Capítulo 11 Introducción a Ciencia de Datos en Python
11.1 Introducción al uso de plataforma Google Colab
Google Colaboratory, o Google Colab es una plataforma de Google Research que permite a cualquier persona escribir y ejecutar código Python a través del navegador. Es especialmente adecuado para el aprendizaje automático (machine learning), el análisis de datos y la educación. Un aspecto importante es que Google Colab se base se basa en la interfase de Jupyter Notebook.
Algunas de las ventajas de usar esta plataforma respecto al trabajo directo en consola o mediante el uso de entornos de desarrollo (IDE) incluyen:
- No requiere configuración del programa
- La mayoría de librerías y programas ya están preinstalados
- Acceso gratuito a GPU, es decir, se ejecuta en los servidores de Google
- Facilidad para compartir documentos
La plataforma Google Colab se accesa mediante el siguiente link https://colab.research.google.com. Para utilizarla es necesario contar con una cuenta de Gmail, lo que permitirá almacenanar los archivos en la cuenta personal de Google Drive.
Para trabajar en esta plataforma se utilizan documentos denominados notebooks de Colab, los cuales son entornos interactivos que permiten escribir y ejecutar código Python. Estos documentos tienen la extensión .ipynb y se pueden cargar directamente a la plataforma. En nuestro caso, vamos a crear un documento desde cero e iremos copiando y pegando el texto y código desde este archivo html.
Procederemos a crear un nuevo archivo haciendo click en Archivo > block de notas nuevo. Una segunda opción para crearlo sería abrir el Google Drive, hacer click en Nuevo > más opciones > tipo Google Colaboratory. Ahora, se le puede asignar un nombre al notebook generado con extensión .ipynb, el cual se guardará automáticamente en el Google Drive.
Tipos de celdas en el notebook
Un notebook (cuaderno) de Colab es en realidad una lista de celdas. Las celdas contienen: 1) textos explicativos o, 2) código ejecutable además del resultado de la ejecución del código (salida). Para seleccionar una celda, simplemente haga click sobre ella.
Para abrir una celda de código simplemente haga click en la barra + Código. Para ejecutar el código puede presionar el símbolo de play a la izquierda de la celda o las teclas Cmd/Ctrl+Enter.
Para abrir una celda de texto simplemente haga click en la barra + Texto. Las celdas de texto utilizan la sintaxis de Markdown. Para ver el texto fuente de Markdown, haga doble click en una celda de texto. La fuente junto con la versión renderizada se mostrará.
Las celdas se pueden mover hacia arriba o abajo seleccionándolas y haciendo click a la flecha respectiva en la barra de herramientas que aparece en el borde superior derecho.
11.2 Introducción al lenguaje Python
Es un lenguaje de programación interpretado de alto nivel que ofrece una sintáxis amigable y fácil de entender. Hace hincapié en la legibilidad de su código y por eso se utiliza para desarrollar una gran cantidad de aplicaciones. Además, es un lenguaje de código abierto y multiplataforma.

11.2.1 Tipos básicos de datos
| Nombre | Nombre común | Ejemplo |
|---|---|---|
| Entero o integer | int | 1, 2, 100 |
| Punto Flotante | float | 13.32 |
| Conjunto de caracteres | string | Hola |
| Booleano | boolean | True o False |
A continuación, algunas operaciones básicas para definir algunas variables. La función type() permite ver el tipo de dato asociado a la variable. En Python el tipo de variable es dinámicamente tipado.
11.2.2 Strings
Una de las grandes virtudes de Python es su capacidad para el manejo de strings. Un string es una cadena de texto. Se escribe entre comillas. Cada caracter tiene una posición asignada, que inicia siempre en cero. Para acceder a una posición específica o extraer una subcadena se usan paréntesis cuadrados.
P = 'PYTHON'
print(P[0:2])Algunas de las funciones más utilizadas para modificar strings son las siguientes:
| Nombre del método | Sintaxis para una variable x | Efecto |
|---|---|---|
| strip() | x.strip() | Quita los espacios en blanco al inicio y al final |
| lower() | x.lower() | Convierte las mayúsculas en minúsculas |
| count() | x.count() | Cuenta el número de veces que aparece un texto dentro de otro |
| len() | x.len() | Obtiene el número de caracteres de una cadena |
| replace() | x.replace() | Reemplaza todas las letras igual a la indicada por otra especificada |
| split() | x.split() | Parte el String cada vez que se encuentra con un caracter separador |
La concatenación es la acción de combinar dos o más strings mediante el operador aritmético de suma +
nombre = "Mariana"
apellido = "Gonzáles"
nombre_completo = nombre + " " + apellido
print("Bienvenida, "+nombre_completo.title()+ "!")11.2.3 Conversión de tipos de datos
Al proceso de conversión del tipo de variables se le denomina Casting. Las principales funciones utilizadas son int(), float() y str().
edad = input("Inserta tu edad:")
c = int(edad) #conversión
print(c, type(c))11.2.4 Operadores
Son símbolos que indican al compilador o intérprete que es necesario ejecutar alguna manipulación de los datos. Existen operadores aritméticos (p.e. suma, resta, multiplicación), de comparación (p.e. menor que, mayor o igual que), lógicos (and, or, not) y de pertenencia (in, not in).
x = 2+6
print(x)
print('Hola'*3)
5 <= -3
c = 20
print(((c < 90) or (c > 60)))
nombre = "Elena"
print("e" in nombre)11.2.5 Estructuras de datos
Las estructuras de datos son formas de organización de los datos que permiten leerlos, manipularlos y establecer relaciones entre ellos. Entre las formas más comunes tenemos listas, diccionarios y tuplas.
Las listas se tratan de colecciones de valores encerrados entre paréntesis cuadrados []. Son estructuras muy utilizadas en Python porque tienen mucha versatilidad. Al igual que los strings, tienen posiciones asignadas donde se puede verificar o incluso modificar su contenido con una gran cantidad de funciones disponibles. Las listas pueden tener distintos tipos de datos.
lista = [3, 2, 1, 0.5, "hora del cafe", "torta chilena", "pinto", "jugo"]
print(lista)
lista.append("empanadita")
print(lista)
"pinto" in listaLos diccionarios constituyen otra forma de organización de los datos donde existe una clave y un valor asociado. Para definirlos se usa el símbolo {} y para diferenciar entre clave y valor se usa el símbolo :. La mayoría de funciones utilizadas para modificar listas, también pueden ser utilizadas con diccionarios.
tel = {'Maria': 4098, 'Jorge': 4139}
print(tel)
print(tel.keys())
'Maria' in telLas tuplas son otra forma de organizar los datos. Sin embargo, a diferencia de las listas y los diccionarios son inmutables, es decir, no se pueden modificar. Se definen entre paréntesis (). Su procesamiento es más rápido.
frutas = ('naranja', 'mango', 'sandia', 'banano', 'kiwi')
print(type(frutas))
frutas[1]11.2.6 Condicionales
Son bloques de código que dependiendo de una condición se ejecutan o no. Los test condicionales usan la palabra clave if que tienen como resultado un valor booleano de true o false.
A continuación algunos ejemplos de cómo se utiliza y se lee el condicional if
#1
if si la siguiente condición es verdad:
realizar la siguiente acción
#2
if si la siguiente condición es verdad:
realizar esta acción
else:
sino realizar una la siguiente alternativa
#3
if si la siguiente condición es verdad:
realizar esta acción
elif si esta otra condición es verdad:
realizar esta acción alternativa
else:
sino realizar esta otra acción alternativaPor supuesto, se puede complementar con operadores lógicos (“and” y “or”) para evaluar múltiples condiciones.
Un aspecto importante de la estructura de condicionales es la identación. Este término se refiere a un tipo de notación que delimita la estructura del programa estableciendo bloques de código. En sencillo, es la inclusión de algunos espacios (sangría) en la segunda parte de cada condicional.
c=2
if c>5:
c-=3
elif -2 < c < 3:
c**=2
else:
c+=2
c11.2.7 Ciclos
Los ciclos son bloques de código que se ejecutan iterativamente. En Python se usan las funciones while y for para llevar a cabo los ciclos, los cuales se ejecutan hasta que la condición especificada se cumpla. Las funciones while y for normalmente van acompañadas de un iterador conocida como contador y que se designa con la letra *i**, aunque en realida puede ser cualquier otra letra.
while mientras esta condición sea verdad:
realizar la siguiente acccióni = 1
while i<5:
print(i)
i+=1Dentro de while existen los argumentos break y continue que permiten detener el ciclo aún cuando la condición se cumple o detener la iteración actual y continúar con la siguiente.
i = 5
while i<10:
print(i)
if i==9:
break
i+=1i = 5
while i<8:
i+=1
if i==7:
continue
print(i)Los ciclos (loops) que utilizan for son probablemente los más utilizados en Python y sirven para iterar sobre una secuencia (p.e. un string, estructura de datos, etc). La sintaxis se leería de la siguiente manera:
for para el iterador "i" in la siguiente secuencia:
realizar la siguiente acciónS="Buenos dias"
for i in S:
print(i)También se puede iterar sobre números. Para esto se puede utilizar la función range(). Recordar que en Python siempre se empieza en cero.
for num in range(4):
print(num, num**2) 11.2.8 Funciones
Las funciones son las estructuras esenciales de código en los lenguajes de programación. Constituyen un grupo de instrucciones para resuelver un problema muy concreto.
En Python, la definición de funciones se realiza mediante la instrucción def más un nombre descriptivo de la función, seguido de paréntesis y finalizando con dos puntos (:). El algoritmo que la compone, irá identado. Un parámetro es un valor que la función espera recibir a fin de ejecutar acciones acciones específicas. Una función puede tener uno o más parámetros. La función es ejecutada hasta que sea invocada, es decir, llamada por su nombre, sea con print()o con return().
def nombreFunción(parámetros):
acciones a realizar
return(valor de retorno)def Matarile(nombreviejo,nombrenuevo):
print('Usted ya no se llama %s, ha elegido llamarse %s.' %(nombreviejo,nombrenuevo))
nombreviejo = input('Escriba su nombre: ')
nombrenuevo = input('Escriba cómo quiere llamarse: ')
Matarile(nombreviejo, nombrenuevo)Notar que %s es un operador que se utiliza para dar formato a las variables string, %d a enteros y %f números de punto flotante.
Ejercicio 1. Hacer una función que se llame “multiplicax3” cuyo parámetro sea número y cuya función, como lo dice el nombre, sea multiplicar por 3 el número que se defina al llamar la función
11.2.9 Importación de bibliotecas y módulos
Una de las principales características de Python es que dispone de diferentes tipos de librerías o bibilotecas. En síntesis, una librería responde al conjunto de funcionalidades que permiten al usuario llevar a cabo nuevas tareas que antes no se podían realizar. Cada una de las librerías disponen de diferentes módulos que son los que le otorgan funciones específicas. Python posee una gran cantidad de librerías útiles en diferentes campos como la visualización, cienca de datos, cálculos numéricos, bioinformática o inteligencia artificial.
Algunas de las más conocidas son:
- numpy para manejo de matrices y vectores.
- pandas para manipulación y análisis de datos
- matplotlib para generación de gráficos
- biopython para bioinformática
- TensorFlow, Keras, Scikit-learn, para machine learnig y deep learning.
import numpy
import matplotlib.pyplot # se importa módulo pyplot dentro de matplotlibMuchas veces se utilizan alias de los nombres del programa para reducir la cantidad de texto a digitar posteriormente
import numpy.random as npr11.3 Manipulación de Datos
11.3.1 NumPy

NumPy (Numerical Python), es una biblioteca de Python que da soporte para crear vectores y matrices grandes multidimensionales, junto con una gran colección de funciones matemáticas de alto nivel. La funcionalidad principal de NumPy es su estructura de datos ndarray (arreglos), para una matriz de n dimensiones, sobre las cuales se pueden realizar operaciones matemátias de manera eficiente.
Crearemos una lista usando codigo nativo de Python y lo convertiremos en una matriz unidimensional con la función np.array()
import numpy as np
list1 = [6,8,10,12]
array1 = np.array(list1)
print(array1)Los ndarrays son estructuras de datos genéricas para almacenar datos homogéneos. Son equivalentes a las matrices y los vectores en álgebra, por lo que también se les puede aplicar operaciones matemáticas. Notar que las operaciones matemáticas se pueden realizar en todos los valores en un ndarray a la vez.
Los arreglos se encierran entre [], pero al imprimirlos no están separados por comas. Hay diferentes formas de crear arreglos con propiedades específicas, lo que les provee bastante flexibilidad.
En el siguiente cuadro se presentan algunas de esas funciones:
| Función | Resultado |
|---|---|
| array() | Crea un arreglo con los datos especificados |
| empty() | Crea un arreglo vacío |
| zeros() | Crea un arreglo de ceros |
| ones() | Crea un arreglo de unos |
| full() | Crea un arreglo lleno |
| arange() | Crea un arreglo en rango desde inicial a final y pasos intermedios |
| linspace() | Crea un arreglo rango desde inicial a final y una cantidad deseada de elementos |
| logspace() | Crea un arreglo con espaciado logarítmico |
| geomspace() | Crea un arreglo con espaciado logarítmico en una progresión geométrica |
| random() | Crea una matriz de números entre 0.0 y 1.0 |
`
print(np.array([[1,2],[3,4]]),'\n')
print(np.ones((3,4),'\n'))
print(np.arange(10,30,5),'\n')
print(np.linspace(0,5/3,6),'\n')
print(np.random.rand(2,3),'\n')Otros argumentos importantes de objetos numpy son los siguientes:
| Argumento | Resultado |
|---|---|
| shape | Tupla con el número de elementos por dimensión |
| ndim | El número de dimensiones |
| size | Cantidad elementos en un arreglo |
| dtype | Tipo de datos que guarda un arreglo |
| T | La transpuesta de un arreglo |
| flatten() | Colapsa arreglo en una dimensión |
| fill() | Rellena el arreglo con el valor especificado |
| reshape() | Retorna un arreglo con el forma especificada |
| resize() | Cambia el tamaño y forma |
arr1 = np.array([np.arange(0,5), np.arange(0,5)*5])
print(arr1)
print(arr1.shape)
print(arr1.size)
print(arr1.ndim)
print(arr1.T)Con el slicing podemos obtener porciones del arreglo original
arr = np.array([1,2,3,4,5,6,7])
print(arr[1:3])# de 1 al 3 en índice
print(arr[4:])# de la posición 4 en adelante
print(arr[::2])# de uno por medio11.3.2 Pandas

Pandas (PANel DAta) es una biblioteca Python para manipulación y análisis de datos. Fue construida sobre NumPy. Ofrece estructuras de datos y operaciones para manipular tablas numéricas y series temporales.
Series. Una serie es un arreglo de datos indexados donde los valores que se guardan con un índice explícito. La función pd.Series()se utiliza para la creación de series. Para crear una serie con índice, tenemos que proporcionar un índice con el mismo número de elementos.
import pandas as pd
import numpy as np
data = np.array(['g', 'e', 'e', 'k', 'm'])
ser = pd.Series(data, index =[10, 11, 12, 13, 14])
print(ser) Diccionarios. Si se usan diccionarios, las llaves se toman como índices y los valores los números de la serie.
dic = {'manzanas' : 10,
'peras' : 20,
'chayotes' : 30,
'uvas' : 40}
ser = pd.Series(dic)
print(ser) Accesar datos de series. Para acceder a un dato específico de la serie, hay que acceder al índice del mismo como con arreglos y listas.
print(ser['peras'], ser[1])DataFrames. En un DataFrame (tabla de datos), a diferencia de los ndarrays de NumPy, se pueden tener distintos tipos de datos. Cada columna es un objeto de tipo Series de Pandas. Las filas se identifican con un índice y las columnas con una etiqueta. Se usa la función pd.DataFrame() para crearlos.
datos = [[10, 11, 12, 13],
[20, 21, 22, 23],
[30, 31, 32, 33]]
columnas = ['C1', 'C2', 'C3', 'C4'] # definimos los nombres de las columnas
filas = ['F1', 'F2', 'F3'] # definimos los nombres de las filas
df = pd.DataFrame(datos, columns=columnas, index=filas)
print(df)DataFrames a partir de diccionarios
datos = {
'Nombre' : ['Juan', 'Laura', 'Pepe'],
'Edad': [42, 40, 37],
'Departamento': ['biología', 'química', 'geología']}
df = pd.DataFrame(datos)
print(df)Descarga de archivos. Pandas posee una gran cantidad de formas para leer y escribir datos en diferentes formatos. Generalmente se debe indicar el path o dirección del archivo, así como el delimitador de los datos o el nombre de la hoja en algunos casos. La función pd.read_csv() permite cargar archivos .csv y guardarlos en un objeto de Pandas.
csv_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data'
col_names = ['Sepal_Length','Sepal_Width','Petal_Length','Petal_Width','Species']
iris = pd.read_csv(csv_url, names = col_names)
irisResumen estadístico
iris.describe()Ordenamiento. Podemos ordenar de forma descendente de acuerdo a los valores de una variable
iris.sort_values(by='Sepal_Width', ascending=False).head(5)Eliminación de filas
iri = iris.drop([0])
iriEliminación de columnas. El parámetro axis=1 implica que la eliminación se refiere a columnas
iri = iris.drop(['Petal_Width'],axis=1)
iri.head()Fitrado de filas
iris[0:5]Selección de columnas
iris['Sepal_Length'].head()
iris.Sepal_Length.head()Selección de filas y columnas
iris.loc[0:5, ['Sepal_Length', 'Petal_Length']]Selección por posición
iris.iloc[10:14, 0:2]Selección usando condicionales
iris[(iris['Sepal_Length'] == 4.9) & (iris['Petal_Length'] > 1.4)] Concatenar dataframes agregando filas
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index = [0, 1, 2, 3])
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']},
index = [4, 5, 6, 7])
df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
'B': ['B8', 'B9', 'B10', 'B11'],
'C': ['C8', 'C9', 'C10', 'C11'],
'D': ['D8', 'D9', 'D10', 'D11']},
index = [8, 9, 10, 11])
pd.concat([df1, df2, df3]) Unir dataframes agregando columnas
left = pd.DataFrame({'Key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'Key': ['K0', 'K1', 'K2', 'K3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, how ='inner', on ='Key') Agrupamiento La función groupby() se utiliza para separar por grupos los datos de acuerdo a variables específicas. Sobre esta agrupación se pueden realizar diferentes tipos de cálculos.
| Función | Salida |
|---|---|
| sum() | Suma |
| count() | Conteo |
| min() | Valor mínimo |
| max() | Valor máximo |
| mean() | Media |
| median() | Mediana |
iris.groupby(['Species'])[['Sepal_Length']].mean()
iris.groupby(['Species']).mean()11.4 Visualización de Datos
11.4.1 Matplotlib

Matplotlib es una biblioteca de Python para la generación de gráficos por medio de capas sucesivas. Se inicia con un lienzo en blanco sobre el cual se van agregando capas, lo que permite aumentar la complejidad del gráfico según las necesidades.
Sin embargo, todo gráfico Matplotlib debe tener al menos tres elementos: a) los datos, b) la función para crear el gráfico p.e. plt.plot() y c) la función para mostrar el gráfico plt.show(). Sobre estas estas se pueden modificar una gran cantidad de detalles que se pueden ver con más detalle en el siguiente cheatsheet
import matplotlib.pyplot as plt
import numpy as np
x = [21,22,23,4,5,6,77,8,9,10,31,32,33,34,35,36,37,18,49,50,100]
plt.hist(x, bins =5)
plt.show()Gráfico de Barras
from matplotlib import colors
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
canton = ['San Carlos', 'Guatuso', 'Upala', 'Los Chiles', 'Sarapiquí']
especies = [25, 32, 34, 20, 25]
fig, ax = plt.subplots() # establecer lienzo
ax.set_ylabel('especies') #etiqueta eje
ax.set_title('Cantidad de especies por canton') # titulo eje
plt.bar(canton, especies, color = "green") # grafico barras
plt.style.use('fast') # estilo
plt.savefig('barras.png') # para salvar
plt.show()# para mostrarGráfico de líneas
x = np.linspace(0, 2, 100)
plt.plot(x, x, label='linear')
plt.plot(x, x**2, label='quadratic')
plt.plot(x, x**3, label='cubic')
plt.xlabel('Eje X')
plt.ylabel('Eje Y')
plt.title("Grafico de lineas")
plt.legend()
plt.savefig('lineas.png')
plt.show()Gráfico de dispersión
import numpy as np
import matplotlib.pyplot as plt
N = 50
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N)
area = (30 * np.random.rand(N))**2
plt.scatter(x, y, s=area, c=colors, alpha=0.5)
plt.xlabel('Eje X')
plt.ylabel('Eje Y')
plt.title("Grafico de dispersión")
plt.show()11.4.2 seaborn

El paquete Seaborn es una biblioteca de visualización basada en matplotlib. Proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos e informativos.
Sus funciones de ploteo operan en dataframes y arrays, realizando internamente el mapeo semántico y la agregación estadística necesarios para producir gráficos informativos. Su API declarativa orientada a dataframes le permite concentrarse en lo que significan los diferentes elementos de sus gráficos, en lugar de los detalles de cómo dibujarlos.
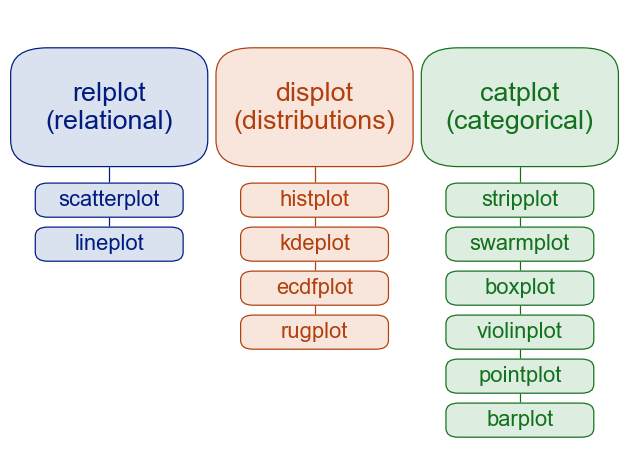
Principales funciones para generar gráficos en seaborn. Imagent tomada de https://seaborn.pydata.org/tutorial/function_overview.html
Gráfico de líneas
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_theme(style="whitegrid")#establecer tema
#generar datos
rs = np.random.RandomState(365)
values = rs.randn(365, 4).cumsum(axis=0)
dates = pd.date_range("1 1 2021", periods=365, freq="D")
data = pd.DataFrame(values, dates, columns=["A", "B", "C", "D"])
data = data.rolling(7).mean()
sns.lineplot(data=data, palette="tab10", linewidth=2.5)#crear gráfico de lineasGráfico de Barras
import seaborn as sns
sns.set_theme(style="whitegrid")# establecer tema
penguins = sns.load_dataset("penguins")# cargar datos
g = sns.catplot(
data=penguins, kind="bar",
x="species", y="body_mass_g", hue="sex",
ci="sd", palette="dark", alpha=.6, height=6)#visualizar grafico de barras
g.set_axis_labels("", "Body mass (g)")#modificar ejes y leyendas
g.legend.set_title("")Gráfico de regresión lineal múltiple
import seaborn as sns
sns.set_theme()
penguins = sns.load_dataset("penguins") # cargar los datos
g = sns.lmplot(
data=penguins,
x="bill_length_mm", y="bill_depth_mm", hue="species",
height=5) # para crear visualización, gráfico de regresión múltiple
g.set_axis_labels("Bill length (mm)", "Bill depth (mm)")# modificar etiquetas de ejesGráficos Compuestos
import seaborn as sns
sns.set_theme()
penguins = sns.load_dataset("penguins")
sns.jointplot(data=penguins, x="flipper_length_mm", y="bill_length_mm", hue="species")11.5 Aprendizaje Automático
En esta sección veremos algunos de los principales algoritmos de aprendizaje automático como Decision Trees, Random Forest, Boosted Regression Trees, Naive Bayes, Support Vector Machines y K-means. La teoría detrás de cada uno de ellos ha sido expuesta con mayor detalle en capítulos anteriores, por lo que nos enfocaremos en su implementación en lenguaje Python.
11.5.1 Decision Trees
La mayoría de algoritmos de aprendizaje automático están implementados en la biblioteca sklearn. Importaremos el set de datos y haremos la partición en el set de entrenamiento y el set de prueba.
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
data = load_iris() #cargar dataset iris
X = data.data #extraer atributos
y = data.target #extraer atributos de etiquetados
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, random_state = 50, test_size = 0.25) #particiónSe genera el modelo y se visualiza el árbol de decisión
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier() #crear clasificador
clf = clf.fit(X_train,y_train) #crear modelo
from sklearn import tree
tree.plot_tree(clf)Se realiza la predicción y la estimación de la predicción en set de entrenamiento y set de prueba
11.5.2 Random Forest
Importaremos el set de datos y haremos la partición en el set de entrenamiento y el set de prueba.
from sklearn import datasets
iris = datasets.load_iris()#cargamos el data set iris
X = iris.data
y = iris.target #reconoce automaticamente variable con etiquetas "Species"
from sklearn.model_selection import train_test_split # función para separar set de datos
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training Luego se genera el modelo y se hace la predicción en el set de prueba.
from sklearn.ensemble import RandomForestClassifier
clf=RandomForestClassifier(n_estimators=100)#crear clasificador
clf.fit(X_train,y_train)#generar el modelo
y_pred=clf.predict(X_test)#hacer la predicciónSe calcula la predicción del modelo en el set de prueba
from sklearn import metrics
print("Accuracy:",metrics.accuracy_score(y_test, y_pred)) # medir la precisiónSe calcula el valor de importancia de las variables predictoras
import pandas as pd
feature_imp = pd.Series(clf.feature_importances_,index=iris.feature_names).sort_values(ascending=False)
feature_imp11.5.3 Boosted Regression Trees
import xgboost as xgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
brt = xgb.XGBClassifier(objective='multi:softprob', num_class=2, n_estimators = 50, use_label_encoder=False)#crea clasificador
brt.fit(X_train,y_train)# genera el modelo
pred = brt.predict_proba(X_test)# realiza predicción en set de prueba
print(pred[:5])
brt.feature_importances_# valor de importancia de variables predictoras11.5.4 Naive Bayes
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.35, random_state=0)
gnb = GaussianNB()
y_pred = gnb.fit(X_train, y_train).predict(X_test)
print("De un total de %d puntos, se falló en la cantidad siguiente : %d"
% (X_test.shape[0], (y_test != y_pred).sum()))11.5.5 SVM
from sklearn import datasets, svm
data = load_iris() #cargar dataset iris
X = data.data #extraer atributos
y = data.target #extraer atributos de etiquetados
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training
from sklearn.svm import SVC
model=SVC()#clasificador
model.fit(X_train, y_train)#modelo
pred=model.predict(X_test)#predicción en set de prueba
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test,pred))#matriz de confusión
print(classification_report(y_test, pred))#reporte11.5.6 K-means
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import MinMaxScaler
data = load_iris() #cargar dataset iris
X = data.data #extraer atributos
y = data.target #extraer atributos de etiquetados
from sklearn.cluster import KMeans # encontrar número optimo clusters
wcss = []
for i in range(1, 11):
kmeans = KMeans(n_clusters = i, init = 'k-means++', max_iter = 300, n_init = 10, random_state = 0)
kmeans.fit(X)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('The elbow method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
iris = load_iris() #cargar dataset iris
X = iris.data #extraer atributos
y = iris.target #extraer atributos de etiquetados
km = KMeans(n_clusters=3, max_iter = 100)
km= km.fit(X)#modelo
pred= km.predict(X)#predicción
pd.crosstab(y,km.labels_)#matriz de confusión11.6 Aprendizaje Profundo (Deep Learning)
Veremos a continuación dos ejemplos de implementaciones del uso de redes neuronales para el aprendizaje profundo. Las bases teóricas fueron presentadas en un capítulo anterior.
11.6.1 Red Neuronal Multicapa
#Importar librerias
import keras
import pandas as pd
import numpy as np
from sklearn.preprocessing import normalize
from sklearn.datasets import load_iris
iris = datasets.load_iris()
data = load_iris() #cargar dataset iris
X = data.data #extraer atributos
y = data.target #extraer atributos de etiquetados
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training
#Modulo de Red Neuronal
from keras.models import Sequential
from keras.layers import Dense,Activation,Dropout
from keras.utils import np_utils
# Ajustar variables de salida
y_train=np_utils.to_categorical(y_train,num_classes=3)
y_test=np_utils.to_categorical(y_test,num_classes=3)
# Establecer arquitectura de red neuronal y compilar
model=Sequential()
model.add(Dense(1000,input_dim=4,activation='relu'))
model.add(Dense(500,activation='relu'))
model.add(Dense(300,activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(3,activation='softmax'))
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
#ajustar modelo
model.fit(X_train,y_train,validation_data=(X_test,y_test),batch_size=20,epochs=10,verbose=1)
#hacer predicción
prediction=model.predict(X_test)
length=len(prediction)
y_label=np.argmax(y_test,axis=1)
predict_label=np.argmax(prediction,axis=1)
accuracy=np.sum(y_label==predict_label)/length * 100
print("precisión dataset",accuracy )11.6.2 Red Neuronal Convolucional con Python
Para el set de datos se utilizará el set de datos MNIST que consta de una gran colección de imágenes de dígitos escritos a mano. Es un conjunto de datos muy popular en el campo del procesamiento de imágenes.
# Importar bibliotecas
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPool2D
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
from tensorflow.keras.layers import Dense
#Bajar datos de mnist
(X_train,y_train) , (X_test,y_test)=mnist.load_data()
#cambiar formato
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], X_train.shape[2], 1))
X_test = X_test.reshape((X_test.shape[0],X_test.shape[1],X_test.shape[2],1))
print(X_train.shape)
print(X_test.shape)
#normalizar valores de pixeles
X_train=X_train/255
X_test=X_test/255
#Definir arquitectura del modelo
model=Sequential()
model.add(Conv2D(32,(3,3),activation='relu',input_shape=(28,28,1)))
model.add(MaxPool2D(2,2))
model.add(Flatten())
model.add(Dense(100,activation='relu'))
model.add(Dense(10,activation='softmax'))
#Compilar
model.compile(loss='sparse_categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
#Correr modelo
model.fit(X_train,y_train,epochs=10)
#evaluar el modelo
model.evaluate(X_test,y_test)11.7 Recursos complementarios
- https://f0nzie.github.io/yongks-python-rmarkdown-book/index.html
- https://colab.research.google.com/notebooks/basic_features_overview.ipynb
- https://colab.research.google.com/notebooks/snippets/importing_libraries.ipynb
- https://docs.python.org/3/tutorial/
- https://swcarpentry.github.io/python-novice-inflammation/
- https://bioinf.comav.upv.es/courses/unix/expresiones_regulares.html
- https://docs.python.org/3.8/tutorial/datastructures.html
- https://betterprogramming.pub/numpy-illustrated-the-visual-guide-to-numpy-3b1d4976de1d
- https://es.acervolima.com/python-fusionar-unir-y-concatenar-dataframes-usando-panda/
- https://matplotlib.org/stable/plot_types/index.html
- https://matplotlib.org/cheatsheets/
- https://seaborn.pydata.org/examples/index.html
- https://link.springer.com/book/10.1007/978-3-319-63913-0