3.1 Registro de población
Registro de Población, regulado en el art. 51.4 de la Ley Foral de Estadística, proporcionado por el Instituto de estadística de Navarra.
3.1.1 Carga
Nastat lo proporciona en forma de fichero de texto. Cada persona está en una línea del fichero. Los campos tienen longitud fija.
nastat_personas <- read_fwf("./datos/nastat/A180101P31O.txt",
locale = readr::locale(encoding = "latin1"),
fwf_positions(
c( 6, 26, 32, 57, 63, 88,
90, 93, 101, 102, 103, 111,
112, 172, 174, 178, 210, 260,
265, 270, 497, 544),
c( 25, 31, 56, 62, 87, 89,
92, 100, 101, 102, 110, 111,
131, 173, 176, 184, 234, 264,
269, 294, 497, 546),
col_names=c('NOMB', 'PART1','APE1', 'PART2','APE2', 'CPRON',
'CMUNN','FNAC', 'TIDEN','LEXTR','IDEN', 'LIDEN',
'NDOCU','DIST', 'SECC', 'CUN', 'NENTSIC','CVIA',
'TVIA', 'NVIAC','SEXO', 'NACI')
),
col_types=cols(CPRON = col_integer(), FNAC = col_date('%Y%m%d'), IDEN = col_integer())
,na=c('',' ','00000000','00000000000000000000')
)3.1.2 Análisis
Número total de registros
## [1] 653953En cuanto a los valores no conocidos, vemos que practicamente todos los registros tienen nombre y primer apellido, pero hay muchos sin identificador oficial. También hay muchos sin segundo apellido, pero eso no tiene por qué ser un error, ya que hay extranjeros que no lo usan.
nastat_personas %>%
select(bdc_id_oficial, bdc_nombre, bdc_apellido_1, bdc_apellido_2,
bdc_fecha_nacimiento, bdc_sexo, bdc_municipio_domicilio) %>%
plot_missing()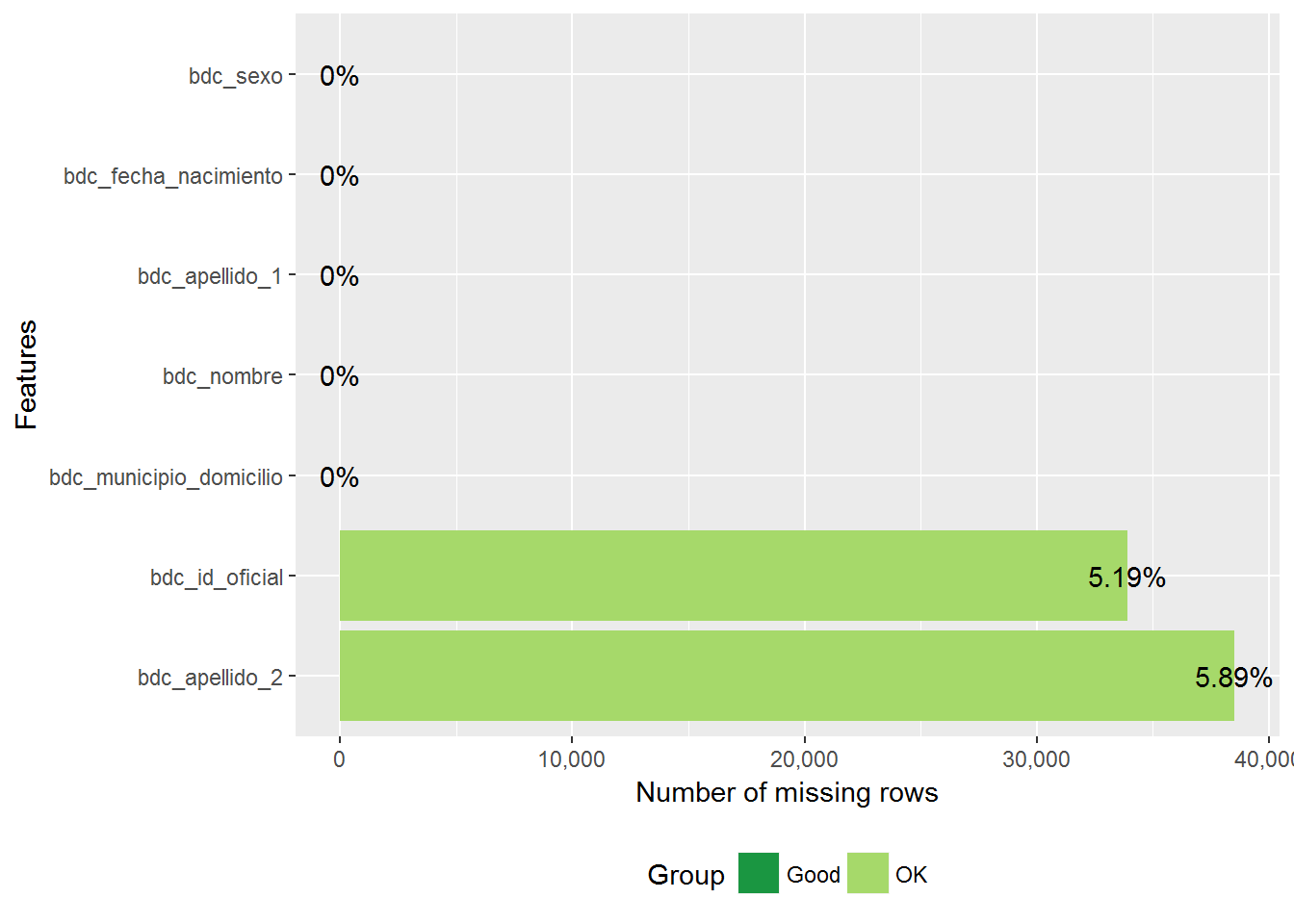
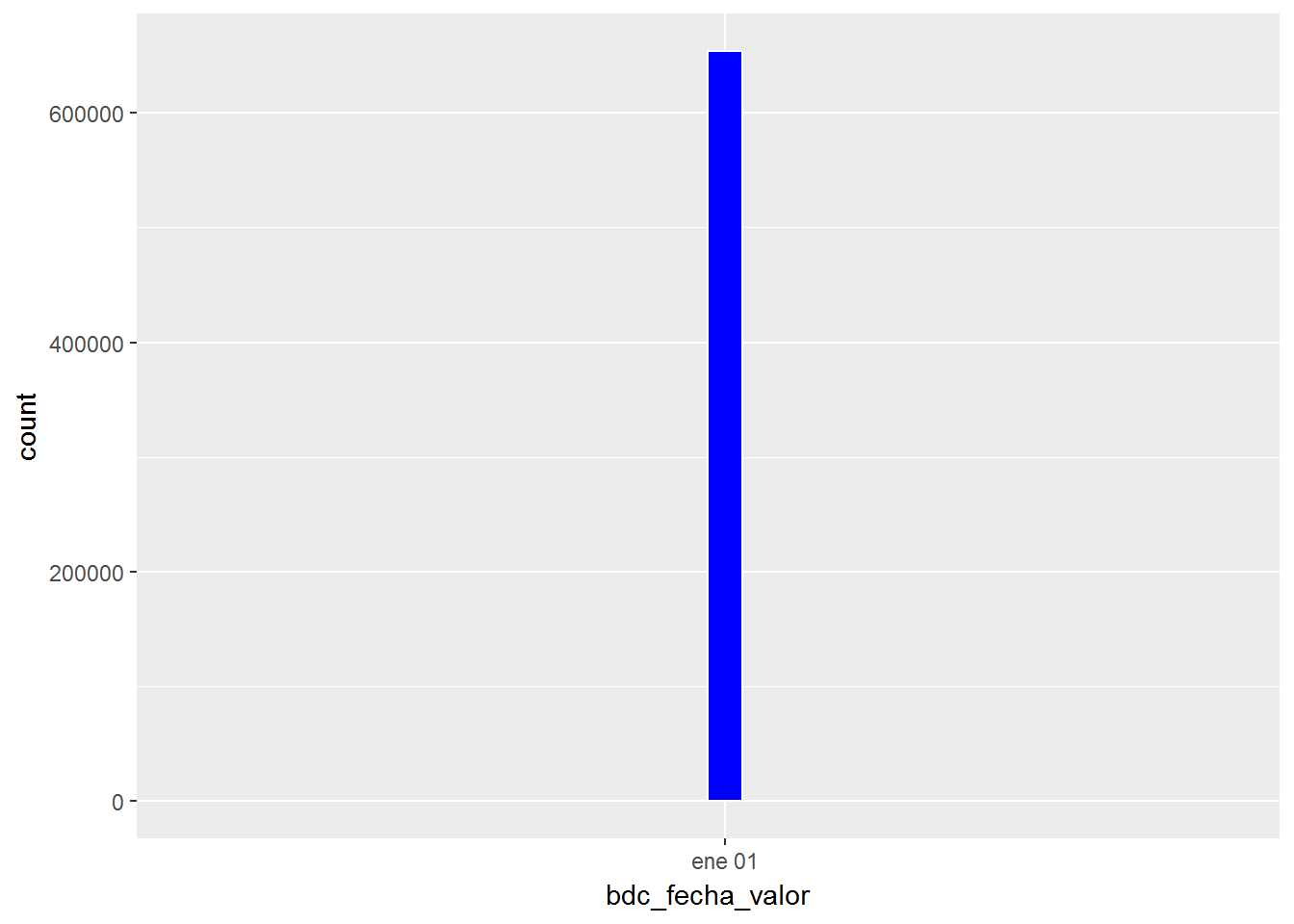
Estra es la distribución de los datos según la fecha de la observación. Los datos provienen del padrón, que se actualiza sólo dos veces al año, por lo que todas las observaciones son de 1/1/2018
Viendo la distribución de las personas sin identificar en función de la edad vemos que la mayor parte son de los nacidos a partir de 2000, es decir, los menores de edad:
nastat_personas %>%
filter(is.na(nastat_personas$bdc_id_oficial)) %>%
ggplot(aes(x=year(bdc_fecha_nacimiento))) + geom_histogram(color="white", fill = "blue")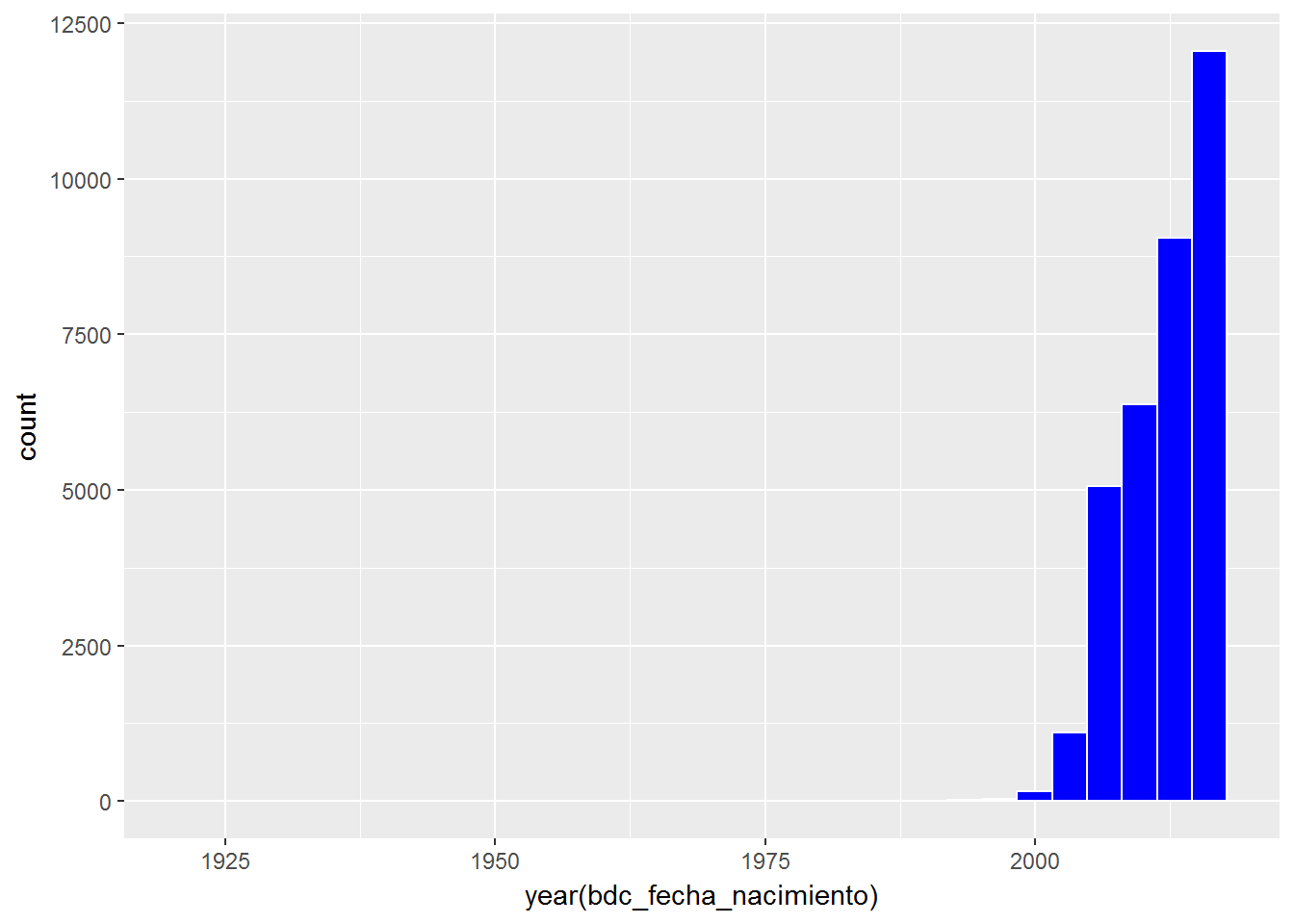
No obstante, también hay unos pocos mayores de edad sin identificador oficial:
nastat_personas %>%
filter(is.na(bdc_id_oficial)) %>%
filter(year(bdc_fecha_nacimiento) < 2000) %>%
ggplot(aes(x=year(bdc_fecha_nacimiento))) + geom_histogram(color="white", fill = "blue")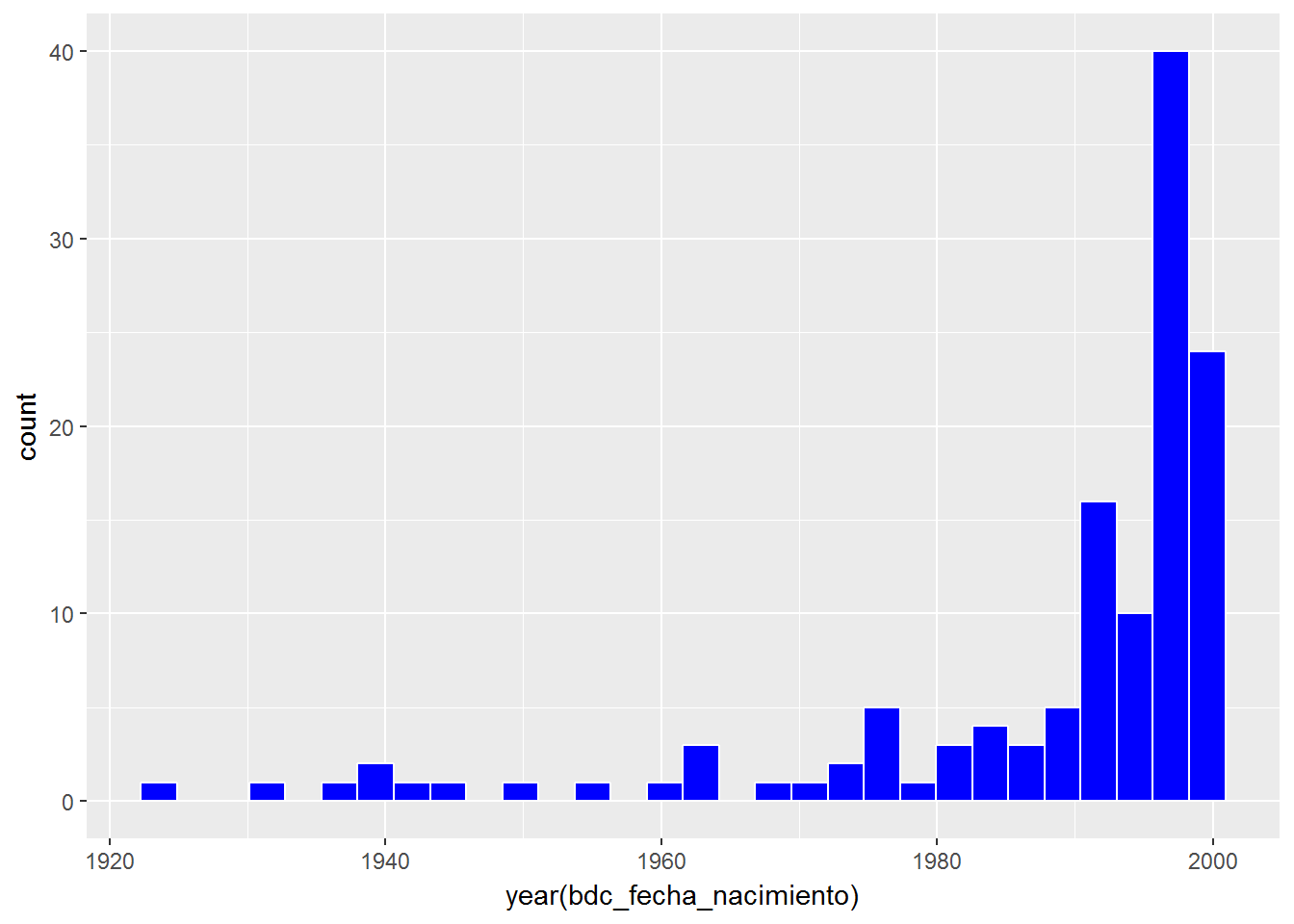
3.1.3 Normalizado
Para poder enlazar los registros hay que normalizarlos. Por ejemplo, el nombre “MARIA NIEVES” puede aparecer de varias formas diferentes.
nastat_personas %>% select(bdc_nombre) %>%
subset(grepl("^(M\\.|M?|MARI|MARIA)+ NIEVES$",bdc_nombre)) %>% unique() %>% pulcro()| bdc_nombre |
|---|
| M. NIEVES |
| MARIA NIEVES |
| MARI NIEVES |
Preprocesado del nombre y apellidos:
nastat_personas <- nastat_personas %>% preproceso_nombre_apellidos()
nastat_personas %>% select(bdc_nombre) %>%
subset(grepl("^(M\\.|M?|MARI|MARIA)+ NIEVES$",bdc_nombre)) %>%
unique() %>% pulcro()| bdc_nombre |
|---|
| MARIA NIEVES |
El identificador oficial también necesita normalizarse. Por ejemplo, algunos DNIs tienen signos de puntuación:
nastat_personas %>% select(bdc_id_oficial) %>%
subset(grepl("[[:punct:]]",bdc_id_oficial)) %>%
unique() %>% sample_n(10) %>% pulcro()| bdc_id_oficial |
|---|
| 1199509/2 |
| 05/000117607 |
| 4812544-1 |
| 592-1606778-54 |
| X-2223973-B |
| 30877444-2 |
| 14029/01 |
| 65/0312289 |
| 00000000-T |
| 11117684-J |
Preprocesado del id oficial. Después del procesado no queda ningún DNI con signos de puntuación:
nastat_personas <- nastat_personas %>% preproceso_id_oficial()
nastat_personas %>% select(bdc_id_oficial) %>%
subset(grepl("[[:punct:]]",bdc_id_oficial)) # %>% unique() %>% pulcro()## # A tibble: 0 x 1
## # ... with 1 variables: bdc_id_oficial <chr>