2.6 Approximating probabilities: Simulation margin of error
The probability of an event can be approximated by simulating the random phenomenon a large number of times and computing the relative frequency of the event. After enough repetitions we expect the simulated relative frequency to be close to the true probability, but there probably won’t be an exact match. Therefore, in addition to reporting the approximate probability, we should also provide a margin of error which indicates how close we think our simulated relative frequency is to the true probability.
Section 1.2.1 introduced the relative frequency interpretation in the context of flipping a fair coin. After many flips of a fair coin, we expect the proportion of flips resulting in H to be close to 0.5. But how many flips is enough? And how “close” to 0.5? We’ll investigate these questions now.
Consider Figure 2.9 below. Each dot represents a set of 10,000 fair coin flips. There are 100 dots displayed, representing 100 different sets of 10,000 coin flips each. For each set of flips, the proportion of the 10,000 flips which landed on head is recorded. For example, if in one set 4973 out of 10,000 flips landed on heads, the proportion of heads is 0.4973. The plot displays 100 such proportions; similar values have been “binned” together for plotting. We see that 97 of these 100 proportions are between 0.49 and 0.51, represented by the blue dots. So if “between 0.49 and 0.51” is considered “close to 0.5”, then yes, in 10000 coin flips we would expect41 the proportion of heads to be close to 0.5.
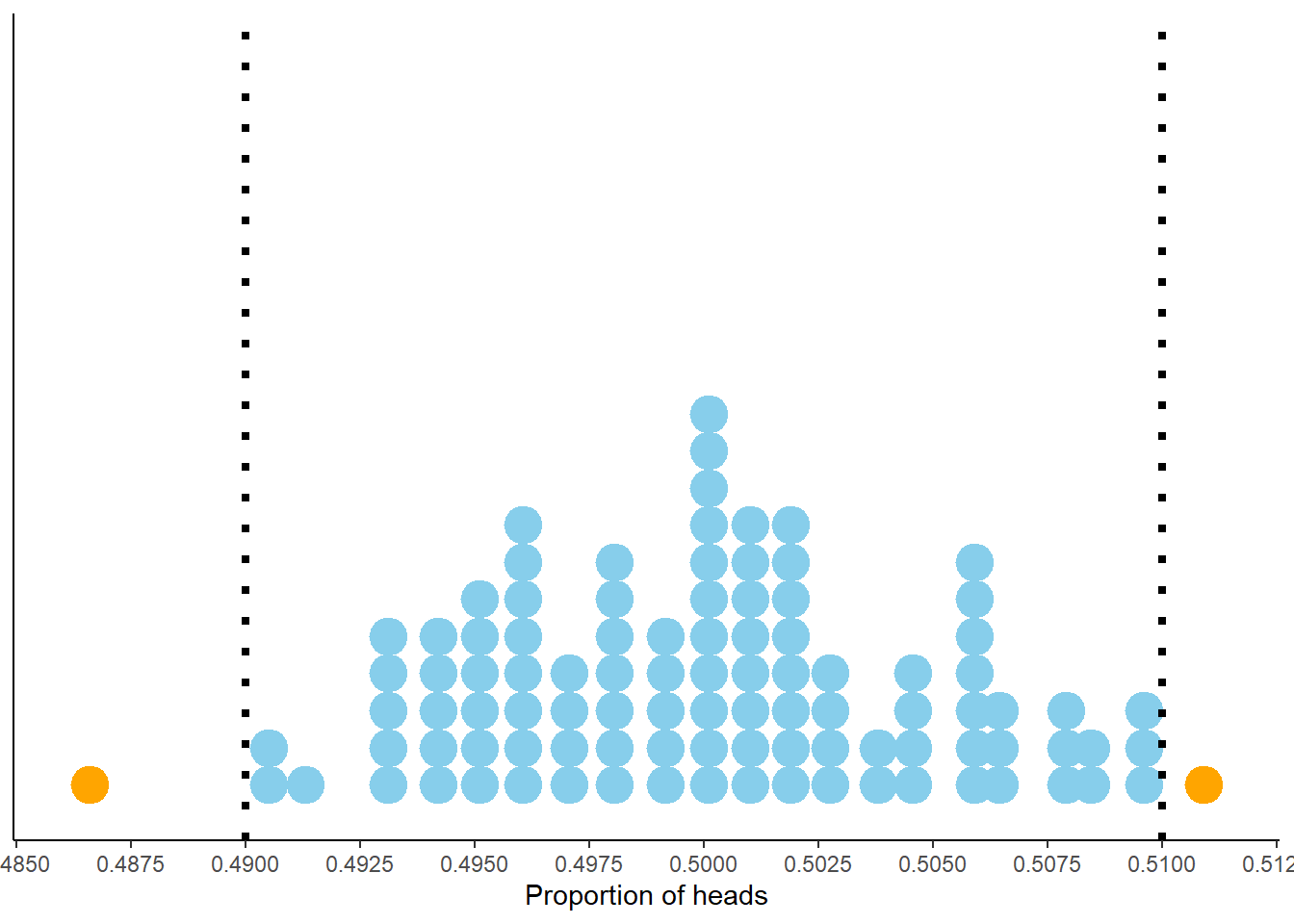
Figure 2.9: Proportion of flips which are heads in 100 sets of 10,000 fair coin flips. Each dot represents a set of 10,000 fair coin flips. In 97 of these 100 sets the proportion of heads is between 0.49 and 0.51 (the blue dots).
Our discussion of Figure 2.9 suggests that 0.01 might be an appropriate margin of error for a simulation based on 10,000 flips. Suppose we perform a simulation of 10000 flips with 4973 landing on heads. We could say “we estimate that the probability that a coin land on heads is equal to 0.4973”. But such a precise estimate would almost certainly be incorrect, due to natural variability in the simulation. In fact, only 0 sets42 resulted in a proportion of heads exactly equal to the true probability of 0.5.
A better statement would be “we estimate that the probability that a coin land on heads is 0.4973 with a margin of error43 of 0.01”. This means that we estimate that the true probability of heads is within 0.01 of 0.4973. In other words, we estimate that the true probability of heads is between 0.4873 and 0.5073, an interval whose endpoints are \(0.4973 \pm 0.01\). This interval estimate is “accurate” in the sense that the true probability of heads, 0.5, is between 0.4873 and 0.5073. By providing a margin of error, we have sacrificed a little precision — “equal to 0.4973” versus “within 0.01 of 0.4973” — to achieve greater accuracy.
Let’s explore this idea of “accuracy” further. Recall that Figure 2.9 displays the proportion of flips which landed on heads for 100 sets of 10000 flips each. Suppose that for each of these sets we form an interval estimate of the probability that the coin lands on heads by adding/subtracting 0.01 from the simulated proportion, as we did for \(0.4973 \pm 0.01\) in the previous paragraph. Figure 2.10 displays the results. Even though the proportion of heads was equal to 0.5 in only 0 sets, in 97 of these 100 sets (the blue dots/intervals) the corresponding interval contains 0.5, the true probability of heads. For almost all of the sets, the interval formed via “relative frequency \(\pm\) margin of error” provides an accurate estimate of the true probability. However, not all the intervals contain the true probability, which is why we often qualify that our margin of error is for “95% confidence” or “95% accuracy”. We will see more about “confidence” soon. In any case, the discussion so far, and the results in Figure 2.9 and Figure 2.10, suggest that 0.01 is a reasonable choice for margin of error when estimating the probability that a coin lands on heads based on 10000 flips.
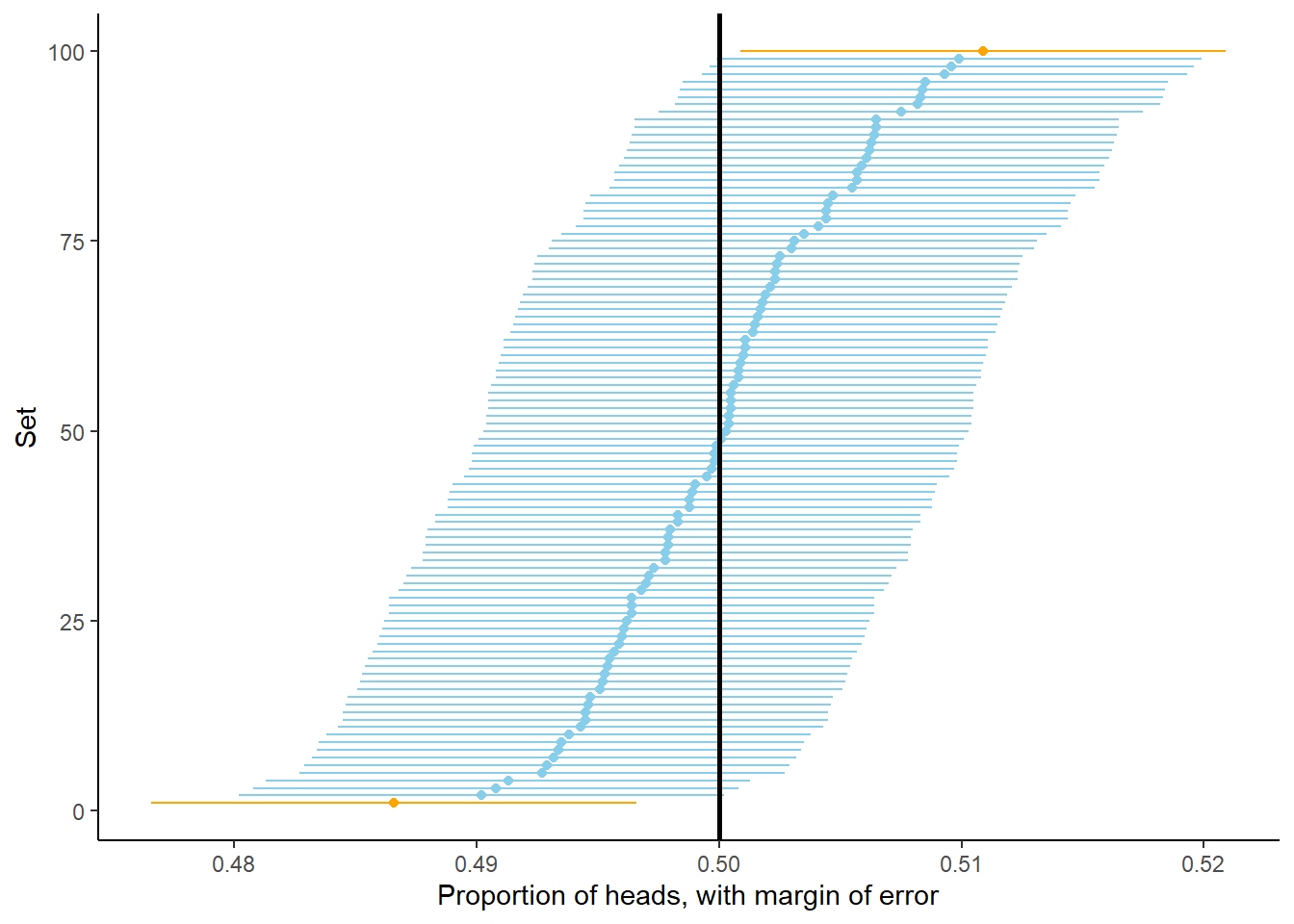
Figure 2.10: Interval estimates of the probability of heads based on 100 sets of 10,000 fair coin flips. Each dot represents the proportion of heads in a set of 10,000 fair coin flips. (The sets have been sorted based on their proportion of heads.) For each set an interval is obtained by adding/subtracting the margin of error of 0.01 from the proportion of heads. In 97 of these 100 sets (the blue dots/intervals) the corresponding interval contains the true probability of heads (0.5, represented by the vertical black line).
What if we want to be stricter about what qualifies as “close to 0.5”? That is, what if a margin of error of 0.01 isn’t good enough? You might suspect that with even more flips we would expect to observe heads on even closer to 50% of flips. Indeed, this is the case. Figure 2.11 displays the results of 100 sets of 1,000,000 fair coin flips. The pattern seems similar to Figure 2.9 but pay close attention to the horizontal axis which covers a much shorter range of values than in the previous figure. Now 95 of the 100 proportions are between 0.499 and 0.501. So in 1,000,000 flips we would expect44 the proportion of heads to be between 0.499 and 0.501, pretty close to 0.5. This suggests that 0.001 might be an appropriate margin of error for a simulation based on 1,000,000 flips.
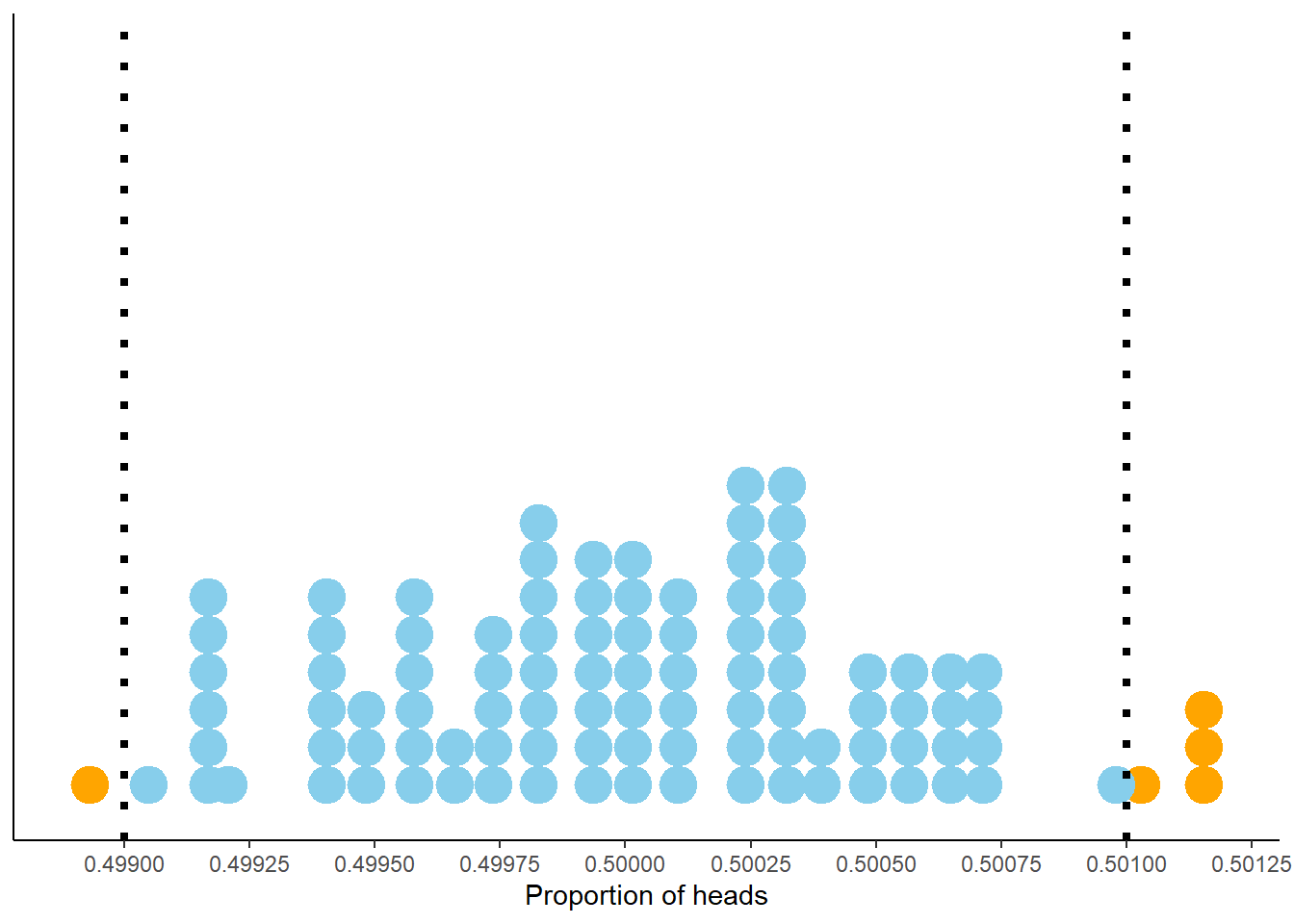
Figure 2.11: Proportion of flips which are heads in 100 sets of 1,000,000 fair coin flips. Each dot represents a set of 1,000,000 fair coin flips. In 95 of these 100 sets the proportion of heads is between 0.499 and 0.501 (the blue dots).
What about even more flips? In Figure 2.12 each dot represents a set of 100 million flips. The pattern seems similar to the previous figures, but again pay close attention the horizontal access which covers a smaller range of values. Now 98 of the 100 proportions are between 0.4999 and 0.5001. So in 100 million flips we would expect45 the proportion of heads to be between 0.4999 and 0.5001, pretty close to 0.5. This suggests that 0.0001 might be an appropriate margin of error for a simulation based on 100,000,000 flips.
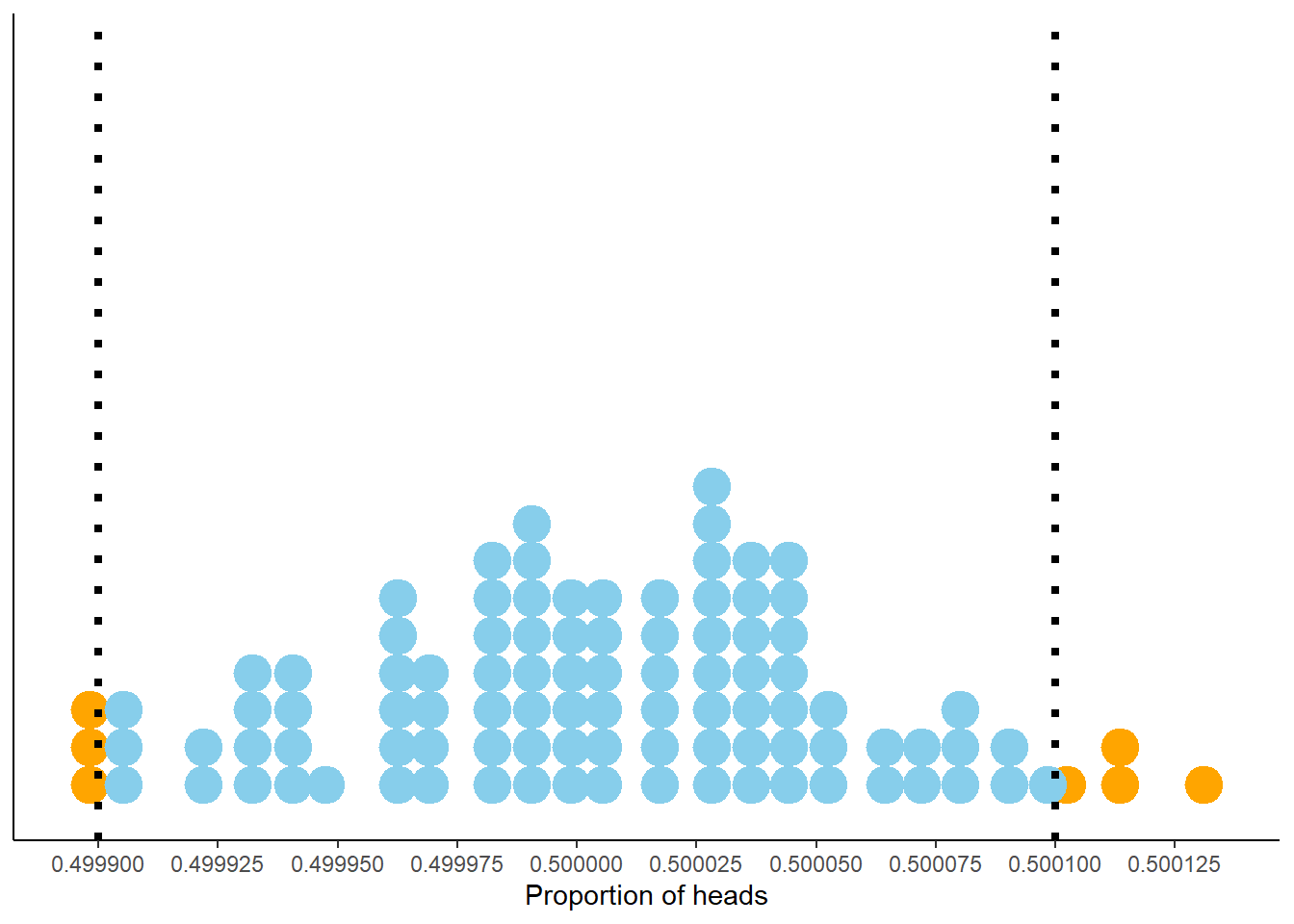
Figure 2.12: Proportion of flips which are heads in 100 sets of 100,000,000 fair coin flips. Each dot represents a set of 100,000,000 fair coin flips. In 98 of these 100 sets the proportion of heads is between 0.4999 and 0.5001 (the blue dots).
The previous figures illustrate that the more flips there are, the more likely it is that we observe a proportion of flips landing on heads close to 0.5. We also see that with more flips we can refine our definition of “close to 0.5”: increasing the number of flips by a factor of 100 (10,000 to 1,000,000 to 100,000,000) seems to give us an additional decimal place of precision (\(0.5\pm0.01\) to \(0.5\pm 0.001\) to \(0.5\pm 0.0001\).)
2.6.1 A closer look at margin of error
We will now carry out an analysis similar to the one above to investigate simulation margin of error and how it is influenced by the number of simulated values used to compute the relative frequency. Continuing the dice example, suppose we want to estimate \(p=\textrm{P}(X=6)\), the probability that the sum of two rolls of a fair four-sided equals six. We saw in Section ?? that the true probability is \(p=3/16=0.1875\).
We will perform a “meta-simulation”. The process is as follows
- Simulate two rolls of a fair four-sided die. Compute the sum (\(X\)) and see if it is equal to 6.
- Repeat step 1 to generate \(n\) simulated values of the sum (\(X\)). Compute the relative frequency of sixes: count the number of the \(n\) simulated values equal to 6 and divide by \(n\). Denote this relative frequency \(\hat{p}\) (read “p-hat”).
- Repeat step 2 a large number of times, recording the relative frequency \(\hat{p}\) for each set of \(n\) values.
Be sure to distinguish between steps 2 and 3. A simulation will typically involve just steps 1 and 2, resulting in a single relative frequency based on \(n\) simulated values. Step 3 is the “meta” step; we see how this relative frequency varies from simulation to simulation to help us in determing an appropriate margin of error. The important quantity in this analysis is \(n\), the number of simulated values used to compute the relative frequency in a single simulation. We wish to see how \(n\) impacts margin of error. The number of simulations in step 3 just needs to be “large” enough to provide a clear picture of how the relative frequency varies from simulation to simulation. The more the relative frequency varies from simulation to simulation, the larger the margin of error needs to be.
We can combine steps 1 and 2 of the meta-simulation to put it in the framework of the simulations from earlier in this chapter. Namely, we can code the meta-simulation as a single simulation in which
- A sample space outcome represents \(n\) values of the sum of two fair-four sided dice
- The main random variable of interest is the proportion of the \(n\) values which are equal to 6.
Let’s first consider \(n=100\). The following Symbulate code defines the probability space corresponding to 100 values of the sum of two-fair four sided dice. Notice the use of apply which functions much in the same way46 as RV.
n = 100
P = BoxModel([1, 2, 3, 4], size = 2).apply(sum) ** n
P.sim(5)| Index | Result |
|---|---|
| 0 | (7, 5, 5, 5, 6, ..., 4) |
| 1 | (6, 5, 5, 6, 5, ..., 6) |
| 2 | (5, 5, 3, 6, 4, ..., 6) |
| 3 | (3, 7, 5, 2, 2, ..., 8) |
| 4 | (3, 4, 4, 3, 7, ..., 3) |
In the code above
BoxModel([1, 2, 3, 4], size = 2)simulates two rolls of a fair four-sided die.apply(sum)computes the sum of the two rolls** nrepeats the processntimes to generate a set ofnindependent values, each value representing the sum of two rolls of a fair four-sided dieP.sim(5)simulates 5 sets, each set consisting ofnsums
Now we define the random variable which takes as an input a set of \(n\) sums and returns the proportion of the \(n\) sums which are equal to six.
phat = RV(P, count_eq(6)) / n
phat.sim(5)| Index | Result |
|---|---|
| 0 | 0.19 |
| 1 | 0.14 |
| 2 | 0.26 |
| 3 | 0.23 |
| 4 | 0.22 |
In the code above
phatis anRVdefined on the probability spaceP. Recall that an outcome ofPis a set ofnsums (and each sum is the sum of two rolls of a fair four-sided die).- The function that defines the
RViscount.eq(6), which counts the number of values in the set that are equal to 6. We then47 divide byn, the total number of values in the set, to get the relative frequency. (Remember that a transformation of a random variable is also a random variable.) phat.sim(5)generates 5 simulated values of the relative frequencyphat. Each simulated value ofphatis the relative frequency of sixes innsums of two rolls of a fair four-sided die.
Now we simulate and summarize a large number of values of phat.
We’ll simulate 100 values for illustration (as we did in Figures 2.9, 2.11, and 2.12).
Be sure not to confuse 100 with n.
Remember, the important quantity is n, the number of simulated values used in computing each relative frequency.
phat.sim(100).plot(type = "impulse", normalize = False)
plt.ylabel('Number of simulations');
plt.show()
We see that the 100 relative frequencies are roughly centered around the true probability 0.1875, but there is variability in the relative frequencies from simulation to simulation. From the range of values, we see that most relative frequencies are within about 0.08 or so from the true probability 0.1875. So a value around 0.08 seems like a reasonable value of the margin of error, but the actual value depends on what we mean by “most”. We can get a clearer picture if we run more simulations. The following plot displays the results of 10000 simulations, each resulting in a value of \(\hat{p}\). Remember that each relative frequency is based on \(n=100\) sums of two rolls.
phats = phat.sim(10000)
phats.plot(type = "impulse", normalize = False)
plt.ylabel('Number of simulations');
plt.show()
Let’s see how many of these 10000 simulated proportions are within 0.08 of the true probability 0.1875.
1 - (phats.count_lt(0.1875 - 0.08) + phats.count_gt(0.1875 + 0.08)) / 10000## 0.9614In roughly 95% or so of simulations, the simulated relative frequency was within 0.08 of the true probability. So 0.08 seems like a reasonable margin of error for “95% confidence” or “95% accuracy”. However, a margin of error of 0.08 yields pretty imprecise estimates, ranging from about 0.10 to 0.27. Can we keep the degree of accuracy at 95% but get a smaller margin of error, and hence a more precise estimate? Yes, if we increase the number of repetitions used to compute the relative frequency.
Now we repeat the analysis, but with \(n=10000\). In this case, each relative frequency is computed based on 10000 independent values, each value representing a sum of two rolls of a fair four-sided die. As before we start with 100 simulated relative frequencies.
n = 10000
P = BoxModel([1, 2, 3, 4], size = 2).apply(sum) ** n
phat = RV(P, count_eq(6)) / n
phats = phat.sim(100)
phats.plot(type = "impulse", normalize = False)
plt.ylabel('Number of simulations');
plt.show()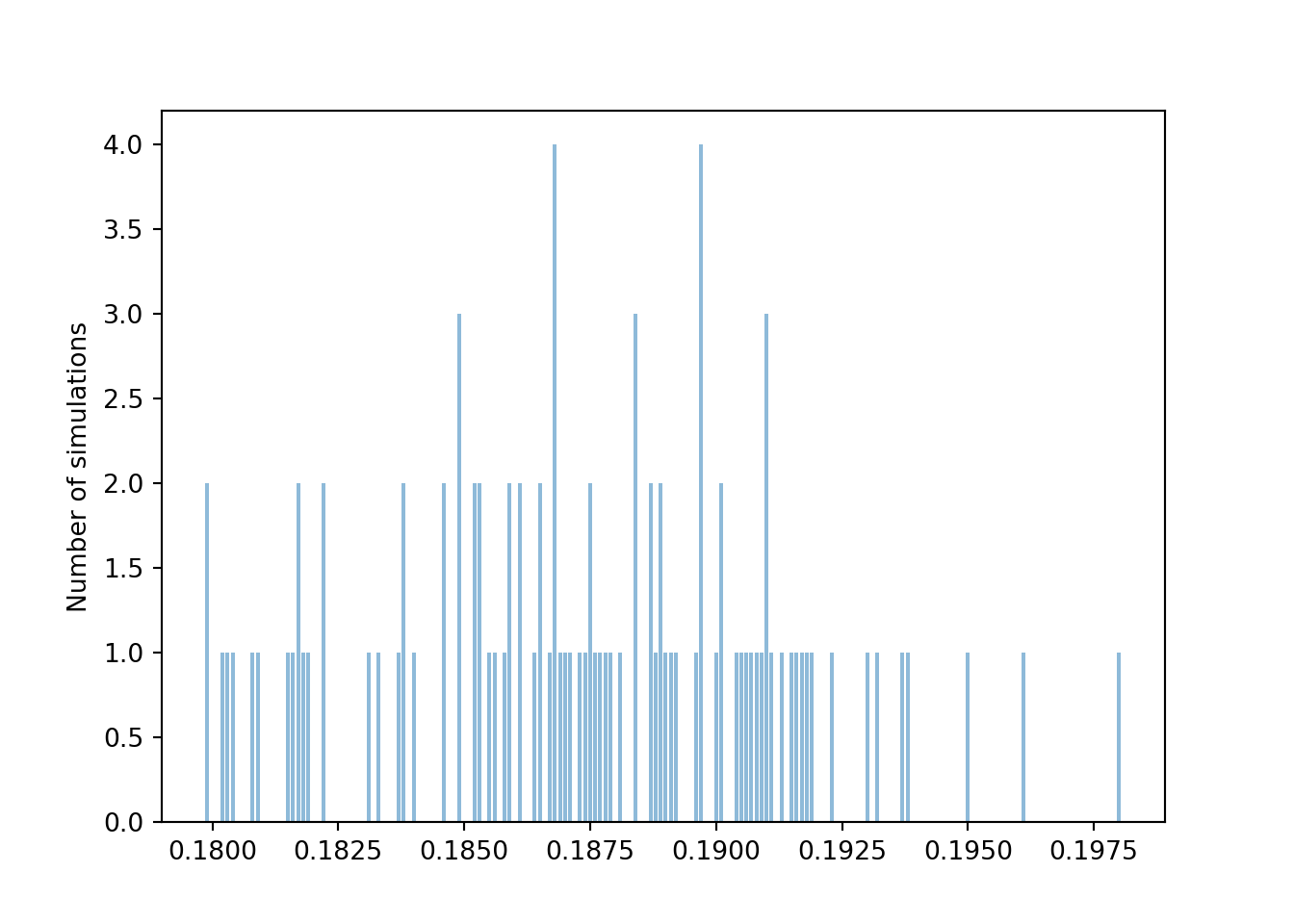
Again we see that the 100 relative frequencies are roughly centered around the true probability 0.1875, but there is less variability in the relative frequencies from simulation to simulation for \(n=10000\) than for \(n=100\). Pay close attention to the horizontal axis. From the range of values, we see that most relative frequencies are now within about 0.008 of the true probability 0.1875.
1 - (phats.count_lt(0.1875 - 0.008) + phats.count_gt(0.1875 + 0.008)) / 100## 0.98As with \(n=100\), running more than 100 simulations would give a clearer picture of how much the relative frequency based on \(n=10000\) simulated values varies from simulation to simulation. But even with just 100 simulations, we see that a margin of error of about 0.008 is required for roughly 95% accuracy when \(n=10000\), as opposed to 0.08 when \(n=100\). As we observed in the coin flipping example earlier in this section, it appears that increasing \(n\) by a factor of 100 yields an extra decimal place of precision. That is, increasing \(n\) by a factor of 100 decreases the margin of error by a factor of \(\sqrt{100}\). In general, the margin of error is inversely related to \(\sqrt{n}\).
| Probability that | True value | 95% m.o.e. (n = 100) | 95% m.o.e. (n = 10000) | 95% m.o.e. (n = 1000000) |
|---|---|---|---|---|
| A fair coin flip lands H | 0.5000 | 0.1000 | 0.0100 | 1e-03 |
| Two rolls of a fair four-sided die sum to 6 | 0.1875 | 0.0781 | 0.0078 | 8e-04 |
The two examples in this section illustrate that the margin of error also depends somewhat on the true probability. The margin of error required for 95% accuracy is larger when the true probability is 0.5 than when it is 0.1875. It can be shown that when estimating a probability \(p\) with a relative frequency based on \(n\) simulated repetitions, the margin of error required for 95% confidence48 is \[ 2\frac{\sqrt{p(1-p)}}{\sqrt{n}} \] For a given \(n\), the above quantity is maximized when \(p\) is 0.5. Since \(p\) is usually unknown — the reason for performing the simulation is to approximate it — we plug in 0.5 for a somewhat conservative margin of error of \(1/\sqrt{n}\).
For a fixed \(n\), there is a tradeoff between accuracy and precision. The factor 2 in the margin of error formula above corresponds to 95% accuracy. Greater accuracy would require a larger factor, and a larger margin of error, resulting in a wider — that is, less precise — interval. For example, 99% confidence requires a factor of roughly 2.6 instead of 2, resulting in an interval that is roughly 30 percent wider. The confidence level does matter, but the primary influencer of margin of error is \(n\), the number of repetitions on which the relative frequency is based. Regardless of confidence level, the margin of error is on the order of magnitude of \(1/\sqrt{n}\).
In summary, the margin of error when approximating a probability based on a simulated relative frequency is roughly on the order \(1/\sqrt{n}\), where \(n\) is the number of independently simulated values used to calculate the relative frequency. Warning: alternative methods are necessary when the actual probability being estimated is very close to 0 or to 1.
A probability is a theoretical long run relative frequency. A probability can be approximated by a relative frequency from a large number of simulated repetitions, but there is some simulation margin of error. Likewise, the average value of \(X\) after a large number of simulated repetitions is only an approximation to the theoretical long run average value of \(X\). The margin of error is also on the order of \(1/\sqrt{n}\) where \(n\) is the number of simulated values used to compute the average. We will explore margins of error for long run averages in more detail later.
Pay attention to the wording: \(n\) is the number of independently49 simulated values used to calculate the relative frequency. This is not necessarily the number of simulated values. For example, suppose we use simulation to approximate the probability that the larger of two rolls of a fair four-sided die is 4 when the sum is equal to 6. We might start by simulating 10000 pairs of rolls. But the sum would be equal to 6 in only about 1875 pairs, and it is only these pairs that would be used to compute the relative frequency that the larger roll is 4 to approximate the probability of interest. The appropriate margin of error is roughly \(1/\sqrt{1875} \approx 0.023\). Compared to 0.01 (based on the original 10000 repetitions) the margin of error of 0.023 results in intervals that are 130 percent wider. Carefully identifying the number of values used to calculate the relative frequency is especially important when determining appropriate simulation margins of error for approximating conditional probabilities, which we’ll discuss in more detail later.
2.6.2 Approximating multiple probabilities
When using simulation to estimate a single probability, the primary influencer of margin of error is \(n\), the number of repetitions on which the relative frequency is based. It doesn’t matter as much whether we use, say, 95% versus 99% confidence. That is, it doesn’t matter too much whether we compute our margin of error using \[ 2\frac{\sqrt{p(1-p)}}{\sqrt{n}}, \] with a multiple of 2 for 95% confidence, or if we replace 2 by 2.6 for 99% confidence. (Remember, we can plug in 0.5 for the unknown \(p\) for a conservative margin of error.) A margin of error based on 95% or 99% (or another confidence level in the neighborhood) provides a reasonably accurate estimate of the probability. However, using simulation to approximate multiple probabilities simultaneously requires a little more care with the confidence level.
In the previous section we used simulation to estimate \(\textrm{P}(X=6)\). Now suppose we want to approximate the distribution of the random variable \(X\), the sum of two rolls of a fair four-sided equals six. We could run a simulation like the one in Section 2.5.4 to obtain results like those in Figure 2.6 and the table before it. Each of the relative frequencies in the table is an approximation of the true probability, and so each of the relative frequencies should have a margin of error, say 0.01 for a simulation based on 10000 repetitions. Thus, the simulation results yield a collection of seven interval estimates, an interval estimate of \(\textrm{P}(X = x)\) for each value of \(x = 2,3,4,5,6,7,8\). Each interval in the collection either contains the respective true probability or not. The question is then: In what percent of simulations will every interval in the collection contain the respective true probability?
Figure 2.13 summarizes the results of 100 simulations. Each simulation consists of 10000 repetitions, with results similar to those in Figure 2.6 and the table before it. Each simulation is represented by a row in Figure 2.13, consisting of seven 95% interval estimates, one for each value of \(x\). Each panel represents a different values of \(x\); for each value of \(x\), around 95 out of the 100 simulations yield estimates that contain the true probability \(\textrm{P}(X=x)\), represented by the vertical line.
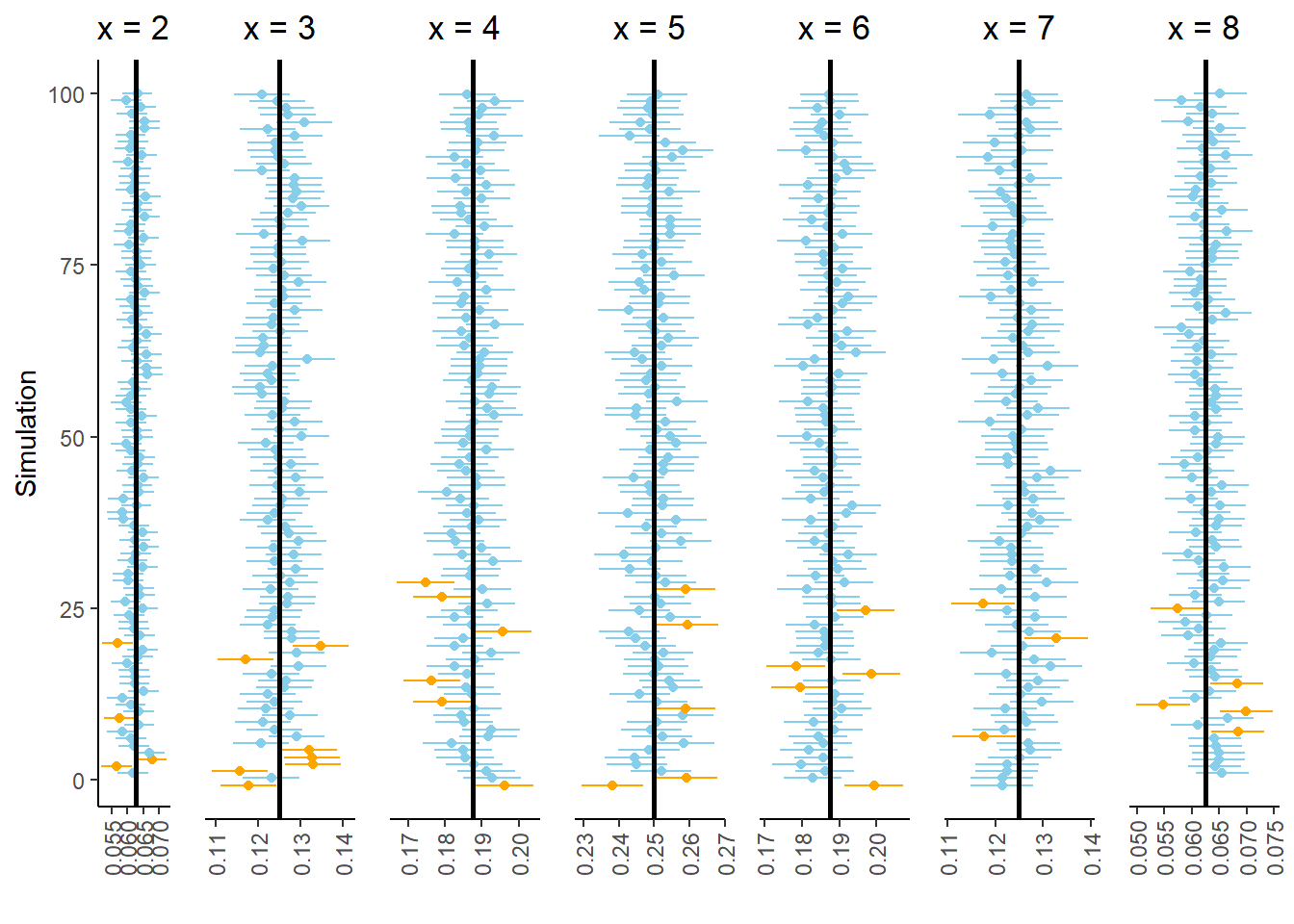
Figure 2.13: Results of 100 simulations. Each simulation yields a collection of seven 95% confidence intervals.
However, let’s zoom in on the bottom of Figure 2.13. Figure 2.14 displays the results of the 24 simulations at the bottom of Figure 2.13. Look carefully row by row in Figure 2.14; in each of these simulations at least one of the seven intervals in the collection does not contain the true probability. In other words, every interval in the collection contains the respective true probability in only 76 of the 100 simulations (the other simulations in Figure 2.13.) While we have 95 percent confidence in our interval estimate of \(\textrm{P}(X = x)\) for any single \(x\), we only have around 76 percent confidence in our approximate distribution of \(X\). Our confidence “grade” has gone from A range (95 percent) to C range (76 percent).
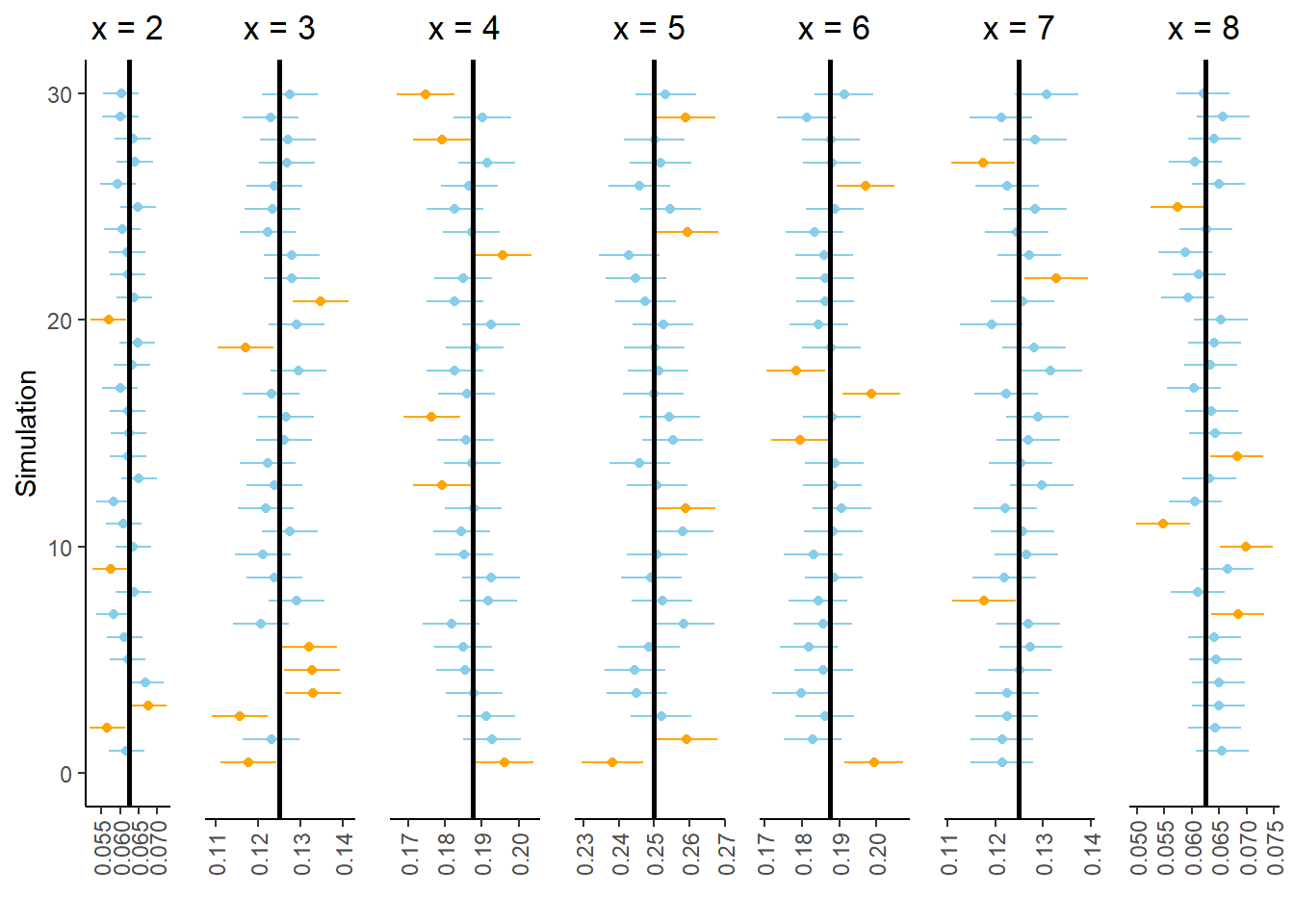
Figure 2.14: Subset of 24 simulations from Figure 2.13. In each of these simulations, at least one 95% confidence interval does not contain the respective true probability.
When approximating multiple probabilities based on a single simulation, such as when approximating a distribution, margins of error and interval estimates need to be adjusted to obtain simultaneous 95% confidence. The easiest way to do this is to make all of the intervals in the collection wider.
There are many procedures for adjusting a collection of interval estimates to achieve simultaneous confidence; we won’t get into any technical details. As a very rough, but simple and typically conservative rule, when approximating many probabilities based on a single simulation, we recommend making the margin of error twice as large as when approximating a single probability. That is, use a margin of error of \(2/\sqrt{n}\) (rather than \(1/\sqrt{n}\)) to achieve simultaneous 95% confidence when approximating many probabilities based on a single simulation.
2.6.3 Beware a false sense of precision
Why don’t we always run something like one trillion repetitions so that our margin of error is tiny? There is a cost to simulating and storing more repetitions in terms of computational time and memory. Also, remember that simulating one trillion repetitions doesn’t guarantee that the margin of error is actually based on anywhere close to one trillion repetitions, especially when conditioning on a low probability event.
Most importantly, keep in mind that any probability model is based on a series of assumptions and these assumptions are not satisfied exactly by the random phenomenon. A precise estimate of a probability under the assumptions of the model is not necessarily a comparably precise estimate of the true probability. Reporting probability estimates out to many decimal places conveys a false sense of precision and should typically be avoided.
For example, the probability that any particular coin lands on heads is probably not 0.5 exactly. But any difference between the true probability of the coin landing on heads and 0.5 is likely not large enough to be practically meaningful50. That is, assuming the coin is fair is a reasonable model.
Suppose we assume that the probability that a coin lands on heads is exactly 0.5 and that the results of different flips are independent. If we flip the coin 1000 times the probability that it lands on heads at most 490 times is 0.2739864. (We will see a formula for computing this value later.) If we were to simulate one trillion repetitions (each consisting of 1000 flips) to estimate this probability then our margin of error would be 0.000001; we could expect accuracy out to the sixth decimal place. However, reporting the probability with so many decimal places is somewhat disingenuous. If the probability that the coin lands on heads were 0.50001, then the probability of at most 490 heads in 1000 flips would be 0.2737757. If the probability that the coin lands on heads were 0.5001, then the probability of at most 490 heads in 1000 flips would be 0.2718834. Reporting our approximate probability as something like 0.2739864 \(\pm\) 0.000001 says more about the precision in our assumption that the coin is fair than it does about the true probability that the coin lands on heads at most 490 times in 1000 flips. A more honest conclusion would result from running 10000 repetitions and reporting our approximate probability as something like 0.27 \(\pm\) 0.01. Such a conclusion reflects more genuinely that there’s some “wiggle room” in our assumptions, and that any probability computed according to our model is at best a reasonable approximation of the “true” probability.
For most of the situations we’ll encounter in this book, estimating a probability to within 0.01 of its true value will be sufficient for practical purposes, and so basing approximations on 10000 simulated values will be appropriate. Of course, there are real situations where probabilities need to be estimated much more precisely, e.g., the probability that a bridge will collapse. Such situations require more intensive methods.
In 10000 flips, the probability of heads on between 49% and 51% of flips is 0.956, so 97 out of 100 provides a rough estimate of this probability. We will see how to compute such a probability later.↩︎
This is difficult to see in Figure 2.9 due to the binning. But we can at least tell from Figure 2.9 that at most a handful of the 100 sets resulted in a proportion of heads exactly equal to 0.5.↩︎
Technically, we should say ”a margin of error for 95% confidence of 0.01”. We’ll discuss ”confidence” in a little more detail soon.↩︎
In 1,000,000 flips, the probability of heads on between 49.9% and 50.1% of flips is 0.955, and 95 out of 100 sets provides a rough estimate of this probability.↩︎
In 100 million flips, the probability of heads on between 49.99% and 50.01% of flips is 0.977, and 98 out of 100 sets provides a rough estimate of this probability.↩︎
One difference between
RVandapply:applypreserves the type of the input object. That is, ifapplyis applied to aProbabilitySpacethen the output will be aProbabilitySpace; ifapplyis applied to anRVthen the output will be anRV. In contrast,RValways creates anRV.↩︎Unfortunately, for techincal reasons,
RV(P, count_eq(6) / n)will not work. It is possible to divide bynwithinRVif we define a custom functiondef rel_freq_six(x): return x.count_eq(6) / nand then defineRV(P, rel_freq_six).↩︎We will see the rationale behind this formula later. The factor 2 comes from the fact that for a Normal distribution, about 95% of values are within 2 standard deviations of the mean. Technically, the factor 2 corresponds to 95% confidence only when a single probability is estimated. If multiple probabilities are estimated simultaneously, then alternative methods should be used, e.g., increasing the factor 2 using a Bonferroni correction. For example, a multiple of 5 rather than 2 produces very conservative error bounds for 95% confidence even when many probabilities are being estimated.↩︎
In all the situations in this book the values will be simulated independently. However, there are many simulation methods where this is not true, most notably MCMC (Markov Chain Monte Carlo) methods. The margin of error needs to be adjusted to reflect any dependence between simulated values.↩︎
There is actually some evidence that a coin flip is slightly more likely to land the same way it started; e.g, a coin that starts H up is more likely to land H up. But the tendency is small.↩︎