36 Strategic Dynamic Models
(Tülin Erdem and Keane 1996) is a good paper to think of structural modeling in marketing
What is interesting and impactful?
Correctness is not king
-
Challenge audience assumptions
Too strong = absurd
Took weak = not interesting
Sweet spot
Pitfall in Empirical Approach
Selective (biased) sample
Omit competition
-
Ignore
Dynamics
Heterogeneity
Endogeneity
Marketing Complexity
Sales response to a single marketing instrument
Marketing Mix Interaction
Competitive Effects
Delayed Response
Multiple Territories
Multiple products
Functional Interactions
Multiple Goals
Methodology
Verbal Model
Mathematical Model
Purpose
-
Measurement models
- Conjoint model
Decision support models
Theoretical models
36.1 Market Entry
Pioneering paradox
-
Market entry massively important
Big decision
Start of business strategy
-
Perennial conflicts:
Pioneer vs. 2nd move vs. late entry
Incumbent vs. Entrant
Huge payoff if played well
-
One explanation: Fixation
Fixation: focus on micro hurdle /breakthrough
Entrenchment: hang on to /perfect early success
Marketing Myopia
Baggage: routines. bureaucracy hinders vision
Another explanation: high failure rate of ideas
Third Explanation: Trend Projection Hot hand bias
Anything can be wrong. As a reviewer you have to say why you have a better explanation for a result
36.1.1 (Peter N. Golder and Tellis 1993)
-
Downfall of previous research using PIMS and ASSESSOR or business press:
survivorship bias
single-informant self-reports: measurement errors
Half of market pioneers fail and mean market share is lower (compared to previous studies)
Early market leaders have greater long-term success and enter about 13 years after the first pioneers
-
Theories of pioneer advantages
-
Consumer-based:
Uncertainty in trying later entrants
Consumer stable preferences
Learning theory: pioneer = standard
Positioning advantage
Consumer with high switching costs will stay
-
Product-based:
- Barrier to entry: economies of scale + learning + technological leadership + limited suppliers
-
-
Theories of pioneer disadvantages
Free-riders: late entrants can come in at lower cost
Shifts in technology, customer needs
Incumbent inertia
Improper positioning (late entrants can pick optimal position later because pioneers’ high cost of switching)
changing resource requirement
insufficient investments
-
Data: historical analysis based on all publicly available sources of info.
Prospective contrast to retrospective (from database)
Might be less biased because of multiple sources (instead of single informants).
Examples: business week, advertising age
-
Criteria for selection:
Competence
Objectivity
Reliability
Corroboration: Confirmation Bias?
-
Sampling (have to justify you chose what you choose): before sampling was drawn.
Sample 1: consumer goods + new product categories and its extensions.
Sample 2: categories from Advertising Age
Sample 3: acknowledged pioneers
-
Limitation:
Did not consider marketing mix
Customer-oriented definition of product category = arbitrary
Sample selection
Uncertainty regarding survivorship bias
36.1.2 (J. Johnson and Tellis 2008)
Market entry into China and India
Smaller firms are more successful than larger firms
Markets that are more open have less success rate.
Success is greater for companies (1) enter earlier, (2) have greater control of entry mode, (3) similar to the host country.
India is a tougher market than China (i.e., less successes)
-
Drivers of Entry success:
-
Firm differentiation
-
Firm strategy
-
Entry mode: export, license and franchise, alliance, joint venture, wholly owned subsidiary (related to degrees of control over its marketing resources from lowest to highest). Opposite prediction
Resource-based: degree of control increases with success likelihood, and help control resource leakage, and complementary resources.
Transactions cost: cost increases with degree of control (high investment -> high levels of investment to break even).
-
Entry timing:
Early entry: lock up key resources (e.g., distribution channels + suppliers), create standard, consumer preferences, exploit governmental incentives.
Late entry: pioneers usually don’t have long-term success (Peter N. Golder and Tellis 1993), learn lesson from early entrants, lower learning curve
-
-
Firm resources: Firm size
Larger > Smaller: more resources, more product- and marketing-specific knowledge, can absorb more negative periods
Smaller > larger: less bureaucracy, which lower innovative ability (Chandy and Tellis 2000)
-
-
Country differentiation
-
Host-country characteristics:
-
Openness: lack of regulatory and obstacles to entry
Good: increase demand, competition on quality, higher efficiency and lower prices
Bad: increase competition from foreign entrants (thin margins, high cost of purchases, hiring of talent).
-
Country risk: negatively affect entry success
Political: tariffs, regulations
Financial + Economic: recession, currency crises, inflation.
-
-
-
Host-home location
Cultural distance: closer better
-
Economic distance:
- Closer better: similar market segments (transformable market demand knowledge), similar physical infrastructure (greater efficiency in operations, lowering costs), more market knowledge
-
-
Data: historical analysis where data meet the following criteria:
Competence
Neutrality / Objectivity
Reliability
Corroboration
Contemporaneity
-
Small sample size
192 from China
64 from India
| Variable | Measure | Source |
|---|---|---|
| Success | Degree of success numerical rating | Historical Analysis from LexisNexis and ABI/INFORM |
| Entry mode | 6 points scale based on (E. Anderson and Gatignon 1986) | Archival data |
| Entry timing | Arbitrary: China: 1978, India 1991. | Archival data |
| Firm size | year-end sales for the focal firm | Compustat, Mergent Online |
| Economic distance | (D. Mitra and Golder 2002) | International Financial Statistics yearbook |
| Cultural distance | Follow (Kogut and Singh 1988) | Hofstede (1991, 2001) |
| Openness | Fraction of foreign direct investment over the host country’s GDP | International Monetary Fund |
| Country Risk | Based on International Country Risk Guide (Erb, Harvey, and Viskanta 1996) | International Country Risk Guide |
36.1.3 (Zervas, Proserpio, and Byers 2017)
Use DiD identification strategy
-
sharing economy decreases demand for hotel via less aggressive hotel room pricing.
- Those with low price and don’t cater to business travelers suffer most.
Data: from Airbnb (using review history) and 300 hotels in Texas (Texas Comptroller of Public Accounts),
-
Dependent variables:
Cumulative measure
Instantaneous measure
10% increases in the market share of Airbnb lead to .39% decrease in hotel room revenue
36.2 Product Adoption and Diffusion
36.2.1 Background
Every new thing either diffuses through population or fails
Researchers are interested in the shape and processes of diffusion
Bass is the first to model in marketing
Diffusion in different fields:
Demography
Archaeology
Geography
Epidemiology
Sociology
Linguistics
Physics
Cosmology
Models of Diffusion
Negative Exponential
Bass
FDA
Network
Levels of analysis:
Class:
Category
Technology
Brand
Classic model
does not account fro marketing mix
requires peak sales for stable estimates (if you have the peaks, you don’t need the model)
no repurscrhsases
no multiple generation
does not fit viral patterns
36.2.1.1 (Chandrasekaran and Tellis 2007) A review of new products diffusion
Products = idea, person, good, or service
New product \(\neq\) innovation
| In econ | In marketing | |
|---|---|---|
| Diffusion | “the spread of an innovation across social groups over time (p. 39) | “the communication of an innovation through the population” |
| Phenomenon (spread of a product) \(\neq\) drivers (communication) | Phenomenon (spread of a product) = driver (communication) |
This paper focuses on the econ definition
Product’s life cycle stages:
- Commercialization: when the product was first sold
- Takeoff: dramatic and sustained increase in sales
- Introduction: between commercialization and takeoff
- Slowdown: decreasing in sales
- Growth: between takeoff and slowdown
- Maturity: Slowdown until decline.
Generalizations:
Shape of the Diffusion Curve: cumulative sales over time is S-shaped curve.
-
Parameters of the Bass model:
-
Coefficient of innovation or external influence (\(p\))
mean between 0.0007 and 0.03
mean for developed countries is 0.001 and developing countries is 0.0003
-
Coefficient of imitation or internal influence (\(q\))
mean between 0.38 and 0.53
industrial/medical innovation > consumer durables
0.51 for developed countries and 0.56 for developing countries
-
the market potential (\(\alpha\) or \(m\))
- 0.52 for developed countries and 0.17 for developing countries.
-
-
Cautions regarding the parameters:
Time to peak sales: 19 years for developing and 16 for developed countries.
Biases in parameter estimation: static models (e.g., Bass) lead to downward biases in market potential and innovation while upward bias in imitation.
Drivers: WOM, communication, economics, marketing mix variables (e.g., prices, consumer heterogeneity, consumer learning), purchasing power parity adjusted per capita income, international trade.
-
Turning points of the diffusion curve
-
Takeoff
Time to takeoff: 6-10 years (varies by countries,products, time).
Drivers: price decrease
-
Slowdown
Sales decline by 15-32%
Drivers: price decline, market penetration, wealth (GNP), and info cascades (fast takeoff = fast decline)
-
-
Findings across stages
-
Duration:
introduction: 6-10 years
growth: 8-10 years
early maturity: 5 years
-
duration of growth:
time saving products > non-time saving products
leisure enhancing products < non-leisure enhancing products
introduction and early maturity duration get shorter over time (but not growth)
Price: price reduction is getting larger as time progresses (for both introduction nd growth).
-
Growth rates:
Introduction: 31%
Takeoff: 428%
Growth: 45%
Slowdown: -15%
Early maturity: -25%
Late maturity: 3.7%
-
Future Research:
Measurement: When to start or stop, or takeoff, differentiation between first purchases and repurchases, demand is better than supply measure,
Theories: no reconciliation yet
Models: comprehensive (from commercialization to takeoff, growth, and slowdown)
Findings: More fine-tune subgroups, include failed diffusion, and consider other countries.
Specification
The probability that an individual will purchase at time \(T\) is a function of the number of previous buyers.
\[ P(t) = \frac{f(t)}{1 - F(t)} = p + \frac{q}{m} Y(t) \]
where
\(P(t)\) = hazard rate
\(Y(t)\) = cumulative number of adopters at \(t\)
\(p\) = probability of an initial purchase at time 0 (when \(Y(0) = 0\)) (also known as innovators importance).
\(\frac{q}{m} Y(t)\) = pressure of prior adopters on imitators
\(m\) = number of initial purchases before any replacement purchases (i.e., market size)
\(F(t)\) = cumulative fraction of adopters at time \(t\)
\(f(t)\) = likelihood of purchase at time \(t\)
Rearrange the formula to get the likelihood of purchase at time \(t\)
\[ f(t) = (p + q F(t) ) [1 - F(t)] \]
The number of adoptions at time \(t\) is
\[ S(t) = mf(t) = pm + (q - p) Y(t) - \frac{q}{m} Y^2(t) \]
then Bass solves the differential equation:
\[ dt = \frac{dF}{p + (q - p) F - qF^2} \]
to obtain cumulative adoption at time \(t\)
\[ F(t) = \frac{1 - e^{-( p + q)t}}{q + (q/p) e^{-( p + q)t}} \]
Hence, the cumulative number of adopters is
\[ Y(t) = m \frac{1 - e^{-( p + q)t}}{q + (q/p) e^{-( p + q)t}} \]
Rewriting the number of adoptions at time \(t\)
\[ S_t = a + bY_{t-1} + c Y^2_{t-1}, t = 2, 3, \dots \]
where
\(S_t\) = sales at time \(t\)
\(Y_{t-1}\) = cumulative sales through period \(t-1\)
\(a = p \times m\)
\(b = q - p\)
\(c = - q /m\)
Equivalently,
\[ p = a/m \\ q = -cm \\ m = (-b \pm (b^2 - 4 ac)^{1/2})/2c \]
Strengths
Good fit to the S-shaped curve (thank to the quadratic term)
-
Appealing interpretations:
\(p\) = coefficient of innovation (i.e., spontaneous rate of adoption in the population) or external influence (e.g., mass -media communications)
\(q\) = coefficient of imitation (i.e., effect of prior cumulative adopters on adoption) or internal influence (e.g., interpersonal communication influence from prior adopters).
Good application: time (\(t\)) or magnitude (\(S(t)\)) of peak sales.
\[ t^* = \frac{1}{p + q} \times \ln (\frac{q}{p}) \\ S(t)^* = m \times \frac{(p + q)^2}{4q} \]
-
Incorporated prior literature
If \(p =0\), the Bass model is a logistic diffusion function (driven only be imitation adoption)
If \(q = 0\), the Bass model is an exponential function (driven only innovation adoption)
Limitations
Bass requires 2 most important events that we want to predict in the first place: takeoff and slowdown to have stable estimates.
Unstable estimates after incorporating new observations.
Do not directly account for marketing mix variables (price, promotion), but indirectly capture by \(m, p\)
Assumes product definition is static (no growth or changes in product as time progresses)
-
Using OLS which can cause
Multicollinearity between \(Y_{t-1}, Y^2_{t-1}\) (making the estimates unstable)
Do not estimate the SE for \(p, q, m\)
Time interval bias (model uses discrete time series data to estimate a continuous model)
-
Hard to determine starting and ending points of the the sales time.
Supposedly, we need to use first adoptions of new product as sales (\(S_t\)), but data could not capture this, only both first purchases and repurchases
Sales should start from the first year of commercialization, but usually we only have reports when products are selling well already
No clear stopping rule for the time interval.
Improvements
-
Incorporating marketing mix
Price: affect market potential (\(m\)) and probability of adoption (\(P(t)\)) and heterogeneous across products
Advertising
Distribution: 2 adoption processes: retailer and consumer, where number of retailers who affect determine the market potential \(m\) for consumers
(Bass, Krishnan, and Jain 1994) incorporate both price and promotion to the Generalized Bass model
\[ \frac{f(t)}{1 - F(t)} = (p + q F(t) )x(t) \]
where \(x(t)\) is the current marketing effort (sum of advertising and price) on the conditional probability of product adoption at time \(t\) such that
\[ x(t) = 1 + \beta_1 \frac{\Delta P(t)}{P(t-1)} + \beta_2 \frac{\Delta A(t)}{A(t-1)} \]
where
\(\Delta P(t) = P(t) - P(t-1)\) rate of changes in price
\(\Delta A(t) = A(t) - A(t-1)\) rate of changes in advertising
When prices and advertising remain constant, GB model reduces to Bass model. But it seems like they only stop at 2 variables (not all marketing mix variables or macro and micro econ variables - income changes).
-
Incorporate supply restrictions
- Include another stage between potential adopter to adopters which is waiting applicants.
\[ \frac{d A(t)}{dt} = [p + \frac{q_1}{m}A(t) + \frac{q_2}{m} N(t)][ m - A(t) - N(t) ] - c(t) A(t) \\ = \text{[Waiting population + Adopters] - conversion rate of applicants to adopters}\\ \]
and
\(\frac{d N(t)}{dt} = c(t) A(t)\)
where
\(d(A)/dt\) is the rate of changes of waiting applicants
\(c(t)\) is the supply coefficient
the second equation is the impact of supply restrictions on adoption rate
The growth of new applicants is
\[ \frac{d Z(t)}{dt} = \frac{d A(t)}{dt} + \frac{dN(t)}{dt} \\ = (p + \frac{q_1}{m} A(t) + \frac{q_2}{m} N(t) ) (m - A(t) - N(t)) \]
To incorporate waiting applicants abandoning their adoption decision after some time see (Ho, Savin, and Terwiesch 2002)
-
Incorporate competitive effects
Instead of using product category as the unit of analysis, we can model at the brand level (different brand might have different rate of diffusion).
-
A new brand can
increase the entire market potential (\(m\)) (by increased promotion and product variety)
compete in the existing market potential (interfere the diffusion process of other brands)
Diffusion depends on the order of entry and competition.
-
Incorporate complementary effects
- In market that has indirect network externalities, co-diffusion exists and asymmetric
Incorporate technological generations for successive generations of the same product (i.e., substitution effects).
\[ S_1(t) = m_1F_1(t) - m_1 F_1(t) F_2(t - r_2) \]
where \(r_2\) is the introduction time of the next-generation product.
\[ S_2(t) = F_2(t- r_2) [m_2 + F_1(t) m_1] \]
where
\(S_i(t)\) = sales of generation \(i\)
\(F_i(t)\) = fraction of adoption for each generation
\(m_i\) = market potential for each generation
Leapfrogging behavior is possible (i.e., skip a generation to buy the next one) (Mahajan and Muller 1996)
-
Incorporate time-varying parameters
Model market potential (\(m\)) as a function of time-varying exogenous and endogenous variables (Mahajan and Peterson 1978)
Model coefficient of imitation to be time-varying (Easingwood, Mahajan, and Muller 1983)
\[ \frac{d F(t)}{dt} = [ p + q F(t)^\delta][ 1 - F(t)] \]
where \(\delta\) is the nonuniform influence
when \(\delta = 1\), the model becomes the Bass model
When \(\delta \in [0,1]\), means high initial coefficient of imitation,
When \(\delta >1\), means delay in influence -> lower and later peak.
Different adopters could influence later adopters differently (people who adopted more recently are more vocal) (Sharma and Bhargava 1994)
- Incorporate replacement and mufti-unit purchases
(Balasubramanian and Kamakura 1989)
\[ y(t) = [a + bX(t)][\alpha \text{Population}(t) P^\beta (t) - X(t)] + r(t) + e(t) \]
where
\(y(t)\) = sales
\(P(t)\) = price index
\(X(t)\) = total units in use at the beginning of year \(t\) with dead units are replaced already
\(r(t)\) = number o units that have died or need replacement at year \(t\)
\(a\) = coefficient of innovation
\(b\) = coefficient imitation
\(\beta\) = price change effect on ultimate penetration
\(\alpha\) = ultimate penetration (price is at its original level)
(Steffens 2003) models multiple units purchase by a single household.
Incorporate trail-repeat purchases
Incorporate variations across countries
Evaluation:
- All of the improvements still rest on the assumption of one driving mechanism: knowledge dispersion through WOM.
Improvements in estimation
MLE: avoid time-interval bias, but underestimates the SE (Schmittlein and Mahajan 1982)
-
Non linear least squares: (V. Srinivasan and Mason 1986) need lots of obs
Estimates are more flexible
No time-interval bias
valid SE
-
Hierarchical Bayesian method
Incorporate parameter updating
Problem with definition of similar products (fixed by (Bayus 1993) with product segmentation scheme)
Adaptive techniques: stochastic techniques (parameter vary over time) ((J. Xie et al. 1997)augmented Kalman filter)
-
Genetic algorithms:
can find global optimum
better estimate (less bias).
Alternative models of diffusion
-
Alternative drivers:
-
Affordability: (Peter N. Golder and Tellis 1998) model as Cobb-Douglas model:
\(S = P^{\beta_1} \times I^{\beta-2} \times CS^{\beta_3} \times MP^{\beta_4} \times e^\epsilon\)
Sales = product (price, income, consumer sentiment, market presence)
(Horsky 1990) incoproates both price and income and WOM on sales growth.
Heterogeneity: aggregate level diffusion models: (J. H. Roberts and Urban 1988), (Oren and Schwartz 1988), (Chatterjee and Eliashberg 1990), (Bemmaor 1984) (Song and Chintagunta 2003b), (Sinha and Chandrashekaran 1992) (Karshenas and Stoneman 1993)
Strategy: model supply side: (market entry, marketing mix, location) (Dekimpe, Parker, and Sarvary 2000), (Bulte and Lilien 2001),(Bart J. Bronnenberg and Mela 2004)
-
-
Alternative phenomena:
-
Spatial diffusion (Mahajan and Peterson 1979), (Redmond 2003), (Garber et al. 2004)
Contagious diffusion (infectious diseases)
Expansion diffusion (one source like wildfire)
Hierarchical diffusion (ordered series of classes)
Relocation diffusion:
Diffusion of entertainment products: follow exponential decay (Eliashberg and Sawhney 1994), (Eliashberg et al. 2000), (Elberse and Eliashberg 2003), (Moe and Fader 2002), (J. Lee, Boatwright, and Kamakura 2003)
-
Modeling the turning points in diffusion
-
Takeoff: follow (Peter N. Golder and Tellis 1997) definition: “point of transition from the introduction stage to the growth stage”
-
Measurement
(Peter N. Golder and Tellis 1997): threshold takeoff (compare to other in the categories)
Logistic curve rule: first turning point of the logistic curve (max of the 2nd derivative) (hindsight only)
Maximum growth rule: largest sales increases within 3 years (not size invariant)
(Agarwal and Bayus 2002) measure based on annual percentage change in sales
(Stremersch and Tellis 2004) adapted the threshold method for international markets
(Garber et al. 2004) rule of thumb: 10-20 market penetration
-
Drivers
(Peter N. Golder and Tellis 1997) price declines lead to takeoff
(Agarwal and Bayus 2002) increase in firm entry lead to better product quality, marketing infrastructures
(Tellis, Stremersch, and Yin 2003) venturesome culture lead to takeoff
Model: either proportional hazards (Peter N. Golder and Tellis 1997) or log-logistic hazard (Tellis, Stremersch, and Yin 2003)
Evaluation: Only model successful innovation so far.
-
-
Slowdown: point of transition from the growth stage to the maturity stage (Peter N. Golder and Tellis 1997)
Measurement: (Peter N. Golder and Tellis 2004) “operationalize as the first year of two consecutive years after takeoff in which sales are lower than the highest previous sales.” (p.72)
-
Explanation:
Dual-market phenomenon: early adopters vs. early majority (Goldenberg, Libai, and Muller 2001)
Informational cascades: negative cascades (Peter N. Golder and Tellis 2004)
Affordability(Peter N. Golder and Tellis 2004)
-
Modeling:
Cellular automata models: (Goldenberg, Libai, and Muller 2001)
Hazard models: (Peter N. Golder and Tellis 2004)
Evaluation: still new can have more research
36.2.1.2 (Bass 1969)
Assumption:
The timing of a consumer’s initial purchase is correlated with the number of previous
This paper looks at new class of products (not new brands or new models of older products)
Focus on infrequently purchased products
Theory of Adoption and Diffusion
Innovators: adopt independently (regardless of others’ opinions): pressure to adopt does not increase with the growth of the adoption.
Imitators (include early adopters, early majority, late majority): adoption depends on the timing of adoption (i.e., influenced by the decisions of others to adopt.
Laggards
“The probability that an initial purchase will be made at \(T\) given that no purchase has yet been made is a linear function of the number of previous buyers” (p. 216)
\[ P(T) = p + \frac{q}{m} Y(T) \]
where \(p\) and \(q/m\) are constants
\(Y(T)\) is the number of previous buyers.
When \(Y(T) = 0\), \(p\) represents the probability of an initial purchase at \(T = 0\)
\((q/m) Y(T)\) is the pressures on imitators to adopt.
Model Assumptions:
36.2.2 Discussion
36.2.2.1 (Sood, James, and Tellis 2009)
Functional regression
-
Contributions:
Theoretically sound (integrate info across categorizes)
Augmented Functional regression outperforms existing models
Product-specific effects are more helpful in predicting penetration than country-specific effects.
They use yearly cumulative penetration of each category as the unit of analysis (i.e., curve/ function).
-
3 functional data analysis techniques:
Functional principal components
functional regression
functional cluster analysis
To treat discrete intervals: use smoothing spline to generate continuous smooth curves
Even though the spline approach requires a lot of data to smooth, other appearances to create smoothness are still available. Hence, you can still use function regression and or cluster with 2 or 3 time points.
-
Advantage s of functional regression:
incorporate info from other products
nonparametric fitting procedure
uses the functional nature of the penetration curves.
Predictions on: number of years to take off, peak marginal penetration and the level of peak marginal penetration
Good: tell a story from simple to more sophisticated model to justify their improvements in the paper.
-
2 dimensions that are not captured by simple extrapolation models:
info from prior history of the new product
intrinsic info across products and countries.
-
Classic Bass model ignores:
other categories (fixed by meta-bass and augmented meta-bass)
uses parametric methods.
-
Questions:
Technically could redo the analysis with new dataset (including 2009 till now) to see the out of sample performance.
No hypothesis, just model and probable explanation
Use only curves under the same category to predict the new product (not all categories).
36.2.2.2 (Appel, Libai, and Muller 2019)
Growth, Popularity and the Long Tail: Evidence from Digital Markets
part of MSI’s working paper series and MSI insights
Context: digitized markets (long-tail markets)
Most popular products do have S-shaped curve, but lower-popularity products exponential-like decline (“slide”) or a combination of slide and bell (S&B) are more common.
-
Shortcomings of previous research:
- Pro-innovation bias: success correlates with importance in the new product development research
Data: SourceForge (exclude inactive and less than 200 downloads): 5 years with high Gini coefficient - 0.96 (i.e., high concentration).
-
Dominant patterns:
-
A bell-shaped pattern: bell (popular products)
- Caveat in the movie market: popular products decline over time.
An exponential-like decline beginning at launch: slide
Combination of the first 2: S&B
-
Proposed model: inception model (inception effect = heightened external growth).
-
Long-tail market:
Supply side: low cost of inventory, stocking, efficient delivery, and low cost of new products development.
Demand-side: easy to search, recommendation system, social networks and online communities.
Popularity = extent of demand = number of downloads.
The shape of new product growth: previous literature says S-shaped
-
Non-S-shaped markets:
-
r-shaped cumulative curve: because of
Large budget for promotion: movies
Pre-launch buzz: on social media
-
The role of popularity on the shape of growth: was ignored in the literature
Free and Open-Source Software (FOSS)
-
Data Analysis:
Stage 1: To facilitate comparison, scale pattern to a (0,1) by dividing each observation by the total sum of downloads, and smooth the graph using Hodrick-Prescott filter
Stage 2: Use peaks-and-troughs algorithm for the classification
Descriptive: the S-shaped curve is representative for more popular products, while for those that are not as popular, we have a blend of S&B and slide as well.
Try to observe the same pattern with smartphone app download (data provided by Mobility - an anonymous app providers for businesses)
-
Drivers of Multi-pattern Growth
-
Analogy to movies (characterized by an exponential decline): not similar because
different product types (utilitarian vs. entertainment)
Different pattern exhibited by popular and unpopular: while in movies the exponential decline is from blockbuster, and sleepers has a bell shape, under this dataset, less popular product has the exponential decline, while the popular products are bell-shaped.
Analogy to supermarkets: not good because FDP is affected by social influence, supermarkets are usually under large investments and not much social influence.
-
The inception alternative: 2 influences of new product growth
Internal: from previous adopters
External (not from previous adopters): marketing mix, social media posts, recommendation, expert opinions, influencers. Expected to stronger early on and decay. (i.e., inception effect - external influence as a function of time with an initial external influence parameter \(p(t) = pe^{\delta t}\))
-
The relationship between inception and popularity: The higher the product’s popularity, the lower the share of adoptions due to the inception effects (i.e., products with high initial investment that failed to reach critical is less popular).
Inception is typically a necessary but not sufficient condition to reach popularity.
36.2.2.3 (Tellis et al. 2020)
No awards (nominated only)
Emotion is more effective than information
brand hurts, but branding is used a lot
surprise and humor are good, but videos don’t use
Limitation: Because these emotions are rare, maybe that why they are effective. But if everyone starts using these tactics, maybe that they wont’ work anymore.
36.2.2.4 (Chandrasekaran, Tellis, and James 2020)
Was rejected 5 times.
Leapfrogging, Cannibalization, and survival during disruptive technological change
-
2 types of dilemma when it comes to new technology:
Incumbent: invest in new technology or old or both
Entrant: target niche or mass.
Solution: relation between new technology and old one (i.e., high rate of disengagement - cannibalization or low rate of disengagement- coexistence)
-
Data:
Successive technology penetration across multiple countries and years
Sales of contemporaneous pair across multiples countries
Case analyses
“Disruption occurs if the incumbent focuses on the old technology to the exclusion of the new one” (p. 4)
-
Definitions:
Successive/New technology: not new version/generations of the same product
Cannibalization: “the extent to which the successive technology”eats” into real or potential sales (or penetration) of the old technology due to substitution.”(p. 5)
Rate of disengagement \(F_{12}\): (account for partial substitution)
-
Adopter segments for a new successive technology:
Leapfroggers: adopt new, but would never have adopted the old
Switchers: Adopted old, but switch to new once it’s introduced
Opportunists: wait for the old, but end up with the new one.
Dual users: both technologies
Models: based on (J. A. Norton and Bass 1987)
\[ S_1 (t) = m_1 F_1(t) (1- F_{12}(t- \tau_2 + 1)) \\ S_2 (t) = F_2(T- \tau_2 + 1) (m_2 + m_1 F_1(t)) \]
where
- \(S_i(t)\) = penetration of technology \(i\) in period \(t\)
- \(m_1\) = long-run penetration for technology 1
- \(m_1 + m_2\) = long-run penetration for technology 2
The fraction of all potential technology_g consumers for each technology (g = technology 1 or 2)
\[ F_g(t) = \frac{p_g(1 - e^{-(p_g + q_g)^t})}{p_g + q_g e^{-(p_g + q_g)t}} \]
where
\(t \ge 0\)
\(g = 1, 2\)
\(p\) = innovation coefficient
\(q\) = imitation coefficient
\(p_{12}, q_{12}\) = disengagement coefficients
\(F_1, F_2, F_{12}\) = adoption rate of technology 1, technology 2, and disengagement rate at which technology 1 customers abandon to get technology 2
Model contributions:
Model the adoption rate of technology 2 different from disengagement rate of technology 1 (\(F_2 \neq F_{12}\))
Varying \(p, q\) (for different technologies)
\(F_1\) has the same function form as \(F_1, F_2\) (because it fits the data well, and reduces to previous model which matches previous literature)
Model can be applied to both generational and technology diffusion
Model Estimation
Using nonlinear least squares to estimate the parameters that that minimize
\[ \sum_{i = 1}^n (s_{i1} - m_1 F_1(t_i)) (1 - F_{12} (t_i - \tau_2 + 1))^2 \\ + \sum_{i=1}^n (s_{i2} - F_2 (t_i - \tau_2 + 1)(m_2 + m_1F_1(t_i)))^2 \]
Segments of adopters
\[ S_2(t) = L_2(t) + DU_2(t) + SW_2(t) + O_2(t) \]
while
\[ S_1(t) = L_1(t) - CAN_2(t) = L_1(t) - (SW_2(t) + O_2(t)) \]
where
\(SW\) = switchers
\(O\) = Opportunists
\(CAN\) = Canalization
\(L\) = Leapfroggers
\(DU\) = dual -users
Market growth segment = sum(leapfroggers, dual users)
Cannibalization = sum(switchers, opportunists).
36.2.2.5 (Prins and Verhoef 2007) Marketing effects on adoption timing
Studies the effects of direct marketing and mass marketing on adoption timing (in the context of a new e-service among existing customers)
Data: 6k customers of a Dutch telecom operator over 25 months
-
Findings:
advertising shortens the time to adoption (including those by competitors)
Mass marketing has a greater effect on loyal customers (compared direct marketing)
-
Related literature:
Adoption
customer management
Adoption timing is defined as “the time between the introduction and the adoption of the new service” (p. 170) following (Jan-Benedict E. M. Steenkamp and Gielens 2003)
Switchers to competitive services are considered as non-adopters (even if they adopt comeptitor’s new service). It’s valid when the focus is on the adoption of the folca company’s new service among existing customers.
(Donkers, Franses, and Verhoef 2003) demonstrates that if oversampling is not accompanied by stratfied sampling on the independent variables, it should not affect the parameter estimates or SE for are event in binnary choice models.
Meausres of Time to adoption: For each tiem period \(t\), a customer can either adopt the new serive or not. The time to adoption for each customer is the time elasped in \(t\) since the intro of the service. Dependent vairable = indivudal time to adoption.
36.3 Take-off Disruption
Marginal Prob vs. Hazard of Death (what is the conditional probability of dying conditional on you are alive)
Sometimes we study takeoff instead of sales of new products because new products either takeoff or die, wee dont’ see flat salles. (managerial implication: invest if takeoff)
We have to wait at least till the peak of the hazard function (5 years)
Pervasiveness of disruption: US
36.3.1 Disruptive Technologies
Companies stay too close to their current customers, without accounting for future ones.
-
For each industry, there is performance trajectory that help track new technology performance in comparison with old ones’.
Sustaining technology: maintain the rate of improvement
Disruptive technology:
-
Solution to cultivate disruptive technologies:
Is the technology disruptive or sustaining?
What is the strategic significance of the disruptive technology?
Where is the initial market for the disruptive technology?
There should be a separate organization or business that handle disruptive technology
36.3.2 (Peter N. Golder and Tellis 1997) takeooff
-
Key issues:
How long does it typically take a product to take off?
Is there a takeoff pattern?
Can we predict takeoff?
If the baseline sales is small, it takes a large increase in sales to takeoff, but if the baseline sales is big, it takes only a small increase in sales to takeoff. Hence, there is a threshold for takeoff
-
Definition of takeoff: “the first year in which an individual category’s growth rate relative to base sales crosses this threshold.” (p. 256) or “the point of transition from the introductory stage to the growth stage of the product file cycle.” (p. 257)
- Metric: the first large increase in sales in the new category (still don’t quite understand)
Operational definition of takeoff: “threshold for takeoff as a plot of the percentage increase in sales relative to its base sales that demarcates the takeoff.” (p. 259)
Independent variables: price, year of introduction, market penetration (percentage of households that have purchased a new product), and controls (product specific, and economic variables)
-
Found:
price at takeoff is lower than price at the introduction stage
Average time to takeoff is 6 years
penetration at takeoff is 1.7%
Products usually takeoff around 3 price points: $1000, $500, $100
Model: Cox’s proportional hazard mode
\[ h_i(t) = h(t; z_{it}) = h_0 (t) \times e^{z_{it} \beta} \]
where
\(h_0(t)\) is the baseline hazard function
\(z_{it}\) are the independent variables
\(\beta\) is the same for all categories (questionable choice)
Do not include unbosomed heterogeneity because each event is unique (non repeated)
Samples:
- 11 consumer durables (usually studied in diffusion research)
- 10 recently introduced consumer durables
- 10 categories during the review process.
Model performance
\(U^2\) measure reduction in uncertainty
Forecasts: (1) at introduction (2) one year ahead
36.3.3 (Chandy and Tellis 2000) Incumbent’s curse
- Present this paper
- Definition: “A radical product innovation is a new product that incorporates a substantially different core technology and provides substantially higher customer benefits relative to previous products in the industry” (Chandy and Tellis 1998).
- Theory of S-curves: figure 1
- Reasons incumbents don’t like radical innovations:
Perceived incentives: prospect theory (incumbents stand to lose, innovators stand to gain)
Organizational filter: resources are invested in important tasks that yield money.
Organizational routines: repetitive tasks are very efficient.
Opportunities of incumbents: market capabilities (customer knowledge, customer franchise, market power)
- Size and incumbency are positively correlated
Theory of (bureaucratic) inertia: it’s hard to get new idea through a large firm because of filtering and screening + no incentives to do so.
Opportunities of large firms: financial and technical capabilities
- There are more nonincumbents (i.e., small firms) as innovators in the US than other countries (e.g., Japan, or Western Europe) because of (1) institution (2) culture
- Historical analysis: 1 author + 9 assistants over 4 years
- Sample frame:
Product classes: consumer durables + office products
High unit sales (> 1 mil) (from Predicasts)
Radically new technology: (1) identify the most significant product innvoaitosn in each product category (2) 3 experts rate the radicalness
- Measures
Radical innovation means (1) differences in core technology: utilizing a distinct core technology (2) superiority in user benefits:gives a lot more value to the customer than the first product in the same category.
Firm size: employees, sales volumn, value of asset from Moody’s Industrial Manual and S&P manual, for private firms: company directories - Industrial laboratories Directory, Edison Electric Light Co.
Innovator (firm that first commercialized the radical innovation) and incumbent (firms that sell previous generation product on the introduction date)
- Results: 64 out of 93 innovations have data.
- Categorical Analysis:
Large firms are more likely to be incumbents
Small firms were more radical in their innovation before the World War 2, large firms are radical in their innovation recently.
US innovators are from non-incumbent. Before the World War II, the US innovation were likely to come from smaller firms, but recent US innovation tend to come from large firms.
- Multivariate
While larger organizations have historically introduced fewer innovative inventions, the tendency in recent years has been the polar opposite.
In recent years, US corporations have developed more radical ideas than non-US firms.
- Further Analyses
Relevant Population: Large firms account for a significantly higher proportion of radical innovations when compared to its total number of firms in the economy. In any product class (incumbent vs. non), the number of incumbent is much smaller than non incumbents, but incumbents still account for half of the nubmer of radical innovations.
Alternative measure of firm size
Radical Innovator: but what if incumbents can be early entrants?
36.3.4 (Tellis, Stremersch, and Yin 2003) International Takeoff
137 products across 10 categories inn 16 countries
Parametric hazard model
Takeoff in Europe (e.g., 6 years after introductionn) is different from those in US
Time-to-takeoff varies by countries and categories
Not much evidence for the effect of culture and economic factors on inter-country differences in time-to-takeoff
Use waterfall strategy when going international.
Countries with less uncertainty avoidance will have greater adoption
Countries with higher education will have greater adoption
36.3.5 (Hauser, Tellis, and Griffin 2006)Review on Innovation
5 fields
Consumer response to innovation
Organzattion and innovation
Market entry strategies
prescriptive technique for product development processes
Defense against market entry
36.3.6 (Chandrasekaran and Tellis 2008) Global Takeoff
16 products in 31 countries
Parametric hazard model
Economic variable (developed vs. developing) (isn’t this kinda contradict (Tellis, Stremersch, and Yin 2003), product types (work vs. fun), cultural clusters, calendar time can affect takeoff time
Takeoff is getting shorter over time
36.3.7 (Sood and Tellis 2011) Predict takeoff
36.3.8 (M. Zhang and Luo 2016) Restaurant survival from Yelp
36.4 Advertising Response (Effectiveness)
Consumer response to advertising
Key issues
Does advertising work?
When, where, why and for how long?
5 effects of ad exposure
Short
Sleeper
Hysteresis
Long
Instant
Simple model of ad response
\[ S_t = \alpha + \beta A_t + \mu_t \]
- Does not capture the carryover effect
Using (Koyck 1954) model captures carryover
\[ S_t + \alpha + \beta A_t + \beta \lambda A_{t-1} + \dots + \epsilon_t \]
This is a moving average model with an infinite lag that precisely captures carryover effect of advertising
Then, we need the Koyck transformation, lag on period and multiply by \(\lambda\) (carryover effect) (\(0 < \lambda < 1\))
Then
\[ \lambda S_{t-1} = \alpha \lambda + \beta \lambda A_{t-1} + \dots + \epsilon_t \lambda \]
With subtraction,
\[ \begin{aligned} S_t - \lambda S_{t-1} &= \alpha - \alpha \lambda + \beta A_t + \epsilon_t - \epsilon_t \lambda \\ S_t &= \alpha - \alpha \lambda + \lambda S_{t-1} + \beta A_t + \epsilon_t - \epsilon_t \lambda \\ S_t &= \alpha + \lambda S_{t-1} + \beta A_t + u_t \end{aligned} \]
Pros:
An infinite lag series turns to 1 period auto-regressive model
easy to estimate
\(\lambda\) is the carryover or decay in effect of advertising
\(\beta\) = current effect of ad
\(\beta \lambda/ (1- \lambda)\) carryover effect of ad
\(\beta / (1- \lambda)\) = total effect advertising
p% duration interval = \(\log (1-p) / \log \lambda\)
If include a lagged ad term
\[ S_t = \alpha + \lambda S_{t-1} + \beta A_t + \beta_1 A_{t-1} + \mu_t \]
Separate inertia from ad carryover
separate out decay from multiple independent variables
identify shape of decay
(Clarke 1976) found major limitation of Koyck model
Aggregation bias: the larger the data interval: the larger the estimated \(\lambda\), the larger the estimated carryover effect, the longer the estimated duration of ad
People used to think the best data interval time is the inter-purchase time. But (Tellis and Franses 2006) showed that unit exposure time is the optimal data interval (the smallest interval within which advertising occurs only once and at the same time every period)
General Autoregressive distributed Lag Model (ADL, ARMA)
\[ S_t = \alpha + \lambda S_{t-1} + \lambda S_{t-2} + \dots + \beta A_t + \beta A_{t-1} + \dots + \mu_t \]
pros:
-
rich variety of decay shapes
\(\beta\) affect number and position of bumps
\(\lambda\) affect speed of decay
precursor to Vector Autoregressive model (VAR)
cons:
aggregate data at population level and time cannot identify ad exposure
aggregate time cannot identify treated period
reverse causality: ad set on expected sales
multicollinearity
Major advances in ad response modeling:
-
Dis-aggregate data
modeling at individual household, consumer
modeling by day, hour
modeling moment-to-moment
modeling exposure (not $)
-
quasi-experiments
DID
Synthetic control
36.4.1 (Tellis, Chandy, and Thaivanich 2000) Direct TV ad
Study Context
A referral is “a call by a customer for the firm’s service” (p. 33)
-
Theory of message repetition:
A current effect on behavior
A carryover effect on behavior
A non behavior effect on attitude and memory
-
Research questions:
-
Given current brand equity, what is the effect of advertising on referrals?
Ad placement
Creatives
Time period
Age and repetition
Is marginal benefit greater than marginal cost for advertising?
-
Model
\[ R_t = \alpha + \gamma_1 R_{t-1} + \gamma_2 R_{t-2} + \gamma_3 R_{t-3} + \dots \\ + \beta_0 A_t + \beta_1 A_{t-1} + \beta A_{t-2} + \dots + \epsilon \]
where
\(A\) = advertising
\(R\) = referral
Controls: Opening hour + time of the day.
Expect:
Morning ads have longer decay than other time
Differences in creatives
Transfer function analysis
temporal patterns: auto correlations + partial auto-correlation show patterns at the hourly and weekly level
-
Lag structure: 3 lags on the dependent, and 4 lags on the independent (advertising)
-
Why there are lags of the dependent variable:
Algebraic: if didn’t have of the dependent, the independent lag would be infinite
Intuitive: separate the effect of carry over effect of advertising and inertia.
-
Error patterns:
\[ R_t = \alpha + v(\mathbf{B})A_t +N_t \]
where
\(R_t, A_t\) stationary
\(v(\mathbf{B})\) transfer function of advertising on referrals where \(v(\mathbf{B}) = Cw(B)B^b / \delta(B)\)
\(N_t = [\theta(B) / \phi(B)](1- B)^d a_t\) where \(a_t \sim N(0)\)
Advertising Effects (decay)
Total effects of advertising = sum of ad coefficients divided by (1 - sum of lag-referral coefficients)
\[ \text{Total Effect} = \frac{\sum_{l = 0}^n \beta_l }{(1- \sum_{j=1}^p \lambda_l)} \]
where \(l\) is the index for the time lag
and the partial advertising effect at each time period is
\[ TA_{t-l} = \beta_l A_{t-l} + \sum_{j=0}^l \lambda_j TA_{t-l+j} \]
Results
Advertising effect dissipate after 8 hours
Ad Effectiveness varies by station
Creatives also varies
36.4.2 (Tellis and Franses 2006) Optimal Data Interval for estimating ad response (on sales)
- Such a seminal paper
- This could also be applied to firm optimal interval for estimating announcement effect on stock performance.
Too disaggregate does not lead to disaggregate bias
Optimal interval is unit exposure time (not inter-purchase time)
To get the true estimates, it depends on the unit exposure time (instead of assumption of the advertising process)
Definition:
| Term | Definition |
|---|---|
| Data Interval | temporal level of the records |
| Inter purchase time | Smallest calendar time between any two consumer purchases |
| Duration Interval | Length of time that advertising effect lasts |
| Calendar time | Discrete time period |
| Exposure time | Moment a pulse of ad first hits a consumer |
| p% duration interval | length of time that accounts for \(p\)% of the advertising effect |
| Current effect of ad | portion of the total advertising effect that occurs in the same time period as the exposure |
| Duration interval bias | carryover effect estimated at the true interval - estimated on aggregate data |
Optimal interval balances between storage cost and estimate unbiasedness
Koyck model
- \(s_t, a_t\) are sales and ad at the true microdata interval
\[ s_t = \mu + \beta a_t + \beta \lambda a_{t-1} + \beta \lambda^2 a_{t-2} + \dots + \epsilon_t \]
where
\(\epsilon \sim N(0, \sigma^2_\epsilon)\)
\(\beta\) = current effect of advertising
\(\beta/(1- \lambda)\) = carryover effect
\(\lambda\) determines the duration interval (what do we call this term)
Using (Koyck 1954) transformation (i.e., multiply both sides by \(1 - \lambda L\) where \(L\) is the familiar lag operator \(L^k y_t = y_{t-k}\)) then
\[ s_t = \lambda s_{t-1} + \beta a_t + \epsilon_t - \lambda \epsilon_{t-1} \]
For aggregate data, denote \(S_T\) as the aggregate sales series from aggregating sales in the \(K\) periods from the current to the \(K-1\) prior period that are sampled at the current period
\[ \begin{aligned} S_T &= s_t + s_{t-1}+ s_{t-2}+ \dots + s_{t-(K-1)} \\ & = (1 + L + L^2 + \dots + L^{K-1})s_t \end{aligned} \]
Hence,
\[ A_T = (1 + L + L^2 + \dots + L^{K-1}) a_t \\ \epsilon_T = (1 + L + L^2 + \dots + L^{K-1}) \epsilon_t \\ S_{T-1} = (1 + L + L^2 + \dots + L^{K-1}) s_{t-K} \]
The true aggregate form of the micromodel
\[ S_T = \lambda^K S_{T-1} + \beta A_T + \beta \lambda (1 + \lambda L + \lambda^2 L^2 + \dots + \lambda^{K-1} L^{K-1}) \\ \times (1 + L + \dots + L_{K-1})a_{t-1} + \epsilon_T - \lambda^K \epsilon_{T-1} \]
The bias stem from the fact that
\[ A_{T-1} \neq (1 + \lambda L + \lambda^2 L^2 + \dots + \lambda^{K-1} L^{K-1}) \\ \times (1 + L + \dots + L_{K-1})a_{t-1} \]
because it was lost in aggregation
With optimal data interval (1 exposure pulse per interval), we can recover the carryover effect
\[ \frac{\beta_1 + \beta_2}{1 - \lambda^K} \]
and the true duration interval is
\[ \sqrt[K]{\hat{\lambda}^K} \]
the the current effect is \(\beta\)
When we have even more dis aggregate data than the optimal interval, we just have to adjust the formula to recover the true effects.
36.4.3 (T. S. Teixeira, Wedel, and Pieters 2010) Ad Pulsing to prevent consumer ad avoidance
Model: probit with MCMC
Data: eye-tracking on 31 commercials for 2000 participants.
New metric to predict attention dispersion based on eye-tracking data.
-
Optimization of ads:
problem: minimize avoidance subject to a given level of brand activity level
Solution: Pulsing
36.4.4 (Sethuraman, Tellis, and Briesch 2011) Advertising effectiveness meta-analysis
Data: 1960 - 2008, 56 studies.
Average short-term ad elasticity is .12
a decline in the advertising elasticity over time.
advertising elasticity is higher
for durable goods (vs. nondurables)
in the early stage than the mature stage of the life cycle
yearly data than quarterly data
ad is measured in gross rating points than monetary terms
Long-term ad elasticity is .24
36.4.5 (Liaukonyte, Teixeira, and Wilbur 2015) TV advertising on online shopping
Impression merging process: human coders
Data: $3.4 bil spending by 20 brands, consists of traffic and transactions and content measures for 1,2224 commercials.
Dif-n-dif: 2 mins pre/post windows of time. (similar to regression discontinuity)
Action-focus content increases direct website traffic and sales conditional on visitation
Info and emotion-focus content reduce web traffic while increases purchases, and positive net effect on sales for most brands.
Imagery-focus ad content decreases direct traffic to the website
-
After the tv ad
consumer choose whether to visit the website
consumer then determine whether to buy a product
-
Data:
-
Online traffic: comScore Media Metrix
Direct traffic
Search engine referrals
Transaction Count
TV Ad Data: Kantar Media
-
Argument for no endogeneity problem is that brands can’t manipulate the exact time the ad will air. (since hte ad will be placed in a 15-min window while the research design looks at the 4 minutes windows). For the case that the authors look at the 2-hour window, they use the dif-n-dif design where they pick the largest brands within each product category that did not advertise
36.4.6 (Tirunillai and Tellis 2017) TV ad on Online chatter: synthetic control
Raw metrics
- Reviews: from Amazon, Epinions, cnet, twitter, YouTube, Facebook
Volume of reviews
valence of the review (positive vs. negative)
Polarity (entropy)
- Blogs: from Spinn3r
Volume
In-degree (links) of the brand website
In-degree (links) of blog posts
Volume of blogs that gain/lose rank
Using Dynamic factor analysis
\[ Y_t = \xi f_t + \epsilon_t \\ f_t = \Psi f_{t-1} + \eta_t \]
where
\(Y_t\) raw measure of reviews and blogs
\(f_t\) is the underlying factors
\(\xi\) is the factors loadings
\(\epsilon\) idiosyncratic error
\(\eta\) = white noise where \(E(\epsilon_t \eta'_{t-k})=0\)
Dimension of chatter (using dynamic factor analysis)
-
Content-based dimensions:
Popularity: loads on volume of reviews and blogs
Negativity: loads positively on positive valence and polarity and negatively on positive valence
-
Information spread dimensions:
Visibility: loads on the volume of blogs and the in-degree links of the brand website
Virality: loads on volume of blogs that gained rank and in-degree of the blogs
TV ad causally increases a short positive effect on online chatter (info-spread > content-based)
Ad can reduce the negativity in online chatter in the short-term.
Ad can
simulate conversation online
trigger brand recall
Interpreting experience: give more favorable assessment toward the brand
Refute negatives: greater credibility and persuasiveness
Empirical Setting: A campaign: Let’s Do Amazing (ad duration). 20 days after the campaign date)>
Method:
Synthetic control (synthetic brand): the difference might already account for the spillover effect of the focal brands on other brands in the same industry (authors argue that there was no spillover effect).
No justification for 70 days before and 20 days after
To make sure YouTube did not affect much, the authors use data from Visible Measures to assess viewership, and TV viewership from https://tvlistings.zap2it.com/?aid=gapzap and Nielsen TV Ratings and Stradegy (need to ask about this company).
Authors also use Vector Auto-regressive model to examine the short-term and long-term dynamics between the dependent (chatter metrics) and independent variables (advertising).
36.5 Marketing Return
Event Analysis
Nature of series
- Continuous
Univariate: Class Bass, Classic FDA
Multivariate Unidirectional: functional regression, classic Koyck, ADL, ARIMA
Multivariate Multidirectional: VAR, VARX, PVAR, Simultaneous Equation
- Punctuated
Event is dependent: Hazard models, split hazard, bivariate hazard
Evident is independent: Event analysis, synthetic control, DID
Decreasing rigor of causal inference
- Lab Experiment
- Field Experiment
- Nature Experiment
- Instrumental Variables
- Granger causality (improves with shocks)
- Times series regression (improves with shocks)
- Cross-sectional regression
Levels of testing causality in field
Correlation
Multiple regression: control for other plausible causes
Times series model (use of current and past values: Koyck, ADL, ARIMA)
First differences (effect of changes)
Lag of first differences (Arellano & Bond)
Granger causality (use of only past values of independent variables + control of past values of dependent variables (VAR), preferably in differences).
Intervention or event analysis
Natural experiments
RCT
Concept of Abnormal Return:
Stock price (\(P_t\)) = random walk
Return = \(P_t - P_{t-1}\) = white noise
Panel Regression
Sample similar firms, \(j\)
Identify each of their similar events: First stage regression (WRDS)
Estimate abnormal returns of each of these firms associated with each of those events \(e_{jt}\)
2nd stage: equation
Pool abnormal returns
Estimate factors that may affect the distribution of \(e_{jt}\)
Strength of event analysis
Increases with clearly defined event, narrow window of treatment, removal of confounding events
Long time series for baseline
large number of firms
diverse contexts of treatments
Extraction effects of known predictors
temporal dependent series (returns)
punctuated independent series: event
Focus on effects of event on series of returns
simulates a natural experiment
Define: a natural or artificial shock
Types of natural experiments:
Compare treated vs. untreated
compared before and after
DiD
Synthetic control
Types of pre-temporal controls
One prior period
baseline of prior period
synthetic control
function of known factors (Fama-French 4)
Cross-over (treated becomes control and rev)
Time capsule in Marketing
| Event | Source |
|---|---|
| market Entry | Factiva, Lexis-Nexis |
| new product | Factiva, Thomson Reuters |
| Consumers satisfaction | CSI |
| Innovation activities | Factiva, Cap IQ |
| Acquisitions | Factiva, SDC platinum |
| Quality | Web chat, product reviews |
| Advertising | TNS Stradegy, YouTube |
| Recalls | Govt web, others |
| Sales | Yahoo fin, 10k GFK, euromonitor, Nielsen |
| Earnings | SEC Filings |
| Stock Prices | CRSP, WRDS |
36.5.1 (Fornell et al. 2006) Customer satisfaction and stock return
Historically, people understand that customer satisfaction affects firm economic performance. But we haven’t studied the relationship between customer satisfaction and stock performance.
People don’t incorporate the info about customer satisfaction into the stock price right away (market is not so efficient)
-
From the literature, we understand that there are 4 determinants of a company’s market value
Acceleration of cash flow: speed of buyer response marketing efforts
increase in cash cash flows: repeat business and low marginal costs of sales
reduction in cash flow risk: lower by satisfaction
increase in the residual value of the business
Data: Compsutat + American Customer Satisfaction Index
Regression (correlation) analysis
\[ \ln Market value = \alpha + \beta_1 \ln Book value \\ + \beta_2 \ln Bookvalueliability + \beta_3 \ln ACSI \]
There is evidence for a correlation market value and customer satisfaction.
However, investors don’t always respond positively to increased satisfaction news
The firms is giving away consumer surplus
firms that already have leads over competition
Why trade-off between satisfaction and productivity
reverse causality
timing expectation (i.e., measurement of satisfaction)
36.5.1.1 Event study
- Suing market model to estimate abnormal return
\[ AR_{jt} = R_{jt} - (\alpha_j + \beta_j R_{mt}) \]
where \(j\) = firm, and \(t\) = day
estimation period = 255 days ending 46 days before the event date (McWilliams and Siegel 1997)
one-day event period = day when Wall Street Journal publish ACSI announcement.
-
5 days before and after event to rule out other news (PR Newswire, Dow Jones, Business Wires)
M&A, Spin-offs, stock splits
CEO or CFO changes,
Layoffs, restructurings, earnings announcements, lawsuits
No evidence for the effect of ACSI on CAR
36.5.2 (S. Srinivasan and Hanssens 2009) Marketing and Firm Value
Marketing investments don’t always translate to firm value readily.
-
Marketing investments are typically intangible:
brand equity
customer equity
customer satisfaction
R&D
product quality
specific marketing-mix actions
-
Market is not so efficient: e.g.
- Intangible-intensive firms are usually undervalued (Lev 1989)
Market Valuation Modeling:
-
Fame-French factor explains excess returns come from
market risk factor: excess return on a broad market portfolio
size risk factor: difference in return between a large and small cap portfolio
value risk factor: difference in return between high and low book-to-market stocks
Momentum: Carhart (1997)
-
Metrics:
Top-line (revenue)
bottom-line (earnings) surprises
Methods: 4-factor model can still have omitted variables
Metrics on Marketing and Firm value
-
Market cap: need to
isolate the book value (using Tobin’s q)
Incorporate random-walk behavior in stock prices (first difference of log(stock price))
stock returns
| Method | Characteristics | Litimations | Examples | Dependent/Independent |
|---|---|---|---|---|
| Four Factor Model | Assume efficient market theory |
sensitive to benchmark portfolio correlation analysis can contain omitted variable bias examine cross-sectional variation only |
Tobin’s q/ Branding strategy Firm val/ brand value estimates Stock returns/ brand valuation |
|
| Event Study |
Assume efficient market Causal Analysis |
can’t measure long-term effect |
(Horsky and Swyngedouw 1987): name change (Chaney, Devinney, and Winer 1991): new product intro (Lane and Jacobson 1995): brand extension |
Stock returns/ name events Stock returns/ new product intro Stock returns/ brand extensions Stock returns/ Internet channel |
| Calendar protfolio |
Include firms with certain to measure long-term impact more accurate than event studies |
Can’t measure per event effect might be sensitive to benchmark prtofolio |
(A. Sorescu, Shankar, and Kushwaha 2007) | Stock returns/ new product |
| Stock return response model |
based on Carhart (1997) and EMH account dynamic properties of stock returns incorporate continuous events |
detailed data at the brand so business unit level marketing info must be public single equation model without temporal chain |
(D. A. Aaker and Jacobson 1994) |
Stock returns/ perceived quality Stock return / brand attitude stock return/ strategic shifts Stock returns/ marketing actions |
| Persistence modeling |
system of equations: consumer (demand equation), manager (decision rule equation), competition, (competitive reaction equation), investor (stock price equation) VAR: examines both short-term and long-term robust to deviations from stationarity incorporate dynamic feedback loops |
detailed data at the business unit level time-series over a long horizon reduced-form models |
Firm value/ new product intro, sales promotions stock returns/ advertising |
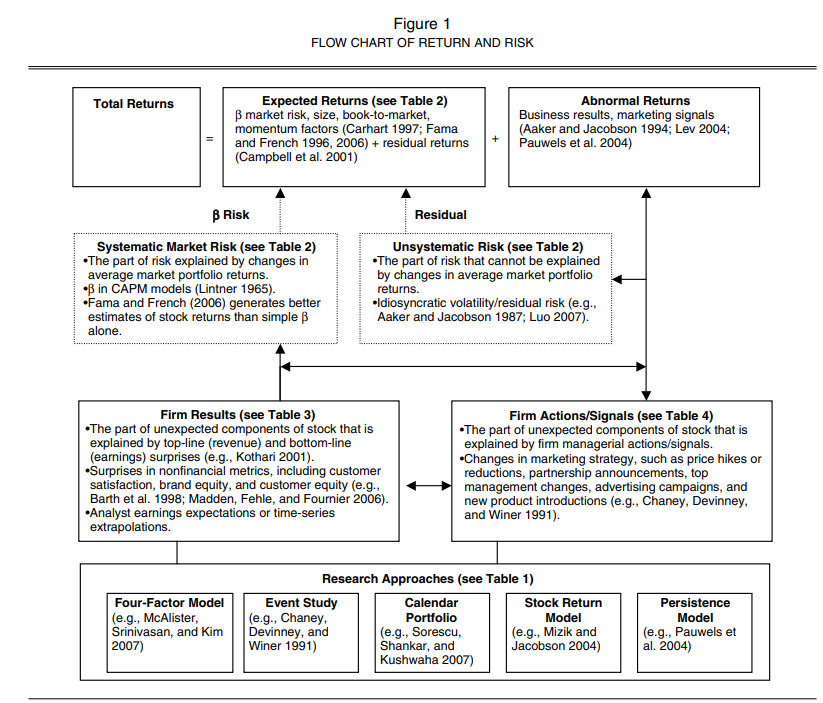
4 factor model:
\[ R_{it} - R_{rf,t} = \alpha_i + \beta_i (R_{mt} - R_{rf,t}) + s_i SMB_t \\ h_i HML_t + u_i UMD_t + \epsilon-{it} \]
where
\(R_{it}\) = stock return for firm \(i\) at time \(t\)
\(R_{rf,t}\) = risk-free rate in period \(t\)
market factor = \(R_{mt}\) = market return in period \(t\)
Size factor = \(SMB_t\) = return on a value-weighted portfolio of small stocks - the return of big stocks
Value factor = \(HML_t\) = return on a vlaue-weighted portfolio of high book-to-market stocks - return on a value-wegihted portfolio of low book-to-market stocks
Momentum factor \(UMD_t\) = average return on 2 high prior-return portfolio - the average return on two low prior return portfolio
36.5.3 (Sood and Tellis 2009) Innovation and Stock Return
Innovation is important for firms
But firms are cautious when investing in R&D (long-term effect hard to justify)
Finding: innovations effect on stock prices is underestimated when events are distinct vs. aggregate
3 types of innovation activities
- Initiation: alliance, funding, expansions
- Development: Prototypes, patents
- Commercialization: Porudct Launch, awards
Takeaways
Total market returns to an innovation project: 643 mil (compared to 49 mil the return to an average event in the innovation project)
Positive events increase returns for all three types of events
Negative events decrease return for development and commercialization stages only
The absolute value of the market returns is higher for negative announcements than for positive announcements
36.5.4 (Jacobson and Mizik 2009b)
Disagreeing with previous research conclusion that there was a systemic mispricing of customer satisfaction into the stock price (Fornell et al. 2006) (Aksoy et al. 2008), the anomaly stem from only a small group of satisfaction leaders in the computer and internet sector. (i.e., sampling bias).
This study is consistent with (O’Sullivan, Hutchinson, and O’Connell 2009)
36.5.5 (Jacobson and Mizik 2009a)
36.5.6 (Borah and Tellis 2014) Choice of Payoff from announcements (Innovations)
- Whether a firm should make, buy or ally regarding new technologies
Innovation phases:
- Initiation
Make
Buy
Ally
- Development
- Commercialization
New product launch
initial shipments
new app and markets for the new products
awards
Models
- Model of returns
- Model of investment choice: multinomial logit model
- Model of payoffs:
36.5.7 (Tirunillai and Tellis 2012) Chatter effect on stock performance
Research questions:
Cor(UGC, stock performance)
What is the direction of causality
Among the UGC metrics, which best relates to stock performance
What are the dynamics of the relationship in terms of wear-in, war-out, and duration?
Data: 4 years, 6 markets , 15 firms
Findings:
Volume of chatter increases abnormal returns by a few day (using Granger causality tests) and trading volume
Positive UGC has no effect on abnormal returns
Negative UGC has negative effect on abnormal returns with a short “wear-in” and long “wear-out”
Interaction between chatter volume and negative chatter have a positive effect on trading volume
negative UGC positively correlates with idiosyncratic risk
Positive UGC has no effect on the idiosyncratic risk
Offline ad also increases the volume of chatter and decreases negative chatter
UGC:
- Product reviews + product ratings
Stock performance:
A measure of shareholder value
Available at the daily level
Assumption:
Market is not efficient: it takes time for the market to reflect info about UGC.
-
Asymmetric response across UGC metrics:
Losses loom larger than gain
investors discount positive info because it’s unreliable
Positive messages are usually influenced by the firms, but not negative
Sampling:
Product categories that have rich data on UGC (digital, high tech and popular consumer durable)
Product categories that reviews are related to sales
Public firm only
No M&A during the period
The sample markets should be representative of the whole market.
Time: June 2005 - Jan 2010
Media:
Product reviews instead of text or videos, etc because intuitively people use this form to express their opinion
Consumer reviews instead of evaluations, blogs, forums, because it’s more focused and greater signal-to-noise ratio
Consumer reviews instead of expert review because of wisdom of the crowds
3 popular websites: Amazon.com, Epinions.com, Yahoo! Shopping.
ratings + text reviews
Measures
UGC: ratings, volume chatter, positive valence, negative valence
-
Stock market performance
Abnormal returns: Fame-French (1993) three-factor + Carhart 1997 momentum factor.
Idiosyncratic risk: same model as abnormal returns
Trading volume: = daily turnover = volume of trade / shares outstanding at the end of the day
Using EGARCH specification:
\[ R_{i,t} - R_{f,t} = \alpha_i + \beta_{i, MKT} (R_{MKT, t} - R_{f,t}) + \beta_{i, SMB} SMB_t \\ + \beta_{i, HML} HML_t + \beta_{i, MOM} MOM_t + \epsilon_{i,t} \]
where
- \(\epsilon_{i,t} \sim N(0, \sigma_{i,t})\)
\[ \ln(\sigma^2_{i,t} ) = a_i + \sum_{j = 1}^p b_{i,j} \ln (\sigma^2_{i,t-j}) \\ + \sum_{k=1}^q c_{i,k}\{ \Theta (\frac{\epsilon_{i, t - k}}{\sigma_{i, t - k}}) + \Gamma (| \frac{\epsilon_{i, t-k}}{\sigma_{i, t-k}}| - (\frac{2}{\pi})^{1/2})\} \]
Control Variables
Analysts’ Forecasts: IBES Database
Advertising: TV ad from TNS media Intelligence
Media Citations: Number of articles in print media from LexisNexis (with relevancy score above 60%) and Factiva (using company tag)
New product Announcement: also LexisNexis and Factiva (following (Sood, James, and Tellis 2009))
Models
Vector Auto-regression (VAR)
can handle continuous events (instead of discrete events used in event studies)
account for immediate and lagged-term of the independent variables
capture the carryover effects over time with the generalized impulse response function
Controls for trends, seasonality, non-stationary, serial correlation, and reserve causality (Luo 2009)
Procedure
- Estimate the stationary (unit roots + co-integration) properties of stock performance and UGC
Stationarity test: Augmented Dickey-Fuller test + Kwiatkowski-Philips-Schmidt-Shin test
Co-integration: Johansen’s procedure (Johansen et al. 1992)
- Granger causality test
- Estimate dynamics of carryover effect using impulse response function
- Not sensitive to the causal ordering to the causal ordering of the variable in the system of equations
- Estimate the effect of UGC using variance decomposition: relative importance of metrics of UGC
36.6 Creativity
Implications of social media
- Wisdom of the Crowds
- Advertising almost free
36.6.1 (Bayus 2013) Crowdsourcing New Product Ideas over Time
from dell’s IdeaStorm community, serial ideators are more likely to have 1 idea that the organization will implement, but they don’t repeat this success.
-
Negative effect of past success can be mitigated for idators with more diverse commenting activity
- Fixation effect = unconscious plagiarism (or cryptomnesia) (R. L. Marsh and Landau 1995) (R. L. Marsh, Ward, and Landau 1999)
-
Good
First paper to study crowdfunding of ideas
Good theory: fixation effect
Good descriptive analysis
-
Cons
- Model: not taken into account rare events.
36.6.2 (Toubia and Netzer 2017) Idea generation, creativity, prototypicality
Creativity = balance(novelty , familiarity)
Beauty in avergeness effect
Automate read ideas to identify promising ones
Research questions
- How novelty and familiarity defined in the idea generation context? From literature using Geneplore
“novelty is the association of word stems that do not appear frequently together in text related to the topic under consideration” (p. 3)
“familiarity is the association of word stems that appear frequently together” (p. 3)
- How should novelty and familiarity be measured? semantic network co-word analysis (by the combinations of word stem instead of the word itself)
- What is the optimal balance between novelty and familiarity? beauty in averageness effect
idea = “a document made of words that attempts to add value given a particular idea generation topic” p. 2
Automatically recommend words to improve idea
Baseline for semantic network:
Pre-test idea: consumers generate initial set of ideas on a topic
Google results: top search (might be biased to high-quality contents)
Used Jaccard index for edge weights
Control variables: (Barrat, Barthélemy, and Vespignani 2007)
Frequencies of nodes in the network: average edge weight, coefficient of variation of edge weights, minimum edge weight, maximum edge weight, average node frequency, coefficient of variation of node frequencies, minimum node frequency, maximum node frequency, and the number of nodes in the subnetwork, length of the idea using number of characters
Clustering coefficients of the nodes in the network; average node clustering coefficient, coefficient of variation of node clustering coefficients, minimum node clustering coefficient, and maximum node clustering coefficient.
Prototypical distribution of edge weights using mean of the prototypical distribution
Measure distance between two distributions - The Kolmogorov-Smirnov statistics (2 cdfs). Alternatively could use Kullback-Leibler divergence
Idea evaluation: manual with 4 dimension: creativity, purchase interest, predicted popularity, writing quality
Alternative measure to edge weight distributions: Info retrieval literature: vector space representation: each document as a vector with dimensionality equal to the number of word stems in our dictionary (i.e., number of nodes in our semantic network
Specification of the baseline semantic network is dangerous to the sub-network distribution.
Robust to synonyms
Strengths:
Good way to measure a complex and highly qualitative construct
Good connection between the theory and method
-
Robust
- Different measures, ideas, evaluators, baseline networks.
Cons
- With other representations, the results do not hold
36.6.3 (Y. “Max”. Wei, Hong, and Tellis 2021) Machine leaning creativity
Crowdfunding: for both finance and marketing (market reaction, advertise ideas)
Combinatorial theory:
measure novelty, overshooting and undershooting, measure styles of imitation
-
Research questions
How to measure the similarity between all the projects on crowdfunding sites in an objective and automated way?
-
The relationship between the similarity pattern and funding performance
Can previous successful projects that are similar product a new project’s success?
Do people value novelty?
whether to overshoot or undershoot the funds raised?
Do people value atypicality?
Recommendation from the similarity measure
Data: 98,058 Kickstarter projects from 2009 - 2017 (from 3 categories: Film & Video, Music and publishing. only English.
-
Techniques: Semantic Similarity
Word2vec: word-level similarity
Word Mover’s Distance (WMD): Document-level similarity \(w_{ij} = \delta^{|t_i - t_j|} \times L(\gamma_0 - \gamma_1 d_{ij})\) where \(0 < \delta \le 1\) is the decay factor, \(d_{ij}\) is the WMD between 2 projects and \(L\) is the logistic function and \(\gamma\) are chosen based
-
Similarity network where each node is a project,and the strength of a link
Increases with degree of similarity
decreases with the time lapse between 2 projects
-
Funding performance
Whether the funding is successful
How much money is raised
-
Findings
The average level of success by prior projects is a good predictor of the current project’s funding performance
High novelty means less similar to all previous projects, good projects are balanced of being novel and appearing familiar to investors
Goals should be set close to the number by prior similar projects
An inverted U-shaped relation between atypicality (borrow from another stream) and funding performance
-
Recommendations:
goals should be benched marked by other previous projects ( \(\pm 10\)% goal adjustment)
project should be similar to prior projects
Combinotorial
-
Geneplore framework
Generation process: retrieve prior info and recombine in a creative way
Exploration process: these recombinations will be elaborated
Results are robust against unweighted network whether link is present when it passes certain threshold.
Network-based metrics
Amount of prior similarity: degree of similarity
Prior success rate: weighted average of previous similar projects.
Prior success residual: reweigh the success rate with other control variables
Goal overshoot: difference between the focal project’ funding goal and the average of previous project funding goal (in log)
Atypicality: use unweighted network (using the cutoff of .5), atypicality = proportion of isolated in \(i\) subnetwork.
Control variables
- Project-related features
Log funding goal
log number of images
Dummy for video
Log length of the project depreciation text
Dummy for project category
Time trend and quarter dummies
- Creator-related features
Dummy for prior project
Average success rate of the creator’s prior projects
Models
Success: logistic
Fund raised: regression
Information weighting: \(I_i\equiv \log(1 + \sum_{j:T_j<t_i}w_{ij})\) choosing this specification because
- when there is no similarity between the focal project and prior projects, the information weight should be 0
- Under the Bayesian framework, there is a diminishing return of more signals.
Info weight is used for all metrics except similarity and atypicality
36.6.4 Can AI do ideation? 2022
Basic research question: How to screen ideas
Based on 3 models:
Word Colocation
Content Atypicality
Inspiration Redundancy
Prediciton mode
LASSO
Random Forest
RuleFit
36.6.5 (Berger and Packard 2018) Content Atypicality
- Ideas are better if they are different from other in the same contest.
36.6.6 (Stephen, Zubcsek, and Goldenberg 2016) The Effects of Network Structure on Redundancy of Ideas
- Ideators with more diverse background tend to have better idea.
36.7 Quality
Fundamental concept in many disciplines: policy, economics, consumer behavior, marketing strategy
Quality: attribute on which all (most) consumers prefer more to less (e.g., speed, reliability, durability, power). (Tellis and Wernerfelt 1987)
Market for quality (Klein and Leffler 1981): why quality commands a premium
Measurement of objective quality
-
Consumer reports (historically, until 2010)
Since 1935
Blind experiments with products
evaluated by experts
Problem: quality is multi-dimensional, composite quality depends on choice of dimensions and weights to combine them.
-
Solutions:
(Kopalle and Hoffman 1992): ranking products on quality not too noisy even if the weights are uncorrelated. but you still need attributes of quality to be positively correlated.
(Tellis and Johnson 2007): expert reviews: published quality ratings are good indicator of quality
(Tirunillai and Tellis 2014): wisdom of the crowds
36.7.1 (Tellis, Yin, and Niraj 2009) Network effects and quality in high tech
Evidence for market efficiency (defined as the best quality brand should have the largest market share)
Both quality and network effect affect market share flows (network effect > quality)
Network effect: “the increase in a consumer’s utility from a product when the number of other users of that product increases.” (p. 135)
Quality is defined as “a composite of a brand’s attributes, on each of which all consumers prefer more to less.” (p. 136) (e.g., reliability, performance, convenience).
Quality seems to be the driving force of the market (market share, return on investment, premium prices charged, advertising, perception of quality, stock market return, p. 136)
Theoretical cases: table 1
Sampling: Personal computer
Data: from International Data Corporation and Dataquest
36.7.2 (Peter N. Golder, Mitra, and Moorman 2012) An Integrative Framework for Quality
Quality processes:
Quality production process: focus on firms.. depedns on attribute design, process design, resoruce inptus and methods of controlling the production process.
-
Quality experience process: focus on customers
-
What the firm deliver and what the customer perceive can be different (relative to expectation) depends on
customer measurement knowledge
motivation
emotions
Experienced Attribute Quality vs. Delivered Attribute
-
-
Quality evaluation process: based on transactional and global judgments
“is the conversion of perceived attributes into an aggregated evaluation of quality, which is a summary jdugment of the customer’s experience of the firm’s offering.” (p. 9)
Evaluated aggregated quality is based on customer expertise and attribute characteristics
Customer Expectations: (1) “Will” expectation (2) “Ideal” expectation (3) “Should” expectation (perceived quality and fairness)
Quality is defined as ” a set of three distinct states of an offering’s attributes’ relative performance generated while producing, experiencing, and evaluating the offering.” (p. 2)
Figure 1 shows the framework
Typology of attribute types:
- Customer preference: homogeneous vs. heterogneous
- Measures ambiguity: unambiguous vs. ambiguous
| Customer preference | |||
|---|---|---|---|
| Homogenous | Heterogeneous | ||
| Measure ambiguity | Unambiguous | Universal attributes (flight delay) | Preference attributes (meal cuisine type, cabin temperature) |
| Ambiguous | Idiosyncratic attributes (art, beauty) |
36.7.3 (Tirunillai and Tellis 2014) Mining Quality from Consumer Reviews
use unsupervised LDA to measure quality dimensions in UGC
Data: 350,000 consumer reviews from (Tirunillai and Tellis 2012)
-
Results
- Dynamic analysis allows marketers to track the value of variables over time and dynamically map competitive brand positions on those dimensions.
| Market | Dimension | Across markets | Heterogeneity | Stability |
|---|---|---|---|---|
| Vertically differentiated (computer) | Objective dimensions dominate | Similiar | Low across dimensions | high over time |
| Horizontally differentiated (Shoes, toys) | Subjective dimensions dominate | Vary | High across dimensions | Low over time |