Solutions for tasks in tutorials
This is where you’ll find solutions for all of the tutorials (mostly after we have discussed them in the seminar).
Solutions for Tutorial 3
Task 3.1
Create a data frame called data. The data frame should contain the following variables (in this order):
- a vector called food. It should contain 5 elements, namely the names of your five favourite dishes.
- a vector called description. For every dish mentioned in food, please describe the dish in a single sentence (for instance, if the first food you describe is “pizza”, you could write: “This is an Italian dish, which I prefer with a lot of cheese.”)
- a vector called rating. Rate every dish mentioned in food with 1-5 (using every number only once), i.e., by rating your absolute favorite dish out of all five with a 1 and your least favorite dish out of all five with a 5.
Solution:
data <- data.frame("food" = c("pizza", "pasta", "ice cream", "crisps", "passion fruit"),
"description" = c("Italian dish, I actually prefer mine with little cheese",
"Another Italian dish",
"The perfect snack in summer",
"Potatoes and oil - a luxurious combination",
"A fruit that makes me think about vacation"),
"Rating" = c(3,1,2,4,5))
data## food description Rating
## 1 pizza Italian dish, I actually prefer mine with little cheese 3
## 2 pasta Another Italian dish 1
## 3 ice cream The perfect snack in summer 2
## 4 crisps Potatoes and oil - a luxurious combination 4
## 5 passion fruit A fruit that makes me think about vacation 5Task 3.2
Can you sort the data in your data set by rating - with your favorite dish (i.e., the one rated “1”) on top of the list and your least favourite dish (i.e., the one rated “5”) on the bottom?
Important: You do not yet know this command - you’ll have to google for the right solution. Please do and note down the exact search terms you used for googling, so we can discuss them next week.
Solution:
library("dplyr")
data <- data%>%arrange(Rating)
data## food description Rating
## 1 pasta Another Italian dish 1
## 2 ice cream The perfect snack in summer 2
## 3 pizza Italian dish, I actually prefer mine with little cheese 3
## 4 crisps Potatoes and oil - a luxurious combination 4
## 5 passion fruit A fruit that makes me think about vacation 5Solutions for Tutorial 5
Task 5.1
Read the data set into R. Writing the corresponding R code, find out
- how many observations and how many variables the data set contains.
Solution:
data <- read.csv2("data_tutorial4.txt", sep = ",")#number of rows / observations
nrow(data)## [1] 85#number of columns / variables
ncol(data)## [1] 13Task 5.2
Writing the corresponding R code, find out
- how many candy bars contain chocolate.
- how many candy bars contain fruit flavor.
Solution:
table(data$chocolate)##
## 0 1
## 48 37table(data$fruity)##
## 0 1
## 47 38Task 5.3
Writing the corresponding R code, find out
- the name(s) of candy bars containing both chocolate and fruit flavor.
Solution:
#Solution 1: base R
data$competitorname[data$chocolate==1 & data$fruity==1]## [1] "Tootsie Pop"#Solution 2: dplyr
data %>% filter(chocolate==1 & fruity == 1) %>% select(competitorname)## competitorname
## 1 Tootsie PopTask 5.4
Create a new data frame called data_new. Writing the corresponding R code,
- reduce the data set only observations containing chocolate but not caramel. The data set should also only include the variables competitorname and pricepercent.
- round the variable pricepercent to two decimals.
- sort the data by pricepercent in descending order, i.e., make sure that candy bars with the highest price are on top of the data frame and those with the lowest price on the bottom.
Solution:
#Solution 1: base R
data_new <- data[data$chocolate == 1 & data$caramel==0,]
data_new$pricepercent <- round(as.numeric(data_new$pricepercent),2)
data_new[order(data_new$pricepercent, decreasing = TRUE),c("competitorname", "pricepercent")]## competitorname pricepercent
## 63 Nestle Smarties 0.98
## 24 Hershey's Krackel 0.92
## 25 Hershey's Milk Chocolate 0.92
## 26 Hershey's Special Dark 0.92
## 41 Mr Good Bar 0.92
## 40 Mounds 0.86
## 85 Whoppers 0.85
## 6 Almond Joy 0.77
## 43 Nestle Butterfinger 0.77
## 44 Nestle Crunch 0.77
## 33 Peanut butter M&M's 0.65
## 34 M&M's 0.65
## 48 Peanut M&Ms 0.65
## 53 Reese's Peanut Butter cup 0.65
## 54 Reese's pieces 0.65
## 55 Reese's stuffed with pieces 0.65
## 2 3 Musketeers 0.51
## 11 Charleston Chew 0.51
## 28 Junior Mints 0.51
## 29 Kit Kat 0.51
## 76 Tootsie Roll Juniors 0.51
## 75 Tootsie Pop 0.32
## 78 Tootsie Roll Snack Bars 0.32
## 52 Reese's Miniatures 0.28
## 23 Hershey's Kisses 0.09
## 60 Sixlets 0.08
## 77 Tootsie Roll Midgies 0.01#Solution 1: dplyr
data %>% filter(chocolate == 1 & caramel == 0) %>%
select(competitorname, pricepercent) %>%
mutate(pricepercent = as.numeric(pricepercent)) %>%
mutate(across(2, round, 2)) %>%
arrange(desc(pricepercent))## competitorname pricepercent
## 1 Nestle Smarties 0.98
## 2 Hershey's Krackel 0.92
## 3 Hershey's Milk Chocolate 0.92
## 4 Hershey's Special Dark 0.92
## 5 Mr Good Bar 0.92
## 6 Mounds 0.86
## 7 Whoppers 0.85
## 8 Almond Joy 0.77
## 9 Nestle Butterfinger 0.77
## 10 Nestle Crunch 0.77
## 11 Peanut butter M&M's 0.65
## 12 M&M's 0.65
## 13 Peanut M&Ms 0.65
## 14 Reese's Peanut Butter cup 0.65
## 15 Reese's pieces 0.65
## 16 Reese's stuffed with pieces 0.65
## 17 3 Musketeers 0.51
## 18 Charleston Chew 0.51
## 19 Junior Mints 0.51
## 20 Kit Kat 0.51
## 21 Tootsie Roll Juniors 0.51
## 22 Tootsie Pop 0.32
## 23 Tootsie Roll Snack Bars 0.32
## 24 Reese's Miniatures 0.28
## 25 Hershey's Kisses 0.09
## 26 Sixlets 0.08
## 27 Tootsie Roll Midgies 0.01Solutions for Tutorial 6
Task 6.1
Writing the corresponding R code,
- add the value of the previous observation in the data set to every value belonging to the variable trust_politics. Save the resulting vector in a variable called trust_politics_new.
In this case, the first observation should be coded as NA. The second observation should include the sum of the first and the second observation, the third observation should include the values of the second and third observation, etc.
Solution:
data <- read.csv2("data_tutorial 6.txt")#write loop for second to last observation
for (i in (2:nrow(data))){ #include second to last observation
#change value: overwrite each value with value of that observation and the one before (i-1)
data$trust_politics_new[i] <- data$trust_politics[i] + data$trust_politics[i-1]
} #close loop
#set first observation to NA
data$trust_politics_new[1] <- NAhead(data[c("trust_politics", "trust_politics_new")])## trust_politics trust_politics_new
## 1 3 NA
## 2 2 5
## 3 1 3
## 4 2 3
## 5 3 5
## 6 1 4Thus:
- the first row is set to NA.
- the second row contains the sum of the first and second observation (3 + 2 = 5).
- the third row contains the sum of the second and third observation (2 + 1 = 3).
- etc.
Task 6.2
Writing the corresponding R code,
- create a new function called stupid_sum()
- the function should have two arguments that need to be filled: a vector x and a vector y
- the function should print the sum of both vectors if both vectors include numeric data.
- the function should print the error “I simply can’t” if any of the two vectors include any type of non-numeric data.
Solution:
stupid_sum <- function (x,y) #define arguments of function
{
#first: what should happen if both x and y numeric?
if(is.numeric(x)== TRUE & is.numeric(y) == TRUE){
result <- sum(x+y)
}
#second: what should happen otherwise?
else{
result <- "I simply can't"
}
return(result) #define that function should only return the object result
}#When testing the function
stupid_sum(x = data$trust_politics, y = data$trust_news_media)## [1] 5010stupid_sum(x = data$trust_politics, y = data$country)## [1] "I simply can't"Solutions for Tutorial 8
Task 8.1
Try to re-create as much as possible of the following graph depicting the distribution of respondents’ age across countries.
Hint: For the geometric component, check out the geom_histogram() function.
Solution:
data <- read.csv2("data_tutorial 8.txt")plot <- ggplot(data, aes(x = age)) +
geom_histogram(binwidth = 10, fill = "gray90", colour = "red") +
labs(title = "Age of respondents across countries",
x = "Age (in years)",
y = "Count of respondents for each age group") +
theme_classic() +
facet_wrap(~ country, nrow = 2)
plot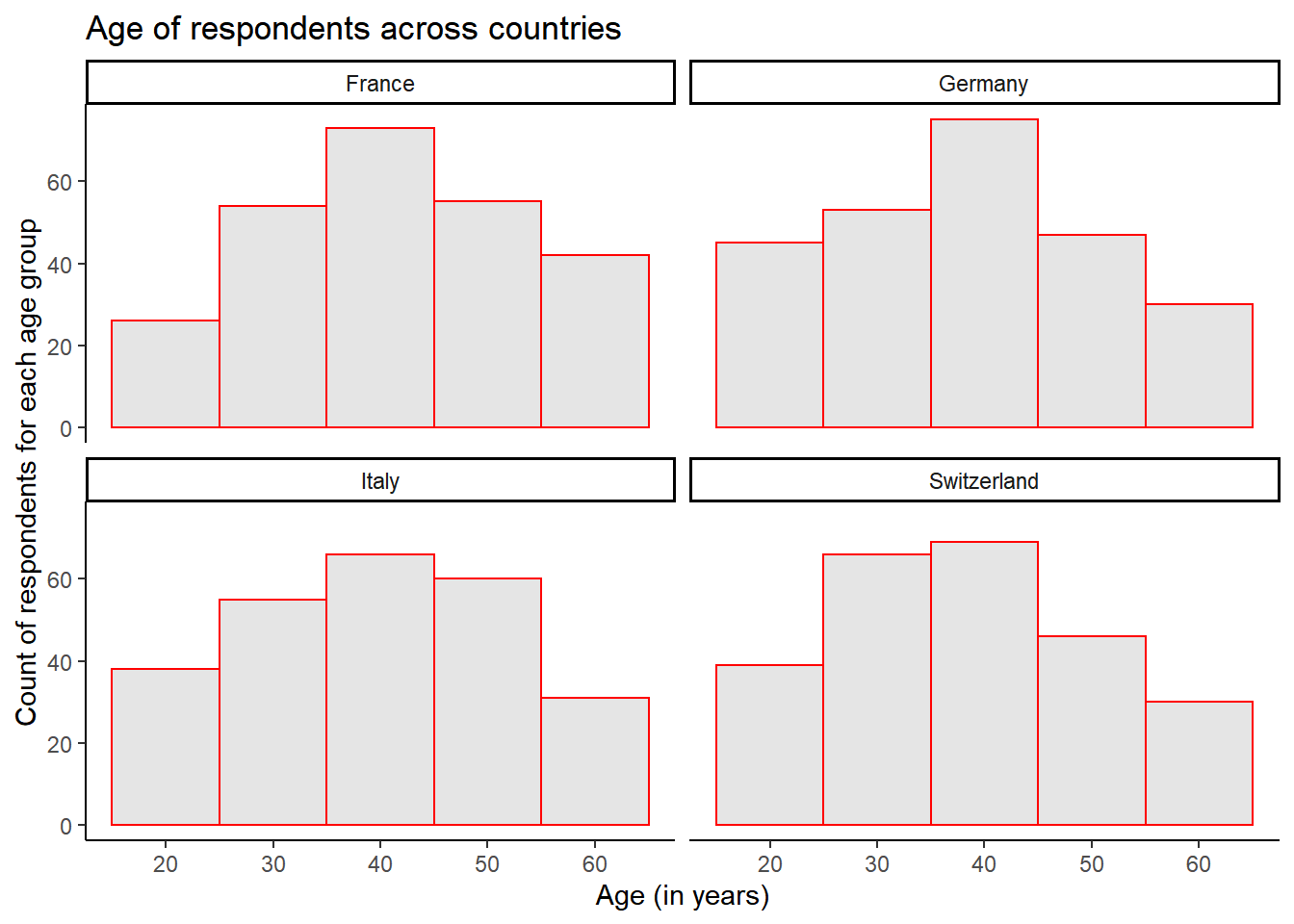
Solutions for Tutorial 9
Task 9.1
Writing the corresponding code, replace all blank spaces in the element sentences with the word space.
Solution:
sentences <-c("Climate change is a crisis all across the world - but how come we've not taken it serious?",
"CLIMATE CHANGE - the world issue that strikes specifically the poorest 20% around the globe.",
"Global warming is a problem, but we've known that for a while now.",
"Climate scepticism under the microscope: A debate between scientists and scepticists across the world",
"No one's safe? Why this might, after all, not be true when it comes to global warming",
"We've failed: The climate crisis is dooming")
gsub(pattern="[[:blank:]]", replacement = "space", x = sentences)## [1] "Climatespacechangespaceisspaceaspacecrisisspaceallspaceacrossspacethespaceworldspace-spacebutspacehowspacecomespacewe'vespacenotspacetakenspaceitspaceserious?"
## [2] "CLIMATEspaceCHANGEspace-spacethespaceworldspaceissuespacethatspacestrikesspacespecificallyspacethespacepoorestspace20%spacearoundspacethespaceglobe."
## [3] "Globalspacewarmingspaceisspaceaspaceproblem,spacebutspacewe'vespaceknownspacethatspaceforspaceaspacewhilespacenow."
## [4] "Climatespacescepticismspaceunderspacethespacemicroscope:spaceAspacedebatespacebetweenspacescientistsspaceandspacescepticistsspaceacrossspacethespaceworld"
## [5] "Nospaceone'sspacesafe?spaceWhyspacethisspacemight,spaceafterspaceall,spacenotspacebespacetruespacewhenspaceitspacecomesspacetospaceglobalspacewarming"
## [6] "We'vespacefailed:spaceThespaceclimatespacecrisisspaceisspacedooming"Task 9.2
Writing the corresponding code, count how many times the pattern climate change occurs in lowercase or uppercase in each sentence in sentences.
Solution:
str_count(string = sentences,
pattern = "[c|C][l|L][i|I][m|M][a|A][t|T][e|E] [c|C][h|H][a|A][n|N][g|G][e|E]")## [1] 1 1 0 0 0 0Task 9.3
Writing the corresponding code, count how many times, in total, the pattern climate change occurs in lowercase or uppercase in the vector sentences.
Solution:
sum(str_count(string = sentences,
pattern = "[c|C][l|L][i|I][m|M][a|A][t|T][e|E] [c|C][h|H][a|A][n|N][g|G][e|E]"))## [1] 2Task 9.4
Let’s say you want to rewrite these sentences for them to be a bit more “formal”.
Writing the corresponding code, replace all somewhat colloquial abbreviations in the form of the pattern we’ve (in lowercase and uppercase) with the pattern we have. Save your result in the new vector sentences_formal.
Solution:
gsub(pattern="'ve", " have", sentences)## [1] "Climate change is a crisis all across the world - but how come we have not taken it serious?"
## [2] "CLIMATE CHANGE - the world issue that strikes specifically the poorest 20% around the globe."
## [3] "Global warming is a problem, but we have known that for a while now."
## [4] "Climate scepticism under the microscope: A debate between scientists and scepticists across the world"
## [5] "No one's safe? Why this might, after all, not be true when it comes to global warming"
## [6] "We have failed: The climate crisis is dooming"Solutions for Tutorial 12
For this task, we’ll work with a new corpus: speeches_sotu.rda. The corpus includes “State of the Union Addresses” from US presidents since the 1790s.
You’ll find the corpus in OLAT (via: Materials / Data for R).
Source: The American Presidency Project, accessed via the quanteda corpus package.
load("corpus_sotu.rda")Task 12.1
Writing the corresponding R code, tokenize the corpus to sentences (not words) and save your result in a new object called data_new.
Solution:
data_new <- corpus_reshape(corpus(data$text), to = "sentences")Task 12.2
Writing the corresponding R code, find out in how many sentences presidents use the term “United States”, i.e., in how many sentences the feature United States occurs.
Solution:
sum(grepl("United States",as.character(data_new)))## [1] 4419Solutions for Tutorial 13
Using the dfm we just created, run a model with K = 20 topics including the publication month as an independent variable.
Is there a topic in the immigration corpus that deals with racism in the UK?
If yes: Which topic(s) - and how did you come to that conclusion?
Solution:
model_20 <- stm(documents = dfm_stm$documents,
vocab = dfm_stm$vocab,
K = 20,
prevalence = ~month,
data = data,
verbose = FALSE)#We could, for example, check the top terms of each document to find related topics
topics_20 <- labelTopics(model_20, n=10)
topics_20 <- data.frame("features" = t(topics_20$frex))
colnames(topics_20) <- paste("Topics", c(1:20))
topics_20## Topics 1 Topics 2 Topics 3 Topics 4 Topics 5 Topics 6 Topics 7 Topics 8 Topics 9 Topics 10
## 1 print cent express telegraph racist guardian tax tories scottish net
## 2 indop per theexp teluk poster grdn taxpayers miliband passengers migration
## 3 ind ethnic editorial dt posters guardiancouk £ voters border tens
## 4 independent minority c group candidates pages pensions conservatives salmond bulgarians
## 5 1st white opinion sun bnp theguardiancom pay seats scotland target
## 6 frontpage study daim thesun ukips bbc benefits ed scots figures
## 7 | minorities javid media ukip grultd taxes vote alex statistics
## 8 voices communities columns <U+7AB6> newark thatcher income election checks numbers
## 9 letters groups daily online lampitt pounds wage parties calais students
## 10 morris population photo page candidate humphrys billion votes snp romanians
## Topics 11 Topics 12 Topics 13 Topics 14 Topics 15 Topics 16 Topics 17 Topics 18 Topics 19 Topics 20
## 1 nanny prince film pupils lib bit lords financial deported merkel
## 2 cable hitler music school clegg got seekers web deportation referendum
## 3 cheap charles theatre schools dems things bill redistribute yashika eu
## 4 metropolitan church novel serco nick hes justice paste judge movement
## 5 brokenshire christian art visas dem doesnt miller ftcom wood brussels
## 6 elite putin award places debate quite commons ft bageerathi germany
## 7 vince royal son primary farage ive asylum email court angela
## 8 wealthy ukraine beautiful cancer debates thats mps please mauritius union
## 9 lima religious america patients cleggs im committee post removal membership
## 10 downing russia history education nigel everything aid ftcma detention german#It seems like, for example, Topic 5 deals with racism.
#Next, we may want to read a document from this topic
findThoughts(model_20, data$text, topics=5, n=1)##
## Topic 5:
##
## politics
## ukip candidate in scuffle with disabled protester
## laura pitel political correspondent
## 535 words
## 20 may 2014
## 0101
## thetimescouk
## timeuk
## english
## © 2014 times newspapers ltd all rights reserved
## the man vying to become ukip's first mp was accused of scuffling with a disabled protester yesterday as tensions grew over the party's alleged racism
## roger helmer an mep who will fight the parliamentary by-election in newark next month tried to take a megaphone from david challinor a miner who lost the use of one arm in an industrial accident
## mr challinor claimed that one of mr helmer's aides "lunged" at him after he approached the mep outside a café in retford nottinghamshire with a group of demonstrators "they were shouting 'get that megaphone!' and then this youth jumped up and lunged at me trying to pull it" he told the retford times "he was trying to take it from my right arm which i've had five operations on and can't straighten"
## mr helmer denied that he or his staff had assaulted mr challinor a labour district councillor but said that he had tried to take the megaphone to respond to allegations about his expense claims in the european parliament
## john mann the local labour mp said that mr challinor made a statement to the police about the incident mr helmer said that any attempt to take the matter to the police would be "vexatious" he added "i am certainly not apologising to him they should be apologising to us for harassment and deliberately provocative behaviour"
## the row came as nigel farage was forced to back down further over remarks about romanians while a string of senior labour figures broke cover to brand him a racist the ukip leader said that he was sorry if he "gave the impression" during an interview last week that he was discriminating against those from the eastern european nation
## he said that he regretted using the words "you know what the difference is" when asked to explain the difference between romanians and germans though he insisted that there was a "real problem" with organised crime among some romanians in london that had been "brushed under the carpet"
## accusations of racism continued to dog the party as the founder of ukip the academic alan sked revived claims that mr farage described black voters as "the n***** vote" in a private exchange in 1997 ukip dismissed the claim by mr sked who left the party almost 20 years ago as "absurd"
## yvette cooper the shadow home secretary yesterday defied her party leader by describing mr farage's remarks about romanians as racist ms cooper who is tipped as a future labour leader told itv "it's not racist to be worried about immigration or to want stronger controls but it is racist to somehow stir up fears about romanians living next door"
## wary of being seen to insult voters who are concerned about immigration eSolutions for Graded task in R (I)
Graded Task 1.1
Writing the corresponding R code, create a data frame with the name dataframe. The data frame should include 20 observations and the following three variables:
- as its first variable, a vector called numbers consisting of all numbers from 1 to 20.
- as its second variable, a vector called letters consisting of all letters from a to t.
- as its third variable, a vector called sentence consisting of sentence “This is a task”, repeated 20 times.
Solution:
dataframe <- data.frame("numbers" = c(1:20),
"letters" = letters[1:20],
"sentence" = rep("This is a task", 20))
dataframe## numbers letters sentence
## 1 1 a This is a task
## 2 2 b This is a task
## 3 3 c This is a task
## 4 4 d This is a task
## 5 5 e This is a task
## 6 6 f This is a task
## 7 7 g This is a task
## 8 8 h This is a task
## 9 9 i This is a task
## 10 10 j This is a task
## 11 11 k This is a task
## 12 12 l This is a task
## 13 13 m This is a task
## 14 14 n This is a task
## 15 15 o This is a task
## 16 16 p This is a task
## 17 17 q This is a task
## 18 18 r This is a task
## 19 19 s This is a task
## 20 20 t This is a taskGraded Task 1.2
Writing the corresponding R code, create a new vector called numbers consisting of all numbers from 1 to 100. Replace the first and the last element of the vector with the number 0. Afterwards, divide every single value in the vector by 2.
Solution:
numbers <- c(1:100)
numbers[c(1,100)] <- 0
numbers <- numbers/2
numbers## [1] 0.0 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 9.5 10.0 10.5 11.0 11.5
## [24] 12.0 12.5 13.0 13.5 14.0 14.5 15.0 15.5 16.0 16.5 17.0 17.5 18.0 18.5 19.0 19.5 20.0 20.5 21.0 21.5 22.0 22.5 23.0
## [47] 23.5 24.0 24.5 25.0 25.5 26.0 26.5 27.0 27.5 28.0 28.5 29.0 29.5 30.0 30.5 31.0 31.5 32.0 32.5 33.0 33.5 34.0 34.5
## [70] 35.0 35.5 36.0 36.5 37.0 37.5 38.0 38.5 39.0 39.5 40.0 40.5 41.0 41.5 42.0 42.5 43.0 43.5 44.0 44.5 45.0 45.5 46.0
## [93] 46.5 47.0 47.5 48.0 48.5 49.0 49.5 0.0Graded Task 1.3
Writing the corresponding R code, create a vector called numbers2 consisting of all numbers from 1 to 100. Next, replace every third value in numbers2 with a 2.
Solution:
numbers2 <- c(1:100)
numbers2[c(FALSE, FALSE, TRUE)] <- 2
numbers2## [1] 1 2 2 4 5 2 7 8 2 10 11 2 13 14 2 16 17 2 19 20 2 22 23 2 25 26 2 28
## [29] 29 2 31 32 2 34 35 2 37 38 2 40 41 2 43 44 2 46 47 2 49 50 2 52 53 2 55 56
## [57] 2 58 59 2 61 62 2 64 65 2 67 68 2 70 71 2 73 74 2 76 77 2 79 80 2 82 83 2
## [85] 85 86 2 88 89 2 91 92 2 94 95 2 97 98 2 100Graded Task 1.4
For the next tasks, we’ll again use the data set “data_tutorial6.txt” (via OLAT/Materials/Data for R). The data set has already been introduced and explained in Tutorial 6: Control structures & functions in R, so you should know it already.
The data set consists of data that is completely made up - a survey with 1000 citizens in Europe.
The data file “data_tutorial6.txt” is structured as follows:
- Each row contains the answer for a single citizen.
- Each column contains all values given by citizens for a single variable.
The five variables included here are:
- country: the country in which each citizen was living at the time of the survey (France/Germany/Italy/Switzerland)
- date: the date on which each citizen was surveyed (from 2021-09-20 to 2021-10-03)
- gender: each citizen’s gender (female/male/NA)
- trust_politics: how much each citizen trusts the political system (from 1 = no trust at all to 4 = a lot of trust)
- trust_news_media: how much each citizen trusts the news media (from 1 = no trust at all to 4 = a lot of trust)
Read in the data set:
data <- read.csv2("data_tutorial 6.txt")This is how the data looks like in R:
head(data)## country date gender trust_politics trust_news_media
## 1 Germany 2021-09-20 female 3 1
## 2 Switzerland 2021-10-02 male 2 1
## 3 France 2021-09-21 <NA> 1 3
## 4 Italy 2021-10-03 male 2 2
## 5 Germany 2021-09-21 female 3 1
## 6 Switzerland 2021-09-20 male 1 2Writing the corresponding R code, create a new data frame called data_new consisting only of those observations where respondents were interviewed in October (not September) and were respondents indicated that their gender was either male or female (i.e., did not reply with NA).
Moreover, the data frame data_new should only include the variables “date”, “gender”, “trust_politics”, and “trust_news_media”.
Solution:
library("dplyr")
data_new <- data %>%
select(c("date", "gender", "trust_politics", "trust_news_media")) %>%
filter(date %in% c("2021-10-02","2021-10-03")) %>%
filter(!is.na(gender))
head(data_new)## date gender trust_politics trust_news_media
## 1 2021-10-02 male 2 1
## 2 2021-10-03 male 2 2
## 3 2021-10-02 male 4 4
## 4 2021-10-02 female 1 4
## 5 2021-10-03 male 4 1
## 6 2021-10-02 female 4 3str(data_new)## 'data.frame': 253 obs. of 4 variables:
## $ date : chr "2021-10-02" "2021-10-03" "2021-10-02" "2021-10-02" ...
## $ gender : chr "male" "male" "male" "female" ...
## $ trust_politics : int 2 2 4 1 4 4 3 2 3 4 ...
## $ trust_news_media: int 1 2 4 4 1 3 3 4 1 4 ...Graded Task 1.5
Writing the corresponding R code, generate the following descriptive statistics on the full data set data (i.e., including all N = 1,000 observations) for the variable gender:
- the absolute number of female respondents, the absolute number of male respondents, and the absolute number of respondents with a missing value for gender.
- the relative percentage of female respondents and the relative percentage of male respondents (when excluding NAs). Thus, the relative percentage of female and male respondents should sum up to 100%.
Solution:
#absolute number of male and female respondents
table(data$gender)
#absolute number of respondents with NA as a response
data$gender %>% is.na() %>% sum()
# % of male and female respondents (excluding NAs)
data %>%
#exclude cases with NA for gender questions
filter(!is.na(gender)) %>%
#group by gender
group_by(gender) %>%
#create variable incl. the number of respondents for male/female as a response
summarise(n=n())%>%
#create a variable containing the % of respondents for male/female as a response
mutate(freq=n/sum(n)*100)Graded Task 1.6
Writing the corresponding R code, write your own custom function with the name stats_helper.
The function should only need one argument called x for which it should be able to execute the following task:
Given a vector x with numeric data, the function should paste the following sentence: “This variable has a mean of M = XY with a standard deviation of SD = XY. In total, XY out of N = XY observations are missing.”
Important: The values XY should be replaced with whatever mean, standard deviation, missing values, and total observations of x has (rounded to two decimals). That is, the function should calculate these values on its own for any x it is given.
Below, you see what the function should do when tested for two variables from the data frame data:
Solution:
stats_helper <- function (x)
{
name <- names(x)
mean <- round(mean(x),2)
sd <- round(sd(x),2)
na <- sum(is.na(x))
n <- length(x)
result <- paste0("This variable has a mean of M = ", mean,
" with a standard deviation of SD = ", sd, ". In total, ", na, " out of N = ", n, " observations are missing.")
return(result)
}
#When testing the function
stats_helper(x = data$trust_politics)## [1] "This variable has a mean of M = 2.54 with a standard deviation of SD = 1.1. In total, 0 out of N = 1000 observations are missing."stats_helper(x = data$trust_news_media)## [1] "This variable has a mean of M = 2.46 with a standard deviation of SD = 1.12. In total, 0 out of N = 1000 observations are missing."Solutions for Graded task in R (II)
For this task, we’ll again work with a text corpus already included in the R-Package Quanteda-Corpora-Package. For simplicity, I have already downloaded the corpus (with some minor specifications). You can find the corresponding R file in OLAT (via: Materials / Data for R) with the name immigration_news.rda.
These files are news articles from the UK reporting on the topic of immigration from 2014. The data is in a similar format as you would get if you read their text with the readtext package.
Source of the data set: Nulty, P. & Poletti, M. (2014). “The Immigration Issue in the UK in the 2014 EU Elections: Text Mining the Public Debate.” Presentation at LSE Text Mining Conference 2014. Accessed via the quanteda corpus package.
load("immigration_news.rda")Graded Task 2.1
Writing the corresponding R code, create a new variable called words in the data frame data, which contains the number of words each article includes. What is the average number of words each article includes across the whole corpus?
Important: Please do not count the number of words yourself. Each article already contains a string pattern indicating the number of words at the beginning of each text (e.g., the first text contains the string pattern “933 words”). Thus, you simply need to extract this string.
Solution:
library("stringr")
data$words <- str_extract(data$text, "[0-9]+ words")
data$words <- as.numeric(gsub(" words", "", data$words))
mean(data$words)## [1] 728.258Graded Task 2.2
Writing the corresponding R code, create a new variable called headline in the data frame data, which contains the headline of each article.
Important: For simplicity, an article’s headline is here defined as any text before the word count in the article (we ignore the fact that this sometimes also includes the author’s name). Thus, you simply have to extract all text before the word count of the respective article.
Solution:
data$headline <- sub("[0-9]+ words.*", "", data$text)
writeLines(data$headline[1:2])## support for ukip continues to grow in the labour heartlands and miliband should be scared
## by leo mckinstry
##
##
## news
## 30 lawless migrants try to reach uk each night
## giles sheldrickGraded Task 2.3
Writing the corresponding R code, create a new variable called date in the data frame data. It should contain the year, month, and day each article was published.
Using this variable, please plot the amount of coverage across time. The final graph does not have to look exactly like the one you see below (in terms of colors or design, etc.).
What is important is that is that you somehow visualize how many articles were published on each day.
Solution:
#First, we extract the date
data$date <- str_extract(string = data$text,
pattern = "[0-9]+ (january|february|march|april|may|june|july|august|september|october|november|december) 2014")
data$month <- str_extract(string = data$date,
pattern = "january|february|march|april|may|june|july| august|september|october|november|december")
data$day <- str_extract(string = data$text,
pattern = "[0-9]+ (january|february|march|april|may|june|july|august|september|october|november|december) 2014")
data$day <- str_extract(string = data$day,
pattern = "[0-9]+")
data$date <- paste(data$day, data$month,"2014")
data$date <- as.Date(data$date, format = "%d %B %Y")
#Next, we plot the graph
library("ggplot2")
ggplot(data, aes(x = date)) +
geom_bar() +
labs(title = "Number of articles across time",
x = "Time",
y = "Number of articles") +
theme_classic()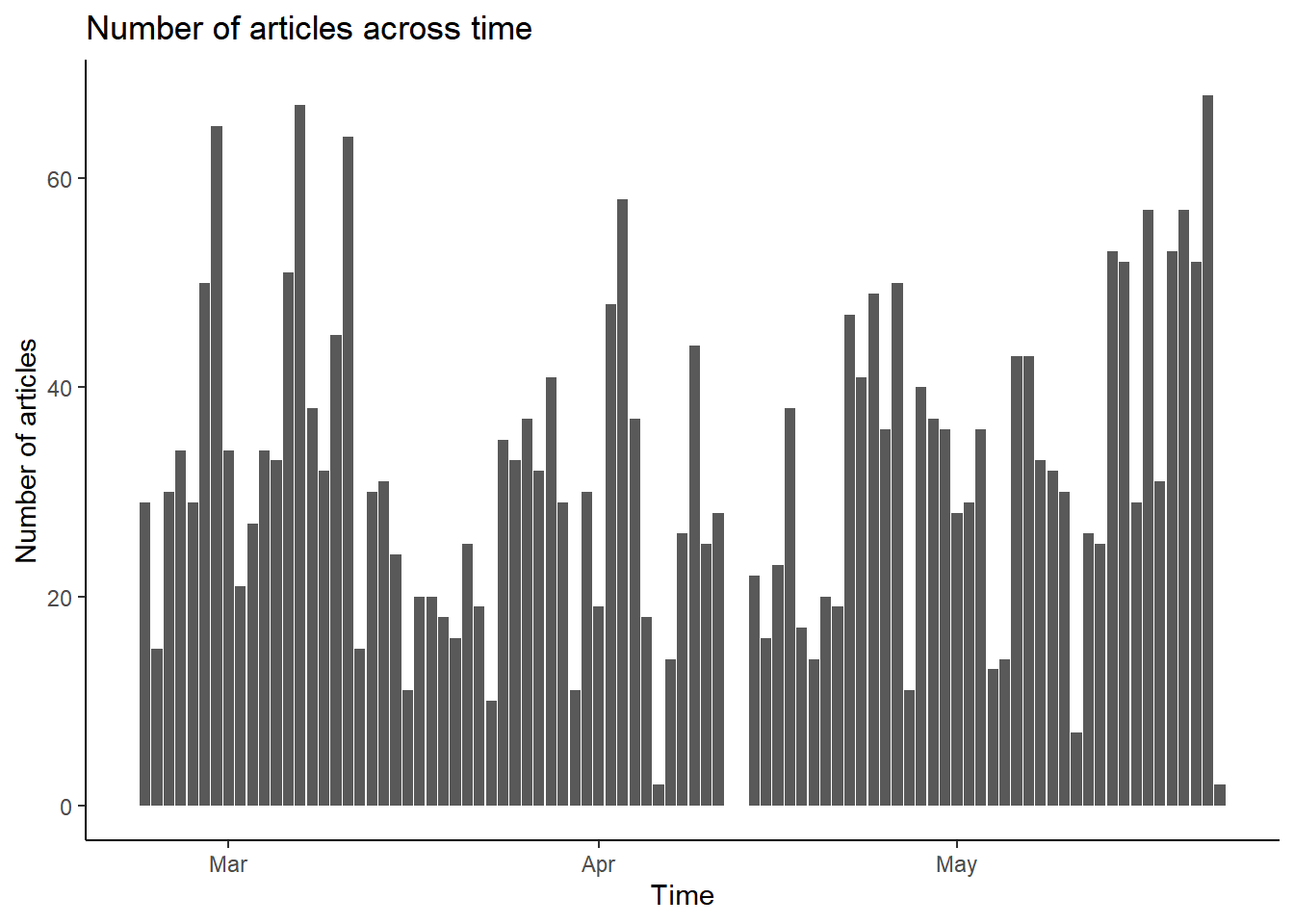
Graded Task 2.4
Writing the corresponding R code, please count how many articles by the newspaper The Daily Express as well as the newspaper The Financial Times the corpus contains (separately). The name of the outlet publishing each article is given in the article (see the beginning of each article) - again, you simply have to extract this information from the variable text in the data frame data.
Solution:
This task was a bit tricky for two reasons:
- First, you need to make sure to only retrieve the name of the outlet if it actually identifies the outlet publishing the article.
This means that we cannot simply search for the name of the outlet. Take for instance the string pattern “the financial times”.
If we look at text number 282, we see that the text contains the pattern “the financial times” - however, the article was not published by the financial times.
Instead, the article talks about another article by the financial times.
kwic(tokens(data$text[282]), pattern = "financial", window = 3)## Keyword-in-context with 1 match.
## [text1, 64] article for the | financial | times chancellor georgeArticle 282 was, in fact, published by another outlet - the Daily Express:
writeLines(substr(data$text[282],1,200))## germany backs two-speed europe in boost to david camerons eu renegotiation bid
## by owen bennett - political reporter
## 521 words
## 28 march 2014
## 1411
## expresscouk
## exco
## english
## copyright 2014
## germanys- Secondly, you need to account for the fact that the name of the outlet is often written differently.
For instance, the first and second text were both published by the Daily Express (its online and its print version, which go by different handles):
writeLines(substr(data$text[1:2],1,200))## support for ukip continues to grow in the labour heartlands and miliband should be scared
## by leo mckinstry
## 933 words
## 10 april 2014
## 1415
## expresscouk
## exco
## english
## copyright 2014
## nigel farage's ove
##
## news
## 30 lawless migrants try to reach uk each night
## giles sheldrick
## 402 words
## 14 april 2014
## the daily express
## theexp
## 1 scotland
## 4
## english
## c 2014 express newspapers
## exclusive
## at least 30 despeConsidering both issues, you can easily get the corresponding outlet identifiers by
- Making sure that the identifier for each outlet appears after the publication date of the article.
- Making sure that you include different spellings for outlets, if necessary.
sum(grepl("2014 express newspapers|expresscouk",data$text))## [1] 325sum(grepl("2014 the financial times",data$text))## [1] 207Graded Task 2.5
Writing the corresponding R code and using the same corpus, please create a document_feature_matrix called dfm based on the full corpus. Which are the three most frequent features in your corpus?
Solution:
dfm <- dfm(data$text)## Warning: 'dfm.character()' is deprecated. Use 'tokens()' first.topfeatures(dfm,n=3)## the to of
## 69066 34040 30360Graded Task 2.6
Writing the corresponding R code, please count: How many texts contain both the words immigration and racism?
Solution:
data$match <- 0
data$match[grep("immigration",data$text)] <- 1
data$match2 <- 0
data$match2[grep("racism",data$text)] <- 1
nrow(data[data$match==1 & data$match2==1,])## [1] 80Solutions for Graded task in R (III)
Graded Task 3.1
Writing the corresponding R code, please save the top 20 terms describing each topic (according to FREX weighting) in a new object called top_terms.
Which of these topics include the term “inflation” among their top 20 terms? Please automatically retrieve the number of these topics (e.g., “Topic 1”, or “Topic 2”, or “Topic 3 and Topic 4” etc.).
Solution:
library("stm")
#Save top 20 features across topics and forms of weighting
labels <- labelTopics(model, n=20)
#only keep FREX weighting
top_terms <- data.frame("features" = t(labels$frex))
#assign topic number as column name
colnames(top_terms) <- paste("Topic", c(1:30))
#Return the result
top_terms[grepl("inflation", top_terms)]## Topic 5 Topic 29
## 1 alliance inflation
## 2 productivity oil
## 3 viet-nam strategic
## 4 rates spending
## 5 spending adversaries
## 6 subsidies recession
## 7 deficits arms
## 8 tax energy
## 9 reducing petroleum
## 10 investment hopes
## 11 recovery crude
## 12 cut long-term
## 13 deficit growth
## 14 cuts barrels
## 15 percent realism
## 16 inflation cut
## 17 reductions taxpayers
## 18 growth deficits
## 19 recessions worse
## 20 needy grossGraded Task 3.2
Especially topics 5, 12 and 29 seem to touch upon financial and economic issues.
Writing the corresponding R code, please calculate the overall number of speeches in which topics 5, 12 and 29 are the main topic according to the Rank-1 metric. In short: How many speeches seem to focus on the economy/financial issues, as indicated by the prevalence of topics 5, 12, and 29 as the main topic in these speeches?
Please note: Your answer should be single number - the number of speeches where either topic 5, 12, or 29 are the main topic.
Solution:
top_terms[c(5,12,29)]## Topic 5 Topic 12 Topic 29
## 1 alliance dollars inflation
## 2 productivity fiscal oil
## 3 viet-nam estimated strategic
## 4 rates expenditures spending
## 5 spending reconversion adversaries
## 6 subsidies authorizations recession
## 7 deficits veterans arms
## 8 tax recommended energy
## 9 reducing liquidation petroleum
## 10 investment housing hopes
## 11 recovery receipts crude
## 12 cut wartime long-term
## 13 deficit peacetime growth
## 14 cuts lend-lease barrels
## 15 percent million realism
## 16 inflation demobilization cut
## 17 reductions wage taxpayers
## 18 growth construction deficits
## 19 recessions appropriations worse
## 20 needy loans grossdata$main <- NA
theta <- make.dt(model)
#calculate Rank-1
for (i in 1:nrow(data)){
column <- theta[i,-1]
maintopic <- colnames(column)[which(column==max(column))]
data$main[i] <- maintopic
}
table(data$main)##
## Topic1 Topic10 Topic11 Topic12 Topic13 Topic14 Topic15 Topic16 Topic17 Topic18 Topic19 Topic2 Topic20 Topic21 Topic22
## 3 1 10 4 5 8 18 9 8 11 8 4 2 2 5
## Topic23 Topic24 Topic25 Topic26 Topic27 Topic28 Topic29 Topic3 Topic30 Topic4 Topic5 Topic6 Topic7 Topic8 Topic9
## 1 16 2 4 11 2 7 6 1 11 5 4 13 4 8#Overall number of topics containing this as their main topic?
sum(nrow(data[data$main %in% c("Topic5", "Topic12", "Topic29"),]))## [1] 16Graded Task 3.3
Writing the corresponding R code, please plot the effects of party affiliation on the prevalence of the economy-focused topics 5, 12, and 29.
In short, the graph should indicate where there is a significant correlation between a president’s party affiliation (Democratic vs. Republican) on the prevalence with which a president discusses economic issues in a speech (similar to the one below, but the graphs do not have to match exactly):
Do Democrats more often discuss the economy in their speeches than Republicans (or vice versa)?
Hint: Have a look at the STM vignette if you are uncertain about how to plot the influence of categorical independent variables on topic prevalence.
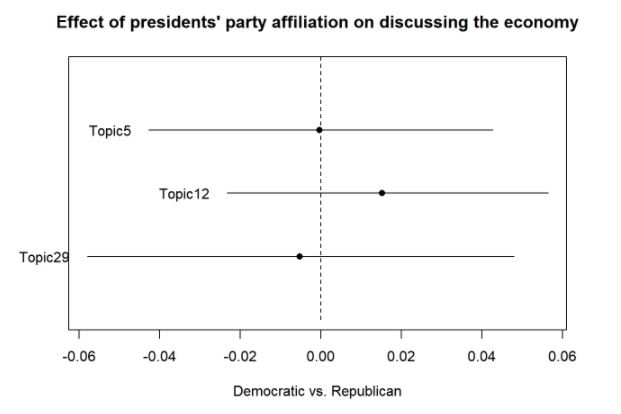
Solution:
effect <- estimateEffect(formula=~party, stmobj=model, metadata=data)
plot(effect, "party",
method = "difference",
topics = c(5,12,29), model = model,
cov.value1 = "Democratic", cov.value2 = "Republican",
xlab="Democratic vs. Republican",
main="Effect of presidents' party affiliation on discussing the economy",
labeltype = "custom",
custom.labels=c("Topic5", "Topic12", "Topic29"))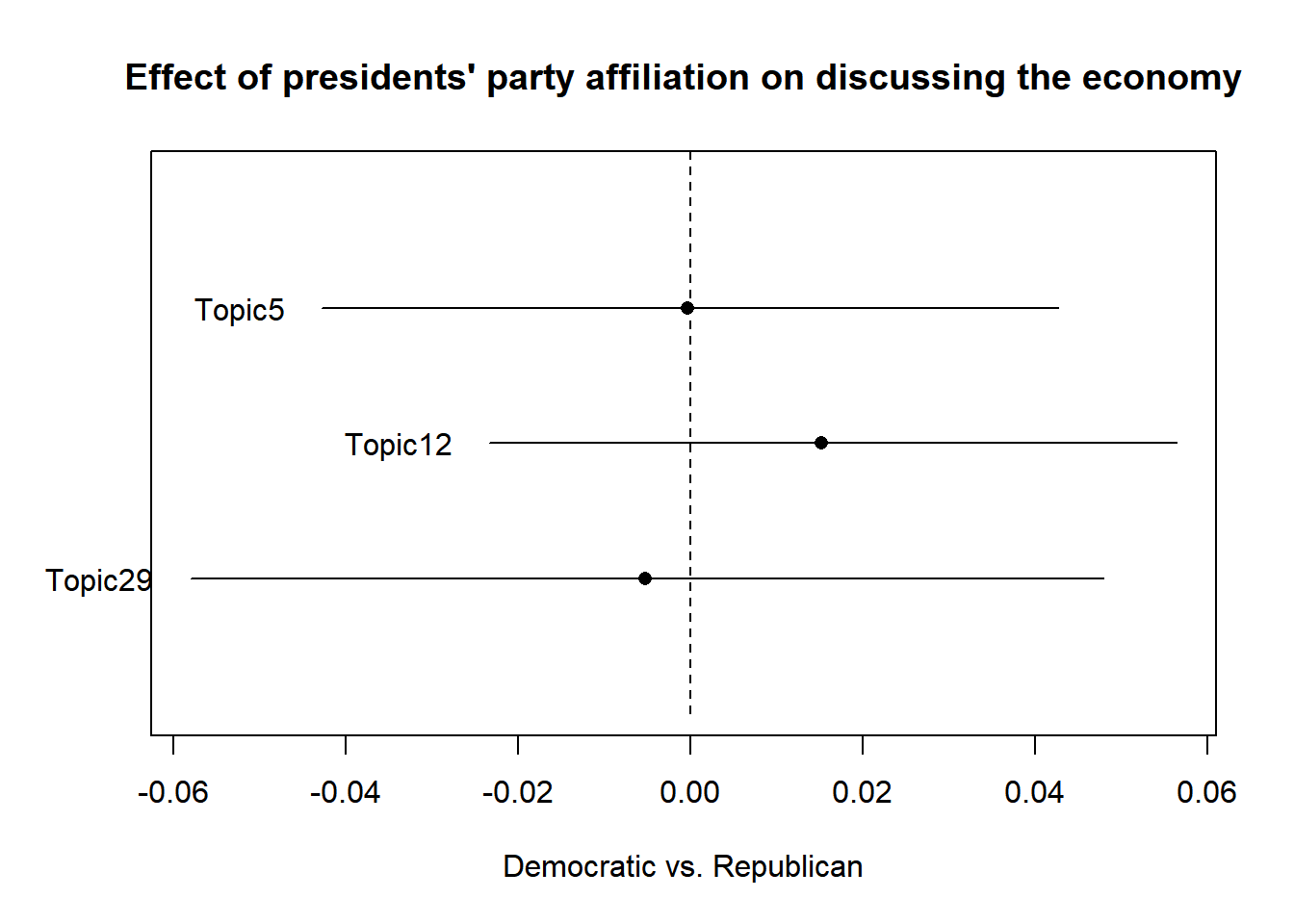
Graded Task 3.4
Writing the corresponding R code, retrieve the document-topic matrix of the stm model model. Based on the matrix: Retrieve the doc_ids of those 5 speeches that have the highest conditional probability for the topic Iraq_War/Terrorism (Topic 19) according to the document-topic matrix.
Solution: You could simply use the findThoughts() command included in the stm package as many of you did.
Another approach would be to retrieve the top documents yourself (both approaches are fine):
library("dplyr")
theta <- make.dt(model) %>% arrange(Topic19) %>% round(4)
data$doc_id[theta$docnum[((nrow(theta)-4):nrow(theta))]]## [1] "Bush-2004" "Bush-2005" "Bush-2006" "Bush-2007" "Bush-2003"Graded Task 3.5
Writing the corresponding R code, please validate your results.
First, assign each speech a single main topic based on the Rank-1 value.
Next, assume that we manually coded 15 speeches for whether or not they actually deal with the Iraq_War/Terrorism (Topic 19) as their main topic. The results of this manual coding - i.e., the manual gold standard - are saved in the object manual_validation.
This data frame contains the following vectors:
- doc_id: the name of the speech that was coded
- text: the text of the speech that was coded
- manual: the manual coding - a binary variable indicating whether the Iraq War/Terrorism (Topic 19) is the main topic of the speech (1) or not (0) according to the manual coding.
Using both the automated classification of main topics and the manually coded gold standard, calculate the precision, recall, and F1 value for your automated content analysis correctly classifying speeches as having the Iraq_War/Terrorism as their main topic.
In one sentence, please summarize: Do you think that your automated content analysis is “good enough” for automatically measuring which speeches discuss the Iraq_War/Terrorism?
Solution: As indicated by the high Recall, Precision and F1 value, the automated analysis works well.
#calculate Rank-1
theta <- make.dt(model)
for (i in 1:nrow(data)){
column <- theta[i,-1]
maintopic <- colnames(column)[which(column==max(column))]
data$main[i] <- maintopic
}
data$automated[data$main=="Topic19"] <- 1
data$automated[data$main!="Topic19"] <- 0
table(data$automated)##
## 0 1
## 185 8confusion <- merge(data[,c("doc_id", "automated")],
manual_validation[,c("doc_id", "manual")],
by="doc_id")
colnames(confusion) <- c("ID", "automated", "manual")
#transform classifications to factor format
confusion$automated <- as.factor(confusion$automated)
confusion$manual <- as.factor(confusion$manual)
#calculate confusion matrix
library("caret")
result <- confusionMatrix(data = confusion$automated,
reference=confusion$manual,
mode = "prec_recall",
positive = "1")
result$byClass[5:7]## Precision Recall F1
## 0.8750000 1.0000000 0.9333333Graded Task 3.6
Writing the corresponding R code, please count: Which president(s) discuss the “war on terror” by using this term in at least one speech?
Solution:
library("stringr")
data$President[grepl("[w|w]ar on [t|T]error", data$text)] %>% unique()## [1] "Bush"