Chapter 9 單變數分配
我們有時會需要畫出變數的分配:
間斷變數:
geom_bar(),geom_col()主要以count的方式來呈現分配
連續變數:
geom_histogram(),geom_freqpoly()主要以bin-then-count的方式來呈現分配
geom_bar()和geom_col()用在x為間斷變數時。geom_histogram()和geom_freqpoly()用在x為連續變數,但想看它的分配時(透過區間切割)。
9.1 範例資料:匯率
每月升值率
# 匯率以2017年1月為基期
exData7 <- read_csv("https://raw.githubusercontent.com/tpemartin/github-data/master/exData7.csv")新台幣90後的每年月升值率正/負次數
exData7 %>%
mutate(
升值=(月升值率>0)
) -> exData7
exData7 %>%
filter(幣別=="新台幣NTD/USD",年份 %>% between(1990,1995)) -> exDataTWpost90s9.2 台幣升貶頻率分析
exDataTWpost90s %>%
ggplot(aes(x=年份)) +
geom_bar(aes(weight=升值)) +
geom_hline(yintercept=6,color="red") -> p1p1+
scale_y_continuous(
limits=c(0,13),
breaks=c(0,2,4,6,8,10,12)
) -> p1
p1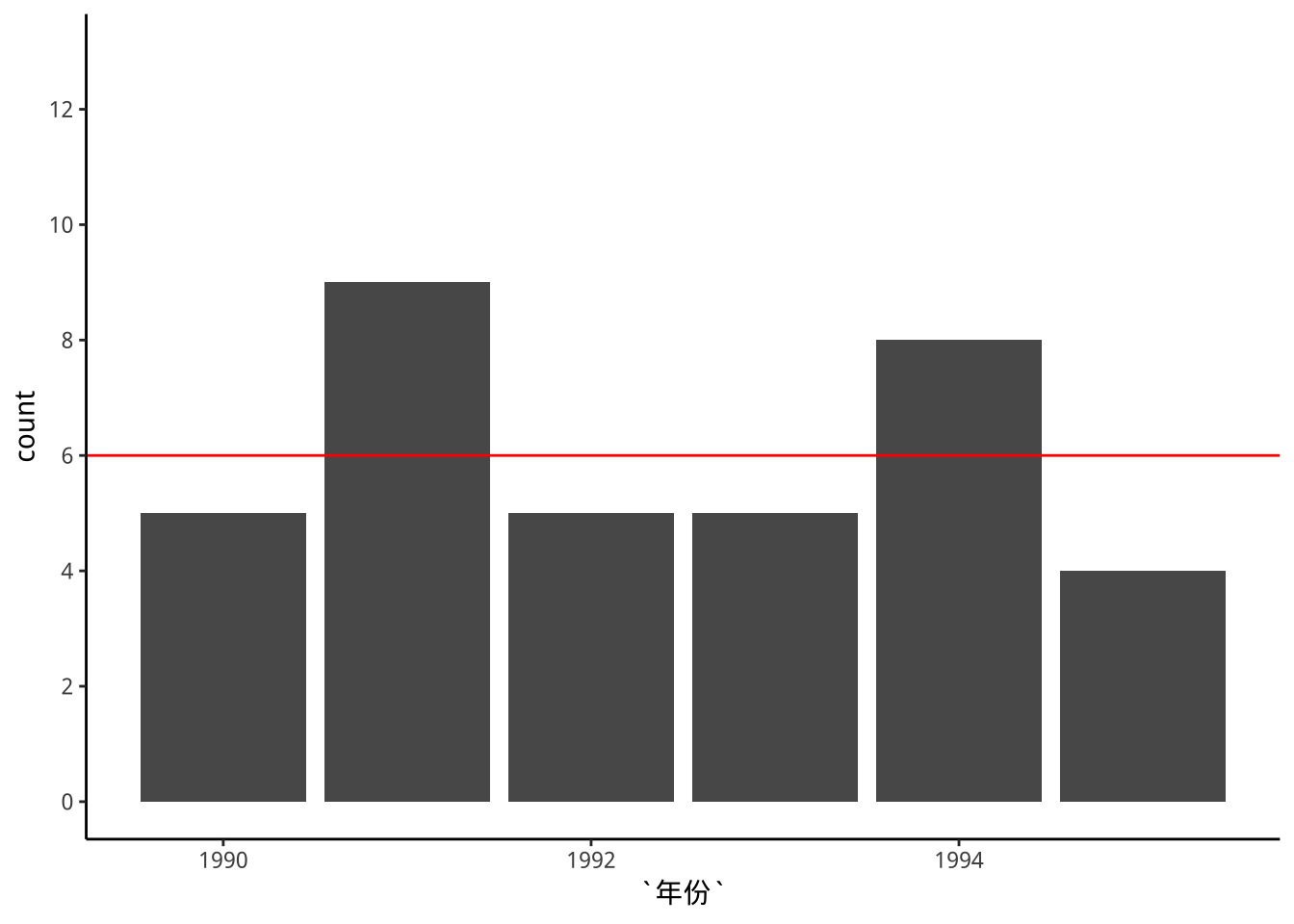 升值月份數超過6的年份很少,大部份的年裡新台幣月貶值的次數較多。
升值月份數超過6的年份很少,大部份的年裡新台幣月貶值的次數較多。
要突顯不同年份升/貶值次數「相對」多寡,你有比較好的想法嗎?
exDataTWpost90s %>%
mutate(
升值=as.factor(升值)
) -> exDataTWpost90s
exDataTWpost90s %>%
mutate(
升值=ordered(升值,levels=c("FALSE","TRUE"))
) ->
exDataTWpost90sexDataTWpost90s %>%
ggplot(aes(x=年份)) +
geom_bar(aes(fill=ordered(升值))) -> p2
p2p2 +
scale_fill_manual(
labels=c("貶值","升值"),
values=c("#ccd8e5","#ffa500")
)+
labs(fill=NULL)+
geom_hline(yintercept=6, color="red",alpha=0.3)+
scale_y_continuous(
limits=c(0,13),
breaks=c(0,2,4,6,8,10,12)
)9.3 scale_x/y...(expand) 調整座標標預留空間
scale_y_...(expand=...) and scale_y_...(expand=...)
Vector of range expansion constants used to add some padding around the data, to ensure that they are placed some distance away from the axes.
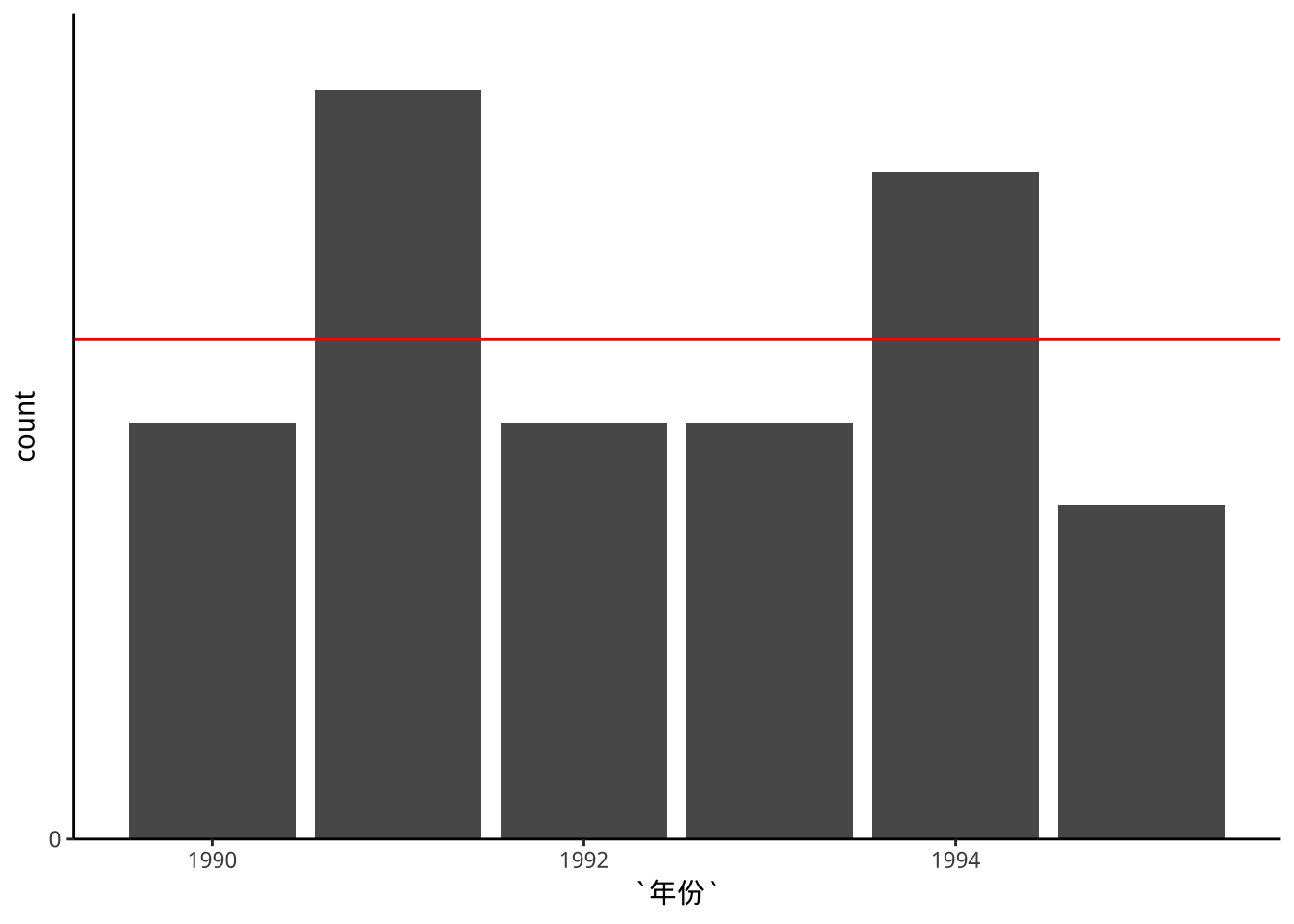
p1+
scale_y_discrete(
limits=c(0,13),
breaks=c(0,2,4,6,8,10,12),
expand=expand_scale(mult=c(0,0.1)) # 調整座標標預留空間
)
9.4 geom_histogram()
9.4.1 Usage
geom_histogram(mapping = NULL, data = NULL, stat = "bin",
position = "stack", ..., binwidth = NULL, bins = NULL,
na.rm = FALSE, show.legend = NA, inherit.aes = TRUE)透過binning把原本連續的x變數,間斷化成為以區間來分類的類別變數,每一個bin(即類別)的樣本個數(相對於其他bin)某種程度即代表了x變數的出象機率分佈狀況。
bins (default: 30):要將連續x資料range分成「多少個」等距的桶子(bins)。
例如:
x<-c(0.1, 2.3, 1.1, 2.5)若bins=2, 則每個bin的寛度是(2.5-0.1)/2; 第1個bin包含[0.1,1.3],第2個bin包含(1.3,2.5]。而原本x為numeric, 透過binning會變成
xbinned <- c("[0.1,1.3]","(1.3,2.5]","[0.1,1.3]","(1.3,2.5")binwidth: 指定bin寬。例如上述的例子也可以透過
binwidth=1.2達成binwidth與bins兩者擇一來使用就好。
若x為date class,則binwidth代表「天」數;若x為time class,則binwidth為「秒」數
diamonds$carat %>% range## [1] 0.20 5.019.4.2 p3
升值率的次數分佈圖
exDataTWpost90s %>%
ggplot(aes(x=月升值率))+
geom_histogram() -> p3
p3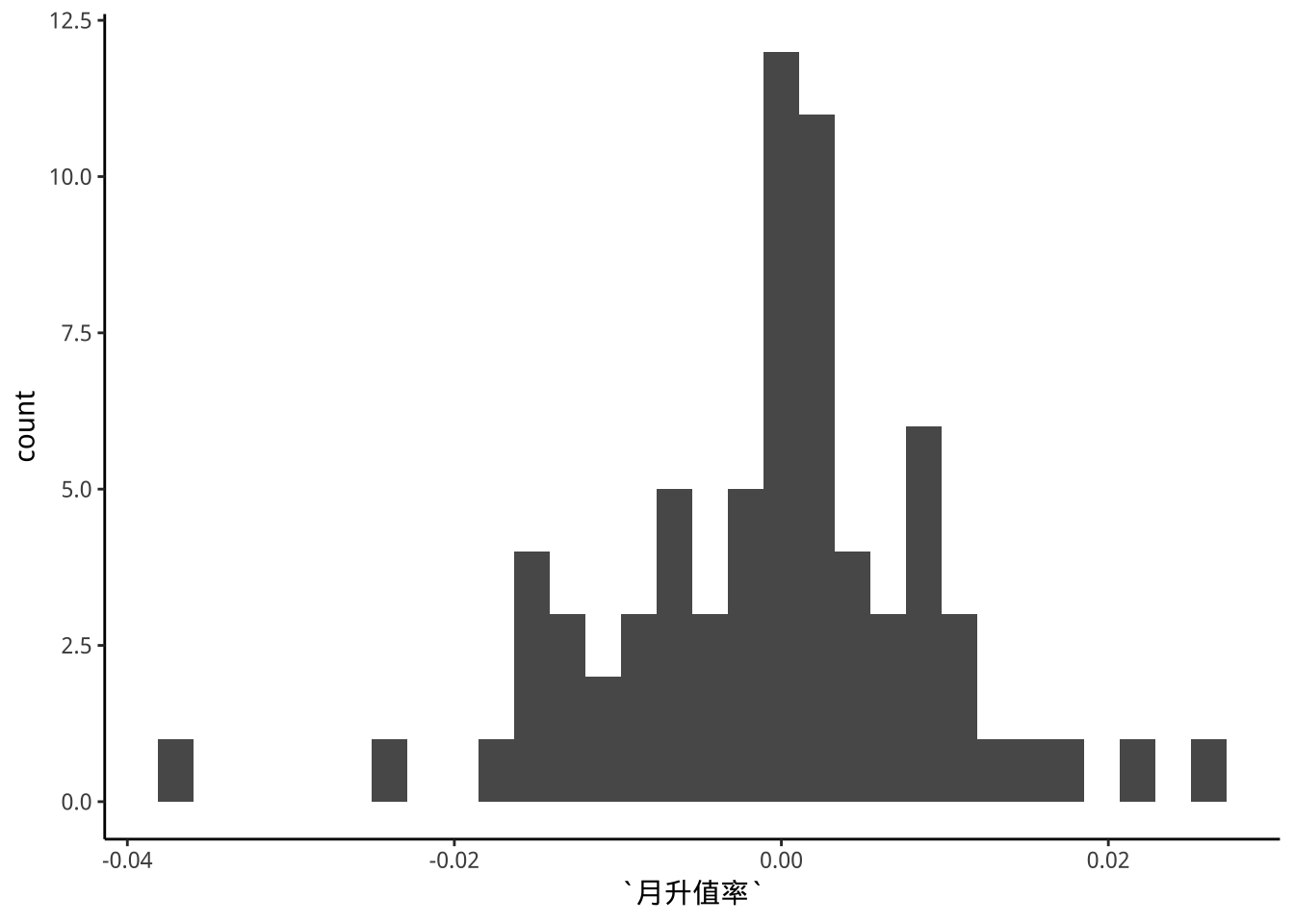
9.4.3 p4
exDataTWpost90s %>%
ggplot(aes(x=月升值率))+
geom_histogram(bins=50) -> p4
p4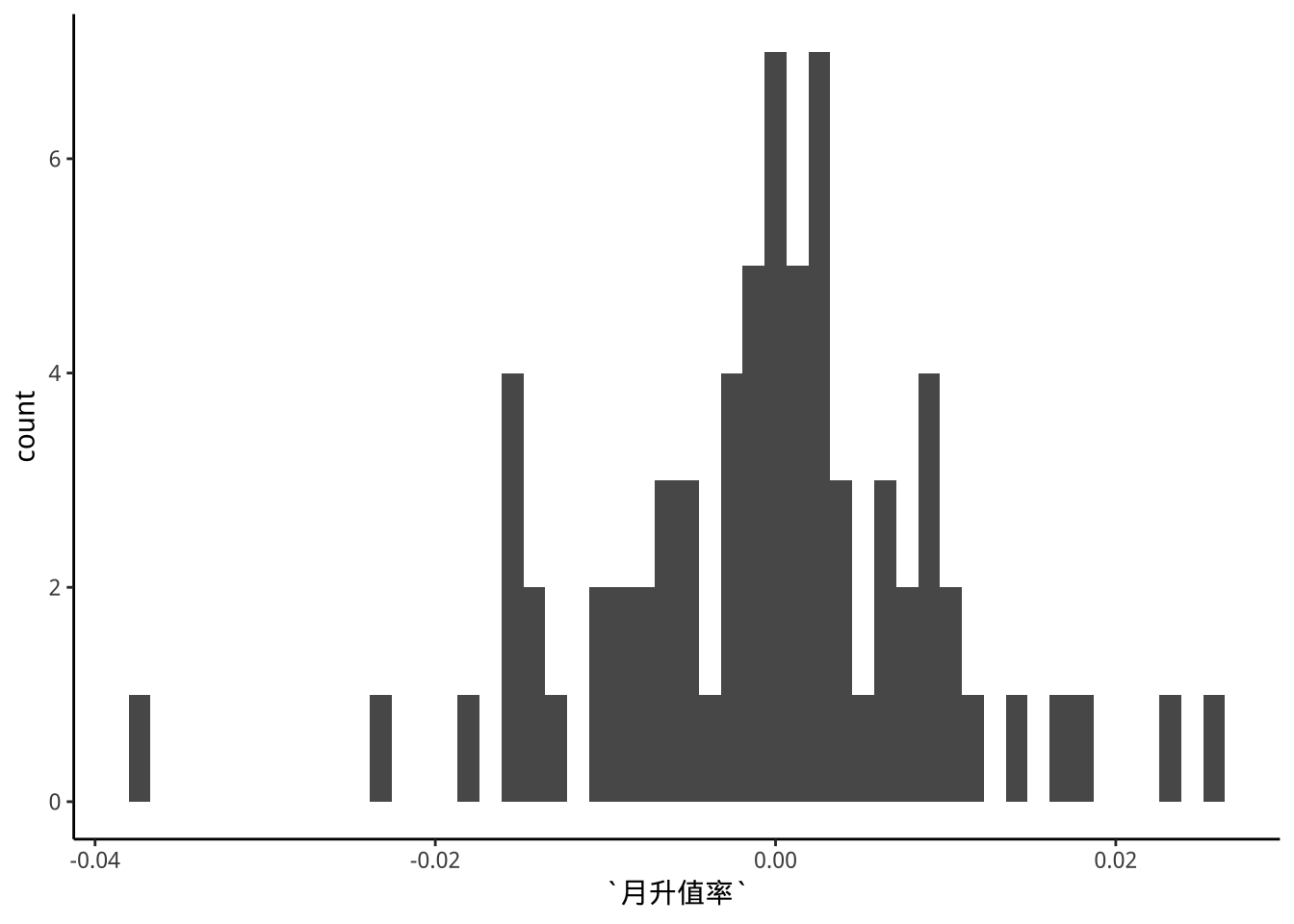
bins數越多,分配會有什麼變化現象?
原則上「樣本越大」、「資料越集中」則bin數目越多。有不少決定bins或binwidth的公式,大致上大同小異。這裡我們使用grDevices::nclass.FD(), 依Freedman-Diaconis法則選bins數。
9.4.4 p5: Freedman-Diaconis法則選bins數
binsNumber<- grDevices::nclass.FD(exDataTWpost90s$月升值率)
exDataTWpost90s %>%
ggplot(aes(x=月升值率))+
geom_histogram(bins=binsNumber) -> p5
p5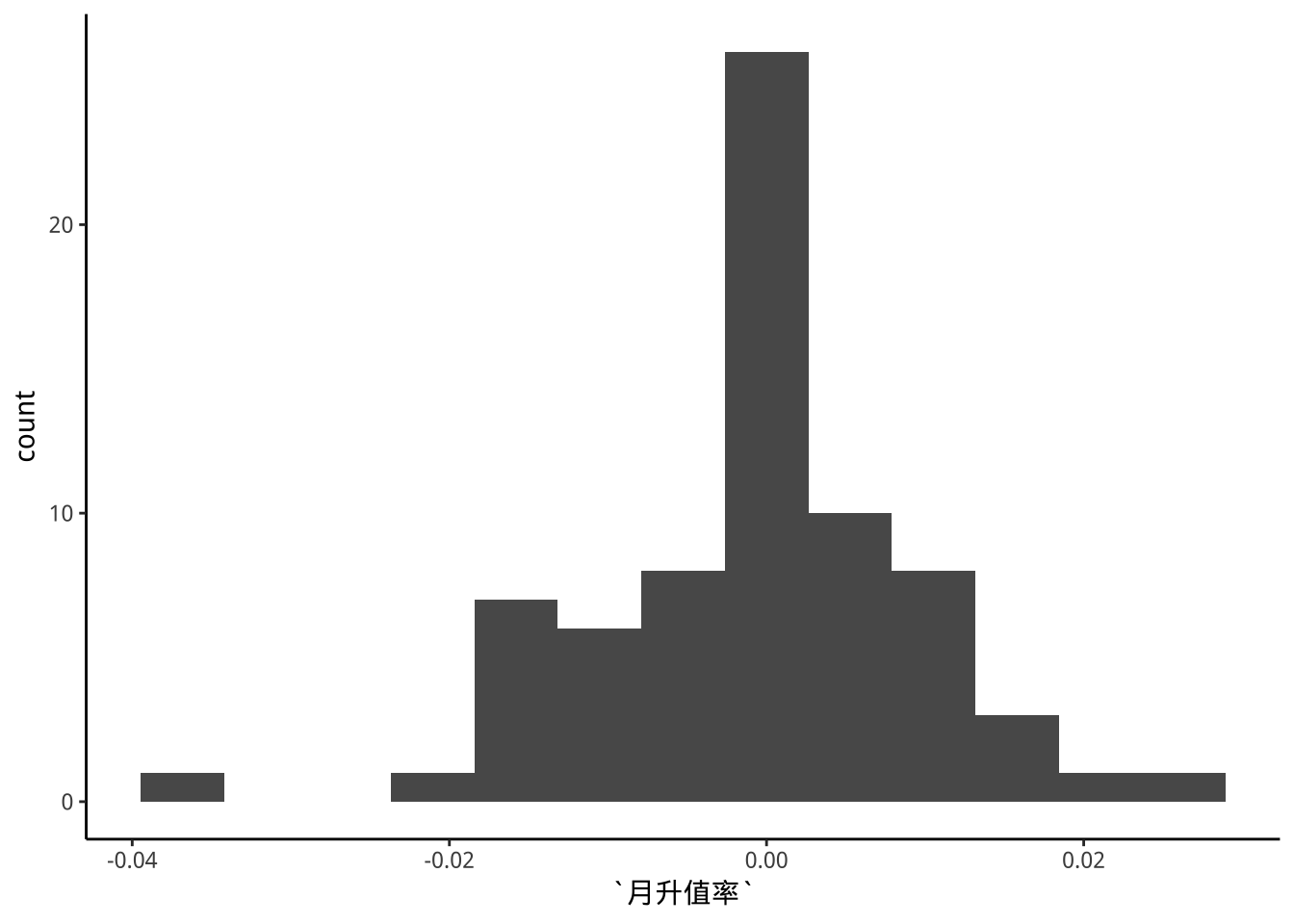
9.4.5 p6: aes::fill拆解每個月的貢獻
exDataTWpost90s %>%
ggplot(aes(x=月升值率))+
geom_histogram(
aes(fill=ordered(月份)),
bins=binsNumber) -> p6
p6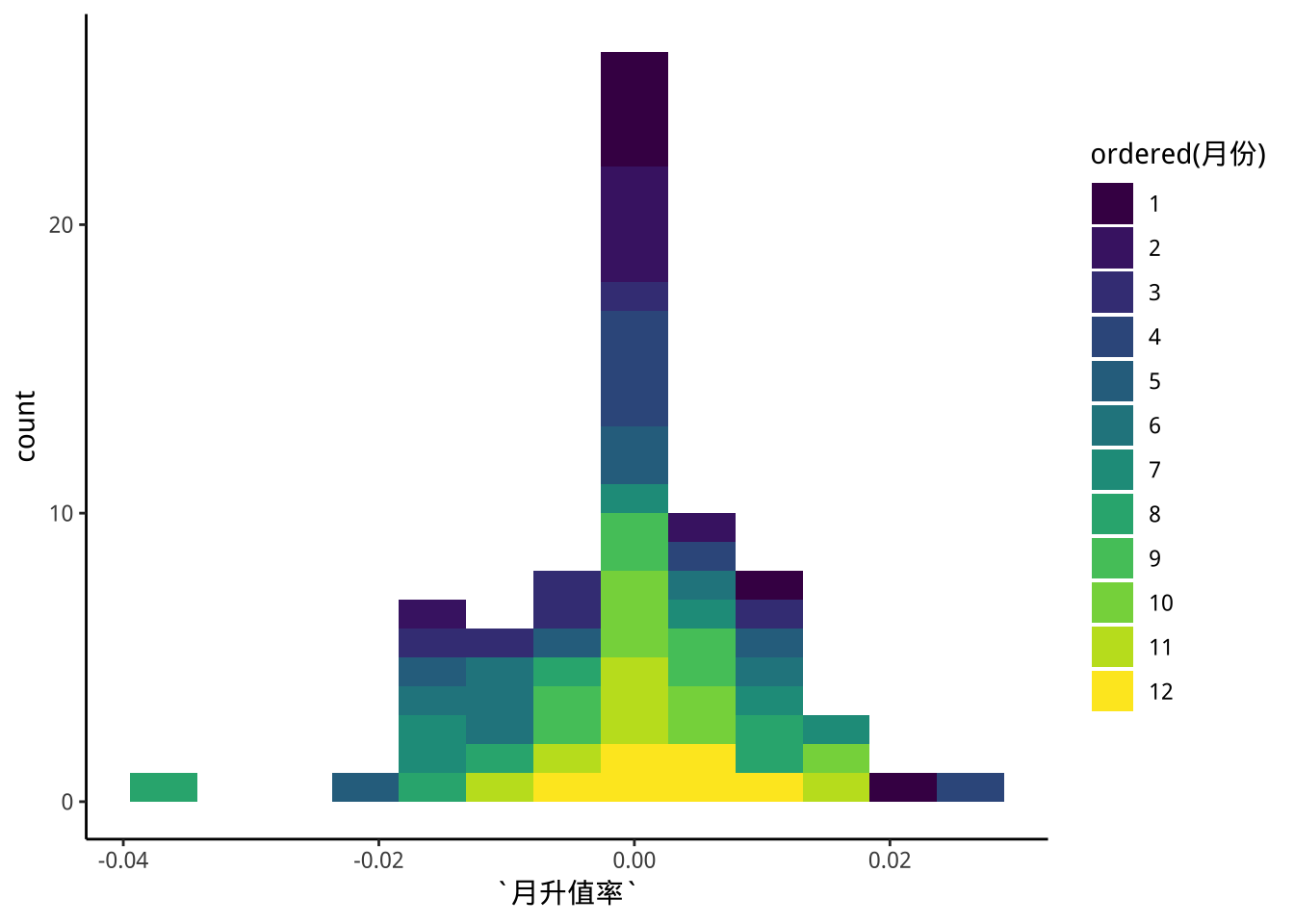
請問你如何把圖改成1月在最底層,而12月在最上層。
9.5 geom_freqpoly()
9.5.1 Usage
geom_freqpoly(mapping = NULL, data = NULL, stat = "bin",
position = "identity", ..., na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE)若要比較不同的分配,用線圖較佳。
exData7 %>%
filter(年份 %>% between(1990,2018)) %>%
na.omit ->
exData89.5.2 p7: 跨類比較
exData8 %>% filter(幣別=="新台幣NTD/USD") %>%
{grDevices::nclass.FD(.$月升值率)} -> binsNumber2
exData8 %>%
ggplot(aes(x=月升值率))+
geom_freqpoly(
aes(color=幣別),
bins=binsNumber2
) -> p7
p7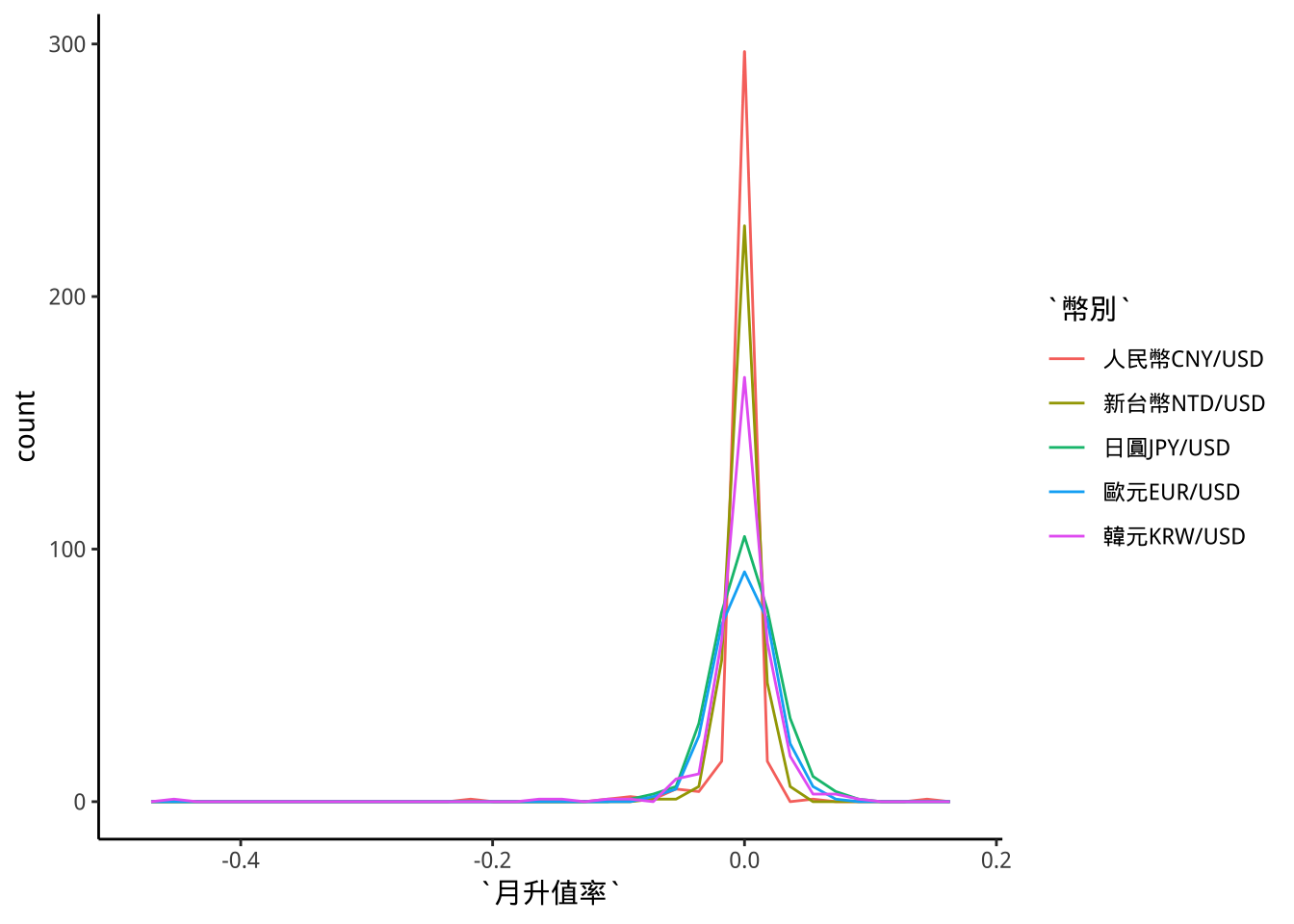
如何將月升值率限制在-0.15到0.15間?
p7+
scale_x_continuous(
limits = c(-0.15,0.15)
)
9.5.3 p8: 透過aes::weight改成比例
exData8 %>% group_by(幣別) %>%
mutate(權重=1/n()) %>%
ungroup -> exData9
exData9 %>%
ggplot(aes(x=月升值率))+
geom_freqpoly(
aes(color=幣別,weight=權重),
bins=binsNumber2
) -> p8
p8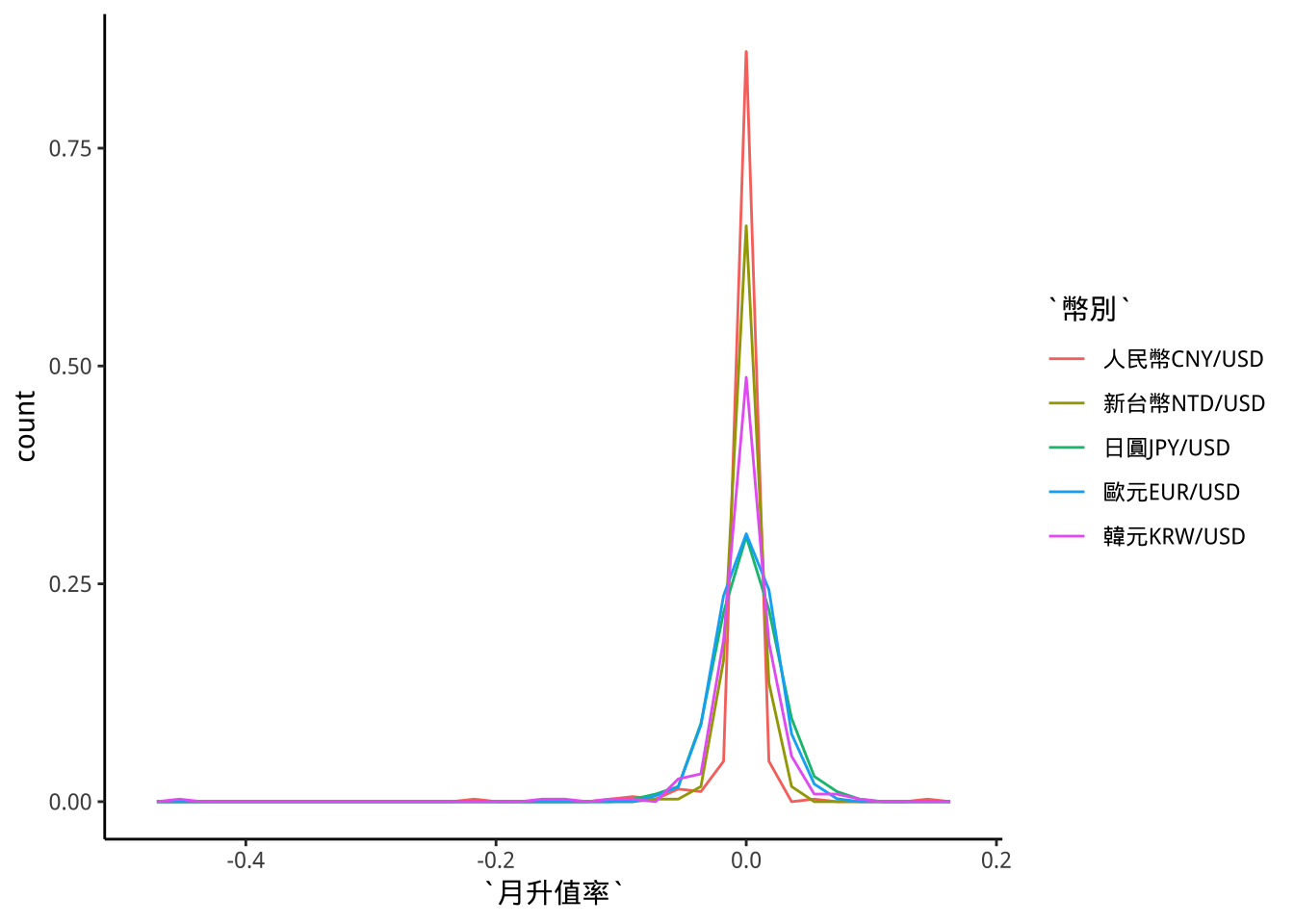
9.5.4 間斷變數與geom_freqpoly
間斷變數在做跨類分配比較時,有時用geom_freqpoly()比較能看出各中差異,然而它內定的stat="bin"必需改成間斷變數的stat="count"。
library(readr)
library(dplyr)
library(lubridate)
libraryData <- read_csv("https://raw.githubusercontent.com/tpemartin/github-data/master/libraryData.csv")
libraryData %>%
mutate(
月=month(借閱時間)
) %>%
select(
月,讀者年級
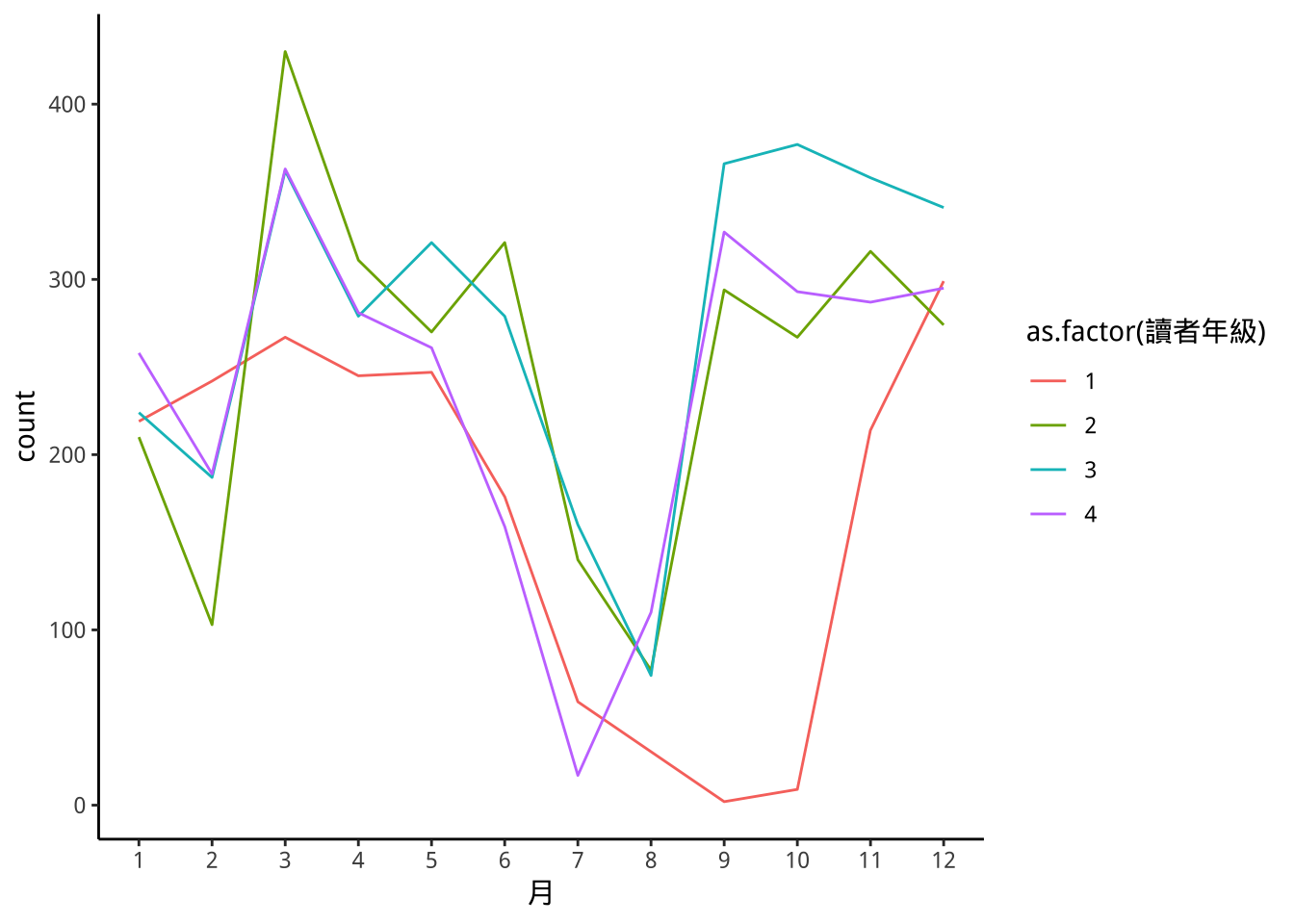
) -> monthGradesmonthGrades %>%
ggplot(aes(x=月))+
geom_bar(aes(fill=as.factor(讀者年級),
group=讀者年級),position="dodge")+
scale_x_continuous(
breaks=c(1:12)
)
monthGrades %>%
ggplot(aes(x=月))+
geom_freqpoly(aes(color=as.factor(讀者年級)),stat="count")+
scale_x_continuous(
breaks=c(1:12)
)
9.6 箱形圖:geom_boxplot()
Usage:
geom_boxplot(mapping = NULL, data = NULL, stat = "boxplot",
position = "dodge2", ..., outlier.colour = NULL,
outlier.color = NULL, outlier.fill = NULL, outlier.shape = 19,
outlier.size = 1.5, outlier.stroke = 0.5, outlier.alpha = NULL,
notch = FALSE, notchwidth = 0.5, varwidth = FALSE, na.rm = FALSE,
show.legend = NA, inherit.aes = TRUE)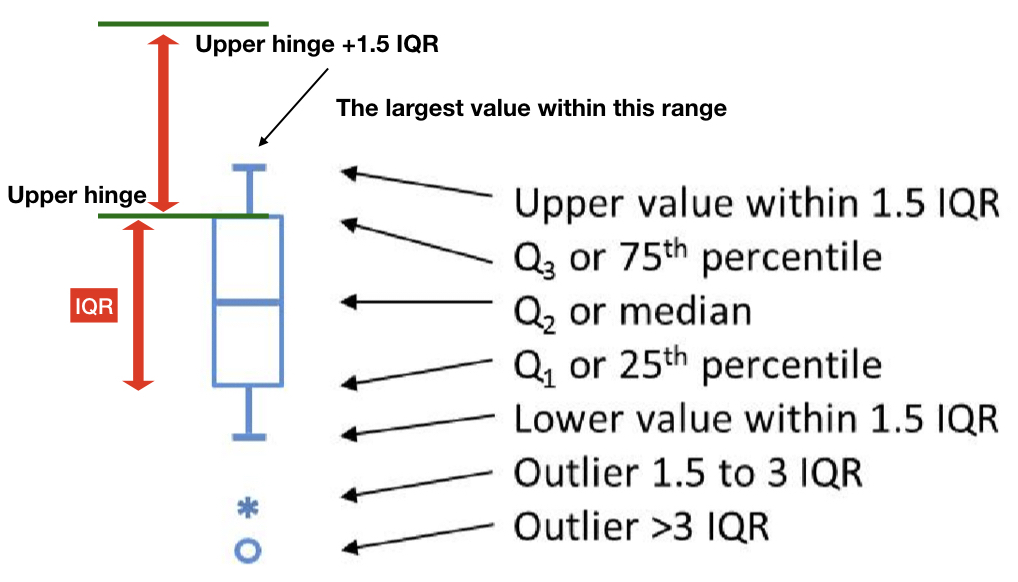
9.6.1 p9: 範例
不同年級的借閱數之分佈差異
libraryData %>%
group_by(學號,讀者年級) %>%
summarise(
借閱次=n(),
學院=first(學院)
) -> libraryEachGradelibraryEachGrade %>% group_by(讀者年級) %>%
mutate(權重=1/n()) -> libraryEachGrade
libraryEachGrade %>% group_by(讀者年級) %>%
summarise(
binsNumber=grDevices::nclass.FD(借閱次)
)## # A tibble: 4 x 2
## 讀者年級 binsNumber
## <dbl> <dbl>
## 1 1 45
## 2 2 58
## 3 3 46
## 4 4 50libraryEachGrade %>%
ggplot(aes(x=借閱次))+
geom_freqpoly(aes(color=as.factor(讀者年級),weight=權重),bins=50)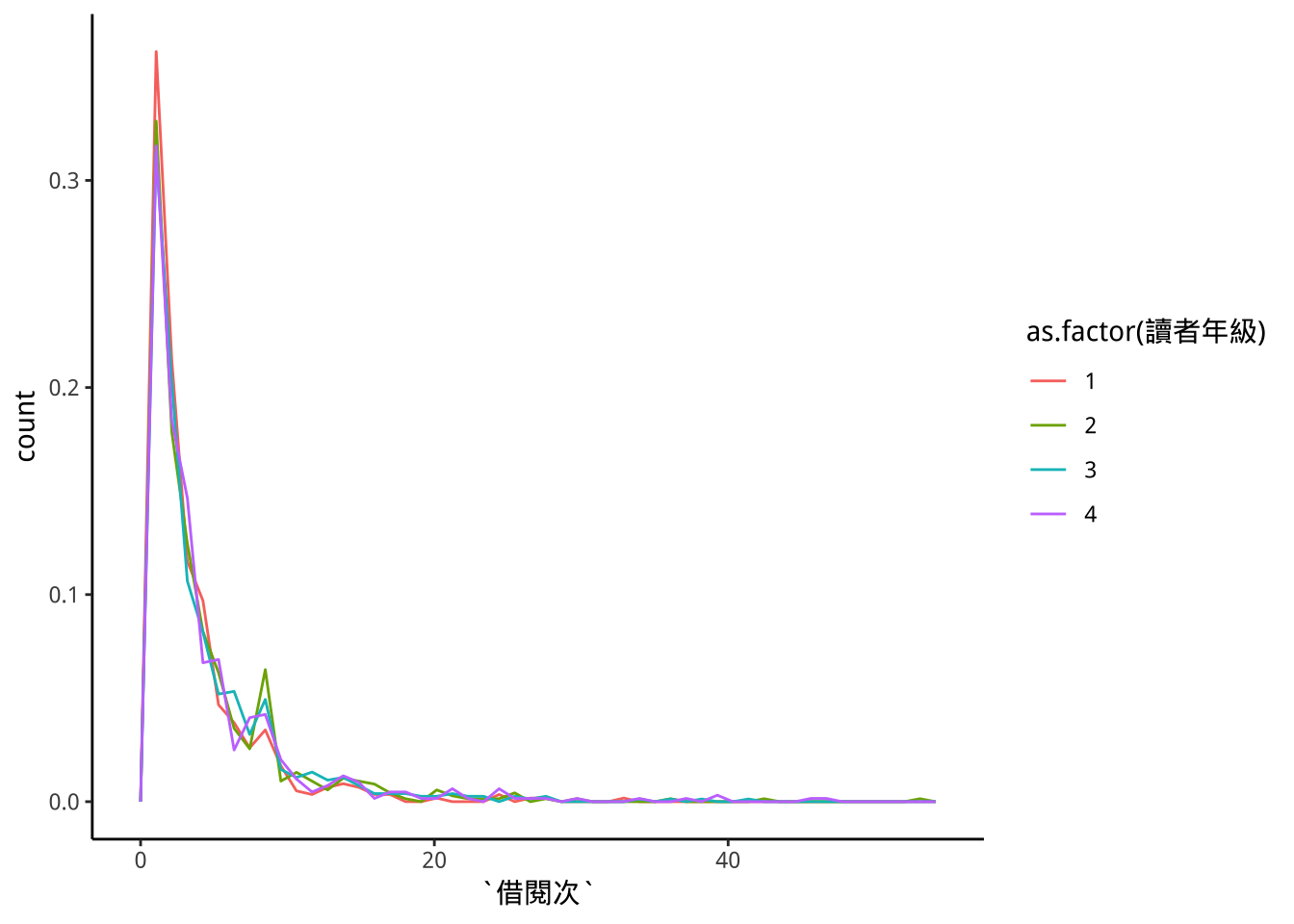
libraryEachGrade %>%
ggplot(aes(x=as.factor(讀者年級)))+
geom_boxplot(aes(y=借閱次))->p9; p9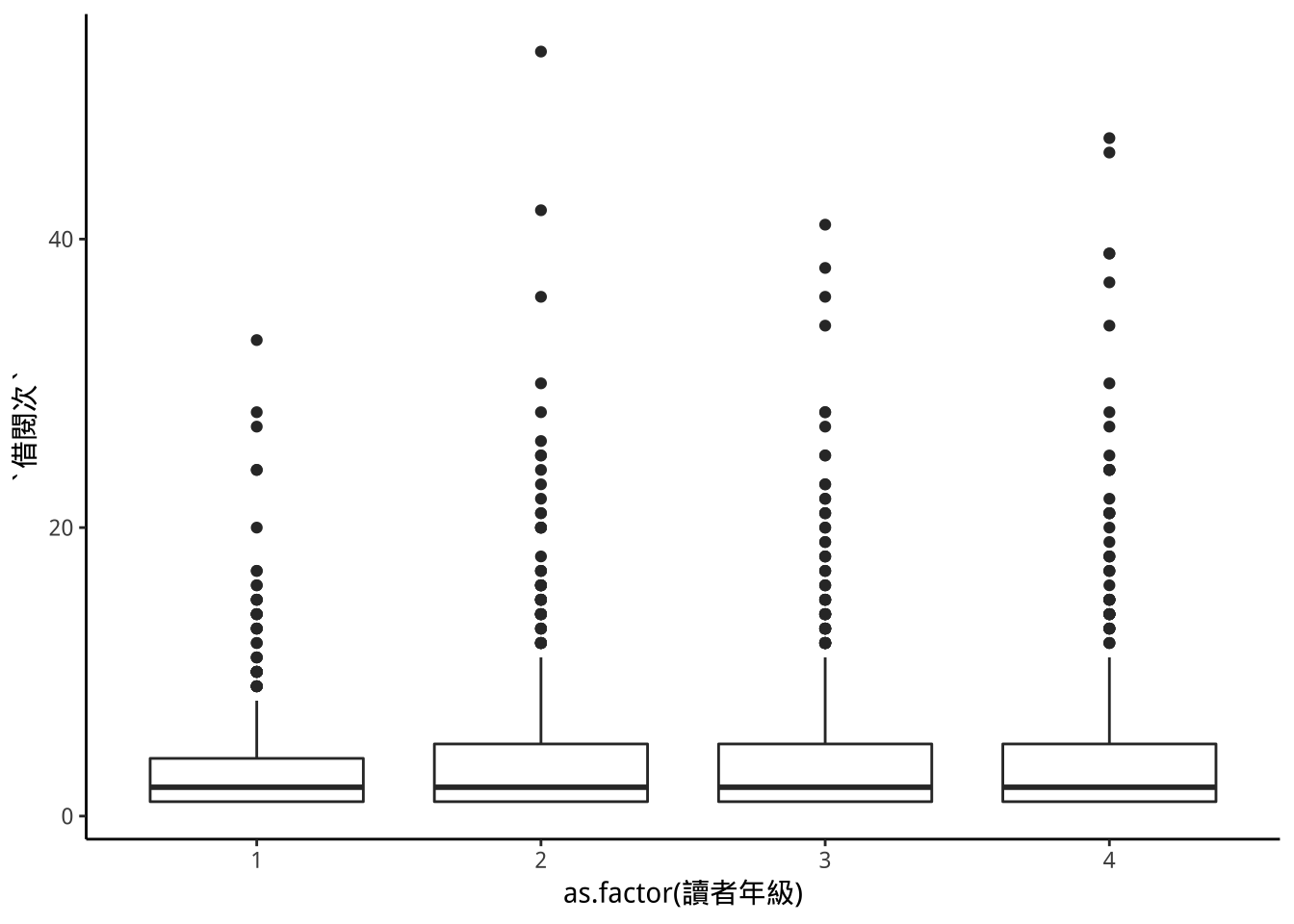
9.6.2 p10: 設定y limits
p9+
scale_y_continuous(limits=c(0,10)) -> p10; p10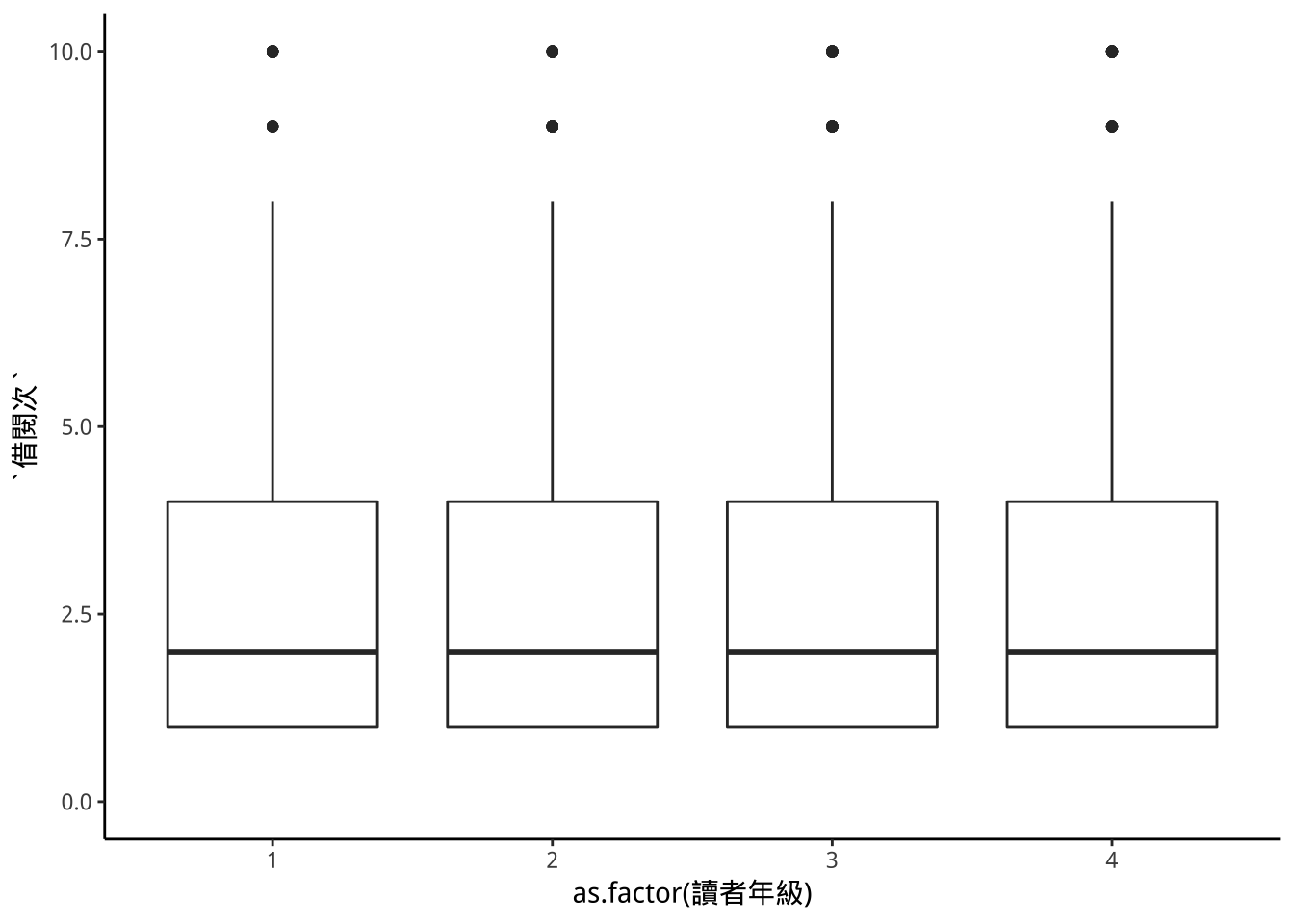
9.6.3 p11: 不同學院
libraryEachGrade %>%
ggplot(aes(x=as.factor(讀者年級)))+
geom_boxplot(aes(y=借閱次,color=學院))-> p11; p11
9.7 多格圖面呈現:facet_grid() 與 facet_wrap()
libraryEachGrade %>%
ggplot(aes(x=as.factor(讀者年級)))+
geom_boxplot(aes(y=借閱次))+
facet_grid(~學院)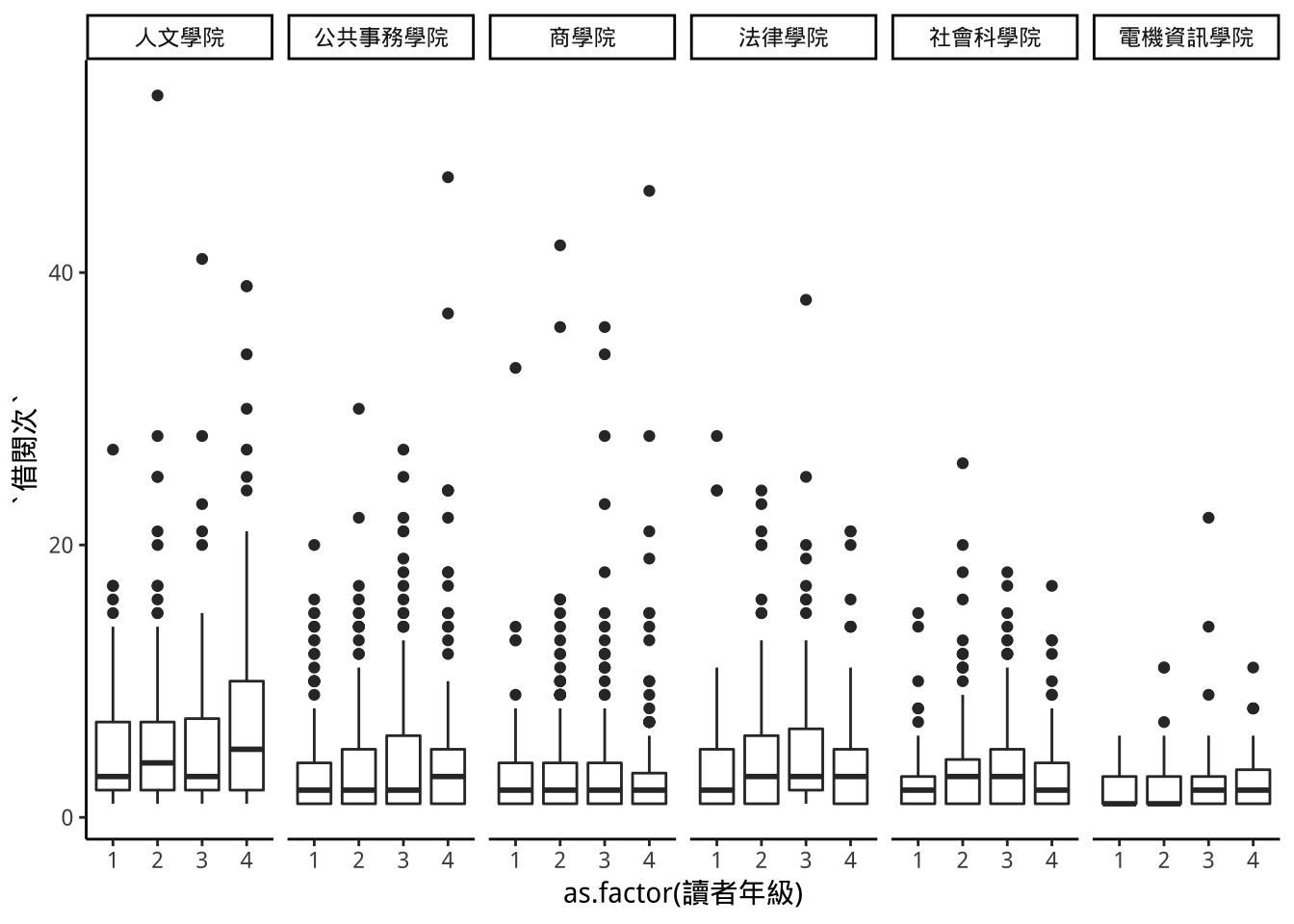
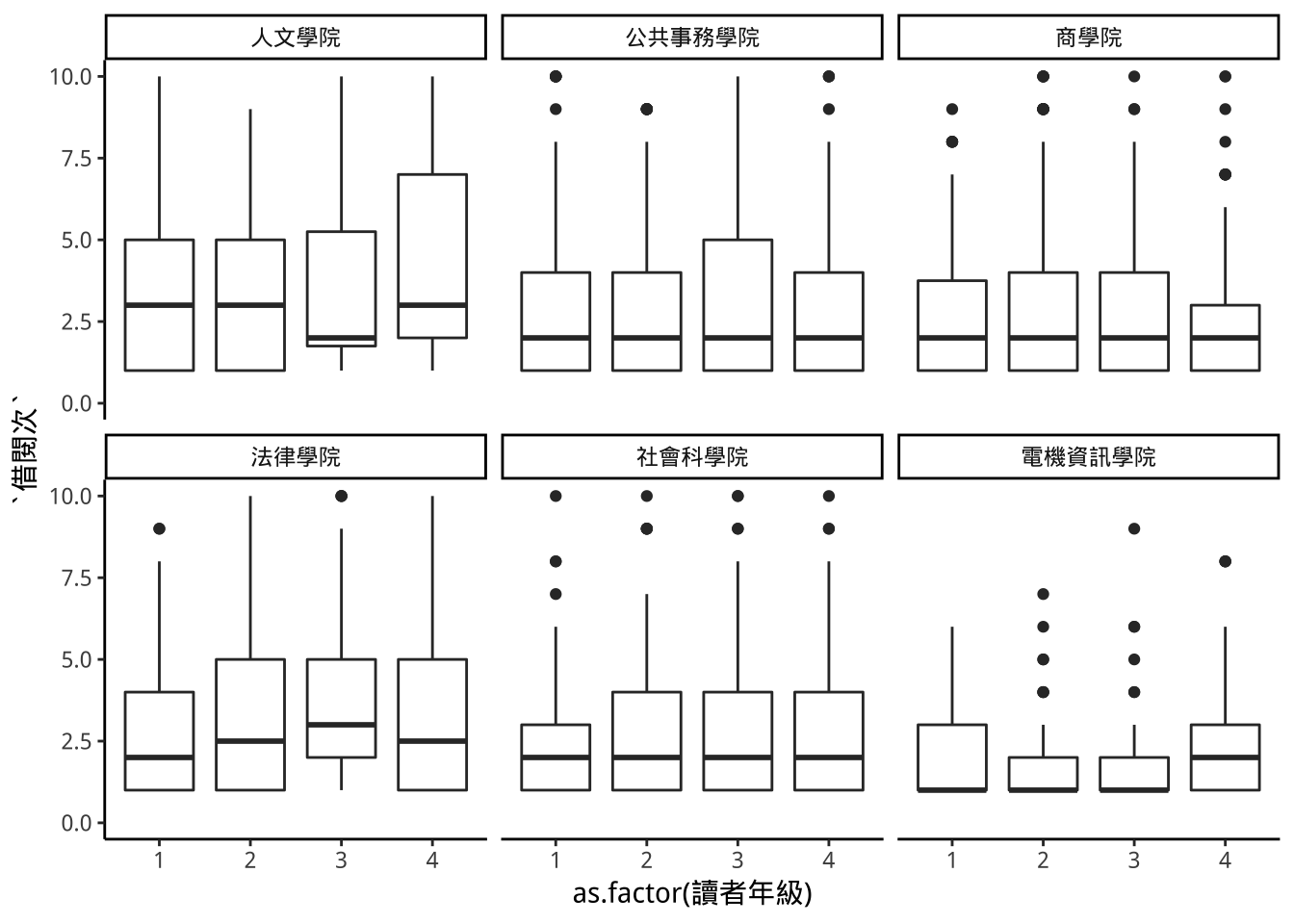
libraryEachGrade %>%
ggplot(aes(x=as.factor(讀者年級)))+
geom_boxplot(aes(y=借閱次))+
facet_wrap(~學院,nrow=2,ncol=3)+
scale_y_continuous(limits=c(0,10))