Die Analogie einer Schätzung zu einem Bogenschuss macht deutlich, dass ein Punktschätzer zwar interessant ist, dass man aber nicht erkennt, wie zuverlässig die Schätzung ist. Darf man davon ausgehen, dass der Schätzer dicht am wahren Parameter liegt? Oder ist zu befürchten, dass die Schätzung vielleicht deutlich daneben liegt? Einen Bogenschützen kann man bitten, mehrfach auf die Zielscheibe zu schießen, damit seine Zielgenauigkeit gemessen werden kann. Eine Stichprobe wird jedoch in der Realität nicht wiederholt gezogen, sondern nur einmal. Kann man dennoch allein auf Grundlage einer einzelnen Stichprobe die Schätzgenauigkeit bewerten? In diesem Kapitel wird gezeigt, dass das tatsächlich machbar ist.
Das Ziel einer Intervallschätzung besteht darin, nicht nur einen Punkt als Schätzung zu liefern, sondern ein Intervall, in dem der wahre Parameterwert mit einer (vorgegebenen) hohen Wahrscheinlichkeit liegt.
11.1 Konfidenzintervalle
Um etwas über den interessierenden Parameter \(\theta\) der Zufallsvariable \(X\) zu lernen, wird eine einfache Stichprobe \(X_1,\ldots,X_n\) erhoben.
Definition: Konfidenzintervall
Ein Intervall \([\hat\theta_u(X_1,\ldots,X_n);\hat\theta_o(X_1,\ldots,X_n)]\) mit der Eigenschaft \[
P(\hat\theta_u(X_1,\ldots,X_n)\le \theta\le \hat\theta_o(X_1,\ldots,X_n))=1-\alpha
\] heißt Konfidenzintervall (engl. confidence interval) für \(\theta\) zum (Konfidenz-)Niveau \(1-\alpha\).
Die Definition ist schwieriger zu verstehen, als es zunächst den Anschein hat. Das liegt daran, dass es sich bei den Intervallgrenzen um Zufallsvariablen handelt. Sowohl die Untergrenze als auch die Obergrenze sind Statistiken im Sinne von Abschnitt 9.2, d.h. sie hängen von der Stichprobe ab. Da die Stichprobenelemente Zufallsvariablen sind, sind auch die Intervallgrenzen zufällig. Nur aus diesem Grund ist es möglich, eine Wahrscheinlichkeitsaussage darüber zu treffen, ob der wahre Wert von dem Intervall überdeckt wird, denn der wahre Wert ist keine Zufallsvariable, sondern eine (leider unbekannte) reelle Zahl.
Nach der Realisation der Stichprobe sind die konkreten Stichprobenelemente reelle Zahlen. Aus dem Konfidenzintervall wird das konkrete Konfidenzintervall (oder der Wert oder die Realisation des Konfidenzintervalls), \[
[\hat\theta_u(x_1,\ldots,x_n);\hat\theta_o(x_1,\ldots,x_n)].
\] Das konkrete Konfidenzintervall hat eine reelle Untergrenze und eine reelle Obergrenze, es handelt sich also um ein ganz normales Intervall. Eine Wahrscheinlichkeitsaussage darüber, ob dieses Intervall den wahren Wert überdeckt, ist nicht möglich bzw. nicht sinnvoll. Ohne Zufallsvorgang kann man keine Wahrscheinlichkeitsaussagen machen.
11.2 Konfidenzintervall für den Erwartungswert
Wie findet man ein Konfidenzintervall für einen interessierenden Parameter? Auf die Konstruktionsmethoden gehen wir in diesem Kurs nicht ein, sie werden in den Bachelor-Wahlpflichtmodulen Advanced Statistics und Econometrics behandelt. Stattdessen wird im folgenden gezeigt, wie Konfidenzintervalle für den Erwartungswert\(\mu\) einer Verteilung \(X\) aussehen. Der Fokus auf den Erwartungswert darf aber nicht den Blick darauf verstellen, dass auch für jede andere Art von Parameter Konfidenzintervalle gebildet werden können. Es ist also auch möglich, ein Konfidenzintervall für die Varianz oder Standardabweichung oder auch für ein Quantil zu erstellen. In vielen Anwendungen interessiert man sich besonders für Zusammenhangsmaße, z.B. für den Korrelationskoeffizienten. Auch dafür gibt es Konfidenzintervalle. In ökonomischen Studien werden oft Modelle mit (vielen) Parametern geschätzt, und auch dafür können Konfidenzintervalle konstruiert werden. Ein gutes Verständnis der Konfidenzintervalle für Erwartungswerte ist jedoch ein solides Fundament, um sich später schnell mit anderen Arten von Konfidenzintervallen zurechtzufinden.
Wir gehen zunächst davon aus, dass die Verteilung von \(X\) vollständig unbekannt ist. Wir wissen beispielsweise nicht, ob \(X\) normalverteilt ist. Das ist offensichtlich eine sehr realistische Annahme, denn in den meisten empirischen Anwendungen ist die Verteilung von \(X\) unbekannt. Um etwas über den Erwartungswert zu lernen, müssen wir die Realität beobachten. Dafür wird aus \(X\) eine einfache Stichprobe vom Umfang \(n\) gezogen. Das Stichprobenmittel \(\bar X\) ist der (Punkt-)Schätzer für den unbekannten Erwartungswert.
Aus dem zentralen Grenzwertsatz (Abschnitt 8.3) folgt, dass bei großen Stichproben approximativ \[
\sqrt{n}\frac{\bar X-\mu}{\sigma}\stackrel{appr}{\sim} N(0,1)
\] gilt. Da die Approximation für große \(n\) sehr genau ist, wird im folgenden nicht mehr jedesmal extra darauf hingewiesen, dass es sich nur um eine Approximation handelt.
Man kann zeigen, dass der zentrale Grenzwertsatz auch dann weiterhin gilt, wenn bei der Standardisierung des Stichprobenmittels die Populationsstandardabweichung \(\sigma\) durch die Stichprobenstandardabweichung \(S\) ersetzt wird. Wegen des Gesetzes der großen Zahl konvergiert die Stichprobenstandardabweichung \(S\) gegen die wahre Standardabweichung \(\sigma\), wenn \(n\to\infty\) geht. Für große \(n\) gilt also auch \[
\sqrt{n}\frac{\bar X-\mu}{S}\sim N(0,1).
\] Wenn der Ausdruck auf der linken Seite einer Standardnormalverteilung folgt, dann gilt für einen vorgegeben (typischerweise kleinen) Wert von \(\alpha\)\[
P\left(-u_{1-\alpha/2}\le \sqrt{n}\frac{\bar X-\mu}{S}\le u_{1-\alpha/2}\right)=1-\alpha,
\] wobei \(u_{1-\alpha/2}\) das \((1-\alpha/2)\)-Quantil der \(N(0,1)\) ist. Die Wahrscheinlichkeit, dass eine standardnormalverteilte Zufallsvariable kleiner (oder gleich) \(u_{1-\alpha/2}\) ist, beträgt also per Definition des Quantils gerade \(1-\alpha/2\). Wegen der Symmetrie ist die Wahrscheinlichkeit, dass eine standardnormalverteilte Zufallsvariable kleiner ist als \(-u_{1-\alpha/2}\) gerade \(\alpha/2\) (vgl. Abschnitt 5.3.1). Zusammengenommen ist also die Wahrscheinlichkeit, zwischen den beiden Grenzen zu liegen gerade \(1-\alpha/2-\alpha/2=1-\alpha\), wie die folgende Abbildung zeigt. Die beiden äußeren, rot schraffierten Flächen stehen jeweils für eine Wahrscheinlichkeit von \(\alpha/2\). Die hellblau schraffierte Fläche steht für eine Wahrscheinlichkeit von \(1-\alpha\).
Innerhalb der Wahrscheinlichkeit (in den runden Klammern) stehen zwei Ungleichungen. Diese Ungleichungen formen wir nun Schritt für Schritt so um, dass am Ende der unbekannte Erwartungswert \(\mu\) alleine in der Mitte steht.
Wir haben nun zwar erreicht, dass der unbekannte Parameter \(\mu\) alleine in der Mitte steht. Aber leider hat er das falsche Vorzeichen. Deshalb multiplizieren wir nun die Ungleichungen mit \((-1)\). Dabei drehen sich die Ungleichungszeichen um (denn 2 ist zwar kleiner als 3, aber \(-2\) ist größer als \(-3\)),
In einem letzten Schritt ändern wir noch die Reihenfolge der drei Ausdrücke, so dass der kleinste Ausdruck auf der linken Seite steht. Das dient der besseren Lesbarkeit.
Mit anderen Worten: Wenn \(\alpha\) auf einen kleinen Wert (z.B. 0.05) gesetzt wird, dann wird mit einer hohen Wahrscheinlichkeit von \(1-\alpha\) (z.B. 0.95) der wahre Erwartungswert \(\mu\) in dem (zufälligen) Konfidenzintervall \[
\left[\bar X-u_{1-\alpha/2}\cdot \frac{S}{\sqrt{n}}, \bar X+u_{1-\alpha/2}\cdot \frac{S}{\sqrt{n}}\right]
\] liegen. Wir haben also das gesuchte Konfidenzintervall gefunden!
Der Term \(S/\sqrt{n}\) ist gerade der Standardfehler des Stichprobenmittels \(\bar X\) (vgl. Abschnitt 10.2.1). Das Konfidenzintervall kann also auch so geschrieben werden: \[
\bar X\pm \text{Quantil}\cdot se(\bar X).
\] Aus den Formeln lassen sich mehrere Einsichten gewinnen:
Das Konfidenzintervall liegt symmetrisch um den Punktschätzer \(\bar X\) herum.
Je größer die Stichprobenvarianz \(S^2\) (bzw. -standardabweichung \(S\)) ist, desto größer ist der Standardfehler \(se(\bar X)\) und desto breiter ist deshalb das Konfidenzintervall. Das ist plausibel, denn eine hohe Stichprobenvarianz deutet auf eine hohe Populationsvarianz hin, die wiederum zu einer starken Streuung der Stichprobenelement führt, so dass es einen starken Zufallseinfluss auf \(\bar X\) gibt. Der Wert \(\bar X\) ist also für großes \(S\) weniger zuverlässig, daher muss das Intervall breiter sein.
Je größer der Stichprobenumfang \(n\) ist, desto schmaler ist das Intervall. Jedoch ist der Einfluss nicht proportional zu \(n\), sondern nur proportional zur Wurzel von \(n\). Vervierfacht man den Stichprobenumfang, dann halbiert sich die Breite des Konfidenzintervalls. Will man die Breite auf ein Zehntel reduzieren, braucht man also eine hundertmal größere Stichprobe. Es ist also gar nicht so leicht, die Genauigkeit um eine Kommastelle zu verbessern!
Je kleiner \(\alpha\) gewählt wird, desto breiter wird das Intervall. Die Wahrscheinlichkeit \(\alpha\), dass der Erwartungswert verfehlt wird, sollte also nicht extrem klein gewählt werden. Der üblichste Wert in den Wirtschaftswissenschaften ist \(\alpha=0.05\), auch \(\alpha=0.01\) oder \(\alpha=0.1\) kommen häufig vor.
Das Konfidenzintervall hat zufällige Grenzen. Wenn die Stichprobe tatsächlich realisiert wird, erhält man das konkrete Konfidenzintervall, indem die Schätzer \(\bar X\) und \(S\) durch die Schätzwerte \(\bar x\) und \(s\) ersetzt werden. Das konkrete Konfidenzintervall ist \[
\left[\bar x-u_{1-\alpha/2}\cdot \frac{s}{\sqrt{n}}, \bar x+u_{1-\alpha/2}\cdot \frac{s}{\sqrt{n}}\right].
\] Dieses Intervall hat reelle Unter- und Obergrenzen. Eine Wahrscheinlichkeitsaussage, ob der wahre Erwartungswert in diesem konkreten Intervall liegt, ergibt keinen Sinn, weil hier nichts Zufälliges mehr vorkommt.
Beispiel: Netzwerke
Für eine Studie soll das Arbeitsklima in einem großen Unternehmen untersucht werden. Dazu wird eine einfache Stichprobe vom Umfang \(n=50\) aus allen Arbeitnehmern des Unternehmens gezogen. Jede Person wird befragt, zu wie vielen Arbeitskollegen sie eine “gute Beziehung” hat (in der Studie wird genauer definiert, was darunter zu verstehen ist). Die Zufallsvariable \(X\) ist also die Anzahl an Arbeitskollegen, zu denen eine gute Beziehung besteht, von einer zufällig aus der Population ausgewählten Person. Die Realisation der Stichprobe \(X_1,\ldots,X_n\) liegt als Vektor gut in R vor. Die ersten sechs Werte sind
Der Punktschätzung 4.16 für den Erwartungswert ist also recht präzise.
Spezialfall: Normalverteilung
In manchen Anwendungen ist die Annahme einer Normalverteilung durchaus sinnvoll und plausibel. So können erfahrungsgemäß Messfehler oder Produktionsabweichungen ziemlich gut durch eine Normalverteilung modelliert werden. Unter der Annahme einer Normalverteilung kann man Konfidenzintervalle herleiten, die nicht nur approximativ, sondern exakt und sogar in kleinen Stichproben gültig sind.
Wie sehen die Grenzen eines Konfidenzintervalls für den Erwartungswert \(\mu\) einer normalverteilten Zufallsvariable \(X\) aus? Wir gehen wieder davon aus, dass die Varianz \(\sigma^2\) von \(X\) unbekannt ist. Wäre die Varianz \(\sigma^2\) bekannt, dann könnte man die Formel \[
\sqrt{n}\frac{\bar X-\mu}{\sigma}\sim N(0,1)
\] für die Herleitung des Konfidenzintervall nutzen, die für jeden beliebigen Stichprobenumfang exakt gilt. Was passiert, wenn man \(\sigma\) durch die Stichprobenstandardabweichung \(S\) ersetzt? Man kann zeigen (das tun wir jedoch in diesem Kurs nicht), dass dann die folgende Beziehung gilt: \[
\sqrt{n}\frac{\bar X-\mu}{S}\sim t_{n-1}.
\] Standardisiert man das Stichprobenmittel also nicht mit der wahren Standardabweichung \(\sigma\), sondern mit der geschätzten Standardabweichung \(S\), dann folgt die resultierende Zufallsvariable nicht mehr einer Standardnormalverteilung, sondern einer t-Verteilung mit \(n-1\) Freiheitsgraden (s. Abschnitt 5.3.5 zur t-Verteilung). Im Vergleich zur Normalverteilung hat die t-Verteilung stärkere Flanken, besonders bei einer geringen Zahl von Freiheitsgraden. Es gibt mehr Ausreißer als bei der Standardnormalverteilung. Für \(n\to\infty\) konvergiert die t-Verteilung gegen die Standardnormalverteilung. Praktisch gesehen gibt es kaum noch einen Unterschied zwischen der Standardnormalverteilung und der t-Verteilung, wenn die Zahl der Freiheitsgrade größer als etwa 50 ist.
Das \((1-\alpha/2)\)-Quantil der t-Verteilung mit \(n-1\) Freiheitsgraden bezeichnen wir mit \(t_{n-1,1-\alpha/2}\). Die Wahrscheinlichkeit, dass eine t-verteilte Zufallsvariable mit \(n-1\) Freiheitsgraden kleiner als dieses Quantil ist, beträgt per Definition \(1-\alpha/2\). Wegen der Symmetrie der t-Verteilung ist die Wahrscheinlichkeit, einen Wert kleiner als \(-t_{n-1,1-\alpha/2}\) zu erhalten, gerade \(\alpha/2\). Folglich gilt \[
P\left(-t_{n-1,1-\alpha/2}\le \sqrt{n}\frac{\bar X-\mu}{S}\le t_{n-1,1-\alpha/2}\right)=1-\alpha.
\] Von hier aus können wir die gleichen Herleitungsschritte durchführen wie oben, d.h. im Fall einer großen Stichprobe aus einer beliebigen Verteilung. Am Ende erhält man vollkommen analog das Konfidenzintervall \[
\left[\bar X-t_{n-1,1-\alpha/2}\cdot \frac{S}{\sqrt{n}}, \bar X+t_{n-1,1-\alpha/2}\cdot \frac{S}{\sqrt{n}}\right].
\] Wenn die Stichprobe realisiert wurde, kann man die Stichprobenelemente durch ihre Realisationen ersetzen. Aus dem Konfidenzintervall wird das konkrete Konfidenzintervall \[
\left[\bar x-t_{n-1,1-\alpha/2}\cdot \frac{s}{\sqrt{n}}, \bar x+t_{n-1,1-\alpha/2}\cdot \frac{s}{\sqrt{n}}\right].
\]
Beispiel: Konfidenzintervall für Erwartungswert einer Normalverteilung
In einer Brauerei soll die Qualitätskontrolle sicherstellen, dass die in der Produktion eingesetzte Gerste im Mittel einen Kohlenhydratanteil von 63 Prozent besitzt. Es ist plausibel davon auszugehen, dass der Kohlenhydratanteil einer Normalverteilung folgt. Allerdings sind der Erwartungswert und die Varianz der Normalverteilung nicht bekannt. Bei der Anlieferung der Gerste wird eine Stichprobe vom Umfang \(n=8\) entnommen. Jedes Stichprobenelement wird genau analysiert. Bei der konkreten Messung ergaben sich die folgenden acht Werte, die in dem R-Vektor anteil abgelegt sind:
kleiner als der Sollwert 63, aber die Messungen zeigen, dass zwischen den Stichprobenelementen ziemlich große Unterschiede bestehen. Sollte die Annahme der Lieferung verweigert werden, weil der Kohlenhydratgehalt im Mittel zu niedrig ist?
Der Unsicherheit der Messungen kann durch eine Intervallschätzung Rechnung getragen werden. Wir berechnen aus den 8 Werten das konkrete 0.95-Konfidenzintervall. Um die Intervallgrenzen zu bestimmen, braucht man das \((1-\alpha/2)\)-Quantil der t-Verteilung mit \(n-1=7\) Freiheitsgraden. In R erhält man es durch
alpha <-0.05qnt <-qt(1-alpha/2, df=7)print(qnt)
[1] 2.364624
Die Untergrenze des Konfidenzintervalls ist
mean(kohlenhyd) - qnt *sd(kohlenhyd)/sqrt(8)
[1] 57.53852
Und die Obergrenze ist
mean(kohlenhyd) + qnt *sd(kohlenhyd)/sqrt(8)
[1] 62.48648
Der Sollwert (63) wird also von dem Intervall nicht überdeckt. Die Brauerei sollte die Annahme der Gerste-Lieferung verweigern.
Spezialfall: Anteile
Ein Spezialfall einer beliebigen, d.h. nicht-normalen Verteilung ist die Bernoulli-Verteilung. Der Parameter \(\pi\) der Verteilung steht für den Anteil der Populationsmitglieder, die eine interessierende Eigenschaft aufweisen. Der Schätzer für den wahren Anteil ist der Stichprobenanteil, der normalerweise mit \(\hat\pi\) (und nicht mit \(\bar X\)) bezeichnet wird, obwohl es sich formal um das normale Stichprobenmittel handelt (vgl. Abschnitt 10.2.1), \[
\hat\pi =\frac{\text{Anzahl }X_i
\text{ mit der Eigenschaft}}{n}.
\] Wie sieht das Konfidenzintervall in diesem Fall aus? Da die Varianz einer Bernoulli-Verteilung \(\pi(1-\pi)\) beträgt, ergibt sich die Stichprobenstandardabweichung für die Bernoulli-Verteilung als \(\sqrt{\hat\pi (1-\hat\pi)}\). Daher lautet das approximative Konfidenzintervall \[
\left[\hat\pi-u_{1-\alpha/2}\cdot \sqrt{\frac{\hat\pi (1-\hat\pi)}{n}},
\hat\pi+u_{1-\alpha/2}\cdot \sqrt{\frac{\hat\pi (1-\hat\pi)}{n}}\right].
\] Leider erlaubt diese Notation keine explizite Unterscheidung zwischen dem (zufälligen) Konfidenzintervall und dem (nicht zufälligen) konkreten Konfidenzintervall. Die Bedeutung ergibt sich jedoch fast immer aus dem Zusammenhang.
Beispiel: Wahlumfrage
Durch eine Wahlumfrage soll ermittelt werden, wie hoch aktuell der Anteil der Wahlberechtigten ist, der die SPD wählen will. Die “interessierende Eigenschaft” ist also: “die befragte Person will die SPD wählen”. Aus der Wahlpopulation wird eine einfache Stichprobe vom Umfang \(n=1000\) erhoben. Jede Person wird befragt, ob sie die SPD wählen will. Der Anteil der SPD-Wähler in der konkreten Stichprobe ist \(\hat\pi=0.273\). Das konkrete 0.95-Konfidenzintervall für den Populationsanteil der SPD-Wähler ist
Die Genauigkeit der Schätzung ist also nicht besonders hoch, obwohl der Stichprobenumfang relativ groß ist.
Zusammenfassend haben wir gesehen, dass die Konfidenzintervalle für den Erwartungswert immer von der Form \[
\text{Punktschätzer} \pm \text{Quantil}\cdot \text{Standardfehler}
\] sind. Ferner haben wir gesehen, dass man für normalverteilte Populationen exakte Konfidenzintervalle berechnen kann, die sogar bei kleinen Stichproben gültig sind. Wenn die Population einer beliebigen Verteilung folgt, lassen sich die Konfidenzintervalle nur approximativ bestimmen. Die Approximation ist umso besser, je größer der Stichprobenumfang ist.
11.3 Monte-Carlo-Simulation
Konfidenzintervalle sind zufällige Intervalle, die mit einer vorgegebenen hohen Wahrscheinlichkeit den wahren Erwartungswert überdecken. Leider gilt diese einfache Interpretation nicht für die konkreten Konfidenzintervalle, die aus den tatsächlich erhobenen konkreten Daten errechnet werden. Das liegt daran, dass das konkrete Intervall feste (nicht zufällige) Grenzen hat. Eine Aussage über die Überdeckungswahrscheinlichkeit des wahren Werts, der ja ebenfalls nicht zufällig ist, ergibt keinen Sinn. Ohne Zufall keine Wahrscheinlichkeit!
Für das Verständnis von Konfidenzintervallen hilft es sehr, eine Monte-Carlo-Simulation durchzuführen. Im folgenden wird Schritt für Schritt erklärt, wie eine solche Simulation in R aussieht.
Zuerst legt man die Populationsverteilung fest. Wie soll die Zufallsvariable \(X\) verteilt sein? In diesem Beispiel gehen wir von einer Situation aus, die in etwa dem Beispiel der Qualitätskontrolle in einer Brauerei entspricht. Die Zufallsvariable \(X\) habe eine Normalverteilung mit Erwartungswert \(\mu=63\) und Varianz \(\sigma^2=16\) (bzw. Standardabweichung \(\sigma=4\)), \[
X\sim N(63, 4^2).
\] In der Simulation tun wir so, als ob zwar bekannt ist, dass \(X\) einer Normalverteilung folgt, dass aber die Varianz und der Erwartungswert unbekannt sind. Ferner legen wir den Stichprobenumfang und das Konfidenzniveau fest. Der Umfang sei \(n=8\), und das Konfidenzniveau sei 0.95 \((\alpha=0.05)\). Außerdem definieren wir einen Zähler, mit dem nachgehalten wird, wie oft die Konfidenzintervalle den wahren Erwartungswert überdecken.
In der Monte-Carlo-Simulation wird nicht nur eine Stichprobe vom Umfang \(n\) gezogen, sondern sehr viele. Das lässt sich mit einer Schleife leicht in R umsetzen. Sei \(R=10000\) die Zahl der Schleifendurchläufe. In jedem Schleifendurchlauf
wird eine Stichprobe x als Vektor der Länge n aus der Zufallsvariable \(X\) gezogen
werden aus der Stichprobe x die konkreten Intervallgrenzen k_oben und k_unten berechnet
wird kontrolliert, ob das konkrete Konfidenzintervall den wahren Wert (63) überdeckt. Wenn ja, wird der Zähler um 1 erhöht.
Das R-Programm sieht folgendermaßen aus:
mu <-63sigma <-4n <-8alpha <-0.05R <-10000# (1-alpha/2)-Quantil der t-Verteilung# mit n-1 Freiheitsgradenqnt <-qt(1-alpha/2, df=n-1)# Initialisierung eines Zählersz <-0for(r in1:R){# Ziehung der Stichprobe x <-rnorm(n, mean=mu, sd=sigma)# Berechnung der Intervallgrenzen k_unten <-mean(x) - qnt *sd(x)/sqrt(n) k_oben <-mean(x) + qnt *sd(x)/sqrt(n)# Wird der wahre Wert mu überdeckt? # Wenn ja, setze den Zähler hochif(k_unten <= mu & mu <= k_oben){ z <- z+1 }}
Der Anteil der Überdeckungen von \(\mu\) konvergiert nach dem Gesetz der großen Zahl gegen die theoretische Wahrscheinlichkeit einer Überdeckung. In dieser Simulation ergab sich
print(z/R)
[1] 0.9486
Dieser Wert liegt sehr nahe an dem theoretischen Wert von \(1-\alpha=0.95\). Führt man die Simulation erneut durch, realisiert sich natürlich ein leicht anderer Wert. Je größer \(R\), desto näher liegt der Anteil der Überdeckungen am theoretischen Wert.
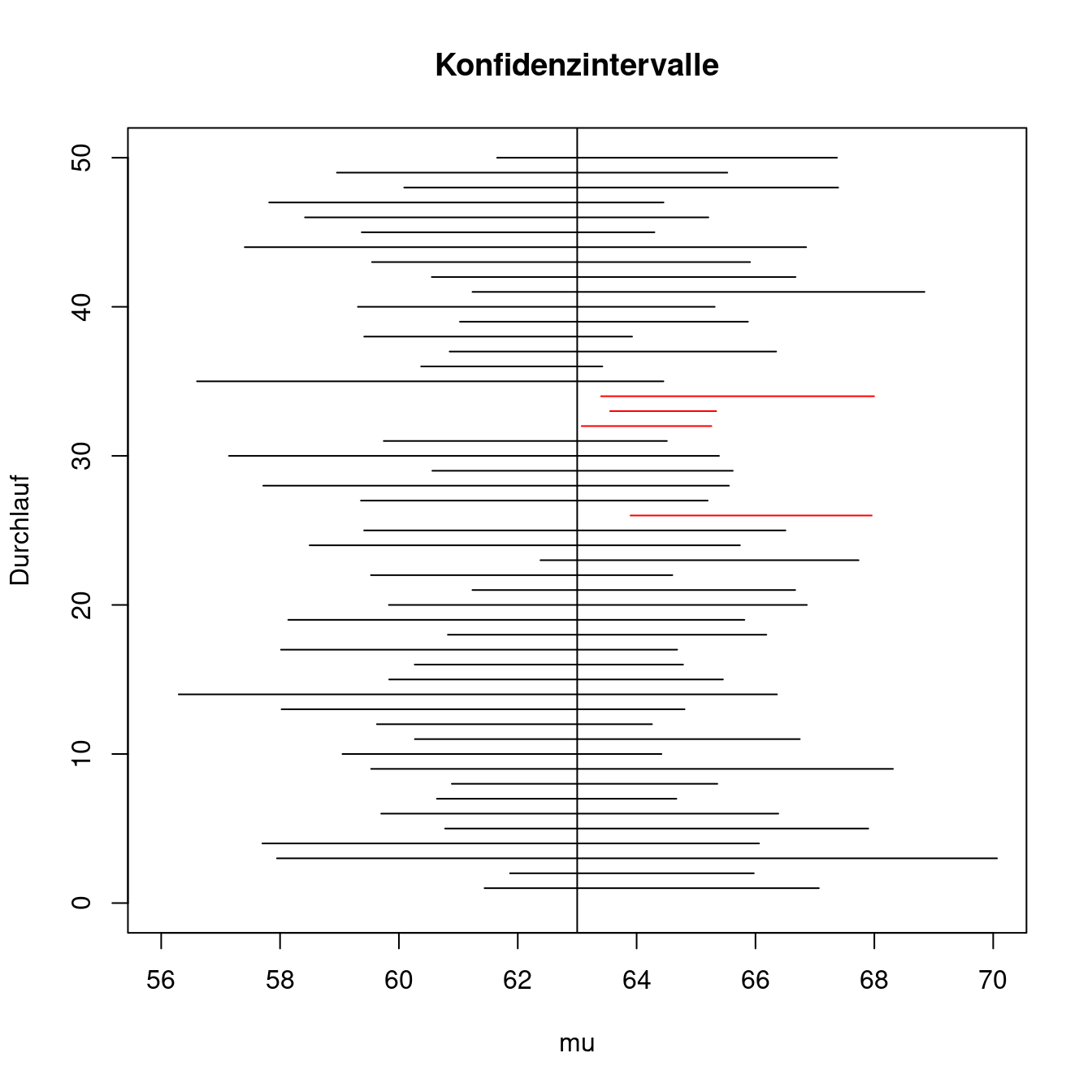
Für eine deutlich kleinere Anzahl an Schleifendurchläufen, z.B. \(R=50\), kann man sämtliche Intervalle auch grafisch darstellen. Dadurch wird die Zufälligkeit der Konfidenzintervalle gut veranschaulicht. Vor dem Start der Schleife wird eine fast leere Grafik vorbereitet, in der nur der wahre Wert durch einen senkrechten Strich gezeigt wird. Der R-Code dazu lautet
R <-50# Vorbereitung einer leeren Grafikplot(c(56,70), c(0,R),type="n",xlab="mu", ylab="Durchlauf")# Einzeichnen des wahren Erwartungswertsabline(v=mu)
Die Option type="n" im plot-Befehl legt fest, dass nichts gezeichnet wird (außer dem Koordinatensystem). Der Befehl abline fügt in eine vorhandene Grafik eine Gerade ein. Vertikale Linien erzeugt man mit der Option v=... (weitere Hinweise zum Plotbefehl und den Linienbefehlen finden Sie in Abschnitt A.5 oder über die Hilfefunktion).
Innerhalb der Schleife wird in jedem Durchlauf eine Linie in die Grafik eingefügt, die das Konfidenzintervall darstellt. Wenn der wahre Wert überdeckt wird, ist die Linie schwarz. Wenn das Intervall den wahren Wert verfehlt, wird sie rot gefärbt. Der folgende R-Code ersetzt den if-Befehl in der Schleife:
if(k_unten <= mu & mu <= k_oben){ z <- z+1lines(x=c(k_unten, k_oben), y=c(r, r))} else {lines(x=c(k_unten, k_oben), y=c(r, r), col="red")}
Ersetzt man den entsprechenden R-Code vor bzw. in der Schleife, so erhält man eine Abbildung, in der alle (konkreten) Konfidenzintervalle übereinander als waagerechte Linien erscheinen. Nur die roten Linien überdecken den wahren Wert nicht.
Es ist wichtig, sich klar zu machen, dass jedes Konfidenzintervall aus einer eigenen Stichprobe errechnet wird. Es werden \(R=50\) Stichproben gezogen. Alle Stichproben haben einen Umfang von \(n=8\). Auf diese Weise macht das Simulations-Experiment deutlich, dass die Stichprobenelemente zufällig sind und dass folglich auch die Konfidenzintervalle zufällig sind.
 Die Analogie einer Schätzung zu einem Bogenschuss macht deutlich, dass ein Punktschätzer zwar interessant ist, dass man aber nicht erkennt, wie zuverlässig die Schätzung ist. Darf man davon ausgehen, dass der Schätzer dicht am wahren Parameter liegt? Oder ist zu befürchten, dass die Schätzung vielleicht deutlich daneben liegt? Einen Bogenschützen kann man bitten, mehrfach auf die Zielscheibe zu schießen, damit seine Zielgenauigkeit gemessen werden kann. Eine Stichprobe wird jedoch in der Realität nicht wiederholt gezogen, sondern nur einmal. Kann man dennoch allein auf Grundlage einer einzelnen Stichprobe die Schätzgenauigkeit bewerten? In diesem Kapitel wird gezeigt, dass das tatsächlich machbar ist.
Die Analogie einer Schätzung zu einem Bogenschuss macht deutlich, dass ein Punktschätzer zwar interessant ist, dass man aber nicht erkennt, wie zuverlässig die Schätzung ist. Darf man davon ausgehen, dass der Schätzer dicht am wahren Parameter liegt? Oder ist zu befürchten, dass die Schätzung vielleicht deutlich daneben liegt? Einen Bogenschützen kann man bitten, mehrfach auf die Zielscheibe zu schießen, damit seine Zielgenauigkeit gemessen werden kann. Eine Stichprobe wird jedoch in der Realität nicht wiederholt gezogen, sondern nur einmal. Kann man dennoch allein auf Grundlage einer einzelnen Stichprobe die Schätzgenauigkeit bewerten? In diesem Kapitel wird gezeigt, dass das tatsächlich machbar ist.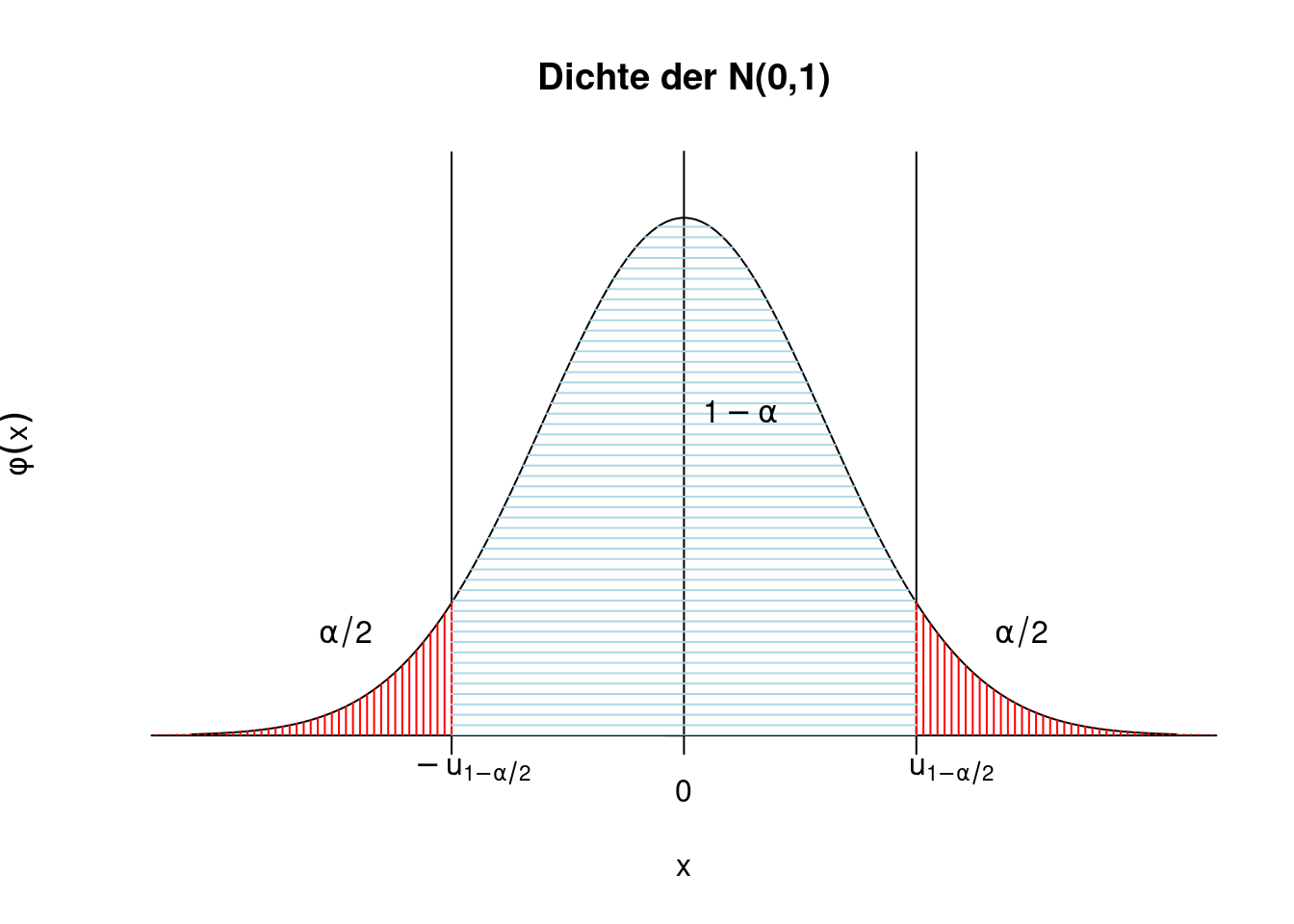
 Für eine Studie soll das Arbeitsklima in einem großen Unternehmen untersucht werden. Dazu wird eine einfache Stichprobe vom Umfang
Für eine Studie soll das Arbeitsklima in einem großen Unternehmen untersucht werden. Dazu wird eine einfache Stichprobe vom Umfang  In einer Brauerei soll die Qualitätskontrolle sicherstellen, dass die in der Produktion eingesetzte Gerste im Mittel einen Kohlenhydratanteil von 63 Prozent besitzt. Es ist plausibel davon auszugehen, dass der Kohlenhydratanteil einer Normalverteilung folgt. Allerdings sind der Erwartungswert und die Varianz der Normalverteilung nicht bekannt. Bei der Anlieferung der Gerste wird eine Stichprobe vom Umfang
In einer Brauerei soll die Qualitätskontrolle sicherstellen, dass die in der Produktion eingesetzte Gerste im Mittel einen Kohlenhydratanteil von 63 Prozent besitzt. Es ist plausibel davon auszugehen, dass der Kohlenhydratanteil einer Normalverteilung folgt. Allerdings sind der Erwartungswert und die Varianz der Normalverteilung nicht bekannt. Bei der Anlieferung der Gerste wird eine Stichprobe vom Umfang