3.5 readxl
要想将其他类型的数据导入 R 中,可以先从下列的 tidyverse 包开始。对矩形型数据来说:
haven可以读取 SPSS、Stata 和 SAS文件:

配合专用的数据库后端程序(如 RMySQL,RSQLite,RpostgreSQL等),DBI可以对相应数据库进行SQL查询,并返回一个数据框
readxl专门为读取 Excel 文件打造(.xlsx和xls均可)
下面主要介绍 readxl 的用法,不同于readr,readxl 不是 tidyverse 的核心包,我们总需要显示地加载它:
read_excel() 是 readxl 中的核心函数,它的第一个参数path接受 xlsx 或 xls 文件的路径。但由于一个 Excel 文件(工作簿)经常包含多个工作表,所以我们在读取时需要指明某张工作表,excel_sheets() 函数返回一个工作簿文件中各个工作表(sheet)的名字:
获悉一个工作簿内部的表结构以后,可以使用 sheets 参数指定要读取的表,可以是一个整数(第几张彪),也可以是字符串(表明), read_excel() 默认读取第一张表:
经常会在读取 Excel 文件时遇到的一个问题是,有些人喜欢在表格的前面几行或最后几行添加一些元数据(metadata),比如在 deaths.xlsx 中:

默认设置下,read_excel() 会将这些元数据一并读入:
deaths
#> # A tibble: 18 x 6
#> `Lots of people` ...2 ...3 ...4 ...5 ...6
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 simply cannot resist writ~ <NA> <NA> <NA> <NA> some notes
#> 2 at the top <NA> of their spreadsh~
#> 3 or merging <NA> <NA> <NA> cells
#> 4 Name Professi~ Age Has ki~ Date of bi~ Date of death
#> 5 David Bowie musician 69 TRUE 17175 42379
#> 6 Carrie Fisher actor 60 TRUE 20749 42731
#> # ... with 12 more rows一个很有用的方法是通过 Sstudio 的 File \(\rightarrow\) Import Dataset \(\rightarrow\) From Excel 接口导入数据,我们可以通过预览来观察导入后的数据,还可以对read_excel()的导入参数进行设置:
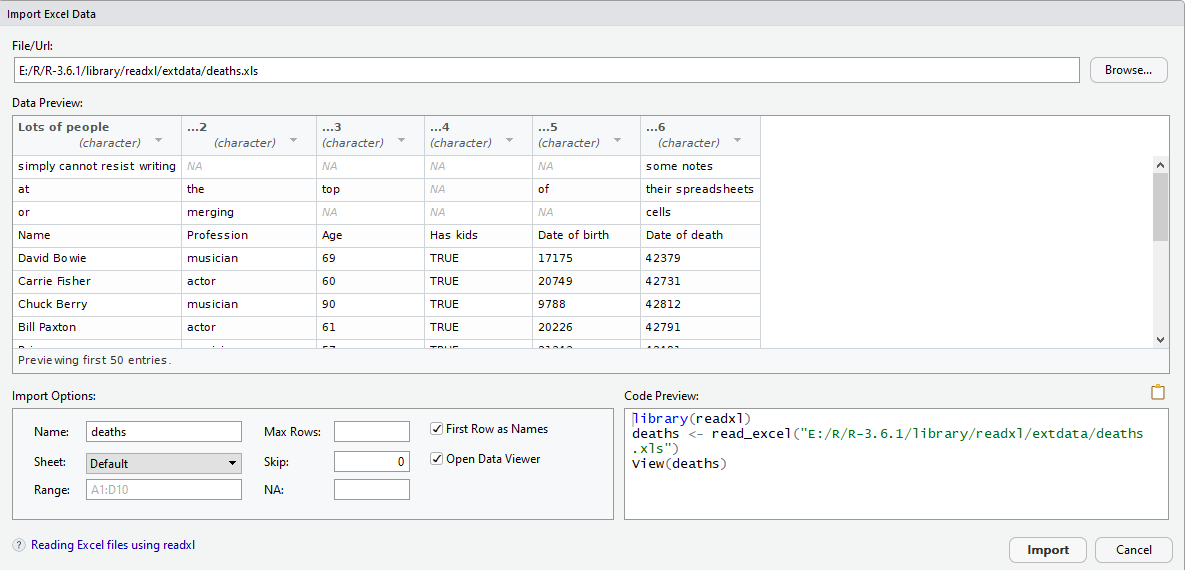
对于deaths.xlsx这个Excel文件,可以结合使用n_max 和 skip 参数去除不想读取的部分(分别对应图形界面里的Max Rows和Skip:
read_excel(path, skip= 4, n_max = 10)
#> # A tibble: 10 x 6
#> Name Profession Age `Has kids` `Date of birth` `Date of death`
#> <chr> <chr> <dbl> <lgl> <dttm> <dttm>
#> 1 David Bow~ musician 69 TRUE 1947-01-08 00:00:00 2016-01-10 00:00:00
#> 2 Carrie Fi~ actor 60 TRUE 1956-10-21 00:00:00 2016-12-27 00:00:00
#> 3 Chuck Ber~ musician 90 TRUE 1926-10-18 00:00:00 2017-03-18 00:00:00
#> 4 Bill Paxt~ actor 61 TRUE 1955-05-17 00:00:00 2017-02-25 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00 2016-04-21 00:00:00
#> 6 Alan Rick~ actor 69 FALSE 1946-02-21 00:00:00 2016-01-14 00:00:00
#> # ... with 4 more rowsread_excel() 中另一个很有用的参数是 range,用于指定一块 Excel 表中要读取的区域:
read_excel(path, sheet = "arts", range = "A5:F15")
#> # A tibble: 10 x 6
#> Name Profession Age `Has kids` `Date of birth` `Date of death`
#> <chr> <chr> <dbl> <lgl> <dttm> <dttm>
#> 1 David Bow~ musician 69 TRUE 1947-01-08 00:00:00 2016-01-10 00:00:00
#> 2 Carrie Fi~ actor 60 TRUE 1956-10-21 00:00:00 2016-12-27 00:00:00
#> 3 Chuck Ber~ musician 90 TRUE 1926-10-18 00:00:00 2017-03-18 00:00:00
#> 4 Bill Paxt~ actor 61 TRUE 1955-05-17 00:00:00 2017-02-25 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00 2016-04-21 00:00:00
#> 6 Alan Rick~ actor 69 FALSE 1946-02-21 00:00:00 2016-01-14 00:00:00
#> # ... with 4 more rows
## 还可以在range中指定列名
read_excel(path, range = "arts!A5:F15")
#> # A tibble: 10 x 6
#> Name Profession Age `Has kids` `Date of birth` `Date of death`
#> <chr> <chr> <dbl> <lgl> <dttm> <dttm>
#> 1 David Bow~ musician 69 TRUE 1947-01-08 00:00:00 2016-01-10 00:00:00
#> 2 Carrie Fi~ actor 60 TRUE 1956-10-21 00:00:00 2016-12-27 00:00:00
#> 3 Chuck Ber~ musician 90 TRUE 1926-10-18 00:00:00 2017-03-18 00:00:00
#> 4 Bill Paxt~ actor 61 TRUE 1955-05-17 00:00:00 2017-02-25 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00 2016-04-21 00:00:00
#> 6 Alan Rick~ actor 69 FALSE 1946-02-21 00:00:00 2016-01-14 00:00:00
#> # ... with 4 more rows与 range 相关的帮助函数cell_rows()、cell_cols()和cell_limits()可以为区域选择提供更大的自由度,下面的示例中使用文件geometry.xls,读取预览:
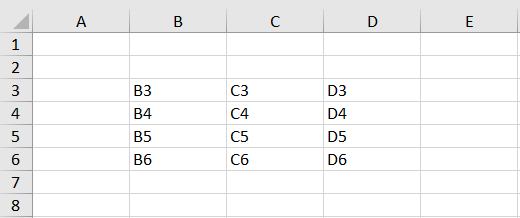
path <- readxl_example("geometry.xls")
# Specify only the rows or only the columns
read_excel(path, range = cell_rows(3:6))
#> # A tibble: 3 x 3
#> B3 C3 D3
#> <chr> <chr> <chr>
#> 1 B4 C4 D4
#> 2 B5 C5 D5
#> 3 B6 C6 D6
read_excel(path, range = cell_cols("C:D"))
#> # A tibble: 3 x 2
#> C3 D3
#> <chr> <chr>
#> 1 C4 D4
#> 2 C5 D5
#> 3 C6 D6
read_excel(path, range = cell_cols(2))
#> # A tibble: 3 x 1
#> B3
#> <chr>
#> 1 B4
#> 2 B5
#> 3 B6
# Specify exactly one row or column bound
read_excel(path, range = cell_rows(c(5, NA)))
#> # A tibble: 1 x 3
#> B5 C5 D5
#> <chr> <chr> <chr>
#> 1 B6 C6 D6
read_excel(path, range = cell_rows(c(NA, 4)))
#> # A tibble: 3 x 3
#> ...1 ...2 ...3
#> <chr> <chr> <chr>
#> 1 <NA> <NA> <NA>
#> 2 B3 C3 D3
#> 3 B4 C4 D4
read_excel(path, range = cell_cols(c("C", NA)))
#> # A tibble: 3 x 2
#> C3 D3
#> <chr> <chr>
#> 1 C4 D4
#> 2 C5 D5
#> 3 C6 D6
read_excel(path, range = cell_cols(c(NA, 2)))
#> # A tibble: 3 x 2
#> ...1 B3
#> <lgl> <chr>
#> 1 NA B4
#> 2 NA B5
#> 3 NA B6
# General open rectangles
# upper left = C4, everything else unspecified
read_excel(path, range = cell_limits(c(4, 3), c(NA, NA)))
#> # A tibble: 2 x 2
#> C4 D4
#> <chr> <chr>
#> 1 C5 D5
#> 2 C6 D6
# upper right = D4, everything else unspecified
read_excel(path, range = cell_limits(c(4, NA), c(NA, 4)))
#> # A tibble: 2 x 4
#> ...1 B4 C4 D4
#> <lgl> <chr> <chr> <chr>
#> 1 NA B5 C5 D5
#> 2 NA B6 C6 D63.5.1 Multi-row headers in Excel
https://debruine.github.io/posts/multi-row-headers/
In section 3.4.5 (Example: multi-row headers) we learn how to tackle with multi-row-headers in a text File. In Excel this is trickier. But the ultimate goal is always firrst extracting header rows (more than 1), composing one formatted row header and then set it to col_names when importing, and skip the some rows in the original data.

Extracting head rows
data_head <- read_excel("data/3headers_demo.xlsx",
col_names = FALSE,
n_max = 3)
#> New names:
#> * `` -> ...1
#> * `` -> ...2
#> * `` -> ...3
#> * `` -> ...4
#> * `` -> ...5
#> * ...
data_head %>% slider::slide(~ as.vector(fill(.x, .direction = "down")))
#> [[1]]
#> # A tibble: 1 x 8
#> ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 SUB1 <NA> <NA> <NA> SUB2 <NA> <NA> <NA>
#>
#> [[2]]
#> # A tibble: 1 x 8
#> ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 COND1 <NA> COND2 <NA> COND1 <NA> COND2 <NA>
#>
#> [[3]]
#> # A tibble: 1 x 8
#> ...1 ...2 ...3 ...4 ...5 ...6 ...7 ...8
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 X Y X Y X Y X YCurrently I have come up with no ways of dealing with data_hand in this given form without resorting to the weird t(). So I followed the blog and transpose it to take advantage of tidyr::fill(). Yet I feel that there is some function in the slider package could solve this. I will look into this and may update the solution.
names <- data_head %>%
t() %>%
as_tibble() %>%
fill(1:3, .direction = "down") %>% # from tidyr
mutate(names = str_c(V1, V2, V3, sep = "_")) %>%
pull(names)
read_excel("data/3headers_demo.xlsx", col_names = names, skip = 3)
#> # A tibble: 6 x 8
#> SUB1_COND1_X SUB1_COND1_Y SUB1_COND2_X SUB1_COND2_Y SUB2_COND1_X SUB2_COND1_Y
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 0.832 0.788 0.394 0.206 0.933 0.153
#> 2 0.415 0.137 0.981 0.749 0.105 0.657
#> 3 0.558 0.0956 0.305 0.354 0.362 0.846
#> 4 0.433 0.828 0.285 0.624 0.0439 0.538
#> 5 0.655 0.650 0.920 0.253 0.812 0.346
#> 6 0.0679 0.698 0.398 0.692 0.528 0.109
#> # ... with 2 more variables: SUB2_COND2_X <dbl>, SUB2_COND2_Y <dbl>