4.5 Enlazado
Fastlink tiene dos modos de funcionamiento. Se puede llamar a cada una de las partes del proceso por separado (más flexibilidad) o se puede llamar a un ‘wrapper’ que ejecuta el enlazado en un único paso (por cada ‘cluster’).
dfA <- subset(nastat_personas, cluster == 1)
dfB <- subset(registra_personas, cluster == 1)
matches.out <- fastLink(
dfA = dfA, dfB = dfB,
varnames = varnames,
stringdist.match = stringdist.match,
partial.match = partial.match,
verbose = TRUE,
n.cores = 1
)====================
fastLink(): Fast Probabilistic Record Linkage
====================
Calculating matches for each variable.
Matching variable bdc_id_oficial using string-distance matching.
Matching variable bdc_nombre using string-distance matching.
Matching variable bdc_apellido_1 using string-distance matching.
Matching variable bdc_apellido_2 using string-distance matching.
Matching variable bdc_fecha_nacimiento using string-distance matching.
Matching variable bdc_municipio_domicilio using string-distance matching.
Matching variable bdc_sexo using exact matching.
Calculating matches for each variable took 3.68 minutes.
Getting counts for parameter estimation.
Parallelizing calculation using OpenMP. 1 threads out of 4 are used.
Getting counts for parameter estimation took 2.81 minutes.
Running the EM algorithm.
Running the EM algorithm took 0.41 seconds.
Getting the indices of estimated matches.
Parallelizing calculation using OpenMP. 1 threads out of 4 are used.
Getting the indices of estimated matches took 1.27 minutes.
Deduping the estimated matches.
Deduping the estimated matches took 0.03 minutes.
Getting the match patterns for each estimated match.
Getting the match patterns for each estimated match took 0 minutes.Tarda menos de 8 minutos en procesar un ‘cluster’ de cada base de datos. En el ejemplo hay 100 clusters, por lo que tardaría 800 minutos (13,3 horas) en enlazar las dos bases de datos.
Muestra con probabilidad mayor de 0.95
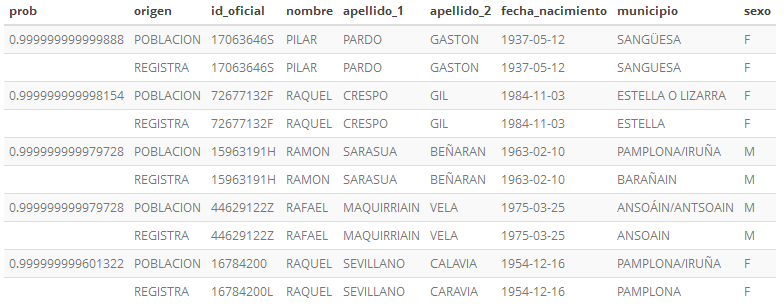
Figura 4.1: Resultado prob > 0.95
El primer enlazado no tiene probabilidad 1 por la diéresis de SANGÜESA. Es una posible mejora en el preprocesado de datos. El segundo enlazado tiene menos probabilidad que el primero por la diferencia en los municipios (“ESTELLA O LIZARRA”" frente a “ESTELLA”). El uso de un Nomenclator para los municipios también sería una mejora.
Muestra con probabilidad entre 0.80 y 0.95
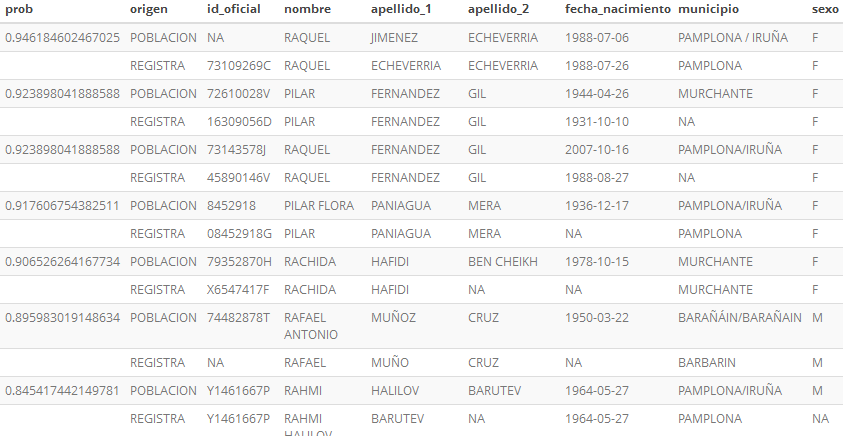
Figura 4.2: Resultado 0.80 < prob < 0.95