Capítulo 3 Visualización de Datos
La visualización de datos es la presentación en formato gráfico de datos o información. El fin principal es transmitir la esencia de los datos de manera funcional y estética. Esto porque las palabras no siempre son suficientes para brindar imágenes claras de lo que sucede (por eso una imagen dice más que mil palabras), o porque para el cerebro los datos crudos son difíciles de procesar o interpretar.
Además, la mente humana es muy receptiva a la información visual. Estamos naturalmente entrenados para percibir el ambiente a través de nuestra vista. Por esta razón la visualización de datos es una herramienta poderosa para la comunicación. Es tan importante como un buen análisis de datos.
Los gráficos son la principal herramienta para la visualización de datos. Algunos principios sobre los la utilidad de los gráficos son los siguientes:
- Los gráficos permiten simplificar información compleja.
- Los humanos necesitamos de ayuda visual.
- Un gráfico es más accesible que una tabla.
- Los gráficos concuerdan con lo que los ojos tienen capacidad de percibir.
- Los gráficos ayudan al cerebro a entender y memorizar mejor.

Imagen tomada de https://venngage.com/blog/data-visualization-infographic/
Objetivos de la Visualización
- Responder preguntas
- Ver datos en contexto
- Encontrar patrones subyacentes
- Argumentar o contar una historia
- Entendimiento profundo de los datos
- Registrar, analizar y comunicar
- Contribuir a tomar (buenas) decisiones
El principal desafío de la visualización es representar datos abstractos reforzando los aspectos cognitivos
3.1 El ojo y la visión
El ojo es quizás uno de los órganos más complejos del cuerpo. Sus diferentes partes trabajan conjuntamente para visualizar el mundo que nos rodea. Recibe información en forma de luz, la transforma en señal eléctrica y la transporta a la parte posterior del cerebro para que se produzca la visión. Algunos detalles adicionales del funcionamiento del ojo humano se pueden observar en el siguiente video.
El ojo humano es capaz de absorber y procesar instantáneamente más de diez millones de datos por segundo. Para que podamos ver, tienen que ocurrir las siguientes etapas:
- Percepción: luz entra en el ojo a través de órganos transparentes (córnea, humor acuoso, cristalino y humor vítreo) donde se busca, sigue y enfoca la imagen. La acomodación es el enfoque para ver con nitidez, dura aproximadamente 200 milisegundos.
- Transformación: la energía luminosa llega a la retina (a la mácula), donde se activan las células sensoriales (conos y bastones) que transforman la luz en energía nerviosa.
- Transmisión: los impulsos nerviosos viajan del nervio óptico hasta la corteza cerebral.
- Interpretación: en la corteza cerebral se interpretan, reconocen y procesan los impulsos. Por tanto, no vemos las imágenes con nuestros ojos, las vemos con nuestros cerebros.
Por tanto, lo que ve el ojo no es igual a lo que el cerebro percibe. Es decir, la realidad es (en realidad) una interpretación del cerebro…
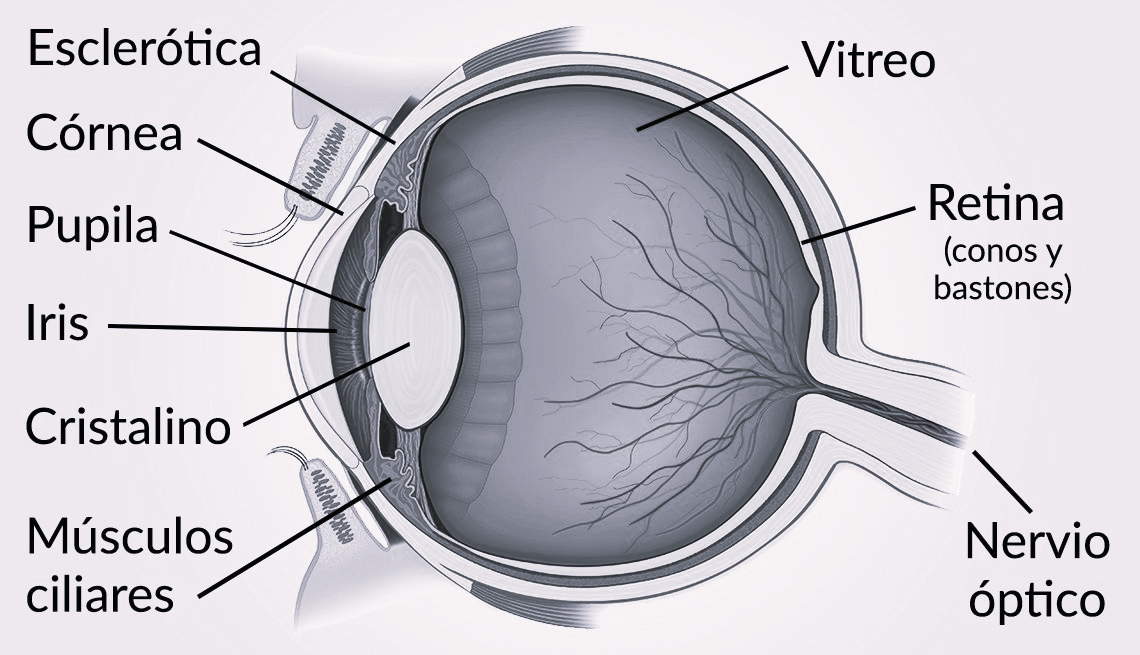
Anatomía del ojo humano. Créditos: LAUREN SHAVELL / GETTY IMAGES /AARP tomada de aarp.org
3.2 Resolución del ojo humano
- Hay alrededor de 6 millones de conos, que son las células sensibles a la luz y color.
- Por otro lado, hay entre 90 y 126 millones de bastones, que son las que permiten la visión en condiciones de baja luminosidad.
- Los conos capturan alrededor de 6 megapíxeles a color
- Los bastones consiguen alrededor de 100 megapixeles en blanco y negro
- El ojo recorre su campo de visión para componer una imagen y captura el equivalente a 576 megapíxeles.
*Esto implica que el ojo puede percibir mejor las figuras en blanco y negro con los contornos bien delimitados. Si una figura no se aprecia bien en blanco y negro, dificilmente mejorará a color
3.3 Visión fotópica
- Es la percepción visual que se produce con altos niveles de iluminación.
- Posibilita al ojo la correcta interpretación del color y está basada en la respuesta de los conos.
- Los organismos tricromáticos, como los humanos, poseen tres tipos de conos: Rojos, Verdes y Azules. Cada uno de ellos posee un fotopigmento con una curva característica de absorción respecto de la longitud de onda.
- Esto constituye el punto de partida (y a la vez una limitación) fisiológica para la percepción del color.
- Sin embargo, la percepción de detalles finos (agudeza visual) depende de este tipo de visión.
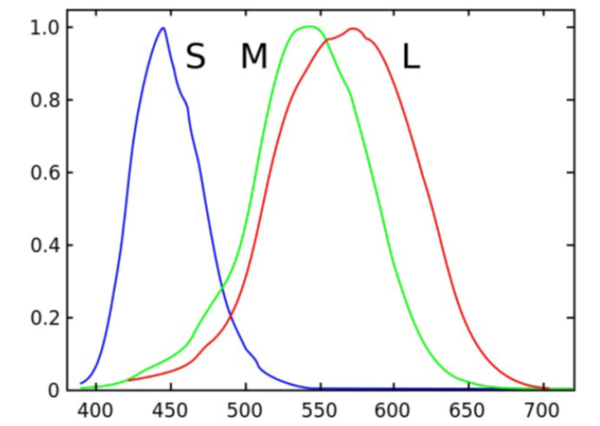
Curva de absorción de fotopigmentos respecto de la longitud de onda. Imagen tomada de https://es.slideshare.net/txipi/bilbostack2015-garaizar
3.4 Percepción visual rápida
La percepción visual es la capacidad de interpretar el entorno circundante mediante el procesamiento de la información contenida en la luz visible.
La percepción visual rápida ocurre de manera inconsciente a una velocidad extremadamente alta y permite detectar un conjunto específico de atributos visuales llamados atributos de preatención.
Estos atributos determinan qué información llama prioritariamente nuestra atención. Nuestros ojos se sienten atraídos por patrones familiares. Vemos lo que esperamos ver. Esto es importante porque nos permite dirigir la atención de nuestro espectador hacia la información más importante.
Entre los atributos visuales de preatención están la forma, el color, la posición espacial y el movimiento.
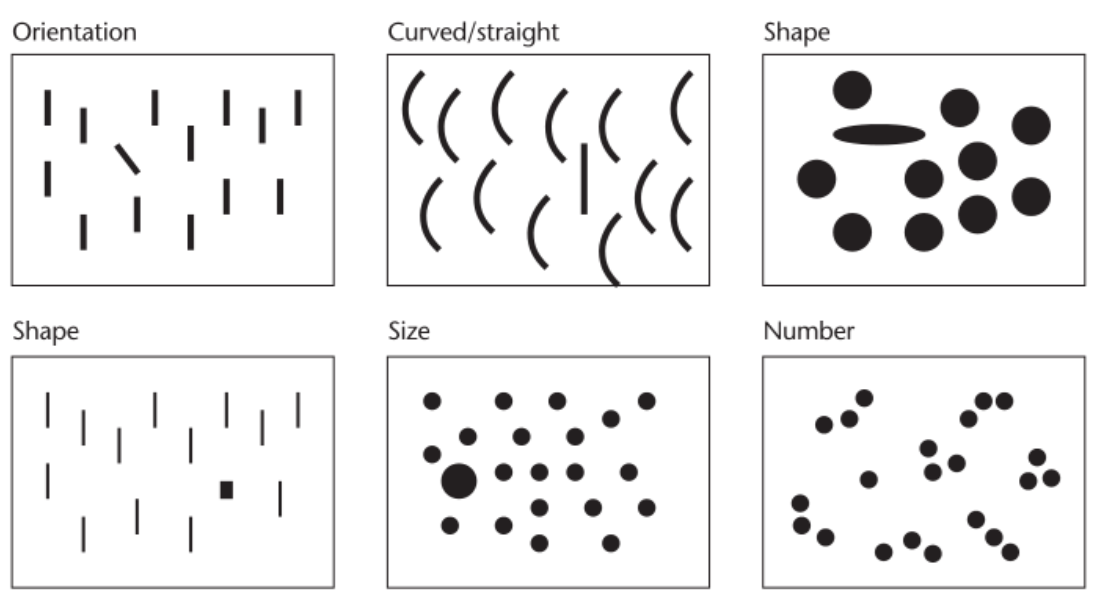
La percepción visual rápida nos permite notar anomalías muy rápidamente anomalías. Imagen tomada de https://es.slideshare.net/txipi/bilbostack2015-garaizar
3.5 Principios de Gestalt
Gestalt fue un movimiento que se inició en la década de 1920 en Berlín, Alemania. La palabra alemana significa patrón, figura o forma. Se buscaba entender cómo nuestras mentes perciben las cosas como un todo, en lugar de ver individualmente los objetos. Mediante principios básicos demostraron que nuestro cerebro siempre va a intentar simplificar y organizar imágenes complejas.
3.5.1 Principio de proximidad
Los objetos más cercanos entre si tienden a verse como una unidad.

Sin embargo, el efecto de las conexiones es más potente que la proximidad, el color, el tamaño o la forma.
3.5.2 Principio de semejanza
Los objetos similares tienden a verse como una unidad. La tendencia es a formar grupos con los que son iguales.

3.5.3 Principio de cerramiento o autocompletado
Cuando percibimos una figura que no está cerrada o delimitada por contornos, nuestro cerebro trabaja rellenando la información que falta, transmitiendo una sensación de la forma completa.

Imagen tomada de https://www.pinterest.es/polespi/gestalt/
3.5.4 Principio de continuidad
Tendemos a percibir objetos continuos a pesar de que estén interrumpidos. Este principio se basa en la idea de que el ojo humano va a seguir siempre el camino visual más suave, menos forzado y más coherente.

3.5.5 Principio de figura y fondo
Este principio describe la tendencia que tiene el ojo humano a ver un objeto separado de lo que le rodea. Sin embargo, el cerebro no puede interpretar un objeto como figura o fondo al mismo tiempo.

Poster de la pelicula Pedro y el Lobo tomada de https://i.imgur.com/b33IrLD.jpg

3.6 Semiología
Es la ciencia que trata de los sistemas de comunicación de las sociedades humanas, estudiando las propiedades generales de los sistemas de signos, incluyendo los códigos (organización de los signos) y la cultura (contexto generador).
Signo Cualquier cosa que pueda considerarse como substituto significante de cualquier otra cosa. Compuesto por el significante (aspecto del signo) y el significado (emoción o conducta asociada).
Tipos de signos:
- Iconos: guarda relación o parecido a referente
- Indicadores: relación natural o causa efecto
- Símbolos: relación arbitraria o convencional
Un entendimiento apropiado de los principios de la semiología nos permite agregar valor a los mensajes que queremos comunicar a través de nuestros datos y gráficos
3.7 Escogencia de gráficos
Casi siempre se puede elegir racionalmente el mejor gráfico para representar nuestros datos. Sin embargo, hay algunas preguntas que pueden ayudar a la escogencia del gráfico apropiado:
- ¿Cuál es la historia que sus datos tratan de contar?
- ¿Qué tipo de datos se tienen?
- ¿Qué tipo de gráfico mostrará sus datos de la manera más simple y eficiente?
- ¿Quién es tu audiencia?
Se presenta a continuación un esquema que también podría ser de ayuda para la escogencia del tipo de gráfico.
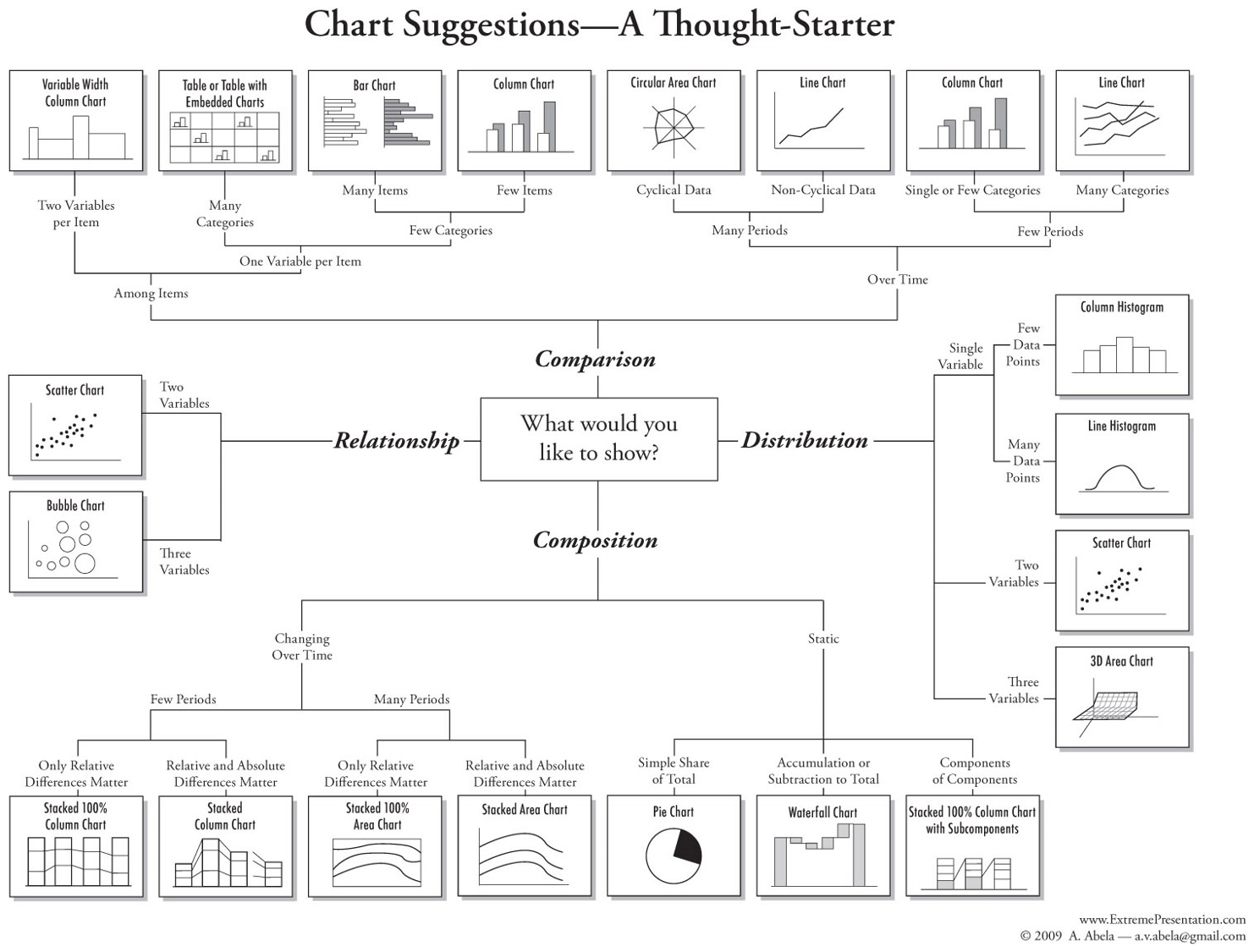
Algunas sugerencias generales de tipos gráficos de acuerdo al tipo de datos son las siguientes:
- Valores en el tiempo: Grafico de barras, lineas o puntos
- Comparación por tamaño o proporción: Gráfico de barras
- Correlación: Gráfico de dispersión
- Distribución de datos: Grafico de barras, box plot o strip plot.
3.8 Recomendaciones generales
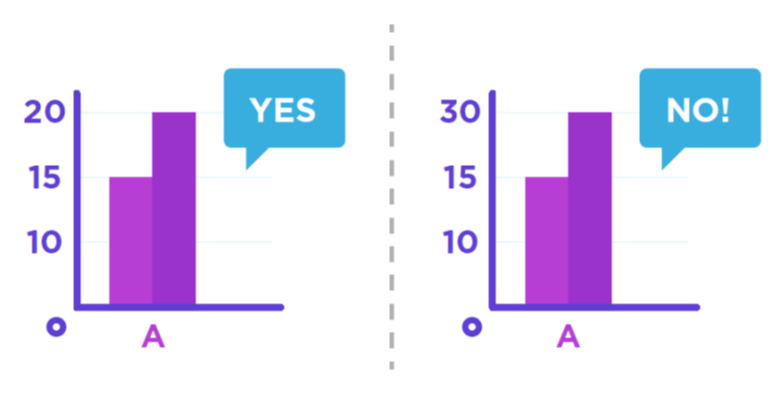
3.8.1 Iniciar siempre el eje de valores en cero
Los ejes truncado son engañosos.
Imagen tomada de https://www.slideshare.net/24Slides/how-to-visualize-data-like-a-pro
3.8.3 Graficos de líneas
Deberían tener máximo 4 líneas. Además, son preferibles las líneas sólidas a las punteadas.
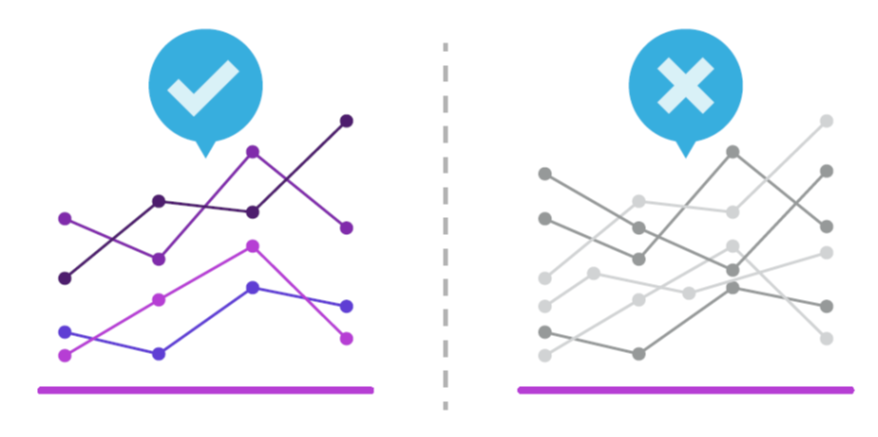
3.8.4 Evite usar gráficos circulares y en 3D
En general tenemos problemas para intepretar ángulos, áreas y estructuras tridimensionales.
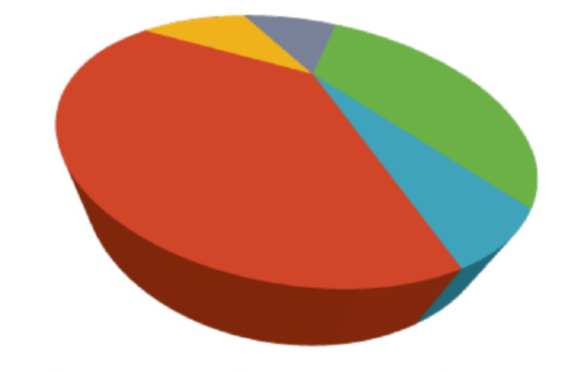

{kind=link}
3.9 Gráficos con ggplot2
ggplot2 es un sistema para crear gráficos utilizando una sintáxis lógica y simple. Usted proporciona los datos, le dice cómo asignar variables y qué tipo de gráfico quiere.
Este programa es considerado quizás el más elegante y versátil en la actualidad. En la mayoría de los casos, comienza con el comando ggplot(), se proporciona un conjunto de datos y un mapeo estético (con aes()). Luego se pueden agregar capas del tipo de gráfico que se desea (como geom_point() o geom_histogram()) y otras especificaciones como el facetado (facet_wrap()).
En general, a la hora de generar (buenos) gráficos con este, o cualquier otro, programa se deben considerar los siguientes aspectos:
- Los ejes deben estar claramente etiquetados.
- Las letras deben ser lo suficientemente grandes para verse con claridad.
- Los ejes no deben ser engañosos (empezar en cero)
- Los datos deben mostrarse de forma adecuada teniendo en cuenta el tipo de datos que tiene.
A continuación, se presentarán algunos tipos de graficos que se pueden hacer con ggplot2 con el fin de mostrar los principios básicos de la gramática del programa, los cuales puede ser extrapolados a lmuchos otros tipos de gráficos.
3.9.1 Gráficos de puntos
De la base de datos palmerpenguins vamos a graficar la relación entre dos variables de mediciones corporales para cada una de las especies de pinguinos. Primero, con ggplot se llaman los datos, se especifican las variables de los ejes y además, con el parámetro color, se designa una variable a remarcar. Con geom_point() se indica que va a ser un gráfico de puntos. Con la función labs()se puede especificar el texto con el nombre de los ejes que se visualizará. Con scale_color_brewer()se puede seleccionar la paleta de colores de preferencia incluida dentro del paquete RColorBrewer. La función theme_bw() permite escoger el estilo de visualización del gráfico. Además, con esta función theme()también permite hacer ajustes en todos los textos que aparecen en el gráfico.
library(ggplot2)
library(palmerpenguins)
library(RColorBrewer)
ggplot(data= penguins,
aes(x=bill_length_mm,
y=bill_depth_mm,
color= species))+
geom_point()+
labs(
x = "Length[mm]",
y= "Depth[mm]")+
scale_color_brewer(palette = "Dark2")+
theme_bw()+
theme(axis.text.x = element_text(size = 8),
axis.text.y = element_text(size = 8),
axis.title.y = element_text(size = 10,face="bold"),
axis.title.x = element_text(size = 10,face="bold"),
legend.text = element_text(size = 9),
legend.title = element_blank())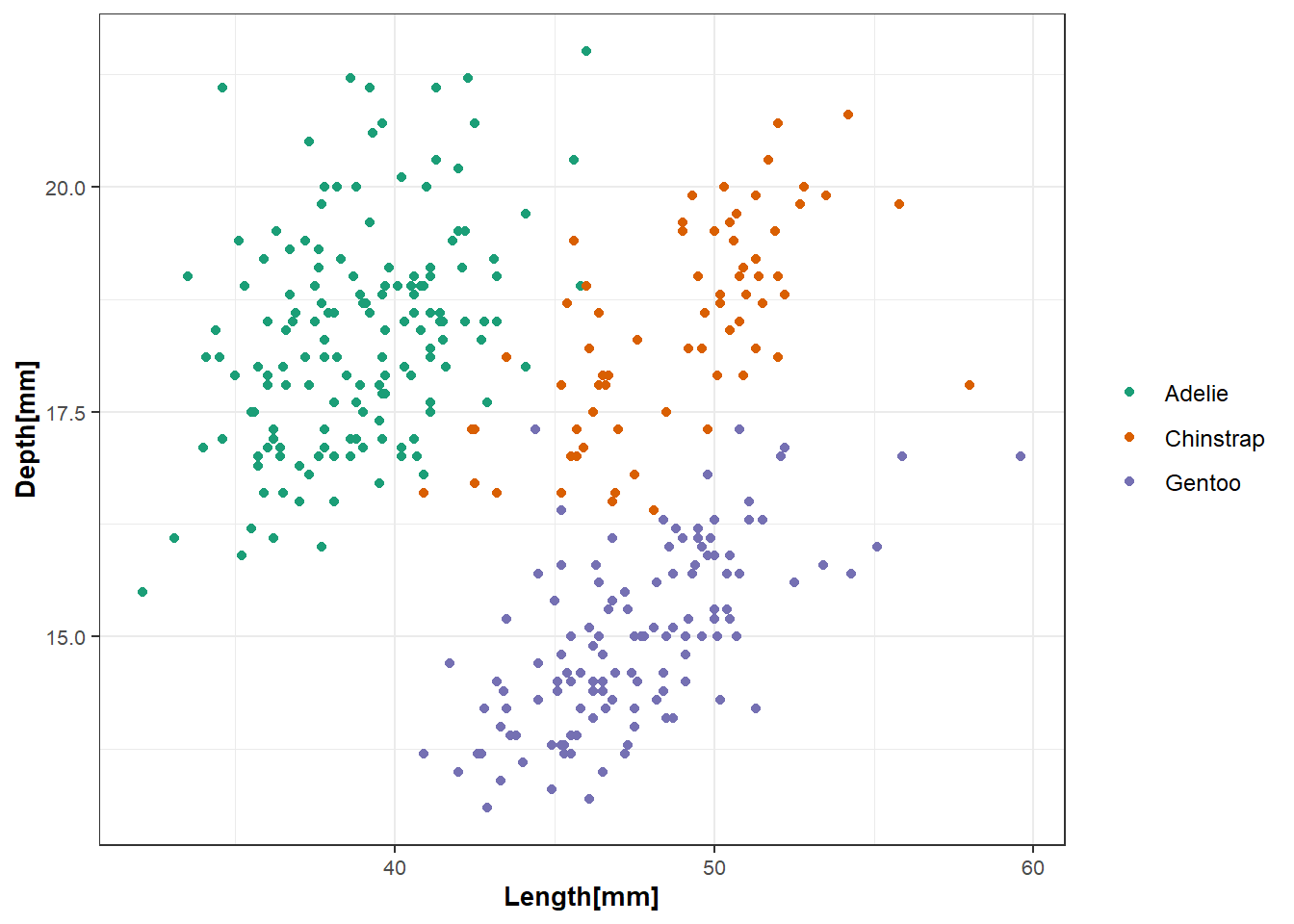
Una de las grandes ventajas de ggplot2 es su versatilidad. Esto incluye la posibilidad de incorporar elementos de visualización y edición de otros programas. De esta manera es útil incorporar temas (Themes), que son opciones de visualización preconfigurados como por ejemplo los del programa ggthemes y los de hrbrthemes.
library(ggplot2)
library(palmerpenguins)
library(hrbrthemes)
library(ggthemes)
ggplot(data= penguins,
aes(x=bill_length_mm,bill_depth_mm, color=species))+
geom_point()+
labs(
x = "Length[mm]",
y= "Depth[mm]")+
theme_ipsum_ps()+
scale_color_fivethirtyeight()3.9.2 Gráficos de cajas
Se usa la función geom_boxplot() para generar los gráficos de cajas y bigotes (boxplots), los cuales son una presentación visual que describen la dispersión y simetría de los datos.
Para separar las facetas por la variable isla se utiliza la función facet_wrap(). Las faceta son gráficos de subconjuntos de datos, basadas en una variable de tipo factor. Además, se utiliza la preconfiguración de visualización theme_ipsum_ps() del programa hrbrthemes.
library(ggplot2)
library(palmerpenguins)
library(ggplot2)
library(palmerpenguins)
library(hrbrthemes)
library(ggthemes)
ggplot(penguins, aes(species, bill_length_mm))+
geom_boxplot(aes(fill = species), width = 1, show.legend = FALSE) +
facet_wrap(~island)+
xlab("Species")+ylab("Bill length (mm)")+
ggtitle("Bill length by species and island")+
theme_ipsum_ps()
3.9.3 Histogramas
Los histogramas se generan con la función geom_histogram() donde el parámetro bins permite definir la cantidad de unidades en las cuales se subividirán los datos del histograma. Notar que el programa ggdark, el cual está contenido dentro de ggplot2 proporciona versiones oscuras de todos los temas disponibles.
library(ggplot2)
library(palmerpenguins)
ggplot(penguins,
aes(x=body_mass_g,
fill=species))+
geom_histogram(bins=30, alpha=0.4)+
scale_fill_brewer(
type="qual",
palette = "Dark2")+
ggdark::dark_mode()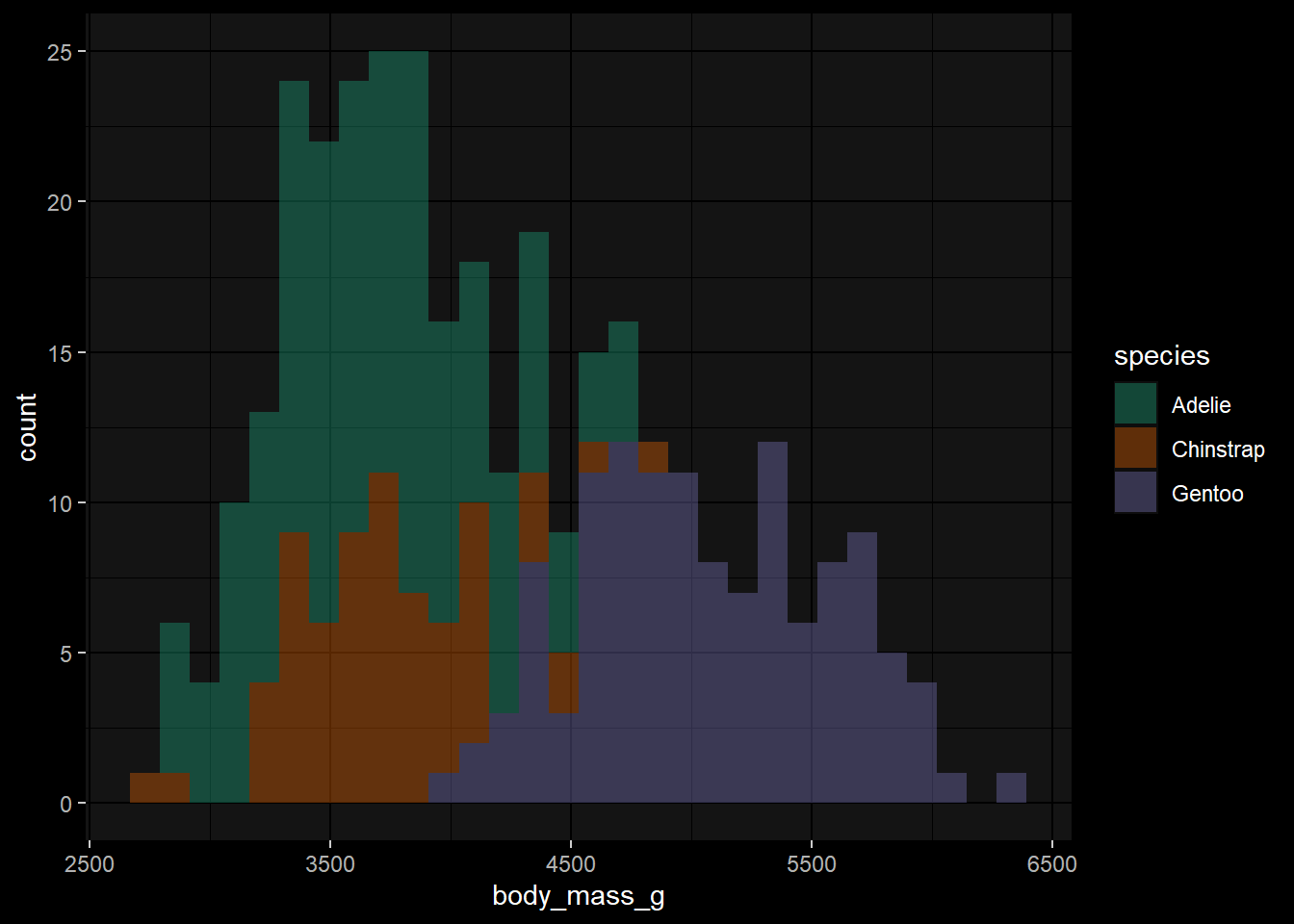
3.9.4 Gráficos de barras
En el siguiente ejemplo se puede ver cómo se pueden procesar los datos y hacer un gráfico a la vez. Se puede realizar un conteo de las especies de pingüinos usando la función count(). Se calcula la proporción como una nueva variable con mutate(). Se reordenan las barras de forma descendente, con las especies de pingüinos con la mayor proporción en la parte superior con la función fct_reorder() del paquete forcats. Para ajustar el eje x pasando de proporción a porcentajes se utiliza la función label_percent()del programa scales. El argumento accuracy permite especificar el número de decimales.
library(ggplot2)
library(dplyr)
library(forcats)
library(scales)
penguins %>%
count(species) %>%
mutate(prop = n / sum(n)) %>%
ggplot(aes(x = prop, y = fct_reorder(species, prop),fill=species)) +
geom_col(show.legend = FALSE) +
scale_x_continuous(labels = label_percent(accuracy = 1)) +
labs(x = "Percentage",y = "Species")+
ggtitle("Species distribution of penguins")+
theme_bw()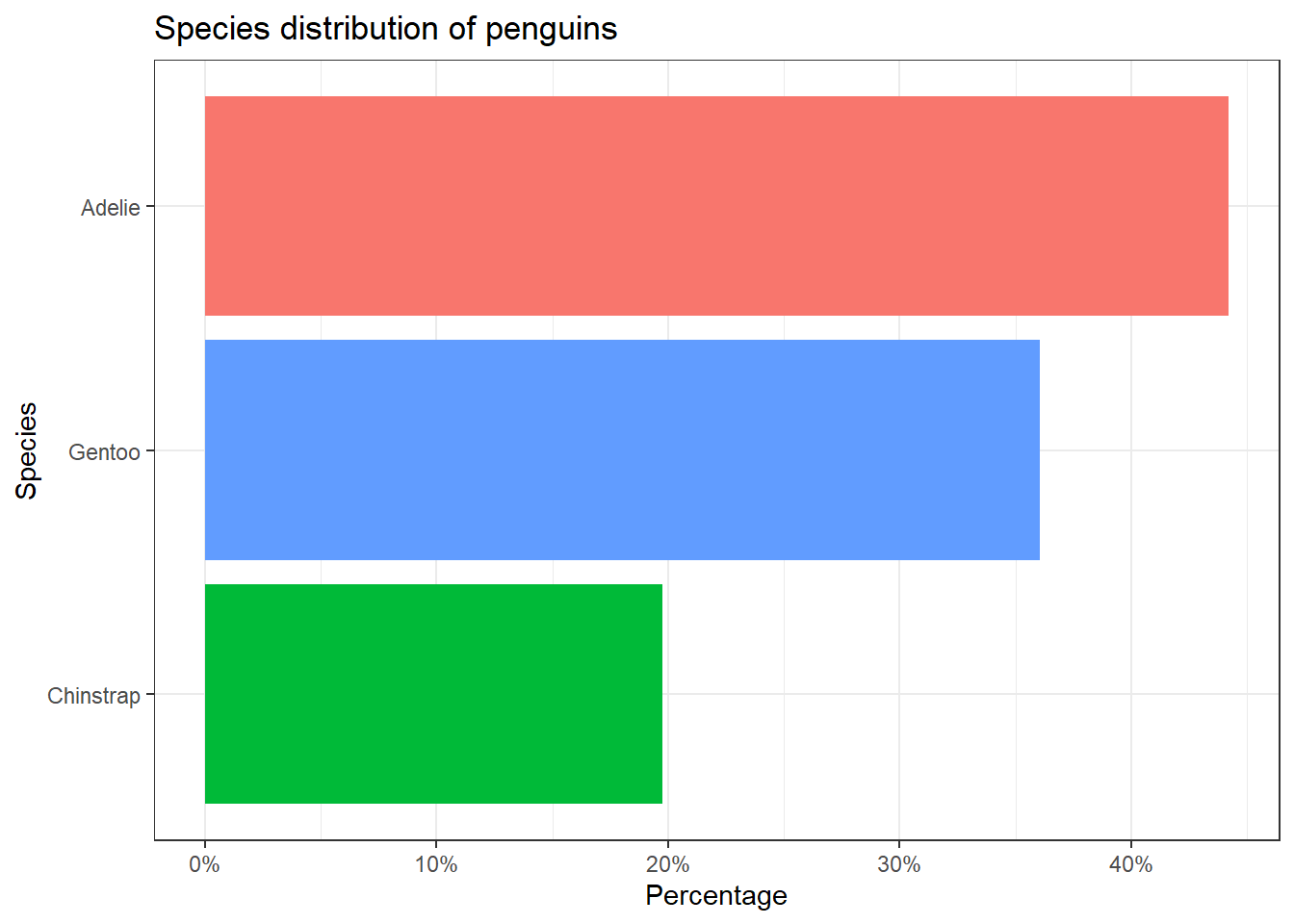
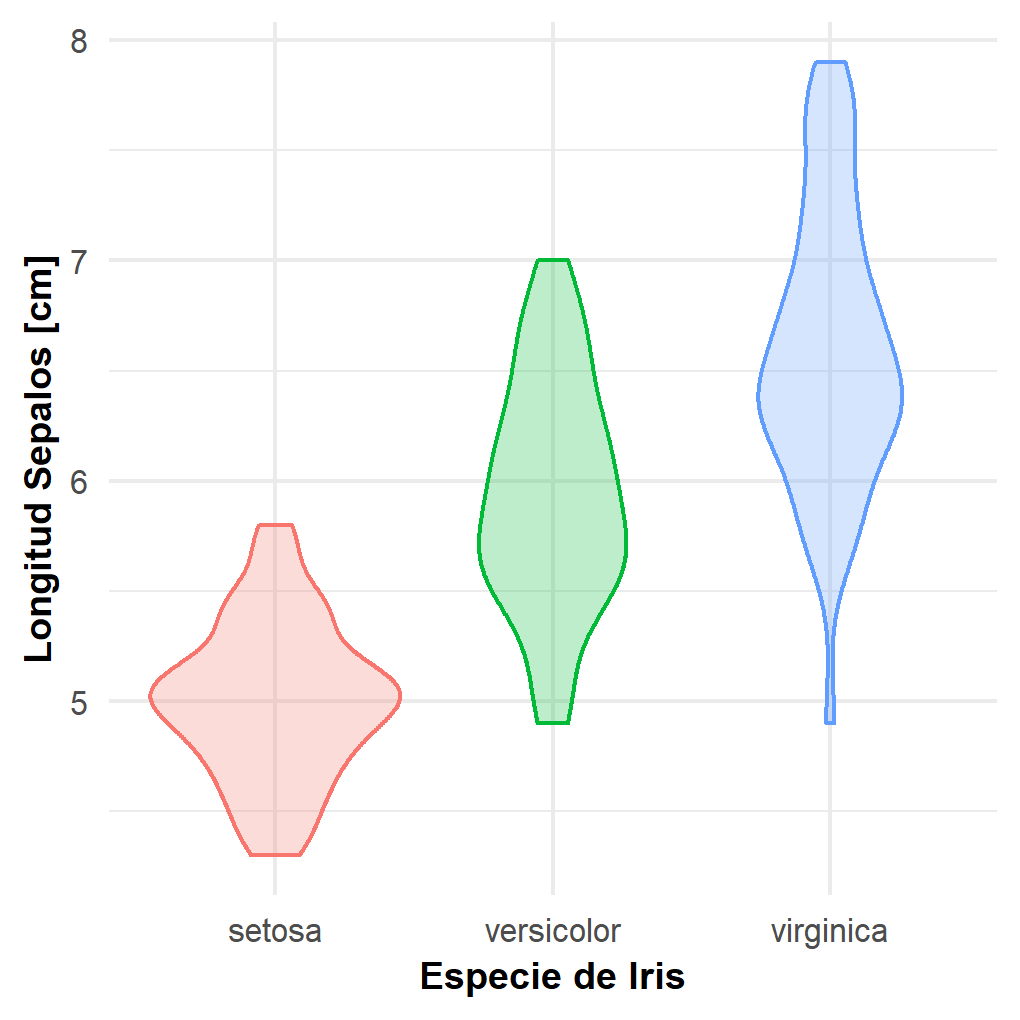
Ejercicio 1. A partir del siguiente gráfico de violin de la distribución de datos de la longitud de sépalos de la flor de iris [data(iris)], infiera el código utilizado para hacerlo.
3.9.5 Gráficos con información estadística
ggstatsplot es una extensión del paquete ggplot2 para crear gráficos con detalles de pruebas estadísticas. En un flujo de trabajo típico de análisis de datos exploratorios, la visualización de datos y el modelado estadístico son dos fases diferentes: la visualización informa al modelado y el modelado, a su vez, puede sugerir un método de visualización diferente. La idea central de ggstatsplot es combinar estas dos fases, lo que hace que la exploración de datos sea más simple y rápida.
library(ggplot2)
library("ggstatsplot")
ggbetweenstats(
data = iris,
x = Species,
y = Sepal.Length,
title = "Distribution of sepal length across Iris species")3.9.6 Gráficos especiales para análisis de RandomForest
El paquete ggRandomForests se utiliza para descubrir asociaciones de variables en los modelos de RandomForest (bosque aleatorios), de regresión y clasificación. Usa el paquete ggplot2 para trazar el diagnóstico y los resultados de asociación de variables.
En el siguiente ejemplo se graficarán los valores de importancia de las diferentes variables utilizadas para clasificar las especies de Iris.
library("ggRandomForests")
rfsrc_iris <- rfsrc(Species ~ ., data = iris)
data(rfsrc_iris, package="ggRandomForests")
gg_dta <- gg_vimp(rfsrc_iris)
plot(gg_dta)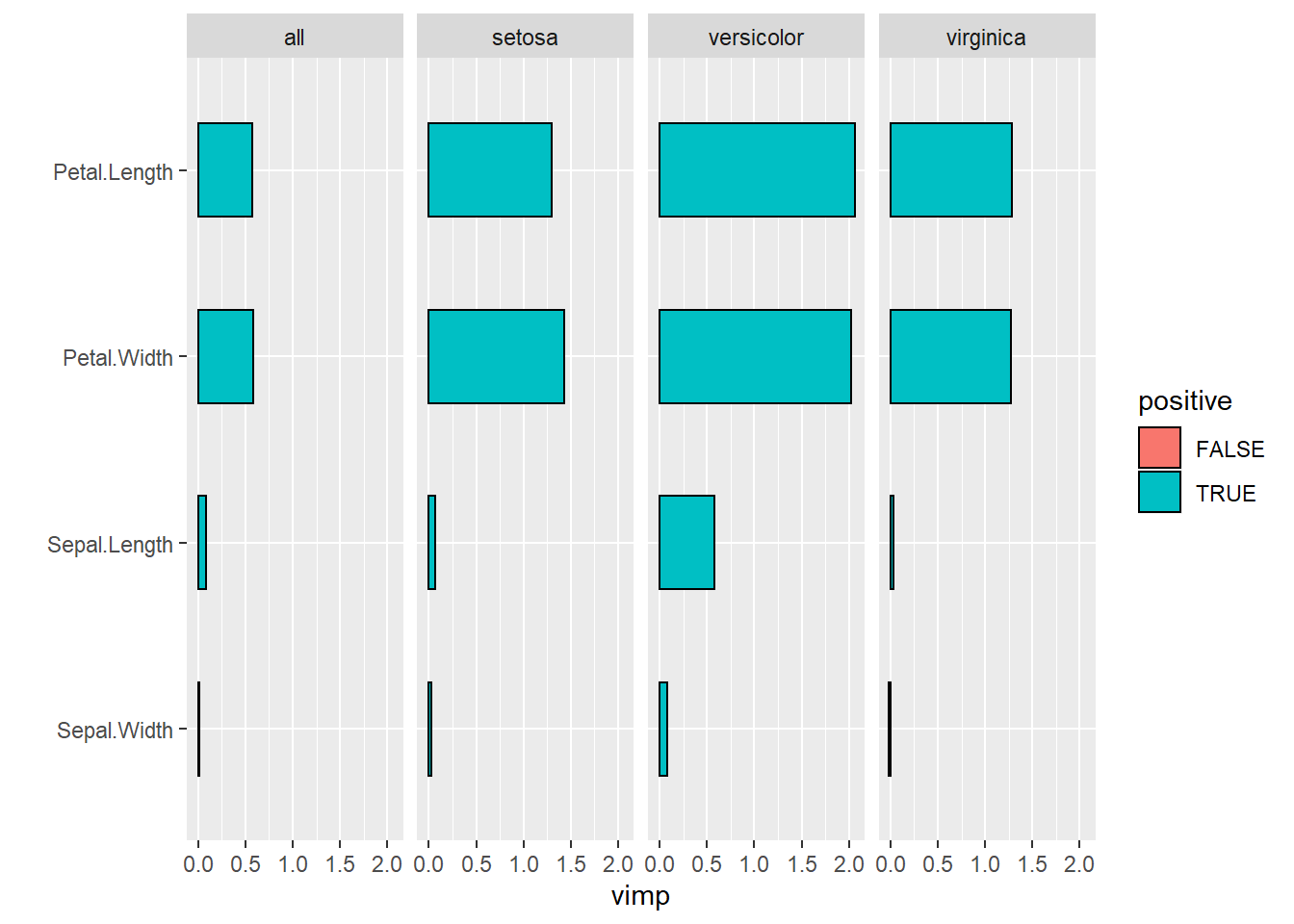
3.9.7 Combinación de múltiples gráficos
El paquete patchwork permite combinar de manera simple varios gráficos de ggplot2 en un mismo gráfico. Proporciona una interfaz simple para organizar gráficos en una cuadrícula y agregarles etiquetas.
library(ggplot2)
library(patchwork)
p1 <- ggplot(iris,aes(Petal.Length, Petal.Width,color=Species)) +
geom_point() +
ggtitle('Plot 1')
p2 <- ggplot(iris,aes(Species, Petal.Length, color = Species)) +
geom_boxplot(show.legend = FALSE) +
ggtitle('Plot 2')
p3= ggplot(iris, aes(Petal.Length, fill=Species))+
geom_histogram(bins=30, alpha=0.4, show.legend = FALSE)+
ggtitle('Plot 3')
p2+p3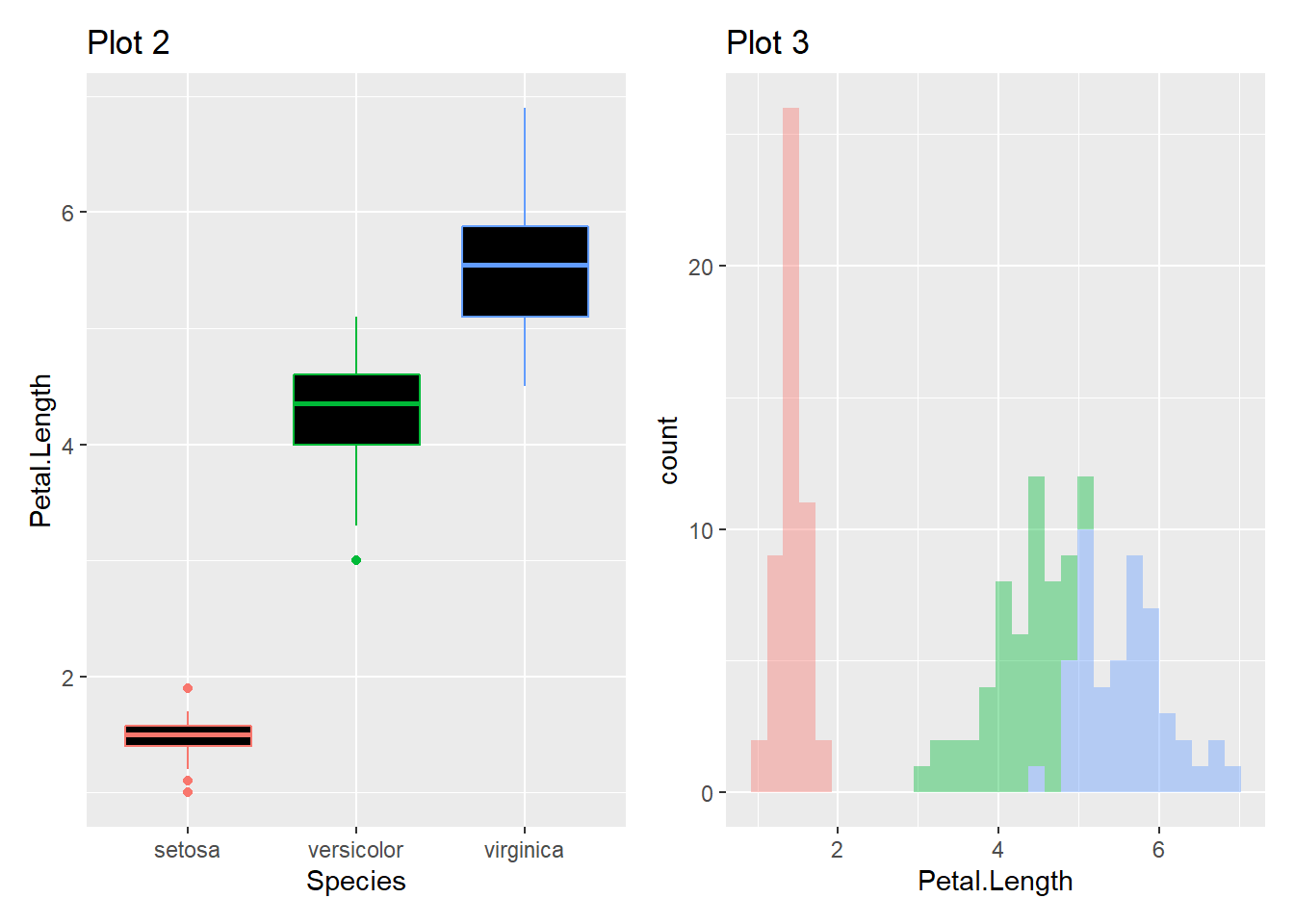
Los gráficos se pueden anotar con la función plot_annotation()
(p1)/(p2+p3)+
plot_annotation(
title="Plots Iris")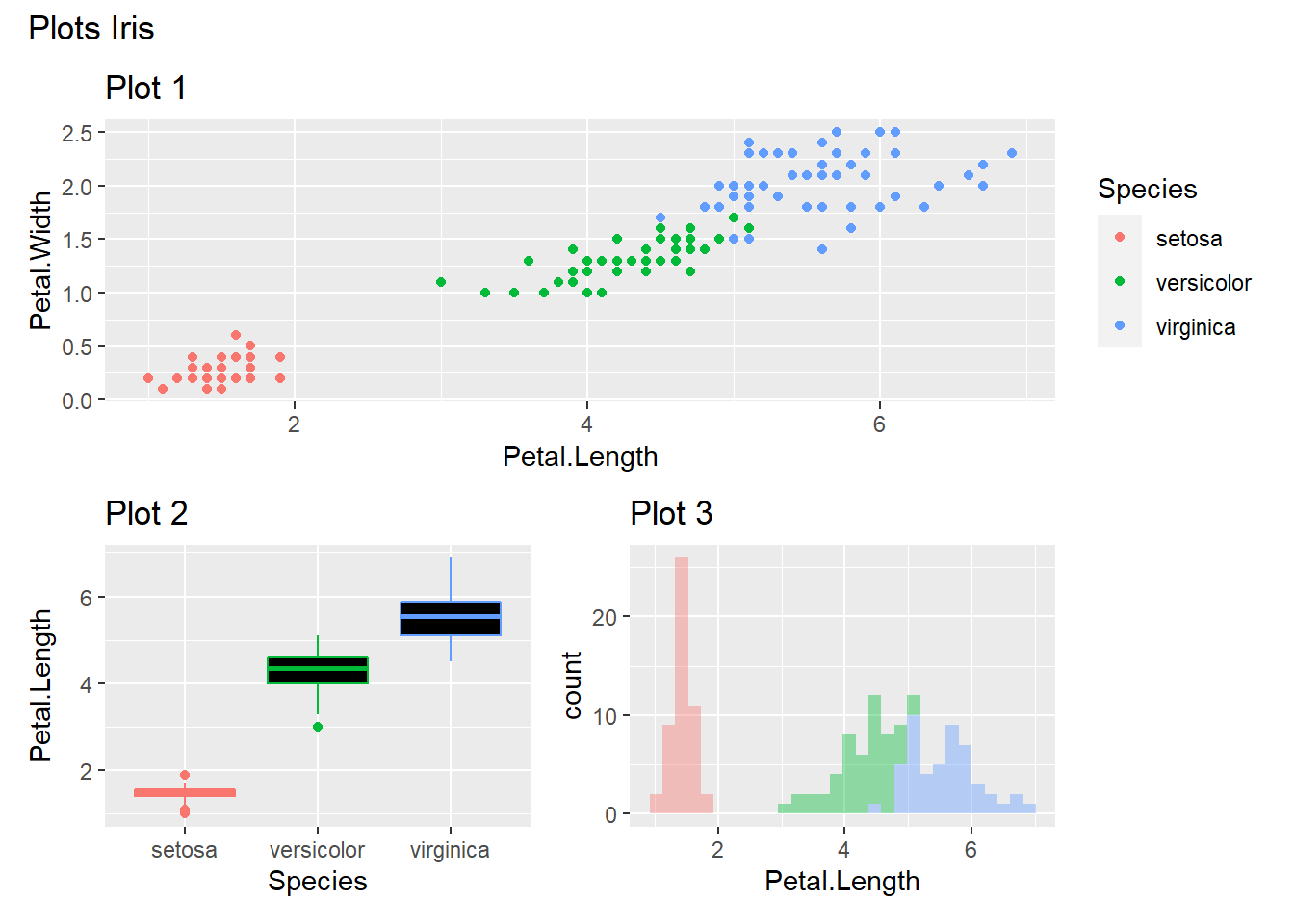
Además, las legendas se pueden reubicar al final con la función plot_layout()
p1+p2+p3+
plot_layout(
guides="collect")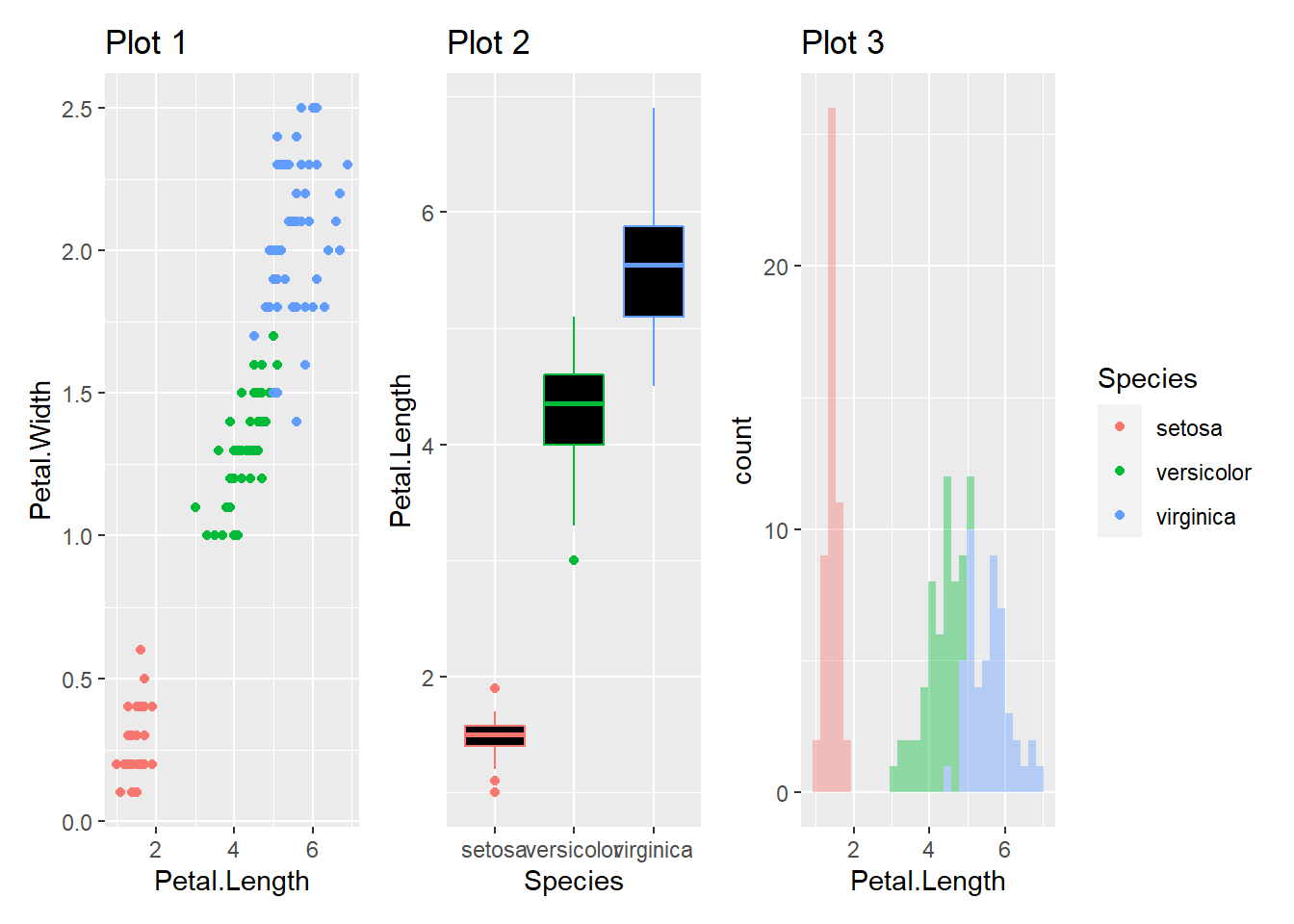
Ejercicio 2. Infiera el código utilizado para generar el siguiente gráfico de la relación de diferentes variables en la base de datos data(airquality). El panel 1 es un gráfico de cajas de las variaciones de temperatura por mes, el panel 2 es un gráfico de barras del valor medio de Ozono por mes y el panel 3 grafica la relación entre temperatura y ozono junto con un modelo de regresión lineal
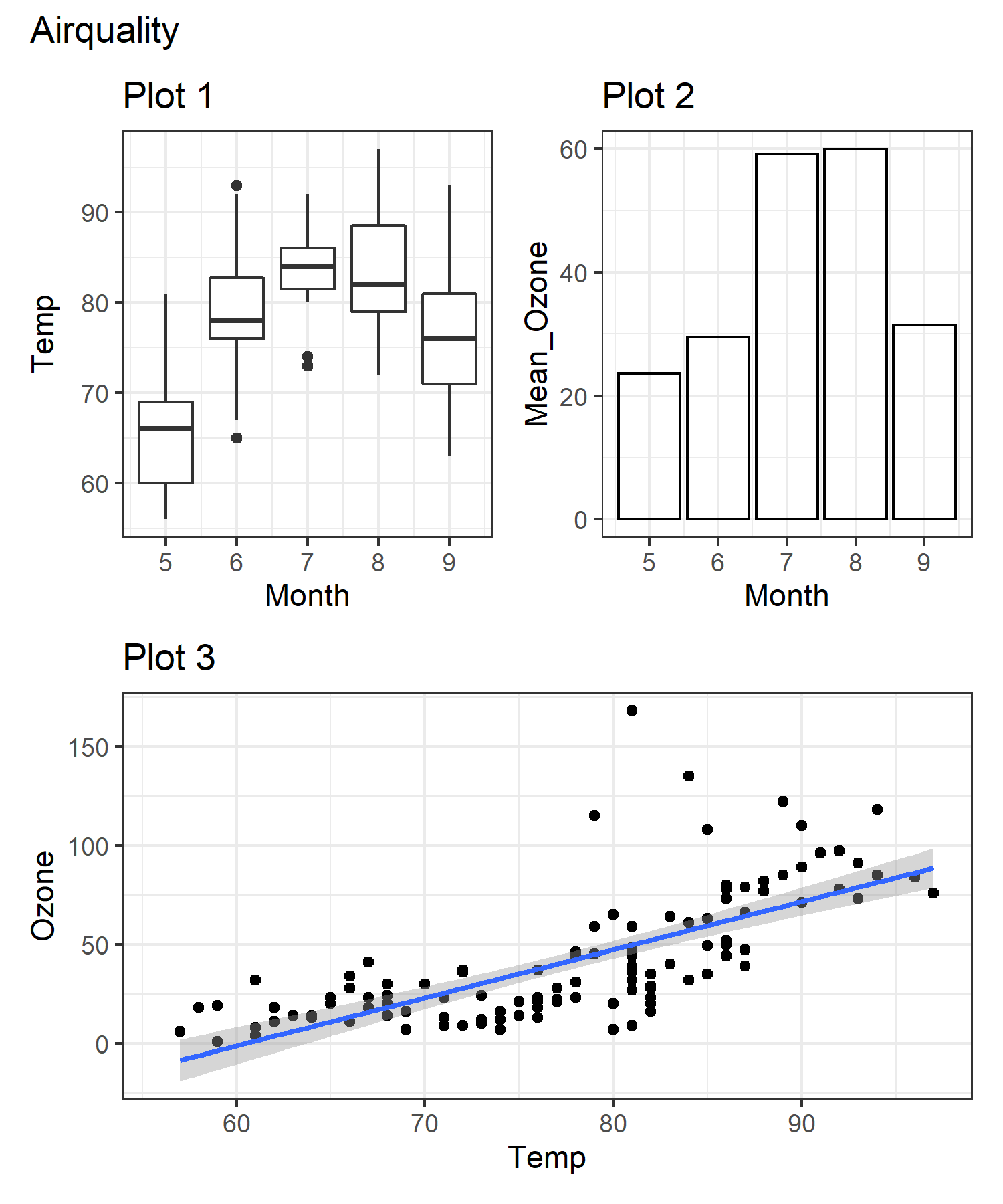
3.9.8 Gráficos interactivos con Plotly
La biblioteca de Plotly permite crear gráficos interactivos, con calidad de publicación, a partir de prácticamente cualquier gráfico generado en ggplot2 mediante la función ggplotly().
library(ggplot2)
library(plotly)
library(palmerpenguins)
library(hrbrthemes)
plot=ggplot(data= penguins,
aes(x=bill_length_mm,bill_depth_mm, color=species))+
geom_point(show.legend = FALSE)+
labs(
subtitle = "Relationship lenght and weight penguins",
x = "Length[mm]",
y= "Depth[mm]")+
theme_ipsum_rc()
ggplotly(plot)Para exportar la figura como un html a la carpeta de trabajo se puede hacer lo siguiente:
plotly = ggplotly(plot)
htmlwidgets::saveWidget(plotly, "plotly.html")3.9.9 Gráficos con gganimate
El paquete gganimate amplía la gramática de gráficos implementada por ggplot2 para incluir la descripción de la animación. Lo hace proporcionando una gama de nuevas clases de gramática que se pueden agregar al objeto de la trama como por ejemplo la personalización de cómo cambian los datos el tiempo. Para el ejemplo ilustraremos la evolución de los valores de la expectativa de vida en diferentes países agrupados por continentes de la base de datos de gapminder.
library(ggplot2)
library(gganimate)
library(gapminder)
ggplot(gapminder, aes(gdpPercap, lifeExp, size = pop, colour = country)) +
geom_point(alpha = 0.7, show.legend = FALSE) +
scale_colour_manual(values = country_colors) +
scale_size(range = c(2, 12)) +
scale_x_log10() +
facet_wrap(~continent) +
# Here comes the gganimate specific bits
labs(title = 'Year: {frame_time}', x = 'GDP per capita', y = 'life expectancy') +
transition_time(year) +
ease_aes('linear')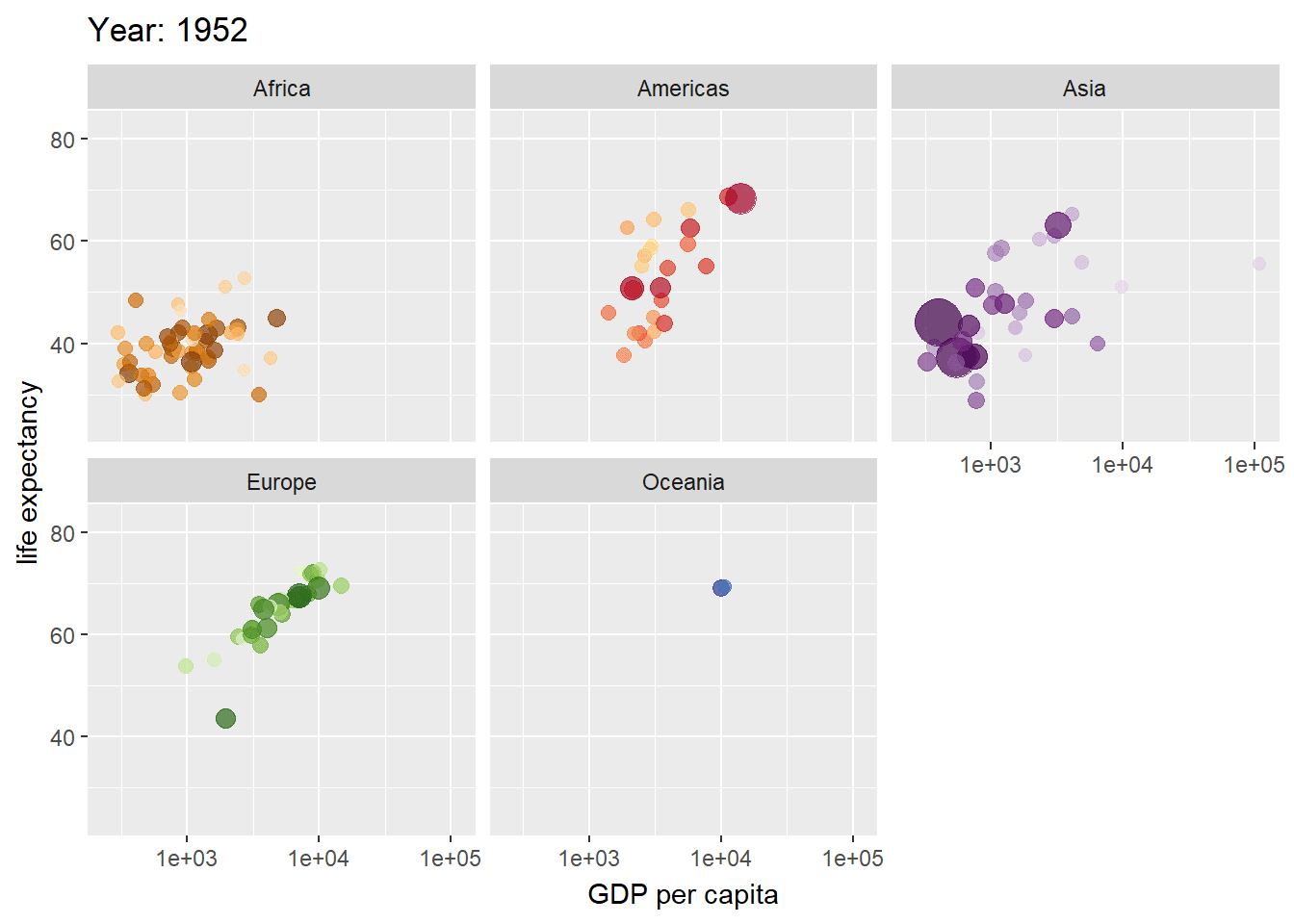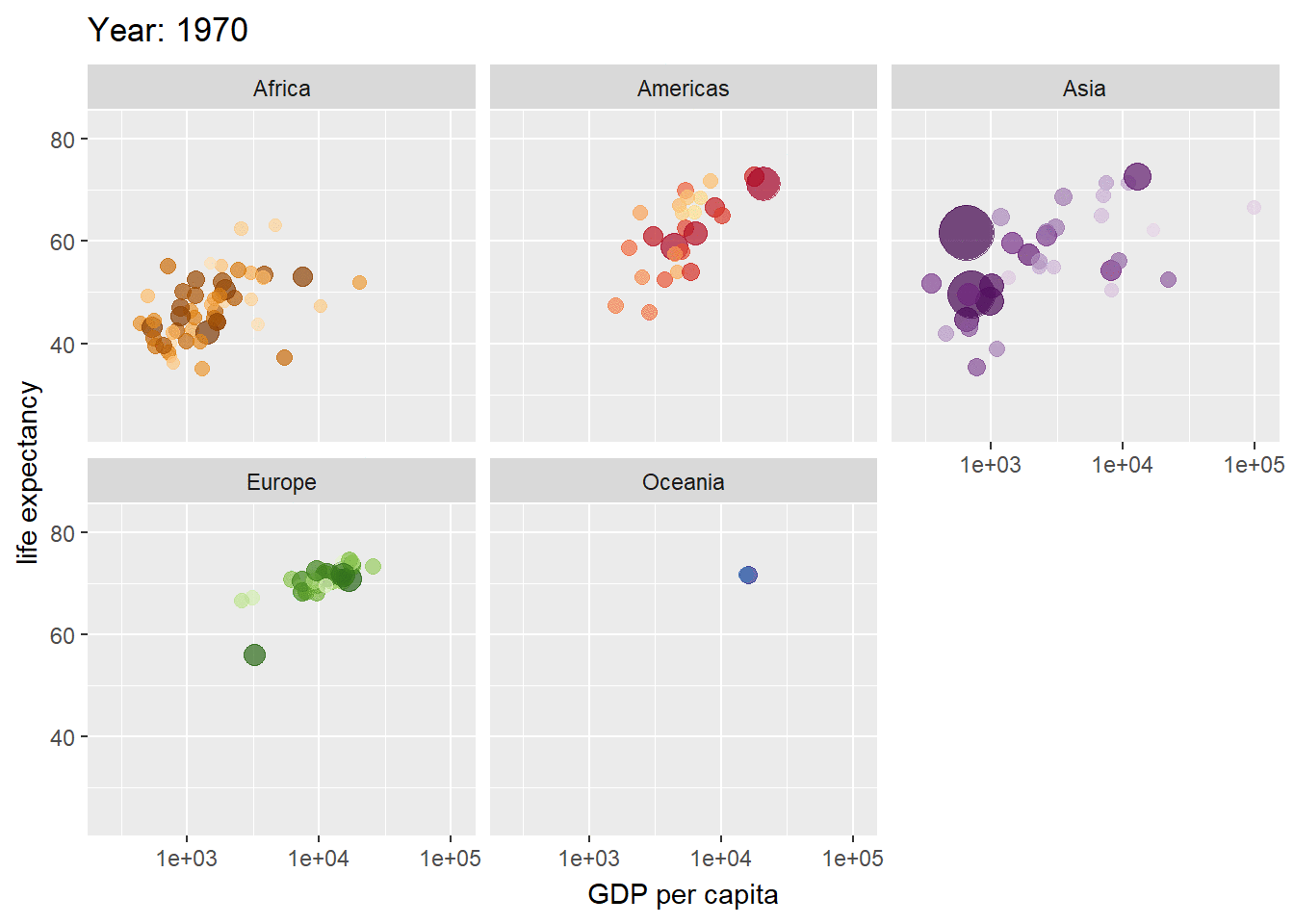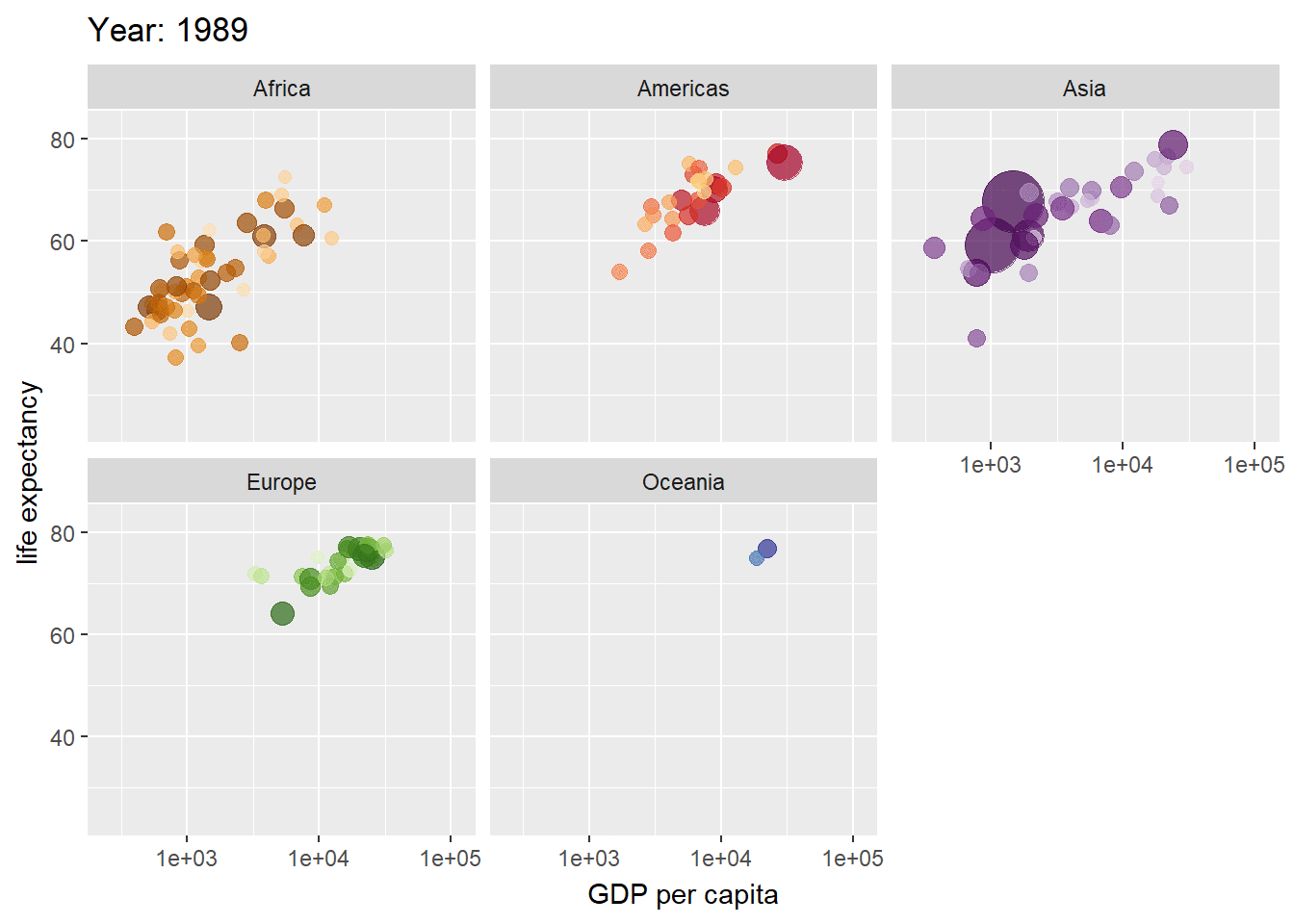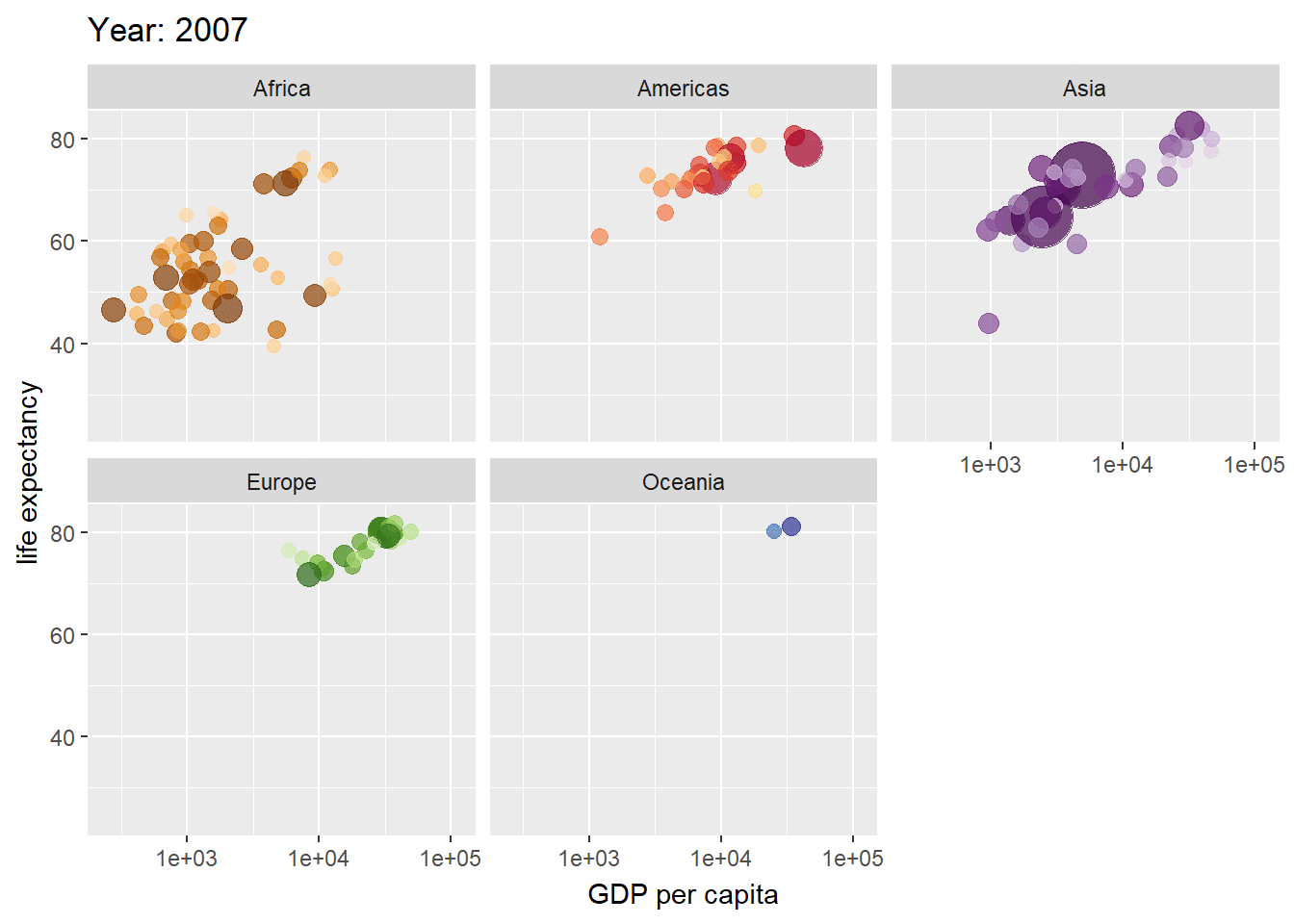
3.9.10 Páneles de control con Shiny
Shiny es una de las maneras más fáciles para generar paneles de control interactivos (dashboards) con información de datos, de manera que las personas usuarias pueden manipularlos directamente y hacer sus propios análisis. Por su simpleza, Shiny es muy utilizado por investigadores sin un background en desarrollo de código. Algunos ejemplos de dashboards en ciencias de la vida incluyen un Genome Browser de adenocarcinomas o un visualizador de imágenes tridimensionales del cerebro.
En el siguiente ejemplo se creará una aplicación simple para ver el resumen de diferentes bases de datos. Los componentes clave de cada aplicación Shiny son la IU (abreviatura de interfaz de usuario) que define cómo se ve su aplicación y la función del servidor que define cómo funciona su aplicación. El tercer componente son las expresiones reactivas.
library(shiny)
ui <- fluidPage(
selectInput("dataset", label = "Dataset", choices = ls("package:datasets")),
verbatimTextOutput("summary"),
tableOutput("table"))
server <- function(input, output, session) {
# Se crea expresión reactiva
dataset <- reactive({
get(input$dataset, "package:datasets")})
output$summary <- renderPrint({
# Expresión reactiva para llamar función
summary(dataset())})
output$table <- renderTable({
dataset()})
}
shinyApp(ui, server)Notar que se define la interfaz de usuario, es decir, la página web HTML con la que interactúan las personas, que en este caso, es una página que contiene las bases de datos.
fluidPage() es una función de diseño que configura la estructura visual básica de la página. selectInput() es un control de entrada que permite interactuar con la aplicación proporcionando un valor. En este caso, es un cuadro de selección con la etiqueta “Conjunto de datos”. verbatimTextOutput() y tableOutput() son controles de salida que le indican a Shiny dónde colocar la salida renderizada.
Se especifica el comportamiento de la aplicación definiendo una función de servidor. En este sentido, Shiny usa programación reactiva para hacer que las aplicaciones sean interactivas, donde se le indica al programa cómo realizar los diferentes cálculos. Además, la función output$summary y output$table indica la receta para un formato de salida (p.e, resumen y tabla) el cual es renderizado para obtener la representación visual específica, mediante la función render{Type}.
Finalmente, la aplicación se corre con la función shinyApp (ui, server) para construir e iniciar la aplicación desde la interfaz de usuario y el servidor. Al cerrar la consola aparece una dirección http la cual indica el url donde se ubica la app.
3.10 Recursos complementarios
- https://clauswilke.com/dataviz/
- https://ggplot2-book.org/
- https://r-graph-gallery.com/
- https://www.data-to-viz.com/
- https://yutannihilation.github.io/allYourFigureAreBelongToUs/ggthemes/
- https://github.com/hrbrmstr/hrbrthemes
- https://education.rstudio.com/blog/2020/07/teaching-the-tidyverse-in-2020-part-2-data-visualisation/
- https://jhudatascience.org/tidyversecourse/get-data.html
- https://r4ds.had.co.nz/index.html
- https://mdsr-book.github.io/mdsr2e/ch-vizI.html
- https://venngage.com/blog/data-visualization-infographic/
- https://es.slideshare.net/txipi/bilbostack2015-garaizar
- https://www.slideshare.net/24Slides/how-to-visualize-data-like-a-pro
- https://cedricscherer.netlify.app/2019/08/05/a-ggplot2-tutorial-for-beautiful-plotting-in-r/?fbclid=IwAR38EiUTuJfHvijEWIoi335aiiS5tDLPGlI1SEhz066dZnSByxsul2K745c
- https://www.sportsmith.co/articles/10-step-data-viz-guide/
- https://www.r-bloggers.com/2022/03/r-shiny-in-life-sciences-top-7-dashboard-examples/
- https://mastering-shiny.org/
Solución a ejercicios
Ejercicio 1
library(ggplot2)
#ggsave("violin_iris.png", width = 3.4, height = 3.4,dpi = 300)
ggplot(iris) +
geom_violin(aes(x = Species, y = Sepal.Length, color = Species, fill=Species),
alpha = 0.25, show.legend = FALSE)+
labs(
x = "Especie de Iris",
y= "Longitud Sepalos [cm]")+
theme_minimal()+
theme(
axis.text.x = element_text(size=8),
axis.text.y = element_text(size=8),
axis.title.x = element_text(size=9,face = "bold"),
axis.title.y = element_text(size=9,face = "bold"))Ejercicio 2
library(ggplot2)
library(dplyr)
library(patchwork)
ggsave("airquality.png", width = 5, height = 6,dpi = 300)
p1=ggplot(airquality,aes(x=Month, y=Temp, group=Month)) +
geom_boxplot()+
theme_bw()+ ggtitle('Plot 1')
p2=airquality %>%
group_by(Month) %>%
summarise(Mean_Ozone = mean(Ozone, na.rm=TRUE)) %>%
ggplot(aes(x=Month, y=Mean_Ozone))+
geom_bar(stat="identity", fill=NA, colour="black")+
theme_bw()+ ggtitle('Plot 2')
p3=ggplot(airquality,aes(Temp, Ozone)) +
geom_point() + geom_smooth(method='lm')+
theme_bw()+ggtitle('Plot 3')
(p1+p2)/(p3)+
plot_annotation(
title="Airquality")
dev.off()