8 Tutorial 8: Visualizing data
After working through Tutorial 8, you’ll…
- understand how to visualize data using R
Important:
In this tutorial, I’ll only introduce you to the mere basics of visualizing data in R.
The goal is for you to be proficient enough to create basic graphs using R (not SPSS or Excel). However, please be aware that there are many, many more options than the ones I’ll talk about in Tutorial 8.
In particular, if you have any questions about visualizing data in R, do rely on the following two great tutorials/guides:
- Chang, W. R (2021) R Graphics Codebook. Practical Recipes for Visualizing Data. Link
- Wickham, H., Navarro, D., & Pedersen, T. L. (2021). ggplot2: elegant graphics for data analysis. Online, work-in-progress version of the 3rd edition. Link
Data
For this tutorial, we’ll use data similar to the one introduced in Tutorial 6: Control structures & functions in R.
Please use the data set “data_tutorial 8.txt” (via OLAT/Materials/Data for R). I’ve slightly adapted the data for the purpose of this tutorial (meaning it slighly differs from the data set used in Tutorial 6 and 7).
Remember: The data set consists of data that is completely made up - a survey with 1000 citizens in Europe.
The three variables included here are:
- country: the country in which each citizen was living at the time of the survey (France/ Germany/ Italy/ Switzerland)
- age: each citizen’s age (from 18 to 65)
- trust: how much each citizen trusts the news media (“no trust at all”, “little trust”, “some trust”, “a lot of trust”)
Read in the data set:
data <- read.csv2("data_tutorial 8.txt")This is how the data looks like in R:
str(data)## 'data.frame': 1000 obs. of 3 variables:
## $ country: chr "Germany" "Switzerland" "France" "Italy" ...
## $ age : int 37 33 49 31 50 45 44 57 42 48 ...
## $ trust : chr "no trust at all" "no trust at all" "some trust" "little trust" ...8.1 The basic logic of ggplot2
In this tutorial, we’ll work with the ggplot2 package.
While you can also visualize data using base R, the ggplot2 package makes this so much easier that I won’t teach you the “base R” version of visualizing data.
We’ve already talked about the package in the seminar - you may remember that the package is part of the tidyverse.
The ggplot2 package is based on an underlying logic.7 Understanding this underlying logic will help you to create graphs in a flexible and quick way.
Drawing mainly on Wickham et al. (2021), visualizing data with ggplot2 follows a simple logic. To create a graph, we use existing data and tell R how this data should be mapped:
“A graphic maps the data to the aesthetic attributes (colour, shape, size) of geometric objects (points, lines, bars).” Wickham et al., 2021, no page; bold words inserted by author
This is, indeed, a very brief description of all the things possible with ggplot2. In short, you have to specify the following three components to create a ggplot graph with the ggplot() command:
- data, i.e., the data that should be visualized
- aesthetics, i.e., which data (for instance variables) should be mapped to which visual elements using aes()
- geometrics, i.e., the type of graph that should be created
However, you can specify far more details, for instance the…
- scales of your graph, for instance how the x and y axis should be presented and scaled
- themes of your graph, for instance using a predefined set of backgrounds
- facets of your graph, for instance how many subplots the graph should contain to map relationships across units
(and many more - but these are the things we’ll cover in Tutorial 8).
Before doing anything else, install the ggplot2 package and activate it.
install.packages("ggplot2")
library("ggplot2")Our goal for today: Using data, reproduce the following graph plot to visualize respondents’ trust in news media across countries.
plot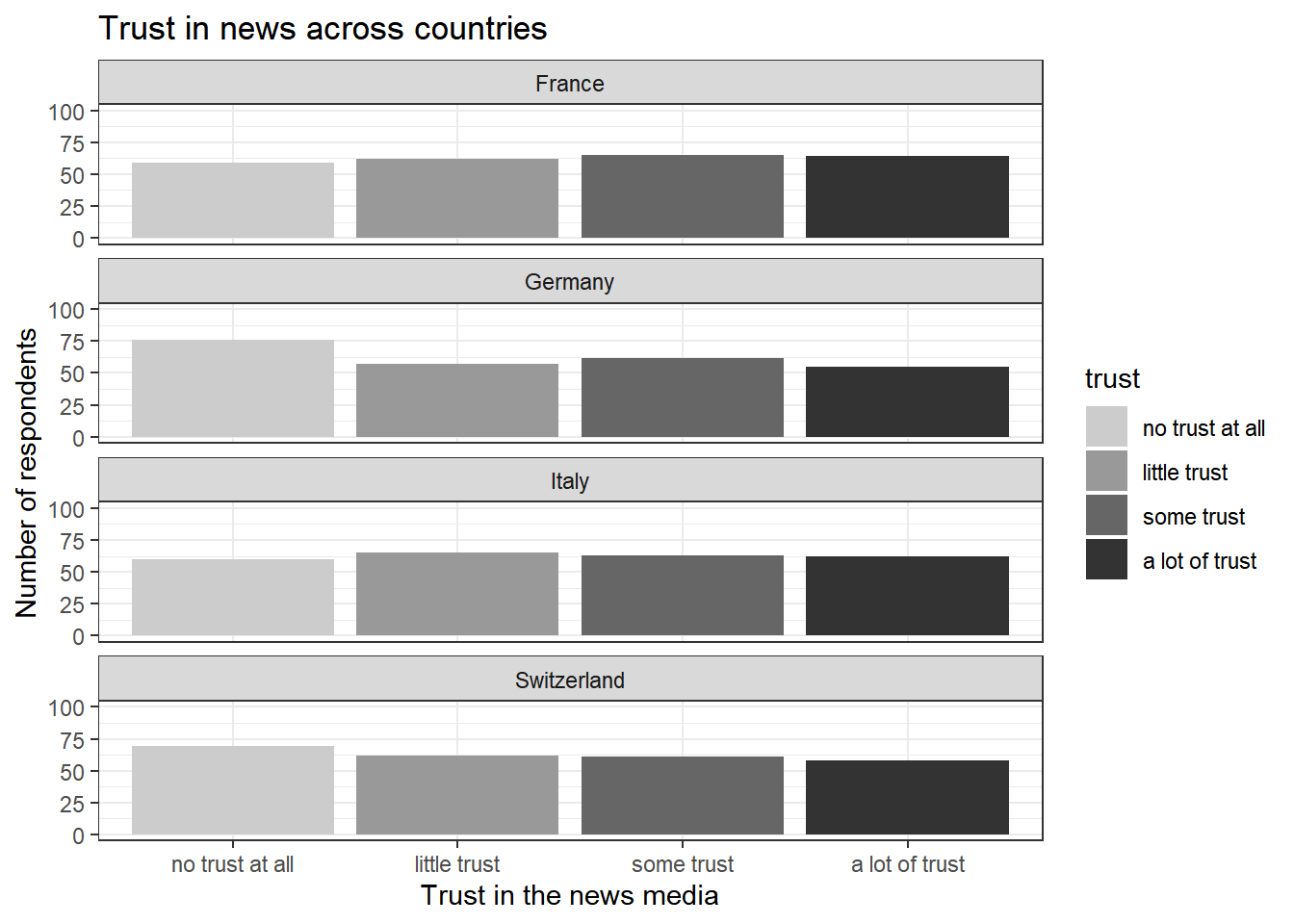
8.1.1 Data
Let’s start with the most basic step: Telling R which data to use to create a graph with the ggplot() command.
Specifying the data is a necessary argument for the ggplot() function, meaning that you have to tell R which data to use.
We’ll start by plotting the data for just one country: Switzerland. For simplicity, we’ll create a new data frame data_Switzerland containing data only for Swiss respondents.
When plotting this data frame data_Switzerland with ggplot(), nothing much happens:
R does not give us an error message, but only creates an “empty” graph.
The reason: We haven’t specified which variables should be visualized and how (i.e., the other 2 necessary components for creating a graph).
data_Switzerland <- data[data$country=="Switzerland",]
ggplot(data_Switzerland)
8.2 Aesthetics
Next, we need to pass values to the aesthetics component.
This is a necessary component, meaning that you have to tell R which data (for instance variables) should be mapped to which visual elements using aes().
In aes(), you can for instance pass values to the following arguments:
- x: the variable that should be mapped to the x axis
- y: the variable that should be mapped to the y axis
- fill: the variable that should be used for filling a geometric object with a specific color
- colour: the variable that should be used for outlining a geometric object with a specific color
(and many more - but these are the things we’ll cover in Tutorial 8).
Let’s set the x for our plot first:
We want the x axis to depict the count of respondents answering with “no trust at all”, “little trust”, “some trust”, and “a lot of trust”. Thus we set x = trust via aes().
If we run the following command, we see that the unique values of the vector trust_new have been added to the graph at its bottom: R now knows which variable should be mapped to the x axis.
However, the graph does not show us any results yet - remember that we haven’t defined the geometrics part as the last necessary component, i.e., the type of graph that should be created.
ggplot(data_Switzerland, aes(x = trust))
Moreover, the values of the variable trust seem to be in a weird order (i.e., “a lot of trust” is followed by “little trust”). Let’s fix that.
As of now, the values are ordered alphabetically:
- a lot of trust
- little trust
- no trust at all
- some trust
However, we want these values to ordered in a meaningful way - for instance starting with low trust values followed by higher trust values:
- no trust at all
- little trust
- some trust
- a lot of trust
To define the order in which values of a variables should be displayed, we transform trust to a factor with levels following a specific order:
data$trust <- factor(data$trust, levels = c("no trust at all",
"little trust",
"some trust",
"a lot of trust"))
data_Switzerland <- data[data$country=="Switzerland",](This may also serve as a reminder as to why I introduced you to factors in Tutorial 3: Objects & structures in R - we will need this type of data now).
ggplot(data_Switzerland, aes(x = trust))
This worked: The order of unique values for the x axis now makes far more sense: from low trust scores on the left to high trust scores on the right.
8.3 Geometrics
Lastly, we need to define the geometric component as the last necessary component: You have to tell R which type of graph should be created.
You can, for instance, use the following commands to create different graphs (simply type in geom in the script and R Studio will automatically propose a lot options to you, including:
- geom_bar() to create a bar chart
- geom_line() to create a line graph
- geom_point() to create a scatter plot
- geom_boxplot() to create a box plot
(and many more - but these are the things we’ll cover in Tutorial 8).
Here, we want to create a simple count of unique values in trust_news.
To do so, we have to use a bar chart using geom_bar(). We add this new layer using a + sign:
ggplot(data_Switzerland, aes(x = trust)) +
geom_bar()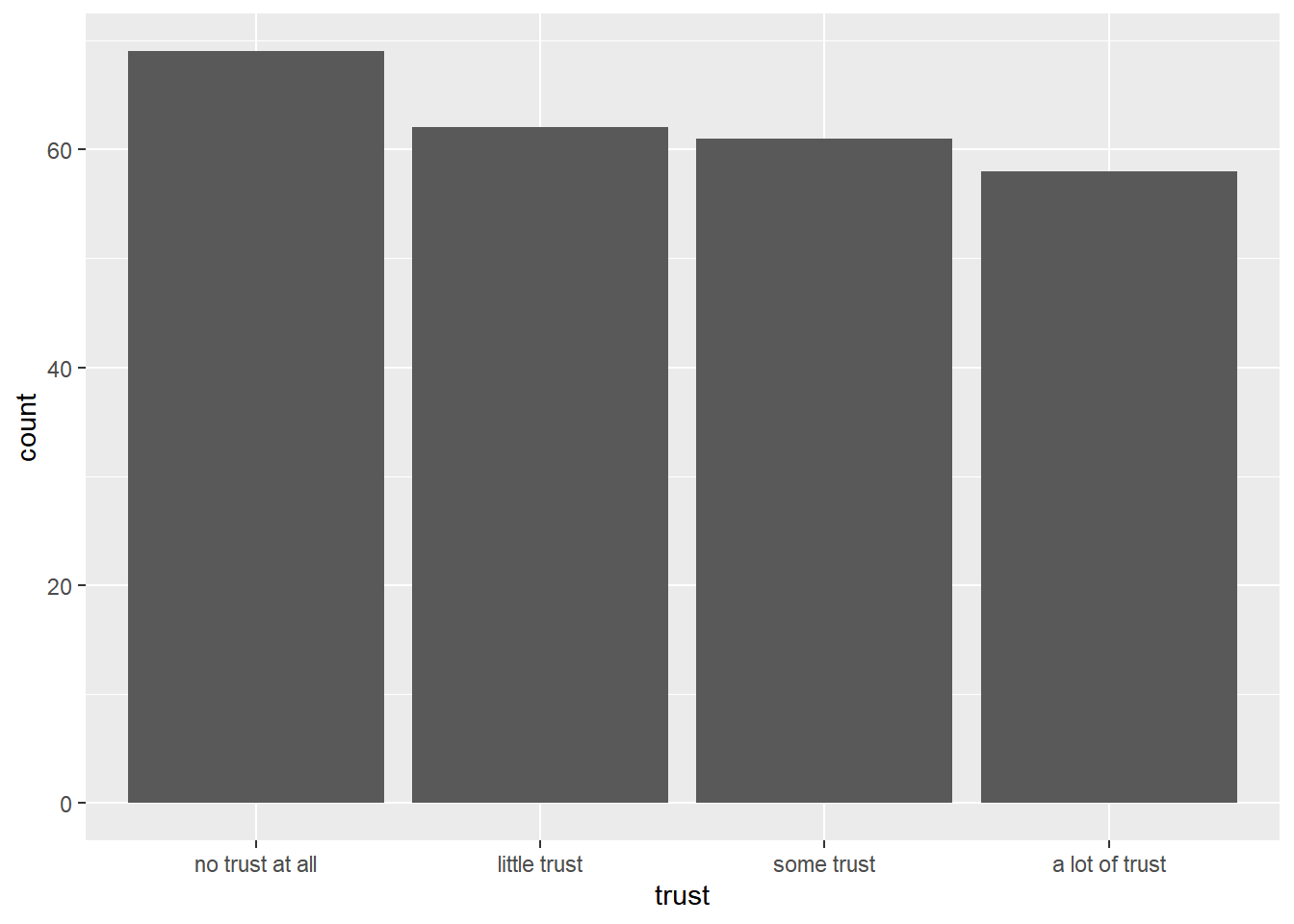
Great: this worked! We have created the first graph bearing some resemblance to the one in the beginning.
Adding color
We now want R to fill these single bar charts with different colors based on their unique value - i.e., for the value “no trust at all” to be filled with a different color than the value “a little trust” and so forth.
We can do that using the fill() argument in aes():
ggplot(data_Switzerland, aes(x = trust, fill = trust)) +
geom_bar()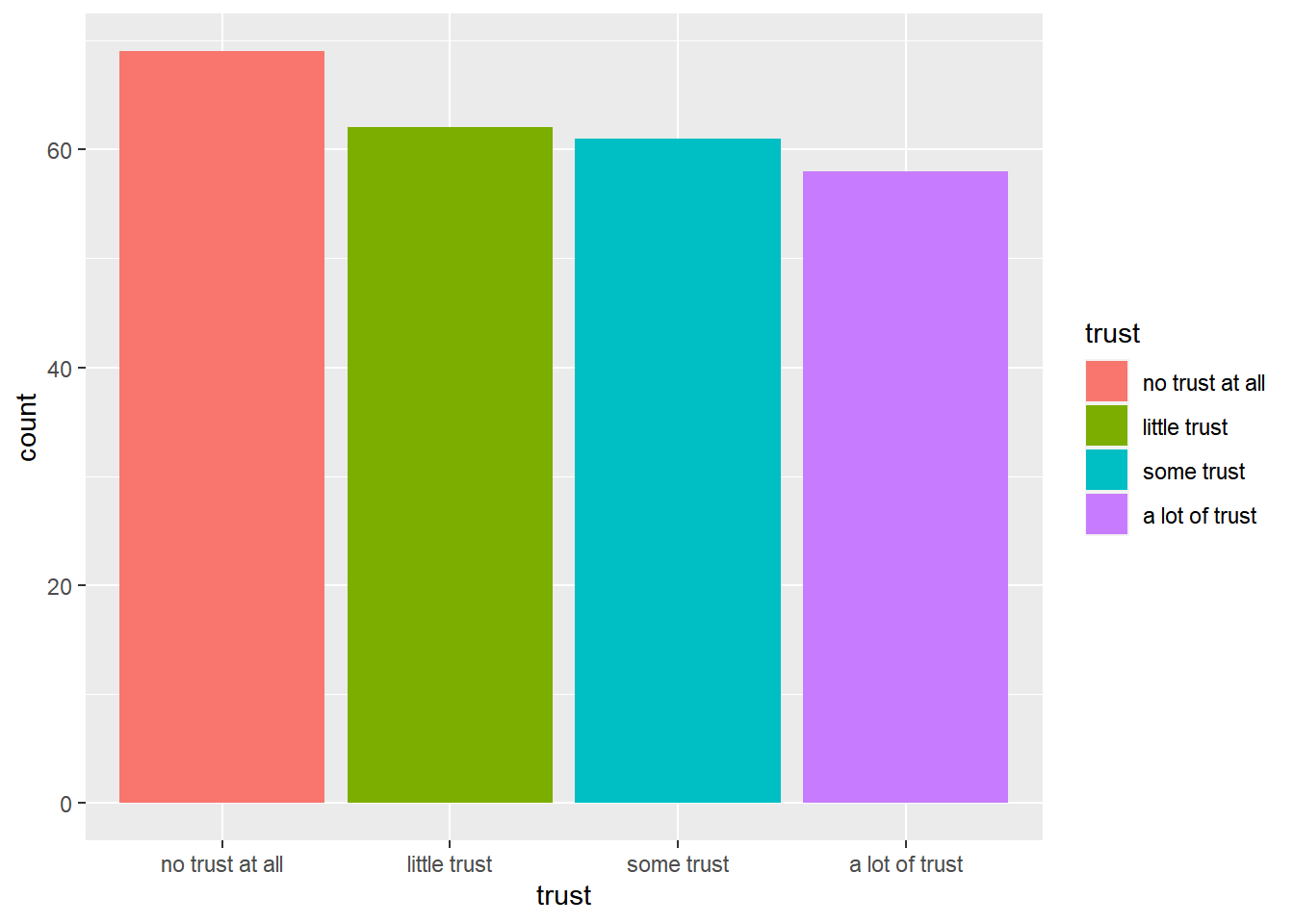
For now, please ignore that the colors are not the ones used in the final graph - we will change this in a bit.
Adding a title and clear names for each axis
Lastly, we will now assign our graph a clear title. We will also change the titles for the x and y axis (which are now simply labelled using the variables’ names in data_Switzerland).
You should always assign clear titles to graphs, axes, legends, etc. for readers to understand what type of data graphs visualize and which variables they contain.
We can add a title for the graph as well as both axes using the labs() command:
ggplot(data_Switzerland, aes(x = trust, fill = trust)) +
geom_bar() +
labs(title = "Trust in news in Switzerland",
x = "Trust in the news media",
y = "Number of respondents")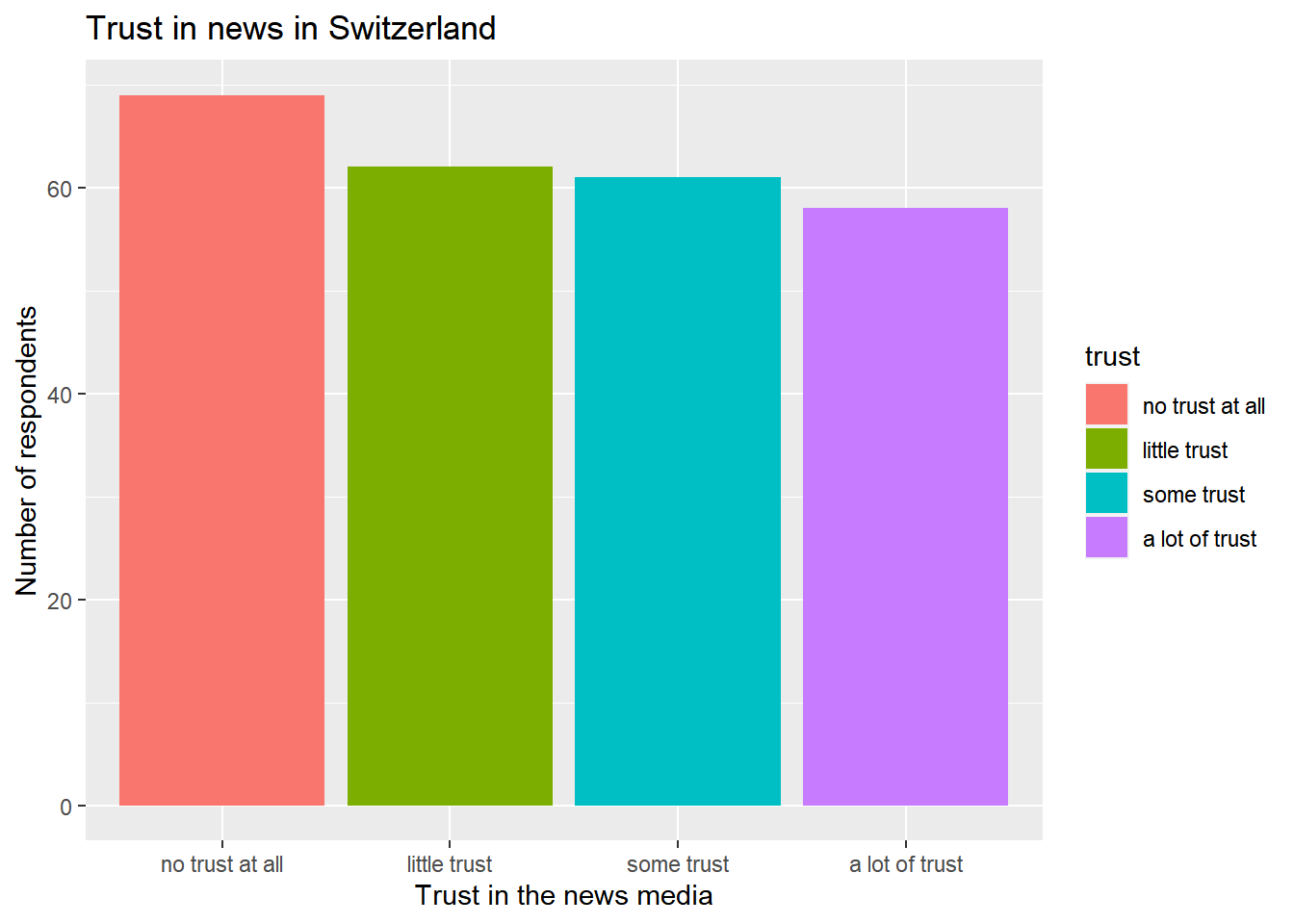
Other types of graphs
Please note that we could also create any other type of graph.
For instance, if we wanted to create a line showing how two variables are related (for instance, how respondents’ trust in the news is related to their age), we could define both variable as the x and the y argument of the aes() component and, for example, plot a scatter plot.
The following graph shows us how age and trust relate to each other, indicating that older people may have more trust in the news media, at least in Switzerland:
ggplot(data_Switzerland, aes(x = age, y = trust)) +
geom_point()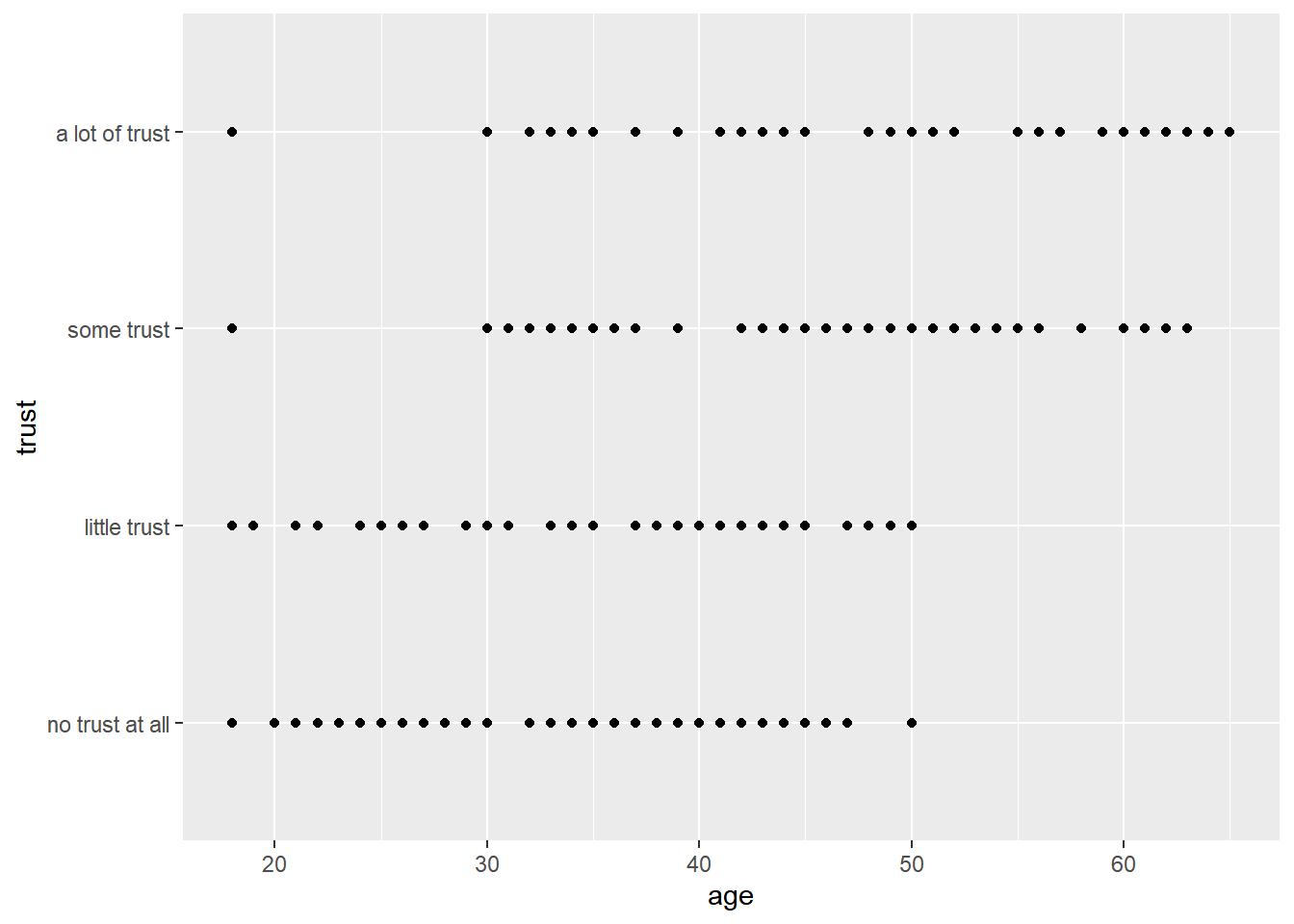
You may be more familiar with the box plot format (often used in descriptive statistics to visualize average values of variables and deviations from these values):
ggplot(data_Switzerland, aes(x = age, y = trust)) +
geom_boxplot()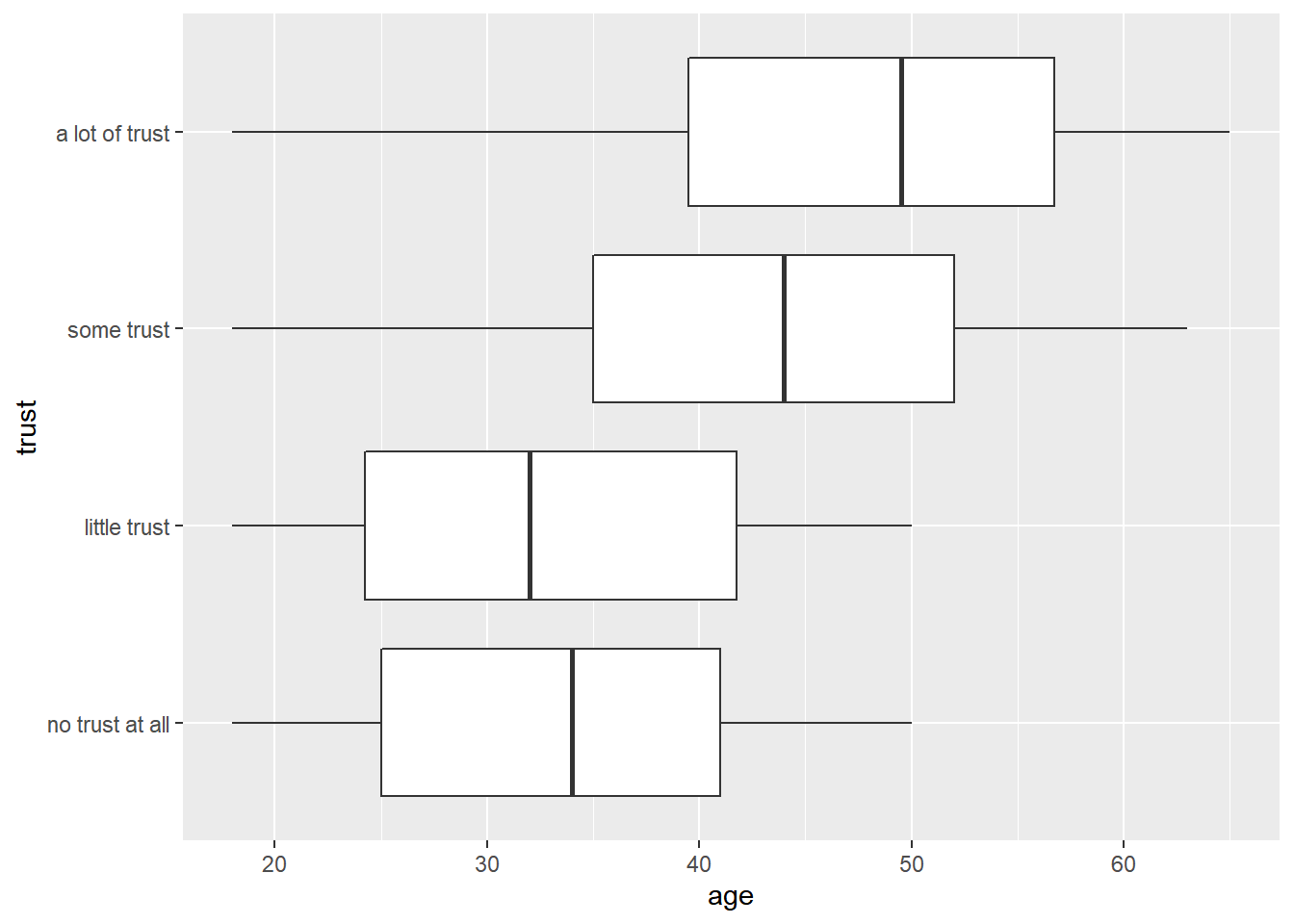
However, for now let’s go back to our original graph.
To make our graph look more like the graph at the beginning of the Tutorial, we’ll now have to rescale our x and y axis.
8.4 Scales
Scales are the first component we deal with that you do not have to specify to create a graph.
Still, you will often use your own setting to make your graph more understandable, thereby changing existing scales.
You can for example change:
- how the x and y axis should be scaled or titled
- how the legend should be presented
Changing the range of our scales
Remember, this is how our graph looks like for now:
ggplot(data_Switzerland, aes(x = trust, fill = trust)) +
geom_bar() +
labs(title = "Trust in news in Switzerland",
x = "Trust in the news media",
y = "Number of respondents")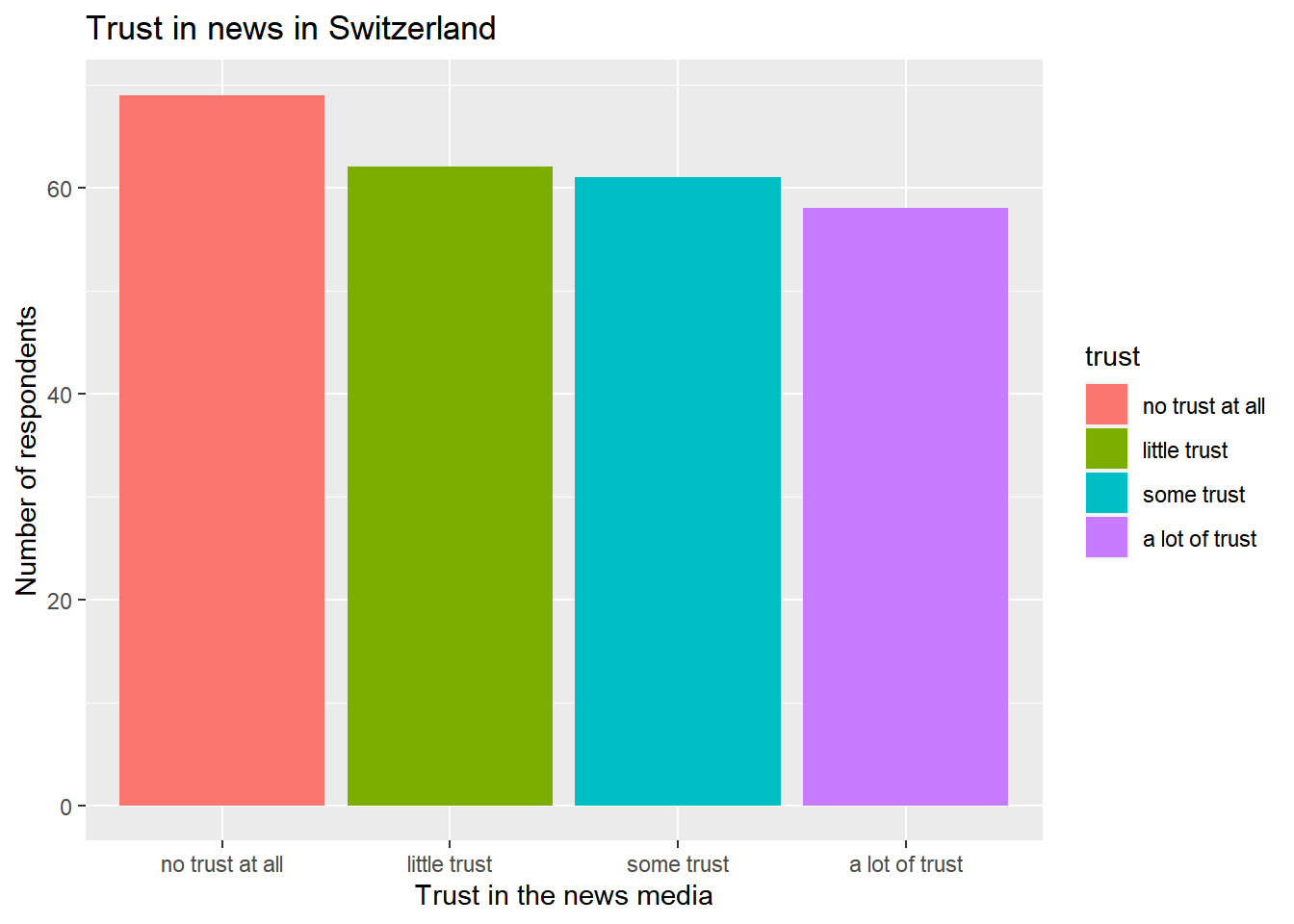
As indicated by the graph above, most people in Switzerland said that they have no trust in the news at all (69 respondents), fewer have little trust (62 respondents), some trust (61 respondents), or a lot of trust (58 respondents):
table(data_Switzerland$trust)##
## no trust at all little trust some trust a lot of trust
## 69 62 61 58However, these values may look different for other countries - for instance, more than 76 respondents in Germany said that they have no trust at all:
table(data$trust[data$country=="Germany"])##
## no trust at all little trust some trust a lot of trust
## 76 57 62 55So far, the graph above only ranges from 0 (lowest values on the y axis) to 70 (highest values on the y axis) on the y axis (see the cut-off around 70).
To better compare values across countries later on, it may be useful to set the limits of the y axis manually and allow for bigger counts to also be included.
We can manually set the limits of continuous variables using the scale_x_continuous() or scale_y_continuous() command.
Here, we ask R to include values from 0 to 100 on the y axis using scale_y_continuous():
ggplot(data_Switzerland, aes(x = trust, fill = trust)) +
geom_bar() +
labs(title = "Trust in news in Switzerland",
x = "Trust in the news media",
y = "Number of respondents") +
scale_y_continuous(limits = c(0, 100)) 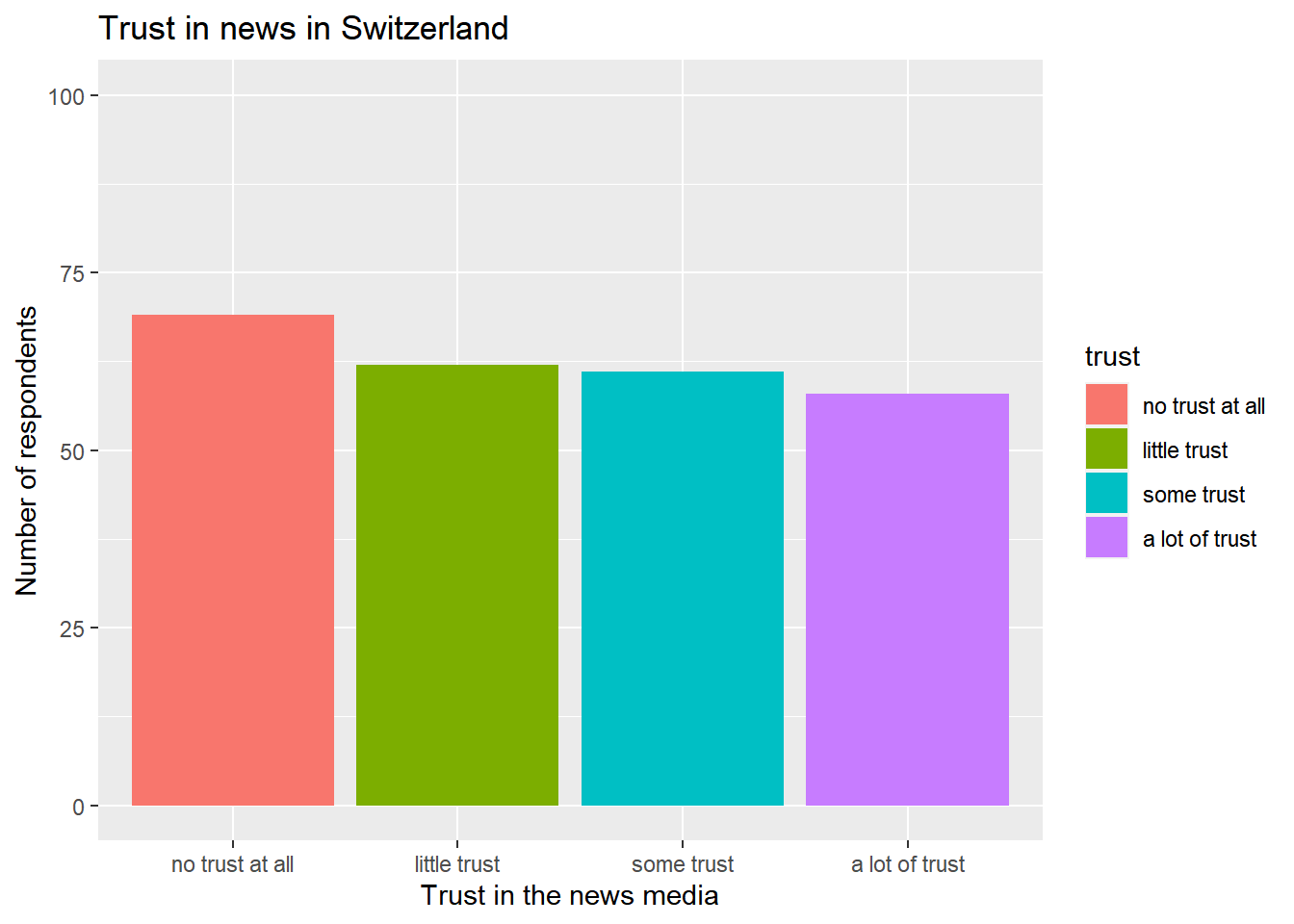
Compare both graphs: The data is exactly the same, we have just “stretched” the graph a little by extending the y axis.
Changing the colors used in the plot
Next, we may want to change the colors of our plot. As for now, R has automatically chosen colors.
However, you may want to change this - for instance, to create a graph in black/white only or to only use colorblind-friendly colors.
There are a lot of different colors in R, as you can for instance see in this overview. Moreover, there are nice color palettes including a range of colors that work well together for data visualization, as you can see in this overview. Of particular popularity here is, for example, the RColorBrewer package offering some really nice palettes for visualization.
For our graph, we want to go with a classic black/white scheme:
- We want higher trust scores to be depicted in darker gray.
- We want lower trust scores to be depicted in lighter gray.
To set this manually, we can use the scale_fill_manual() function.
In short, you tell R for which value of a variables which color should be used. To do so, use scale_fill_manual().
I simply checked out some gray colors here and then went with a selection of grays: gray 80, gray 60, gray 40, and gray 20.
We now add these new colors using scale_fill_manual():
ggplot(data_Switzerland, aes(x = trust, fill = trust)) +
geom_bar() +
labs(title = "Trust in news in Switzerland",
x = "Trust in the news media",
y = "Number of respondents") +
scale_y_continuous(limits = c(0, 100)) +
scale_fill_manual(values = c("no trust at all" = "gray80",
"little trust" = "gray60",
"some trust" = "gray40",
"a lot of trust" = "gray20"))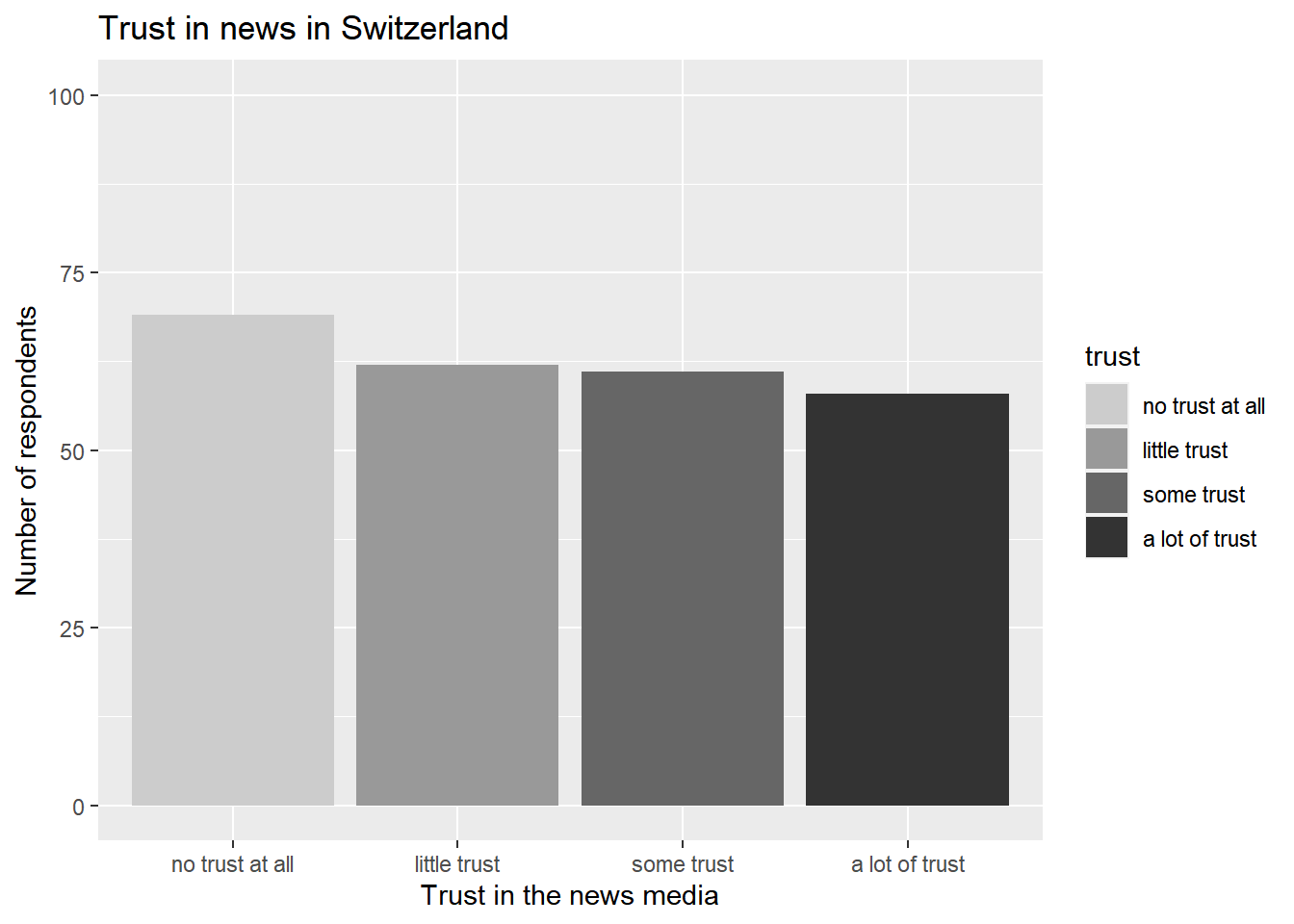
8.5 Themes
Themes are the next component we deal with that you do not have to specify to create a graph - but oftentimes, you will because setting a theme allows you to create more beautiful graphs.
The creators of ggplot2 have come up with some nice visual settings for graphs. Best check out this overview here.
If you type in theme and wait for R to auto-complete your search, you will see some of these themes, for instance the light theme theme_light(), which we can add again as a new layer using the + symbol:
ggplot(data_Switzerland, aes(x = trust, fill = trust)) +
geom_bar() +
labs(title = "Trust in news in Switzerland",
x = "Trust in the news media",
y = "Number of respondents") +
scale_y_continuous(limits = c(0, 100)) +
scale_fill_manual(values = c("no trust at all" = "gray80",
"little trust" = "gray60",
"some trust" = "gray40",
"a lot of trust" = "gray20")) +
theme_light()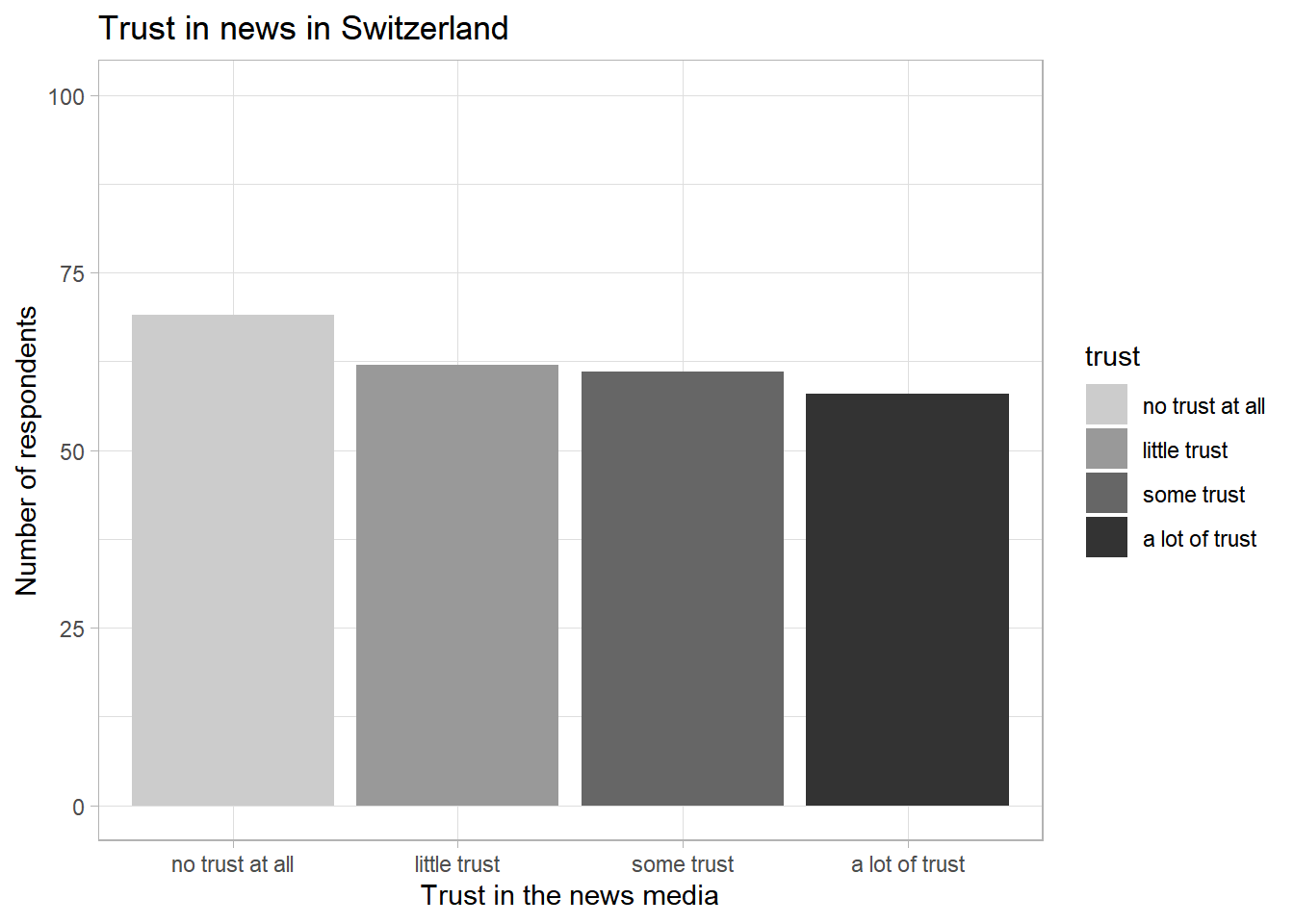
… or the classic theme using theme_classic():
ggplot(data_Switzerland, aes(x = trust, fill = trust)) +
geom_bar() +
labs(title = "Trust in news in Switzerland",
x = "Trust in the news media",
y = "Number of respondents") +
scale_y_continuous(limits = c(0, 100)) +
scale_fill_manual(values = c("no trust at all" = "gray80",
"little trust" = "gray60",
"some trust" = "gray40",
"a lot of trust" = "gray20")) +
theme_classic()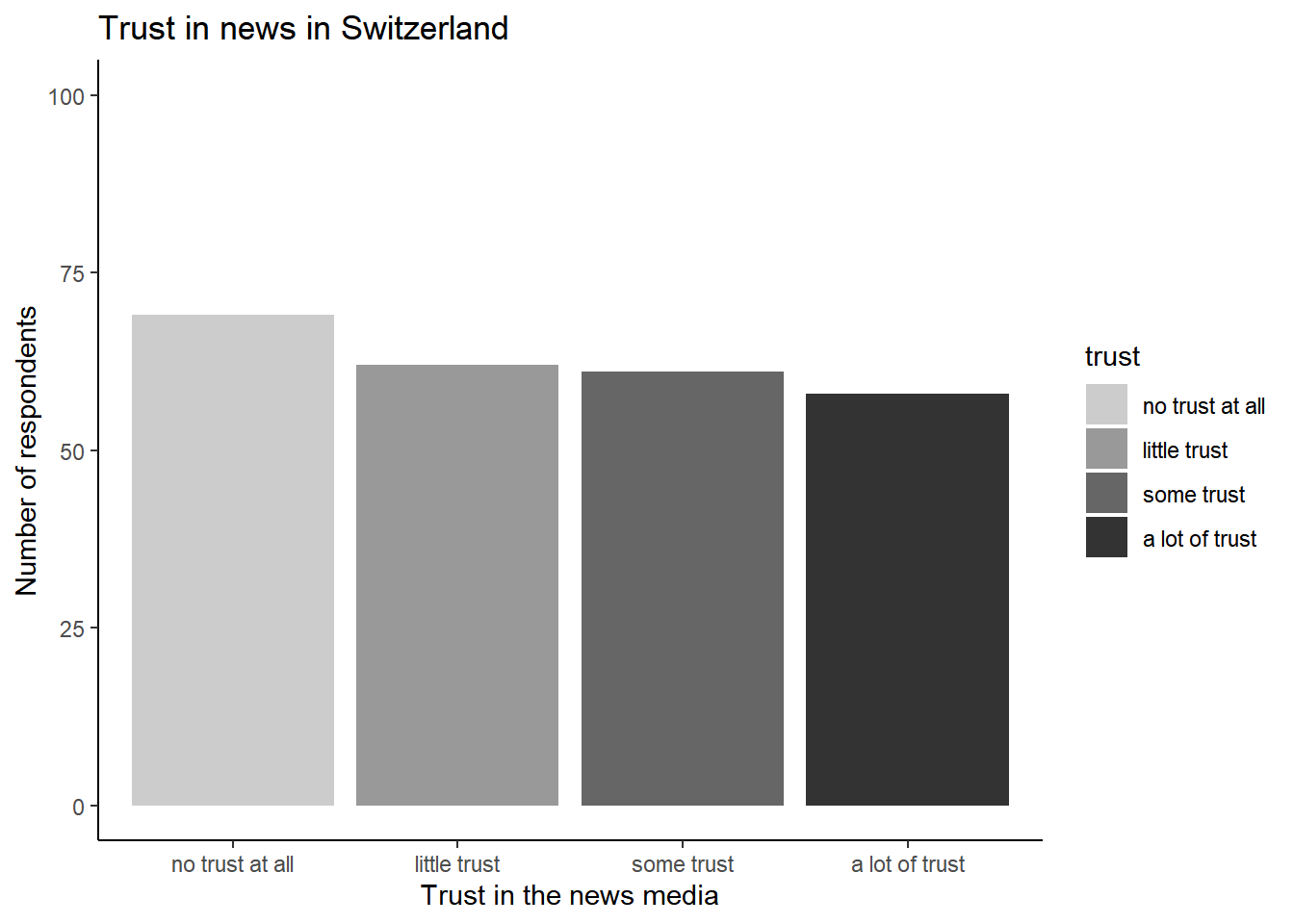
Since we work with a black and white color schema, I went with the theme_bw() for the graph depicted at the beginning of Tutorial 8:
ggplot(data_Switzerland, aes(x = trust, fill = trust)) +
geom_bar() +
labs(title = "Trust in news in Switzerland",
x = "Trust in the news media",
y = "Number of respondents") +
scale_y_continuous(limits = c(0, 100)) +
scale_fill_manual(values = c("no trust at all" = "gray80",
"little trust" = "gray60",
"some trust" = "gray40",
"a lot of trust" = "gray20")) +
theme_bw()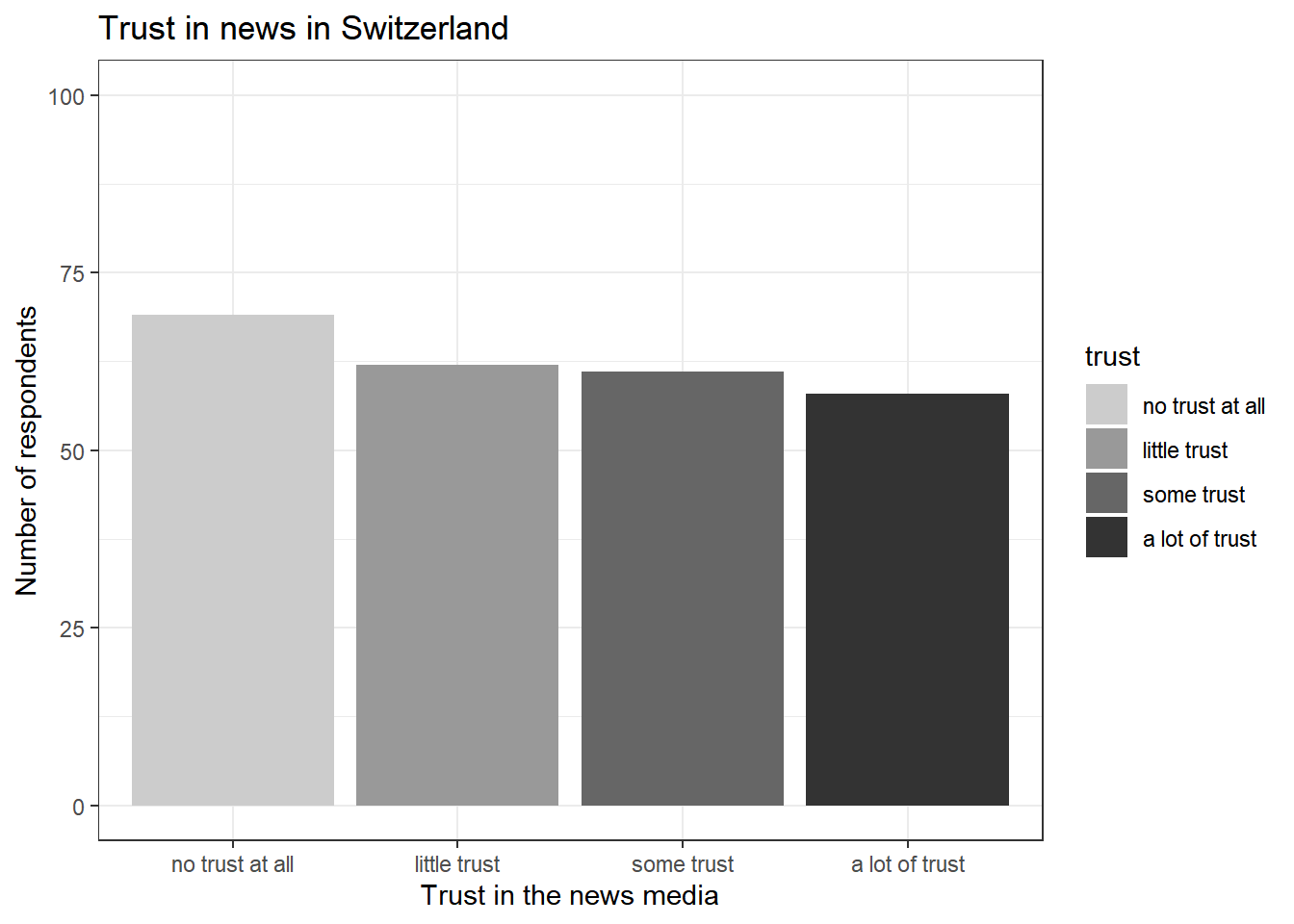
8.6 Facets
We’re almost there - we have now created a graph for one of the four countries.
How do we create the same graph, but include trust scores across all four countries at once?
The answer: We’ll use the facet_wrap() command.
Facets are the next component we deal with that you do not have to specify to create a graph. Using facets may also not always be necessary - if you do not want to visualize similar relationships across groups, everything you learned so far will be more than enough.
However, for graphs to include comparisons of the same relationship across units, facet_wrap() is very helpful.
In short, we’ll need the following arguments to re-create the graph from the beginning of Tutorial 8 using facet_wrap():
- facets: the grouping variable, indicating across which units our data should be visualized
- nrow: the number of rows in which results should be displayed. We could, for example, display all four graphs (1 for each country) into a single row by setting nrow = 4. Or we could create a 2x2 design by setting nrow = 2, and so forth.
To re-create the full graph, three things need to be changed or added:
- We now use the full data set (see that we use data instead of data_Switzerland right after ggplot()).
- Accordingly, we change our title to Trust in news across countries using labs().
- Lastly, we add the facet_wrap() command and tell R to display the count of respondents for each unique value of trust across countries, with every country being depicted in a single row by setting nrow to 4:
ggplot(data, aes(x = trust, fill = trust)) +
geom_bar() +
labs(title = "Trust in news across countries",
x = "Trust in the news media",
y = "Number of respondents") +
scale_y_continuous(limits = c(0, 100)) +
scale_fill_manual(values = c("no trust at all" = "gray80",
"little trust" = "gray60",
"some trust" = "gray40",
"a lot of trust" = "gray20")) +
theme_bw() +
facet_wrap(~ country, nrow = 4)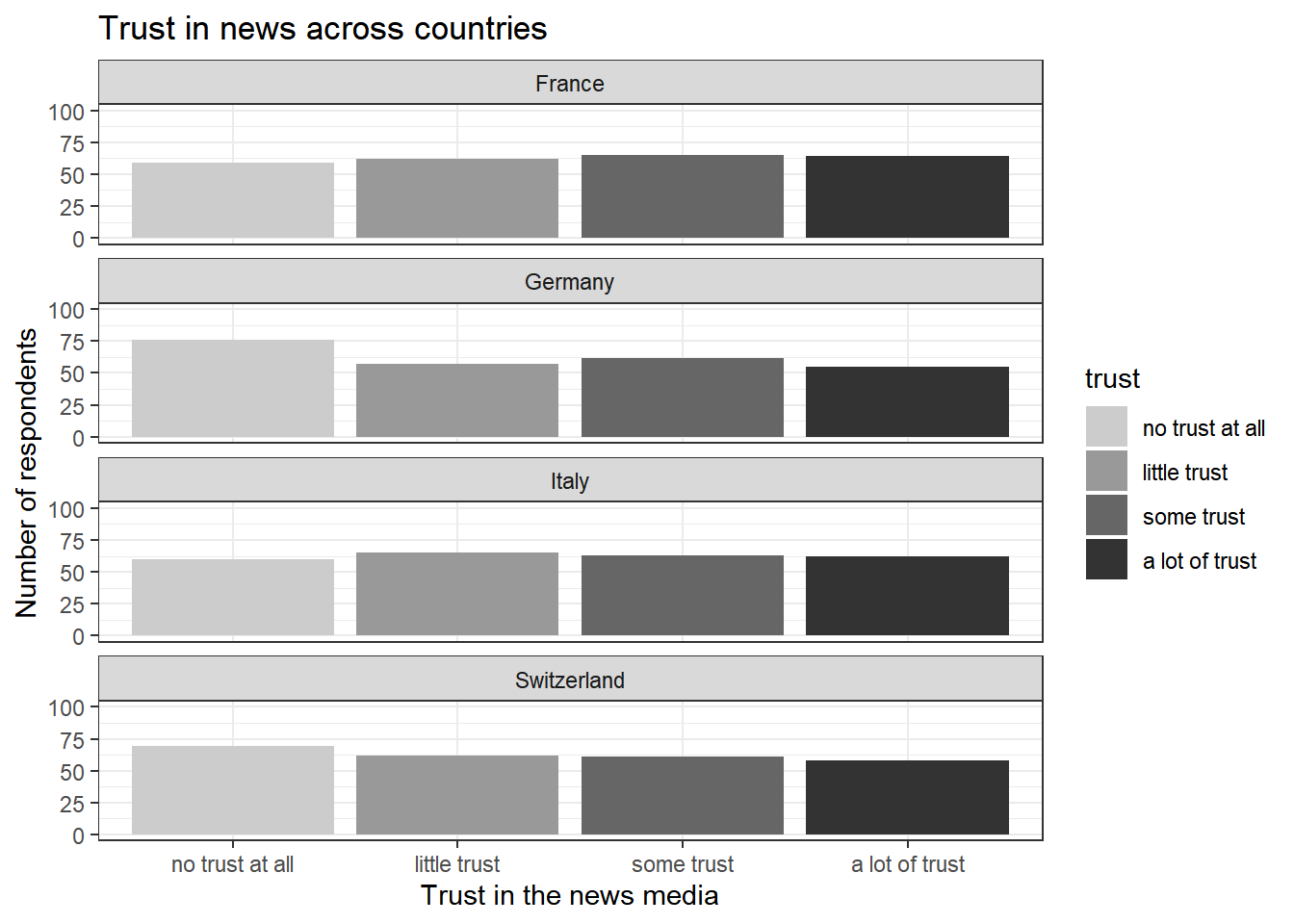
That’s it - we have recreated our graph, nice work!
8.7 Saving images
Lastly, you may want to save your graph externally to later use the image for reports or seminar papers, for instance.
To do so, you can simply use the ggsave() command:
Save the plot in an object - here the object plot. Next, save it to your computer using ggsave().
Important: Make sure to specify the correct name of your image, including in what format it should be used. I went for a jpeg image here as indicated by the name “myplot.jpeg”:
plot <- ggplot(data, aes(x = trust, fill = trust)) +
geom_bar() +
labs(title = "Trust in news across countries",
x = "Trust in the news media",
y = "Number of respondents") +
scale_y_continuous(limits = c(0, 100)) +
scale_fill_manual(values = c("no trust at all" = "gray80",
"little trust" = "gray60",
"some trust" = "gray40",
"a lot of trust" = "gray20")) +
theme_bw() +
facet_wrap(~ country, nrow = 4)
ggsave(filename = "myplot.jpeg", plot)8.8 Take Aways
- creating a graph: ggplot()
- Mapping data to visuals: aes(x, y, color, fill, etc.)
- Choosing the type of graph to be created: geom_bar(), geom_line(), geom_point(), geom_boxplot() (for example)
- Adding titles: labs() (for example)
- Changing the limits/values in x or y axis: scale_x_continuous(), scale_y_continuous() (for example)
- Assigning colors to values: scale_fill_manual() (for example)
- Setting a graph’s theme: theme_classic(), theme_light(), theme_bw() (for example)
- Plotting distributions/relationships by groups: facet_wrap()
- Saving images: ggsave()
8.9 More tutorials on this
You still have questions? The following tutorials & papers can help you with that:
- Chang, W. R (2021) R Graphics Codebook. Practical Recipes for Visualizing Data. Link
- Wickham, H., Navarro, D., & Pedersen, T. L. (2021). ggplot2: elegant graphics for data analysis. Online, work-in-progress version of the 3rd edition. Link
- Hehman, E., & Xie, S. Y. (2021). Doing Better Data Visualization. _Advances in Methods and Practices in Psychological Science__. DOI: 10.1177/25152459211045334 Link
- R Codebook by J.D. Long and P. Teetor, Tutorial 10
8.10 Test your knowledge
You’ve worked through all the material of Tutorial 8? Let’s see it - the following tasks will test your knowledge.
8.10.1 Task 8.1
Try to re-create as much as possible of the following graph depicting the distribution of respondents’ age across countries.
Hint: For the geometric component, check out the geom_histogram() function.
plot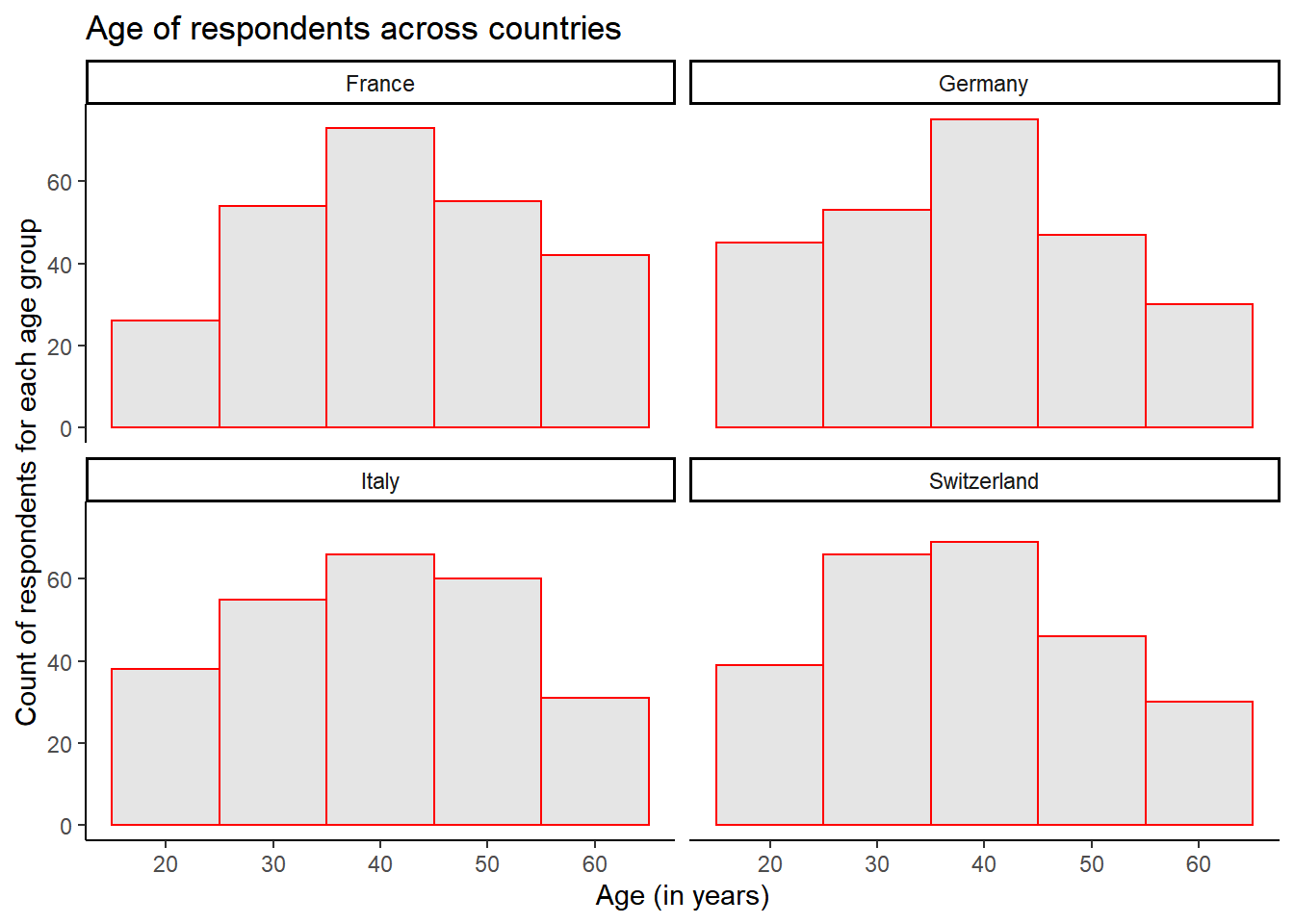
Let’s keep going: Introduction to Automated Content Analysis in R.
see here for further information: http://vita.had.co.nz/papers/layered-grammar.pdf↩︎