6.5 separate() and untie()
separate() 和 untie() 函数则是为了解决以下问题:多个变量挤在了同一列中,或者一个变量分散到了不同列中。
6.5.1 separate()
table3
#> # A tibble: 6 x 3
#> country year rate
#> * <chr> <int> <chr>
#> 1 Afghanistan 1999 745/19987071
#> 2 Afghanistan 2000 2666/20595360
#> 3 Brazil 1999 37737/172006362
#> 4 Brazil 2000 80488/174504898
#> 5 China 1999 212258/1272915272
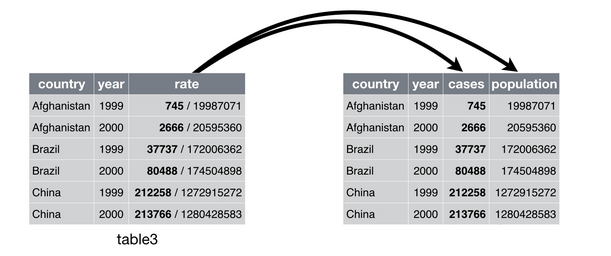
#> 6 China 2000 213766/1280428583在 table3 中,rate 同时包含了 cases 和 population 两个变量,我们需要把它拆分(separate)为两列,separate() 函数可以将这一混杂的列拆分成多个变量,它包含以下四个主要参数:
* data: 需要调整的数据框
* col: 需要进行拆分的列的列名
* into: 拆分后新生成变量的列名,格式为字符串向量
* sep: 对如何拆分原变量的描述,其可以是正则表达式,如 _ 表示通过下划线拆分,或 [^a-z] 表示通过任意非字符字母拆分,或一个指定位置的整数。默认情况下,sep将认定一个非字符字母进行划分
# 这个例子里,sep 不是必需的
table3 %>%
separate(col = rate,into = c("cases","population"))
#> # A tibble: 6 x 4
#> country year cases population
#> <chr> <int> <chr> <chr>
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583整理的图示:
注意,以上输出的tibble中,cases 和 population被设定为字符串类型,使用convert = T将其转换为数值变量
table3 %>%
separate(rate, into = c("cases", "population"), convert = T)
#> # A tibble: 6 x 4
#> country year cases population
#> <chr> <int> <int> <int>
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583A seemingly similar function tidyr::separate_rows() separate existing columns based on sep, and then breaks each component into new rows, instead of columns:
df <- tibble(
x = 1:3,
y = c("a", "d,e,f", "g,h"),
z = c("1", "2,3,4", "5,6")
)
df %>% separate_rows(y, z, sep = ",")
#> # A tibble: 6 x 3
#> x y z
#> <int> <chr> <chr>
#> 1 1 a 1
#> 2 2 d 2
#> 3 2 e 3
#> 4 2 f 4
#> 5 3 g 5
#> 6 3 h 6The multiple choice data mentioned in 6.3.2 can easily be solved when using separate_rows():
6.5.2 unite()
unite() 是 separate() 的逆运算——它可以将多列合并为一列.
在 table5 中,原来的 year 变量被拆成了两个列,可以用 unite(),只需要指定要合并后的列名和要合并的列。默认情况下,新列中将用_分隔符
table5
#> # A tibble: 6 x 4
#> country century year rate
#> * <chr> <chr> <chr> <chr>
#> 1 Afghanistan 19 99 745/19987071
#> 2 Afghanistan 20 00 2666/20595360
#> 3 Brazil 19 99 37737/172006362
#> 4 Brazil 20 00 80488/174504898
#> 5 China 19 99 212258/1272915272
#> 6 China 20 00 213766/1280428583
unite(table5, col = year, century, year)
#> # A tibble: 6 x 3
#> country year rate
#> <chr> <chr> <chr>
#> 1 Afghanistan 19_99 745/19987071
#> 2 Afghanistan 20_00 2666/20595360
#> 3 Brazil 19_99 37737/172006362
#> 4 Brazil 20_00 80488/174504898
#> 5 China 19_99 212258/1272915272
#> 6 China 20_00 213766/1280428583sep = "" 可以取消分隔符:
unite(table5, col = year, century, year, sep="")
#> # A tibble: 6 x 3
#> country year rate
#> <chr> <chr> <chr>
#> 1 Afghanistan 1999 745/19987071
#> 2 Afghanistan 2000 2666/20595360
#> 3 Brazil 1999 37737/172006362
#> 4 Brazil 2000 80488/174504898
#> 5 China 1999 212258/1272915272
#> 6 China 2000 213766/1280428583整理的图示:
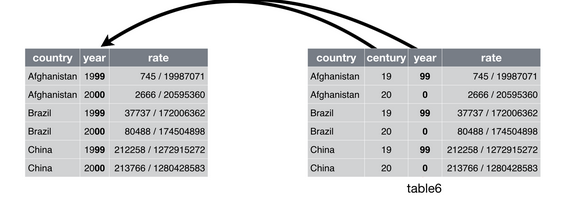
table6 <- unite(table5,col = year,century,year,sep="")
table5
#> # A tibble: 6 x 4
#> country century year rate
#> * <chr> <chr> <chr> <chr>
#> 1 Afghanistan 19 99 745/19987071
#> 2 Afghanistan 20 00 2666/20595360
#> 3 Brazil 19 99 37737/172006362
#> 4 Brazil 20 00 80488/174504898
#> 5 China 19 99 212258/1272915272
#> 6 China 20 00 213766/12804285836.5.3 Exercises
separate()中的extra和fill参数的作用是什么?用下面两个数据框进行实验:
tibble(x = c("a,b,c", "d,e,f,g", "h,i,j")) %>%
separate(x, into = c("one", "two", "three"))
#> # A tibble: 3 x 3
#> one two three
#> <chr> <chr> <chr>
#> 1 a b c
#> 2 d e f
#> 3 h i j
tibble(x = c("a,b,c", "d,e", "f,g,i")) %>%
separate(x, into = c("one", "two", "three"))
#> # A tibble: 3 x 3
#> one two three
#> <chr> <chr> <chr>
#> 1 a b c
#> 2 d e <NA>
#> 3 f g iextra 用来告诉 separate() 函数如何处理分列过程中多出来的元素(too many pieces,即 into 指定的列数小于原数据中某行可分的元素个数),fill 负责如何处理元素不够的情况(not enough pieces,即into指定的列数大于原数据中某行可分的元素个数)。默认情况下,extra = "drop",separate() 将丢弃多余的元素,并生成一条警告信息:
tibble(x = c("a,b,c", "d,e,f,g", "h,i,j")) %>%
separate(x, into = c("one", "two", "three"), extra = "drop")
#> # A tibble: 3 x 3
#> one two three
#> <chr> <chr> <chr>
#> 1 a b c
#> 2 d e f
#> 3 h i jextra = "merge"将把多余的元素和前一个元素当做一个整体:
tibble(x = c("a, b, c", "d, e, f, g", "h, i, j")) %>%
separate(x, c("one", "two", "three"), extra = "merge")
#> # A tibble: 3 x 3
#> one two three
#> <chr> <chr> <chr>
#> 1 a b c
#> 2 d e f, g
#> 3 h i j对于元素过少的情况,默认的fill = "warn"将会用NA进行填充,但会生成一条警告。fill = "right"会尽可能让靠左的列拥有可用的元素,用NA填充右边的列;fill = "left"正好相反。这两种手动设置都不会产生warning:
tibble(x = c("a, b, c", "d, e, ", "h, i, j")) %>%
separate(x, c("one", "two", "three"), fill = "left")
#> # A tibble: 3 x 3
#> one two three
#> <chr> <chr> <chr>
#> 1 a b "c"
#> 2 d e ""
#> 3 h i "j"
tibble(x = c("a,b,c", "d, e, ", "h, i, j")) %>%
separate(x, c("one", "two", "three"),fill = "right")
#> # A tibble: 3 x 3
#> one two three
#> <chr> <chr> <chr>
#> 1 a b "c"
#> 2 d e ""
#> 3 h i "j"2.
unite()和separate()均有一个remove参数,它的作用是什么?
remove控制是否在unite()或separate()输出的数据框中保留原来的列,默认remove = T。如果想保留原来未合并/分离的格列,可以设置remove = F
table5
#> # A tibble: 6 x 4
#> country century year rate
#> * <chr> <chr> <chr> <chr>
#> 1 Afghanistan 19 99 745/19987071
#> 2 Afghanistan 20 00 2666/20595360
#> 3 Brazil 19 99 37737/172006362
#> 4 Brazil 20 00 80488/174504898
#> 5 China 19 99 212258/1272915272
#> 6 China 20 00 213766/1280428583
table5 %>% unite(col = year_unite,century,year,sep = "",remove = F)
#> # A tibble: 6 x 5
#> country year_unite century year rate
#> <chr> <chr> <chr> <chr> <chr>
#> 1 Afghanistan 1999 19 99 745/19987071
#> 2 Afghanistan 2000 20 00 2666/20595360
#> 3 Brazil 1999 19 99 37737/172006362
#> 4 Brazil 2000 20 00 80488/174504898
#> 5 China 1999 19 99 212258/1272915272
#> 6 China 2000 20 00 213766/1280428583separate() 类似的函数 extract() 的用法
separate()函数的分列操作是基于参数 sep 的,无论是给 sep 传入字符串指定分隔符,还是用数值指定分隔的位置,separate() 必须要有一个分隔符才能正常运作(可以把sep = n看做第 n 个和第 n+1 个元素之间的一个空白分隔符)
extract()用一个正则表达式regex描述要分隔的列col中存在的模式,在正则表达式中的每个子表达式(用()定义)将被认为是into中的一个元素,因此,extract()比separate()使用起来更加广泛灵活。例如下面的数据集无法用separate()分列,因为无法用一个各行的分隔符(的位置)不一样,但用extract()中的正则表达式就很简单:
tibble(x = c("X1", "X20", "AA11", "AA2")) %>%
extract(x, c("variable", "id"), regex = "([A-Z]+)([0-9]+)")
#> # A tibble: 4 x 2
#> variable id
#> <chr> <chr>
#> 1 X 1
#> 2 X 20
#> 3 AA 11
#> 4 AA 2适当设计regex,实现的效果可以与设置sep完全一致:
# example with separators
tibble(x = c("X_1", "X_2", "AA_1", "AA_2")) %>%
extract(x, c("variable", "id"), regex = "([A-Z]+)_([0-9])")
#> # A tibble: 4 x 2
#> variable id
#> <chr> <chr>
#> 1 X 1
#> 2 X 2
#> 3 AA 1
#> 4 AA 2
# example with position
tibble(x = c("X1", "X2", "Y1", "Y2")) %>%
extract(x, c("variable", "id"), regex = "([A-Z])([0-9])")
#> # A tibble: 4 x 2
#> variable id
#> <chr> <chr>
#> 1 X 1
#> 2 X 2
#> 3 Y 1
#> 4 Y 2