Chapter 7 Importing data: statistical software
In this chapter:
Importing survey data from statistical software packages that include labelled data formats, with an emphasis on SPSS
Importing survey data from an Excel file, including the data dictionary created by survey software, and creating labels from the data dictionary.
Importing plain-text data and applying syntax from statistical software packages to apply labels and output as statistical software data formats, with an emphasis on SPSS.
7.1 Statistical software
If you are one or work with statisticians, economists, sociologists, survey practitioners, and many others, you will find yourself encountering data files created using the software packages SAS, SPSS, and Stata. These tools have been around a long time (SAS and SPSS trace their history back to the late 1960s, and Stata was created in 1985), and over the years they have evolved, demonstrated their robustness, and have become common in many academic, corporate, and government settings.
A feature of these programs is that the variables and the associated values can be labelled. If you’re familiar with R, value labelling is conceptually similar to the use of factor labels. These labels can carry a great deal of detail to which you might otherwise not have easy access.
The R package {haven} (Wickham and Miller 2021) provides the functionality to read these three types of files. 12 There are other packages related to {haven} that we will also use.
library(haven)
In the following examples, we will use versions of the data in the {palmerpenguins} data (A. M. Horst, Hill, and Gorman 2022; A. Horst 2020). We will work with SPSS formatted files; the approach is similar for SAS and Stata formats, and only differs in the details. For example, the haven::read_() functions vary only with the extension; a Stata data file has the extension “.dta”, so the read function is read_dta():
The equivalent for a SAS file is as follows:
Here’s the code to read that same data file in SPSS’s “.sav” format and assigns it to an R object penguins_sav:
## # A tibble: 344 × 8
## species island bill_length_mm bill_depth_mm
## <dbl+lbl> <dbl+lbl> <dbl> <dbl>
## 1 1 [Adelie] 3 [Torgerse… 39.1 18.7
## 2 1 [Adelie] 3 [Torgerse… 39.5 17.4
## 3 1 [Adelie] 3 [Torgerse… 40.3 18
## 4 1 [Adelie] 3 [Torgerse… NA NA
## 5 1 [Adelie] 3 [Torgerse… 36.7 19.3
## 6 1 [Adelie] 3 [Torgerse… 39.3 20.6
## 7 1 [Adelie] 3 [Torgerse… 38.9 17.8
## 8 1 [Adelie] 3 [Torgerse… 39.2 19.6
## 9 1 [Adelie] 3 [Torgerse… 34.1 18.1
## 10 1 [Adelie] 3 [Torgerse… 42 20.2
## # ℹ 334 more rows
## # ℹ 4 more variables: flipper_length_mm <dbl>,
## # body_mass_g <dbl>, sex <dbl+lbl>, year <dbl>You will notice that the values of the variables in the .sav version of the penguins dataframe are different than what was read in from the .csv version. All of the variables, including those that were character strings, are numeric. For example in the variable “species” the values are a column of “1”s, “2”s, and “3”s instead of being the names of the species.
Note also that in the variable descriptions, it includes <S3: haven_labelled> for those that bring the SPSS labels with them.
7.1.1 {labelled} -
Once we have read our SAS, SPSS, or Stata data into R using one of the {haven} functions, the package {labelled}(Larmarange 2022) gives us a range of powerful tools for working with the variable labels, value labels, and defined missing values.
The first function we will use is look_for(), which returns the labels, column types, and values of the variables in our data.
## pos variable label col_type missing
## 1 species — dbl+lbl 0
##
##
## 2 island — dbl+lbl 0
##
##
## 3 bill_length_mm — dbl 2
## 4 bill_depth_mm — dbl 2
## 5 flipper_length_mm — dbl 2
## 6 body_mass_g — dbl 2
## 7 sex — dbl+lbl 11
##
## 8 year — dbl 0
## values
## [1] Adelie
## [2] Chinstrap
## [3] Gentoo
## [1] Biscoe
## [2] Dream
## [3] Torgersen
##
##
##
##
## [1] female
## [2] male
## In this view, we can spot the species names in the “values” column. Also notice that the “col_type” column shows “dbl+lbl”: double and label. In this dataframe, no labels have been defined.
The function var_label() allows us to add a descriptive label to a variable. In the next code chunk, we add a label to the species variable:
We can see that the label is now incorporated into the dataframe using the look_for() function:
## pos variable label col_type missing
## 1 species Penguin ~ dbl+lbl 0
##
##
## 2 island — dbl+lbl 0
##
##
## 3 bill_length_mm — dbl 2
## 4 bill_depth_mm — dbl 2
## 5 flipper_length_mm — dbl 2
## 6 body_mass_g — dbl 2
## 7 sex — dbl+lbl 11
##
## 8 year — dbl 0
## values
## [1] Adel~
## [2] Chin~
## [3] Gent~
## [1] Bisc~
## [2] Dream
## [3] Torg~
##
##
##
##
## [1] fema~
## [2] male
## It’s also possible to add multiple labels. Note that in this example, a label is added to both “dbl+lbl” and “dbl” types.
## pos variable label col_type missing
## 1 species Penguin ~ dbl+lbl 0
##
##
## 2 island Island o~ dbl+lbl 0
##
##
## 3 bill_length_mm — dbl 2
## 4 bill_depth_mm — dbl 2
## 5 flipper_length_mm — dbl 2
## 6 body_mass_g Weight, ~ dbl 2
## 7 sex — dbl+lbl 11
##
## 8 year — dbl 0
## values
## [1] Adel~
## [2] Chin~
## [3] Gent~
## [1] Bisc~
## [2] Dream
## [3] Torg~
##
##
##
##
## [1] fema~
## [2] male
## 7.1.1.1 Using labels
The labels in an dataframe created by {haven} can be converted to a factor type, using the unlabelled() function.
If we were to tally the number of penguins in each species using the penguins dataframe that originated from the SPSS file, we would see this:
## # A tibble: 3 × 2
## species n
## <dbl+lbl> <int>
## 1 1 [Adelie] 152
## 2 2 [Chinstrap] 68
## 3 3 [Gentoo] 124In this version, the “species” variable retains the numeric values.
By applying the unlabelled() function, the “haven_labelled” type variables are transformed into factor types, with the labels (that is, the species names) now the shown in our summary table:
## # A tibble: 3 × 2
## species n
## <fct> <int>
## 1 Adelie 152
## 2 Chinstrap 68
## 3 Gentoo 124An alternative approach is to the explicitly change the variable type, with a to_factor transformation inside one of the mutate functions, mutate() and mutate_if(). In this first example, the variable species is mutated from labelled to factor type.
## # A tibble: 3 × 2
## species n
## <fct> <int>
## 1 Adelie 152
## 2 Chinstrap 68
## 3 Gentoo 124In this second variant, the mutate_if(is.labelled) function transforms all of the labelled variables.
## # A tibble: 5 × 3
## # Groups: species [3]
## species island n
## <fct> <fct> <int>
## 1 Adelie Biscoe 44
## 2 Adelie Dream 56
## 3 Adelie Torgersen 52
## 4 Chinstrap Dream 68
## 5 Gentoo Biscoe 1247.1.2 Reading an SPSS survey file: “Video”
The functionality of a labelled dataframe is very beneficial when working with survey data. The dataframe can contain the variable codes as captured in the form, the values associated with those values, as well as the text of the question in the label.
The file used in this example comes from the University of Sheffield Mathematics and Statistics Help’s “Datasets for Teaching”
This dataset was collected by Scott Smith (University of Sheffield) to evaluate the use of best method for informing the public about a certain medical condition. There were three videos (New general video A, new medical profession video B, the old video C and a demonstration using props D). He wanted to see if the new methods were more popular so collected data using mostly Likert style questions about a range of things such as understanding and general impressions. This reduced dataset contains some of those questions and 4 scale scores created from summing 5 ordinal questions to give a scale score.
If you were working in SPSS, when you open the file, you would see the data like this:
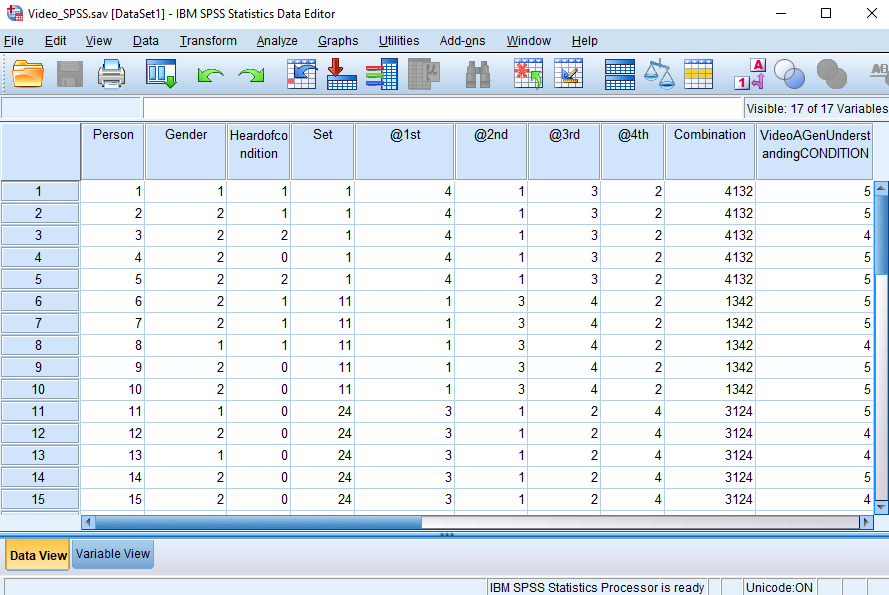
SPSS also gives you the option to view the variables:
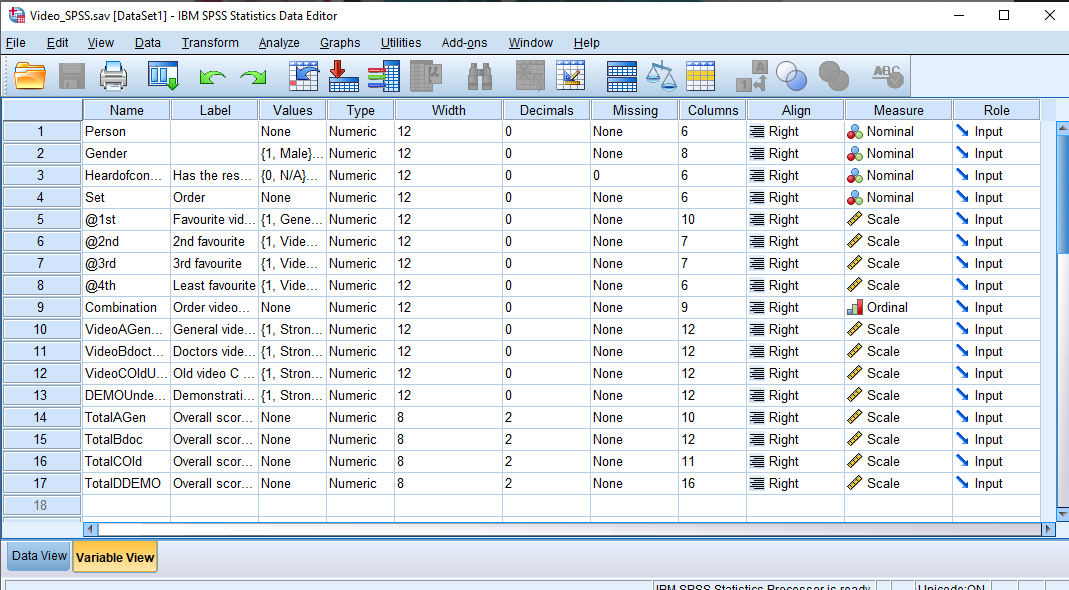
In this view, we can see both the variable names and the variable labels (in this case, the precise wording of the survey question).
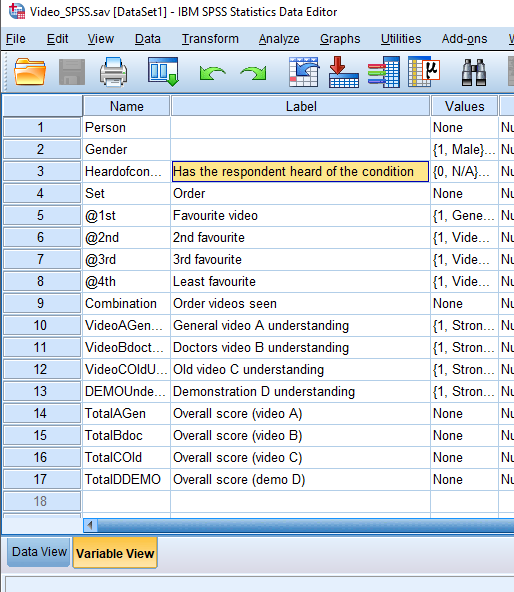
And we can also drill deeper, and see the value labels:
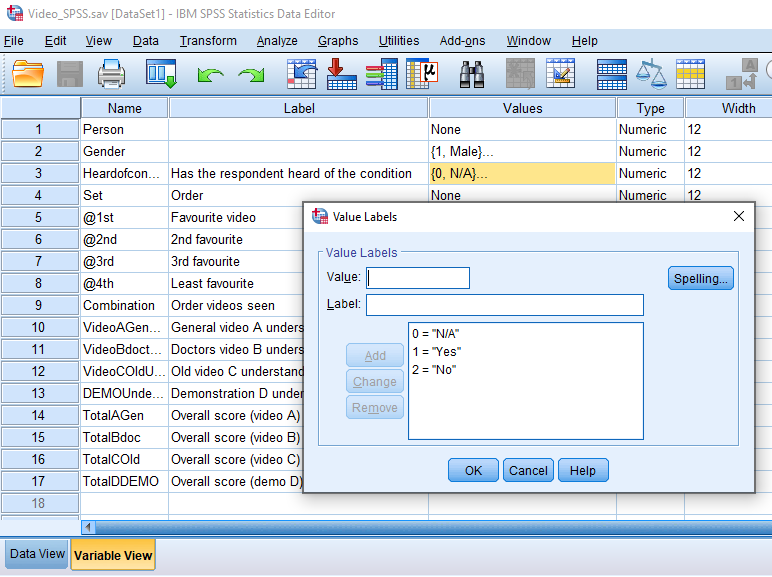
The R package {haven} allows us to capture all of this information.
7.1.2.1 Read SPSS data into R
For the first step, we will read in the data from the SPSS file with the default parameters.
## # A tibble: 20 × 17
## Person Gender Heardofcondition Set `@1st`
## <dbl> <dbl+lbl> <dbl+lbl> <dbl> <dbl+lbl>
## 1 1 1 [Male] 1 [Yes] 1 4 [Demonst…
## 2 2 2 [Female] 1 [Yes] 1 4 [Demonst…
## 3 3 2 [Female] 2 [No] 1 4 [Demonst…
## 4 4 2 [Female] NA 1 4 [Demonst…
## 5 5 2 [Female] 2 [No] 1 4 [Demonst…
## 6 6 2 [Female] 1 [Yes] 11 1 [General…
## 7 7 2 [Female] 1 [Yes] 11 1 [General…
## 8 8 1 [Male] 1 [Yes] 11 1 [General…
## 9 9 2 [Female] NA 11 1 [General…
## 10 10 2 [Female] NA 11 1 [General…
## 11 11 1 [Male] NA 24 3 [Old vid…
## 12 12 2 [Female] NA 24 3 [Old vid…
## 13 13 1 [Male] NA 24 3 [Old vid…
## 14 14 2 [Female] NA 24 3 [Old vid…
## 15 15 2 [Female] NA 24 3 [Old vid…
## 16 16 1 [Male] 2 [No] 10 2 [Medical…
## 17 17 1 [Male] 2 [No] 10 2 [Medical…
## 18 18 2 [Female] 1 [Yes] 10 2 [Medical…
## 19 19 2 [Female] 1 [Yes] 10 2 [Medical…
## 20 20 1 [Male] 1 [Yes] 10 2 [Medical…
## # ℹ 12 more variables: `@2nd` <dbl+lbl>,
## # `@3rd` <dbl+lbl>, `@4th` <dbl+lbl>,
## # Combination <dbl>,
## # VideoAGenUnderstandingCONDITION <dbl+lbl>,
## # VideoBdoctorUnderstandingCONDITION <dbl+lbl>,
## # VideoCOldUnderstandingCONDITION <dbl+lbl>,
## # DEMOUnderstandingCONDITION <dbl+lbl>, …Some of the variable names have leading @ (at sign)—they will cause us some headaches later, so let’s use the clean_names() function from the {janitor} package (Firke 2021)13 to clean them up.
Now, we can use the look_for() function from {labelled} to view the contents of the dataframe:
7.1.2.2 Handling missing values
Very often, SPSS files will have “user defined missing values.” In the video survey file, they have been coded as “NA”. But often, the analysis of survey results will have multiple types of “missing values”:
respondent left the question blank
respondent didn’t answer the question because of skip logic (in other words, the respondent didn’t see the question)
the analyst may have decided to code “Don’t know” or “Not applicable” as “missing” when calculating the percentages of responses in the other categories.
Depending on the circumstance, you may want to count some of these. For example, if there a lot of “Don’t know” and “Not applicable” responses, you may wish to analyze which one it is (they mean very different things!) If they are all coded as “NA”, you have lost the ability to gain that insight.
In the code below, adding the user_na = TRUE argument to the read_spss() function maintains the original values.
df_video <- read_spss(dpjr::dpjr_data("Video_SPSS.sav"), user_na = TRUE)
df_video <- janitor::clean_names(df_video)
df_video## # A tibble: 20 × 17
## person gender heardofcondition set x1st
## <dbl> <dbl+lbl> <dbl+lbl> <dbl> <dbl+lbl>
## 1 1 1 [Male] 1 [Yes] 1 4 [Demonst…
## 2 2 2 [Female] 1 [Yes] 1 4 [Demonst…
## 3 3 2 [Female] 2 [No] 1 4 [Demonst…
## 4 4 2 [Female] 0 (NA) [N/A] 1 4 [Demonst…
## 5 5 2 [Female] 2 [No] 1 4 [Demonst…
## 6 6 2 [Female] 1 [Yes] 11 1 [General…
## 7 7 2 [Female] 1 [Yes] 11 1 [General…
## 8 8 1 [Male] 1 [Yes] 11 1 [General…
## 9 9 2 [Female] 0 (NA) [N/A] 11 1 [General…
## 10 10 2 [Female] 0 (NA) [N/A] 11 1 [General…
## 11 11 1 [Male] 0 (NA) [N/A] 24 3 [Old vid…
## 12 12 2 [Female] 0 (NA) [N/A] 24 3 [Old vid…
## 13 13 1 [Male] 0 (NA) [N/A] 24 3 [Old vid…
## 14 14 2 [Female] 0 (NA) [N/A] 24 3 [Old vid…
## 15 15 2 [Female] 0 (NA) [N/A] 24 3 [Old vid…
## 16 16 1 [Male] 2 [No] 10 2 [Medical…
## 17 17 1 [Male] 2 [No] 10 2 [Medical…
## 18 18 2 [Female] 1 [Yes] 10 2 [Medical…
## 19 19 2 [Female] 1 [Yes] 10 2 [Medical…
## 20 20 1 [Male] 1 [Yes] 10 2 [Medical…
## # ℹ 12 more variables: x2nd <dbl+lbl>, x3rd <dbl+lbl>,
## # x4th <dbl+lbl>, combination <dbl>,
## # video_a_gen_understanding_condition <dbl+lbl>,
## # video_bdoctor_understanding_condition <dbl+lbl>,
## # video_c_old_understanding_condition <dbl+lbl>,
## # demo_understanding_condition <dbl+lbl>,
## # total_a_gen <dbl>, total_bdoc <dbl>, …What were “NA” in the first version are now “0”.
7.1.2.3 Exploring the data
The attributes() function gives us a way to view the details of the variables.
First, we can look at the attributes of the whole dataframe.
## $class
## [1] "tbl_df" "tbl" "data.frame"
##
## $row.names
## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
## [18] 18 19 20
##
## $names
## [1] "person"
## [2] "gender"
## [3] "heardofcondition"
## [4] "set"
## [5] "x1st"
## [6] "x2nd"
## [7] "x3rd"
## [8] "x4th"
## [9] "combination"
## [10] "video_a_gen_understanding_condition"
## [11] "video_bdoctor_understanding_condition"
## [12] "video_c_old_understanding_condition"
## [13] "demo_understanding_condition"
## [14] "total_a_gen"
## [15] "total_bdoc"
## [16] "total_c_old"
## [17] "total_ddemo"Or we can use the dollar sign method of specifying a single variable; in this case, heardofcondition:
## $label
## [1] "Has the respondent heard of the condition"
##
## $na_values
## [1] 0
##
## $class
## [1] "haven_labelled_spss" "haven_labelled"
## [3] "vctrs_vctr" "double"
##
## $format.spss
## [1] "F12.0"
##
## $display_width
## [1] 6
##
## $labels
## N/A Yes No
## 0 1 2In the output above, the $label is the question, and the $labels are the labels associated with each value, including N/A. Note that there’s also a $na_values shown.
You can also string these together in our code. For example, if we want to see the value labels and nothing else, the code would be as follows:
## N/A Yes No
## 0 1 27.1.3 Factors
Factors behave differently than labels: they don’t preserve both the label and the value. Instead they display the value and preserve the sort order (that can be either automatically set or defined in the code).
In the code below, we will set all of the variables in the df_video dataframe as factors. In the first code chunk there are no additional parameters.
## # A tibble: 20 × 17
## person gender heardofcondition set x1st x2nd
## <dbl> <fct> <fct> <dbl> <fct> <fct>
## 1 1 Male Yes 1 Demonstr… Vide…
## 2 2 Female Yes 1 Demonstr… Vide…
## 3 3 Female No 1 Demonstr… Vide…
## 4 4 Female N/A 1 Demonstr… Vide…
## 5 5 Female No 1 Demonstr… Vide…
## 6 6 Female Yes 11 General … Vide…
## 7 7 Female Yes 11 General … Vide…
## 8 8 Male Yes 11 General … Vide…
## 9 9 Female N/A 11 General … Vide…
## 10 10 Female N/A 11 General … Vide…
## 11 11 Male N/A 24 Old vide… Vide…
## 12 12 Female N/A 24 Old vide… Vide…
## 13 13 Male N/A 24 Old vide… Vide…
## 14 14 Female N/A 24 Old vide… Vide…
## 15 15 Female N/A 24 Old vide… Vide…
## 16 16 Male No 10 Medical … Demo…
## 17 17 Male No 10 Medical … Demo…
## 18 18 Female Yes 10 Medical … Demo…
## 19 19 Female Yes 10 Medical … Demo…
## 20 20 Male Yes 10 Medical … Demo…
## # ℹ 11 more variables: x3rd <fct>, x4th <fct>,
## # combination <dbl>,
## # video_a_gen_understanding_condition <fct>,
## # video_bdoctor_understanding_condition <fct>,
## # video_c_old_understanding_condition <fct>,
## # demo_understanding_condition <fct>,
## # total_a_gen <dbl>, total_bdoc <dbl>, …In this second chunk, the levels parameter is set to both.
## # A tibble: 20 × 17
## person gender heardofcondition set x1st x2nd
## <dbl> <fct> <fct> <dbl> <fct> <fct>
## 1 1 [1] Male [1] Yes 1 [4] … [1] …
## 2 2 [2] Female [1] Yes 1 [4] … [1] …
## 3 3 [2] Female [2] No 1 [4] … [1] …
## 4 4 [2] Female [0] N/A 1 [4] … [1] …
## 5 5 [2] Female [2] No 1 [4] … [1] …
## 6 6 [2] Female [1] Yes 11 [1] … [3] …
## 7 7 [2] Female [1] Yes 11 [1] … [3] …
## 8 8 [1] Male [1] Yes 11 [1] … [3] …
## 9 9 [2] Female [0] N/A 11 [1] … [3] …
## 10 10 [2] Female [0] N/A 11 [1] … [3] …
## 11 11 [1] Male [0] N/A 24 [3] … [1] …
## 12 12 [2] Female [0] N/A 24 [3] … [1] …
## 13 13 [1] Male [0] N/A 24 [3] … [1] …
## 14 14 [2] Female [0] N/A 24 [3] … [1] …
## 15 15 [2] Female [0] N/A 24 [3] … [1] …
## 16 16 [1] Male [2] No 10 [2] … [4] …
## 17 17 [1] Male [2] No 10 [2] … [4] …
## 18 18 [2] Female [1] Yes 10 [2] … [4] …
## 19 19 [2] Female [1] Yes 10 [2] … [4] …
## 20 20 [1] Male [1] Yes 10 [2] … [4] …
## # ℹ 11 more variables: x3rd <fct>, x4th <fct>,
## # combination <dbl>,
## # video_a_gen_understanding_condition <fct>,
## # video_bdoctor_understanding_condition <fct>,
## # video_c_old_understanding_condition <fct>,
## # demo_understanding_condition <fct>,
## # total_a_gen <dbl>, total_bdoc <dbl>, …7.2 Creating a labelled dataframe from an Excel file
You might encounter a circumstance where the data collectors have originally used SPSS, SAS, or Stata{Stata}, but share the data as an Excel file. This might be because the receiving organization does not have the proprietary software, and the ubiquity of Excel as an analytic tool makes it a functional choice.
Typically in these circumstances, the data collectors make the data available in two parts:
The individual records, with the variables coded numerically.
A separate “code book”, with the labels associated with each numeric value.
In the following example, the Palmer penguins data (A. Horst 2020) has been stored in an Excel file. The first sheet in this Excel file contains the data, where the values in the three character variables (species, island, and sex) have been converted to numeric codes. For example, for the species variable, the Adelie penguins are represented by the value “1”, Chinstrap are represented by “2”, and Gentoo are represented by “3”.
penguins_path <- dpjr::dpjr_data("penguins_labelled.xlsx")
penguins_data <- read_excel(penguins_path, sheet = "penguins_values")
head(penguins_data)A glance at the dataframe shows that the variables species, island, and sex are all coded as numeric variables. Unlike the “.sav” file we read earlier in this chapter, this dataframe does not carry the labels as part of the variable.
We could write some code to apply labels and change the variable type, using the val_labels() function from the {labelled} package:
# assign the species names as labels
labelled::val_labels(penguins_data$species) <-
c("Adelie" = 1, "Chinstrap" = 2, "Gentoo" = 3)
# view the labels
val_labels(penguins_data$species)
# another way to view the labels
attr(penguins_data$species, "labels")We can also use R to read in the values and apply them programmatically. This will save time and effort and reduce the risk of typographical errors, particularly if there are many variables and those variables have many values to label.
If we return to the Excel file “penguins_labelled.xlsx” we find that the second sheet in the Excel file is called “penguins_codebook_source”. This sheet contains the output SPSS creates when the “DISPLAY DICTIONARY” syntax (or the “File > Display Data File Information > Working File” GUI menu sequence) in SPSS is used to produce the “dictionary” (or codebook). There is information about each of the variables, including whether that variable is nominal or scale.
Of particular interest to us are the values associated with each variable. This information is saved under the heading “Variable Values”; for the penguins data file, this appears in row 36 of the Excel sheet.
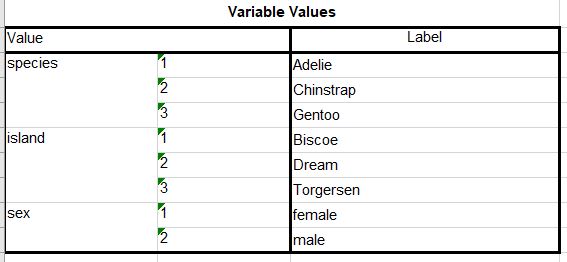
First, we read the contents of a specific rectangle of data in the second sheet in the Excel file, containing the code book. Note that we start reading at row 37, so that “Value” and “Label” are assigned as our variable names. In this code, the “anchored” approach is used, where the upper left corner Excel cell is specified, and then the number of rows and columns to be read in the dim = argument.
penguins_path <- dpjr::dpjr_data("penguins_labelled.xlsx")
penguins_code <- read_excel(penguins_path,
sheet = "penguins_codebook",
range = anchored("A37", dim = c(9, 3)))
penguins_codeWe have read the table as output by SPSS and saved in the Excel file, but there is additional wrangling required.
The first step in the pipe is to rename the variables. Not only has the name Value been given to the “Variable” column, but the name of the value column has been interpreted as blank and has been assigned the variable name ...2.
The second step is to use the {dplyr} fill() function to populate the missing values in the variable variable. The default direction of the fill is downwards, so we don’t need to specify the direction as an argument. We will examine other options for cleaning data later.
penguins_code <- penguins_code |>
# rename variables
rename(Value = "variable",
...2 = "variable_value",
Label = "variable_label") |>
# fill in blank names
fill(variable) |>
# change to numeric
mutate(variable_value = as.numeric(variable_value))
penguins_codeAt this point, there are two possible solutions:
Join the values from the “penguins_code” dataframe, so that in addition to the variable with numeric values, there is also a variable with the character strings.
Using the functions in the {labelled} package, convert the variables into “labelled” type, so the the numeric values remain and the labels are applied. In this scenario, the end-state is the same as reading the SPSS file directly.
Final step: join variables
7.3 Creating a labelled dataframe from SPSS syntax
In the previous chapter, we imported data files that had been created using the software packages SAS, SPSS, and Stata. We also saw how to work with labelled variables.
In our quest for data to analyze, we might come across a circumstance where an organization has collected survey data, and the data collectors have published the individual records, allowing researchers like you and me to further explore the data.
These data files contain individual records, rather than a data file that has been summarized with counts and percentages. A file with the individual records is sometimes referred to as a “micro-file”, and one that has been anonymized for publication might be described as a Public-Use Micro File (abbreviated as “PUMF”) or Public Use Microdata Sample (PUMS)\index{PUMS|see {Public-Use Micro File}}.
In this chapter, we will look at two circumstances where the data collectors have done just that. But rather than releasing the micro-data in a variety of formats, they have published a bundle that contains the raw text flat file along with syntax (code) files that apply variable names, variable labels, and value labels. This is great if we have a license for one of those proprietary software tools14, but what if we are an R user?
Fortunately for us, there is a package that has functions to read a raw text file, and apply SPSS syntax to create an R object with labelled variables: {memisc} (Elff et al. 2021).
library(memisc)
7.3.1 National Travel Survey (NTS)
Our first example uses information from the National Travel Survey (NTS), collected and published by Statistics Canada (Statistics Canada 2021).
Step 1 - Download the “SPSS” zip file for the 2020 reference period, and unzip it in the project sub-folder “data”. This should create a sub-folder, so that the file path is now “data\2020-spss”
The zip file does not include an SPSS-format data file (.sav). Instead, the folder has a fixed-width text file for each of the three survey components (person, trips, and visits), and corresponding SPSS syntax files that can be used to read the files into the correct variables and to apply the variable and value labels.
For this example, we will use the 2020 NTS “Person” file. The raw data file provided by Statistics Canada is “PERSON_NTS2020_PUMF.txt”.
Step 2 - Use the SPSS syntax files (in R)
The bundle also includes separate SPSS syntax files with the “.sps” extension. Because Canada is a bilingual country, Statistics Canada releases two versions of the label syntax files, one in English and the other in French. They can be differentiated through the last letter of the file name, before the extension. These are:
variable labels: “Person_NTS2020_Pumf_vare.sps” (The equivalent file with French variable labels is “Person_NTS2020_Pumf_varf.sps”.)
variable values: “Person_NTS2020_Pumf_vale.sps”
missing values: “Person_NTS2020_Pumf_miss.sps”
This structure works very well with the {memisc} functions, and these files do not require any further manipulation. (As we will see in our second example, this is not always the case.)
Because Statistics Canada has made the data available from other years, we will consciously create flexible code that will permit us to rerun our code later with a minimum number of changes. Accordingly, we will assign the year of the data as an object.
We can now use the object with the year number in a variety of ways, as we define the locations of the various input files. Note that this code uses the glue() function from the {glue} package to create the file name strings, and the here() function from the {here} package to determine the file path relative to our RStudio project location.
# define locations of input files
nts_year_format <- glue(nts_year, "-SPSS")
input_folder <- here("data", nts_year_format)
input_folder## [1] "E:/github_book/data_preparation_journey/data/2020-SPSS"## [1] "E:/github_book/data_preparation_journey/data/2020-SPSS/Layout_cards"# use the above to create objects with file names and paths
data_file_1 <- glue("PERSON_NTS", nts_year, "_PUMF.txt")
data_file <- glue(input_folder, "/Data_Données/", data_file_1)
data_file## E:/github_book/data_preparation_journey/data/2020-SPSS/Data_Données/PERSON_NTS2020_PUMF.txtcolumns_file_1 <- glue("Person_NTS", nts_year, "_Pumf_i.sps")
columns_file <- glue(layout_folder, columns_file_1, .sep = "/")
columns_file## E:/github_book/data_preparation_journey/data/2020-SPSS/Layout_cards/Person_NTS2020_Pumf_i.spsvariable_labels_1 <- glue("Person_NTS", nts_year, "_Pumf_vare.sps")
variable_labels <- glue(layout_folder, variable_labels_1, .sep = "/")
variable_values_1 <- glue("Person_NTS", nts_year, "_Pumf_vale.sps")
variable_values <- glue(layout_folder, variable_values_1, .sep = "/")
missing_values_1 <- glue("Person_NTS", nts_year, "_Pumf_miss.sps")
missing_values <- glue(layout_folder, missing_values_1, .sep = "/")The next stage is to create a definition of the dataset using the memisc::spss.fixed.file() import procedure.
# read file, create datafile with nested lists
nts_person_2020 <- memisc::spss.fixed.file(
data_file,
columns_file,
varlab.file = variable_labels,
codes.file = variable_values,
missval.file = missing_values,
count.cases = TRUE,
to.lower = TRUE
)
# convert the resulting object into a "data.set" format
nts_person_2020_ds <- memisc::as.data.set(nts_person_2020)That dataset object is now converted into a tibble, using the as_haven() function. This tibble has all of the variable and value labels assigned, accessible via the functions in the {labelled} package.
## # A tibble: 79,771 × 13
## pumfid verdate refyear quarter inf_q01 inf_q02
## * <dbl> <chr> <int+lbl> <int+l> <int+l> <int+lb>
## 1 1006690 10/12/2… 2020 [Yea… 1 [Ref… 1 [Yes] 35 [Ont…
## 2 1006691 10/12/2… 2020 [Yea… 1 [Ref… 1 [Yes] 35 [Ont…
## 3 1006692 10/12/2… 2020 [Yea… 1 [Ref… 1 [Yes] 24 [Que…
## 4 1006693 10/12/2… 2020 [Yea… 1 [Ref… 1 [Yes] 35 [Ont…
## 5 1006694 10/12/2… 2020 [Yea… 1 [Ref… 1 [Yes] 24 [Que…
## 6 1006695 10/12/2… 2020 [Yea… 1 [Ref… 1 [Yes] 35 [Ont…
## 7 1006696 10/12/2… 2020 [Yea… 1 [Ref… 1 [Yes] 13 [New…
## 8 1006697 10/12/2… 2020 [Yea… 1 [Ref… 1 [Yes] 11 [Pri…
## 9 1006698 10/12/2… 2020 [Yea… 1 [Ref… 1 [Yes] 35 [Ont…
## 10 1006699 10/12/2… 2020 [Yea… 1 [Ref… 1 [Yes] 35 [Ont…
## # ℹ 79,761 more rows
## # ℹ 7 more variables: page_grp <int+lbl>,
## # gend_bin <int+lbl>, incomgr2 <int+lbl>,
## # memc18up <int+lbl>, memclt18 <int+lbl>,
## # resprov <int+lbl>, pumfwp <dbl>In our final step, we save the dataframe as SPSS, Stata, and RDS files for future use.
One important note for Stata users is that there is a “version” argument, which allows us to create a file that can be read by older versions of Stata (the default is Stata 15).
# export haven format table as SPSS .sav file
haven::write_sav(nts_person_2020_hav,
here("data_output", "nts_person_2020.sav"))
# export haven format table as Stata .dta file
haven::write_dta(nts_person_2020_hav,
here("data_output", "nts_person_2020.13.dta"),
version = 13)
# export RDS
readr::write_rds(nts_person_2020_hav,
here("data_output", "nts_person_2020.rds"))References
The reference page for {haven} is here: https://haven.tidyverse.org/index.html↩︎
The reference page for {janitor} is here: http://sfirke.github.io/janitor/↩︎
Or a friend we can bribe with the promise of a chocolate bar.↩︎