1.1 filter()
filter() 可以基于观测值筛选行,符合条件的行留下,不符合条件的被剔除,最终得到一个观测子集。第一个参数是数据集的名称,第二个参数以及随后的参数是用来筛选行的条件。例如,我们可以使用以下代码筛选出一月一日的所有航班(条件:月 = 1 且 日 = 1)
flights %>%
filter(month == 1, day == 1)
#> # A tibble: 842 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ... with 836 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>思考筛选的方式:
以行为单位,如果该行满足所指定的条件,则被筛选出 ; 若不满足,则被剔除。使用filter()时,总应该从每一行的角度来思考问题。
1.1.1 Operators
为了有效地进行筛选,R 提供了一套标准的运算符,包括比较运算符和逻辑运算符。
比较运算符: ==、!= 、 > 、 >= 、 < 、 <=
当开始编写条件时,最容易犯的错误就是用=而不是==来测试是否相等。R 对于这种错误会提供一条启发性的错误信息:
在判断是否相等时,还有另一个常见问题:浮点数。例如,下面的结果可能出人意料:
计算机使用的是有限位运算,不能存储无限位的数。因此我们看到的每个数都是一个近似值。比较浮点数是否相等时,不能用==,而应该用near(),它用于比较两个数值向量是否相等,且带有一定容忍度(tolerence):
**逻辑运算符*
filter()中的多个参数是“与”的关系,如 data %>% filter(condition_1,condition_2,···,condition_n) 表示的是“我希望同时筛选出满足这n个条件的行。如果要实现其他类型的组合,需要使用逻辑(布尔)运算符。&表示与,|表示或,!表示非。下图给出了布尔运算的完整集合:
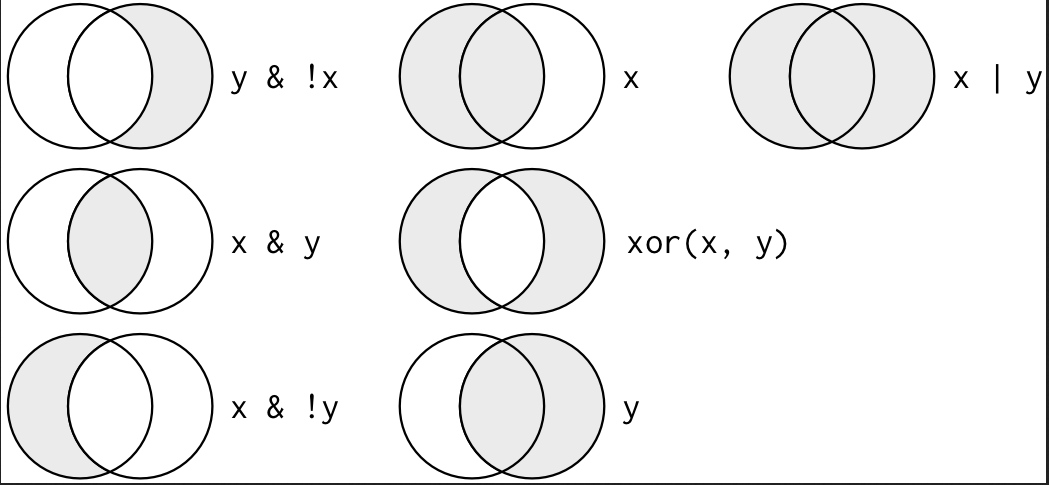
例如,想要找出11月 或 12月出发的所有航班:
flights %>% filter(month == 11 | month == 12)
#> # A tibble: 55,403 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 11 1 5 2359 6 352 345
#> 2 2013 11 1 35 2250 105 123 2356
#> 3 2013 11 1 455 500 -5 641 651
#> 4 2013 11 1 539 545 -6 856 827
#> 5 2013 11 1 542 545 -3 831 855
#> 6 2013 11 1 549 600 -11 912 923
#> # ... with 55,397 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>这种问题有一个有用的简写形式:x %in% y,这个表达式在x被包含于y的时候返回TRUE,我们可以这样改写上面的代码:
flights %>% filter(month %in% c(11, 12)) ## 找出所有月份值包含在该向量里的行
#> # A tibble: 55,403 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 11 1 5 2359 6 352 345
#> 2 2013 11 1 35 2250 105 123 2356
#> 3 2013 11 1 455 500 -5 641 651
#> 4 2013 11 1 539 545 -6 856 827
#> 5 2013 11 1 542 545 -3 831 855
#> 6 2013 11 1 549 600 -11 912 923
#> # ... with 55,397 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>有时可以使用德摩根律来将筛选条件简化:!(x & y)等价于!x | !y,而!(x | y)等价于!x & !y。例如,如果想要找出延误时间(到达和出发)都不多于两个小时的航班,以下两种方式均可:
flights %>% filter(arr_delay <= 120 & dep_dealy <= 120 )
flights %>% filter(!(arr_delay > 120| dep_delay > 120 ))
dplyr中另外一个对筛选有帮助的函数是between(x, left, right),它用于判断x是否落在left和right两个值确定的闭区间里。
例如找出所有在11月和12月出发的航班也可以这样表达:
flights %>% filter(between(month, 11, 12))
#> # A tibble: 55,403 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 11 1 5 2359 6 352 345
#> 2 2013 11 1 35 2250 105 123 2356
#> 3 2013 11 1 455 500 -5 641 651
#> 4 2013 11 1 539 545 -6 856 827
#> 5 2013 11 1 542 545 -3 831 855
#> 6 2013 11 1 549 600 -11 912 923
#> # ... with 55,397 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>有些时候,filter() 函数中用来筛选的条件可能比较复杂,需要书写令人费解的逻辑表达式,这时候可以考虑创建一个新变量代表逻辑判断的结果。这样检查代码会容易很多。我们很快就会介绍如何创建新变量。
1.1.2 Missing values
NA (not available)表示未知的值、缺失值,缺失值一个很重要的特点是它是“可传染的”。如果运算中包含了缺失值,那么运算结果一般来说也会是缺失值。
以上的表达式的结果都是NA,这很好理解,如果R不知道表达式其中的一个量究竟是什么值,自然表达式的结果也就不可知。
还要注意一件事:
这样理解:
令 x 为Mary的年龄,我们不知道她有多大:x <- NA
令 y 为John的年龄,我们同样不知道他又多大:x <- NA
Mary和John的年龄相同吗?: x == y
不知道!
鉴于此,使用NA == x来判断x是否是缺失值不可行。我们用函数is.na()进行判断:
前面说过,filter() 实际上是在提问:某行的某个 \ 某些变量满足给定的条件吗?如果为 TRUE,则筛选出该行。如果该行在涉及变量上的取值是 NA,那么逻辑表达式也会返回 NA,这些行将被返回结果为 FALSE 的行一并被排除。如果想保留缺失值,同样可以利用逻辑表达式指出:
df <- tibble(x = c(1, NA, 3))
df %>% filter(is.na(x) | x > 1)
#> # A tibble: 2 x 1
#> x
#> <dbl>
#> 1 NA
#> 2 3For more topics on missing values, see section 6.6 and Chapter 17.
1.1.3 Exercises
到达时间延误两小时或更多的航班
flights %>% filter(arr_delay >= 120)
#> # A tibble: 10,200 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 811 630 101 1047 830
#> 2 2013 1 1 848 1835 853 1001 1950
#> 3 2013 1 1 957 733 144 1056 853
#> 4 2013 1 1 1114 900 134 1447 1222
#> 5 2013 1 1 1505 1310 115 1638 1431
#> 6 2013 1 1 1525 1340 105 1831 1626
#> # ... with 10,194 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>飞往休斯顿(IAH机场或者HOU机场)的航班
flights %>% filter(dest == "IAH" | dest == "HOU")
#> # A tibble: 9,313 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 623 627 -4 933 932
#> 4 2013 1 1 728 732 -4 1041 1038
#> 5 2013 1 1 739 739 0 1104 1038
#> 6 2013 1 1 908 908 0 1228 1219
#> # ... with 9,307 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>也可以写成filter(flights, dest %in% c("HOU","IAH"))
由联合航空(United)、美利坚航空(American)或者三角洲航空(Delat)运营的航班
carrier列代表了航空公司,但是用两个字母缩写表示:
flights["carrier"]
#> # A tibble: 336,776 x 1
#> carrier
#> <chr>
#> 1 UA
#> 2 UA
#> 3 AA
#> 4 B6
#> 5 DL
#> 6 UA
#> # ... with 336,770 more rows我们可以在airlines数据集中找到这些缩写的含义:
airlines
#> # A tibble: 16 x 2
#> carrier name
#> <chr> <chr>
#> 1 9E Endeavor Air Inc.
#> 2 AA American Airlines Inc.
#> 3 AS Alaska Airlines Inc.
#> 4 B6 JetBlue Airways
#> 5 DL Delta Air Lines Inc.
#> 6 EV ExpressJet Airlines Inc.
#> # ... with 10 more rows三角洲航空对应 “DL”,“UA” 代表联合航空,“AA”代表美利坚航空
flights %>% filter(carrier %in% c("DL", "UA", "AA"))
#> # A tibble: 139,504 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 554 600 -6 812 837
#> 5 2013 1 1 554 558 -4 740 728
#> 6 2013 1 1 558 600 -2 753 745
#> # ... with 139,498 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>夏季(7月、8月、9月)出发的航班
flights %>% filter(month %in% c(7, 8, 9))
#> # A tibble: 86,326 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 7 1 1 2029 212 236 2359
#> 2 2013 7 1 2 2359 3 344 344
#> 3 2013 7 1 29 2245 104 151 1
#> 4 2013 7 1 43 2130 193 322 14
#> 5 2013 7 1 44 2150 174 300 100
#> 6 2013 7 1 46 2051 235 304 2358
#> # ... with 86,320 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>另一种写法:filter(flgihts,month >= 7, month <= 9)
用between()函数的写法:
flights %>% filter(between(month,7,9))
#> # A tibble: 86,326 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 7 1 1 2029 212 236 2359
#> 2 2013 7 1 2 2359 3 344 344
#> 3 2013 7 1 29 2245 104 151 1
#> 4 2013 7 1 43 2130 193 322 14
#> 5 2013 7 1 44 2150 174 300 100
#> 6 2013 7 1 46 2051 235 304 2358
#> # ... with 86,320 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>到达时间延误超过两小时,但出发时间没有延误的航班
flights %>% filter(dep_delay > 120 ,
arr_delay <= 120)
#> # A tibble: 1,262 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 1540 1338 122 2020 1825
#> 2 2013 1 2 2334 2129 125 33 2242
#> 3 2013 1 3 1321 1115 126 1450 1257
#> 4 2013 1 3 1758 1550 128 2240 2050
#> 5 2013 1 3 1933 1730 123 2131 1953
#> 6 2013 1 4 1602 1359 123 1715 1517
#> # ... with 1,256 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>延误至少一小时,但飞行过程弥补回30分钟的航班
flights %>% filter(dep_delay - arr_delay > 30)
#> # A tibble: 17,950 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 701 700 1 1123 1154
#> 2 2013 1 1 820 820 0 1249 1329
#> 3 2013 1 1 840 845 -5 1311 1350
#> 4 2013 1 1 857 851 6 1157 1222
#> 5 2013 1 1 909 810 59 1331 1315
#> 6 2013 1 1 1025 951 34 1258 1302
#> # ... with 17,944 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>出发时间在午夜和早上6点之间(包括0点和6点)的航班
在变量dep_time中,0 点用数值 2400 代表:
summary(flights$dep_time)
#> Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
#> 1 907 1401 1349 1744 2400 8255出于这点,不能简单写成dep_time <= 600,而是如下:
flights %>% filter(dep_time <= 600 | dep_time == 2400)
#> # A tibble: 9,373 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ... with 9,367 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>sum(is.na(flights$dep_time))
#> [1] 8255
flights %>% filter(is.na(dep_time))
#> # A tibble: 8,255 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 NA 1630 NA NA 1815
#> 2 2013 1 1 NA 1935 NA NA 2240
#> 3 2013 1 1 NA 1500 NA NA 1825
#> 4 2013 1 1 NA 600 NA NA 901
#> 5 2013 1 2 NA 1540 NA NA 1747
#> 6 2013 1 2 NA 1620 NA NA 1746
#> # ... with 8,249 more rows, and 11 more variables: arr_delay <dbl>,
#> # carrier <chr>, flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>注意到,所有dep_time为 NA 的航班在有关实际到达、出发情况的变量上取值皆为 NA,这些很可能是被取消的航班。
# 其他变量中的缺失值
flights %>%
summarize_all( ~ sum(is.na(.)))
#> # A tibble: 1 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <int> <int> <int>
#> 1 0 0 0 8255 0 8255 8713 0
#> # ... with 11 more variables: arr_delay <int>, carrier <int>, flight <int>,
#> # tailnum <int>, origin <int>, dest <int>, air_time <int>, distance <int>,
#> # hour <int>, minute <int>, time_hour <int>NA ^ 0的值不是NA,而NA * 0的值是NA ?为什么NA | TRUE 的值不是NA?为什么FALSE & NA的值不是NA,能找出一般规律吗?
只要表达式的值被NA背后的未知量所决定,就返回NA
对于所有 x 的取值,都有\(x ^ 0 = 1\),NA ^ 0不取决于 NA 到底可能是什么值。
但对于\(x * 0\),如果x趋近于正负无穷( R 用-inf 和 inf代表),则R会返回 NaN 错误(not a number),只要知道 NA 究竟是什么,才能知道该表达式的结果
同样,对于 NA | TRUE,不论 NA 是什么,该表达式总为真 ; 对于NA & FALSE,不论 NA 是什么,该表达式总为假。
而 NA & TRUE和NA | FALSE则会返回 NA:
1.1.4 slice()
slice() 及相关帮助函数同样可以用来筛选行,
mtcars %>% slice(1L)
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> 1 21 6 160 110 3.9 2.62 16.5 0 1 4 4
# Similar to tail(mtcars, 1):
mtcars %>% slice(n())
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> 1 21.4 4 121 109 4.11 2.78 18.6 1 1 4 2
mtcars %>% slice(5:n())
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> 1 18.7 8 360.0 175 3.15 3.44 17.0 0 0 3 2
#> 2 18.1 6 225.0 105 2.76 3.46 20.2 1 0 3 1
#> 3 14.3 8 360.0 245 3.21 3.57 15.8 0 0 3 4
#> 4 24.4 4 146.7 62 3.69 3.19 20.0 1 0 4 2
#> 5 22.8 4 140.8 95 3.92 3.15 22.9 1 0 4 2
#> 6 19.2 6 167.6 123 3.92 3.44 18.3 1 0 4 4
#> 7 17.8 6 167.6 123 3.92 3.44 18.9 1 0 4 4
#> 8 16.4 8 275.8 180 3.07 4.07 17.4 0 0 3 3
#> 9 17.3 8 275.8 180 3.07 3.73 17.6 0 0 3 3
#> 10 15.2 8 275.8 180 3.07 3.78 18.0 0 0 3 3
#> 11 10.4 8 472.0 205 2.93 5.25 18.0 0 0 3 4
#> 12 10.4 8 460.0 215 3.00 5.42 17.8 0 0 3 4
#> 13 14.7 8 440.0 230 3.23 5.34 17.4 0 0 3 4
#> 14 32.4 4 78.7 66 4.08 2.20 19.5 1 1 4 1
#> 15 30.4 4 75.7 52 4.93 1.61 18.5 1 1 4 2
#> 16 33.9 4 71.1 65 4.22 1.83 19.9 1 1 4 1
#> 17 21.5 4 120.1 97 3.70 2.46 20.0 1 0 3 1
#> 18 15.5 8 318.0 150 2.76 3.52 16.9 0 0 3 2
#> 19 15.2 8 304.0 150 3.15 3.44 17.3 0 0 3 2
#> 20 13.3 8 350.0 245 3.73 3.84 15.4 0 0 3 4
#> 21 19.2 8 400.0 175 3.08 3.85 17.1 0 0 3 2
#> 22 27.3 4 79.0 66 4.08 1.94 18.9 1 1 4 1
#> 23 26.0 4 120.3 91 4.43 2.14 16.7 0 1 5 2
#> 24 30.4 4 95.1 113 3.77 1.51 16.9 1 1 5 2
#> 25 15.8 8 351.0 264 4.22 3.17 14.5 0 1 5 4
#> 26 19.7 6 145.0 175 3.62 2.77 15.5 0 1 5 6
#> 27 15.0 8 301.0 335 3.54 3.57 14.6 0 1 5 8
#> 28 21.4 4 121.0 109 4.11 2.78 18.6 1 1 4 2
# Rows can be dropped with negative indices:
slice(mtcars, -(1:4))
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> 1 18.7 8 360.0 175 3.15 3.44 17.0 0 0 3 2
#> 2 18.1 6 225.0 105 2.76 3.46 20.2 1 0 3 1
#> 3 14.3 8 360.0 245 3.21 3.57 15.8 0 0 3 4
#> 4 24.4 4 146.7 62 3.69 3.19 20.0 1 0 4 2
#> 5 22.8 4 140.8 95 3.92 3.15 22.9 1 0 4 2
#> 6 19.2 6 167.6 123 3.92 3.44 18.3 1 0 4 4
#> 7 17.8 6 167.6 123 3.92 3.44 18.9 1 0 4 4
#> 8 16.4 8 275.8 180 3.07 4.07 17.4 0 0 3 3
#> 9 17.3 8 275.8 180 3.07 3.73 17.6 0 0 3 3
#> 10 15.2 8 275.8 180 3.07 3.78 18.0 0 0 3 3
#> 11 10.4 8 472.0 205 2.93 5.25 18.0 0 0 3 4
#> 12 10.4 8 460.0 215 3.00 5.42 17.8 0 0 3 4
#> 13 14.7 8 440.0 230 3.23 5.34 17.4 0 0 3 4
#> 14 32.4 4 78.7 66 4.08 2.20 19.5 1 1 4 1
#> 15 30.4 4 75.7 52 4.93 1.61 18.5 1 1 4 2
#> 16 33.9 4 71.1 65 4.22 1.83 19.9 1 1 4 1
#> 17 21.5 4 120.1 97 3.70 2.46 20.0 1 0 3 1
#> 18 15.5 8 318.0 150 2.76 3.52 16.9 0 0 3 2
#> 19 15.2 8 304.0 150 3.15 3.44 17.3 0 0 3 2
#> 20 13.3 8 350.0 245 3.73 3.84 15.4 0 0 3 4
#> 21 19.2 8 400.0 175 3.08 3.85 17.1 0 0 3 2
#> 22 27.3 4 79.0 66 4.08 1.94 18.9 1 1 4 1
#> 23 26.0 4 120.3 91 4.43 2.14 16.7 0 1 5 2
#> 24 30.4 4 95.1 113 3.77 1.51 16.9 1 1 5 2
#> 25 15.8 8 351.0 264 4.22 3.17 14.5 0 1 5 4
#> 26 19.7 6 145.0 175 3.62 2.77 15.5 0 1 5 6
#> 27 15.0 8 301.0 335 3.54 3.57 14.6 0 1 5 8
#> 28 21.4 4 121.0 109 4.11 2.78 18.6 1 1 4 2当要求依据某种排序选出前 / 后 n个观测时,slice_max() 和 slice_min() 可以很好地完成任务
# top 5 cars with largest mpg
mtcars %>% slice_max(order_by = mpg, n = 5)
# top 10% cars with least mpg, with ties not kept together
mtcars %>% slice_min(order_by = mpg, prop = 0.05, with_ties = FALSE)slice_head() and slice_tail() select the first or last rows. slice_sample() randomly selects rows.