,5^2)\) and \(C \sim N(260,4^2)\), and we want:
\[ P(C <L) = P(C-L <0).\] Note that \(C-L\) follows a normal distribution (use Definition 5.7.6. Sums of Normal random variables with \(n=2\), \(X_1 =C\), \(X_2=L\), \(a_1 =1\) and \(a_2 =-1\)) with \(C-L \sim N(260-250,25+16) = N(10,41)\).
Note that the answer is given by pnorm(-1.56) and for the answer rounded to 4 decimal places round(pnorm(-1.56),4).
- Let \(L_i \sim N(250,5^2)\) denote the total number of lemonade dispensed into the \(i^{th}\) cup. Then the total amount of lemonade dispensed into 8 cups is \(S = L_1 + L_2 + \ldots + L_8 \sim N (2000,200)\). Therefore
\[ P(S >1970) = P \left( \frac{S -2000}{\sqrt{200}} >\frac{1970 -2000}{\sqrt{200}} \right) = P(Z>-2.12) = 1 - \Phi (-2.12) = 0.9830. \]
Student Exercises
Attempt the exercises below.
Let \(X\) be a continuous random variable with pdf
\[ f_X(x)= \left\{ \begin{array}{ll} k x^3 & \text{if } 0<x<1, \\
k e^{1-x} & \text{if } x \ge 1, \\
0 & \text{otherwise.} \end{array} \right.\]
- Evaluate \(k\) and find the (cumulative) distribution function of \(X\).
- Calculate \(P (0.5<X<2)\) and \(P(X>2|X>1)\).
Solution to Exercise 5.1.
- Since \(f\) is a pdf, \(\int_{-\infty}^\infty f(x) dx=1\). Thus,
\[ \int_0^1 k x^3 dx + \int_1^\infty k e^{1-x} dx = 1 \quad\Rightarrow\quad
k\left(\frac{1}{4}+1\right) = 1 \quad\Rightarrow\quad k=\frac{4}{5}.\]
Recall that \(F_X(x)=\int_{-\infty}^x f(t) dt\). Thus, \(F_X(x)=0\) if \(x\le0\). If \(0<x<1\), then
\[ F_X(x) = \int_0^x \frac{4}{5} t^3 dt = \frac{x^4}{5} \] and, if \(x>1\), then\[ F_X(x) = \int_0^1 \frac{4}{5} t^3 dt + \int_1^x \frac{4}{5} e^{1-t} dt = \frac{1}{5} + \frac{4}{5} (1-e^{1-x}) = 1-\frac{4}{5}e^{1-x}.\] Thus,\[ F_X(x) = \begin{cases} 0 & \text{if } x\le0, \\ \frac{x^4}{5} & \text{if } 0<x\le1, \\ 1-\frac{4}{5}e^{1-x} & \text{if } x>1. \end{cases} \] Below are plots of \(f_X(x)\) and \(F_X (x)\) on the range \((0,5)\).
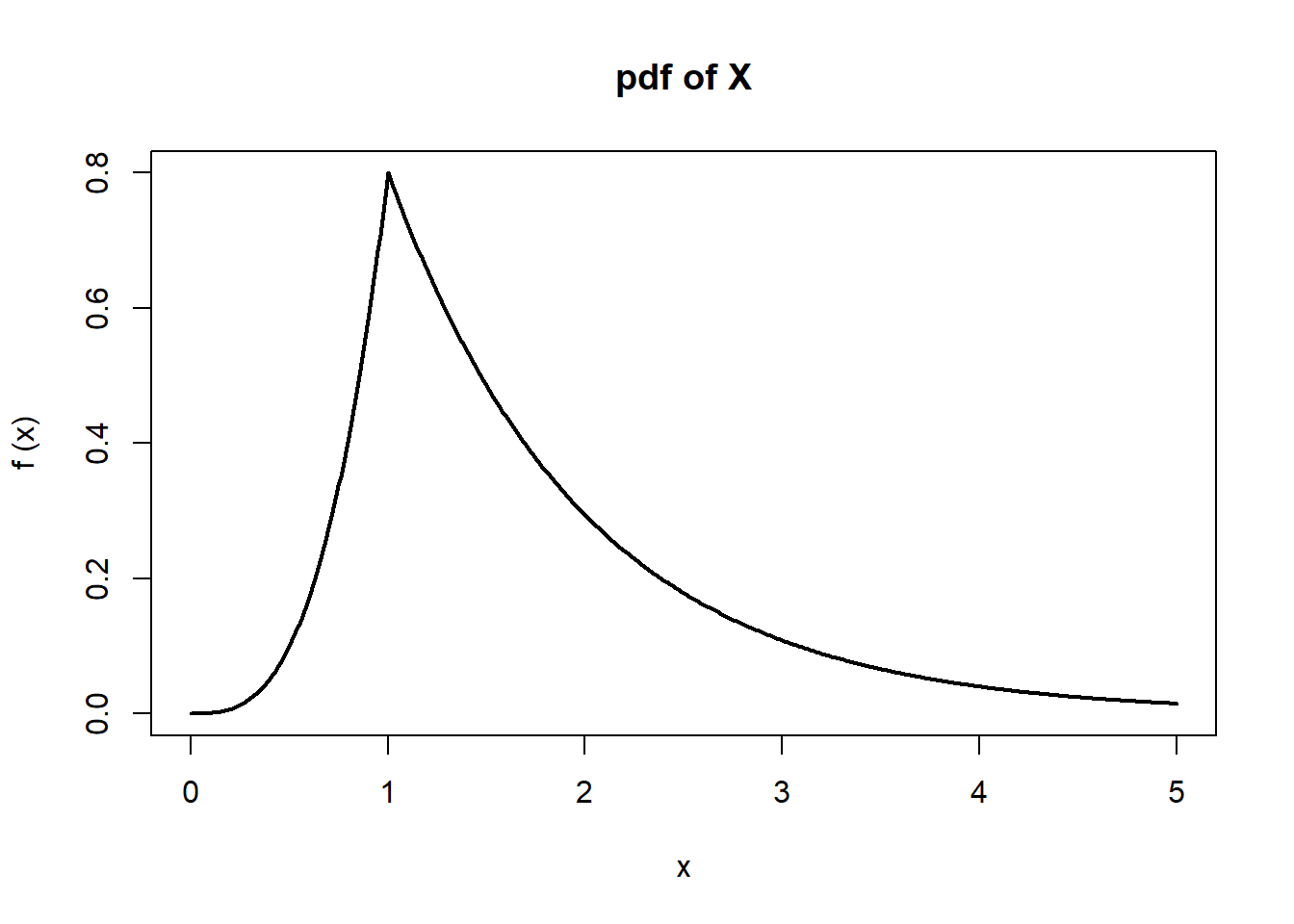
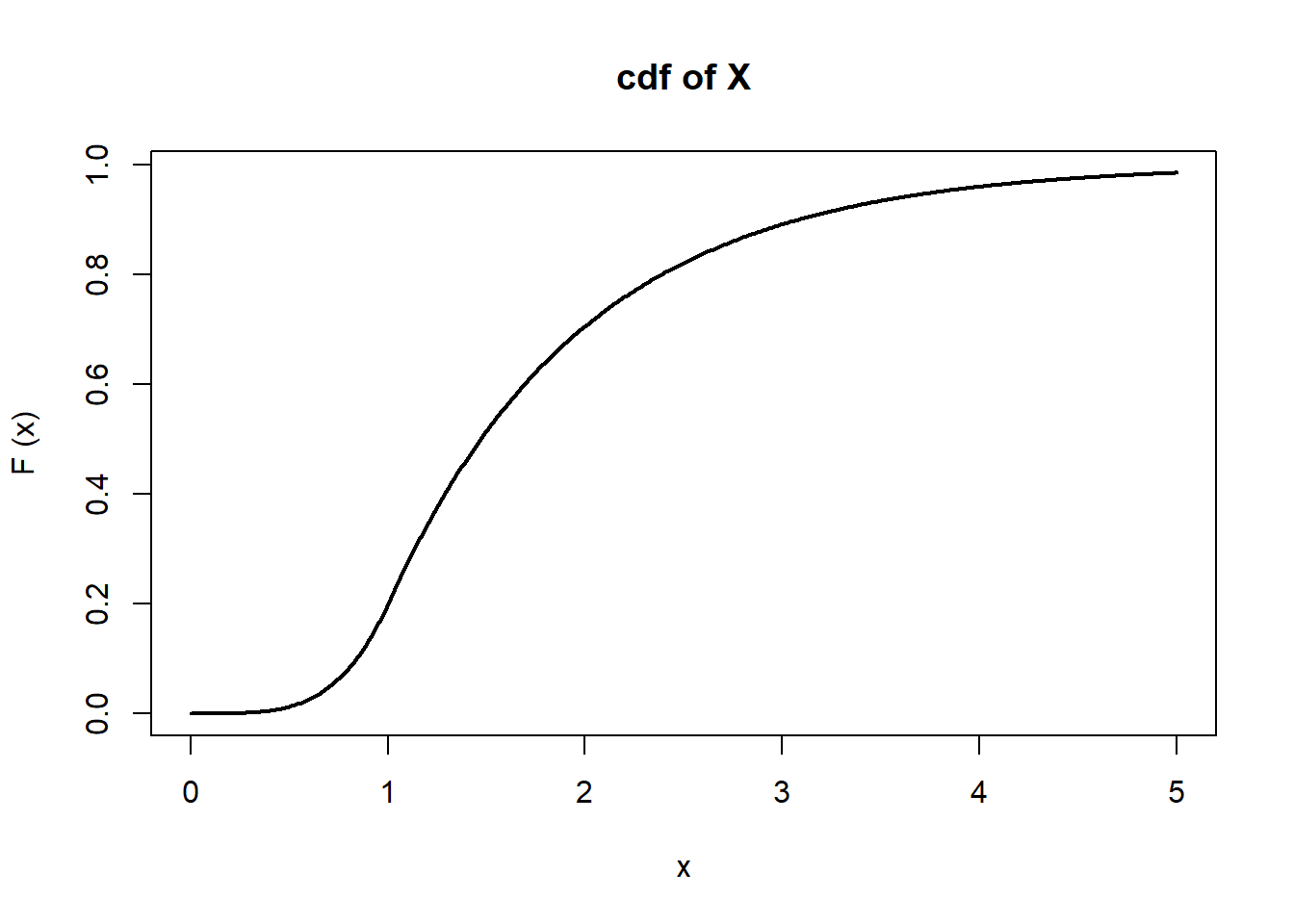
\[\begin{eqnarray*} P( 1/2<X<2 ) &=& \int_{1/2}^2 f_X(x) dx = \int_{1/2}^1 \frac{4}{5}x^3 dx + \int_1^2 \frac{4}{5} e^{1-x} dx \\ &=& \left[\frac{x^4}{5}\right]_{1/2}^1 + \left[-\frac{4}{5}e^{1-x}\right]_1^2 = \frac{3}{16}+\frac{4}{5}(1-e^{-1}) \\ &=& 0.6932. \end{eqnarray*}\] Since\[ P(X>2)= \int_2^\infty \frac{4}{5} e^{1-x} dx = \left[-\frac{4}{5} e^{1-x} \right]_2^\infty = \frac{4}{5} e^{-1} \] and\[ P(X>1) = \int_1^\infty \frac{4}{5} e^{1-x} dx = \left[-\frac{4}{5} e^{1-x} \right]_1^\infty = \frac{4}{5} ,\] we have\[ P(X>2|X>1)= \frac{P(X>2,X>1)}{P(X>1)} = \frac{P(X>2)}{P(X>1)}= e^{-1} =0.3679.\]
The time that a butterfly lives after emerging from its chrysalis is a random variable \(T\), and the probability that it survives for more than \(t\) days is equal to \(36/(6+t)^2\) for all \(t>0\).
- What is the probability that it will die within six days of emerging?
- What is the probability that it will live for between seven and fourteen days?
- If it has lived for seven days, what is the probability that it will live at least seven more days?
- If a large number of butterflies emerge on the same day, after how many days would you expect only \(5\%\) to be alive?
- Find the pdf of \(T\).
- Calculate the mean life of a butterfly after emerging from its chrysalis.
Solution to Exercise 5.2.
- \(P(T \leq 6) = 1-P (T>6) = 1-\frac{36}{12^2} = \frac{3}{4}\).
- \(P(7<T\le14)= P(T>7)-P(T>14) = \frac{36}{13^2}-\frac{36}{20^2} = \frac{2079}{16900}=0.1230.\)
- \(P(T>14|T>7)= \frac{P(T>14,T>7)} {P(T>7)}=\frac{P(T>14)} {P(T>7)} =\left(\frac{13}{20}\right)^2=0.4225.\)
- Let \(d\) be the number of days after only which 5% of the butterflies are expected to be alive. Then, \(P(T>d)=1/20\). Thus,
\[\begin{eqnarray*} \frac{36}{(6+d)^2}= \frac{1}{20} \quad &\Rightarrow& \quad (6+d)^2=20\times36 \quad \Rightarrow \quad 6+d = 12\sqrt5 \\ \quad &\Rightarrow& \quad d=12\sqrt5-6=20.83. \end{eqnarray*}\] - Let \(f_T\) and \(F_T\) be the pdf and distribution function of \(T\), respectively. Then, for \(t>0\),
\[ F_T(t)= P(T\le t) = 1-P(T>t) = 1- \frac{36}{(6+t)^2},\] so\[ f_T(t)= \frac{d \;}{dt} F_T(t)=\frac{72}{(6+t)^3}.\] Clearly, \(f_T(t)=0\) for \(t\le0\).
\[E[T]=\int_{-\infty}^\infty t f_T(t) dt = \int_0^\infty \dfrac{72t}{(6+t)^3}dt.\] Substituting \(x=6+t\) gives\[ E[T]=\int_6^\infty \frac{72(x-6)}{x^3}dx=\left[-\frac{72}{x}+\frac{3\times72}{x^2}\right]_6^\infty=6.\]
A type of chocolate bar contains, with probability \(0.1\), a prize voucher.
Whether or not a bar contains a voucher is independent of other bars. A hungry
student buys 8 chocolate bars. Let \(X\) denote the number of vouchers that she finds.
- What sort of distribution does \(X\) have?
- How likely is it that the student finds no vouchers?
- How likely is it that she finds at least two vouchers?
- What is the most likely number of vouchers that she finds?
A second student keeps buying chocolate bars until he finds a voucher. Let \(Y\) denote the number of bars he buys.
- What is the probability mass function of \(Y\)?
- How likely is it that the student buys more than 5 bars?
- What is \(E[Y]\)?
- If each bar costs 35p, what is the expected cost to the student?
A third student keeps buying chocolate bars until they find 4 vouchers. In doing so, they buys a total of \(W\) bars.
- What is the distribution of \(W\)?
- What is the probability that this student buys exactly 10 bars?
Solutions to Exercise 5.3.
- \(X \sim {\rm Bin} (8,0.1)\).
- \(P(X=0) = (0.9)^8 = 0.4305\).
\[P(X \geq 2) = 1 - P(X =0) - P(X=1) = 1 - (0.9)^8 - 8(0.9)^7(0.1) = 0.1869.\] - \(X=0\) Since the probability mass function has only one maximum, and
\(0.4305= P(X=0) > P(X=1) =0.3826\).
- \(Y \sim {\rm Geom}(0.1)\), so \(P(Y=k) = (0.9)^{k-1}(0.1), \; \; k=1, 2, 3, \ldots\).
- \(P(Y >5) =0.9^5\) (the probability of starting with 5 failures), so \(P(Y > 5) =0.5905\).
- For a \({\rm Geom}(p)\), the mean is \(1/p\), so \(E [Y] = 1/(0.1) = 10\).
- Cost (in pence) is \(35Y\), so \(E [35Y]= 35E [Y] = 350p\), or £3.50.
- \(W\) is negative binomial with parameters 4 and 0.1. \(W \sim {\rm Neg Bin} (4,0.1)\).
- \(P(W=10) = \binom{9}{3} (0.1)^4 (0.9)^6 = 0.004464\).
A factory produces nuts and bolts on two independent machines. The external diameter of the bolts is normally distributed with mean 0.5 cm and the internal diameter of the nuts is normally distributed with mean 0.52 cm. The two machines have the same variance which is determined by the rate of production. The nuts and bolts are produced at rate which corresponds to a standard deviation \(\sigma=0.01\) cm and a third machine fits each nut on to the corresponding bolt as they are produced, provided the diameter of the nut is strictly greater than that of the bolt, otherwise it rejects both.
- Find the probability that a typical pair of nut and bolt is rejected.
- If successive pairs of nut and bolt are produced independently, find the probability that in 20 pairs of nut and bolt at least 1 pair is rejected.
- The management wishes to reduce the probability that a typical pair of nut and bolt is rejected to 0.01. What is the largest value of \(\sigma\) to achieve this?
Solutions to Exercise 5.4.
- Let \(X\) denote the internal diameter of a typical nut and \(Y\) denote the external diameter of a typical bolt. Then \(X \sim N(0.52,0.01^2)\) and \(Y \sim N(0.50,0.01^2)\).
A pair of nut and bolt is rejected if \(W=X-Y\le 0\). Since \(X\) and \(Y\) are independent, \(W \sim N(0.52-0.50, 0.01^2+0.01^2)=N(0.02, 0.0002)\). Thus the probability that a pair is rejected is\[P(W \le 0)=P\left(\frac{W-0.02}{\sqrt{0.0002}} \le \frac{0-0.02}{\sqrt{0.0002}} \right)=P(Z \le -\sqrt{2}), \] where \(Z=(W-0.02)/\sqrt{0.0002} \sim N(0,1)\).
Hence the required probability is \(\Phi(-\sqrt{2})= 0.0786\) using pnorm(-sqrt(2)).
- The probability that no pair is rejected is \((1-0.0786)^{20}\), since successive pairs are produced independently, so the probability that at least one pair is rejected is \(1-(1-0.0786)^{20}= 0.8055\).
- Arguing as in (a), the probability a pair is rejected is \(\Phi(-0.02/(\sqrt{2}\sigma))\). We want \(c\) such that \(\Phi(c)=0.01\) which gives \(c = -2.3263\). (This is given by
qnorm(0.01)). Therefore we require \[-0.02/(\sqrt{2}\sigma) \le -2.3623 \iff \sigma \le 0.02/(2.362 \times \sqrt{2})= 0.0060.\] Hence the largest value of \(\sigma\) is 0.0060.