Chapter 8 Bar
長條圖主要用在
- 比較不同類別/群體間的特徵差異
8.1 兩種長條圖:geom_bar 與 geom_col
長條圖分成兩類:
geom_bar(aes(x=...)):只有x軸變數;y軸透過計算,如y為統計x變數分群下的統計值(內定是計數(即數每群有多少“個”),並用y軸長條高度代表。- x為男/女性:y軸為男/女性毎別資料筆數。
geom_col(aes(x=...,y=...)):有x軸變數,也指定y軸變數;x代表類別,y軸代表長條高度。- x為不同職業,y為平均薪資:y也是搜集來的資料。
8.2 基本範例資料
範例:geom_col
初任人員平均經常性薪資
startSalaryTopCat<- read_csv("https://raw.githubusercontent.com/tpemartin/github-data/master/startSalaryTopCat.csv")
startSalaryTopCat %>% filter(
str_detect(大職業別,"部門")
) -> dataTwoSectorsdataTwoSectors %>% ggplot(aes(x=大職業別))+
geom_col(aes(y=`經常性薪資-薪資`))->p1
p1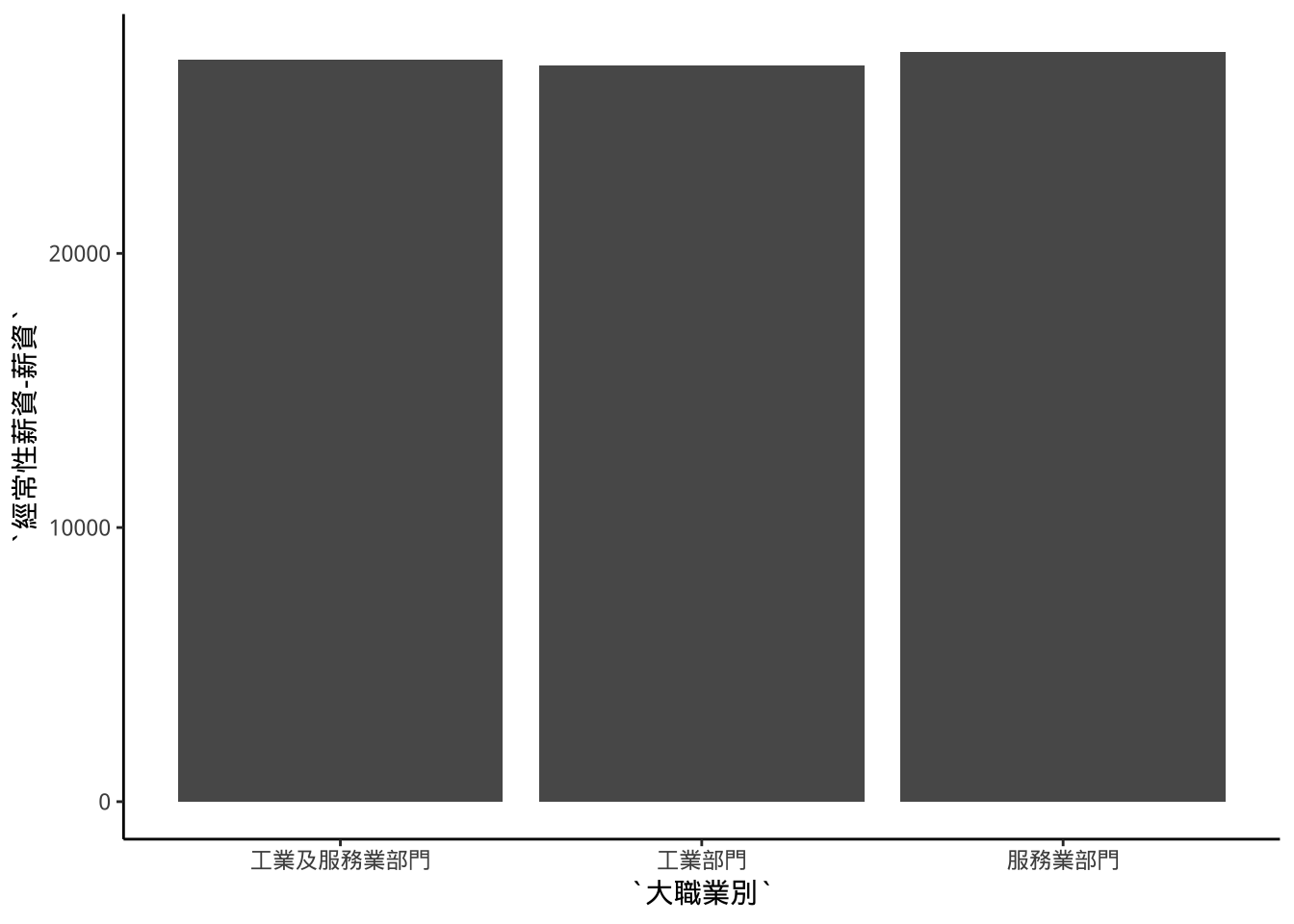
若改成geom_bar()會變成什麼狀況?
範例:geom_bar
大一問卷資料
classSample<- read_csv("https://raw.githubusercontent.com/tpemartin/github-data/master/classSample.csv")
classSample %>%
mutate_at(
vars(-c(3,4)),
funs(
as.factor(.)
)
) -> classSamplegeom_bar()內訂y軸呈現x各類別樣本個數的計數(count)。
classSample %>%
filter(入學年=="107") ->
freshmen
freshmen %>%
ggplot(aes(x=性別))+
geom_bar()->p2
p2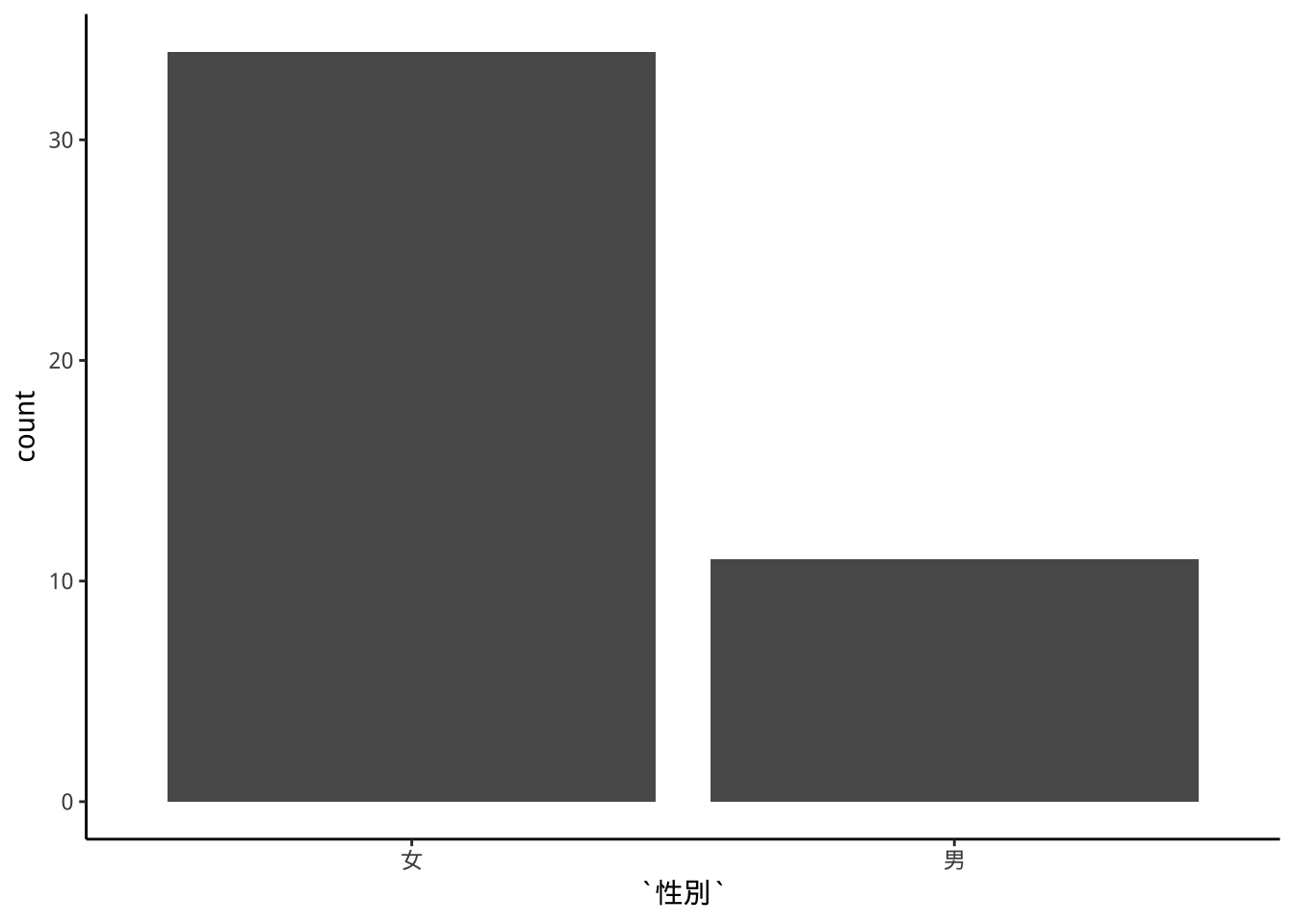
上述geom_bar()若強行給y軸變數會如何呢?
8.3 labs():aes座標名稱
labs(..., title = waiver(), subtitle = waiver(), caption = waiver(),
tag = waiver())所有的aes mapping元素均可以透過
+labs(aesName="名稱")來變更。若不要有元素座標名稱:
+labs(aesName=NULL)
p1+
labs(x=NULL,y=NULL) -> p1
p1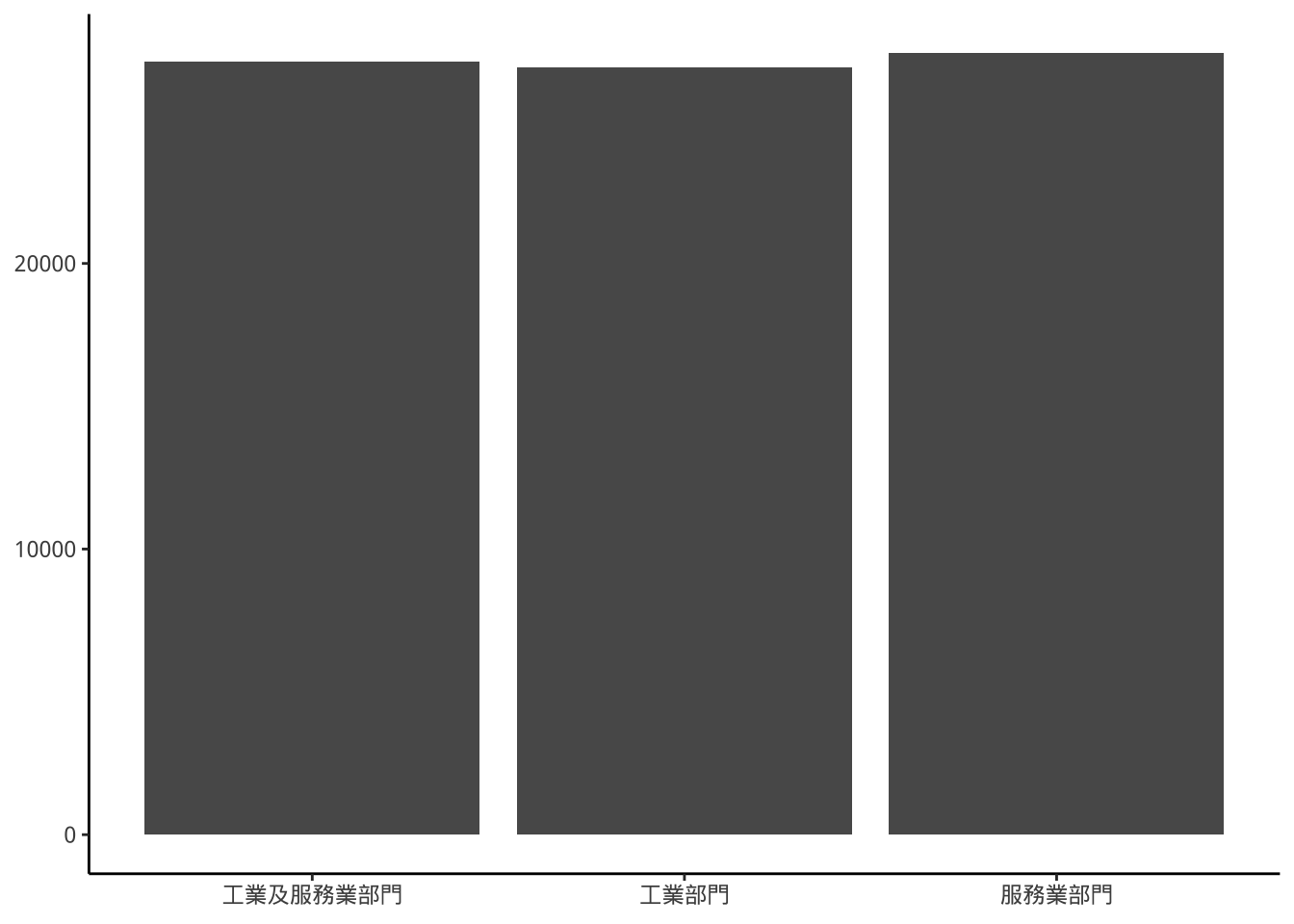
p2+
labs(x=NULL,y=NULL)-> p2
p2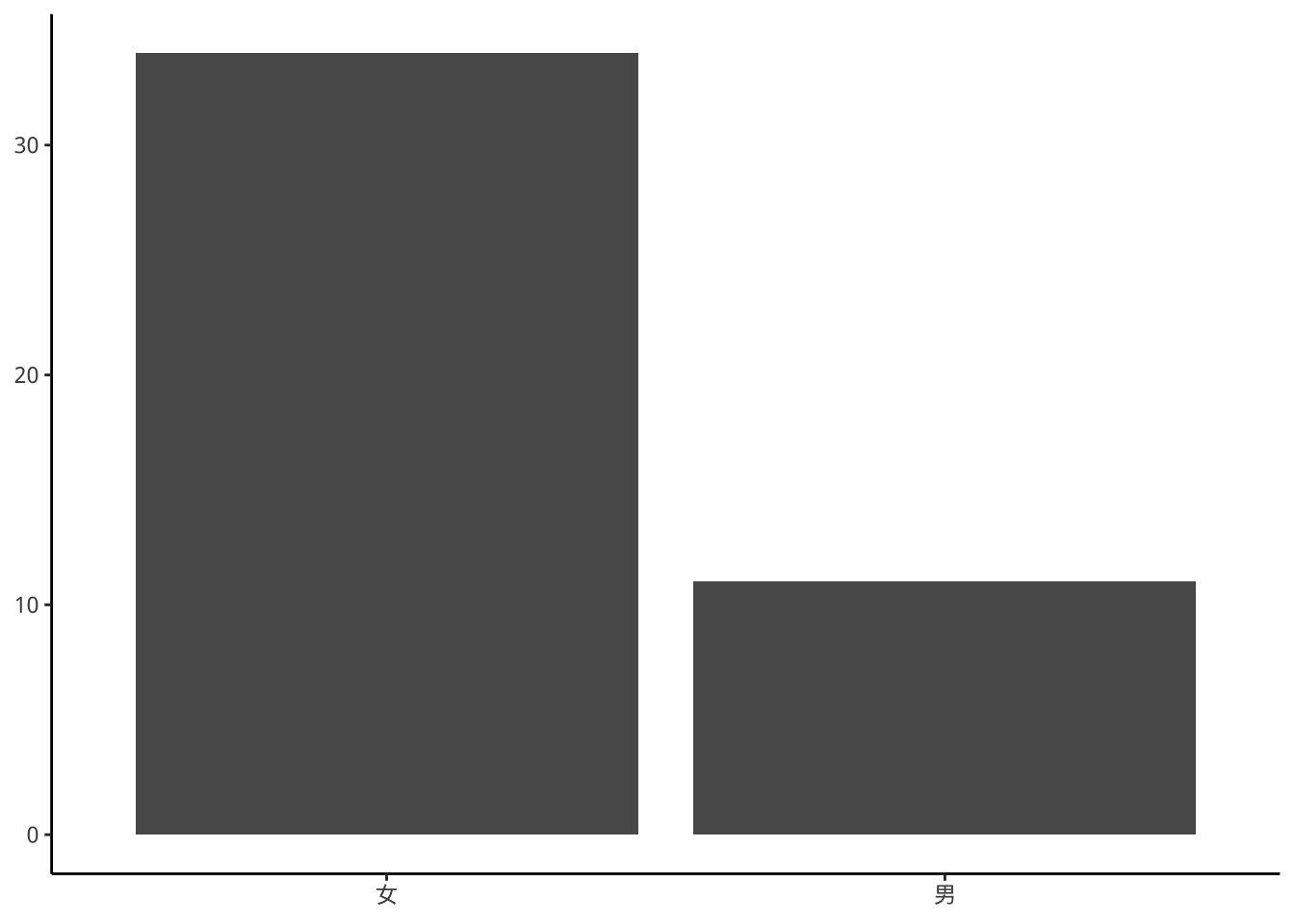
8.4 Usage
geom_col(mapping = NULL, data = NULL, position = "stack", ...,
width = NULL, na.rm = FALSE, show.legend = NA,
inherit.aes = TRUE)geom_bar(mapping = NULL, data = NULL, stat = "count",
position = "stack", ..., width = NULL,
na.rm = FALSE, show.legend = NA, inherit.aes = TRUE)8.5 aesthetics: fill (填色)
工業部門與服務業部門的初任薪資差異有多大?
startSalaryTopCat$部門<-"服務業部門"
startSalaryTopCat$部門[2:7]<-"工業部門"
startSalarySecCat <- startSalaryTopCat[-c(1,2,8),]startSalarySecCat %>% ggplot(aes(x=大職業別))+
geom_col(aes(y=`經常性薪資-薪資`,fill=部門))+
theme(
axis.text.x=
element_text(
angle=90,
hjust=1,
vjust=0.5)) -> p3
p3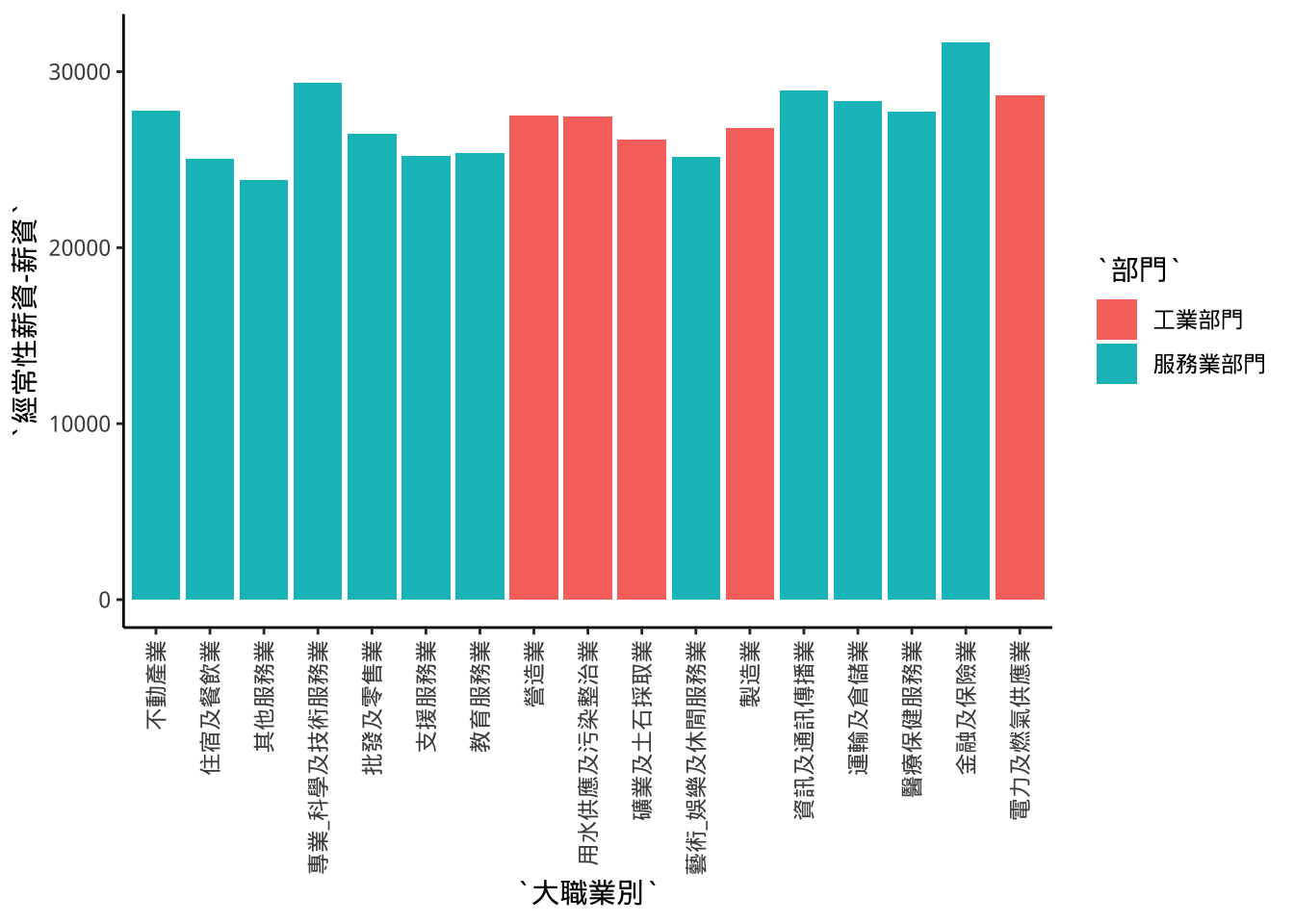
大一男女性比例用不同顏色表示。
8.6 幾何位置(position)
geom_bar(position="XXX")其中XXX有以下選擇:
- dodge:躲避
- fill:填滿(標準化成同高度,呈現比重變化用)
- stack:疊上
8.6.1 stack:堆疊
強調各大類總額差別
及各大類總額的次類組成份子大小


freshmen %>%
mutate(有課外活動=(本學期目前已參加之課外活動!="無")) ->
freshmen2
freshmen2 %>%
ggplot(aes(x=有課外活動))+
geom_bar(aes(fill=性別)) 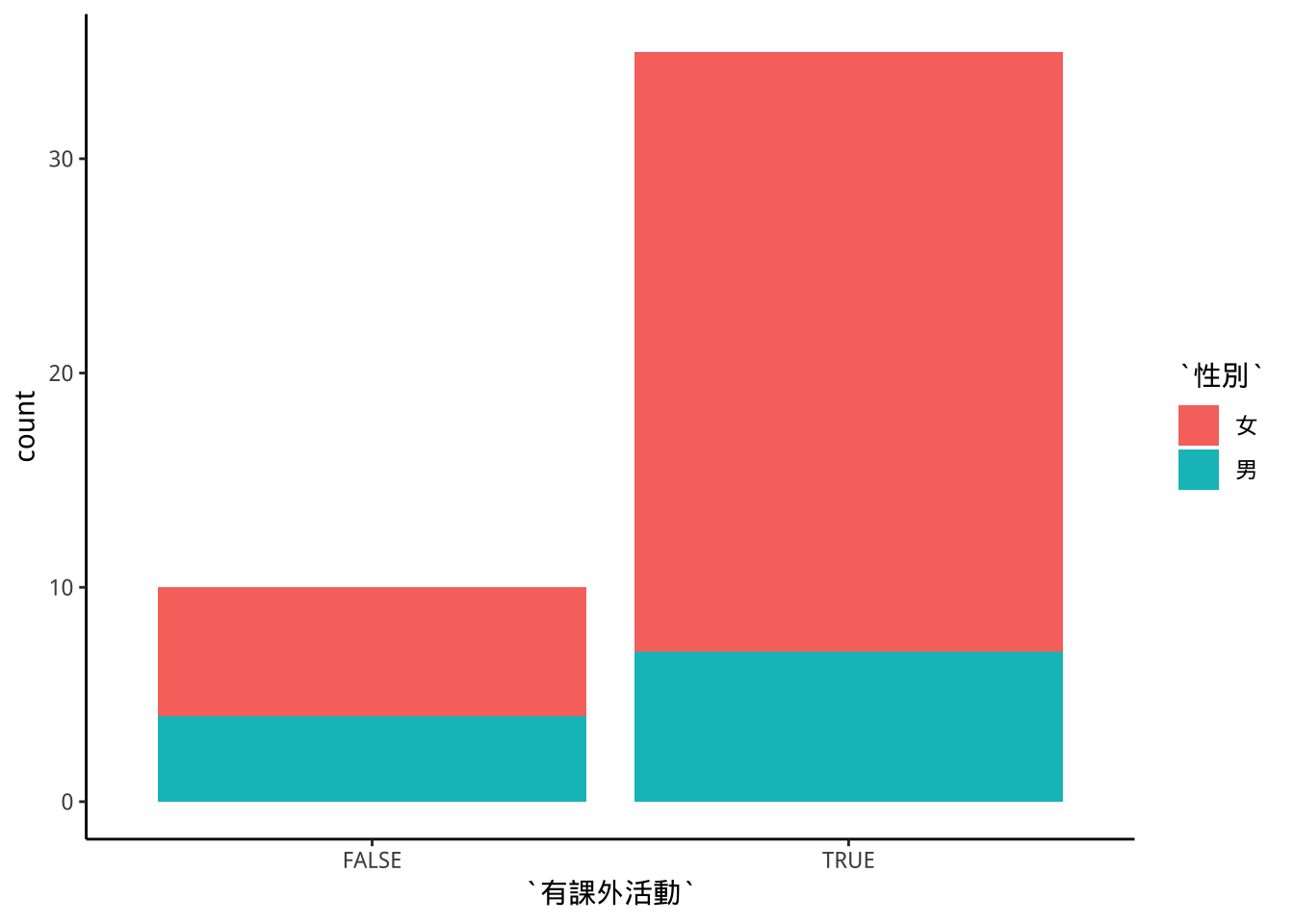
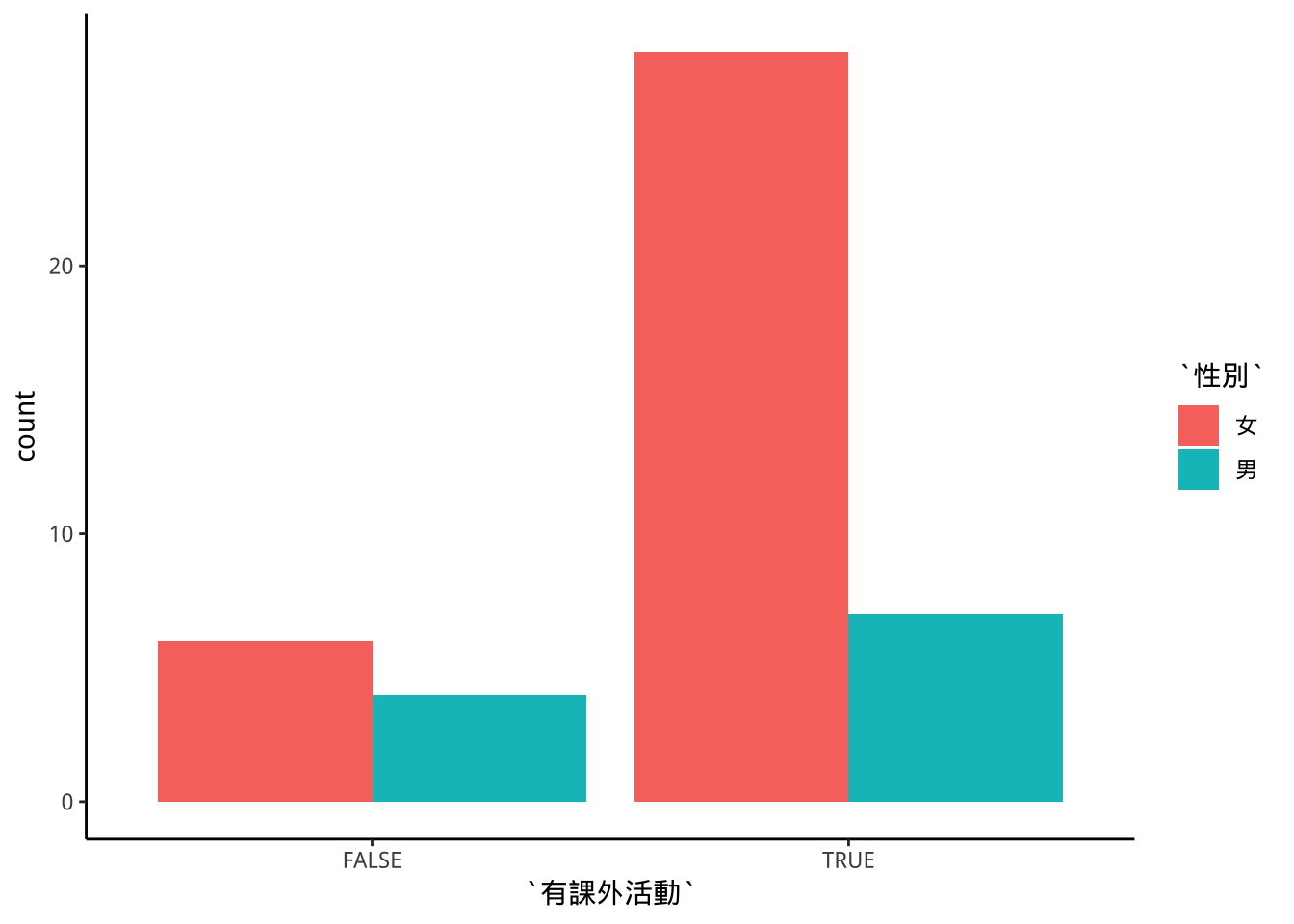
8.6.2 dodge:平行排列
比較各大項內的小項差異
也比較各小項在各大項內的差異

freshmen2 %>%
ggplot(aes(x=有課外活動))+
geom_bar(aes(fill=性別),
position = "dodge"
) 
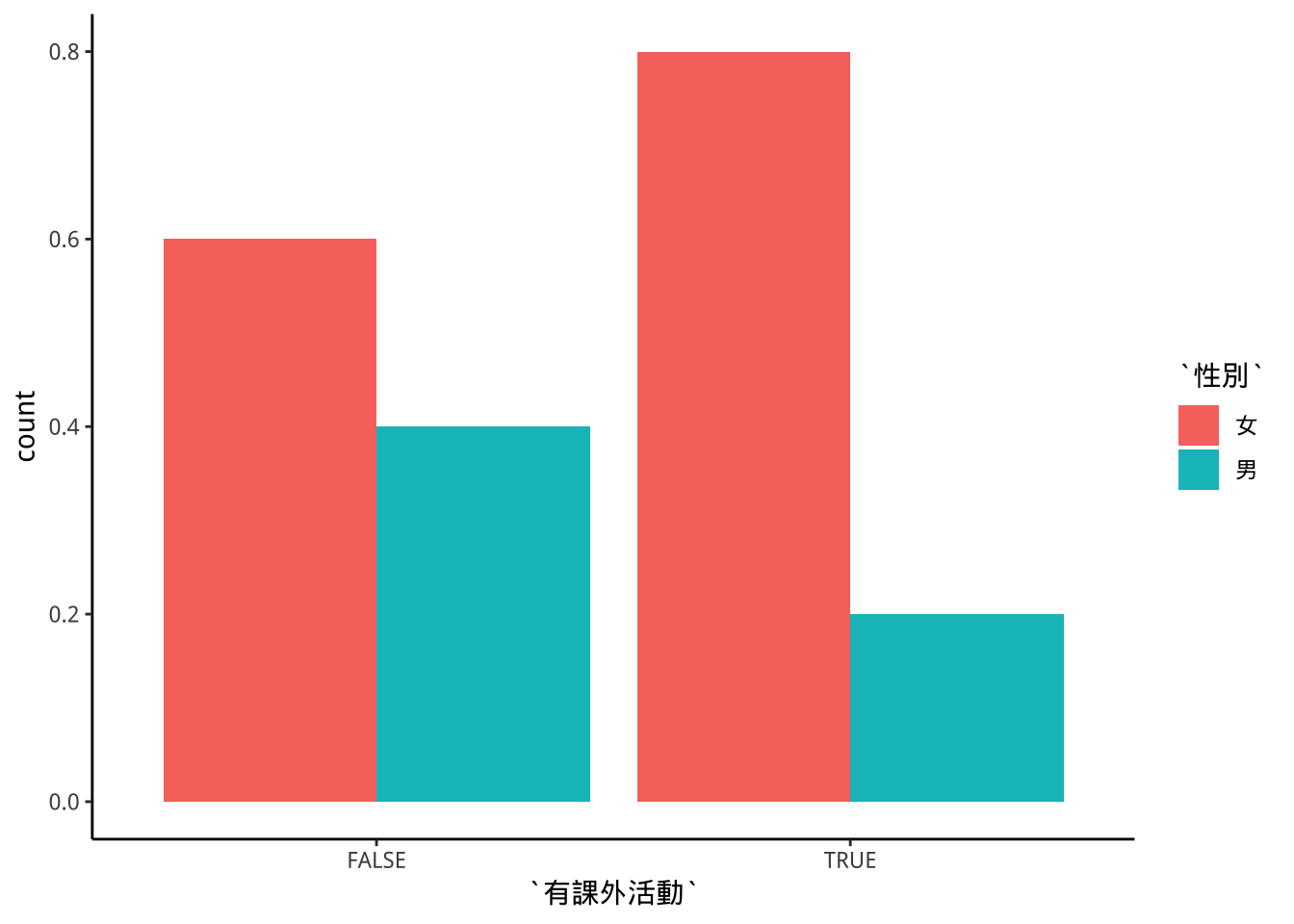
8.6.3 fill:百分比成份拆解
- 強調組成份子比例的變化。

freshmen2 %>%
ggplot(aes(x=有課外活動))+
geom_bar(aes(fill=性別),
position = "fill"
)+
scale_fill_brewer(type="qual")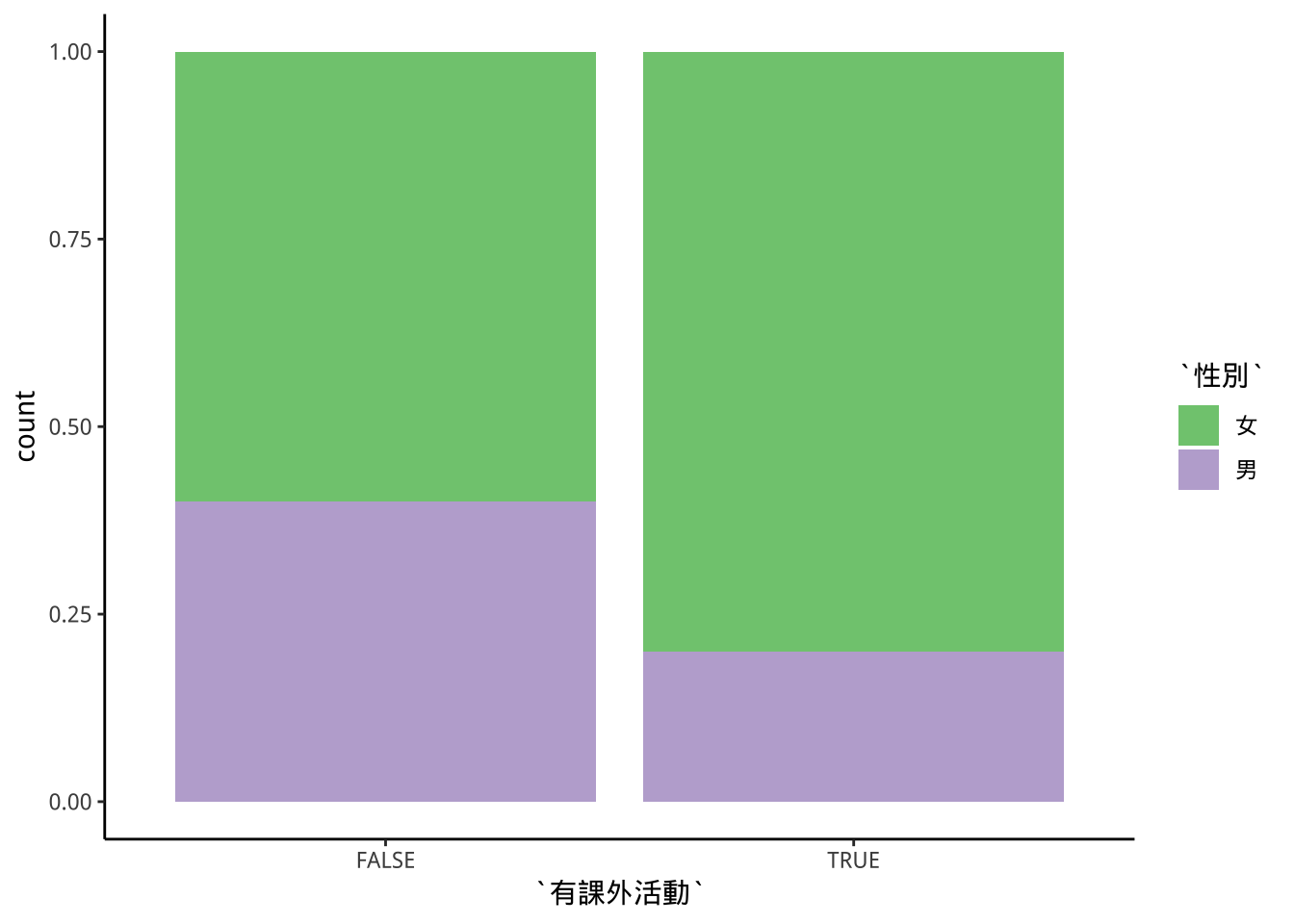
8.7 類別排序
8.7.1 x mapping
將p3圖依薪資高低畫出(最高在左),要如何做?
- 透過
scale_x_discrete(limits=...)
startSalarySecCat$`經常性薪資-薪資` %>%
sort(., decreasing=T,
index.return=T) -> sortOut
xlim <- startSalarySecCat$大職業別[sortOut$ix]
p3+scale_x_discrete(
limits=xlim
)->p4
p4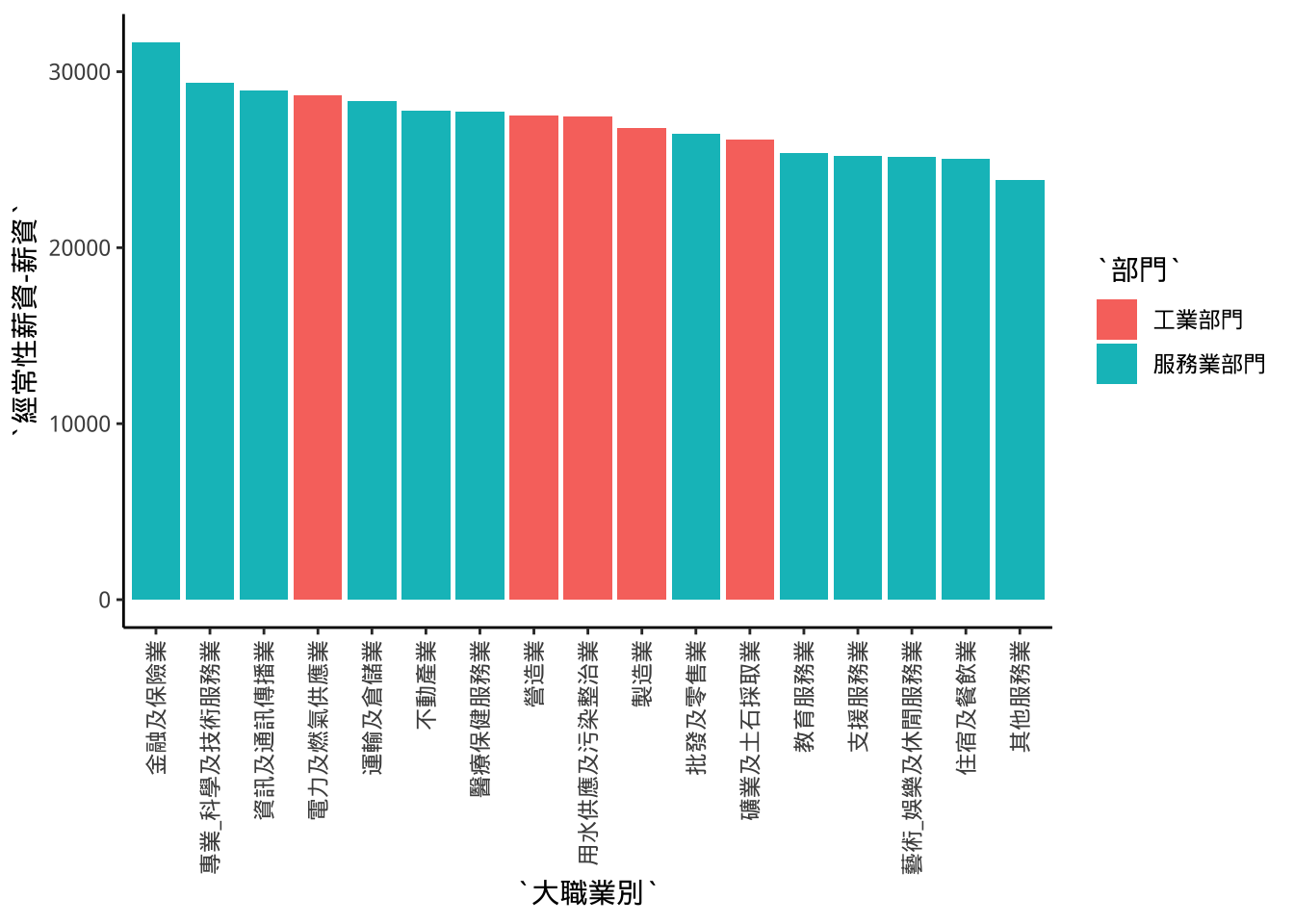
8.7.2 fill mapping
先將性別排序可以改變fill長條呈現順序。
freshmen2 %>%
mutate(性別=ordered(性別,
levels=c("男","女"))) -> freshmen3
freshmen3 %>%
ggplot(aes(x=有課外活動))+
geom_bar(aes(fill=性別),
position = "dodge"
)+
scale_fill_brewer(type="qual")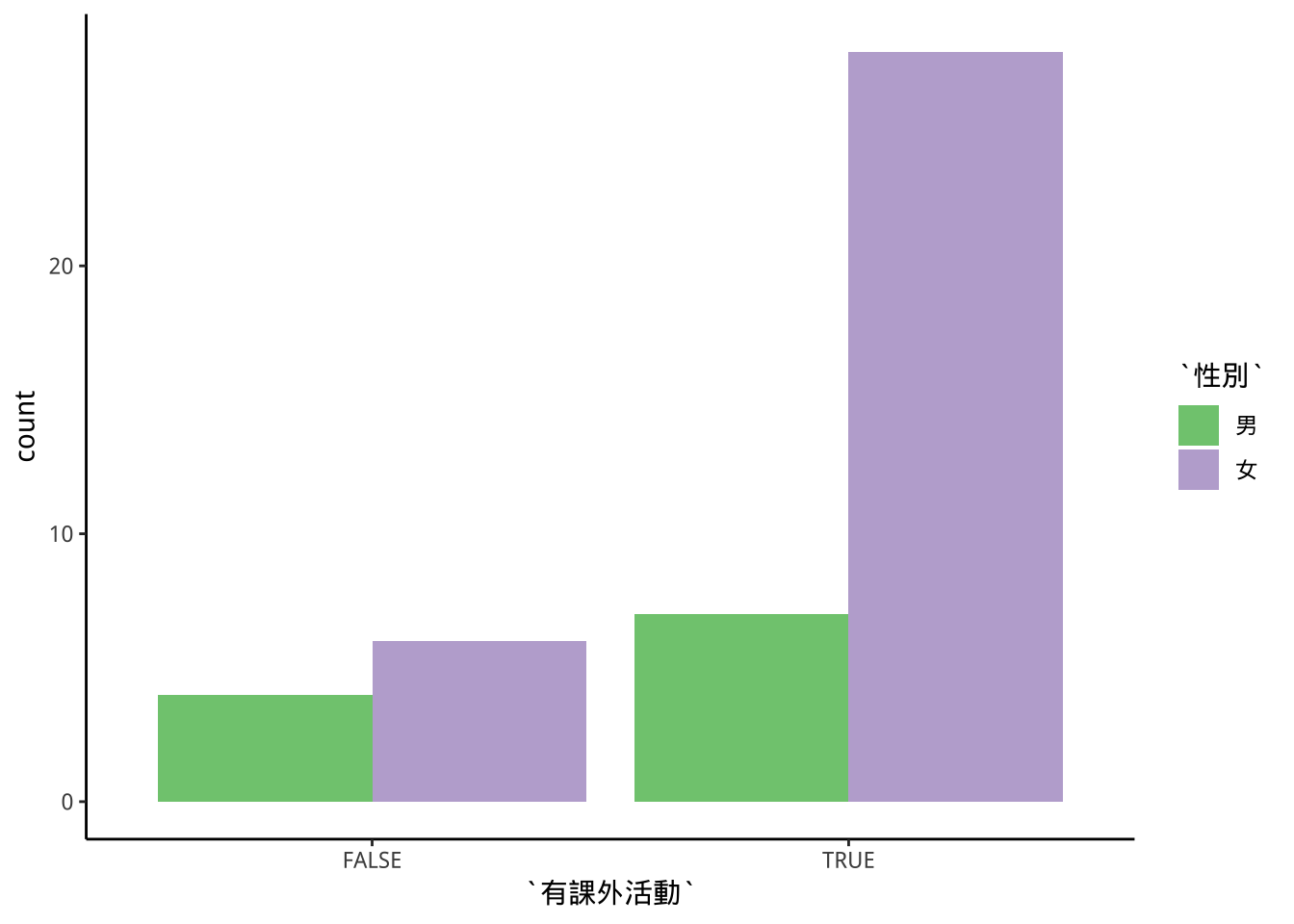
8.8 aesthetics:weight
內定是由系統來count(計算個數),可以透過weight來更改每筆計算權重。
freshmen2 %>%
# 依**有課外活動**分群,群內的每筆權重為 1/群內人數
group_by(有課外活動) %>%
mutate(權重=1/n()) -> freshmen4 # n(): 計算群內樣本數
freshmen4 %>%
ggplot(aes(x=有課外活動))+
geom_bar(aes(fill=性別,weight=權重),
position = "dodge"
) 
8.9 轉軸
+coord_flip()
p4+
coord_flip()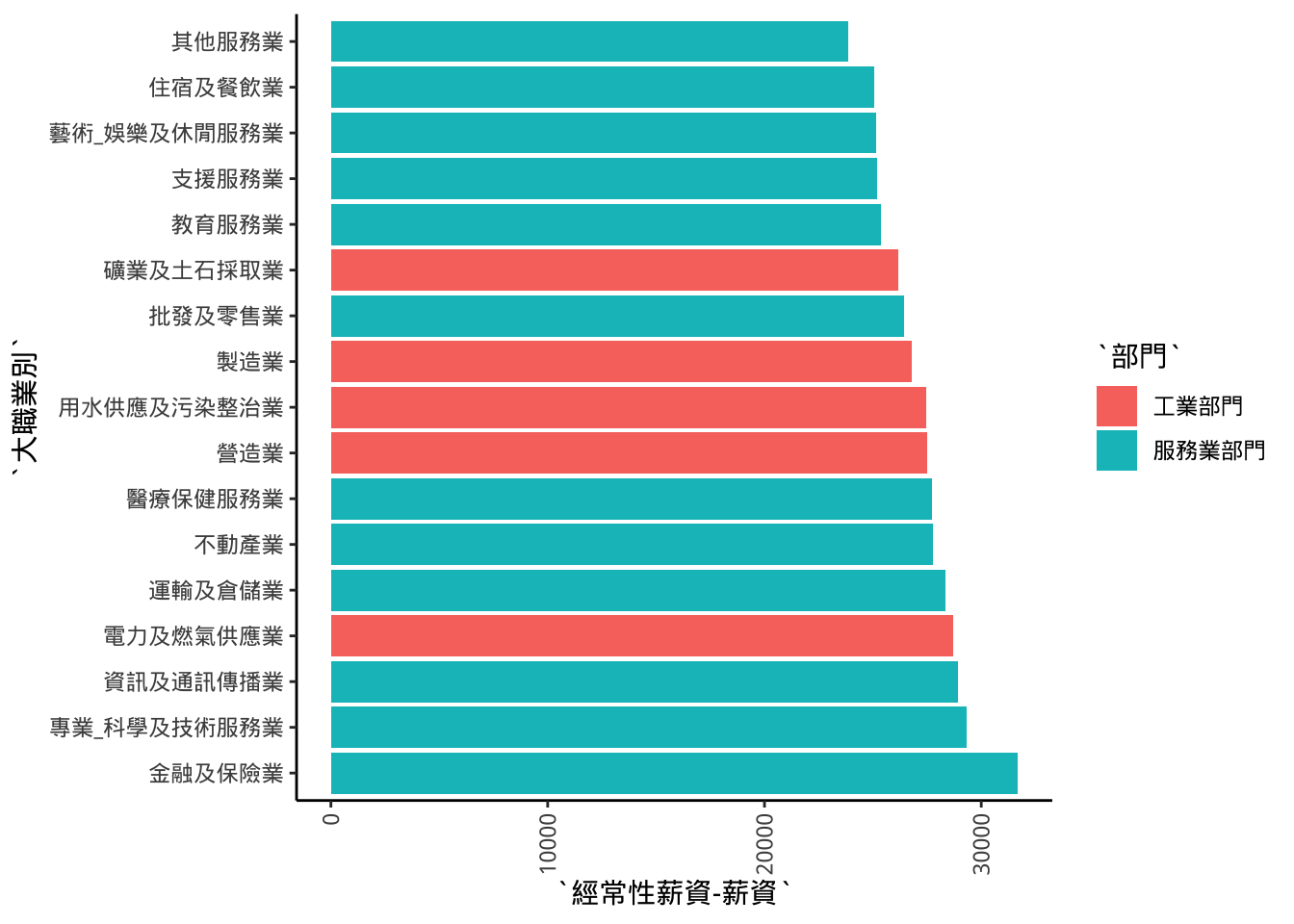
原本的y軸可能需要換到「右側」:
p4+
scale_y_continuous(position = "right")->p5
p5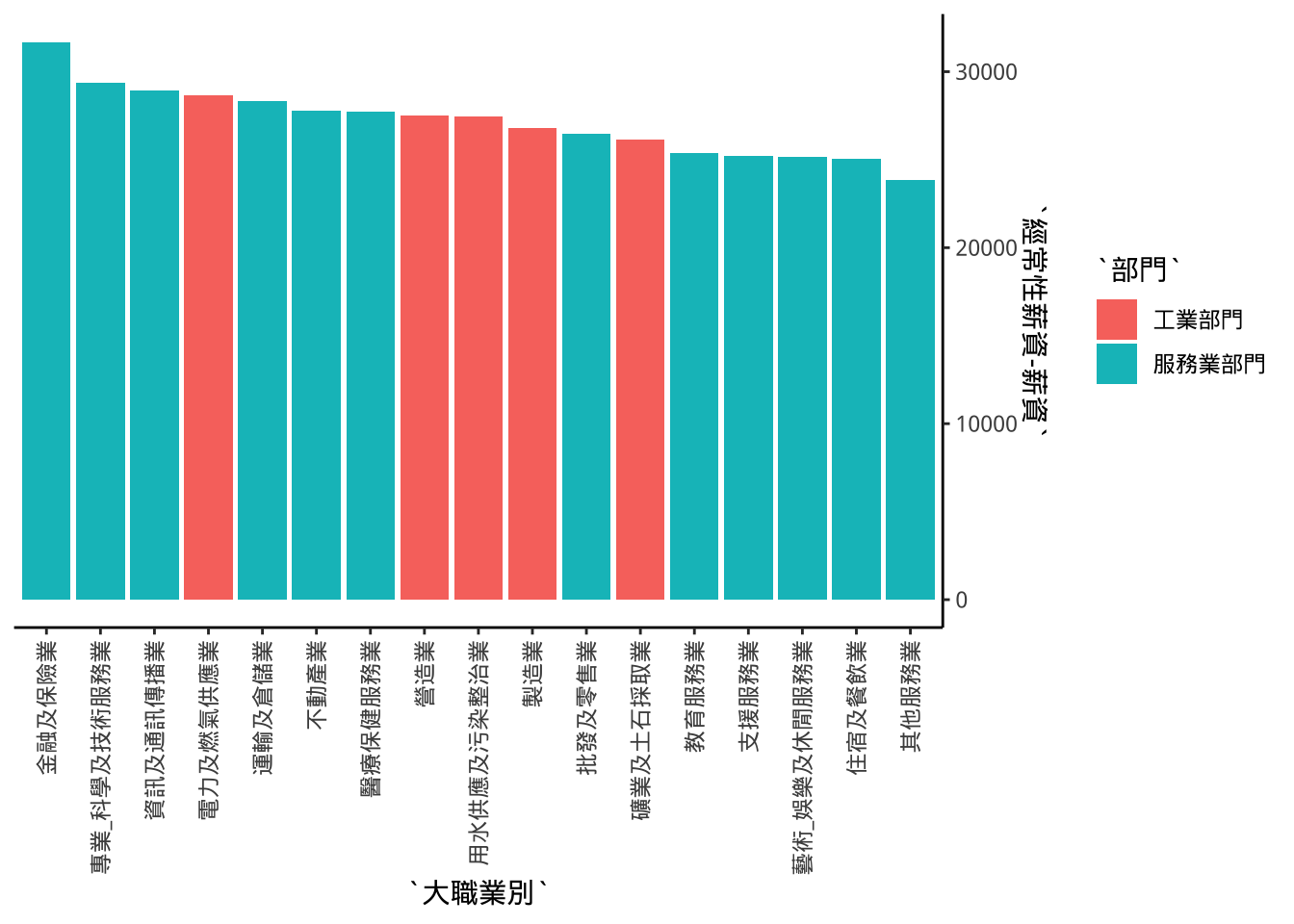
原本設定的「由大到小」,變成反的,可透過rev()顛倒順序。
p5+scale_x_discrete(
limits=rev(xlim) # xlim為先前定義的順序
)+coord_flip()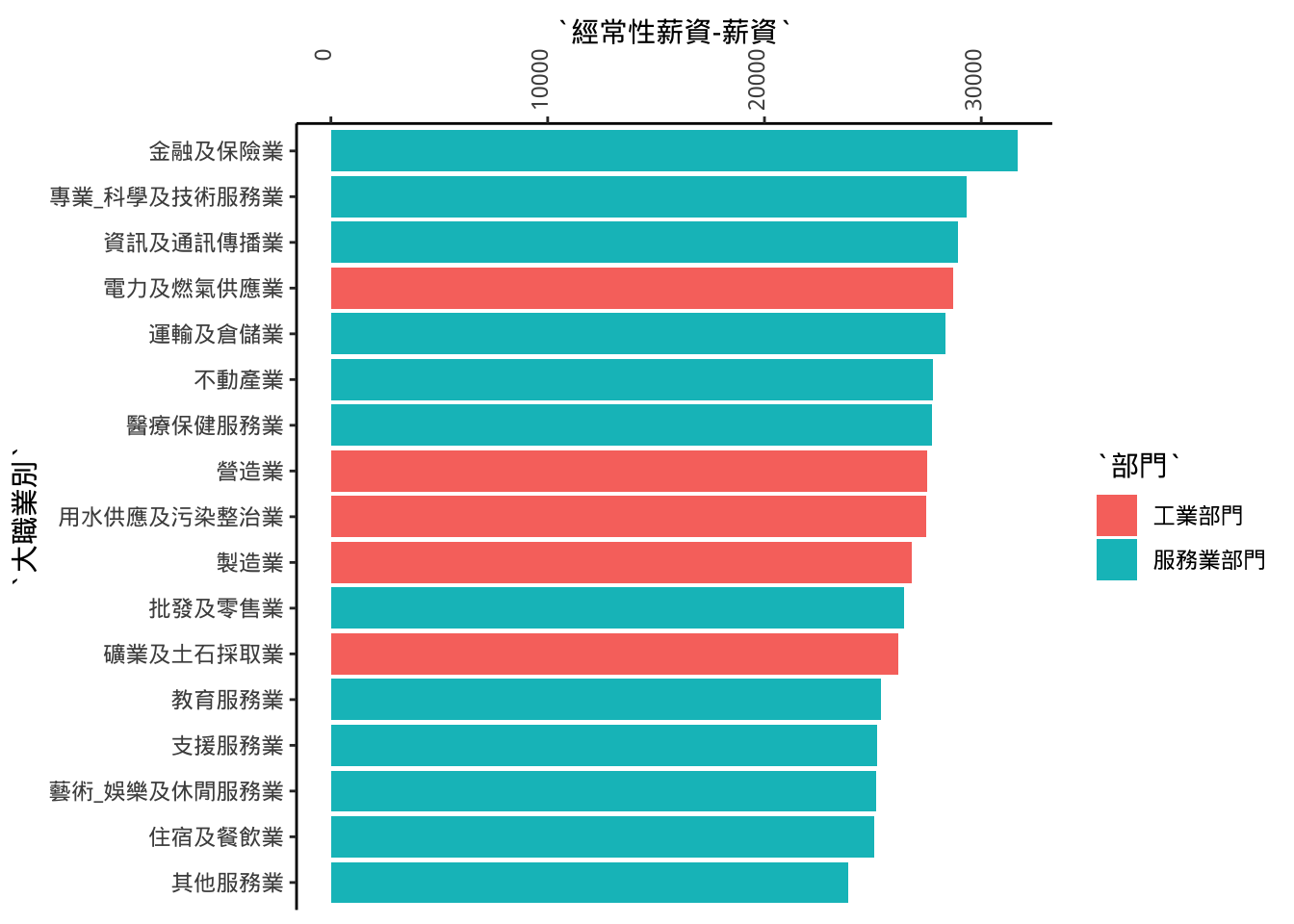
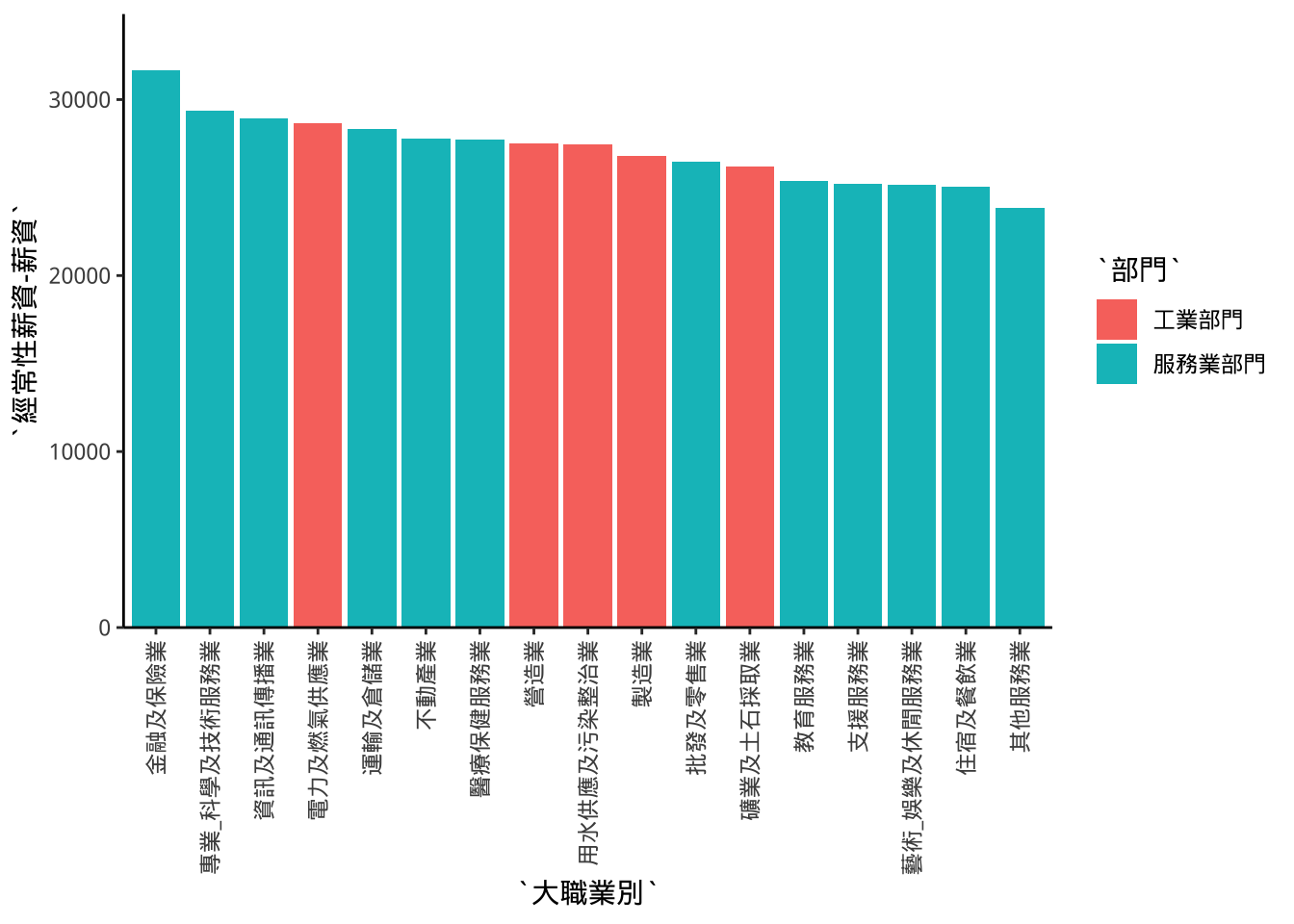
8.10 間距
與軸線的間距
scale_x/y_...(expand=expand_scale(...))
expand_scale(mult=..., add=...)mult: 要以limit往下/上限延伸「1+多少」比例 add: 要以limit往下/上限延伸「多少」單位
p4+scale_y_continuous(
expand=expand_scale(mult = c(0,0.1))
)
長條粗細
geom_bar/col(width=...)
startSalarySecCat %>%
ggplot(aes(x=大職業別))+
theme(
axis.text.x=
element_text(
angle=90,
hjust=1,
vjust=0.5))-> p5basep5base + geom_col(
aes(y=`經常性薪資-薪資`,fill=部門),
width=0.5)-> p7
p7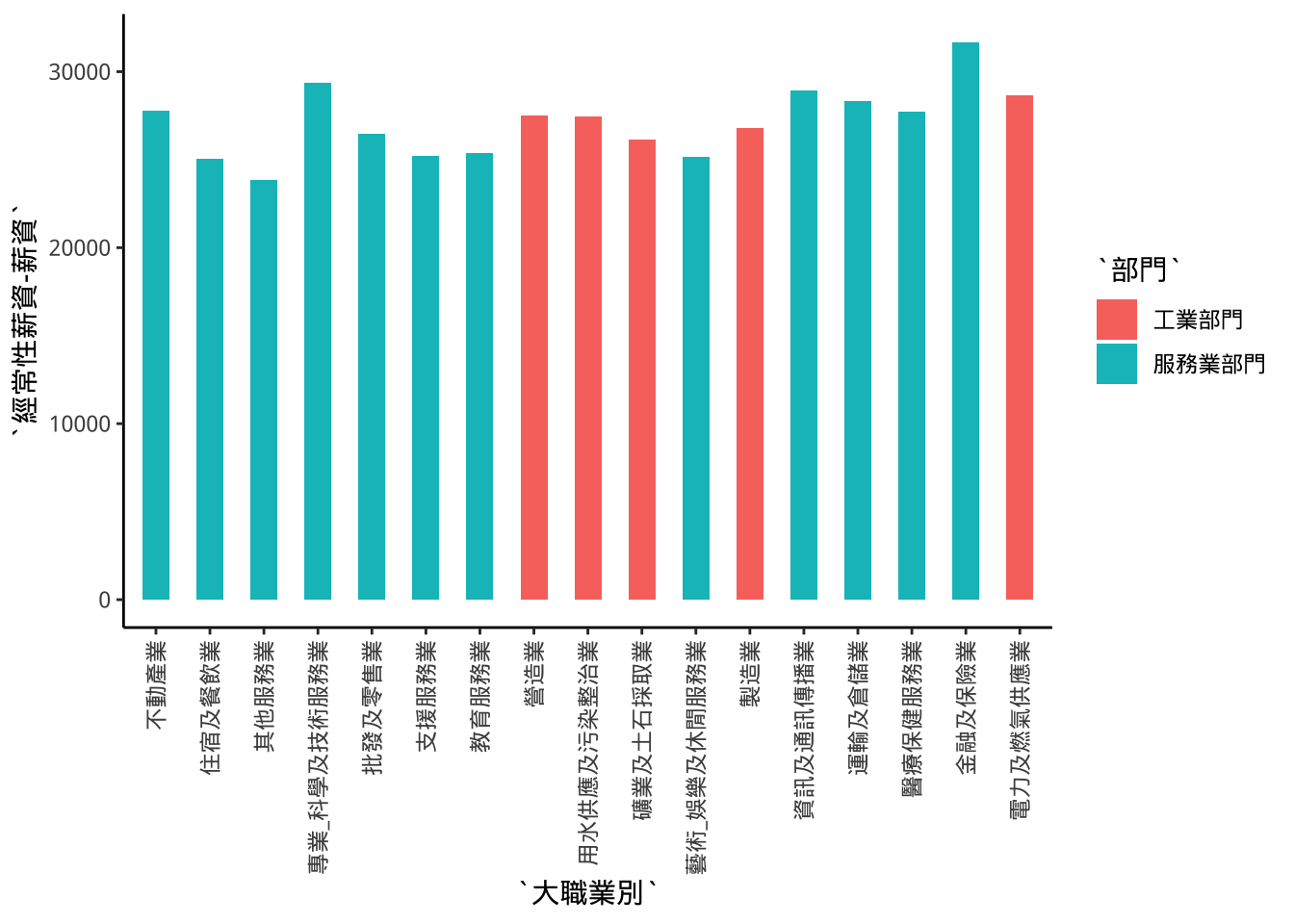
分類距離
建議用字體大小來控制,之後輸出時再輸成大張的圖即可。
p7 +
theme(axis.text.x = element_text(size=5)) ->
p8
p8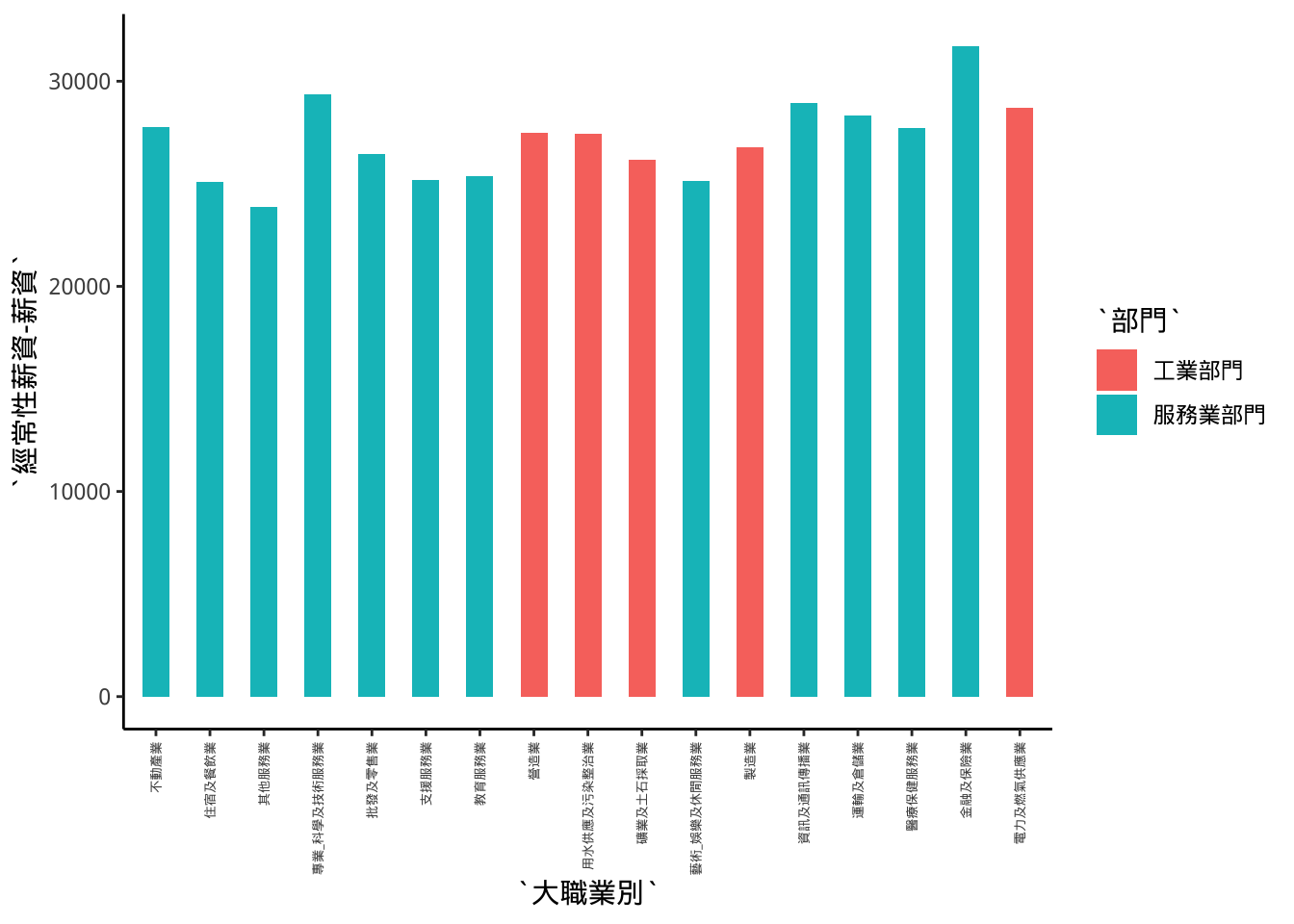
成品
p5base +
geom_col( #基本長條圖含寬度設定
aes(y=`經常性薪資-薪資`,fill=部門),
width=0.8
)+
scale_y_continuous( #去除長條底部留白,並將軸線置右
expand=expand_scale(mult = c(0,0.10)),
position="right"
)+
scale_x_discrete(limit=rev(xlim))+ #x分類排序
theme(axis.text=element_text(size=7))+ #縮小軸線標示文字字體
coord_flip()+ #翻轉兩軸
labs(x=NULL,y=NULL,fill=NULL)+ #去除mapping標題
theme(axis.text.x = #數字調整水平置中 #coord_flip之後的軸用**視覺上的軸**來定義x/y
element_text(
angle=0,
hjust=0.5))-> p9
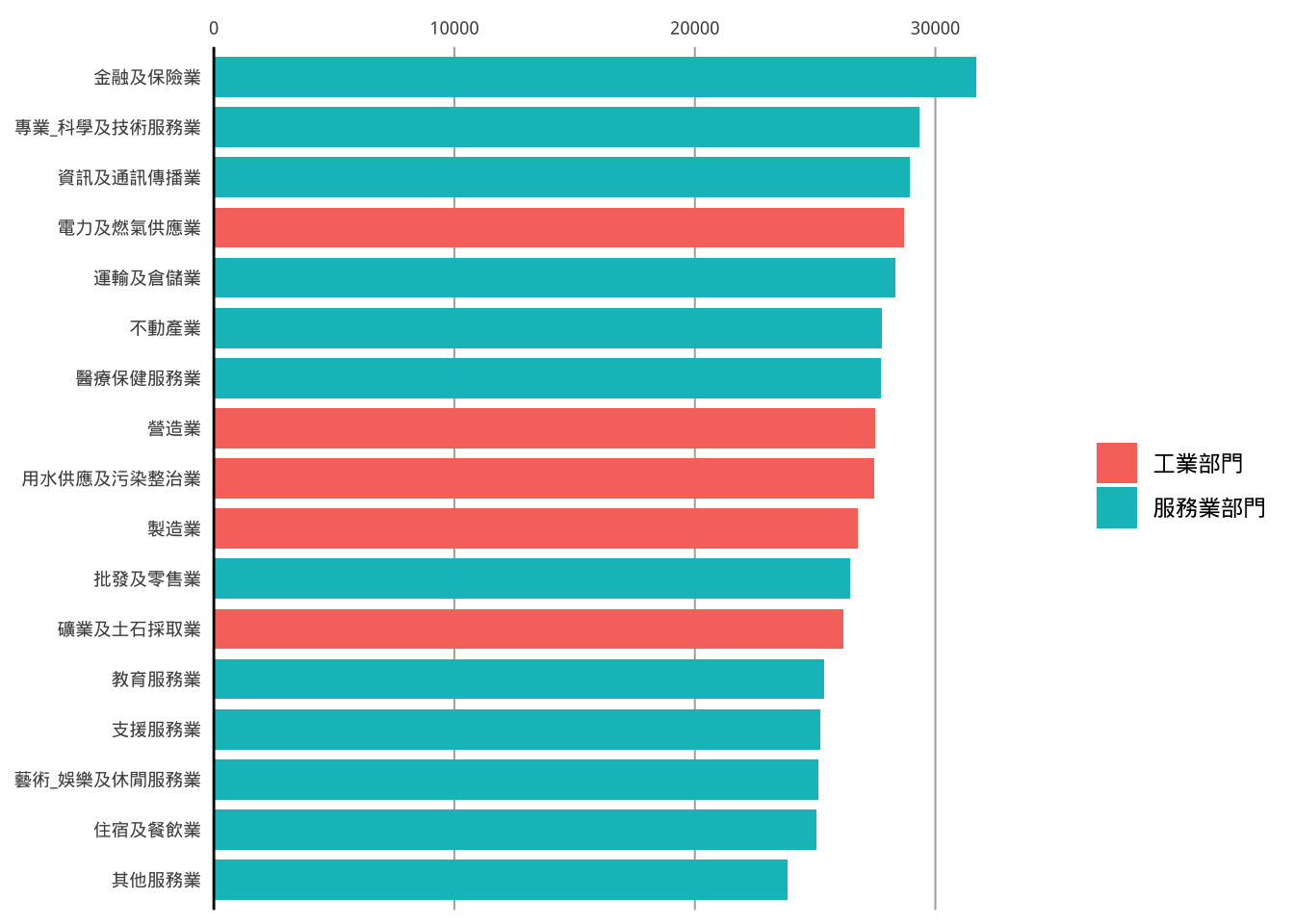
p9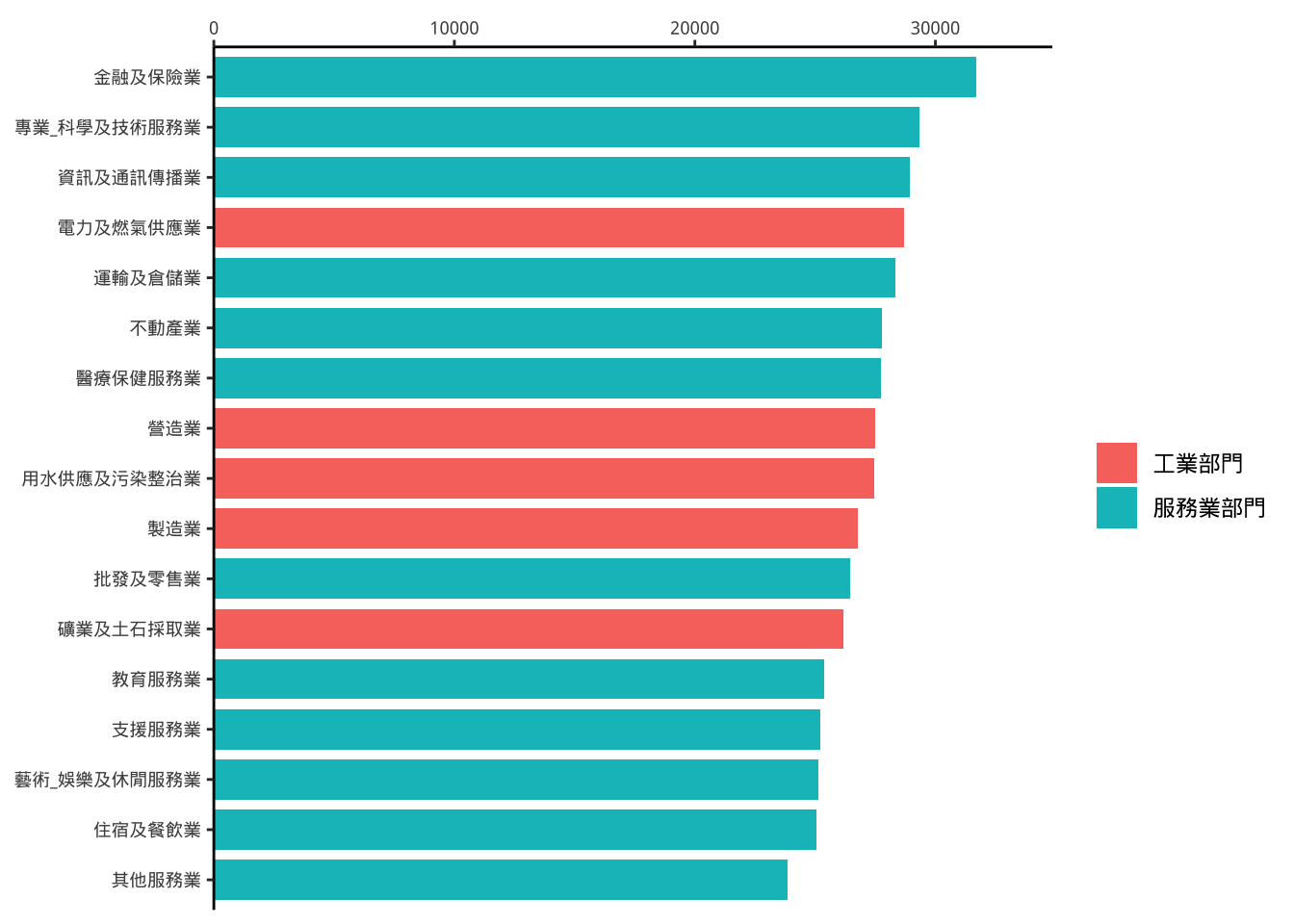
值得注意的是:
theme()是視覺美化的調整,所以x/y軸的設定是以視覺上看到的為準,因此一但做了coord_flip(),theme裡的x/y指的也會更著改變。scale_x/y_...()是aes mapping的函數定義調整,它並不是跟著視覺來走,所以即使視覺上做了coord_flip(),scale_x/y_所指的x/y並沒有改變。
請進一步將p9改良成如下成品,並存成p10。(圖面標線請用“#adadad”顏色)
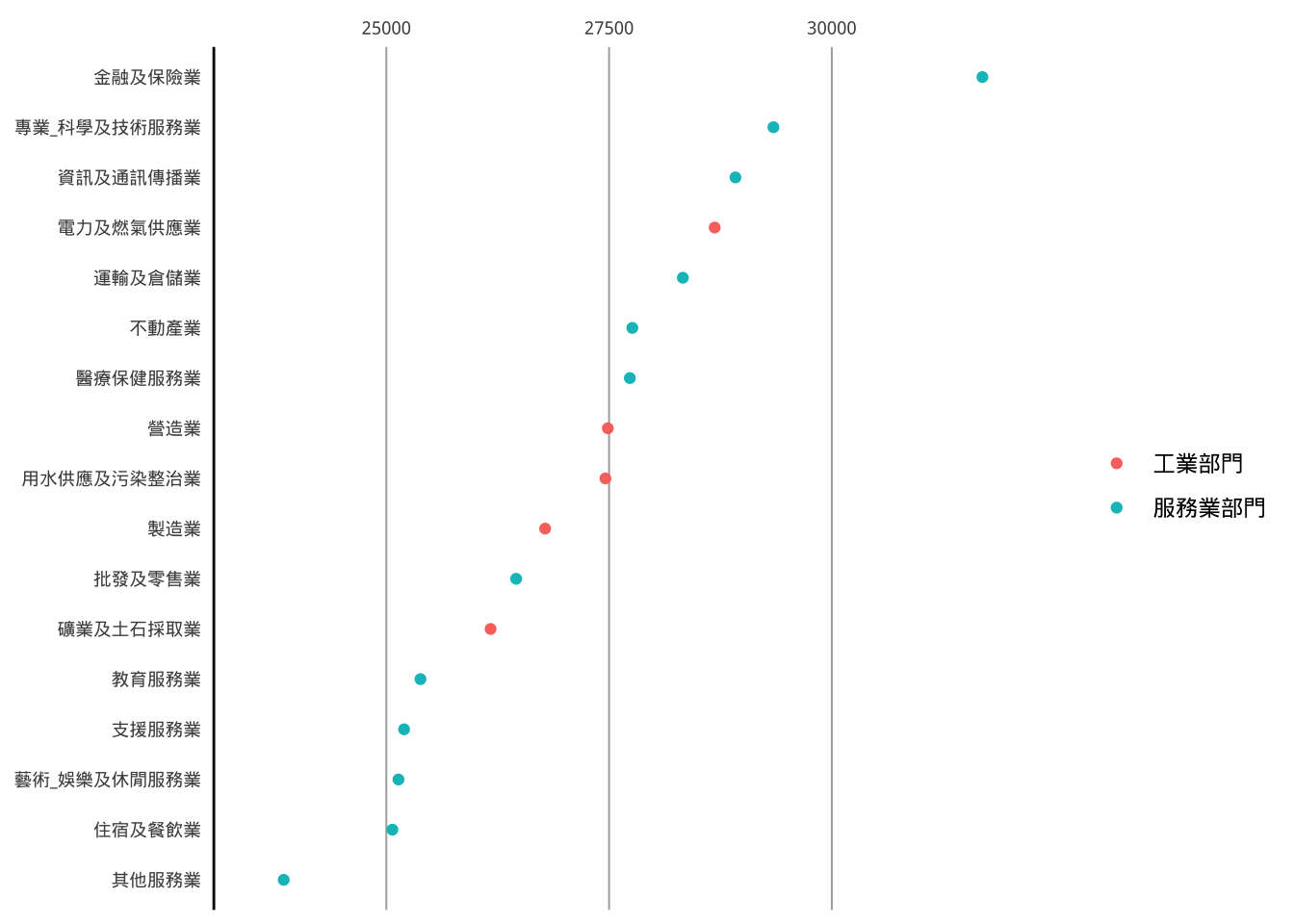
請從p5base架構如下成品。(圖面標線請用“#adadad”顏色)
8.11 scale_y_continuous(expand=...)
試著將p1的y軸範圍定在22000到30000元
p1+scale_y_continuous(limits=c(22000,30000))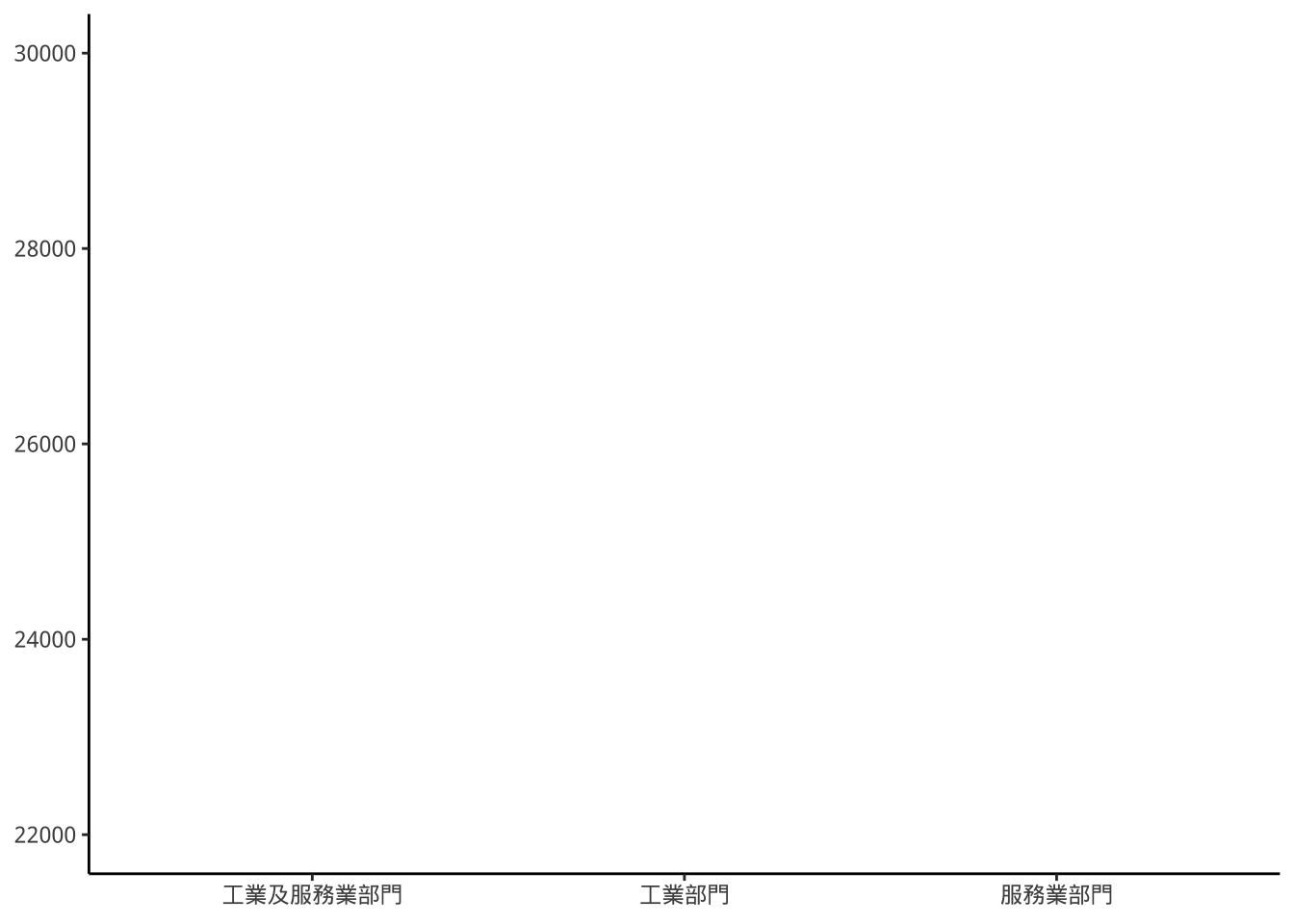
scale內定對「不在limits範圍」的圖形均「不會畫出來」,以長條圖來說,一個高度為25000的長條,它是0與25000的一對y值來定義,故此長條代表的是0與25000(下限/上限)一對資料,而非只有25000;由於下限0無法被limits包含,所以這個長條不在limits範圍。這些資料稱為out-of-bound data,內定是排除不畫,除非透過oob=...設定。
解決方法
設定oob(out of bounds)圖形處理方式。並使用scales套件
8.11.0.1 scales::rescale_none()
強制保留圖形。
library(scales)
p1+scale_y_continuous(
limits=c(22000,30000),
oob=rescale_none)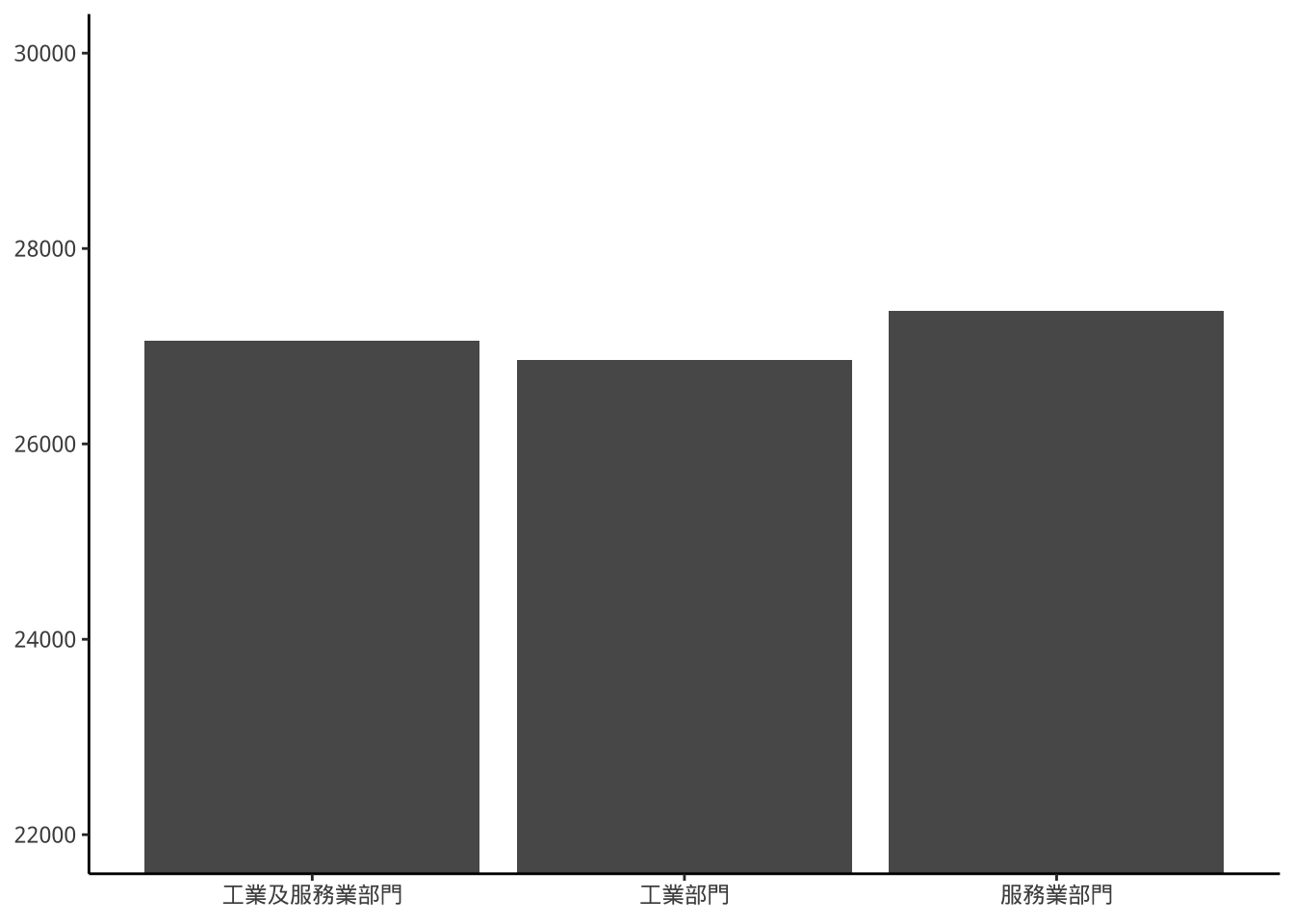
8.11.0.2 scales::squish()
資料縮到limits範圍。
library(scales)
p1+scale_y_continuous(
limits=c(22000,30000),
oob=squish)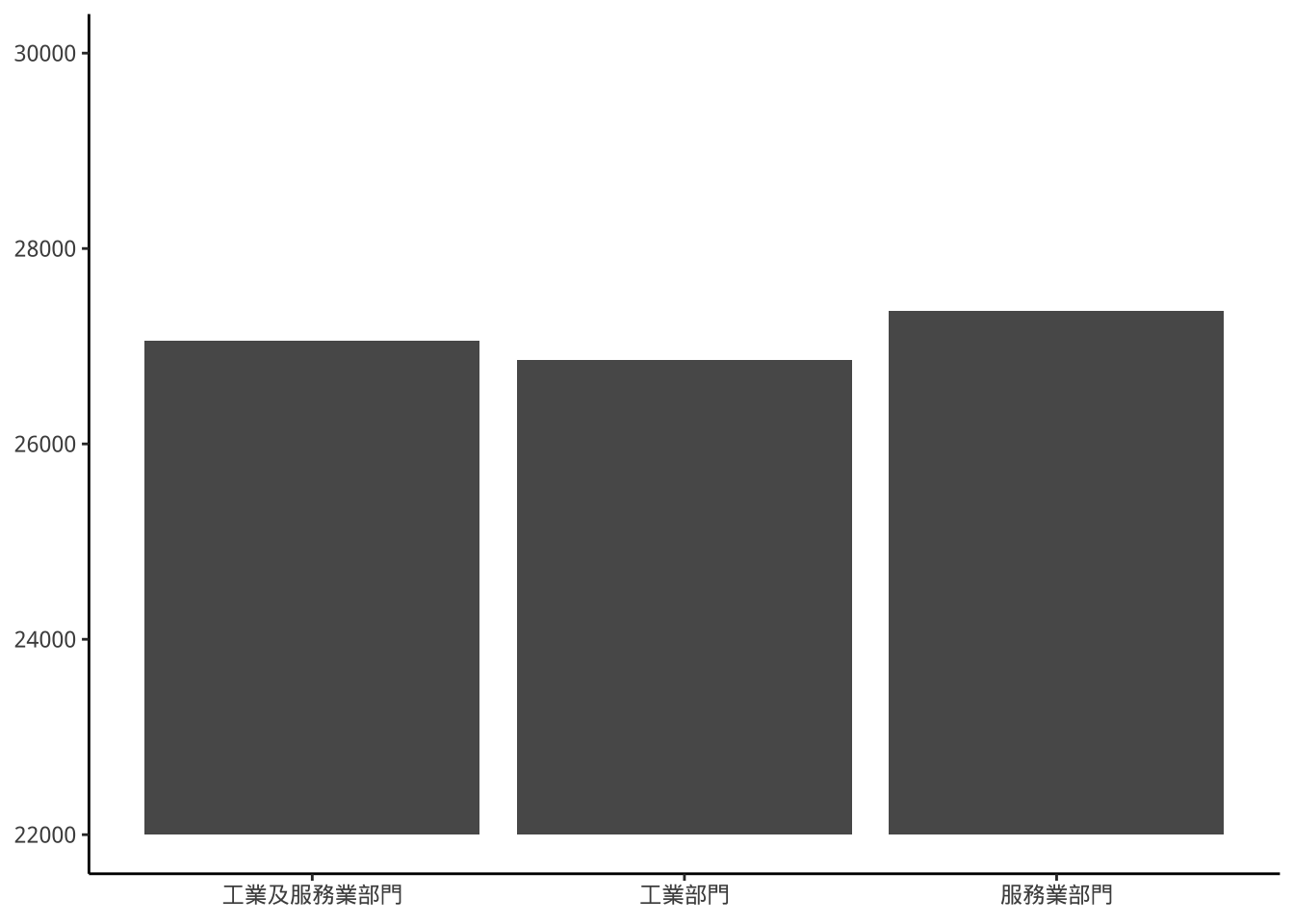
squish的圖20000以下沒有長條圖影,rescale_none則有,因為前者把資料縮到範圍內,所以20000以下沒有資料,後者是把資料原封不動保留,所以20000以下還是有長條圖影。
8.12 Daily Charts


