Chapter 6 Loading and saving data
6.1 Loading data
In this chapter, we will further discuss loading and saving data. R can load many different data files, such as Excel files, CSV files, Stata files, SAS files, and more.
An easy way to load data is to use one of the RStudio options. In the environment screen on the top right, we have an option named Import Dataset that can load text data, excel data, SPSS data, SAS data, and Stata data.
When you use this option for the first time you will be asked to download the “haven” package. If you click on the install option it will automatically download the haven package.
As an example, we are going to look at how we can load Excel files by using this option. First of all, we click on the button Import Dataset.
Figure 6.1: Import dataset
Next, we click From Excel… and then a large screen will appear.
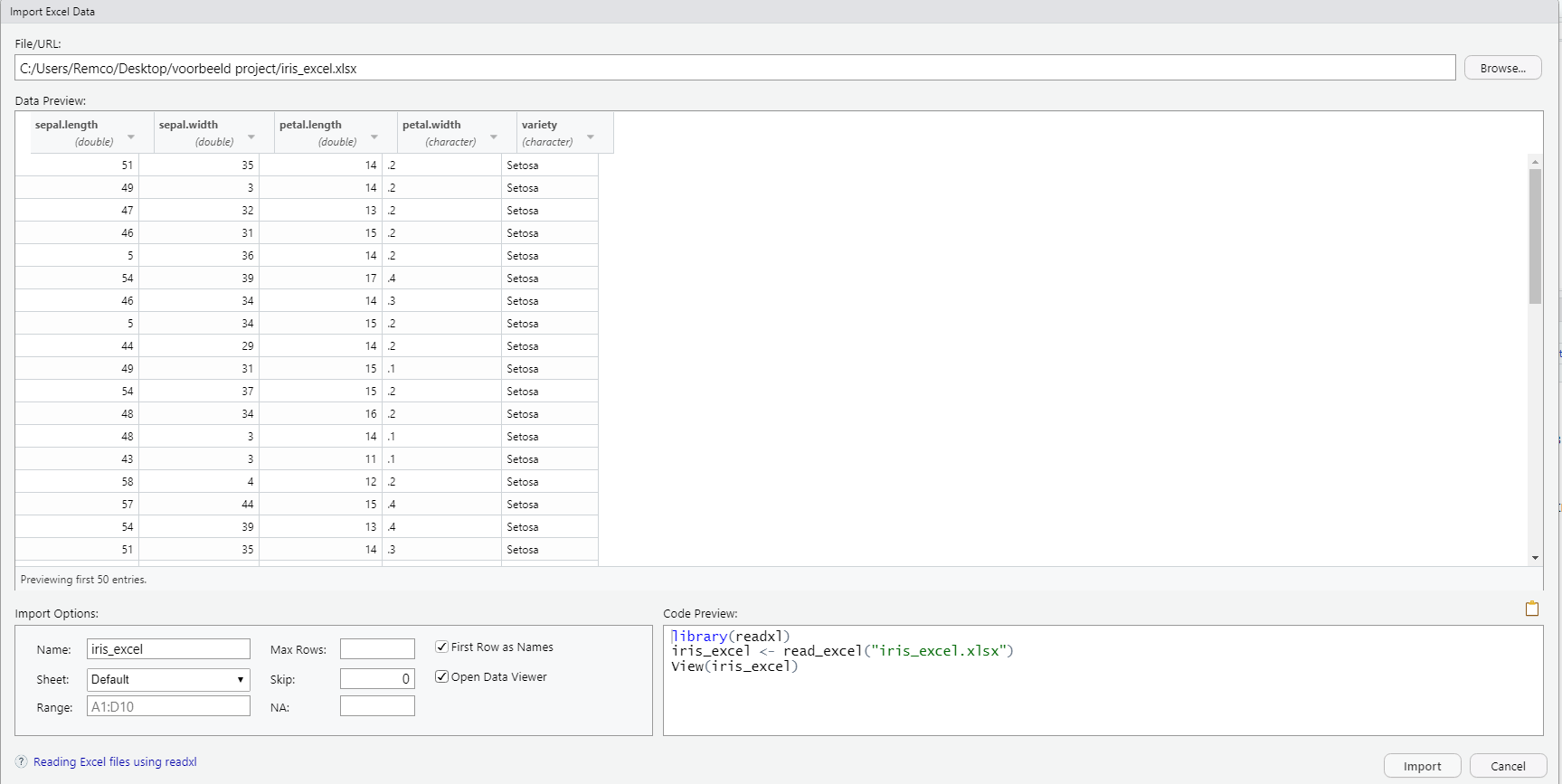
Figure 6.2: Loading data I
At the top of the screen, you will see a bar with File/URL and next to it you will find an option called Browse… When you click on browse you can navigate to your excel file and then a preview will be given of the data. In this case, we loaded a dataset with 4 variables: sepal.length, sepal.width, petal.length, petal.width, and the outcome named species. This is a dataset that is often used for classification. The typical purpose of this dataset is to predict the iris species based on the other 4 variables.

Figure 6.3: Iris dataset
In figure 6.2 we see several import options at the bottom left of the screen. For example, we can give our data a name under Name, and if we have missing values that are encoded in a certain way, such as 999 for example, we can fill that in under NA so that R will also code these values as missing values. Another important option for Excel files is the option First Row as Names. Usually, in Excel files the first row is used to name the variables which is also the case here, so make sure that this option is checked. Finally, we see a code preview at the bottom right of the screen and R will execute that code to load our excel data file:
library(readxl)
iris_excel <- read_excel("iris_excel.xlsx")
View(iris_excel)We see that R loads in the readxl package (so if you want to load excel files in this way make sure the readxl packet is installed). Furthermore, we see that R uses the read_excel() function and that it assigns the dataset to the variable named iris_excel on the second line. Finally, we see View(iris_excel) on the last line of code and this opens the data in a new screen.
The reason that we zoomed in on the code they used to load the Excel file is because we can also type this code ourselves in a new file and then execute it to accomplish the same thing. One important thing is to work with projects and put the file you want to load into the folder of that project. If you do that R will automatically search for a file called iris_excel in the folder of the project you are working in. If you don’t do that you will have to specify a file path for R to find your file, but that is usually more difficult than working with projects.
If we followed all these steps and pressed the import button at the bottom right of the screen Global Environment we now see that we have a variable iris_excel with 150 observations and 5 variables, which corresponds to the excel file and now we can work with this file in R.
Similarly, we can also load Spss files. For example, when we go back to Import Dataset, then press from Spss… we get another screen with File/URL, Browse, Import options, and a Code Preview. This screen will look similar to this:
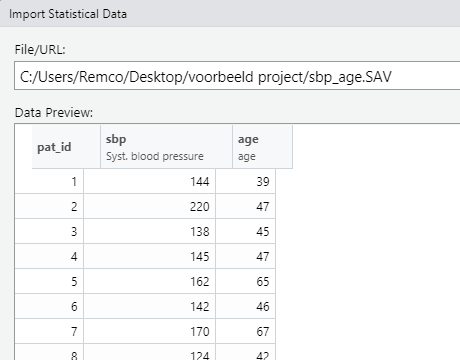
Figure 6.4: Loading data II
Furthermore, there are fewer import options than we had when loading our excel file. In this case, we only have the Name and Format options and option whether we want to open the Data Viewer or not.
foreign package
An alternative way to load data is to use the foreign package. This package can be used to load SAS, SPSS, and Stata files to name a few examples. For example, we can use the read.ssd() function to open SAS files, the read.spss() function to open Spss files, and the read.dta() function to load Stata data.
If you want to load data in this way then make sure you have installed the foreign package and load the package in the following way:
library(foreign)If we want to load the same SPSS file as we did before, we can type the following code:
dataset1 <- read.spss(file = "sbp_age.sav", to.data.frame = TRUE)This code saves our data file under the variable named dataset1 and we also need to specify where our data file is stored (if you are working with a project and your SPSS file is stored there then this will work fine). Also, we see an argument name to.data.frame = TRUE. This means that R should load the data as a data frame.
load
The load() function can also be used to open datasets or other objects. This can be done with the following code:
load("iris.RData")The extension in this case is called .RData and we will soon see how we can save datasets with this extension.
CSV files
Before we move on to saving data we are going to look at CSV files. CSV stands for comma-separated values file and this means that all data is separated with commas. These files are used quite often, therefore we will discuss this in the book. A CSV file may look like this:
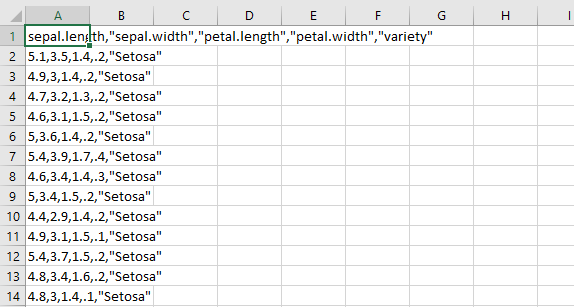
Figure 6.5: CSV file
Here we see the same iris data file, but now as a CSV file. Again, we see the names of the variables in the first row, but now they are separated with commas just like the rest of the values. To load CSV files we can use the read.csv() function which is already installed by default.
For example, if we want to load this CSV file we can use the following code:
dataset_iris <- read.csv("iris.csv", header = TRUE)When we execute the code our data file will be stored under the variable named dataset_iris.
6.2 Saving data
Now that we know how to load data, it is also useful to know how to store data. For example, if we have worked with an SPSS file in R and we have edited some values then we can save the data in a certain way so that we can easily import it into SPSS again.
We will discuss 2 options to save data.
write.table
We can save files as CSV files with the write.table() function. For example, if we load the iris data under the variable named dataset_iris and we want to save it then we can do that with the following code:
write.table(dataset_iris, file = "examplesave.csv", row.names = FALSE, sep = ",")The first argument that we specify is the name of our variable which is dataset_iris and the second argument is file = to name the saved datafile. Also, we see 2 additional arguments named row.names = FALSE and sep = “,”. The sep argument tells R to separate all variables and values with commas which makes it a CSV file. Furthermore, there is an argument named row.names = FALSE and this prevents R from creating an extra column with the names of the rows.
If we want to save our files so that we can easily import it to SPSS later, we need to type the following code:
write.table(dataset_iris, file = "iris R bestand", row.names = FALSE, sep = ",", dec = ",", "row.names = FALSE")This separates all values and variables with a “;” and uses “,” for decimal values as indicated by the “dec” argument.
Save
Finally, we can also use the save() function to save data files. When we use this function the files will be saved with a .RData extension.
If we want to save our iris dataset, for example, we can use the following code:
save(dataset_iris, file = "iris.RData")Once we have done that, our data file is saved with a .RData extension and we can load it with the load() function as explained earlier.