2.5 Prueba de concepto
En la prueba de concepto hemos seguido el proceso seguido en el libro ‘Data Matching’ de Peter Christen.

El siguiente gráfico ilustra el proceso general propuesto por el libro. Incluye referencias a los capítulos y secciones:
![Data Matching [@DataMatching]](imagenes/data.matching.book.general.process.png)
Figura 2.11: Data Matching (Christen 2012)
- Preproceso de datos: las bases de datos a enlazar pueden variar en formato, estructura y contenido. El preproceso de datos limpia y estandariza la información, y es imprescindible para que los siguientes pasos del proceso tengan éxito.
- Borrado de caracteres indeseados. Por ejemplo, los puntos y guiones que pueden tener los DNIs, de manera que ‘29.151.222-X’ se transforma en ‘29151222X’
- Simplificación. Por ejemplo, sustitución de las vocales acentuadas por su correspondiente sin acentuar.
- Expansión de abreviaturas. Por ejemplo, se transforma ‘Mª’, ‘M.’, ‘Mari’, etc por MARIA
- Indexado: potencialmente, cada registro de una base de datos a enlazar tendría que compararse con cada registro de la otra, pero la mayoría de estas comparaciones serán claramente no coincidentes. El indexado reduce el número de comparaciones evitando aquellas menos coincidentes.
- Comparación de registros: los registros se comparan buscando similitud en las variables que los componen.
- Clasificación: en función de la similitud los pares se clasifican en positivos, negativos o pendientes de revisión.
- Revisión manual: aquellos pares clasificados como pendientes de revisión se clasifican manualmente, a menudo usando otras fuentes de información.
- Evaluación: finalmente se evalúa la calidad y complejidad del proceso de enlazado de registros.
La prueba de concepto trata de seguir el ciclo de un proyecto típico en ciencia de datos:
![R for Data Science [@R4DS]](imagenes/data-science.png)
Figura 2.12: R for Data Science (Grolemund and Wickham 2017)
2.5.1 Origen de datos
Las bases de datos utilizadas han sido:
1. El Registro de Población, regulado en el art. 51.4 de la Ley Foral de Estadástica, proporcionado
por el Instituto de estadástica de Navarra.
2. La base de datos de personas del programa de Gestión para el Registro y seguimiento de documentos Registr@ proporcionada
por el Servicio de Sistemas de Información Corporativos de la DGITIP.
2.5.2 Preprocesado de datos
Las bases de datos a enlazar pueden variar en formato, estructura y contenido. El preproceso de datos limpia y estandariza la información, y es imprescindible para que los siguientes pasos del proceso tengan éxito.
El Registro de Población tiene 653.953 registros. Sólo faltan datos en el identificador oficial y el segundo apellido, pero eso es normal, ya que los menores de 14 años no tienen obligación de tener DNI y muchos extranjeros no usan segundo apellido.
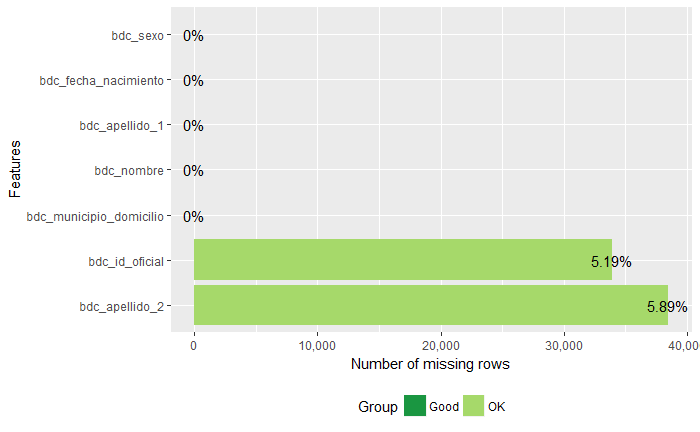
Figura 2.13: Registro de Población: valores desconocidos
El formato de los datos es variado. Por ejemplo, los identificadores oficiales:
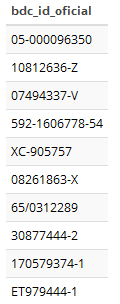
Figura 2.14: Registro de Población: formato del id. oficial
La base de datos de personas de Registr@ tiene 753834 registros. En cuanto a los valores no conocidos, hay unos cuantos sin id oficial, y muchos sin nombre, municipio o segundo apellido. Más de un treinta por ciento no tienen fecha de nacimiento y ninguno tiene registrado el sexo.
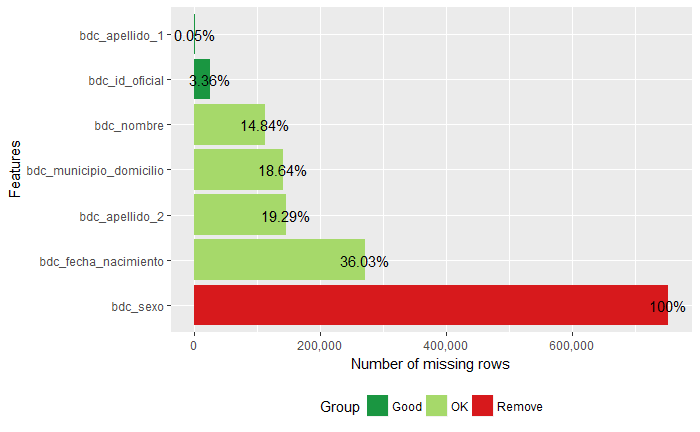
Figura 2.15: Registr@: valores desconocidos
Incluye personas físicas y jurídicas, y no tienen ninguna variable explícita que las distinga. Filtrando aquellos registros que tienen identificador oficial de persona jurídica y aquellos que no tienen nombre (parece que se corresponden con personas jurídicas), nos quedan 641.051 registros.
El formato de los datos es también variopinto. Por ejemplo, los identificadores oficiales:
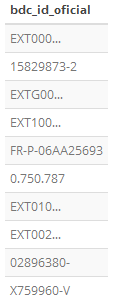
Figura 2.16: Registr@: formato del id. oficial
Se han preprocesado los identificadores, nombres y apellidos de las dos bases de datos para que tengan formatos similares.
Para saber más, consultar el capítulo 3.
2.5.3 Enlazado probabilístico
En ausencia de identificadores de entidad únicos, los atributos disponibles en común en dos bases de datos (como los nombres, direcciones o fechas de nacimiento de los pacientes o clientes) deben utilizarse para hacer coincidir los registros.
Como los valores en tales atributos pueden estar equivocados, faltantes o sin datos, y debido a que la cantidad de valores y las distribuciones pueden diferir entre atributos, deben asignarse diferentes pesos a diferentes atributos cuando se utilizan para calcular las similitudes entre los registros.
Además dichos pesos no solo deben depender de las características generales de los atributos; también deben depender de los valores de atributos reales en un determinado par de registros candidatos. Por ejemplo, si dos registros tienen un valor de apellido ‘Smith’, el peso otorgado para este acuerdo de valores debe ser más pequeño que el peso dado a dos registros que ambos tienen el valor del apellido ‘Dijkstra’, asumiendo que el número de personas con el apellido ‘Dijkstra’ es mucho más pequeño que el número de personas con el apellido ‘Smith’ en las bases de datos. Esto se debe a la probabilidad de que dos registros seleccionados al azar tengan el valor del apellido ‘Smith’ es mucho más alto que la probabilidad de que tengan el apellido ‘Dijkstra’.
El paquete Fastlink (Enamorado, Fifield, and Imai 2018a) implementa este algoritmo para el entorno de computación estadística R.
Para enlazar dos bases de datos tendríamos que comparar, en principio, cada registro de una de ellas con cada registro de la otra. Comparar dos bases de datos de seiscientos mil registros cada una son trescientas sesenta mil millones de comparaciones. Para reducir drásticamente el número de comparaciones Fastlink implementa técnicas de indexado (‘indexing’ o también ‘clustering’) para hacer conjuntos disjuntos de registros con mayor probabilidad de enlazado. Se eligen claves formadas por los campos de las bases de datos de mejor calidad (completos y correctos) y que estén distribuidos de forma que los grupos tengan tamaños similares.
FastLink clasifica cada par de registros con una probabilidad de coincidencia. Por ejemplo, una muestra con probabilidad mayor de 0.95:
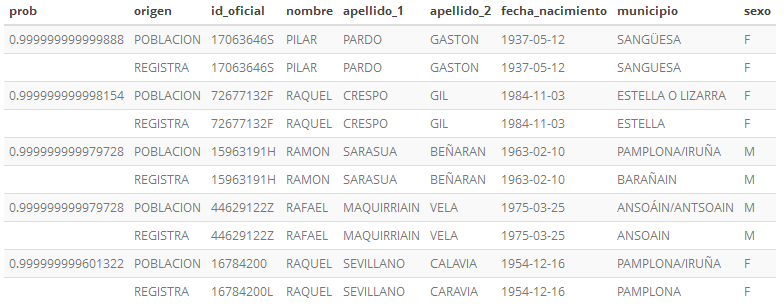
Figura 2.17: Fastlik. Resultado con prob > 0.95
Para saber más, consultar el capítulo 4.
2.5.4 Aprendizaje máquina
Según (Christen 2012) Los métodos supervisados de clasificación más populares para el enlazado de registros son los árboles de decisión (Decision Trees) y las máquinas de vectores de soporte (Support Vector Machines, SVMs).
En esta prueba de concepto hemos aplicado la clasificación mediante árboles de decisión y bosques aleatorios (‘Random Forest’). Los bosques aleatorios se basan en combinar múltiples arboles de decisión.
Los árboles de decisión tienen la ventaja de que pueden representarse gráficamente. Este es un árbol de decisión obtenido en la prueba de concepto. Las variables de decisión son las distancias entre cadenas de caracteres, es decir, cuántos caracteres hay que cambiar/quitar/añadir para obtener la misma cadena.
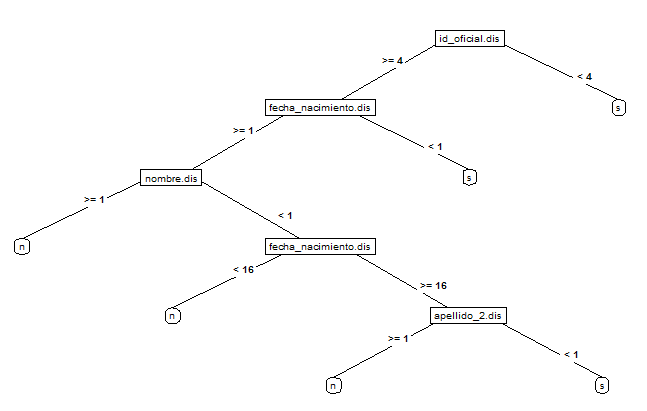
Figura 2.18: Arbol de decisión
Y este es el árbol obtenido añadiendo variables sintéticas, lo que se denomina Ingeniería de Características (‘Feature engineering’). El árbol es más sencillo y en la decisión participa como variable sintética el nombre completo (nombre + primer apellido + segundo apellido)
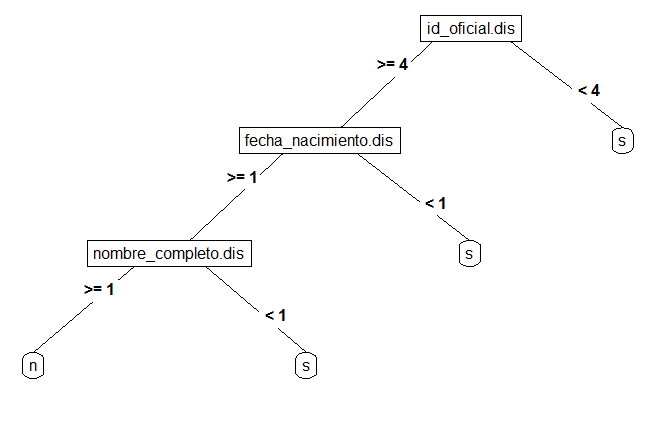
Figura 2.19: Arbol de decisión mejorado
El mayor inconveniente de la clasificación supervisada es la necesidad de un conjunto de datos representativos correctamente clasificados a mano.
Para paliar este inconveniente, los datos que el modelo no ha sido capaz de clasificar, o mejor dicho, que ha clasificado como pendientes de revisión, se pueden usar para reentrenar el modelo, mejorándolo. Es lo que se denomina Aprendizaje activo.
![Aprendizaje activo [@DataMatching]](imagenes/data.matching.book.active.learning.png)
Figura 2.20: Aprendizaje activo (Christen 2012)
Para saber más, consultar el capítulo 5.
2.5.5 Resultados
La Matriz de confusión, también conocida como matriz de errores, es una tabla que ayuda a visualizar el rendimiento de un algoritmo de clasificación.
![[@udemy]](imagenes/matriz.confusion.png)
Figura 2.21: (Portilla 2018)
![[@udemy]](imagenes/matriz.confusion.2.png)
Figura 2.22: (Portilla 2018)
Las métricas con las que comparamos los resultados son la exactitud, sensibilidad y precisión (Accuracy, recall & precision)
![[@udemy]](imagenes/matriz.confusion.3.png)
Figura 2.23: (Portilla 2018)
- La Exactitud (accuracy) responde a la pregunta ¿Cuál es la proporción de predicciones correctas?
- La Sensibilidad (recall) responde a la pregunta ¿Qué proporción de positivos reales se han predicho correctamente?
- La Precisión (precision) responde a la pregunta ¿Qué proporción de predicciones positivas es correcta?
Los algoritmos comparados han sido:
- Determinista 1: algoritmo de cruce de LAKORA.
- Determinista 2: algoritmo de un cruce puntual entre los datos del Padrón y los de la TIS.
- Probabilistico: algoritmo de cruce probabilístico con FastLink.
- Decision Tree (NA): árbol de decisión con datos no disponibles (Not Available).
- Decision Tree: árbol de decisión tratando los datos no disponibles.
- Decision Tree (FE): árbol de decisión con ingeniería de características (Feature Engineering).
- Random forest: bosque aleatorio.
- Random forest (FE): bosque aleatorio con ingeniería de características.
Los resultados comparativos se han obtenido sobre un conjunto de datos clasificados manualmente (ver sección 5.2). El conjunto se ha separado en dos subconjuntos, uno de entrenamiento, con el 70% de los registros, y otro de pruebas, con el 30% restante.
Los modelos de aprendizaje máquina se han entrenado con el conjunto de datos de entrenamiento y se han probado sobre el conjunto de datos de prueba. Los algoritmos deterministas y probabilísticos se han aplicado directamente al conjunto de pruebas.
Los resultados obtenidos son los siguientes:
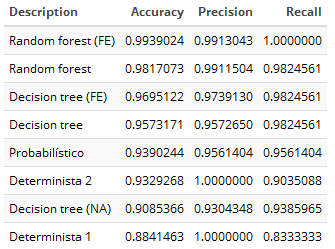
Figura 2.24: Resultados iniciales
El resultado de los algoritmos deterministas es menor de lo esperado. En particular, el segundo de ellos, aplicado para cruzar el Padrón con la base de datos de la tarjeta sanitaria, obtuvo en su momento un resultado en un rango de entre 0,97 y 1 en la exactitud y precisión. Entendemos que es debido a que las bases de datos cruzadas (Registr@ frente a TIS) son de muy diferente calidad, particularmente en cuanto a los campos vacíos de Registr@.
Para comparar en mayor igualdad de condiciones hemos repetido la clasificación sólo con los registros que tienen informados el nombre, primer apellido y fecha de nacimiento. El resultado se acerca mucho más al esperado.
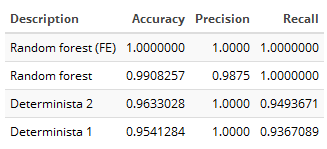
Figura 2.25: Resultados en igualdad de condiciones
Como conclusión, la clasificación probabilística y, sobre todo, la clasificación mediante aprendizaje máquina representan una mejora frente a los algoritmos deterministas, mejora que es mayor cuanto menos calidad tienen las bases de datos a cruzar.
Para saber más, consultar la sección 5.5.
References
Christen, Peter. 2012. Data Matching, Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. https://www.springer.com/in/book/9783642311635.
Grolemund, Garrett, and Hadley Wickham. 2017. R for Data Science. https://r4ds.had.co.nz/.
Enamorado, Ted, Ben Fifield, and Kosuke Imai. 2018a. FastLink: Fast Probabilistic Record Linkage with Missing Data.
Portilla, Jose. 2018. Data Science and Machine Learning Bootcamp with R. https://www.udemy.com/data-science-and-machine-learning-bootcamp-with-r/.