3 Daten importieren
Der erste Schritt einer jeden Datenanalyse besteht darin, die Daten in das Programm R zu importieren. Dieser Schritt ist nicht immer einfach, wenn man noch neu in R ist. Das liegt unter anderem daran, dass es mehrere Wege gibt, die Daten zu laden. Wir besprechen in diesem Kapitel die wichtigsten Möglichkeiten, die Daten zu importieren.
Die Daten per Hand in R einzutippen, ist meist keine gute Idee. Man sollte das höchstens tun, wenn die Zahl der Beobachtungen sehr klein ist (siehe dazu Kapitel 2.3).
3.1 Dateiformate
Es gibt viele Datenformate, die man leicht an den Endungen der Dateinamen erkennt. Falls bei Ihnen die Endungen (extensions) der Dateinamen nicht angezeigt werden, sollten Sie das in den Einstellungen ändern. In den Wirtschaftswissenschaften sind diese Formate besonders gängig:
- Textdateien (gewöhnlich mit der Endung
csv, manchmal mit der Endungtxt) - Stata (
dta) - Exceltabellen (
xlsxoderxls) - SPSS (
sav) - SAS (
sdx)
Alle diese Datenformate lassen sich nach R importieren, man braucht dazu allerdings teilweise zusätzliche Pakete. In diesem Kurs arbeiten wir ganz überwiegend mit csv-Dateien und behandeln die anderen Formate nur flüchtig.
 Im Learnweb ist die maximale Größe für Dateien 100 MB. Das reicht für sehr große
Im Learnweb ist die maximale Größe für Dateien 100 MB. Das reicht für sehr große csv-Dateien nicht aus. Deshalb finden Sie im Learnweb komprimierte Versionen der csv-Dateien mit der Endung zip. Manche zip-Dateien enthalten nicht nur den eigentlichen Datensatz, sondern zusätzliche Informationen in Form von weiteren Daten oder in Form einer pdf-Datei mit der Datensatzbeschreibung (“Codebook”).
- Kopieren Sie die
zip-Dateien, mit denen Sie arbeiten wollen, auf Ihren Computer (z.B. durch Klicken mit der rechten Maustaste, dann “Speichern unter…”). - Anschließend entpacken Sie die
zip-Datei. In den meisten Fällen starten Sie das Entpacken durch einen Doppelklick auf diezip-Datei. - Nun können Sie die ausgepackten Dateien in ein anderes Verzeichnis verschieben.
3.2 Pfade
Das Arbeitsverzeichnis können Sie, wie wir bereits im Kapitel 1 zu RStudio gesehen haben, über den Menu-Punkt “Session”/“Set Working Directory…” festlegen. In der Konsole kann das Arbeitsverzeichnis interaktiv durch die Funktion getwd() (get working directory) angezeigt werden. Und mit der Funktion setwd(...) (set working directory) kann man das Arbeitsverzeichnis neu festlegen.
Für das Importieren von Daten müssen Sie R wissen lassen, wo Ihre Daten-Datei abgelegt ist. Wenn die Datei nicht im Arbeitsverzeichnis liegt, können Sie die Lage entweder durch einen absoluten Pfad oder durch einen relativen Pfad angeben.
Absolute Pfade beginnen immer im Root-Verzeichnis. Das Root-Verzeichnis wird in R durch den Schrägstrich (/) gekennzeichnet - auch unter Windows, obwohl dort normalerweise der Backslash (\) für Pfadangaben verwendet werden muss.
Beispiele:
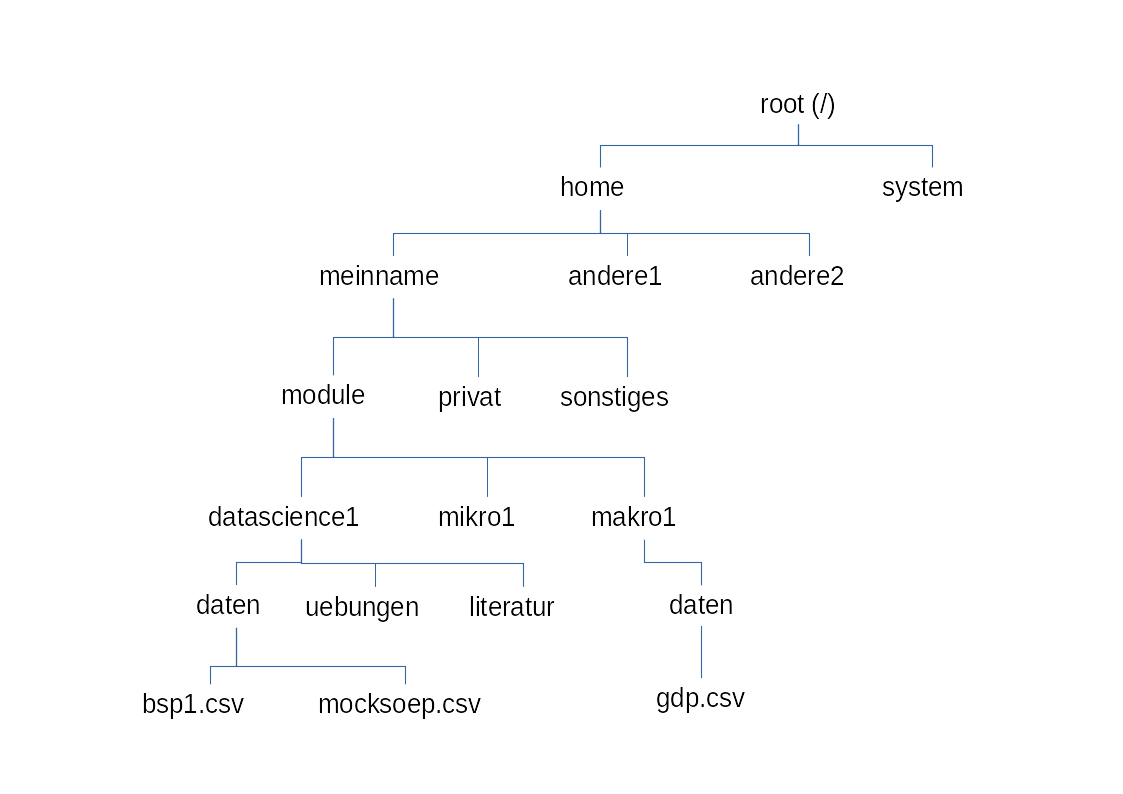
Die folgende Abbildung zeigt einen fiktiven Ausschnitt aus dem Verzeichnissystem eines Computers.
Eine absolute Pfadangabe auf die Datei bsp1.csv (unten links) könnte in einem Linux-System etwa so aussehen:
/home/meinname/module/datascience1/daten/bsp1.csvWenn Sie mit einem Mac arbeiten, wäre der obere Teil des Baums etwas anders strukturiert. Der absolute Pfad könnte so lauten:
/Users/meinname/module/datascience1/daten/bsp1.csvUnter unter Windows würde es etwa so aussehen:
c:/Dokumente/module/datascience1/daten/bsp1.csvRelative Pfade beginnen immer im aktuellen Arbeitsverzeichnis. Mit zwei Punkten (..) wird das nächsthöhere Verzeichnis im Verzeichnisbaum bezeichnet. In R werden Verzeichnisse in der Pfadangabe immer durch einen Slash (/) getrennt - auch unter Windows, obwohl dort normalerweise der Backslash verwendet wird.
Angenommen, das Verzeichnis datascience1 ist das aktuelle Arbeitsverzeichnis. Sie können dann die Datei bsp1.csv im Unterverzeichnis daten so finden:
daten/bsp1.csvWenn Sie von dem gleichen Arbeitsverzeichnis aus auf die Datei gdp.csv in Ihren Makro-Unterlagen zugreifen wollen, dann lautet der relative Pfad so:
../makro1/daten/gdp.csv3.3 Interaktiver Import
Wenn die Daten lokal auf der Festplatte Ihres Rechners gespeichert oder über eine URL abrufbar sind, können Sie die Daten nach R importieren, indem Sie im oberen rechten Fenster auf den Reiter “Environment” gehen und anschließend “Import Dataset” klicken.
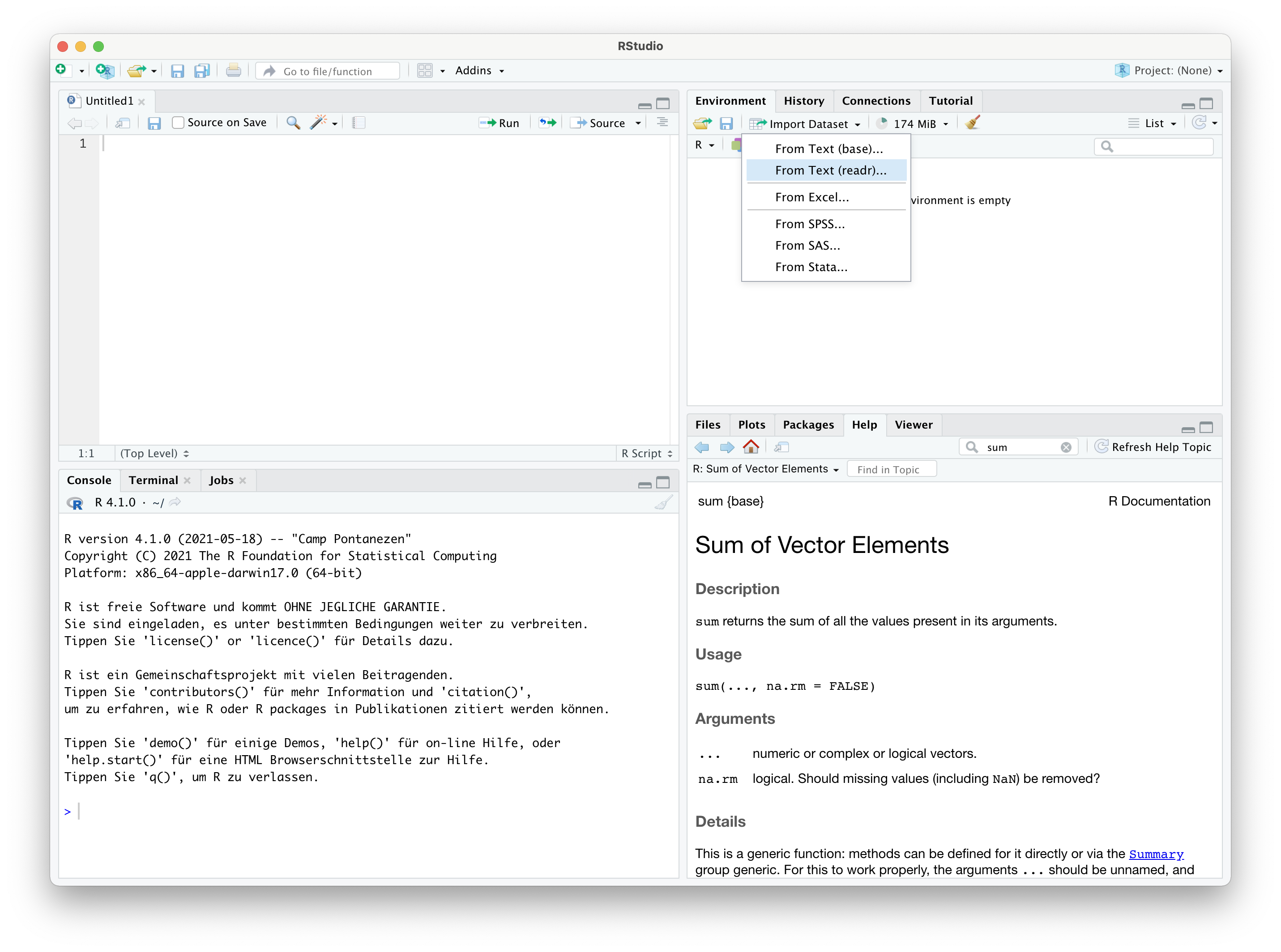
Es öffnet sich ein kleines Menu, Sie können nun auswählen, in welchem Format Ihre Daten vorliegen. Wenn es sich um csv-Dateien handelt, wählen Sie “From Text (readr)…”. Es öffnet sich ein Fenster.
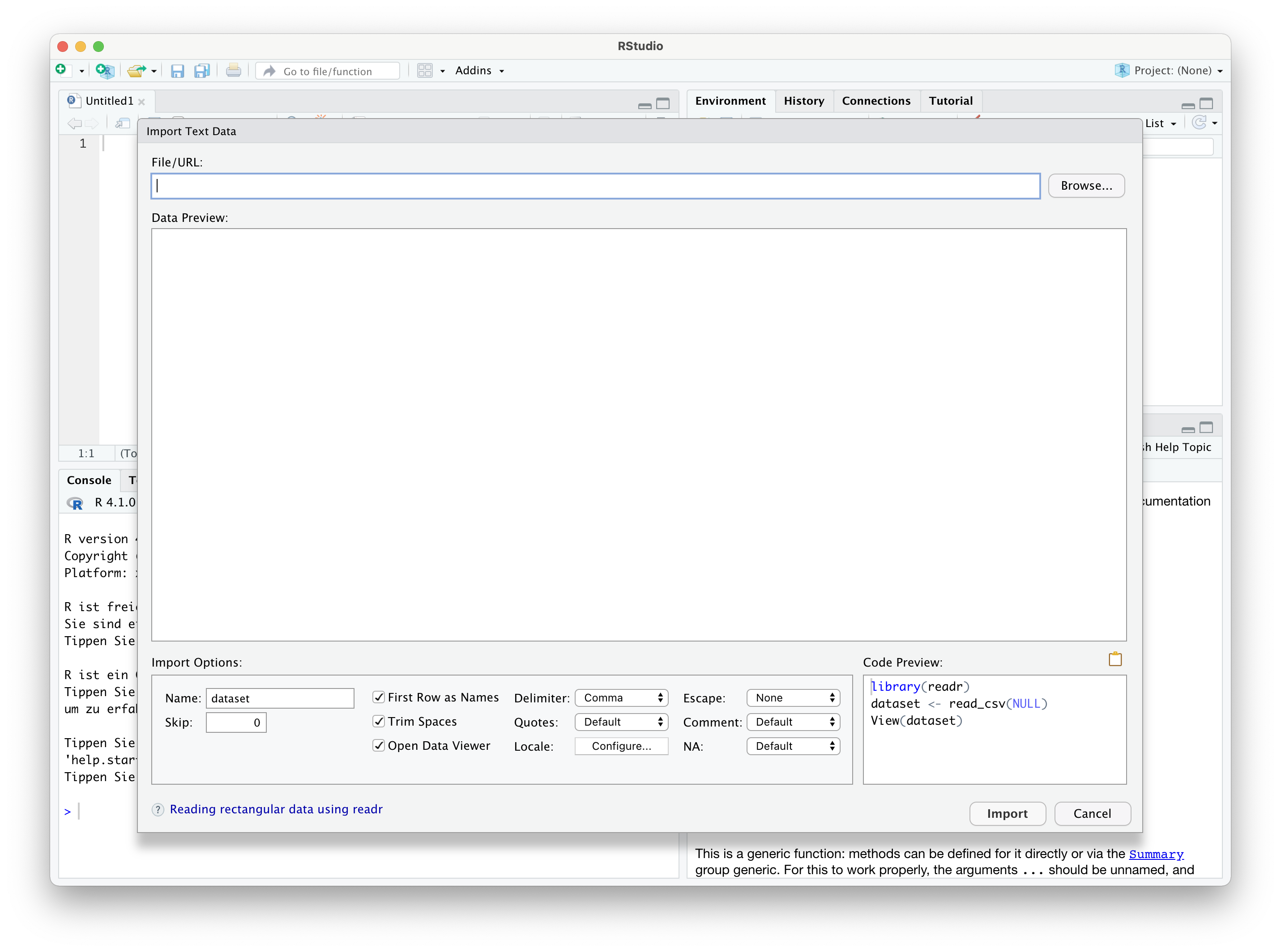
In der oberen Zeile geben Sie an, wo die Daten zu finden sind. Der Ort kann eine lokale Datei auf Ihrer Festplatte, einem Netzlaufwerk oder einem USB-Stick sein oder aber eine URL, also eine Internetadresse, unter der die Datei zu finden ist. Im Folgenden betrachten wir nur den Fall lokal abgespeicherter Dateien.
Die Importoptionen unten links dienen dazu, das Datenformat genauer zu spezifizieren. Hier wird beispielsweise festgelegt, ob die Dateneinträge durch Kommas oder durch Semikolons getrennt sind, ob Nachkommastellen durch ein Komma (wie im Deutschen) oder durch einen Punkt (wie im Englischen) getrennt werden. Außerdem können Sie bestimmen, unter welchem Namen der Dataframe abgespeichert werden soll. Der große Bereich in der Mitte zeigt an, wie die Daten interpretiert werden. Wenn hier alles so aussieht, wie Sie es gerne haben möchten, wird durch einen Klick auf “Import” der Datensatz eingelesen und im Workspace abgespeichert.
In dem unteren rechten Bereich sehen Sie, welche Befehle in R ausgeführt wurden, um die Daten im gewünschten Format einzulesen. Diese Befehlsfolge können Sie kopieren und in ein Script einbauen, wenn Sie beim nächsten Mal die Daten automatisch einlesen lassen wollen.
Die Datenformate Excel, SPSS, SAS, und Stata werden auf ähnliche Weise interaktiv eingelesen.
3.4 Kommando-gesteuerter Import
Wenn ein Datensatz nicht nur einmal eingelesen wird, sondern mehrfach, dann ist der interaktive Weg ziemlich umständlich, weil man sich jedesmal durch den Weg zu der Datei klicken muss. In diesem Fall bietet es sich an, den Einlesebefehl direkt in das Script zu schreiben.
Benutzen Sie beim ersten Einlesen das interaktive Fenster (wie oben beschrieben) und kopieren Sie die Befehlsfolge aus dem unteren rechten Bereich in das Script. Nun können Sie einfach das Script ausführen und die Datei wird dann automatisch neu eingelesen.
3.5 APIs
API steht für Application Programming Interface, es handelt sich (zumindest im Kontext dieser Veranstaltung) um standardisierte Zugänge zu Datensätzen.
Es gibt eine sehr große Zahl von APIs für ganz unterschiedliche Daten, manche davon sind kostenpflichtig. Wir beschränken uns in diesem Modul auf einige R-Pakete, die APIs zum kostenlosen Datendownload bereitstellen und die für wirtschaftswissenschaftliche Fragestellungen interessant sein können. Es sind die R-Pakete wiesbaden, bundesbank, fredr und tidyquant. Außerdem werden noch ergänzend die Pakete wbstats (Weltbank) OECD und eurostat beschrieben.
 Die Datensätze, die im folgenden über die APIs geladen werden, finden Sie zum Teil auch auf der Learnweb-Seite dieses Kurses. Es ist also nicht in jedem Fall nötig, die Daten aus den Originalquellen herunterzuladen, um die Berechnungen aus diesem Lehrbuch nachzuvollziehen. Sie sollten aber im weiteren Verlauf Ihres Studiums (und darüber hinaus!) im Hinterkopf behalten, dass es viele öffentlich und frei zugängliche Quellen für ökonomische Daten gibt. Der Zugang zu Daten wird in schnellem Tempo einfacher und umfangreicher. Die Zugangswege ändern sich allerdings ebenfalls relativ schnell, so dass die Informationen in diesem Abschnitt vielleicht schon bald nicht mehr aktuell sind.
Die Datensätze, die im folgenden über die APIs geladen werden, finden Sie zum Teil auch auf der Learnweb-Seite dieses Kurses. Es ist also nicht in jedem Fall nötig, die Daten aus den Originalquellen herunterzuladen, um die Berechnungen aus diesem Lehrbuch nachzuvollziehen. Sie sollten aber im weiteren Verlauf Ihres Studiums (und darüber hinaus!) im Hinterkopf behalten, dass es viele öffentlich und frei zugängliche Quellen für ökonomische Daten gibt. Der Zugang zu Daten wird in schnellem Tempo einfacher und umfangreicher. Die Zugangswege ändern sich allerdings ebenfalls relativ schnell, so dass die Informationen in diesem Abschnitt vielleicht schon bald nicht mehr aktuell sind.
Um Daten aus den Originalquellen herunterzuladen, installieren Sie bitte die Pakete wiesbaden, bundesbank, fredr und tidyquant auf Ihrem Rechner (in Kapitel 1.3 wird erklärt, wie man Pakete in R installiert).
Die Funktionen, die von den Paketen bereitgestellt werden, sind erst nutzbar, nachdem die Pakete durch library(PAKETNAME) aktiviert wurden. Im Gegensatz zur Installation, die nur einmal erfolgt, muss der library-Befehl nach jedem neuen Start von R erneut eingegeben werden. Natürlich kann das auch innerhalb eines Scripts erfolgen.
Die Datensätze, die man mit Hilfe der APIs laden kann, sind teilweise sehr groß - zu groß, um sie einfach auf dem Bildschirm anzuzeigen. Wir werden in Kapitel 4 Methoden kennen lernen, wie man gezielt auf die Variablen oder Beobachtungen zugreift, die einen interessieren. In Kapitel 5 lernen Sie, wie man die Daten grafisch darstellt.
3.5.1 Destatis
![]() Jeder Staat hat eine Statistikbehörde, in Deutschland ist es das Statistische Bundesamt (auch als Destatis bezeichnet), zusätzlich haben die Bundesländer noch eigene Statistikbehörden: die Statistischen Landesämter. Das Statistische Bundesamt sammelt Daten und stellt statistische Informationen bereit. Zielgruppen sind Politik und Verwaltung, aber auch die Wirtschaft und interessierte Privatpersonen.
Jeder Staat hat eine Statistikbehörde, in Deutschland ist es das Statistische Bundesamt (auch als Destatis bezeichnet), zusätzlich haben die Bundesländer noch eigene Statistikbehörden: die Statistischen Landesämter. Das Statistische Bundesamt sammelt Daten und stellt statistische Informationen bereit. Zielgruppen sind Politik und Verwaltung, aber auch die Wirtschaft und interessierte Privatpersonen.
Für R gibt es ein Paket, mit dem der Zugang zur API des Statistischen Bundesamt sehr einfach ist. Das Paket heißt wiesbaden (Wiesbaden ist der Standort des Bundesamts). Wenn Sie auf das Destatis-API zugreifen wollen, installieren Sie das Paket und aktivieren Sie es durch den Befehl library(wiesbaden).
Um das API zu nutzen, muss man sich auf der Internetseite Genesis-Online registrieren. Zur kostenlosen Registrierung gelangen Sie über “Anmeldung”, “Registrierung”. Am Ende des Registrierungsprozesses haben Sie einen Nutzernamen und ein Passwort. Mit diesen beiden Angaben können Sie das R-Paket nutzen.
Ob die Registrierung erfolgreich war und der Datenzugang jetzt möglich ist, kann man durch folgenden Befehl nachprüfen:
test_login(genesis=c(db='de',
user="KENNUNG",
password="PASSWORT"))wobei Sie Ihre Kennung und Ihr Passwort entsprechend einsetzen müssen. Wenn alles richtig läuft, erhalten Sie die Meldung, dass Sie erfolgreich an- und abgemeldet wurden.
Wie lädt man nun einen Datensatz als Dataframe in R herunter? Der erste Schritt ist die Identifikation des Datensatz-Codes auf den Internetseiten der Genesis-Datenbank.
Beispiel:
Wir klicken uns wie folgt durch die Genesis-Seiten zu den Daten über Studierende in Deutschland:
- 2 Bildung, Sozialleistungen, Gesundheit, Recht
- 21 Bildung und Kultur, Forschung und Entwicklung
- 21311 Statistik der Studenten
Die einzelnen Datensätze werden von Destatis “Tabellen” bzw. “Tables” genannt. Leider sind die Bezeichnungen auf den tieferen Ebenen nicht identisch mit den Bezeichnungen für die API. Darum ist der nächste Schritt eine Auflistung aller Datensätze, deren Bezeichnung mit “21311” beginnt:
TABLES <- retrieve_datalist("21311*",
genesis=c(db='de',
user="KENNUNG",
password="PASSWORT"))Der Dataframe TABLES enthält nun alle Datensätze, deren Namen mit “21311” beginnt (das *-Zeichen bedeutet, dass der Rest des Namens keine Rolle spielt). Leider sind die Tabellennamen zu lang, um sie hier auszugeben. Ersatzweise wird darum hier nur verkürzt der eine Datensatz ausgegeben, den wir weiter betrachten wollen. Er ist in Zeile 12:
TABLES[12,]
#> tablename description
#> 2 21311BS012 Studierende, D.insg., Stud.fach, National., Geschl., SemesterDer gesuchte Datensatz hat also die Bezeichnung 21311BS012. Über diesen Datensatz finden wir folgende Metadaten (also Daten über den Datensatz):
retrieve_metadata("21311BS012",
genesis=c(db='de',
user="KENNUNG",
password="PASSWORT")) name description unit
1 BIL002 Studierende Anzahl
2 DINSG Deutschland insgesamt
3 BILSF1 Studienfach
4 NAT Nationalität
5 GES Geschlecht
6 SEMEST Semester Es gibt also sechs Variablen. Die Ausprägungen einer Variable kann man mit der Funktion retrieve_valuelabel anzeigen lassen. Für das Studienfach BILSF1 ergibt sich eine lange Liste aller Studienfächer, von der hier nur die ersten zehn Zeilen angezeigt werden:
studfach <- retrieve_valuelabel("BILSF1",
genesis=c(db='de',
user="KENNUNG",
password="PASSWORT"))
head(studfach, 10) BILSF1 description
1 SF001 Ägyptologie
2 SF002 Afrikanistik
3 SF003 Agrarwissenschaft/Landwirtschaft
4 SF004 Interdisz. Studien (Schwerpunkt Geisteswiss.)
5 SF005 Klassische Philologie
6 SF006 Amerikanistik/Amerikakunde
7 SF007 Angewandte Kunst
8 SF008 Anglistik/Englisch
9 SF009 Anthropologie (Humanbiologie)
10 SF010 Arabisch/ArabistikDie Abkürzung SF001 steht also für das Studienfach “Ägyptologie” etc. Entsprechend kann man für die Variable NAT herausfinden, dass die Ausprägungen NATA und NATD für Menschen mit ausländischer bzw. deutscher Staatsangehörigkeit stehen. Und beim Geschlecht (GES) gibt es die beiden Ausprägungen GESM für männlich und GESW für weiblich.
Jetzt fehlt nur noch der eigentliche Datensatz 21311BS012. Wir laden ihn mit der Funktion retrieve_data und speichern ihn als Dataframe unter dem Namen studis.
studis <- retrieve_data("21311BS012",
genesis=c(db='de',
user="KENNUNG",
password="PASSWORT"))Der Befehl retrieve_data gibt eine (hier unterdrückte) Nachricht aus, die einige Informationen über den Datensatz enthält. Leider entspricht das Format des Datensatzes nicht exakt den Angaben der Metadaten. Trotzdem können die Variablen leicht identifiziert werden. Die Variablennamen sind
names(studis)[1] "id21311" "DINSG" "BILSF1" "NAT" "GES"
[6] "SEMEST" "BIL002_val" "BIL002_qual"Der Dataframe studis ist umfangreich, die Zahl der Beobachtungen und die Zahl der Variablen sind:
dim(studis)[1] 26522 8Sie lernen im nächsten Kapitel, wie man interessante Informationen aus einem großen Dataframe herauslesen kann. An dieser Stelle betrachten wir exemplarisch nur die ersten 10 Zeilen des Dataframes. Sie sehen wie folgt aus:
head(studis, 10) id21311 DINSG BILSF1 NAT GES SEMEST BIL002_val BIL002_qual
1 D DG SF001 NATA GESM WS 1998/99 40 e
2 D DG SF001 NATA GESM WS 1999/00 43 e
3 D DG SF001 NATA GESM WS 2000/01 41 e
4 D DG SF001 NATA GESM WS 2001/02 48 e
5 D DG SF001 NATA GESM WS 2002/03 54 e
6 D DG SF001 NATA GESM WS 2003/04 48 e
7 D DG SF001 NATA GESM WS 2004/05 46 e
8 D DG SF001 NATA GESM WS 2005/06 47 e
9 D DG SF001 NATA GESM WS 2006/07 37 e
10 D DG SF001 NATA GESM WS 2007/08 32 eIn der ersten Zeile sieht man, dass es im WS 1998/99 40 ausländische Männer gab, die in Deutschland Ägyptologie studiert haben. Ein Jahr später waren es 43 (wie man in der zweiten Zeile sieht).
3.5.2 Bundesbank
 Zu den Aufgaben der Bundesbank gehören u.a. die Geldpolitik und die Bankenaufsicht. Die Bundesbank stellt auch einen umfangreichen Datenbestand zur Verfügung. Das R-Paket
Zu den Aufgaben der Bundesbank gehören u.a. die Geldpolitik und die Bankenaufsicht. Die Bundesbank stellt auch einen umfangreichen Datenbestand zur Verfügung. Das R-Paket bundesbank bietet einen bequemen Zugriff auf die API. Installieren Sie das Paket, wenn Sie den direkten Datenzugang zur Bundesbank nutzen wollen. Sobald das Paket installiert ist, kann es durch library(bundesbank) aktiviert werden.
library(bundesbank)Nach dem Aktivieren des Pakets steht Ihnen die Funktion getSeries zur Verfügung. Als Argument erwartet die Funktion den Namen der Zeitreihe (in Anführungsstrichen), die Sie herunterladen möchten. Leider sind die Namen nicht selbsterklärend. Die Internetseite der Zeitreihen-Datenbanken hilft bei der Suche.
Beispiel:
Klickt man auf der Internetseite der Zeitreihen-Datenbanken auf
- Indikatorensätze
- Indikatorensystem Wohnimmobilienmarkt
- Preisindikatoren
- Preise für Wohnimmobilien in deutschen Städten
so erhält man eine Liste mit den entsprechenden Zeitreihen. Die kryptischen Kürzel in der linken Spalte sind die Namen der Datensätze. In der Spalte daneben wird genau beschrieben, um welche Daten es sich handelt.
Mit der Funktion
x <- getSeries("BBDY1.A.B10.N.G100.P0020.A")wird einer der Datensätze in den Dataframe x importiert. Die ersten Zeilen sehen wie folgt aus:
head(x) dates values
1 2004-12-31 101.8
2 2005-12-31 100.5
3 2006-12-31 100.0
4 2007-12-31 99.9
5 2008-12-31 99.7
6 2009-12-31 98.8Die letzten Zeilen lauten:
tail(x) dates values
15 2018-12-31 159.5
16 2019-12-31 170.5
17 2020-12-31 182.9
18 2021-12-31 198.1
19 2022-12-31 210.0
20 2023-12-31 204.7Das Preisniveau lag also 2022 rund doppelt so hoch wie 2004.
3.5.3 FRED
![]() Die Internet-Seite Federal Reserve Economic Data (FRED) bietet sehr viele Daten zum Herunterladen an. Zum größten Teil handelt es sich um Daten aus den USA, zu einem kleineren Teil gibt es auch internationale Daten. Über die FRED-Internetseite kann man die Bezeichnungen der Variablen herausfinden, die einen interessieren. Mit Hilfe dieser Bezeichnungen lassen sich über die API dann die Daten herunterladen.
Die Internet-Seite Federal Reserve Economic Data (FRED) bietet sehr viele Daten zum Herunterladen an. Zum größten Teil handelt es sich um Daten aus den USA, zu einem kleineren Teil gibt es auch internationale Daten. Über die FRED-Internetseite kann man die Bezeichnungen der Variablen herausfinden, die einen interessieren. Mit Hilfe dieser Bezeichnungen lassen sich über die API dann die Daten herunterladen.
Der Datenzugang über die FRED API ist nur möglich, wenn man auf der Seite Federal Reserve Economic Data ein Konto für sich eingerichtet und einen “API Key” beantragt hat. Beides ist kostenlos und sehr schnell umzusetzen. Bitte speichern Sie Ihren API Key so ab, dass Sie jederzeit darauf zugreifen können.
Beispiel:
Der saisonbereinigte prozentuale Zuwachs der Arbeitsproduktivität aller Beschäftigten (außerhalb des Landwirtschaftssektors) hat in der FRED-API die Bezeichnung PRS85006091. Mit dem Befehl
library(fredr)
fredr_set_key("XXXXXX") # Geben Sie hier Ihren API Key an.
arbeitsprod <- fredr_series_observations("PRS85006091")wird ein Dataframe arbeitsprod heruntergeladen, dessen Anfang wie folgt aussieht:
head(arbeitsprod)# A tibble: 6 × 5
date series_id value realtime_start realtime_end
<date> <chr> <dbl> <date> <date>
1 1948-01-01 PRS85006091 3.8 2024-05-30 2024-05-30
2 1948-04-01 PRS85006091 1.2 2024-05-30 2024-05-30
3 1948-07-01 PRS85006091 4.5 2024-05-30 2024-05-30
4 1948-10-01 PRS85006091 0.7 2024-05-30 2024-05-30
5 1949-01-01 PRS85006091 1.3 2024-05-30 2024-05-30
6 1949-04-01 PRS85006091 2.6 2024-05-30 2024-05-30 In der Spalte value sind die monatlichen Wachstumsraten für die Monate ab dem ersten Quartal 1948 (Spalte date) zu finden. In Kapitel 5.3 lernen Sie, wie man die Entwicklung der Arbeitsproduktivität grafisch darstellen kann.
3.5.4 Weltbank
![]() Die Weltbank unterstützt eine Vielzahl an Entwicklungsprojekten. Sie stellt eine umfangreiche Datensammlung frei zugänglich zur Verfügung. Mit Hilfe des R-Pakets
Die Weltbank unterstützt eine Vielzahl an Entwicklungsprojekten. Sie stellt eine umfangreiche Datensammlung frei zugänglich zur Verfügung. Mit Hilfe des R-Pakets wbstats kann man die Daten sehr einfach direkt über die API herunterladen, sofern man die Daten-Bezeichnung kennt. Mit der Funktion
wb_search("SUCHWORT", "indicator")erhält man eine Liste von Datensätzen, die den Suchbegriff enthalten.
Beispiel:
Informationen über Daten zu Netto-Migrationszahlen erhält man durch
library(wbstats)
wb_search("migration", "indicator")# A tibble: 1 × 3
indicator_id indicator indicator_desc
<chr> <chr> <chr>
1 SM.POP.NETM Net migration Net migration is the net total of migrants during …Das Kürzel für den gesuchten Datensatz ist also SM.POP.NETM. Das Importieren der Daten in einen Dataframe erfolgt durch die Funktion wb_data.
x <- wb_data("SM.POP.NETM")Die ersten paar Zeilen des Dataframes lauten
head(x)# A tibble: 6 × 9
iso2c iso3c country date SM.POP.NETM unit obs_status footnote last_updated
<chr> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr> <date>
1 AW ABW Aruba 1960 0 <NA> <NA> <NA> 2024-05-30
2 AW ABW Aruba 1961 -569 <NA> <NA> <NA> 2024-05-30
3 AW ABW Aruba 1962 -609 <NA> <NA> <NA> 2024-05-30
4 AW ABW Aruba 1963 -646 <NA> <NA> <NA> 2024-05-30
5 AW ABW Aruba 1964 -684 <NA> <NA> <NA> 2024-05-30
6 AW ABW Aruba 1965 -726 <NA> <NA> <NA> 2024-05-30 Offensichtlich enthält der Dataframe die Nettomigrationszahlen mehrerer Länder aus mehreren Jahren. Zum Beispiel sind im Jahr 1965 aus Aruba 726 Menschen mehr ausgewandert als eingewandert. Wie man gezielt auf einzelne Länder oder Jahre zugreift oder Werte aggregiert, wird in Kapitel 4 erklärt.
3.5.5 tidyquant
![]() Das Paket
Das Paket tidyquant ist ziemlich umfangreich. Es erlaubt einen einheitlichen Datenzugang zu mehreren Datenbanken. Wir konzentrieren uns hier jedoch nur auf einen sehr kleinen Ausschnitt, nämlich auf das Laden von Finanzmarktdaten, und zwar aus der Yahoo-Datenbank. Für seriösere Datenanalysen brauchen Sie einen Zugang zu den Finanzmarkt-Datenbanken von Eikon oder Bloomberg. Unsere Fakultät hat zwar eine Eikon-Lizenz, sie ist aber Studierenden nur im Rahmen von Abschlussarbeiten zugänglich. Zum Erlernen der Verfahren ist es aber unproblematisch, mit der weniger seriösen Datenquelle Yahoo zu arbeiten.
Die wichtigste Funktion zum Herunterladen der Daten heißt tq_get. Details zu der Funktion findet man mit der Hilfefunktion (z.B. F1 drücken, wenn der Cursor auf dem Funktionsnamen steht). Um mit der Funktion tq_get die Informationen zu einem Wertpapier mit dem Symbol XYZ zu laden und in dem Dataframe x zu speichern, gibt man folgendes ein.
library(tidyquant)
x <- tq_get("XYZ",
from="JJJJ-MM-TT",
to="JJJJ-MM-TT")Dabei sind from und to Datumsangaben, es werden alle Börsentage von from bis to heruntergeladen, sofern sie in der Datenbank vorhanden sind. Das Datumsformat muss die Form “Jahr-Monat-Tag” (mit Minuszeichen dazwischen) haben. Die Monats- und Tagangaben müssen numerisch und zweistellig sein.
Es ist auch möglich, Informationen zu mehr als einem Wertpapier zu laden, indem man einen Vektor von Symbolen als erstes Argument eingibt, z.B.
wp_liste <- c("ABC","XYZ")
x <- tq_get(wp_liste,
from="JJJJ-MM-TT",
to="JJJJ-MM-TT")Beispiel:
Wir möchten den Verlauf des DAX Performance Index anzeigen. Auf der Internetseite von Yahoo Finance findet man, dass das Symbol des DAX Performance Index ^GDAXI lautet.
library(tidyverse)
x <- tq_get("^GDAXI",
from="2014-01-01",
to="2024-01-31")Der Start und das Ende dieses Datensatzes sehen so aus.
head(x)# A tibble: 6 × 8
symbol date open high low close volume adjusted
<chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ^GDAXI 2014-01-02 9598. 9621. 9394. 9400. 90956900 9400.
2 ^GDAXI 2014-01-03 9410. 9453. 9368. 9435. 58772900 9435.
3 ^GDAXI 2014-01-06 9419. 9469. 9400. 9428 53653700 9428
4 ^GDAXI 2014-01-07 9446. 9519. 9417. 9506. 79946800 9506.
5 ^GDAXI 2014-01-08 9513. 9516. 9468. 9498. 90140400 9498.
6 ^GDAXI 2014-01-09 9492. 9550. 9403. 9422. 98917000 9422.tail(x)# A tibble: 6 × 8
symbol date open high low close volume adjusted
<chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ^GDAXI 2024-01-23 16753. 16753. 16627. 16627. 64365600 16627.
2 ^GDAXI 2024-01-24 16793. 16921. 16761. 16890. 74569200 16890.
3 ^GDAXI 2024-01-25 16850. 16917. 16786. 16907. 62016700 16907.
4 ^GDAXI 2024-01-26 16879. 16968. 16849. 16961. 84664200 16961.
5 ^GDAXI 2024-01-29 16925. 16942. 16860. 16942. 65956600 16942.
6 ^GDAXI 2024-01-30 16991. 17000. 16947. 16972. 61107500 16972.Die letzte Spalte (adjusted) des Datensatzes ist der um Aktiensplits, Dividendenzahlungen etc. bereinigte Kursverlauf. Die Anzahl an Beobachtungen beträgt
dim(x)[1][1] 2561Nun speichern wir den bereinigten Kursverlauf als eigenständigen Vektor unter dem Names DAXAdj.
DAXAdj <- x$adjustedDieser Vektor hat die Länge (nicht die Dimension!)
length(DAXAdj)[1] 2561Wie der Kursverlauf visualisiert werden kann, wird später im Kapitel 5 gezeigt.
3.6 Einige weitere Quellen
Es gibt sehr viele Datenquellen und der Zugang zu interessanten Daten wird durch die Open-Data-Bewegung immer leichter. Im folgenden sind exemplarisch einige Datensätze und -quellen aufgelistet, die für ökonomische Fragestellungen nützlich sind. Einige davon sind via API zugänglich, bei anderen ist der Datenzugang anders geregelt. Alle Quellen können Sie im Laufe Ihres Studiums nutzen (zumindest später für eine Abschlussarbeit).
3.6.1 Eikon Refinitiv
![]() Bei Refinitiv Eikon handelt es sich um eine kommerzielle Datenbank zu Finanzmarktdaten. Unsere Fakultät hat zwar eine Lizenz für Refinitiv Eikon, aber für Studierende ist der direkte Zugang nur im Rahmen von Abschlussarbeiten möglich. Wir werden in diesem Kurs mit einigen Datensätzen arbeiten, die aus dieser Datenbank heruntergeladen wurden. Diese Datensätze werden im Learnweb bereitgestellt.
Bei Refinitiv Eikon handelt es sich um eine kommerzielle Datenbank zu Finanzmarktdaten. Unsere Fakultät hat zwar eine Lizenz für Refinitiv Eikon, aber für Studierende ist der direkte Zugang nur im Rahmen von Abschlussarbeiten möglich. Wir werden in diesem Kurs mit einigen Datensätzen arbeiten, die aus dieser Datenbank heruntergeladen wurden. Diese Datensätze werden im Learnweb bereitgestellt.
3.6.2 Bloomberg
 Bloomberg ist ebenfalls ein kommerzieller Anbieter von Finanzmarktdaten. Die Lizenz unserer Fakultät wurde jedoch nicht weiter verlängert und ist inzwischen abgelaufen. Sie können in diesem Kurs mit einem etwas älteren Datensatz arbeiten, der aus Bloomberg heruntergeladen wurde. In dem Datensatz sind hochfrequente Informationen (alle fünf Minuten) über einen Zeitraum von etwa einem halben Jahr zu vier Aktien abgespeichert. Der Datensatz wird im Learnweb bereitgestellt.
Bloomberg ist ebenfalls ein kommerzieller Anbieter von Finanzmarktdaten. Die Lizenz unserer Fakultät wurde jedoch nicht weiter verlängert und ist inzwischen abgelaufen. Sie können in diesem Kurs mit einem etwas älteren Datensatz arbeiten, der aus Bloomberg heruntergeladen wurde. In dem Datensatz sind hochfrequente Informationen (alle fünf Minuten) über einen Zeitraum von etwa einem halben Jahr zu vier Aktien abgespeichert. Der Datensatz wird im Learnweb bereitgestellt.
3.6.3 SOEP
 Das sozio-ökonomische Panel (SOEP) ist eine Langzeitstudie, die vom DIW Berlin betreut wird. Alljährlich wiederkehrend werden seit 1986 einige tausend Personen zu ihrer Situation befragt. Die Variablen decken viele Lebensbereiche ab, z.B. gibt es Variablen zum Haushalt, zur Familie, zum Einkommen, zum Arbeitsangebot, zum Freizeitverhalten, zu den subjektiven Einstellungen und anderes mehr.
Das sozio-ökonomische Panel (SOEP) ist eine Langzeitstudie, die vom DIW Berlin betreut wird. Alljährlich wiederkehrend werden seit 1986 einige tausend Personen zu ihrer Situation befragt. Die Variablen decken viele Lebensbereiche ab, z.B. gibt es Variablen zum Haushalt, zur Familie, zum Einkommen, zum Arbeitsangebot, zum Freizeitverhalten, zu den subjektiven Einstellungen und anderes mehr.
Die Datennutzung ist nur möglich, wenn man einen Nutzungsvertrag abschließt. In diesem Kurs nutzen wir als Ersatz den Datensatz mocksoep, der zwar den SOEP-Daten ähnelt, aber keine Originaldaten enthält.
3.6.4 FDZs
![]() Die wichtigsten administrativen Institutionen in Deutschland haben Forschungsdatenzentren (FDZ), zum Beispiel die Statistischen Ämter (FDZ der statistischen Ämter), die Rentenversicherung (FDZ der Rentenversicherung) und die Bundesagentur für Arbeit (FDZ der Bundesagentur).
Die wichtigsten administrativen Institutionen in Deutschland haben Forschungsdatenzentren (FDZ), zum Beispiel die Statistischen Ämter (FDZ der statistischen Ämter), die Rentenversicherung (FDZ der Rentenversicherung) und die Bundesagentur für Arbeit (FDZ der Bundesagentur).
Der Zugang zu den administrativen Daten ist im Allgemeinen nur eingeschränkt möglich (z.B. im Rahmen einer Abschlussarbeit), um den Datenschutz zu garantieren. Es gibt jedoch auch einige (meist ältere) Datensätze, die für jeden frei zugänglich sind. Einige dieser sogenannten Campus-Files werden wir in diesem Kurs verwenden. Auch diese Datensätze finden Sie auf der Learnweb-Seite dieses Kurses.
3.6.5 Gapminder
![]() Zum eigenständigen Experimentieren und Herumspielen eignen sich sehr gut die äußerst umfangreichen internationalen Daten der unabhängigen schwedischen Stiftung Gapminder. Laut eigenen Angaben kämpft Gapminder gegen bestürzend falsche Vorstellungen und will eine fakten-basierte Weltsicht fördern. Der Datenzugang erfolgt nicht über eine API, sondern über “normale” Internetseiten. Im folgenden wird für eine Gapminder-Teilmenge beschrieben, wie man online auf die Daten zugreift und sie direkt als Dataframe importiert, ohne sie zuvor lokal auf dem eigenen Rechner zu speichern.
Zum eigenständigen Experimentieren und Herumspielen eignen sich sehr gut die äußerst umfangreichen internationalen Daten der unabhängigen schwedischen Stiftung Gapminder. Laut eigenen Angaben kämpft Gapminder gegen bestürzend falsche Vorstellungen und will eine fakten-basierte Weltsicht fördern. Der Datenzugang erfolgt nicht über eine API, sondern über “normale” Internetseiten. Im folgenden wird für eine Gapminder-Teilmenge beschrieben, wie man online auf die Daten zugreift und sie direkt als Dataframe importiert, ohne sie zuvor lokal auf dem eigenen Rechner zu speichern.
- Wählen Sie aus der Variablen-Liste die Variable aus, die Sie gerne importieren möchten. (Leider gibt es vereinzelt Variablen, die zwar in der Liste aufgeführt sind, aber trotzdem nicht herunterladbar sind.) Die Tabelle ist sehr breit, so dass Sie ggf. nach rechts scrollen müssen, um die Variablenbeschreibung zu lesen. Sie können immer nur eine der Variablen zurzeit importieren. Natürlich können Sie später mehrere Variablen zusammenspielen (s. dazu Kapitel 4).
- Klicken Sie im oberen rechten Fenster von RStudio auf den Reiter “Environment” und anschließend auf “Import Dataset”. Wählen Sie “From Text (readr)…”.
- Kopieren Sie folgende URL in die obere Zeile (File/URL). Ersetzen Sie dabei XXXXX durch den Dateinamen in der ersten Spalte der Variablen-Liste:
https://raw.githubusercontent.com/open-numbers/ddf--gapminder--systema_globalis/master/countries-etc-datapoints/ddf--datapoints--XXXXX--by--geo--time.csv- Klicken Sie auf “Update”. Eine Voransicht der Daten wird nun im Fenster angezeigt. Hier können Sie kontrollieren, ob alles korrekt angezeigt wird.
- Unter den “Import Options” (unten links) können Sie festlegen, unter welchem Objektnamen der Dataframe gespeichert werden soll.
- Durch einen Klick auf “Import” (unten rechts) werden die Daten importiert. Sie können den Code aus dem “Code Preview”-Fenster in ein Script importieren, um den Datensatz beim nächsten Mal direkt herunterladen zu können.
Der importierte Dataframe hat drei Spalten. Die erste Spalte (geo) gibt die Region an, im allgemeinen handelt es sich dabei um Staaten. Die Staaten sind durch die üblichen ISO-Abkürzungen bezeichnet. Die zweite Spalte (time) gibt das Jahr der Beobachtung an. Die dritte Spalte enthält die Variablenwerte.
Beispiel:
Wir laden die Zahl der Patent-Bewilligungen, die oft als Maßstab für die Innovationsfreudigkeit einer Gesellschaft angesehen wird. In der Variablen-Liste finden wir die Variable patents_granted_total. Als Dataframe-Namen wählen wir patente. Das oben beschriebene Vorgehen liefert den Einlese-Code
patente <- read_csv("https://raw.githubusercontent.com/open-numbers/ddf--gapminder--systema_globalis/master/countries-etc-datapoints/ddf--datapoints--patents_granted_total--by--geo--time.csv")Führt man den Code aus, erhält man eine Nachricht darüber, welche Spalten in welcher Form eingelesen wurden (hier nicht angezeigt). Die ersten sechs Beobachtungen des Datensatzes sehen so aus:
head(patente)# A tibble: 6 × 3
geo time patents_granted_total
<chr> <dbl> <dbl>
1 abw 2002 3
2 alb 1999 52
3 alb 2000 203
4 alb 2001 502
5 arg 1984 1677
6 arg 1986 598Man sieht, dass es im Jahr 1986 in Argentinien 598 Patentebewilligungen gab.
3.6.6 Penn World Table
![]() Der Datensatz Penn World Table 10.01 liefert Informationen über das Bruttoinlandsprodukt und eine Reihe anderer makroökonomischer Größen von über 180 Staaten über einen Zeitraum von 1950 bis 2019 (wenn auch leider mit größeren Datenlücken). Der PWT-Datensatz steht als R-Paket zur Verfügung. Wenn Sie ihn nutzen möchten, installieren Sie zunächst das Paket
Der Datensatz Penn World Table 10.01 liefert Informationen über das Bruttoinlandsprodukt und eine Reihe anderer makroökonomischer Größen von über 180 Staaten über einen Zeitraum von 1950 bis 2019 (wenn auch leider mit größeren Datenlücken). Der PWT-Datensatz steht als R-Paket zur Verfügung. Wenn Sie ihn nutzen möchten, installieren Sie zunächst das Paket pwt10. Anschließend können Sie den Datensatz in R zugänglich machen, indem Sie
library(pwt10)
data("pwt10.0")eingeben. Dadurch wird ein Dataframe pwt10.0 erzeugt, der alle Daten enthält. Mit dem Befehl
names(pwt10.0)können Sie die Namen aller Variablen des Dataframes anzeigen lassen. Eine ausführliche Beschreibung der Variablen finden Sie in Tabelle 1 in dem Artikel The Next Generation of the Penn World Table, American Economic Review 105, 2015, S. 3150-3182.
3.6.7 Eurostat
![]() Eurostat ist die Statistik-Behörde der Europäischen Union. Eurostat stellt für viele Themenfelder Daten und Statistiken über Europa bereit. Die Daten sind harmonisiert, so dass sie über die einzelnen Staaten hinweg vergleichbar sind. Mit dem R-Paket
Eurostat ist die Statistik-Behörde der Europäischen Union. Eurostat stellt für viele Themenfelder Daten und Statistiken über Europa bereit. Die Daten sind harmonisiert, so dass sie über die einzelnen Staaten hinweg vergleichbar sind. Mit dem R-Paket eurostat ist der Zugriff auf die Eurostat-API relativ einfach. Die Funktion
search_eurostat("SUCHWORT")` gibt eine Tabelle aller Datensätze aus, in deren Beschreibung das SUCHWORT vorkommt. Im Internet findet man einen Überblick über den Datenbestand von Eurostat.
Beispiel:
Um alle Datensätze mit dem Begriff “Youth unemployment” zu finden und unter dem Name dslist zu speichern, gibt man folgendes ein:
library(eurostat)
dslist <- search_eurostat("Youth unemployment")
head(dslist)# A tibble: 4 × 9
title code type last.update.of.data last.table.structure…¹ data.start
<chr> <chr> <chr> <chr> <chr> <chr>
1 Youth unemp… yth_… data… 13.06.2024 24.04.2024 1983
2 Youth unemp… yth_… data… 13.06.2024 24.04.2024 1995
3 Youth unemp… yth_… data… 13.06.2024 24.04.2024 1999
4 Youth unemp… yth_… data… 13.06.2024 24.04.2024 1999
# ℹ abbreviated name: ¹last.table.structure.change
# ℹ 3 more variables: data.end <chr>, values <dbl>, hierarchy <dbl>Wenn wir uns für die Arbeitslosigkeitsquoten von Jugendlichen in Europa nach Geschlecht, Alter und Ausbildung interessieren - also für den Datensatz mit dem Code yth_empl_090 -, dann können wir sie mit dem Befehl
x <- get_eurostat("yth_empl_090")in einen Dataframe mit dem Namen x laden. Der Dataframe ist groß. Die Anzahl der Zeilen und Spalten sind
dim(x)[1] 186270 8Der Dataframe enthält nicht nur Daten über eine Variable, sondern über mehrere Variablen (z.B. Arbeitslosenzahlen für bestimmte Altersgruppen). Wie man gezielt auf die Variable(n) zugreift, für die man sich interessiert, betrachten wir in Kapitel 4.
Ohne den Kenn-Code des Datensatzes kann man ihn nicht laden. Die Suche nach Datensätzen und ihren Codes ist am einfachsten über die Internetseite von Eurostat (“Daten”/“Datenbank”). Sobald man den Code des Datensatzes kennt, kann man den Datensatz mit der Funktion get_eurostat herunterladen.
3.6.8 OECD
![]() Die OECD ist ein Zusammenschluss von überwiegend reichen Ländern. Sie hat eine recht umfangreiche Datenbank, die allgemein zugänglich ist. Die Daten der OECD lassen sich mit Hilfe des R-Pakets
Die OECD ist ein Zusammenschluss von überwiegend reichen Ländern. Sie hat eine recht umfangreiche Datenbank, die allgemein zugänglich ist. Die Daten der OECD lassen sich mit Hilfe des R-Pakets OECD einfach (wenn auch nicht sehr schnell) importieren, allerdings nur wenn man bereits die genaue Bezeichnung der Variablen kennt. Einen Überblick über das Datenangebot der OECD findet man auf der Internetseite der OECD.
Beispiel:
Es gibt insgesamt rund 1500 Datensätze, die jeweils eine mehr oder weniger große Zahl von Variablen beinhalten. Die Liste der Datensätze kann man mit der Funktion erhalten.
library(OECD)
liste_datensaetze <- get_datasets()Die ersten acht Datenbanken sind folgende:
head(liste_datensaetze, 8)# A tibble: 8 × 2
id title
<chr> <chr>
1 QNA Quarterly National Accounts
2 PAT_IND Patent indicators
3 TEL Telecommunications database
4 SNA_TABLE11 11. Government expenditure by function (COFOG)
5 LFS_SEXAGE_I_R LFS by sex and age - indicators
6 EO78_MAIN Economic Outlook No 78 - December 2005 - Annual Projections fo…
7 ANHRS Average annual hours actually worked per worker
8 GOV_DEBT Central Government Debt Die Ausgabe ist etwas unübersichtlich, weil einige Einträge sehr lang sind. Wir laden nun als Beispiel den Datensatz ANHRS herunter (Average annual hours actually worked per worker).
anhrs <- get_dataset("ANHRS")Der Anfang des Dataframes anhrs sieht so aus:
head(anhrs)# A tibble: 6 × 6
COUNTRY EMPSTAT FREQUENCY ObsValue TIME_FORMAT Time
<chr> <chr> <chr> <chr> <chr> <chr>
1 AUS TE A 1876 P1Y 1985
2 AUS TE A 1877 P1Y 1986
3 AUS TE A 1889 P1Y 1987
4 AUS TE A 1885 P1Y 1988
5 AUS TE A 1875 P1Y 1989
6 AUS TE A 1853 P1Y 1990 Nicht alle Variablennamen und Werte sind selbsterklärend. Wenn man nähere Auskünfte über die Variablen und ihre Ausprägungen braucht, hilft die Funktion
get_data_structure("ANHRS")Die liefert als Output eine umfangreiche Auflistung aller Variablennamen und die Bedeutung aller Ausprägungen. Der Output wird hier nicht wiedergegeben, da er zu umfangreich ist. Aus der Beschreibung der Datensatzstruktur wird klar, dass die erste Beobachtung für das Land Australien steht, es um die Gesamtbeschäftigung (total employment) geht, die Beobachtung sich auf ein Jahr bezieht, dass es sich um das Jahr 1985 handelt und dass die durchschnittliche Jahresarbeitszeit 1876 Stunden betrug.
Wie man aus dem Dataframe anhrs die Informationen herausziehen kann, die einen interessieren, und wie man sie darstellen kann, lernen Sie in den folgenden Kapiteln.