5.5 Comparación de resultados
Los algoritmos comparados son:
- Determinista 1: algoritmo de cruce de LAKORA.
- Determinista 2: algoritmo de un cruce puntual entre los datos del Padrón y los de la TIS.
- Probabilistico: algoritmo de cruce probabilístico con FastLink.
- Decision Tree (NA): árbol de decisión con datos no disponibles (Not Available).
- Decision Tree: árbol de decisión tratando los datos no disponibles.
- Decision Tree (FE): árbol de decisión con ingeniería de características (Feature Engineering).
- Random forest: bosque aleatorio.
- Random forest (FE): bosque aleatorio con ingeniería de características.
Los resultados comparativos se han obtenido sobre un conjunto de datos clasificados manualmente (ver sección 5.2). El conjunto se ha separado en dos subconjuntos, uno de entrenamiento, con el 70% de los registros, y otro de pruebas, con el 30% restante (ver sección 5.4.1).
Los modelos de aprendizaje máquina se han entrenado con el conjunto de datos de entrenamiento y se han probado sobre el conjunto de datos de prueba. Los algoritmos deterministas y probabilísticos se han aplicado directamente al conjunto de pruebas.
5.5.1 Resultados iniciales
Los resultados que hemos obtenido, ordenados por la suma de las tres métricas (exactitud, precisión y Sensibilidad), son los siguientes:
| Description | Accuracy | Precision | Recall |
|---|---|---|---|
| Random forest (FE) | 0.9939024 | 0.9913043 | 1.0000000 |
| Random forest | 0.9817073 | 0.9911504 | 0.9824561 |
| Decision tree (FE) | 0.9695122 | 0.9739130 | 0.9824561 |
| Decision tree | 0.9573171 | 0.9572650 | 0.9824561 |
| Probabilístico | 0.9390244 | 0.9561404 | 0.9561404 |
| Determinista 2 | 0.9329268 | 1.0000000 | 0.9035088 |
| Decision tree (NA) | 0.9085366 | 0.9304348 | 0.9385965 |
| Determinista 1 | 0.8841463 | 1.0000000 | 0.8333333 |
En el cruce determinista del Padron contra la TIS se registraron los resultados obtenidos, en la siguiente tabla. La primera columna indica la condición de enlazado que cumplen los registros, la segunda es el número de registros afectados:
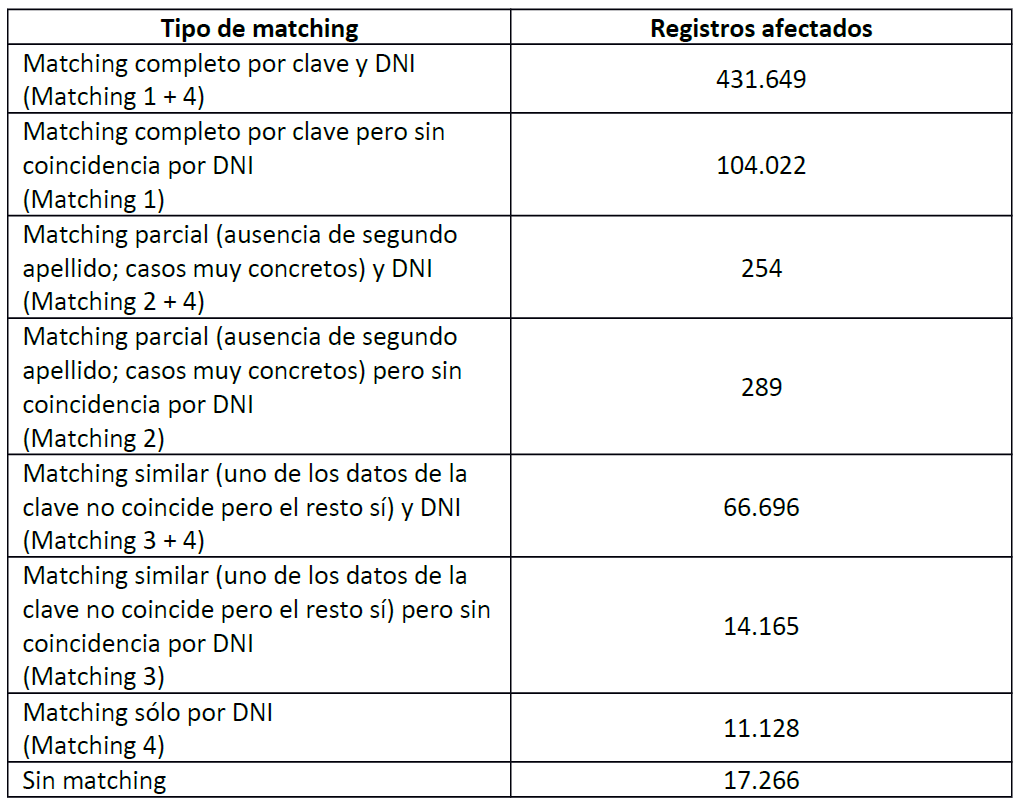
Figura 5.6: Resultado del cruce entre TIS y Padrón
Podemos usar estos datos para comprobar los resultados obtenidos en la prueba de concepto. Los datos que nos interesan son la cifra de registros enlazados (628203) y la cifra de registros no enlazados (17266).
Asumiendo que no hay falsos positivos, la cifra de registros enlazados corresponden con los ciertos positivos, y la cifra de registros no enlazados corresponde con la suma de los ciertos negativos y los falsos negativos. Por lo tanto, tenemos:
\(FP = 0\)
\(TP = 628203\)
\(TN + FN = 17266\)
\(Total = FP+TP+TN+FN = 0+TP+TN+FN = 645469\)
Como no hay falsos positivos, la precisión sería 1:
\(Precision=\frac{TP}{TP+FP}=\frac{TP}{TP+0}=1\)
No podemos calcular la sensibilidad, pero sí el rango en el que se mueve:
\(Recall=\frac{TP}{TP+FN}\)
\(FN=0\implies TN=17266\implies Recall_{max}=\frac{TP}{TP+0}=1\)
\(TN=0\implies FN=17266\implies Recall_{min}=\frac{628203}{628203+17266}=0.9732505\)
y lo mismo para la exactitud:
\(Accuracy=\frac{TP+TN}{Total}=\frac{TP+TN}{FP+TP+TN+FN}\)
\(FN=0\implies Accuracy_{max}=\frac{TP+TN}{0+TP+TN+0} = 1\)
\(TN=0\implies Accuracy_{min}=\frac{628203+0}{0+628203+0+17266}=0.9732505\)
Estos resultados son mucho mejores que los que hemos obtenido en la prueba de concepto. Dado que los algoritmos son prácticamente iguales la diferencia tiene que ser debida a que el algoritmo se utilizó para cruzar dos bases de datos de buena calidad (Padrón y TIS) y en nuestro caso hemos cruzado el Registro de Población, de igual calidad que el Padrón, con Registr@, que es de peor calidad, particularmente menos completa. Esto se ve claramente en los siguientes gráficos, que muestran las variables sin informar del conjunto de observaciones en las que el algoritmo determinista ha acertado la clasificación:
library(DataExplorer)
determinista.2.aciertos %>%
select(bdc_id_oficial, bdc_nombre, bdc_apellido_1, bdc_apellido_2,
bdc_fecha_nacimiento) %>%
plot_missing()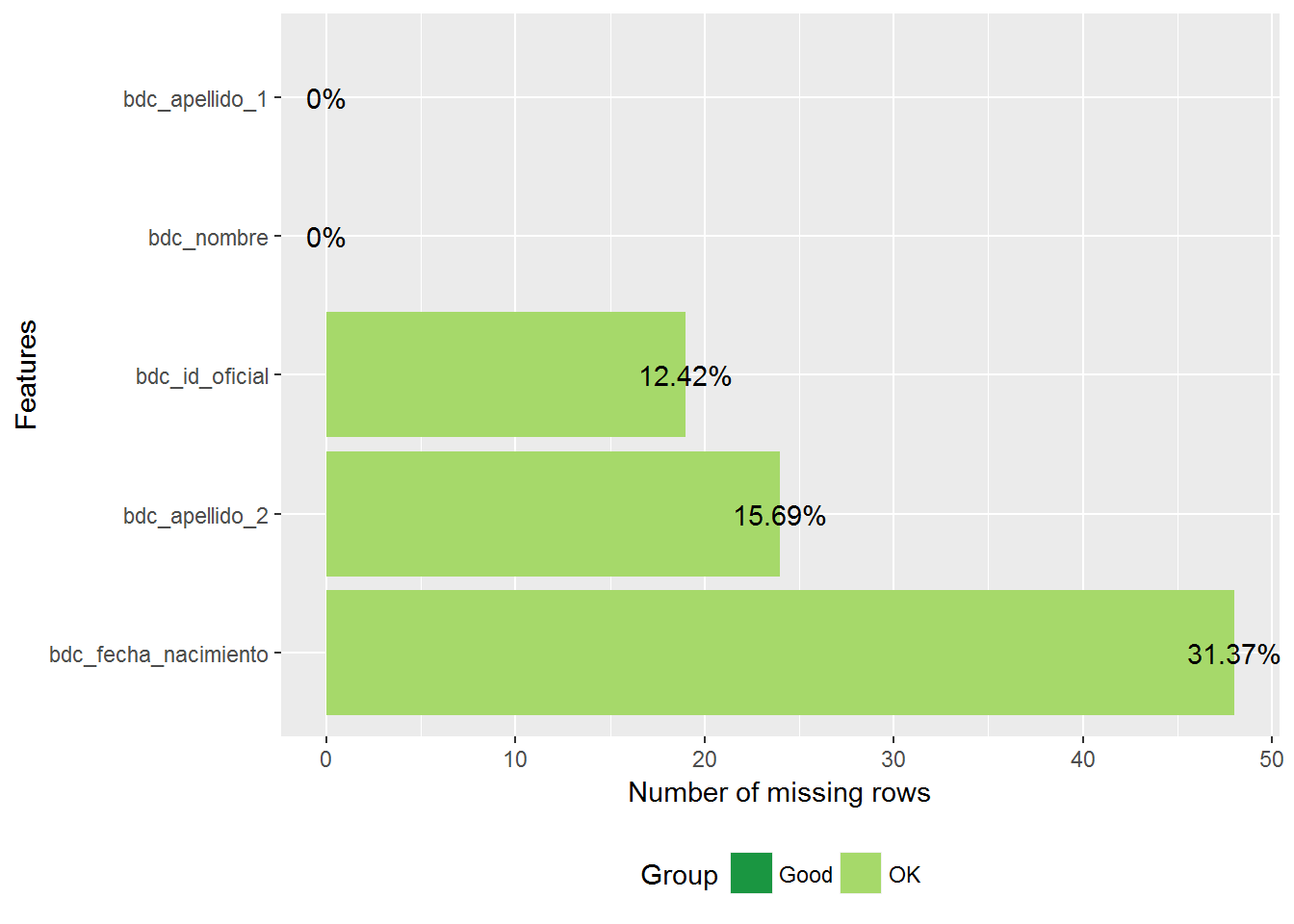
Y lo mismo para las observaciones en las que ha fallado la clasificación:
determinista.2.fallos %>%
select(bdc_id_oficial, bdc_nombre, bdc_apellido_1, bdc_apellido_2,
bdc_fecha_nacimiento) %>%
plot_missing()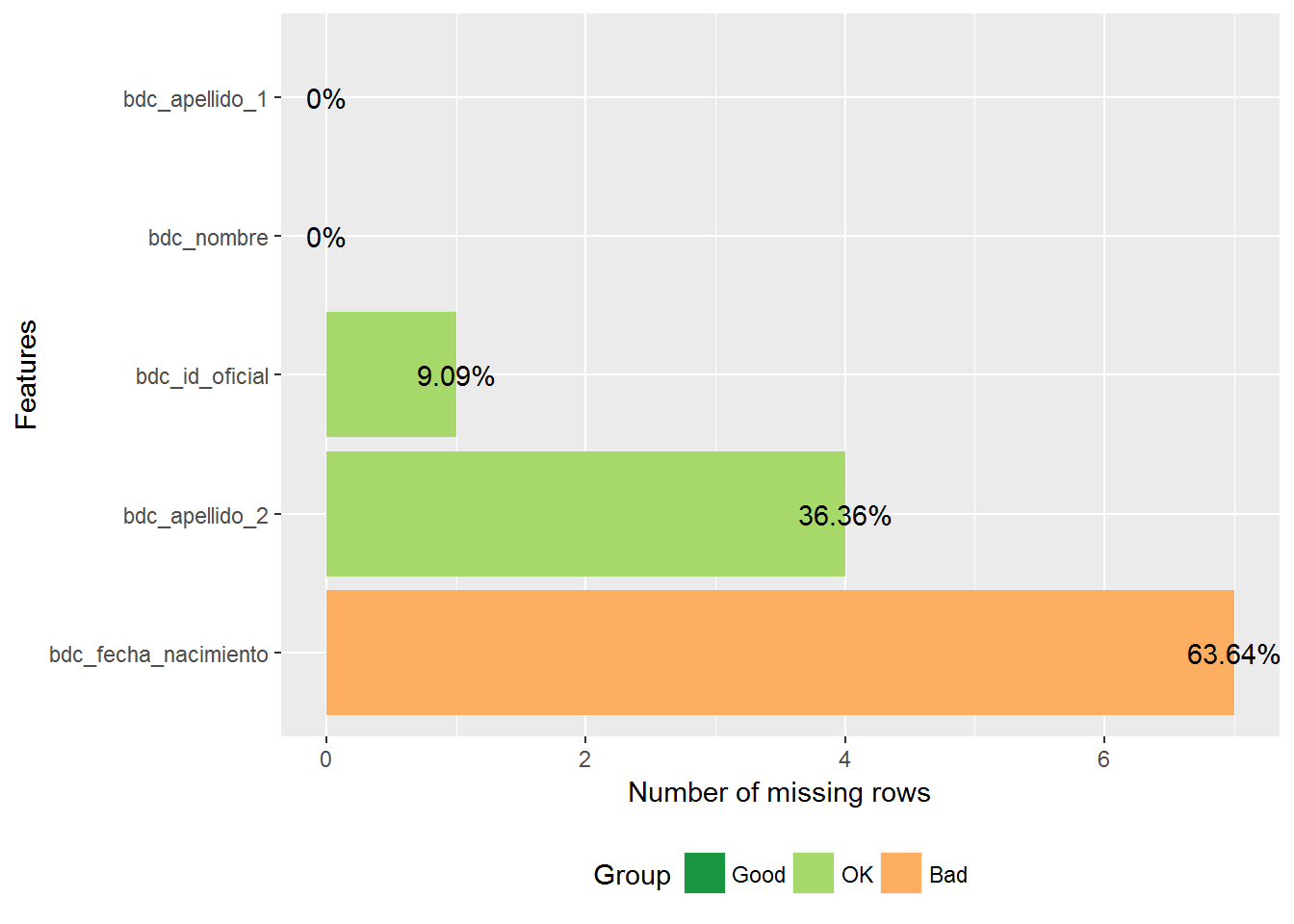
5.5.2 Igualdad de condiciones
Para comparar en mayor igualdad de condiciones vamos a repertir la clasificación con los registros que tienen informados el nombre, primer apellido y fecha de nacimiento:
filtro <- function(df) filter(df, !is.na(bdc_nombre.x) &
!is.na(bdc_nombre.y) &
!is.na(bdc_apellido_1.x) &
!is.na(bdc_apellido_1.y) &
!is.na(bdc_fecha_nacimiento.x) &
!is.na(bdc_fecha_nacimiento.y))
train <- train %>% filtro()
test <- test %>% filtro()
train_sin_na <- train_sin_na %>% filtro()
test_sin_na <- test_sin_na %>% filtro()train %>%
select(bdc_id_oficial, bdc_nombre, bdc_apellido_1, bdc_apellido_2,
bdc_fecha_nacimiento) %>%
plot_missing()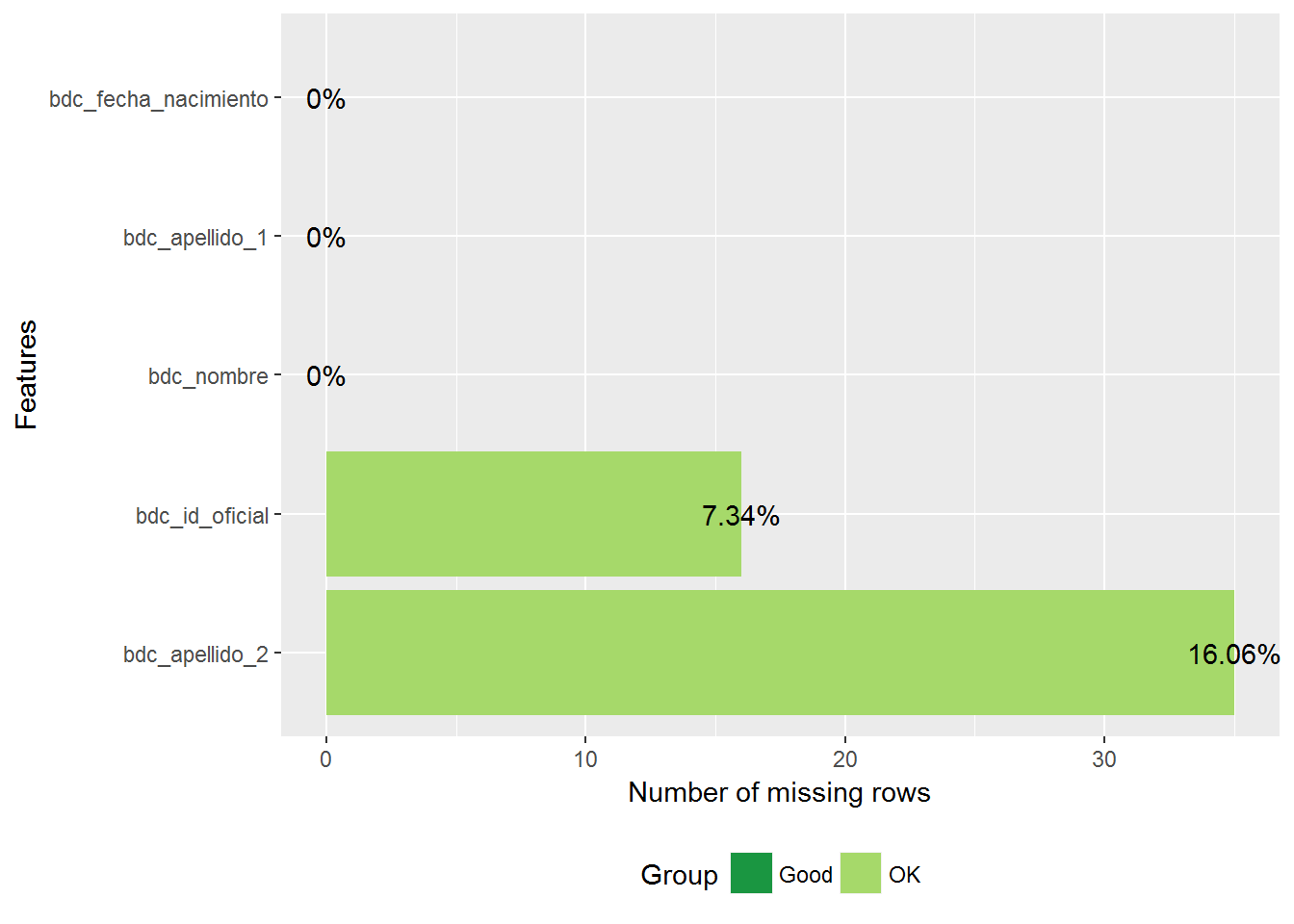
y volvemos a probar:
# Determinista 1
pred<- clasificador_determinista_1()
cm <- confusionMatrix(table(pred, test$clase), positive = "s")
resu2 <- data.frame(Description = "Determinista 1",
Accuracy = cm$overall["Accuracy"],
Precision = cm$byClass["Precision"],
Recall = cm$byClass["Recall"],
row.names=NULL, stringsAsFactors = FALSE)
# Determinista 2:
pred<- clasificador_determinista_2()
cm <- confusionMatrix(table(pred, test$clase), positive = "s")
resu2[2,] = list("Determinista 2",
cm$overall["Accuracy"], cm$byClass["Precision"], cm$byClass["Recall"])
# Bosque aleatorio:
pred <- clasificador_bosque()
cm <- confusionMatrix(table(pred, test_sin_na$clase), positive = "s")
resu2[3,] = list("Random forest",
cm$overall["Accuracy"], cm$byClass["Precision"], cm$byClass["Recall"])
# Bosque aleatorio con ingeniería de características:
pred <- clasificador_bosque_fe()
cm <- confusionMatrix(table(pred, test_sin_na$clase), positive = "s")
resu2[4,] = list("Random forest (FE)",
cm$overall["Accuracy"], cm$byClass["Precision"], cm$byClass["Recall"])
resu2 %>% arrange(desc(Accuracy+Precision+Recall)) %>% pulcro()| Description | Accuracy | Precision | Recall |
|---|---|---|---|
| Random forest | 0.9908257 | 0.9875000 | 1.0000000 |
| Random forest (FE) | 0.9816514 | 0.9753086 | 1.0000000 |
| Determinista 2 | 0.9633028 | 1.0000000 | 0.9493671 |
| Determinista 1 | 0.9541284 | 1.0000000 | 0.9367089 |
Este resultado se parece mucho más al esperado. También mejoran el resultado los algoritmos de aprendizaje máquina, pero las diferencias son menores.
5.5.3 Conclusiones
Como conclusión, la clasificación probabilística y, sobre todo, la clasificación mediante aprendizaje máquina representan una mejora frente a los algoritmos deterministas, mejora que es mayor cuanto menor es la calidad de las bases de datos a enlazar.